
키워드:OpenAI 코덱스, AI 소프트웨어 개발, 멀티모달 모델, AI 음성 생성, 데이터 필터링, 코덱스 연구 프리뷰 버전, 미니맥스 스피치-02, BLIP3-o 멀티모달 모델, 프리셀렉트 데이터 필터링, SWE-1 모델 시리즈
🔥 주요 뉴스
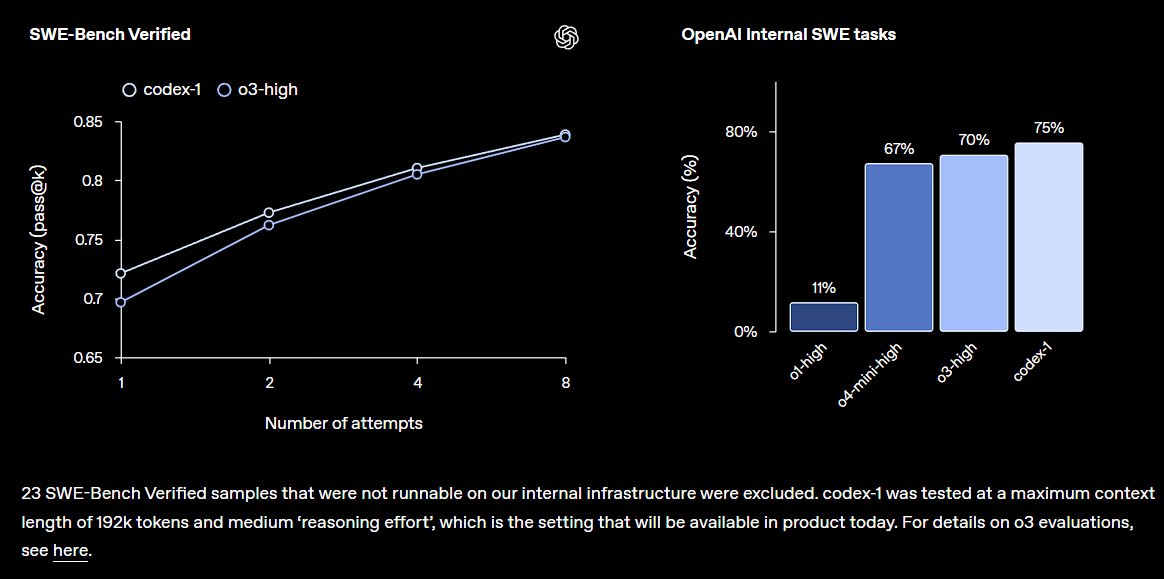
OpenAI, Codex 연구 프리뷰 버전 발표, ChatGPT에 통합: OpenAI가 클라우드 기반 소프트웨어 엔지니어링 에이전트인 Codex를 출시했습니다. Codex는 대규모 코드베이스를 이해하고, 새로운 기능을 작성하며, 오류를 수정하고, 여러 작업을 병렬로 처리할 수 있습니다. Codex는 o3으로 미세 조정한 codex-1 모델을 기반으로 하며 SWE-bench에서 우수한 성능을 보였습니다. 이 기능은 ChatGPT Pro, Team, Enterprise 사용자에게 점진적으로 공개될 예정이며, 개발자 생산성을 크게 향상시키는 것을 목표로 하며, AI가 소프트웨어 개발 분야에서 더욱 핵심적인 역할을 할 것임을 예고합니다. 커뮤니티는 이에 대해 긍정적인 반응을 보이고 있지만, 실제 효과와 잠재적인 버그에 대해서도 주목하고 있습니다 (출처: OpenAI, OpenAI Developers, scaling01, dotey)
Microsoft 대규모 감원, 업계 충격 속 AI 주도 조직 변화 가속화: Microsoft가 전 세계적으로 약 6,000명을 감원한다고 발표했습니다. 이는 관리 계층을 단순화하고 프로그래머 비율을 높이기 위한 조치로, 해고된 직원 중에는 25년 경력의 뛰어난 공헌을 한 베테랑 및 TypeScript 핵심 개발자도 포함되어 있습니다. 이번 감원은 AI 기술로 인한 효율성 향상 및 일부 업무 자동화와 관련된 것으로 여겨지며, AI 시대에 기술 대기업들이 비용을 통제하고 인력 구조를 최적화하려는 추세를 반영합니다. 이 사건은 AI가 고용 시장에 미치는 영향, 기업 충성도, 미래 업무 방식에 대한 광범위한 논의를 불러일으켰습니다 (출처: WeChat, NeelNanda5)
MiniMax, Speech-02 음성 모델 발표하며 글로벌 순위 정상 등극: MiniMax가 차세대 음성 모델 Speech-02를 출시했습니다. 이 모델은 Artificial Analysis Speech Arena와 Hugging Face TTS Arena라는 두 권위 있는 음성 평가에서 OpenAI와 ElevenLabs를 제치고 모두 1위를 차지했습니다. 이 모델은 초현실적인 의인화, 개인화된 음색 맞춤 설정(32개 언어 및 억양 지원, 몇 초의 참조만으로 복제 가능), 다양성 측면에서 뛰어난 성능을 보였으며, Flow-VAE 기술을 혁신적으로 채택하여 복제 디테일을 향상시켰습니다. 이 기술은 “AI阿祖” 영어 학습, 고궁 AI 가이드 등의 장면에 적용되어 중국산 대형 모델이 AI 음성 생성 분야에서 선도적인 위치에 있음을 보여줍니다 (출처: WeChat, WeChat)
Salesforce 등 기관, 통합 멀티모달 모델 BLIP3-o 발표: Salesforce Research가 여러 대학과 공동으로 완전 오픈소스 통합 멀티모달 모델 BLIP3-o를 발표했습니다. 이 모델은 “선이해 후생성” 전략을 채택하고 자기 회귀 아키텍처와 확산 아키텍처를 결합했습니다. 모델은 CLIP 특징과 Flow Matching을 혁신적으로 사용하여 훈련함으로써 생성된 이미지의 품질, 다양성 및 프롬프트 정렬 능력을 크게 향상시켰습니다. BLIP3-o는 여러 벤치마크 테스트에서 우수한 성능을 보였으며, 이미지 편집 및 시각적 대화와 같은 복잡한 멀티모달 작업으로 확장되어 멀티모달 AI 기술의 발전을 촉진하고 있습니다 (출처: 36氪)

