
키워드:Gemini 2.5 Pro, Veo 3, OpenAI, Jony Ive, Claude 4 Opus, AI 동영상 생성, AI 에이전트, 멀티모달 모델, Deep Think 모드, 동영상 생성 모델, AI 추론 능력, AI 하드웨어 설계, 소프트웨어 엔지니어링 최적화
🔥 주요 뉴스
구글, Gemini 2.5 Pro Deep Think 및 Veo 3 공개, AI 추론 및 비디오 생성의 새로운 지평 열어: Google I/O 컨퍼런스에서 구글은 복잡한 문제 해결을 위해 특별히 설계된 Gemini 2.5 Pro의 Deep Think 모드를 출시했습니다. 이 모드는 USAMO와 같은 수학 경시 대회의 어려운 문제에서 뛰어난 성능을 보여주며, 다단계 추론과 다양한 증명 방법(예: 귀류법, 롤의 정리)을 통해 복잡한 대수 문제를 해결하는 등 AI의 고급 추론 능력에서 중대한 발전을 입증했습니다. 동시에 구글이 공개한 비디오 생성 모델 Veo 3는 사실적인 장면, 제어 가능한 캐릭터 일관성, 사운드 합성 및 다양한 편집 기능(장면 전환, 참조 이미지 생성, 스타일 전이, 시작 및 끝 프레임 지정, 부분 편집 등)을 통해 AI 비디오 생성 분야에서 새로운 기준을 제시하며 광범위한 주목을 받고 있습니다 (출처: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI, Jony Ive 회사 인수에 65억 달러 투자, AI 기반 차세대 컴퓨터 공동 개발: OpenAI는 Apple의 전 최고 디자인 책임자 Jony Ive와 협력하고 그의 회사를 인수하여 AI 기반 차세대 컴퓨터를 공동 개발한다고 발표했습니다. 이는 OpenAI가 하드웨어 분야로 확장하고 AI 기능을 컴퓨팅 장치에 깊이 통합하여 인간-컴퓨터 상호 작용 방식을 재편하려는 시도로 해석됩니다. Jony Ive는 Apple 재직 시절 뛰어난 디자인으로 명성을 얻었으며, 그의 합류는 새로운 장치가 디자인과 사용자 경험에서 중대한 혁신을 이루어 기존 컴퓨팅 장치 형태에 도전할 것임을 예고합니다 (출처: op7418, TheRundownAI, BorisMPower)
Anthropic 개발자 컨퍼런스 개최 임박, Claude 4 Opus 출시 가능성, 소프트웨어 엔지니어링 역량에 초점: Anthropic이 첫 번째 개발자 컨퍼런스를 곧 개최할 예정이며, 커뮤니티에서는 차세대 모델 Claude 4(Sonnet 4 및 Opus 4 포함)가 이번 컨퍼런스에서 공개될 가능성이 높다고 추측하고 있습니다. Claude Sonnet 3.7 API가 “사고 과정” 없이 빠른 도구 사용과 같이 Claude 4와 유사한 동작을 보인다는 징후도 있습니다. Anthropic은 OpenAI와 구글이 “만능 모델”을 추구하는 경로와는 달리 소프트웨어 엔지니어링 난제 해결에 집중하고 있는 것으로 보입니다. TIME지 또한 Claude 4 Opus 출시를 간접적으로 확인하며 AI 코딩 및 복잡한 작업 처리 능력에 대한 시장의 기대를 더욱 높였습니다 (출처: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
OpenAI와 구글의 AI 생태계 전략 차이: 전함 조립 대 제국 개조: OpenAI와 구글은 각각 “생태계 구축”과 “생태계 개조”라는 두 가지 다른 경로를 통해 미래 AI 플랫폼의 “주 운영 체제” 지위를 놓고 경쟁하고 있습니다. OpenAI는 하드웨어(io), 데이터베이스(Rockset), 도구 체인(Windsurf), 협업 도구(Multi) 등을 인수하여 처음부터 완전한 AI 역량을 구축하고 있습니다. 반면 구글은 Gemini 모델을 기존 제품(검색, 안드로이드, Docs, YouTube 등)에 깊이 통합하고 기본 시스템을 개조하여 AI 네이티브화를 실현하는 방식을 선택했습니다. 두 회사의 전략은 다르지만, AI 시대의 궁극적인 플랫폼 구축이라는 목표는 동일합니다 (출처: dotey)
🎯 동향
마이크로소프트, “에이전트 네트워크” 비전 공개, AI 에이전트가 차세대 업무 핵심 될 것 강조: 마이크로소프트 CEO Satya Nadella는 Build 2025 컨퍼런스 및 인터뷰에서 회사의 “에이전트 네트워크(agentic web)” 비전을 설명했습니다. 그는 미래 AI 에이전트가 비즈니스 및 M365 생태계의 핵심 요소가 될 것이며, 심지어 “AI 에이전트 관리자”와 같은 새로운 직업을 창출할 수도 있다고 보았습니다. 코드의 95%가 AI에 의해 생성될 때 인간의 역할은 이러한 에이전트를 관리하고 조정하는 것으로 전환될 것입니다. 마이크로소프트는 Azure AI Foundry, Copilot Studio 및 NLWeb과 같은 개방형 프로토콜을 통해 개방형 에이전트 생태계를 구축하고 있으며 Teams를 다중 에이전트 협업 허브로 만들고 있습니다 (출처: rowancheung, TheTuringPost)
MMaDA: 텍스트 추론, 멀티모달 이해 및 이미지 생성을 통합한 멀티모달 확산 언어 모델 발표: 연구진은 MMaDA(Multimodal Large Diffusion Language Models)라는 새로운 유형의 멀티모달 확산 기반 모델을 출시했습니다. 이 모델은 혼합 장기 연쇄 사고(Mixed Long-CoT)와 통합 강화 학습 알고리즘 UniGRPO를 통해 텍스트 추론, 멀티모달 이해 및 이미지 생성 능력을 통합했습니다. MMaDA-8B는 멀티모달 이해 측면에서 Show-o 및 SEED-X를 능가하며, 텍스트-이미지 생성 측면에서는 SDXL 및 Janus보다 우수합니다. 모델과 코드는 Hugging Face에 공개되었습니다 (출처: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: 확산 언어 모델을 위한 캐시 메커니즘 설계, 추론 속도 대폭 향상: 확산 언어 모델(DLMs)의 느린 추론 속도 문제를 해결하기 위해 연구자들은 dKV-Cache 메커니즘을 제안했습니다. 이 방법은 자기 회귀 모델의 KV-Cache에서 아이디어를 얻어 지연 및 조건부 캐싱 전략을 통해 DLM의 노이즈 제거 프로세스를 위한 키-값 캐시를 설계합니다. 실험 결과 dKV-Cache는 2~10배의 추론 가속을 달성하여 DLM과 자기 회귀 모델 간의 속도 격차를 크게 줄였으며, 긴 시퀀스에서는 성능을 향상시키고 기존 DLM에 훈련 없이 적용할 수 있음을 보여주었습니다 (출처: NandoDF, HuggingFace Daily Papers)

Imagen4, 디테일 재현에서 뛰어난 성능, 이미지 생성의 최종 단계에 근접: Imagen4 모델은 복잡한 텍스트 프롬프트에 따라 이미지를 생성하는 데 있어 강력한 디테일 재현 능력을 보여주었습니다. 예를 들어, 특정 색상, 물체, 위치, 조명 및 분위기와 같은 25개의 구체적인 디테일을 포함하는 이미지를 생성할 때 Imagen4는 그중 23개를 성공적으로 재현했습니다. 이러한 높은 충실도와 복잡한 지시에 대한 정확한 이해는 텍스트-이미지 생성 기술이 사용자의 상상을 완벽하게 재현할 수 있는 “최종 단계” 수준에 근접하고 있음을 시사합니다 (출처: cloneofsimo)

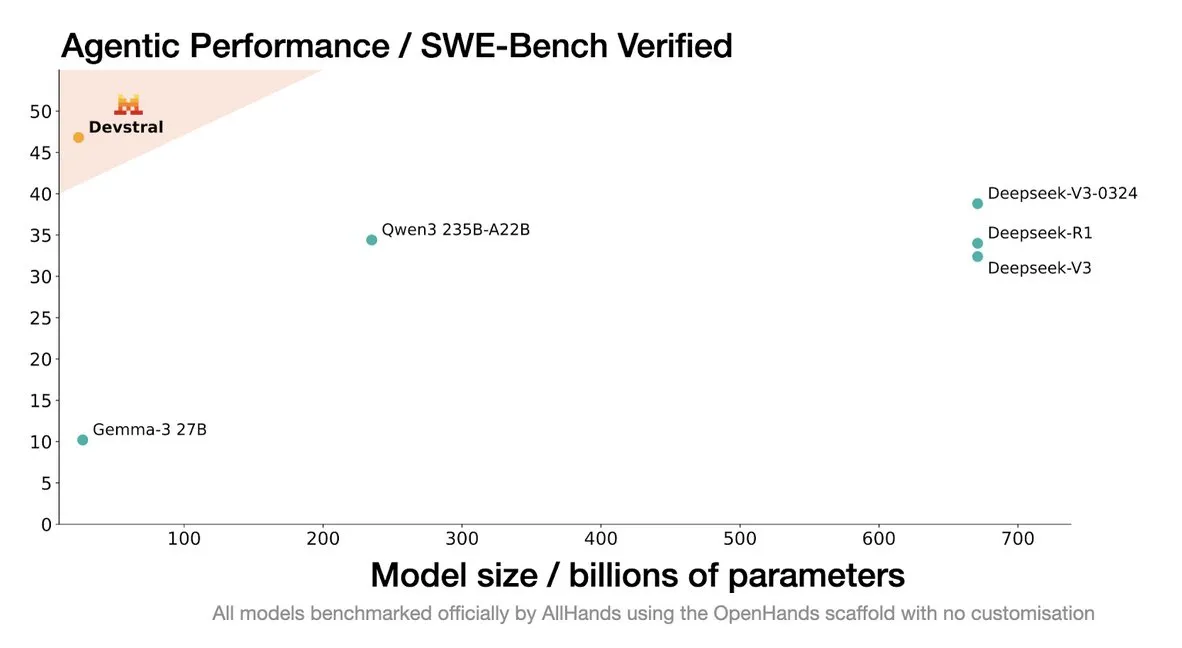
Mistral, 코딩 에이전트 전용 Devstral 모델 출시: Mistral AI는 코딩 에이전트 전용으로 설계된 오픈 소스 모델인 Devstral을 출시했으며, allhands_ai와 협력하여 개발했습니다. 4비트 DWQ 양자화 버전은 Hugging Face(mlx-community/Devstral-Small-2505-4bit-DWQ)에 공개되어 M2 Ultra와 같은 장치에서 원활하게 실행되며 코드 생성 및 이해 측면에서 최적화 가능성을 보여줍니다 (출처: awnihannun, clefourrier, GuillaumeLample)
바이트댄스, Gemini급 멀티모달 모델 훈련 보고서 발표, 통합 Transformer 아키텍처 채택: 바이트댄스는 Gemini급 네이티브 멀티모달 모델 훈련 방법을 상세히 설명하는 37페이지 분량의 보고서를 공개했습니다. 가장 주목할 만한 점은 “통합 Transformer”(Integrated Transformer) 아키텍처로, 이 아키텍처는 동일한 백본 네트워크를 GPT와 유사한 자기 회귀 모델과 DiT와 유사한 확산 모델로 동시에 사용하여 멀티모달 통합 모델링 분야에서의 탐구를 보여줍니다 (출처: NandoDF)

