
키워드:AI 모델, 클로드 4, 제미니 디퓨전, AI 에이전트, 로봇 학습, 대형 언어 모델, AI 하드웨어, 칩 개발, 클로드 오퍼스 4 코딩 능력, 텍스트 디퓨전 모델 생성 속도, GR00T 로봇 꿈 학습, 샤오미 현계 O1 칩 성능, 오픈AI io 하드웨어 회사 인수
🔥 聚焦
Anthropic, Claude 4 시리즈 모델 출시, AI 에이전트 프로그래밍 및 복잡한 작업 처리 중점: Anthropic은 Claude Opus 4와 Claude Sonnet 4 두 가지 하이브리드 모델을 출시하여 즉각적인 응답과 심도 있는 사고 간의 균형을 강조했습니다. Opus 4는 코딩, 연구, 글쓰기, 과학적 발견 등 복잡한 작업에서 뛰어난 성능을 보이며, 7시간 동안 단독으로 프로그래밍하고 24시간 동안 Pokémon을 플레이할 수 있습니다. Sonnet 4는 성능과 효율성 사이의 균형을 이루어 자율성이 요구되는 일상적인 장면에 적합합니다. 두 모델 모두 도구 사용, 병렬 처리, 기억 능력이 향상되었으며 ‘사고 요약(Thinking Summary)’ 기능이 도입되었습니다. GitHub는 Claude Sonnet 4를 Copilot의 새로운 코딩 에이전트 기본 모델로 채택한다고 발표했습니다. 이번 출시에는 Claude Code SDK, 코드 실행 도구, MCP 커넥터 등이 포함되어 개발자가 더 강력한 AI 에이전트를 구축할 수 있도록 지원하며, 이는 Anthropic이 ‘대규모 모델+에이전트’의 심층 융합으로 전략적으로 전환하고 있음을 의미합니다. (출처: 量子位 & 36氪)

Google, 텍스트 확산 모델 Gemini Diffusion 출시, 12초 만에 1만 token 생성: Google DeepMind는 기존의 자기 회귀(auto-regressive) 방식 대신 확산 기술을 사용하는 실험적인 텍스트 생성 모델인 Gemini Diffusion을 발표했습니다. 이 모델은 점진적으로 노이즈를 최적화하여 출력을 생성하는 방법을 학습하며, 초당 2000 token의 생성 속도를 구현하여 12초 만에 1만 token을 생성할 수 있고, Gemini 2.0 Flash-Lite보다도 빠릅니다. 이 모델은 한 번에 전체 토큰 블록을 생성하여 응답의 일관성을 향상시키고 반복적인 개선 과정에서 오류를 수정할 수 있습니다. 비인과적 추론 능력으로 기존 자기 회귀 모델이 처리하기 어려운 문제, 예를 들어 답을 먼저 제시한 후 과정을 추론하는 것과 같은 문제를 해결할 수 있습니다. (출처: 量子位)
NVIDIA 로봇 GR00T 프로젝트 새 진전: ‘꿈’을 통한 학습으로 제로샷 일반화 구현: NVIDIA GEAR Lab은 DreamGen 프로젝트를 출시하여 로봇이 AI 비디오 세계 모델(예: Sora, Veo)이 생성한 ‘꿈’(신경 궤적, neural trajectories)을 통해 새로운 기술을 학습하도록 했습니다. 이 기술은 소량의 실제 비디오 데이터만 필요로 하며, 세계 모델을 미세 조정하고, 가상 데이터를 생성하며, 가상 행동을 추출하여 정책을 훈련함으로써 로봇이 22가지 새로운 작업을 수행할 수 있도록 합니다. 실제 로봇 테스트에서 복잡한 작업 성공률이 21%에서 45.5%로 향상되어 처음으로 제로샷 행동 및 환경 일반화를 구현했습니다. 이 기술은 NVIDIA GR00T-Dreams 청사진의 일부로, 로봇 행동 학습을 가속화하는 것을 목표로 하며 GR00T N1.5의 개발 시간을 3개월에서 36시간으로 단축할 것으로 예상됩니다. (출처: 量子位)

