키워드:AI 프로그래밍 에이전트, 코덱스, 음성 대형 모델, AI 에이전트, 오픈AI, 미니맥스, 알리바바, 큐웬, 코덱스 프리뷰 버전, 스피치-02 음성 모델, 월드PM 연구, 패스트VLM 시각 언어 모델, FG-CLIP 크로스모달 모델
🔥 주요 뉴스
OpenAI, AI 프로그래밍 에이전트 Codex 프리뷰 버전 출시: OpenAI가 5월 16일 심야에 클라우드 기반 소프트웨어 엔지니어링 에이전트 Codex의 프리뷰 버전을 출시했습니다. Codex는 소프트웨어 엔지니어링에 최적화된 o3 변종 모델 codex-1로 구동되며, 프로그래밍, 코드 라이브러리 질의응답, 버그 수정 및 풀 리퀘스트(pull request) 제출 등의 작업을 병렬 처리할 수 있습니다. 클라우드 샌드박스 환경에서 실행되며, 사용자 코드 라이브러리를 미리 로드하고 작업 완료 시간은 1~30분입니다. 현재 ChatGPT Pro, Team 및 Enterprise 사용자에게 공개되었으며, Plus 및 Edu 사용자는 곧 이용 가능할 예정입니다. 동시에 Codex CLI용 경량 모델 codex-mini(o4-mini 기반)를 출시했으며, API 가격은 입력 100만 토큰당 1.5달러, 출력 100만 토큰당 6달러입니다. (출처: 36氪, 机器之心, op7418)
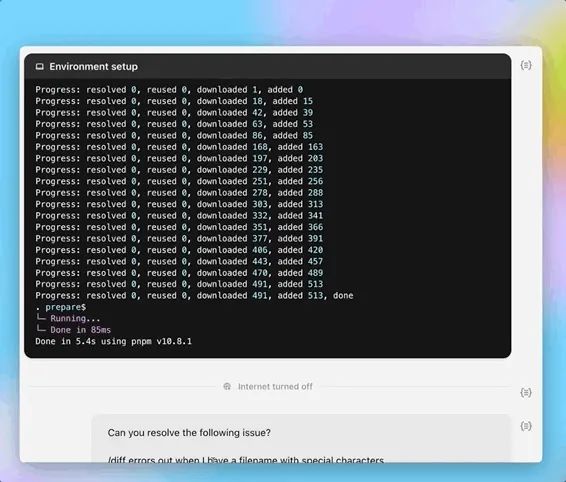
MiniMax, Speech-02 음성 대형 모델 출시로 글로벌 평가 차트 정상 등극: 중국 AI 기업 MiniMax가 최근 출시한 텍스트 음성 변환(TTS) 대형 모델 Speech-02-HD가 Artificial Analysis Speech Arena와 Hugging Face TTS Arena V2 두 글로벌 권위 있는 음성 벤치마크 평가에서 모두 1위를 차지하며 OpenAI와 ElevenLabs를 넘어섰습니다. 이 모델은 초현실적 의인화, 개인화 및 다양성 특징을 갖추고 있으며, 32개 언어를 지원하고 최소 10초의 음성 샘플만으로도 실제와 같은 음색 복제가 가능합니다. 이전에 화제가 되었던 “AI 다니엘 우(Daniel Wu)” 영어 학습 앱이 MiniMax 기술을 사용했습니다. Speech-02의 핵심 혁신에는 학습 가능한 화자 인코더와 Flow-VAE 플로우 매칭 모델이 포함되어 음질과 유사성을 향상시켰습니다. (출처: 36氪, karminski3)
AI Agent, 시장 관심 집중 속 대기업들 레이아웃 가속화: AI 에이전트(Agent)가 AI 분야의 새로운 초점으로 떠오르면서, Manus 등 범용 Agent 플랫폼의 공개 등록이 열풍을 일으키고 있으며, 모회사 Monica는 최근 7,500만 달러 규모의 신규 투자를 유치하여 기업 가치가 약 5억 달러에 달하는 것으로 알려졌습니다. Baidu(Xīnxiǎng), ByteDance(Kòuzi Kōngjiān), Alibaba(Xīnliú) 등 대기업들은 자체 Agent 제품 또는 플랫폼을 잇달아 출시하며 AI 시대의 관문을 선점하기 위해 경쟁하고 있습니다. Agent는 자료 제작, 웹 페이지 디자인, 여행 계획 등 더 복잡한 작업을 수행할 수 있습니다. 현재 범용 Agent는 여러 애플리케이션 간 작업 및 심층 작업 수행 능력에 여전히 부족함이 있으며, 불완전한 생태계와 데이터 사일로가 주요 과제입니다. MCP 프로토콜이 상호 연결성 해결의 핵심으로 간주되지만, 아직 참여자는 적습니다. B2B 수직 분야 Agent는 특정 장면에 집중하고 맞춤화가 용이하여 상용화를 먼저 실현할 가능성이 높은 것으로 평가됩니다. (출처: 36氪, 36氪)

Alibaba, 인간 선호도 모델링의 스케일링 법칙 탐구하는 WorldPM 연구 발표: Alibaba Qwen 팀은 《Modeling World Preference》라는 논문을 발표하여 인간 선호도 모델링이 스케일링 법칙(Scaling Laws)을 따른다는 것을 밝혀냈으며, 이는 다양한 인간 선호도가 통일된 표현을 공유할 수 있음을 시사합니다. 이 연구는 1,500만 개의 선호도 쌍을 포함하는 StackExchange 데이터셋을 사용하여 1.5B에서 72B 파라미터의 Qwen2.5 모델에서 실험을 진행했습니다. 결과에 따르면, 선호도 모델링은 객관적 및 견고성 지표에서 훈련 규모가 증가함에 따라 로그 손실 감소를 보였으며, 72B 모델은 일부 도전적인 작업에서 창발 현상을 나타냈습니다. 이 연구는 선호도 미세 조정을 위한 효과적인 기반을 제공하며, 논문과 모델(WorldPM-72B)은 모두 오픈소스로 공개되었습니다. (출처: Alibaba_Qwen)