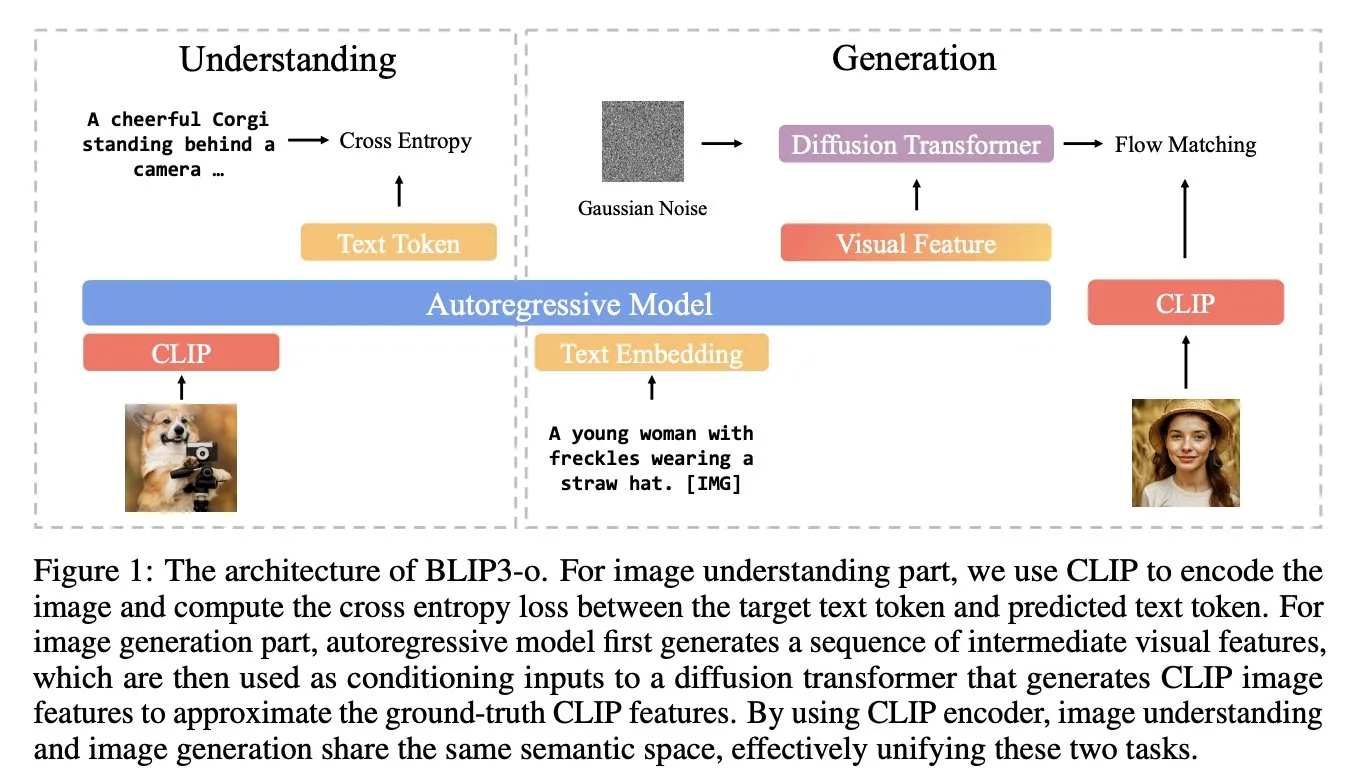
BLIP3-o: Salesforce, GPT-4o급 이미지 생성 능력 잠금 해제 목표로 완전 오픈소스 통합 멀티모달 모델 시리즈 출시: Salesforce 연구팀은 GPT-4o와 유사한 이미지 생성 능력을 잠금 해제하는 것을 목표로 하는 완전 오픈소스 통합 멀티모달 모델 그룹인 BLIP3-o 시리즈 모델을 출시했습니다. 이 프로젝트는 모델뿐만 아니라 2,500만 개의 데이터가 포함된 사전 훈련 데이터셋도 공개하여 멀티모달 연구의 개방성을 촉진합니다 (출처: arankomatsuzaki)
구글, 저자원 장치용 멀티모달 모델 Gemma 3n E4B 프리뷰 버전 출시: 구글은 Hugging Face에 Gemma 3n E4B-it-litert-preview 모델을 출시했습니다. 이 모델은 텍스트, 이미지, 비디오 및 오디오 입력을 처리하고 텍스트 출력을 생성하도록 설계되었으며, 현재 버전은 텍스트 및 시각 입력을 지원합니다. Gemma 3n은 새로운 Matformer 아키텍처를 채택하여 여러 모델을 중첩하고 2B 또는 4B 매개변수를 효과적으로 활성화할 수 있도록 하며, 저자원 장치에서 효율적으로 실행되도록 특별히 최적화되었습니다. 이 모델은 약 11조 개의 토큰으로 구성된 멀티모달 데이터를 기반으로 훈련되었으며, 지식은 2024년 6월까지입니다 (출처: Tim_Dettmers, Reddit r/LocalLLaMA)
연구, 대규모 모델의 언어 특정 지식(LSK) 현상 밝혀내: 새로운 연구는 언어 모델에 존재하는 “언어 특정 지식”(Language Specific Knowledge, LSK) 현상을 탐구했습니다. 이는 모델이 특정 주제나 영역을 처리할 때 특정 비영어 언어에서 영어보다 더 나은 성능을 보일 수 있다는 것입니다. 연구에 따르면 특정 언어(심지어 저자원 언어)에서 연쇄적 사고 추론을 수행하면 모델 성능이 향상될 수 있습니다. 이는 문화 특정 텍스트가 해당 언어에서 더 풍부하여 특정 지식이 “전문가” 언어에만 존재할 수 있음을 시사합니다. 연구자들은 이러한 LSK를 측정하고 활용하기 위해 LSKExtractor 방법을 설계했으며, 여러 모델과 데이터셋에서 평균 정확도가 상대적으로 10% 향상되었습니다 (출처: HuggingFace Daily Papers)
DeepMind Veo 3 비디오 생성 효과 놀라워, 사실적인 디테일로 주목: Google DeepMind의 비디오 생성 모델 Veo 3는 장면 전환, 참조 이미지 기반 생성, 스타일 전이, 캐릭터 일관성, 시작 및 끝 프레임 지정, 비디오 스케일링, 객체 추가 및 동작 제어 등 강력한 비디오 생성 능력을 선보였습니다. 생성된 비디오의 사실성과 복잡한 지시에 대한 이해 능력은 사용자들로 하여금 AI 비디오 생성 기술의 빠른 발전에 감탄하게 했으며, 일부 사용자는 이를 활용하여 전문 제작 수준의 광고 영상을 만들기도 했습니다 (출처: demishassabis, , Reddit r/ChatGPT)
Moondream 시각 언어 모델, 4비트 양자화 버전 출시, VRAM 크게 줄이고 속도 향상: Moondream 시각 언어 모델(VLM)이 4비트 양자화 버전을 출시하여 VRAM 사용량을 42% 줄이고 추론 속도를 34% 향상시키면서도 99.4%의 정확도를 유지했습니다. 이러한 최적화 덕분에 이 강력한 소형 VLM은 객체 감지 등의 작업에서 배포 및 사용이 더욱 용이해져 개발자들로부터 호평을 받고 있습니다 (출처: Sentdex, vikhyatk)
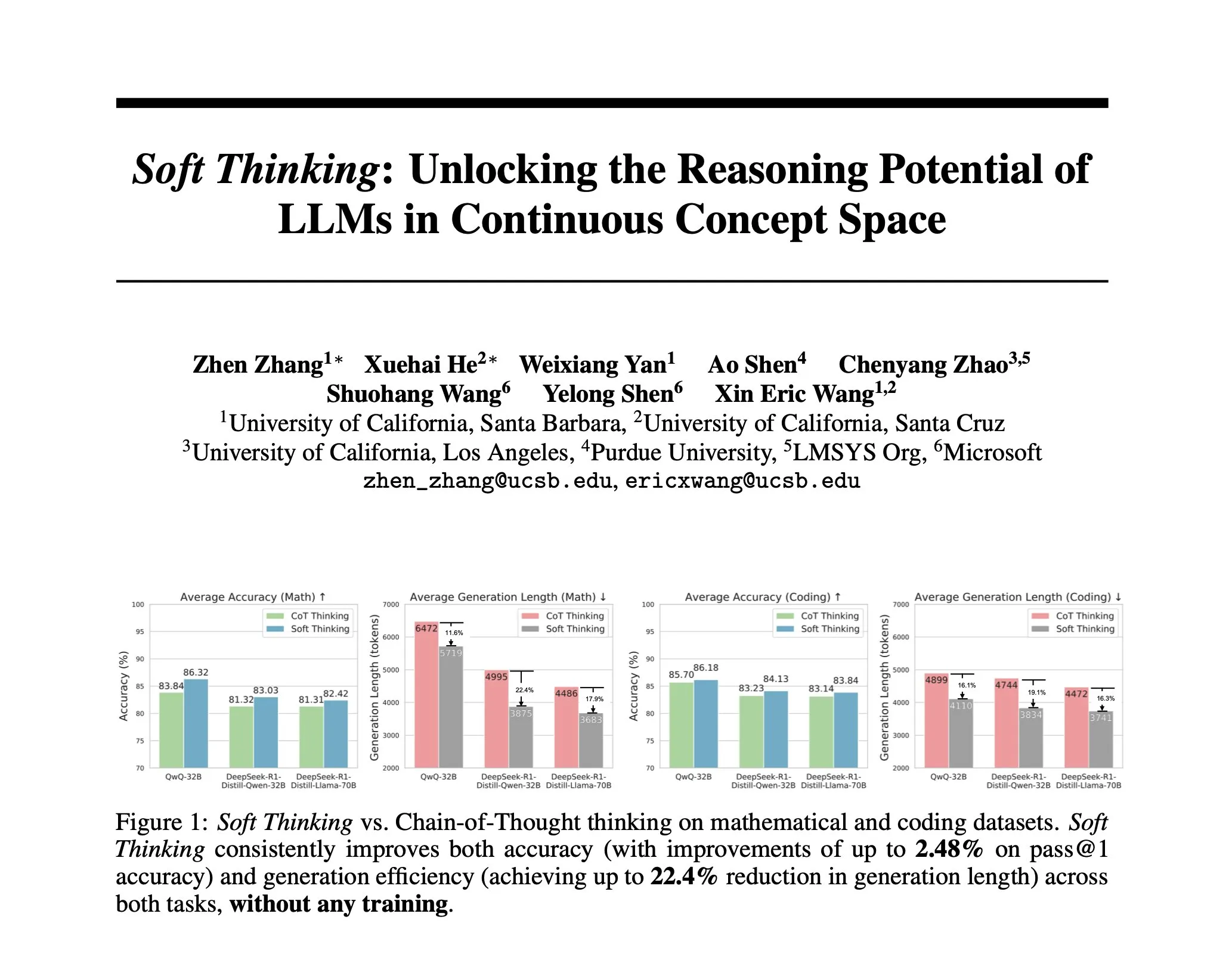
연구, Soft Thinking 제안: 인간의 “부드러운” 추론을 모방하는 비훈련 방법: AI 추론을 이산적인 토큰에 제약받지 않는 인간의 유연한 사고에 더 가깝게 만들기 위해 연구자들은 Soft Thinking 방법을 제안했습니다. 이 방법은 추가 훈련 없이 연속적이고 추상적인 개념 토큰을 생성하며, 이 토큰들은 확률 가중 임베딩 혼합을 통해 다양한 의미를 부드럽게 융합하여 더 풍부한 표현과 다양한 추론 경로에 대한 원활한 탐색을 가능하게 합니다. 실험 결과, 이 방법은 수학 및 코드 벤치마크에서 정확도를 최대 2.48%(pass@1) 향상시키면서 토큰 사용량을 최대 22.4%까지 줄였습니다 (출처: arankomatsuzaki)
IA-T2I 프레임워크: 인터넷을 활용하여 텍스트-이미지 생성 모델의 불확실한 지식 처리 능력 향상: 기존 텍스트-이미지 생성 모델이 불확실한 지식(예: 최근 사건, 희귀 개념)을 포함하는 텍스트 프롬프트를 처리하는 데 부족한 점을 해결하기 위해 IA-T2I(Internet-Augmented Text-to-Image Generation) 프레임워크가 제안되었습니다. 이 프레임워크는 능동적 검색 모듈을 통해 참조 이미지가 필요한지 판단하고, 계층적 이미지 선택 모듈을 사용하여 검색 엔진 반환 결과에서 가장 적합한 이미지를 선택하여 T2I 모델을 강화하며, 자가 반성 메커니즘을 통해 생성된 이미지를 지속적으로 평가하고 최적화합니다. 특별히 구축된 Img-Ref-T2I 데이터셋에서 IA-T2I는 GPT-4o보다 약 30%(인간 평가) 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
MoI (Mixture of Inputs)로 자기 회귀 생성 품질 및 추론 능력 향상: 표준 자기 회귀 생성 과정에서 토큰 분포 정보를 버리는 문제를 해결하기 위해 연구자들은 Mixture of Inputs (MoI) 방법을 제안했습니다. 이 방법은 추가 훈련 없이 토큰을 생성한 후, 생성된 이산 토큰과 이전에 버려진 토큰 분포를 혼합하여 새로운 입력을 구성합니다. 베이즈 추정을 통해 토큰 분포를 사전 확률로, 샘플링된 토큰을 관측값으로 간주하고, 전통적인 원-핫 벡터 대신 연속적인 사후 기대값을 새로운 모델 입력으로 사용합니다. MoI는 수학 추론, 코드 생성 및 박사급 질의응답 작업에서 Qwen-32B, Nemotron-Super-49B 등 여러 모델의 성능을 지속적으로 향상시켰습니다 (출처: HuggingFace Daily Papers)
ConvSearch-R1: 강화 학습을 통한 대화형 검색에서의 질의 재작성 최적화: 대화형 검색에서 문맥 의존적 질의의 모호성, 생략 및 지시 문제를 해결하기 위해 ConvSearch-R1 프레임워크가 제안되었습니다. 이 프레임워크는 강화 학습을 통해 검색 신호를 직접 활용하여 질의 재작성을 최적화하는 자가 구동 방식을 최초로 채택하여, 외부 재작성 감독(예: 인공 주석 또는 대규모 모델)에 대한 의존성을 완전히 제거했습니다. 두 단계 방법에는 자가 구동 전략 예열과 검색 유도 기반 강화 학습(등급 장려 보상 메커니즘 채택)이 포함됩니다. 실험 결과, ConvSearch-R1은 TopiOCQA 및 QReCC 데이터셋에서 이전 SOTA 방법보다 현저히 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
ASRR 프레임워크, 대규모 언어 모델의 효율적인 적응형 추론 실현: 대규모 추론 모델(LRM)이 간단한 작업에서 불필요한 추론으로 인해 과도한 계산 비용이 발생하는 문제를 해결하기 위해 연구자들은 적응형 자가 복구 추론(Adaptive Self-Recovery Reasoning, ASRR) 프레임워크를 제안했습니다. 이 프레임워크는 모델의 “내부 자가 복구 메커니즘”(답변 생성 시 암묵적으로 추론 보충)을 밝혀내 불필요한 추론을 억제하고, 정확도 인지 길이 보상 조정을 도입하여 문제 난이도에 따라 추론 노력을 적응적으로 할당합니다. 실험 결과, ASRR은 성능 손실을 최소화하면서 추론 예산을 크게 줄이고 안전성 벤치마크에서 무해율을 향상시킬 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
