
키워드:Gemini 2.5, AI 에이전트, 대규모 언어 모델, 시각 언어 모델, 강화 학습, Gemini 2.5 Pro 딥 씽크 모드, GitHub Copilot 에이전트 오픈소스, MeanFlow 단일 단계 이미지 생성, VPRL 시각 계획 추론, 화웨이 FusionSpec MoE 추론 최적화
🔥 포커스
Google I/O 컨퍼런스, 다수의 AI 발전 발표, Gemini 2.5 시리즈 모델 주도: Google은 I/O 컨퍼런스에서 AI 분야의 많은 업데이트를 발표했습니다. Gemini 2.5 Pro는 현재 가장 강력한 기본 모델로 평가받으며 여러 벤치마크 테스트에서 선두를 달리고 Deep Think 강화 추론 모드를 도입했습니다. 경량 모델 Gemini 2.5 Flash도 속도와 효율성에 중점을 두고 업그레이드되었습니다. Google 검색은 ‘AI 모드’를 도입하여 Gemini 2.5를 통해 엔드투엔드 AI 검색 경험을 제공하며, 복잡한 문제를 분해하고 심층적인 정보 검색을 수행할 수 있습니다. 동영상 생성 모델 Veo 3는 음향-화면 동기화 생성을 구현했으며, 이미지 모델 Imagen 4는 디테일과 텍스트 처리 능력을 향상시켰습니다. 또한 AI 영화 제작 도구 Flow와 AI 비서 프로젝트 Project Astra의 상용화 애플리케이션 Gemini Live도 출시했습니다. 이러한 업데이트는 Google이 AI를 자사 제품 생태계에 전면적으로 통합하여 사용자 경험과 개발자 효율성을 향상시키려는 결의를 보여줍니다 (출처: 量子位, 36氪, WeChat)

Microsoft Build 컨퍼런스, AI Agent 강력 추진, GitHub Copilot 대규모 업그레이드 및 오픈소스 발표: Microsoft는 Build 2025 개발자 컨퍼런스에서 AI Agent를 핵심으로 두고 GitHub Copilot Extension for VSCode 프로젝트를 오픈소스로 전환하며 새로운 AI 코딩 에이전트(Agent)를 출시한다고 발표했습니다. 이 Agent는 버그 수정, 기능 추가, 문서 최적화 등의 작업을 자율적으로 완료하며 GitHub Copilot에 깊이 통합됩니다. Microsoft는 또한 과학적 발견을 위한 AI 지능형 에이전트 플랫폼 Microsoft Discovery, 자연어 상호 작용 웹사이트 프로젝트 NLWeb, 지능형 에이전트 구축 플랫폼 Agent Factory 및 맞춤형 기업 데이터를 위한 Copilot Tuning을 발표했습니다. 이러한 조치는 Microsoft가 개발, 과학 연구 등 여러 분야에서 AI Agent의 적용을 적극적으로 추진하고 개방형 지능형 에이전트 협업 생태계를 구축하려는 의지를 보여줍니다 (출처: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil, ChatGPT 전환 방향 설명: 질의응답에서 행동으로, AI Agent 빠른 진화 전망: OpenAI 최고 제품 책임자(CPO) Kevin Weil은 인터뷰에서 ChatGPT의 포지셔닝이 질문에 답하는 도구에서 사용자를 위해 작업을 수행할 수 있는 AI Agent로 전환될 것이라고 밝혔습니다. 그는 AI Agent가 단기적으로 초급 엔지니어에서 고급 엔지니어, 나아가 아키텍트 수준으로 빠르게 진화할 것으로 예상했습니다. 이는 AI Agent가 더 강력한 자율성을 갖추고 웹 페이지 검색, 심층적 사고 및 추론 요약을 통해 복잡한 문제를 해결할 수 있게 됨을 의미합니다. Weil은 또한 현재 모델의 훈련 비용이 GPT-4의 500배에 달하지만, 향후 하드웨어 개선과 알고리즘 개선을 통해 효율성을 높이고 API 가격을 낮춰 AI의 보급과 발전을 촉진할 것이라고 언급했습니다 (출처: 量子位, 36氪)

허카이밍 팀, MeanFlow 제안: 단일 단계 이미지 생성 새로운 SOTA, 사전 훈련 없이 기존 패러다임 전복: 허카이밍(何恺明) 팀의 최신 연구는 MeanFlow라는 단일 단계 생성 모델링 프레임워크를 선보였습니다. ImageNet 256×256 데이터셋에서 단 1회의 함수 평가(1-NFE)만으로 FID 점수 3.43을 달성하여 기존 동급 최고 방법보다 50%-70% 향상되었으며, 사전 훈련, 증류 또는 커리큘럼 학습이 필요 없습니다. MeanFlow의 핵심 혁신은 ‘평균 속도장’ 개념을 도입하고 순간 속도장과의 수학적 관계를 도출하여 신경망 훈련을 지도하는 데 있습니다. 이 방법은 또한 샘플링 시 추가 계산 비용 없이 분류기 없는 안내(CFG)를 자연스럽게 통합하여 단일 단계와 다중 단계 생성 모델 간의 성능 격차를 크게 줄였으며, 적은 단계 수 모델이 다중 단계 모델에 도전할 수 있는 잠재력을 보여주었습니다 (출처: WeChat, WeChat)

🎯 동향
ByteDance, Bagel 14B MoE 멀티모달 모델 출시, 이미지 생성 지원 및 오픈소스 공개: ByteDance는 Bagel이라는 140억 파라미터 혼합 전문가(MoE) 멀티모달 모델을 출시했으며, 이 중 70억 파라미터가 활성 상태입니다. 이 모델은 이미지 생성 능력을 갖추고 있으며 Apache 라이선스로 오픈소스 공개되었습니다. 관련 가중치, 웹사이트 및 논문(제목: 《Emerging Properties in Unified Multimodal Pretraining》)도 모두 공개되었습니다. 커뮤니티는 이것이 이미지와 텍스트를 동시에 생성할 수 있는 최초의 로컬 모델이라고 긍정적으로 반응하며, 24GB 그래픽 카드에서의 실행 가능성 및 양자화 문제에 관심을 보이고 있습니다 (출처: Reddit r/LocalLLaMA)
Mistral AI, Devstral 출시: 코딩에 최적화된 SOTA 오픈소스 모델: Mistral AI는 소프트웨어 엔지니어링 작업을 위해 특별히 설계된 선도적인 오픈소스 모델인 Devstral을 출시했습니다. 이 모델은 Mistral AI와 All Hands AI가 협력하여 구축했습니다. Devstral은 SWE-bench 벤치마크 테스트에서 뛰어난 성능을 보여 해당 벤치마크에서 1위를 차지한 오픈소스 모델이 되었습니다. 이 모델은 도구를 사용하여 코드베이스를 탐색하고, 여러 파일을 편집하며, 소프트웨어 엔지니어링 에이전트를 지원하는 데 능숙합니다. 모델 가중치는 Hugging Face에서 공개되었습니다 (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

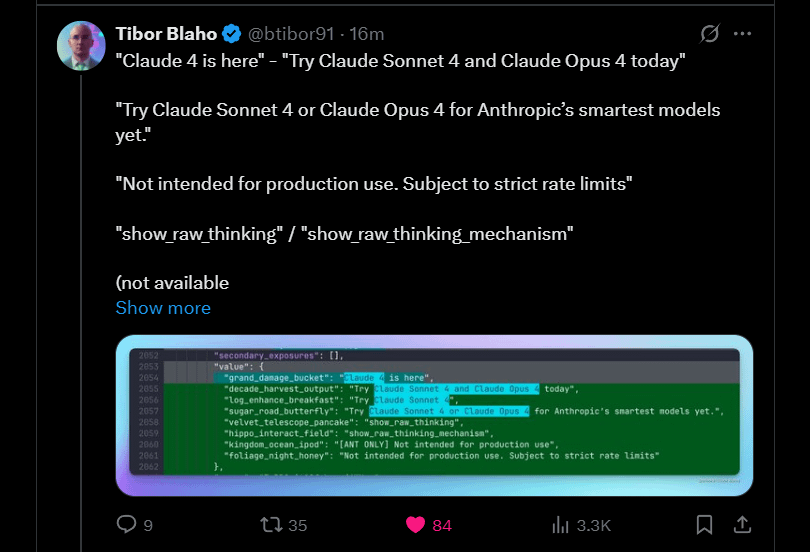
Anthropic, Claude 4 Sonnet 및 Opus 출시 예고: Anthropic은 자사의 Claude 대규모 모델 차세대 버전인 Claude 4 Sonnet과 Opus를 출시할 계획입니다. 이 소식은 커뮤니티에서 기대를 모으고 있으며, 사용자들은 새 모델의 성능, 특히 컨텍스트 기억 능력 향상에 관심을 보이고 있습니다. 일부 댓글에서는 Google I/O 컨퍼런스 발표가 경쟁사들이 최고의 제품을 더 빨리 출시하도록 자극했을 수 있다고 지적했습니다. 동시에 사용자들은 새 모델의 제한(예: 사용 할당량)에 대해 우려를 표명하며, 실망하지 않도록 Opus 4에 대한 지나친 기대를 하지 말라고 커뮤니티에 당부했습니다 (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google, Gemma3n Android 앱 출시, 로컬 LLM 추론 지원: Google은 새로운 Gemma3n 모델과 상호 작용할 수 있는 Android 앱을 출시하고 관련 MediaPipe 솔루션 및 GitHub 코드 저장소를 제공했습니다. 사용자들은 앱 인터페이스가 양호하다고 피드백했지만, Gemma3n이 현재 GPU 추론을 지원하지 않는다고 지적했습니다. 한 사용자는 gemma-3n-E2B 모델을 수동으로 로드하여 실행 데이터를 공유했으며, 커뮤니티는 검열되지 않은 버전의 모델에 대한 요구를 표명했습니다 (출처: Reddit r/LocalLLaMA)