🎯 동향
Google DeepMind와 Anthropic, AI 설명 가능성 연구에서 의견 차이: Google DeepMind는 최근 “기계론적 설명 가능성(mechanistic interpretability)”을 더 이상 연구 중점으로 두지 않겠다고 발표했습니다. 희소 오토인코더(SAE) 등의 방법을 통해 AI 내부 작동을 역공학하는 경로가 매우 어렵고 SAE 자체에 고유한 결함이 있다고 판단했기 때문입니다. 반면 Anthropic CEO Dario Amodei는 해당 분야 연구를 강화해야 한다고 주장하며, 향후 5~10년 내에 “AI의 MRI”를 실현할 수 있을 것이라고 낙관했습니다. AI의 “블랙박스” 특성은 많은 위험의 근원이며, 기계론적 설명 가능성은 모델의 특정 뉴런과 회로의 기능을 이해하는 것을 목표로 하지만, 10년 이상의 연구 성과는 제한적이어서 연구 경로에 대한 심도 있는 반성을 불러일으키고 있습니다. (출처: WeChat)

Poe 보고서, AI 모델 시장 구도 변화 공개, OpenAI와 Google 선두: Poe의 최신 AI 모델 사용 보고서에 따르면, 텍스트 생성 분야에서는 GPT-4o(35.8%)가 선두를 달리고 있으며, 추론 분야에서는 Gemini 2.5 Pro(31.5%)가 정상을 차지했습니다. 이미지 생성은 Imagen3, GPT-Image-1 및 Flux 시리즈가 주도하고 있습니다. 비디오 생성 분야에서는 Runway의 점유율이 하락하고, Kuaishou의 Kling이 다크호스로 부상했습니다. 에이전트 측면에서는 OpenAI의 o3가 연구 테스트에서 Claude와 Gemini보다 우수한 성능을 보였습니다. Anthropic의 Claude는 시장 점유율이 다소 하락했습니다. 보고서는 추론 능력이 핵심 경쟁 요소가 되었으며, 기업은 평가 시스템을 구축하고 빠르게 변화하는 시장에 대응하기 위해 다양한 모델을 유연하게 선택해야 한다고 지적했습니다. (출처: WeChat)

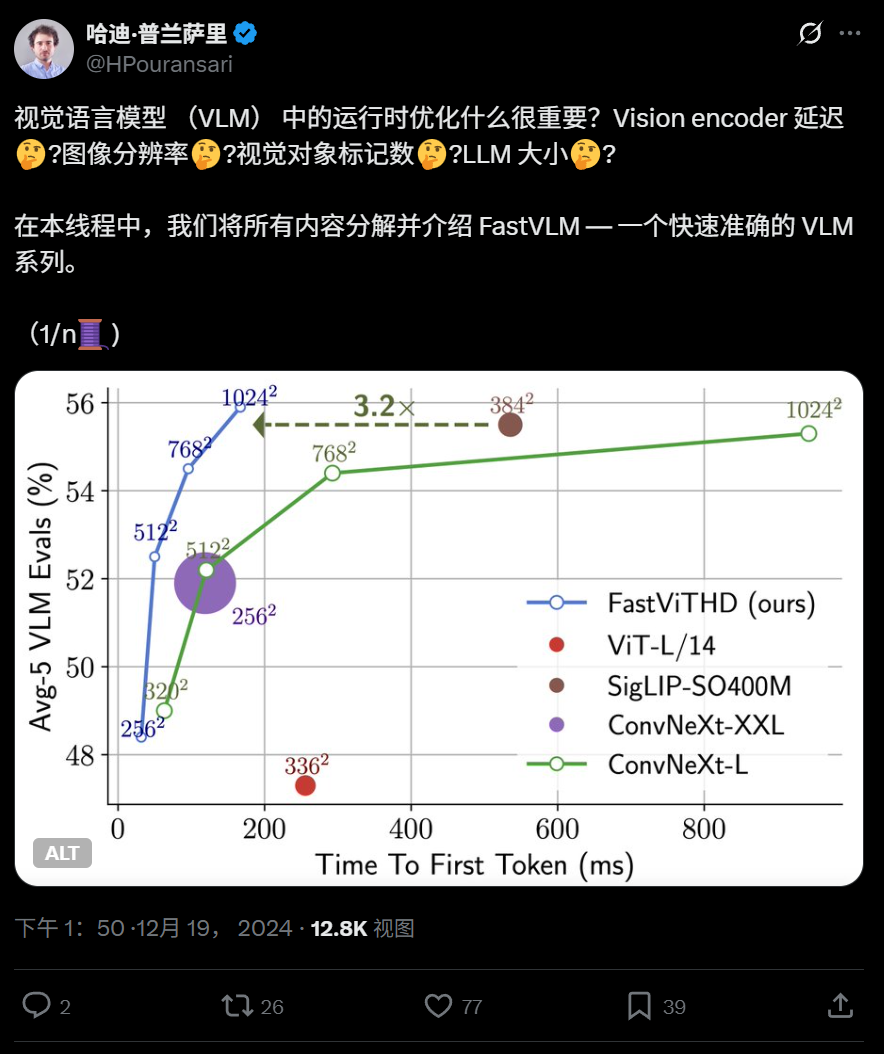
Apple, iPhone에서 실행 가능한 고효율 비전 언어 모델 FastVLM 오픈소스 공개: Apple이 iPhone 등 엣지 디바이스에서 효율적으로 실행되도록 특별히 설계된 비전 언어 모델 FastVLM을 오픈소스로 공개했습니다. 이 모델은 새로운 하이브리드 비전 인코더 FastViTHD(컨볼루션 레이어와 Transformer 모듈을 결합하고 다중 스케일 풀링 및 다운샘플링 기술 채택)를 통해 비전 토큰 수를 현저히 줄였으며(ViT보다 16배 적음), 첫 번째 토큰 출력 속도는 유사 모델 대비 85배 향상되었습니다. FastVLM은 주요 LLM과 호환되며, 0.5B, 1.5B, 7B 파라미터 버전이 이미 출시되어 엣지 AI 애플리케이션의 이미지 이해 속도와 사용자 경험을 향상시키는 것을 목표로 합니다. (출처: WeChat)
360, 차세대 이미지-텍스트 크로스모달 모델 FG-CLIP 출시, 세분화된 정렬 능력 향상: 360 인공지능 연구원이 기존 CLIP 모델의 이미지-텍스트 세분화 이해 부족 문제를 해결하기 위해 차세대 이미지-텍스트 크로스모달 모델 FG-CLIP을 개발했습니다. FG-CLIP은 2단계 훈련 전략을 채택합니다: 전역적 대조 학습(멀티모달 대형 모델이 생성한 긴 설명을 통합)과 국소적 대조 학습(영역-텍스트 주석 데이터와 어려운 세분화된 네거티브 샘플 학습 도입)을 통해 이미지의 국소적 세부 사항과 텍스트의 미세한 속성 차이를 정확하게 포착합니다. 이 모델은 ICML 2025에 채택되었으며, Github와 Huggingface에 오픈소스로 공개되었고 가중치는 상업적으로 사용 가능합니다. (출처: WeChat)

