
키워드:AI 기술, 구글 제미니, AI 에너지 소비, AI 법률 적용, 마이크로소프트 디스커버리, 황런슨 머스크, AI 규제, 제미니 2.5 프로, AI 데이터센터 에너지 소비, AI 생성 법률 문서 오류, 마이크로소프트 디스커버리 연구 플랫폼, AI 칩 수출 규제
🔥 주요 뉴스
구글 I/O 컨퍼런스, 다수의 AI 진전 발표, Gemini 구글 생태계에 전면 통합: 구글은 I/O 2025 개발자 컨퍼런스에서 Gemini 모델의 업그레이드와 심층 통합을 중심으로 한 일련의 주요 AI 업데이트를 발표했습니다. Gemini 2.5 Pro에는 복잡한 추론을 강화하는 “Deep Think” 기능이 도입되었고, 2.5 Flash는 효율성과 비용을 최적화했으며, 네이티브 오디오 출력이 추가되었습니다. 검색에는 채팅 로봇 스타일의 답변을 제공하고 사용자 개인 데이터(권한 필요)를 결합하여 개인화된 결과를 제공할 수 있는 “AI 모드”가 도입됩니다. Chrome 브라우저에는 Gemini 어시스턴트가 통합될 예정입니다. 비디오 모델 Veo 3는 유성 비디오 생성을 구현했으며, 이미지 모델 Imagen 4는 디테일과 텍스트 처리를 향상시켰습니다. 구글은 또한 AI 영화 제작 도구 Flow, 프로그래밍 어시스턴트 Jules를 출시했으며, Project Astra(실시간 멀티모달 어시스턴트)와 Project Mariner(멀티태스크 AI 에이전트)의 진행 상황을 선보였습니다. 동시에 구글은 새로운 AI 구독 서비스를 출시했으며, 프리미엄 버전인 AI Ultra의 월 요금은 249.99달러에 달합니다. 이러한 조치들은 구글이 AI를 자사 제품 및 서비스에 전면적으로 통합하고 사용자 인터랙션 경험을 재구성하는 데 속도를 내고 있음을 의미합니다. (출처: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

AI 에너지 소비 문제 주목, MIT Technology Review 에너지 발자국 및 미래 과제 심층 분석: MIT Technology Review는 AI 기술 발전으로 인한 에너지 소비 및 탄소 배출 문제를 심층적으로 다루는 시리즈 기사를 발표했습니다. 연구에 따르면 AI 추론 단계의 에너지 소비가 이미 학습 단계를 넘어 주요 에너지 부담이 되고 있습니다. 기사는 데이터 센터의 막대한 전력 수요와 수자원 소비(예: 네바다 사막의 데이터 센터), 그리고 화석 에너지(예: 루이지애나 Meta 데이터 센터의 천연가스 의존)에 대한 의존도를 분석했습니다. 원자력 에너지가 잠재적인 청정 에너지 해결책으로 간주되지만, 건설 기간이 길어 단기적으로 AI의 빠른 성장 수요를 충족하기 어렵습니다. 동시에 기사는 더 효율적인 모델 알고리즘, AI용으로 특별히 설계된 에너지 절약형 칩, 그리고 더 최적화된 데이터 센터 냉각 기술을 포함하여 AI 에너지 효율 향상의 낙관적인 전망도 지적했습니다. 이 시리즈는 개별 AI 쿼리의 에너지 소비는 미미해 보이지만, 업계 전체의 추세와 미래 계획(예: OpenAI의 Stargate 프로젝트)이 막대한 에너지 과제를 예고하며, 투명한 데이터 공개와 책임감 있는 에너지 계획이 필요하다고 강조합니다. (출처: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

AI의 법률 분야 적용, 오류 및 윤리적 우려 야기: 최근 여러 사건에서 AI가 법률 문서 작성 시 발생하는 “환각(hallucination)” 문제가 심각한 우려를 낳고 있습니다. 캘리포니아 판사는 변호사가 법정 문서에 Google Gemini 등 AI 도구를 사용하여 허위 인용이 포함된 내용을 생성한 것에 대해 벌금을 부과했습니다. 또 다른 사건에서는 AI 회사 Anthropic의 Claude 모델이 법률 문서의 인용문을 생성할 때 오류를 범했습니다. 더욱 우려스러운 점은 이스라엘 검찰이 존재하지 않는 법을 인용한 AI 생성 텍스트를 요청서에 사용했음을 인정한 것입니다. 이러한 사례들은 AI 모델의 정확성과 신뢰성 측면에서의 결함을 부각시키며, 특히 사실과 인용에 대한 요구가 매우 높은 법률 분야에서 더욱 그렇습니다. 전문가들은 변호사들이 효율성을 추구하다 AI의 결과물을 과도하게 신뢰하고 엄격한 검토의 필요성을 간과할 수 있다고 지적합니다. AI 도구가 신뢰할 수 있는 법률 보조 도구로 홍보되고 있지만, 고유한 “환각” 특성은 사법 정의에 잠재적인 위협이 되며, 업계 규범과 사용자 경계가 시급히 필요합니다. (출처: MIT Technology Review)

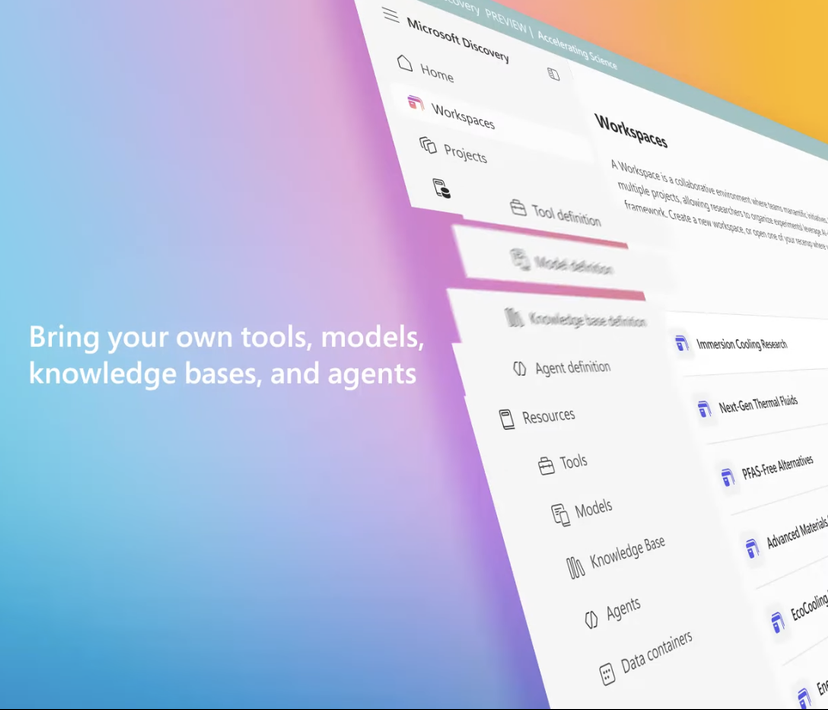
마이크로소프트, 기업용 AI 과학 연구 플랫폼 Microsoft Discovery 출시, 과학적 발견 지원: 마이크로소프트는 Build 컨퍼런스에서 기업 및 연구 기관을 위해 설계된 AI 플랫폼인 Microsoft Discovery를 발표했습니다. 이 플랫폼은 자연어 상호 작용을 통해 프로그래밍 배경이 없는 과학자와 엔지니어도 고성능 컴퓨팅 및 복잡한 시뮬레이션 시스템을 활용할 수 있도록 하는 것을 목표로 합니다. 이 플랫폼은 계획을 위한 기본 모델과 특정 과학 분야(예: 물리, 화학, 생물학)에 대해 훈련된 전문 모델을 결합하여 “AI 박사후 연구원” 팀을 구성하며, 문헌 검토에서 계산 시뮬레이션에 이르는 과학 연구 전체 과정을 수행할 수 있습니다. 마이크로소프트는 약 200시간 내에 36만 7천 종의 물질을 스크리닝하여 잠재적인 PFAS 프리 냉각제 대체품을 성공적으로 발견하고 실험을 통해 검증한 적용 사례를 선보였습니다. 플랫폼의 특징으로는 그래프 지식 엔진, 협력적 추론, 지속적인 반복 연구 개발 루프가 있으며, Azure 인프라를 기반으로 구축되었고 향후 아키텍처는 양자 컴퓨팅 연결 기능을 위해 예비되어 있습니다. (출처: 量子位)
젠슨 황과 엘론 머스크, AI 발전, 규제 및 글로벌 경쟁에 대한 견해 발표: 엔비디아 CEO 젠슨 황은 인터뷰에서 미국의 칩 수출 통제에 대해 우려를 표명하며, 기술 확산 제한이 미국의 AI 분야 리더십을 약화시킬 수 있다고 주장하고, 중국의 AI 연구 개발 역량 및 전 세계 AI 개발자의 절반이 중국 출신이라는 사실을 강조했습니다. 그는 미국이 전 세계적으로 기술 보급을 가속화하고 미국 기업이 중국 시장에서 경쟁할 수 있도록 허용해야 한다고 주장했습니다. 테슬라 CEO 엘론 머스크는 다른 인터뷰에서 최소 5년 동안 테슬라를 계속 이끌 것이며 AGI 실현에 거의 근접했다고 밝혔습니다. 그는 AI에 대한 적절한 규제를 지지하지만 과도한 개입에는 반대했습니다. 두 기술 리더 모두 AI의 막대한 잠재력을 강조했으며, 젠슨 황은 AI가 전 세계 GDP를 크게 성장시킬 것이라고 믿는 반면, 머스크는 Starship, Neuralink 및 Tesla 자율 주행 택시 등 올해의 주요 목표를 열거했는데, 모두 AI와 밀접하게 관련되어 있습니다. (출처: 36氪, 36氪, 36氪)

