
키워드:AI 프로그래밍 에이전트, 코덱스, 알파이볼브, AI 추론 패러다임, MoE 모델, AI 칩, AI 교육, AI 드라마, 오픈AI 코덱스-1 모델, 구글 딥마인드 알파이볼브, 바이트댄스 시드1.5-VL, Q웬 파스케일 기술, 엔비디아 GB300 시스템
🔥 포커스
OpenAI, 새로운 모델 codex-1 기반 클라우드 AI 프로그래밍 에이전트 Codex 공개: OpenAI가 소프트웨어 엔지니어링에 최적화된 o3 특별 조정 버전 codex-1을 기반으로 하는 클라우드 AI 프로그래밍 에이전트 Codex를 출시했습니다. Codex는 클라우드 샌드박스에서 여러 작업을 안전하게 병렬 처리할 수 있으며, GitHub와 통합되어 코드 라이브러리를 직접 호출하여 모듈을 빠르게 구축하고, 코드 라이브러리 문제를 해결하며, 취약점을 수정하고, PR을 제출하며, 자동으로 테스트 및 검증할 수 있습니다. 과거 며칠 또는 몇 시간이 걸리던 작업을 Codex는 30분 이내에 완료할 수 있습니다. 이 도구는 ChatGPT Pro, Enterprise 및 Team 사용자에게 공개되었으며, 개발자의 “10배 엔지니어”가 되어 소프트웨어 개발 프로세스를 재편하는 것을 목표로 합니다. (출처: 36Kr)
구글 DeepMind, AI 자율 진화로 수학 및 알고리즘 혁신을 이룬 AlphaEvolve 출시: 구글 DeepMind의 AI 시스템 AlphaEvolve는 자가 진화와 대규모 언어 모델 훈련을 통해 여러 수학 및 과학 분야에서 혁신을 이루었습니다. 4×4 행렬 곱셈 알고리즘(56년 만의 최초 개선), 육각형 채우기 문제 최적화(16년 만의 최초), 그리고 “접吻数 문제(kissing number problem)”를 발전시켰습니다. AlphaEvolve는 알고리즘을 자율적으로 최적화할 수 있으며, Gemini 모델 훈련을 가속하는 방법을 찾아냈고, 이미 구글 내부 컴퓨팅 인프라 최적화에 적용되어 0.7%의 컴퓨팅 자원을 절약했습니다. 이는 AI가 문제 해결뿐만 아니라 새로운 지식을 발견할 수 있음을 의미하며, 과학 연구 패러다임을 뒤엎고 AI가 과학을 창조할 수 있을 것으로 기대됩니다. (출처: 36Kr)
알트먼, 세콰이어 AI 서밋 강연: AI, 3년 내 현실 세계 진입하여 삶과 일 재편할 것: OpenAI CEO 샘 알트먼은 세콰이어 AI 서밋에서 2025년 AI 에이전트가 실용화되고(특히 코딩 분야), 2026년 AI가 중대한 과학적 발견을 이끌며, 2027년 로봇이 물리적 세계에 진입하여 가치를 창출할 것이라고 예측했습니다. 그는 OpenAI의 초기 탐색부터 ChatGPT 탄생까지의 과정을 회고하며, 미래 AI 제품은 개인의 모든 삶의 경험을 담을 수 있는 “핵심 AI 구독” 서비스가 되어 지능형 기본 인터페이스가 될 것이라고 제안했습니다. OpenAI는 핵심 모델과 응용 시나리오에 집중하고 “소규모 팀, 큰 책임”의 조직 효율성을 유지할 것입니다. (출처: 36Kr)
엔비디아 Computex 강연: 개인용 AI 컴퓨터 생산 돌입, 차세대 GB300 시스템 출시, 대만 AI 슈퍼컴퓨터 구축 계획: 엔비디아 CEO 젠슨 황은 Computex 2025에서 개인용 AI 컴퓨터 DGX Spark가 전면 생산에 돌입하여 몇 주 내에 출시될 것이라고 발표했습니다. 차세대 AI 시스템 GB300(Blackwell Ultra GPU 72개와 Grace CPU 36개 탑재)은 Q3에 출시될 예정입니다. 엔비디아는 TSMC, Foxconn과 협력하여 대만에 AI 슈퍼컴퓨팅 센터를 구축할 것입니다. 동시에 Blackwell RTX Pro 6000 워크스테이션 시리즈와 Grace Blackwell Ultra Superchip을 발표했으며, 7월에는 로봇 훈련용 Newton 물리 엔진을 오픈소스로 공개할 계획입니다. 젠슨 황은 AI가 어디에나 존재하게 될 것이며 그 혁명적인 영향을 거듭 강조했습니다. (출처: 36Kr)

