
키워드:AI 에이전트, 대형 언어 모델, Gemini 2.5 Pro, 엔비디아 AI 슈퍼컴퓨터, 마이크로소프트 빌드 대회, 연구용 AI 에이전트, 추론 능력 평가, AI 프로그래밍, 코딩 에이전트 자동 버그 수정, 마이크로소프트 디스커버리 연구 플랫폼, NVLink Fusion 기술, CloudMatrix 384 슈퍼노드, EdgeInfinite 알고리즘
🔥 포커스
AI 에이전트, 개발 및 과학 연구 패러다임 재정의: Microsoft Build 컨퍼런스에서 버그 자가 수정, 코드 유지보수 Coding Agent 및 아이디어 생성, 결과 시뮬레이션, 자가 학습이 가능한 과학 연구 에이전트 플랫폼 Microsoft Discovery 등 일련의 AI 에이전트 도구 발표. 동시에 OpenAI 최고 제품 책임자 Kevin Weil 및 Anthropic CEO Dario Amodei는 AI가 이미 고급 프로그래밍 능력을 갖추고 있어 초급 프로그래머 일자리가 대체될 수 있으며 개발자 역할이 “AI 유도자”로 전환될 것을 예고. 이러한 발전은 AI 에이전트가 보조 도구에서 복잡한 프로젝트에서 독립적으로 작동할 수 있는 핵심 역량으로 진화하고 있음을 의미하며, 소프트웨어 개발 및 과학 연구의 프로세스와 효율성을 심오하게 변화시킬 것 (출처: GitHub Trending, X)
대규모 언어 모델 추론 능력, 새로운 도전과 평가 직면: 최근 여러 연구와 논의에서 대규모 언어 모델이 복잡한 추론 작업에서 한계를 드러냄. 하버드 대학교 등 기관의 연구에 따르면, 사고의 연쇄(CoT)는 때때로 모델이 지침을 따르는 정확도를 떨어뜨릴 수 있는데, 이는 내용 계획에 지나치게 집중하여 간단한 제약 조건을 무시하기 때문임. 동시에 부품 가공과 같은 현실 세계 물리적 작업과 정육면체 쌓기 문제와 같은 복잡한 시각 공간 추론도 o3, Gemini 2.5 Pro를 포함한 최상위 AI 모델의 부족함을 드러냄. 모델 능력을 보다 정확하게 평가하기 위해 EMMA, SPOT 등 새로운 벤치마크가 제안되었으며, 이는 AI가 멀티모달 융합, 과학적 검증 등에서 실제 수준을 감지하여 모델이 더욱 견고하고 신뢰할 수 있는 추론으로 진화하도록 추진하는 것을 목표로 함 (출처: HuggingFace Daily Papers, 量子位)
Google AI 전방위적 공세, Gemini 2.5 Pro 강력한 성능 과시: Google은 AI 분야에서 전면적인 공세를 펼치고 있으며, Gemini 2.5 Pro 모델은 여러 벤치마크 테스트(예: LMSYS Chatbot Arena)에서 뛰어난 성능을 보였으며, 특히 긴 컨텍스트와 비디오 이해 측면에서 최고 수준에 도달했고 WebDev Arena에서는 이전 버전을 능가함. Google Cloud Next ‘25 컨퍼런스에서 Google은 Gemini 2.5 Flash, Imagen 3, Veo 2, Vertex AI Agent Development Kit (ADK) 및 Agent2Agent (A2A) 프로토콜을 포함한 200여 개의 업데이트를 발표하여 AI를 클라우드 플랫폼의 모든 계층에 통합하고 기업의 대규모 배포를 추진하려는 결의를 보여줌. Google Labs도 NotebookLM 등 AI 네이티브 혁신 제품을 지속적으로 인큐베이팅하며 강력한 제품 혁신 및 반복 능력을 보여주고 있음 (출처: Google, GoogleDeepMind)
NVIDIA, 데스크톱급 AI 슈퍼컴퓨터 및 엔터프라이즈급 AI 팩토리 솔루션 발표: NVIDIA는 Computex 컨퍼런스에서 GB300 슈퍼칩을 탑재한 개인용 AI 컴퓨터 DGX Station을 포함한 여러 주요 신제품을 발표했으며, 최대 784GB의 통합 메모리를 갖추고 1T 파라미터 대형 모델 실행을 지원함. 또한 기업용 RTX PRO Server를 출시하여 AI 에이전트, 물리적 AI, 과학 컴퓨팅 등 다양한 애플리케이션을 가속화함. 동시에 NVIDIA는 반맞춤형 NVLink Fusion 기술과 NVIDIA AI 데이터 플랫폼을 출시하고 Disney 등과 협력하여 물리적 AI 엔진 Newton을 개발한다고 발표함. 이러한 조치는 NVIDIA가 칩 회사에서 AI 인프라 회사로 전환하고 있으며 데스크톱에서 데이터 센터에 이르는 완전한 AI 생태계를 구축하는 것을 목표로 함을 보여줌 (출처: nvidia, 量子位)

🎯 동향
Kimi.ai, 장문 텍스트 사고 모델 kimi-thinking-preview 출시: Kimi.ai는 최신 장문 텍스트 사고 모델 kimi-thinking-preview를 출시했으며, 현재 platform.moonshot.ai에서 이용 가능함. 이 모델은 뛰어난 멀티모달 및 추론 능력을 갖춘 것으로 알려졌으며, 신규 사용자는 등록 시 5달러 쿠폰을 받아 체험할 수 있음. 커뮤니티에서는 제3자가 이 모델을 평가할 것을 제안하며, Kimi가 이전에 전용 사고 모델을 통해 livecodebench에서 선두를 차지했다고 언급함 (출처: X)
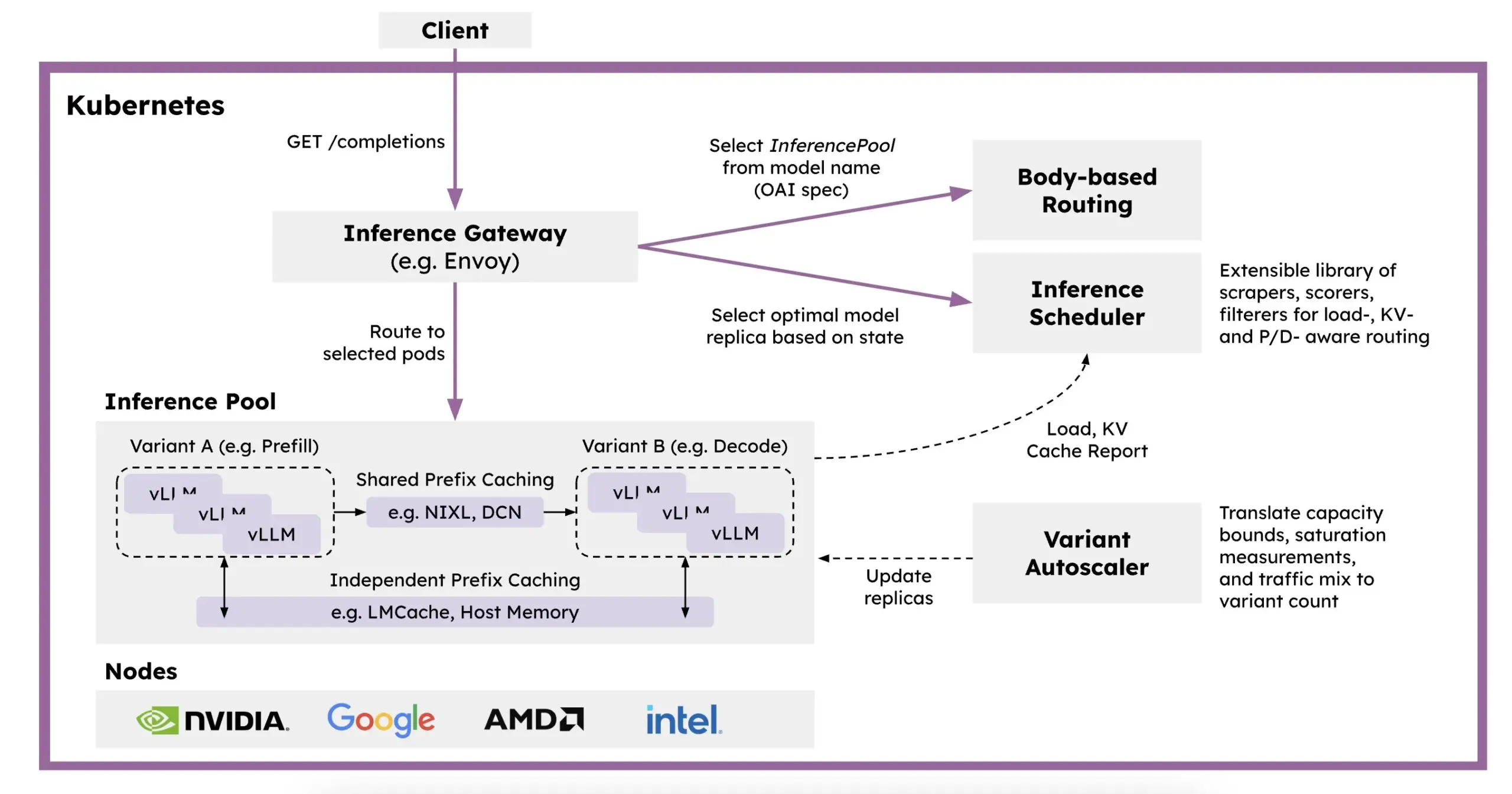
Red Hat, Kubernetes 기반 분산 추론 프레임워크 llm-d 출시: LLM 추론 속도 저하, 높은 비용 및 확장성 문제를 해결하기 위해 Red Hat은 Kubernetes 네이티브 분산 추론 프레임워크인 llm-d를 출시함. 이 프레임워크는 vLLM, 지능형 스케줄링 및 분리된 컴퓨팅을 활용하여 LLM 추론을 최적화함. llm-d는 고성능 LLM 추론 엔진인 vLLM, 컨테이너 오케스트레이션 표준인 Kubernetes, Gateway API 확장을 통해 지능형 라우팅을 구현하는 Inference Gateway (IGW) 등 세 가지 오픈소스 기반 위에 구축되어 LLM 추론의 효율성과 확장성을 향상시키는 것을 목표로 함 (출처: X, X)
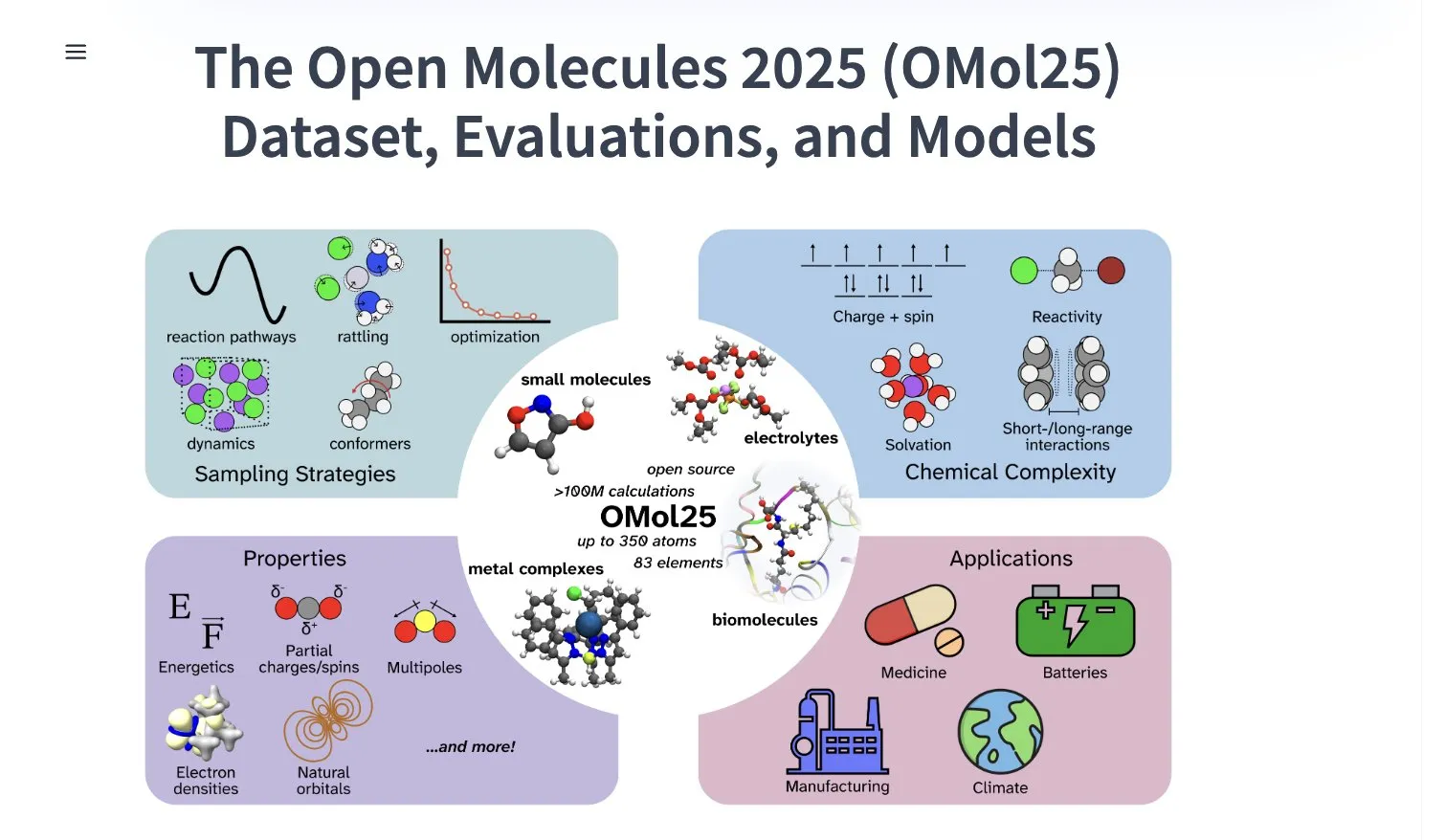
Meta AI, 1억 개 이상의 분자 구조체 포함된 OMol25 데이터셋 공개: Meta AI는 HuggingFace에 1억 개 이상의 분자 구조체를 포함하고 83가지 원소와 다양한 화학 환경을 포괄하는 OMol25 데이터셋을 공개함. 이 데이터셋은 DFT(밀도 범함수 이론) 수준의 정확도를 달성하면서 계산 비용을 대폭 절감할 수 있는 머신러닝 모델을 훈련하는 것을 목표로 함. 이는 약물 발견, 첨단 소재 설계, 청정 에너지 솔루션 등 분야의 연구 및 응용을 가속화하는 데 도움이 될 것임 (출처: X)
Gemini 2.5 Pro, 독일 지역 iOS 앱스토어 NotebookLM에 출시: Google의 NotebookLM 앱(Gemini 2.5 Pro 통합)이 독일 지역 iOS App Store에 출시됨. 이전에는 EU 지역 iOS 버전이 TestFlight를 통해서만 제공되었음. 동시에 Android 버전은 더 광범위하게 사용 가능한 것으로 보임. NotebookLM은 사용자가 긴 문서, 노트 등을 이해하고 처리하는 데 도움을 주는 것을 목표로 함 (출처: X)
ByteDance AI 연구 활발, 최근 다수 논문 발표: ByteDance 산하 SEED 팀은 지난 두 달 동안 모델 병합, 강화 학습 기반 적응형 사고의 연쇄(AdaCoT), 잠재 표현을 통한 추론 최적화(LatentSeek) 등 AI 관련 연구 논문을 최소 13편 발표함. 이러한 연구는 ByteDance가 대규모 언어 모델의 효율성, 추론 능력 및 훈련 방법 향상에 지속적으로 투자하고 탐색하고 있음을 보여줌 (출처: X, X)
AI 기반 차세대 아연 배터리, 99.8% 효율 및 4300시간 작동 시간 달성: 인공지능 최적화를 통해 차세대 아연 배터리가 99.8%의 쿨롱 효율과 최대 4300시간의 작동 시간을 달성함. 이 기술 혁신은 AI가 재료 과학 및 에너지 저장 분야에서 응용 잠재력을 보여주며, 보다 효율적이고 오래 지속되는 배터리 기술 발전을 촉진하여 재생 에너지 저장 및 휴대용 전자 장치에 중요한 의미를 가질 것으로 기대됨 (출처: X)

