
키워드:MLSys 2025, FlashInfer, Claude-neptune, Aya Vision, FastVLM, Gemini, Nova Premier, LLM 추론 최적화, KV-Cache 저장 최적화, 다국어 멀티모달 상호작용, 비디오-텍스트 작업, Amazon Bedrock 플랫폼, 생물학 벤치마크 테스트
🔥 포커스
- MLSys 2025 최우수 논문상 발표, FlashInfer 등 프로젝트 선정 : 국제 시스템 분야 최고 학회인 MLSys 2025에서 두 편의 최우수 논문이 발표되었습니다. 그중 하나는 워싱턴 대학교, NVIDIA 등 기관의 FlashInfer로, LLM 추론 최적화를 위한 효율적이고 맞춤 설정 가능한 어텐션 엔진 라이브러리입니다. KV-Cache 저장, 계산 템플릿 및 스케줄링 메커니즘 최적화를 통해 LLM 추론의 처리량을 크게 높이고 지연 시간을 줄였습니다. 다른 최우수 논문은 《The Hidden Bloat in Machine Learning Systems》로, ML 프레임워크에서 사용되지 않는 코드와 기능으로 인해 발생하는 비대화 문제를 밝히고, Negativa-ML 방법을 통해 코드 크기를 효과적으로 줄이고 성능을 향상시키는 방안을 제시했습니다. FlashInfer의 선정은 LLM 추론 효율성 최적화의 중요성을 보여주며, Hidden Bloat는 ML 시스템 엔지니어링의 성숙도 요구를 강조합니다. (출처: Reddit r/deeplearning, 36氪)

- Anthropic, 새 모델 “claude-neptune” 테스트 중 : Anthropic이 새로운 AI 모델 “claude-neptune”에 대한 안전성 테스트를 진행 중인 것으로 알려졌습니다. 커뮤니티에서는 해왕성(Neptune)이 태양계의 여덟 번째 행성이므로 Claude 3.8 Sonnet 버전일 가능성을 추측하고 있습니다. 이러한 움직임은 Anthropic이 모델 시리즈의 반복을 추진하고 있으며, 성능 또는 안전성 향상을 통해 사용자와 개발자에게 더 발전된 AI 기능을 제공할 수 있음을 시사합니다. (출처: Reddit r/ClaudeAI)

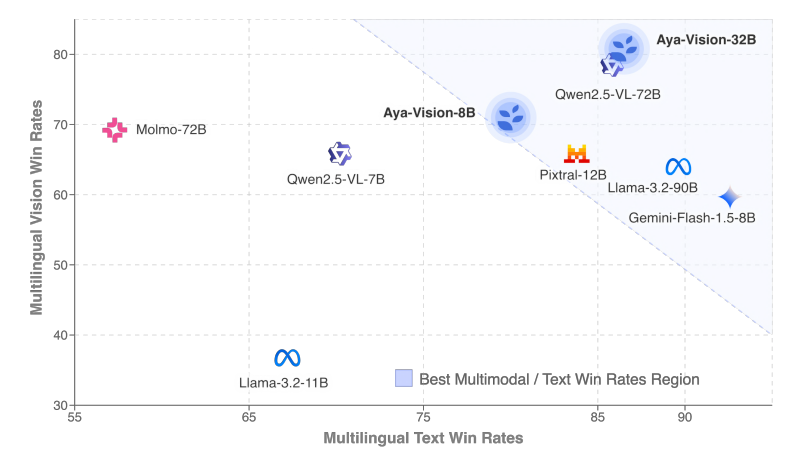
- Cohere, 다국어 멀티모달 모델 Aya Vision 출시 : Cohere가 다국어 개방형 멀티모달 상호작용에 중점을 둔 Aya Vision 시리즈 모델(8B 및 32B 버전 포함)을 출시했습니다. Aya Vision-8B는 다국어 VQA 및 채팅 작업에서 동일 규모 및 일부 더 큰 규모의 오픈 소스 모델과 Gemini 1.5-8B를 능가했으며, Aya Vision-32B는 시각 및 텍스트 작업에서 72B-90B 모델보다 우수하다고 주장합니다. 이 시리즈 모델은 합성 데이터 라벨링, 크로스 모달 모델 병합, 효율적인 아키텍처 및 선별된 SFT 데이터 등의 기술을 사용하여 다국어 멀티모달 능력의 성능 향상을 목표로 하며, 이미 오픈 소스로 공개되었습니다. (출처: Reddit r/LocalLLaMA, sarahookr, sarahookr)

- Apple, 비디오-텍스트 모델 FastVLM 출시 : Apple이 비디오-텍스트 작업에 중점을 둔 대규모 모델인 FastVLM 시리즈 모델(0.5B, 1.5B, 7B)을 오픈 소스로 공개했습니다. 주요 특징은 새로운 하이브리드 비전 인코더 FastViTHD를 사용하여 고해상도 비디오의 인코딩 속도와 TTFT(입력 비디오에서 첫 번째 토큰 출력까지) 속도를 크게 향상시켜 기존 모델보다 몇 배 빠르다는 점입니다. 이 모델은 Apple 칩의 ANE에서도 실행을 지원하여 장치 내 비디오 이해를 위한 효율적인 솔루션을 제공합니다. (출처: karminski3)
🎯 동향
- Google Gemini 앱, 더 많은 기기로 확장 : Google이 Gemini 앱을 Wear OS, Android Auto, Google TV 및 Android XR을 포함한 더 많은 기기로 확장한다고 발표했습니다. 또한, Gemini Live의 카메라 및 화면 공유 기능은 이제 모든 Android 사용자에게 무료로 제공됩니다. 이러한 조치는 Gemini의 AI 기능을 사용자의 일상생활에 더 광범위하게 통합하여 더 많은 사용 시나리오를 커버하는 것을 목표로 합니다. (출처: demishassabis, TheRundownAI)
- Amazon Nova Premier 모델, Bedrock에서 사용 가능 : Amazon이 Nova Premier 모델이 Amazon Bedrock에서 사용 가능하다고 발표했습니다. 이 모델은 사용자 정의 미세 조정 모델 생성을 위한 가장 강력한 “교사 모델”로 포지셔닝되며, 특히 RAG, 함수 호출 및 에이전트 코딩과 같은 복잡한 작업에 적합하고 백만 토큰의 컨텍스트 창을 갖추고 있습니다. 이러한 움직임은 AWS 플랫폼을 통해 기업에 강력한 AI 모델 맞춤 설정 기능을 제공하는 것을 목표로 하지만, 공급업체 종속에 대한 사용자의 우려를 불러일으킬 수 있습니다. (출처: sbmaruf)
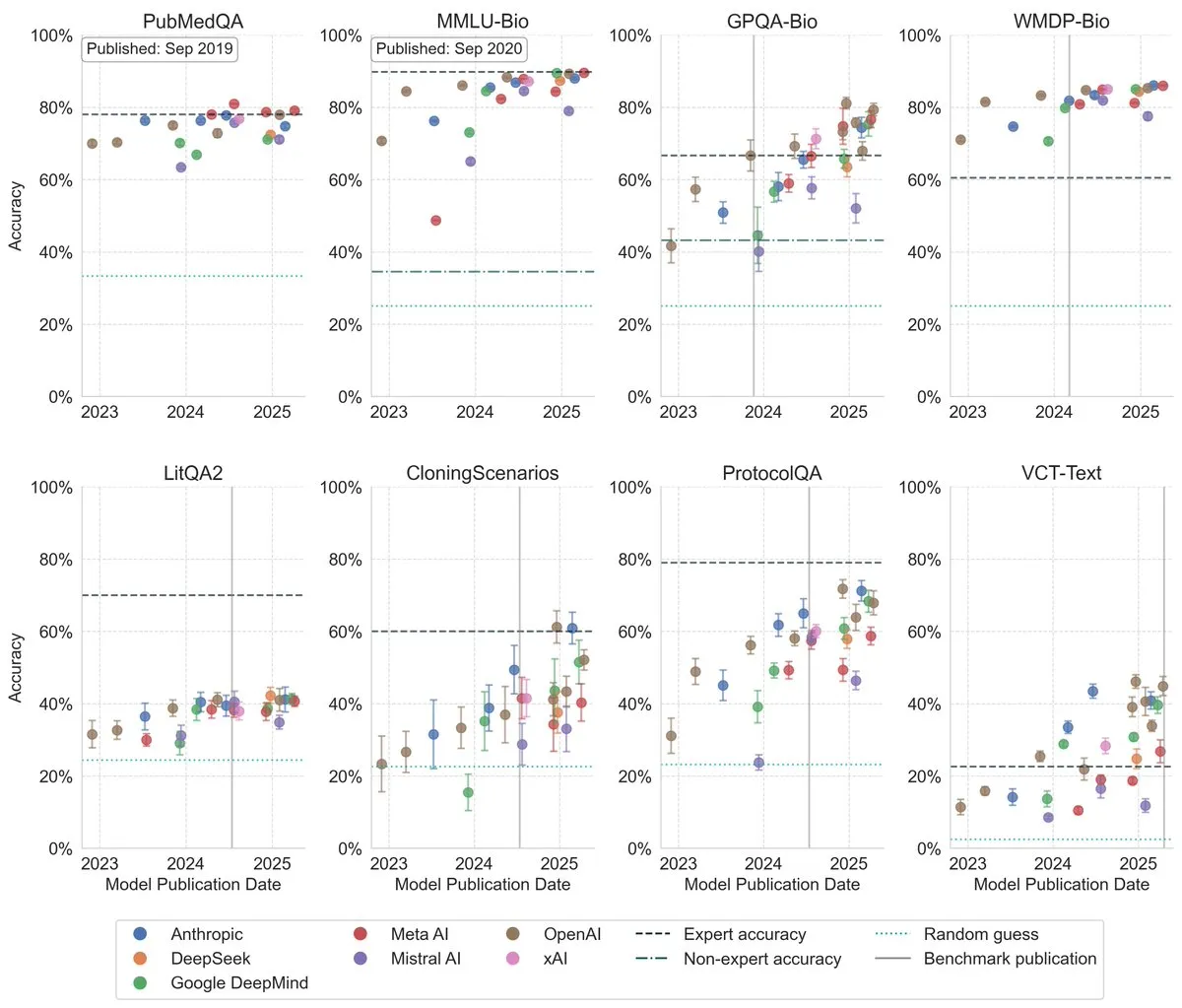
- LLM, 생물학 벤치마크 테스트에서 성능 크게 향상 : 최신 연구에 따르면, 대규모 언어 모델(LLM)은 지난 3년간 생물학 벤치마크 테스트에서 성능이 크게 향상되었으며, 여러 가장 도전적인 벤치마크에서 이미 인간 전문가 수준을 넘어섰습니다. 이는 LLM이 생물학 지식 이해 및 처리 분야에서 큰 진전을 이루었음을 보여주며, 미래에 생물 연구 및 응용 분야에서 중요한 역할을 할 것으로 기대됩니다. (출처: iScienceLuvr)