MoT (Mixture-of-Thought) 프레임워크, 논리 추론 능력 향상: 인간이 다양한 추론 양식(자연어, 코드, 기호 논리)을 활용하여 논리 문제를 해결하는 것에서 영감을 받아 연구자들은 Mixture-of-Thought (MoT) 프레임워크를 제안했습니다. MoT는 LLM이 새롭게 도입된 진리표 기호 양식을 포함한 세 가지 상호 보완적인 양식에 걸쳐 추론할 수 있도록 합니다. 두 단계 설계(자가 진화 MoT 훈련 및 MoT 추론)를 통해 MoT는 FOLIO 및 ProofWriter와 같은 논리 추론 벤치마크에서 단일 양식 연쇄 사고 방법보다 현저히 우수한 성능을 보였으며, 평균 정확도가 최대 11.7% 향상되었습니다 (출처: HuggingFace Daily Papers)
RL Tango: 강화 학습을 통한 생성기와 검증기 공동 훈련으로 언어 추론 강화: 기존 LLM 강화 학습 방법에서 검증기(보상 모델)가 고정되거나 감독 미세 조정으로 인해 발생하는 보상 해킹 및 일반화 부족 문제를 해결하기 위해 RL Tango 프레임워크가 제안되었습니다. 이 프레임워크는 강화 학습을 통해 LLM 생성기와 생성적, 과정 수준의 LLM 검증기를 교대로 동시에 훈련합니다. 검증기는 결과 수준의 검증 정확성 보상만을 기반으로 훈련되며 과정 수준의 주석이 필요 없어 생성기와 효과적인 상호 촉진을 형성합니다. 실험 결과, Tango의 생성기와 검증기는 7B/8B 규모 모델에서 모두 SOTA 수준에 도달했습니다 (출처: HuggingFace Daily Papers)
pPE: 강화 미세 조정(RFT)을 돕는 사전 프롬프트 엔지니어링: 연구는 강화 미세 조정(Reinforcement Fine-Tuning, RFT)에서 사전 프롬프트 엔지니어링(prior prompt engineering, pPE)의 역할을 탐구했습니다. 추론 시 프롬프트 엔지니어링(iPE)과 달리, pPE는 훈련 단계에서 지시(예: 단계별 추론)를 질의 앞에 배치하여 언어 모델이 특정 행동을 내재화하도록 유도합니다. 실험에서는 5가지 iPE 전략(추론, 계획, 코드 추론, 지식 회상, 빈 예시 활용)을 pPE 방법으로 전환하여 Qwen2.5-7B에 적용했습니다. 결과적으로 모든 pPE 훈련 모델이 iPE 해당 모델보다 우수했으며, 특히 빈 예시 pPE는 AIME2024 및 GPQA-Diamond와 같은 벤치마크에서 가장 큰 향상을 보여 pPE가 RFT에서 충분히 연구되지 않은 효과적인 수단임을 밝혔습니다 (출처: HuggingFace Daily Papers)
BiasLens: 인공 테스트셋 없이 LLM 편향 평가 프레임워크: 기존 LLM 편향 평가 방법이 인공적으로 구축된 레이블 데이터에 의존하고 적용 범위가 제한적인 문제를 해결하기 위해 BiasLens 프레임워크가 제안되었습니다. 이 프레임워크는 모델 벡터 공간 구조에서 출발하여 개념 활성화 벡터(CAV)와 희소 자동 인코더(SAE)를 결합하여 해석 가능한 개념 표현을 추출하고, 목표 개념과 참조 개념 간의 표현 유사성 변화를 측정하여 편향을 정량화합니다. BiasLens는 레이블 데이터가 없는 상황에서 전통적인 편향 평가 지표와 강력한 일관성(스피어만 상관 계수 r > 0.85)을 보였으며, 기존 방법으로는 감지하기 어려운 편향 형태를 밝혀낼 수 있습니다 (출처: HuggingFace Daily Papers)
HumaniBench: 인간 중심의 대규모 멀티모달 모델 평가 프레임워크: 현재 LMM이 공정성, 윤리, 공감 등 인간 중심 표준에서 부족한 성능을 보이는 문제를 해결하기 위해 HumaniBench가 제안되었습니다. 이는 32K개의 실제 세계 이미지-텍스트 질의응답 쌍을 포함하는 포괄적인 벤치마크로, GPT-4o 보조 주석을 거쳐 전문가 검증을 받았습니다. HumaniBench는 공정성, 윤리, 이해, 추론, 언어 포용성, 공감 및 견고성 등 7가지 인간 중심 AI 원칙을 평가하며, 7가지 다양한 작업을 포괄합니다. 15개 SOTA LMM 테스트 결과, 비공개 소스 모델이 전반적으로 우수했지만 견고성과 시각적 위치 파악은 여전히 약점으로 나타났습니다 (출처: HuggingFace Daily Papers)
AJailBench: 최초의 대규모 오디오 언어 모델 탈옥 공격 종합 벤치마크: 대규모 오디오 언어 모델(LAM)의 탈옥 공격에 대한 안전성을 체계적으로 평가하기 위해 AJailBench가 제안되었습니다. 이 벤치마크는 먼저 10개 위반 범주를 포괄하는 1495개의 적대적 오디오 프롬프트로 구성된 AJailBench-Base 데이터셋을 구축했습니다. 이 데이터셋 기반 평가 결과, 기존 SOTA LAM은 모두 일관된 견고성을 보이지 않았습니다. 보다 현실적인 공격을 시뮬레이션하기 위해 연구자들은 오디오 교란 도구 키트(APT)를 개발하여 베이즈 최적화를 통해 미묘하고 효율적인 교란을 검색하고 확장된 데이터셋 AJailBench-APT를 생성했습니다. 연구에 따르면 미미하고 의미를 보존하는 교란만으로도 LAM의 안전 성능을 현저히 저하시킬 수 있습니다 (출처: HuggingFace Daily Papers)
WebNovelBench: LLM 장편 소설 창작 능력 평가 벤치마크: LLM 장편 서사 능력 평가의 어려움을 해결하기 위해 WebNovelBench가 제안되었습니다. 이 벤치마크는 4000편 이상의 중국 웹 소설 데이터셋을 활용하여 평가를 개요에서 이야기 생성 작업으로 설정했습니다. LLM을 평가자로 사용하는 방법을 통해 8가지 서사 품질 차원에서 자동 평가를 수행하고, 주성분 분석을 사용하여 점수를 집계하며, 인간 작품과 백분위 순위 비교를 수행합니다. 실험은 인간 걸작, 인기 웹 소설 및 LLM 생성 콘텐츠를 효과적으로 구분했으며, 24개 SOTA LLM에 대한 종합 분석을 수행했습니다 (출처: HuggingFace Daily Papers)
MultiHal: LLM 환각 평가를 위한 다국어 지식 그래프 기반 데이터셋: 기존 환각 평가 벤치마크가 지식 그래프 경로 및 다국어성 측면에서 부족한 점을 보완하기 위해 MultiHal이 제안되었습니다. 이는 지식 그래프 기반의 다국어, 다중 홉 벤치마크로, 생성 텍스트 평가를 위해 특별히 설계되었습니다. 연구팀은 개방형 도메인 지식 그래프에서 14만 개의 경로를 발굴하고 2.59만 개의 고품질 경로를 선별했습니다. 기준선 평가 결과, 다국어 및 다중 모델에서 지식 그래프 강화 RAG(KG-RAG)는 일반 질의응답에 비해 의미 유사성 점수에서 절대적으로 약 0.12~0.36점 향상되어 지식 그래프 통합의 잠재력을 보여주었습니다 (출처: HuggingFace Daily Papers)
Llama-SMoP: 희소 혼합 프로젝터 기반 LLM 오디오-비디오 음성 인식 방법: LLM이 오디오-비디오 음성 인식(AVSR)에서 계산 비용이 높은 문제를 해결하기 위해 Llama-SMoP가 제안되었습니다. 이는 효율적인 멀티모달 LLM으로, 희소 혼합 프로젝터(SMoP) 모듈을 채택하여 희소 게이팅 혼합 전문가(MoE) 프로젝터를 통해 추론 비용 증가 없이 모델 용량을 확장합니다. 실험 결과, 모달리티 특정 라우팅 및 전문가를 채택한 Llama-SMoP DEDR 구성은 ASR, VSR 및 AVSR 작업에서 모두 우수한 성능을 달성했으며, 전문가 활성화, 확장성 및 노이즈 견고성 측면에서도 좋은 성능을 보였습니다 (출처: HuggingFace Daily Papers)
VPRL: 강화 학습 기반 순수 시각 계획 프레임워크, 텍스트 추론 성능 능가: 케임브리지 대학교, 런던 대학교 칼리지 및 구글 연구팀은 순전히 이미지 시퀀스에 의존하여 추론하는 새로운 패러다임인 VPRL(Visual Planning with Reinforcement Learning)을 제안했습니다. 이 프레임워크는 그룹 상대 정책 최적화(GRPO)를 활용하여 대규모 시각 모델을 사후 훈련하고, 시각적 상태 전환을 통해 보상 신호를 계산하고 환경 제약 조건을 검증합니다. FrozenLake, Maze 및 MiniBehavior와 같은 시각적 탐색 작업에서 VPRL의 정확도는 최대 80.6%에 달하여 텍스트 기반 추론 방법(예: Gemini 2.5 Pro의 43.7%)보다 현저히 우수했으며, 복잡한 작업과 견고성 측면에서도 더 나은 성능을 보여 시각적 계획의 우월성을 입증했습니다 (출처: 量子位)