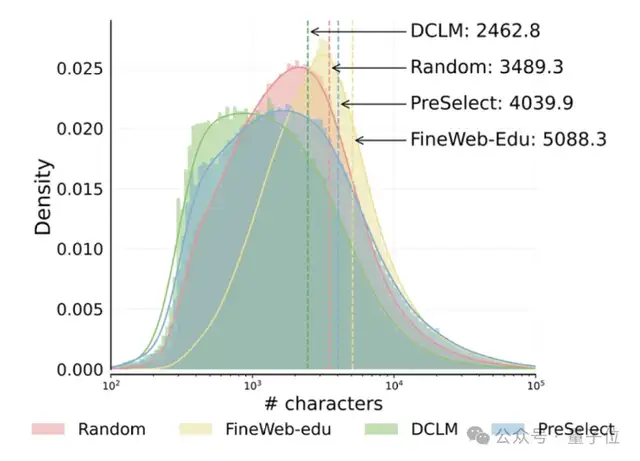
홍콩과기대와 vivo, PreSelect 데이터 필터링 방안 제시, 사전 훈련 효율 10배 향상: 홍콩과학기술대학교와 vivo AI Lab이 협력하여 경량급 고효율 데이터 선택 방법인 PreSelect를 제시했으며, 이는 ICML 2025에 채택되었습니다. 이 방법은 “예측 강도” 지표를 통해 모델의 특정 능력에 대한 데이터의 기여도를 정량화하고, fastText 평가기를 사용하여 전체 훈련 데이터를 필터링함으로써 계산 요구량을 10배 줄이면서 모델 효과를 평균 3% 향상시킬 수 있습니다. PreSelect는 고품질의 다양한 데이터를 보다 객관적이고 일반화된 방식으로 필터링하여 기존의 규칙 기반 또는 모델 기반 필터링 방법의 한계를 극복하는 것을 목표로 합니다 (출처: 量子位)
🎯 동향
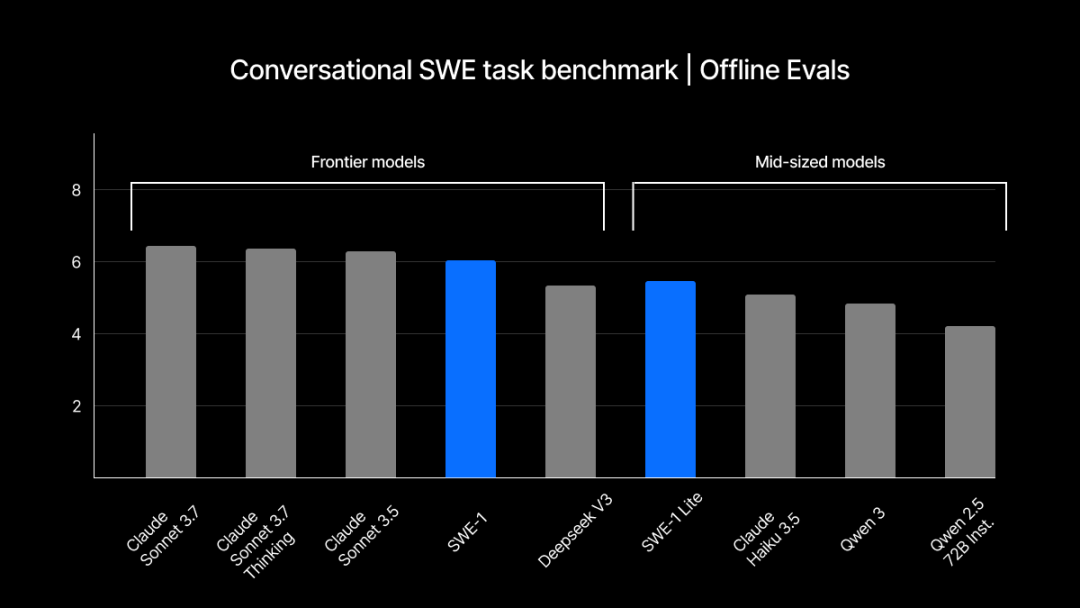
Windsurf, 자체 개발 SWE-1 시리즈 모델 발표, 소프트웨어 엔지니어링 프로세스 최적화: Windsurf가 개발 효율성을 99% 향상시키는 것을 목표로 하는 소프트웨어 엔지니어링 최적화 모델 시리즈 SWE-1을 처음으로 출시했습니다. 이 시리즈에는 SWE-1(Claude 3.5 Sonnet에 근접한 도구 호출 능력, 더 낮은 비용), SWE-1-lite(고품질, Cascade Base 대체), SWE-1-mini(작고 빠름, 저지연 시나리오용)가 포함됩니다. 핵심 혁신은 “흐름 인식”(Flow Awareness) 시스템으로, AI와 사용자가 작업 타임라인을 공유하여 효율적인 협업과 미완료 상태에 대한 이해를 실현합니다 (출처: WeChat, WeChat)
ChatGPT 기억 메커니즘 리버스 엔지니어링, 세 가지 기억 하위 시스템 공개: OpenAI가 ChatGPT에 도입한 “채팅 기록” 기억 기능이 기술 애호가들에 의해 분석되어, 현재 대화 기록, 대화 기록(요약 및 내용 검색 기반), 사용자 통찰(여러 대화 분석 기반 생성, 신뢰도 포함)의 세 가지 하위 시스템을 포함할 수 있음이 밝혀졌습니다. 이러한 메커니즘은 RAG 및 벡터 공간과 같은 기술을 통해 보다 개인화되고 효율적인 상호 작용 경험을 제공하는 것을 목표로 합니다. 공식적으로는 사용자 경험을 향상시킬 수 있다고 밝혔지만, 커뮤니티의 반응은 엇갈리며 일부 사용자는 기능 불안정 또는 버그를 보고하고 있습니다 (출처: WeChat, 量子位)
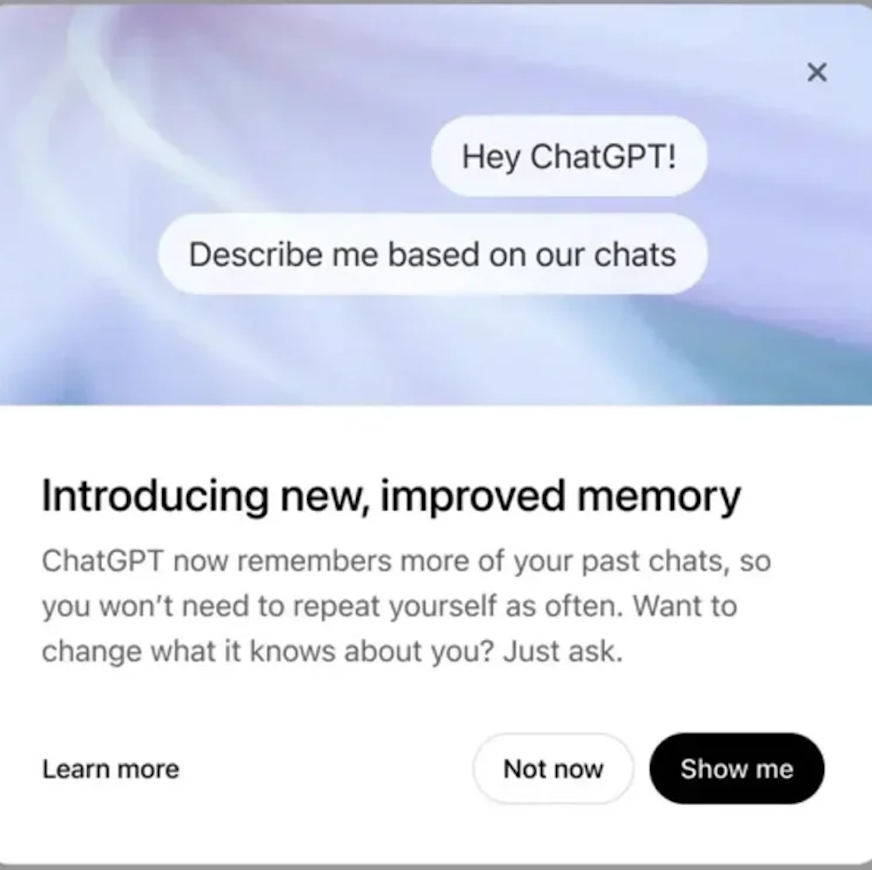
텐센트 Hunyuan Image 2.0 발표, 실시간 “말하면서 그리기” 지원: 텐센트 Hunyuan이 Hunyuan Image 2.0 모델을 출시하여 밀리초 단위 응답의 실시간 텍스트-이미지 생성 기능을 구현했습니다. 사용자가 텍스트나 음성 설명을 입력하면 이미지가 실시간으로 생성되고 조정됩니다. 새로운 모델은 실시간 드로잉 보드도 지원하여 사용자가 손으로 그린 스케치와 텍스트 설명을 결합하여 이미지를 생성할 수 있습니다. 모델은 사실감, 의미론적 준수(멀티모달 대형 언어 모델을 텍스트 인코더로 적용), 이미지 인코더/디코더 압축률 측면에서 크게 향상되었으며 강화 학습을 통해 후훈련 최적화를 진행했습니다 (출처: 量子位)
TII, Falcon-Edge 시리즈 BitNet 모델 및 onebitllms 미세 조정 라이브러리 발표: TII가 Falcon-Edge를 출시했습니다. 이는 1B 및 3B 파라미터 규모의 컴팩트 언어 모델 시리즈로, 크기는 각각 600MB와 900MB에 불과합니다. 이 모델들은 BitNet 아키텍처를 채택하여 성능 손실 거의 없이 bfloat16으로 복원할 수 있습니다. 초기 결과에 따르면 다른 소형 모델보다 성능이 우수하며 Qwen3-1.7B와 비슷하지만 메모리 사용량은 1/4에 불과합니다. 동시에 발표된 onebitllms 라이브러리는 BitNet 모델의 미세 조정을 위해 특별히 제작되었습니다 (출처: Reddit r/LocalLLaMA, winglian)