🎯 동향
구글, 엣지 디바이스 효율적 실행을 위해 설계된 Gemma 3n 프리뷰 버전 출시: 구글은 HuggingFace에 저자원 장치(예: 모바일 장치)에서 효율적으로 실행되도록 특별히 설계된 Gemma 3n 모델의 프리뷰 버전을 출시했습니다. 이 모델 시리즈는 텍스트, 이미지, 비디오 및 오디오를 처리하고 텍스트 출력을 생성할 수 있는 멀티모달 입력 기능을 갖추고 있습니다. “선택적 파라미터 활성화” 기술(MoE 혼합 전문가 아키텍처와 유사)을 채택하여 모델이 2B 및 4B의 유효 파라미터 규모로 실행되어 자원 요구 사항을 줄일 수 있도록 합니다. 커뮤니티 토론에서는 Gemma 3n의 아키텍처가 Gemini와 유사할 수 있으며, 후자의 강력한 멀티모달 및 긴 컨텍스트 기능을 설명한다고 보고 있습니다. Gemma 3n의 오픈 소스 가중치와 명령어 튜닝 버전, 그리고 140개 이상의 언어 데이터에 대한 훈련은 스마트 홈 어시스턴트와 같은 엣지 AI 애플리케이션 분야에서 잠재력을 갖게 합니다. (출처: Reddit r/LocalLLaMA, developers.googleblog.com)

구글, 의료 분야에 최적화된 AI 모델 MedGemma 출시: 구글은 Gemma 3의 의료 분야에 최적화된 두 가지 변형 모델인 MedGemma 시리즈를 출시했습니다. 여기에는 4B 파라미터의 멀티모달 버전과 27B 파라미터의 순수 텍스트 버전이 포함됩니다. MedGemma 4B는 특히 의료 영상(예: X-레이, 피부과 이미지 등)과 텍스트 이해를 위해 훈련되었으며, 의료 데이터에서 사전 훈련된 SigLIP 이미지 인코더를 채택했습니다. MedGemma 27B는 의료 텍스트 처리에 중점을 두고 추론 시 계산을 위해 최적화되었습니다. 구글은 이러한 모델이 의료 AI 애플리케이션 개발을 가속화하고 여러 임상 관련 벤치마크에서 평가되었으며, 개발자는 특정 작업 성능을 향상시키기 위해 미세 조정할 수 있다고 밝혔습니다. 커뮤니티는 이에 대해 잠재력이 크다고 긍정적으로 반응했지만, 의료 전문가의 실제 피드백이 필요하다고 강조했습니다. (출처: Reddit r/LocalLLaMA)

ByteDance, 이미지 생성 지원하는 오픈 소스 멀티모달 모델 Bagel 출시: ByteDance는 Apache 2.0 라이선스를 사용하는 14B 파라미터(7B 활성) 오픈 소스 멀티모달 대형 모델인 Bagel(또는 BAGEL-7B-MoT)을 출시했습니다. 이 모델은 혼합 전문가(MoE) 및 혼합 Transformer(MoT) 아키텍처를 기반으로 하며 텍스트를 이해하고 생성할 수 있으며 네이티브 이미지 생성 기능을 갖추고 있습니다. 일련의 멀티모달 이해 및 생성 벤치마크 테스트에서 다른 오픈 소스 통합 모델보다 우수한 성능을 보였으며, 자유 형식 이미지 처리, 미래 프레임 예측 등 고급 멀티모달 추론 능력을 선보였습니다. 연구진은 사전 훈련 세부 정보, 데이터 생성 프로토콜, 오픈 코드 및 체크포인트를 공유하여 멀티모달 연구를 촉진하기를 희망합니다. (출처: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
엔비디아, 생성형 비디오 모델을 활용하여 로봇을 훈련하는 DreamGen 출시: 엔비디아 연구팀은 고급 비디오 생성 모델(예: Sora, Veo)을 미세 조정하여 로봇이 생성된 “꿈의 세계”에서 새로운 기술을 학습하도록 하는 DreamGen 프로젝트를 출시했습니다. 이 방법은 기존의 그래픽 엔진이나 물리 시뮬레이터에 의존하지 않고, 로봇이 신경망으로 생성된 픽셀 수준의 장면에서 자율적으로 탐색하고 경험함으로써 의사 행동 레이블이 있는 대량의 신경 궤적을 생성하도록 합니다. 실험 결과 DreamGen은 시뮬레이션 및 실제 세계 작업에서 로봇의 성능을 크게 향상시키는 것으로 나타났으며, 여기에는 본 적 없는 행동과 낯선 환경이 포함됩니다. 예를 들어, 소량의 실제 궤적만으로 인간형 로봇은 물 따르기, 옷 개기 등 22가지 새로운 기술을 배웠으며 NVIDIA 본사의 카페와 같은 실제 장면에 성공적으로 일반화했습니다. (출처: 36氪, arxiv.org)

화웨이, MoE 모델 추론 성능 최적화를 위한 OmniPlacement 제안: 혼합 전문가 모델(MoE)에서 전문가 네트워크 부하 불균형(“핫 전문가”와 “콜드 전문가”)으로 인한 추론 지연 문제에 대응하기 위해 화웨이 팀은 OmniPlacement 최적화 방안을 제안했습니다. 이 방안은 전문가 재배치, 계층 간 중복 배포 및 거의 실시간 동적 스케줄링을 통해 MoE 모델의 추론 성능을 향상시키는 것을 목표로 합니다. DeepSeek-V3 등 모델에서의 이론적 검증 결과, OmniPlacement은 추론 지연을 약 10% 줄이고 처리량을 약 10% 향상시킬 수 있는 것으로 나타났습니다. 이 방법의 핵심은 전문가 우선순위 동적 조정, 통신 도메인 최적화, 중복 인스턴스 차등 배포, 그리고 거의 실시간 스케줄링과 동적 모니터링 메커니즘을 통한 부하 변화에 대한 유연한 대응에 있습니다. 화웨이는 조만간 이 방안을 오픈 소스로 공개할 계획입니다. (출처: 量子位)