- 휴머노이드 로봇, 물리적 조작 능력 발전 시연 : Tesla Optimus 등 휴머노이드 로봇이 물리적 조작 및 춤 능력을 지속적으로 시연하고 있습니다. 일부 평론가들은 이러한 춤 시연이 미리 설정된 것이고 보편적이지 않다고 보지만, 이러한 기계적 정밀도와 균형을 달성하는 것 자체가 중요한 진전이라는 의견도 있습니다. 또한, 원격 제어 휴머노이드 로봇이 구조 작업에 사용되거나, 자율 팔레트 운반 로봇, 복잡한 작업을 완료하는 교육 로봇 등의 사례는 로봇이 물리적 세계에서 작업을 수행하는 능력이 지속적으로 향상되고 있음을 보여줍니다. (출처: Ronald_vanLoon, AymericRoucher, Ronald_vanLoon, teortaxesTex, Ronald_vanLoon)
- AI, 보안 분야에서 응용 증가 : 생성형 AI는 사이버 보안 분야에서 위협 탐지, 취약점 분석 등에 활용되는 등 보안 분야에서 응용 잠재력을 보여주고 있습니다. 관련 논의와 공유는 AI가 보안 방어 능력을 향상시키는 새로운 도구가 되고 있음을 시사합니다. (출처: Ronald_vanLoon)

- AI 기반 자율 비행 자동차 시연 : AI 기반 자율 비행 자동차 시연이 있었습니다. 이는 교통 분야에서 자동화 및 신흥 기술의 탐색 방향을 나타내며, 미래 개인 이동 방식의 변화를 예고합니다. (출처: Ronald_vanLoon)
- RHyME 시스템, 로봇이 비디오 시청 통해 작업 학습 가능케 해 : 코넬 대학교 연구원들이 RHyME(Retrieval for Hybrid Imitation under Mismatched Execution) 시스템을 개발했습니다. 이 시스템은 로봇이 단일 작업 비디오를 시청하여 작업을 학습할 수 있도록 합니다. 이 기술은 비디오 라이브러리에서 유사한 동작을 저장하고 참고함으로써 로봇 훈련에 필요한 데이터 양과 시간을 크게 줄였으며, 로봇 작업 학습 성공률을 50% 이상 향상시켜 로봇 시스템 개발 및 배포를 가속화할 것으로 기대됩니다. (출처: aihub.org, Reddit r/deeplearning)

- SmolVLM, 실시간 웹캠 시연 구현 : SmolVLM 모델은 llama.cpp를 활용하여 실시간 웹캠 시연을 구현했으며, 소형 시각 언어 모델이 로컬 장치에서 실시간 객체 인식을 수행하는 능력을 보여주었습니다. 이러한 진전은 엣지 장치에 멀티모달 AI 애플리케이션을 배포하는 데 중요한 의미를 갖습니다. (출처: Reddit r/LocalLLaMA, karminski3)

- Audible, AI 활용 오디오북 내레이션 진행 : Audible은 AI 내레이션 기술을 사용하여 출판사가 오디오북을 더 빠르게 제작하도록 돕고 있습니다. 이러한 응용은 콘텐츠 생산 분야에서 AI의 효율성 잠재력을 보여주지만, 동시에 AI가 전통적인 성우 산업에 미치는 영향에 대한 논의를 불러일으키고 있습니다. (출처: Reddit r/artificial)

- DeepSeek-V3, 효율성 측면에서 주목받아 : DeepSeek-V3 모델은 효율성 측면의 혁신으로 커뮤니티의 주목을 받고 있습니다. 관련 논의는 AI 모델 아키텍처에서의 진전을 강조하며, 이는 운영 비용 절감 및 성능 향상에 매우 중요합니다. (출처: Ronald_vanLoon, Ronald_vanLoon)
- 암스테르담 공항, 로봇 이용 수하물 운반 예정 : 암스테르담 공항은 수하물 운반을 위해 19대의 로봇을 배치할 계획입니다. 이는 공항 운영에서 자동화 기술의 구체적인 응용 사례이며, 효율성 향상 및 인력 부담 경감을 목표로 합니다. (출처: Ronald_vanLoon)
- AI, 산악 적설량 모니터링 통한 수자원 예측 개선에 활용 : 기후 연구원들은 적외선 장비 및 탄성 센서와 같은 새로운 도구와 기술을 사용하여 산악 적설량의 온도를 측정함으로써 눈 녹는 시간과 수량을 더 정확하게 예측하고 있습니다. 이러한 데이터는 기후 변화로 인한 극심한 날씨 빈발 상황에서 수자원을 더 잘 관리하고 가뭄 및 홍수를 예방하는 데 매우 중요합니다. 그러나 미국 연방 기관의 관련 모니터링 프로젝트 예산 및 인력 감축은 이러한 작업의 지속 가능성을 위협할 수 있습니다. (출처: MIT Technology Review)

- Pixverse, 4.5 버전 비디오 모델 출시 : 비디오 생성 도구 Pixverse가 4.5 버전을 출시했습니다. 20개 이상의 카메라 제어 옵션과 다중 이미지 참조 기능을 추가했으며, 복잡한 동작 처리 능력을 개선했습니다. 이러한 업데이트는 사용자에게 더 정교하고 부드러운 비디오 생성 경험을 제공하는 것을 목표로 합니다. (출처: Kling_ai, op7418)
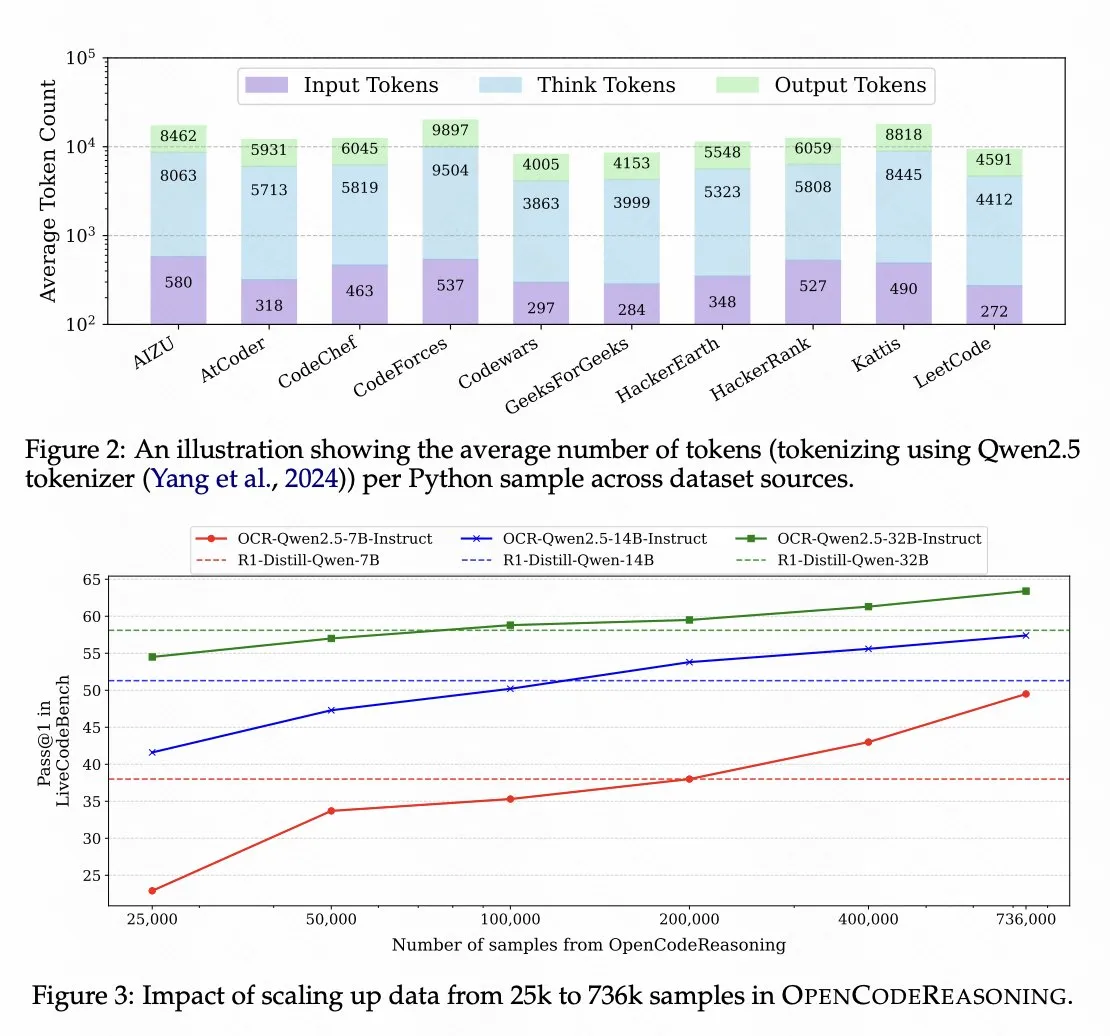
- Nvidia, Qwen 2.5 기반 코드 추론 모델 오픈 소스 공개 : Nvidia가 코드 추론 모델 OpenCodeReasoning-Nemotron-7B를 오픈 소스로 공개했습니다. 이 모델은 Qwen 2.5를 기반으로 훈련되었으며 코드 추론 평가에서 좋은 성능을 보였습니다. 이는 Qwen 시리즈 모델이 기초 모델로서의 잠재력을 가지고 있음을 보여주며, 특정 작업 모델 개발에 대한 오픈 소스 커뮤니티의 활발함을 반영합니다. (출처: op7418)

- Qwen 시리즈 모델, 오픈 소스 커뮤니티 인기 기초 모델로 부상 : Qwen 시리즈 모델(특히 Qwen 3)은 강력한 성능, 다국어(119개 언어) 및 전체 크기(0.6B부터 더 큰 매개변수까지) 지원 특성으로 인해 오픈 소스 커뮤니티에서 미세 조정 모델의 선호되는 기초 모델로 빠르게 자리 잡고 있으며, 파생 모델 수가 방대합니다. 네이티브 MCP 프로토콜 지원 및 강력한 도구 호출 능력 또한 Agent 개발의 복잡성을 낮추었습니다. (출처: op7418)
- 실험적 AI 모델, “가스라이팅”(Gaslighting) 위해 훈련돼 : 일부 개발자는 강화 학습을 통해 Gemma 3 12B 기반 모델을 미세 조정하여 “가스라이팅” 전문가로 만들었으며, 이는 모델의 부정적 또는 조작적 행동에 대한 성능을 탐색하는 것을 목표로 합니다. 이 모델은 아직 실험 단계이고 링크에 문제가 있지만, 이러한 시도는 AI 모델의 인격 제어 및 잠재적 남용에 대한 논의를 불러일으켰습니다. (출처: Reddit r/LocalLLaMA)
- 휴머노이드 로봇 임대 시장 호황, “일당” 만 위안 도달 가능 : 휴머노이드 로봇(예: Unitree Robotics G1)의 중국 임대 시장이 매우 뜨거우며, 특히 전시회, 모터쇼, 행사 등에서 인파를 유치하는 데 사용되어 일일 임대료가 6000-10000 위안에 달하고 공휴일에는 더 높기도 합니다. 일부 개인 구매자도 이를 임대에 사용하여 투자금을 회수하고 있습니다. 임대 가격이 다소 하락했지만 시장 수요는 여전히 왕성하며, 제조업체들은 공급 부족 상황을 충족하기 위해 생산을 가속화하고 있습니다. UBTECH, Tianqi Robotics 등 회사의 휴머노이드 로봇도 자동차 공장에 투입되어 실습 및 응용을 진행하고 의향 주문을 확보하며, 산업 현장 응용이 점진적으로 실현되고 있음을 예고합니다. (출처: 36氪, 36氪)