Perplexity, AI 스마트 브라우저 Comet 초기 테스트 출시: Perplexity는 초기 테스터에게 에이전트 기능을 갖춘 웹 브라우저 Comet을 출시하기 시작함. 이 브라우저는 새로운 “분위기 브라우징”(vibe browsing) 경험을 제공할 것으로 예상되며, Perplexity의 강력한 AI 검색 및 정보 통합 능력을 결합하여 사용자에게 더욱 스마트하고 개인화된 웹 브라우징 방식을 제공할 수 있음 (출처: X)
Intel, 대용량 메모리 탑재한 가성비 Arc Pro B 시리즈 그래픽 카드 출시: Intel은 Arc Pro B50(16GB 메모리, 299달러)과 AI 워크스테이션용으로 설계된 Arc Pro B60(24GB 메모리, 단일 카드 500달러) 그래픽 카드를 출시함. B60은 AI 추론 테스트에서 NVIDIA RTX A1000보다 우수한 성능을 보였으며, 더 큰 메모리로 대형 모델 실행 시 더 유리함. Project Battlematrix 워크스테이션은 Xeon 프로세서를 사용하며 최대 8개의 B60 GPU(총 192GB 메모리)를 장착하여 700억+ 파라미터 모델을 지원함. 이는 Intel이 AI 하드웨어 시장에서 가성비 돌파구를 모색하는 전략으로 간주됨 (출처: 量子位)

Huawei Cloud, CloudMatrix 384 슈퍼노드 출시로 AI 컴퓨팅 파워 향상: Huawei Cloud는 CloudMatrix 384 슈퍼노드를 출시하여 완전 피어 투 피어 상호 연결 아키텍처를 채택, 384개의 AI 가속 카드를 상호 연결하여 슈퍼 클라우드 서버를 형성하고 최대 300Pflops의 컴퓨팅 파워를 제공함으로써 AI 훈련 및 추론에서의 통신 효율성, 메모리 월 및 안정성 문제를 해결하고자 함. 이 아키텍처는 특히 MoE 모델에 대한 친화성, 네트워크를 통한 컴퓨팅 강화, 스토리지를 통한 컴퓨팅 강화 등의 특징을 강조하며, DeepSeek-R1 등 대형 모델의 추론 서비스를 지원하는 데 이미 적용됨 (출처: 量子位)

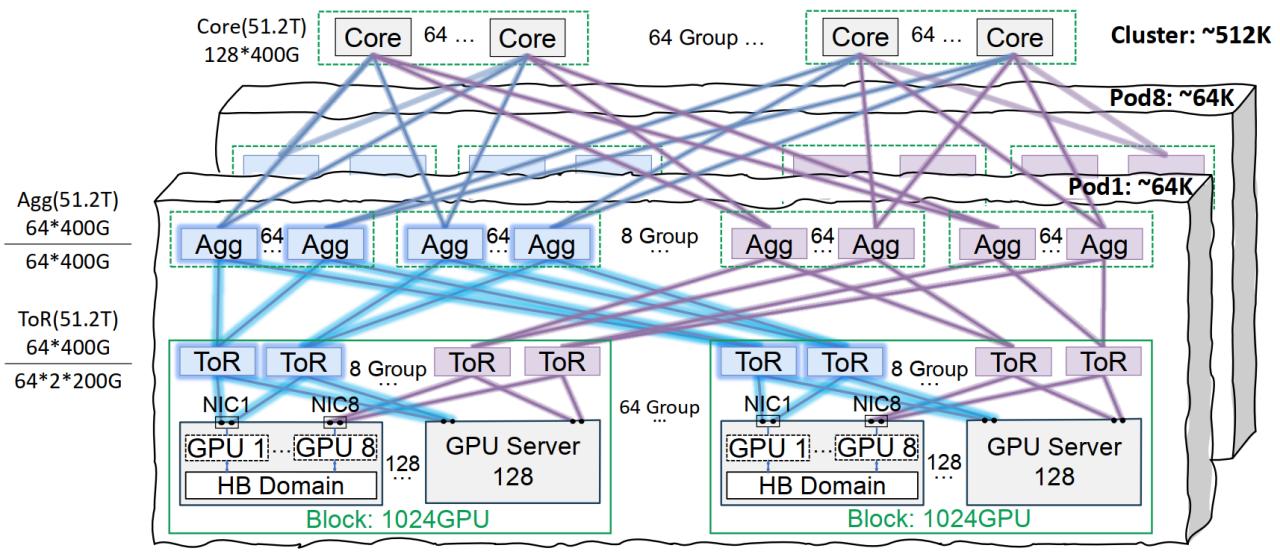
Tencent Cloud Xingmai 네트워크 인프라, 대형 모델 훈련 최적화: Tencent Cloud는 대규모 AI 모델 훈련 및 추론을 위해 특별히 설계된 Xingmai 고성능 네트워크 인프라 솔루션을 출시함. 이 솔루션은 동일 궤도 상호 연결 아키텍처(단일 Pod 6.4만 GPU, 전체 클러스터 51.2만 GPU 네트워킹 지원), 최적화된 전원 관리 및 냉각 솔루션, 지능형 모니터링 시스템을 통해 기존 데이터 센터의 네트워크, 배포 밀도 및 장애 위치 파악 문제를 해결함. Xingmai는 Tencent Hunyuan 등 자체 개발 사업을 지원하고 DeepSeek의 DeepEP 통신 프레임워크에 성능 최적화를 제공함 (출처: 量子位)
Stability AI, sv4d2.0 모델 출시, 비디오 생성 분야 복귀 예고 가능성: Stability AI가 Hugging Face에 sv4d2.0이라는 모델을 출시하여 커뮤니티의 주목을 받음. 구체적인 내용은 많지 않지만, 이는 Stability AI가 비디오 생성 또는 관련 3D/4D 분야에서 새로운 기술 진전이나 제품 업데이트가 있음을 의미할 수 있으며, 조정 기간을 거친 후 AI 생성 분야의 선두로 복귀할 가능성을 시사함 (출처: X)
Meta AI, Adjoint Sampling 학습 알고리즘 발표: Meta AI는 스칼라 보상 기반 생성 모델 훈련을 위한 새로운 학습 알고리즘 Adjoint Sampling을 제안함. 이 알고리즘은 FAIR에서 개발한 이론적 기초를 기반으로 하며 확장성이 뛰어나 향후 확장 가능한 샘플링 방법 연구의 기초가 될 것으로 기대됨. 관련 연구 논문, 모델, 코드 및 벤치마크가 공개됨 (출처: X)
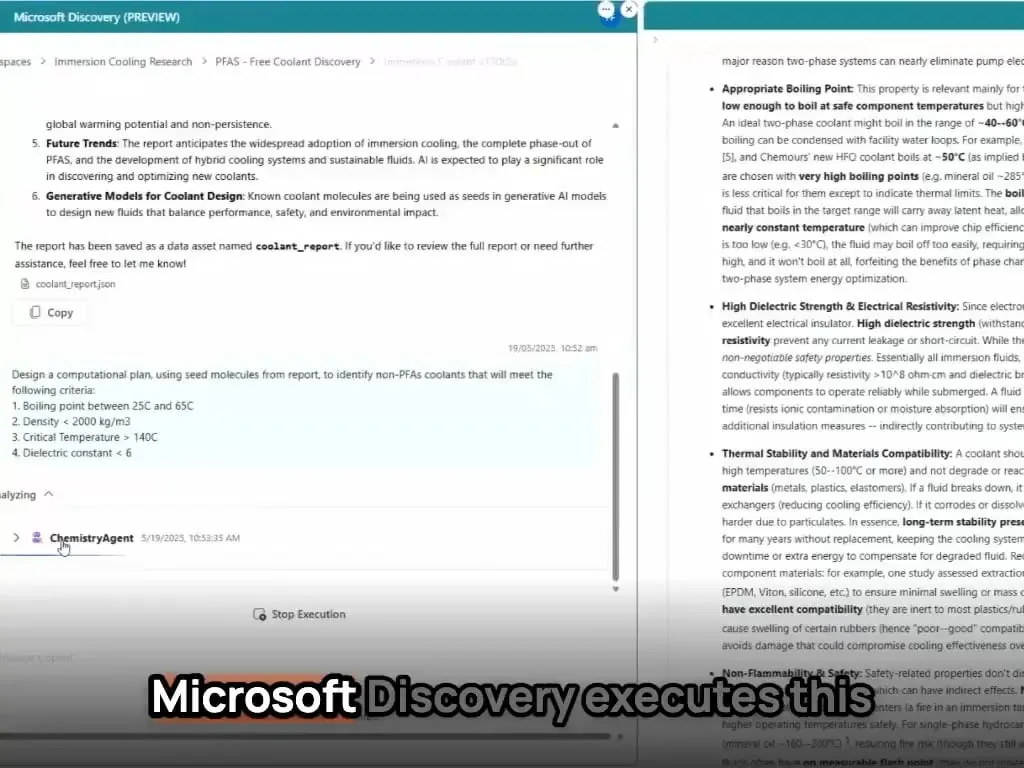
Microsoft AI 에이전트, 몇 시간 만에 신소재 발견 및 합성 완료: Microsoft는 과학 연구 개발에서 AI 에이전트의 강력한 능력을 선보임. 이러한 에이전트는 과학 문헌을 스캔하고, 계획을 수립하고, 코드를 작성하고, 시뮬레이션을 실행하며, 일반적으로 수년간의 연구 개발이 필요한 새로운 데이터 센터 냉각제의 발견을 몇 시간 만에 완료함. 더 나아가 팀은 AI가 설계한 새로운 냉각제를 성공적으로 합성하고 실제 마더보드에서 시연하여 재료 과학 등 분야에서 AI의 자율적 발견 및 창조 가속화에 대한 엄청난 잠재력을 보여줌 (출처: Reddit r/artificial)
BAAI, 코드 및 멀티모달 검색에 특화된 BGE 시리즈 벡터 모델 3종 발표: BAAI(智源研究院)는 대학과 공동으로 BGE-Code-v1(코드 벡터 모델), BGE-VL-v1.5(범용 멀티모달 벡터 모델), BGE-VL-Screenshot(시각화 문서 벡터 모델)을 출시함. 이 모델들은 CoIR, Code-RAG, MMEB, MVRB 등 벤치마크에서 우수한 성능을 보였으며, BGE-Code-v1은 Qwen2.5-Coder-1.5B, BGE-VL-v1.5는 LLaVA-1.6, BGE-VL-Screenshot은 Qwen2.5-VL-3B-Instruct를 기반으로 하여 코드 검색, 이미지-텍스트 이해 및 복잡한 시각 문서 검색 성능 향상을 목표로 하며, 전면 오픈소스화됨 (출처: WeChat)
Huawei OmniPlacement 기술, MoE 모델 추론 최적화, DeepSeek-V3 지연 시간 이론적으로 10% 감소: 혼합 전문가(MoE) 모델에서 전문가 네트워크 부하 불균형(“핫 전문가” 대 “콜드 전문가”)으로 인한 추론 성능 제한 문제를 해결하기 위해 Huawei 팀은 OmniPlacement 기술을 제안함. 이 기술은 전문가 재배치, 계층 간 중복 배포 및 거의 실시간 동적 스케줄링을 통해 DeepSeek-V3 등 모델에서 이론적으로 추론 지연 시간을 약 10% 줄이고 처리량을 약 10% 향상시킬 수 있음. 이 솔루션은 곧 전면 오픈소스화될 예정임 (출처: WeChat)