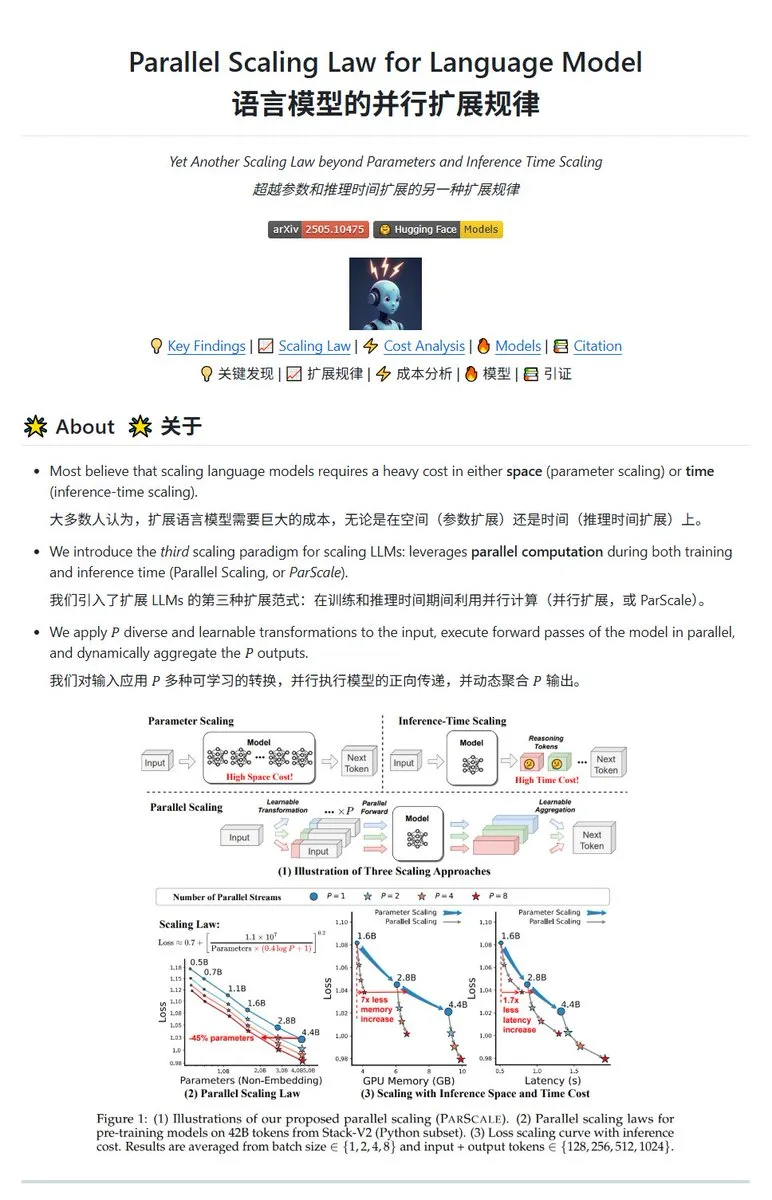
Qwen, ParScale 병렬 확장 기술 발표, 소형 모델로 대형 모델 효과 달성 가능: Qwen 팀이 병렬 추론을 통해 모델 능력을 향상시키는 ParScale 기술을 출시했습니다. 이 방법은 n개의 병렬 스트림을 사용하여 추론하며, 각 스트림은 학습 가능한 차별화된 변환을 사용하여 입력을 처리하고, 마지막으로 동적 집계 메커니즘을 통해 결과를 병합합니다. 연구에 따르면 P개의 병렬 스트림 효과는 모델 매개변수 양을 O(log P)배 증가시키는 것과 유사하며, 예를 들어 30B 모델은 8개의 병렬 스트림을 통해 42.5B 모델의 효과를 얻을 수 있습니다. 이 기술은 메모리 점유율을 크게 늘리지 않고 모델 성능을 향상시키거나, 병렬도를 높여 기존 모델 규모를 줄일 수 있을 것으로 기대되지만, 계산 요구 사항 증가와 추론 속도 저하를 대가로 할 수 있습니다. (출처: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 동향
Poe 보고서: OpenAI와 구글이 AI 경쟁 선두, Anthropic은 약세: Poe의 최신 사용 보고서(2025년 1~5월)에 따르면 AI 시장 구도가 급변하고 있습니다. 텍스트 생성 분야에서는 GPT-4o(35.8%)가 선두를 달리고 있으며, Gemini 2.5 Pro는 추론 능력에서(31.5%) 정점을 찍었습니다. 이미지 생성은 Imagen3, GPT-Image-1, Flux 시리즈가 주도하고 있습니다. 비디오 생성 분야에서는 Kling-2.0-Master가 두각을 나타내며 Runway의 점유율이 크게 하락했습니다. 에이전트 측면에서는 o3가 최고의 성능을 보였습니다. 보고서는 추론 능력이 핵심 경쟁 분야가 되었으며, Anthropic의 Claude 시장 점유율이 하락했고 DeepSeek R1 사용자 점유율도 최고점에서 하락했다고 지적했습니다. 기업은 복잡한 작업에서 모델의 정확성과 신뢰성에 주목하고 AI 모델을 유연하게 선택해야 합니다. (출처: 36Kr)

Meta 플래그십 AI 모델 Behemoth(Llama 4) 출시 지연, AI 전략 조정 가능성: 보도에 따르면 Meta가 원래 4월에 출시할 예정이었던 2조 매개변수 대형 모델 Behemoth(Llama 4)가 성능 미달로 인해 가을 또는 그 이후로 연기되었습니다. 이 모델은 30T 멀티모달 토큰을 사용하여 32K GPU에서 사전 훈련되었으며, OpenAI, 구글 등과 경쟁하는 것을 목표로 합니다. 개발 난항은 Llama 4 팀의 성과에 대한 내부 실망감을 불러일으켰고 AI 제품 팀 조정으로 이어질 수 있습니다. 동시에 Llama 1 초기 팀 14명 중 11명이 이미 퇴사했습니다. Meta 임원은 “팀의 80%가 사임했다”는 소문을 부인하며, 퇴사자는 주로 Llama 1 논문 팀 출신이라고 강조했습니다. 이 사건은 Meta가 AI 경쟁에서 병목 현상에 빠진 것이 아니냐는 외부의 우려를 가중시켰습니다. (출처: 36Kr)

ByteDance와 구글 DeepMind, 효율성 및 생산 시스템 적용에 초점 맞춘 새로운 MoE 모델 연구 발표: ByteDance 논문 《MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production》은 대규모 MoE 모델의 효율적인 훈련을 위해 특별히 설계된 생산 시스템을 소개합니다. 이 시스템은 연산자 수준에서 통신과 계산을 중첩시켜 Megatron-LM보다 1.88배 높은 효율성을 달성했으며, 이미 데이터 센터에서 제품 모델(예: Internal-352B, 32개 전문가, top-3) 훈련에 배포되었습니다. 구글 DeepMind는 AI 자가 진화와 LLM 훈련을 통해 수학 및 알고리즘 분야에서 혁신을 이룬 AlphaEvolve를 발표했습니다. 예를 들어 4×4 행렬 곱셈과 육각형 채우기 문제를 개선하여 AI의 과학적 발견 잠재력을 보여주었습니다. (출처: teortaxesTex, 36Kr)

OpenAI, AI 추론 패러다임 논의하며 성능 향상의 핵심 역할 강조: OpenAI 연구원 Noam Brown은 AI 발전이 방대한 데이터로 다음 단어를 예측하는 사전 훈련 패러다임에서 추론 패러다임으로 진입했다고 지적했습니다. 사전 훈련 비용은 엄청나지만, 추론 패러다임은 모델의 “사고” 시간(추론 계산량)을 늘려 답변의 질을 향상시키며, 훈련 비용이 동일하더라도 마찬가지입니다. 예를 들어, o 시리즈 모델은 수학 경시대회(AIME)와 박사급 과학 문제(GPQA)에서 더 긴 추론 시간을 통해 GPT-4o를 훨씬 뛰어넘는 정확도를 얻었습니다. OpenAI 수석 경제학자 Ronnie Chatterji는 AI가 기업 환경을 어떻게 재편하는지에 대해 논의하며, 핵심은 기업이 AI를 통합하여 인간의 역할을 강화하거나 대체하는 방법과 AI 기술이 가치 사슬에 어떻게 내장되는지에 있다고 말했습니다. (출처: 36Kr)

구글 CEO 피차이, “구글은 죽었다”는 주장에 AI 기반 검색 진화와 인프라 우위 강조하며 반박: 구글 CEO 순다르 피차이는 인터뷰에서 “구글 검색이 AI로 대체될 것”이라는 우려에 대해, 구글이 “AI 개요” 및 “AI 모드”와 같은 기능을 통해 검색을 반응형 쿼리에서 예측적이고 개인화된 지능형 비서로 전환하고 있다고 밝혔습니다. 그는 구글의 AI 인프라(자체 개발 TPU, 대규모 데이터 센터)와 모델 효율성에 대한 장기적인 투자가 핵심 우위이며, 높은 가성비로 첨단 모델을 제공할 수 있다고 강조했습니다. 피차이는 AI가 “모든 시나리오의 기술 플랫폼”이며 검색, YouTube, Cloud 등 핵심 사업을 재편하고 새로운 형태를 창출할 것이라고 믿습니다. 그는 또한 중국 AI(예: DeepSeek)의 경쟁력을 무시할 수 없으며 전력이 AI 발전의 핵심 병목 현상이 될 것이라고 지적했습니다. (출처: 36Kr)