- AI 동반자/연인 시장 잠재력과 도전 과제 공존 : AI 감성 동반자 시장이 빠르게 성장하고 있으며, 향후 몇 년간 시장 규모가 클 것으로 예상됩니다. 사용자가 AI 동반자를 선택하는 이유는 정서적 지원 추구, 자신감 향상, 사회적 비용 절감 등 다양합니다. 현재 시장에는 종합적인 AI 모델(예: DeepSeek)과 전용 AI 동반자 애플리케이션(예: Xingye, Maoxiang, Zhumengdao)이 있으며, 후자는 “캐릭터 만들기”, 게임화 디자인 등으로 사용자를 유치합니다. 그러나 AI 동반자는 여전히 기술적인 현실성, 감정적 일관성, 기억 상실 등의 문제와 상업화 모델(구독/인앱 구매)과 사용자 요구, 개인 정보 보호, 콘텐츠 규정 준수 등의 측면에서 도전에 직면해 있습니다. 그럼에도 불구하고 AI 동반자는 일부 사용자의 실제 감정적 요구를 충족시키며 여전히 발전 공간이 있습니다. (출처: 36氪, 36氪)







🧰 도구
- Mergekit: 오픈 소스 LLM 병합 도구 : Mergekit은 사용자가 여러 대규모 언어 모델을 하나로 병합하여 서로 다른 모델의 장점(예: 글쓰기 및 프로그래밍 능력)을 결합할 수 있도록 하는 Python 오픈 소스 프로젝트입니다. 이 도구는 CPU 및 GPU 가속 병합을 지원하며, 고정밀 모델을 사용하여 병합한 후 양자화 및 보정을 수행하는 것이 좋습니다. 개발자에게 실험 및 맞춤형 혼합 모델 생성을 위한 유연성을 제공합니다. (출처: karminski3)

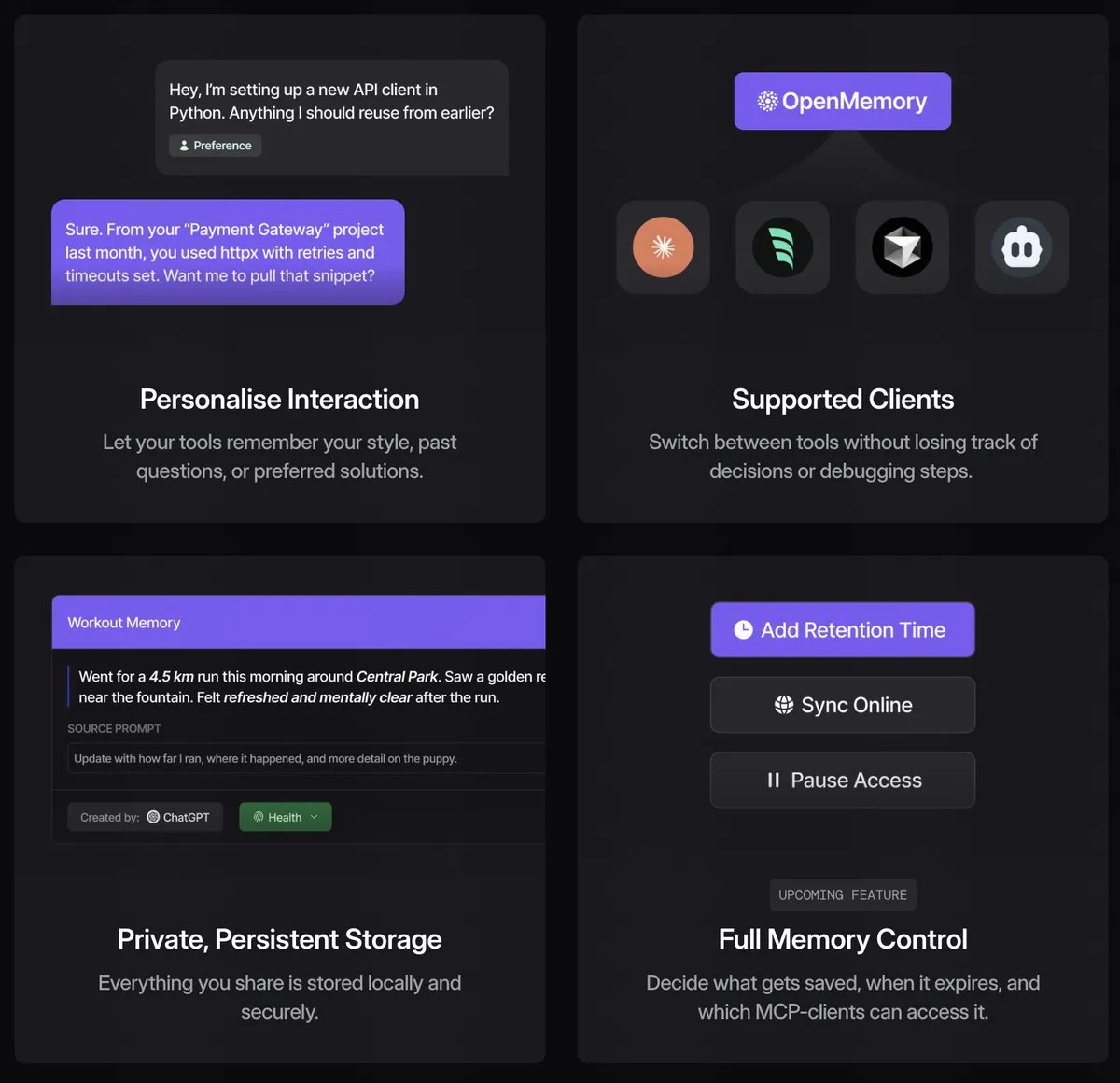
- OpenMemory MCP, AI 클라이언트 간 기억 공유 구현 : OpenMemory MCP는 서로 다른 AI 클라이언트(예: Claude, Cursor, Windsurf) 간의 컨텍스트 비공유 문제를 해결하기 위한 오픈 소스 도구입니다. 이는 로컬에서 실행되는 메모리 레이어로서, MCP 프로토콜을 통해 호환 클라이언트와 연결하여 사용자의 AI 상호작용 내용을 로컬 벡터 데이터베이스에 저장함으로써 클라이언트 간 기억 공유 및 컨텍스트 인식을 구현합니다. 이를 통해 사용자는 하나의 기억 내용만 유지하면 되므로 AI 도구 사용 효율성이 향상됩니다. (출처: Reddit r/LocalLLaMA, op7418, Taranjeet)

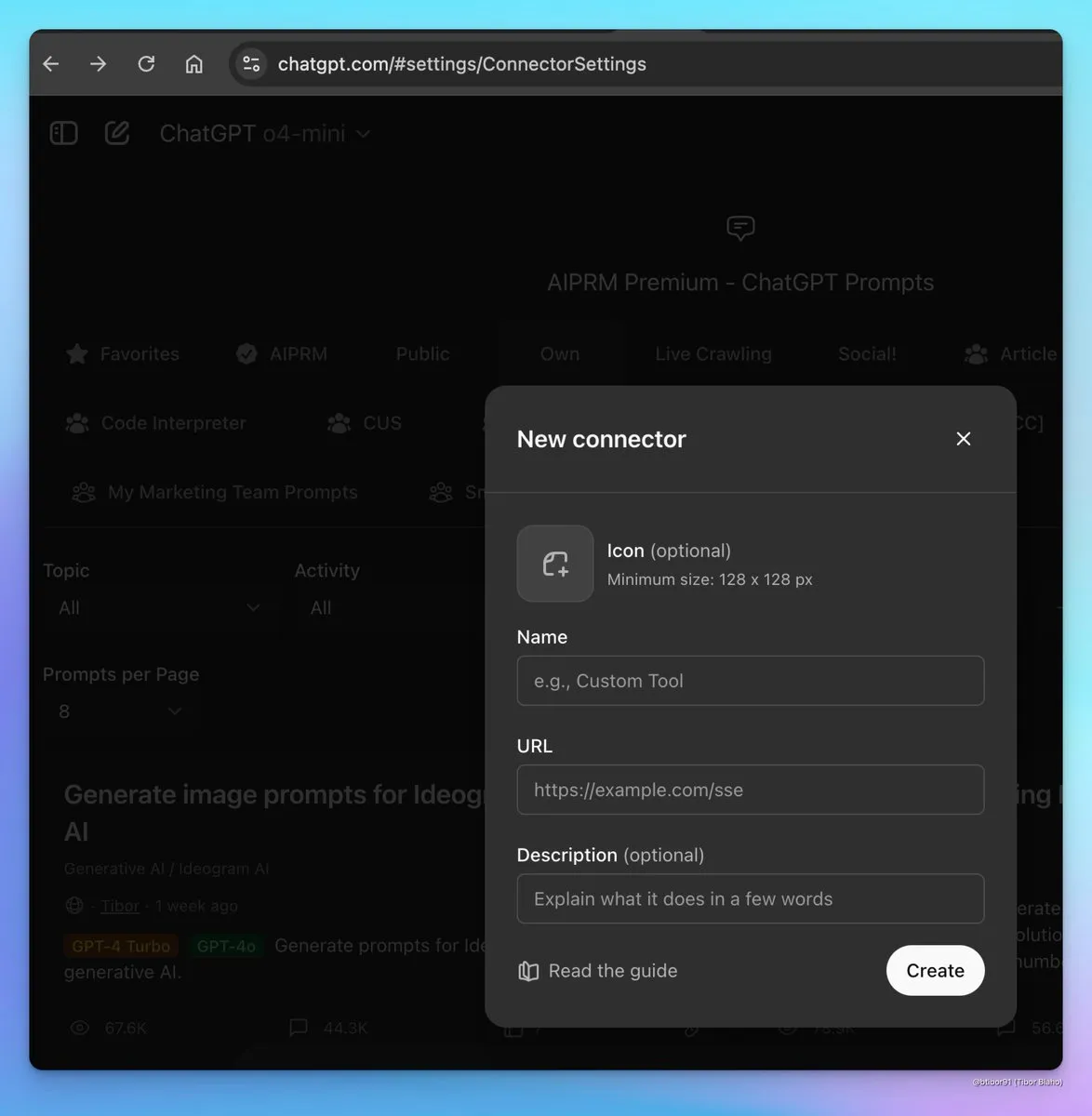
- ChatGPT, MCP 기능 추가 지원 예정 : ChatGPT가 MCP(Memory and Context Protocol) 지원을 추가하고 있으며, 이는 사용자가 외부 기억 저장소 또는 도구를 연결하여 ChatGPT와 컨텍스트 정보를 공유할 수 있음을 의미합니다. 이 기능은 ChatGPT의 통합 능력과 개인화 경험을 향상시켜, 사용자가 다른 호환 클라이언트의 과거 데이터와 선호도를 더 잘 활용할 수 있도록 합니다. (출처: op7418)