vivo, EdgeInfinite 알고리즘 발표, 모바일 단말기에서 128K 장문 텍스트 효율적 처리 실현: vivo AI 연구원은 ACL 2025에서 연구를 발표하고, 단말기 장치용으로 특별히 설계된 EdgeInfinite 알고리즘을 출시함. 이 알고리즘은 훈련 가능한 게이트 메모리 모듈과 메모리 압축/해제 기술을 통해 Transformer 아키텍처에서 초장문 텍스트를 효율적으로 처리함. 이 알고리즘은 BlueLM-3B 모델에서 테스트되었으며, 10GB GPU 메모리 장치에서 128K 토큰을 처리할 수 있고 LongBench의 여러 작업에서 우수한 성능을 보이며 첫 단어 출력 시간과 메모리 사용량을 현저히 줄임 (출처: WeChat)

🧰 도구
LlamaParse 업데이트, 문서 분석 능력 강화: LlamaParse는 AI 에이전트 기반 문서 분석 도구로서의 성능을 향상시키는 여러 업데이트를 발표함. 새로운 기능에는 Gemini 2.5 Pro, GPT-4.1 지원, 기울기 감지 및 신뢰도 점수 추가가 포함됨. 또한 사용자가 분석 구성을 코드 라이브러리에 직접 복사할 수 있도록 코드 스니펫 버튼을 도입하고, 사용 사례 사전 설정 및 렌더링/원본 Markdown 간 전환 내보내기 기능을 추가함 (출처: X)
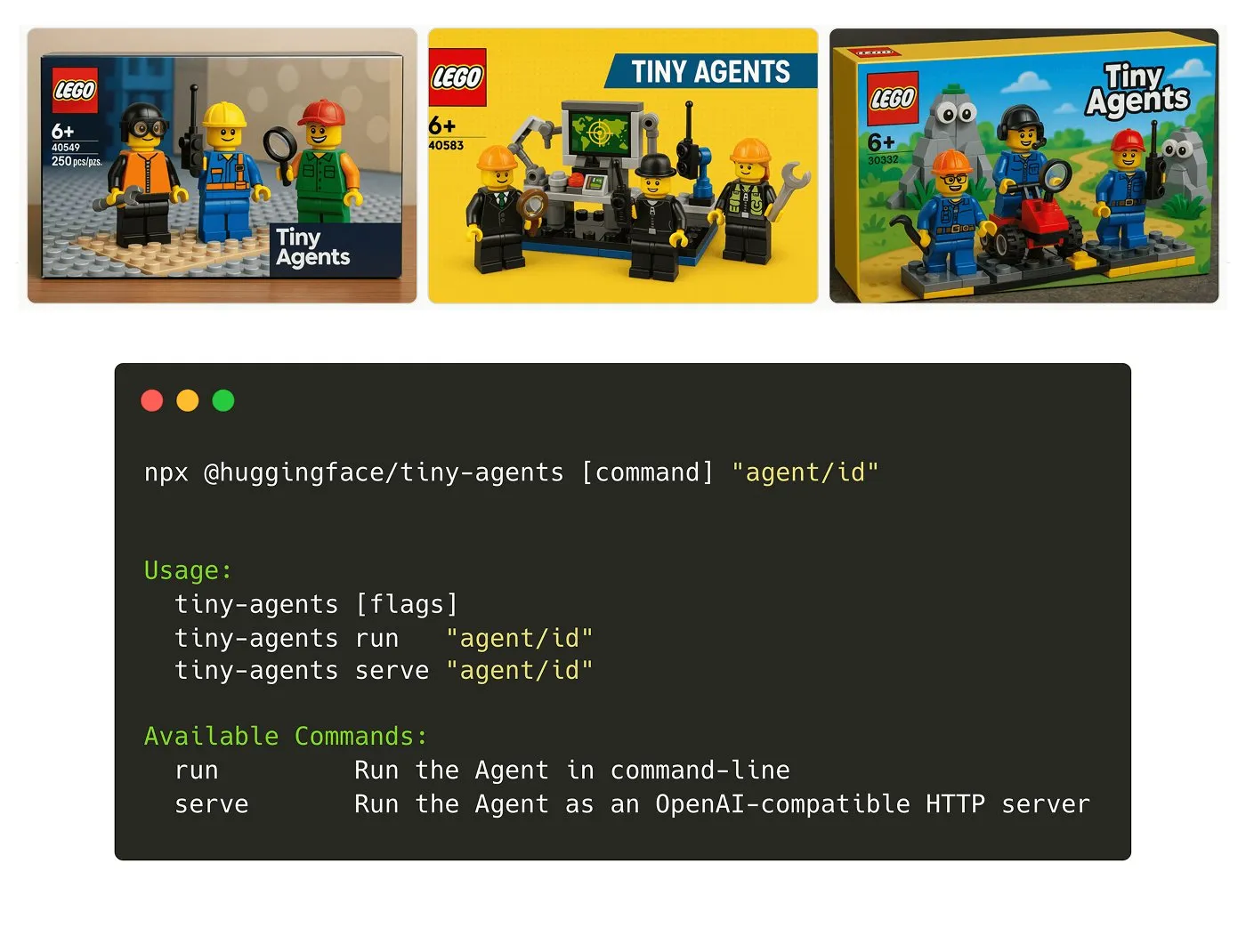
Hugging Face, Tiny Agents NPM 패키지 출시: Julien Chaumond는 가볍고 조합 가능한 에이전트 NPM 패키지인 Tiny Agents를 출시함. 이는 Hugging Face의 Inference Client 및 MCP(Model Component Protocol) 스택을 기반으로 구축되었으며, 개발자가 소규모 에이전트 애플리케이션을 빠르게 시작하고 구축할 수 있도록 지원하는 것을 목표로 함. 공식적으로 시작 가이드가 제공됨 (출처: X)
LangGraph 플랫폼, MCP 지원 추가로 에이전트 통합 간소화: LangGraph 플랫폼은 이제 MCP(Model Component Protocol)를 지원하며, 플랫폼에 배포된 각 에이전트는 자동으로 MCP 엔드포인트를 노출함. 이는 사용자가 이러한 에이전트를 도구로 활용하여 MCP 스트리밍 HTTP를 지원하는 모든 클라이언트에서 사용자 지정 코드를 작성하거나 추가 인프라를 구성할 필요 없이 사용할 수 있음을 의미하며, 에이전트 간의 통합 및 상호 운용성을 간소화함 (출처: X)

