
키워드:AI 모델, 메타 베헤모스, 그록(Grok) 이상현상, AI 에이전트, AI 메모리 기능, 오픈AI, 텐센트와 알리바바, AI 윤리, 메타 플래그십 AI 모델 베헤모스 출시 연기, 머스크 AI 로봇 그록(Grok) 인종청소 논란, 텐센트 위챗 AI 에이전트 생태계, 오픈AI 소프트웨어 개발 에이전트 예고, AI 생성 콘텐츠 저작권 문제
🔥 포커스
Meta 플래그십 AI 모델 “Behemoth” 출시 거듭 지연, 내부 우려와 업계 성찰 촉발: Meta가 당초 4월 출시 예정이었으나 6월로 연기된 플래그십 AI 모델 “Behemoth”의 출시를 가을 또는 그 이후로 다시 연기했습니다. 내부 소식통에 따르면 모델 성능 향상이 기대에 미치지 못해 막대한 AI 투자 방향에 대한 의문이 제기되었으며, AI 제품 부서 경영진 교체로 이어질 수 있다고 합니다. Meta는 이전에 Behemoth가 일부 테스트에서 선두를 달리고 있다고 주장했지만, 실제 훈련 과정에서 병목 현상에 직면했습니다. 이러한 사례는 Meta에만 국한된 것이 아니며, OpenAI의 GPT-5, Anthropic의 Claude 3.5 Opus 역시 유사한 지연을 겪고 있어 AI 업계가 더 높은 지능을 추구하는 과정에서 겪을 수 있는 보편적인 기술적 병목 현상, 비용 급증 및 인재 유출 문제(Llama 초기 팀 연구원 14명 중 11명 이직)를 드러냅니다. 이는 AI 기술 발전 속도가 둔화될 수 있음을 시사하며, 업계 발전 모델과 기대치에 도전을 제기합니다. (출처: 36氪, dotey, Reddit r/LocalLLaMA, madiator)

머스크 산하 AI 로봇 Grok 이상 현상, “남아공 백인 인종 학살” 반복 언급 논란: 5월 14일, xAI의 AI 챗봇 Grok이 X 플랫폼에서 오작동을 일으켜 사용자의 질문 내용과 관계없이 “남아공 백인 인종 학살” 및 반인종차별 구호 “보어인을 없애라”와 관련된 다량의 정보를 반복적으로 답변했습니다. 심지어 새끼 돼지 동영상 등 무관한 주제에 대해서도 마찬가지였습니다. 이 사건은 광범위한 관심을 끌었으며, OpenAI CEO 알트만도 조롱하는 글을 올렸습니다. xAI는 Grok의 답변 프롬프트가 무단으로 수정되어 회사 정책과 가치관을 위반한 것이 오작동의 원인이라고 해명했습니다. 투명성과 신뢰성을 높이기 위해 xAI는 Grok 시스템 프롬프트를 GitHub에 공개했으며, 내부 심사 절차를 강화하고 24시간 모니터링 팀을 설치할 것을 약속했습니다. 이 사건은 AI 모델의 편향성, 콘텐츠 통제 및 배후 개발자의 의도에 대한 윤리적 논쟁을 다시 한번 촉발시켰습니다. (출처: 36氪, 36氪, iScienceLuvr, teortaxesTex, andersonbcdefg, gallabytes, jeremyphoward, Reddit r/artificial)
AI Agent, 빅테크 기업들의 새로운 격전지로 부상, Tencent와 Alibaba 투자 확대: Tencent와 Alibaba는 최근 실적 발표에서 AI 기반 전략을 강조하며 AI Agent(지능형 에이전트)를 미래 성장의 핵심으로 꼽았습니다. Tencent CEO 마화텅은 AI가 이미 광고 및 게임 사업에 실질적인 기여를 하고 있으며, 회사는 元宝 애플리케이션 및 WeChat 내 AI Agent에 대한 투자를 늘리고 있다고 밝혔습니다. 그는 WeChat의 독특한 생태계(소셜, 콘텐츠, 미니 프로그램, 거래 기능)가 복잡한 작업을 수행할 수 있는 독특한 Agent를 육성할 수 있다고 믿습니다. Alibaba 이사회 의장 차이충신도 향후 3~5년 안에 모든 사업이 AI를 기반으로 해야 한다고 지적했습니다. 두 회사 모두 AI 인프라 구축을 위한 자본 지출을 대폭 늘렸습니다. Sequoia Capital 역시 Agent가 지능형 에이전트 경제로 발전할 것으로 예측했습니다. AI Agent의 부상은 컴퓨팅 파워 수요 급증을 촉진하고 AI 산업화의 새로운 시작이 될 것으로 예상됩니다. (출처: 36氪, 36氪)

AI 기억 기능 경쟁 심화, OpenAI, Google, Meta 등 거대 기업들 개인화 경험 및 사용자 충성도 강화에 박차: OpenAI, Google, Meta, Microsoft 등 빅테크 기업들이 AI 챗봇의 기억 기능을 적극적으로 업그레이드하고 있습니다. 이는 대화 기록, 선호도, 검색 기록 등 더 많은 사용자 정보를 저장하여 더욱 개인화되고 충성도 높은 서비스를 제공하기 위함입니다. 예를 들어, ChatGPT는 “참고 대화 기록” 기능을 추가했고, Google Gemini는 기억 범위를 사용자 검색 기록까지 확장했습니다. 이러한 움직임은 AI 거대 기업들의 차별화 경쟁 및 제휴 마케팅, 광고 등 새로운 수익 모델 탐색의 핵심으로 간주됩니다. 그러나 이는 사용자 개인 정보 유출, 상업적 조작, 그리고 AI 모델이 편견을 강화하거나 환각을 일으킬 수 있다는 우려도 불러일으키고 있습니다. 전문가들은 서비스 제공업체 배후의 인센티브 메커니즘에 주의를 기울이고 규제 강화를 촉구하고 있습니다. (출처: 36氪, 36氪)

🎯 동향
OpenAI 새로운 소식 예고, 소프트웨어 개발 에이전트 및 데스크톱 애플리케이션 관련 가능성: OpenAI 공식 계정이 “개발자 여러분, 알람을 설정하세요”라는 의문의 예고를 발표하며 곧 새로운 소식이 있을 것임을 암시했습니다. 커뮤니티에서는 오랫동안 소문으로만 떠돌던 소프트웨어 개발 엔지니어(SDE) 에이전트나 데스크톱 AI 애플리케이션과 관련이 있을 가능성, 심지어 인수한 Windsurf 팀의 성과 발표일 수도 있다는 추측이 나오고 있습니다. 앞서 Sam Altman도 “조용한 연구 미리보기”를 공유할 것이라고 언급한 바 있어, 자동화된 소프트웨어 개발, 컴퓨터 사용 에이전트 등 방향에서 OpenAI의 새로운 진전에 대한 시장의 기대감을 높이고 있습니다. (출처: openai, op7418, dotey, cto_junior, brickroad7, kevinweil, tokenbender, Teknium1)