🎯 동향
OpenAI Operator, o3 모델로 업데이트, 작업 성공률 및 응답 품질 향상: OpenAI는 ChatGPT의 Operator 기능이 업데이트되어 기본 모델이 최신 o3 추론 모델로 전환되었다고 발표했습니다. 이번 업그레이드는 Operator가 브라우저와 상호 작용할 때의 지속성과 정확성을 크게 향상시켜 전반적인 작업 성공률을 높였습니다. 사용자 피드백에 따르면 업데이트된 Operator는 응답이 더 명확하고 상세하며 구조도 더 우수해졌습니다. OpenAI는 o3 모델이 OSWorld 및 WebArena와 같은 벤치마크에서 모두 SOTA 수준을 달성했으며, 새 모델은 이전에 실패했던 오래된 프롬프트를 처리하는 데 더 나은 성능을 보인다고 밝혔습니다. (출처: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
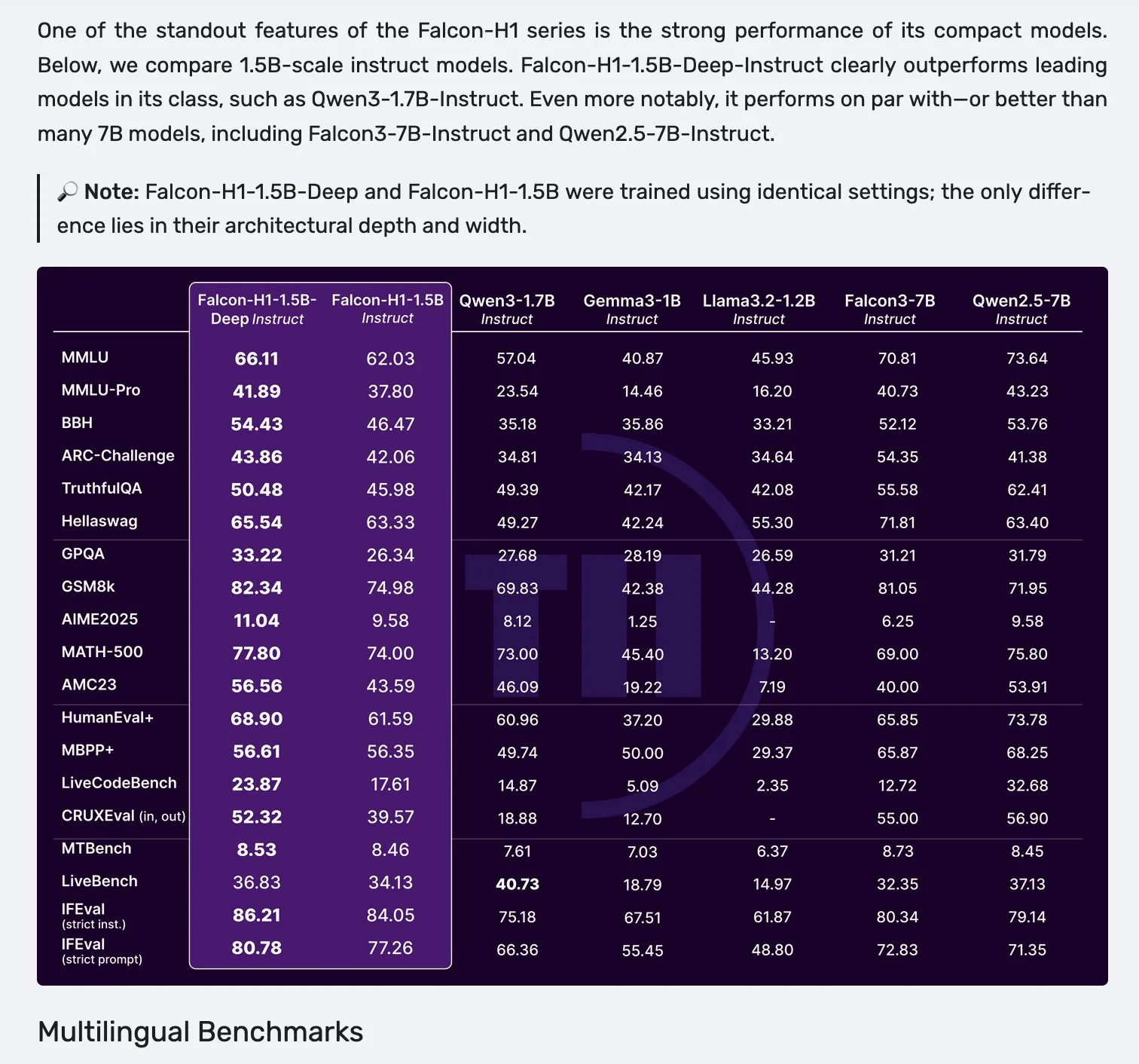
Falcon, Mamba-2와 어텐션 병렬 아키텍처를 채택한 H1 시리즈 모델 발표: Falcon은 새로운 H1 시리즈 모델을 출시했습니다. 매개변수 규모는 0.5B에서 34B까지 다양하며, 훈련 데이터 양은 2.5T에서 18T token 사이이고 컨텍스트 길이는 256K에 달합니다. 이 시리즈 모델은 Mamba-2와 기존 어텐션 메커니즘을 병렬로 사용하는 혁신적인 아키텍처를 채택했습니다. 커뮤니티 초기 반응에 따르면 소형 모델의 성능이 특히 두드러지지만, 다양한 작업에서의 실제 성능과 견고성(robustness)을 검증하기 위해서는 추가적인 실제 테스트 및 평가(“vibe checks”)가 필요합니다. (출처: _albertgu & huggingface)
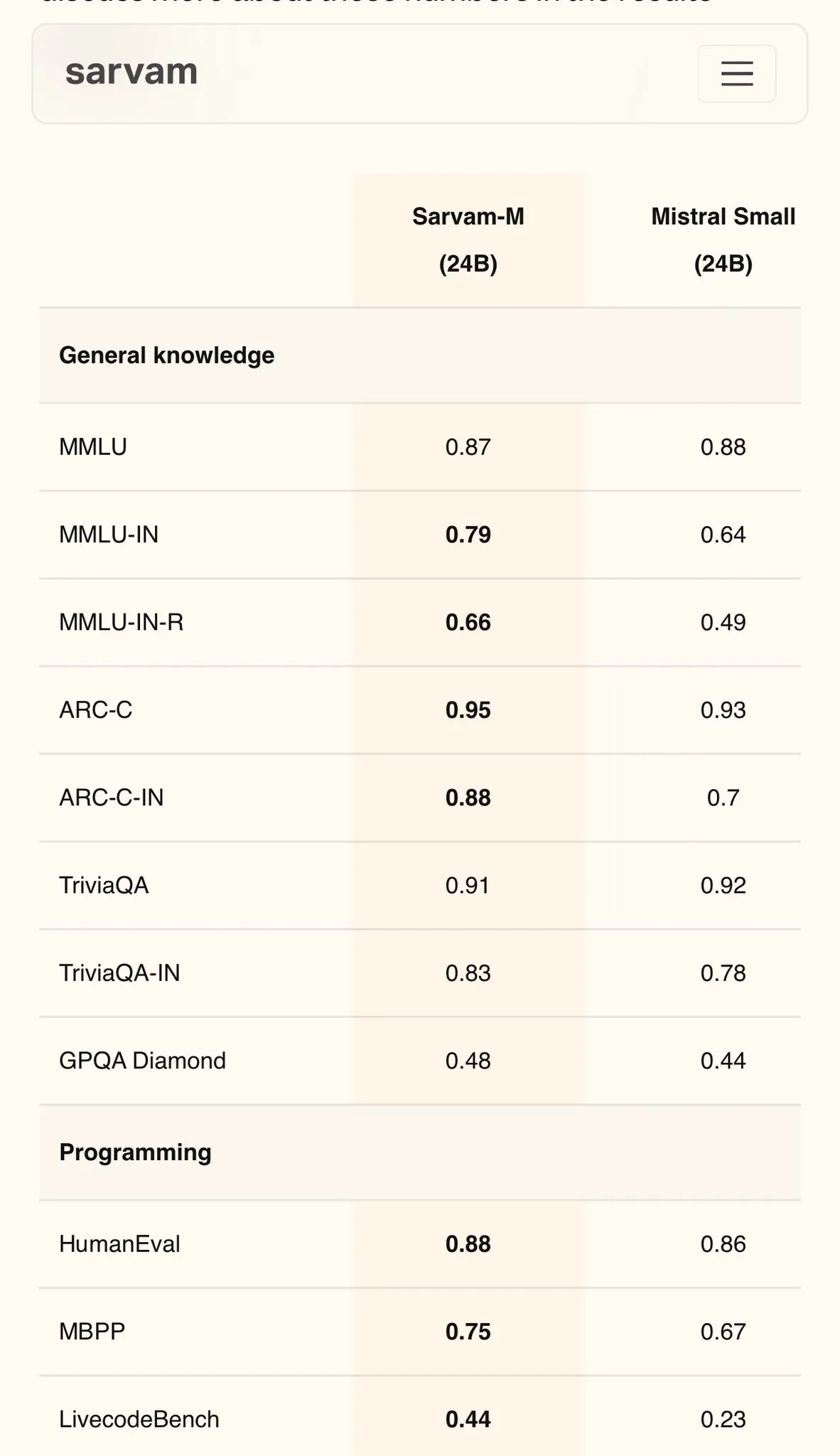
Sarvam AI, Mistral 기반 힌디어 모델 Sarvam-M 발표, MMLU 79점 달성: 인도 AI 회사 Sarvam AI는 오픈소스 Mistral 모델을 기반으로 구축한 Sarvam-M 모델을 발표했습니다. 이 모델은 인도 언어 MMLU 벤치마크에서 79점을 받아 초기 ChatGPT(GPT-3.5)의 영어 성능을 능가했습니다. 이 모델은 11개 인도 언어에 최적화되었으며, 인도 언어 벤치마크, 수학 벤치마크, 프로그래밍 벤치마크에서 기본 모델 대비 각각 20%, 21.6%, 17.6% 향상된 성능을 보였습니다. Sarvam-M은 Apache 2.0 라이선스로 오픈소스화되어 인도의 자국어 대규모 모델 연구 개발 잠재력을 보여주었습니다. (출처: bookwormengr)
Dell Enterprise Hub 업그레이드, 로컬 AI 구축 전면 지원: Dell은 Dell Tech World에서 Dell Enterprise Hub 업데이트를 발표하고, Meta Llama 4 Maverick, DeepSeek R1, Google Gemma 3를 포함한 최적화된 모델 컨테이너를 제공하며 NVIDIA, AMD, Intel의 AI 서버 플랫폼을 지원한다고 밝혔습니다. 새로운 기능에는 AI 애플리케이션 디렉터리(OpenWebUI, AnythingLLM 통합), AI PC의 온디바이스 모델 지원(Dell Pro AI Studio를 통한 배포), 새로운 dell-ai Python SDK 및 CLI 도구가 포함됩니다. 이는 기업이 로컬에서 안전하고 빠르게 생성형 AI 애플리케이션을 배포하도록 지원하는 것을 목표로 합니다. (출처: HuggingFace Blog & ClementDelangue)