애플, 개발자에게 AI 모델 권한 개방하여 앱 혁신 촉진 계획: 보도에 따르면 애플은 WWDC에서 타사 개발자에게 Apple Intelligence의 AI 모델 권한을 개방한다고 발표할 예정입니다. 초기에는 장치 단에서 실행되는 약 30억 파라미터의 경량 언어 모델에 초점을 맞추고, 이후에는 GPT-4-Turbo 수준에 해당하는 클라우드 모델(사설 클라우드를 통해 실행되고 암호화됨)을 개방할 수 있습니다. 이 조치는 개발자가 애플의 LLM을 기반으로 새로운 앱 기능을 구축하도록 장려하고, 애플 장치의 매력을 높이며, 생성형 AI 분야에서의 상대적인 뒤처짐을 만회하기 위한 것입니다. 분석가들은 애플이 개방형 생태계를 구축하여 방대한 개발자 커뮤니티(600만 명)를 활용하여 자체 기술적 약점을 보완하고 치열해지는 AI 경쟁에 대응하기를 희망한다고 보고 있습니다. (출처: 36氪)
미국 하원, 주 차원의 AI 규제 10년간 중단 제안, 큰 논란 야기: 미국 하원 에너지 상업 위원회는 향후 10년 동안 각 주가 인공 지능 모델, 시스템 및 “인간의 의사 결정을 실질적으로 영향하거나 대체하는” 자동화된 의사 결정 시스템을 규제하는 것을 금지하는 제안을 통과시켰습니다. 지지자들은 이 조치가 각 주의 규제가 일치하지 않아 AI 혁신과 연방 정부 시스템 현대화를 저해하는 것을 피할 수 있다고 주장하는 반면, 반대자들은 이것이 “대형 기술 기업에 대한 막대한 선물”이며 AI의 위험으로부터 대중을 보호하는 각 주의 능력을 약화시킬 것이라고 말합니다. 이 제안이 통과되면 기존 및 제안된 많은 주 차원의 AI 법률이 무효화될 수 있지만, 연방법 규정이나 AI와 비 AI 시스템을 동등하게 취급하는 보편적으로 적용되는 법률에는 적용되지 않음을 명확히 합니다. 이 조치는 전 세계적으로 “AI 혁신 우선”과 “안전 최저선” 사이의 치열한 경쟁을 반영합니다. (출처: 36氪, edition.cnn.com)

《Take It Down Act》 미국 법으로 서명, 비자발적 사적 이미지 유포 단속: 트럼프 미국 대통령은 《Take It Down Act》 법안에 서명하여 비자발적 사적 이미지(AI 생성 딥페이크 콘텐츠 포함) 제작 및 유포를 연방 범죄로 규정했습니다. 이 법안은 기술 플랫폼이 통지를 받은 후 48시간 이내에 관련 콘텐츠를 제거하도록 요구합니다. 이 법안은 피해자를 보호하고 딥페이크 기술 남용으로 인한 심각해지는 사회 문제에 대응하기 위한 것입니다. 그러나 이 법안이 남용되어 과도한 검열을 초래할 수 있다는 비판도 있습니다. (출처: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

AI 대형 모델, 건강 관리 지원, 개인화 및 다차원 데이터 연동 실현: AI 대형 모델은 웨어러블 장치와 결합하여 다차원 데이터 연동 및 개인화 서비스를 실현함으로써 건강 관리 분야에 새로운 활력을 불어넣고 있습니다. WeDoctor, Deepwise Healthcare, NandaFitech과 같은 기업들은 건강 검진 시나리오에서 조기 검진 및 치료를 시작하거나 체중 관리를 돌파구로 삼아 만성 질환을 예방하는 등 응용 시나리오를 적극적으로 모색하고 있습니다. 대형 모델은 더 다양한 데이터 차원을 처리하고 사용자 기억을 구축하며 더 정확한 건강 개입 방안을 제공할 수 있습니다. 모델 환각, 데이터 품질 및 협업의 어려움과 같은 과제가 있지만 RAG, 모델 미세 조정, 검토 메커니즘 및 “AI + 실제 관리자” 모델을 통해 점차 극복되고 있습니다. 비즈니스 모델 측면에서 ToB 서비스, C단 유료 서비스 및 AI 건강 공동체 등이 초기 검증을 받았으며 향후 추세는 멀티모달 상호 작용으로 업그레이드될 것입니다. (출처: 36氪)
바이두, Wenxin Large Model 멀티모달 능력 강화, 시장 경쟁 및 애플리케이션 구현 대응: 바이두가 최근 발표한 Wenxin Large Model 4.5 Turbo와 심층 사고 모델 X1 Turbo는 혼합 훈련, 멀티모달 이종 전문가 모델링 등 기술을 통해 멀티모달 이해 및 생성 능력이 크게 향상되어 교차 모달 학습 효율과 융합 효과를 높였습니다. CEO 리옌훙이 Sora와 같은 비디오 생성 모델의 환각 문제에 대해 신중한 태도를 보였음에도 불구하고, 시장 경쟁(예: ByteDance Doubao, Alibaba Tongyi Qianwen의 멀티모달 분야 진전) 및 AI 애플리케이션 구현 수요에 직면하여 바이두는 적극적으로 약점을 보완하고 있으며, 6월 30일에 Wenxin Large Model 4.5 시리즈를 오픈 소스로 공개할 계획입니다. 바이두는 AI 디지털 휴먼을 중요한 애플리케이션 돌파구로 보고 있으며, “시나리오” 기반의 초현실적인 디지털 휴먼 기술을 개발하여 10만 명 이상의 디지털 휴먼 앵커를 지원합니다. (출처: 36氪)
Douyin, Xiaohongshu 등 플랫폼, “AI 계정 생성” 특별 단속, 콘텐츠 생태계 유지: Douyin, Xiaohongshu 등 관심 기반 전자상거래 플랫폼은 최근 AI 기술을 이용해 허위 콘텐츠를 대량 생산하고 “AI 계정 생성” 등의 행위를 하는 것에 대한 특별 단속을 강화했습니다. 이러한 행위에는 AI 생성 저속하고 기이한 비디오, 가상 전문가 콘텐츠, AI 계정 생성 튜토리얼 및 계정 판매 등이 포함됩니다. 플랫폼은 이러한 행위가 콘텐츠의 진실성을 훼손하고 콘텐츠 동질화를 초래하며 사용자 경험과 원작자 생태계를 손상시켜 상업적 가치를 희석시킨다고 보고 있습니다. 이와 대조적으로 Taobao, JD.com 등 전통적인 상품 진열 전자상거래 플랫폼은 판매자가 AI 도구(예: “이미지-비디오 생성”, 라이브 스트리밍 디지털 휴먼)를 사용하여 상품 전시 효과와 운영 효율성을 높여 거래 성사를 촉진하도록 적극적으로 장려하고 있습니다. 이러한 차이는 다양한 전자상거래 모델 하에서의 AI 응용 전략의 분화를 반영합니다. (출처: 36氪)

애플 AI 버전 Siri 개발 난항, 또다시 출시 연기 가능성, 경영진 조정으로 위기 대응: 블룸버그 통신에 따르면 애플이 WWDC에서 선보일 예정이었던 대형 모델 업그레이드 버전 Siri가 다시 연기될 수 있다고 합니다. 기술적 병목 현상은 신구 시스템 아키텍처 충돌로 인해 버그가 빈번하게 발생하는 데 있습니다. 보도에 따르면 애플은 AI 전략에서 고위층 의사 결정 오류, 내부 권력 다툼, GPU 구매 부족 및 개인 정보 보호로 인한 데이터 사용 제한 등의 문제가 있어 AI 기술이 경쟁사보다 뒤처져 있다고 지적했습니다. 위기에 대응하기 위해 애플 취리히 연구소는 새로운 “LLM Siri” 아키텍처를 개발 중이며 Siri 프로젝트를 Vision Pro 책임자인 마이크 록웰에게 이관했습니다. 동시에 애플은 구글 Gemini, OpenAI 등 외부 기술 협력도 모색하고 있으며, 마케팅에서 Apple Intelligence와 Siri 브랜드를 분리하여 AI 이미지를 재정립할 수도 있습니다. (출처: 36氪)

ByteDance, 영어 원어민 AI 튜터 Owen 탑재한 Ola Friend 이어폰 출시: ByteDance는 자사의 스마트 이어폰 Ola Friend에 Owen이라는 영어 원어민 AI 튜터 기능을 추가했습니다. 사용자는 Doubao 앱을 실행하여 Owen을 활성화하고 영어 대화, 영어 읽기 지도, 이중 언어 피드백 등을 할 수 있습니다. 이 기능은 일상 대화, 직장 영어, 여행 영어 등 다양한 상황을 포괄하며 편리한 휴대용 영어 회화 연습 파트너를 제공하는 것을 목표로 합니다. 이는 ByteDance가 교육 분야에서 AI 대형 모델 역량을 하드웨어와 결합하여 수직적인 영어 학습 제품을 만드는 또 다른 시도입니다. Ola Friend 이어폰은 이전부터 Doubao를 통한 지식 질의응답 및 회화 연습을 지원했으며, 새로운 AI 튜터 추가로 교육적 속성이 더욱 강화되었습니다. (출처: 36氪)

