키워드:OpenAI, Jony Ive, AI 하드웨어, Google I/O, Gemini, Mistral AI, Devstral, AI 프로그래밍, OpenAI의 io 인수, Gemini 2.5 Pro, Devstral 오픈소스 모델, AI 영화 제작 도구 Flow, AI 프로그래밍 에이전트 Jules
🔥 집중 조명
OpenAI, Jony Ive의 AI 하드웨어 스타트업 io를 65억 달러에 인수 발표: OpenAI는 전 Apple 최고 디자인 책임자 Jony Ive가 SoftBank와 협력하여 설립한 AI 하드웨어 회사 io를 약 65억 달러에 인수한다고 발표했습니다. Jony Ive는 OpenAI의 크리에이티브 디렉터로 합류하여 제품 디자인을 총괄할 예정입니다. io 팀 약 55명은 OpenAI에 합류하여 새로운 형태의 AI 하드웨어 장치 개발에 주력하며, 첫 제품은 2026년에 출시될 것으로 예상됩니다. 이번 인수는 OpenAI가 하드웨어 분야에 본격적으로 진출하여 AI 네이티브 개인 컴퓨팅 장치 및 인터랙티브 경험을 구축하고, 기존 스마트폰 및 컴퓨팅 장치 시장 구도에 도전할 가능성을 시사합니다. (출처: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

구글 I/O 컨퍼런스, 다수의 AI 모델 및 애플리케이션 발표, AI의 일상 통합 강조: 구글은 I/O 2025 개발자 컨퍼런스에서 Gemini 2.5 Pro 및 그 심층 사고 버전, 경량 Gemini 2.5 Flash, 텍스트 확산 모델 Gemini Diffusion, 이미지 생성 모델 Imagen 4 및 비디오 생성 모델 Veo 3를 발표했습니다. Veo 3는 오디오 및 대화가 포함된 비디오 생성을 지원하며 놀라운 효과를 선보였습니다. 구글은 또한 Veo, Imagen 및 Gemini를 통합한 AI 영화 제작 애플리케이션 Flow를 출시했습니다. AI 검색 기능은 AI 요약, Deep Search 및 개인 정보를 통합하고 AI Mode를 출시할 예정입니다. 구글은 AI 기술을 기존 제품 및 서비스에 원활하게 통합하여 AI 기술을 “보이지 않게” 만들고 사용자 경험을 향상시키는 것을 목표로 한다고 강조했습니다. (출처: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