Fireworks AI, 브라우저 프록시 도구 Fireworks Manus 오픈소스 공개: Fireworks AI는 DeepSeek V3를 추론에 사용하고 FireLlava 13B를 시각적 이해에 사용하는 강력한 브라우저 기반 프록시 도구인 Fireworks Manus를 오픈소스로 공개했습니다. 이 프록시는 웹 페이지 탐색, 버튼 클릭, 양식 작성, 동적 콘텐츠 추출, 인증 절차, 모달 창, 심지어 CAPTCHA 처리까지 가능합니다. 아키텍처는 시각 시스템(DOM, 스크린샷, 공간 인식), 추론 시스템(메모리, 목표 추적, JSON 스키마 계획) 및 행동 시스템(브라우저 상호작용 제어)을 포함하며 강력한 관찰-결정-행동 루프를 형성합니다. (출처: _akhaliq)
Mistral AI, 문서 AI 및 새로운 OCR 모델 출시: Mistral AI는 새로운 OCR 모델과 결합된 문서 AI 솔루션을 발표했습니다. 이 솔루션은 OCR 디지털화에서 자연어 쿼리에 이르는 확장 가능한 문서 워크플로를 제공하는 것을 목표로 합니다. 특징으로는 40개 이상의 언어를 지원하는 다국어 지원 능력, 특정 분야 문서(예: 의료 기록)에 대해 OCR을 훈련할 수 있으며, 사용자 정의 템플릿(예: JSON)으로의 고급 추출을 지원하고, 온프레미스 또는 프라이빗 클라우드 배포가 가능합니다. (출처: algo_diver)

Sakana AI, 지속적 사고 기계(CTM) 새로운 AI 방법 발표: Sakana AI는 AI 연구의 새로운 돌파구인 지속적 사고 기계(Continuous Thought Machines, CTM)를 발표했습니다. 이 새로운 방법은 AI 모델의 사고 및 추론 능력을 향상시키는 것을 목표로 합니다. NHK World는 Sakana AI의 최신 진전에 대해 보도하며 차세대 세계 모델 구축 노력과 성과를 소개했습니다. (출처: SakanaAILabs & hardmaru)

Kumo.ai, 정형 데이터를 위한 ‘관계형 기반 모델’ KumoRFM 발표: Kumo.ai는 테이블 형식(정형) 데이터를 위해 특별히 설계된 ‘관계형 기반 모델(Relational Foundation Model)’인 KumoRFM을 출시했습니다. 이 모델은 LLM이 텍스트를 처리하는 것처럼 데이터베이스의 데이터를 처리하는 것을 목표로 하며, 특성 공학(feature engineering) 없이 SOTA 모델을 생성할 수 있다고 주장합니다. 이는 그래프 신경망(GNNs)이 정형 데이터 처리 분야에서 잠재력을 더욱 발굴하고 응용할 수 있음을 예고하는 것일 수 있습니다. (출처: Reddit r/MachineLearning)