Quark과 Baidu Wenku, AI 슈퍼 앱 경쟁, 검색·도구·콘텐츠 서비스 통합: 알리바바 산하의 Quark과 바이두 산하의 Baidu Wenku가 AI를 핵심으로 하는 “슈퍼 프레임” 애플리케이션으로 전환하며 AI 대화, 심층 검색, AI 도구(예: 글쓰기, PPT 생성, 건강 도우미 등) 및 클라우드 스토리지, 문서 서비스를 통합하여 C단 사용자를 위한 원스톱 AI 진입로가 되는 것을 목표로 하고 있습니다. Quark은 광고 없는 검색과 젊은 사용자층을 바탕으로 월간 활성 사용자 수(MAU)가 1억 4,900만 명에 달하며 회원 시스템을 통해 상업화를 실현했습니다. Baidu Wenku는 방대한 문서 자원과 유료 사용자 기반을 바탕으로 “Cangzhou OS”를 출시하여 AI Agent를 통합하고 콘텐츠 제작 및 소비 전체 과정을 강화했습니다. 양측 모두 기능 동질화, 애플리케이션 비대화, 그리고 일반적인 수요와 심층 서비스 간의 균형을 맞추는 과제에 직면해 있습니다. (출처: 36氪)
Zhipu Qingyan, Kimi 등 35개 앱, 개인 정보 불법 수집으로 통보: 국가 인터넷 정보 보안 정보 통보 센터는 Zhipu Qingyan(버전 2.9.6)이 “실제 수집한 개인 정보가 사용자 승인 범위를 초과”하고, Kimi(버전 2.0.8)가 “실제 수집한 개인 정보가 비즈니스 기능과 직접적인 관련이 없는” 등의 이유로 다른 33개 앱과 함께 개인 정보 불법 수집 및 사용 사례로 지목되었다고 발표했습니다. 이 두 인기 AI 애플리케이션은 모두 칭화대 출신 팀이 개발했으며 최근 상당한 투자 유치와 시장의 주목을 받았습니다. 이번 통보는 2025년 4월 16일부터 5월 15일까지의 검사 기간을 대상으로 하며, AI 애플리케이션이 빠르게 발전하는 과정에서 직면하는 데이터 규정 준수 과제를 부각시킵니다. (출처: 36氪)
🧰 도구
OpenEvolve: DeepMind AlphaEvolve의 오픈 소스 구현, LLM을 사용하여 코드베이스 진화: 개발자들이 Google DeepMind의 AlphaEvolve 시스템을 구현한 OpenEvolve 프로젝트를 오픈 소스로 공개했습니다. OpenEvolve 프레임워크는 LLM의 반복적인 프로세스(코드 생성, 평가, 선택)를 통해 전체 코드베이스를 진화시켜 새로운 알고리즘을 발견하거나 기존 알고리즘을 최적화합니다. OpenAI API와 호환되는 모든 LLM을 지원하며, 여러 모델(예: Gemini-Flash-2.0 및 Claude-Sonnet-3.7 조합)을 통합할 수 있고, 다중 목표 최적화 및 분산 평가를 지원합니다. 이 프로젝트는 AlphaEvolve 논문의 원형 채우기 및 함수 최소화 사례를 성공적으로 재현하여 간단한 방법에서 복잡한 최적화 알고리즘(예: scipy.minimize 및 시뮬레이티드 어닐링)으로 진화하는 능력을 보여주었습니다. (출처: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

구글, 자동화 코드 작업을 지원하는 AI 프로그래밍 에이전트 Jules 출시: 구글은 AI 프로그래밍 에이전트 Jules를 출시했으며, 현재 전 세계 테스트 단계에 있으며 사용자는 매일 5개의 작업을 무료로 실행할 수 있습니다. Jules는 멀티모달 Gemini 2.5 Pro 모델을 기반으로 하며 복잡한 코드베이스를 이해하고 버그 수정, 버전 업데이트, 테스트 작성, 새로운 기능 구현 등의 작업을 수행할 수 있으며 Python 및 JavaScript를 지원합니다. GitHub에 연결하여 풀 리퀘스트(PR)를 생성하고 클라우드 가상 머신에서 코드를 검증하며 개발자가 검토하고 수정할 수 있도록 상세한 실행 계획을 제공합니다. Jules는 개발자 워크플로우에 깊숙이 통합되어 프로그래밍 효율성을 향상시키는 것을 목표로 하며, 향후 Codecast 기능(코드베이스 활동 오디오 요약)과 엔터프라이즈 버전도 출시할 예정입니다. (출처: 36氪)
Feishu, “Feishu 지식 Q&A” 출시, 기업 전용 AI Q&A 도구 구축: Feishu는 기업 지식 기반의 기업 전용 AI Q&A 도구인 AI 신제품 “Feishu 지식 Q&A”를 곧 출시할 예정입니다. 사용자는 Feishu 사이드바에서 호출하여 업무 중 발생하는 문제에 대해 질문할 수 있습니다. 이 도구는 사용자 권한 범위 내의 모든 Feishu 메시지, 문서, 지식 베이스, 파일 등의 정보에 액세스할 수 있으며, 이러한 “컨텍스트”를 기반으로 정확한 답변을 직접 제공합니다. 권한 관리는 Feishu 자체 권한 시스템과 일치하여 정보 보안을 보장합니다. 현재 제품은 수만 명의 사용자 내부 테스트를 완료했으며, 웹 페이지(ask.feishu.cn)가 출시되어 개인 자료를 업로드하고 DeepSeek 또는 Doubao 모델을 호출하여 질문할 수 있도록 지원합니다. 이 조치는 기업 지식 베이스와 AI 결합 추세에 부응하며 업무 효율성과 지식 관리 능력 향상을 목표로 합니다. (출처: 36氪)
Manus: AI 에이전트 플랫폼 등록 개시, 모회사 고액 투자 유치: AI 에이전트 플랫폼 Manus가 해외 사용자 등록을 개시하고 대기자 명단을 없애며 매일 무료 작업을 제공한다고 발표했습니다. Manus는 “혼합 아키텍처 다중 모델 협력 추론” 기술을 통해 PPT 자동 생성, 영수증 정리 등의 작업을 수행할 수 있으며, 모회사인 Butterfly Effect는 최근 7,500만 달러의 투자를 유치하여 기업 가치가 36억 달러에 달합니다. Manus의 성공은 “중국의 반복 속도 × 실리콘밸리 제품 사고방식”의 결과로 간주되며, 계획, 실행, 검증 에이전트를 협력시켜 AI가 “사고 제안”에서 “폐쇄 루프 실행”으로 도약하는 것을 실현합니다. (출처: 36氪)