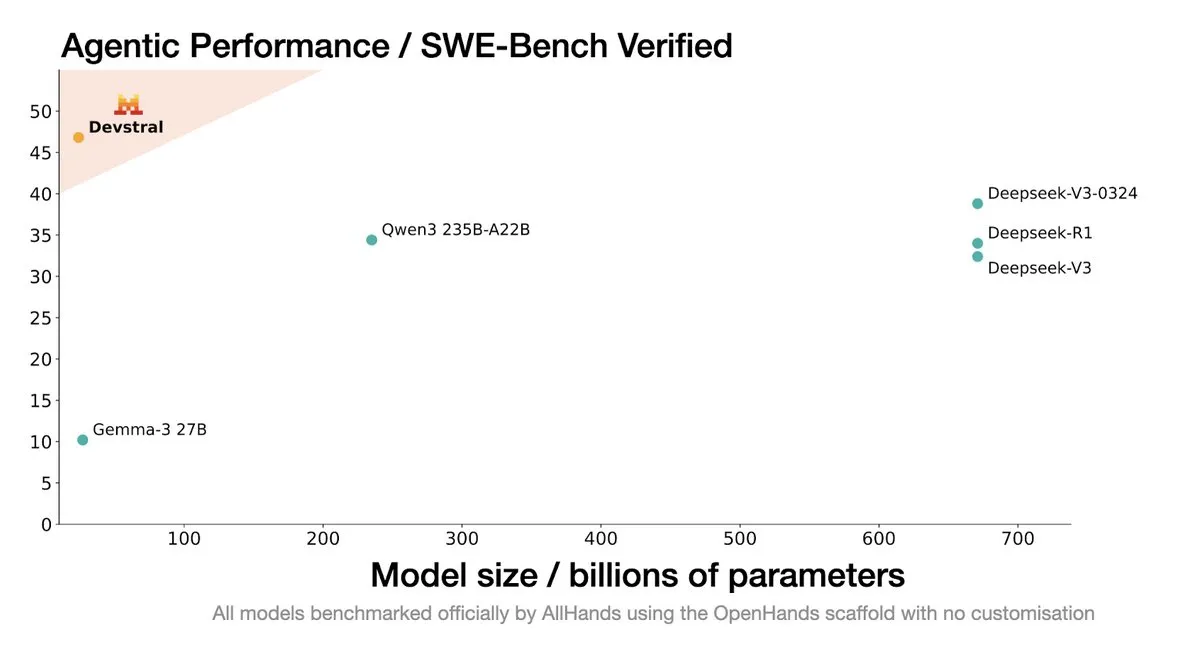
Mistral AI, 코딩 에이전트 전용 SOTA 오픈 소스 모델 Devstral 출시: Mistral AI는 All Hands AI와 협력하여 코딩 에이전트 전용 SOTA 오픈 소스 모델인 Devstral을 출시했습니다. 이 모델은 SWE-Bench Verified 벤치마크 테스트에서 우수한 성능을 보였으며, DeepSeek 시리즈와 Qwen3 235B를 능가했습니다. 매개변수 수는 24B에 불과하며 단일 RTX4090 카드 또는 32G 메모리의 Mac에서 실행할 수 있습니다. Devstral은 실제 GitHub Issue를 대상으로 학습되었으며, 대규모 코드베이스에서의 문맥 이해, 구성 요소 관계 식별 및 복잡한 함수 오류 식별을 강조합니다. Apache 2.0 오픈 소스 라이선스를 채택하여 이전 Codestral보다 더 개방적입니다. (출처: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
구글 DeepMind CTO Koray Kavukcuoglu, Veo 3, Deep Think 및 AGI 진행 상황 설명: Google I/O 컨퍼런스 기간 동안 DeepMind CTO Koray Kavukcuoglu는 인터뷰를 통해 비디오 생성 모델 Veo 3의 발전(예: 오디오-비디오 동기화), Gemini 2.5 Pro의 Deep Think 강화 추론 모드(병렬적 사고 사슬을 통한 추론) 및 AGI에 대한 견해를 논의했습니다. Kavukcuoglu는 규모가 AGI를 실현하는 유일한 요소가 아니며, 아키텍처, 알고리즘, 데이터 및 추론 기술이 동등하게 중요하다고 강조했습니다. AGI의 실현은 기초 연구의 돌파구와 핵심 혁신이 필요하며 단순한 엔지니어링 축적이 아니라고 말했습니다. 그는 또한 “분위기 코딩(vibe coding)”이 비코딩 배경을 가진 사람들이 애플리케이션을 구축할 수 있도록 역량을 부여할 것으로 기대했습니다. (출처: demishassabis, 36氪)
🎯 동향
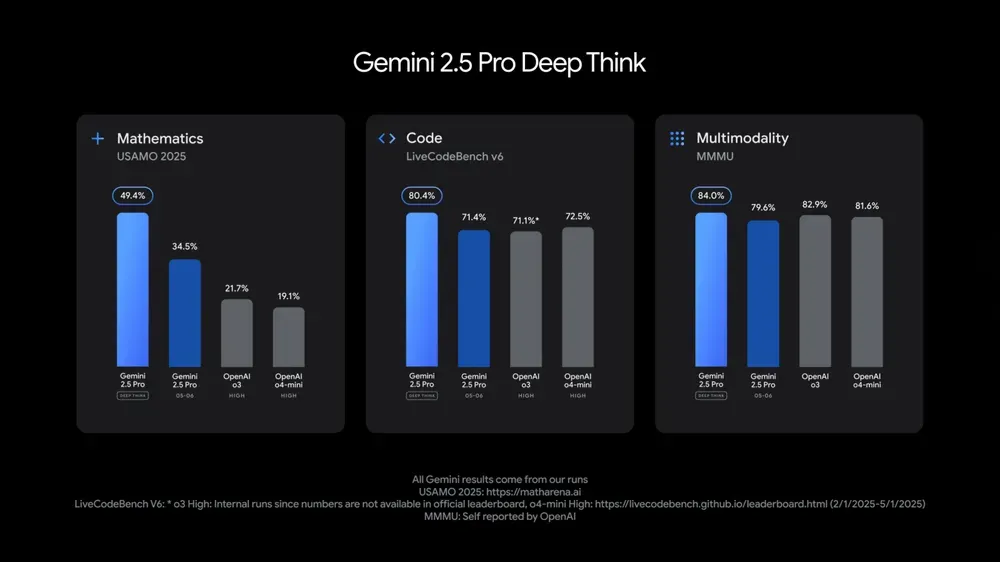
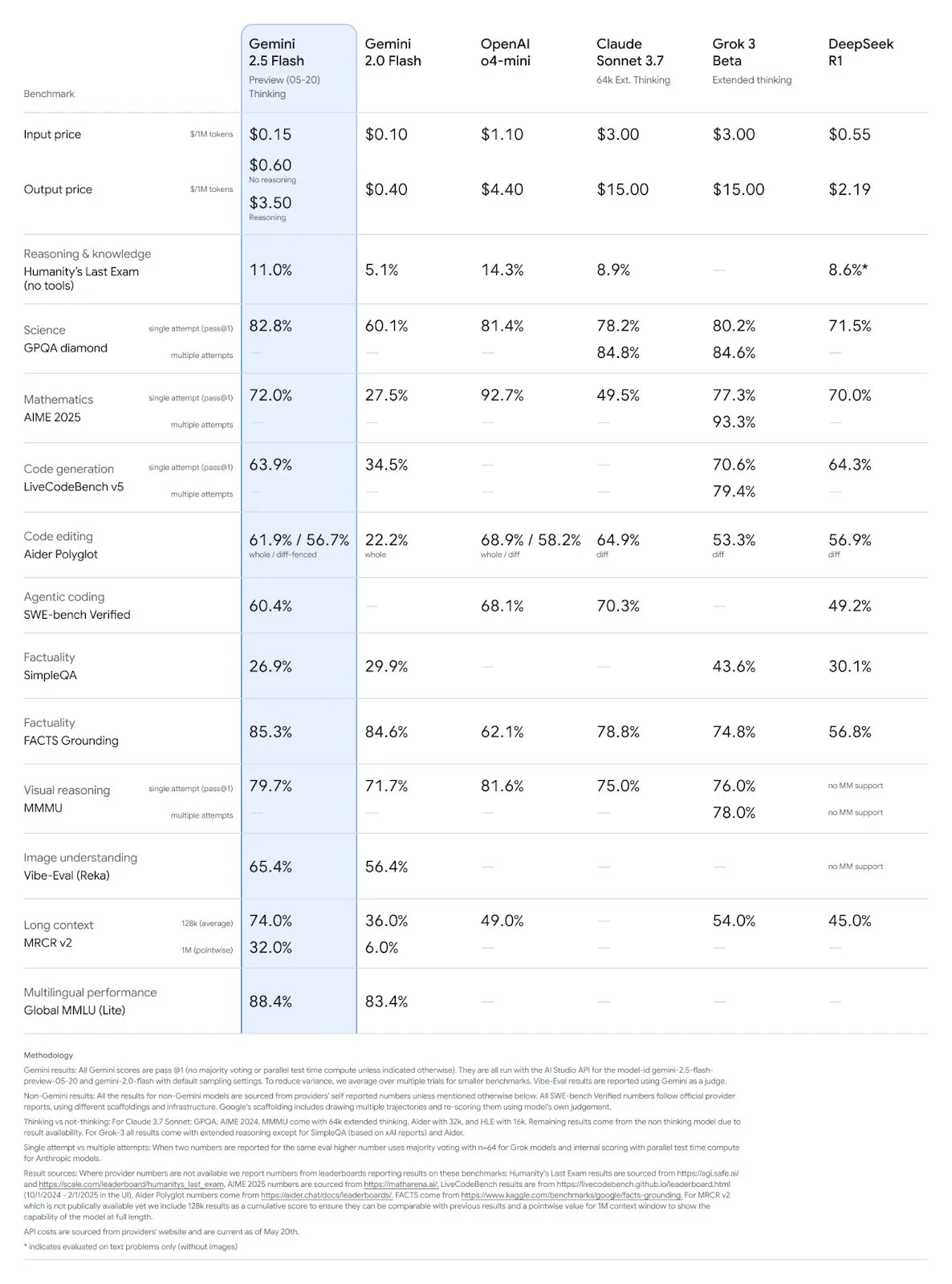
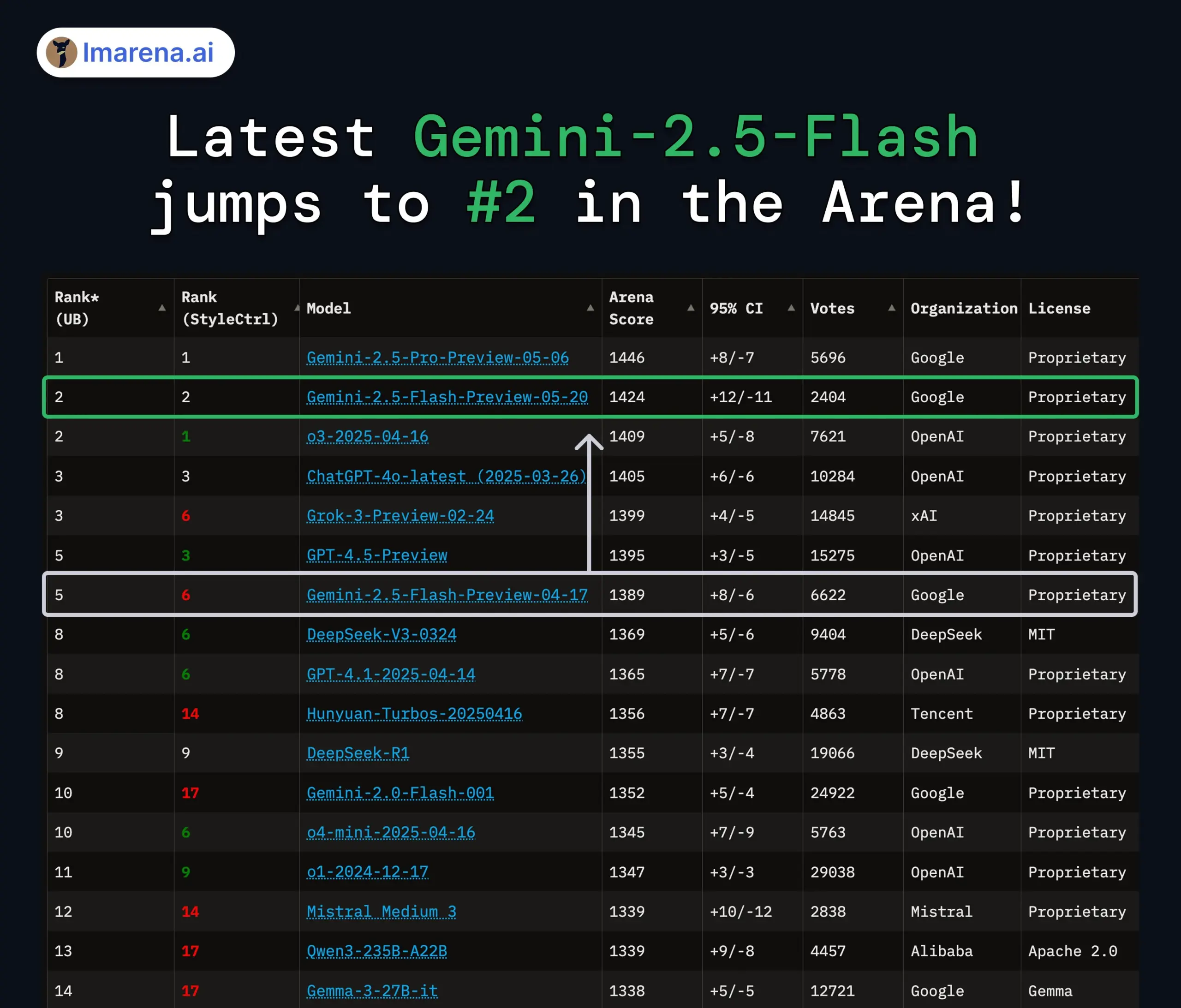
구글 Gemini 2.5 Pro 및 Flash 모델 업데이트, 성능 대폭 향상: 구글은 I/O 컨퍼런스에서 Gemini 2.5 Pro 및 Flash 모델이 6월에 정식 출시될 것이라고 발표했습니다. Gemini 2.5 Pro는 세계에서 가장 지능적인 AI 모델로 알려져 있으며, 새로운 심층 사고 버전이 추가되어 여러 테스트에서 선두를 달리고 있습니다. 경량 모델인 Gemini 2.5 Flash는 효율성이 22% 향상되었고 토큰 소비는 20%-30% 감소했으며, 네이티브 오디오 생성 기능을 갖추고 있습니다. LMArena 데이터에 따르면 새로운 버전의 Gemini-2.5-Flash는 챗봇 아레나 순위에서 2위로 크게 뛰어올랐으며, 특히 코딩, 수학 등 하드코어 작업에서 뛰어난 성능을 보였습니다. (출처: natolambert, demishassabis, karminski3, lmarena_ai)
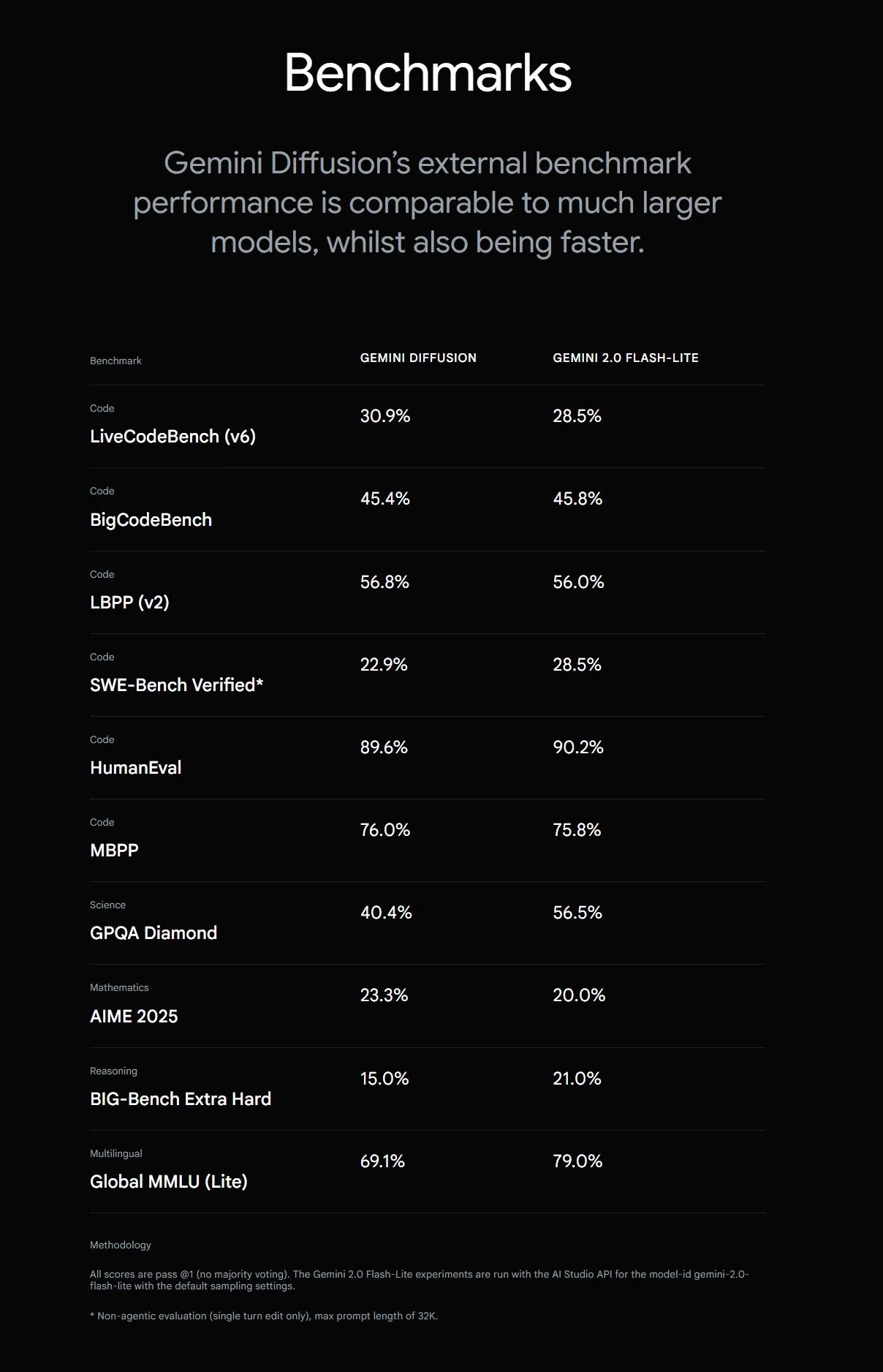
구글, Gemini Diffusion 출시, 텍스트 생성 속도 5배 향상: Google DeepMind는 실험적인 텍스트 생성 모델 Gemini Diffusion을 출시했습니다. 이 모델의 생성 속도는 이전 가장 빠른 모델보다 5배 빠르며, 특히 프로그래밍 능력이 뛰어나 초당 2000 토큰(토큰화 등 오버헤드 포함)에 달합니다. 기존 자기 회귀 모델과 달리 확산 모델은 비인과적 추론을 수행할 수 있어 후속 답변을 미리 “생각”할 수 있으며, 특정 계산 문제, 소수 찾기와 같이 전역적 추론이 필요한 복잡한 문제 해결에서 GPT-4o보다 우수한 성능을 보입니다. 현재 이 모델은 개발자 신청 테스트만 가능합니다. (출처: OriolVinyalsML, dotey, karminski3)
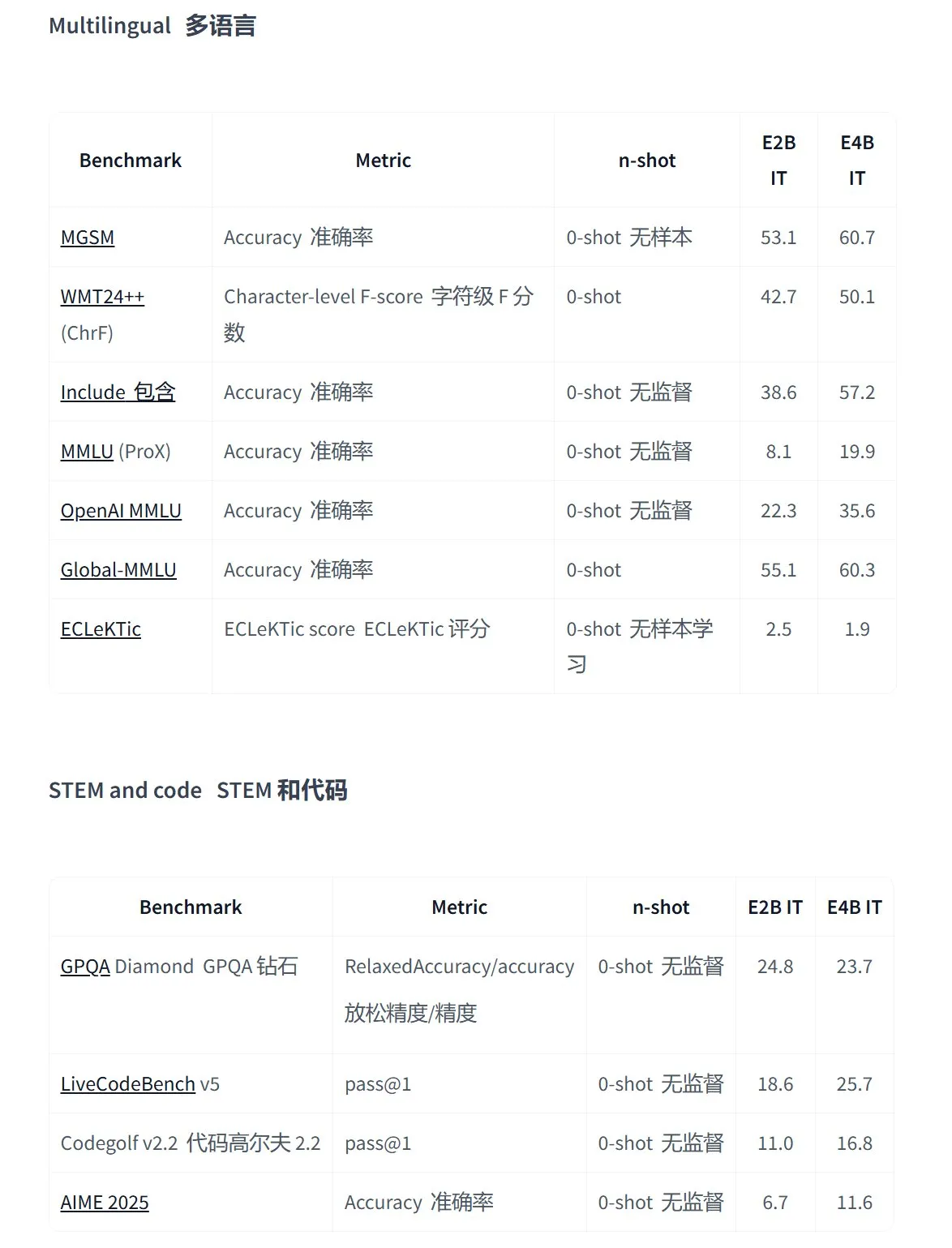
구글, 온디바이스 멀티모달 애플리케이션용 Gemma 3n 시리즈 오픈 소스 모델 출시: 구글은 저전력 장치용으로 설계된 차세대 고효율 멀티모달 오픈 소스 모델 Gemma 3n을 출시했습니다. 이 모델은 텍스트, 음성, 이미지, 비디오 입력을 지원하고 다국어 처리가 가능합니다. 이 시리즈 모델(예: gemma-3n-E4B-it-litert-preview 및 gemma-3n-E2B-it-litert-preview)은 크기가 작고(3-4.4GB), 2GB RAM 장치에서 실행할 수 있으며, 지식은 2024년 6월까지입니다. 현재 AI Studio 및 AI Edge 플랫폼에서 개발자에게 미리보기를 제공하고 있습니다. (출처: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
OpenAI Responses API, MCP 지원, 이미지 생성 및 코드 인터프리터 기능 추가: OpenAI 개발자 플랫폼은 Responses API(이전 Assistants API)에 중요한 업데이트를 발표했습니다. 원격 모델 컨텍스트 프로토콜(MCP) 서버 지원이 추가되어 AI 에이전트가 외부 도구 및 서비스와 더욱 유연하게 상호 작용할 수 있게 되었습니다. 또한 API에는 이미지 생성 기능과 코드 인터프리터 기능이 통합되어 적용 시나리오와 개발 잠재력이 더욱 확장되었습니다. (출처: gdb, npew, OpenAIDevs, snsf)
xAI API, 실시간 검색 기능 Grok Live Search 통합: xAI는 API에 Live Search 기능을 추가하여 Grok이 X 플랫폼, 인터넷, 뉴스 등에서 실시간으로 데이터를 검색할 수 있도록 했다고 발표했습니다. 이 기능은 현재 베타 테스트 단계이며, 개발자들이 Grok의 최신 정보 획득 및 처리 능력을 강화하고 더 동적이고 정보가 풍부한 AI 애플리케이션 구축을 지원하기 위해 한시적으로 무료로 사용할 수 있습니다. (출처: xai, TheGregYang, yoheinakajima)