AI 교육 분야 스타트업 현황: 이 기사는 2025년에 주목할 만한 AI 교육 스타트업 13곳을 소개합니다. 이들은 개인화된 학습 경로, 지능형辅导 시스템, 자동 채점, 몰입형 콘텐츠 제작 등을 통해 교육 방식을 바꾸고 있습니다. 예를 들어, Merlyn은 음성 인식 AI 비서로 교사의 행정 부담을 덜어주고, Brisk Teaching은 Chrome 확장 프로그램으로 교육 작업을 간소화하며, Edexia는 AI 채점 플랫폼으로 교사의 스타일을 학습합니다. Storytailor는 독서 치료와 AI를 결합하여 개인화된 이야기를 만들고, Brainly는 AI 강화 숙제辅导를 제공합니다. 이들 회사는 효율성 향상부터 개인화 학습 및 교육 형평성 실현에 이르기까지 교육 분야에서 AI의 광범위한 적용 가능성을 보여줍니다. (출처: 36Kr)
AI 단편 드라마, 기술 및 상업화 문제 직면, 제작 효과와 기대치 간 격차 존재: AI 도구가 단편 드라마 제작 비용을 절감하고 제작 기간을 단축할 것으로 기대되지만, 업계 종사자들은 AI 단편 드라마가 주체 일관성, 입 모양 동기화, 카메라 언어의 자연스러움 등에서 현저한 기술적 어려움에 직면하여 많은 작품이 “PPT식 단편 드라마”처럼 보인다고 지적합니다. AI는 초현실적인 아이디어를 이해하기 어려워 판타지, SF 장르의 발휘를 제한합니다. 현재 AI 기술은 완전한 단편 드라마보다는 단편 영화 제작에 더 적합하며 상업화 전망은 불투명합니다. 보나 필름, 화책 그룹과 같은 대형 영화 제작사는 자원 우위를 바탕으로 돌파구를 마련할 가능성이 더 높지만, 대부분의 소규모 제작자는 높은 시행착오 비용, 빠른 기술 반복으로 인한 작품의 빠른 노후화 등의 문제에 직면해 있습니다. (출처: 36Kr)
MSI, NVIDIA GB10 슈퍼칩 탑재 AI PC 출시, 6144 CUDA 코어 및 128GB LPDDR5X 메모리 포함: MSI는 NVIDIA GB10 슈퍼칩을 탑재한 AI PC인 EdgeExpert MS-C931 S를 선보였습니다. 이 칩은 6144개의 CUDA 코어와 128GB LPDDR5X 메모리를 갖춘 것으로 확인되었습니다. 이는 ASUS, Dell, Lenovo에 이어 NVIDIA DGX Spark 아키텍처 기반의 개인용 AI 컴퓨터를 출시한 또 다른 제조업체입니다. 이러한 제품의 출시는 고성능 AI 컴퓨팅 능력이 개인 및 엣지 장치로 점차 확산되고 있음을 의미하지만, 가격 책정으로 인해 Mac Mini와 같은 제품과 경쟁하기 어려울 수 있다는 의견도 있습니다. (출처: Reddit r/LocalLLaMA)
Qwen3-30B, VLLM에서 높은 처리량 달성, 데이터셋 관리에 적합: Qwen3-30B-A3B 모델은 VLLM 프레임워크와 RTX 3090s 그래픽 카드에서 뛰어난 추론 속도(5K t/s 사전 채우기, 1K t/s 생성)를 보여 데이터셋 필터링 및 관리와 같은 작업에 매우 적합합니다. QwQ에 비해 약간의 회귀가 있을 수 있지만, 속도 우위로 인해 데이터 처리 측면에서 더 실용적입니다. 현재 주요 문제는 훈련 속도가 매우 느리다는 것이지만, Hugging Face Transformers 라이브러리에는 이 문제를 해결하려는 PR이 있으며, 향후 Qwen3-30B를 기반으로 개선된 데이터셋의 RpR 모델이 출시될 것으로 기대됩니다. (출처: Reddit r/LocalLLaMA)
Bilibili, 다양한 2차원 스타일 지원하는 애니메이션 비디오 생성 모델 Index-AniSora 오픈소스 공개: Bilibili는 AniSora 기술 프레임워크(IJCAI25에 채택됨)를 기반으로 하는 2차원 비디오 생성 전용 오픈소스 모델 Index-AniSora를 출시했습니다. 이 모델은 만화를 한 번의 클릭으로 애니메이션으로 생성할 수 있으며, 일본 애니메이션, 중국 창작 애니메이션, 만화 각색, VTuber 등 다양한 스타일을 지원합니다. AniSora 시스템은 천만 개 수준의 고품질 텍스트-비디오 쌍 데이터셋을 구축하고, 통합 확산 생성 프레임워크를 개발하며 시공간 마스크 메커니즘을 도입하여 캐릭터 입 모양, 동작을 정교하게 제어합니다. 동시에 Bilibili는 애니메이션 비디오용 평가 기준과 VLM 최적화 기반 자동 평가 시스템을 설계했습니다. 오픈소스 콘텐츠에는 AniSoraV1.0(CogVideoX-5B 기반), AniSoraV2.0(Wan2.1-14B 기반, 화웨이 910B 훈련 지원) 및 관련 데이터셋 구축 및 평가 도구가 포함될 예정입니다. (출처: WeChat)

ByteDance, 시각 언어 모델 Seed1.5-VL 발표, 멀티모달 작업에서 우수한 성능: ByteDance는 532M 매개변수 시각 인코더와 20B 활성 매개변수의 전문가 혼합(MoE) LLM으로 구성된 시각 언어 모델 Seed1.5-VL을 출시했습니다. 이 모델은 60개의 공개 벤치마크 중 38개에서 SOTA 성능을 달성했으며, GUI 제어 및 게임 플레이와 같은 에이전트 중심 작업에서 OpenAI CUA 및 Claude 3.7과 같은 주요 시스템을 능가하여 강력한 멀티모달 이해 및 추론 능력을 보여주었습니다. (출처: WeChat)
Nous Research, 40B 매개변수 LLM 분산 사전 훈련 실현하는 Psyche Network 출시: Nous Research는 DeepSeek V3 MLA 아키텍처 기반의 분산형 훈련 네트워크인 Psyche Network를 발표했습니다. 첫 번째 테스트에서 400억 매개변수 대규모 언어 모델에 대한 사전 훈련을 수행했습니다. 이 네트워크는 DisTrO 최적화 프로그램과 맞춤형 P2P 네트워크 스택을 활용하여 전 세계 분산 GPU 컴퓨팅 성능을 통합하고, 개인과 소규모 그룹이 단일 H/DGX에서 훈련하고 3090 GPU에서 실행할 수 있도록 합니다. 이는 기술 대기업의 컴퓨팅 성능 독점을 깨고 대규모 모델 훈련에 더 쉽게 접근할 수 있도록 하는 것을 목표로 합니다. (출처: 量子位)