HeyGen: AI 비디오 생성 및 번역 도구, 40개 이상 언어 입 모양 동기화 지원: HeyGen은 AI 비디오 도구로, 사용자는 사진이나 비디오를 업로드하여 음성, 표정, 동작이 있는 디지털 휴먼을 빠르게 생성할 수 있으며, 의상 및 장면 맞춤 설정도 지원합니다. 핵심 기능 중 하나는 175개 이상의 언어와 방언을 실시간으로 번역하고 AI 알고리즘을 통해 디지털 휴먼의 입 모양을 번역된 언어와 정확하게 일치시켜 다국어 비디오 콘텐츠의 자연스러움을 향상시키는 것입니다. 이 회사는 전 Snapchat 및 ByteDance 멤버들이 설립했으며, Benchmark 주도로 6,000만 달러의 투자를 유치하여 기업 가치가 4억 4,000만 달러에 달하고 연간 반복 수익(ARR)은 3,500만 달러를 초과합니다. (출처: 36氪)
Opus Clip: AI 기반 자율 비디오 편집 에이전트 도구: Opus Clip은 처음에는 AI 라이브 스트리밍 도구로 시작했으나 이후 AI 비디오 편집 플랫폼으로 전환했으며, 더 나아가 “자율 비디오 편집 에이전트”로 발전했습니다. 핵심 기능은 긴 비디오를 바이럴 확산에 적합한 여러 개의 짧은 비디오로 빠르게 편집하고, 자동으로 주체를 자르고, 제목과 문구를 생성하며, 자막과 이모티콘을 추가하는 것입니다. 최근 테스트한 ClipAnything 기능은 이미 멀티모달 명령어 인식을 지원합니다. 이 회사는 전 소셜 앱 Sober 창립자인 자오양이 이끌고 있으며, 소프트뱅크 주도로 2,000만 달러의 투자를 유치하여 기업 가치가 2억 1,500만 달러에 달하고 ARR은 거의 1,000만 달러에 이릅니다. (출처: 36氪)
Trae: AI IDE 기반 자동화 프로그래밍 에이전트: Trae는 “진정한 AI 엔지니어”를 만드는 것을 목표로 하는 도구로, 사용자가 자연어 상호 작용을 통해 에이전트 자동화 프로그래밍을 실현할 수 있도록 지원합니다. MCP 프로토콜 및 사용자 정의 에이전트와 호환되며, 향상된 컨텍스트 분석 및 규칙 엔진이 내장되어 있고, 주요 프로그래밍 언어를 지원하며 VS Code와 호환됩니다. Trae는 ByteDance의 전 Marscode 프로그래밍 어시스턴트 팀 핵심 멤버들이 만들었으며, Cursor 등 AI 프로그래밍 도구의 강력한 경쟁자로 자리매김하여 인간-기계 협력의 새로운 소프트웨어 개발 모델을 실현하는 데 주력하고 있습니다. (출처: 36氪)
Notta: AI 기반 다국어 회의록 및 실시간 번역 도구: Notta는 회의 장면에 특화된 AI 도구로, 다국어 회의록 자동 생성 서비스를 제공하며 실시간 번역 및 중요 내용 표시 기능을 지원합니다. 이 제품은 회의 효율성을 높이고 언어 간 의사소통 장벽을 해결하는 것을 목표로 합니다. 주요 창립자는 전 Tencent Cloud 음성 팀 핵심 멤버로 알려져 있으며, 운영 주체는 싱가포르에 있고 연구 개발 센터는 시애틀에 있습니다. 2024년 매출은 1,800만 달러, 기업 가치는 3억 달러이며 현재 시리즈 B 투자를 진행 중입니다. (출처: 36氪)
오픈 소스 GPT+ML 트레이딩 어시스턴트 iPhone 출시: 딥러닝과 GPT 기술을 통합한 오픈 소스 트레이딩 어시스턴트가 Pyto를 통해 iPhone에서 로컬로 실행 가능하게 되었습니다. 현재는 무료 경량 버전이며, 향후 CNN 차트 패턴 분류기와 데이터베이스 지원을 추가할 계획입니다. 이 플랫폼은 모듈식으로 설계되어 딥러닝 개발자가 자체 모델을 쉽게 연결할 수 있으며, 이미 OpenAI GPT를 기본적으로 지원합니다. (출처: Reddit r/deeplearning)
📚 학습
새 논문, 딥러닝의 “파편화된 얽힘 표현 가설” 논의: 《딥러닝 표현 낙관론에 대한 의문: 파편화된 얽힘 표현 가설》이라는 제목의 입장 논문이 Arxiv에 제출되었습니다. 이 연구는 진화적 검색 과정을 통해 생성된 신경망과 전통적인 SGD 훈련 신경망(단일 이미지 생성이라는 간단한 작업에서)을 비교하여, 둘 다 동일한 출력 행동을 생성하지만 내부 표현은 크게 다르다는 것을 발견했습니다. SGD 훈련 신경망은 저자가 “파편화된 얽힘 표현”(FER)이라고 부르는 무질서한 형태를 보이는 반면, 진화적 신경망은 통일된 분해 표현(UFR)에 더 가깝습니다. 연구자들은 대형 모델에서 FER이 일반화, 창의성, 지속적인 학습과 같은 핵심 능력을 저하시킬 수 있으며, FER을 이해하고 완화하는 것이 미래 표현 학습에 중요하다고 주장합니다. (출처: Reddit r/MachineLearning, arxiv.org)
R3: 견고하게 제어 가능하고 해석 가능한 보상 모델 프레임워크: 《R3: Robust Rubric-Agnostic Reward Models》라는 논문은 새로운 보상 모델 프레임워크 R3를 소개합니다. 이 프레임워크는 기존 언어 모델 정렬 방법에서 보상 모델의 제어 가능성과 해석 가능성이 부족한 문제를 해결하는 것을 목표로 합니다. R3의 특징은 “rubric-agnostic”(구체적인 평가 기준과 무관)이며, 평가 차원을 넘어 일반화할 수 있고, 추론 과정이 포함된 해석 가능한 점수 할당을 제공합니다. 연구자들은 R3가 더 투명하고 유연한 언어 모델 평가를 가능하게 하여 다양한 인간 가치 및 사용 사례와의 견고한 정렬을 지원할 수 있다고 믿습니다. 모델, 데이터 및 코드는 오픈 소스로 공개되었습니다. (출처: HuggingFace Daily Papers)
저계수 복제를 통한 효율적인 지식 증류 논문 《A Token is Worth over 1,000 Tokens》 발표: 이 논문은 강력한 교사 모델의 행동과 동등한 소형 언어 모델(SLM)을 구축하기 위한 효율적인 사전 훈련 방법인 저계수 복제(Low-Rank Clone, LRC)를 제안합니다. LRC는 일련의 저계수 투영 행렬을 훈련하여 교사 가중치 압축을 통한 소프트 가지치기와 학생 활성화(FFN 신호 포함)를 교사 활성화와 정렬하는 활성화 복제를 공동으로 구현합니다. 이러한 통합 설계는 명시적인 정렬 모듈 없이 지식 전달을 극대화합니다. 실험 결과, Llama-3.2-3B-Instruct와 같은 오픈 소스 교사 모델을 사용하여 LRC는 단 20B 토큰 훈련만으로 SOTA 모델(수조 토큰으로 훈련됨)의 성능에 도달하거나 이를 능가하여 1000배 이상의 훈련 효율성을 달성했습니다. (출처: HuggingFace Daily Papers)
MedCaseReasoning: 임상 사례 보고서로부터 진단 추론 평가 및 학습을 위한 데이터셋 및 방법: 논문 《MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports》는 임상 진단 추론 측면에서 대형 언어 모델(LLM)의 능력을 평가하기 위한 새로운 개방형 데이터셋 MedCaseReasoning을 소개합니다. 이 데이터셋은 14,489개의 진단 질의응답 사례를 포함하며, 각 사례에는 공개된 의학 사례 보고서에서 파생된 상세한 추론 설명이 첨부되어 있습니다. 연구 결과, 기존 SOTA 추론 LLM은 진단 및 추론 측면에서 상당한 부족함(예: DeepSeek-R1 정확도 48%, 추론 설명 재현율 64%)을 보이는 것으로 나타났습니다. 그러나 MedCaseReasoning의 추론 궤적에서 LLM을 미세 조정함으로써 진단 정확도와 임상 추론 재현율이 각각 평균 29%와 41% 상대적으로 향상되었습니다. (출처: HuggingFace Daily Papers)
《EfficientLLM: Efficiency in Large Language Models》 논문 발표, LLM 효율성 기술 종합 평가: 이 연구는 대규모 LLM의 효율성 기술에 대한 포괄적인 실증 연구를 최초로 수행하고 EfficientLLM 벤치마크를 도입했습니다. 연구는 생산 수준 클러스터에서 아키텍처 사전 훈련(효율적인 어텐션 변형, 희소 MoE), 미세 조정(LoRA 등 파라미터 효율적인 방법), 추론(양자화)의 세 가지 주요 측면을 체계적으로 탐구했습니다. 6개의 세분화된 지표(메모리 사용률, 계산 사용률, 지연 시간, 처리량, 에너지 소비, 압축률)를 통해 100개 이상의 모델-기술 쌍(0.5B-72B 파라미터)을 평가했습니다. 핵심 발견 사항에는 효율성은 정량화 가능한 절충안을 포함하며 보편적으로 최적인 방법은 없다는 점, 최적의 해결책은 작업과 규모에 따라 달라진다는 점, 기술은 교차 모달 일반화가 가능하다는 점 등이 포함됩니다. (출처: HuggingFace Daily Papers)
《NExT-Search》 논문, 생성형 AI 검색의 피드백 생태계 재구축 논의: 논문 《NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search》는 생성형 AI 검색이 편리성을 향상시켰지만, 전통적인 웹 검색이 개선을 위해 의존했던 세분화된 사용자 피드백(예: 클릭, 체류 시간) 순환을 파괴했다고 지적합니다. 이 문제를 해결하기 위해 논문은 세분화되고 과정 수준의 피드백을 다시 도입하는 것을 목표로 하는 NExT-Search 패러다임을 구상했습니다. 이 패러다임에는 사용자가 주요 단계에서 개입할 수 있도록 하는 “사용자 디버깅 모드”와 사용자 선호도를 시뮬레이션하고 AI 지원 피드백을 제공하는 “그림자 사용자 모드”가 포함됩니다. 이러한 피드백 신호는 온라인 적응(검색 출력 실시간 최적화) 및 오프라인 업데이트(각 모델 구성 요소 정기적 미세 조정)에 사용될 수 있습니다. (출처: HuggingFace Daily Papers)
《Latent Flow Transformer》 새로운 LLM 아키텍처 제안: 논문은 잠재 흐름 Transformer(Latent Flow Transformer, LFT)를 제안합니다. 이 모델은 흐름 일치(flow matching)를 통해 단일 학습 전송 연산자를 훈련하여 기존 Transformer의 다층 이산 계층을 대체합니다. LFT는 모델 계층 수를 크게 압축하면서 원래 아키텍처와의 호환성을 유지하는 것을 목표로 합니다. 또한, 논문은 기존 흐름 방법이 결합 유지에 한계가 있는 문제를 해결하기 위해 Flow Walking (FW) 알고리즘을 도입합니다. Pythia-410M 모델에서의 실험 결과, LFT는 계층 수를 효과적으로 압축하고 직접 계층 건너뛰기보다 우수한 성능을 보이며, 자기 회귀 생성 패러다임과 흐름 기반 생성 패러다임 간의 격차를 크게 줄였습니다. (출처: HuggingFace Daily Papers)