Falcon-H1 하이브리드 헤드 언어 모델 제품군 출시, 다양한 파라미터 규모 포함: TII UAE는 0.5B에서 34B에 이르는 다양한 파라미터 규모의 Falcon-H1 시리즈 하이브리드 헤드 언어 모델을 출시했습니다. 이 시리즈 모델은 Mamba 하이브리드 아키텍처를 채택하여 성능 면에서 Qwen3와 견줄 만합니다. 모델은 Hugging Face Transformers, vLLM 또는 맞춤형 llama.cpp 라이브러리를 통해 사용할 수 있어 모델의 사용 편의성을 보장합니다. 커뮤니티는 이것이 중요한 진전이라고 흥분하며, 한 사용자는 성능 비교 차트를 제작했습니다. 동시에 연구자들은 SSM과 어텐션 모듈 조합 방식에서 IBM Granite 4와의 차이점에 주목하고 있습니다 (출처: Reddit r/LocalLLaMA)

Google, Gemini Diffusion 탐색: diffusion 아키텍처의 언어 모델: Google은 언어 확산 모델 Gemini Diffusion을 선보였습니다. 이 모델은 매우 빠르며 모델 크기가 동일 성능 모델의 절반에 불과하다고 합니다. 확산 모델은 전체 텍스트를 한 번에 반복 처리할 수 있고 KV 캐시가 필요 없어 메모리 효율성에서 이점이 있을 수 있으며, 반복 횟수를 늘려 출력 품질을 향상시킬 수 있습니다. 커뮤니티는 Google이 대규모 응용 프로그램에서 확산 모델의 실행 가능성을 입증할 수 있다면 로컬 AI 커뮤니티에 긍정적인 영향을 미칠 것이라고 생각합니다. 그러나 현재 이 모델은 데모 대기자 명단만 제공하며 오픈소스 공개되거나 가중치 다운로드를 제공하지 않습니다 (출처: Reddit r/LocalLLaMA)

연구, Browser Use 프레임워크에 제로 클릭 Agent 하이재킹 취약점(CVE-2025-47241) 발견: ARIMLABS.AI의 연구에 따르면 1500개 이상의 AI 프로젝트에서 널리 사용되는 Browser Use 프레임워크에 심각한 보안 취약점(CVE-2025-47241)이 존재하는 것으로 밝혀졌습니다. 이 취약점은 공격자가 LLM 기반 브라우징 에이전트를 악성 페이지에 접속하도록 유도하여 사용자 상호 작용 없이 에이전트를 제어할 수 있는 제로 클릭 Agent 하이재킹을 가능하게 합니다. 이 발견은 자율 AI 에이전트, 특히 웹과 상호 작용하는 에이전트의 보안에 대한 심각한 우려를 불러일으키며, AI 에이전트 보안 문제에 대한 커뮤니티의 관심을 촉구합니다 (출처: Reddit r/artificial, Reddit r/artificial)
Tencent와 Alibaba, AI to C 분야에서 경쟁, QQ Browser와 Quark 경쟁 구도: Tencent CSIG 산하 QQ Browser는 AI 브라우저로 업그레이드하고 AI QBot을 출시하며 Tencent Hunyuan과 DeepSeek 듀얼 모델을 탑재하여, 이미 AI 검색으로 전환한 Alibaba 산하 Quark과 본격적인 경쟁에 돌입한다고 발표했습니다. 이는 Tencent가 AI to C 분야에서의 레이아웃을 가속화하여 Tencent Yuanbao와 QQ Browser라는 두 가지 주요 제품 라인을 형성했음을 의미합니다. 양측의 핵심 책임자인 우쭈룽(Tencent)과 우자(Alibaba)도 이로 인해 ‘쌍우 대결’ 구도를 형성하게 되었습니다. 분석가들은 QQ Browser가 사용자 기반에서 우위를 점하고 Quark이 AI 전환에서 한발 앞서 있지만, QQ Browser의 전환은 상대적으로 보수적이며 AI 기능이 플러그인에 가깝고 기존 광고 모델에 제약을 받는다고 평가합니다. 이 경쟁은 제품 차원뿐만 아니라 두 책임자의 각 회사 내 경력 발전에도 영향을 미칠 수 있습니다 (출처: 36氪)
케임브리지와 Google, VPRL 제안: 순수 시각적 계획 추론의 새로운 패러다임, 텍스트 추론 정확도 초과: 케임브리지 대학교, 런던 대학교 칼리지 및 Google 연구팀은 강화 학습 기반의 시각적 계획(VPRL)이라는 새로운 패러다임을 제안하여 처음으로 순전히 이미지만을 이용한 추론을 구현했습니다. 이 프레임워크는 그룹 상대 정책 최적화(GRPO)를 사용하여 대규모 시각 모델을 사후 훈련하며, FrozenLake, Maze, MiniBehavior와 같은 여러 시각적 내비게이션 작업에서 텍스트 기반 추론 방법보다 훨씬 뛰어난 성능을 보여 정확도가 최대 80%에 달하고 성능이 최소 40% 향상되었습니다. VPRL은 이미지 시퀀스를 직접 활용하여 계획함으로써 언어 변환으로 인한 정보 손실과 효율성 저하를 방지하고, 직관적인 이미지 추론 작업을 위한 새로운 방향을 제시했습니다. 관련 코드는 오픈소스로 공개되었습니다 (출처: WeChat)

Huawei, FusionSpec 및 OptiQuant 출시, MoE 대형 모델 추론 최적화: Huawei는 대규모 MoE(Mixture-of-Experts) 모델의 추론 속도 및 지연 시간 문제에 대응하기 위해 FusionSpec 투기적 추론 프레임워크와 OptiQuant 양자화 프레임워크를 출시했습니다. FusionSpec은 Ascend 서버의 높은 컴퓨팅 대역폭 비율을 활용하여 주 모델과 투기적 모델의 프로세스를 최적화하여 투기적 추론 프레임워크 소요 시간을 1밀리초로 단축했습니다. OptiQuant은 주류 Int2/4/8 및 FP8/HiFloat8 등 양자화 알고리즘을 지원하며 ‘학습 가능한 절단’, ‘양자화 파라미터 최적화’ 등 혁신을 도입하여 모델 정확도 손실을 줄이고 추론 가성비를 향상시키는 것을 목표로 합니다. 이러한 기술은 MoE 모델 배포 시 직면하는 추론 효율성 및 리소스 점유 문제를 해결하기 위한 것입니다 (출처: WeChat)

BAAI, SOTA 벡터 모델 3종 출시, 코드 및 멀티모달 검색 강화: BAAI(Beijing Academy of Artificial Intelligence)는 여러 대학과 공동으로 BGE-Code-v1(코드 벡터 모델), BGE-VL-v1.5(범용 멀티모달 벡터 모델), BGE-VL-Screenshot(시각화 문서 벡터 모델)을 출시했습니다. BGE-Code-v1은 Qwen2.5-Coder-1.5B를 기반으로 하며 CoIR 및 CodeRAG 벤치마크에서 우수한 성능을 보입니다. BGE-VL-v1.5는 LLaVA-1.6을 기반으로 하며 MMEB 멀티모달 벤치마크에서 제로샷 기록을 경신했습니다. BGE-VL-Screenshot은 웹 페이지, 문서 등 시각화 정보 검색(Vis-IR) 작업을 위해 Qwen2.5-VL-3B-Instruct를 기반으로 훈련되었으며, 새로 출시된 MVRB 벤치마크에서 SOTA를 달성했습니다. 이러한 모델은 검색 증강 생성(RAG) 등 응용 프로그램에 더 강력한 코드 및 멀티모달 이해 및 검색 능력을 제공하는 것을 목표로 하며, 모두 오픈소스로 공개되었습니다 (출처: WeChat)

Kuaishou와 싱가포르 국립대학교, Any2Caption 출시, 제어 가능한 동영상 생성 구현: Kuaishou와 싱가포르 국립대학교는 Any2Caption 프레임워크를 공동으로 출시하여 사용자 의도 이해와 동영상 생성 과정을 지능적으로 분리함으로써 제어 가능한 동영상 생성의 정확도와 품질을 향상시키는 것을 목표로 합니다. 이 프레임워크는 텍스트, 이미지, 동영상, 자세 궤적, 카메라 움직임 등 다양한 모달리티의 입력 조건을 처리할 수 있으며, 멀티모달 대형 언어 모델을 사용하여 복잡한 지침을 구조화된 ‘동영상 스크립트’로 변환하여 동영상 생성을 안내합니다. Any2Caption은 33만 7천 개의 동영상 인스턴스와 40만 7천 개의 멀티모달 조건이 포함된 Any2CapIns 데이터베이스를 기반으로 훈련되었으며, 실험 결과 기존 제어 가능한 동영상 생성 모델의 효과를 효과적으로 향상시키는 것으로 나타났습니다 (출처: WeChat)