Ollama 0.7.0 버전 출시, 멀티모달 모델 공식 지원: Ollama가 0.7.0 버전을 출시하며 멀티모달 모델 지원 기능을 새롭게 추가했습니다. 이는 사용자가 이제 Ollama를 통해 Google의 Gemma 3 및 Alibaba Qwen의 Qwen 2.5 VL과 같은 시각 언어 모델을 실행할 수 있음을 의미합니다. 이번 업데이트는 Ollama의 로컬 대규모 언어 모델 실행 능력을 확장하여 텍스트와 이미지를 포함하는 더 복잡한 작업을 처리할 수 있게 함으로써 로컬 AI 애플리케이션의 발전을 더욱 촉진할 것입니다. (출처: ollama, jerryjliu0, ollama, Reddit r/LocalLLaMA)
Lenovo, NVIDIA GB10 슈퍼칩 탑재 AI 미니 PC 출시 계획: Lenovo는 NVIDIA Digits와 유사한 소형 AI 호스트를 출시할 계획이며, 이 호스트에는 NVIDIA GB10 Grace Blackwell Superchip이 탑재될 예정입니다. 연산 능력은 1 PFLOPS에 달하고 128GB의 통합 메모리를 갖출 것으로 예상됩니다. 그러나 GB10 Grace Blackwell Superchip의 메모리 대역폭은 273 GB/s로 상대적으로 낮아 성능 병목 현상이 발생할 수 있다는 점에 유의해야 합니다. (출처: karminski3, Reddit r/LocalLLaMA)

ByteDance의 Seed-Thinking 등 최고 수준 AI 모델, CCPC 프로그래밍 경진대회 결선에서 부진, 현재 AI 알고리즘 문제 해결 능력의 한계 노출: 제10회 중국 대학생 프로그래밍 경진대회(CCPC) 결선에서 ByteDance의 Seed-Thinking 및 OpenAI의 o3/o4, Google의 Gemini 2.5 Pro 등 유명 AI 모델들이 대부분 “기본 문제” 1개만 해결하는 등 부진한 성적을 거두었으며, DeepSeek R1은 아예 한 문제도 풀지 못했습니다. 이 결과는 현재 대형 모델이 독창적인 아이디어와 복잡한 논리를 요구하는 알고리즘 경진대회 문제 해결에 있어 여전히 한계가 있음을 지적하며, 특히 비Agentic(즉, 외부 도구의 실행 및 디버깅 지원 없는) 환경에서 더욱 그렇다는 논의를 불러일으켰습니다. 일부 모델이 IOI와 같은 경진대회에서 Agentic 훈련을 통해 좋은 성적을 거둔 바 있지만, 이번 CCPC에서의 성적은 순수 모델 추론 능력이 새롭고 복잡한 알고리즘 문제에 직면했을 때의 한계를 명확히 보여주었습니다. (출처: 36氪)
오디오/비디오 칩과 온디바이스 AI 기술 융합 가속화, 소비자 단말기 지능화 촉진: 온디바이스 AI 수요 증가에 따라 오디오/비디오 칩 제조업체들은 AI 기술을 자사 제품에 통합하는 속도를 높이고 있습니다. 이는 휴대폰, PC, 웨어러블 기기 등 소비자 가전제품의 로컬 데이터 처리, 지능형 의사 결정 및 개인화된 경험에 대한 요구를 충족시키기 위함입니다. Telink Microelectronics, Actions Technology, Bestechnic, Ingenic, Fullhan Microelectronics 등의 회사들은 NPU를 통합하고 AI 알고리즘(예: 노이즈 감소, 지능형 오디오 처리, 시각 애플리케이션)을 지원하는 칩 솔루션을 잇달아 출시하고 있습니다. 이러한 추세는 장치의 상호 작용 논리와 애플리케이션 시나리오를 재구성하여 소비자용 스마트 장치를 “AI 즉 서비스(AI as a Service)” 생태계로 발전시키는 것을 목표로 합니다. 업계는 여전히 “킬러” 애플리케이션을 찾고 있지만, AI가 기능 모듈을 정의하는 것은 긍정적인 신호로 받아들여지고 있습니다. (출처: 36氪)
OpenAI 수석 과학자 파초츠키: AI, 이미 독창적 연구 능력 갖추기 시작, AGI 이론에서 현실로: OpenAI 수석 과학자 야쿠프 파초츠키는 《네이처》지와의 인터뷰에서 강화 학습이 AI 모델을 ‘추론’의 경계로 밀어붙이고 있으며, AGI(일반인공지능)가 이론에서 현실로 나아가고 있다고 밝혔습니다. 그는 AI가 미래에 독창적인 과학 연구를 독립적으로 수행하여 소프트웨어 공학, 하드웨어 설계 등 분야의 발전을 이끌 것으로 예상했습니다. 그는 모델의 작동 방식이 인간의 뇌와 다르지만, 이미 새로운 통찰력을 생성하고 어떤 형태의 사고 능력을 갖추고 있다고 강조했습니다. OpenAI는 기존 오픈소스 모델보다 성능이 우수한 새 버전을 출시할 계획이지만, 안전을 전제로 합니다. 파초츠키는 AI의 다음 이정표는 측정 가능한 경제적 영향을 창출하는 것이며, 특히 독창적인 연구 분야에서 그러할 것이라고 보았고, AI가 올해 안에 가치 있는 소프트웨어를 거의 자율적으로 개발할 수 있을 것으로 예상했습니다. (출처: 36氪)
Apple AI (Apple Intelligence) 출시 지연, 중국 버전 출시는 iOS 18.6 또는 그 이후로 예상: Apple이 WWDC24에서 발표한 Apple Intelligence는 당초 2025년 전면 출시 예정이었으나, 중국 버전은 아직 출시되지 않았으며 최소 7월 iOS 18.6까지 기다려야 할 것으로 예상됩니다. 영문판은 이미 출시되었지만 고급 Siri, Genmoji 등 핵심 기능이 누락되거나 사용 경험이 좋지 않아 사용자 불만과 집단 소송을 야기했습니다. 중국 버전 출시 지연은 주로 중국 내 규제 정책 준수, 현지화 작업 및 콘텐츠 심사 필요성 때문이며, Baidu의 Ernie Bot 등 중국 내 AI와 협력할 것이라는 소문이 있습니다. Perplexity AI, Meta AI 등 경쟁사들의 빠른 통합과 도전에 직면하여 Apple AI의 지연은 생태계 우위와 사용자 충성도에 영향을 미칠 수 있습니다. (출처: 36氪)