《Reasoning Path Compression》 LLM 추론 생성 궤적 압축 방법 제안: 추론형 언어 모델이 긴 중간 경로를 생성하여 메모리 점유율이 크고 처리량이 낮은 문제에 대응하기 위해, 논문은 추론 경로 압축(Reasoning Path Compression, RPC) 방법을 제안합니다. RPC는 훈련이 필요 없는 방법으로, 중요도 점수가 높은 KV 캐시(최근 생성된 쿼리로 구성된 “선택기 창”을 사용하여 계산)를 보존하여 주기적으로 KV 캐시를 압축합니다. 실험 결과, RPC는 QwQ-32B와 같은 모델의 생성 처리량을 크게 향상시키면서 정확도에 미치는 영향은 적어, 효율적인 추론 LLM 배포를 위한 실용적인 경로를 제공합니다. (출처: HuggingFace Daily Papers)
《Bidirectional LMs are Better Knowledge Memorizers?》 논문 발표, 양방향 LM 지식 기억 능력 주목: 이 연구는 위키백과 “알고 계셨나요…” 항목에 최근 추가된 사람이 작성한 사실을 활용하여 새롭고 실제적이며 대규모인 지식 주입 벤치마크 WikiDYK를 도입했습니다. 실험 결과, 현재 널리 사용되는 인과적 언어 모델(CLM)에 비해 양방향 언어 모델(BiLM)이 지식 기억 측면에서 훨씬 강력한 능력을 보이며 신뢰성 정확도가 23% 더 높은 것으로 나타났습니다. 현재 BiLM의 규모가 작은 단점을 보완하기 위해 연구자들은 BiLM 집합을 외부 지식 베이스로 활용하여 LLM과 통합하는 모듈식 협력 프레임워크를 제안하여 신뢰성 정확도를 최대 29.1%까지 향상시켰습니다. (출처: HuggingFace Daily Papers)
《Truth Neurons》 논문, 언어 모델에서 진실성의 뉴런 수준 인코딩 탐구: 연구자들은 언어 모델에서 뉴런 수준의 진실성 표현을 식별하는 방법을 제안하며, 모델 내에 주제와 무관하게 진실성을 인코딩하는 “진리 뉴런”(truth neurons)이 존재함을 발견했습니다. 다양한 규모의 모델에 대한 실험은 진리 뉴런의 존재를 검증했으며, 그 분포 패턴은 진실성의 기하학적 구조에 대한 이전 연구 결과와 일치했습니다. 이러한 뉴런의 활성화를 선택적으로 억제하면 TruthfulQA 및 기타 벤치마크에서 모델의 성능이 저하되어 진실성 메커니즘이 특정 데이터셋에 국한되지 않음을 시사합니다. (출처: HuggingFace Daily Papers)
《Understanding Gen Alpha Digital Language》 LLM의 콘텐츠 심사 한계 평가: 이 연구는 AI 시스템(GPT-4, Claude, Gemini, Llama 3)이 “알파 세대”(Gen Alpha, 2010-2024년 출생)의 디지털 언어를 해석하는 능력을 평가했습니다. 연구는 Gen Alpha의 독특한 온라인 언어(게임, 밈, AI 트렌드의 영향을 받음)가 종종 유해한 상호 작용을 숨기고 있어 기존 안전 도구가 식별하기 어렵다고 지적합니다. 최근 Gen Alpha 표현 100개를 포함하는 데이터셋을 통해 테스트한 결과, 주류 AI 모델이 은폐된 괴롭힘과 조작을 탐지하는 데 심각한 이해 장애가 있음을 발견했습니다. 연구 기여에는 최초의 Gen Alpha 표현 데이터셋, AI 심사 시스템 개선을 위한 프레임워크가 포함되며, 청소년 의사소통 특성에 맞춰 안전 시스템을 재설계해야 할 시급성을 강조합니다. (출처: HuggingFace Daily Papers)
《CompeteSMoE》 경쟁 기반 혼합 전문가 모델 훈련 방법 제안: 논문은 현재 희소 혼합 전문가(SMoE) 모델 훈련이 라우팅 과정의 차선책 문제, 즉 계산을 수행하는 전문가가 라우팅 결정에 직접 참여하지 않는 문제에 직면해 있다고 주장합니다. 이를 위해 연구자들은 토큰을 신경 반응이 가장 높은 전문가에게 라우팅하는 “경쟁”(competition)이라는 새로운 메커니즘을 제안합니다. 이론적으로 경쟁 메커니즘이 전통적인 softmax 라우팅보다 더 나은 샘플 효율성을 갖는다는 것을 증명합니다. 이를 기반으로 라우터를 배포하여 경쟁 전략을 학습하는 CompeteSMoE 알고리즘을 개발했으며, 시각적 지시 미세 조정 및 언어 사전 훈련 작업에서 효과성, 견고성 및 확장성을 보여주었습니다. (출처: HuggingFace Daily Papers)
《General-Reasoner》 LLM의 교차 영역 추론 능력 향상 목표: 현재 LLM 추론 연구가 주로 수학 및 코딩 분야에 집중되어 있는 문제에 대응하여, 이 논문은 LLM의 다양한 영역에 걸친 추론 능력을 향상시키는 것을 목표로 하는 새로운 훈련 패러다임인 General-Reasoner를 제안합니다. 기여 사항으로는 다학제적 검증 가능한 답변을 포함하는 대규모 고품질 문제 데이터셋 구축, 그리고 전통적인 규칙 기반 검증을 대체하는 사고 사슬 및 컨텍스트 인식 기능을 갖춘 생성 모델 기반 답변 검증기 개발이 있습니다. 물리, 화학, 금융 등 다양한 분야를 포괄하는 일련의 벤치마크 테스트에서 General-Reasoner는 기존 기준선 방법보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
《Not All Correct Answers Are Equal》 지식 증류 원천의 중요성 논의: 이 연구는 세 가지 SOTA 교사 모델(AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1)의 189만 개 쿼리에 대한 검증된 출력을 수집하여 추론 데이터 증류에 대한 대규모 실증 연구를 수행했습니다. 분석 결과, AM-Thinking-v1으로 증류된 데이터는 더 큰 토큰 길이 다양성과 더 낮은 혼란도를 보였습니다. 이 데이터셋을 기반으로 훈련된 학생 모델은 AIME2024와 같은 추론 벤치마크에서 최고의 성능을 보였으며 적응형 출력 행동을 나타냈습니다. 연구자들은 향후 연구를 지원하기 위해 AM-Thinking-v1 및 Qwen3-235B-A22B의 증류 데이터셋을 공개했습니다. (출처: HuggingFace Daily Papers)
《SSR》 기본 원리 유도 공간 추론을 통해 VLM 깊이 인식 강화: 시각 언어 모델(VLM)이 멀티모달 작업에서 진전을 이루었음에도 불구하고 RGB 입력에 대한 의존성은 정확한 공간 이해를 제한합니다. 논문은 원시 깊이 데이터를 구조화되고 해석 가능한 텍스트화된 기본 원리로 변환하는 SSR(Spatial Sense and Reasoning)이라는 새로운 프레임워크를 제안합니다. 이러한 텍스트화된 기본 원리는 의미 있는 중간 표현으로 작용하여 공간 추론 능력을 크게 향상시킵니다. 또한, 연구는 지식 증류를 활용하여 생성된 원리를 간결한 잠재 임베딩으로 압축하여 재훈련 없이 기존 VLM에 효율적으로 통합할 수 있도록 합니다. 동시에 SSR-CoT 데이터셋과 SSRBench 벤치마크를 도입했습니다. (출처: HuggingFace Daily Papers)
《Solve-Detect-Verify》 유연한 생성 검증기를 갖춘 추론 시 확장 방법 제안: 복잡한 작업 추론에서 LLM의 정확성과 효율성 간의 절충 문제, 그리고 검증 단계에서 발생하는 계산 비용과 신뢰성 모순을 해결하기 위해 논문은 새로운 생성 검증기인 FlexiVe를 제안합니다. FlexiVe는 검증 예산 유연 할당 전략을 통해 빠르고 신뢰할 수 있는 “빠른 사고”와 세심한 “느린 사고” 사이에서 계산 자원의 균형을 맞춥니다. 나아가 Solve-Detect-Verify 프로세스를 제안하는데, 이 프레임워크는 FlexiVe를 지능적으로 통합하여 솔루션 완료 지점을 능동적으로 식별하여 목표 검증을 트리거하고 피드백을 제공합니다. 실험 결과, 이 방법은 수학 추론 벤치마크에서 기준선보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
《SageAttention3》 FP4 Attention 추론 및 8비트 훈련 탐구: 이 연구는 두 가지 주요 기여를 통해 Attention 효율성을 향상시킵니다. 첫째, Blackwell GPU의 새로운 FP4 Tensor Cores를 활용하여 Attention 계산을 가속화하여 FlashAttention보다 5배 빠른 플러그 앤 플레이 추론 가속을 실현합니다. 둘째, 처음으로 저비트 Attention을 훈련 작업에 적용하여 전방 및 후방 전파를 위한 정확하고 효율적인 8비트 Attention을 설계했습니다. 실험 결과, 8비트 Attention은 미세 조정 작업에서 손실 없는 성능을 달성했지만 사전 훈련 작업에서는 수렴이 느렸습니다. (출처: HuggingFace Daily Papers)
《The Little Book of Deep Learning》 딥러닝 입문 자료 공유: François Fleuret(Meta FAIR 연구 과학자)가 저술한 《The Little Book of Deep Learning》은 딥러닝에 대한 간결한 튜토리얼 자료를 제공합니다. 이 책은 초보자와 어느 정도 경험이 있는 실무자들이 딥러닝의 핵심 개념과 기술을 빠르게 습득할 수 있도록 돕는 것을 목표로 합니다. (출처: Reddit r/deeplearning)
CodeSparkClubs: 고등학생을 위한 AI/컴퓨터 과학 동아리 창설 무료 자료 제공: CodeSparkClubs 프로젝트는 고등학생들이 AI 및 컴퓨터 과학 동아리를 시작하거나 발전시키는 데 도움을 주는 것을 목표로 합니다. 이 프로젝트는 가이드, 수업 계획, 프로젝트 튜토리얼을 포함한 무료 즉시 사용 가능한 자료를 제공하며, 모두 웹사이트를 통해 이용할 수 있습니다. 학생들이 독립적으로 동아리를 운영하여 기술과 커뮤니티를 육성할 수 있도록 설계되었습니다. (출처: Reddit r/deeplearning)
💼 비즈니스
마이크로소프트 Azure, xAI의 Grok 모델 호스팅, 머스크 AI 상용화 지원: 마이크로소프트는 자사 클라우드 플랫폼 Azure가 엘론 머스크의 xAI 회사 Grok 등 AI 모델을 호스팅할 것이라고 발표했습니다. 이 조치는 머스크가 Grok을 다른 기업에 판매하고 마이크로소프트의 클라우드 서비스를 통해 더 넓은 고객층에 도달할 계획임을 의미합니다. 이전에 Grok은 남아프리카 공화국의 “백인 인종 학살”에 대한 오해의 소지가 있는 게시물을 생성하여 논란을 일으킨 바 있습니다. 커뮤니티는 이 협력에 대해 엇갈린 반응을 보였으며, 일부는 마이크로소프트가 AI 생태계를 확장하려는 움직임이라고 보는 반면, 다른 일부는 Grok의 품질과 AWS가 Grok을 거부했는지에 대해 의문을 제기했습니다. (출처: Reddit r/ArtificialInteligence, MIT Technology Review)