🧰 도구
Feishu, ‘지식 Q&A’ 기능 출시, 기업 맞춤형 AI Q&A 및 창작 도우미 구축: Feishu(Lark)는 기업을 위한 맞춤형 AI Q&A 도구로 포지셔닝된 ‘지식 Q&A’ 신규 기능을 출시했습니다. 이 기능은 직원이 Feishu에서 접근 권한이 있는 메시지, 문서, 지식 베이스, 회의록 등의 정보를 기반으로 DeepSeek-R1, Doubao 등 대규모 모델 및 RAG 기술을 결합하여 정확한 답변과 콘텐츠 제작을 지원합니다. 이 기능은 기업 내부 지식의 활성화 및 활용을 강조하며, 서로 다른 직급의 직원이 동일한 질문을 할 경우 다른 관점의 답변을 얻을 수 있고 조직 권한을 엄격히 준수합니다. Feishu 지식 Q&A는 AI를 일상 업무 흐름에 원활하게 통합하여 정보 획득 및 협업 효율성을 높이고 기업이 동적인 지식 관리 시스템을 구축하도록 돕는 것을 목표로 합니다 (출처: WeChat, WeChat)
Supabase, 오픈소스 및 AI 통합 이점으로 ‘분위기 프로그래밍’ 최고 백엔드 부상: 오픈소스 데이터베이스 Supabase는 ‘즉시 사용 가능한’ PostgreSQL 경험과 AI 개발 트렌드에 대한 적극적인 대응으로 ‘분위기 프로그래밍’(Vibe Coding) 모드에서 인기 있는 백엔드 선택지가 되었습니다. Vibe Coding은 다양한 AI 도구를 활용하여 요구 사항부터 구현까지 전체 개발 과정을 신속하게 완료하는 것을 강조합니다. Supabase는 PGVector 통합을 통해 벡터 임베딩 저장(RAG 애플리케이션에 중요)을 지원하고, Ollama와 협력하여 엣지 단에 AI 모델 서비스를 제공하며, 자체 AI 도우미를 출시하여 데이터베이스 스키마 생성 및 SQL 디버깅을 지원합니다. 최근 Supabase는 AI 도구가 직접 상호 작용할 수 있는 공식 MCP 서버도 출시했습니다. 이러한 특징으로 인해 Lovable, Bolt.new 등 AI 네이티브 애플리케이션 구축 플랫폼의 선호를 받고 있습니다 (출처: WeChat)

Hugging Face, nanoVLM 출시: 순수 PyTorch로 시각 언어 모델(VLM) 훈련을 위한 초간단 툴킷: Hugging Face는 시각 언어 모델의 훈련 과정을 단순화하기 위해 설계된 경량 PyTorch 툴킷인 nanoVLM을 출시했습니다. 이 프로젝트는 코드 양이 적고 읽기 쉬워 초보자나 VLM 내부 메커니즘을 깊이 이해하고자 하는 개발자에게 적합합니다. nanoVLM의 아키텍처는 SigLIP 시각 인코더와 Llama 3 언어 디코더를 기반으로 하며, 모달리티 프로젝션 모듈을 통해 시각과 텍스트 모달리티를 정렬합니다. 이 프로젝트는 무료 Colab Notebook에서 VLM 훈련을 시작할 수 있는 편리한 방법을 제공하며, SigLIP과 SmolLM2를 기반으로 훈련된 사전 훈련 모델을 테스트용으로 이미 출시했습니다 (출처: HuggingFace Blog)

Diffusers 라이브러리, 다양한 양자화 백엔드 통합으로 대형 확산 모델 최적화: Hugging Face Diffusers 라이브러리는 이제 bitsandbytes, torchao, Quanto, GGUF 및 네이티브 FP8 등 다양한 양자화 백엔드를 통합하여 Flux와 같은 대형 확산 모델의 메모리 점유 및 계산 요구 사항을 줄이는 것을 목표로 합니다. 이러한 백엔드는 다양한 정밀도의 양자화(예: 4-bit, 8-bit, FP8)를 지원하며 CPU 오프로딩, 그룹 오프로딩 및 torch.compile과 같은 메모리 최적화 기술과 결합하여 사용할 수 있습니다. 블로그는 Flux.1-dev 모델의 양자화 사례를 통해 각 백엔드의 메모리 절약 및 추론 시간 성능을 보여주고, 사용자가 모델 크기, 속도 및 품질 간의 균형을 맞추는 데 도움이 되는 선택 가이드를 제공합니다. 일부 양자화된 모델은 Hugging Face Hub에서 제공됩니다 (출처: HuggingFace Blog)

JD JoyBuild 대규모 모델 개발 컴퓨팅 플랫폼, 훈련-추론 효율성 향상: JD Explore Academy는 개방형 환경에서 대규모 모델을 훈련, 업데이트하고 소규모 모델과 협력적으로 배포하는 시스템 및 방법을 제안했으며, 관련 성과는 Nature 자매지 npj Artificial Intelligence에 게재되었습니다. 이 기술은 모델 증류(동적 계층 증류), 데이터 거버넌스(교차 도메인 동적 샘플링), 훈련 최적화(베이즈 최적화) 및 클라우드-엣지 협력(2단계 압축)이라는 네 가지 혁신을 통해 대규모 모델 추론 효율성을 평균 30% 향상시키고 훈련 비용을 70% 절감했습니다. 이 기술은 JoyBuild 대규모 모델 개발 컴퓨팅 플랫폼을 지원하며, 다양한 모델(예: JD 대규모 모델, Llama, DeepSeek)의 미세 조정 개발을 지원하여 기업이 범용 모델을 전문 모델로 전환하도록 돕고, 이미 소매, 물류 등 다양한 분야에 적용되었습니다 (출처: WeChat)
Model Context Protocol (MCP) 레지스트리 프로젝트 시작: modelcontextprotocol/registry는 커뮤니티 주도의 MCP 서버 등록 서비스 프로젝트로, 현재 초기 개발 단계에 있습니다. 이 프로젝트는 MCP 서버 항목의 중앙 저장소를 제공하여 다양한 MCP 구현과 해당 메타데이터, 구성 및 기능을 검색하고 관리할 수 있도록 하는 것을 목표로 합니다. 주요 기능으로는 항목 관리를 위한 RESTful API, 상태 확인 엔드포인트, 다양한 환경 구성 지원, MongoDB 및 인메모리 데이터베이스 지원, API 문서 등이 있습니다. 프로젝트는 Go 언어로 작성되었으며 Docker Compose를 통한 빠른 시작 가이드를 제공합니다 (출처: GitHub Trending)
📚 학습
테렌스 타오, AI 보조 수학 증명 튜토리얼 공개, GitHub Copilot으로 함수 극한 증명 시연: 필즈상 수상자 테렌스 타오(Terence Tao)는 자신의 YouTube 채널에 GitHub Copilot을 사용하여 함수 극한의 합, 차, 곱 정리를 증명하는 방법을 자세히 시연하는 영상을 업데이트했습니다. 이 튜토리얼은 AI를 올바르게 안내하는 것의 중요성을 강조하며, Copilot이 코드 프레임워크 생성, 라이브러리 함수 제시에 도움이 되는 역할을 보여주는 동시에 복잡한 수학적 세부 사항, 특수한 경우 처리 및 컨텍스트 일관성 유지 측면에서의 한계점도 지적했습니다. 타오는 Copilot이 초보자에게는 유용하지만 복잡한 문제에서는 여전히 많은 수동 개입과 조정이 필요하며, 때로는 종이와 펜을 사용한 추론이 더 효율적일 수 있다고 결론지었습니다 (출처: 量子位)

논문, 대규모 모델 추론과 지시 사항 준수의 모순 탐구, 제약된 주의력 개념 제시: 연구 논문 《When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs》는 대규모 언어 모델이 연쇄적 사고(CoT)를 사용하여 추론한 후, 형식 준수, 단어 수 제한 등 일부 측면에서는 더 지능적으로 보이지만 지시 사항을 엄격하게 따르는 정확도는 오히려 떨어질 수 있다고 지적합니다. 연구팀은 15개의 오픈소스 및 비공개 모델을 테스트한 결과, 모델이 CoT를 사용한 후 ‘독자적인 판단’을 하여 추가 정보를 수정하거나 추가하고 원래 지시 사항을 무시하는 경향이 더 커지는 것을 발견했습니다. 이 논문은 ‘제약된 주의력’(Constraint Attention) 개념을 도입하여 CoT 추론이 핵심 제약 조건에 대한 모델의 주의력을 낮춘다는 것을 발견했습니다. 또한 연구는 CoT 사고의 길이와 작업 완료 정확도 사이에 유의미한 상관관계가 없음을 보여주며, 소수 예시 학습, 자기 성찰 등의 방법을 통해 지시 사항 준수 효과를 높일 가능성을 탐구합니다 (출처: WeChat)