Ollama 새 엔진, 멀티모달 지원 강화: Ollama가 엔진을 업데이트하여 멀티모달 모델에 대한 기본 지원을 제공하고, 모델별 최적화 및 메모리 관리 개선을 허용합니다. 사용자는 LangChain 통합을 통해 Llama 4, Gemma 3 등 멀티모달 모델을 시도해 볼 수 있습니다. Google AI 개발자도 Ollama와 Gemma 3를 사용한 함수 호출 가이드를 발표하여 실시간 검색 등의 기능을 구현할 수 있도록 했습니다 (출처: LangChainAI, ollama)
Grok, 이미지 생성 가로세로 비율 제어 기능 추가: xAI의 Grok 모델이 이제 사용자가 이미지 생성 시 원하는 가로세로 비율을 지정할 수 있도록 하여 이미지 제작에 더 큰 유연성과 제어력을 제공합니다 (출처: grok)
Google AI Studio 업데이트, 생성 미디어 페이지 및 사용 대시보드 추가: Google의 ai.studio 플랫폼이 새로운 랜딩 페이지 디자인, 내장된 사용 현황 대시보드, 새로운 생성 미디어(gen media) 페이지를 포함한 일련의 업데이트를 진행했습니다. 이는 곧 있을 I/O 컨퍼런스에서 더 많은 관련 발표가 있을 수 있음을 예고합니다 (출처: matvelloso)
LatitudeGames, 새 모델 Harbinger-24B (New Wayfarer) 발표: LatitudeGames가 Hugging Face에 Harbinger-24B라는 새 모델을 발표했으며, 코드명은 New Wayfarer입니다. 커뮤니티는 이에 관심을 보이며 Qwen3 32B나 Llama 4 Scout 등 다른 모델을 미세 조정하지 않은 이유에 대해 논의하고 있습니다 (출처: Reddit r/LocalLLaMA)