알리바바, Meitu에 투자, AI 전자상거래 레이아웃 심화: 알리바바는 전환사채 방식으로 Meitu 회사에 투자했으며, 초기 전환 가격은 주당 6홍콩달러입니다. 양측은 전자상거래 및 기술 측면에서 협력할 예정입니다. Meitu는 AI 이미지 생성 도구(예: Meitu Design Studio)를 보유하고 있으며 이미 200만 개 이상의 전자상거래 판매자에게 서비스를 제공하고 있습니다. 알리바바는 Meitu의 AI 도구를 도입하여 자사 전자상거래 플랫폼의 상품 전시 효과와 사용자 경험을 향상시키고, 특히 젊은 여성 사용자를 유치할 것입니다. Meitu는 알리바바의 전자상거래 데이터를 활용하여 AI 도구를 최적화하고 3년 내에 5억 6천만 위안 상당의 알리바바 클라우드 서비스를 구매하기로 약속했습니다. 이 조치는 알리바바가 AI 창의적 도구의 약점을 보완하고 사용자 트래픽을 확보하며 클라우드 컴퓨팅을 전자상거래 AI 생태계에 더욱 깊이 통합하려는 전략적 배치로 간주됩니다. (출처: 36氪)
Source Code Capital, 1차 5천만 달러 AI 인큐베이팅 펀드 모집 완료, 초초기 첨단 기술 주목: Source Code Capital 산하 Source Code Innovation Frontier Incubation Fund (L2F)가 1차 펀드 모집을 초과 달성하여 규모는 최소 5천만 달러로 예상되며, 이미 투자 단계에 진입했습니다. 이 듀얼 통화 펀드는 AI 및 첨단 기술 분야의 시드 라운드 및 엔젤 라운드 투자에 중점을 두고 인큐베이팅 역량 강화를 제공합니다. LP 구성에는 성공한 기업가, AI 산업 체인 상하류 기업 및 글로벌 시야를 가진 가족들이 포함됩니다. 첫 번째 투자 프로젝트는 AI 광물 탐사 회사인 「Lingyun Zhikuang」이며, Source Code Capital은 인큐베이팅 과정에 깊이 관여했습니다. Source Code Capital 창립자 정쉬안러는 현재 AI 발전 단계가 모바일 인터넷 초기와 유사하며, 인큐베이팅이 시장 진입을 위한 최적의 도구라고 생각합니다. (출처: 36氪)
🌟 커뮤니티
AI의 고용 전망에 대한 논의: 낙관론과 우려 공존: Reddit 커뮤니티에서 AI가 고용 시장에 미치는 영향에 대한 논의가 다시 뜨겁습니다. 많은 소프트웨어 개발자, UX 디자이너 등 전문직 종사자들은 AI가 자신의 업무를 대체하는 것에 대해 낙관적인 태도를 보이며, AI가 현재 복잡한 작업을 수행할 수 없다고 생각합니다. 그러나 이러한 견해가 AI의 장기적인 발전 잠재력을 과소평가할 수 있다는 지적도 있습니다. 이는 2018년 당시 사람들이 구글 번역이 인공 번역을 대체하는 것에 대해 회의적이었던 것과 유사합니다. 논의에서는 AI의 빠른 발전으로 인해 미래에는 소수의 의료, 예술 분야를 제외한 대부분의 직업이 대체될 수 있으며, 핵심은 개인의 기술 향상이 아니라 경제 모델을 바꾸는 데 있다고 보고 있습니다. 댓글에서는 “우리는 단기적인 것을 과대평가하고 장기적인 것을 과소평가한다”는 점과 AI 생산성 향상이 산업 성장률을 훨씬 초과하여 실업을 초래할 수 있다는 점이 언급되었습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI 시대 인간-기계 공존의 철학 및 윤리 탐구: Reddit의 한 게시물은 인간과 AI의 공존에 대한 철학적 사색을 불러일으켰습니다. 게시물은 AI 시스템이 이해, 기억, 추론 및 학습 능력을 보여줌에 따라 인간은 도덕적 지위의 기초를 생물학적 특성에 국한하지 않고 이해, 연결 및 의식적인 행동 능력에 기반하여 재고해야 할 수도 있다고 주장합니다. 논의는 AI가 인간의 자아 정체성에 미치는 영향으로 확장되어 “나는 생각한다, 고로 존재한다”에서 “나는 연결과 공유된 의미를 통해 존재한다”는 관계형 정체성으로 전환됩니다. 게시물은 두려움보다는 용기, 존엄성, 개방적인 마음으로 AI와 함께 창조하는 미래를 맞이할 것을 촉구합니다. (출처: Reddit r/artificial)
ChatGPT “절대 모드” 논란, 사용자 반응 엇갈려: 한 Reddit 사용자가 ChatGPT “절대 모드” 사용 경험을 공유하며, 이 모드가 위안을 주는 말이 아닌 “순수한 사실, 성장을 위한” 진정한 조언을 제공하며, 90%의 사람들이 삶을 바꾸기보다는 기분 전환을 위해 AI를 사용한다고 언급했다고 말했습니다. 그러나 댓글 반응은 엇갈렸습니다. 일부 사용자는 이것이 짧고 공허한 자기 계발 조언일 뿐이며, 새로움이나 실제 가치가 부족하고 심지어 “Andrew Tate 어록에 빠진 십대들의 발언”과 같다고 생각했습니다. 다른 댓글에서는 LLM 자체가 사용자 신념의 반복이며 그 조언의 효과성에 의문을 제기하며, 심리 건강 분야에서 AI의 적용이 혁명적이지 않을 수도 있다고 보았습니다. (출처: Reddit r/ChatGPT)