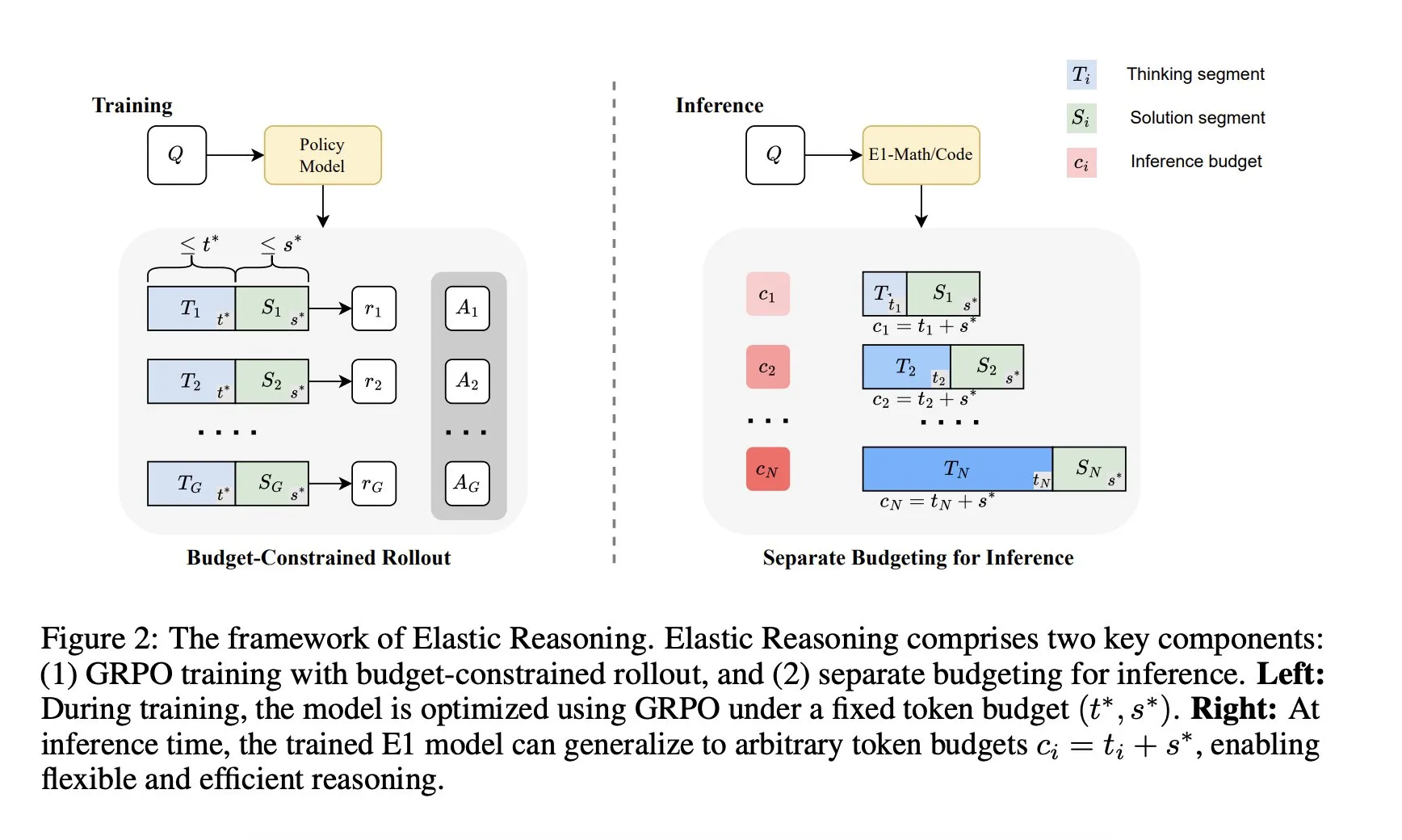
Salesforce AI 연구소, ‘탄력적 추론(Elastic Reasoning)’ 프레임워크 출시: Salesforce AI 연구소는 성능 저하 없이 LLM 추론 예산 제약 문제를 해결하는 것을 목표로 하는 ‘탄력적 추론(Elastic Reasoning)’이라는 새로운 프레임워크를 발표했습니다. 이 프레임워크는 ‘사고’ 단계와 ‘솔루션’ 단계를 분리하고 각각에 독립적인 Token 예산을 설정하며, 예산 제약이 있는 rollout 훈련을 결합합니다. 연구 결과에 따르면 E1-Math-1.5B는 AIME2024에서 35%의 정확도를 달성하고 Token을 32% 줄였으며, E1-Code-14B는 Codeforces에서 1987점을 기록했습니다. 모델은 재훈련 없이 모든 예산에 일반화될 수 있습니다. (출처: ClementDelangue)
🧰 도구
ChatGPT, RDKit 라이브러리 통합, 분자 화학 정보 분석, 조작 및 시각화 가능: ChatGPT는 이제 RDKit 라이브러리를 통해 분자 및 화학 정보를 분석, 조작 및 시각화할 수 있습니다. 이 새로운 기능은 건강, 생물학, 화학 등 과학 연구 분야에 중요한 실용적 가치를 가지며, 연구자들이 복잡한 화학 데이터와 구조를 더 편리하게 처리하도록 도울 수 있습니다. (출처: gdb & openai)
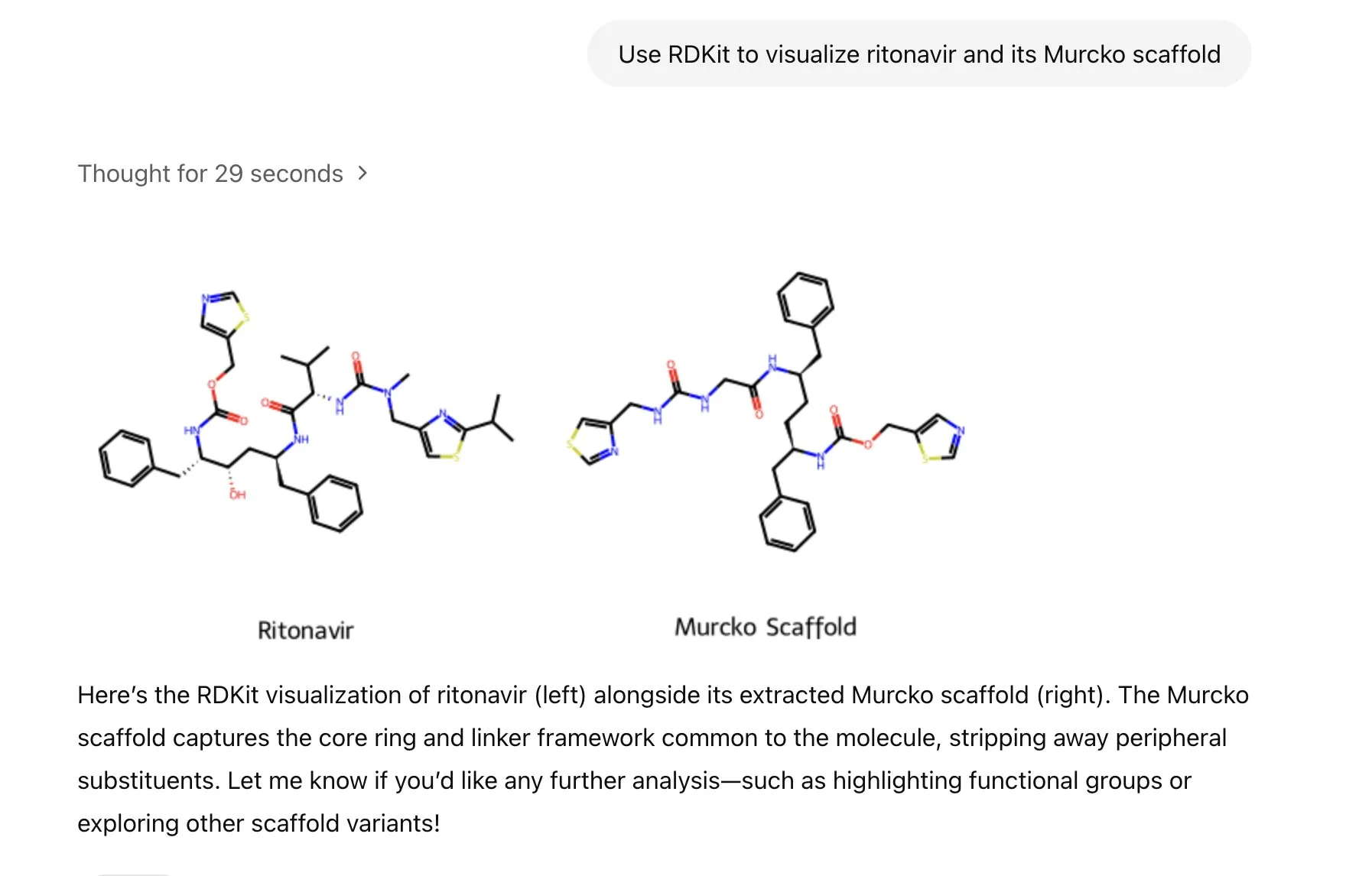
LlamaIndex, AI 이미지 창작 정밀 제어를 위한 이미지 생성 에이전트 출시: LlamaIndex는 프롬프트 최적화, 이미지 생성 및 시각적 피드백 루프를 자동화하여 사용자가 구상하는 AI 이미지를 정확하게 창작하도록 돕는 오픈소스 이미지 생성 에이전트 프로젝트를 발표했습니다. 이 에이전트는 OpenAI의 이미지 생성 API와 Google Gemini의 시각 능력을 활용하는 멀티모달 도구이며, LlamaIndex와 원활하게 통합되어 OpenAI 이미지 생성 기능을 지원합니다. (출처: jerryjliu0)
Haystack 팀, AI 파이프라인 배포 간소화를 위한 Hayhooks 발표: Haystack 팀은 Haystack 파이프라인을 프로덕션 준비가 된 REST API로 변환하거나 MCP 도구로 노출할 수 있는 오픈소스 패키지 Hayhooks를 출시했습니다. 이는 완전한 사용자 정의를 지원하며 코드 양이 매우 적습니다. 이를 통해 AI 애플리케이션 배포 프로세스를 가속화하여 개발자가 AI 모델과 프로세스를 프로덕션 환경에 더 편리하게 통합할 수 있도록 하는 것을 목표로 합니다. (출처: dl_weekly)
Runway iOS 앱, Gen-4 References 기능 출시, 언제 어디서나 현실을 스토리로 전환: Runway는 iOS 앱의 Gen-4 References 기능이 현재 사용 가능하다고 발표했습니다. 사용자는 현실 세계의 모든 것을 공유 가능한 스토리로 전환할 수 있습니다. 이 기능은 텍스트-이미지 변환, References, Gen-4 및 간단한 추적 및 색상 보정 기술을 결합하여 일반적인 촬영을 대규모 프로덕션으로 전환할 수 있습니다. (출처: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel, 캐릭터 애니메이션 제작 지원하는 3D 애니메이션 AI 도구 모음 출시: OpenAI 과학자, Google 디자이너 및 Pixar, Sony, Riot Games 개발자가 공동으로 설립한 Cartwheel이 3D 애니메이션 AI 도구 모음을 발표했습니다. 이 도구 모음은 비디오, 텍스트 및 대규모 모션 라이브러리를 3D 캐릭터 애니메이션으로 변환할 수 있으며, 애니메이션 제작 프로세스를 혁신하는 것을 목표로 합니다. (출처: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM, Red Hat, 오픈소스 분산 LLM 추론 프레임워크 공동 출시: Google, IBM, Red Hat이 공동으로 오픈소스 K8s 네이티브 분산 LLM 추론 프레임워크인 llm-d를 발표했습니다. 이 프레임워크는 고성능 LLM 추론 서비스를 제공하는 것을 목표로 하며, 주요 특징으로는 고급 캐싱 및 라우팅(vLLM을 통한 추론 스케줄러 최적화), 분리된 서비스(특수 인스턴스에서 vLLM을 사용하여 사전 채우기/디코딩 실행), vLLM을 사용한 분리된 접두사 캐시(제로 비용 호스트/원격 오프로딩 및 공유 캐시 지원) 및 계획된 변형 자동 확장 기능을 포함합니다. 초기 결과에 따르면 llm-d는 TTFT를 최대 3배까지 줄이고 SLO를 충족하면서 QPS를 약 50% 향상시킬 수 있습니다. (출처: algo_diver)