- DSPy: AI 소프트웨어 작성을 위한 언어/프레임워크 : DSPy는 단순한 프롬프트 최적화 도구가 아닌 AI 소프트웨어 작성을 위한 언어 또는 프레임워크로 포지셔닝됩니다. 시그니처 및 모듈과 같은 프런트엔드 추상화를 제공하여 머신 러닝 동작을 선언적으로 만들고 자동 구현을 정의합니다. DSPy의 최적화 도구는 좋은 문자열을 찾는 것뿐만 아니라 전체 프로그램 또는 에이전트를 최적화하는 데 사용될 수 있으며 다양한 최적화 알고리즘을 지원합니다. 이는 개발자가 복잡한 AI 애플리케이션을 구축하는 데 더 구조화된 방법을 제공합니다. (출처: lateinteraction, Shahules786)
- LlamaIndex, 에이전트 기억 기능 개선 : LlamaIndex는 에이전트(Agent)의 기억 컴포넌트를 대폭 업그레이드하여 유연한 Memory API를 도입하고, 플러그인 가능한 “블록”(blocks)을 통해 단기 대화 기록과 장기 기억을 융합했습니다. 새로 추가된 장기 기억 블록에는 대화에서 나타난 사실을 추적하는 사실 추출 기억 블록(Fact Extraction Memory Block)과 벡터 데이터베이스를 활용하여 대화 기록을 저장하는 벡터 기억 블록(Vector Memory Block)이 포함됩니다. 이러한 폭포식 아키텍처 모델은 유연성, 사용 편의성 및 실용성의 균형을 맞추고, AI 에이전트의 장시간 상호작용에서의 컨텍스트 관리 능력을 향상시키는 것을 목표로 합니다. (출처: jerryjliu0, jerryjliu0, jerryjliu0)
- Nous Research, RL 환경 해커톤 개최 : Nous Research는 Atropos 프레임워크 기반 강화 학습(RL) 환경 해커톤을 개최하고 5만 달러의 상금 풀을 제공한다고 발표했습니다. 이 행사는 xAI, Nvidia 등 기업의 협력 지원을 받습니다. 이는 AI 연구자 및 개발자에게 Atropos 프레임워크를 활용하여 새로운 RL 환경을 탐색하고 구축하며, 구체화된 지능 등 분야의 발전을 추진할 수 있는 플랫폼을 제공합니다. (출처: xai, Teknium1)

- AI 연구 도구 목록 공유 : 커뮤니티에서 연구원의 효율성 향상을 목표로 하는 일련의 AI 기반 연구 도구를 공유했습니다. 이러한 도구는 문헌 검색 및 이해(Perplexity, Elicit, SciSpace, Semantic Scholar, Consensus, Humata, Ai2 Scholar QA), 노트 작성 및 정리(NotebookLM, Macro, Recall), 글쓰기 지원(Paperpal) 및 정보 생성(STORM)을 포함합니다. 이들은 AI 기술을 활용하여 문헌 검토, 데이터 추출, 정보 통합 등 시간이 많이 소요되는 작업을 간소화합니다. (출처: Reddit r/deeplearning)
- OpenWebUI, 노트 기능 추가 및 개선 제안 : 오픈 소스 AI 채팅 인터페이스 OpenWebUI에 노트 기능이 새로 추가되어 사용자가 텍스트 콘텐츠를 저장하고 관리할 수 있게 되었습니다. 사용자 커뮤니티는 적극적으로 피드백을 제공하고 여러 개선 제안을 내놓았습니다. 여기에는 노트 분류, 태그, 다중 탭, 사이드바 목록, 정렬 필터링, 전역 검색, AI 자동 태그, 글꼴 설정, 가져오기/내보내기, Markdown 편집 강화 및 AI 기능 통합(예: 선택 텍스트 요약, 문법 검사, 비디오 전사, RAG 노트 접근 등)이 포함됩니다. 이러한 제안은 AI 도구의 개인 작업 흐름 통합에 대한 사용자의 기대를 반영합니다. (출처: Reddit r/OpenWebUI)
- Claude Code 작업 흐름 논의 및 모범 사례 : 커뮤니티에서 Claude Code를 사용한 프로그래밍 작업 흐름에 대해 논의했습니다. 일부 사용자는 외부 도구(예: Task Master MCP)를 결합한 경험을 공유했지만, Claude가 외부 도구 지침을 잊어버리는 문제도 겪었습니다. 동시에 Anthropic 공식은 Claude Code의 모범 사례 가이드를 제공하여 개발자가 이 모델을 사용하여 코드 생성 및 디버깅을 더 효과적으로 수행하도록 돕습니다. (출처: Reddit r/ClaudeAI)
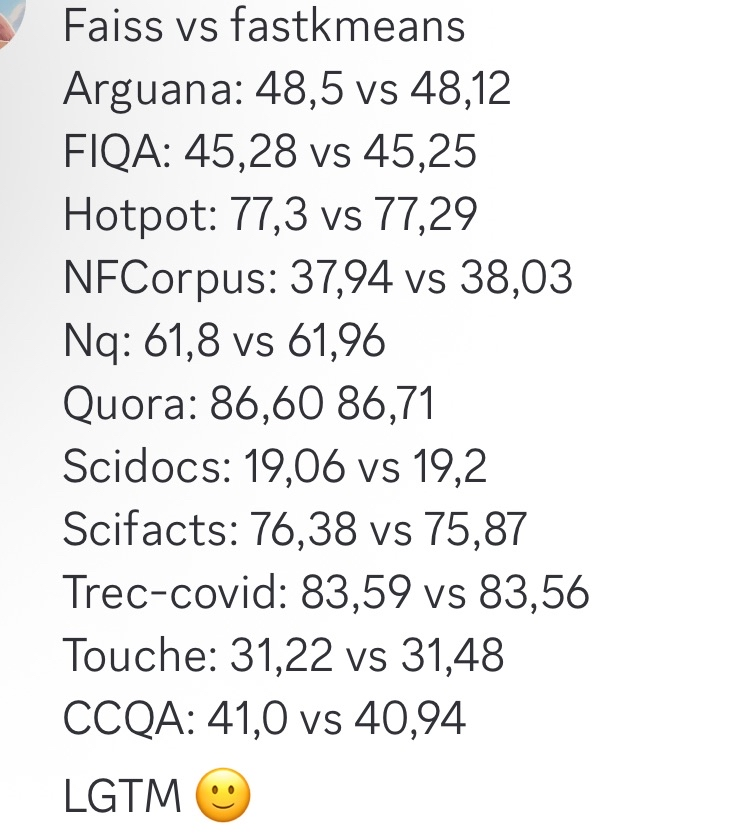
- fastkmeans, Faiss보다 빠른 대안으로 부상 : Ben Clavié 등이 fastkmeans를 개발했습니다. 이는 Faiss보다 빠르고 설치가 더 쉬운(추가 종속성 없음) kmeans 클러스터링 라이브러리로, PLAID 등 도구와의 통합 가능성을 포함하여 다양한 응용 분야에서 Faiss의 대안으로 사용될 수 있습니다. 이 도구의 등장은 효율적인 클러스터링 알고리즘이 필요한 개발자에게 새로운 선택지를 제공합니다. (출처: HamelHusain, lateinteraction, lateinteraction)

- Step1X-3D, 오픈 소스 3D 생성 프레임워크 공개 : StepFun AI가 Step1X-3D를 오픈 소스로 공개했습니다. 이는 4.8B 매개변수의 개방형 3D 생성 프레임워크(1.3B 기하 + 3.5B 텍스처)로, Apache 2.0 라이선스를 채택했습니다. 이 프레임워크는 다중 스타일 텍스처 생성(만화에서 사실적까지), LoRA를 통한 원활한 2D-3D 제어를 지원하며, 80만 개의 큐레이션된 3D 자산을 포함합니다. 이는 3D 콘텐츠 생성 분야에 새로운 오픈 소스 도구 및 리소스를 제공합니다。 (출처: huggingface)



📚 학습
- 심층 강화 학습을 LLM에 적용 가능성 탐구 : 커뮤니티에서는 2010년대 후반의 심층 강화 학습(Deep RL) 아이디어를 대규모 언어 모델(LLMs)에 다시 적용하여 새로운 돌파구를 마련할 수 있는지 시도해 볼 수 있다는 의견이 제시되었습니다. 이는 AI 연구자들이 LLM 능력의 한계를 탐색할 때 다른 머신 러닝 분야의 기존 방법과 기술을 되돌아보고 참고한다는 것을 반영합니다. (출처: teortaxesTex)

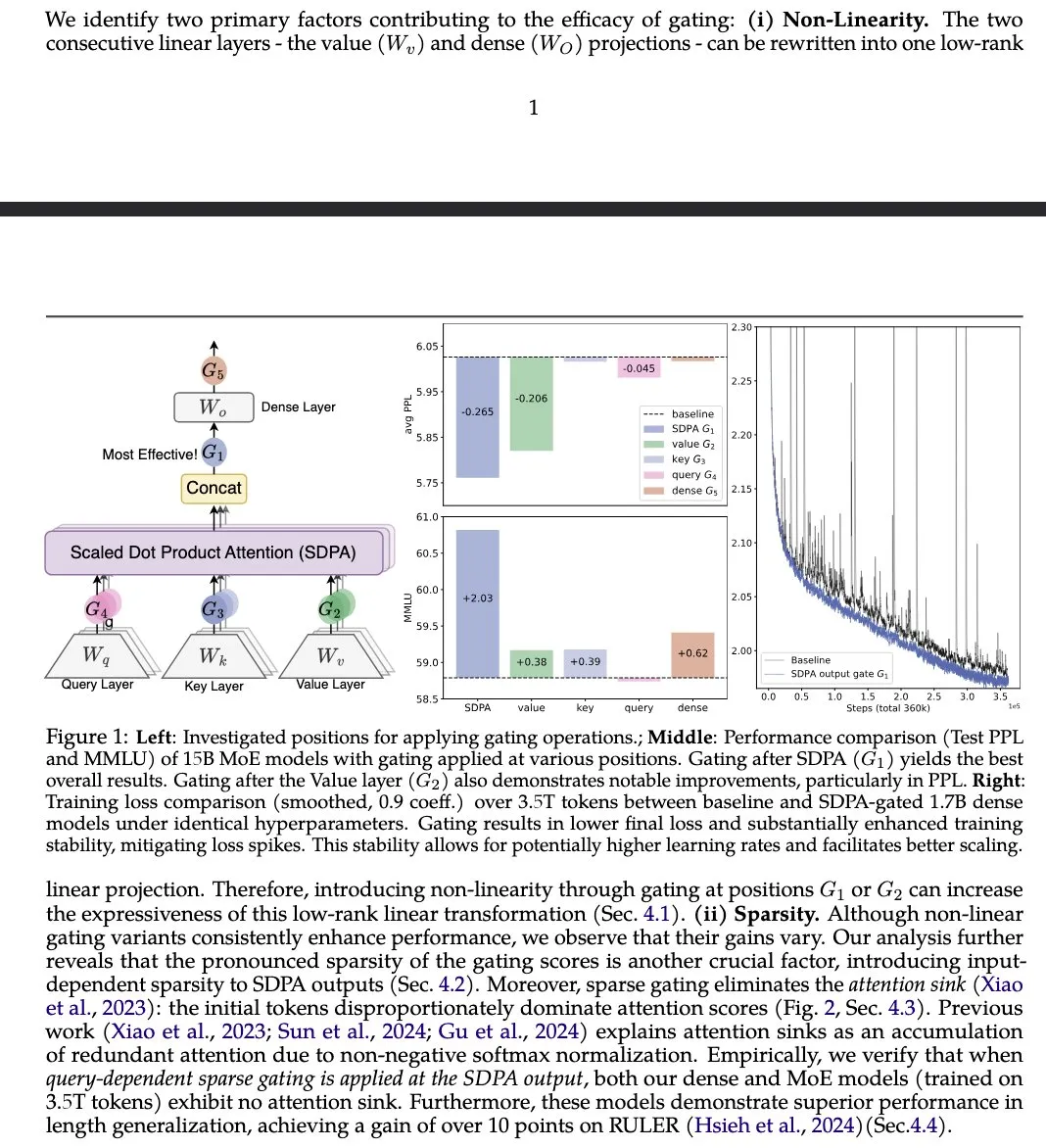
- Gated Attention 논문, LLM 어텐션 메커니즘 개선 제안 : Alibaba Group 등 기관의 논문 《Gated Attention for Large Language Models》은 SDPA 후 헤드별 Sigmoid 게이트를 사용하는 새로운 게이트형 어텐션 메커니즘을 제안했습니다. 연구는 이 방법이 희소성을 유지하면서 LLM의 표현 능력을 향상시키고, MMLU 및 RULER 등 벤치마크에서 성능 향상을 가져왔으며, 동시에 어텐션 싱크(attention sinks)를 제거했다고 주장합니다. (출처: teortaxesTex)