🧰 도구
Adopt AI, 600만 달러 투자 유치, AI Agent를 통해 소프트웨어 상호작용 재구성 목표: 스타트업 Adopt AI가 600만 달러의 시드 라운드 투자를 유치했습니다. Agent Builder와 Agent Experience라는 두 가지 주요 기능을 통해 기존 기업용 소프트웨어에 코드 없이 자연어 상호작용 기능을 신속하게 통합하는 것을 목표로 합니다. 이 기술은 애플리케이션 구조와 API를 자동으로 학습하여 자연어로 호출할 수 있는 작업을 생성하고, Pass-through 아키텍처를 통해 데이터 보안을 보장하며, 소프트웨어 채택률과 효율성을 높이고 기업 비용을 절감하는 것을 목표로 합니다 (출처: WeChat)

바이트댄스 Volcano Engine, 고도로 DIY 가능한 미니 AI 하드웨어 데모 출시: Volcano Engine이 미니 AI 하드웨어 데모를 발표하고 클라이언트/서버 코드를 오픈소스로 공개했습니다. 이 하드웨어는 고도의 자유로운 맞춤 설정을 지원하며, Volcano 대형 모델, Coze 지능형 에이전트, 그리고 FastGPT와 같은 OpenAI API 호환 타사 대형 모델 및 MiniMax를 포함한 다양한 TTS 음성에 연결할 수 있습니다. 사용자는 젊은 주걸륜, 하경 등 특정 캐릭터와의 대화를 DIY로 구현하거나 AI 음성 고객 서비스와 같은 애플리케이션을 구축하여 풍부한 AI 상호작용 경험을 제공받을 수 있습니다 (출처: WeChat)

Runway, Gen-4 References API 출시, 개발자 이미지 생성 애플리케이션 구축 지원: Runway가 널리 사용되는 Gen-4 References 이미지 생성 모델을 API를 통해 개발자에게 공개했습니다. 이 모델은 범용성과 유연성으로 유명하며, 참조 이미지를 기반으로 스타일이 일관된 새로운 이미지를 생성할 수 있습니다. API 출시는 개발자가 이 강력한 이미지 생성 기능을 자신의 애플리케이션과 워크플로에 통합할 수 있게 해줄 것입니다 (출처: c_valenzuelab)

Zencoder, 코딩 최적화 AI 에이전트 플랫폼 Zen Agents 출시: AI 스타트업 Zencoder(정식 명칭 For Good AI Inc.)가 코딩 작업에 최적화된 AI 에이전트를 만들기 위한 클라우드 플랫폼 Zen Agents를 발표했습니다. 이는 소프트웨어 개발의 효율성과 품질을 향상시키는 것을 목표로 합니다 (출처: dl_weekly)
llmbasedos: MCP 기반의 초소형 Linux 배포판, 로컬 LLM 최적화: 한 개발자가 llmbasedos를 구축했습니다. 이는 Arch Linux 기반의 최소화된 배포판으로, 로컬 환경을 LLM 프론트엔드(예: Claude Desktop, VS Code)의 일등 시민으로 전환하는 것을 목표로 합니다. MCP(Model Context Protocol) 프로토콜을 통해 로컬 기능(파일, 메일, 프록시 등)을 노출하며, 오프라인 모드(llama.cpp 포함) 또는 GPT-4o, Claude 등 클라우드 모델 연결을 지원하여 개발자가 새로운 기능을 신속하게 추가할 수 있도록 합니다 (출처: Reddit r/LocalLLaMA)
PDF 파일에서 LLM 및 Linux 시스템 실행 가능성 주목: 기술 애호가 Aiden Bai가 PDF 파일에서 소형 언어 모델(예: TinyStories, Pythia, TinyLLM)을 실행하는 프로젝트 “llm.pdf”를 선보였습니다. 이는 모델을 JavaScript로 컴파일하고 PDF의 JS 지원을 활용하여 구현됩니다. 댓글에서는 이전에 PDF에서 Linux 시스템(RISC-V 에뮬레이터 사용)을 실행한 선례가 있다는 지적도 있었습니다. 이는 PDF가 동적 콘텐츠 컨테이너로서의 잠재력을 보여주지만, 보안 및 실용성에 대한 논의도 불러일으키고 있습니다 (출처: WeChat)

OpenAI Codex CLI 도구 업데이트, ChatGPT 로그인 및 새 mini 모델 지원: OpenAI 개발자 팀이 Codex CLI 도구 개선 사항을 발표했습니다. 여기에는 ChatGPT 계정을 통한 로그인 지원으로 API 조직에 빠르게 연결하고, 저지연 코드 질의응답 및 편집 작업에 최적화된 codex-mini 모델 추가가 포함됩니다 (출처: openai, dotey)
상탕과기 대형 모델 일체형 머신, IDC 추천 받아, 日日新 및 DeepSeek 등 모델 지원: IDC가 발표한 《중국 AI 대형 모델 일체형 머신 시장 분석 및 브랜드 추천, 2025》 보고서에서 상탕과기(SenseTime)의 대형 모델 일체형 머신이 선정되었습니다. 이 일체형 머신은 상탕 대형 장치 AI 인프라를 기반으로 하며, 고성능 컴퓨팅 칩과 추론 가속 엔진을 탑재하고, 상탕 “日日新SenseNova V6” 및 DeepSeek 등 주류 대형 모델을 지원합니다. 또한 전체 공급망의 자주적 통제 솔루션을 제공하여 총소유비용(TCO)을 최적화하며, 이미 의료, 금융 등 여러 산업에 적용되었습니다 (출처: 量子位)