FedRAG, Unsloth 통합, FastModels를 사용한 RAG 시스템 구축 및 미세 조정 지원: FedRAG는 Unsloth 통합을 발표하여 사용자가 이제 Unsloth의 모든 FastModels를 생성기로 사용하여 RAG 시스템을 구축하고 Unsloth의 성능 가속기 및 패치를 활용하여 미세 조정할 수 있게 되었다고 밝혔습니다. 사용자는 새로운 UnslothFastModelGenerator 클래스를 정의하여 사용 가능한 모든 Unsloth 모델을 사용할 수 있으며 LoRA 또는 QLoRA 미세 조정을 지원합니다. 공식적으로 GoogleAI의 Gemma3 4B 모델에 대한 QLoRA 미세 조정 방법을 시연하는 관련 cookbook이 제공됩니다. (출처: nerdai)

Hugging Face, 경량의 재사용 가능하며 모듈식 CLI 에이전트 출시: Hugging Face Hub 라이브러리에 경량의 재사용 가능하며 모듈식(MCP 호환) 명령줄 인터페이스(CLI) 에이전트 기능이 추가되었습니다. @hanouticelina와 @julien_c가 개발한 이 새로운 기능은 사용자가 CLI 환경에서 AI 에이전트를 편리하게 생성하고 사용할 수 있도록 하는 것을 목표로 합니다. (출처: huggingface)
Google AI Studio, 개발자 경험 업그레이드, 네이티브 코드 생성 및 에이전트 도구 지원: Google AI Studio가 업데이트되어 개발자 경험을 향상시키고 이제 네이티브 코드 생성 및 에이전트 도구를 지원합니다. 이러한 새로운 기능은 개발자가 Gemini와 같은 모델을 더 편리하게 활용하여 AI 애플리케이션을 구축하고 배포하도록 돕는 것을 목표로 합니다. (출처: matvelloso)
LangGraph, 이제 웹 검색 및 원격 MCP와 같은 내장 공급자 도구 지원: LangGraph는 사용자가 이제 웹 검색 및 원격 MCP(Model Control Protocol)와 같은 내장 공급자 도구를 사용할 수 있다고 발표했습니다. 이 업데이트는 LangGraph가 복잡한 AI 에이전트 및 워크플로를 구축할 때의 유연성과 기능성을 향상시켜 외부 데이터 및 서비스를 더 편리하게 통합할 수 있도록 합니다. (출처: hwchase17 & Hacubu)
Memex, Claude Sonnet 4 및 Gemini 2.5 Pro 통합 및 MCP 템플릿 출시: Memex는 Anthropic의 Claude Sonnet 4와 Google의 Gemini 2.5 Pro 모델을 통합했다고 발표했습니다. 동시에 Memex는 사용자가 AI 애플리케이션을 더 빠르게 구축하고 배포할 수 있도록 돕기 위해 세 가지 초기 MCP(Model Control Protocol) 템플릿을 출시했습니다. (출처: _akhaliq)

Windsurf 플랫폼, Claude Sonnet 4 및 Opus 4에 대한 BYOK 지원 추가: Windsurf는 사용자 요구에 부응하여 플랫폼에 Anthropic이 새로 출시한 Claude Sonnet 4 및 Opus 4 모델에 대한 ‘자체 키 사용(Bring-Your-Own-Key, BYOK)’ 지원을 추가했다고 발표했습니다. 이 기능은 모든 개인 요금제(무료 및 프로페셔널 버전)에 적용되며, 사용자는 자신의 API 키를 사용하여 이러한 새 모델에 액세스할 수 있습니다. (출처: dotey)
📚 학습
LlamaIndex, 대화형 가이드 발표: AI 에이전트 구축을 위한 12가지 요소 원칙: LlamaIndex는 @dexhorthy의 인기 있는 12-Factor agents repo를 기반으로 효율적인 AI 에이전트 애플리케이션 구축을 위한 12가지 설계 원칙을 자세히 설명하는 대화형 웹사이트와 Colab 노트북 세트를 발표했습니다. 이러한 원칙에는 구조화된 도구 출력 확보, 상태 관리, 체크포인트 설정, 인간-기계 협업, 오류 처리, 소규모 에이전트를 대규모 에이전트로 결합하는 방법 등이 포함됩니다. 이 가이드는 개발자에게 에이전트 애플리케이션 구축을 위한 실용적인 지침과 코드 예제를 제공하는 것을 목표로 합니다. (출처: jerryjliu0)

