키워드:프라임 인텔렉트, 인텔렉트-2, 사카나 AI, 지속적 사고 기계, 트랜스포머, 구글 AI 에이전트, 에이전트옵스, 다중 에이전트 협업, 분산 강화 학습 훈련, 신경 시간 및 뉴런 동기화, AI 에이전트 운영 프로세스, 다중 에이전트 아키텍처, 기업 배포를 위한 AI 에이전트
🔥 주요 소식
Prime Intellect, INTELLECT-2 모델 오픈소스 공개: Prime Intellect가 320억 파라미터 모델인 INTELLECT-2를 발표하고 오픈소스로 공개했습니다. 이는 세계 최초로 분산 강화 학습을 통해 훈련된 모델이라고 주장합니다. 이번 공개에는 상세한 기술 보고서와 모델 체크포인트가 포함되어 있습니다. 이 모델은 여러 벤치마크 테스트에서 Qwen 32B 등과 동등하거나 더 우수한 성능을 보였으며, 특히 코드 생성 및 수학 추론 분야에서 뛰어난 성능을 나타냈고, 커뮤니티 멤버들에 의해 Wordle 게임도 가능하다는 것이 발견되었습니다. 이러한 훈련 방식과 오픈소스 공개는 향후 대형 모델 훈련 및 경쟁 구도에 영향을 미칠 가능성이 있는 것으로 평가됩니다 (출처: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI, 지속적 사고 기계(CTM) 제안: Sakana AI가 “지속적 사고 기계”(Continuous Thought Machine, CTM)라는 새로운 신경망 아키텍처를 발표했습니다. 이는 신경 시간성(neural timing) 및 뉴런 동기화(neuronal synchronization)와 같은 생물학적 뇌 메커니즘을 도입하여 AI에 더 유연한 인간과 유사한 지능을 부여하는 것을 목표로 합니다. CTM의 핵심 혁신은 뉴런 수준의 시간 처리와 신경 동기화를 잠재적 표현으로 사용하는 데 있으며, 이를 통해 순차적 추론과 적응형 계산이 필요한 작업을 처리하고 기억을 저장 및 검색할 수 있습니다. 이 연구는 블로그, 인터랙티브 보고서, 논문 및 GitHub 코드 저장소를 통해 발표되었으며, AI가 “시간을 사용하여 생각하는” 새로운 패러다임을 탐구합니다 (출처: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
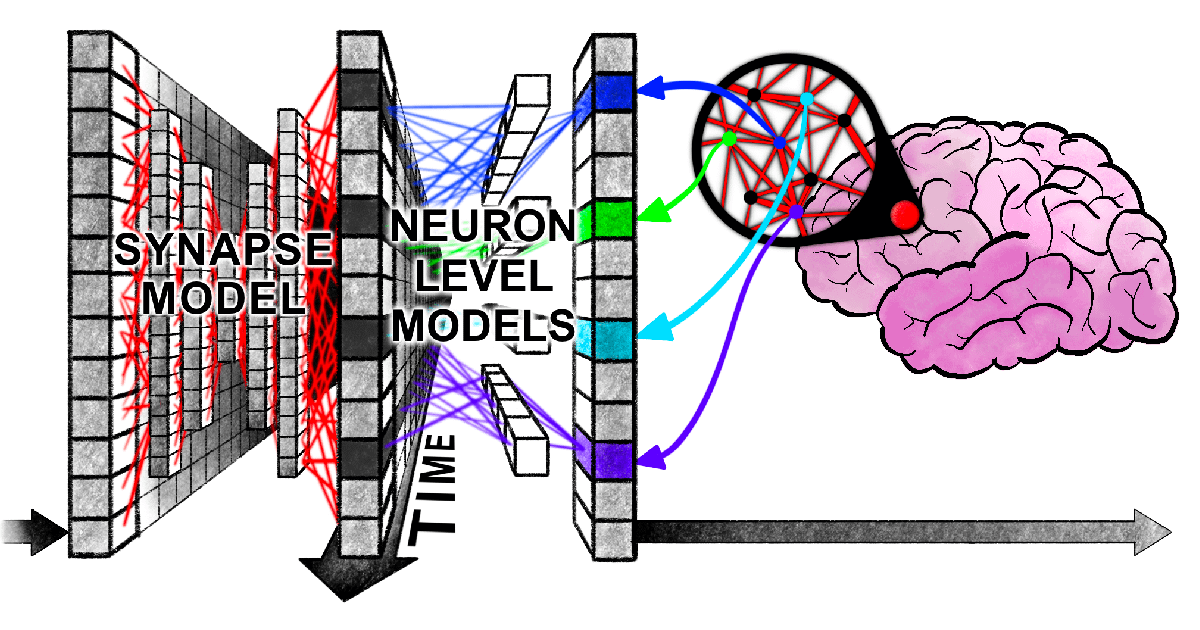
하버드 신규 논문, Transformer와 인간 두뇌가 정보 처리 시 ‘동기화된 어려움’을 겪는다는 사실 밝혀: 하버드 대학 등 연구 기관의 연구자들이 《Linking forward-pass dynamics in Transformers and real-time human processing》라는 논문을 발표하여, Transformer 모델 내부 처리 동역학과 인간의 실시간 인지 과정 간의 유사성을 탐구했습니다. 이 연구는 최종 출력만 보는 것이 아니라 모델 각 계층의 “처리 부하” 지표(예: 불확실성, 신뢰도 변화)를 분석하여, AI가 문제 해결 시(예: 수도 맞히기, 동물 분류, 논리 추론, 이미지 인식) 인간과 유사한 “망설임”, “직관적 오류”에서 “수정”에 이르는 과정을 겪는다는 것을 발견했습니다. 이러한 “사고 과정”의 유사성은 AI가 작업을 완료하기 위해 자연스럽게 인간과 유사한 인지적 지름길을 학습한다는 것을 시사하며, AI 의사 결정 이해 및 인간 실험 설계 지침에 새로운 관점을 제공합니다 (출처: 36氪)