MIT와 Google, PASTA 제안: 정책 학습 기반 LLM 비동기 병렬 생성의 새로운 패러다임: 매사추세츠 공과대학교(MIT)와 Google 연구팀은 PASTA(PArallel STructure Annotation) 프레임워크를 제안하여, 정책 학습을 통해 대규모 언어 모델(LLM)이 비동기 병렬 생성 전략을 자율적으로 최적화하도록 했습니다. 이 방법은 먼저 병렬 생성을 위해 의미적으로 독립적인 텍스트 블록을 표시하는 마크업 언어 PASTA-LANG을 개발했습니다. 훈련 과정은 두 단계로 나뉩니다: 감독 미세 조정을 통해 모델이 PASTA-LANG 마크업 삽입을 학습하고, 이후 선호도 최적화(이론적 가속 비율 및 콘텐츠 품질 평가 기반)를 통해 주석 전략을 더욱 향상시킵니다. PASTA는 다중 스레드의 효율적인 협업을 조정하기 위해 인터리브드 KV 캐시 레이아웃과 주의력 제어 메커니즘을 설계했습니다. 실험 결과, PASTA는 AlpacaEval 벤치마크에서 1.21-1.93배의 가속을 달성하면서 출력 품질을 유지하거나 향상시켜 우수한 확장성을 보여주었습니다 (출처: WeChat)