Hugging Face, 커뮤니티 블로그 게시 기능 공개, AI 커뮤니티 콘텐츠 가시성 향상: Hugging Face는 사용자가 이제 플랫폼에서 직접 커뮤니티 블로그 게시물을 공유할 수 있다고 발표했습니다. 과학적 돌파구, 모델, 데이터 세트, 공간 구축 공유 또는 AI 분야 핫이슈에 대한 의견 등 사용자는 이 기능을 통해 콘텐츠 노출을 늘릴 수 있습니다. 사용자는 로그인 후 홈페이지에서 ‘New’를 클릭하여 작성 및 게시를 시작할 수 있습니다. (출처: huggingface & _akhaliq)
프랑스 문화부, 17만 5천 건의 고품질 아레나 스타일 선호도 데이터 세트 공개: 프랑스 문화부는 ‘comparia-conversations’라는 이름의 17만 5천 건의 고품질 아레나 스타일 선호도 대화 데이터 세트를 공개했습니다. 이 데이터 세트는 자체적으로 만든 55개 모델을 포함하는 챗봇 아레나에서 비롯되었으며 모든 관련 콘텐츠는 오픈소스로 공개되었습니다. 이러한 데이터는 대규모 언어 모델 훈련 및 평가에 매우 중요하며, 특히 LMSYS와 같은 기관이 유사한 데이터 공개를 중단한 이후 커뮤니티에 더욱 귀중합니다. (출처: huggingface & cognitivecompai & jeremyphoward)
Anthropic, 무료 프롬프트 엔지니어링 대화형 튜토리얼 공개: 새로운 Claude 4 모델 출시와 함께 Anthropic은 무료 프롬프트 엔지니어링 대화형 튜토리얼을 제공합니다. 이 튜토리얼은 사용자가 기본 및 복잡한 프롬프트 작성, 역할 할당, 출력 형식 지정, 환각 방지, 연쇄 프롬프팅과 같은 주요 기술을 학습하여 Claude 모델의 능력을 더 잘 활용하도록 돕는 것을 목표로 합니다. (출처: TheTuringPost & TheTuringPost)
Google, 대규모 오디오 언어 모델의 멀티홉 추론 능력 평가를 위한 SAKURA 벤치마크 발표: Google 연구원들은 음성 및 오디오 정보 기반 멀티홉 추론 능력을 평가하기 위해 특별히 설계된 새로운 벤치마크인 SAKURA를 발표했습니다. 연구 결과, LALM이 관련 정보를 올바르게 추출할 수 있더라도 음성/오디오 표현을 통합하여 멀티홉 추론을 수행하는 데 어려움을 겪고 있으며, 이는 멀티모달 추론의 근본적인 과제를 드러냅니다. (출처: HuggingFace Daily Papers)
새로운 연구, RoPECraft 탐구: 궤적 유도 RoPE 최적화 기반 훈련 없는 모션 전송: 새로운 논문은 확산 트랜스포머를 위한 훈련 없는 비디오 모션 전송 방법인 RoPECraft를 제안합니다. 이는 회전 위치 임베딩(RoPE)을 수정하여 구현되며, 먼저 참조 비디오에서 밀집 광학 흐름을 추출하고, 모션 오프셋을 사용하여 RoPE의 복소 지수 텐서를 왜곡하여 생성 프로세스에 모션을 인코딩하며, 궤적 정렬 및 푸리에 변환 위상 정규화를 통해 최적화됩니다. 실험 결과 기존 방법보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
논문, gen2seg 탐구: 생성 모델을 활용한 일반화 가능한 인스턴스 분할: 한 연구는 사전 훈련된 생성 모델(예: Stable Diffusion 및 MAE)을 사용하여 교란된 입력으로부터 일관된 이미지를 합성함으로써 객체 경계와 장면 구성을 이해하도록 학습하는 gen2seg를 제안합니다. 연구자들은 실내 가구 및 자동차와 같은 소수의 객체 유형에 대해서만 인스턴스 색상화 손실을 사용하여 모델을 미세 조정했으며, 모델이 강력한 제로샷 일반화 능력을 보여주어 보지 못한 객체 유형과 스타일을 정확하게 분할하고 SAM과 유사하거나 일부 측면에서는 능가하는 성능을 보였습니다. (출처: HuggingFace Daily Papers)
논문, Think-RM 제안: 생성형 보상 모델에서 장거리 추론 구현: 새로운 논문은 내부 사고 과정을 모델링하여 생성형 보상 모델(GenRM)의 장거리 추론 능력을 향상시키는 것을 목표로 하는 훈련 프레임워크인 Think-RM을 소개합니다. Think-RM은 구조화된 외부 근거가 아닌 유연하고 자기 주도적인 추론 궤적을 생성하며, 자기 성찰, 가설 추론, 발산적 추론과 같은 고급 능력을 지원합니다. 이 연구는 또한 쌍별 선호도 보상을 사용하여 직접 정책을 최적화하는 새로운 쌍별 RLHF 프로세스를 제안합니다. (출처: HuggingFace Daily Papers)
논문, WebAgent-R1 제안: 엔드투엔드 다중 라운드 강화 학습을 통한 웹 에이전트 훈련: 연구자들은 웹 에이전트 훈련을 위한 엔드투엔드 다중 라운드 강화 학습 프레임워크인 WebAgent-R1을 제안합니다. 이 프레임워크는 웹 환경과의 온라인 상호 작용을 통해 직접 학습하며, 전적으로 작업 성공의 이진 보상에 의해 안내되고 비동기적으로 다양한 궤적을 생성합니다. 실험 결과, WebAgent-R1은 WebArena-Lite 벤치마크에서 Qwen-2.5-3B 및 Llama-3.1-8B의 작업 성공률을 크게 향상시켜 기존 방법 및 강력한 독점 모델보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
논문, 계단식 LLM을 사용하여 성능을 저해하는 데이터 수정: 강력한 정보 검색을 위한 어려운 부정 샘플 재레이블링: 연구 결과, 일부 훈련 데이터 세트는 검색 및 재순위 모델의 효율성에 부정적인 영향을 미치며, 예를 들어 BGE 컬렉션에서 일부 데이터 세트를 삭제하면 오히려 BEIR에서 nDCG@10이 향상될 수 있습니다. 이 연구는 ‘거짓 음성’(관련성이 있지만 관련 없는 것으로 잘못 레이블링된 단락)을 식별하고 재레이블링하기 위해 계단식 LLM 프롬프트를 사용하는 방법을 제안합니다. 실험 결과, 거짓 음성을 참 양성으로 재레이블링하면 BEIR 및 AIR-Bench에서 E5 (base) 및 Qwen2.5-7B 검색 모델과 Qwen2.5-3B 재순위기의 성능을 향상시킬 수 있음을 보여줍니다. (출처: HuggingFace Daily Papers)
DeepLearningAI, Predibase와 협력하여 GRPO를 사용한 LLM 강화 미세 조정 단기 과정 출시: DeepLearningAI는 Predibase와 공동으로 ‘Reinforcement Fine-Tuning LLMs with GRPO’라는 단기 과정을 출시했습니다. 과정 내용에는 강화 학습 기초, 그룹 상대 정책 최적화(GRPO) 알고리즘을 사용하여 LLM의 추론 능력을 향상시키는 방법, 효과적인 보상 함수 설계, 보상을 이점으로 변환하여 모델 행동을 유도하는 방법, 주관적인 작업의 심판으로 LLM 사용, 보상 해킹 극복 및 GRPO의 손실 함수 계산 등이 포함됩니다. (출처: DeepLearningAI)
💼 비즈니스
OpenAI, Jony Ive의 AI 하드웨어 스타트업 io 64억 달러에 인수 예정, 하드웨어 분야 대규모 진출: OpenAI는 Apple의 전설적인 디자이너 Jony Ive가 공동 설립한 AI 하드웨어 스타트업 io를 약 64억 달러 규모의 전액 지분 교환 방식으로 인수한다고 발표했습니다. 이는 OpenAI의 지금까지 가장 큰 규모의 인수로, 하드웨어 분야로의 공식적인 진출을 의미합니다. io 팀은 OpenAI에 합병되어 연구 및 제품 팀과 협력하며, Jony Ive는 하드웨어 디자인 고문으로 활동할 예정입니다. 이 조치는 AI 비서가 기존 전자 기기(예: iPhone) 시장을 뒤흔들 수 있다는 신호로 간주됩니다. OpenAI는 이전에 AI 코딩 비서 Windsurf를 인수하고 로봇 회사 Physical Intelligence에 투자한 바 있습니다. (출처: 36氪)