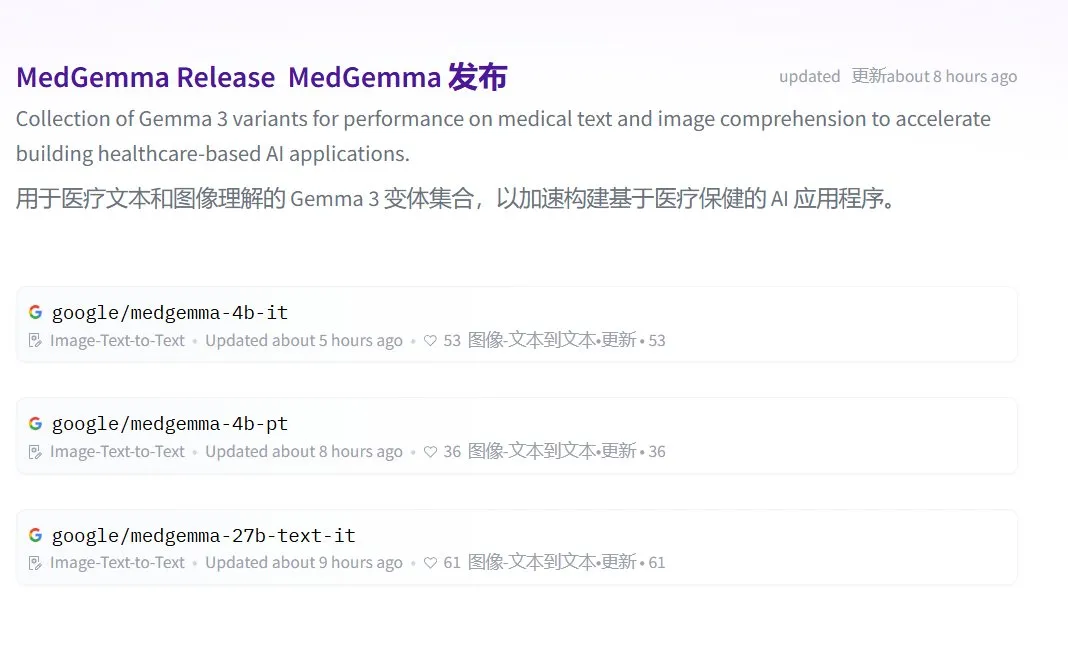
구글, MedGemma 시리즈 오픈 소스 의료 대규모 모델 출시: 구글은 Gemma 3 아키텍처 기반의 오픈 소스 의료 모델 MedGemma를 출시했습니다. 여기에는 medgemma-4b-pt(기본 모델), medgemma-4b-it(멀티모달, 의학 영상 진단) 및 medgemma-27b-text-it(순수 텍스트, 진료 기록)가 포함됩니다. 이 모델들은 의료 텍스트 및 이미지 이해를 위해 특별히 훈련되었으며, 보조 진단, 진료 기록 분석 등 의료 분야에서 AI의 응용 능력을 향상시키는 것을 목표로 합니다. 모델은 Hugging Face에서 공개되었습니다. (출처: JeffDean, karminski3)
텐센트 Hunyuan 대규모 모델 다수 제품 업그레이드, 에이전트 개방형 플랫폼 출시: 텐센트 Hunyuan은 플래그십 빠른 사고 모델 TurboS와 심층 사고 모델 T1의 반복 업그레이드를 발표했으며, TurboS는 코드, 수학 능력에서 전 세계 상위 10위권에 진입했습니다. 새로운 시각적 심층 추론 모델 T1-Vision과 엔드투엔드 음성 통화 모델 Hunyuan Voice를 출시했습니다. 기존 지식 엔진은 RAG 및 Agent 기능을 통합한 “텐센트 클라우드 에이전트 개발 플랫폼”으로 업그레이드되었습니다. Hunyuan 이미지 2.0, 3D v2.5 및 게임 비전 생성 모델도 동시에 출시되었으며, 멀티모달 기본 모델 및 플러그인을 지속적으로 오픈 소스화할 계획입니다. (출처: 36氪)