Google, 확산 모델을 이용해 이미지 광원 및 그림자 정밀 제어하는 LightLab 출시: Google 연구팀이 단일 이미지를 기반으로 광원을 세밀하게 파라미터화하여 제어할 수 있는 LightLab 프로젝트를 발표했습니다. 사용자는 가시광원의 강도, 색상, 주변광의 강도를 조절하고 가상 광원을 장면에 삽입할 수 있습니다. LightLab은 특수 제작된 데이터셋(실제 제어된 조명 사진 쌍과 대규모 합성 렌더링 이미지 포함)에서 확산 모델을 미세 조정하여 구현되며, 빛의 선형 특성을 이용해 광원과 주변광을 분리하고 다양한 조명 변화 이미지를 대량으로 합성하여 훈련합니다. 이 모델은 간접 조명, 그림자, 반사와 같은 복잡한 조명 효과를 이미지 공간에서 직접 시뮬레이션할 수 있습니다. (출처: WeChat)

Tencent, GRPO 및 RCS 강화 학습 방법 제안, 의도 탐지 일반화 성능 향상: Tencent PCG 소셜 라인 연구팀은 의도 인식 작업에 그룹화된 상대적 정책 최적화(GRPO) 알고리즘과 보상 기반 커리큘럼 샘플링 전략(RCS)을 결합한 강화 학습 방법을 제안했습니다. 이 방법은 모델이 알 수 없는 의도에 대한 일반화 능력을 크게 향상시켰으며(새로운 의도 및 교차 언어 능력에서 최대 47% 향상), 특히 “사고(Thought)”를 도입한 후 복잡한 의도 탐지의 일반화 능력이 더욱 강화되었습니다. 실험 결과, RL 훈련 모델은 일반화 성능에서 SFT 모델보다 우수했으며, 사전 훈련된 모델 기반이든 명령어 미세 조정 모델 기반이든 GRPO 훈련 후 성능이 유사했습니다. (출처: WeChat)

난양공대 등, RAG 기반 고해상도 이미지 인식 향상시키는 RAP 프레임워크 제안: 난양공과대학교 타오다청(Tao Dacheng) 교수팀 등은 멀티모달 대형 언어 모델(MLLM)이 고해상도 이미지를 처리할 때 발생하는 정보 손실 문제를 해결하기 위해 훈련이 필요 없는 RAG 기술 기반의 고해상도 이미지 인식 플러그인 Retrieval-Augmented Perception (RAP)을 제안했습니다. RAP은 사용자 질문과 관련된 이미지 블록을 검색하고, Spatial-Awareness Layout 알고리즘을 사용하여 상대적 위치 관계를 유지하며, Retrieved-Exploration Search (RE-Search)를 통해 유지할 이미지 블록 수 K를 자율적으로 선택하여 입력 이미지 해상도를 효과적으로 낮추면서 핵심 시각 정보를 보존합니다. 실험 결과, RAP은 HR-Bench 4K 및 8K 데이터셋에서 정확도를 각각 최대 21% 및 21.7% 향상시켰습니다. 이 성과는 ICML 2025에서 Spotlight 논문으로 채택되었습니다. (출처: WeChat)

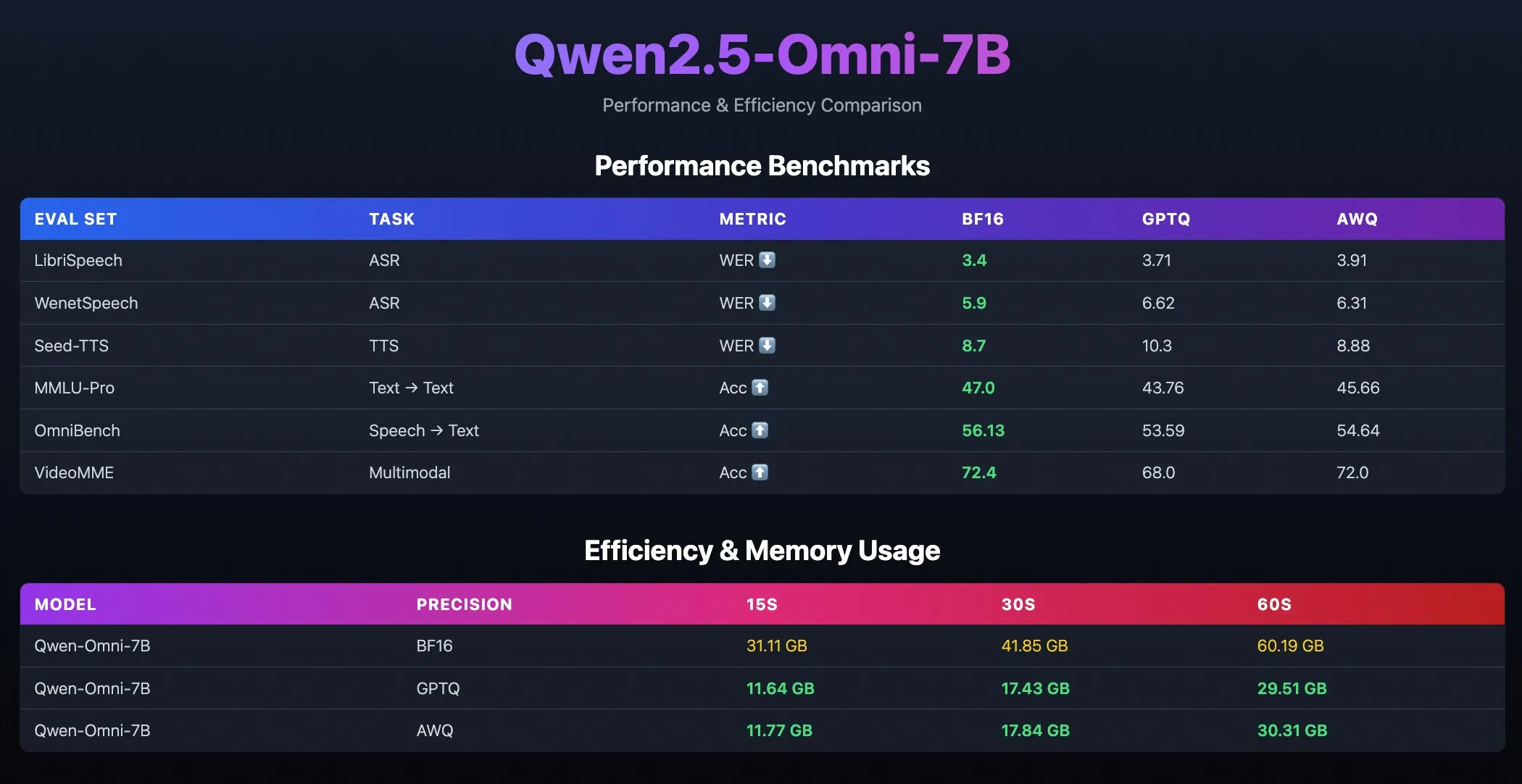
Qwen2.5-Omni-7B 양자화 모델 출시: Alibaba Qwen 팀이 Qwen2.5-Omni-7B 모델의 양자화 버전(GPTQ 및 AWQ 최적화 체크포인트 포함)을 출시했습니다. 이 모델들은 Hugging Face와 ModelScope에 공개되었으며, 강력한 멀티모달 능력을 유지하면서 더 효율적이고 자원 소모가 적은 배포 옵션을 제공하는 것을 목표로 합니다. (출처: Alibaba_Qwen, karminski3, reach_vb)
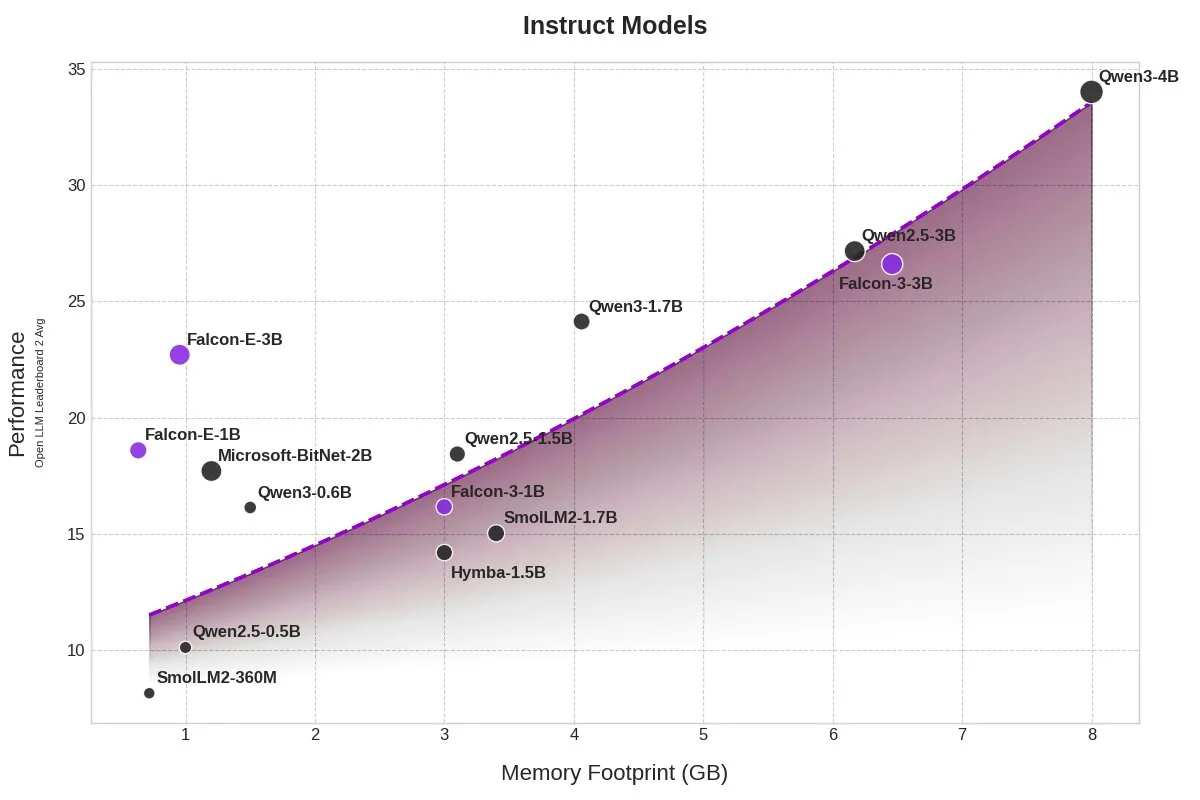
TII, BitNet 모델 Falcon-E-1B/3B 출시, 메모리 점유율 대폭 감소: 기술 혁신 연구소(TII)가 Microsoft의 1-bit 정밀도 모델 프레임워크 BitNet을 기반으로 한 새로운 모델 시리즈 Falcon-Edge를 출시했으며, Falcon-E-1B와 Falcon-E-3B를 포함합니다. 이 모델들은 Qwen3-1.7B와 유사한 성능을 보이면서도 메모리 점유율은 1/4에 불과하다고 합니다. TII는 동시에 사용자가 NVIDIA 그래픽 카드에서 이러한 1-bit 모델을 직접 미세 조정할 수 있도록 지원하는 미세 조정 라이브러리 onebitllms를 출시했습니다. (출처: karminski3)
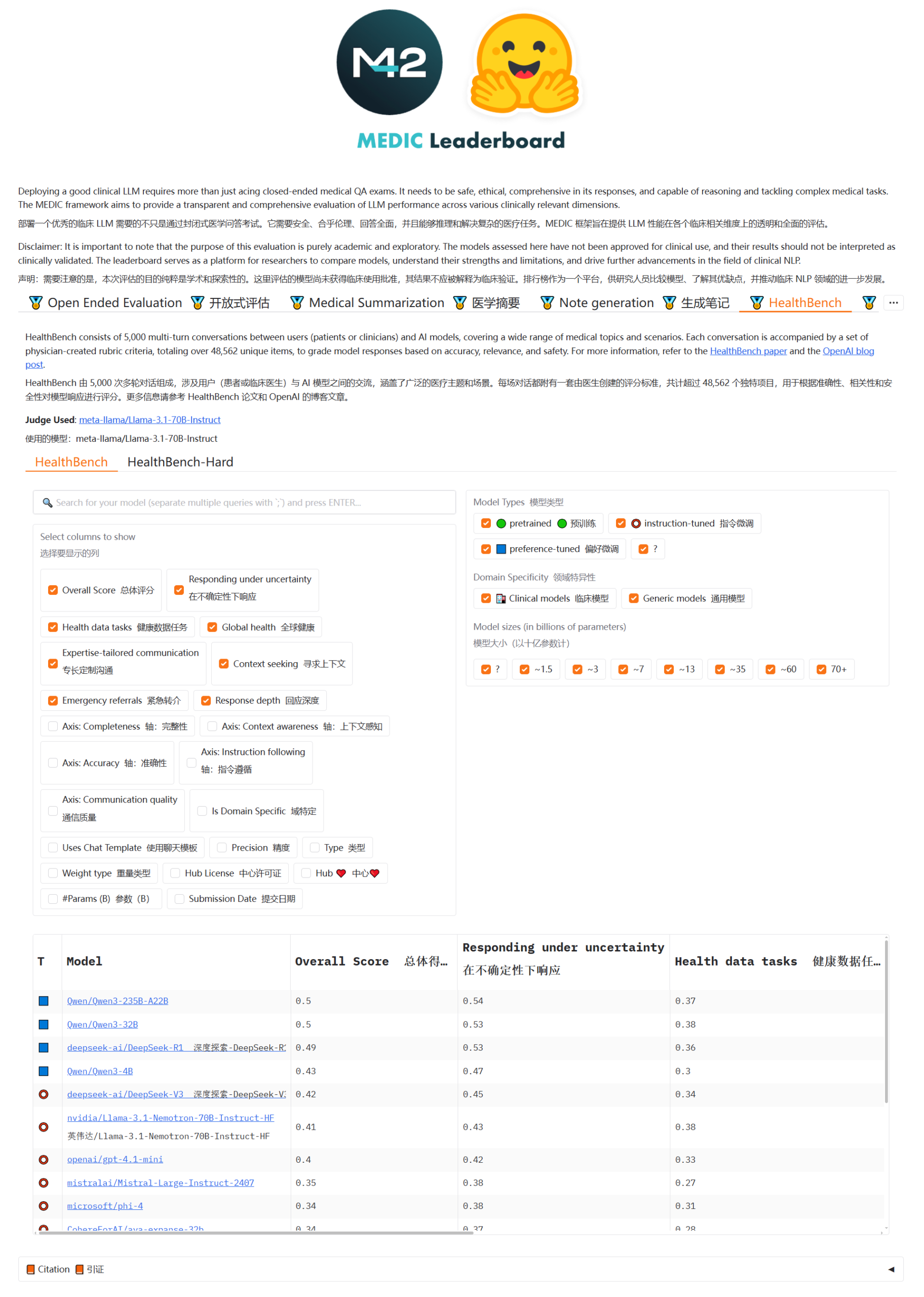
Qwen3 및 DeepSeek 모델, MEDIC-Benchmark 의료 질의응답 순위에서 선두: Qwen3 모델이 최근 발표된 MEDIC-Benchmark 의료 질의응답 순위에서 1위와 2위를 차지했습니다. 또한, 상위 5위권은 모두 Qwen 및 DeepSeek 시리즈 모델이 차지하여, 이들 중국산 대형 모델이 전문 의료 분야에서 강력한 질의응답 능력을 보여주었습니다. (출처: karminski3)