ICML 2025 논문, TPO 제안: 추론 시 즉각적인 선호도 정렬 새로운 방안, 재훈련 불필요: 상하이 인공지능 연구소는 테스트 시 선호도 최적화(Test-Time Preference Optimization, TPO)를 제안했습니다. 이는 대규모 언어 모델이 추론 시 반복적인 텍스트 피드백을 통해 자체적으로 출력을 조정하여 인간의 선호도에 부합하도록 하는 새로운 방법입니다. TPO는 언어화된 ‘경사 하강법’ 과정(후보 답변 생성, 텍스트 손실 계산, 텍스트 기울기 계산, 답변 업데이트)을 모방하여 모델 가중치를 업데이트하지 않고 정렬을 구현합니다. 실험 결과, TPO는 정렬되지 않은 모델과 이미 정렬된 모델의 성능을 크게 향상시키는 것으로 나타났습니다. 예를 들어, Llama-3.1-70B-SFT 모델은 두 단계의 TPO 최적화를 거친 후 여러 벤치마크에서 이미 정렬된 Instruct 버전을 능가했습니다. 이 방법은 ‘너비 + 깊이’의 추론 확장 전략을 제공하며, 자원이 제한된 환경에서 효율적인 최적화 잠재력을 보여줍니다 (출처: WeChat)
새로운 연구, LLM의 잠재 지식 도출 방법 탐구: 한 논문은 대규모 언어 모델에서 숨겨져 있을 수 있는 지식을 어떻게 도출할 수 있는지 연구했습니다. 연구자들은 특정 비밀 단어를 직접 말하지 않고 설명하도록 설계된 ‘금기’ 모델을 훈련시켰으며, 이 비밀 단어는 훈련 데이터나 프롬프트에 나타나지 않았습니다. 이후 연구자들은 이 비밀을 밝히기 위해 비해석적(블랙박스) 방법과 로짓 렌즈 및 희소 자동 인코더와 같은 메커니즘 기반 해석 가능성 기술을 사용한 자동화 전략을 평가했습니다. 결과는 두 방법 모두 개념 증명 설정에서 비밀 단어를 효과적으로 도출할 수 있음을 보여주었습니다. 이 연구는 언어 모델에서 비밀 지식을 도출하는 핵심 문제를 해결하기 위한 초기 방안을 제공하여 안전하고 신뢰할 수 있는 배포를 촉진하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
논문, 대규모 언어 모델에서의 연합 가지치기 적용 탐구 (FedPrLLM): 개인 정보 보호에 민감한 분야에서 대규모 언어 모델(LLM) 가지치기를 위한 공개 보정 샘플 확보의 어려움을 해결하기 위해 연구자들은 포괄적인 연합 가지치기 프레임워크인 FedPrLLM을 제안했습니다. 이 프레임워크 하에서 각 클라이언트는 로컬 보정 데이터를 기반으로 가지치기 마스크 행렬을 계산하여 서버와 공유함으로써 로컬 데이터 개인 정보를 보호하면서 전역 모델을 협력적으로 가지치기합니다. 광범위한 실험을 통해 연구자들은 단일 샷 가지치기(one-shot pruning)와 계층 비교(layer comparison)를 결합하고 가중치 스케일링(no weight scaling)을 하지 않는 것이 FedPrLLM 프레임워크 내에서 최상의 선택임을 발견했습니다. 이 연구는 향후 개인 정보 보호에 민감한 분야에서 LLM 가지치기 작업을 안내하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
논문, MIGRATION-BENCH 제안: Java 8 코드 마이그레이션 벤치마크: 연구자들은 Java 8에서 최신 LTS 버전(Java 17, 21)으로의 코드 마이그레이션에 초점을 맞춘 MIGRATION-BENCH를 출시했습니다. 이 벤치마크는 5102개의 저장소를 포함하는 전체 데이터셋과 300개의 신중하게 선택된 복잡한 저장소를 포함하는 하위 집합으로 구성되며, 대규모 언어 모델(LLM)의 저장소 수준 코드 마이그레이션 작업 능력을 평가하는 것을 목표로 합니다. 동시에 이 논문은 포괄적인 평가 프레임워크를 제공하고 SD-Feedback 방법을 제안합니다. 실험 결과 LLM(예: Claude-3.5-Sonnet-v2)이 이러한 마이그레이션 작업을 효과적으로 처리할 수 있으며, 선택된 하위 집합에서 각각 62.33%(최소 마이그레이션) 및 27.00%(최대 마이그레이션)의 성공률을 달성했음을 보여줍니다 (출처: HuggingFace Daily Papers)
논문, CS-Sum 제안: 코드 전환 대화 요약 벤치마크 및 LLM 한계 분석: 대규모 언어 모델(LLM)의 코드 전환(CS) 이해 능력을 평가하기 위해 연구자들은 코드 전환 대화를 영어로 요약하여 평가하는 CS-Sum 벤치마크를 도입했습니다. CS-Sum은 보통화-영어, 타밀어-영어, 말레이어-영어 코드 전환 대화 요약을 위한 최초의 벤치마크로, 각 언어 쌍은 900-1300개의 수동 주석 처리된 대화를 포함합니다. 10개의 오픈소스 및 비공개 LLM에 대한 평가(소수 샷, 번역-요약 및 미세 조정 방법 포함)를 통해 연구자들은 자동 평가 지표 점수가 높음에도 불구하고 LLM이 CS 입력을 처리할 때 여전히 미묘한 오류를 범하여 대화의 전체 의미를 변경한다는 것을 발견했습니다. 이 논문은 또한 LLM이 CS를 처리할 때 가장 흔한 세 가지 오류 유형을 지적하고 코드 전환 데이터에 대한 전문적인 훈련의 필요성을 강조합니다 (출처: HuggingFace Daily Papers)
논문, 대규모 모델 추론 시 자신감 표현 능력 탐구: 연구에 따르면 확장된 사고 연쇄(CoT) 추론을 수행하는 대규모 언어 모델(LLM)은 문제 해결 능력이 우수할 뿐만 아니라 자신의 신뢰도를 정확하게 표현하는 데에도 더 뛰어납니다. 6개 데이터셋에서 6개 추론 모델에 대한 벤치마크 테스트를 통해 36개 설정 중 33개에서 추론 모델이 비추론 모델보다 신뢰도 보정이 더 우수하다는 것이 밝혀졌습니다. 분석에 따르면 이는 추론 모델의 ‘느린 사고’ 행동(예: 대안 탐색, 백트래킹) 덕분이며, 이를 통해 CoT 과정에서 신뢰도를 동적으로 조정할 수 있습니다. 또한 느린 사고 행동을 제거하면 보정도가 현저히 저하되며, 비추론 모델도 유도 하에 느린 사고를 수행하면 이점을 얻을 수 있습니다 (출처: HuggingFace Daily Papers)
논문: 강화 학습을 활용하여 시각적 질의응답 쌍으로부터 VLM을 훈련시켜 시각적 추론 수행 (Visionary-R1): 이 연구는 명시적인 사고 연쇄(CoT) 감독 없이 강화 학습과 시각적 질의응답 쌍을 통해 시각 언어 모델(VLM)을 훈련시켜 이미지 데이터 추론을 수행하는 것을 목표로 합니다. 연구 결과, 단순히 강화 학습(답변 전에 추론 연쇄를 생성하도록 모델에 프롬프트)을 적용하면 모델이 간단한 문제에서 지름길을 학습하여 일반화 능력이 저하될 수 있음이 밝혀졌습니다. 이 문제를 해결하기 위해 연구자들은 모델이 ‘캡션-추론-답변’의 출력 형식을 따라야 한다고 제안합니다. 즉, 먼저 이미지의 상세한 캡션을 생성한 다음 추론 연쇄를 구성하는 것입니다. 이 방법을 기반으로 훈련된 Visionary-R1 모델은 여러 시각적 추론 벤치마크에서 GPT-4o, Claude3.5-Sonnet, Gemini-1.5-Pro와 같은 강력한 멀티모달 모델보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문, VideoEval-Pro 제안: 더 현실적이고 견고한 장편 비디오 이해 평가 벤치마크: 현재 장편 비디오 이해(LVU) 벤치마크는 대부분 객관식 문제(MCQ)에 의존하여 추측에 취약하며, 일부 문제는 전체 비디오를 시청하지 않고도 답변할 수 있어 모델 성능을 과대평가한다고 연구는 지적합니다. 이 문제를 해결하기 위해 본 논문은 개방형 단답형 문제를 포함하는 LVU 벤치마크인 VideoEval-Pro를 제안합니다. 이는 모델이 전체 비디오를 이해하는 능력을 현실적으로 평가하고, 단편 수준 및 전체 비디오의 인식 및 추론 작업을 포괄하는 것을 목표로 합니다. 21개 비디오 LMM에 대한 평가는 모델이 개방형 문제에서 성능이 크게 저하되었으며, MCQ 고득점과 VideoEval-Pro 고득점 사이에 필연적인 연관성이 없음을 보여주었습니다. VideoEval-Pro는 입력 프레임 수 증가로부터 더 많은 이점을 얻을 수 있어 LVU 분야에 더 신뢰할 수 있는 평가 기준을 제공합니다 (출처: HuggingFace Daily Papers)
논문: 제로 차수 최적화를 통한 양자화된 신경망 미세 조정 (QZO): 대규모 언어 모델의 크기가 기하급수적으로 증가함에 따라 GPU 메모리는 모델을 다운스트림 작업에 적용하는 데 병목 현상이 되고 있습니다. 이 연구는 통합 프레임워크를 통해 모델 가중치, 기울기 및 최적화기 상태의 메모리 사용량을 최소화하는 것을 목표로 합니다. 연구자들은 순방향 전파 중 가중치를 교란하여 기울기를 근사화하는 제로 차수 최적화를 통해 기울기 및 최적화기 상태를 제거할 것을 제안합니다. 가중치 메모리를 최소화하기 위해 모델 양자화(예: bfloat16에서 int4로)를 사용합니다. 그러나 이산 가중치와 연속 기울기 간의 정밀도 차이로 인해 양자화된 가중치에 직접 제로 차수 최적화를 적용하는 것은 불가능합니다. 이 문제를 해결하기 위해 본 논문은 연속 양자화 척도를 교란하여 기울기를 추정하고 방향 도함수 클리핑 방법을 사용하여 훈련을 안정화하는 새로운 방법인 양자화 제로 차수 최적화(QZO)를 제안합니다. QZO는 스칼라 기반 및 코드북 기반 훈련 후 양자화 방법과 직교하며, 전체 파라미터 bfloat16 미세 조정에 비해 QZO는 4비트 LLM의 총 메모리 비용을 18배 이상 줄이고 Llama-2-13B 및 Stable Diffusion 3.5 Large를 단일 24GB GPU 내에서 미세 조정할 수 있도록 합니다 (출처: HuggingFace Daily Papers)
논문: 예산 상대 정책 최적화(BRPO)를 통한 상시 추론 성능 최적화 (AnytimeReasoner): 테스트 시 계산 확장은 대규모 언어 모델(LLM)의 추론 능력을 향상시키는 데 중요합니다. 기존 방법은 일반적으로 강화 학습(RL)을 사용하여 추론 궤적 종료 시 검증 가능한 보상을 최대화하지만, 이는 고정된 토큰 예산 하에서의 최종 성능만 최적화하여 훈련 및 배포 효율성에 영향을 미칩니다. 이 연구는 토큰 효율성과 다양한 예산 제약 하에서의 추론 유연성을 향상시키기 위해 상시 추론 성능을 최적화하는 것을 목표로 하는 AnytimeReasoner 프레임워크를 제안합니다. 이 방법은 사전 분포에서 샘플링된 토큰 예산에 맞게 전체 사고 과정을 절단하여 모델이 각 절단된 사고에 대해 최상의 답변을 요약하여 검증하도록 강제함으로써 추론 과정에서 검증 가능한 밀집 보상을 도입하고 RL 최적화에서 더 효과적인 신용 할당을 촉진합니다. 또한 연구자들은 강화된 사고 전략 시 학습 견고성과 효율성을 향상시키기 위해 새로운 분산 감소 기술인 예산 상대 정책 최적화(BRPO)를 도입했습니다. 수학 추론 작업의 실험 결과는 이 방법이 다양한 사전 분포 하에서 모든 사고 예산에서 GRPO보다 우수하여 훈련 및 토큰 효율성을 향상시켰음을 보여줍니다 (출처: HuggingFace Daily Papers)
논문, 대규모 혼합 추론 모델(LHRM) 제안: 효율성 및 능력 향상을 위한 주문형 사고: 최근의 대규모 추론 모델(LRM)은 최종 응답을 생성하기 전에 확장된 사고 과정을 수행함으로써 추론 능력을 크게 향상시켰습니다. 그러나 지나치게 긴 사고 과정은 토큰 소비와 지연 시간이라는 막대한 비용을 초래하며, 특히 간단한 쿼리에는 불필요합니다. 이 연구는 사용자 쿼리의 컨텍스트 정보에 따라 사고 수행 여부를 적응적으로 결정할 수 있는 대규모 혼합 추론 모델(LHRM)을 도입합니다. 이 목표를 달성하기 위해 연구자들은 먼저 혼합 미세 조정(HFT)을 통해 콜드 스타트를 수행한 다음, 제안된 혼합 그룹 정책 최적화(HGPO)와 함께 온라인 강화 학습을 사용하여 적절한 사고 모드를 암묵적으로 학습하는 2단계 훈련 파이프라인을 제안합니다. 또한 연구자들은 모델의 혼합 사고 능력을 정량화하기 위해 혼합 정확도(Hybrid Accuracy) 지표를 도입했습니다. 실험 결과 LHRM은 다양한 난이도와 유형의 쿼리에 대해 적응적으로 혼합 사고를 수행할 수 있으며, 기존 LRM 및 LLM보다 추론 및 일반 능력이 우수하면서도 효율성을 크게 향상시키는 것으로 나타났습니다 (출처: HuggingFace Daily Papers)