알리바바, 저장대학교와 협력하여 병렬 컴퓨팅 확장 법칙 ParScale 제안: 알리바바 연구팀은 저장대학교와 협력하여 새로운 Scaling Law인 병렬 컴퓨팅 확장 법칙(ParScale)을 제안했습니다. 이 법칙은 훈련 및 추론 기간 동안 모델 병렬 컴퓨팅을 늘리면 매개변수를 늘리지 않고도 대규모 모델의 능력을 향상시키고 추론 효율성을 높일 수 있다고 지적합니다. 매개변수 확장과 비교하여 ParScale은 메모리 증가량이 4.5%에 불과하고 지연 시간 증가량은 16.7%입니다. 이 방법은 입력 다양화 변환, 병렬 처리 및 동적 집계 출력을 통해 구현되며, 특히 수학, 프로그래밍 등 강력한 추론 작업에서 두드러진 성능을 보입니다. (출처: 36氪)
마이크로소프트, 대규모 대기 기본 모델 Aurora 출시, 예측 속도 5000배 향상: 마이크로소프트와 협력사들은 100만 시간 이상의 지구물리학 데이터를 기반으로 훈련된 최초의 대규모 대기 기본 모델 Aurora를 출시했습니다. 이 모델은 대기 질, 열대성 저기압 경로, 파랑 역학 및 고해상도 날씨를 보다 정확하고 효율적으로 예측할 수 있습니다. 첨단 수치 예보 시스템 IFS와 비교하여 Aurora는 계산 속도가 약 5000배 향상되었으며 여러 핵심 예측 분야에서 SOTA를 달성했습니다. 이 모델 아키텍처는 유연하여 특정 작업에 맞게 미세 조정할 수 있으며 지구 시스템 예측의 대중화를 촉진할 것으로 기대됩니다. (출처: 36氪)

구글 AI 검색, 다수의 지능형 기능 통합한 AI Mode 출시 예정: 구글은 검색 엔진에 “가장 강력한 AI 검색”이라고 불리는 “AI 모드(AI Mode)”를 출시한다고 발표했습니다. 이 모드는 Gemini 2.5를 기반으로 하며, 더 강력한 추론 능력, 더 긴 쿼리 지원, 멀티모달 검색 및 즉각적인 고품질 답변을 제공합니다. 향후 “딥 서치(Deep Search)” 기능을 통합하여 수백 개의 쿼리를 동시에 수행하고 종합 보고서를 제공할 예정이며, Gmail 등 개인 데이터 및 Project Astra의 실시간 카메라 상호 작용, Project Mariner의 자동 작업 관리 기능도 통합할 계획입니다. (출처: dotey, Google)