오픈소스 워크플로우 자동화 도구 n8n, 중국어 지원 추가: 널리 사용되는 오픈소스 워크플로우 자동화 도구 n8n이 이제 커뮤니티에서 제공하는 현지화 패키지를 통해 중국어 인터페이스를 지원합니다. 사용자는 해당 버전의 현지화 파일을 다운로드하고 간단한 Docker 구성 수정을 통해 n8n에서 중국어로 작업할 수 있어 국내 사용자의 사용 장벽을 낮췄습니다 (출처: WeChat)

git-bug: Git에 내장된 분산형 오프라인 우선 버그 추적기: git-bug는 문제, 댓글 등을 일반 파일이 아닌 객체로 Git 저장소에 내장하여 분산형 오프라인 우선 버그 추적을 구현하는 오픈소스 도구입니다. GitHub, GitLab 등 플랫폼과 브리지를 통해 문제를 동기화하고 CLI, TUI 및 웹 인터페이스를 제공합니다 (출처: GitHub Trending)

PyLate, PLAID 인덱스 통합으로 대규모 데이터셋 모델 벤치마크 효율 향상: Antoine Chaffin이 PyLate(ColBERT 모델용 훈련 및 추론 생태계)에 PLAID 인덱스가 통합되었다고 발표했습니다. 이 통합을 통해 사용자는 매우 큰 규모의 데이터셋에서 최적의 모델을 효과적으로 벤치마크할 수 있게 되어 다양한 검색 순위표에서 SOTA를 달성하는 데 편리함을 제공합니다 (출처: lateinteraction, tonywu_71)

Neon: 오픈소스 서버리스 PostgreSQL 데이터베이스: Neon은 오픈소스 서버리스 PostgreSQL 대체 솔루션으로, 스토리지와 컴퓨팅을 분리하여 자동 확장, 코드형 데이터베이스 브랜칭, 제로 스케일링 기능을 구현합니다. 이 프로젝트는 GitHub에서 주목받고 있으며, 탄력적이고 확장 가능한 데이터베이스 솔루션이 필요한 AI 및 기타 애플리케이션 개발자에게 새로운 선택지를 제공합니다 (출처: GitHub Trending)

Unmute.sh: 맞춤형 프롬프트 및 음성 지원하는 새로운 AI 음성 채팅 도구: Unmute.sh는 사용자가 프롬프트(prompt)를 맞춤 설정하고 다양한 음성을 선택할 수 있는 기능을 특징으로 하는 새로운 AI 음성 채팅 도구로, 사용자에게 더욱 개인화되고 유연한 음성 상호작용 경험을 제공합니다 (출처: Reddit r/artificial)
📚 학습
세계 최초 멀티모달 제너럴리스트 모델 평가 프레임워크 General-Level 및 벤치마크 General-Bench 발표: ICML‘25 (Spotlight)에 채택된 한 연구에서 새로운 멀티모달 대형 모델(MLLM) 평가 프레임워크 General-Level과 관련 데이터셋 General-Bench를 제안했습니다. 이 프레임워크는 5단계 등급 체계를 도입하여 모델의 “협력적 일반화 효과”(Synergy), 즉 지식이 서로 다른 모달리티나 작업 간에 이전되어 향상되는 능력을 핵심적으로 평가합니다. General-Bench는 현재 가장 규모가 크고 포괄 범위가 넓은 MLLM 평가 벤치마크로, 700개 이상의 작업, 32만 개 이상의 테스트 데이터를 포함하며 이미지, 비디오, 오디오, 3D 및 언어의 5대 모달리티와 29개 분야를 포괄합니다. 순위표에 따르면 GPT-4V 등 모델은 현재 Level-2(협력 없음)에 불과하며, Level-5(전체 모달리티 완전 협력)에 도달한 모델은 아직 없습니다 (출처: WeChat)

논문 J1, 강화 학습을 통해 LLM-as-a-Judge의 사고 장려 제안: “J1: Incentivizing Thinking in LLM-as-a-Judge via RL”이라는 제목의 새 논문(arxiv:2505.10320)은 강화 학습(RL)을 활용하여 평가자로서의 대형 언어 모델(LLM-as-a-Judge)이 단순히 피상적인 판단을 내리는 것이 아니라 더 깊이 있는 “사고”를 하도록 장려하는 방법을 탐구합니다. 이 방법은 LLM이 복잡한 작업을 평가할 때의 정확성과 신뢰성을 향상시킬 수 있습니다 (출처: jaseweston)

새로운 프레임워크 TREQA, LLM을 활용하여 복잡한 텍스트 번역 품질 평가: 기존 기계 번역(MT) 지표가 복잡한 텍스트 평가에 있어 부족한 점을 해결하기 위해 연구자들이 TREQA 프레임워크를 제안했습니다. 이 프레임워크는 대형 언어 모델(LLM)을 사용하여 원본 텍스트와 번역된 텍스트에 대한 질문을 생성하고, 이러한 질문에 대한 답변을 비교하여 번역이 핵심 정보를 유지했는지 평가합니다. 이 방법은 장문 번역의 품질을 보다 포괄적으로 측정하는 것을 목표로 합니다 (출처: gneubig)

