
키워드:딥마인드, 알파이볼브, 오션베이스, 파워RAG, 메타, 라마 4 베헤모스, 큐wen, 월드PM-72B, AI 고급 알고리즘 설계, Data×AI 전략, RAG 애플리케이션 개발, 대규모 선호 모델, 행렬 곱셈 알고리즘 혁신
# 🔥 핫이슈
**DeepMind, AlphaEvolve 출시: AI, 고급 알고리즘 설계로 역사적 혁신 달성**: DeepMind가 Gemini 기반의 진화적 코딩 에이전트인 AlphaEvolve를 공개했습니다. 이 에이전트는 처음부터 알고리즘을 설계하고 최적화할 수 있습니다. 수학, 기하학, 조합론 등 50개 분야의 미해결 문제 테스트에서 AlphaEvolve는 75%의 경우 인간이 발견한 기존 최적의 해결책을 재발견했으며, 20%의 경우 이를 개선했습니다. 더욱 주목할 점은 고전적인 Strassen 알고리즘보다 빠른 행렬 곱셈 알고리즘(56년 만의 혁신)을 발견했으며, AI 칩 회로 설계 및 자체 훈련 알고리즘을 개선할 수 있다는 것입니다. 이는 AI가 자동화된 과학적 발견과 자기 진화 측면에서 중요한 진전을 이루었음을 의미하며, 하드웨어 설계부터 질병 치료에 이르기까지 복잡한 문제 해결을 AI가 가속화할 수 있음을 시사합니다 (출처: [YouTube – Two Minute Papers](https://www.youtube.com/watch?v=T0eWBlFhFzc))
**OceanBase 개발자 컨퍼런스, Data×AI 전략 및 첫 RAG 제품 PowerRAG 발표**: 제3회 개발자 컨퍼런스에서 OceanBase는 Data×AI 전략을 상세히 설명하고 AI 애플리케이션 제품인 PowerRAG를 출시했습니다. 이 제품은 즉시 사용 가능한 RAG(검색 증강 생성) 애플리케이션 개발 기능을 제공하며, 문서 지식 베이스, 지능형 대화 등 AI 애플리케이션 구축을 간소화하는 것을 목표로 합니다. OceanBase CTO 양촨후이(杨传辉)는 회사가 TP/AP/AI 혼합 워크로드와 벡터 데이터베이스를 지원하기 위해 통합 데이터베이스에서 통합 데이터 플랫폼으로 발전하고 있다고 밝혔습니다. 앤트그룹 CTO 허정위(何征宇) 또한 앤트그룹의 핵심 AI 시나리오에서 OceanBase의 활용을 지원할 것이라고 밝혔습니다. OceanBase는 또한 선도적인 벡터 성능과 JSON 압축 능력을 선보이며 AI 시대의 데이터 문제를 해결하는 데 주력하고 있습니다 (출처: [量子位](https://www.qbitai.com/2025/05/284444.html))
**MIT, 한 학생의 AI 연구 논문에 대한 지지 철회**: 월스트리트저널(WSJ) 보도에 따르면, 매사추세츠 공과대학교(MIT)가 한 학생이 발표한 AI 연구 논문에 대한 지지를 공개적으로 철회했습니다. 이러한 조치는 일반적으로 연구의 타당성, 방법론 또는 윤리적 측면에서 기관이 지지를 철회할 만큼 심각한 문제가 발생했음을 의미합니다. 이러한 사건은 학계에서 드문 일이며, 특히 주목받는 AI 분야에서는 관련 연구원의 평판과 연구 방향에 영향을 미칠 수 있고, 학문적 진실성과 연구 품질에 대한 논의를 촉발할 수 있습니다. 구체적인 원인과 논문 세부 정보는 추후 공개될 예정입니다 (출처: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1konws0/mit_says_it_no_longer_stands_behind_students_ai/))
# 🎯 동향
**Meta, Llama 4 Behemoth 출시 연기 및 창립 팀원 이탈 보도**: 소셜 미디어와 Reddit 커뮤니티에서 Meta Platforms가 차세대 대규모 언어 모델 Llama 4 Behemoth의 출시를 연기했다는 소식이 전해졌습니다. 동시에 Llama v1 연구에 참여했던 초기 연구원 14명 중 11명이 회사를 떠났다는 소문도 있습니다. 이 소식은 Meta AI 팀의 안정성과 향후 대형 모델 연구 개발 일정에 대한 우려를 불러일으켰습니다. 만약 사실이라면, 이는 치열한 대형 모델 경쟁에서 Meta의 입지에 영향을 미칠 수 있습니다 (출처: [Reddit r/artificial](https://preview.redd.it/hhsmnxxlxa1f1.png?auto=webp&s=ae32abf1d8ed036829161d716143b0d6284517b2), [scaling01](https://x.com/scaling01/status/1923715027653025861))
**Qwen, 대규모 선호도 모델 WorldPM-72B 출시**: Alibaba Qwen 팀이 728억 개의 파라미터를 가진 선호도 모델 WorldPM-72B를 공개했습니다. 