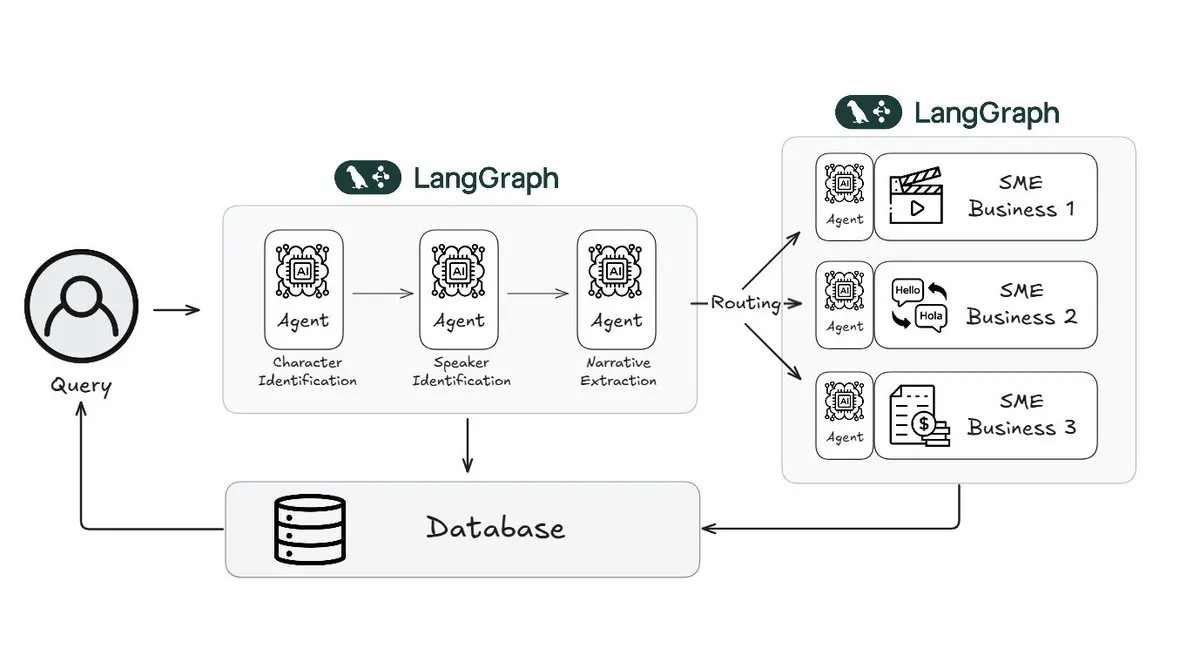
Webtoon, LangGraph 활용하여 스토리 검토 작업량 70% 감소: 디지털 만화 선두 주자인 Webtoon은 Webtoon Comprehension AI (WCAI)를 구축하여 방대한 콘텐츠 라이브러리의 서사 이해를 자동화하는 데 LangGraph를 사용함. WCAI는 지능형 멀티모달 에이전트를 통해 수동 탐색을 대체하여 캐릭터 및 화자 식별, 줄거리 및 분위기 추출, 자연어 통찰력 쿼리를 수행할 수 있게 되어 마케팅, 번역 및 추천 팀의 작업량을 70% 줄이고 창의성을 향상시킴 (출처: X)
OpenMemory MCP, AI 도구 간 영구적 개인 메모리 공유 실현: Mem0 프로젝트는 AI 애플리케이션에 플랫폼 및 세션 간 영구적 개인 메모리를 제공하기 위한 OpenMemory MCP 서버를 출시함. 사용자는 로컬에 배포하고 MCP 프로토콜을 통해 OpenMemory를 Cursor와 같은 클라이언트 도구에 연결하여 메모리 추가, 검색, 목록화 및 삭제를 실현할 수 있음. 이 도구는 대시보드를 통해 메모리 관리 기능을 제공하며, AI 에이전트의 개인화 및 컨텍스트 이해 능력을 향상시킬 것으로 기대됨 (출처: WeChat)

Miaoduo AI 2.0 출시, 인터페이스 디자인 AI 어시스턴트로 포지셔닝: Miaoduo AI 2.0은 인터페이스 디자인 분야의 AI 어시스턴트로 출시되어 사용자와 협력하여 디자인 작업을 완료하는 것을 목표로 함. 새 버전은 AI 매직 박스를 통해 상호 작용을 강화하고, 대화형 편집 및 반복적인 디자인 솔루션을 지원하며, 사전 설정된 스타일이나 사용자 입력(장문 텍스트, 스케치, 참조 이미지)을 기반으로 여러 버전의 인터페이스를 생성하고 주류 디자인 시스템과 호환됨. 또한 이미지-텍스트 처리, 디자인 컨설팅 및 바로 가기 명령(자연어를 API 호출로 변환)과 같은 기능도 제공함. Miaoduo AI는 MCP 프로토콜을 지원하고 디자인 초안 데이터를 최적화하여 대형 모델이 읽을 수 있도록 하여 높은 재현율의 프런트엔드 코드를 생성함 (출처: 量子位)

llmbasedos: MCP 기반 오픈소스 부팅 가능 AI 운영 체제 개념 증명: 개발자 iluxu는 Microsoft가 “AI 앱용 USB-C” 개념(MCP 기반)을 발표하기 3일 전에 llmbasedos 프로젝트를 오픈소스화함. 이 프로젝트는 USB 또는 가상 머신에서 빠르게 부팅할 수 있는 AI 운영 체제로, FastAPI 게이트웨이를 통해 JSON-RPC로 소형 Python 데몬과 통신하여 사용자 스크립트가 간단한 cap.json 구성을 통해 ChatGPT/Claude/VS Code 등에 의해 호출될 수 있도록 함. 기본적으로 오프라인 llama.cpp를 사용하며 GPT-4o 또는 Claude 3으로 전환할 수도 있으며, 개방형 AI 애플리케이션 연결 표준을 추진하는 것을 목표로 함 (출처: Reddit r/LocalLLaMA)
📚 학습
지식 증류(KD)는 왜 효과적인가? 새로운 연구가 간결한 설명 제공: 조경현 등은 지식 증류(KD)의 효과성에 대한 간결한 설명을 제시함. 그들은 교사 모델의 낮은 엔트로피 근사 샘플링을 사용하면 학생 모델이 더 높은 정밀도를 갖지만 재현율은 낮아진다고 가정함. 자기 회귀 언어 모델은 본질적으로 무한 계단식 혼합 분포이므로 SmolLM을 통해 이 가설을 검증함. 이 연구는 현재 평가 방법이 정밀도에 지나치게 초점을 맞추고 재현율 손실을 간과할 수 있으며, 이는 대규모 범용 모델이 놓칠 수 있는 내용 및 사용자 그룹과 관련이 있다고 주장함 (출처: X)

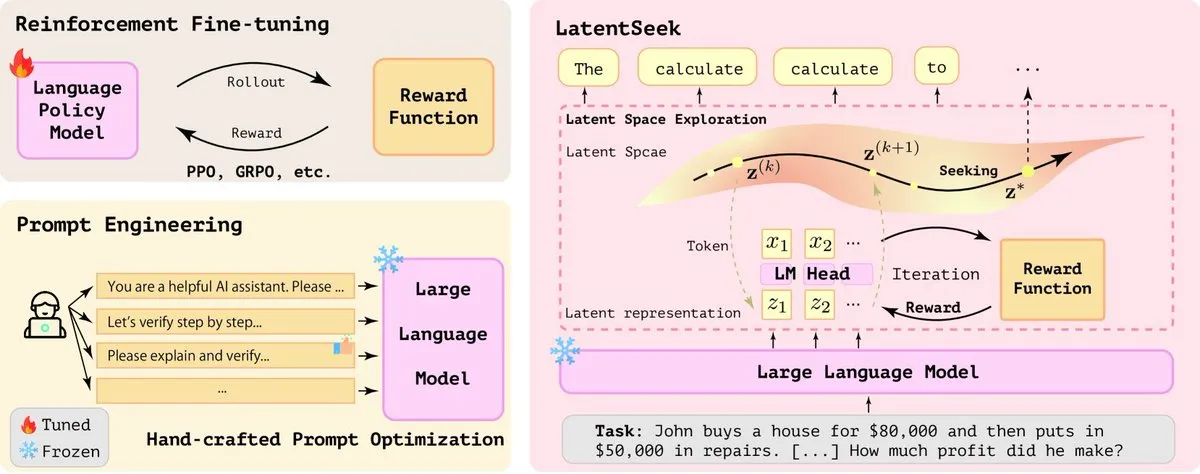
LatentSeek: 잠재 공간 정책 경사 최적화를 통한 LLM 추론 능력 향상: ‘Seek in the Dark’라는 논문은 테스트 시 잠재 공간에서의 인스턴스 수준 정책 경사를 통해 대규모 언어 모델(LLM)의 추론 능력을 향상시키는 새로운 패러다임인 LatentSeek를 제안함. 이 방법은 훈련, 데이터 또는 보상 모델 없이 잠재 표현을 최적화하여 모델의 추론 과정을 개선하는 것을 목표로 함. 이 훈련 무관 방법은 LLM의 복잡한 추론 작업 성능 향상에 잠재력을 보여줌 (출처: X)
Microsoft, CoML 제안: 언어 모델의 연쇄 모델 학습: Microsoft Research는 새로운 학습 패러다임인 “연쇄 모델 학습”(Chain-of-Model Learning, CoML)을 제안함. 이 방법은 은닉 상태의 인과 관계를 연쇄 구조로 각 계층 네트워크에 통합하여 모델 훈련의 확장 효율성과 배포 시 추론 유연성을 향상시키는 것을 목표로 함. 핵심 개념인 “연쇄 표현”(CoR)은 각 계층의 은닉 상태를 여러 하위 표현 연쇄로 분해하며, 후속 연쇄는 이전 모든 연쇄의 입력 표현에 접근할 수 있어 모델이 연쇄를 추가하여 점진적으로 확장하고 다양한 수의 연쇄를 선택하여 다양한 규모의 하위 모델을 탄력적 추론에 제공할 수 있도록 함. 이 원리에 기반하여 설계된 CoLM(연쇄 언어 모델) 및 그 변형인 CoLM-Air(KV 공유 메커니즘 도입)는 표준 Transformer와 동등한 성능을 보여주면서 점진적 확장 및 탄력적 추론의 이점을 제공함 (출처: X, HuggingFace Daily Papers)