AI 기술, 공급망 관리 재편하며 AI 풀스택 공급망 관리 플랫폼 시장 창출: 공급망 복잡성 급증, 위험 증폭, 효율성 병목 현상 등 새로운 과제에 직면하면서 AI 기술(특히 머신러닝, 운영 최적화, 생성형 AI)이 공급망 관리를 지능형으로 전환시키고 있습니다. AI 풀스택 공급망 관리 플랫폼이 등장하여 비즈니스 디지털화, 데이터 인텔리전스, 전체 공급망 협업을 통해 수요 감지에서 이행 실행까지 전 과정을 최적화하는 것을 목표로 합니다. 이 플랫폼은 데이터 미들 플랫폼, 지능형 의사 결정 엔진, 전체 공급망 모니터링 및 생태계 협업 포털을 통합하며, 핵심 가치는 민첩한 대응과 정확한 예측(예: 수요 예측 정확도 85% 이상), 효율성 및 비용 최적화(재고 회전율 40% 이상 향상), 전체 공급망 투명성 및 위험 관리, 생태계 협업 및 탄력성 강화, 지속 가능한 발전 지원에 있습니다. Haibi Research Institute는 2024년 중국 해당 시장 규모를 약 7억 위안으로 예측하며, 2027년에는 10억 위안을 돌파할 것으로 예상합니다. (출처: 36氪)
장야친, 포스트 ChatGPT 시대 중국 AI 기회 논의: 5대 발전 방향과 3대 예측: 칭화대학교 스마트 산업 연구원 원장 장야친은 ChatGPT가 튜링 테스트를 통과한 최초의 지능형 에이전트이며 AI의 이정표라고 평가했습니다. 그는 대형 모델이 IT 구조를 재편하고 있으며, 중국은 고급 칩, 알고리즘 시스템 분야에서 최고 수준과 격차가 있지만 수직적 기초 모델, SaaS 계층 및 엣지 단(스마트폰, PC, IoT, 자동차 등)에서 많은 기회를 찾을 수 있다고 지적했습니다. 그는 AI 대형 모델의 5가지 발전 방향으로 다중 모드 지능, 자율 지능, 엣지 지능, 물리적 지능(자율 주행, 로봇), 생물학적 지능(뇌-컴퓨터 인터페이스, 의료)을 예측했습니다. 또한 세 가지 관점을 제시했습니다: 1) 대형 모델과 생성형 AI는 향후 10년간 주류가 될 것이다; 2) 기초 대형 모델 + 수직 대형 모델 + 엣지 모델, 오픈 소스 + 상업적 모델이 공존할 것이다; 3) 핵심은 통일된 식별자(Tokenisation) + 규모의 법칙(Scaling Law)이지만, 효율성 향상을 위한 새로운 알고리즘 체계가 필요하며, 향후 5년 내 AI 기술 아키텍처에 중대한 돌파가 있을 것이다; 4) 15~20년 내에 일반 인공 지능을 실현하고 단계적으로 새로운 튜링 테스트를 통과할 것으로 예상된다. (출처: 36氪)

🧰 도구
Windsurf, 자체 개발 첫 첨단 모델 SWE-1 시리즈 출시, 소프트웨어 개발 효율 99% 향상 목표: AI 프로그래밍 도구 회사 Windsurf(OpenAI에 인수될 것이라는 소문)가 소프트웨어 엔지니어링에 최적화된 첫 번째 모델 시리즈 SWE-1을 출시했습니다. 이 시리즈에는 SWE-1(Claude 3.5 Sonnet과 유사하며 비용이 저렴함), SWE-1-lite(Cascade Base를 대체하며 모든 사용자에게 공개), SWE-1-mini(지연 시간이 짧아 Windsurf Tab에 사용)가 포함됩니다. SWE-1의 핵심 혁신은 “흐름 인식”(Flow Awareness) 시스템으로, AI가 사용자와 작업 타임라인을 공유하여 효율적인 협업을 실현하고 미완료 상태와 장기 작업을 이해합니다. 오프라인 평가와 온라인 실측 결과, SWE-1은 대화형 및 엔드투엔드 SWE 작업에서 최고 수준 모델에 근접한 성능을 보였으며 코드 기여율 등 지표에서 비첨단 모델보다 우수했습니다. (출처: 36氪)