엔비디아, 향후 5년간 AI 기술 로드맵 발표, AI 인프라 기업으로 전환: 엔비디아 CEO 젠슨 황은 COMPUTEX 2025에서 회사 포지셔닝을 AI 인프라 기업으로 조정하고 향후 5년간의 기술 로드맵을 발표했습니다. 그는 AI 인프라가 전력이나 인터넷처럼 어디에나 존재하게 될 것이며, 엔비디아는 AI 시대의 “공장”을 건설하는 데 주력하고 있다고 강조했습니다. 전환을 지원하기 위해 엔비디아는 공급망 “친구 관계”를 확대하고 TSMC 등과 협력을 심화하며, 중국 대만 지역에 사무소(NVIDIA Constellation)와 최초의 거대 AI 슈퍼컴퓨터를 설립할 계획입니다 (출처: 36氪)

구글, AI 안경 프로젝트 재개, Android XR 플랫폼 및 타사 기기 출시: 구글은 I/O 2025 컨퍼런스에서 AI/AR 안경 프로젝트를 재개하고 XR 기기용으로 특별히 개발된 Android XR 플랫폼을 발표했으며, 이 플랫폼 기반의 두 가지 타사 기기인 삼성의 Project Moohan(Vision Pro 경쟁 모델)과 Xreal의 Project Aura를 선보였습니다. 구글은 스마트폰 분야에서 Android의 성공을 재현하여 XR 기기의 “안드로이드 모멘트”를 만들고 미래 환경 컴퓨팅 및 공간 컴퓨팅 플랫폼을 구축하는 것을 목표로 합니다. 업그레이드된 Gemini 2.5 Pro 멀티모달 대형 모델과 Project Astra 지능형 에이전트 기술을 결합하여 차세대 AI/AR 안경은 음성 이해, 실시간 번역, 상황 인식 및 복잡한 작업 수행 측면에서 혁신적인 경험을 제공할 것입니다 (출처: 36氪)

ARC-AGI-2 챌린지 원칙 업데이트, 다단계 문맥 추론 강조: 새로 발표된 ARC-AGI-2 논문은 해당 챌린지의 설계 원칙을 업데이트했습니다. 새로운 원칙은 작업 해결에 다중 규칙, 다단계 및 문맥 추론 능력을 요구합니다. 그리드는 더 커지고 더 많은 객체를 포함하며 여러 상호 작용 개념을 인코딩합니다. 작업은 참신하고 재사용할 수 없어 기억력을 제한합니다. 이러한 설계는 의도적으로 무차별 대입 프로그램 합성을 억제합니다. 인간 해결자는 작업당 평균 2.7분이 소요되는 반면, 최상위 시스템(예: OpenAI o3-medium)의 점수는 약 3%에 불과하며 모든 작업에는 명확한 인지적 노력이 필요합니다 (출처: TheTuringPost, clefourrier)
Skywork, 8시간 업무를 8분으로 단축 목표로 하는 슈퍼 에이전트 출시: Skywork는 사용자의 8시간 업무량을 8분으로 압축할 수 있다고 주장하는 AI 작업 공간 에이전트인 Skywork Super Agents를 출시했습니다. 이 제품은 AI 작업 공간 에이전트의 선구자로 자리매김하고 있으며, 구체적인 기능과 구현 방식은 추가 관찰이 필요합니다 (출처: _akhaliq)
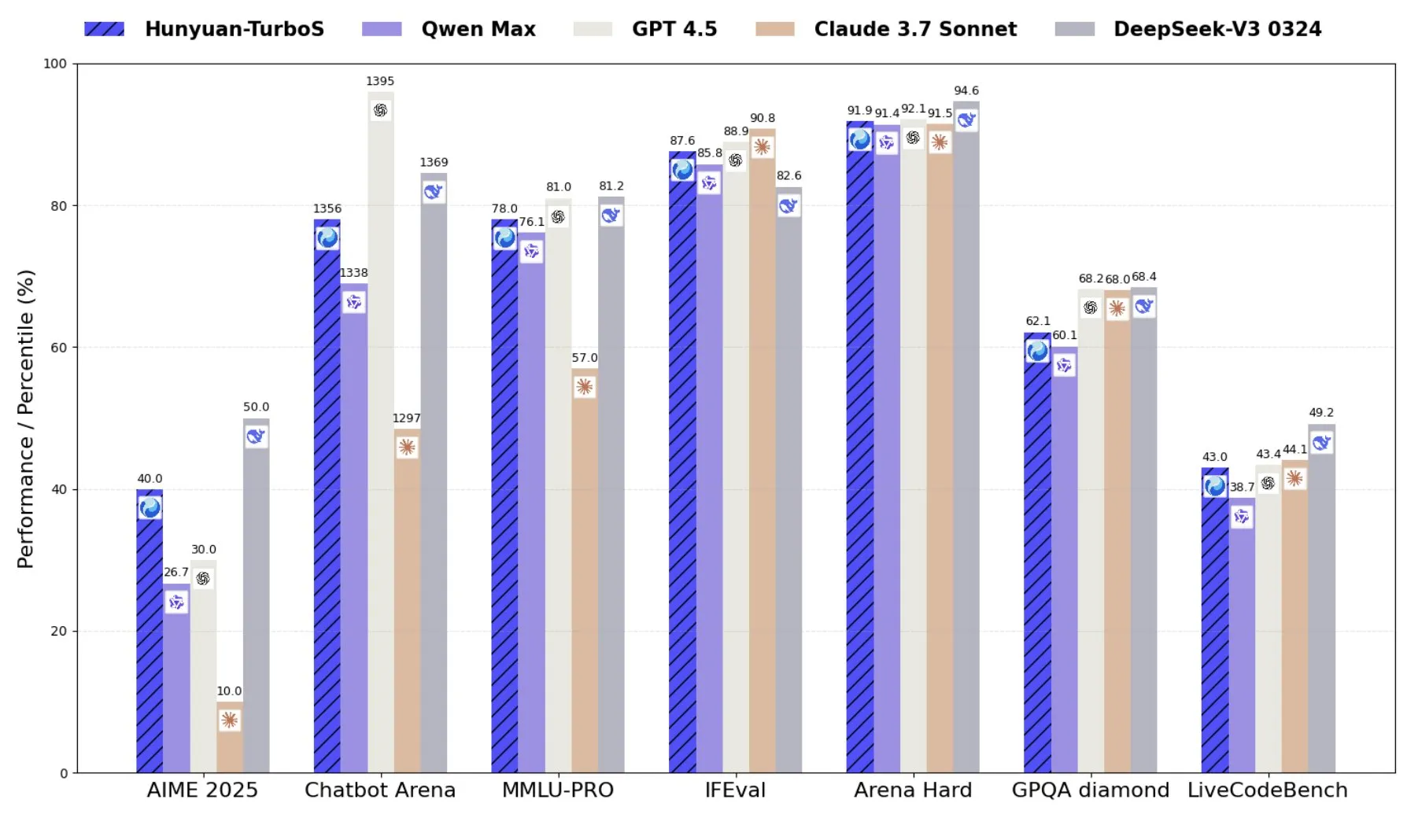
텐센트, Transformer와 Mamba를 결합한 혼합 전문가 모델 Hunyuan-TurboS 출시: 텐센트는 Transformer와 Mamba의 혼합 전문가(MoE) 아키텍처를 채택한 Hunyuan-TurboS 모델을 출시했습니다. 이 모델은 560억 개의 활성 매개변수를 보유하고 있으며 16조 개의 토큰으로 훈련되었습니다. Hunyuan-TurboS는 빠른 응답 모드와 심층 “사고” 모드를 동적으로 전환할 수 있으며 LMSYS Chatbot Arena에서 전체 상위 7위 안에 들었습니다 (출처: tri_dao)
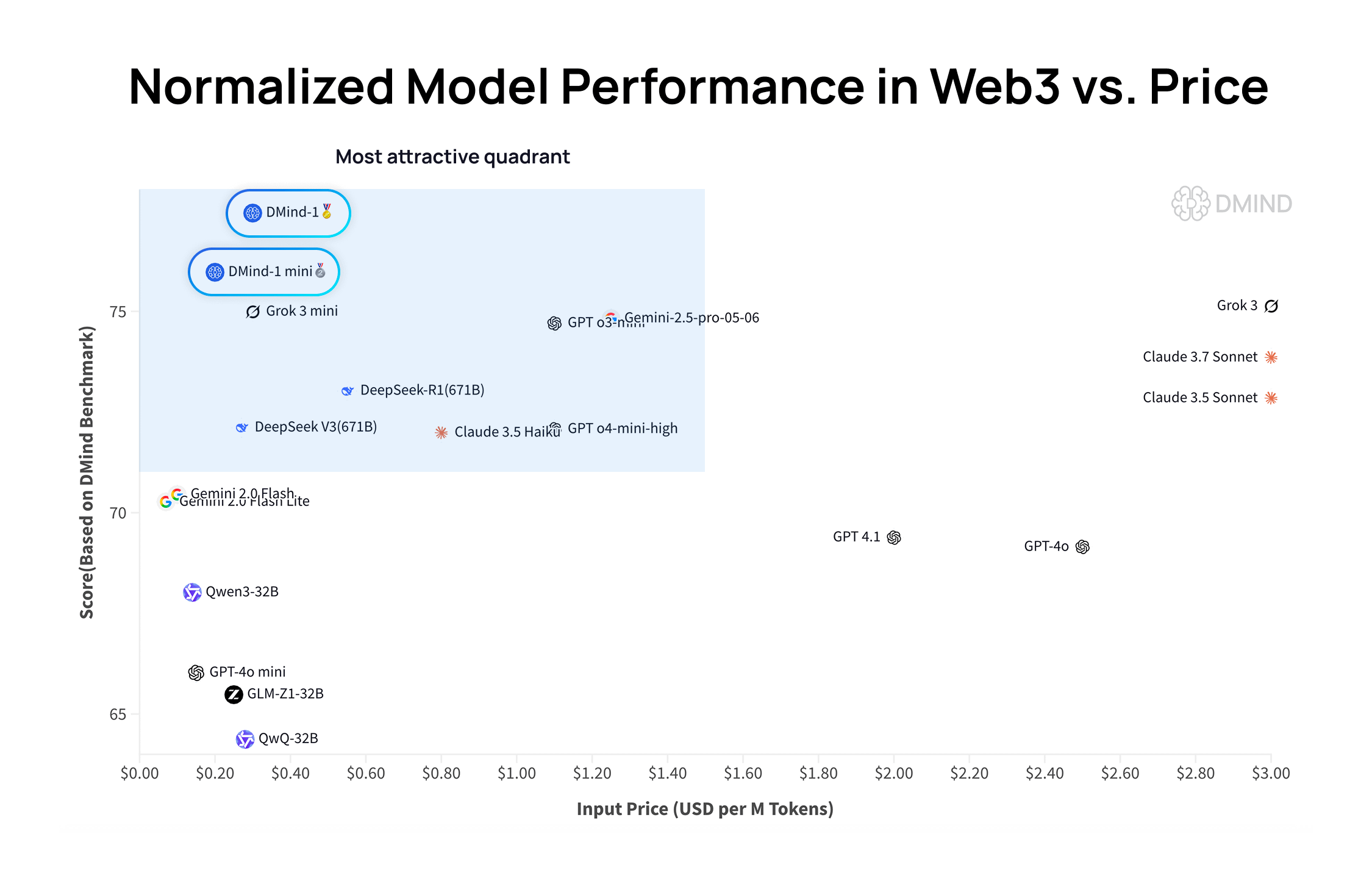
DMind-1: Web3 시나리오를 위해 설계된 오픈소스 대규모 언어 모델: DMind AI는 Web3 시나리오에 최적화된 오픈소스 대규모 언어 모델인 DMind-1을 출시했습니다. DMind-1 (32B)은 Qwen3-32B를 기반으로 미세 조정되었으며 대량의 Web3 특정 지식을 사용하여 AI+Web3 애플리케이션의 성능과 비용 균형을 맞추는 것을 목표로 합니다. Web3 벤치마크 평가에서 DMind-1은 주류 범용 LLM보다 우수한 성능을 보였으며 토큰 비용은 약 10%에 불과했습니다. 동시에 출시된 DMind-1-mini (14B)는 DMind-1 성능의 95% 이상을 유지하면서 지연 시간과 계산 효율성에서 더 우수합니다 (출처: _akhaliq)
LightOn, 추론 집약적 검색 작업에서 뛰어난 성능을 보이는 소형 매개변수 모델 Reason-ModernColBERT 출시: LightOn은 단 1억 4,900만 개의 매개변수만 가진 후기 상호작용 모델인 Reason-ModernColBERT를 출시했습니다. 인기 있는 BRIGHT 벤치마크 테스트(추론 집약적 검색에 중점)에서 이 모델은 매개변수 양이 45배 더 큰 모델을 능가하며 여러 분야에서 SOTA 수준에 도달하는 등 뛰어난 성능을 보였습니다. 이 성과는 특정 작업에서 후기 상호작용 모델의 효율성을 다시 한번 입증했습니다 (출처: lateinteraction, jeremyphoward, Dorialexander, huggingface)