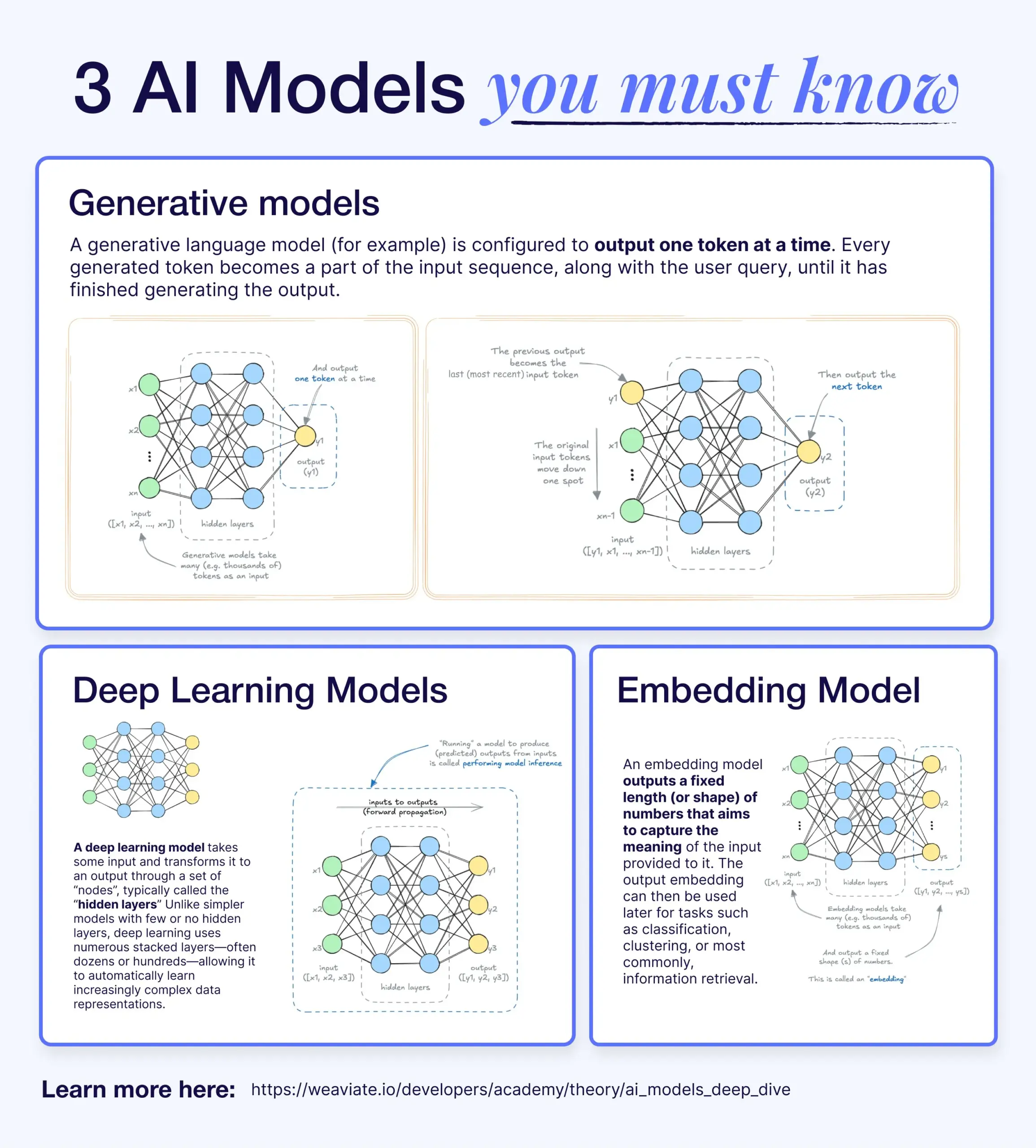
딥러닝, 생성 모델, 임베딩 모델의 차이점과 연관성: 한 과학 기사가 딥러닝 모델, 생성 모델, 임베딩 모델 간의 관계를 설명함. 딥러닝 모델은 다층 신경망을 통해 수치 입출력을 처리하는 기본 아키텍처임. 생성 모델은 훈련 데이터와 유사한 새로운 콘텐츠(예: GPT, DALL-E)를 만드는 데 특화된 딥러닝 모델의 한 종류임. 임베딩 모델도 딥러닝 모델의 한 종류로, 데이터(텍스트, 이미지 등)를 의미 정보를 포착하는 수치 벡터 표현으로 변환하는 데 사용되며 유사성 검색 및 RAG 시스템에 자주 사용됨. 많은 AI 시스템에서 이러한 모델은 협력적으로 작동하며, 예를 들어 RAG 시스템은 검색을 위해 임베딩 모델을 활용한 다음 생성 모델이 응답을 생성함 (출처: X)
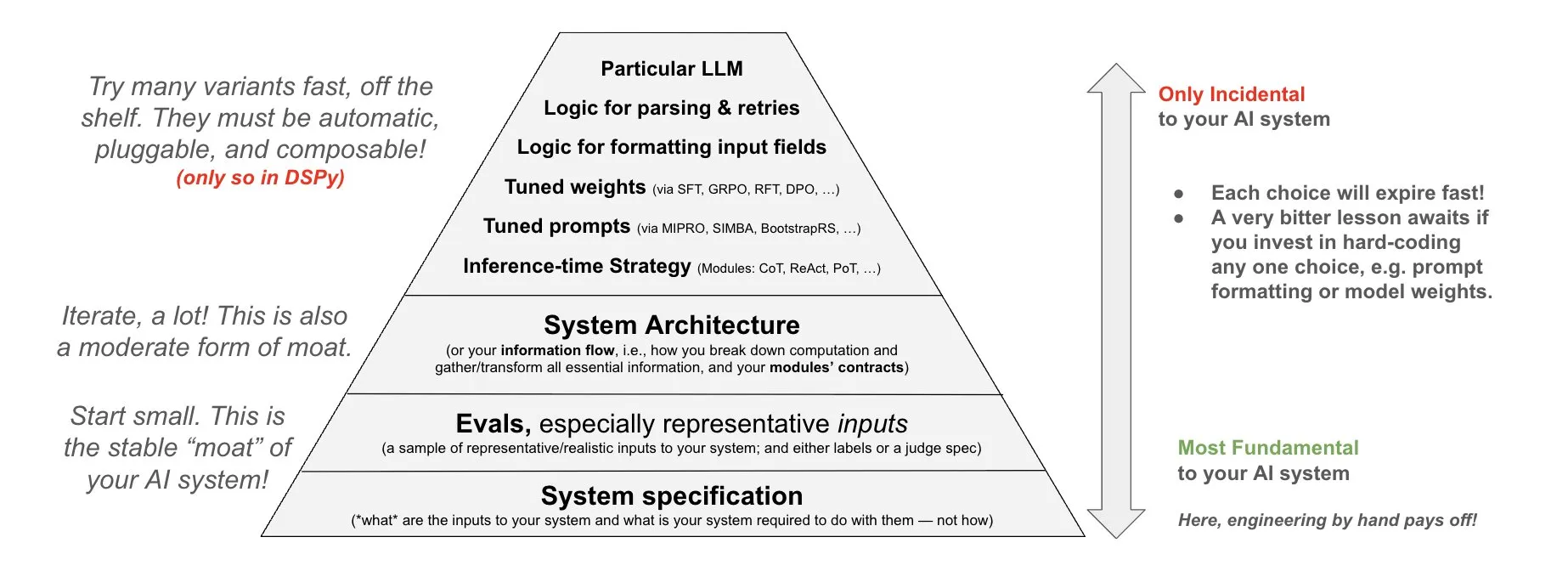
DSPy, AI 시스템 투자 철학 제시: DSPy는 AI 시스템 투자에 대한 철학을 공유하며, AI 시스템의 세 가지 기본 계층인 데이터, 모델, 알고리즘에 노력을 집중해야 한다고 강조함. 그들은 조합 가능한 최상위 모듈(Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules)을 제공함으로써 개발자가 이 세 가지 기본 계층을 빠르게 반복하여 더 강력한 AI 시스템을 구축할 수 있다고 주장함 (출처: X)
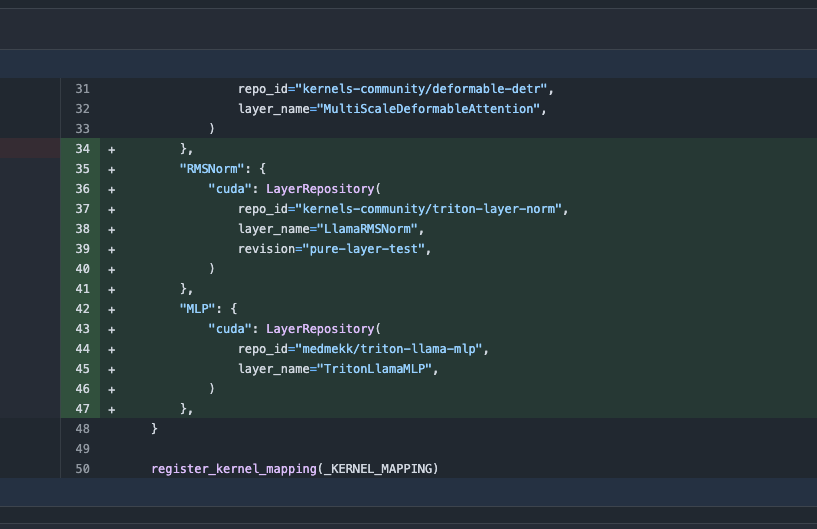
Transformers 라이브러리 업데이트, 최적화된 커널 자동 전환으로 성능 향상: 최신 버전의 Hugging Face Transformers 라이브러리는 하드웨어가 허용할 때 최적화된 커널로 자동 전환하는 기능을 구현함. 이 업데이트는 kernels 라이브러리를 통합하여 Llama와 같은 인기 모델에 대해 Hugging Face Hub에서 가장 인기 있는 커뮤니티 커널을 활용하여 호환되는 하드웨어에서 모델 실행 효율성과 성능을 향상시키는 것을 목표로 함 (출처: X)
ARC-AGI-2 벤치마크 발표, 최첨단 AI 추론 시스템에 도전: François Chollet 등은 ARC-AGI-2 벤치마크에 대한 논문을 발표하여 설계 원칙, 도전 과제, 인간 성능 분석 및 현재 모델 성능을 자세히 설명함. 이 벤치마크는 AI의 추상적 추론 능력을 평가하는 것을 목표로 하며, 인간은 100%의 작업을 해결할 수 있지만 현재 최첨단 AI 모델의 점수는 5% 미만으로 고급 추상적 추론 측면에서 AI와 인간 사이에 여전히 큰 격차가 있음을 보여줌 (출처: X)

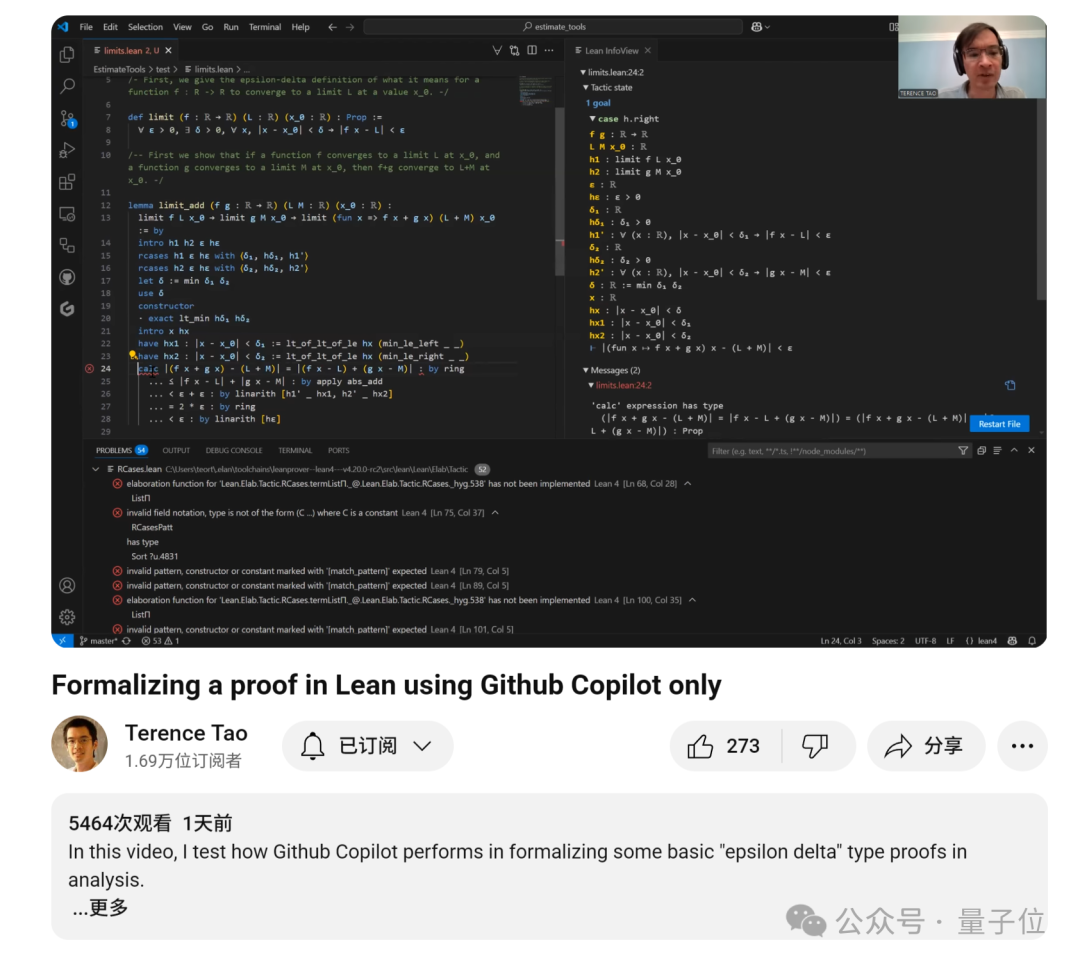
테렌스 타오, GitHub Copilot 활용 함수 극한 증명 튜토리얼 공개: 수학자 테렌스 타오가 GitHub Copilot을 활용하여 합, 차, 곱 정리 등 함수 극한 문제를 증명하는 방법을 시연하는 비디오 튜토리얼을 공개함. 그는 Copilot이 코드 프레임워크를 빠르게 생성하고 기존 라이브러리 함수를 제시할 수 있지만, 복잡한 수학적 세부 사항, 특수 상황 처리 및 창의적인 해결책에서는 여전히 많은 수동 개입과 조정이 필요하며, 때로는 종이와 펜으로 추론한 후 형식적 검증을 진행하는 것이 더 효율적일 수 있다고 강조함 (출처: 36氪)
PhyT2V 프레임워크, LLM 활용하여 텍스트-비디오 생성의 물리적 일관성 향상: 피츠버그 대학교 연구팀은 대규모 언어 모델 기반 연쇄 추론(CoT)과 반복적 자기 수정 메커니즘을 통해 텍스트 프롬프트를 최적화하여 기존 텍스트-비디오(T2V) 모델이 생성하는 콘텐츠의 물리적 현실감을 향상시키는 PhyT2V 프레임워크를 제안함. 이 방법은 모델 재훈련 없이 이미 생성된 비디오와 프롬프트 간의 의미적 불일치를 분석하고 물리적 규칙을 결합하여 프롬프트를 수정함으로써 T2V 모델이 분포 외(OOD) 시나리오를 처리할 때 물리적 일관성을 높이는 것을 목표로 함. 실험 결과, PhyT2V는 CogVideoX, OpenSora 등 모델이 VideoPhy, PhyGenBench 등 벤치마크에서 성능을 현저히 향상시키는 것으로 나타남 (출처: WeChat)