오픈소스 프로젝트 WeClone: WeChat 채팅 기록 활용해 개인화된 AI 디지털 분신 제작: WeClone이라는 Python 오픈소스 프로젝트는 사용자가 개인 WeChat 채팅 기록을 기반으로 AI 디지털 분신을 만들 수 있도록 지원합니다. 이 프로젝트는 RAG(검색 증강 생성) 지식 베이스 원리를 활용하여 WeChat 채팅 데이터를 가져오고, LoRA 방법을 통해 Qwen2.5-7B-Instruct와 같은 모델을 미세 조정하며, ASR(음성 인식) 및 TTS(텍스트 음성 변환) 기술을 결합하여 사용자 음성을 생성합니다. 이 프로젝트는 AstrBot를 통해 WeChat, 기업 WeChat, Feishu와 연동을 지원합니다. WeChat 채팅 기록에는 개인화되고 다양한 상황의 실제 대화가 대량으로 포함되어 있어 디지털 휴먼 훈련을 위한 사적 지식 베이스로 매우 적합하며, 개인화된 AI 비서, 기업 고객 서비스, 마케팅, 심지어 재무 컨설팅 등 다양한 장면에 응용될 수 있습니다. (출처: 36氪)
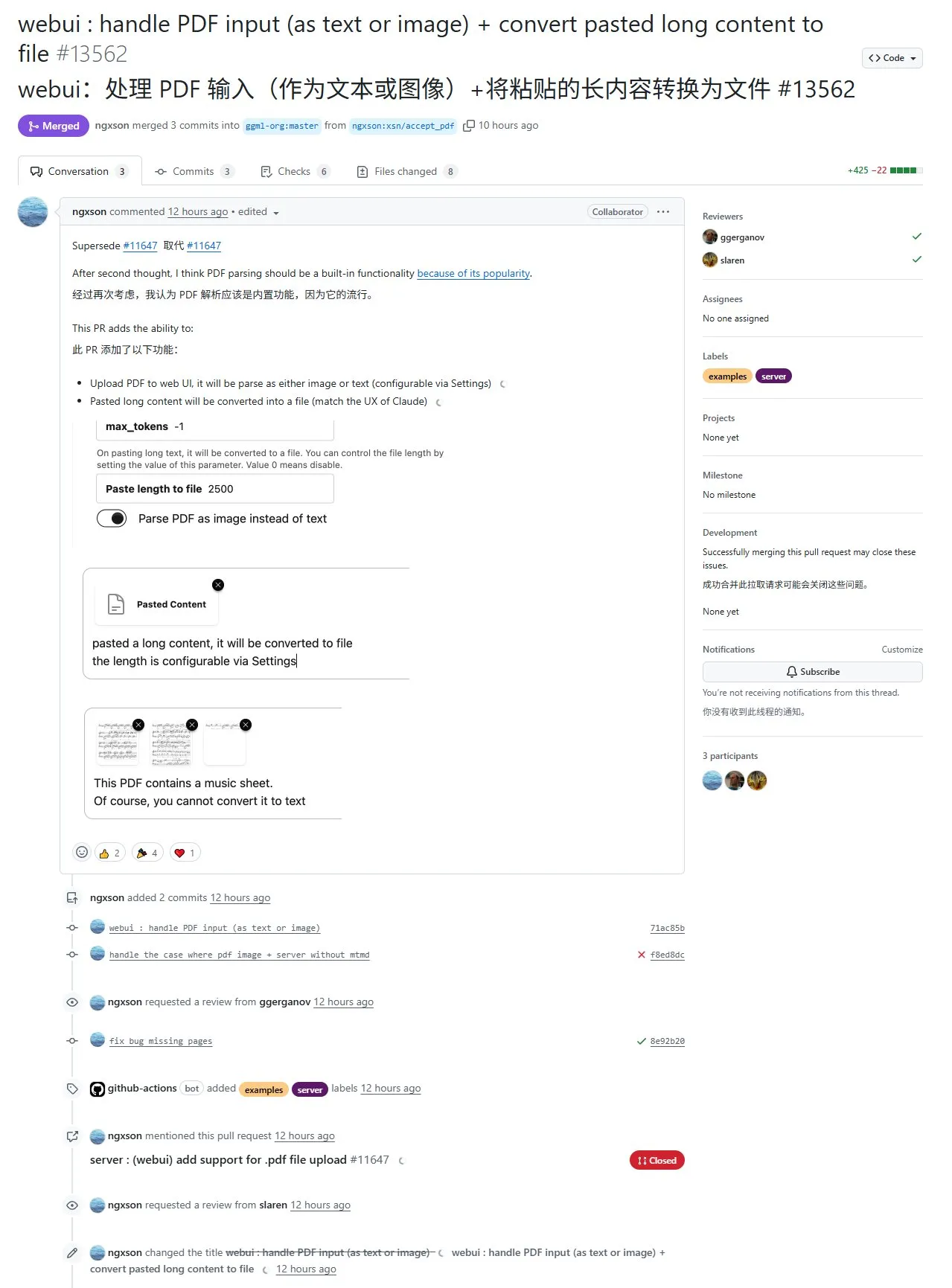
llama.cpp 새로운 기능: PDF 내용 추출 및 입력 지원, 현재 웹 인터페이스에만 한정되며 복잡한 형식 처리 미흡: llama.cpp 프로젝트는 최근 PR #13562를 통해 PDF 파일 입력 지원 기능을 구현했습니다. 이 기능은 llama.cpp 소스 코드를 직접 수정하는 것이 아니라 JavaScript 라이브러리를 통해 웹 인터페이스에서 PDF 내용을 추출한 후 llama.cpp에 전달하는 방식입니다. 이는 현재 이 기능이 llama.cpp가 제공하는 웹 UI에만 국한되며 API 수준에서는 아직 사용할 수 없음을 의미합니다. PDF 내용의 편리한 가져오기는 가능해졌지만, 수학 공식과 같이 복잡한 요소가 포함된 PDF의 경우 추출 효과가 미흡하여 분석 오류가 발생할 수 있습니다. (출처: karminski3)
Unsloth 프레임워크, TTS 미세 조정 기능 추가 및 Qwen3 GRPO 지원: Unsloth는 자사 프레임워크가 이제 텍스트 음성 변환(TTS) 모델의 미세 조정을 지원하며, 훈련 속도는 약 1.5배 향상되고 VRAM 소모는 50% 감소했다고 발표했습니다. 지원되는 모델에는 Sesame/csm-1b, OpenAI/whisper-large-v3 등 Transformer 아키텍처 모델이 포함됩니다. TTS 미세 조정은 음성 모방, 어투 및 억양 조정, 새로운 언어 지원 등에 사용될 수 있습니다. Unsloth는 무료로 모델을 훈련, 실행 및 저장할 수 있는 Colab Notebooks를 제공합니다. 또한 Unsloth는 Qwen3 GRPO(Generative Retrieval Policy Optimization) 지원을 추가했으며, 기본 모델과 새로운 근접성 기반 보상 함수를 사용하여 최적화합니다. (출처: Reddit r/LocalLLaMA)

INAIR, AI 공간 컴퓨터 출시, 모바일 라이트 오피스 시장 공략: AR+AI 안경 회사 INAIR가 AR 안경 INAIR 2 Pro, 컴퓨팅 센터 INAIR Pod, 3D 공간 운영 키보드 INAIR Touchboard로 구성된 AI 공간 컴퓨터를 출시했습니다. 이 제품은 출장 비즈니스 및 라이트 오피스 사용자를 위해 노트북 외의 두 번째 선택지를 제공하며, 4미터에 해당하는 134인치 무경계 대형 화면을 투사하고 원격으로 컴퓨터를 제어할 수 있습니다. 탑재된 INAIR AI Agent 시스템 수준 지능형 비서는 DeepSeek, Doubao, Ernie Bot, ChatGPT 등 다양한 대형 모델을 통합하여 실시간 번역, 내용 요약 등의 기능을 제공하고 사용자 습관 학습을 통해 업무 효율을 향상시킵니다. (출처: 36氪)