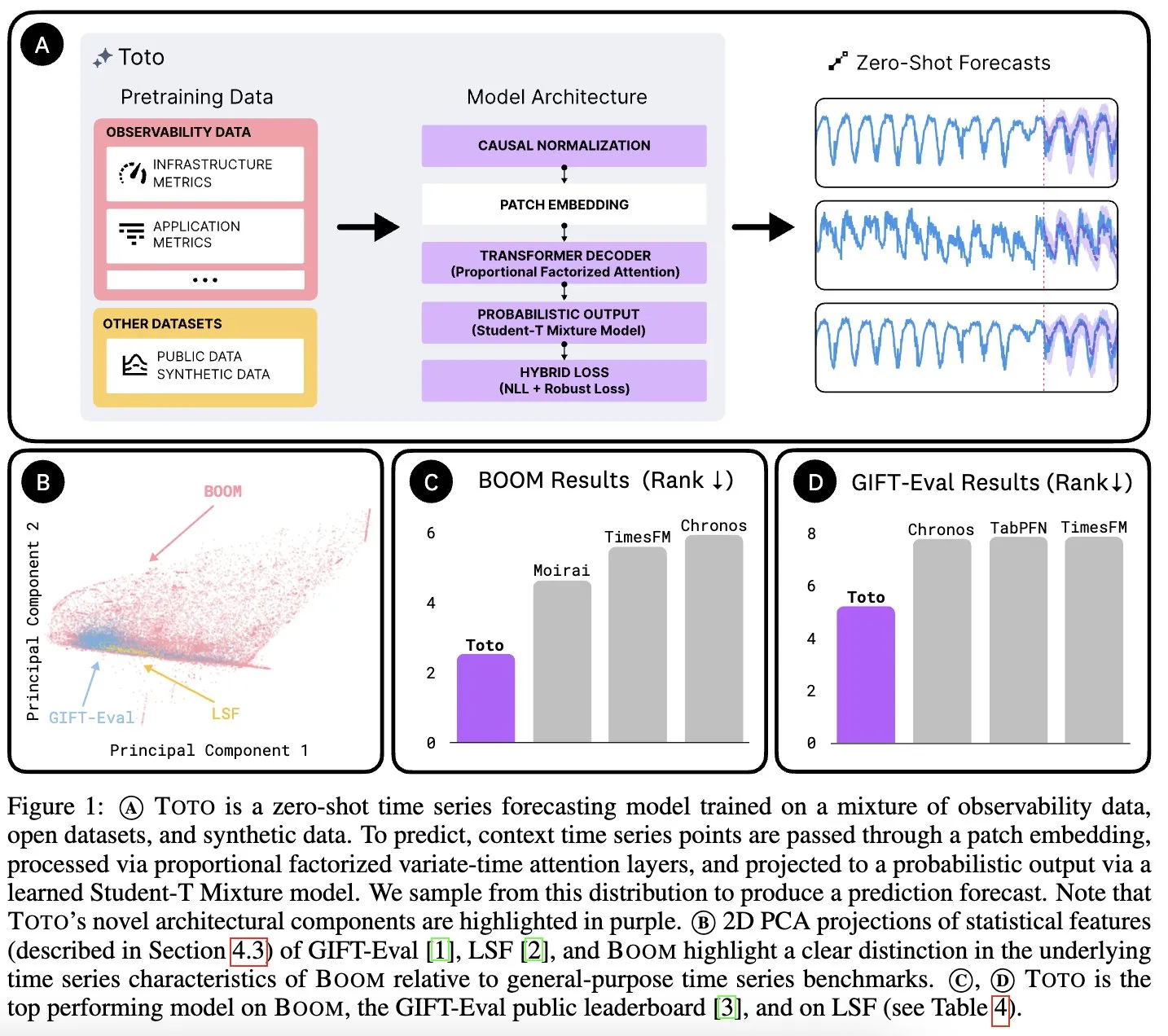
Datadog AI Research, 시계열 기초 모델 Toto 및 관측 지표 벤치마크 BOOM 발표: Datadog AI Research는 새로운 시계열 기초 모델인 Toto를 출시했으며, 관련 벤치마크 테스트에서 기존 SOTA 모델을 크게 앞섰습니다. 동시에 현재 가장 큰 관측 가능성 지표 벤치마크인 BOOM도 발표했습니다. 두 가지 모두 Apache 2.0 라이선스로 오픈소스화되어 시계열 분석 및 관측 가능성 분야의 연구와 응용을 촉진하는 것을 목표로 합니다 (출처: jefrankle, ClementDelangue)
TII, Falcon-H1 시리즈 하이브리드 Transformer-SSM 모델 출시: 아랍에미리트 기술 혁신 연구소(TII)는 Transformer 어텐션 메커니즘과 Mamba2 상태 공간 모델(SSM) 헤드를 결합한 하이브리드 아키텍처 언어 모델 그룹인 Falcon-H1 시리즈 모델을 출시했습니다. 이 시리즈 모델은 매개변수 규모가 0.5B에서 34B까지 다양하며 최대 256K의 컨텍스트 길이를 지원합니다. 여러 벤치마크 테스트에서 Qwen3-32B, Llama4-Scout 등 최상위 Transformer 모델보다 우수하거나 필적하는 성능을 보였으며, 특히 다국어(기본적으로 18개 언어 지원) 및 효율성 측면에서 강점을 보였습니다. 모델은 vLLM, Hugging Face Transformers 및 llama.cpp에 통합되었습니다 (출처: Reddit r/LocalLLaMA)

MIT 연구: AI, 인간 개입 없이 시각과 청각의 연관성 학습 가능: MIT 연구진은 인간의 명시적인 지도나 레이블링된 데이터 없이 시각 정보와 해당 소리 간의 연관성을 자율적으로 학습할 수 있는 AI 시스템을 선보였습니다. 이러한 능력은 AI가 인간처럼 세상을 이해하고 인식할 수 있도록 하는 보다 포괄적인 멀티모달 AI 시스템 개발에 매우 중요합니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