구글 Imagen 4 이미지 생성 모델 출시, 속도와 디테일 대폭 향상: 구글은 최신 텍스트-이미지 변환 모델 Imagen 4를 출시하며, 이전 세대에 비해 생성 속도가 3~10배 향상되었고 이미지 디테일이 더욱 풍부해졌으며 효과가 더욱 정확해졌고 텍스트 렌더링 능력도 크게 향상되었다고 밝혔습니다. Imagen 4는 직물, 물방울, 동물 털 등 복잡한 물체를 생성할 수 있으며, 해상도는 최대 2K에 달하고 카드, 포스터, 만화 제작 등을 지원합니다. 이 모델은 현재 Gemini App, Whisk 및 Workspace 애플리케이션, Vertex AI에서 무료로 제공됩니다. (출처: dotey, GoogleDeepMind)
연구 결과, AI 프로그래밍 보조 도구가 생성한 코드에 “소프트웨어 패키지 환각” 위험 존재: USENIX Security 2025에 곧 발표될 연구에 따르면, AI가 생성한 코드에는 “소프트웨어 패키지 환각” 현상이 보편적으로 존재하며, 이는 참조된 타사 라이브러리가 전혀 존재하지 않는다는 것을 의미합니다. 이 연구는 16가지 주요 대규모 언어 모델을 테스트한 결과, 20% 이상의 코드가 허구의 소프트웨어 패키지에 의존하고 있으며, 그중 오픈 소스 모델의 비율이 더 높다는 것을 발견했습니다. 이는 공격자가 이러한 허구의 패키지 이름을 이용하여 악성 코드를 게시할 수 있는 공급망 공격의 기회를 만듭니다. Apple, Microsoft 등 회사들도 이러한 의존성 혼동 공격으로 피해를 입은 바 있습니다. (출처: 36氪)

Suno, Remix 기능 출시, 사용자가 기존 곡 기반으로 2차 창작 가능: AI 음악 생성 플랫폼 Suno가 Remix 기능을 출시하여 사용자가 플랫폼의 모든 곡을 선택하여 재창작할 수 있도록 했습니다. 사용자는 곡을 커버(Cover), 확장(Extend) 또는 프롬프트 재사용(Reuse Prompt) 등의 작업을 할 수 있습니다. Remix 창작물에는 원본 자료의 출처 정보가 유지되며, 사용자는 언제든지 자신의 작품에 대한 Remix 권한을 켜거나 끌 수 있습니다. (출처: SunoMusic)
연구 결과, 모든 임베딩 모델이 유사한 의미 구조 학습: Jack Morris 등 연구자들은 서로 다른 임베딩 모델이 학습한 의미 구조가 매우 유사하며, 심지어 페어링된 데이터 없이 구조 정보만으로도 서로 다른 모델의 임베딩 공간 간에 매핑할 수 있다는 사실을 발견했습니다. 이 발견은 임베딩 공간에 어떤 보편적인 기하학적 구조가 존재할 수 있음을 시사하며, 모델 간 호환성, 전이 학습 및 임베딩의 본질을 이해하는 데 중요한 의미를 갖습니다. (출처: menhguin, torchcompiled, dilipkay, jeremyphoward)
논문, 강화 학습 미세 조정(RFT)의 “환각세” 문제 논의: Taiwei Shi 등의 연구에 따르면, 강화 학습 미세 조정(RFT)은 대규모 언어 모델의 추론 능력을 향상시키는 동시에 모델이 답변할 수 없는 문제에 직면했을 때 자신 있게 환각적인 답변을 생성하게 만들 수 있으며, 이를 “환각세(hallucination tax)”라고 명명했습니다. 연구는 SUM 데이터셋(합성된 답변 불가능한 수학 문제)을 도입하여 검증한 결과, 표준 RFT 훈련이 모델의 거부율을 현저히 낮춘다는 것을 발견했습니다. RFT에 소량의 SUM 데이터를 추가함으로써 모델의 적절한 거부 행동을 효과적으로 복원하고, 자체 불확실성 및 지식 경계에 대한 인식을 향상시킬 수 있습니다. (출처: teortaxesTex)

🧰 도구
구글, Veo, Imagen, Gemini 통합 AI 영화 제작 도구 Flow 출시: 구글은 최신 비디오 생성 모델 Veo 3, 이미지 생성 모델 Imagen 4, 멀티모달 모델 Gemini를 통합한 AI 영화 제작 도구 Flow를 출시했습니다. 사용자는 Flow를 통해 자연어 및 리소스 관리를 사용하여 텍스트 프롬프트에서 클립 생성, 장면 조합, 내러티브 구성, 자주 사용하는 요소 소재로 저장 등 영화 수준의 단편을 쉽게 만들 수 있습니다. 이 도구는 크리에이터가 영화적 질감을 가진 작품을 빠르고 효율적으로 제작할 수 있도록 돕는 것을 목표로 합니다. 현재 미국 지역 Google AI Pro 및 Ultra 구독자에게 공개되었습니다. (출처: dotey, op7418)

구글, Gemini 2.5 Pro 기반 클라우드 AI 프로그래밍 에이전트 Jules 출시: 구글은 Gemini 2.5 Pro 기반의 AI 프로그래밍 에이전트 Jules를 출시했습니다. Jules는 백그라운드에서 코드 저장소의 작업(예: 버그 수정, 코드 리팩토링)을 자동으로 처리하며, 다중 작업 병렬 처리를 지원합니다. 또한 Jules는 매일 업데이트되는 Codecasts 팟캐스트를 제공하여 사용자가 코드 저장소의 최신 동향을 파악하도록 돕습니다. 현재 이 도구는 무료 체험이 가능합니다. (출처: dotey, karminski3, GoogleDeepMind)
LangChain, 오픈 소스 노코드 에이전트 플랫폼 Open Agent Platform (OAP) 출시: LangChain은 일반 사용자를 위한 오픈 소스 노코드 플랫폼인 Open Agent Platform (OAP)을 출시했습니다. 이 플랫폼은 AI 에이전트 구축, 프로토타이핑 및 배포를 지원합니다. OAP는 웹 UI를 통해 에이전트를 구축하고, RAG 서버에 연결하여 정보 검색을 개선하며, MCP를 통해 외부 도구를 확장하고, Agent Supervisor를 사용하여 다중 에이전트 워크플로를 조정할 수 있도록 지원합니다. 비전문 개발자도 LangGraph 에이전트의 강력한 기능을 활용할 수 있도록 하는 것을 목표로 합니다. (출처: LangChainAI, Hacubu)