행렬과 그 전치 행렬의 곱셈에 대한 효율적인 계산 방법 발견: Dmitry Rybin 등이 행렬과 그 전치 행렬의 곱셈을 더 빠르게 계산하는 알고리즘(arxiv:2505.09814)을 발견했습니다. 이 기초적인 돌파구는 데이터 분석, 칩 설계, 무선 통신 및 LLM 훈련 등 여러 분야에 심오한 영향을 미칩니다. 이러한 계산은 해당 분야에서 흔히 사용되는 작업이기 때문입니다. 이는 성숙한 계산 선형 대수 분야에서도 여전히 개선의 여지가 있음을 다시 한번 증명합니다 (출처: teortaxesTex, Ar_Douillard)

DeepLearningAI: 소량 샘플 미세 조정으로 LLM 추론 능력 크게 향상 가능: 연구에 따르면 단 1,000개의 샘플로 대형 언어 모델을 미세 조정하는 것만으로도 추론 능력을 크게 향상시킬 수 있습니다. 실험 모델 s1은 추론 시 “Wait”라는 단어를 추가하여 추론 과정을 확장했으며, AIME 및 MATH 500과 같은 벤치마크에서 우수한 성능을 거두었습니다. 이 저자원 방법은 강화 학습 없이 소량의 데이터로도 고급 추론을 가르칠 수 있음을 보여줍니다 (출처: DeepLearningAI)
Hugging Face, 풍부한 컨텍스트 AI 애플리케이션 구축을 위한 무료 MCP 과정 출시: Hugging Face가 Anthropic과 협력하여 “MCP: Build Rich-Context AI Apps with Anthropic”이라는 무료 과정을 출시했습니다. 이 과정은 개발자가 MCP(Model Context Protocol) 아키텍처를 이해하고, MCP 서버 및 호환 애플리케이션을 구축하고 배포하는 방법을 학습하여 AI 애플리케이션과 도구 및 데이터 소스의 통합을 단순화하도록 돕는 것을 목표로 합니다. 현재 3,000명 이상의 학생이 등록했습니다 (출처: DeepLearningAI, huggingface, ClementDelangue)
awesome-gpt4o-images 프로젝트, GPT-4o 이미지 생성 우수 사례 수집: Jamez Bondos가 만든 GitHub 프로젝트 awesome-gpt4o-images가 33일 만에 5,700개 이상의 스타를 받았습니다. 이 프로젝트는 GPT-4o로 생성된 우수한 이미지 사례와 프롬프트를 수집하고 전시하며, 현재 거의 100개의 사례가 있으며 정리 및 검증 후 지속적으로 업데이트될 예정으로 AIGC 커뮤니티에 귀중한 창의적 자원을 제공합니다 (출처: dotey)
Yann LeCun, 자기 지도 학습(SSL) 강연 공유: Yann LeCun이 자기 지도 학습(SSL)에 대한 강연 내용을 공유했습니다. SSL은 중요한 기계 학습 패러다임으로, 모델이 레이블 없는 데이터에서 효과적인 표현을 학습하도록 하여 대규모 레이블링 데이터에 대한 의존도를 줄이고 모델 일반화 능력을 향상시키는 데 중요한 의미를 갖습니다 (출처: ylecun)
Hugging Face 논문 포럼, AI 논문 선별 위한 우수 자원으로 부상: Dwarkesh Patel이 Hugging Face의 논문 포럼을 추천하며, 지난 한 달간 최고의 AI 논문을 선별하는 데 훌륭한 자원이라고 평가했습니다. 이 플랫폼은 연구자들이 최신 AI 연구 동향을 발견하고 논의할 수 있는 편리한 채널을 제공합니다 (출처: dwarkesh_sp, huggingface)
ACL 2025 채택 결과 발표, 알리바바 국제 AIB팀 다수 논문 선정: 자연어 처리 최고 학회 ACL 2025의 채택 결과가 발표되었습니다. 올해 투고량이 사상 최고치를 기록하며 경쟁이 치열했습니다. 알리바바 국제 AI Business팀의 다수 논문이 채택되었으며, Marco-o1 V2, Marco-Bench-IF, HD-NDEs(환각 탐지를 위한 신경 미분 방정식) 등 일부 성과는 높은 평가를 받아 주 학회 장문으로 채택되었습니다. 이는 알리바바 국제의 AI 분야에 대한 지속적인 투자와 인재 양성이 성과를 거두기 시작했음을 반영합니다 (출처: 量子位)