이 모델은 1,500만 개의 인간 쌍 비교 데이터에 대한 사전 훈련을 통해 인간 선호도의 통합된 표현을 학습합니다. 주로 보상 모델로 사용되어 후보 응답의 품질을 평가하고 RLHF(인간 피드백 기반 강화 학습) 및 콘텐츠 순위 지정을 지원하여 모델과 인간 가치의 일치도를 높이는 것을 목표로 합니다. 이는 확장 가능한 선호도 학습의 실증적 증거이며 객관적인 지식 선호도와 주관적인 평가 스타일 모두를 개선합니다 (출처: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kompbk/new_new_qwen/))
**Pivotal Token Search (PTS) 기술 오픈소스 공개, LLM 훈련 효율 최적화**: Pivotal Token Search (PTS)라는 새로운 기술이 제안되고 오픈소스로 공개되었습니다. 이 기술은 언어 모델 생성 과정에서 “핵심 결정 지점”(즉, Pivotal Tokens)을 식별하여 직접 선호도 최적화(DPO) 훈련을 최적화하는 것을 목표로 합니다. 핵심 아이디어는 모델이 답변을 생성할 때 소수의 토큰이 최종 결과의 성공 여부에 결정적인 역할을 한다는 것입니다. 이러한 핵심 지점에 대해 DPO 쌍을 생성함으로써 더 효율적인 훈련과 더 나은 결과를 얻을 수 있습니다. 이 프로젝트는 Microsoft의 Phi-4 논문에서 영감을 얻었으며 관련 코드, 데이터셋 및 사전 훈련된 모델이 공개되었습니다 (출처: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1komx9e/p_pivotal_token_search_pts_optimizing_llms_by/))
**ByteDance, DanceGRPO 출시: 시각적 생성을 위한 통합 강화 학습 프레임워크**: ByteDance가 확산 모델 및 교정 흐름(rectified flows)을 위한 시각적 생성을 위해 특별히 설계된 통합 강화 학습(RL) 프레임워크인 DanceGRPO를 출시했습니다. 이 프레임워크는 강화 학습을 통해 이미지 및 비디오 합성의 품질과 효과를 향상시켜 시각 콘텐츠 제작 분야에 새로운 기술 경로를 제공하는 것을 목표로 합니다 (출처: [_akhaliq](https://x.com/_akhaliq/status/1923736714641584254))
**Google, LightLab 출시: 확산 모델을 통한 이미지 광원 제어**: Google 연구원들이 LightLab 프로젝트를 선보였습니다. 이 기술은 확산 모델을 사용하여 이미지의 광원을 정교하게 제어할 수 있습니다. 소규모의 고도로 선별된 데이터셋에서 확산 모델을 미세 조정함으로써 LightLab은 생성된 이미지의 조명 효과를 효과적으로 조작하여 이미지 편집 및 콘텐츠 제작에 새로운 가능성을 제공합니다 (출처: [_akhaliq](https://x.com/_akhaliq/status/1923849291514233322), [_rockt](https://x.com/_rockt/status/1923862256451793289))
**AI의 장기 기억 기능, 아키텍처 및 경제적 영향에 대한 고찰 촉발**: OpenAI가 ChatGPT에 장기 기억 기능을 도입한 것은 AI 시스템이 무상태 응답 모델에서 지속적이고 컨텍스트가 풍부한 서비스 모델로 전환하는 것으로 간주됩니다. 이러한 변화는 사용자 경험을 향상시키는 동시에 새로운 컴퓨팅 부담(예: 메모리 저장, 검색, 보안 및 일관성 유지)을 야기하여 컴퓨팅 수요의 “롱테일 효과”를 초래할 수 있습니다. 경제적으로 개인화된 컨텍스트를 유지하는 비용은 API 가격 책정, 구독 등급 등을 통해 개발자와 사용자에게 외부화될 수 있으며 동시에 생태계의 잠금 효과를 증가시킬 수 있습니다 (출처: [Reddit r/deeplearning](https://www.reddit.com/r/deeplearning/comments/1kon0oo/memory_as_strategy_how_longterm_context_reshapes/))
**Anthropic, 경쟁에 대응하기 위해 새로운 Claude 모델 출시 가능성**: 소셜 미디어와 Reddit 커뮤니티에서는 Anthropic이 최근 새로운 Claude 모델(또는 Claude 3.8)을 출시할 수 있다는 소문이 돌고 있습니다. 이는 Google 등 경쟁사들이 AI 모델(예: Gemini)의 코딩 능력 등에서 빠르게 발전하는 것에 대응하여 Claude 시리즈 모델의 시장 경쟁력을 유지하기 위한 조치로 추측됩니다 (출처: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1kols5s/will_we_see_anthropic_release_a_new_claude_model/))
# 🧰 툴
**ByteDance, 노드 기반 프로세스 구축 엔진 FlowGram.AI 오픈소스 공개**: ByteDance가 노드 기반 프로세스 구축 엔진인 FlowGram.AI를 출시했습니다. 