🧰 툴
Sim Studio: 오픈소스 AI 에이전트 워크플로우 빌더: Sim Studio는 직관적인 인터페이스를 제공하는 오픈소스 경량 AI 에이전트 워크플로우 구축 플랫폼으로, 사용자는 다양한 도구를 연결하는 LLM 애플리케이션을 빠르게 구축하고 배포할 수 있습니다. 클라우드 호스팅 버전과 자체 호스팅(Docker 환경 권장, Ollama와 같은 로컬 모델 지원)을 지원합니다. 기술 스택에는 Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow, Turborepo가 포함됩니다. (출처: GitHub Trending)

Cherry Studio: 포괄적인 기능을 갖춘 오픈소스 LLM 프론트엔드 데스크톱 애플리케이션 주목: Cherry Studio는 RAG, 웹 검색, 로컬 모델(Ollama, LM Studio를 통해 연결) 및 클라우드 모델(예: Gemini, ChatGPT) 액세스 등 다양한 기능을 통합한 오픈소스 LLM 프론트엔드 데스크톱 애플리케이션입니다. 사용자 피드백에 따르면 MCP(다중 제어 프로토콜) 지원 및 관리가 Open WebUI 및 LibreChat보다 우수하며 설치 및 설정이 쉽습니다. 이 애플리케이션은 Obsidian 지식 베이스에 직접 연결하는 것도 지원합니다. 일부 사용자는 출처에 대해 우려를 표명하지만, 포괄적인 기능 세트로 인해 매력적인 선택이 되고 있습니다. (출처: Reddit r/LocalLLaMA)

MLX-LM-LoRA: MLX 모델에 LoRA 추가 및 다양한 훈련 방법 지원: 오픈소스 프로젝트 mlx-lm-lora를 사용하면 Apple MLX 프레임워크의 모델에 LoRA(Low-Rank Adaptation) 모듈을 통합할 수 있습니다. 이 프로젝트는 LoRA 추가를 지원할 뿐만 아니라 ORPO, DPO, CPO, GRPO 등 다양한 정렬 훈련 방법을 내장하고 있어 사용자가 자신의 필요에 따라 모델을 미세 조정하고 맞춤형 LoRA 모듈을 생성하여 선호하는 MLX 모델에 적용할 수 있도록 합니다. (출처: karminski3)
DeepDrone: Qwen 기반 AI 제어 드론 프로젝트 오픈소스 공개: 한 개발자가 Qwen 대형 모델을 기반으로 DeepDrone이라는 AI 제어 드론 프로젝트를 만들고 HuggingFace와 GitHub에 오픈소스로 공개했습니다. 이 프로젝트는 대형 언어 모델을 드론 자율 제어에 적용할 수 있는 잠재력을 보여주며, AI의 자동화 및 잠재적인 군사적 응용에 대한 논의를 불러일으켰습니다. (출처: karminski3)
Qwen Web Dev: 한 번의 프롬프트로 웹사이트 생성 및 배포: Alibaba Qwen 팀은 Qwen Web Dev 도구가 향상되어 사용자가 프롬프트 하나만으로 웹사이트를 생성하고 한 번의 클릭으로 배포할 수 있다고 발표했습니다. 이 도구는 웹 개발의 장벽을 낮추고 사용자가 아이디어를 실제 액세스 가능한 웹사이트로 더 편리하게 전환하여 전 세계와 공유할 수 있도록 하는 것을 목표로 합니다. (출처: Alibaba_Qwen, huybery)
SuperGo.AI: 8가지 LLM 모델을 통합한 단일 인터페이스 도구: AI 애호가가 SuperGo.AI라는 도구를 개발했습니다. 이 도구는 하나의 인터페이스에 8가지 서로 다른 역할의 LLM(예: AI 슈퍼 브레인, AI 상상력, AI 윤리, AI 우주 등)을 통합합니다. 이러한 AI 역할은 서로를 인식하고 상호 작용할 수 있으며, 사용자는 “창의적”, “과학적”, “혼합” 모드를 선택하여 혼합된 응답을 얻을 수 있습니다. 이 도구는 새로운 다중 AI 협업 경험을 제공하는 것을 목표로 하며 현재 유료 장벽은 없습니다. (출처: Reddit r/artificial)
Kokoro-JS: 무제한 로컬 텍스트 음성 변환(TTS) 구현: Kokoro-JS는 100% 로컬에서 실행되고 100% 오픈소스인 텍스트 음성 변환 도구로, 브라우저 측에서 약 300MB의 AI 모델을 다운로드하여 구현됩니다. 사용자가 입력한 텍스트는 어떤 서버로도 전송되지 않아 개인 정보 보호 및 오프라인 사용성을 보장합니다. 이 도구는 무제한 TTS 기능을 제공하는 것을 목표로 합니다. (출처: Reddit r/LocalLLaMA)
📚 학습
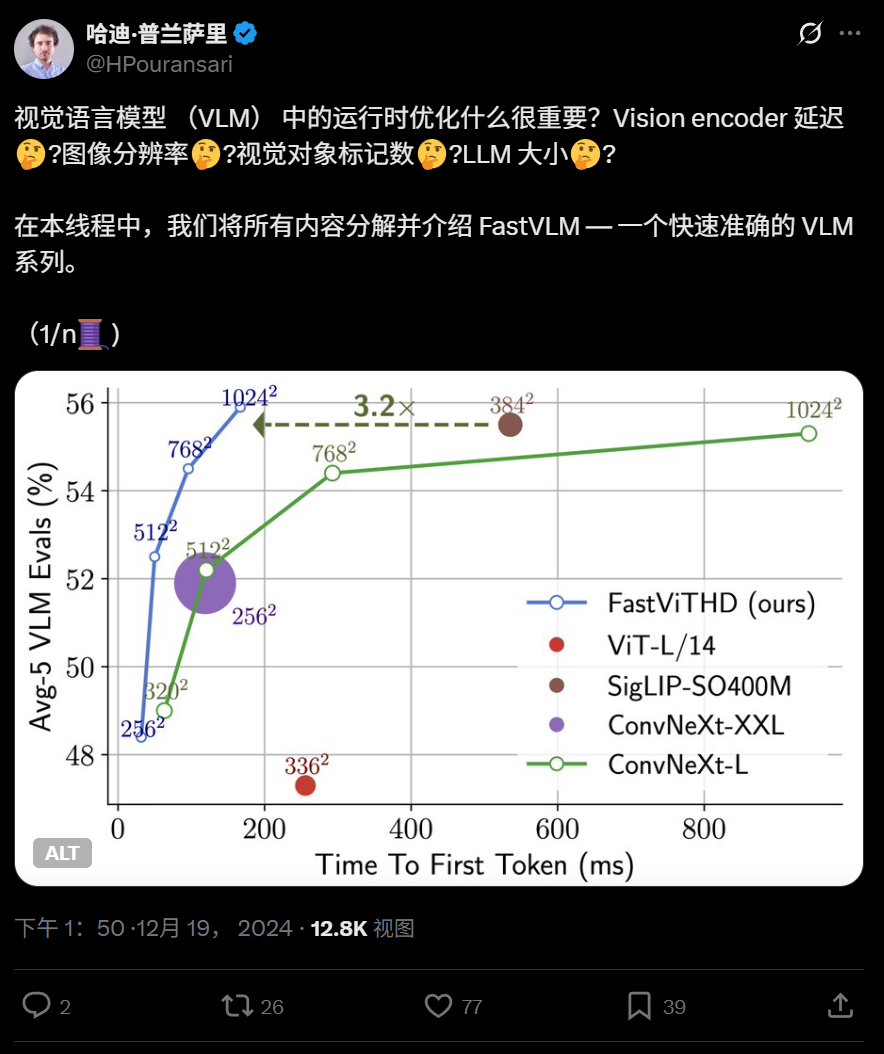
애플, 단말기 실행 최적화된 고효율 시각 언어 모델 FastVLM 오픈소스 공개: 애플은 iPhone 등 기기에서 효율적으로 실행되도록 특별히 설계된 시각 언어 모델 FastVLM을 오픈소스로 공개했습니다. FastVLM은 컨볼루션 계층과 Transformer 모듈을 결합한 새로운 하이브리드 시각 인코더 FastViTHD를 도입하고, 다중 스케일 풀링 및 다운샘플링 기술을 채택하여 이미지 처리에 필요한 시각 토큰 수를 크게 줄였습니다(기존 ViT보다 16배 적음). 첫 번째 토큰 출력 속도는 85배 향상되었습니다. 이 모델은 주류 LLM과 호환되며, MLX 프레임워크 기반의 iOS/macOS 데모 애플리케이션을 이미 제공하여 엣지 장치 및 실시간 이미지-텍스트 작업에 적합합니다. (출처: WeChat)
하얼빈 공대와 펜실베이니아대, KAN 기반 3D 포인트 클라우드 분석 개선한 PointKAN 제안: 하얼빈 공업대학교(선전)와 펜실베이니아 대학교 연구팀이 Kolmogorov-Arnold Networks(KANs) 기반의 새로운 3D 인식 아키텍처 PointKAN을 출시했습니다. PointKAN은 기존 MLP의 고정 활성화 함수를 학습 가능한 활성화 함수로 대체하여 복잡한 기하학적 특징 학습 능력을 향상시켰습니다. 기하학적 아핀 모듈과 병렬 로컬 특징 추출 모듈을 포함합니다. 연구팀은 또한 Efficient-KANs 구조를 채택한 PointKAN-elite 버전을 제안했습니다. 이 버전은 유리 함수를 기저 함수로 사용하고 매개변수를 그룹화하여 공유함으로써 매개변수 수와 계산 복잡성을 크게 줄였으며, 분류, 부분 분할 및 소수 샘플 학습 작업에서 SOTA 성능을 보여주었습니다. (출처: 量子位)