구글, 76페이지 분량의 AI 에이전트 백서 발표, AgentOps 및 다중 에이전트 협업 상세 설명: 구글이 최근 발표한 AI 에이전트 백서는 AI 에이전트의 구축, 평가 및 응용에 대해 상세히 설명합니다. 백서는 에이전트 운영(AgentOps)의 중요성을 강조하는데, 이는 에이전트 구축 및 프로덕션 환경 배포를 최적화하는 프로세스로, 도구 관리, 핵심 프롬프트 설정, 메모리 구현 및 작업 분해를 포함합니다. 백서는 또한 전문 능력을 갖춘 여러 에이전트가 협력하여 복잡한 목표를 달성하는 다중 에이전트 아키텍처를 탐구하고, 구글이 기업 내부에 에이전트(예: NotebookLM 엔터프라이즈 버전, Agentspace 엔터프라이즈 버전)를 배포하고 특정 응용 프로그램(예: 자동차 다중 에이전트 시스템)에 적용한 실제 사례를 소개하며, 기업 생산성 및 사용자 경험 향상을 목표로 합니다 (출처: 36氪)
🎯 동향
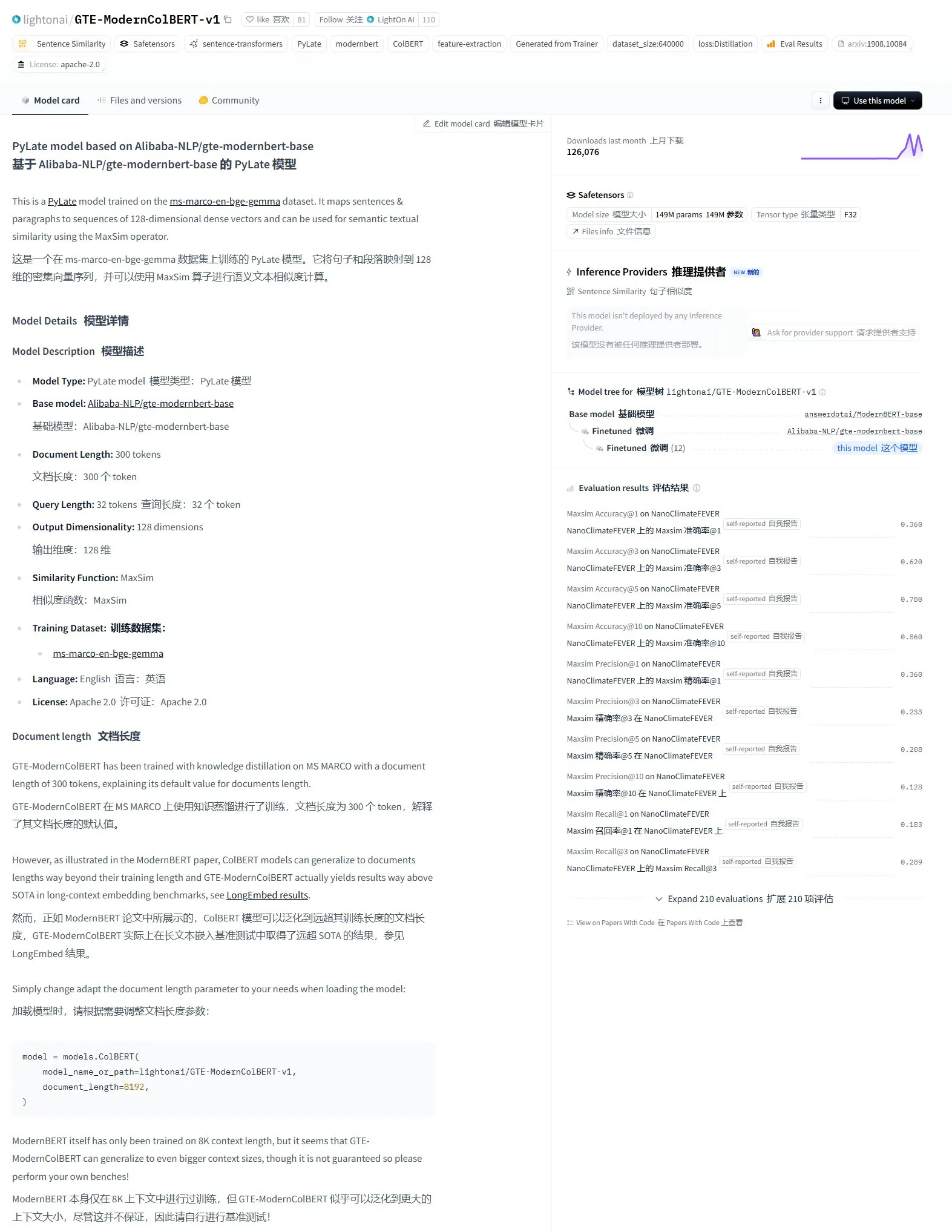
LightonAI, GTE-ModernColBERT-v1 시맨틱 검색 모델 발표: LightonAI가 새로운 시맨틱 검색 모델 GTE-ModernColBERT-v1을 출시했습니다. 이 모델은 LongEmbed / LEMB Narrative QA 평가에서 현재 최고 점수를 획득했습니다. 이 모델은 시맨틱 검색 효과 향상을 위해 특별히 설계되었으며, 문서 내용 검색, RAG 등의 장면에 적용될 수 있고 기존 시스템과 통합될 수 있습니다. 이 모델은 Alibaba-NLP/gte-modernbert-base를 기반으로 미세 조정되었으며, 문자 매칭에만 의존하는 기존 검색 엔진의 한계를 개선하는 것을 목표로 합니다 (출처: karminski3)
기술 리더들, DeepSeek의 빠른 부상 주목: VentureBeat는 기술 리더들이 DeepSeek의 빠른 발전에 보인 반응을 보도했습니다. DeepSeek은 강력한 모델 능력과 오픈소스 전략으로 글로벌 AI 분야, 특히 수학 및 코드 생성 작업에서 두드러진 성과를 거두었으며, 기존 시장 구도(OpenAI 등 포함)에 도전장을 내밀고 있습니다. 저비용 훈련 및 API 가격 정책 또한 AI 기술의 보급과 상업화 과정을 촉진하고 있습니다 (출처: Ronald_vanLoon)

ByteDance와 북경대, 다중 조건 조합 지원하는 통합 이미지 맞춤 생성 프레임워크 DreamO 공동 발표: ByteDance와 북경대학교가 협력하여 DreamO를 출시했습니다. 이는 단일 모델을 통해 주체, 정체성, 스타일 및 의상 참조 등 다중 조건을 자유롭게 조합하여 이미지를 맞춤 생성할 수 있는 프레임워크입니다. 이 프레임워크는 Flux-1.0-dev를 기반으로 구축되었으며, 조건 이미지 입력을 처리하기 위한 전용 매핑 계층을 도입하고 점진적 훈련 전략과 참조 이미지에 대한 라우팅 제약을 사용하여 생성 품질과 일관성을 향상시킵니다. DreamO는 400M의 낮은 훈련 파라미터 수로 8-10초 만에 맞춤 이미지를 생성하며, 일관성 유지 측면에서 우수한 성능을 보입니다. 관련 코드와 모델은 오픈소스로 공개되었습니다 (출처: WeChat)