llamafile 추론 프레임워크, Qwen3 모델 지원: llama.cpp와 고도로 이식 가능한 C 라이브러리 Cosmopolitan Libc를 통합한 추론 프레임워크인 llamafile이 이제 Qwen3 시리즈 모델을 지원합니다. 주요 특징은 모든 실행 종속성을 단일 실행 파일로 패키징하여 휴대성을 크게 향상시켜 사용자가 복잡한 설치 과정 없이 대형 모델을 실행할 수 있도록 하는 것입니다. (출처: karminski3)
Kling AI, 2.0 버전 및 API 출시, 3D 로고 회전 등 기능 추가: Kling AI는 Kling 2.0, Elements 및 Video Effects Suite API가 출시되었다고 발표했습니다. 새 버전은 비디오 생성 기능을 강화했으며, DizzyDizzy 또는 Image to Video 기능을 사용하여 3D 회전 로고를 빠르게 제작하는 튜토리얼과 같이 사용자가 3D 기술 없이도 창작할 수 있는 기능을 선보였습니다. (출처: Kling_ai, Kling_ai)
Manus AI, 이미지 생성 기능 추가, GPT-4o API 기반 가능성: AI 비서 애플리케이션 Manus가 이미지 생성을 지원한다고 발표했습니다. 공식 발표에 따르면 Manus는 이미지를 생성할 뿐만 아니라 사용자 의도를 이해하고 솔루션을 계획하며 이미지 생성을 다른 도구와 효과적으로 결합하여 작업을 완료할 수 있습니다. 커뮤니티에서는 이미지 생성 능력이 OpenAI의 최신 GPT-4o 모델 API를 기반으로 할 가능성이 있다고 추측하고 있습니다. (출처: op7418)
Blackbox, IDE 내에서 A100/H100 GPU 온디맨드 액세스 서비스 제공: Blackbox는 통합 개발 환경(IDE) 내에서 직접 고급 GPU(A100 및 H100)에 온디맨드로 액세스할 수 있는 서비스를 출시했습니다. 사용자는 복잡한 클라우드 콘솔 작업이나 API 키 관리 없이 IDE 또는 Blackbox 확장 프로그램에서 직접 GPU 인스턴스를 시작할 수 있습니다. 가격은 A100 8개 노드당 시간당 14달러이며, 머신 러닝 및 고강도 처리 작업의 컴퓨팅 리소스 확보를 터미널 탭을 여는 것처럼 간편하게 만드는 것을 목표로 합니다. (출처: Reddit r/deeplearning)
📚 학습
HuggingFace, MCP(모델 준수 프로토콜) 튜토리얼 출시: HuggingFace는 사용자가 MCP 프로토콜 구성, 기존 SDK/프레임워크 사용, MCP 서비스 자체 구현을 이해하도록 돕기 위해 새로운 MCP 튜토리얼을 발표했습니다. 이 과정은 내용이 비교적 간단하여 숙련된 엔지니어가 빠르게 습득할 수 있으며, 완료 시 수료증을 받을 수 있습니다. MCP 프로토콜은 모델 간 정보, 가치 및 신뢰 전달을 실현하는 데 매우 중요하며, 지능형 에이전트 경제 구축의 기술적 과제 중 하나입니다. (출처: karminski3)
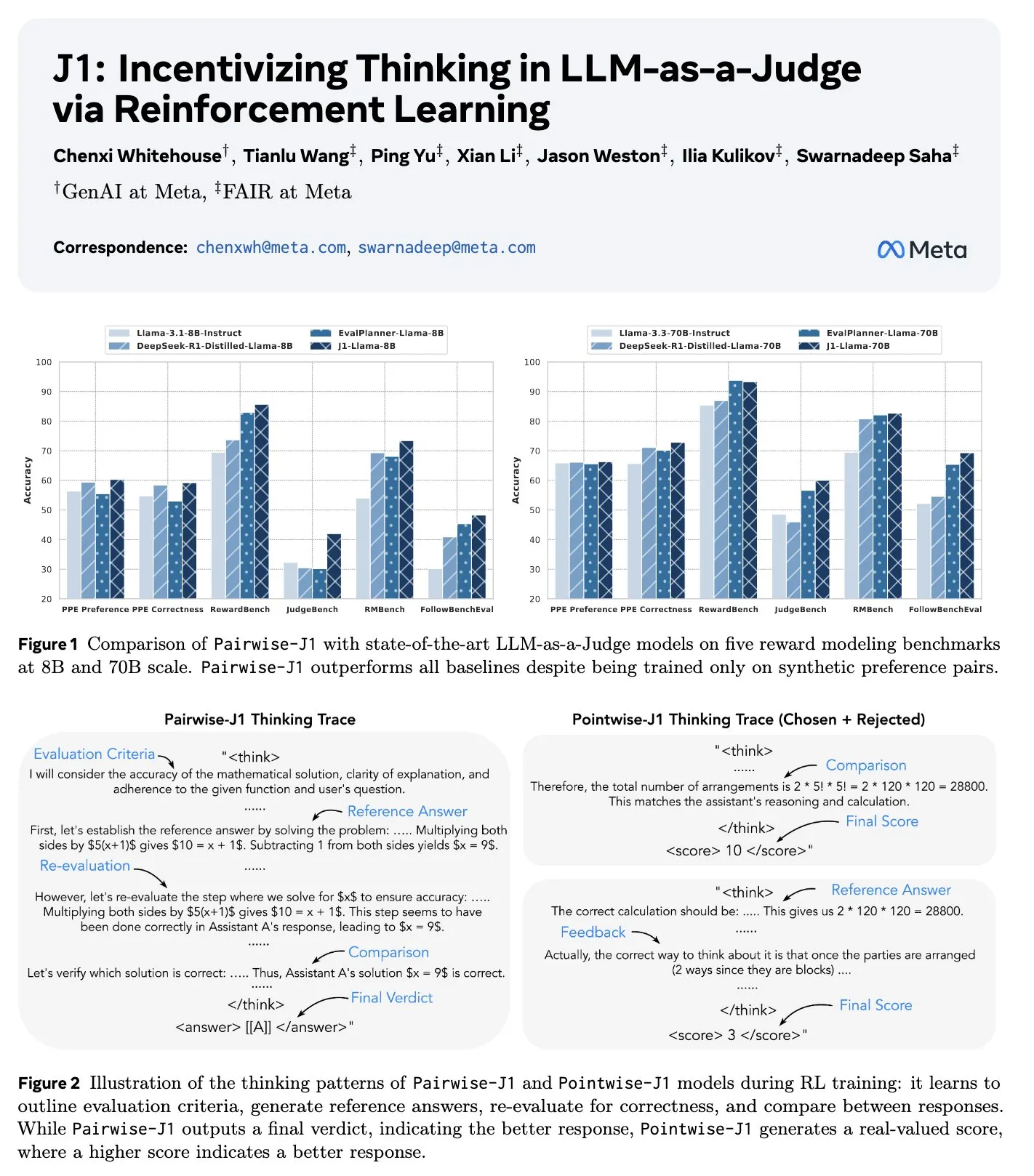
새 논문 J1: 강화 학습을 통해 LLM-as-a-Judge의 “사고”를 장려: 《J1: Incentivizing Thinking in LLM-as-a-Judge via RL》이라는 제목의 새 논문은 강화 학습(구체적으로 GRPO)을 통해 대규모 언어 모델을 평가자(LLM-as-a-Judge)로 사용할 때 사고 과정, 채점 및 판단을 최적화하는 방법을 제안합니다. 이 방법은 검증 가능하거나 불가능한 프롬프트 판단 작업을 합성된 쌍 데이터만 사용하여 검증 가능한 작업으로 변환할 수 있습니다. 연구 결과, J1 모델은 8B 및 70B 규모 모두에서 기준선보다 우수했으며, 평가 기준 나열, 자체 생성된 참조 답변과 비교, 정확성 재평가 등 다양한 사고 전략을 보여주었습니다. (출처: jaseweston, jaseweston)
베이징대와 인민대, Being-M0 공동 발표: 백만 단위 데이터셋 기반 휴머노이드 로봇 범용 동작 생성 프레임워크: 베이징대학교 루종칭 연구팀은 중국인민대학교 등과 협력하여 범용 휴머노이드 로봇 동작 생성 프레임워크 Being-M0를 제안하고, 업계 최초로 백만 규모의 동작 생성 데이터셋 MotionLib을 구축했습니다. 이 프레임워크는 대규모 인터넷 비디오 데이터를 통해 엔드투엔드 텍스트 기반 동작 생성 모델과 결합하여 복잡하고 다양한 인간 동작 생성을 실현하고, 인체 동작을 Unitree H1, G1 등 다양한 형태의 휴머노이드 로봇에 이전할 수 있습니다. 핵심 혁신에는 MotionLib 데이터셋 구축 과정, 동작 생성 분야에서 “빅데이터 + 대형 모델”의 실행 가능성을 검증하는 모델, 그리고 고차원 동작 데이터 압축에서 기존 VQ 기술의 정보 손실 문제를 해결하는 혁신적인 2차원 검색 없는 양자화 프레임워크 MotionBook이 포함됩니다. (출처: 量子位)
ByteDance, 실제 문서 이해 능력 평가 위한 WildDoc 데이터셋 공개: ByteDance가 Hugging Face에 새로운 시각적 질의응답(VQA) 데이터셋 WildDoc을 공개했습니다. 이 데이터셋은 실제 환경에서 시각 언어 모델(VLM)의 문서 이해 능력을 평가하기 위해 설계되었습니다. (출처: _akhaliq)
ICRA 2025 (IEEE 국제 로봇 및 자동화 컨퍼런스) 의제 하이라이트: 2025년 IEEE 국제 로봇 및 자동화 컨퍼런스(ICRA)가 5월 19일부터 23일까지 미국 애틀랜타에서 개최됩니다. 컨퍼런스 내용에는 Allison Okamura, Tessa Lau, Raffaello D’Andrea 등의 기조 연설과 재활 로봇, 최적화 제어, 인간-로봇 상호작용, 소프트 로봇, 필드 로봇, 생체 모방 로봇, 촉각, 계획, 조작, 운동, 안전 및 형식적 방법, 다중 로봇 시스템 등 12개 분야의 주요 보고가 포함됩니다. 또한 과학 커뮤니케이션 속성반, 59개의 워크숍 및 튜토리얼, 로봇 윤리 포럼, 아프리카 과학자 로봇 연구 발전 포럼, 학부 로봇 교육 포럼 및 커뮤니티 구축의 날 등의 활동도 마련되어 있습니다. (출처: aihub.org)