dstack, 분산 훈련 위한 빠른 상호 연결 설정 가이드 발표: dstack이 NVIDIA 또는 AMD 클러스터에서 분산 훈련을 하는 사용자를 위해 dstack을 통해 빠른 상호 연결을 설정하는 방법에 대한 간결한 가이드를 제공했습니다. 이 가이드는 사용자가 클라우드 또는 로컬에서 AI 워크로드를 확장할 때 네트워크 성능을 최적화하는 데 도움을 주기 위한 것입니다 (출처: algo_diver)
AssemblyAI, LLM 프롬프트 기술 향상을 위한 10가지 팁 영상 공유: AssemblyAI가 YouTube 영상을 통해 대형 언어 모델(LLM) 프롬프트(prompting) 효과를 개선하는 10가지 팁을 공유했습니다. 이는 사용자가 LLM과 더 효과적으로 상호작용하여 원하는 출력을 얻도록 돕기 위한 것입니다 (출처: AssemblyAI)
LangGraph.js 학습 자료 모음 “awesome-langgraphjs” 주목: Brace가 “awesome-langgraphjs”라는 GitHub 저장소를 만들어 LangGraph.js로 구축된 오픈소스 프로젝트와 YouTube 튜토리얼 영상을 수집하고 관리하고 있습니다. 이 자료는 LangGraph.js를 사용하여 다중 에이전트 시스템부터 풀스택 채팅 애플리케이션에 이르기까지 다양한 애플리케이션을 구축하려는 개발자에게 편의를 제공합니다 (출처: LangChainAI)
💼 비즈니스
알리바바 AI 전략 전환 효과, 클라우드 사업 및 AI 제품 매출 크게 성장: 알리바바 2025년 4분기 재무 보고서에 따르면, 특정 사업을 제외한 전체 매출은 전년 동기 대비 10% 증가했으며, 클라우드 인텔리전스 사업 매출은 18% 증가했습니다. 이 중 AI 관련 제품 매출은 7분기 연속 세 자릿수 성장을 기록했습니다. 알리바바는 AI를 핵심 전략으로 삼고 향후 3년간 3,800억 위안 이상을 투자하여 클라우드 컴퓨팅 및 AI 인프라를 업그레이드할 계획입니다. 오픈소스인 통이치엔원(Qwen-3) 모델은 여러 글로벌 순위에서 1위를 차지했으며, 파생 모델은 10만 개를 넘어 기술력과 오픈소스 생태계의 활력을 보여줍니다. 알리바바는 자동차, 통신, 금융 등 산업에서 AI 적용을 가속화하고 있습니다 (출처: 36氪)
동영상 편집 앱 Mojo, Dailymotion에 인수: 동영상 편집 앱 Mojo (@mojo_video_app)가 Dailymotion에 인수되었습니다. Mojo의 동영상 편집 기술은 Dailymotion의 소셜 앱과 B2B 제품에 통합될 예정이며, 양사는 유럽 차세대 소셜 비디오 플랫폼을 공동으로 구축하는 것을 목표로 합니다 (출처: ClementDelangue)
Cohere, Ottogrid 인수하여 기업 AI 역량 강화: AI 회사 Cohere가 스타트업 Ottogrid를 인수했다고 발표했습니다. 이번 인수는 Cohere의 기업용 AI 솔루션 역량을 강화할 것으로 예상되지만, 구체적인 거래 조건과 Ottogrid의 기술 방향은 자세히 공개되지 않았습니다 (출처: aidangomez, nickfrosst)

🌟 커뮤니티
AI Agent, 업무 방식 변화 논의 촉발, 미래는 실시간 전략 게임과 유사할 수도: Will Depue는 미래의 업무가 《스타크래프트》나 《에이지 오브 엠파이어》와 유사한 방식으로 진화할 수 있다고 제안했습니다. 인간이 약 200개의 소형 지능형 에이전트를 지휘하여 작업을 처리하고, 정보를 수집하며, 시스템을 설계하는 방식입니다. Sam Altman은 이를 리트윗하며 동의를 표했습니다. Fabian Stelzer는 이를 “저그 러시 코딩”(Zerg rush coded)이라고 익살스럽게 표현했습니다. 이러한 관점은 AI Agent가 작업 흐름과 인간-기계 협업 방식을 어떻게 재편할지에 대한 커뮤니티의 상상과 논의를 반영합니다 (출처: willdepue, sama, fabianstelzer)
xAI의 Grok 로봇 답변 논란, 프롬프트 무단 수정 의혹: xAI는 X 플랫폼의 Grok 응답 로봇 프롬프트가 5월 14일 새벽에 무단으로 수정되어 특정 사건(예: 트럼프 관련 사건)에 대한 분석이 비정상적이거나 주류 정보와 불일치하게 보였다고 인정했습니다. 커뮤니티는 이 문제에 높은 관심을 보였으며, Clement Delangue 등은 투명성 제고를 위해 Grok의 오픈소스를 촉구했습니다. Colin Fraser 등 사용자는 Grok의 시간대별 답변을 비교하여 시스템 프롬프트 수정 내역을 리버스 엔지니어링하려고 시도했습니다 (출처: ClementDelangue, menhguin, colin_fraser)

Meta Llama4팀 대량 퇴사설, 커뮤니티 오픈소스 AI 전망 우려: 커뮤니티 소식에 따르면 Meta의 Llama4팀 구성원 약 80%(기존 14명 팀에서 11명 퇴사)가 이미 사임했으며, 주력 모델 Behemoth 출시가 지연되었다고 합니다. 이 사건은 광범위한 관심을 불러일으켰으며, Nat Lambert 등 업계 관계자들은 이에 대해 안타까움을 표했습니다. Scaling01은 Meta가 새로운 Llama 마케팅 총괄이 필요할 수 있다고 논평했습니다. TeortaxesTex 등 사용자는 이것이 오픈소스 AI 발전에 부정적인 영향을 미칠 수 있다고 우려하며, 심지어 중국이 오픈소스의 마지막 희망이 될 것인지에 대해 논의하기도 했습니다 (출처: teortaxesTex, Dorialexander, scaling01)

전쟁에서의 AI 활용 및 윤리 문제 주목: Reddit 커뮤니티에서 전쟁에서의 AI 활용에 대해 논의하며, 이미 감시 및 전투원 위치 파악에 사용되어 정보 분석을 통해 군사 정보를 제공하고 있다고 지적했습니다. 논의에서는 미국 군이 1991년부터 DART와 같은 AI 도구를 사용해 왔다고 언급했습니다. 사용자들은 AI 무기화가 가져올 수 있는 치명적인 위험과 인류에 대한 잠재적 위협을 우려하며, 관련 국제 조약 및 조치 제정 상황에 주목하고 있습니다. OpenAI의 사용 지침에서도 군사적 용도 금지 조항이 삭제되어 추가적인 고민을 불러일으키고 있습니다 (출처: Reddit r/ArtificialInteligence)
대형 언어 모델, CCPC 프로그래밍 대회에서 부진한 성적, 현재 한계 노출: 제10회 중국 대학생 프로그래밍 경진대회(CCPC) 결선에서 바이트댄스 Seed-Thinking 등 여러 유명 대형 언어 모델(o3/o4, Gemini 2.5 pro, DeepSeek R1 포함)이 부진한 성적을 거두어 대부분 기본 문제만 해결하거나 0점을 받았습니다. 공식 관계자는 모델이 순수하게 자율적으로 시도했으며 인공적인 개입은 없었다고 설명했습니다. 커뮤니티 분석에 따르면, 이는 현재 대형 모델이 고도로 혁신적이고 복잡한 알고리즘 문제를 해결하는 데 있어, 특히 비Agentic(즉, 도구 보조 실행 및 디버깅 없음) 모드에서의 한계를 드러낸 것입니다. OpenAI o3가 IOI 대회에서 Agentic 훈련을 통해 금메달을 딴 것과 대조됩니다 (출처: WeChat)