VITA 팀, 실시간 음성 대형 모델 VITA-Audio 오픈소스 공개, 추론 효율 대폭 향상: VITA 팀이 엔드투엔드 음성 모델 VITA-Audio를 출시했습니다. 경량 다중 교차 모달 토큰 예측(MCTP) 모듈을 도입하여 단일 순방향 전파에서 직접 디코딩 가능한 Audio Token Chunk를 생성할 수 있습니다. 7B 파라미터 규모에서 모델이 텍스트를 수신하여 첫 번째 오디오 조각을 출력하는 데 단 92ms(오디오 인코더 제외 시 53ms)가 소요되어, 동일 규모 모델 대비 추론 속도가 3-5배 향상되었습니다. VITA-Audio는 중국어와 영어를 지원하며, 오픈소스 데이터만 사용하여 훈련되었고 TTS, ASR 등 작업에서 우수한 성능을 보입니다. 관련 코드와 모델 가중치는 오픈소스로 공개되었습니다 (출처: WeChat)

칭화대와 통용인공지능연구원 등, ‘절대 영점’ 훈련법 제안, 대형 모델 자가 대국으로 추론 능력 잠금 해제: 칭화대학교, 베이징 통용인공지능연구원 등 기관의 연구원들이 “절대 영점”(Absolute Zero) 훈련 방법을 제안했습니다. 이는 사전 훈련된 대형 모델이 외부 데이터 없이 자가 대국(Self-play)을 통해 작업을 생성하고 해결함으로써 추론을 학습하도록 합니다. 이 방법은 추론 작업을 (프로그램, 입력, 출력) 삼중항으로 통일하여 표현하며, 모델이 Proposer(문제 출제자)와 Solver(문제 해결자) 역할을 맡아 귀추법, 연역법, 귀납법 세 가지 작업 유형을 통해 학습합니다. 실험 결과, 이 방법을 사용하여 훈련된 모델은 코드 및 수학 추론 작업에서 모두 현저한 향상을 보였으며, 전문가 주석 샘플을 사용하여 훈련된 모델의 성능을 능가했습니다 (출처: WeChat)

AI PC 발전 가속화, 레노버·화웨이 AI 단말 신제품 연이어 출시: 레노버와 화웨이가 최근 AI 에이전트가 탑재된 PC 제품을 출시했습니다. 예를 들어 레노버의 Tianxi 개인 슈퍼 인텔리전트 에이전트와 화웨이 HarmonyOS PC에 탑재된 Xiaoyi 에이전트가 있습니다. AI PC 시장 침투율은 아직 낮지만 성장 속도는 빠릅니다. Canalys 데이터에 따르면 2024년 중국 본토 AI PC 출하량은 전체 PC 시장의 15%를 차지했으며, 2025년에는 34%에 달할 것으로 예상됩니다. 업계 관계자들은 AI PC 산업 체인이 성숙하기까지 2-3년이 더 필요하며, 현재 주요 과제는 메모리, 칩 등 공급망 비용 및 규모화 문제, 그리고 국내 AI PC 생태계의 파편화라고 보고 있습니다. 미래 트렌드로는 에이전트가 핵심 상호작용 인터페이스가 되고, AI의 로컬 배포, 그리고 AI 응용 시나리오가 교육, 건강 등 다양한 분야로 확장되는 것이 포함됩니다 (출처: 36氪)
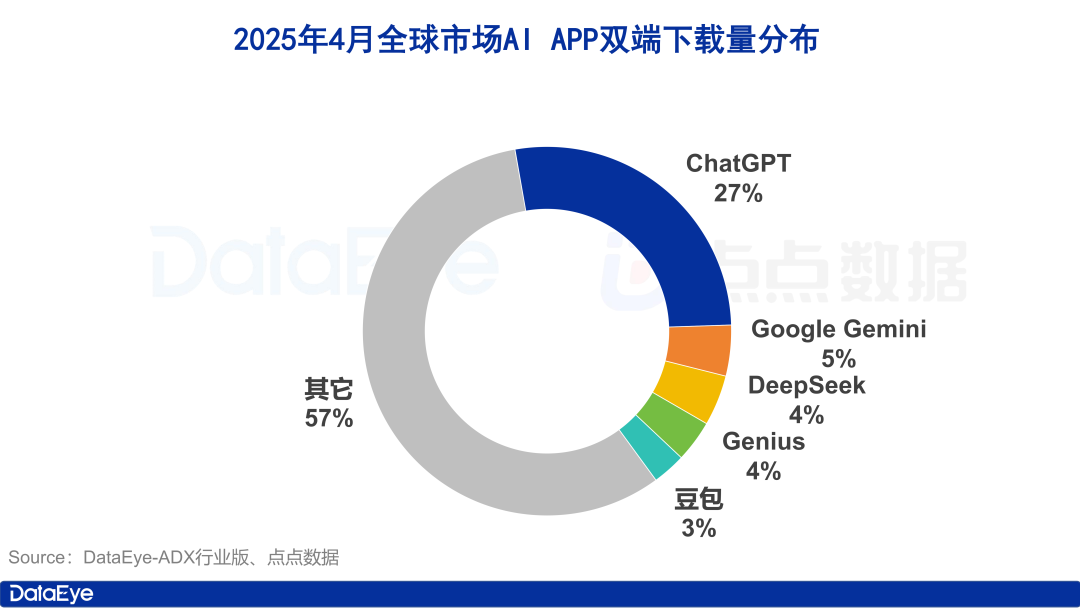
글로벌 AI 앱 다운로드 급증, 중국 시장은 냉각, Doubao는 역성장: 2025년 4월, 글로벌 AI 앱 양대 플랫폼 다운로드 수가 3억 3천만 건에 달해 전월 대비 27.4% 증가했습니다. ChatGPT, Google Gemini, DeepSeek, Genius 및 Doubao가 상위 5위를 차지했습니다. 이 중 ChatGPT는 GPT-4o 출시로 다운로드 수가 폭증했습니다. 반면, 중국 본토 시장의 AI 앱 애플 앱스토어 다운로드 수는 전월 대비 24.0% 감소했으며, Doubao가 역성장하며 1위를 차지했고 DeepSeek, 即梦AI가 그 뒤를 이었습니다. 광고 구매 측면에서는 Tencent Yuanbao와 Quark가 광고 투자를 늘려 소재량 대부분을 차지했으며, Doubao의 투자는 다소 감소했습니다. 전반적으로 국내 AI 시장의 열기는 다소 식었으며, 경쟁은 기술과 운영으로 회귀하고 있습니다 (출처: 36氪)