피츠버그 대학교, AI 생성 비디오의 물리적 현실성 향상시키는 PhyT2V 프레임워크 제안: 피츠버그 대학교 지능형 시스템 연구소는 텍스트-비디오(T2V) 모델이 생성하는 콘텐츠의 물리적 일관성을 향상시키기 위한 PhyT2V 프레임워크를 개발했습니다. 이 방법은 모델 재훈련이나 대규모 외부 데이터 없이 대규모 언어 모델(LLM) 기반의 연쇄 추론(CoT)과 반복적인 자가 수정 메커니즘을 통해 텍스트 프롬프트를 여러 차례 물리적 규칙 분석 및 최적화합니다. PhyT2V는 물리적 규칙, 의미적 불일치를 식별하고 수정된 프롬프트를 생성하여 주류 T2V 모델(예: CogVideoX, OpenSora)이 현실적인 물리적 시나리오(고체, 유체, 중력 등)에서 일반화 능력을 향상시키며, 특히 분포 외 시나리오에서 효과가 뛰어나 물리적 상식(PC) 및 의미 준수도(SA) 지표가 최대 2.3배 향상되었습니다. (출처: WeChat)
LLM 최신 연구 동향: 멀티모달, 테스트 시점 정렬, 에이전트, RAG 최적화 등: 한 주간 LLM 연구 진행 상황은 다음과 같습니다. 1. 워싱턴 대학교는 모델 수정이나 로짓 접근 없이 테스트 시점에 정렬을 개선하는 방법인 QALIGN을 제안하여 MCMC를 통해 텍스트 생성에서 더 나은 정렬을 달성했습니다. 2. UCLA는 생의학 분야 인코더의 컨텍스트 길이를 8192 토큰으로 확장한 Clinical ModernBERT를 사전 훈련했습니다. 3. Skoltech은 외부 정보(개체 인기도, 문제 유형)를 기반으로 하는 경량 LLM 독립적 적응형 RAG 검색 방법을 제안했습니다. 4. PSU는 LLM 다중 에이전트 시스템의 자동화된 오류 귀인 문제를 정의하고 평가 데이터셋과 방법을 개발했습니다. 5. 푸단 대학교는 다차원 제약 프레임워크와 자동화된 지침 생성 프로세스를 제안하여 LLM 지침 준수 능력을 향상시켰습니다. 6. a-m-team은 DeepSeek-R1-671B에 필적하는 수학 코딩 능력을 갖춘 AM-Thinking-v1(32B)을 오픈소스로 공개했습니다. 7. 샤오미는 사전 훈련 및 사후 훈련 최적화를 통해 추론 작업에서 뛰어난 성능을 보이는 MiMo-7B를 출시했습니다. 8. MiniMax는 32개 언어 제로샷 음색 복제를 지원하는 MiniMax-Speech 자기 회귀 TTS 모델을 제안했습니다. 9. ByteDance는 멀티모달 작업 및 에이전트 중심 작업에서 뛰어난 성능을 보이는 Seed1.5-VL 시각 언어 모델을 구축했습니다. 10. 세계 최초의 32B 매개변수 언어 모델 INTELLECT-2가 분산 강화 학습 훈련을 실현하고 PRIME-RL 프레임워크를 제안했습니다. (출처: WeChat)
AAAI 2025 워크숍, 신경 추론, 수학적 발견 및 AI 가속 과학 공학 주목: AAAI 2025 워크숍은 과학 분야에서의 AI 응용을 중점적으로 논의했습니다. 그중 “신경 추론과 수학적 발견” 워크숍은 블랙박스 신경망이 수학적 추측을 제안하고 새로운 기하학적 도형을 생성하는 데 사용될 수 있음을 강조했지만, 기호 수준의 논리적 추론에는 도달할 수 없다고 지적하고 학제 간 접근 방식을 제안했습니다. 또 다른 “AI 가속 과학 및 공학” 워크숍(제4회, 주제: AI 생명 과학)은 치료 설계의 기초 모델, 약물 발견의 생성 모델, 실험실 폐쇄 루프 항체 설계, 유전체학의 딥 러닝, 생물학적 응용의 인과 추론 등의 의제에 초점을 맞추고 생성 모델이 생명 과학에서 직면하는 도전과 기회를 논의했습니다. (출처: aihub.org)