DSPy 프레임워크와 “쓰라린 교훈” 논의, 규범적 설계와 자동화된 프롬프트 강조: DSPy 관련 논의는 AI의 규모화 발전(Scaling)이 많은 엔지니어링 난제를 우회할 수 있지만(“쓰라린 교훈”), 문제 핵심 규범(요구사항과 정보 흐름)에 대한 신중한 설계를 대체할 수는 없다고 강조합니다. 그러나 규모화는 문제 정의의 추상화 수준을 높일 수 있습니다. 자동화된 프롬프트(예: prompt optimizers)는 “쓰라린 교훈”에 부합하는 계산 능력 활용 방법으로 간주되는 반면, 수동 프롬프트는 모델이 학습하도록 하는 대신 인간의 직관을 주입하기 때문에 이에 위배될 수 있습니다 (출처: lateinteraction, lateinteraction)
AI Agent 추론 시 자기 점검/도구 탐색의 계산 비용 주목: Paul Calcraft는 추론 단계에서 AI Agent가 적극적인 자기 점검, 도구 사용 및 탐색적 워크플로우를 수행하기 위해 막대한 계산 자원(예: 단일 문제 해결에 200달러 이상)을 투입하는 실제 사례에 대해 질문했습니다. 그는 Devin과 그 경쟁자들이 홍보 시연을 위해 그렇게 할 수 있지만, 새로운 솔루션을 찾는 시나리오(FunSearch와 유사하지만 제약이 덜한 경우)에 대해서는 불분명하다고 지적했습니다 (출처: paul_cal)
AI 보조 “분위기 코딩”(Vibe Coding) 논의 촉발: GitHub Copilot과 같은 도구 덕분에 “분위기 코딩”(Vibe Coding, 엄격한 계획보다는 직관과 AI 보조에 더 의존하는 코딩 방식)이 가능해졌으며, 심지어 16세 학생이 Copilot을 사용하여 학교 프로젝트를 완료하기도 했습니다. 커뮤니티는 이 현상에 대해 의견이 분분하며, 일부는 이것이 새로운 프로그래밍 패러다임이라고 생각하는 반면, 다른 일부는 기초와 규범의 중요성을 강조합니다 (출처: Reddit r/ArtificialInteligence, nrehiew_)
Hugging Face Transformers 라이브러리, 새 커뮤니티 게시판 개설: Hugging Face가 핵심 라이브러리 Transformers를 위해 새로운 커뮤니티 게시판을 개설했습니다. 공지 사항, 새로운 기능 소개, 로드맵 업데이트를 게시하고, 라이브러리 사용 또는 모델 문제에 대한 사용자 질문과 토론을 환영하며, 개발자와의 상호 작용 및 지원 강화를 목표로 합니다 (출처: TheZachMueller, ClementDelangue)
AI 개발자, 최고 학회에 “Findings” 논문 트랙 신설 촉구: NeurIPS 등 최고 AI 학회의 투고량이 급증함(예: NeurIPS 25,000편)에 따라 Dan Roy 등은 ACL 등 학회를 본떠 “Findings” 성격의 논문 트랙을 신설할 것을 촉구했습니다. 이는 주 학회 기준에는 미치지 못하지만 여전히 가치 있는 연구에 발표 기회를 제공하고, 심사 부담을 줄이며, 더 광범위한 학술 교류를 촉진하기 위한 것입니다. 제안에는 논문 명확성 향상 등에 초점을 맞춘 경량 심사 등이 포함됩니다 (출처: AndrewLampinen)
💡 기타
AI 기반 외골격, 휠체어 사용자 기립 및 보행 지원: AI 기반 외골격 장치가 휠체어 사용자가 다시 서고 걸을 수 있도록 돕는 능력을 선보였습니다. 이러한 기술은 로봇 공학, 센서 및 AI 알고리즘을 융합하여 사용자 의도를 감지하고 동력 보조를 제공함으로써 거동이 불편한 사람들에게 재활 및 삶의 질 개선의 희망을 가져다줍니다 (출처: Ronald_vanLoon)
AI를 활용한 사용자 이름 아이디어 시각화: Reddit과 X 커뮤니티에서 사용자들이 자신의 소셜 미디어 사용자 이름을 기반으로 AI 이미지 생성 도구(예: ChatGPT 내장 DALL-E 3)를 사용하여 콘셉트 이미지를 만들고 상상력이 풍부한 작품을 공유하는 작은 유행이 일고 있습니다. 이는 AI가 개인화된 창의적 표현 측면에서 재미있는 응용 가능성을 보여줍니다 (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)

아마존 광고, AI 활용하여 브랜드 해외 마케팅 효율 향상: 아마존 광고가 “세계 공공 스크린 실험실” 개념을 선보이며 AI 기술을 활용하여 중국 브랜드의 해외 진출을 지원하는 방법을 제시했습니다. Prime Video 등 미디어 매트릭스를 통해 브랜드 도달 범위를 확대하고, AI 크리에이티브 스튜디오(예: 비디오 생성 도구)를 활용하여 콘텐츠 제작 장벽을 낮추며, 아마존 DSP 및 Performance+와 같은 도구를 통해 광고 게재 및 전환을 최적화합니다. AI는 여기서 창의적인 아이디어 생성부터 효과 측정까지 전체 과정에서 역할을 수행하며, 특히 중소기업을 포함한 브랜드 소유주가 보다 효율적으로 글로벌 브랜드 구축을 수행하도록 돕는 것을 목표로 합니다 (출처: 36氪)