구글 랩스, AI UI 디자인 도구 Stitch 출시: 구글 랩스는 구글의 최신 DeepMind 모델(Gemini 및 Imagen 포함)을 통합한 AI UI 디자인 도구 Stitch를 출시했습니다. 이 도구는 고품질 UI 디자인을 신속하게 생성할 수 있습니다. 사용자는 자연어를 통해 인터페이스 테마를 업데이트하고, 이미지를 자동으로 조정하며, 다국어 콘텐츠 번역을 구현하고, 프런트엔드 코드를 한 번의 클릭으로 내보낼 수 있습니다. Stitch는 이전 Galileo AI의 진화된 버전이며, 창립자는 구글 팀에 합류했습니다. (출처: dotey)
LangChain, 로컬 코드 샌드박스 LangChain Sandbox 출시: LangChain은 AI 에이전트가 신뢰할 수 없는 Python 코드를 로컬에서 안전하게 실행할 수 있도록 하는 LangChain Sandbox를 출시했습니다. 이 도구는 격리된 실행 환경과 구성 가능한 권한을 제공하며, 원격 실행이나 Docker 컨테이너 없이도 여러 실행 간에 세션을 통해 상태를 지속적으로 유지할 수 있도록 지원합니다. 이는 코드를 실행할 수 있는 AI 에이전트(예: codeact agents)를 구축하는 데 더 안전하고 편리한 도구를 제공합니다. (출처: hwchase17, Hacubu)
Vitalops, 자연어로 대규모 데이터셋 처리하는 LLM 도구 Datatune 오픈 소스 공개: Vitalops는 사용자가 자연어 명령을 통해 임의 크기의 데이터셋을 처리할 수 있는 도구인 Datatune을 오픈 소스로 공개했습니다. Datatune은 Map 및 Filter 작업을 지원하며 OpenAI, Azure, Ollama 등 다양한 LLM 서비스 제공업체 또는 사용자 지정 모델에 연결할 수 있고, Dask DataFrame을 활용하여 파티셔닝 및 병렬 처리를 수행합니다. 이 도구는 복잡한 정규 표현식이나 사용자 지정 코드를 대체하여 데이터 정제 및 강화와 같은 작업을 단순화하는 것을 목표로 합니다. (출처: Reddit r/MachineLearning)
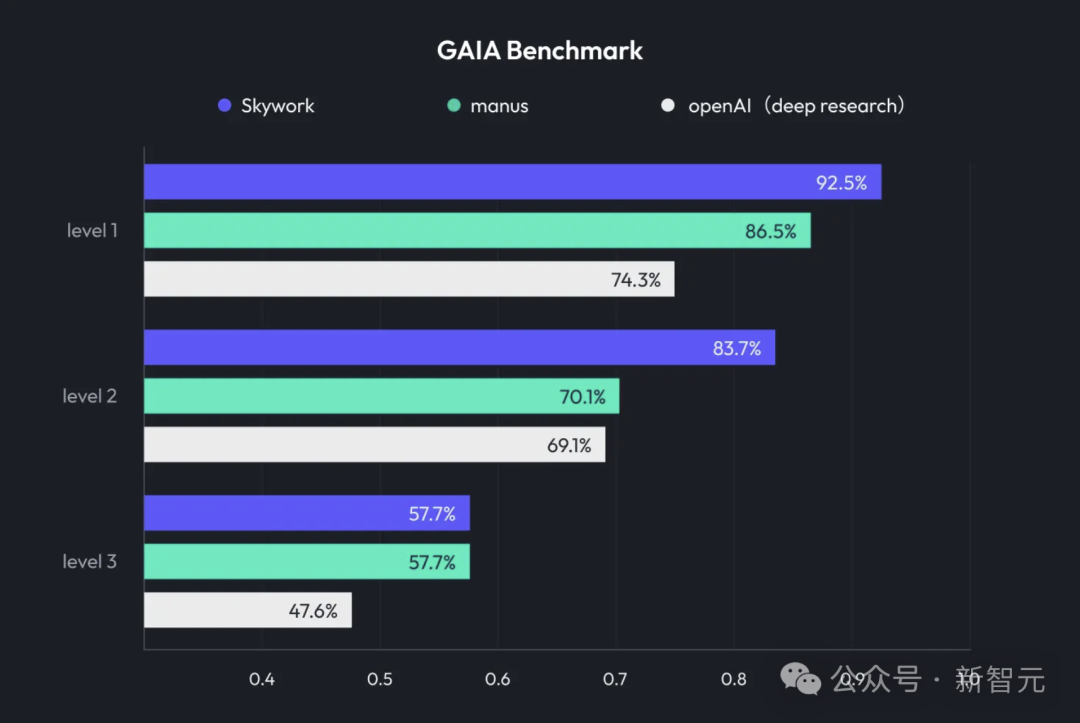
쿤룬완웨이, 딥 리서치와 멀티모달 출력 통합한 Skywork Super Agents 출시: 쿤룬완웨이는 딥 리서치(Deep Research) 능력과 범용 에이전트의 멀티모달 출력 기능을 결합한 AI 사무 제품 Skywork Super Agents를 출시했습니다. 이 제품은 PPT 제작, 문서 작성, 표 처리, 웹 페이지 생성, 팟캐스트 제작 등 다양한 사무 환경을 지원하며, 환각을 줄이기 위해 콘텐츠 출처 추적을 강조하고 온라인 편집 및 내보내기 기능을 제공합니다. 쿤룬완웨이는 또한 Deep Research Agent 프레임워크 및 관련 MCP를 오픈 소스로 공개했습니다. (출처: 36氪)
구글, AI 생성 콘텐츠 식별 돕는 SynthID Detector 출시: 구글은 기자, 미디어 전문가 및 연구자들이 콘텐츠에 SynthID 워터마크가 있는지 쉽게 식별할 수 있도록 돕는 새로운 포털 사이트인 SynthID Detector를 출시했습니다. SynthID는 구글이 개발한 AI 생성 콘텐츠(이미지, 오디오, 비디오 또는 텍스트 포함)에 보이지 않는 워터마크를 추가하는 기술이며, 이 탐지 도구의 출시는 AI 생성 콘텐츠의 투명성과 추적성을 높이는 데 기여합니다. (출처: dotey, Google)
Lark(飞书), 기업 전용 AI Q&A 도구 “지식 Q&A” 기능 출시: Lark(飞书)는 “지식 Q&A” 신기능을 출시했습니다. 이 도구는 기업 직원이 Lark(飞书)에서 접근 권한이 있는 모든 정보(메시지, 문서, 지식 베이스 등)를 기반으로 DeepSeek-R1, Doubao 등 대규모 모델 및 RAG 기술과 결합하여 직원에게 정확한 답변과 콘텐츠 제작 지원을 제공합니다. 특징은 질문자의 기업 내 신분과 권한에 따라 답변이 동적으로 조정되어 AI를 일상 업무 흐름에 원활하게 통합하고 기업 지식 관리 및 활용 효율성을 높이는 것을 목표로 합니다. (출처: 量子位)

Animon: 일본 최초 AI 애니메이션 생성 플랫폼, 일본 애니메이션 스타일과 무제한 무료 생성 강조: 일본 CreateAI 회사(전 Tusimple)는 애니메이션 제작에 특화된 AI 애니메이션 생성 플랫폼 Animon을 출시했습니다. 이 플랫폼은 일본 애니메이션 미학과 AI 기술을 결합하여 화면 스타일 일관성과 효율적인 생산을 강조하며, 개인 사용자는 무료로 무제한 비디오를 생성할 수 있다고 밝혔습니다. Animon은 캐릭터 이미지 업로드와 텍스트 설명을 통해 애니메이션 클립(약 3분)을 빠르게 생성할 수 있도록 지원하며, 애니메이션 제작 장벽을 낮추고 UGC 콘텐츠 생태계를 활성화하는 것을 목표로 합니다. 모회사인 CreateAI는 자체 개발한 대규모 모델 Ruyi를 보유하고 있으며, 《삼체》, 《김용군협전》 등 IP 각색권을 보유하고 “자체 개발 콘텐츠 + UGC 도구 플랫폼” 양륜 구동 전략을 추진하고 있습니다. (출처: 量子位)

📚 학습
DeepLearning.AI, GRPO를 사용한 LLM 강화 세분화 신규 과정 출시: Andrew Ng는 Predibase와 협력하여 “GRPO(Group Relative Policy Optimization)를 사용한 LLM 강화 세분화”를 주제로 한 새로운 단기 과정을 출시한다고 발표했습니다. 이 과정은 강화 학습(특히 GRPO 알고리즘)을 사용하여 대량의 지도 미세 조정 샘플 없이도 LLM의 다단계 추론 작업(예: 수학 문제 해결, 코드 디버깅) 성능을 향상시키는 방법을 가르칩니다. GRPO는 프로그래밍 가능한 보상 함수를 통해 모델을 안내하며, 결과 검증이 가능한 작업에 적합하고 소규모 LLM의 추론 능력을 크게 향상시킬 수 있습니다. (출처: AndrewYNg, DeepLearningAI)
LlamaIndex, Python 대규모 모노레포 관리 경험 공유: LlamaIndex 팀은 650개 이상의 커뮤니티 패키지를 포함하는 Python 모노레포(monorepo) 관리 경험을 공유했습니다. 그들은 Poetry와 Pants에서 uv와 자체 개발한 오픈 소스 빌드 관리 도구 LlamaDev로 이전하여 테스트 실행 속도를 20% 향상시키고 로그를 더 명확하게 만들었으며 로컬 개발을 단순화하고 기여자 진입 장벽을 낮췄습니다. 이 경험은 대규모 Python 프로젝트를 관리해야 하는 팀에게 참고가 될 것입니다. (출처: jerryjliu0)