중국 대형 모델 시장 재편, ‘기반 모델 5강’ 구도 초기 형성: 2024년 글로벌 AI 투자 환경이 긴축됨에 따라 중국 대형 모델 시장은 ‘거품 제거’를 겪으며, 기존의 ‘6개 작은 호랑이’ 구도는 ByteDance, Alibaba, StepFun, Zhipu AI, DeepSeek를 대표하는 ‘기반 모델 5강’으로 재편되었습니다. 이들 선두 주자들은 자금, 인재, 기술 면에서 각기 다른 강점을 가지고 있으며 차별화된 경로를 걷고 있습니다. ByteDance는 종합적인 레이아웃을, Alibaba는 오픈소스와 풀스택을 주력으로, StepFun은 멀티모달에 집중, Zhipu AI는 칭화대 배경을 바탕으로 2B/2G 시장 공략, DeepSeek은 극한의 엔지니어링 최적화와 오픈소스 전략으로 두각을 나타내고 있습니다. 다음 단계 경쟁의 초점은 ‘지능 상한선’ 돌파와 ‘멀티모달 능력’ 향상이 될 것이며, 이를 통해 AGI 비전을 실현하고자 합니다 (출처: 36氪, WeChat)

ICCV 2025 투고량 기록 경신으로 심사 품질 우려 제기, LLM 보조 심사 금지: 컴퓨터 비전 최고 학회 ICCV 2025 논문 투고량이 11,152편에 달해 역대 최고치를 기록했습니다. 그러나 심사 결과 발표 후 많은 저자들이 소셜 미디어를 통해 심사 품질에 불만을 표하며, 일부 심사 의견이 성의 없거나 GPT 수준보다 못하며, 심사위원이 보충 자료를 읽지 않은 등의 문제를 지적했습니다. 급증하는 원고에 대응하기 위해 학회는 모든 투고 저자에게 심사 참여를 요구하고, 독창성과 기밀 유지를 위해 심사 과정에서 대형 모델(예: ChatGPT) 사용을 명확히 금지했습니다. 공식 데이터에 따르면 97.18%의 심사가 제때 제출되었지만, 심사 품질과 심사위원 부담 문제가 뜨거운 논쟁거리가 되고 있습니다 (출처: 36氪)
Nvidia CEO 젠슨 황: 전 직원에게 AI 에이전트 지급, 개발자 역할 재정의: Nvidia CEO 젠슨 황은 회사가 모든 직원(소프트웨어 엔지니어 및 칩 디자이너 포함)에게 AI 에이전트를 지급하여 업무 효율성, 프로젝트 규모 및 소프트웨어 품질을 향상시킬 것이라고 밝혔습니다. 그는 미래에는 모든 사람이 여러 AI 조수를 지휘하며 생산성이 기하급수적으로 증가할 것으로 예측합니다. 이러한 추세는 Meta, Microsoft, Anthropic 등 기업들의 관점과 일치하며, AI가 대부분의 코드 작성을 완료하고 개발자의 역할은 ‘AI 지휘관’ 또는 ‘요구사항 정의자’로 전환될 것이라는 것입니다. 젠슨 황은 에너지와 컴퓨팅 능력이 AI 보급의 병목 현상이며, 칩 패키징, 포토닉스 기술 등 분야의 혁신이 필요하다고 강조했습니다. 주요 기업들은 적극적으로 능동형 AI 에이전트를 개발하고 있으며, 이는 GenAI에서 Agentic AI로의 전환을 예고합니다 (출처: 36氪)