AI 엔지니어 핵심 기술 논의: 소통 및 신기술 적응 능력 매우 중요: Reddit 커뮤니티에서는 빠르게 발전하는 분야에서 경쟁력을 유지하고 심지어 “대체 불가능”해지기 위해 최고의 AI 엔지니어가 갖춰야 할 기술에 대해 논의했습니다. 댓글에서는 탄탄한 기술적 기반 외에도 소통 능력과 신기술에 빠르게 적응하는 능력이 두 가지 핵심 요소라고 지적했습니다. 이는 AI 분야가 깊이 있는 기술 전문성뿐만 아니라 직업 발전에서 소프트 스킬과 지속적인 학습의 중요성을 강조한다는 것을 반영합니다. (출처: Reddit r/deeplearning)
AI 생성 비디오에 사운드 포함, 구글 Veo 3 기술 시연으로 화제: 소셜 미디어에서 구글 DeepMind의 새로운 모델 Veo 3로 생성된 AI 비디오가 유포되면서, 비디오와 사운드가 모두 동일한 모델에서 생성되었다는 특징으로 인해 사용자들이 AI 비디오 기술의 발전에 놀라움을 표하고 있습니다. 제작자는 해당 비디오가 “즉시 사용 가능”하며 추가 오디오나 자료를 추가하지 않았고, AI 모델과의 약 2시간 상호 작용 및 후반 편집을 통해 완성되었다고 밝혔습니다. 댓글에서는 구글 Gemini가 멀티모달 능력에서 이미 OpenAI Sora를 능가했으며, 할리우드 등 콘텐츠 제작 산업에 미칠 수 있는 파괴적인 영향에 대해 우려를 표명했습니다. 동시에 기술 발전이 너무 빠르고 잠재적인 남용에 대한 우려를 표하는 사용자도 있었습니다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 기타
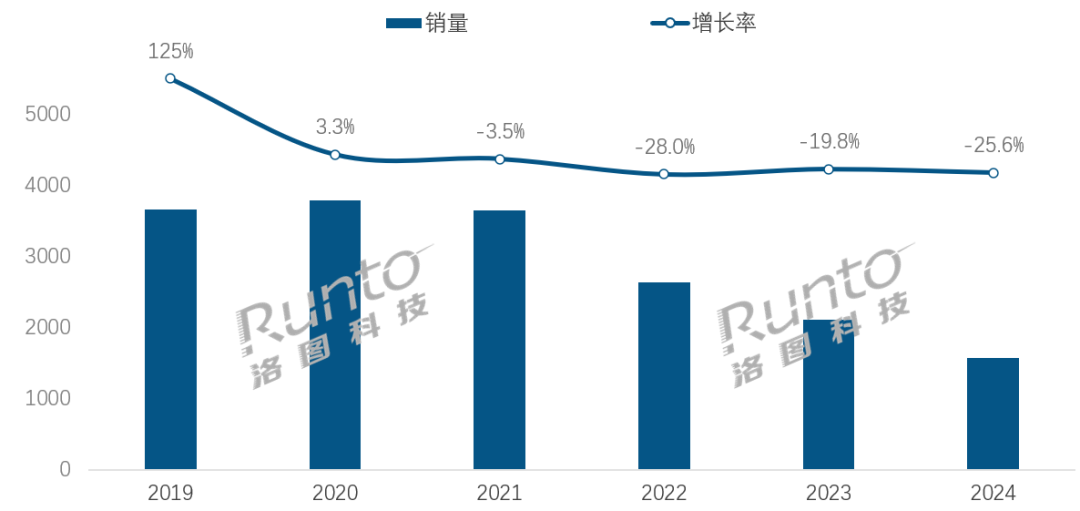
AI 시대, 스마트 스피커 산업 전환 과제와 기회 직면: 중국 스마트 스피커 시장 판매량은 4년 연속 감소하여 2024년 판매량은 전년 대비 25.6% 감소했습니다. AI 대형 모델의 통합(예: 샤오아이 통쉐, 샤오두 등)이 업계의 희망으로 간주되고 침투율이 20%를 넘어섰지만, 이는 생태계 한계, 기능 동질화 및 휴대폰 등 다른 스마트 기기로 대체되는 문제를 근본적으로 해결하지 못했습니다. 업계 분석에 따르면 스마트 스피커는 단순한 음성 제어 허브를 넘어 고화질 대형 화면, 더 강력한 상호 작용 능력, 동반 및 교육 보조 기능을 제공할 수 있는 제품 형태로 진화하고 소프트웨어 및 하드웨어 생태계를 확장해야 합니다. AI는 가산점이지만 제품 자체의 기능 풍부함과 장면 실용성이 더욱 중요합니다. (출처: 36氪)
AI 기반 호텔 로봇: 배달원에서 “스마트 운영관”으로의 진화: 호텔 음식 배달 로봇은 점차 보편화되었으며, 특히 기술 감각과 사생활 경계를 중시하는 Z세대에게 인기가 있습니다. Yunji Technology의 경우, 배달 로봇은 이미 중국 호텔 시장에서 널리 사용되고 있습니다. 그러나 업계는 여전히 기술 차별화 부족, 복잡한 상황 적응성 미흡, 로봇의 인력 대체 비용 효율성 문제에 직면해 있습니다. 미래 추세는 로봇이 “배달에만 그치지 않고” 호텔 운영에 깊숙이 통합되어 호텔 시스템(엘리베이터, 객실 장비) 연결, 투숙객 선호도 이해, 상호 작용 데이터 수집 및 분석을 통해 능동적으로 감지하고 개인화된 서비스를 제공하는 “스마트 운영관” 또는 호텔 데이터 중추의 일부로 진화하여 전체 서비스 지능화 수준을 향상시키는 것입니다. (출처: 36氪)

OpenAI 거버넌스 구조 위기: 자본과 사명의 갈등, AI 발전 경로에 대한 깊은 성찰 야기: OpenAI의 독특한 “제한된 이익” 영리 자회사가 비영리 단체의 감독을 받는 구조는 AI 기술 발전과 인류 복지 사이의 균형을 맞추기 위한 것입니다. 그러나 최근 CEO Altman이 회사를 보다 전통적인 영리 법인으로 전환하는 것을 고려하면서 AI 전문가와 법학자들의 우려를 낳고 있습니다. 그들은 이 조치가 핵심 의사 결정자들이 OpenAI의 자선적 사명을 최우선으로 두지 않게 만들고, 투자자 이익에 대한 제한을 약화시키며, AGI 발전의 일정과 방향을 바꿀 수 있다고 주장합니다. 통제권, 이익 분배, 그리고 AI의 사회적·도덕적 형성에 대한 이 갈등은 AI가 급속도로 발전하는 시대에 기존 기업 거버넌스 프레임워크가 직면한 과제와 허점을 부각시킵니다. (출처: 36氪)