아랍에미리트, 대형 아랍어 AI 모델 출시, 걸프 지역 AI 경쟁 가속화: 아랍에미리트는 대형 아랍어 AI 모델을 출시하여 인공지능 분야에 대한 추가 투자를 알리고 걸프 지역 국가들의 AI 기술 개발 경쟁을 심화시켰습니다. 이는 아랍어의 AI 분야 영향력을 높이고 현지화된 AI 애플리케이션 수요를 충족시키기 위한 조치입니다 (출처: Reddit r/artificial)
분필과기, 특정 분야 대형 모델 출시, “AI+교육” 새로운 패러다임 정의: 분필과기는 텐센트 클라우드 AI 산업 응용 서밋에서 직업 교육 분야의 자체 개발 특정 분야 대형 모델을 선보였습니다. 이 모델은 이미 면접 피드백, AI 문제 풀이 시스템반 등 제품에 적용되어 “가르침, 학습, 연습, 평가, 테스트” 전 과정을 포괄합니다. AI 교사 등의 형태로 “천인일면”에서 “천인천면”의 개인 맞춤형 교육을 실현하고, 자체 개발 대형 모델을 탑재한 AI 하드웨어 제품을 출시하여 교육 지능화 변혁을 추진할 계획입니다 (출처: 量子位)

베이센 쿠쉐위안, 새로운 AI Learning 플랫폼 출시, 5대 AI Agent 도입: 베이센 홀딩스는 쿠쉐위안 인수 후 AI 대형 모델 기반의 새로운 학습 플랫폼 AI Learning을 출시했습니다. 이 플랫폼은 기존 eLearning에 AI 수업 제작 도우미, AI 학습 도우미, AI 연습 파트너, AI 리더십 코치, AI 시험 도우미 등 5가지 지능형 에이전트를 추가하여 Agent 실시간 대화, 기술 훈련, 개인 맞춤형 학습 및 AI 원스톱 수업 제작 및 시험을 통해 전통적인 기업 학습 모델을 혁신하고자 합니다 (출처: 量子位)

포니닷에이아이 Q1 실적: Robotaxi 서비스 매출 전년 동기 대비 8배 급증, 연말까지 무인차 1,000대 배치 예정: 포니닷에이아이는 2025년 1분기 실적을 발표하며 총 매출 1억 200만 위안으로 전년 동기 대비 12% 증가했다고 밝혔습니다. 이 중 핵심인 Robotaxi 서비스 매출은 1,230만 위안으로 전년 동기 대비 200.3% 급증했으며, 승객 요금 수입은 전년 동기 대비 8배나 폭증했습니다. 회사는 2분기부터 7세대 Robotaxi 양산을 시작하여 연말까지 1,000대의 차량을 배치하고, 단일 차량 손익분기점 달성을 목표로 하고 있습니다. 포니닷에이아이는 또한 텐센트 클라우드 및 Uber와 협력하여 각각 위챗과 Uber 플랫폼을 통해 중국 내 및 중동 시장을 확장할 것이라고 발표했습니다 (출처: 量子位)

OpenAI CPO Kevin Weil: ChatGPT, 행동 보조자로 전환, 모델 비용은 이미 GPT-4의 500배: OpenAI 최고 제품 책임자 Kevin Weil은 ChatGPT의 포지셔닝이 질문에 답하는 것에서 사용자를 위해 작업을 수행하는 것으로 전환될 것이며, 웹 브라우징, 프로그래밍, 내부 지식 소스 연결과 같은 도구를 번갈아 사용하여 AI 행동 보조자가 될 것이라고 말했습니다. 그는 현재 모델의 비용이 초기 GPT-4의 500배에 달하지만, OpenAI는 하드웨어 향상과 알고리즘 개선을 통해 효율성을 높이고 API 가격을 낮추기 위해 노력하고 있다고 밝혔습니다. 그는 AI Agent가 빠르게 발전하여 초급 엔지니어 수준에서 1년 안에 아키텍트 수준으로 성장할 것으로 예상했습니다 (출처: 量子位)

🧰 도구
FlowiseAI: AI 에이전트 시각적 구축: FlowiseAI는 사용자가 시각적 인터페이스를 통해 AI 에이전트 및 LLM 애플리케이션을 구축할 수 있도록 하는 오픈 소스 프로젝트입니다. 구성 요소 드래그 앤 드롭, 다양한 LLM, 도구 및 데이터 소스 연결을 지원하여 AI 애플리케이션 개발 프로세스를 간소화합니다. 사용자는 npm 설치 또는 Docker 배포를 통해 Flowise를 빠르게 구축하고 자체 AI 흐름을 테스트할 수 있습니다 (출처: GitHub Trending)

Hugging Face JS 라이브러리 출시, Hub API 및 추론 서비스와의 상호 작용 간소화: Hugging Face는 개발자가 JS/TS를 통해 Hugging Face Hub API 및 추론 서비스와 쉽게 상호 작용할 수 있도록 하는 일련의 JavaScript 라이브러리(@huggingface/inference, @huggingface/hub, @huggingface/mcp-client 등)를 출시했습니다. 이 라이브러리는 리포지토리 생성, 파일 업로드, 10만 개 이상의 모델 추론 호출(채팅 완성, 텍스트-이미지 생성 등 포함), MCP 클라이언트를 사용한 에이전트 구축 등의 기능을 지원하며 다양한 추론 제공업체를 지원합니다 (출처: GitHub Trending)

Jan AI 로컬 실행 환경, Apache 2.0 라이선스로 변경, 기업 사용 장벽 낮춰: Jan AI는 로컬에서 LLM을 실행할 수 있도록 지원하는 오픈소스 도구로, 최근 라이선스를 AGPL에서 더 관대한 Apache 2.0으로 변경했습니다. 이는 기업 및 팀이 AGPL로 인한 규정 준수 문제 걱정 없이 조직 내에서 Jan을 배포하고 사용할 수 있도록 하여, 자유롭게 포크, 수정 및 배포할 수 있게 함으로써 실제 운영 환경에서의 Jan 대규모 채택을 촉진하기 위함입니다 (출처: reach_vb, Reddit r/LocalLLaMA)
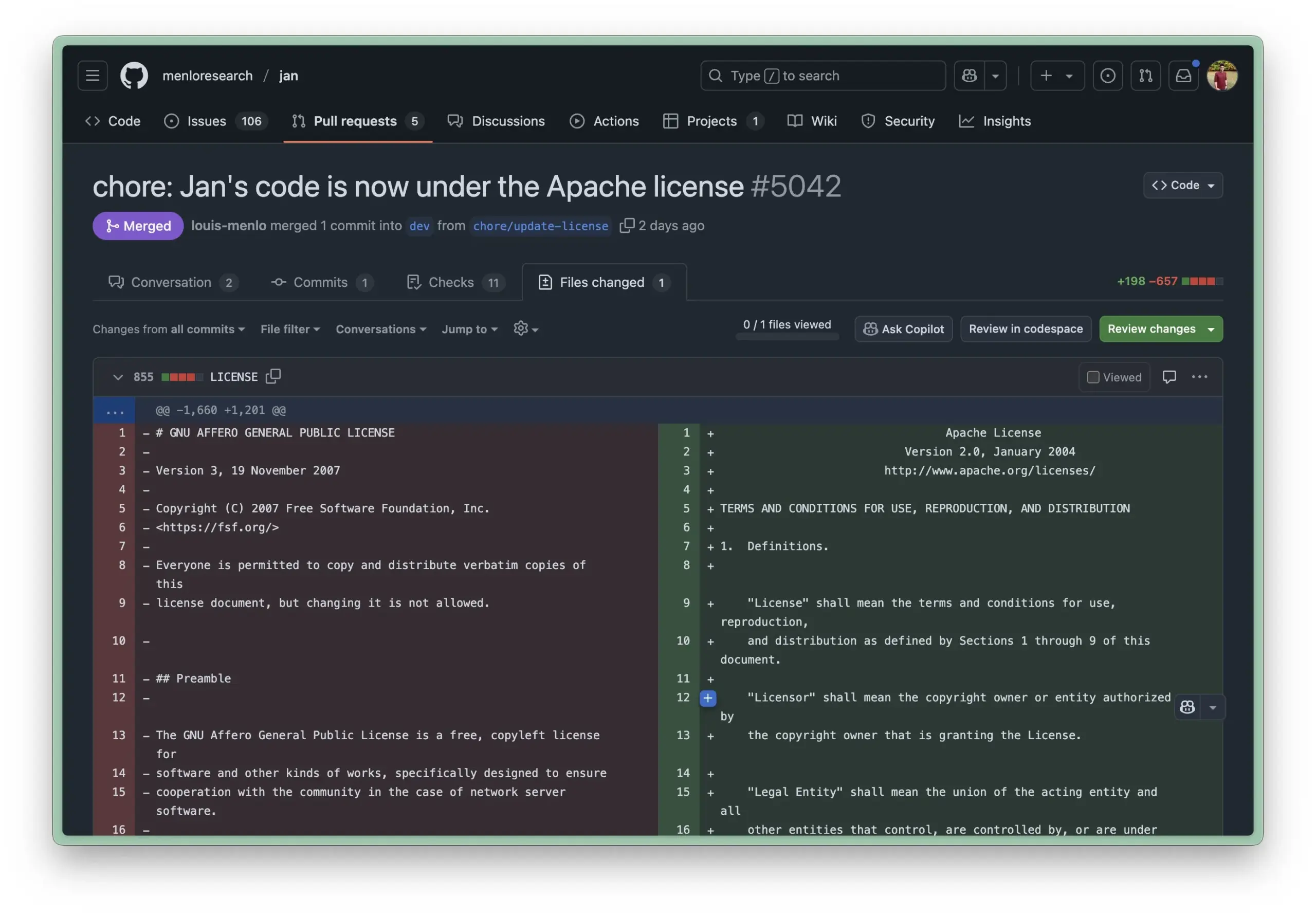
Obsidian, 노트 데이터베이스화 관리 위한 Bases 핵심 플러그인 출시: 지식 관리 소프트웨어 Obsidian이 핵심 플러그인 Bases를 업데이트하여 사용자가 노트 모음을 강력한 데이터베이스로 전환할 수 있게 되었습니다. Bases를 통해 사용자는 사용자 정의 테이블 뷰를 만들고 지식 저장소의 데이터를 시각화하고 대화형으로 조작할 수 있으며, 속성을 통해 노트를 필터링하고 동적 속성을 파생하는 수식을 만들 수 있어 프로젝트 관리, 여행 계획, 독서 목록 등 다양한 시나리오에 적합합니다. 이 기능은 현재 초기 사용자에게 공개되었습니다 (출처: op7418)
Hugging Face, 로컬 모델의 브라우저 및 파일 작업 제어 간소화하는 Tiny Agents 출시: Hugging Face는 MCP 과정에서 사용하기 쉬운 브라우저 제어 설정 프레임워크인 Tiny Agents를 소개했습니다. 사용자는 명령줄, JSON 구성 및 프롬프트 정의를 통해 로컬에서 실행되는 LLM(OpenAI 호환 서버를 통해)이 브라우저(예: Playwright) 또는 로컬 파일 시스템을 제어하도록 할 수 있으며, API를 직접 호출할 필요 없이 llama.cpp와 같은 로컬 모델의 에이전트 애플리케이션에 편의를 제공합니다 (출처: Reddit r/LocalLLaMA)