이는 개발자가 고정 레이아웃 또는 자유 연결 레이아웃의 워크플로를 빠르게 생성할 수 있도록 지원하는 것을 목표로 합니다. 명확한 입력 및 출력이 있는 시각적 워크플로 구축에 특히 적합한 일련의 상호 작용 모범 사례를 제공하며, AI 기능을 통해 워크플로를 강화하는 방법에 중점을 둡니다 (출처: [GitHub Trending](https://github.com/bytedance/flowgram.ai))
**CopilotKit: 심층 통합 AI 어시스턴트 구축을 위한 React UI 및 인프라**: CopilotKit은 애플리케이션 내 AI Copilots, AI 챗봇 및 AI 에이전트 구축을 위한 React UI 구성 요소와 백엔드 인프라를 제공하는 오픈소스 프로젝트입니다. 프론트엔드 RAG, 지식 베이스 통합, 프론트엔드 실행 가능 함수 및 LangGraph와 통합된 CoAgents를 지원하여 개발자가 사용자와 깊이 협력하는 AI 기능을 쉽게 구현할 수 있도록 지원하는 것을 목표로 합니다 (출처: [GitHub Trending](https://github.com/CopilotKit/CopilotKit))
**AI Runner: 다양한 애플리케이션을 지원하는 로컬 오프라인 AI 추론 엔진**: Capsize-Games가 오프라인 실행을 지원하는 AI 추론 엔진인 AI Runner를 출시했습니다. 예술 창작(Stable Diffusion, ControlNet), 실시간 음성 대화(OpenVoice, SpeechT5, Whisper), LLM 챗봇 및 자동화 워크플로를 처리할 수 있습니다. 이 도구는 로컬 실행에 중점을 두어 개발자와 제작자에게 외부 API 없이 AI 도구 세트를 제공하는 것을 목표로 합니다 (출처: [GitHub Trending](https://github.com/Capsize-Games/airunner))
**LangChain, Text-to-SQL 튜토리얼 출시**: LangChain이 LangChain, Ollama의 DeepSeek 모델 및 Streamlit을 사용하여 강력한 자연어-SQL 변환기를 구축하는 방법을 보여주는 튜토리얼을 게시했습니다. 이 도구는 구어체 쿼리를 데이터베이스에서 실행 가능한 SQL 문으로 자동 변환하여 데이터 쿼리 및 분석 프로세스를 간소화하는 직관적인 인터페이스를 만드는 것을 목표로 합니다 (출처: [LangChainAI](https://x.com/LangChainAI/status/1923770538528329826), [hwchase17](https://x.com/hwchase17/status/1923785900535812326))
**LangChain, Telegram 링크 요약기 에이전트 출시**: LangChain 커뮤니티가 LangGraph를 기반으로 구축된 Telegram 지능형 봇을 공유했습니다. 이 봇은 채팅에서 직접 웹 페이지 링크, PDF 문서 및 소셜 미디어 게시물의 내용을 요약하고 다양한 유형의 콘텐츠를 지능적으로 처리하여 간결한 요약 정보를 제공함으로써 정보 획득 효율성을 향상시킵니다 (출처: [LangChainAI](https://x.com/LangChainAI/status/1923785679928004954))
**LangChain과 Box 통합으로 자동화된 문서 매칭 구현**: LangChain이 Box와의 통합 튜토리얼을 게시하여 LangChain의 AI Agents Toolkit과 MCP 서버를 활용하여 구매 워크플로에서 송장과 구매 주문서 매칭을 자동화하는 지능형 에이전트를 구축하는 방법을 보여주었습니다. 이 통합은 기업 문서 처리의 자동화 수준과 효율성을 향상시키는 것을 목표로 합니다 (출처: [LangChainAI](https://x.com/LangChainAI/status/1923800687860748597), [hwchase17](https://x.com/hwchase17/status/1923812839245877559))
**Gradio, MCP 서버 구축 간소화**: Hugging Face 블로그에서 몇 줄의 Python 코드로 Gradio를 사용하여 MCP(Multi-Copilot Platform) 서버를 구축하는 가이드를 소개했습니다. 