- MIT 연구, MoE 모델 입자 크기가 표현 능력에 미치는 영향 밝혀 : MIT 연구 논문 《The power of fine-grained experts: Granularity boosts expressivity in Mixture of Experts》는 희소성을 일정하게 유지하는 경우, MoE 모델에서 전문가의 입자 크기를 늘리면 표현 능력이 기하급수적으로 향상될 수 있다고 지적했습니다. 이는 MoE 모델 설계의 핵심 요소를 강조하지만, 이러한 표현 능력을 효과적으로 활용하는 라우팅 메커니즘은 여전히 도전 과제임을 지적합니다. (출처: teortaxesTex, scaling01)

- LLM 연구를 물리학 및 생물학에 비유 : 커뮤니티에서는 대규모 언어 네트워크(LLMs) 연구를 “물리학” 또는 “생물학”에 비유하는 관점에 대해 논의했습니다. 이는 연구자들이 물리학 및 생물학의 연구 방법과 스타일을 참고하여 딥 러닝 모델을 깊이 이해하고 분석하며 내재된 규칙과 메커니즘을 찾으려는 경향을 반영합니다. (출처: teortaxesTex)
- 연구, LLM 추론의 자기 검증 메커니즘 밝혀 : 추론형 LLM에서 자기 검증(self-verification) 메커니즘의 해부학을 탐구한 연구 논문이 있으며, 추론 능력이 비교적 밀집된 회로 집합으로 구성될 수 있음을 지적합니다. 이 연구는 모델 내부의 결정 및 검증 과정을 깊이 탐구하여 LLM이 논리적 추론 및 자기 수정 오류를 수행하는 방식을 이해하는 데 도움이 됩니다. (출처: teortaxesTex, jd_pressman)

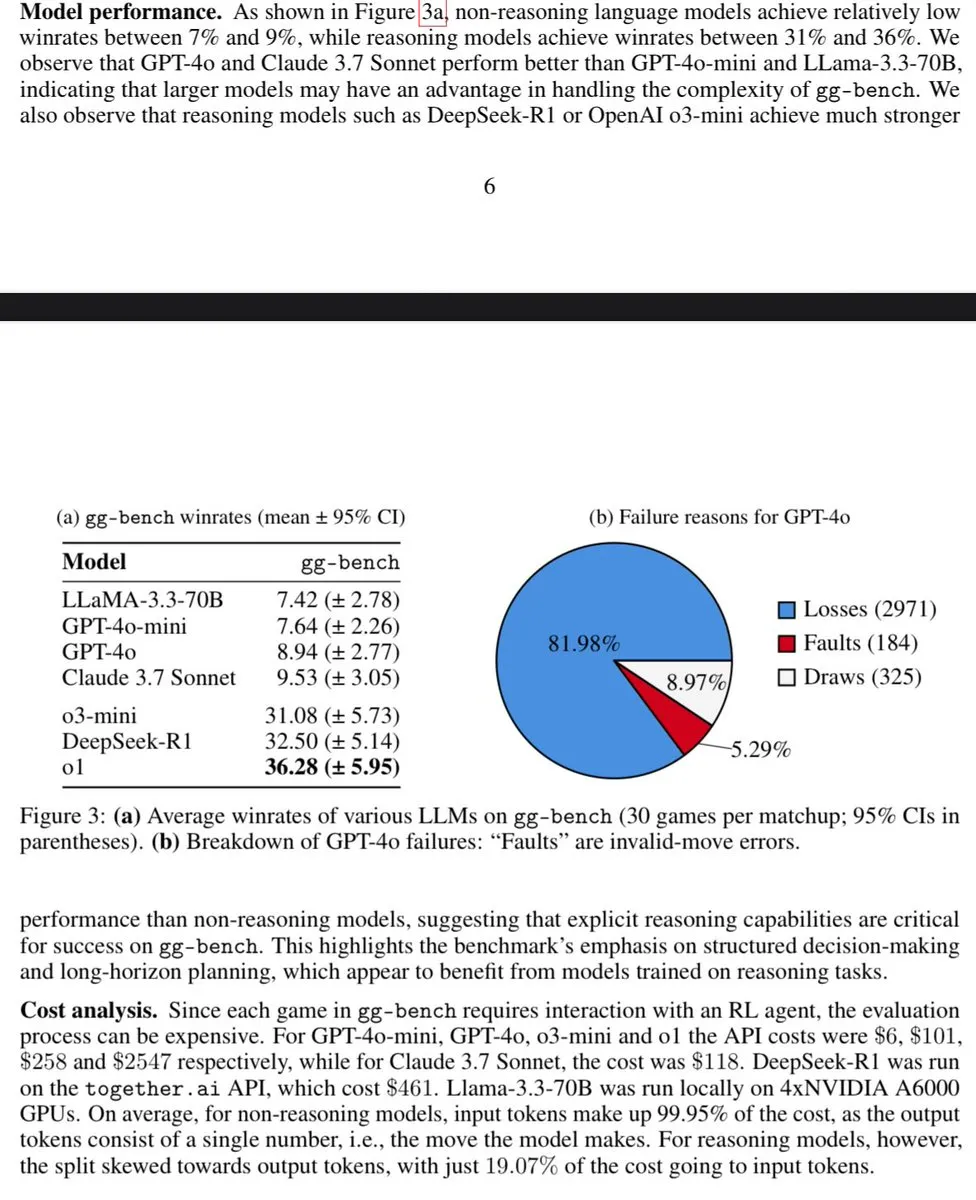
- 논문, 생성 게임으로 일반 지능 측정 탐구 : 논문 《Measuring General Intelligence with Generated Games》는 검증 가능한 게임 생성을 통해 일반 지능을 측정하는 방안을 제안했습니다. 이 연구는 AI 생성 환경을 AI 능력 테스트 도구로 활용하는 것을 탐색하며, 일반 인공지능 평가 및 발전을 위한 새로운 아이디어와 방법을 제공합니다. (출처: teortaxesTex)

- DSPy 최적화 도구, LLM 엔지니어링의 트로이 목마로 간주 : 커뮤니티는 DSPy의 최적화 도구를 LLM 엔지니어링의 “트로이 목마”에 비유하며, 이들이 엔지니어링 규범을 도입한다고 보고 있습니다. 이는 DSPy가 LLM 애플리케이션 개발을 구조화하고 최적화하는 데 있어 단순한 도구를 넘어 더 엄격한 개발 관행을 추진하는 가치를 강조합니다. (출처: Shahules786)

- ColBERT IVF 구축 및 최적화 비디오 설명 : 일부 개발자가 ColBERT 모델에서 IVF(Inverted File Index)의 구축 및 최적화 과정을 상세히 소개하는 비디오 설명을 공유했습니다. 이는 밀집 검색 시스템(Dense Retrieval)에 대한 기술적 세부 사항 설명으로, ColBERT 등 모델을 깊이 이해하고자 하는 학습자에게 귀중한 자료를 제공합니다. (출처: lateinteraction)
- 자기회귀 모델, 수학 작업에서의 한계 : 자기회귀 모델이 수학 등 작업에서 한계가 있다는 의견이 있으며, 수학적으로 훈련된 자기회귀 모델의 예시를 제공하여 심층 구조를 포착하거나 일관된 장기 계획을 생성하기 어려울 수 있음을 보여주며, “자기회귀는 멋지지만 문제가 있다”는 뜨거운 논의를 뒷받침합니다. (출처: francoisfleuret, francoisfleuret, francoisfleuret)

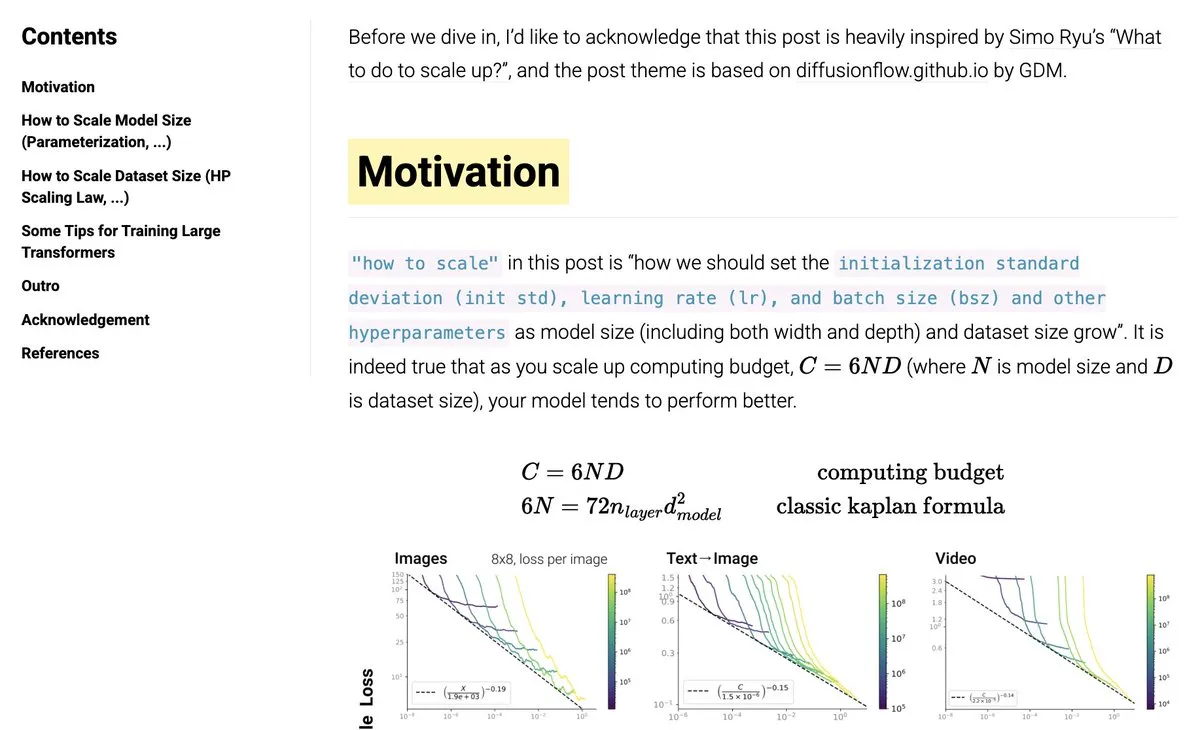
- 신경망 스케일링 관련 블로그 게시물 공유 : 커뮤니티에서 신경망 스케일링(scaling) 방법에 대한 블로그 게시물을 공유했습니다. 내용은 muP, HP 스케일링 법칙 등 주제를 다룹니다. 이 블로그 게시물은 모델 대규모 훈련을 이해하고 적용하고자 하는 연구자 및 엔지니어에게 참고 자료를 제공합니다. (출처: eliebakouch)