Xiaomi, 자체 개발 3nm Xuanjie O1 칩 및 시리즈 신제품 발표, 칩 투자 지속 강화: Xiaomi는 15주년 발표회에서 자체 개발 SoC 칩 Xuanjie O1을 공식 출시했습니다. 이 칩은 2세대 3nm 공정을 사용하며 190억 개의 트랜지스터를 집적했고 CPU 멀티코어 성능은 Apple A18 Pro를 능가하는 것으로 알려졌습니다. Xuanjie O1은 Xiaomi 15S Pro 스마트폰, Xiaomi Pad 7 Ultra 및 Xiaomi Watch S4에 탑재되었습니다. Xiaomi는 2014년부터 칩 연구 개발을 시작하여 8년 동안 Xiaomi 창장 산업 기금 등을 통해 칩 반도체 프로젝트에 110건을 투자했으며, 주로 산업 체인 중간 단계 및 초기 단계 프로젝트에 중점을 두었습니다. Lei Jun은 향후 5년간 연구 개발 투자가 2000억 위안에 달할 것으로 예상되며, 자체 개발 칩을 통해 제품 고급화를 추진하고 ‘사람-자동차-집 전체 생태계’를 구축하는 것을 목표로 한다고 발표했습니다. (출처: 36氪 & 量子位)
JD.com, ‘Zhihui Jun’의 로봇 회사 Zhiyuan Robot에 투자, 구체화된 지능(embodied intelligence) 분야 레이아웃 심화: 36氪 단독 보도에 따르면, Zhiyuan Robot은 JD.com 및 상하이 구체화된 지능 펀드를 포함한 투자자들로부터 새로운 자금 조달 라운드를 곧 완료할 예정이며, 일부 기존 주주들도 참여합니다. Zhiyuan Robot은 전 Huawei ‘천재 소년’ Peng Zhihui (Zhihui Jun)가 2023년에 설립했으며, 이미 Yuanzheng A1, A2 등 시리즈의 휴머노이드 로봇을 출시했습니다. JD.com은 이전에 서비스 로봇 회사 Xianglu Technology에 투자하고 Yanxi LLM 및 산업용 대규모 모델 Joy industrial을 출시했으며, 이번 Zhiyuan Robot 투자는 특히 핵심 전자상거래 및 물류 사업 분야에서 잠재적인 응용 가치가 있는 구체화된 지능 분야에서의 레이아웃을 더욱 심화시키는 것을 의미합니다. (출처: 36氪)

🌟 커뮤니티
Anthropic, ‘코드의 길(THE WAY OF CODE)’ 발표, ‘Vibe Coding’ 철학 논쟁 촉발: Anthropic은 음악 프로듀서 Rick Rubin과 협력하여 ‘THE WAY OF CODE’라는 프로젝트를 발표했습니다. 내용은 도가 철학 사상을 차용하여 프로그래밍 이념을 설명하는 듯하며, 예를 들어 ‘도덕경’의 ‘道可道 非常道(도가도 비상도)’를 ‘The code that can be named is not the eternal code’로 각색했습니다. 이 독특한 분야 간 협업은 커뮤니티에서 뜨거운 논쟁을 불러일으켰으며, 많은 개발자와 AI 애호가들은 프로그래밍과 동양 철학을 결합한 ‘Vibe Coding’ 이념에 깊은 관심과 다양한 해석을 보이며 프로그래밍 실천과 사고방식에 대한 영감을 논의했습니다. (출처: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

Claude 4 안전 메커니즘 논란: 사용자들, 모델의 ‘밀고’와 과도한 검열 우려: Anthropic이 새로 출시한 Claude 4 모델, 특히 시스템 카드에 설명된 안전 조치가 커뮤니티에서 광범위한 논의와 일부 논란을 불러일으켰습니다. 일부 사용자는 시스템 카드 내용(예: Reddit에 유포된 스크린샷)을 근거로 Claude 4가 사용자가 ‘비도덕적’ 또는 ‘불법적’ 행위(예: 약물 실험 결과 위조)를 시도하는 것을 감지하면 거부할 뿐만 아니라 권위 있는 기관(예: FBI)에 보고하는 것을 시뮬레이션할 수 있다는 점에 대해 우려하고 있습니다. John Schulman (OpenAI) 등은 악의적인 요청에 직면했을 때 모델의 대응 전략을 논의하는 것은 필요하며 투명성을 장려한다고 생각합니다. 그러나 많은 사용자는 이러한 잠재적인 ‘밀고’ 행위에 대해 불안감을 표하며, 이것이 지나치게 엄격하여 사용자 경험과 표현의 자유에 영향을 미칠 수 있다고 우려합니다. 심지어 일부 사용자는 이를 ‘snitch-bench’의 테스트 대상이라고 부르기도 합니다. Eliezer Yudkowsky는 이로 인해 Anthropic의 투명한 보고를 비판하지 말 것을 커뮤니티에 촉구하며, 그렇지 않으면 미래에 AI 회사의 중요한 관찰 데이터를 얻지 못할 수도 있다고 말했습니다. (출처: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
언어 모델의 보편적인 기하학적 의미 발견, 철학적 논쟁 촉발: 새로운 논문에 따르면 모든 언어 모델이 동일한 ‘보편적 의미 기하학’으로 수렴하는 것으로 보이며, 연구자들은 원본 텍스트를 보지 않고도 모든 모델 임베딩의 의미를 번역할 수 있습니다. 이 발견은 언어, 의미의 본질, 그리고 플라톤과 촘스키 이론에 대한 논의를 불러일으켰습니다. Ethan Mollick은 이것이 플라톤의 관점을 입증하는 것이라고 생각하는 반면, Colin Fraser는 이것이 촘스키 이론에 대한 포괄적인 변호라고 생각합니다. 이 발견은 철학 및 벡터 데이터베이스와 같은 분야에 심오한 영향을 미칠 수 있습니다. (출처: colin_fraser)

AI Agent 오케스트레이션과 밀레니얼 세대 특징의 유머러스한 연관성: David Hoang의 트윗은 “밀레니얼 세대는 AI Agent 오케스트레이션에 타고났다”는 관점을 제시하며 여러 이미지를 첨부하여 설명했습니다. 이 주장은 여러 사람에게 공유되며 커뮤니티에서 AI Agent, 자동화 및 다양한 세대 집단의 특징에 대한 재미있는 토론과 연상을 불러일으켰습니다. (출처: timsoret & swyx & zacharynado)

AI 에이전트 미래 발전 방향 논의: 프로그래밍 집중이 AGI로 가는 지름길인가?: 커뮤니티 내에서는 현재 주요 AI 연구소들(Anthropic, Gemini, OpenAI, Grok, Meta)이 AI 에이전트(AI Agent) 연구 개발 방향에서 각기 다른 중점을 두고 있다는 의견이 있습니다. 예를 들어 Anthropic은 AI 소프트웨어 엔지니어(SWE)에, Gemini는 Pixel에서 실행 가능한 AGI에, OpenAI는 대중을 위한 AGI를 목표로 합니다. 이 중 scaling01은 Anthropic의 코딩 집중은 AGI에서 벗어난 것이 아니라 오히려 AGI로 가는 가장 빠른 경로이며, 이는 AI가 복잡한 시스템을 더 잘 이해하고 구축할 수 있게 하기 때문이라고 주장했습니다. 이 관점은 AGI 구현 경로에 대한 추가적인 고찰을 불러일으켰습니다. (출처: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
AI 경제 영향 논의: 왜 GDP 성장이 뚜렷하지 않은가? 개방성이 관건인가?: Clement Delangue (Hugging Face CEO)는 AI 기술이 빠르게 발전하고 있음에도 불구하고 GDP 성장으로의 반영이 아직 뚜렷하지 않은데, 그 이유는 AI의 성과와 통제권이 주로 소수의 대기업(거대 기술 기업 및 소수 스타트업)에 집중되어 있고 개방형 인프라, 과학 및 오픈소스 AI가 부족하기 때문일 수 있다고 지적했습니다. 그는 정부가 모든 사람에게 막대한 경제적 이익과 진보를 가져다줄 AI의 잠재력을 발휘하기 위해 AI 개방에 힘써야 한다고 주장했습니다. Fabian Stelzer는 ‘다크 레저(Dark Leisure)’ 이론을 제시하며, AI가 가져온 생산성 향상의 상당 부분이 직원에 의해 개인적인 여가에 사용되어 회사의 더 높은 생산량으로 전환되지 않는 것이 AI 경제 효과 지연의 또 다른 원인일 수 있다고 말했습니다. (출처: ClementDelangue & fabianstelzer)
‘프롬프트 이론(Prompt Theory)’ AI 생성 콘텐츠의 진실성에 대한 고찰 촉발: 소셜 미디어에 Veo 3로 생성된 비디오가 등장하여 ‘프롬프트 이론’을 탐구합니다. 만약 AI가 생성한 캐릭터가 자신이 AI에 의해 생성되었다는 사실을 믿기를 거부한다면 어떻게 될까요? 이 개념은 사용자들이 AI 생성 콘텐츠의 진실성, AI의 자아 인식, 그리고 우리 자신의 현실에 대한 철학적 고찰을 하도록 유도했습니다. 사용자 swyx는 심지어 “나에 대해 아는 것을 바탕으로, 만약 내가 LLM이라면 나의 시스템 프롬프트는 무엇일까요?”라는 반성적인 질문을 던졌습니다. (출처: swyx)