이를 통해 개발자는 다중 에이전트 협업 플랫폼을 보다 편리하게 만들고 배포할 수 있어 이러한 애플리케이션의 개발 장벽을 낮춥니다 (출처: [dl_weekly](https://x.com/dl_weekly/status/1923726779375644809))
**Replicate, 모델 호출 간소화, Codex 등 AI 코드 편집기 적용**: Replicate 플랫폼이 업데이트되어 AI 코드 편집기와 LLM(예: Codex)이 플랫폼의 모든 모델을 더 편리하게 사용할 수 있게 되었습니다. 새로운 기능에는 페이지를 마크다운으로 복사, Claude 또는 ChatGPT에서 직접 로드, 모든 모델에 대한 llms.txt 페이지 제공 등이 포함되어 모델 통합 및 호출을 용이하게 합니다 (출처: [bfirsh](https://x.com/bfirsh/status/1923812545124872411))
**chatllm.cpp, Orpheus-TTS 모델 지원 추가**: 오픈소스 프로젝트 `chatllm.cpp`가 이제 orpheus-tts-en-3b(33억 파라미터)와 같은 Orpheus-TTS 시리즈 음성 합성 모델을 지원합니다. 사용자는 이 도구를 통해 로컬에서 이러한 TTS 모델을 실행하여 텍스트 음성 변환을 구현할 수 있습니다 (출처: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kony6o/orpheustts_is_now_supported_by_chatllmcpp/))
**auto-openwebui: Open WebUI 자동 배포를 위한 Bash 스크립트**: 개발자가 Linux 시스템에서 Docker를 통해 Open WebUI를 자동으로 실행하고 Ollama 및 Cloudflare를 통합하기 위한 auto-openwebui라는 Bash 스크립트를 만들었습니다. 이 스크립트는 AMD 및 NVIDIA GPU를 지원하여 Open WebUI 배포 프로세스를 간소화합니다 (출처: [Reddit r/OpenWebUI](https://www.reddit.com/r/OpenWebUI/comments/1kopl98/autoopenwebui_i_made_a_bash_script_to_automate/))
**GLaDOS 프로젝트, ASR 모델을 Nemo Parakeet 0.6B로 업데이트**: 음성 비서 프로젝트 GLaDOS가 자동 음성 인식(ASR) 모델을 Nvidia의 Nemo Parakeet 0.6B로 업데이트했습니다. 이 모델은 Hugging Face ASR 순위표에서 우수한 성능을 보이며 높은 정확도와 처리 속도를 겸비하고 있습니다. 프로젝트는 오디오 전처리 및 TDT/FastConformer CTC 추론 코드를 재구성하여 의존성을 최소화했습니다 (출처: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kosbyy/glados_has_been_updated_for_parakeet_06b/))
**Runway, References API 및 Figma 플러그인 출시, 이미지 융합 구현**: Runway의 References API는 이제 플러그인 생성에 사용될 수 있으며, 예를 들어 Figma 플러그인은 사용자가 원하는 방식으로 임의의 두 이미지를 융합할 수 있습니다. 이 플러그인 코드는 오픈소스로 공개되어 Runway의 프로그래밍 가능한 이미지 편집 및 제작 능력을 보여줍니다 (출처: [c_valenzuelab](https://x.com/c_valenzuelab/status/1923762194254070008))
**Codex, 코드 마이그레이션 작업에서 고효율성 과시**: 한 개발자가 Codex를 사용하여 레거시 프로젝트를 Python 2.7에서 3.11로 마이그레이션하고 Django 1.x를 5.0으로 업그레이드하는 데 단 12분밖에 걸리지 않았다고 공유했습니다. 이는 AI 코드 도구가 복잡한 코드 업그레이드 및 마이그레이션 작업을 처리하는 데 있어 엄청난 잠재력을 보여주며 개발 시간을 크게 절약할 수 있음을 나타냅니다 (출처: [gdb](https://x.com/gdb/status/1923802002582319516))
**Gyroscope: 프롬프트 엔지니어링을 통한 AI 모델 성능 향상**: 한 사용자가 “Gyroscope”라는 프롬프트 엔지니어링 방법을 공유하며, 이를 Claude 3.7 Sonnet 및 ChatGPT 4o와 같은 채팅 기반 AI에 복사하여 붙여넣으면 안전성, 지능성 측면에서 출력이 30-50% 향상된다고 주장했습니다. 