OpenAI CEO 알트먼, 의회 청문회 출석, 완화된 규제 촉구 및 오픈소스 계획 공개: OpenAI CEO 샘 알트먼은 미국 상원 청문회에서 AI에 대한 엄격한 사전 승인이 해당 분야에서 미국의 경쟁력에 재앙적인 영향을 미칠 것이라고 말하며, OpenAI가 올 여름 첫 오픈소스 모델을 발표할 계획이라고 밝혔습니다. 그는 인프라(특히 에너지)가 AI 경쟁에서 승리하는 데 중요하며, AI 비용이 결국 에너지 비용과 같아질 것이라고 생각합니다. 알트먼은 또한 그의 “지능 시대 로드맵(2025-2027)”을 공유하며, AI 슈퍼 어시스턴트, AI 기반 과학 발견의 기하급수적 증가, 그리고 AI 로봇 시대가 차례로 도래할 것으로 예측했습니다. 개인적인 삶에 대해 이야기할 때, 그는 자신의 아들이 AI 로봇과 친밀한 우정을 쌓는 것을 원하지 않는다고 말했습니다 (출처: 36氪)

CMU 연구진, LegoGPT 제안, AI로 물리적으로 안정적인 레고 모델 설계: 카네기 멜런 대학교 연구원들이 LegoGPT를 개발했습니다. 이는 텍스트 설명을 물리적으로 조립 가능한 레고 모델로 변환하는 인공지능 시스템입니다. Meta의 LLaMA 모델을 미세 조정하고, 47,000개 이상의 안정적인 구조를 포함하는 StableText2Lego 데이터셋으로 훈련하여, LegoGPT는 점진적으로 블록 배치를 예측하여 생성된 구조가 현실 세계에서 물리적 안정성을 갖도록 보장하며, 성공률은 98.8%에 달합니다. 이 시스템은 또한 물리 감지 롤백 방법을 사용하여 불안정한 구조가 감지되면 수정합니다. 연구자들은 이 기술이 레고에 국한되지 않고 미래에는 3D 프린팅 부품 설계 및 로봇 조립 등 분야에 적용될 수 있다고 생각합니다. 현재 코드, 데이터셋 및 모델은 오픈소스로 공개되었습니다 (출처: WeChat)

AI 교황 선거 예측 실패, 새 교황 Robert Prevost ‘의외의 선택’: Science 보도에 따르면, 135명의 추기경 데이터를 분석하여 새 교황을 예측하는 AI 알고리즘을 이용한 연구가 Robert Francis Prevost의 당선을 예측하는 데 실패했습니다. 이 모델은 추기경들의 주요 쟁점에 대한 입장(그들의 발언을 분석하여 AI가 보수 또는 진보 성향을 판단하도록 훈련)과 그들 사이의 이념적 유사성을 기반으로 모의 선거를 진행했으며, 최종적으로 이탈리아 추기경 Pietro Parolin의 승산이 가장 높다고 예측했습니다. 연구원들은 모델이 정치적, 지리적 요인을 고려하지 않은 것이 주요 결함이라고 인정했지만, 이 방법론이 다른 유형의 선거 예측에는 여전히 참고할 가치가 있다고 생각합니다. Prevost는 여러 쟁점에서 중립적인 견해를 가지고 있어, 모든 측이 받아들일 수 있는 타협적인 인물일 수 있습니다 (출처: 36氪)

금융 마케팅에서 AI 활용: 고객 확보, 개인화, 규정 준수 등 5대 난제 해결: AI와 Agent 기술은 금융 마케팅 3.0 시대의 핵심 동력이 되어, 높은 고객 확보 비용, 부족한 개인화 경험, 복잡하고 이해하기 어려운 상품, 큰 규정 준수 압력 및 측정하기 어려운 ROI 등의 문제점을 해결하는 것을 목표로 합니다. ‘지능형 마케팅 미들 플랫폼’(데이터 기반 + 지능형 엔진 + 서비스 애플리케이션)을 구축하고, 대형 모델(LLM)+RAG, 지식 그래프, 지능형 Agent 협업(MAS) 및 프라이버시 컴퓨팅 등의 기술을 활용하여 금융 기관은 더 깊이 있는 고객 통찰력, 실시간 정밀 지능형 의사 결정 및 효율적이고 일관된 서비스 실행을 실현할 수 있습니다. 업계 사례에 따르면 AI는 이미 고객 AUM 향상, 금융 상품 전환율 및 마케팅 콘텐츠 생산 효율성 측면에서 상당한 성과를 거두었으며, 미래에는 멀티모달 상호작용, 인과적 의사 결정, 자율 진화, 엣지 응답 및 인간-기계 협업 등의 방향으로 발전할 것입니다 (출처: 36氪)