저장대학, Rankformer 제안: 순위 직접 최적화하는 Transformer 추천 모델 아키텍처: 저장대학 팀이 순위 목표(예: BPR 손실 함수)에서 직접 파생된 설계를 가진 새로운 그래프 Transformer 추천 모델 아키텍처인 Rankformer를 제안했습니다. Rankformer는 경사 하강 과정에서의 벡터 최적화 방향을 시뮬레이션하여 독특한 그래프 Transformer 메커니즘을 설계하고, 순방향 전파에서 모델이 더 나은 순위 표현을 인코딩하도록 유도합니다. 이 모델은 전역 어텐션 메커니즘을 사용하여 정보를 집계하며, 수학적 변환과 캐시 최적화를 통해 시공간 복잡도를 선형 수준으로 낮췄다고 주장합니다. 이 연구는 WWW 2025 컨퍼런스에 채택되었습니다. (출처: WeChat)
🧰 도구
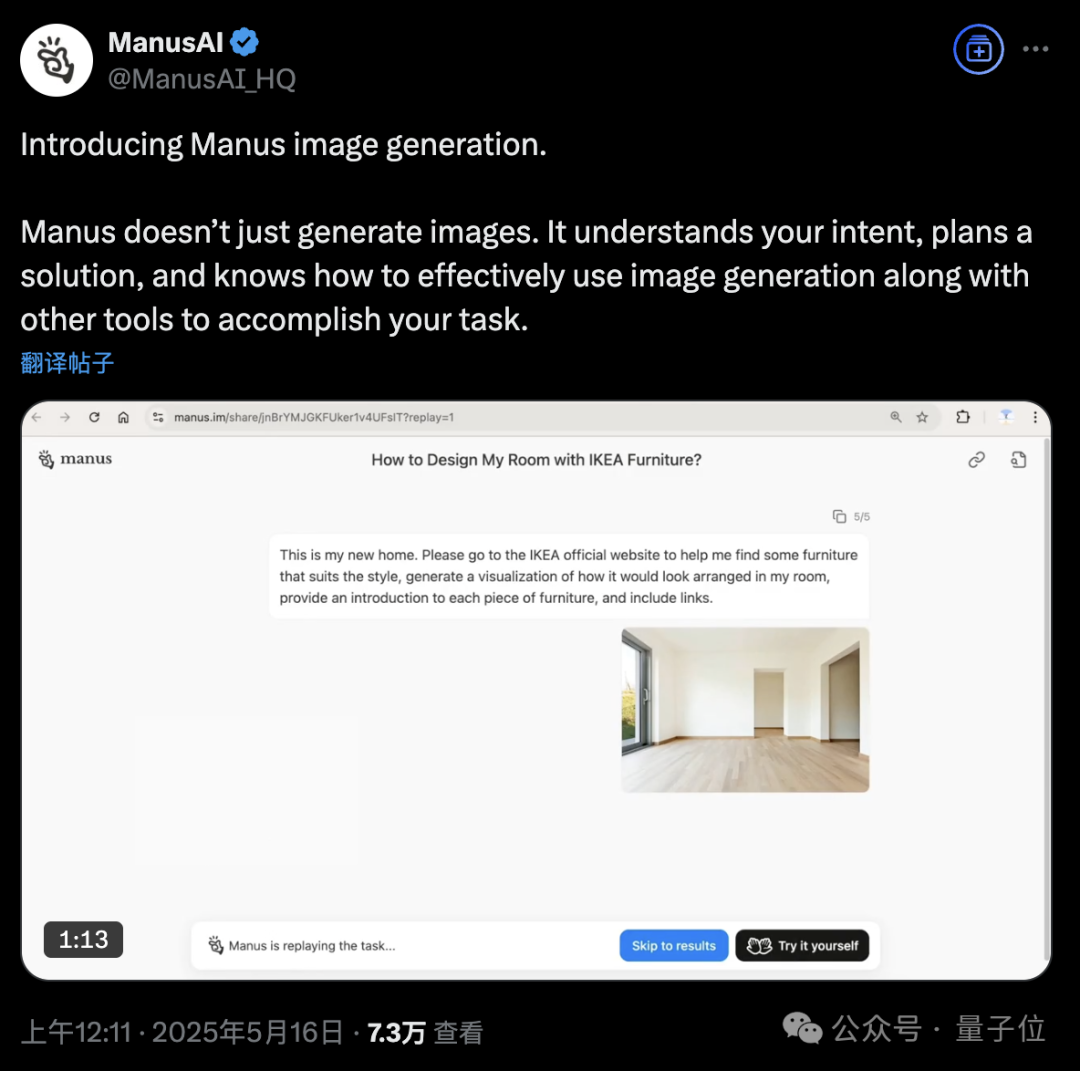
Manus AI Agent 플랫폼, 이미지 생성 기능 추가: AI Agent 플랫폼 Manus가 이미지 생성을 지원한다고 발표했습니다. 기존 AI 드로잉 도구와 달리 Manus는 사용자의 드로잉 목적을 이해하고 생성 계획을 수립할 수 있습니다. 예를 들어, 사용자는 방 사진을 업로드하고 Manus에게 IKEA 공식 웹사이트에서 가구를 찾아 시각화된 인테리어 효과 이미지를 생성하도록 요청하면서 가구 링크를 첨부할 수 있습니다. Manus는 분석, 검색, 가구 필터링, 디자인 전략 작성 등의 단계를 통해 작업을 완료합니다. 이 기능은 에이전트 워크플로우와 이미지 생성을 깊이 있게 결합하는 것을 목표로 합니다. 현재 Manus는 등록이 개방되었으며 1000 포인트를 증정하고 매일 추가로 300 포인트를 증정하며 유료 구독 플랜도 제공합니다. (출처: 36氪, WeChat)
Lovart 디자인 Agent 플랫폼 출시, 창의적 워크플로우에 집중: 신흥 디자인 Agent 플랫폼 Lovart가 출시 후 빠르게 주목받고 있으며, 핵심 이념은 디자이너의 창작 과정(멀티모달 포함)을 Agent 워크플로우로 전환하는 것입니다. Lovart는 캔버스 스타일의 인터랙티브 인터페이스를 제공하여 사용자가 대화를 통해 AI에게 디자인 작업을 지시하고 AI가 계획 및 실행을 담당합니다. 창립자 천몐(陈冕)은 AI 이미지 제품이 Agent 주도의 3.0 단계에 진입했으며, Lovart는 디자이너의 “친구”가 되어 사소한 일은 AI에게 맡기고 디자이너가 창의성에 집중할 수 있도록 하는 것을 목표로 한다고 말했습니다. 제품은 향후 3D 모델링, 비디오, 오디오 기능을 통합하여 “창의 팀” 또는 “디자인 회사”가 될 것입니다. (출처: 36氪)
OpenAI Codex CLI 업데이트, o4-mini 통합 및 무료 API 크레딧 제공: OpenAI가 경량 오픈소스 코딩 에이전트 Codex CLI를 개선했습니다. 새 버전은 codex-1의 간소화 버전인 o4-mini(codex-mini로 명명)로 구동되며, 낮은 지연 시간의 코드 질의응답 및 편집에 최적화되어 있습니다. 사용자는 이제 ChatGPT 계정으로 Codex CLI에 로그인할 수 있으며, Plus 및 Pro 사용자는 각각 5달러와 50달러의 무료 API 크레딧(30일 유효)을 교환하여 codex-mini-latest 모델을 체험할 수 있습니다. (출처: openai, hwchung27, op7418)
DeepSeek 오픈소스 데이터 처리 프레임워크 Smallpond, DuckDB의 3FS 네이티브 액세스 통합: DeepSeek의 오픈소스 데이터 처리 프레임워크 Smallpond는 내부적으로 3FS(DeepSeek File System)와 DuckDB를 사용합니다. 이제 DuckDB는 hf3fs_usrbio 플러그인을 통해 3FS에 네이티브 방식으로 액세스할 수 있게 되어 성능 향상과 오버헤드 감소를 가져올 것입니다. DuckDB 자체도 사용 편의성으로 호평을 받고 있으며, 예를 들어 쿼리문에 URL을 직접 삽입하여 데이터를 처리할 수 있습니다. (출처: karminski3)