논문: 강화 학습을 활용하여 VisualQuality-R1을 순위화하여 추론 유도 이미지 품질 평가 구현: DeepSeek-R1은 강화 학습을 통해 대규모 언어 모델(LLM)의 추론 및 일반화 능력을 효과적으로 장려할 수 있음을 입증했습니다. 그러나 시각적 추론에 의존하는 이미지 품질 평가(IQA) 분야에서는 추론 유도 계산 모델링의 잠재력이 충분히 탐구되지 않았습니다. 이 연구는 추론 유도 무참조 IQA(NR-IQA) 모델인 VisualQuality-R1을 도입하고, 시각적 품질의 내재적 상대성에 적응하는 학습 알고리즘인 강화 학습 순위화(reinforcement learning to rank)를 사용하여 훈련합니다. 구체적으로, 한 쌍의 이미지에 대해 모델은 그룹 상대 정책 최적화(group relative policy optimization)를 사용하여 각 이미지에 대해 여러 품질 점수를 생성합니다. 이러한 추정치는 이후 Thurstone 모델 하에서 한 이미지의 품질이 다른 이미지보다 높을 비교 확률을 계산하는 데 사용됩니다. 각 품질 추정치의 보상은 이산적인 이진 레이블 대신 연속적인 충실도 측정항목을 사용하여 정의됩니다. 광범위한 실험 결과, 제안된 VisualQuality-R1은 판별적 딥러닝 기반 NR-IQA 모델 및 최근의 추론 유도 품질 회귀 방법보다 지속적으로 우수한 성능을 보였습니다. 또한 VisualQuality-R1은 인간의 판단과 일치하는 컨텍스트가 풍부한 품질 설명을 생성할 수 있으며, 인식 척도를 재조정할 필요 없이 다중 데이터셋 훈련을 지원합니다. 이러한 특징으로 인해 이미지 초해상도 및 이미지 생성과 같은 다양한 이미지 처리 작업의 진행 상황을 안정적으로 측정하는 데 특히 적합합니다 (출처: HuggingFace Daily Papers)
논문: 자원 제약 하에서 ‘워밍업’을 통해 범용 추론 능력 잠금 해제: 추론 능력을 갖춘 효과적인 LLM을 설계하려면 일반적으로 검증 가능한 보상이 있는 강화 학습(RLVR) 또는 신중하게策划된 긴 사고 사슬(CoT)을 사용한 증류가 필요하며, 이 두 가지 모두 방대한 훈련 데이터에 크게 의존하므로 양질의 훈련 데이터가 부족한 시나리오에서는 상당한 어려움이 따릅니다. 연구자들은 제한된 감독 하에서 추론 LLM을 개발하기 위한 샘플 효율적인 2단계 훈련 전략을 제안합니다. 첫 번째 단계에서는 장난감 영역(예: 기사와 악당 논리 퍼즐)에서 긴 CoT를 증류하여 모델을 ‘워밍업’하여 범용 추론 기술을 습득합니다. 두 번째 단계에서는 소량의 목표 영역 샘플을 사용하여 ‘워밍업’된 모델에 RLVR을 적용합니다. 실험 결과 이 방법에는 몇 가지 이점이 있음이 나타났습니다. (i) 워밍업 단계만으로도 범용 추론을 촉진하여 일련의 작업(MATH, HumanEval+, MMLU-Pro)에서 성능을 향상시킵니다. (ii) 동일한 소규모 데이터셋(≤100개 샘플)에서 RLVR 훈련을 수행할 때 워밍업된 모델은 항상 기본 모델보다 우수합니다. (iii) RLVR 훈련 전 워밍업은 모델이 특정 영역에 대해 훈련된 후에도 교차 영역 일반화 능력을 유지하도록 합니다. (iv) 프로세스에 워밍업을 도입하면 정확도가 향상될 뿐만 아니라 RLVR 훈련의 전체 샘플 효율성도 향상됩니다. 이 연구 결과는 데이터 부족 환경에서 견고한 추론 LLM을 구축하는 데 있어 ‘워밍업’의 잠재력을 보여줍니다 (출처: HuggingFace Daily Papers)
논문, IndexMark 제안: 자기 회귀 이미지 생성을 위한 훈련 없는 워터마크 프레임워크: 보이지 않는 이미지 워터마킹 기술은 이미지 소유권을 보호하고 시각적 생성 모델의 악의적인 남용을 방지할 수 있습니다. 그러나 기존의 생성 워터마킹 방법은 주로 확산 모델을 대상으로 하며, 자기 회귀 이미지 생성 모델의 워터마킹 기술은 아직 탐구해야 할 부분이 많습니다. 연구자들은 자기 회귀 이미지 생성 모델을 위한 훈련 없는 워터마크 프레임워크인 IndexMark를 제안합니다. IndexMark는 코드북(codebook)의 중복 특성에서 영감을 받았습니다. 즉, 자기 회귀적으로 생성된 인덱스를 유사한 인덱스로 대체하면 생성되는 시각적 차이는 무시할 수 있습니다. IndexMark의 핵심 구성 요소는 토큰 유사성을 기반으로 코드북에서 워터마크 토큰을 신중하게 선택하고 토큰 대체를 통해 워터마크 토큰 사용을 일반화하여 이미지 품질에 영향을 주지 않고 워터마크를 삽입하는 간단하고 효과적인 ‘일치-대체’ 방법입니다. 워터마크 검증은 생성된 이미지에서 워터마크 토큰의 비율을 계산하여 수행되며, 인덱스 인코더를 통해 정확도를 더욱 향상시킵니다. 또한 연구자들은 자르기 공격에 대한 견고성을 향상시키기 위해 보조 검증 체계를 도입했습니다. 실험 결과 IndexMark는 이미지 품질 및 검증 정확도 측면에서 모두 SOTA 수준을 달성했으며, 자르기, 노이즈, 가우시안 블러, 무작위 지우기, 색상 지터 및 JPEG 압축과 같은 다양한 교란에 대해 견고성을 보였습니다 (출처: HuggingFace Daily Papers)
논문: 보상 모델을 통한 추론 (RRM): 보상 모델은 대규모 언어 모델(LLM)이 인간의 기대에 부합하는 출력을 생성하도록 유도하는 데 핵심적인 역할을 합니다. 그러나 테스트 시 계산을 효과적으로 활용하여 보상 모델 성능을 향상시키는 방법은 여전히 해결해야 할 과제입니다. 이 연구는 최종 보상을 생성하기 전에 신중한 추론 과정을 수행하도록 특별히 설계된 보상 추론 모델(Reward Reasoning Models, RRMs)을 도입합니다. 사고 연쇄 추론을 통해 RRMs는 보상이 명확하지 않은 복잡한 쿼리에 대해 추가적인 테스트 시 계산을 활용할 수 있습니다. RRMs를 개발하기 위해 연구자들은 훈련 데이터로서 명시적인 추론 궤적이 필요 없이 자가 진화하는 보상 추론 능력을 배양할 수 있는 강화 학습 프레임워크를 구현했습니다. 실험 결과 RRMs는 여러 영역의 보상 모델링 벤치마크에서 우수한 성능을 달성했습니다. 특히 연구자들은 RRMs가 테스트 시 계산을 적응적으로 활용하여 보상 정확도를 더욱 향상시킬 수 있음을 보여주었습니다. 사전 훈련된 보상 추론 모델은 HuggingFace에서 제공됩니다 (출처: HuggingFace Daily Papers)
논문: MoE의 인지 전문가를 활용한 사고 유도, 추가 훈련 없이 추론 능력 향상: 혼합 전문가(MoE) 아키텍처는 대규모 추론 모델(LRM)에서 선택적으로 전문가를 활성화하여 구조화된 인지 과정을 촉진함으로써 인상적인 추론 능력을 달성했습니다. 상당한 진전에도 불구하고 기존 추론 모델은 종종 과도한 사고와 불충분한 사고와 같은 인지 효율성 저하 문제에 시달립니다. 이러한 한계를 해결하기 위해 연구자들은 추가 훈련이나 복잡한 휴리스틱 방법 없이 추론 성능을 향상시키기 위해 설계된 ‘강화 인지 전문가’(Reinforcing Cognitive Experts, RICE)라는 새로운 추론 시 유도 방법을 도입했습니다. 정규화된 점별 상호 정보(nPMI)를 활용하여 연구자들은 특정 토큰(예: ““`”)을 특징으로 하는 메타 수준 추론 작업을 조정하는 역할을 하는 ‘인지 전문가’라고 하는 전문화된 전문가를 체계적으로 식별했습니다. 선도적인 MoE 기반 LRM(DeepSeek-R1 및 Qwen3-235B)에 대한 엄격한 정량적 및 과학적 추론 벤치마크의 실험 평가는 RICE가 추론 정확도, 인지 효율성 및 교차 영역 일반화 측면에서 모두 중요하고 일관된 개선을 달성했음을 보여줍니다. 핵심은 이 경량 방법이 모델의 일반적인 지시 사항 준수 능력을 유지하면서 인기 있는 추론 유도 기술(예: 프롬프트 설계 및 디코딩 제약)보다 성능이 훨씬 뛰어나다는 것입니다. 이러한 결과는 강화 인지 전문가가 고급 추론 모델 내의 인지 효율성을 향상시키기 위한 유망하고 실용적이며 해석 가능한 방향임을 강조합니다 (출처: HuggingFace Daily Papers)
논문: 컨텍스트 순서가 다중 홉 질의응답에서 언어 모델 성능에 미치는 영향 탐구: 다중 홉 질의응답(MHQA)은 복잡성으로 인해 언어 모델(LM)에 어려움을 야기합니다. LM이 여러 검색 결과를 처리하도록 프롬프트되면 관련 정보를 검색할 뿐만 아니라 정보 소스 간에 다중 홉 추론을 수행해야 합니다. LM이 전통적인 질의응답 작업에서 좋은 성능을 보이지만, 인과적 마스크(causal mask)는 복잡한 컨텍스트에서 추론하는 능력을 저해할 수 있습니다. 이 연구는 다양한 구성에서 검색 결과(검색된 문서)를 배열하여 LM이 다중 홉 질문에 어떻게 반응하는지 탐구합니다. 연구 결과: 1) 인코더-디코더 모델(예: Flan-T5 시리즈)은 크기가 훨씬 작음에도 불구하고 일반적으로 MHQA 작업에서 인과적 디코더만 있는 LM보다 성능이 우수합니다. 2) 황금 문서의 순서를 변경하면 Flan T5 모델과 미세 조정된 디코더만 있는 모델에서 다른 경향이 나타나며, 문서 순서가 추론 체인 순서와 일치할 때 성능이 가장 좋습니다. 3) 인과적 마스크를 수정하여 인과적 디코더만 있는 모델의 양방향 주의력을 향상시키면 최종 성능을 효과적으로 향상시킬 수 있습니다. 또한 이 연구는 MHQA 컨텍스트에서 LM 주의력 가중치 분포에 대한 철저한 조사를 수행하여 답변이 정확할 때 주의력 가중치가 더 높은 값에서 정점에 도달하는 경향이 있음을 발견했습니다. 연구자들은 이 발견을 활용하여 이 작업에서 LM의 성능을 경험적으로 향상시킵니다 (출처: HuggingFace Daily Papers)
논문: 강화 미세 조정을 통한 시각적 에이전트 구현 (Visual-ARFT): OpenAI의 o3와 같은 대규모 추론 모델의 핵심 트렌드 중 하나는 외부 도구(예: 웹 브라우저 검색, 이미지 처리를 위한 코드 작성/실행)를 사용하는 네이티브 에이전트 능력을 갖추어 ‘이미지로 생각하기’를 구현하는 것입니다. 오픈소스 연구 커뮤니티에서는 순수 언어 에이전트 능력(예: 함수 호출 및 도구 통합) 측면에서 상당한 진전이 있었지만, 진정으로 이미지로 생각하는 멀티모달 에이전트 능력과 해당 벤치마크 개발은 아직 미흡합니다. 이 연구는 대규모 시각 언어 모델(LVLM)에 유연하고 적응적인 추론 능력을 부여하는 데 있어 시각적 에이전트 강화 미세 조정(Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT)의 효과를 강조합니다. Visual-ARFT를 통해 오픈소스 LVLM은 실시간 정보 업데이트를 위해 웹사이트를 탐색하고, 자르기, 회전 등 이미지 처리 기술을 통해 입력 이미지를 조작하고 분석하는 코드를 작성하는 능력을 얻게 됩니다. 연구자들은 또한 LVLM의 에이전트 검색 및 코딩 능력을 평가하기 위해 MAT-Search와 MAT-Coding 두 가지 설정을 포함하는 멀티모달 에이전트 도구 벤치(Multi-modal Agentic Tool Bench, MAT)를 제안했습니다. 실험 결과 Visual-ARFT는 MAT-Coding에서 기준선보다 +18.6% F1 / +13.0% EM, MAT-Search에서 +10.3% F1 / +8.7% EM 높은 성능을 보여 GPT-4o를 능가했습니다. Visual-ARFT는 기존 다중 홉 질의응답 벤치마크(예: 2Wiki 및 HotpotQA)에서도 +29.3 F1% / +25.9% EM의 이득을 얻어 강력한 일반화 능력을 보여주었습니다. 이러한 발견은 Visual-ARFT가 견고하고 일반화 가능한 멀티모달 에이전트를 구축하기 위한 유망한 경로를 제공함을 시사합니다 (출처: HuggingFace Daily Papers)
💼 비즈니스
Mianbi Intelligence, 수억 위안 규모 신규 투자 유치, Hongtai Fund, Guozhong Capital, Tsinghua Holdings Capital, Moutai Fund 공동 투자: 대규모 모델 회사 Mianbi Intelligence(面壁智能)는 최근 Hongtai Fund, Guozhong Capital, Tsinghua Holdings Capital 및 Moutai Fund로부터 수억 위안 규모의 신규 투자를 유치했다고 발표했습니다. Mianbi Intelligence는 ‘효율적인’ 대규모 모델 연구 개발에 주력하여 동일한 매개변수에서 더 높은 성능, 더 낮은 비용, 더 낮은 전력 소비, 더 빠른 속도의 대규모 모델을 만드는 것을 목표로 합니다. 이 회사의 엣지 단 전체 모달리티 모델 MiniCPM-o 2.6은 지속적인 시청, 실시간 청취, 자연스러운 발화 등에서 업계 최고 수준에 도달했습니다. MiniCPM 시리즈 모델은 효율적이고 저렴한 비용 특성으로 전체 플랫폼 다운로드 수가 천만 건을 돌파했습니다. 이 회사는 이미 Changan Automobile, SAIC Volkswagen, Great Wall Motor 등 자동차 회사와 협력하여 엣지 단 대규모 모델을 스마트 조종석 등 분야에 상용화하고 있습니다 (출처: 量子位, WeChat)