테스트 결과 구조화된 추론, 책임성 및 추적성 측면에서 상당한 개선이 나타났습니다 (출처: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1komvkz/diy_free_upgrade_for_your_ai/))
**Claude, 프로그래밍 경험 없는 사용자의 코드 프로젝트 완료 지원**: 한 Reddit 사용자가 프로그래밍 경험이 전혀 없는 상태에서 하루 동안 Claude AI를 사용하여 완벽하게 작동하는 텍스트 교환 생성기를 성공적으로 만들었다고 공유했습니다. 이 사례는 대규모 언어 모델이 프로그래밍 지원, 프로그래밍 장벽 완화 측면에서 잠재력을 가지고 있어 비전문가도 소프트웨어 개발에 참여할 수 있음을 강조합니다 (출처: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koouc5/literally_spent_all_day_on_having_claude_code_this/))
# 📚 학습
**Awesome ChatGPT Prompts: ChatGPT 및 기타 LLM을 위한 프롬프트 큐레이션 저장소**: GitHub의 인기 프로젝트 awesome-chatgpt-prompts는 ChatGPT 및 기타 LLM(예: Claude, Gemini, Llama, Mistral)을 위해 세심하게 설계된 수많은 프롬프트를 수집합니다. 이러한 프롬프트는 다양한 역할극 및 작업 시나리오를 다루며 사용자가 AI 모델과 더 잘 상호 작용하고 출력 품질을 향상시키는 데 도움을 주는 것을 목표로 합니다. 이 프로젝트는 prompts.chat 웹사이트와 Hugging Face 데이터셋 버전도 제공합니다 (출처: [GitHub Trending](https://github.com/f/awesome-chatgpt-prompts))
**Lilian Weng, “우리는 왜 생각하는가” 탐구: 모델에 더 많은 사고 시간을 부여하는 것의 중요성**: OpenAI 연구원 Lilian Weng이 블로그 게시물 “Why we think”를 통해 지능형 디코딩, 사고 사슬 추론, 잠재적 사고 등을 통해 모델에 예측 전 “사고” 시간을 더 많이 부여하는 것이 다음 단계의 지능을 여는 데 얼마나 효과적인지 탐구했습니다. 이 글은 모델의 추론 및 계획 능력을 향상시키는 다양한 전략을 심층 분석합니다 (출처: [lilianweng](https://x.com/lilianweng/status/1923757799198294317), [andrew_n_carr](https://x.com/andrew_n_carr/status/1923808008641171645))
**Flash Attention 사전 컴파일된 Wheel 패키지로 설치 간소화**: 커뮤니티에서 Flash Attention의 사전 컴파일된 wheel 패키지를 제공하여 사용자가 Flash Attention 설치 시 겪을 수 있는 장시간 컴파일 문제를 해결하는 것을 목표로 합니다. 이는 개발자가 Flash Attention 최적화가 포함된 딥러닝 환경을 더 빠르게 구축하고 사용할 수 있도록 도와줍니다 (출처: [andersonbcdefg](https://x.com/andersonbcdefg/status/1923774139661418823))
**Maitrix, 대규모 음성-언어 기반 모델 제품군 Voila 출시**: Maitrix 팀이 새로운 대규모 음성-언어 기반 모델 시리즈인 Voila를 출시했습니다. 이 시리즈 모델은 인간-컴퓨터 상호 작용 경험을 새로운 수준으로 끌어올리는 것을 목표로 하며, 음성 이해 및 생성 능력 개선에 중점을 두어 보다 자연스러운 음성 상호 작용 애플리케이션을 지원합니다 (출처: [dl_weekly](https://x.com/dl_weekly/status/1923770946264986048))
**Flash Attention 메커니즘에 대한 심층 이해가 관심사로 부상**: 개발자 커뮤니티에서 Flash Attention의 핵심 메커니즘(“what makes flash attention flash”)을 학습하고 이해하려는 논의가 나타나고 있습니다. Flash Attention은 효율적인 어텐션 메커니즘으로서 대규모 Transformer 모델의 훈련 및 추론에 매우 중요하며, 그 원리와 구현 세부 사항이 주목받고 있습니다 (출처: [nrehiew_](https://x.com/nrehiew_/status/1923782090052559109))
# 🌟 커뮤니티
**저커버그의 Llama-5 직접 파라미터 튜닝 논란, Meta AI 팀원 이탈 주목**: 직원 퇴사 후 저커버그가 직접 Llama-5 훈련을 위해 하이퍼파라미터를 설정하는 패러디 이미지가 소셜 미디어에 퍼지면서 Meta AI 팀의 인재 유출과 저커버그의 직접 챙기는 스타일에 대한 논의가 촉발되었습니다. 