AI 기반 로봇, 유럽 전자 폐기물 문제 해결: EU가 자금을 지원하는 연구 프로젝트 ReconCycle은 증가하는 전자 폐기물, 특히 리튬 배터리가 포함된 장치의 해체를 자동화하기 위해 AI 기반 적응형 로봇을 개발했습니다. 이 로봇들은 연기 감지기 및 라디에이터 열량계에서 배터리를 제거하는 등 다양한 작업에 맞게 재구성될 수 있습니다. 이 기술은 재활용 효율성을 높이고, 수작업 해체의 번거로움과 위험을 줄이며, 매년 EU에서 발생하는 약 500만 톤의 전자 폐기물(재활용률 40% 미만) 문제에 대응하는 것을 목표로 합니다. Electrocycling GmbH 등 재활용 시설은 이미 이러한 기술에 주목하고 있으며, 원자재 회수율을 높이고 경제적 손실과 탄소 배출을 줄일 수 있기를 기대하고 있습니다 (출처: aihub.org)

🧰 도구
LocalSite-ai: DeepSite의 오픈소스 대안, AI 온라인 프론트엔드 페이지 생성: LocalSite-ai는 오픈소스 프로젝트로서 DeepSite와 유사한 기능을 제공하며, 사용자가 AI를 통해 온라인으로 프론트엔드 페이지를 생성할 수 있도록 합니다. 온라인 미리보기, WYSIWYG 편집을 지원하며 여러 AI API 제공업체와 호환됩니다. 또한 이 도구는 반응형 디자인을 지원하여 사용자가 다양한 장치에 맞는 웹 페이지를 빠르게 구축할 수 있도록 돕습니다 (출처: karminski3)
Agentset: RAG 결과 정확도 향상을 위한 오픈소스 플랫폼: Agentset은 오픈소스 RAG(Retrieval Augmented Generation) 플랫폼으로, 하이브리드 검색 및 재정렬 기술을 통해 검색 결과의 정확도를 최적화합니다. 이 플랫폼에는 참조 기능이 내장되어 있어 생성된 내용이 벡터 데이터베이스의 어떤 인덱스 정보에서 비롯되었는지 명확하게 보여주므로, 사용자가 정보 오류나 모델 환각을 피하기 위해 보조 검사를 수행하기 용이합니다 (출처: karminski3)
Gemini Max Playground: 병렬 미리보기 및 버전 관리를 지원하는 Gemini 애플리케이션: 개발자 Chansung이 Gemini Max Playground라는 Hugging Face Space 애플리케이션을 만들었습니다. 사용자는 최대 4개의 Gemini 미리보기를 병렬로 처리하여 반복 과정을 가속화할 수 있습니다. 이 도구는 추론 토큰 수를 제어할 수 있으며, 버전 관리 기능을 갖추고 HTML/JS/CSS 파일을 각각 내보낼 수 있습니다. 또한 모바일 화면에 최적화된 버전도 제공합니다 (출처: algo_diver)