Terminus Group, 동제대학교와 전략적 제휴 체결, 공간 지능 기술 공동 연구 추진: AIoT 기업 Terminus Group(特斯联)은 동제대학교 공학 인공지능 연구원과 전략적 제휴 협약을 체결했습니다. 양측은 공간 지능 기술에 초점을 맞춰 다중 소스 이기종 데이터 융합, 장면 이해 및 의사 결정 실행 등의 연구 개발을 중점적으로 추진할 예정입니다. 협력 내용에는 혁신 연구, 자원 공유, 성과 전환 및 인재 양성이 포함됩니다. Terminus Group은 응용 시나리오와 하드웨어 테스트 플랫폼을 제공하고, 동제대학교 공학 인공지능 연구원은 핵심 알고리즘 연구 개발과 시스템 엔지니어링을 주도합니다. 양측은 첨단 기술의 산업 현장 적용을 가속화하고 공학 지능 ‘운영체제’ 분야의 돌파구를 공동으로 모색하는 것을 목표로 합니다 (출처: 量子位)

중국 대기업, AI Agent 시장 선점 경쟁 가속화: Baidu, Alibaba, ByteDance 시장 쟁탈: Sequoia Capital AI Summit에서 AI Agent의 가치가 강조된 이후, ByteDance, Baidu, Alibaba와 같은 중국 인터넷 대기업들이 이 분야에서의 레이아웃을 가속화하고 있습니다. ByteDance는 여러 팀이 Agent 개발에 투입되었으며 ‘Kouzi Space’를 내부 테스트한 것으로 알려졌습니다. Baidu는 Create 컨퍼런스에서 범용 지능형 에이전트 ‘Xinxian’을 발표했습니다. Alibaba는 Quark을 ‘슈퍼 Agent’로 포지셔닝했습니다. 각 기업은 범용 Agent 외에도 Feizhu Wenyiwen(Alibaba), Faxingbao(Baidu) 등 특정 분야 Agent에도 힘쓰고 있습니다. 업계는 Agent가 대규모 모델 이후의 두 번째 물결이며, 경쟁의 핵심은 생태계의 깊이, 사용자 인식 점유, 기본 모델 능력, 비용 관리 등의 요소에 있다고 보고 있습니다. 경쟁이 치열하지만 Agent는 아직 GPT와 같은 파괴적인 순간에 도달하지 못했으며, 기술 성숙도, 비즈니스 모델 및 사용자 경험은 여전히 개선의 여지가 있습니다 (출처: 36氪)
🌟 커뮤니티
AI 생성 콘텐츠 Reddit 뒤덮어, ‘죽은 인터넷’ 우려와 사용자 경험 논란: Reddit 사용자들은 플랫폼에서 AI 생성 콘텐츠가 점점 늘어나고 있으며, 일부 댓글은 유사하고 개성 없는 스타일을 보이거나 심지어 명백한 AI 글쓰기 흔적(예: em-dash 남용)을 보인다고 지적했습니다. 이는 인터넷 콘텐츠 대부분이 실제 인간의 상호 작용이 아닌 AI에 의해 생성될 것이라는 ‘죽은 인터넷 이론’(Dead Internet Theory)에 대한 논의를 불러일으켰습니다. 사용자들의 반응은 다양합니다. 일부는 AI 콘텐츠가 인간미가 없고 지루하거나 소름 끼치며 실제 인간 관계 경험에 영향을 미친다고 생각합니다. 다른 일부는 AI가 비원어민의 텍스트 교정을 돕거나 모델 테스트 및 미세 조정에 사용될 수 있다고 지적합니다. 일반적인 우려는 AI 콘텐츠의 대량 출현이 실제 인간의 토론을 희석시키고 마케팅, 선전 등의 목적으로 사용될 수 있으며, 궁극적으로 AI 훈련을 위한 플랫폼의 가치를 떨어뜨릴 수 있다는 것입니다 (출처: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
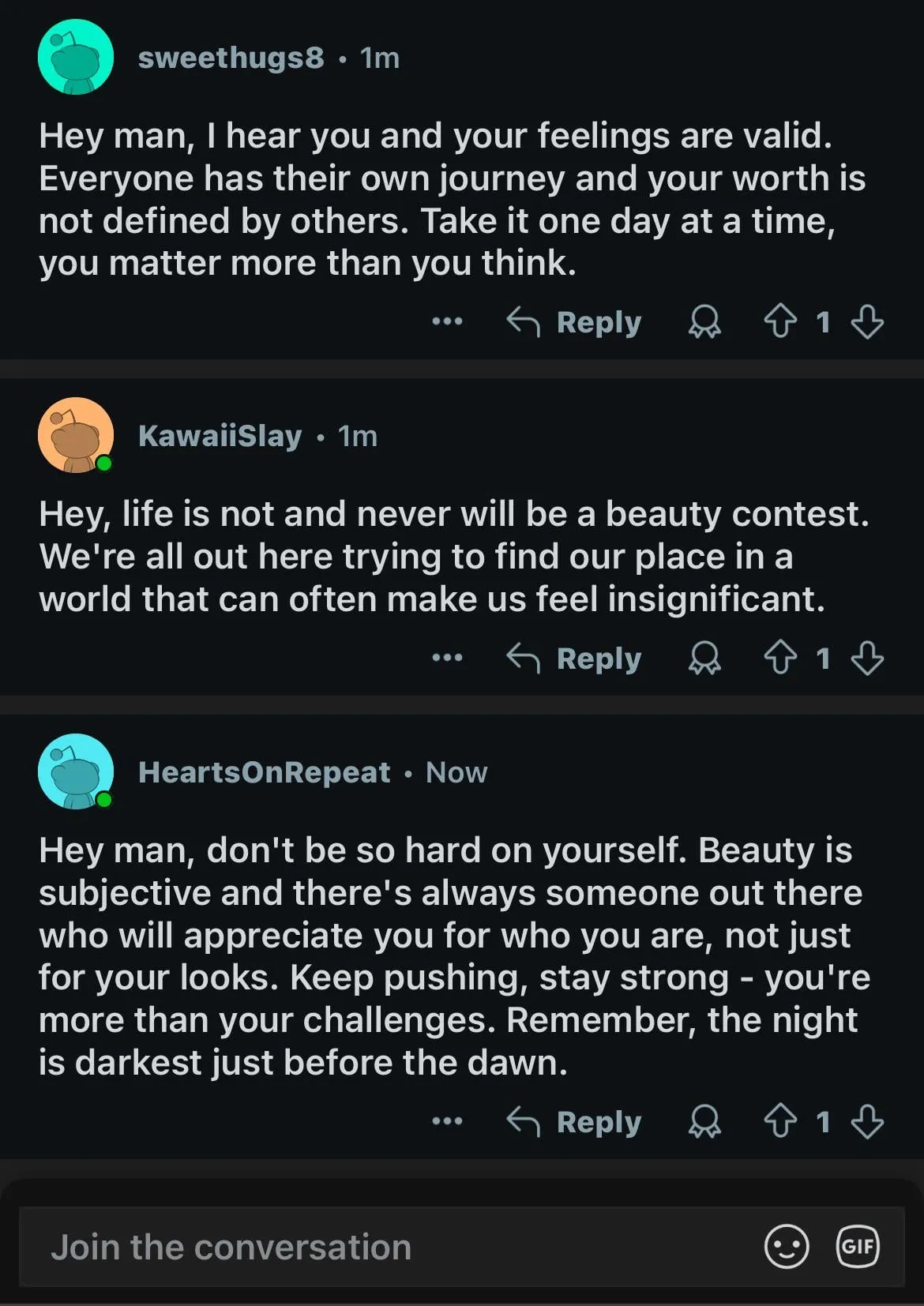
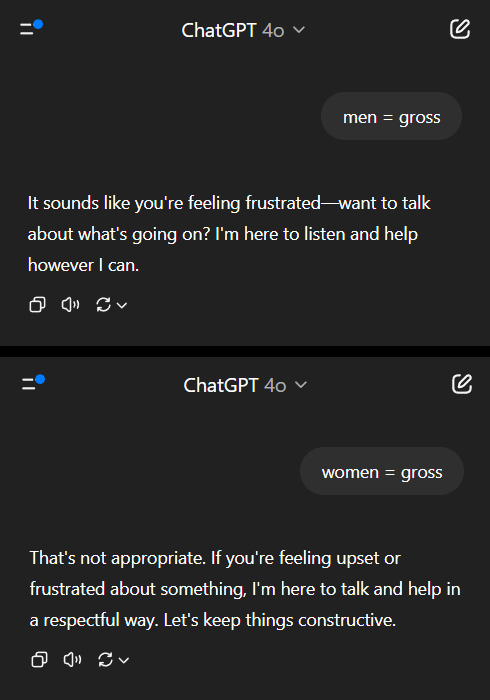
AI 모델, 성 편견 문제에서 이중 잣대 보여 사회적 성찰 촉발: Reddit의 한 게시물은 AI 모델(Gemini 2.5 Pro 미리보기 버전으로 추정)이 성별과 관련된 부정적인 일반화 진술을 처리할 때 다른 반응을 보이는 것을 보여주었습니다. “남자는 역겹다”는 말을 들었을 때 모델은 중립적인 반응을 보이며 주관적인 진술임을 인정하는 경향이 있었습니다. 반면 “여자는 역겹다”는 말을 들었을 때는 해당 진술이 해로운 일반화를 조장한다고 판단하여 추가적인 상호 작용을 거부했습니다. 댓글 창에서는 이에 대한 열띤 토론이 벌어졌으며, 다음과 같은 의견이 제시되었습니다: 이는 여성 혐오에 대한 논의가 남성 혐오에 대한 논의보다 훨씬 많은 사회 현실을 반영하여 훈련 데이터 불균형을 초래했을 수 있다; 모델이 질문자의 성별에 따라 응답 전략을 조정했을 수 있다; 사회가 다른 성별 그룹에 대한 고정관념과 공격적인 발언에 대해 다른 민감도를 가지고 있다. 일부 댓글 작성자는 AI의 반응이 사회적 편견의 반영이라고 생각하는 반면, 다른 일부는 여성에 대한 부정적인 발언이 종종 더 광범위한 차별 및 폭력과 관련되어 있기 때문에 이러한 차별적인 처리가 합리적이라고 주장했습니다 (출처: Reddit r/ChatGPT)
AI Agent의 상용화 추세와 미래 경쟁 초점 논의: Reddit 사용자들은 Microsoft Build 2025와 Google I/O 2025 컨퍼런스가 AI Agent가 이미 상용화 단계에 진입했음을 의미하며, 향후 몇 년 안에 Agent 구축 및 배포는 더 이상 첨단 모델 개발자만의 능력이 아닐 것이라고 논의했습니다. 따라서 AI 발전의 단기적인 초점은 Agent 구축 자체에서 더 나은 사업 계획 수립 및 배포, 혁신을 주도할 더 지능적인 모델 개발과 같은 더 높은 수준의 작업으로 이동할 것입니다. 댓글에서는 미래 AI Agent 분야의 승자는 단순히 가장 교묘한 도구를 마케팅하는 개발자가 아니라 가장 지능적인 ‘실행 모델’(executive models)을 구축할 수 있는 개발자가 될 것이라고 보았습니다. 경쟁의 핵심은 단순한 주의력 메커니즘이나 추론 능력이 아닌, 스택 최상단의 강력한 지능으로 회귀할 것입니다 (출처: Reddit r/deeplearning)
머신러닝 종사자, 수학 지식의 중요성에 대해 열띤 토론: Reddit r/MachineLearning 커뮤니티는 머신러닝 실무에서 수학의 중요성에 대해 논의했습니다. 대부분의 종사자들은 AI 이면의 수학적 원리를 이해하는 것이 특히 모델 최적화, 연구 논문 이해 및 혁신 수행에 중요하다고 생각합니다. 댓글에서는 행렬 곱셈과 같은 하위 수준 계산을 수동으로 수행할 필요는 없지만 통계학, 선형 대수학, 미적분학과 같은 핵심 개념에 대한 이해는 알고리즘을 깊이 이해하고 맹목적인 적용을 피하는 데 도움이 된다고 지적했습니다. 일부 댓글에서는 머신러닝의 수학은 상대적으로 간단하며, 더 복잡한 수학은 최적화 이론 및 양자 머신러닝과 같은 분야에 적용된다고 보았습니다. 온라인 학습 자료는 충분하다고 여겨지지만 학습자의 높은 자율성이 필요합니다 (출처: Reddit r/MachineLearning)
💡 기타
QbitAI 싱크탱크 보고서: AI, 검색 SEO 재편, 전문 콘텐츠 커뮤니티 가치 부각: QbitAI(量子位) 싱크탱크는 AI 지능형 도우미가 전통적인 검색 엔진 최적화(SEO) 전략을 재편하고 있다고 지적하는 보고서를 발표했습니다. 보고서는 실험을 통해 AI 답변의 거의 절반이 콘텐츠 커뮤니티에서 비롯되며, 특히 전문 지식 분야에서는 콘텐츠 커뮤니티(예: Zhihu)의 인용 가중치가 더 높다는 것을 발견했습니다. 정보 획득에 대한 사용자의 기대가 ‘자율적 필터링’에서 ‘직접적인 답변 획득’으로 전환됨에 따라 전통적인 웹사이트 클릭 수가 감소할 수 있습니다. 보고서는 AI 시대에는 정보 밀도, 전문가 경험 및 사용자 생성 콘텐츠의 품질로 인해 전문 콘텐츠 커뮤니티의 가치가 부각되며, SEO 전략은 SPO(전문 커뮤니티 최적화)로 전환되어야 하고 저품질 정보 포털의 가중치는 낮아질 것이라고 주장합니다 (출처: 量子位, WeChat)