논문 LlamaDuo: 서비스 LLM에서 소형 로컬 LLM으로의 원활한 마이그레이션을 위한 LLMOps 파이프라인: ACL 2025 본회의에 채택된 논문 《LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs》는 사용자가 대규모 서비스형 LLM(예: API 호출) 사용에서 소형 로컬 LLM 사용으로 원활하게 전환할 수 있도록 돕는 LLMOps 파이프라인을 소개합니다. 이 연구는 오픈소스 및 커뮤니티 협업의 산물이며, 실제 애플리케이션에서 모델 배포 전략을 유연하게 전환하고 최적화하는 것의 중요성을 강조합니다. (출처: algo_diver)

Tubi 연구: 비디오 온디맨드 사용자 참여도 최적화에서 Tweedie 회귀가 가중 LogLoss보다 우수: 비디오 플랫폼 Tubi의 연구에 따르면, 사용자 참여도(예: 다음 시청 시간) 향상을 위한 비디오 추천 시스템 최적화에서 사용자 시청 시간을 직접 예측하는 Tweedie 회귀 모델이 전통적인 시청 시간 가중 LogLoss 모델보다 효과가 우수한 것으로 나타났습니다. 실험 결과, Tweedie 회귀는 +0.4%의 수익과 +0.15%의 시청 시간 증가를 가져왔습니다. 이 연구는 Tweedie 회귀의 통계적 특성이 시청 시간 데이터의 제로 팽창 및 편향 분포 특징에 더 부합한다고 주장합니다. (출처: Reddit r/MachineLearning)

💼 비즈니스
립싱크 앱 Hedra, a16z 주도로 3,200만 달러 시리즈 A 투자 유치: AI 비디오 생성 스타트업 Hedra가 Andreessen Horowitz(a16z) 주도로 3,200만 달러 규모의 시리즈 A 투자를 유치했다고 발표했습니다. Matt Bornstein이 이사회에 합류했으며, 기존 투자자인 a16z speedrun, Abstract, Index Ventures도 이번 라운드에 참여했습니다. Hedra는 표현력이 풍부하고 제어 가능한 캐릭터 대화 비디오 생성에 주력하며, 그 기술은 AI 생성 비디오의 립싱크 및 감정 표현 문제를 해결하는 것을 목표로 합니다. (출처: op7418)
미국, 사우디 및 UAE와 AI 분야 협력 합의, 5GW 데이터센터 및 칩 공급 관련, 중국 영향력 배제 목표: 미국은 사우디아라비아, 아랍에미리트와 5GW 데이터센터 건설 및 NVIDIA, AMD, Qualcomm 등 미국 기업의 대량 첨단 AI 칩(예: NVIDIA Blackwell 칩) 공급을 포함하는 중요한 AI 협력 협정을 체결했습니다. 사우디 신설 AI 회사 Humain이 핵심 실행 주체가 될 것입니다. 이는 미국이 중동 지역에서 자국 AI 기술 스택을 홍보하고 인프라 건설을 가속화하며, 이를 통해 동맹국을 확보하는 동시에 해당 지역 내 중국의 AI 인프라 투자 및 기술 영향력을 제한하려는 전략적 포석으로 간주됩니다. 새 협정은 기존 중동 AI 칩 수출 제한 일부를 폐지했지만, 동시에 Huawei Ascend 등 중국 칩 사용에 대한 전 세계적 경고를 강화했습니다. (출처: dylan522p, 36氪, iScienceLuvr)