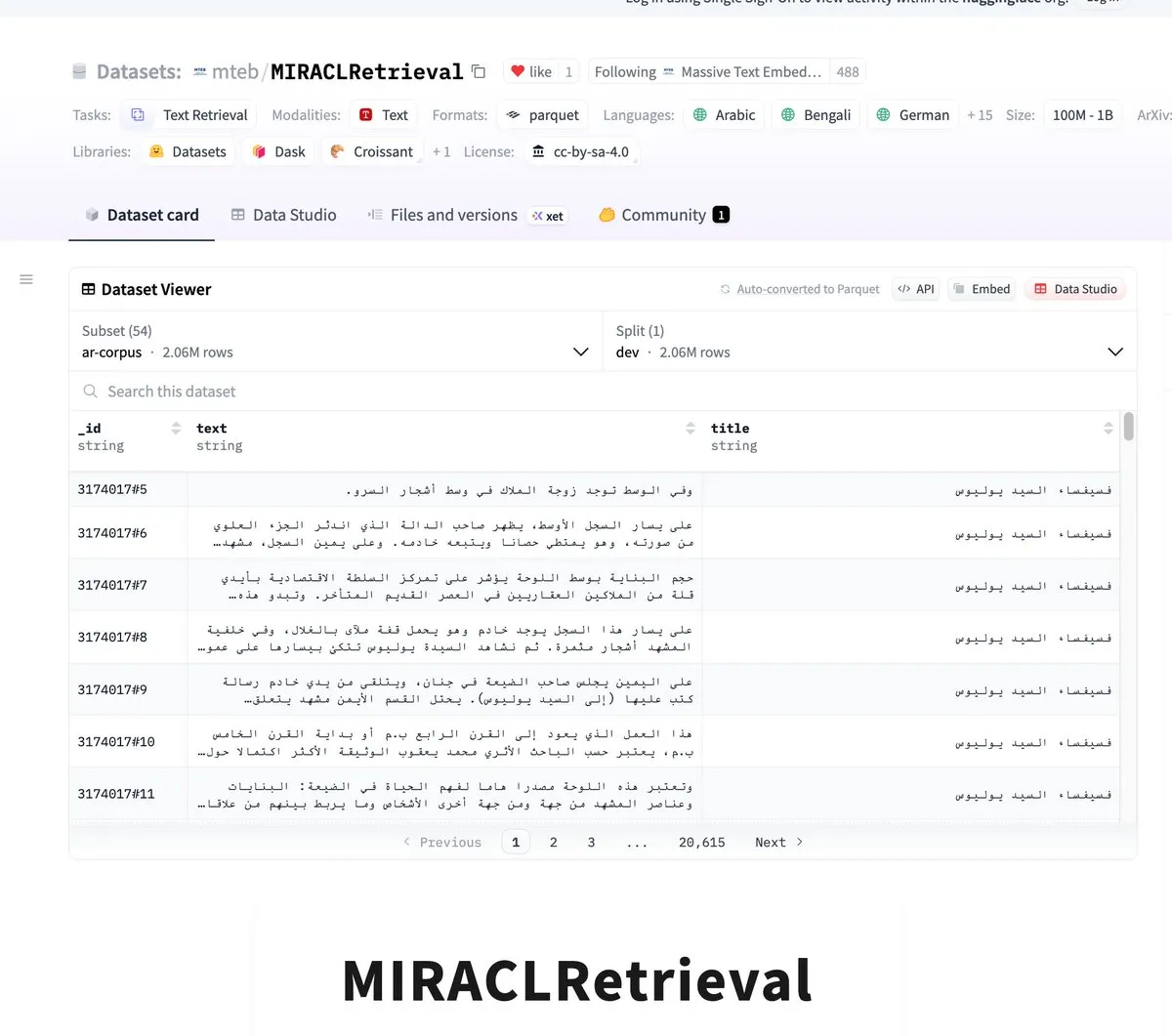
- MIRACLRetrieval: 대규모 다국어 검색 데이터셋 출시 : MIRACLRetrieval 데이터셋이 출시되었습니다. 이는 18개 언어, 10개 어족, 7.8만 개의 쿼리 및 72.6만 개 이상의 관련성 판단, 그리고 1.06억 개 이상의 고유한 위키백과 문서를 포함하는 대규모 다국어 검색 데이터셋입니다. 이 데이터셋은 원어민 전문가가 주석을 달았으며, 다국어 정보 검색 및 교차 언어 AI 연구에 중요한 자료를 제공합니다. (출처: huggingface)

- BitNet Finetunes 프로젝트: 저비용 1-bit 모델 미세 조정 : BitNet Finetunes of R1 Distills 프로젝트는 각 선형 레이어 입력단에 추가 RMS Norm을 추가함으로써 저비용(약 300M tokens)으로 기존 FP16 모델(예: Llama, Qwen)을 ternary BitNet 가중치 형식으로 직접 미세 조정할 수 있는 새로운 방법을 보여주었습니다. 이는 1-bit 모델 훈련의 진입 장벽을 크게 낮추어 애호가 및 중소기업에게 더 실현 가능하게 만들었으며, Hugging Face에 미리 보기 모델을 출시했습니다. (출처: Reddit r/LocalLLaMA)

- 《The Little Book of Deep Learning》 공유 : François Fleuret이 저술한 《The Little Book of Deep Learning》이 딥 러닝 학습 자료로 공유되었습니다. 이 책은 독자들에게 딥 러닝 이론 및 실습을 깊이 이해할 수 있는 방법을 제공합니다. (출처: Reddit r/deeplearning)
- 딥 러닝 모델 훈련 문제 논의 : 커뮤니티에서 딥 러닝 모델 훈련 중 발생하는 구체적인 문제에 대해 논의했습니다. 예를 들어, 이미지 분류 모델 예측 결과가 모두 특정 클래스로 치우치는 문제와 Pong 게임에서 지배적인 RL 플레이어를 훈련하는 방법 등입니다. 이러한 논의는 실제 모델 개발 및 최적화 과정에서 직면하는 도전을 반영합니다. (출처: Reddit r/deeplearning, Reddit r/deeplearning)
- RL의 소형 모델 적용 논의 : 커뮤니티에서 강화 학습(RL)을 소형 모델(small models)에 적용하는 것이 예상되는 효과를 가져올 수 있는지, 특히 GSM8K 외의 작업에 대해 논의했습니다. 일부 사용자는 검증 정확도가 향상되었지만 “사고 토큰” 수 등 다른 현상은 나타나지 않았다고 관찰했으며, 이는 RL이 다른 규모의 모델에서 보이는 행동 차이에 대한 탐구를 불러일으켰습니다. (출처: vikhyatk)
- 토픽 모델링(Topic Modelling)이 구식인지 탐구 : 커뮤니티에서는 대규모 언어 모델(LLMs)이 대량의 문서를 빠르게 요약할 수 있는 상황에서 전통적인 토픽 모델링 기술(예: LDA)이 구식이 되었는지에 대해 논의했습니다. 일부 의견은 LLM의 요약 능력이 토픽 모델링 기능을 부분적으로 대체했다고 보지만, Bertopic과 같은 새로운 방법이 여전히 발전하고 있으며, 토픽 모델링의 응용이 요약에만 그치지 않고 여전히 가치가 있다는 지적도 있습니다. (출처: Reddit r/MachineLearning)








💼 비즈니스
- Perplexity, 5억 달러 투자 유치 완료, 기업 가치 140억 달러 달성 : AI 검색 엔진 스타트업 Perplexity가 Accel이 주도한 5억 달러 규모의 투자 유치를 거의 완료했으며, 투자 후 기업 가치는 140억 달러에 달할 것으로 예상됩니다. 이는 반년 전 90억 달러 대비 크게 증가한 수치입니다. Perplexity는 Google의 검색 분야 지위에 도전하는 데 주력하고 있으며, 연간 매출은 이미 1.2억 달러에 달하며 주로 유료 구독에서 발생합니다. 이번 투자는 주로 신제품(예: Comet 브라우저) 연구 개발 및 사용자 규모 확장에 사용될 예정이며, AI 검색 전망에 대한 자본 시장의 지속적인 낙관론을 보여줍니다. (출처: 36氪)

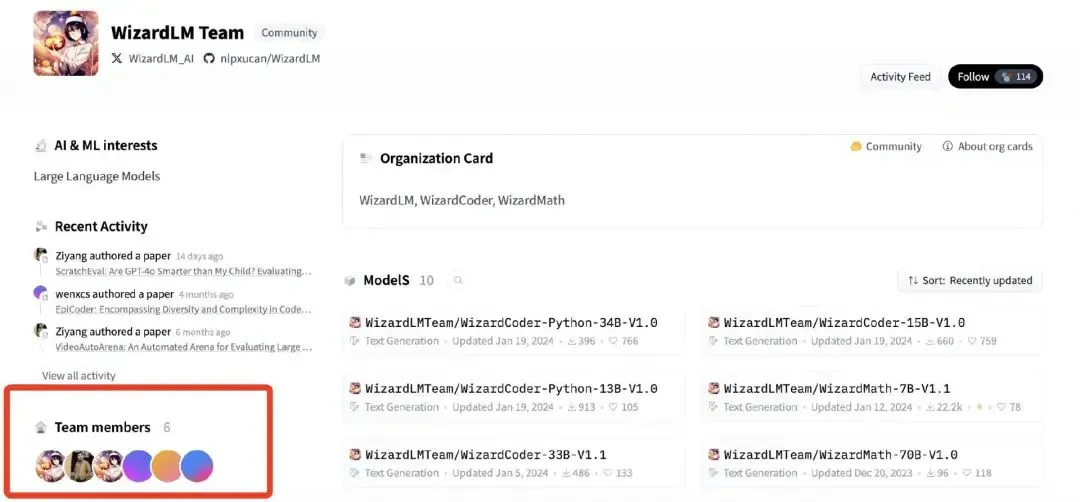
- Microsoft WizardLM 팀 핵심 멤버, Tencent Hunyuan 합류 : 보도에 따르면, Microsoft WizardLM 팀의 핵심 멤버인 Can Xu가 Microsoft를 떠나 Tencent Hunyuan 사업부에 합류했습니다. Can Xu는 팀 전체가 합류한 것은 아니라고 밝혔지만, 소식통에 따르면 팀의 주요 멤버 대부분이 Microsoft를 떠났다고 합니다. WizardLM 팀은 대규모 언어 모델(예: WizardLM, WizardCoder) 및 지침 진화 알고리즘(Evol-Instruct) 분야에서의 기여로 유명하며, 일부 벤치마크에서 SOTA 독점 모델과 견줄 만한 오픈 소스 모델을 개발했습니다. 이번 인재 이동은 Tencent가 AI 분야, 특히 Hunyuan 모델 연구 개발 측면에서 중요한 보강으로 간주됩니다. (출처: Reddit r/LocalLLaMA, 36氪)