구글과 Anthropic, AI 해석 가능성 연구에서 의견 차이, 메커니즘 해석 가능성 도전 직면: AI의 “블랙박스” 특성으로 인해 많은 핵심 분야에서 응용이 제한되고 있습니다. 구글 DeepMind는 최근 “메커니즘 해석 가능성(mechanistic interpretability)” 연구의 우선순위를 낮춘다고 발표했습니다. 희소 자기 인코더(SAE)와 같은 방법을 통해 AI 내부 메커니즘을 역공학하는 것은 객관적인 참조 부족, 개념 불완전 적용, 특징 왜곡 등 여러 문제에 직면하며, 기존 SAE 기술은 핵심 작업에서 필요한 “개념”을 식별하지 못했다고 밝혔습니다. 반면 Anthropic CEO Dario Amodei는 이 분야 연구를 강화해야 한다고 주장하며, 향후 5~10년 내에 “AI의 MRI”를 실현할 수 있을 것이라고 낙관했습니다. 이 논쟁은 AI 행동을 이해하고 제어하는 데 따르는 심층적인 도전을 부각시킵니다. (출처: 36Kr)

베이징대/StepStar/Sizhi Technology, 차세대 GPU 고대역폭 도메인 아키텍처 InfiniteHBD 제안, 비용 절감 및 효율 증대: 기존 고대역폭 도메인(HBD) 아키텍처의 확장성, 비용 및 내결함성 제한에 대응하여 베이징 대학교, StepStar 및 Sizhi Technology 팀은 InfiniteHBD 아키텍처를 제안했습니다. 이 아키텍처는 광 스위칭 모듈(OCSTrx)을 중심으로 하며, 광전 변환 모듈에 저비용 광 스위칭(OCS) 기능을 내장하여 데이터 센터 규모의 동적 재구성 가능한 K-Hop Ring 토폴로지와 노드 수준 장애 격리를 실현합니다. InfiniteHBD의 단위 비용은 NVL-72의 31%에 불과하며, GPU 낭비율은 거의 0에 가깝고, MFU(모델 FLOPs 활용률)는 NVIDIA DGX에 비해 최대 3.37배 향상되어 대규모 대형 모델 훈련을 위한 더 나은 솔루션을 제공합니다. 논문은 SIGCOMM 2025에 채택되었습니다. (출처: WeChat)

OceanBase, PowerRAG 발표, AI 전면 수용, Data×AI 통합 데이터 기반 구축: OceanBase는 개발자 컨퍼런스에서 AI 지향 애플리케이션 제품 PowerRAG를 발표했습니다. 이는 즉시 사용 가능한 RAG 개발 능력을 제공하고 데이터, 플랫폼, 인터페이스 및 애플리케이션 계층을 연결하는 것을 목표로 합니다. CTO 양촨후이는 OceanBase의 AI 전략을 자세히 설명했습니다. Data×AI 능력을 구축하고 통합 데이터베이스에서 통합 데이터 기반으로 발전하는 것입니다. OceanBase는 벡터 능력을 강화하고, 융합 검색을 개선하며, 기업 지식 저장소의 동적 업데이트를 실현하고, 모델 사후 훈련 및 미세 조정을 심층적으로 통합할 것이며, 이미 Dify, FastGPT 등 주류 에이전트 플랫폼 및 MCP 프로토콜에 적응했습니다. 벡터 성능은 VectorDBBench 테스트에서 선도적인 성능을 보였으며, BQ 양자화 알고리즘을 통해 메모리 요구 사항을 크게 줄였습니다. (출처: WeChat)

💼 비즈니스
상하이 국영 투자 계열 펀드, Xinyaohui, Enflame Technology, Biren Technology 등 AI 칩 회사에 투자: 상하이 국유자본투자유한공사(상하이 국투)는 최근 반도체 회사 Xinyaohui, Enflame Technology, Biren Technology와 투자 계약을 체결했습니다. 이전에 선도 AI 모펀드는 Biren Technology의 IPO 전 자금 조달을 주도했습니다. 상하이 국투는 기초 모델, 컴퓨팅 칩, 구현 지능 등 분야에 적극적으로 투자할 것이라고 밝혔습니다. Xinyaohui는 반도체 IP, 특히 Chiplet 기술에 중점을 두고 있으며, 창업자 쩡커창은 이전에 Synopsys 중국 부사장을 역임했습니다. Enflame Technology와 Biren Technology는 모두 GPU 칩 설계 회사입니다. 이는 상하이 국투가 AI 산업 체인의 상류, 특히 컴퓨팅 칩 분야에 중점적으로 투자하고 있음을 보여줍니다. (출처: 36Kr)
Sakana AI, 미쓰비시 UFJ 은행과 포괄적 파트너십 체결, 은행 전용 AI 개발: 일본 AI 스타트업 Sakana AI가 미쓰비시 UFJ 은행(MUFG)과 다년간의 파트너십 계약을 체결했다고 발표했습니다. Sakana AI는 MUFG를 위해 은행 업무에 특화된 AI 에이전트를 개발하여 은행 업무 혁신과 AI의 실제 적용을 추진할 예정입니다. 동시에 Sakana AI의 공동 창업자 겸 COO인 이토 렌은 MUFG의 고문으로 활동하며 은행의 AI 전략 실행을 지원할 것입니다. 이번 협력은 Sakana AI가 첨단 AI 기술을 일본 금융 산업의 구체적인 과제 해결에 적용하는 중요한 단계입니다. (출처: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

01.AI 공동 창업자 구쉐메이 퇴사 후 창업, 회사 사업 중심 B2B로 전환: 01.AI 공동 창업자이자 모델 사전 훈련 및 C2C 제품을 담당했던 구쉐메이가 몇 달 전 퇴사하고 최근 창업을 준비 중입니다. 01.AI는 이 사실을 확인하고 그의 공헌에 감사를 표했습니다. 2025년부터 01.AI의 사업 중심은 AI ToC 애플리케이션 및 모델 API에서 디지털 휴먼, 모델 맞춤화 및 배포 등 B2B 분야로 전환되었습니다. 국내판 사무용 도구 “만지(万知)”와 같은 C2C 제품은 사용자 수가 예상에 미치지 못해 운영이 중단되었으며, 해외 캐릭터 역할극 제품 Mona의 상업화도 이상적이지 않았습니다. 이전에 공동 창업자 다이종홍도 퇴사 후 창업했습니다. (출처: 36Kr)

🌟 커뮤니티
AI 논문 AIGC 검사 논란, 정확성 의문, 학생 졸업에 영향: 올해 많은 대학에서 학생들의 AI 글쓰기 남용을 방지하기 위해 졸업 논문 심사 과정에 AIGC 검사를 도입했습니다. 그러나 이 조치는 광범위한 논란을 불러일으켰습니다. 학생들은 자신이 작성한 내용이 AI 생성으로 잘못 판단되는 경우가 많고, AI 보조 수정 후 의심도가 오히려 높아진다고 불만을 토로했습니다. 심지어 《등왕각서》의 AI 생성 의심도가 99.2%에 달한다는 테스트 결과도 있었습니다. AIGC 검사 도구 자체도 AI로 구동되며, 그 원리는 텍스트 언어 특징과 AI 글쓰기 패턴을 비교 분석하는 것이지만 정확성은 미흡합니다. OpenAI의 초기 도구 정확도는 26%에 불과했습니다. 이러한 불확실성은 학생들에게 혼란과 추가 비용(검사 웹사이트마다 결과가 다르고, 표절률 낮추기 서비스 유료)을 야기할 뿐만 아니라 AI 도구의 본질에 대한 반성을 불러일으켰습니다. AI가 인간의 글쓰기를 모방하고, 다시 AI를 사용하여 인간의 글이 AI와 유사한지 검사하는 것은 본질적으로 논리적 모순이 존재합니다. (출처: 36Kr)