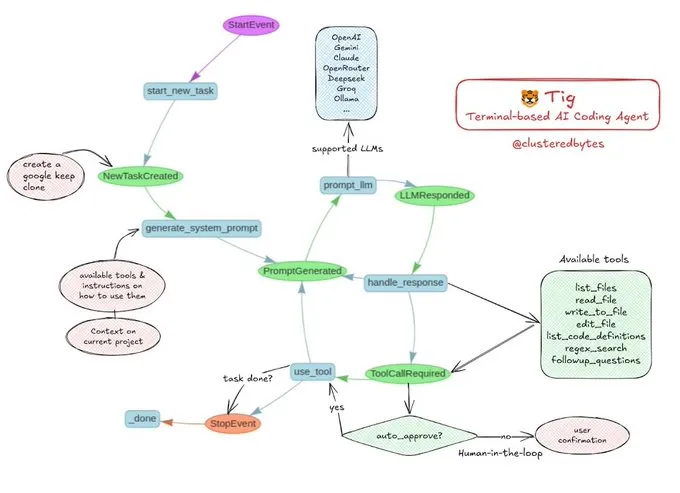
튜토리얼 공유: 자신만의 AI 코딩 에이전트 Tig 구축하기: Jerry Liu는 Tig라는 오픈 소스 AI 코딩 에이전트 프로젝트를 추천했습니다. 이 프로젝트는 터미널 기반의 휴먼인더루프(human-in-the-loop) 코딩 도우미이며 LlamaIndex 워크플로를 사용하여 구축되었습니다. Tig는 다양한 언어의 코드 작성, 디버깅, 분석, 셸 명령어 실행, 코드베이스 검색, 테스트 및 문서 생성 등의 작업을 수행할 수 있습니다. GitHub 저장소는 상세한 구축 가이드를 제공하며, AI 코딩 에이전트 구축을 배우고 싶은 개발자에게 훌륭한 교육 자료입니다. (출처: jerryjliu0)
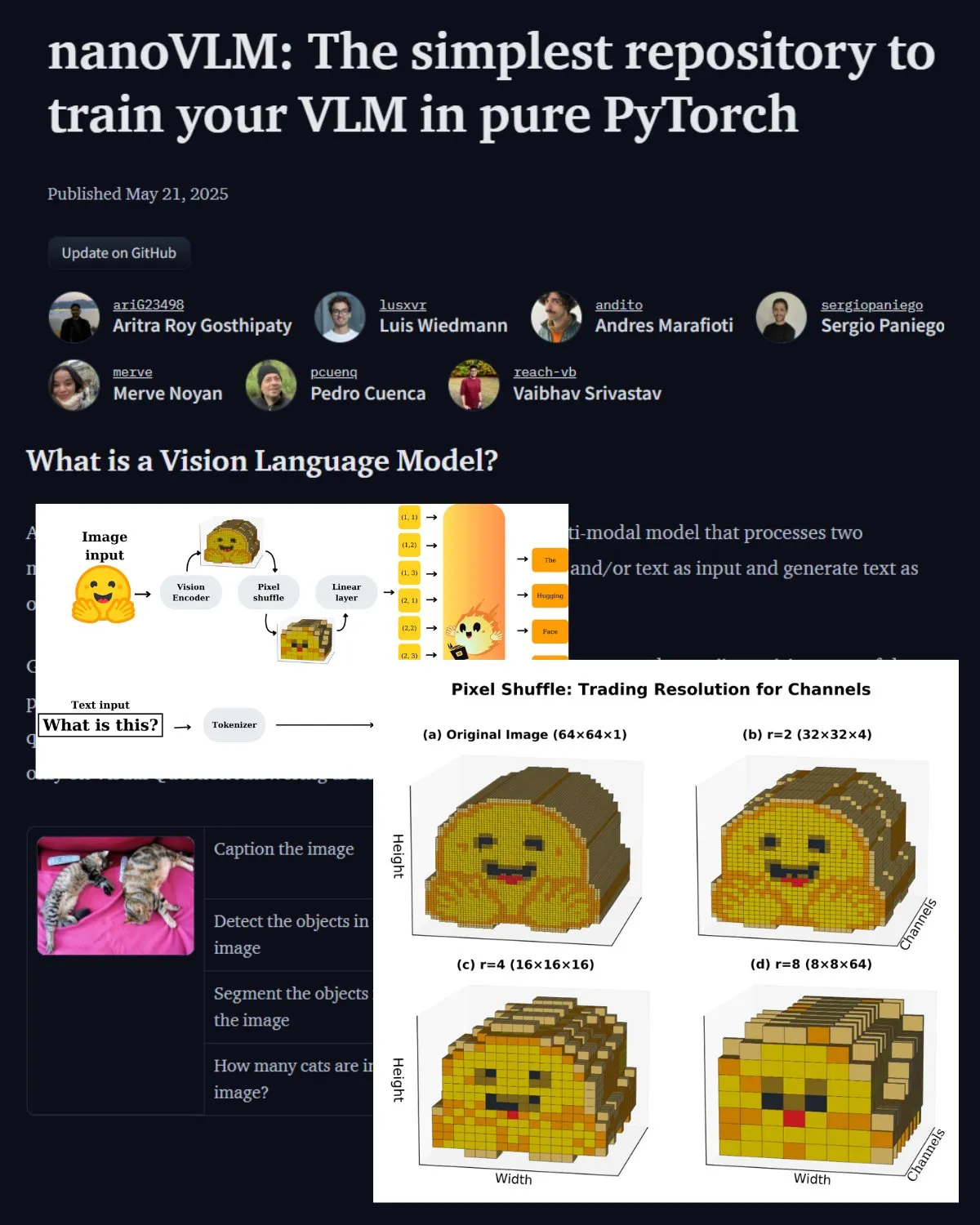
Hugging Face, VLM 중요 블로그 게시물 발표, nanoVLM 커뮤니티 랩 소개: Hugging Face는 시각 언어 모델(VLM)에 관한 블로그 게시물을 발표했습니다. 내용은 VLM 기본 지식, 아키텍처 및 자신만의 경량 VLM을 훈련하는 방법을 다룹니다. 동시에 VLM 미세 조정을 위한 오픈 소스 저장소인 nanoVLM을 소개했으며, 현재 시각 언어 연구를 위한 커뮤니티 랩으로 발전하여 개발자가 VLM 연구를 탐색하고 기여할 수 있도록 돕고 있습니다. (출처: _akhaliq, huggingface)
Serrano Academy, LLM 강화 학습 미세 조정 시리즈 비디오 튜토리얼 공개: Serrano Academy는 강화 학습을 사용한 LLM 미세 조정 및 훈련에 관한 비디오 튜토리얼 시리즈를 완성하여 공개했습니다. 내용은 심층 강화 학습(Deep Reinforcement Learning), RLHF(Reinforcement Learning from Human Feedback), PPO(Proximal Policy Optimization), DPO(Direct Preference Optimization), GRPO(Group Relative Policy Optimization) 및 KL 발산(KL Divergence) 등 핵심 개념과 기술을 다룹니다. (출처: SerranoAcademy)
논문, 대규모 언어 모델의 “빈 레이어” 현상 논의: 한 연구는 지시 조정된 대규모 언어 모델이 추론 과정에서 모든 레이어가 활성화되지 않는 현상을 조사하여 비활성화된 레이어를 “빈 레이어(Voids)”라고 명명했습니다. 연구는 L2 적응형 계산(LAC) 방법을 사용하여 프롬프트 처리 및 응답 생성 단계의 활성화 레이어를 추적한 결과, 서로 다른 단계에서 활성화되는 레이어도 다르다는 것을 발견했습니다. 실험 결과, MMLU 등 벤치마크 테스트에서 Qwen2.5-7B-Instruct의 빈 레이어를 건너뛰면(30% 레이어만 사용) 성능이 향상되어 대부분의 레이어를 선택적으로 건너뛰는 것이 특정 작업에 유리할 수 있음을 시사합니다. (출처: HuggingFace Daily Papers)
연구 제안 “소프트 셔킹”: 연속적인 개념 공간에서 LLM 추론 잠재력 발휘: “Soft Thinking”이라는 논문은 훈련 없이 연속적인 개념 공간에서 부드럽고 추상적인 개념 토큰을 생성하여 인간과 유사한 “소프트” 추론을 시뮬레이션하는 방법을 제안합니다. 이러한 개념 토큰은 토큰 임베딩의 확률 가중 혼합으로 구성되며, 관련된 이산 토큰의 다양한 의미를 캡슐화하여 다양한 추론 경로를 암묵적으로 탐색할 수 있습니다. 실험 결과, 이 방법은 수학 및 코딩 벤치마크에서 pass@1 정확도를 향상시키면서 토큰 사용량을 줄였으며 출력은 해석 가능성을 유지했습니다. (출처: HuggingFace Daily Papers)
논문, 탄력적 추론을 통한 확장 가능한 사고의 사슬 논의: Salesforce 연구자들은 탄력적 추론(Elastic Reasoning)을 통해 확장 가능한 사고의 사슬을 구현하는 방법을 제안했습니다. 이 연구는 대규모 언어 모델이 복잡한 추론 작업을 처리할 때 긴 사고의 사슬을 효과적으로 생성하고 관리하여 추론의 정확성과 효율성을 향상시키는 방법을 해결하는 것을 목표로 합니다. 관련 모델과 코드는 Hugging Face에 공개되었습니다. (출처: _akhaliq)