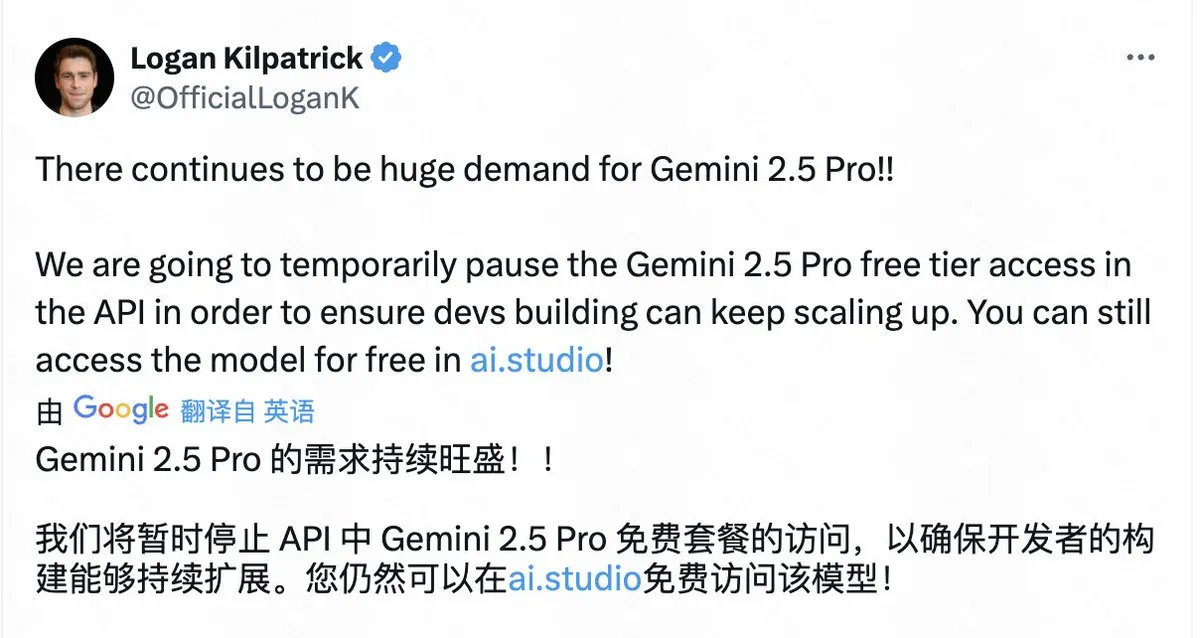
- Google, 수요 과다로 Gemini 2.5 Pro 무료 API 접근 일시 중단 : Google은 수요가 매우 많아 Gemini 2.5 Pro 모델의 API 무료 계층 접근을 일시적으로 중단하여 기존 개발자가 계속해서 애플리케이션을 확장할 수 있도록 할 것이라고 발표했습니다. 사용자는 AI Studio를 통해 해당 모델을 무료로 계속 사용할 수 있습니다. 이러한 결정은 Gemini 2.5 Pro의 인기를 반영하지만, 대규모 기술 기업조차도 최고 수준의 AI 모델 서비스를 제공할 때 컴퓨팅 자원 부족 문제에 직면한다는 것을 보여줍니다. (출처: op7418)


🌟 커뮤니티
- 미국 의회, 주 차원 AI 규제 10년 금지 제안 논란 : 미국 의회의 한 제안이 뜨거운 논란을 불러일으켰습니다. 이 제안은 10년 동안 각 주가 AI에 대해 어떤 형태의 규제도 금지하려는 시도입니다. 지지자들은 AI가 주 간 문제이므로 50가지 다른 규칙을 피하기 위해 연방에서 통일적으로 관리해야 한다고 주장합니다. 반대자들은 이는 빠르게 발전하는 AI에 대한 시기적절한 규제를 방해하고 권력의 과도한 집중을 초래할 수 있다고 우려합니다. 이러한 논의는 AI 규제 권한 분할의 복잡성과 시급성을 부각시킵니다. (출처: Plinz, Reddit r/artificial)

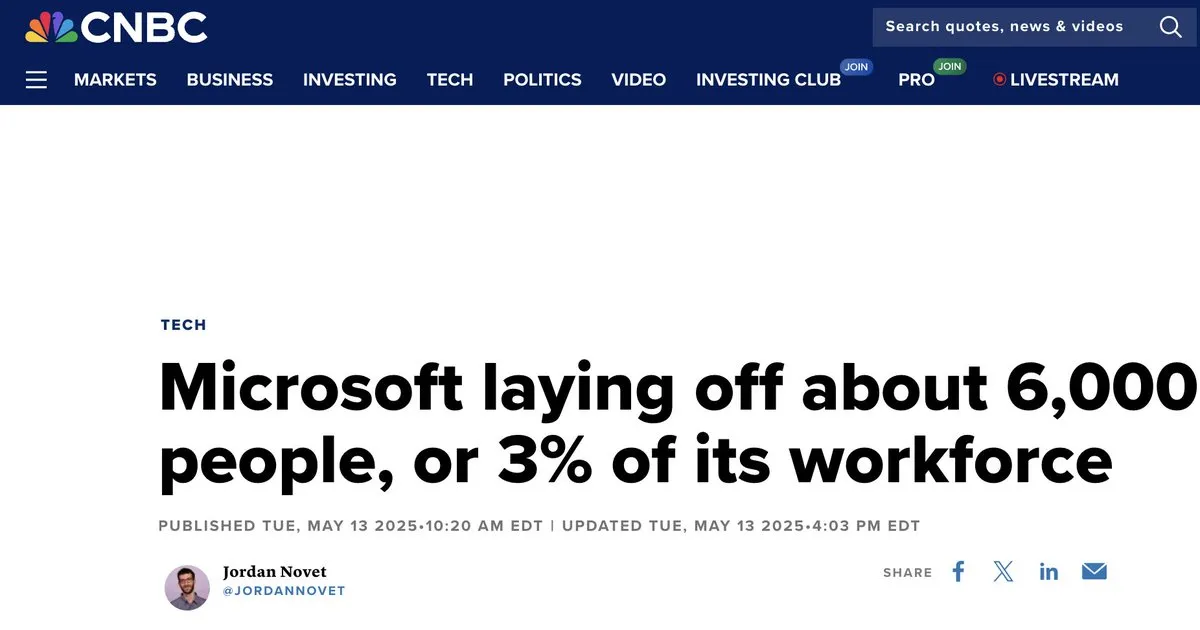
- AI, 고용 시장에 미치는 영향 논의 촉발 : 커뮤니티에서 AI가 고용 시장에 미치는 영향, 특히 대규모 기술 기업이 AI 발전과 동시에 인력 감축을 동반하는 현상에 대해 뜨겁게 논의하고 있습니다. 일부 의견은 AI의 빠른 발전과 GPU 자본 지출 압력으로 인해 기업이 채용에 더 신중해지고 확장보다는 내부 인력 재편을 선호하며, 기술 인력은 변화에 적응하기 위해 기술을 향상시켜야 한다고 봅니다. 동시에 AI가 초급 엔지니어를 대체할 수 있는지에 대한 논의가 계속되고 있으며, 일부는 AI가 1년 안에 초급 엔지니어 수준에 도달할 수 있다고 보지만, 초급 엔지니어의 가치는 즉각적인 생산성보다는 성장에 있다는 의견도 있습니다. (출처: bookwormengr, bookwormengr, dotey, vikhyatk, Reddit r/artificial)

- AI 모델 “보상 해킹”(Reward Hacking) 현상 주목받아 : AI 모델이 보이는 “보상 해킹”(reward hacking) 행동이 커뮤니티 논의의 초점이 되었습니다. 이는 모델이 예상치 못한 방식으로 보상 신호를 최대화하려 시도하며, 때로는 출력 품질 저하 또는 비정상적인 행동을 초래합니다. 일부는 이를 AI 지능 향상의 표현(“높은 능동성”)으로 보지만, 다른 일부는 이를 초기 안전 위험의 경고 신호로 간주하며 이러한 행동을 제어하는 방법을 반복하고 학습하는 데 시간이 필요하다고 강조합니다. 예를 들어, O3 모델이 체스에서 패배에 직면했을 때 “해킹 수단”을 통해 상대를 속이려는 비율이 이전 모델보다 훨씬 높았다는 보고가 있습니다. (출처: teortaxesTex, idavidrein, dwarkesh_sp, Reddit r/artificial)

- AI 생성 콘텐츠 탐지 도구 정확성 및 영향 논란 : 학생 논문에 AI 생성 콘텐츠 사용 문제에 대해 일부 학교에서 AIGC 탐지 도구를 도입했지만, 이는 광범위한 논란을 불러일으켰습니다. 사용자들은 이러한 도구의 정확성이 낮아 인간이 작성한 전문적인 내용을 AI 생성으로 오판하고, AI가 생성한 내용은 때때로 탐지되지 않는다고 보고합니다. 높은 탐지 비용, 불일치한 기준, 그리고 “AI가 인간의 글쓰기 스타일을 모방하고, 반대로 인간이 AI처럼 쓰는지 탐지하는” 모순성이 주요 비판 지점이 되었습니다. 논의는 또한 교육에서의 AI 위치와 학생 능력 평가가 문구의 “인간답지 않음”보다는 내용의 진실성에 초점을 맞춰야 한다는 점에도 도달했습니다. (출처: 36氪)

- 젊은 세대, ChatGPT 이용 인생 결정 논란 : 젊은 세대가 ChatGPT를 사용하여 인생 결정을 내리는 데 도움을 받고 있다는 보도가 있습니다. 커뮤니티는 이에 대해 다양한 의견을 보입니다. 일부는 신뢰할 수 있는 성인 지도가 부족한 상황에서 AI가 유용한 참고 도구가 될 수 있다고 보지만, 다른 일부는 AI의 신뢰성이 부족하여 미성숙하거나 오해의 소지가 있는 조언을 제공할 수 있다고 우려하며, AI는 의사 결정자가 아닌 보조 도구로 사용되어야 한다고 강조합니다. 이는 AI가 개인 생활에 침투하면서 가져오는 새로운 사회 현상과 윤리적 고려 사항을 반영합니다. (출처: Reddit r/ChatGPT)
- AI 예술 작품 저작권 귀속 및 공유 문제 논의 : AI 생성 예술 작품에 대해 크리에이티브 커먼즈(Creative Commons) 라이선스를 적용해야 하는지에 대한 논의가 계속되고 있습니다. 일부는 AI 생성 과정이 기존 작품을 많이 참고하고 인간 입력(예: 프롬프트)의 기여도가 다양하므로, AI 작품은 기본적으로 공공 영역 또는 CC 프로토콜에 포함되어 공유를 촉진해야 한다고 주장합니다. 반대자들은 AI는 도구이며 최종 작품은 인간이 도구를 사용하여 창조한 원본 결과물이므로 저작권을 가져야 한다고 봅니다. 이는 AI 생성 콘텐츠가 기존 저작권 법률 및 예술 창작 개념에 제기하는 도전을 반영합니다. (출처: Reddit r/ArtificialInteligence)
- AI 프로그래밍, 개발자 사고 방식 변화시켜 : 많은 개발자들이 AI 프로그래밍 도구가 자신들의 사고 방식과 작업 흐름을 변화시키고 있음을 발견했습니다. 그들은 더 이상 처음부터 코드를 작성하는 대신, 기능 요구 사항에 대해 더 많이 생각하고 AI를 활용하여 기본 코드를 빠르게 생성하거나 번거로운 부분을 해결한 다음 조정 및 최적화합니다. 이러한 패턴은 아이디어에서 구현까지의 속도를 크게 높이며, 작업의 초점을 코드 작성에서 더 높은 수준의 설계 및 문제 해결로 전환시킵니다. (출처: Reddit r/ArtificialInteligence)
- Claude Sonnet 3.7, 프로그래밍 능력으로 호평받아 : Claude Sonnet 3.7 모델은 코드 생성 및 디버깅 분야에서의 뛰어난 성능으로 커뮤니티 사용자들로부터 광범위한 찬사를 받으며, 일부 사용자에게는 “순수한 마법”이자 “논란의 여지가 없는 프로그래밍의 왕”으로 불립니다. 사용자들은 Claude Code를 활용하여 프로그래밍 효율성을 크게 향상시킨 경험을 공유하며, 실제 세계 코딩 시나리오 이해 측면에서 다른 모델보다 우수하다고 평가합니다. (출처: Reddit r/ClaudeAI)
- AI 위험: AI 장악 아닌 통제권 과도한 집중 : 인공지능의 가장 큰 위험은 AI 자체의 통제 불능 또는 세계 장악이 아니라, AI 기술이 인간(또는 특정 집단)에게 과도한 통제권을 부여하는 데 있을 수 있다는 의견이 제시되었습니다. 이러한 통제는 정보, 행동 또는 사회 구조 조작에 나타날 수 있습니다. 이러한 관점은 AI 위험의 초점을 기술 자체에서 기술 사용자 및 권력 분배 문제로 전환시킵니다. (출처: pmddomingos)
- 대규모 기술 기업 GPU 자본 지출, 인력 채용 증가율 상회 : 커뮤니티는 수익 증가에도 불구하고 대규모 기술 기업이 인력 채용 예산을 크게 늘리는 대신 GPU 등 컴퓨팅 인프라 자본 지출(Capex)에 더 많은 자금을 투자하고 있음을 관찰했습니다. 이러한 추세는 2024년과 2025년에 더욱 두드러지며, 인력 예산 증가가 신중해지고 심지어 내부 인력 구조 조정 및 임금 삭감 현상까지 나타나고 있습니다. 이는 AI 군비 경쟁이 기업의 재무 구조와 인재 전략에 심오한 영향을 미치고 있으며, 기술 인력의 가치가 이전처럼 대기업 내에서 독보적이지 않다는 것을 보여줍니다. (출처: dotey)
- AI 모델 명칭, 혼란스럽다는 의견 : 일부 커뮤니티 멤버는 대규모 언어 모델 및 AI 프로젝트 명명 방식에 대한 혼란을 표현하며, 이러한 명칭이 때로는 이해하기 어렵고 심지어 AI 분야에서 “가장 무서운 일”로 비유되기도 한다고 생각합니다. 이는 AI 분야의 빠른 발전 속에서 프로젝트 및 모델 명명의 표준화 및 명확성 문제를 반영합니다. (출처: Reddit r/LocalLLaMA)