이는 Meta AI의 향후 발전 방향과 내부 동향에 대한 커뮤니티의 관심을 반영합니다 (출처: [scaling01](https://x.com/scaling01/status/1923715027653025861), [scaling01](https://x.com/scaling01/status/1923802857058247136))
**《포트나이트》 AI 다스베이더 악용, 동적 생성 대화의 안전장치 문제**: 게임 내 AI 캐릭터 다스베이더(대화는 Gemini 2.0 Flash가 동적으로 생성하고 음성은 ElevenLabs Flash 2.5가 생성한 것으로 알려짐)가 플레이어에 의해 부적절한 콘텐츠를 생성하는 현상이 논란을 일으켰습니다. 이는 개방형 상호작용 환경에서 동적 AI 생성 콘텐츠에 효과적인 안전장치를 설정하는 동시에 재미와 자유도를 유지하는 것의 어려움을 보여줍니다 (출처: [TomLikesRobots](https://x.com/TomLikesRobots/status/1923730875943989641))
**OpenAI에 대한 비판과 칭찬: 커뮤니티 여론 관찰**: 사용자 `scaling01`은 OpenAI에 대한 부정적인 게시물을 올릴 때 종종 “안티”로 비난받지만, 긍정적인 내용을 올릴 때는 아무도 “찬양론자”라고 부르지 않는다고 지적했습니다. 그는 OpenAI가 소셜 미디어에서 강력한 영향력을 가지고 있기 때문에 자연스럽게 더 많은 긍정적 및 부정적 논의를 유발한다고 생각합니다. 이는 선두 AI 기업에 대한 커뮤니티의 복잡한 감정과 높은 관심을 반영합니다 (출처: [scaling01](https://x.com/scaling01/status/1923723374771003873))
**레거시 코드베이스에서의 Codex 적용 과제**: 개발자 `riemannzeta`는 대규모의 복잡한 레거시 코드베이스(예: 은행의 FORTRAN 코드)에서 Codex와 같은 AI 코드 도구의 실제 적용 가치에 대해 의문을 제기했습니다. LLM이 개인 또는 신규 프로젝트에서는 속도를 크게 향상시킬 수 있지만, 중요한 고객 의존도가 높은 레거시 시스템에서는 AI 생성 코드가 새로운 버그를 유발하지 않도록 한 줄 한 줄 검토해야 하므로 개발자 역할이 코드 검토자로 바뀔 수 있습니다 (출처: [riemannzeta](https://x.com/riemannzeta/status/1923733368627236910))
**AI 추론 연산 능력 병목 현상 과소평가, AGI 발전 제약 가능성**: 다수의 기술 평론가들은 AI 추론 연산 능력이 AGI(범용 인공 지능) 실현의 주요 병목 현상이 될 것이며 그 중요성이 종종 과소평가된다고 강조했습니다. 전 세계적으로 약 1,000만 H100 상당의 연산 능력을 예로 들면, AI가 인간 두뇌의 추론 효율성에 도달하더라도 대규모 AI 개체군을 지원하기 어렵습니다. 또한 AI 연산 능력 증가율(현재 연간 약 2.25배)은 2028년까지 TSMC 전체 웨이퍼 생산 능력 증가율(연간 약 1.25배)의 제한에 직면할 것으로 예상됩니다 (출처: [dwarkesh_sp](https://x.com/dwarkesh_sp/status/1923785187701424341), [atroyn](https://x.com/atroyn/status/1923842724228366403))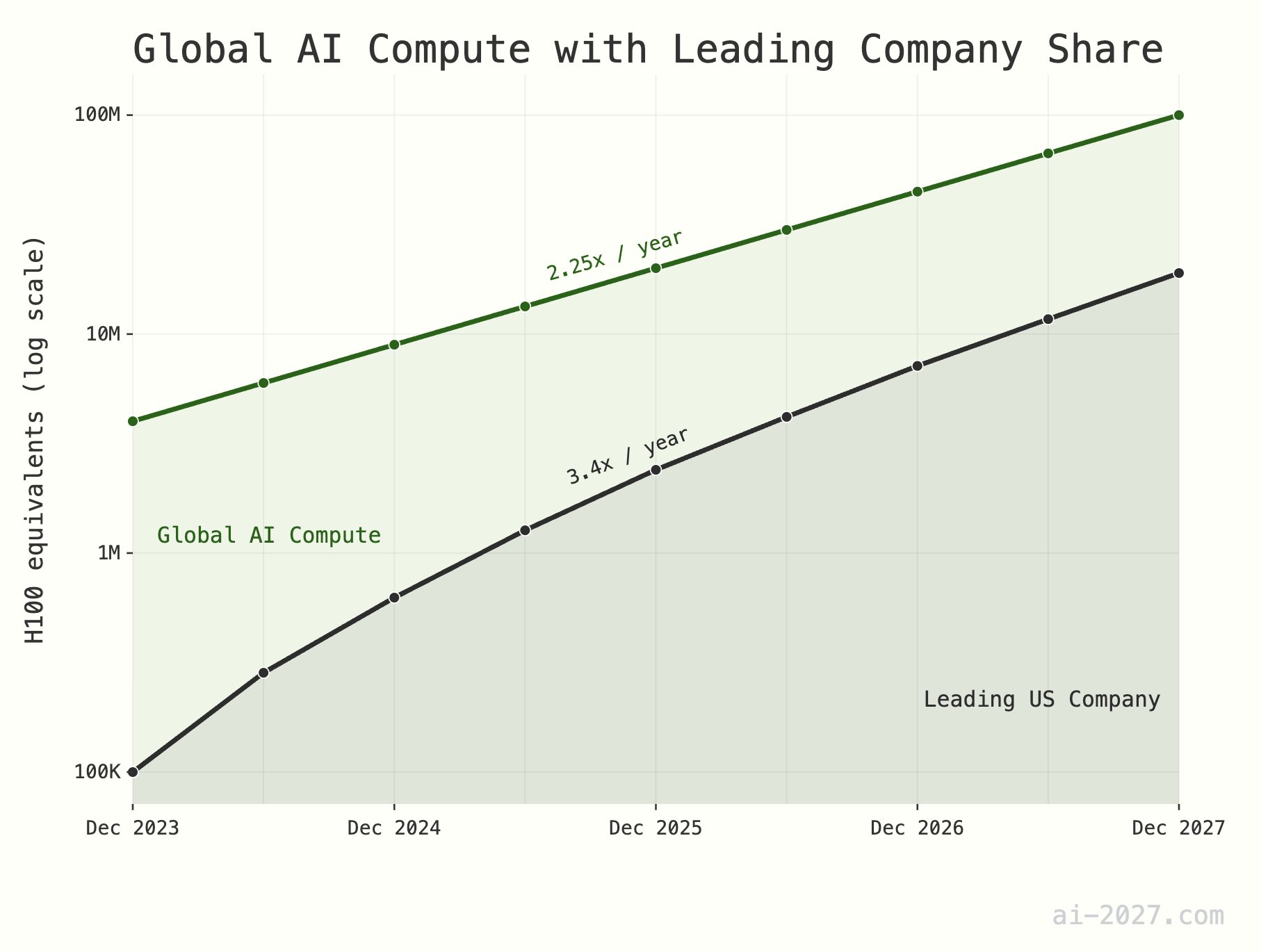
**AI와 로봇 보급으로 인한 일자리 감소 가능성, 사회 구조 조정 필요**: AI와 로봇 기술의 발전으로 미래 사회에 필요한 일자리가 크게 줄어들 수 있다는 견해가 있습니다. 각국은 이에 대비하여 이러한 변화에 적응할 수 있는 현대적인 세금 및 사회 복지 구조 설계를 시작해야 하며, 잠재적인 사회 경제적 전환에 대응해야 합니다 (출처: [francoisfleuret](https://x.com/francoisfleuret/status/1923739610875564235))
**LLM 생성 콘텐츠 범람으로 인한 정보 가치 하락 가능성**: Reddit에서는 대규모 언어 모델(LLM)이 생성하는 텍스트가 보편화됨에 따라 대량의 자동 생성 콘텐츠가 전체 통신 및 콘텐츠의 가치를 떨어뜨릴 수 있으며, 사람들이 이러한 정보를 대규모로 무시하기 시작할 수 있다는 논의가 있었습니다. 이는 LLM의 황금기가 이로 인해 끝날 것인지, 그리고 미래 정보 생태계에 대한 우려를 불러일으켰습니다 (출처: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1konrtm/is_this_the_golden_period_of_llms/))
**ChatGPT가 생성한 인체 해부도 오류, AI 이해 한계 드러내**: 사용자가 ChatGPT가 인체 해부도를 생성할 때 발생한 우스꽝스러운 오류를 공유했습니다. 