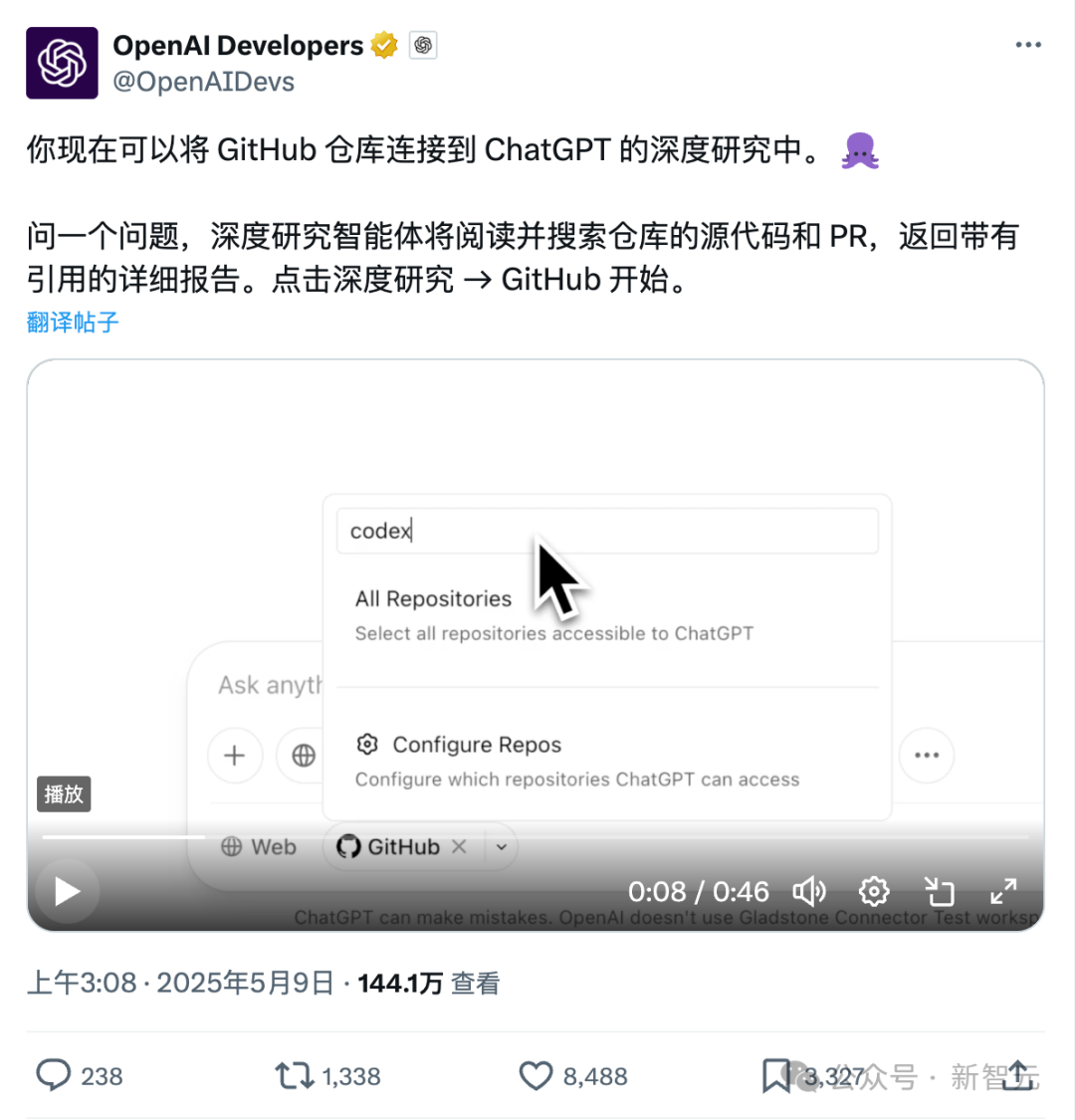
ChatGPT, Github 직접 연결 신기능: 코드 저장소 및 전문 문서 심층 연구: ChatGPT가 최근 출시한 Deep Research 기능에 Github 저장소 직접 연결 기능이 추가되었습니다. 사용자는 ChatGPT에 공개 또는 비공개 저장소 접근 권한을 부여하여 심층 코드 분석, 기능 아키텍처 요약, 기술 스택 식별, 코드 품질 평가 및 프로젝트 적합성 분석 등을 수행할 수 있습니다. 이 기능은 코드에만 국한되지 않고, 사용자는 PDF, Word 등 다양한 문서를 Github 저장소에 업로드하여 ChatGPT를 활용해 특정 분야 자료를 심층 연구할 수 있으며, 이는 제한된 범위의 RAG+MCP 조합을 구현한 것과 같습니다. 이 기능은 현재 Plus 사용자에게 공개되었으며, 연구 범위를 제한함으로써 연구 보고서의 전문성과 정확성을 높이고 환각을 줄일 것으로 기대됩니다. (출처: 36Kr)
AI 에이전트 시장 경쟁 심화, Manus 전면 등록 개방, ByteDance, Baidu 등 대기업 진출: “만능 에이전트”로 불리는 Manus가 5월 12일 전면 등록을 개방한다고 발표하여 사용자는 기다릴 필요 없이 사용 할당량을 받을 수 있게 되었습니다. 동시에 시장에서는 Manus가 15억 달러 가치로 새로운 자금 조달을 진행 중이라는 소문이 돌고 있습니다. 3월 출시 이후 Manus는 에이전트 유형 프로젝트 열풍을 일으켰지만, 트래픽 감소와 경쟁 제품 출현이라는 도전에 직면해 있습니다. ByteDance는 Coze Space를 출시했고, Baidu는 “먀오다(秒哒)”와 “신샹(心响)”을 출시했으며, 디자인 에이전트 Lovart도 테스트를 시작했습니다. 에이전트 시장은 초기 개념 검증에서 제품 기능, 비즈니스 모델 및 사용자 증가의 전방위적인 경쟁으로 전환되고 있습니다. (출처: 36Kr)
AI 보조 코딩, 개발자 작업 흐름 변화시켜 생산성 향상시키지만 과도한 의존 경계해야: Reddit 사용자는 AI 코드 도우미가 특히 대규모 레거시 프로젝트 처리 및 복잡한 코드 이해 측면에서 코딩 경험을 크게 변화시킨 방법을 공유했습니다. AI 도구는 코드를 한 줄씩 설명하고, 제안을 제공하며, 잠재적인 문제를 강조 표시하고, 파일을 요약하고, 코드 조각을 찾고, 주석을 생성하여 마치 24시간 전문가 지도를 받는 것과 같습니다. 댓글에서는 AI가 반복적인 코딩을 완료하고, 효율성을 높이며, 새로운 방법을 안내하고, 주석을 추가하며, 심지어 개발자가 자신의 능력 범위를 벗어나는 작업을 완료하도록 도와 며칠 걸리던 작업을 몇 시간으로 단축한다고 지적했습니다. 그러나 이는 개발자 기술의 진화와 AI 도구에 대한 의존성에 대한 고민을 불러일으키기도 합니다. (출처: Reddit r/artificial)
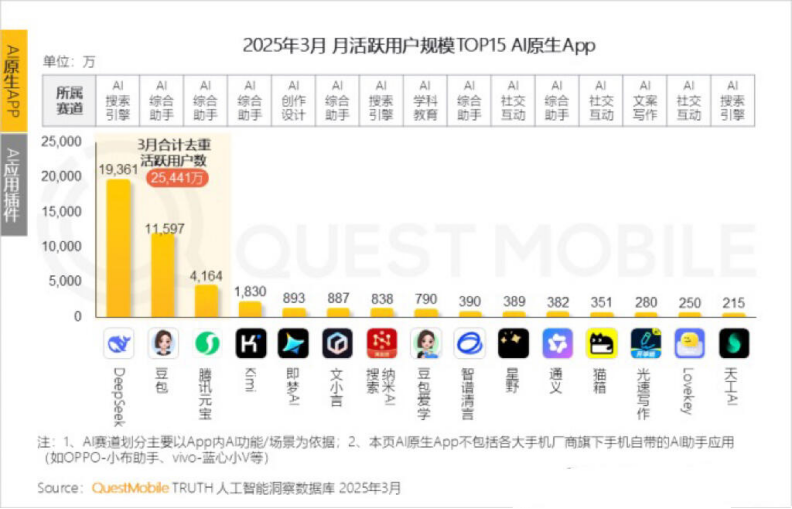
Kimi 월간 활성 사용자 감소, Moonshot AI는 특정 분야 돌파 및 소셜화 전환 모색: Moonshot AI 산하 Kimi Chat의 QuestMobile 데이터 기준 월간 활성 사용자 수가 작년 10월 3600만 명에서 올해 3월 1820만 명으로 감소하여 4위로 하락했습니다. 사용자 유지율을 높이기 위해 Kimi는 일반 대형 모델에서 특정 분야로 확장하고 있습니다. 예를 들어, 차이신 미디어와 협력하여 금융 콘텐츠 검색 품질을 향상시키고, AI 의료 검색 분야를 개척하며, Bilibili 비디오 콘텐츠를 도입하고 있습니다. 동시에 Kimi는 샤오홍슈에서 챌린지를 시작하여 소셜 플랫폼을 통해 더 많은 C단 사용자에게 다가가려고 시도하고 있습니다. 사용자 인터페이스도 멀티모달, 더우바오(豆包) 유사 및 커뮤니티화 방향으로 조정되고 있습니다. DeepSeek과 같은 경쟁자 및 대기업의 AI 애플리케이션 시장 진출에 직면하여 Kimi의 기술 선도적 입지가 흔들리고 상업화 압력이 커지면서 새로운 성장 동력을 적극적으로 찾고 있습니다. (출처: 36Kr)
AI가 1인칭으로 자신을 지칭해야 하는지에 대한 논의: Reddit 사용자는 ChatGPT와 같은 LLM이 “나” 또는 “너”로 자신을 지칭하고 사용자를 부르는 것이 부적절할 수 있다는 논의를 시작했습니다. 그 본질은 “사람”이 아닌 “사물”이기 때문에 “ChatGPT가 당신을 도울 것입니다…”와 같이 3인칭을 사용하여 사용자에게 인격화된 존재라는 인상을 주지 않도록 하여 잠재적인 위험이나 윤리적 문제를 야기하는 것을 피해야 한다고 제안했습니다. 댓글에서는 3인칭이 오히려 자기 인식을 암시한다고 생각하는 사람도 있었고, 3인칭이 어리석고 불편하게 들린다고 느끼는 사람도 있었습니다. 이 논의는 사용자의 AI 정체성定位와 인간-기계 상호 작용 방식에 대한 생각을 반영합니다. (출처: Reddit r/ArtificialInteligence)
💡 기타
MIT, 광범위하게 주목받던 AI 논문 긴급 철회, 데이터 및 연구 진실성 의혹 제기: 매사추세츠 공과대학교(MIT)는 경제학과 박사 과정 학생 에이든 토너-로저스가 작성한 논문 《인공지능, 과학적 발견 및 제품 혁신》을 철회했습니다. 이 논문은 AI 도구가 최고 과학자들의 혁신 효율성을 크게 향상시킬 수 있지만, 과학 연구의 “빈부 격차”를 심화시키고 일반 연구원들의 행복감을 낮출 수 있다는 주장으로 주목받았으며, 노벨상 수상자 등 저명한 교수들의 찬사를 받았습니다. MIT는 연구 진실성 신고를 받고 내부 조사를 진행한 후 논문 데이터 출처, 신뢰성, 유효성 및 연구 진실성에 대한 신뢰를 잃었다고 밝혔으며, arXiv와 《경제학 계간지》에 해당 논문 철회를 요청했습니다. 저자는 MIT를 떠났고, 관련 교수들도 관계를 부인하는 성명을 발표했습니다. 저자는 조사 기간 동안 가짜 도메인을 구매하여 대기업 이메일을 사칭하다 적발되어 기소된 것으로 알려졌습니다. (출처: 36Kr)