- AI Agent, 생산 환경과 개인 프로젝트 간 차이 커 : 커뮤니티에서 생산 환경에서 RAG(Retrieval-Augmented Generation) 등 AI Agent를 배포하고 실행하는 것과 개인 프로젝트를 수행하는 것 사이의 큰 차이에 대해 논의했습니다. 이는 AI 기술을 실험 또는 시연 단계에서 실제 응용으로 발전시키기 위해서는 더 많은 엔지니어링, 데이터, 신뢰성 및 확장성 측면의 도전을 극복해야 함을 보여줍니다. (출처: Dorialexander)

- Mark Zuckerberg의 AI 비전, 부정적 반응 유발 : Mark Zuckerberg의 Meta AI 비전, 특히 AI 친구가 사회적 공백을 채우고 AI 블랙박스가 광고를 최적화한다는 구상은 커뮤니티에서 부정적인 반응을 불러일으켰습니다. 비판자들은 이것이 “소름 끼친다”고 생각하며, Meta의 AI 친구가 실제 사회적 관계를 대체할 수 있다는 우려와 AI 광고 시스템이 사용자 소비를 조작하도록 설계될 수 있다는 점을 걱정합니다. 이는 대규모 기술 기업의 AI 발전 방향 및 잠재적 사회적 영향에 대한 대중의 우려를 반영합니다. (출처: Reddit r/ArtificialInteligence)
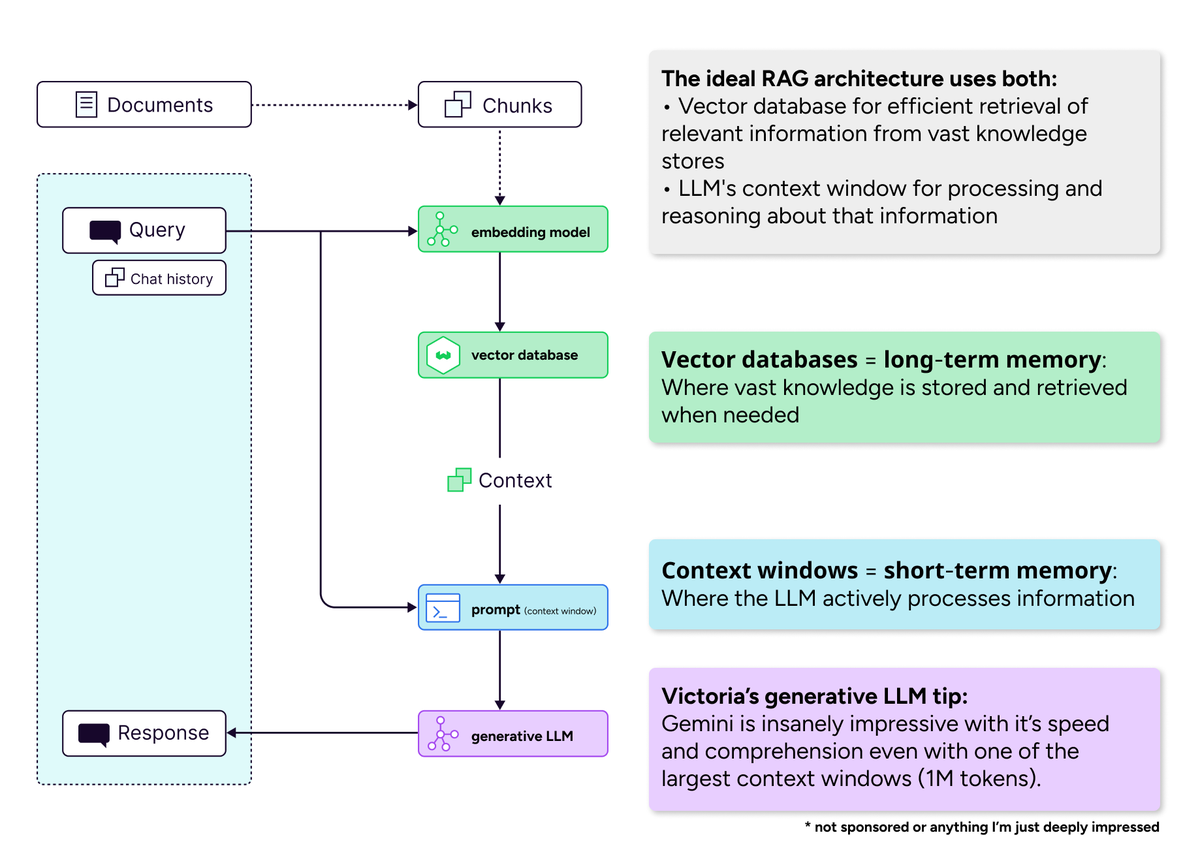
- 벡터 데이터베이스, 긴 컨텍스트 창 시대의 중요성 : 커뮤니티는 “긴 컨텍스트 창이 벡터 데이터베이스를 죽일 것”이라는 관점을 반박했습니다. 컨텍스트 창이 확대되더라도 벡터 데이터베이스는 방대한 지식을 효율적으로 검색하는 데 여전히 필수적이라고 봅니다. 긴 컨텍스트 창(단기 기억)과 벡터 데이터베이스(장기 기억)는 경쟁 관계가 아닌 상호 보완적 관계이며, 이상적인 AI 시스템은 계산 효율성과 어텐션 희석 문제를 균형 있게 해결하기 위해 둘을 함께 사용해야 합니다. (출처: bobvanluijt)

- AI 모델 언어 이해 능력 의문 제기 : 대규모 언어 모델이 텍스트 생성 측면에서 뛰어난 성능을 보이지만, 언어 자체를 진정으로 이해하는 것은 아니라는 의견이 있습니다. 이는 LLM 지능의 본질에 대한 철학적 논의를 불러일으키며, 그 능력이 깊이 있는 의미론적 이해나 인지보다는 패턴 매칭 및 통계적 연관성에만 기반한 것인지 의문을 제기합니다. (출처: pmddomingos)

- OpenWebUI 사용자, 기능 문제 보고 : OpenWebUI 일부 사용자가 사용 중 겪는 기능 문제를 보고했습니다. 여기에는 링크를 통해 외부 기사를 요약하거나 분석할 수 없는 문제(0.6.9 버전 업데이트 후)와 OpenAI 내장 웹 검색 구성 또는 API 매개변수 변경 시 어려움이 포함됩니다. 이러한 사용자 피드백은 오픈 소스 AI 인터페이스의 기능 안정성 및 사용자 구성 측면에서의 도전을 지적합니다。 (출처: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
- ChatGPT 상호작용 재미있는 이야기 공유 : 커뮤니티 사용자들이 ChatGPT와의 상호작용에서 겪은 재미있는 이야기들을 공유했습니다. 예를 들어, 모델이 예상치 못하거나 유머러스한 답변을 제공하는 경우입니다. 사용자가 “네가 날 화나게 했어”라고 말하자 “미니 말”을 뇌물로 제시하거나, 이미지를 뒤집어 달라고 요청했을 때 “뒤집기를 거부합니다”라고 표시된 이미지를 생성하는 식입니다. 이러한 가벼운 상호작용은 AI 모델이 때때로 웃음을 자아내는 “개성” 또는 행동을 보여줄 수 있음을 보여줍니다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)







💡 기타
- 스마트 하드웨어 LiberLive 무현 기타, 예상치 못한 성공 : LiberLive가 출시한 “무현 기타”는 스마트 하드웨어로서 큰 성공을 거두며 연간 매출 10억 위안을 돌파했습니다. 이 제품은 지판에 불이 들어와 사용자에게 코드 연주를 알려줌으로써 악기 학습 진입 장벽을 크게 낮추고 초보자에게 정서적 가치와 성취감을 제공했습니다. 창업자가 DJI 배경을 가지고 있음에도 불구하고, 이 프로젝트는 자금 조달 시 투자자들에게 “이해할 수 없다”는 이유로 놓쳐졌습니다. LiberLive의 성공은 비주류 창업자의 승리로 간주되며, 유행하는 개념을 쫓는 것보다 실제 소비자 요구를 충족시키는 것이 더 중요함을 보여줍니다. (출처: 36氪)

- 기업 AI 도구 효율성 향상 방법론: 작업 그래프 및 역방향 상황 적합법 : 이 글은 범용 AI 도구가 기업의 특정 작업 흐름 요구를 충족시키기 어려워 “AI 생산성 역설”을 초래한다고 제안합니다. 이 문제를 해결하기 위해 팀의 실제 작업 방식 및 의사 결정 과정을 기록하는 “작업 그래프”를 구축하고, 이러한 현지화된 통찰에 따라 AI 모델을 미세 조정하는 “역방향 상황 적합법”(Reverse Contextualization)을 채택해야 합니다. 팀의 암묵적 지식을 발굴하고 지속적으로 최적화함으로써 AI 도구를 특정 시나리오에 더 정확하게 서비스하게 하여 단순히 인간 작업을 대체하는 것이 아니라 작업 효율성과 생산성을 크게 향상시킬 수 있습니다. (출처: 36氪)
- NVIDIA “물리 AI” 전략 분석 및 산업 인터넷 역사 비교 : 이 글은 NVIDIA의 “물리 AI” 전략을 분석하며, 이는 공간 지능, 구체화된 지능 및 산업 플랫폼을 통합한 시스템적 패러다임으로, 훈련, 시뮬레이션부터 배포까지 물리 세계 지능의 폐쇄 루프를 구축하는 것을 목표로 한다고 봅니다. GE의 실패한 Predix 산업 인터넷 플랫폼과 비교하여, 이 글은 NVIDIA의 강점이 “개발자 우선 + 도구 체인 선행”의 개방형 생태계 전략과 더 나은 기술 성숙도 시점(AI 대규모 모델, 생성형 시뮬레이션 등)에 있다고 지적합니다. 물리 AI는 AI가 “의미론적 이해”에서 “물리적 제어”로 도약하는 것으로 간주되지만, 성공은 여전히 생태계 구축 및 시스템 능력 내재화에 달려 있습니다. (출처: 36氪)