ComfyUI, Alibaba Wan2.1-VACE 비디오 모델 네이티브 지원: ComfyUI가 Alibaba Wanxiang(@Alibaba_Wan) 팀의 비디오 생성 모델 Wan2.1-VACE 14B 및 1.3B 버전을 네이티브로 지원한다고 발표했습니다. 이 모델은 ComfyUI에 텍스트-비디오, 이미지-비디오, 비디오-비디오(자세 및 깊이 제어), 비디오 복원(inpainting) 및 확장(outpainting), 캐릭터/객체 참조 등 통합된 비디오 편집 기능을 제공합니다. (출처: TomLikesRobots)
Google AI Studio, Veo 2, Gemini 2.0 및 Imagen 3 통합, 통합 생성 미디어 경험 제공: Google AI Studio가 비디오 모델 Veo 2, Gemini 2.0의 네이티브 이미지 생성/편집 기능, 그리고 최신 텍스트-이미지 생성 모델 Imagen 3를 통합한 새로운 생성 미디어 경험을 출시했습니다. 사용자는 AI Studio에서 이러한 모델들을 무료로 체험할 수 있으며, 개발자도 API를 통해 구축할 수 있습니다. (출처: op7418)
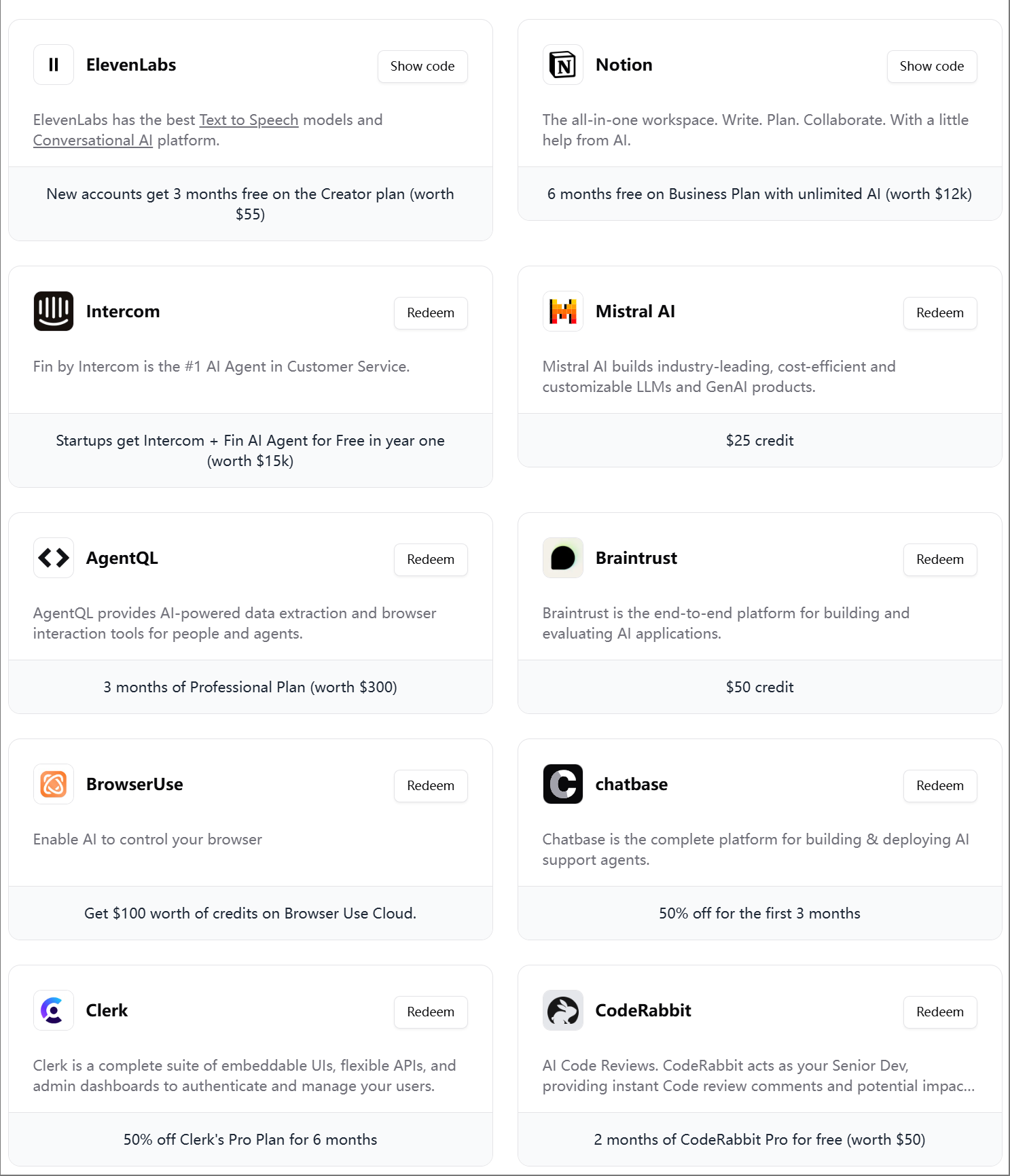
ElevenLabs, 제4차 AI 엔지니어 기프트팩 출시: ElevenLabs가 AI 개발자를 위한 제4차 AI 엔지니어 기프트팩을 출시했습니다. 여기에는 Modal Labs, Mistral AI, Notion, BrowserUse, Intercom, Hugging Face, CodeRabbit 등 다양한 도구 및 서비스의 멤버십과 API 크레딧이 포함되어 있으며, AI 스타트업과 개발자를 지원하는 것을 목표로 합니다. (출처: op7418)
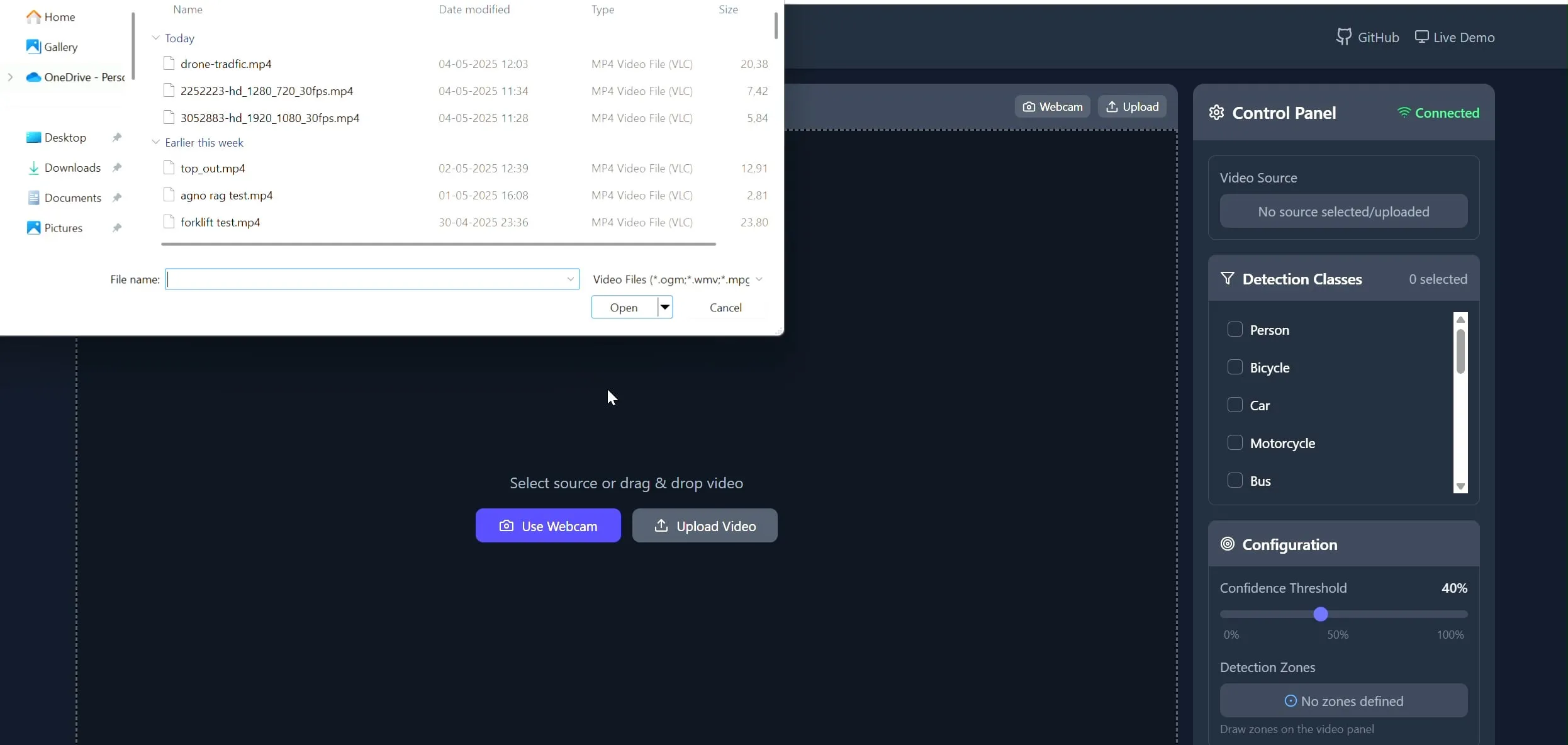
Polygon Zone App: CV 작업을 위한 비디오 맞춤형 다각형 그리기 도구: 개발자 Pavan Kunchala가 Polygon Zone App이라는 도구를 만들었습니다. 이 도구를 사용하면 비디오를 업로드하고 비디오 프레임에 대화형으로 맞춤형 다각형 영역(ROI)을 그린 다음, 이러한 영역 내에서 객체 감지 등 컴퓨터 비전 분석을 실행할 수 있습니다. 이 도구는 CV 프로젝트에서 ROI를 정의하는 번거로운 과정을 단순화하고 JSON 좌표를 수동으로 편집하는 것을 피하기 위해 설계되었습니다. (출처: Reddit r/deeplearning)
📚 학습
AI Evals 과정, 300개 이상 기업 참여 유치: Hamel Husain이 개설한 AI 평가 과정(bit.ly/evals-ai)에 Adobe, Amazon, Google, Meta, Microsoft, NVIDIA, OpenAI 등 유명 기업과 다수의 최고 대학을 포함하여 300개 이상의 기업이 참여했습니다. 이는 업계에서 AI 모델 평가 방법 및 실습에 대한 높은 관심과 수요를 반영합니다. (출처: HamelHusain)
Latent.Space, ChatGPT Codex 사용 설명서 발표: Latent.Space가 《ChatGPT Codex: The Missing Manual》이라는 가이드라인을 발표했습니다. 이 가이드라인은 OpenAI가 새로 출시한 클라우드 기반 자율 소프트웨어 엔지니어 ChatGPT Codex를 효율적으로 사용하는 방법을 자세히 소개합니다. Josh Ma와 Alexander Embiricos가 작성한 이 설명서는 사용자가 코드 라이브러리 작업에서 Codex의 강력한 기능을 최대한 활용할 수 있도록 돕는 것을 목표로 합니다. (출처: swyx)

Qdrant, 로컬 RAG 애플리케이션 튜토리얼 공개: Qdrant Engine이 @maxedapps가 제작한 튜토리얼을 공유했습니다. 이 튜토리얼은 Gemma 3, Ollama, Qdrant Engine을 사용하여 처음부터 100% 로컬에서 실행되는 검색 증강 생성(RAG) 애플리케이션을 구축하는 방법을 시연합니다. 이 튜토리얼은 2시간 분량으로 전체 코드와 단계를 제공하며, 로컬 AI 애플리케이션 실습을 원하는 개발자에게 적합합니다. (출처: qdrant_engine)

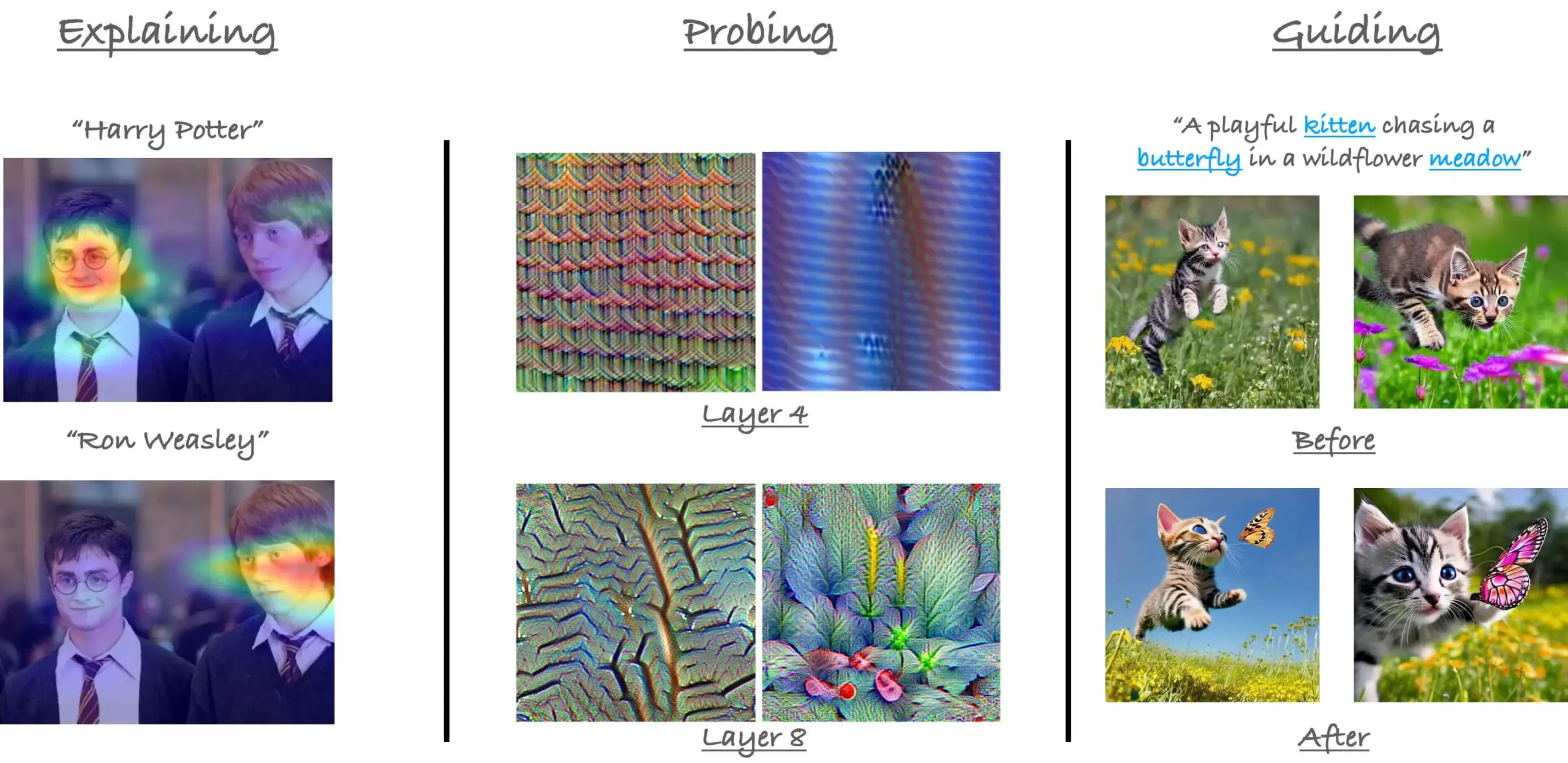