논문 연구: AI 모델은 아픈 아이를 구하기 위해 거짓말을 할까?: LitmusValues라는 연구는 일련의 AI 가치 범주에서 AI 모델의 우선순위를 밝히기 위한 평가 프로세스를 만들었습니다. AIRiskDilemmas(AI 안전 위험과 관련된 시나리오를 포함하는 딜레마 모음)를 수집하여 연구자들은 다양한 가치 충돌 상황에서 AI 모델의 선택을 측정하여 가치 우선순위를 예측하고 잠재적 위험을 식별합니다. 연구 결과, LitmusValues에서 정의된 가치(보살핌 등 포함)는 AIRiskDilemmas에서 이미 관찰된 위험 행동과 HarmBench에서 관찰되지 않은 위험 행동을 예측할 수 있음을 보여줍니다. (출처: HuggingFace Daily Papers)
논문 연구, 가치 기반 강화 학습을 통한 확산 모델의 효율적인 미세 조정 (VARD): 확산 모델은 생성 작업에서 강력한 성능을 보이지만 특정 속성에 맞게 미세 조정하는 것은 여전히 어려운 과제입니다. 기존 강화 학습 방법은 안정성, 효율성 및 미분 불가능한 보상 처리 측면에서 부족함이 있습니다. VARD (Value-based Reinforced Diffusion)는 먼저 중간 상태에서 보상 기대치를 예측하는 가치 함수를 학습한 다음, 이 가치 함수와 KL 정규화를 활용하여 전체 생성 과정에 걸쳐 밀도 높은 감독을 제공합니다. 실험 결과, 이 방법은 궤적 안내를 개선하고 훈련 효율성을 높이며, 복잡한 미분 불가능한 보상 함수를 최적화하는 확산 모델로 RL 응용을 확장할 수 있음을 입증했습니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
LMArena.ai (전 LMSYS.org), a16z와 캘리포니아 대학 투자 회사 주도로 1억 달러 시드 라운드 투자 유치: AI 모델 평가 플랫폼 LMArena.ai(전 LMSYS.org)가 Andreessen Horowitz(a16z)와 캘리포니아 대학 투자 회사(UC Investments) 공동 주도로 1억 달러 규모의 시드 라운드 투자를 유치했다고 발표했습니다. 이 회사는 중립적이고 개방적이며 커뮤니티 중심적인 플랫폼을 구축하여 전 세계가 실제 사용자 쿼리에 대한 AI 모델의 성능을 이해하고 향상시키는 데 도움을 주는 것을 목표로 합니다. 투자 유치 후 회사 가치는 6억 달러에 달합니다. (출처: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
미국 정부, 사우디아라비아와 아랍에미리트에 수백억 달러 규모 AI 기술 및 서비스 판매 발표: 미국 정부는 사우디아라비아 및 아랍에미리트와 수백억 달러 규모의 AI 기술 및 서비스 판매 계약을 체결했다고 발표했습니다. 참여 기업으로는 AMD, Nvidia, Amazon, Google, IBM, Oracle, Qualcomm 등이 있습니다. Nvidia는 사우디 Humain 회사에 GB300 AI 칩 1만 8천 개와 향후 수십만 개의 GPU를 공급할 예정이며, AMD와 Humain은 AI 데이터 센터 건설에 100억 달러를 공동 투자할 것입니다. 이번 조치는 중동 지역에서 미국의 AI 영향력을 강화하고 양국의 경제 다변화를 돕기 위한 것입니다. (출처: DeepLearning.AI Blog)

Meta, 초기 AI 스타트업 지원 위한 Llama 스타트업 프로그램 시작: Meta는 미국 초기 스타트업(투자 유치액 1,000만 달러 미만, 개발자 최소 1명)이 Llama 모델을 활용하여 생성형 AI 애플리케이션 혁신을 이루도록 지원하는 Llama 스타트업 프로그램(Llama Startup Program)을 시작한다고 발표했습니다. 이 프로그램은 클라우드 리소스 상환, Llama 전문가의 기술 지원 및 커뮤니티 리소스를 제공합니다. 신청 마감일은 2025년 5월 30일 오후 6시(태평양 표준시)입니다. (출처: AIatMeta)
🌟 커뮤니티
구글 I/O 컨퍼런스, AI 전면 통합과 미래 전망으로 뜨거운 논쟁: 구글 I/O 컨퍼런스에서 Gemini 시리즈 모델, Veo 3 비디오 생성, Imagen 4 이미지 생성, AI 검색 모드 등 다수의 AI 관련 제품 및 업데이트가 발표되어 커뮤니티에서 광범위한 논의가 이루어졌습니다. 많은 평론가들은 구글이 AI 응용 분야에서 강력한 실력을 보여주었으며, 특히 AI를 기존 제품 생태계에 원활하게 통합하는 전략을 높이 평가했습니다. 동시에 AI 생성 콘텐츠의 진위성, AI 윤리 및 AGI의 미래 경로 등에 대한 주제도 논의의 초점이 되었습니다. (출처: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

AI 하드웨어, 새로운 초점으로 OpenAI와 Jony Ive 협력 주목: OpenAI가 Jony Ive의 AI 하드웨어 회사 io를 인수했다는 소식과 구글이 I/O 컨퍼런스에서 선보인 Android XR 스마트 안경 프로토타입은 AI 하드웨어의 미래에 대한 커뮤니티의 논의에 불을 지폈습니다. Sam Altman과 Jony Ive의 협력은 차세대 AI 기반 개인 컴퓨팅 장치를 만들어 기존 휴대폰과 컴퓨터의 상호 작용 방식을 뒤엎을 것으로 간주됩니다. 커뮤니티는 AI 네이티브 하드웨어가 혁명적인 경험을 가져올 것으로 기대하지만, 그 형태, 기능 및 시장 수용도에도 관심을 기울이고 있습니다. (출처: dotey, sama, dotey, swyx)

소프트웨어 개발에서 AI의 역할과 위험에 대한 논의: Mistral AI가 코딩 에이전트 전용 Devstral 모델을 출시하고 OpenAI가 Codex를 업데이트하면서 소프트웨어 개발에서 AI의 응용에 대한 논의가 촉발되었습니다. 커뮤니티는 AI 프로그래밍 도구의 실제 능력, 생성된 코드의 품질 및 안전성에 주목하고 있습니다. 특히 AI가 생성한 코드가 존재하지 않는 “환각 소프트웨어 패키지”를 참조하여 공급망 보안 위험을 초래할 수 있다는 연구 결과는 개발자들에게 AI가 생성한 코드와 의존성을 신중하게 검증해야 함을 상기시킵니다. (출처: MistralAI, DeepLearning.AI Blog, qtnx_)
AI 모델 평가 및 벤치마크 테스트에 대한 논의 지속: LMArena.ai의 대규모 투자 유치와 다양한 신규 모델의 벤치마크 테스트 결과는 AI 모델 평가를 커뮤니티의 뜨거운 화두로 만들었습니다. 사용자들은 특정 작업(예: 코딩, 수학, 상식 Q&A, 감정 이해)에서 서로 다른 모델의 실제 능력과 기존 평가 시스템의 신뢰성 및 한계에 대해 관심을 갖고 있습니다. 예를 들어, 텐센트가 발표한 SAGE 감성 지능 평가 프레임워크는 “감성 지능” 관점에서 AI 모델에 새로운 평가 차원을 제공하려고 시도합니다. (출처: lmarena_ai, 36氪, natolambert)
유럽 기술 산업 발전 지체에 대한 반성, Yann LeCun “애국심” 부족이 주된 원인이라는 논의 공유: 월스트리트 저널의 유럽 기술 현장이 미국과 중국보다 훨씬 작다는 기사가 논의를 불러일으켰고, Yann LeCun은 Arnaud Bertrand의 논평을 공유했습니다. Bertrand는 유럽 기술 낙후의 핵심 원인은 “애국심” 부족이며, 유럽 언론과 엘리트 계층이 미국 스타트업을 추종하는 경향이 있어 자국 혁신을 소홀히 하여 자국 기업이 초기 지원과 시장 인정을 받기 어렵다고 주장했습니다. 그는 자신이 창업한 HouseTrip의 경험을 예로 들며 유럽에는 자국 혁신에 대한 자신감과 지원 분위기가 부족하다고 지적했습니다. (출처: ylecun)

💡 기타
AI의 에너지 소비 문제 관심 집중: MIT Technology Review는 AI 기술의 급속한 발전으로 인한 에너지 소비 문제와 기후에 미치는 영향에 대해 원탁 토론을 개최했습니다. AI 모델의 규모와 적용 범위가 확대됨에 따라 필요한 전력과 컴퓨팅 자원이 급증하고 있으며, 데이터 센터의 에너지 수요가 새로운 초점이 되고 있습니다. 토론은 단일 AI 쿼리의 에너지 소비, AI의 전체 에너지 발자국 및 이 문제에 대처하는 방법에 초점을 맞췄습니다. (출처: MIT Technology Review, madiator)

Anthropic, 새로운 소식 예고, 커뮤니티 Claude 4 출시 추측: Anthropic 회사는 태평양 표준시 5월 22일 오전 9시 30분(한국 시간 23일 0시)에 라이브 방송을 진행할 것이라고 예고하여, 커뮤니티에서 Claude 차세대 모델(또는 Claude 4) 출시 가능성에 대한 추측을 불러일으켰습니다. 최근 OpenAI와 구글이 연이어 주요 업데이트를 발표한 점을 고려할 때 Anthropic의 이번 행보는 큰 관심을 받고 있습니다. (출처: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
AI와 XR 기술 융합, 구글 Android XR 스마트 안경 프로토타입 공개: 구글은 I/O 컨퍼런스에서 Android XR 스마트 안경 프로토타입을 공개하며 AI와의 심층적인 융합을 강조했습니다. 이 장치는 1인칭 시점 지능형 보조 및 비접촉 보조 기능을 지원하며, 사용자는 자연어를 통해 장치와 상호 작용하여 정보 검색, 일정 관리, 실시간 내비게이션 등을 수행할 수 있습니다. 이는 AI가 차세대 XR 장치의 핵심 상호 작용 및 기능 구동력이 되어 증강 현실 환경에서 사용자 경험을 향상시킬 것임을 예고합니다. (출처: dotey, 36氪)