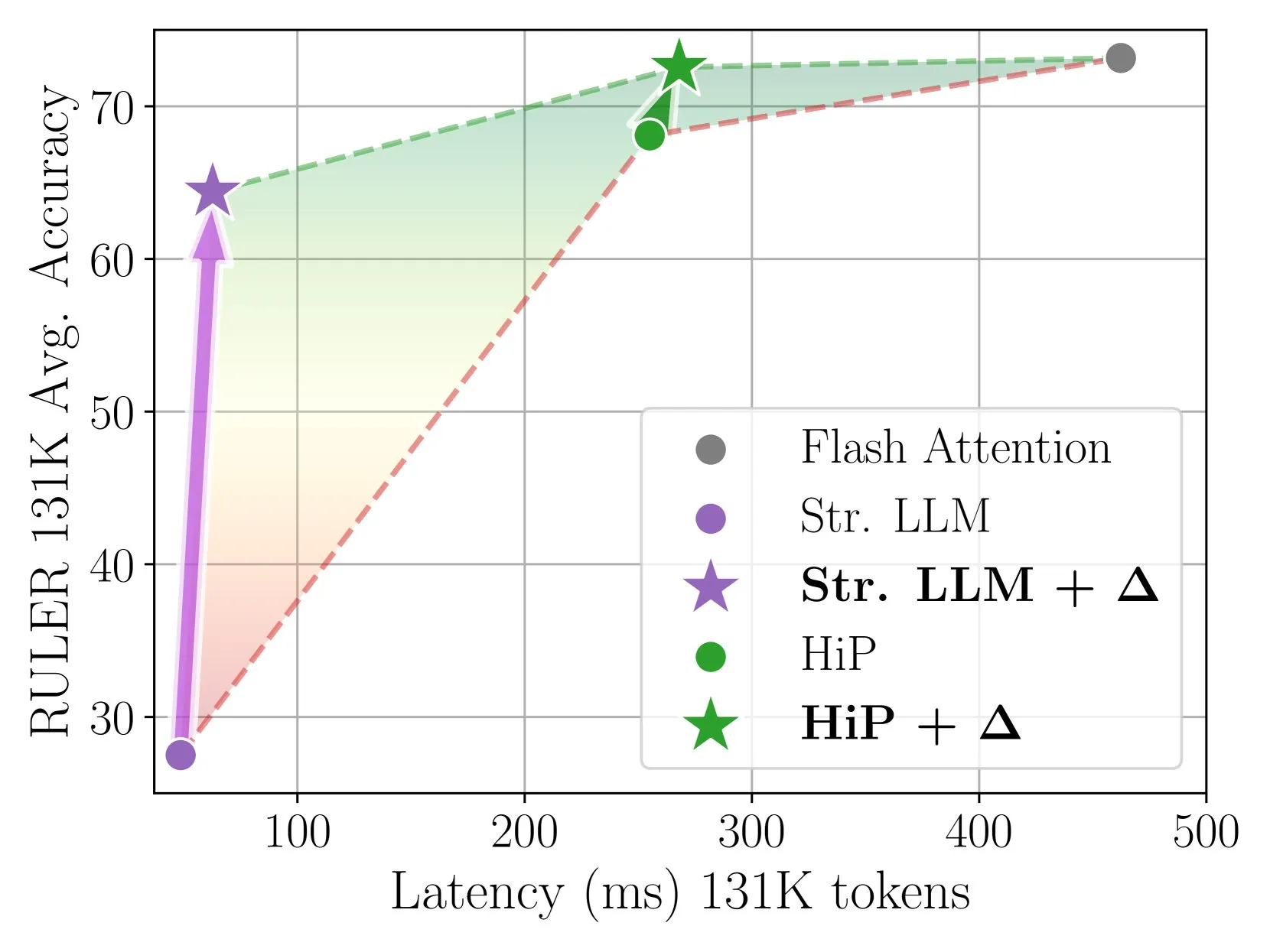
Delta Attention, 증분 보정을 통해 빠르고 정확한 희소 어텐션 추론 실현: 이 연구는 희소 어텐션 계산이 어텐션 출력의 분포 이동을 유발하여 모델 성능을 저하시킨다는 것을 발견함. Delta Attention은 이러한 분포 이동을 보정하여 희소 어텐션의 출력 분포를 전체 어텐션에 더 가깝게 만들어 높은 희소도(약 98.5%)를 유지하면서 성능을 현저히 향상시키고, RULER 벤치마크에서 슬라이딩 윈도우 어텐션(싱크 토큰 포함)의 전체 어텐션 정확도를 88% 회복했으며 계산 오버헤드가 작음. 1M 토큰 사전 채우기 처리 시 Flash Attention 2보다 32배 빠름 (출처: HuggingFace Daily Papers)
Thinkless 프레임워크, LLM이 CoT 추론 시점을 학습하도록 지원: 대규모 언어 모델(LLM)이 모든 쿼리에 복잡한 사고의 연쇄(CoT) 추론을 사용하여 계산 효율성이 저하되는 문제를 해결하기 위해 연구자들은 Thinkless 프레임워크를 제안함. 이 프레임워크는 강화 학습을 통해 LLM을 훈련시켜 작업 복잡도와 자체 능력에 따라 짧은 형식 또는 긴 형식 추론을 적응적으로 선택하도록 함. 핵심 알고리즘 DeGRPO는 학습 목표를 제어 토큰 손실(추론 모드 결정)과 응답 손실(답변 정확도 향상)로 분해하여 훈련 과정을 안정화함. 실험 결과, Thinkless는 Minerva Algebra 등 벤치마크에서 긴 연쇄 사고 사용을 50%-90% 줄여 추론 효율성을 현저히 향상시키는 것으로 나타남 (출처: HuggingFace Daily Papers)
CPGD 알고리즘, 규칙 기반 언어 모델 강화 학습 안정성 향상: 기존 규칙 기반 강화 학습 방법(예: GRPO, REINFORCE++, RLOO)이 언어 모델 훈련 시 발생할 수 있는 훈련 불안정 문제를 해결하기 위해 연구자들은 CPGD(정책 드리프트가 있는 클리핑된 정책 경사 최적화) 알고리즘을 제안함. CPGD는 KL 발산 기반 정책 드리프트 제약을 도입하여 정책 업데이트를 동적으로 정규화하고 로그 비율 클리핑 메커니즘을 활용하여 과도한 정책 업데이트를 방지함. 이론 및 실증 분석 결과, CPGD는 불안정성을 완화하고 훈련 안정성을 유지하면서 성능을 현저히 향상시키는 것으로 나타남 (출처: HuggingFace Daily Papers)
신경-기호 쿼리 컴파일러 QCompiler, RAG 시스템의 복잡한 쿼리 처리 능력 향상: 검색 증강 생성(RAG) 시스템이 중첩 구조와 종속 관계를 가진 복잡한 쿼리를 처리할 때, 특히 리소스가 제한된 상황에서 검색 의도를 정확하게 식별하기 어려운 문제를 해결하기 위해 QCompiler 프레임워크가 제안됨. 이 프레임워크는 언어학적 문법 규칙과 컴파일러 설계에서 영감을 받아 먼저 복잡한 쿼리를 형식화하기 위한 최소 충분 BNF 문법 G[q]를 설계한 다음, 쿼리 표현식 변환기, 어휘 문법 분석기 및 재귀 하강 처리기를 통해 쿼리를 추상 구문 트리(AST) 실행으로 컴파일함. 리프 노드의 하위 쿼리 원자성은 보다 정확한 문서 검색 및 응답 생성을 보장함 (출처: HuggingFace Daily Papers)
Jedi 데이터셋과 OSWorld-G 벤치마크, 컴퓨터 사용 시나리오의 GUI 요소 위치 지정 연구 촉진: 그래픽 사용자 인터페이스(GUI) 위치 지정(자연어 지침을 GUI 작업에 매핑)의 병목 현상을 해결하기 위해 연구자들은 OSWorld-G 벤치마크(텍스트 매칭, 요소 식별, 레이아웃 이해 및 정확한 작업을 포괄하는 564개의 세분화된 주석 샘플)와 대규모 합성 데이터셋 Jedi(400만 샘플)를 공개함. Jedi에서 훈련된 다중 스케일 모델은 ScreenSpot-v2, ScreenSpot-Pro 및 OSWorld-G에서 기존 방법보다 우수하며, 복잡한 컴퓨터 작업(OSWorld)에서 범용 기초 모델의 에이전트 능력을 5%에서 27%로 향상시킬 수 있음 (출처: HuggingFace Daily Papers)
분할 사고 연쇄 추론(Fractured CoT)으로 LLM 추론 효율성 및 성능 향상: CoT 추론으로 인한 높은 토큰 비용 문제를 해결하기 위해 연구자들은 CoT를 중단(추론 완료 전에 중단하고 직접 답변 생성)하면 일반적으로 완전한 CoT와 동등한 성능을 달성하면서 토큰 소비를 현저히 줄일 수 있다는 것을 발견함. 이를 바탕으로 Fractured Sampling 통합 추론 전략을 제안하여 추론 궤적 수, 각 궤적의 최종 해결책 수, 추론 흔적 중단 깊이 등 세 가지 차원을 조정함으로써 여러 추론 벤치마크와 모델 규모에서 더 나은 정확도-비용 균형을 달성하여 보다 효율적이고 확장 가능한 LLM 추론의 길을 열었음 (출처: HuggingFace Daily Papers)
LLM 컨텍스트 조건화 및 PWP 프롬프트를 통한 화학 공식 멀티모달 검증: 연구자들은 구조화된 LLM 컨텍스트 조건화를 탐색하고 영구 워크플로 프롬프트(PWP) 원칙과 결합하여 추론 시 LLM의 행동을 조정함으로써 특히 이미지를 포함하는 복잡한 과학 문서 처리 시 화학 공식과 같은 정확한 검증 작업에서 신뢰성을 향상시키는 것을 목표로 함. 이 방법은 API나 모델 수정 없이 표준 채팅 인터페이스(Gemini 2.5 Pro, ChatGPT Plus o3)만 사용함. 초기 실험 결과, 이 방법은 텍스트 오류 식별을 개선하고 Gemini 2.5 Pro가 수동 검토에서 간과된 이미지 공식 오류를 식별하는 데 도움을 주었음 (출처: HuggingFace Daily Papers)
PWP, 메타 프롬프트 및 메타 추론을 활용한 AI 기반 학술 동료 심사 구현: 연구자들은 표준 LLM 채팅 인터페이스를 통해 과학 원고에 대한 비판적 동료 심사를 구현하는 영구 워크플로 프롬프트(PWP) 방법을 제안함. PWP는 계층적 모듈식 아키텍처(Markdown 구조화)를 채택하여 상세한 분석 워크플로를 정의하고, 메타 프롬프트와 메타 추론을 통해 전문가 심사 과정(암묵적 지식 포함)을 체계적으로 인코딩함. PWP는 LLM이 주장과 증거 구분, 텍스트/이미지/도표 분석 통합, 정량적 타당성 검사 수행 등 체계적인 멀티모달 평가를 수행하도록 유도하며, 테스트 사례에서 방법론적 결함을 성공적으로 식별함 (출처: HuggingFace Daily Papers)
SPOT 벤치마크, AI의 과학 연구 자동 검증 능력 평가: 대규모 언어 모델(LLM)이 학술 원고 자동 검증에서 “AI 공동 과학자”로서의 능력을 평가하기 위해 연구자들은 SPOT 벤치마크를 출시함. 이 벤치마크는 이미 발표된 논문 83편과 정오표 또는 철회를 유발할 수 있는 오류 91개를 포함하며, 원저자와 수동 주석 작성자의 교차 검증을 거침. 실험 결과, 가장 진보된 LLM(예: o3)조차도 SPOT에서 재현율이 21.1%를 넘지 못하고 정밀도가 6.1% 미만이며 모델 신뢰도가 낮고 여러 번 실행 결과가 일치하지 않아 현재 LLM이 신뢰할 수 있는 학술 검증 측면에서 실제 요구와 큰 격차가 있음을 보여줌 (출처: HuggingFace Daily Papers)
ExTrans, 샘플 증강 강화 학습을 통해 다국어 심층 추론 번역 실현: 기계 번역에서 대규모 추론 모델(LRM)의 능력, 특히 다국어 시나리오에서의 능력을 향상시키기 위해 연구자들은 ExTrans를 제안함. 이 방법은 정책 번역 모델과 강력한 LRM(예: DeepSeek-R1-671B)의 번역 결과를 비교하여 보상을 정량화하는 새로운 보상 모델링 방법을 설계함. 실험 결과, Qwen2.5-7B-Instruct를 백본으로 훈련된 모델은 문학 번역에서 SOTA를 달성하고 OpenAI-o1 및 DeepSeeK-R1보다 우수함. 경량 보상 모델링을 통해 이 방법은 단방향 번역 능력을 11개 언어의 90개 번역 방향으로 효과적으로 이전할 수 있음 (출처: HuggingFace Daily Papers)
훈련 가능한 희소 어텐션 VSA, 비디오 확산 모델 가속화: 비디오 확산 Transformer(DiT)에서 3D 전체 어텐션 메커니즘의 2차 복잡도 문제를 해결하기 위해 연구자들은 VSA(훈련 가능한 희소 어텐션)를 제안함. VSA는 경량의 거친 단계를 통해 토큰을 블록으로 모으고 핵심 토큰을 식별한 다음, 이러한 블록 내에서 세분화된 토큰 수준 어텐션 계산을 수행함. VSA는 후처리 분석 없이 종단 간 훈련 가능한 단일 미분 가능 커널이며 FlashAttention3 MFU의 85%를 유지함. 실험 결과, VSA는 확산 손실을 줄이지 않으면서 훈련 FLOPS를 2.53배 줄이고 오픈소스 Wan-2.1 모델의 어텐션 시간을 6배 가속화하여 종단 간 생성 시간을 31초에서 18초로 단축함 (출처: HuggingFace Daily Papers)
SoftCoT++: 소프트 사고 연쇄 추론을 통한 테스트 시 확장: 연속적인 잠재 공간에서 추론을 수행하는 SoftCoT 방법의 탐색 능력을 향상시키기 위해 연구자들은 SoftCoT++를 제안함. 이 방법은 다양한 전용 초기 토큰으로 잠재적 아이디어를 교란하고 대조 학습을 적용하여 소프트 아이디어 표현의 다양성을 촉진함으로써 SoftCoT를 테스트 시 확장(TTS) 패러다임으로 확장함. 실험 결과, SoftCoT++는 SoftCoT의 성능을 현저히 향상시키고 자기 일관성 확장을 갖춘 SoftCoT보다 우수하며, 자기 일관성과 같은 기존 확장 기술과 호환성이 뛰어남 (출처: HuggingFace Daily Papers)
MTVCrafter: 개방형 세계 인체 이미지 애니메이션을 위한 4D 모션 토큰화: 기존 방법이 2D 포즈 이미지에 의존하여 일반화 능력이 제한되는 문제를 해결하기 위해 MTVCrafter는 원시 3D 모션 시퀀스(4D 모션)를 직접 모델링할 것을 제안함. 핵심은 3D 모션 시퀀스를 4D 모션 토큰으로 양자화하여 보다 견고한 시공간 단서를 제공하는 4DMoT(4D 모션 토크나이저)임. 그런 다음 독특한 모션 어텐션과 4D 위치 인코딩으로 설계된 MV-DiT(모션 인식 비디오 DiT)는 이러한 토큰을 컨텍스트로 효과적으로 활용하여 복잡한 3D 세계에서 인체 이미지 애니메이션을 구현함. 실험 결과, MTVCrafter는 FID-VID에서 6.98을 달성하여 SOTA보다 현저히 우수하며 다양한 스타일과 장면의 여러 캐릭터에 잘 일반화됨 (출처: HuggingFace Daily Papers)
QVGen: 양자화 비디오 생성 모델의 한계 추진: 비디오 확산 모델(DM)의 계산 및 메모리 요구량이 큰 문제를 해결하기 위해 QVGen은 극저 비트 양자화(예: 4비트 이하)를 위해 특별히 설계된 새로운 양자화 인식 훈련(QAT) 프레임워크를 제안함. 이론적 분석을 통해 연구자들은 기울기 규범을 줄이는 것이 QAT 수렴에 중요하며, 큰 양자화 오류를 완화하기 위해 보조 모듈(Phi)을 도입한다는 것을 발견함. Phi의 추론 오버헤드를 제거하기 위해 SVD 및 순위 기반 정규화를 통해 Phi를 점진적으로 제거하는 순위 감쇠 전략을 제안함. 실험 결과, QVGen은 4비트 설정에서 처음으로 전체 정밀도와 동등한 품질을 달성하고 기존 방법보다 현저히 우수함 (출처: HuggingFace Daily Papers)
ViPlan: 시각적 계획을 위한 기호 술어 및 시각 언어 모델 벤치마크: VLM 기반 기호 계획과 직접 VLM 계획 방법 간의 비교 격차를 해소하기 위해 ViPlan이 최초의 오픈소스 시각 계획 벤치마크로 제안됨. ViPlan은 시각적 버전의 Blocksworld와 시뮬레이션된 가정용 로봇 환경이라는 두 가지 주요 영역에서 난이도가 증가하는 일련의 작업을 포함함. 9개의 오픈소스 VLM 제품군과 일부 비공개 소스 모델에 대한 벤치마크 테스트 결과, 기호 계획은 Blocksworld(정확한 이미지 위치 지정이 중요)에서 더 우수한 성능을 보였고, 직접 VLM 계획은 가정용 로봇 작업(상식 지식과 오류 복구 능력이 중요)에서 더 나은 성능을 보였음. 연구 결과, CoT 프롬프트는 대부분의 모델과 방법에 큰 이점을 제공하지 않아 현재 VLM의 시각적 추론 능력이 여전히 부족함을 시사함 (출처: HuggingFace Daily Papers)
원시적 외침에서 문법으로: 협력적 채집 환경에서의 언어 진화 연구: 언어의 기원과 진화를 탐구하기 위해 연구자들은 다중 에이전트 채집 게임에서 초기 인류의 협력 시나리오를 시뮬레이션함. 종단 간 심층 강화 학습을 통해 에이전트는 처음부터 행동 및 의사소통 전략을 학습함. 연구 결과, 에이전트가 개발한 의사소통 프로토콜은 자연어의 특징적인 특징인 임의성, 상호 교환성, 변위성, 문화적 전파 및 조합성을 보여줌. 이 프레임워크는 부분적으로 관찰 가능하고 시간적 추론 및 협력 목표 중심의 구체화된 다중 에이전트 환경에서 언어가 어떻게 진화하는지 연구할 수 있는 플랫폼을 제공함 (출처: HuggingFace Daily Papers)
Tiny QA Benchmark++: 초경량 다국어 합성 데이터셋 생성 및 LLM 지속적 평가를 위한 스모크 테스트: Tiny QA Benchmark++ (TQB++)는 LLM 파이프라인에 단위 테스트 방식의 안전망을 제공하기 위한 초경량 다국어 스모크 테스트 스위트로, 몇 초 만에 매우 낮은 비용으로 실행할 수 있음. TQB++는 52개 항목의 영어 골든 세트를 포함하며, 사용자가 사용자 지정 언어, 도메인 또는 난이도의 소규모 테스트 패키지를 생성할 수 있는 LiteLLM 기반 소형 합성 데이터 생성기(pypi 패키지)를 제공함. 이 프로젝트는 이미 10개 언어의 사전 제작 패키지를 제공하며 OpenAI-Evals, LangChain 등 도구를 지원하여 CI/CD 프로세스에 쉽게 통합하여 프롬프트 템플릿 오류, 토크나이저 드리프트 및 미세 조정 부작용을 신속하게 감지하는 데 사용할 수 있음 (출처: HuggingFace Daily Papers)
HelpSteer3-Preference: 다중 작업 및 언어에 걸친 개방형 인간 주석 선호도 데이터셋: 고품질의 다양한 개방형 선호도 데이터에 대한 요구를 충족하기 위해 NVIDIA는 HelpSteer3-Preference 데이터셋을 공개함. 이 데이터셋은 CC-BY-4.0 라이선스를 따르는 40,000개 이상의 인간 주석 선호도 샘플을 포함하며, STEM, 코딩 및 다국어 시나리오 등 LLM의 실제 응용 분야를 포괄함. 이 데이터셋을 사용하여 훈련된 보상 모델(RM)은 RM-Bench(82.4%)와 JudgeBench(73.7%) 모두에서 SOTA 성능을 달성하여 이전 최고 결과보다 약 10% 향상됨. 이 데이터셋은 생성형 RM을 훈련하고 RLHF를 통해 정책 모델을 정렬하는 데에도 사용할 수 있음 (출처: HuggingFace Daily Papers)
SEED-GRPO: 불확실성 인지 정책 최적화를 위한 의미론적 엔트로피 강화 GRPO: GRPO가 정책 업데이트 시 LLM의 입력 프롬프트에 대한 불확실성을 고려하지 않는 문제를 해결하기 위해 연구자들은 SEED-GRPO를 제안함. 이 방법은 의미론적 엔트로피를 통해 LLM의 입력 프롬프트에 대한 불확실성(즉, 여러 생성된 답변의 의미론적 다양성)을 명확하게 측정하고 이를 통해 정책 업데이트의 폭을 조절함. 이러한 불확실성 인지 훈련 메커니즘은 불확실성이 높은 문제에 대해 보다 보수적인 업데이트를 허용하는 동시에 확신 있는 문제에 대한 원래 학습 신호를 유지함. 실험 결과, SEED-GRPO는 5가지 수학 추론 벤치마크 모두에서 SOTA 성능을 달성함 (출처: HuggingFace Daily Papers)
컴퓨터 사용으로부터 범용 사용자 모델(GUM) 생성: 연구자들은 사용자의 컴퓨터와의 모든 상호 작용(예: 장치 스크린샷)을 관찰하여 사용자 지식과 선호도를 학습하고 신뢰도 가중 명제를 구축하는 범용 사용자 모델(GUM) 아키텍처를 제안함. GUM은 비정형 멀티모달 관찰로부터 새로운 명제를 추론하고, 관련 명제를 컨텍스트로 검색하며, 기존 명제를 지속적으로 수정할 수 있음. 이 아키텍처는 채팅 도우미를 강화하고, 운영 체제 알림을 관리하며, 대화형 에이전트가 애플리케이션 전반에 걸쳐 사용자 선호도에 적응할 수 있도록 하는 것을 목표로 함. 실험 결과, GUM은 보정되고 정확한 사용자 추론을 할 수 있으며, GUM 기반 도우미는 사용자가 명시적으로 요청하지 않은 유용한 작업을 능동적으로 식별하고 실행할 수 있음 (출처: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: GitHub의 인기 프로젝트로, 2024년 입문 로드맵, 6주 무료 YouTube 교육 캠프 자료, 프로젝트 사례, 면접 팁, 추천 도서, 커뮤니티 및 뉴스레터 목록을 포함한 포괄적인 데이터 엔지니어링 학습 리소스 저장소를 제공함. 추천 도서에는 《Fundamentals of Data Engineering》, 《Designing Data-Intensive Applications》, 《Designing Machine Learning Systems》가 포함됨. 이 핸드북은 또한 Mage(오케스트레이션), Databricks(데이터 레이크), Snowflake(데이터 웨어하우스), dbt(데이터 품질), LangChain(LLM 애플리케이션 라이브러리) 등 데이터 엔지니어링 각 분야의 회사들을 나열하고 유명 회사의 데이터 엔지니어링 블로그 및 중요 백서 링크를 제공함 (출처: GitHub Trending)
💼 비즈니스
Cohere, SAP와 협력하여 엔터프라이즈급 AI 에이전트를 글로벌 비즈니스에 도입: Cohere는 SAP와 협력하여 엔터프라이즈급 AI 에이전트 기술을 SAP Business Suite에 통합하여 전 세계 기업에 안전하고 확장 가능한 AI 기능을 제공한다고 발표함. Cohere의 최첨단 모델도 SAP AI Core에 탑재되어 기업이 금융, 의료 등 분야에서 다국어, 특정 분야 AI 모델(Command, Embed, Rerank)을 활용하여 기업 AI 애플리케이션을 가속화하고 실제 비즈니스 가치를 창출하는 것을 목표로 함 (출처: X, X)
xAI, 정부 데이터 활용 모색, 기업 및 정부 사업 확장: The Information 보도에 따르면, Elon Musk의 xAI 회사는 정부 기관의 데이터를 활용하여 모델과 애플리케이션을 개발하고 이를 정부 고객에게 판매할 계획임. 이러한 움직임은 xAI의 상업화 전략에서 중요한 부분이 될 수 있지만, 데이터 사용 및 잠재적 편향에 대한 논의를 불러일으킴 (출처: X)
Weaviate, AWS와 글로벌 협력 강화, 생성형 AI 계획 가속화: 벡터 데이터베이스 회사 Weaviate는 AWS와의 글로벌 협력을 강화하여 생성형 AI 프로젝트를 공동으로 가속화한다고 발표함. 이번 협력은 전 세계 개발자에게 더 빠른 속도, 더 큰 규모, 더 나은 개발자 경험을 제공하여 생성형 AI 기술의 적용과 발전을 촉진하는 데 중점을 둘 것임 (출처: X)