CVPR23 ViT의 어텐션 메커니즘 튜토리얼 회고: 연구원 Sayak Paul이 CVPR 2023에서 Hila Chefer와 함께 진행했던 Vision Transformer(ViT)의 어텐션 메커니즘에 대한 튜토리얼을 회고했습니다. 이 튜토리얼은 “설명(explain)”, “탐색(probe)”, “안내(guide)” 세 가지 주제를 중심으로 진행되었으며, ViT 내부의 어텐션 작동 방식을 이해하는 데 도움을 주는 것을 목표로 합니다. (출처: RisingSayak)
Claude Code 사용 팁 공유: 계획, 규칙 및 수동 압축: Reddit 사용자가 Claude Code를 일주일 동안 심층적으로 사용한 경험을 공유하며 계획, 규칙 제정(CLAUDE.md 파일을 통해) 및 자동 압축 한계에 도달하기 전에 수동으로 /compact를 실행하는 것의 중요성을 강조했습니다. 이러한 팁은 특히 대규모 기능을 처리하거나 모델이 궤도를 벗어나는 것을 방지하는 데 있어 생산성과 출력 품질을 높이는 데 도움이 됩니다. 사용자는 이러한 방법을 통해 Claude Code가 복잡한 작업을 효율적으로 완료할 수 있다고 언급했습니다. (출처: Reddit r/ClaudeAI)
AIGCode 창업자 쑤원(宿文) 인터뷰: 자체 개발 대형 모델 고수, Autopilot “L5”급 코드 생성 목표: AIGCode 창업자 쑤원은 인터뷰에서 회사의 목표는 코드 공급의 기반 시설을 만들고 “L5” 수준의 Autopilot 자동 프로그래밍을 실현하여 비프로그래머도 AI를 통해 완전한 애플리케이션을 생성할 수 있도록 하는 것이라고 밝혔습니다. 그는 Coding이 대형 모델을 육성하는 최적의 시나리오이며 코드가 고품질 훈련 데이터라고 생각합니다. AIGCode는 이미 66B 기본 모델 “Xīyuè(锡月)”를 훈련했으며 AutoCoder 제품을 출시했습니다. 쑤원은 AI 제품은 궁극적으로 “두뇌”의 똑똑함으로 경쟁하며, 사전 훈련은 기술의 원동력이므로 비용이 많이 들더라도 자체 개발 모델은 AGI 실현과 제품 핵심 경쟁력 구축에 매우 중요하다고 강조했습니다. (출처: WeChat)

💼 비즈니스
JD.com 지능형 에이전트 플랫폼 및 응용 알고리즘 팀 채용: JD.com 그룹 핵심 프로젝트인 지능형 에이전트 플랫폼 및 응용 알고리즘 팀에서 대형 모델 알고리즘 엔지니어 및 인턴을 채용 중이며, 근무지는 베이징입니다. 주요 기술 방향은 LLM Agent, LLM Reasoning 및 LLM과 강화 학습의 결합입니다. 채용 대상은 2026년 졸업 예정인 석박사 과정 학생(신입), P5-P8에 해당하는 경력직 및 연구형 인턴입니다. 팀은 기술 주도 및 실제 문제 해결을 중시하며, 최고 수준의 AI 컨퍼런스에 논문을 발표한 바 있습니다. (출처: WeChat)

Klarna와 Duolingo의 AI 우선 전략, 도전 직면하며 인간-기계 균형 주목: 금융 기술 회사 Klarna와 언어 학습 앱 Duolingo가 “AI 우선” 전략을 추진한 후 소비자 피드백과 시장 현실의 압력에 직면하고 있습니다. Klarna는 AI로 수백 명의 고객 서비스 직원을 대체했지만 서비스 품질 저하로 인해 현재 다시 인공 고객 서비스 직원을 채용하고 있습니다. Duolingo는 역할 자동화로 인해 사용자 불만을 야기했으며, 많은 사람들이 언어 학습의 핵심은 인간이 주도해야 한다고 생각합니다. 이러한 사례는 기업이 AI 전환 과정에서 혁신과 인문학적 배려의 균형을 맞춰야 하며, 기술도 중요하지만 사용자 신뢰는 여전히 인간이 구축해야 함을 보여줍니다. (출처: Reddit r/ArtificialInteligence)
Databricks, 데이터베이스 스타트업 Neon 10억 달러에 인수 루머: Reddit 커뮤니티에 떠도는 AI 뉴스 요약에 따르면, Databricks가 데이터베이스 스타트업 Neon을 인수했으며 거래 금액은 10억 달러로 알려졌습니다. 이번 인수는 Databricks의 데이터 관리 및 AI 인프라 역량을 강화하기 위한 것으로 보입니다. (출처: Reddit r/ArtificialInteligence)
🌟 커뮤니티