AI 생성 이미지가 인터넷 사기에 이용되어 사용자 경각심 유발: Reddit 사용자는 Facebook 등 소셜 미디어에서 AI로 생성된 인물 이미지를 이용한 상품 홍보 사례를 공유했습니다. 이러한 이미지 속 인물과 장면은 종종 비논리적인 부분(예: 모델이 기이한 방식으로 상자에 드나들거나, 배경에 관련 없는 인물이 등장하는 등)이 있지만, 캐릭터 이미지의 일관성은 높았습니다. 댓글 작성자들은 이러한 AI 생성 콘텐츠가 이미 사기에 이용되고 있다며 사용자들에게 주의를 당부했습니다. Pleasant Green과 같은 블로거들도 이러한 사기를 폭로하는 영상을 제작한 바 있습니다. (출처: Reddit r/ChatGPT)
AI 생성 이미지 스타일 모방 및 프롬프트 추출 논의: 사용자들이 AI 모델(예: DALL-E 3)을 사용하여 특정 예술 스타일(예: 픽사 스타일과 디자이너 토이 스타일을 결합한 살바도르 달리)을 모방하여 인물 초상화를 만드는 방법을 논의하고, 인물 특징, 배경, 빛과 그림자 및 핵심 개념(예: 그림자를 정신적 투영으로 표현)을 강조하는 상세한 프롬프트를 공유했습니다. 또한, 이미지에서 스타일 매개변수를 추출하여 JSON 형식으로 출력하는 프롬프트 템플릿을 제공한 사용자도 있었는데, 이는 사용자가 이미지 스타일을 역공학하는 데 도움을 주기 위한 것이지만 정확한 재현은 여전히 어려운 과제입니다. (출처: dotey, dotey)