🌟 커뮤니티
AI 프로그래밍 에이전트 부상, 프로그래머 직업 전망 논의 촉발: Microsoft, OpenAI 등 기업들이 GitHub Copilot Coding Agent, OpenAI Codex와 같은 AI 프로그래밍 에이전트(Coding Agents)를 잇달아 출시하거나 강화하고 있으며, 이들은 코딩, 버그 수정, 코드 유지보수 등의 작업을 자율적으로 수행할 수 있음. Anthropic CEO Dario Amodei는 AI가 단기적으로 대부분 또는 모든 코드를 작성할 수 있다고 예측했으며, OpenAI CPO Kevin Weil도 AI가 초급 엔지니어에서 아키텍트로 성장할 것이라고 생각함. 이는 프로그래머의 직업 미래에 대한 광범위한 논의를 촉발시킴: 일부는 초급 일자리가 대체되고 AI가 대량의 프로그래밍 작업을 자동화할 것을 우려하는 반면, 다른 일부는 AI가 프로그래머의 효율성을 높여 더 높은 수준의 아키텍처 설계 및 혁신에 집중할 수 있게 하고 역할이 “AI 유도자”로 전환될 것이라고 생각함. 전반적인 추세는 AI와 효율적으로 협력하는 학습이 프로그래머의 핵심 기술이 될 것임을 시사함 (출처: X, X, 36氪, 36氪)
AI Agent 개념 및 표준 논의 활발, MCP 프로토콜 주목: AI Agent 애플리케이션(예: Manus, Genspark Super Agent, Fellou.ai)의 부상과 함께 커뮤니티에서는 Agent의 정의, 능력 등급 및 개발 패러다임에 대한 열띤 논의가 진행 중임. 유명 벤처 캐피털 BVP는 Agent를 L0에서 L6까지 7단계로 구분하는 등급을 제시함. 동시에 모델 컨텍스트 프로토콜(MCP)은 AI 애플리케이션 간 상호 운용성을 실현하는 핵심 기술로 주목받고 있으며, Anthropic, OpenAI, Google 등 해외 대기업들은 이미 MCP를 지원하거나 지원할 계획이며, 국내에서는 Alibaba Cloud, Tencent Cloud 등도 MCP를 중심으로 현지화된 Agent 개발 플랫폼을 구축하기 시작함. 개발자 iluxu는 Microsoft가 “AI 앱용 USB-C” 개념을 제시하기 전에 유사한 llmbasedos 프로젝트를 오픈소스화하여 개방형 Agent 연결 표준을 추진하고자 함 (출처: X, X, WeChat, Reddit r/LocalLLaMA)
LLM, 특정 추론 작업에서 부진한 성능 보여 능력 경계에 대한 논의 촉발: 커뮤니티에서는 LLM이 특정 간단해 보이는 물리적 또는 시각 공간 추론 작업에서 집단적으로 “실패”하는 현상에 대해 열띤 논의를 벌이고 있음. 예를 들어, 더 큰 정육면체를 만들기 위해 정육면체를 쌓는 문제에 대해 o3, Gemini 2.5 Pro와 같은 최상위 모델조차도 잘못된 답변을 제시함. 동시에 한 평가 기사에서는 부품 제조와 같은 기본 물리적 작업에서 LLM(o3 포함)이 숙련된 작업자보다 성능이 떨어지며, 주요 원인은 시각 능력 부족과 물리적 추론 오류, 그리고 실제 세계의 암묵적 지식 부족이라고 지적함. 이러한 사례들은 LLM의 실제 이해 능력, 환각 문제(예: o3가 추론 시 환각률 상승) 및 현재 Benchmark의 유효성에 대한 논의를 촉발하며, AI가 특정 분야 지식과 복잡한 추론 측면에서 여전히 개선의 여지가 많음을 강조함 (출처: 量子位, 36氪)