OpenAI Codex 출시, 개발자들 기대와 신중함 공존하며 뜨거운 반응: OpenAI가 프로그래밍 지능형 에이전트 Codex를 출시한 후 커뮤니티의 반응이 뜨겁습니다. 많은 개발자들이 Codex가 PR 생성, 코드 수정 등의 작업을 자동으로 완료할 수 있다는 점에 흥분을 감추지 못하며, 이는 프로그래밍 효율성을 크게 향상시킬 것이라고 보고 있으며, 심지어 “AGI 순간을 느꼈다”고 말하는 사람도 있습니다. Ryan Pream은 Codex를 사용하여 하루 만에 50개 이상의 PR을 생성한 경험을 공유했습니다. 동시에, 일부 사용자는 Codex가 작업 분할, 테스트 케이스 추가 등에서 개선이 필요하며 현재는 전문가에게 더 적합하다고 지적했습니다. Yohei Nakajima는 초기 사용 경험을 공유하며 GitHub 중심 설계는 합리적이지만 학습 곡선이 가파르다고 평가했습니다. (출처: kevinweil, gdb, itsclivetime, dotey, yoheinakajima, cto_junior)
Meta의 AI 오픈소스 분야 기여 인정받으며 폐쇄와 개방 논의 촉발: Hugging Face CEO Clement Delangue가 Meta를 지지하는 글을 올렸습니다. 그는 Meta가 AI 모델 오픈소스 분야에서 다른 대기업이나 스타트업보다 훨씬 많은 자원을 보유하고 있음에도 불구하고 더 많은 기여를 했으며, 과도한 비난을 받아서는 안 된다고 주장했습니다. 이 견해는 일부 사용자들로부터 공감을 얻었으며, 최첨단 AI 모델 구축이 매우 어렵고 Meta의 개방적인 행동이 해당 분야 발전에 매우 중요하다고 평가했습니다. 그러나 일부에서는(gabriberton) 오픈소스는 지식 우위를 포기하는 것을 의미하며, 본질적으로 폐쇄형 소스가 더 나은 결과를 얻을 수 있다고 지적했습니다. Dorialexander는 미국이 갑자기 “유럽의 대응 방식”(Meta를 변호하는 것을 지칭)을 채택한 것에 대해 이해할 수 없다고 말했습니다. (출처: ClementDelangue, gabriberton, Dorialexander)
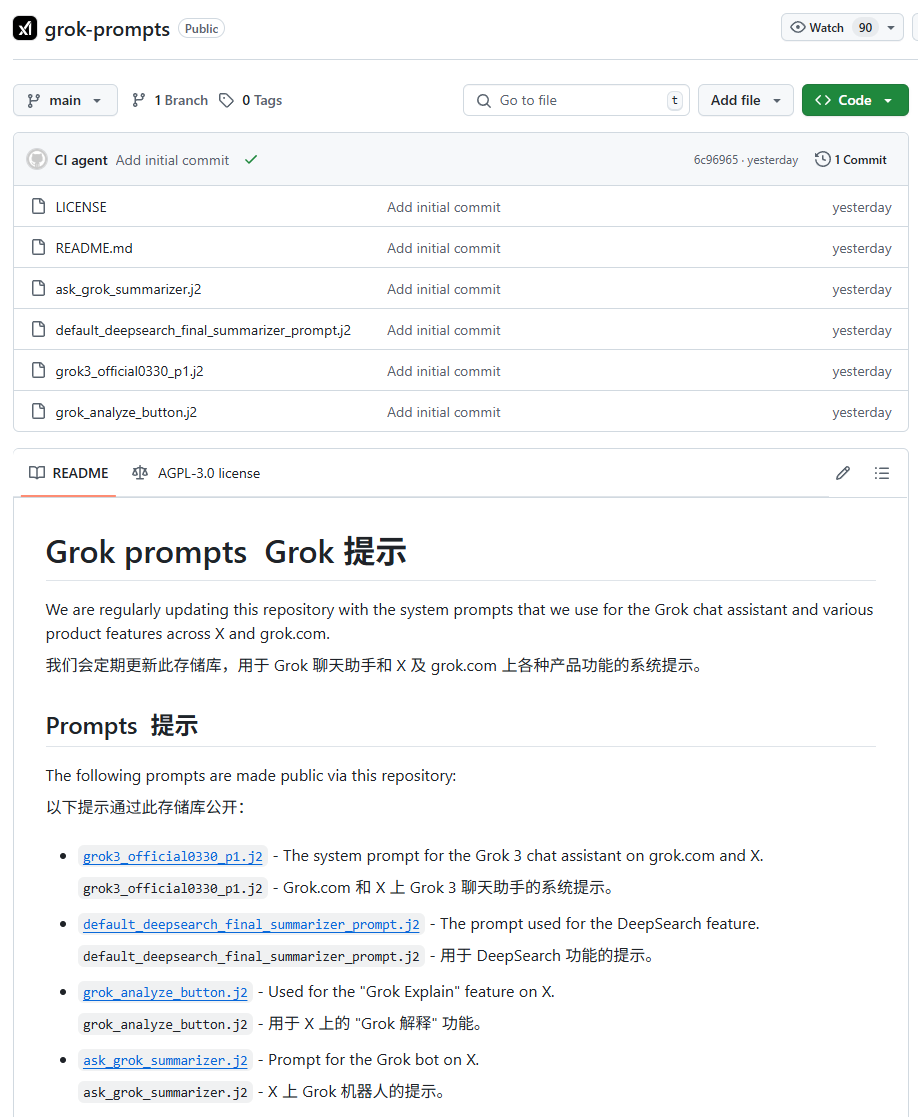
xAI Grok 시스템 프롬프트 유출 및 부적절한 내용 병합 사건 주목: xAI의 Grok 모델 시스템 프롬프트가 GitHub에 유출되었으며, 심지어 DeepSearch의 시스템 프롬프트까지 포함된 것으로 밝혀졌습니다. 더욱 심각한 것은, 한 사용자가 “백인 인종 학살” 등 부적절한 내용이 포함된 PR이 5명의 검토를 거쳐 메인 브랜치에 병합되었다가 이후 복원되고 히스토리가 삭제되었지만, 이 사건은 xAI의 프로세스 관리 및 운영 보안에 중대한 결함이 있음을 드러냈다고 지적했습니다. 이 일은 커뮤니티에서 xAI 내부 프로세스 및 콘텐츠 검토 메커니즘에 대한 광범위한 의문과 논의를 불러일으켰습니다. (출처: karminski3, eliebakouch, colin_fraser, Reddit r/artificial)
AI Agent, 미래 트렌드로 간주되나 도전과 기대 공존: “2025년은 Agent의 해”라는 관점이 커뮤니티에 퍼지면서 AI Agent의 미래 발전에 대한 논의가 활발합니다. 일부에서는 미래의 작업 방식이 《스타크래프트》나 《에이지 오브 엠파이어》와 유사하게 사용자가 다수의 마이크로 에이전트에게 작업을 지시하는 형태가 될 것이라고 예측합니다. 그러나 현재 Agent가 작업 분해, 복잡한 지시 이해 등에서 미숙하며 사용자에게 강력한 계획 능력이 요구된다는 지적도 있습니다. 일부는 AI Agent가 2025년에 기대에 미치지 못할 것이라고 회의적인 반응을 보이며, 하나의 과대광고에서 다른 과대광고로 넘어갈 가능성을 우려하고 2026년에 실질적인 변화가 있기를 기대하고 있습니다. (출처: gdb, EdwardSun0909, op7418, eliza_luth, tokenbender)