개발자, LangChain 및 Ollama 기반 AI 이력서 최적화 애플리케이션 오픈소스 공개: 한 개발자가 AI 기반 이력서 최적화 애플리케이션을 구축하고 오픈소스로 공개했습니다. 사용자가 현재 이력서와 목표 직무 설명을 업로드하면 애플리케이션은 이력서의 키워드를 조정하여 채용 요구 사항에 더 부합하도록 시도합니다. 이 프로젝트의 백엔드는 LangChain을 사용하며 BM25 희소 검색과 밀집 모델을 결합한 하이브리드 검색을 수행합니다. 언어 모델은 Ollama를 통해 로컬에서 실행되며 프론트엔드는 React를 사용합니다. 프로젝트는 현재 개념 증명 단계이며 코드는 GitHub에 공개되었습니다 (출처: Reddit r/deeplearning)
Lovable 애플리케이션 구축 도구, 이미지 처리 기능 강화: AI 애플리케이션 구축 도구 Lovable이 이미지 처리 기능을 개선했다고 발표했습니다. 사용자는 이제 채팅에 이미지를 업로드하고 Lovable에 애플리케이션에서 이러한 이미지 자료를 사용하도록 지시할 수 있어 AI 지원 하에 시각적 요소가 포함된 애플리케이션을 구축하는 사용자 경험을 향상시켰습니다 (출처: op7418)
Helios: AI로 정부 업무 가속화를 시도하는 최초의 플랫폼: Joe Scheidler는 AI를 활용하여 정부 업무 효율성을 높이는 것을 목표로 하는 플랫폼인 Helios를 출시했습니다. 이는 “정부판 Cursor”로 묘사되며, 정부 부서를 명확하게 대상으로 하여 AI 기술을 통해 업무 흐름과 효율성을 최적화하려는 최초의 시도 중 하나입니다. 구체적인 기능과 응용 시나리오는 추가 관찰이 필요합니다 (출처: timsoret)
📚 학습
저장대학교, 《대형 모델 기초》 교재 출간, LLM 지식 체계적 설명 및 지속 업데이트: 저장대학교 LLM 팀이 《대형 모델 기초》 교재를 오픈소스로 공개했습니다. 이 책은 대형 언어 모델에 관심 있는 독자들에게 체계적인 기초 지식과 최신 기술을 소개하는 것을 목표로 합니다. 내용은 전통적인 언어 모델, LLM 아키텍처 진화, Prompt 엔지니어링, 매개변수 효율적 미세 조정, 모델 편집, 검색 증강 생성 등을 포함하며 매월 업데이트될 예정입니다. 각 장에는 최신 동향을 추적할 수 있도록 관련 Paper List가 제공됩니다. 전체 PDF 및 장별 내용은 GitHub에 게시되었습니다 (출처: GitHub Trending)

Hugging Face, 다양한 수준과 분야의 지식을 다루는 10개 무료 AI 강좌 제공: Hugging Face는 플랫폼에서 제공하는 10개의 무료 AI 강좌를 종합했습니다. 내용은 입문부터 고급까지 다양한 인기 AI 주제를 포괄하며, 자연어 처리, 딥러닝, 강화 학습, 오디오 처리, 멀티모달 등을 포함합니다. 이 강좌들은 다양한 수준의 학습자들에게 AI 지식을 체계적으로 학습할 수 있는 귀중한 자원을 제공하며, AI 지식 보급과 오픈 소스 커뮤니티 발전을 더욱 촉진합니다 (출처: huggingface, reach_vb, _akhaliq)

스탠포드 대학교, Marin 8B 모델 훈련 경험과 교훈 공유: 스탠포드 대학교 Percy Liang 팀은 Marin 8B 모델(여러 벤치마크에서 Llama 3.1 8B 기본 모델을 능가)을 처음부터 훈련한 상세한 회고록을 공개했습니다. 이 솔직한 기록에는 팀이 연구 개발 과정에서 발견한 모든 내용과 저지른 실수들이 포함되어 있어 커뮤니티에 귀중한 LLM 실제 구축 경험을 제공하며, 연구 과정에서 시행착오와 반복의 중요성을 강조합니다 (출처: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI, Predibase와 협력하여 강화 미세 조정(RFT) LLM 과정 출시: Andrew Ng의 DeepLearning.AI는 Predibase와 협력하여 GRPO(Group Relative Policy Optimization)를 사용한 강화 미세 조정(RFT)을 통해 LLM 성능을 향상시키는 방법에 대한 무료 단기 과정을 출시했습니다. 이 과정은 Predibase 공동 창립자 겸 CTO인 Travis Addair 등이 강의하며, 학습자가 강화 학습을 활용하여 소량의 레이블링된 데이터만으로 소규모 오픈 소스 LLM을 특정 사용 사례에 맞는 추론 엔진으로 전환하는 방법을 습득하도록 돕는 것을 목표로 합니다 (출처: DeepLearningAI)
Hugging Face 논문 페이지, AI 생성 요약 기능 추가: Hugging Face는 논문 전시 페이지에 새로운 기능을 도입하여 각 논문에 AI가 생성한 한 문장 요약을 제공합니다. 이 요약은 논문의 핵심 내용을 간결하고 명확하게 요약하여 사용자가 연구 문헌을 빠르게 선별하고 이해하도록 돕고 학술 자원의 접근성과 사용 효율성을 향상시킵니다. 이 기능은 오픈 소스 LLM으로 구동되며 “AI가 AI 연구를 지원한다”는 이념을 반영합니다 (출처: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

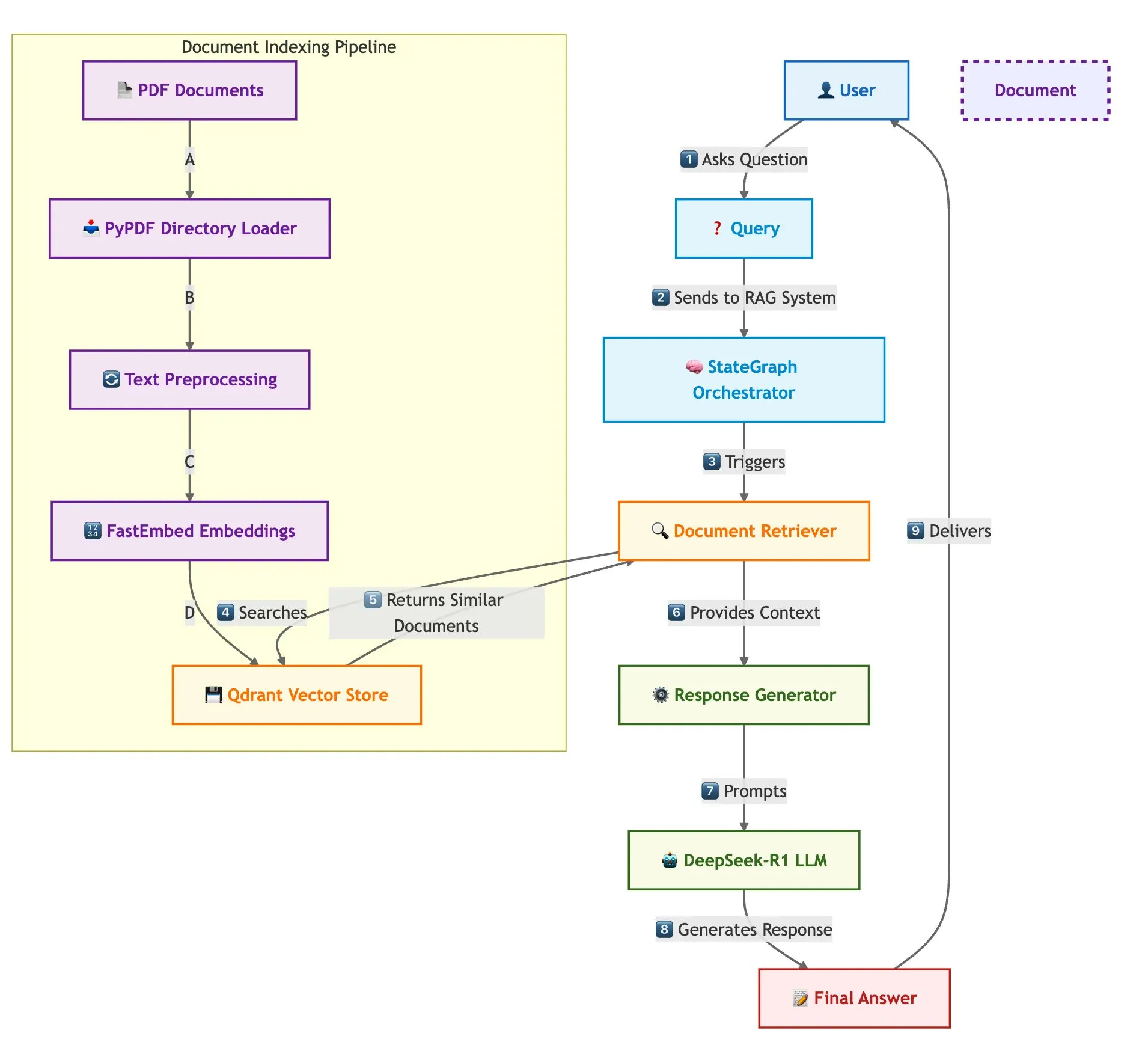
Qdrant, SambaNova 등, 빠른 다중 문서 RAG 시스템 구축 방안 공동 시연: 한 기술 블로그에서 Qdrant 벡터 데이터베이스, SambaNova, DeepSeek-R1 및 LangGraph를 사용하여 고속, 메모리 효율적인 다중 문서 검색 증강 생성(RAG) 시스템을 구축하는 방법을 소개했습니다. 이 방안은 이진 양자화를 통해 32배의 메모리 절약을 달성하고, DeepSeek-R1을 활용하여 빠르고 집중적인 LLM 응답을 제공하며, LangGraph를 통해 모듈식 오케스트레이션을 수행하여 대규모 다중 문서 처리 시나리오에 적합합니다 (출처: qdrant_engine)
LangChain Interrupt 2025 서밋 중국어판 회고록 발표: LangChain Interrupt 2025 서밋의 중국어판 회고록이 발표되었습니다. 이번 서밋에는 전 세계 800여 명이 참여하여 AI 에이전트 구축 경험과 미래 전망을 공유했으며, LangGraph Platform, LangGraph Studio v2 등 다수의 제품을 발표하고 에이전트 엔지니어링, AI 관찰 가능성 등의 주제를 논의했습니다 (출처: hwchase17)
Andi Marafioti, 순수 PyTorch로 시각 언어 모델 훈련 상세 설명하는 nanoVLM 튜토리얼 게시: Andi Marafioti는 순수 PyTorch를 사용하여 처음부터 자체 시각 언어 모델(VLM)을 훈련하는 방법을 상세히 설명하는 새로운 블로그 튜토리얼 nanoVLM을 게시했습니다. 튜토리얼 내용은 이해하기 쉽고 따라 하기 쉬워 초보자가 VLM 훈련 과정을 빠르게 익힐 수 있도록 돕는 것을 목표로 합니다 (출처: LoubnaBenAllal1)