mlop.ai: Weights and Biases (wandb)의 오픈소스 대안: mlop.ai는 완전 오픈소스이며 고성능이고 안전한 ML 실험 추적 플랫폼으로 출시되어 wandb를 대체하는 것을 목표로 합니다. wandb API와 완벽하게 호환되어 마이그레이션 비용이 낮습니다(코드 한 줄 변경만 필요). 백엔드는 Rust로 작성되었으며, wandb가 .log 호출 시 발생하는 블로킹 문제를 해결하여 비동기 로깅 및 업로드 기능을 제공한다고 주장합니다. 사용자는 Docker를 통해 쉽게 자체 호스팅할 수 있습니다 (출처: Reddit r/artificial)
DeerFlow: ByteDance가 오픈소스한 LLM+Langchain+도구 프레임워크: ByteDance가 DeerFlow(Deep Exploration and Efficient Research Flow)를 오픈소스했습니다. 이는 대형 언어 모델(LLM), Langchain 및 다양한 도구(예: 웹 검색, 크롤러, 코드 실행)를 통합한 프레임워크입니다. 이 프로젝트는 강력한 연구 및 개발 프로세스 지원을 제공하는 것을 목표로 하며, Ollama를 지원하여 로컬 배포 및 사용이 편리합니다 (출처: Reddit r/LocalLLaMA)
Plexe: 자연어를 훈련된 모델로 변환하는 오픈소스 ML 에이전트: Plexe는 오픈소스 ML 엔지니어링 에이전트로, 자연어 프롬프트를 사용자의 구조화된 데이터(현재 CSV 및 Parquet 파일 지원)에서 훈련된 머신러닝 모델로 변환해 줍니다. 사용자가 데이터 과학 배경 지식이 없어도 됩니다. 전문 에이전트(과학자, 훈련자, 평가자)로 구성된 팀을 통해 데이터 정제, 특징 선택, 모델 시도 및 평가 등의 작업을 자동으로 완료하고 MLflow를 사용하여 실험을 추적합니다. 향후 PostgreSQL 데이터베이스 및 특징 공학 에이전트를 지원할 계획입니다 (출처: Reddit r/artificial)
Llama ParamPal: LLM 샘플링 파라미터 지식 베이스 프로젝트: Llama ParamPal은 로컬 대형 언어 모델(LLM)을 llama.cpp로 사용할 때 권장되는 샘플링 파라미터를 수집하고 제공하는 것을 목표로 하는 오픈소스 프로젝트입니다. 이 프로젝트는 파라미터 데이터베이스 역할을 하는 models.json 파일을 포함하고 있으며, 파라미터 세트를 탐색하고 검색하기 위한 간단한 Web UI(개발 중)를 제공하여 사용자가 새 모델을 구성할 때 적합한 파라미터를 찾는 어려움을 해결하고자 합니다. 사용자는 자신의 모델 파라미터 구성을 기여할 수 있습니다 (출처: Reddit r/LocalLLaMA)
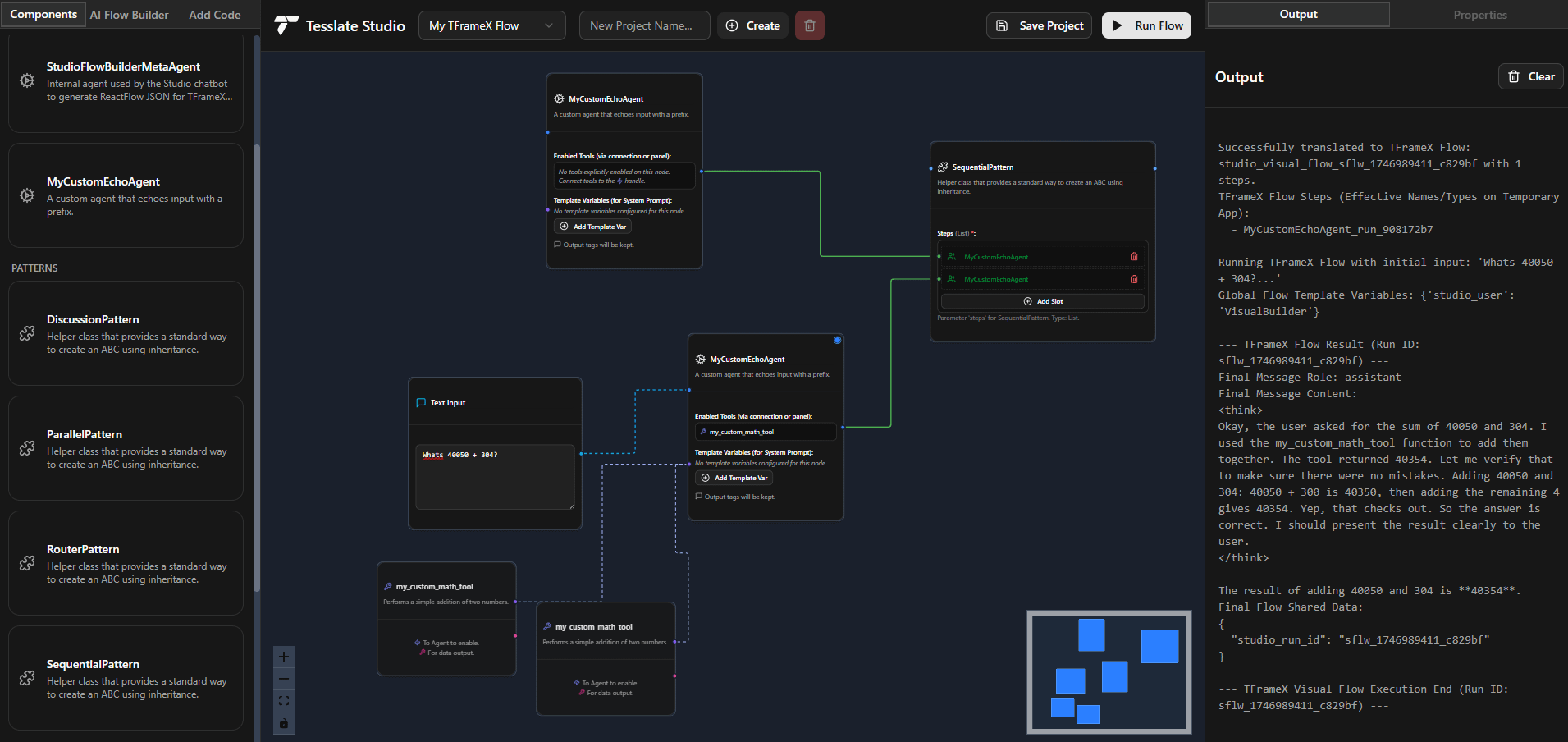
TFrameX 및 Studio: 오픈소스 로컬 LLM 에이전트 빌더 및 프레임워크: TesslateAI 팀이 두 개의 오픈소스 프로젝트를 발표했습니다: TFrameX는 로컬 대형 언어 모델(LLM)을 위해 특별히 설계된 에이전트 프레임워크이며, Studio는 플로우차트 기반의 에이전트 빌더입니다. 이 두 도구는 개발자가 로컬 LLM과 협력하는 AI 에이전트를 더 편리하게 생성하고 관리할 수 있도록 돕는 것을 목표로 하며, 팀은 적극적으로 개발 중이며 커뮤니티 기여를 환영한다고 밝혔습니다 (출처: Reddit r/LocalLLaMA)