미중 기술 경쟁과 AI 발전 전략 주목: NVIDIA CEO 젠슨 황은 인터뷰에서 칩 규제, AI 공장 및 기업 실용주의에 대해 언급했으며, 그의 관점은 현재 미중 기술 경쟁 구도에 대한 심오한 통찰력으로 해석됨. 일부 평론가들은 미국이 중국의 고급 AI 자원 접근을 제한하여 선두 지위를 유지하려 하지만, 이는 양측 모두 손해를 보는 결과를 초래하여 글로벌 AI 발전을 늦출 수 있다고 생각함. 반면 젠슨 황은 진정한 경쟁은 장기적이며, 미국은 단기적인 상대적 우위만을 추구하는 것이 아니라 (칩, 공장, 인프라, 모델, 애플리케이션 등) 전면적으로 선두를 달려야 하며, 그렇지 않으면 AI 시대의 발전 기회를 놓치고 결국 종합 국력 경쟁에서 뒤처질 수 있다고 보는 것으로 보임 (출처: X)
ChatGPT 등 AI 도구의 정신 건강 보조 활용 및 논의: Reddit 커뮤니티 사용자들이 ChatGPT 등 AI 도구를 정신 건강 지원에 활용한 경험을 공유하며, 두 차례의 전문 치료 사이에 도움을 줄 수 있으며 특히 복잡한 감정을 정리하고 표현하는 데 유용하다고 평가함. 사용자들은 AI에게 질문하거나 AI가 자신의 감정에 대해 질문하도록 하여 감정의 원인을 더 잘 이해하고 개선 계획을 수립함. 댓글에는 일부 사용자(자칭 치료사 포함)가 AI가 특정 상황에서는 일부 인간 치료사보다 우수하며, 특히 전문적인 도움을 받기 어렵거나 인간 치료사에 대한 신뢰 장벽이 있는 개인에게 유용하다고 생각함. 그러나 일부 사용자는 AI가 전문 치료를 완전히 대체할 수 없으며 개인 데이터 개인 정보 보호 문제에 주의해야 한다고 경고함 (출처: Reddit r/ChatGPT)
💡 기타
“치즈배(启智杯)” 알고리즘 대회 개최, 3대 AI 첨단 분야 집중: 치위안 연구소(启元实验室)가 총상금 75만 위안 규모의 “치즈배” 알고리즘 대회를 개최함. 대회는 “위성 원격 감지 이미지 견고한 인스턴스 분할”, “임베디드 플랫폼용 드론 지상 목표물 탐지”, “멀티모달 대형 모델 대상 적대적 공격” 등 3개 트랙으로 구성되어 견고한 인식, 경량화 배포, 적대적 방어 등 AI 핵심 기술의 혁신과 응용 확산을 목표로 함. 대회는 국내 연구 기관, 기업 및 사업 단위에 개방됨 (출처: WeChat)

시카고 선타임스 AI 생성 콘텐츠 오류, 존재하지 않는 책과 전문가 추천: 《시카고 선타임스》는 여름 행사 추천 기사 일부 내용이 AI에 의해 생성된 것으로 의심되며, 실제 존재하는 작가가 창작한 허구의 책을 추천하고 존재하지 않는 것으로 보이는 “전문가”의 견해를 인용함. 예를 들어, Min Jin Lee의 《Nightshade Market》과 Rebecca Makkai의 《Boiling Point》를 추천 도서로 올렸지만 이 책들은 존재하지 않음. 이 사건은 뉴스 매체가 AI 생성 콘텐츠를 사용할 때 정확성과 검토 메커니즘에 대한 우려를 불러일으킴 (출처: Reddit r/artificial)
AI 사용이 “부정행위”에 해당하는지에 대한 논의: 커뮤니티에서는 업무 및 학습에서 AI 도구(예: ChatGPT, Claude) 사용의 경계에 대해 논의함. 일반적인 견해는 명확한 금지 규정이 없는 경우(예: 대학 과제), AI 도구를 사용하여 효율성을 높이고 반복적인 작업을 완료하거나 사고를 보조하는 것은 계산기나 검색 엔진을 사용하는 것과 유사하게 “부정행위”가 아니라는 것임. 핵심은 사용자가 AI의 출력을 이해하고 효과적으로 조정 및 검증할 수 있는지, 그리고 AI의 보조 역할을 정직하게 명시하는지(특히 학술적 상황에서) 여부임. 그러나 AI 생성 콘텐츠에 전적으로 의존하고 무분별하게 독창적이라고 주장하는 경우 학문적 부정행위에 해당하거나 개인의 기술 발전에 영향을 미칠 수 있음 (출처: Reddit r/ArtificialInteligence)