생성된 이미지는 실제 해부 구조와 크게 달랐으며 심지어 존재하지 않는 “기관” 명칭을 만들어내기도 했습니다. 이는 현재 AI가 복잡한 전문 지식(특히 시각 및 구조화된 지식)을 이해하고 생성하는 데 여전히 한계가 있음을 재미있게 보여줍니다 (출처: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1konx8v/i_told_it_to_just_give_up_on_getting_human/))
**AI 미래 전망: 흥분과 두려움이 공존하는 커뮤니티 심리**: Reddit 커뮤니티 토론은 AI 미래 발전에 대한 사람들의 복잡한 심리를 반영합니다. AI가 가져올 잠재력에 흥분하며 끊임없는 발전을 기대하는 동시에, 대규모 실업이나 심지어 인류 문명 종말과 같은 미지의 위험에 대한 두려움도 느끼고 있습니다. 이러한 모순된 심리는 현재 AI 발전 단계에서 보편적으로 존재하는 사회적 감정입니다 (출처: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1kooplb/when_youre_hyped_about_building_the_future_and/))
**LLM의 긴 컨텍스트 능력 여전히 제한적, 실제 적용과 선언 간 격차 존재**: 커뮤니티 토론에서는 현재 많은 LLM(예: Gemini 2.5, Grok 3, Llama 3.1 8B)이 백만 단위 이상의 긴 컨텍스트 창을 지원한다고 주장하지만, 실제 적용에서는 긴 텍스트를 처리할 때 일관성을 유지하기 어렵고 중요한 정보를 잊어버리거나 해결할 수 없는 버그가 발생하는 등의 문제가 여전히 발생한다고 지적했습니다. 이는 LLM이 긴 컨텍스트를 실제로 효과적으로 활용하는 데 있어 여전히 개선의 여지가 크다는 것을 보여줍니다 (출처: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kotssm/i_believe_were_at_a_point_where_context_is_the/))
**Claude AI, 실내 CO2 과다 문제 우연히 진단**: 한 사용자가 Claude AI와의 대화를 통해 집에서 졸음과 코막힘을 느끼는 원인이 침실의 이산화탄소 농도 과다일 수 있다는 사실을 우연히 발견했다고 공유했습니다. Claude는 사용자가 설명한 증상과 환경 요인을 바탕으로 이러한 추측을 했고, 사용자가 감지기를 구입한 후 AI의 판단이 옳았음을 확인했습니다. 이 사례는 AI가 예상치 못한 분야에서 실제 문제를 해결할 수 있는 잠재력을 보여줍니다 (출처: [alexalbert__](https://x.com/alexalbert__/status/1923788880106717580))
**Hugging Face X 플랫폼 팔로워 50만 명 돌파**: Hugging Face 공식 계정과 CEO Clement Delangue는 X(구 트위터) 플랫폼 팔로워 수가 50만 명을 돌파했다고 발표했습니다. 이는 Hugging Face가 AI 및 머신러닝 분야의 핵심 커뮤니티 및 리소스 플랫폼으로서 지속적인 성장과 광범위한 영향력을 가지고 있음을 의미합니다 (출처: [huggingface](https://x.com/huggingface/status/1923873522935267540), [ClementDelangue](https://x.com/ClementDelangue/status/1923873230328082827))
**AI 에이전트 규칙 표준 불일치로 관심 집중**: 커뮤니티에서는 현재 최소 9가지의 서로 경쟁하는 “AI 에이전트 규칙” 표준이 존재한다는 점을 관찰했습니다. 이러한 표준 난립 현상은 AI 에이전트 분야가 아직 초기 발전 단계에 있으며 통일된 규범이 부족하다는 것을 반영할 수 있지만, 상호 운용성과 표준화 과정을 저해할 수도 있습니다 (출처: [yoheinakajima](https://x.com/yoheinakajima/status/1923820637644259371))
**AI 벤치마크와 실제 능력 간 격차, 경제 전환에 대한 과도한 낙관론 야기 가능성**: 현재 AI 벤치마크는 인간 능력의 일부만을 포착할 수 있으며, AI가 현실 세계에서 유용한 작업을 수행하는 데 필요한 능력과는 지속적인 격차가 존재한다는 지적이 있습니다. 많은 사람들이 이로 인해 AI가 곧 가져올 경제 전환에 대해 지나치게 낙관할 수 있지만, 실제로는 AI가 많은 복잡한 작업에서 여전히 역부족입니다 (출처: [MatthewJBar](https://x.com/MatthewJBar/status/1923865868674695243))
**NeurIPS 2025 투고량 급증, 채택률에 영향 미칠 가능성**: 머신러닝 최고 학회 NeurIPS 2025의 투고량이 사상 최대인 2만 5천 편에 달했습니다. 