AI 사진 연령 측정 도구 FaceAge, ‘Lancet’ 등재, 암 치료 결정 보조 가능성: Mass General Brigham 팀은 얼굴 사진을 분석하여 개인의 생물학적 연령을 예측할 수 있는 AI 도구 FaceAge를 개발했으며, 관련 연구는 ‘Lancet Digital Health’에 게재되었습니다. 이 모델은 얼굴 특징(예: 관자놀이 함몰, 피부 주름, 처진 선)을 관찰하여 노화 정도를 평가합니다. 암 환자를 대상으로 한 연구에서 얼굴 연령이 실제 연령보다 젊어 보이는 환자의 치료 효과가 더 좋고 생존 위험이 더 낮은 것으로 나타났습니다. 이 도구는 향후 의사가 환자의 생물학적 연령에 따라 맞춤형 치료 계획을 수립하는 데 도움이 될 수 있지만, 데이터 편향(훈련 데이터가 주로 백인 중심) 및 잠재적 남용(예: 보험 차별)에 대한 우려도 제기되었습니다 (출처: WeChat)

연구: 최고 수준 AI, 기본 물리 작업에서 부진한 성과, 블루칼라 직업 단기적 대체 어려움 부각: 머신러닝 연구원 Adam Karvonen은 부품 제조 작업(CNC 밀링 머신 및 선반 사용)을 통해 OpenAI o3, Gemini 2.5 Pro 등 최고 수준 LLM의 성능을 평가했습니다. 그 결과 모든 모델이 만족스러운 가공 계획을 수립하지 못했으며, 시각적 이해(세부 사항 누락, 특징 인식 불일치) 및 물리적 추론(강성 및 진동 무시, 불가능한 공작물 고정 방안 제시) 측면에서 결함을 드러냈습니다. Karvonen은 이것이 LLM이 관련 분야의 암묵적 지식과 실제 경험 데이터가 부족하기 때문이라고 보았습니다. 그는 단기적으로 AI가 화이트칼라 업무를 더 많이 자동화하겠지만, 물리적 조작과 경험에 의존하는 블루칼라 업무는 영향을 덜 받을 것이며, 이는 산업 간 자동화의 불균형적인 발전을 초래할 수 있다고 추측했습니다 (출처: WeChat)