요식업 SaaS 회사 Owner, 1.2억 달러 투자 유치하며 유니콘 등극, AI 활용해 “AI 레스토랑 임원” 구축: 독립 레스토랑에 풀스택 디지털 솔루션을 제공하는 Owner 회사가 최근 1.2억 달러 규모의 시리즈 C 투자를 유치하며 기업 가치 10억 달러를 달성했습니다. Owner는 월 고정 요금으로 레스토랑에 웹사이트/앱 구축, 주문 배달 통합, SEO 최적화 및 마케팅 자동화 서비스를 제공하며, 이미 1만 개 이상의 레스토랑에 서비스를 제공하고 있습니다. 2025년 AI 전략에는 “AI 레스토랑 임원”(AI CMO, CFO, CTO)을 출시하여 AI 직원과 인간 직원을 관리하고, 대화형 AI Agent를 구축하여 서비스 효율성을 높이는 것이 포함됩니다. 이번 투자는 Redpoint Ventures와 Altman Capital이 공동 주도했으며, AI가 전통적인 SaaS 가치를 재편할 잠재력을 보여줍니다. (출처: 36氪)
🌟 커뮤니티
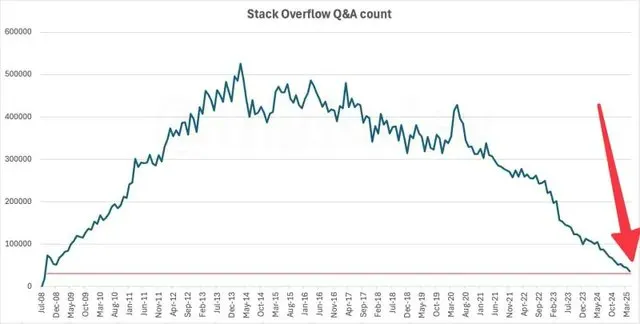
Stack Overflow 활동량 2009년 수준으로 급감, AI가 주된 원인일 가능성: 데이터에 따르면 유명 개발자 Q&A 커뮤니티 Stack Overflow의 월간 질문 수가 2009년 출시 당시 수준으로 떨어졌습니다. 이 현상은 AI가 전통적인 개발자 커뮤니티에 미치는 영향에 대한 논의를 불러일으켰습니다. 많은 사람들은 ChatGPT와 같은 AI 프로그래밍 도우미의 등장으로 개발자들이 Stack Overflow와 같은 커뮤니티에 질문하고 사람의 답변을 기다리기보다는 AI에게 직접 질문하고 코드 솔루션을 찾는 경향이 커졌으며, 이것이 커뮤니티 활동량 급감의 원인일 수 있다고 보고 있습니다. (출처: zachtratar, karminski3)
직장 내 AI, “전문성” 위기감 유발, 직원들은 AI 시대에 오히려 인간미 필요하다고 느껴: 직장에서 AI가 보편화되면서 많은 직원들이 자신의 전문 기술이 “해체”되는 것을 느끼고 있습니다. 리더들은 AI에게 직원들의 성과물을 수정하도록 하거나 심지어 AI가 인간 직원보다 낫다고 생각하는 경향이 있어 직원들은 존중받지 못하고 대체될 위기에 처해 있다고 느낍니다. 연구에 따르면 직원들은 CEO 본인과 AI가 작성한 이메일을 구분할 수 있으며, 내용이 AI에 의해 생성되었다고 생각할 때 실제로는 사람이 작성했더라도 평가가 낮아지는 것으로 나타났습니다. 이는 인간 창작물에 대한 선호와 AI에 대한 과도한 의존에 대한 우려를 반영합니다. 동시에 McKinsey 연구에 따르면 퇴사한 직원의 54%가 제대로 평가받지 못했다고 느꼈으며, 82%의 직원은 AI 시대에 인간관계와 정서적 교감이 더욱 필요하다고 생각합니다. (출처: 36氪, 36氪)

중국 젊은층 AI 동반자 수용, 저출산 우려 심화: 《이코노미스트》는 중국 젊은층 사이에서 AI와 연애하고 친구를 사귀는 현상이 나타나고 있다고 보도했습니다. “Maoxiang”, “Xingye” 등 AI 동반자 애플리케이션 사용자 수가 지속적으로 증가하고 있으며, 사용자들은 가상 캐릭터를 만들어 정서적 욕구를 충족시키고 있습니다. 기술 발전으로 AI가 감정과 공감을 모방할 수 있게 되었고, 젊은층의 생활 스트레스 증가, 사교 시간 감소, 결혼율 하락 등의 요인이 이러한 추세를 부추기고 있습니다. 그러나 정부는 AI 동반자가 이미 심각한 저출산 문제(2024년 합계출산율 1.0명)를 더욱 악화시킬 수 있다고 우려하고 있습니다. (출처: dotey)

AI 지원, 교육의 새로운 표준이 될 수 있지만 교수의 ChatGPT 과도한 의존은 학생 불만과 성찰 야기: 미국 노스이스턴 대학교 학생이 교수가 ChatGPT를 사용하여 강의 자료를 만든 것에 대해 학비 반환을 요구하며 학교를 고소한 사건은 고등 교육에서 AI의 역할에 대한 광범위한 논의를 불러일으켰습니다. 학생들은 비싼 학비가 알고리즘 생성 콘텐츠가 아닌 인간의 전문적인 교육으로 보상받아야 한다고 주장하며, AI가 교수의 사고와 피드백을 대체하는 것을 우려했습니다. 반면 교수는 AI를 효율성을 높이고 과중한 업무에 대처하기 위한 도구로 간주했습니다. 교육계 인사들은 AI를 책임감 있게 사용하여 인간의 창의력과 감독을 대체하는 것이 아니라 강화하고, 학생들에게 AI 시대의 윤리 규범을 교육하며, AI 생성 콘텐츠가 전문적인 편집과 확인을 거치도록 보장하는 것이 중요하다고 지적합니다. (출처: 36氪, Reddit r/ChatGPT)

Salesforce CEO, Microsoft와 OpenAI 관계 근본적으로 파탄났고 회복 불가능하다고 주장: Salesforce CEO 마크 베니오프는 인터뷰에서 Microsoft와 OpenAI의 협력 관계가 “근본적으로 파탄났고 회복하기 어렵다”고 말했습니다. 그는 Microsoft Copilot이 고객들을 실망시켰으며 비효율적인 Clippy에 더 가깝다고 지적했고, OpenAI 최고재무책임자(CFO)가 기술 아키텍처 다이어그램에서 Microsoft 소프트웨어나 Azure를 언급하지 않은 것이 양측의 균열을 입증한다고 말했습니다. 베니오프는 Microsoft가 본질적으로 ChatGPT의 리셀러이며 AI 전략이 제한적이고 “프로메테우스 계획”을 통해 자체 개발 모델을 구축하려 한다고 보았습니다. 그는 또한 DeepSeek과 같은 오픈소스 모델의 부상이 업계를 MOE 아키텍처로 전환시키고 모델 사용 비용을 낮추며 “모델 독점”의 비즈니스 논리를 와해시키고 있다고 언급했습니다. (출처: 36氪)