Ferenc Huszár, 연속 시간 마르코프 연쇄 및 확산 언어 모델에서의 응용 해설: 딥러닝 연구자 Ferenc Huszár는 Mercury 및 Gemini Diffusion과 같은 확산 언어 모델(DLM)의 핵심 구성 요소인 연속 시간 마르코프 연쇄(CTMC) 이면의 직관을 심층적으로 설명하는 블로그 게시물을 발표했습니다. 이 글은 마르코프 연쇄의 다양한 관점과 점 과정과의 연관성을 탐구하여 DLM의 이론적 기초를 이해하는 데 유용한 참고 자료를 제공합니다 (출처: fhuszar)
💼 비즈니스
“인공 AI” 회사 Builder.ai 파산 선고, 약 5억 달러 투자 유치: AI로 소프트웨어 개발을 혁신하겠다고 주장하며 한때 기업 가치가 10억 달러에 달했던 영국 회사 Builder.ai(구 Engineer.ai)가 이번 주 파산 청산을 선언했습니다. 이 회사는 AI 플랫폼의 많은 기능이 실제로는 인도 엔지니어들이 수동으로 작업한 것이라는 폭로가 있었습니다. Microsoft, SoftBank DeepCore 등 유명 기관으로부터 약 5억 달러의 투자를 유치했음에도 불구하고 기술의 진실성 의혹, 재무 관리 혼란 및 창업자 법적 분쟁 등의 문제로 결국 자금이 고갈되었으며, Microsoft에 3,000만 달러, Amazon에 8,500만 달러의 클라우드 서비스 비용을 체납했습니다 (출처: 36氪)

LMArena.ai (구 LMSys), 1억 달러 시드 투자 유치, Gradio 애플리케이션에서 상업화로: 처음에는 Gradio 기반의 학술 프로젝트 LMSys(LLM 경쟁 및 평가용)였던 LMArena.ai가 a16z와 캘리포니아 대학 투자 회사가 주도하는 1억 달러 규모의 시드 투자를 유치했다고 발표했습니다. 이번 투자는 LMArena가 신뢰할 수 있는 AI에 대한 연구와 플랫폼 운영을 계속하는 데 지원될 것이며, 성공적인 오픈 소스 학술 프로젝트가 상업적 운영으로 전환되는 것을 의미합니다. 이는 또한 Gradio와 같은 빠른 프로토타이핑 도구가 영향력 있는 AI 프로젝트를 육성하는 데 있어 잠재력을 가지고 있음을 강조합니다 (출처: ClementDelangue, _akhaliq, clefourrier)
AI 인재 쟁탈전 백열화, OpenAI, 구글 등 천만 달러 연봉으로 인재 영입: 실리콘밸리 AI 분야의 인재 쟁탈전이 백열화 단계에 접어들면서, 최고 연구원(IC)들이 OpenAI, 구글, xAI 등 거대 기업들의 핵심 영입 대상이 되었으며, 연봉과 주식 인센티브를 합쳐 천만 달러를 넘는 것이 일반적입니다. 예를 들어, OpenAI는 SSI로 이직하려던 베테랑 연구원을 붙잡기 위해 200만 달러의 보너스와 2,000만 달러 이상의 주식을 제시했으며, 구글 DeepMind도 최고 인재에게 연봉 2,000만 달러의 대우를 제공합니다. 이러한 치열한 경쟁은 소수의 핵심 인재가 대규모 언어 모델 발전에 미치는 막대한 기여 때문이며, 이들의 거취는 AI 모델의 성패에 직접적인 영향을 미칠 수 있습니다 (출처: 36氪)
🌟 커뮤니티
Sora 중국어 능력 다소 향상된 듯, 그러나 모델 한계 여전히 존재: 소셜 미디어 사용자들은 OpenAI의 비디오 생성 모델 Sora가 중국어 텍스트 처리 능력이 향상되어 중국어 문자가 포함된 장면을 생성할 수 있게 된 것으로 관찰했습니다. 그러나 사용자들은 모델이 여전히 한계가 있으며 생성된 내용이 완벽하지 않다고 지적하며, 이러한 불완전성을 받아들이는 것이 현재 단계에서 AI 모델과 상호 작용하는 일반적인 방식일 수 있다고 언급했습니다 (출처: dotey)

Gemini, 심층 보고서 “시험” 기능 출시, 지식 재활용 및 학습 순환 지원: 구글 Gemini는 사용자가 심층 보고서를 읽은 후 Gemini가 직접 문제를 출제하여 테스트하는 새로운 기능을 출시했습니다. 이 기능은 사용자의 내용에 대한 실제 이해도를 검증하고 “학습 → 시험 → 보충 → 재학습”의 AI 네이티브 학습 순환을 구축하여 AI 시대 학습의 핵심이 독서량이 아닌 지식 재활용 능력에 있음을 강조합니다 (출처: dotey)
ChatGPT 기억 기능, 사용자 통제권 우려 야기: ChatGPT가 새로 출시한 “채팅에서 학습하여 기억” 기능은 모델이 사용자의 과거 대화 정보를 기억하여 후속 상호 작용에서 보다 개인화된 응답을 제공할 수 있도록 합니다. 그러나 일부 고급 사용자들은 이것이 모델과의 상호 작용 방식을 변경한다고 우려하며, 모델의 입력 내용을 완전히 통제하고 싶어 하고 모델이 자신도 모르게 또는 정확하게 통제할 수 없는 상황에서 과거 정보를 사용하는 것을 원하지 않는다고 밝혔습니다 (출처: random_walker)
AI Agent 급속 발전, 미래 업무 방식 변화 가능성: 커뮤니티에서는 AI Agent의 빠른 발전과 미래 업무 방식에 대한 잠재적 영향에 대해 활발히 논의하고 있습니다. AI Agent가 단순한 질의응답 도구에서 코딩, 연구, 고객 지원과 같은 복잡한 작업을 독립적으로 완료할 수 있는 “가상 직원”으로 전환되고 있다는 의견이 지배적입니다. OpenAI CPO Kevin Weil은 AI Agent의 능력이 빠르게 향상되어 초급 엔지니어 수준에서 1년 안에 아키텍트 수준으로 성장할 것으로 예상했습니다. 마이크로소프트 또한 “에이전트 네트워크” 구상을 제시하며 미래 업무가 AI 에이전트 관리 및 조정을 중심으로 전개될 수 있음을 예고했습니다 (출처: rowancheung, 量子位)
AI, 의료 진단 분야 잠재력 크지만 의사 직업 불안 야기: AI는 의료 진단 분야에서 놀라운 능력을 보여주고 있습니다. 예를 들어, o1-preview 모델이 의료 추론 및 진단 작업에서 초인적인 능력을 보였다는 연구 결과나 AI가 몇 초 만에 폐렴을 감지한 사례 등이 주목받고 있습니다. 이로 인해 AI 보조 진단이 뜨거운 주제가 되었지만, 20년 경력의 일부 의사들은 자신의 직업 전망에 대해 우려하며 심지어 맥도날드에서 일하러 가야 할지도 모른다고 농담하기도 합니다. 커뮤니티에서는 AI를 의사를 완전히 대체하는 것이 아니라 효율성과 정확성을 높이는 보조 도구로 보아야 한다는 의견이 나오고 있습니다 (출처: paul_cal, Reddit r/ArtificialInteligence)
뉴스 발행사들, 구글 AI 검색 모델 “절도” 비난: 뉴스 미디어 연합 등 발행사들은 구글의 새로운 AI 검색 모델에 대해 강한 불만을 표하며 이를 “절도”라고 비난했습니다. 그들은 구글 AI가 뉴스 콘텐츠에서 직접 정보를 추출하여 검색 결과에 통합함으로써 뉴스 웹사이트를 우회하고 발행사의 트래픽과 광고 수익을 침해한다고 주장하며, AI 시대의 콘텐츠 저작권 및 공정 사용에 대한 격렬한 논쟁을 촉발시켰습니다 (출처: Reddit r/artificial)
DeepSeek 모델, 중국에서 전통 점술에 사용되며 AI 응용 경계 논의 촉발: 일부 사용자는 DeepSeek 모델이 중국에서 주역 점술과 같은 전통적인 운세 활동에 많이 사용되고 있음을 발견했습니다. 이러한 현상은 AI 응용의 경계와 문화적 적응성에 대한 논의를 촉발시켰으며, 간접적으로 사용자의 AI 능력에 대한 다양한 탐색과 수요를 반영합니다 (출처: menhguin, cto_junior)

💡 기타
Figure사 휴머노이드 로봇, BMW 생산 라인에서 20시간 연속 교대 근무 완료: 휴머노이드 로봇 회사 Figure는 자사 로봇이 BMW X3 생산 라인에서 20시간 연속 교대 근무를 성공적으로 완료했다고 발표했습니다. 이전에는 해당 로봇이 몇 주 동안 10시간 교대 근무 테스트를 진행했습니다. Figure는 이것이 전 세계적으로 휴머노이드 로봇이 자동차 생산 라인에서 이처럼 장시간 연속 작업을 완료한 최초의 사례이며, 산업 자동화 분야에서의 잠재력을 보여준다고 밝혔습니다 (출처: adcock_brett, TheRundownAI)
Agentic AI와 GenAI의 차이점 및 연관성: 커뮤니티에서는 Agentic AI(지능형 에이전트 AI)와 Generative AI(생성형 AI)의 개념에 대해 논의했습니다. 생성형 AI는 주로 새로운 콘텐츠(텍스트, 이미지, 코드 등)를 생성할 수 있는 AI를 의미하는 반면, 지능형 에이전트 AI는 자율성, 목표 지향성 및 환경과의 상호 작용 능력을 더 강조합니다. 지능형 에이전트 AI는 일반적으로 생성형 AI를 핵심 능력 중 하나로 활용하여 작업을 이해, 계획 및 실행하며, AI가 더 높은 수준의 자율 지능으로 발전하는 데 중요한 방향입니다 (출처: Ronald_vanLoon, Ronald_vanLoon)

과학 연구에서 AI의 응용은 과소평가되고 있으며, “결과 미화” 현상 존재: 커뮤니티에서는 과학 연구에서 AI의 응용 잠재력이 크지만 과소평가될 수 있으며, 동시에 연구자들이 발표를 위해 AI 실험 결과를 “미화”하는 현상이 존재한다고 지적했습니다. 예를 들어, 편미분 방정식(PDE)과 같은 분야에서 AI의 실제 성능은 논문에 제시된 것만큼 뛰어나지 않을 수 있습니다. 이는 과학계가 과학적 발견에서 AI의 실제 역할과 한계를 보다 엄격하고 투명하게 평가해야 함을 시사합니다 (출처: clefourrier)