AI, 교육 및 고용 분야에서의 역할에 대한 심도 있는 논의 촉발: Reddit 커뮤니티에서 AI 발전이 전통적인 교육 및 고용 모델에 미치는 영향에 대한 논의가 나타났습니다. 한 사용자는 “이제 학교에 가는 것이 무슨 의미가 있는가?”라고 질문하며 AI가 미래에는 아무도 일할 필요가 없게 만들 것이라고 주장했습니다. 이에 대해 대부분의 댓글은 비판적 사고, 학습 능력 및 사교 기술의 중요성을 강조하며 이것이 AI가 대체할 수 없는 부분이라고 말했습니다. 학교는 지식 전달의 장소일 뿐만 아니라 학습 방법, 사고 방법 및 타인과의 상호 작용 방법을 배우는 환경입니다. AI 주도 세계에서도 이러한 능력은 여전히 매우 중요하며, 심지어 AI 자체를 배워야 할 수도 있습니다. 다른 논의에서는 인간의 가치를 단순히 직업과 동일시해서는 안 되며, AI의 발전은 우리가 직업을 초월한 인간의 의미를 생각하도록 촉구해야 한다고 지적했습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI 여자친구 현상, 사회 윤리 및 인구 문제에 대한 고찰 유발: 이코노미스트가 중국 젊은이들이 AI와 연애하고 친구를 사귀기 시작했다고 보도하면서 네티즌들 사이에서 뜨거운 논쟁이 벌어졌습니다. 일부 댓글은 이 현상을 “모기 수를 줄이기 위해 불임 암컷 모기를 대량으로 야생에 방사하는 것”에 비유하며, AI 파트너가 “항상 당신을 이해하는” 완벽한 경험을 제공할 수 있음에도 불구하고 저출산 문제를 악화시킬 수 있음을 시사했습니다. 이는 AI 기술이 정서적 동반자 분야에 적용되면서 발생하는 복잡한 사회적 영향과 윤리적 고려 사항을 반영합니다. (출처: dotey)
AI 전화 통화의 현실감, 진짜와 가짜 구별 어려움 새로운 도전으로 부상: Reddit 사용자가 학습 기관으로부터 전화를 받았는데, 상대방의 목소리 톤이 자연스럽고 응답이 유창하여 실제 사람인지 AI인지 거의 구별할 수 없었던 경험을 공유했습니다. 몇 분간 대화한 후, 답변이 너무 완벽해서 AI라는 것을 깨달았습니다. 이 경험은 사용자들에게 AI 음성 기술 발전 속도에 대한 놀라움과 약간의 불안감을 안겨주었으며, 미래에는 전화 속 AI를 구별하기 어려워 특히 노인 등 취약 계층에게 사기 위험을 초래할 수 있다는 우려를 낳았습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/artificial)
💡 기타
MIT, AI와 과학적 발견에 관한 사전 인쇄 논문 arXiv 철회 요구 논란: MIT가 자교 박사 과정 학생이 작성한 AI가 재료 과학 혁신에 미치는 영향에 관한 사전 인쇄 논문을 arXiv에서 철회하도록 요구했습니다. 그 이유는 연구 데이터의 출처, 신뢰성 및 유효성에 대해 “확신이 없다”는 것이었습니다. 해당 논문은 AI 보조 연구원이 재료 발견을 44% 증가시키고 특허 출원을 39% 증가시켰다고 지적한 바 있습니다. MIT의 이러한 조치는 논란을 불러일으켰으며, 일부에서는 학문적 자유를 침해하는 행위이며 연구 결론(AI가 최고 연구자의 우위를 강화하고 일반 연구자의 직업 만족도를 낮출 수 있다는 내용)이 자금 제공자의 기대와 부합하지 않기 때문일 수 있다고 주장했습니다. 반면, AI 분야에서는 연구 결과의 엄밀성이 매우 중요하며 사전 인쇄물 주도의 과도한 과장을 경계해야 한다는 의견도 있었습니다. (출처: Reddit r/ArtificialInteligence)
AI 코딩 도구의 보급, 코드 모듈화 및 엔지니어링 실천에 더 높은 요구 제기: E0M은 트위터에서 스타트업의 경쟁 우위가 점점 더 엔지니어의 AI 코딩 도구 채택 속도와 효율성에 달려 있다고 지적했습니다. 우수한 모듈화 코드 실천이 그 어느 때보다 중요해졌으며, 코드 복잡성이 현대 코딩 에이전트의 처리 범위 내에 있다면 빠른 반복이 가능하지만, 반대로 지나치게 복잡한 “스파게티 코드”는 진행 속도를 늦추고 AI를 채택한 경쟁자에게 뒤처질 수 있습니다. (출처: E0M, E0M)
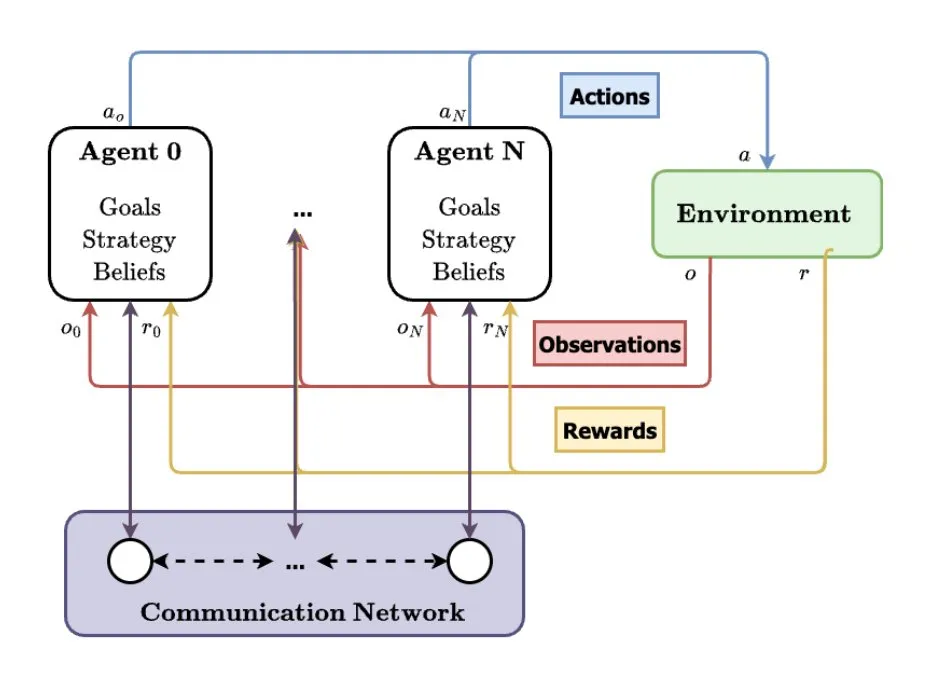
다중 에이전트 시스템(MAS), AI 미래 발전 방향으로 간주: TheTuringPost는 다중 에이전트 시스템(MAS)의 부상 추세를 분석했습니다. 주요 발전에는 다중 에이전트 강화 학습(MARL), 군집 로봇 기술, 상황 인식 MAS(CA-MAS) 및 대형 언어 모델(LLM) 기반 MAS가 포함됩니다. 이러한 기술은 AI 시스템이 협력과 경쟁을 통해 복잡한 문제를 해결할 수 있도록 하며, 재난 대응, 환경 모니터링, 사회 역학 시뮬레이션 등 다양한 분야에 적용되어 집단 지성의 미래를 예고합니다. (출처: TheTuringPost)