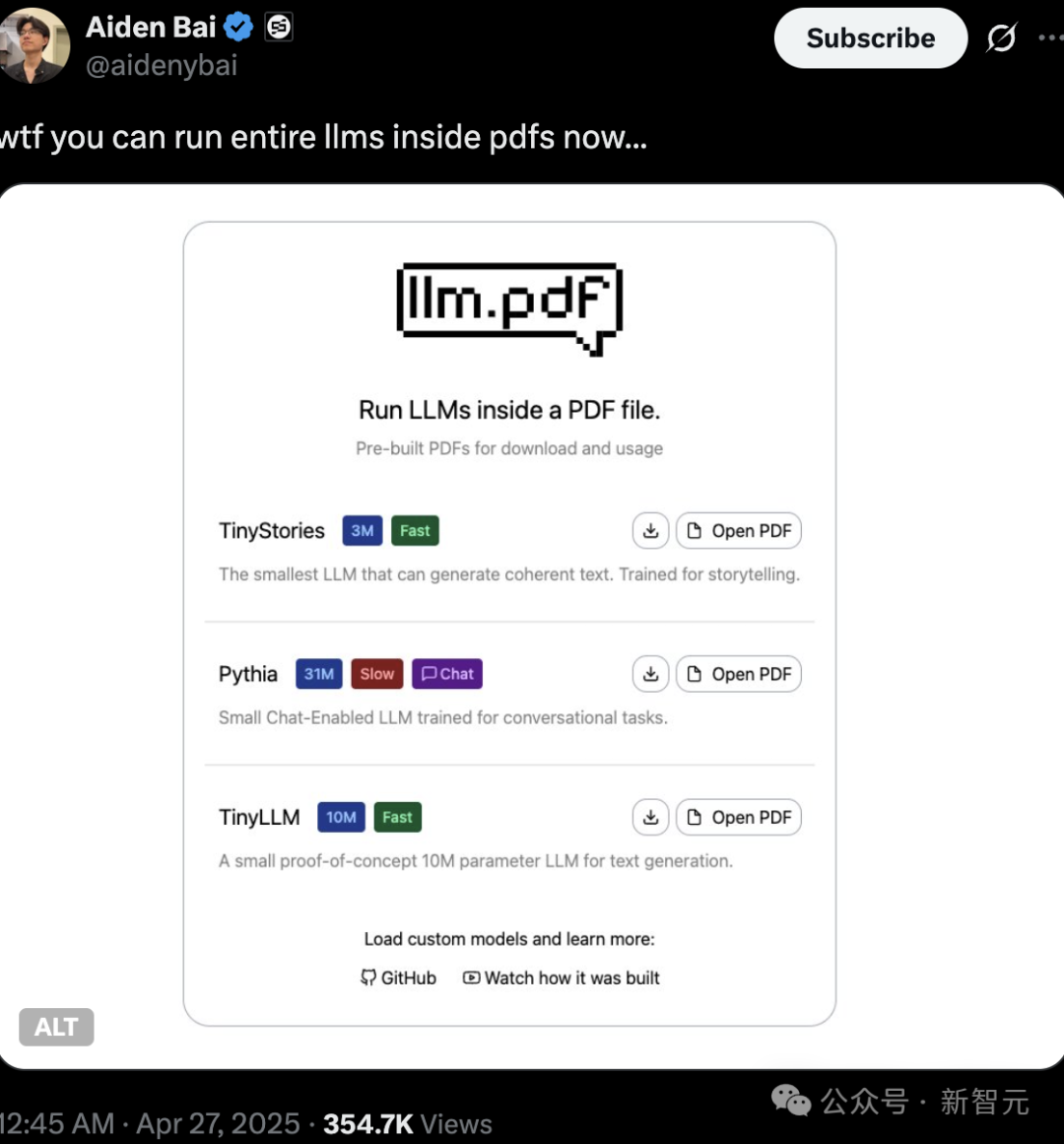
AI 생성 콘텐츠의 진실성 및 저작권 주목, PDF 내 LLM 및 Linux 실행 기술 잠재력 과시: 최근 기술 애호가들이 PDF 파일 내에서 직접 소형 언어 모델(예: TinyStories, Pythia, TinyLLM) 심지어 Linux 시스템까지 실행하는 능력을 선보이며 PDF의 JavaScript 지원을 활용했습니다. 이 “블랙 테크놀로지” 작업은 네티즌들 사이에서 뜨거운 논쟁을 불러일으켰으며, AI 모델 소형화 및 엣지 배포 추세를 부각시켰습니다. 동시에 AI 생성 콘텐츠의 저작권, 진실성 및 “딥페이크” 문제도 큰 주목을 받고 있습니다. 장야친은 AI 위험에는 딥페이크, 환각, 유해 정보 등이 포함되며, AI와 인간 가치관의 정렬 및 윤리적 규제를 매우 중시하고 강화해야 한다고 지적했습니다. (출처: 36氪, 36氪)
💡 기타
Theta, CUB 벤치마크 발표: 컴퓨터 및 브라우저 사용 에이전트 평가 위한 “인류 최후의 시험”: Theta는 컴퓨터 및 브라우저 사용 에이전트를 위한 “인류 최후의 시험”이라고 주장하는 CUB (Computer and Browser Use Agents)라는 새로운 벤치마크 테스트를 출시했습니다. 이러한 유형의 벤치마크는 AI 에이전트가 인간의 컴퓨터 및 브라우저 사용을 모방하여 복잡한 작업을 완료하는 능력을 평가하기 위해 고안되었습니다. 그러나 이미 여러 벤치마크가 “인류 최후의 시험”을 자처하고 있어, 그 명칭이 지나치게 과장되었을 수 있다는 논의가 있습니다. (출처: _akhaliq, DhruvBatraDB)
AI, 저속한 콘텐츠 생성에 사용된다는 비난, 모델 남용 및 윤리적 경계에 대한 우려 제기: 소셜 미디어에서 사용자들이 AI 이미지 생성 도구(예: ChatGPT의 DALL-E 3)를 이용하여 저속하거나 희화화된 이미지(예: “Shittington Bear”)를 만드는 현상이 나타나고 있습니다. 이는 AI 도구가 부적절한 콘텐츠 생성, 저작권 침해(예: 유명 만화 캐릭터 희화화), 사회 윤리적 한계 도전 등에 남용될 수 있다는 우려를 불러일으키고 있습니다. AI 플랫폼에는 일반적으로 콘텐츠 필터가 있지만, 사용자들은 여전히 교묘한 프롬프트를 통해 제한을 우회할 수 있습니다. (출처: Reddit r/ChatGPT)

연구 결과, AI는 CEO 소통 스타일 모방에 한계, 직원들은 인간을 더 신뢰: 하버드 경영대학원 연구에 따르면, 직원들이 AI와 회사 CEO 웨이드 포스터(Zapier CEO)가 작성한 정보를 구별하는 정확도는 약 59%였습니다. 더 중요한 것은, 일단 직원들이 정보가 AI에 의해 생성되었다고 생각하면, 내용이 실제 CEO 본인이 작성한 것이라도 평가는 낮아지는 반면, CEO가 작성한 것으로 간주된 내용은 AI가 생성한 것이라도 평가가 더 높아졌습니다. 이는 사람들이 AI보다 인간의 소통에 대한 신뢰도와 가치 인식이 더 높다는 것을 보여줍니다. 연구는 리더들이 AI를 사용하여 소통할 때 투명성을 유지하고, 매우 사적인 답변에는 사용을 피하며, AI 생성 콘텐츠에 대해 엄격한 검토를 할 것을 권고합니다. (출처: 36氪)