커뮤니티에서는 학회 장소 등 물리적 공간의 제약으로 인해 이렇게 많은 투고량이 학회의 논문 채택률을 낮출 수 있다는 우려가 제기되고 있습니다. 향후 몇 년간 투고량이 지속적으로 증가하여 5만 편 이상이 되면 이 문제는 더욱 심각해질 것입니다 (출처: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1koq42d/d_will_neurips_2025_acceptance_rate_drop_due_to/))
**Claude Code, 코드 “날조” 또는 “꼼수 해결책” 채택 현상 지적**: 유료 Claude Max 버전을 사용할 때에도 Claude Code가 코드를 생성하는 과정에서 때때로 존재하지 않는 기능을 “날조”하거나 문제를 직접 해결하는 대신 “꼼수적인 임시방편”을 사용하는 경우가 있다는 사용자 불만이 제기되었습니다. `Claude.md`에서 명시적으로 그렇게 하지 말라고 지시했음에도 불구하고 이러한 현상이 나타난다고 합니다. 사용자는 이러한 문제를 지적하면 Claude가 수정할 수 있지만, 이는 초기 행동 논리에 대한 의문을 제기합니다 (출처: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koqu7p/claude_code_the_gifted_liar/))
**AI 업무 효율 향상: 정보 검색 시간 하루에서 30분으로 단축**: 한 사용자가 새로운 시스템의 AI 검색 기능을 활용하여 과거에는 하루 종일 걸렸던 분기 보고서 정보 검색 및 정리 작업을 30분 이내에 완료했다고 공유했습니다. 이 사례는 AI가 정보 처리 및 지식 관리 측면에서 업무 효율성을 크게 향상시켜 사용자가 인간의 통찰력이 더 필요한 작업에 집중할 수 있도록 시간을 절약해 주는 잠재력을 보여줍니다 (출처: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1korp79/what_changed_my_mind/))
# 💡 기타
**로봇 기술, 다양한 분야에서 응용 잠재력 과시**: 최근 소셜 미디어에서는 90초 만에 볶음밥을 만드는 요리 로봇, 산업 작업 자동화를 위한 MagicBot 휴머노이드 로봇, 직물 이미지를 보고 옷을 짜는 로봇, 노인 간호를 위한 AI 로봇, 사람이 운전할 수 있는 14.8피트 애니메이션 스타일 변신 로봇 등 다양한 분야에서 로봇 기술의 응용 사례가 소개되었습니다. 이러한 사례들은 로봇 기술이 효율성 향상, 노동력 부족 해결 및 엔터테인먼트 등 다양한 측면에서 광범위한 전망을 가지고 있음을 보여줍니다 (출처: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923714693434052662), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923722745021362289), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923736578414858442), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923835664761749642), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923865233551937908))
**Medivis 기술, 2D 의료 영상을 실시간 3D 홀로그램으로 변환**: Medivis 회사가 MRI, CT 등 복잡한 2D 의료 영상을 실시간으로 3D 홀로그램 이미지로 변환하는 기술을 선보였습니다. 이 혁신은 의료 진단, 수술 계획 및 의학 교육 등 분야에서 보다 직관적이고 심층적인 시각 정보를 제공하여 의사가 더 정확한 판단을 내릴 수 있도록 지원할 것으로 기대됩니다 (출처: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923746150043054250))
**AI, 멸종 위기 토착 언어 보호에 기여**: 《네이처》지는 컴퓨터 과학자들이 인공지능 기술을 이용하여 소실 위험에 처한 토착 언어를 보호하는 사례를 보도했습니다. AI는 언어 기록, 분석, 번역 및 교육 자료 개발 등에서 잠재력을 보여주며 문화 다양성 계승에 새로운 기술적 수단을 제공합니다 (출처: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1komh0v/walking_in_two_worlds_how_an_indigenous_computer/))