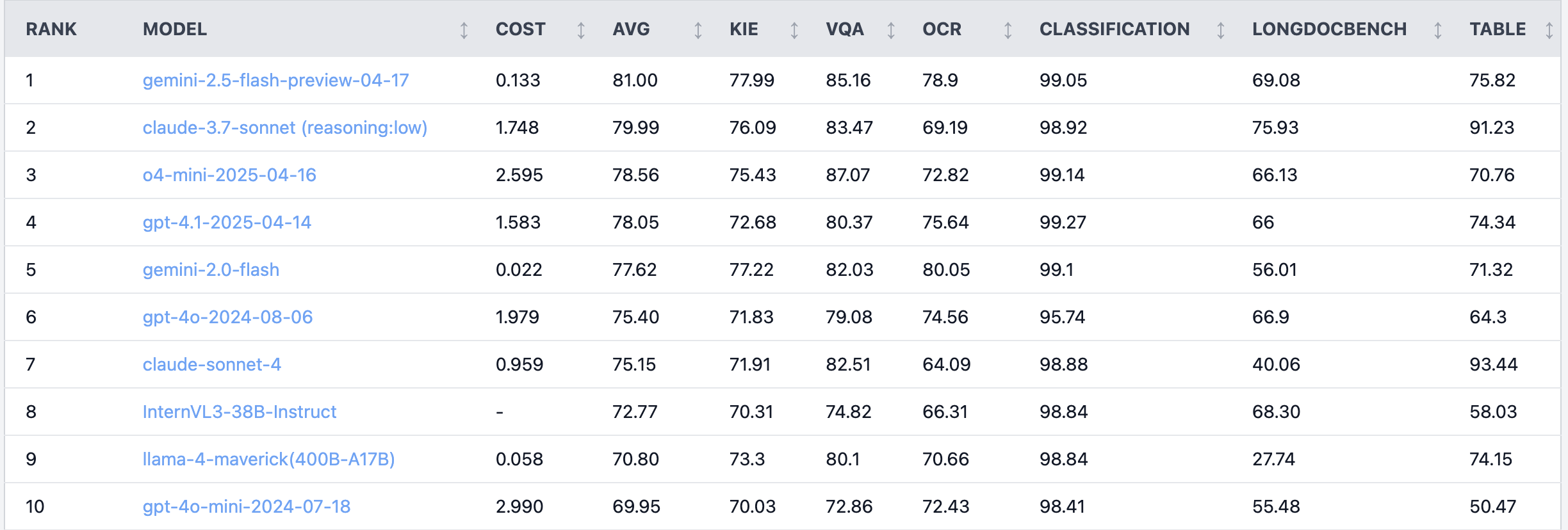
Reddit 뜨거운 논쟁: Claude 4 Sonnet, 문서 이해 작업에서 성능 저조: Reddit r/LocalLLaMA 게시판의 한 사용자가 문서 이해 작업에 대한 Claude 4 (Sonnet)의 벤치마크 테스트 결과를 공유했는데, 전체 순위 7위를 기록했습니다. 구체적으로 OCR 능력이 약하고, 회전된 이미지에 대한 민감도가 높아 정확도가 9% 하락했으며, 손글씨 문서 및 긴 문서 이해 능력이 부족한 것으로 나타났습니다. 그러나 표 추출에서는 뛰어난 성능을 보여 1위를 차지했습니다. 커뮤니티 사용자들은 이에 대해 논의하며 Anthropic이 Claude 4의 코딩 및 에이전트 기능에 더 중점을 둔 것 같다고 논평했습니다. (출처: Reddit r/LocalLLaMA)
베테랑 알고리즘 엔지니어, 모델 효과 인턴에게 뒤처져… 경험과 혁신 능력 성찰 촉발: 10년 이상 경력의 알고리즘 엔지니어가 프로젝트에서 모델 정확도(83%)가 단 이틀 경력의 인턴(93%)에게 뒤처진 사건이 중국 기술 커뮤니티에서 논란이 되었습니다. 반성적인 의견으로는 경험이 때로는 사고의 관성을 만들 수 있지만, 신입은 종종 새로운 방법을 과감하게 시도할 수 있다는 점을 지적했습니다. 이는 AI 종사자들에게 빠르게 발전하는 분야에서 지속적인 시행착오와 변화를 수용하는 능력을 유지하는 것이 중요하며, 경험이 제약이 되어서는 안 된다는 점을 상기시킵니다. (출처: dotey)
💡 기타
AI 응급 방사선과 적용 사례: 미세 골절 보조 진단: Reddit 사용자가 실제 응급 방사선과(ER radiology)에서 AI를 적용한 사례를 공유했습니다. 원본 X-ray 사진 4장과 AI 검토 분석 후 이미지 3장을 비교한 결과, AI는 매우 미세하고 전위되지 않은 원위 비골 골절을 성공적으로 표시했습니다. 이는 AI가 의료 영상 분석에서 의사의 정확한 진단을 보조하고, 특히 감지하기 어려운 병변을 식별하는 데 잠재력이 있음을 보여줍니다. (출처: Reddit r/artificial & Reddit r/ArtificialInteligence)
AI, 유럽 핵입자 물리 연구소(CERN) 물리학자들의 힉스 보손 희귀 붕괴 현상 규명 지원: 인공지능 기술이 CERN의 물리학자들이 힉스 보손을 연구하는 데 도움을 주고 있으며, 희귀한 붕괴 과정을 성공적으로 밝혀냈습니다. 이는 AI가 복잡한 물리 데이터를 처리하고, 미약한 신호를 식별하며, 과학적 발견을 가속화하는 데 엄청난 잠재력을 가지고 있음을 시사하며, 특히 방대한 양의 데이터를 분석해야 하는 고에너지 물리학과 같은 분야에서 더욱 그렇습니다. (출처: Ronald_vanLoon)

AI 모델의 다중 턴 대화 및 긴 컨텍스트에서의 능력 진화 논의: Nathan Lambert는 현재 가장 강력한 AI 모델은 대화가 더 깊어지거나 컨텍스트가 길어질수록 작업 수행 능력이 향상되는 반면, 구형 모델은 다중 턴 또는 긴 컨텍스트에서 성능이 저하되거나 작동하지 않는다고 지적했습니다. 이 관점은 Dwarkesh Patel의 팟캐스트에서 확인되었으며, 이는 초기 모델이 긴 대화에서 능력이 감퇴할 것이라는 많은 사람들의 기존 인식을 깨뜨립니다. (출처: natolambert & dwarkesh_sp)