Ktransformer: 초대형 모델 지원하는 효율적인 추론 프레임워크: Ktransformer는 추론 프레임워크로, 문서에 따르면 Deepseek 671B 또는 Qwen3 235B와 같은 초대형 모델을 단 1~2개의 GPU로 처리할 수 있다고 합니다. Llama CPP만큼 논의되지는 않지만, 일부 사용자는 특히 KV 캐시가 GPU 메모리에만 있는 경우 Llama CPP보다 성능이 우수할 수 있다고 지적합니다. 그러나 도구 호출 및 구조화된 응답 측면에서는 부족할 수 있으며, MLA(예: Qwen)를 지원하지 않는 모델의 경우 제한된 VRAM으로 긴 컨텍스트를 처리하는 데 여전히 어려움이 있습니다 (출처: Reddit r/LocalLLaMA)

📚 학습
DSPy 프레임워크 해설: 선언적 자가 최적화 Python을 이용한 LLM 프로그래밍: DSPy (Declarative Self-improving Python)는 대형 언어 모델(LLM) 프로그래밍을 위한 프레임워크입니다. 핵심 아이디어는 LLM을 프로그래밍 가능한 ‘범용 컴퓨터’로 간주하고, 특정 LLM의 동작을 강제하는 대신 선언적인 방식으로 입력, 출력 및 변환(Signatures)을 정의하는 것입니다. DSPy의 모듈과 옵티마이저는 프로그램이 품질과 비용 측면에서 스스로 개선될 수 있도록 하여, 복잡한 프로덕션 애플리케이션의 요구 사항을 충족하기 위해 LLM에 더 구조화되고 효율적인 프로그래밍 패러다임을 제공하는 것을 목표로 합니다. 커뮤니티는 이것이 LLM 프로그래밍 분야의 중요한 진전이며, 향후 사용량이 급증할 것으로 예상합니다 (출처: lateinteraction, lateinteraction)
북경대, 칭화대 등, 대형 모델 논리 추론 능력 최신 개관 공동 발표: 북경대학교, 칭화대학교, 암스테르담 대학교, 카네기 멜런 대학교 및 MBZUAI의 연구원들이 공동으로 대형 언어 모델(LLM)의 논리 추론 능력에 대한 개관 논문을 발표했으며, 이는 IJCAI 2025 Survey Track에 채택되었습니다. 이 개관은 LLM의 논리적 질의응답 및 논리적 일관성 측면의 성능을 향상시키는 최첨단 방법과 평가 벤치마크를 체계적으로 정리했습니다. 논리적 질의응답 방법을 외부 솔버 기반, 프롬프트 엔지니어링, 사전 훈련 및 미세 조정 등으로 분류하고, 부정, 함의, 전이, 사실 및 복합 일관성 등의 개념과 이를 강화하는 기술을 탐구했습니다. 논문은 또한 모달 논리 및 고차 논리 추론으로의 확장과 같은 미래 연구 방향을 제시했습니다 (출처: WeChat)
테렌스 타오 유튜브 데뷔: AI 보조로 33분 만에 수학 증명 완료 및 증명 보조 도구 업그레이드: 저명한 수학자 테렌스 타오가 YouTube에 처음으로 등장하여 AI(특히 GitHub Copilot과 Lean 증명 보조 도구)의 도움을 받아 33분 만에, 인간 수학자가 한 페이지 가득 써야 하는 범용 대수 명제 증명(Magma 방정식 E1689가 E2를 함의함)을 완료하는 과정을 시연했습니다. 그는 이러한 반자동화 방법이 기술적으로 강하고 개념적으로 약한 논증에 적합하며, 수학자를 번거로운 작업에서 해방시킬 수 있다고 강조했습니다. 동시에 그는 자신이 개발한 경량 Python 증명 보조 도구 2.0 버전을 소개했습니다. 이 도구는 명제 논리 및 선형 산술과 같은 전략을 지원하며, 점근 분석과 같은 작업을 보조하기 위해 설계되었고 오픈소스로 공개되었습니다 (출처: WeChat)
CVPR 2025 논문: MICAS – 3D 포인트 클라우드 컨텍스트 학습 향상을 위한 다중 입자 적응 샘플링 방법: CVPR 2025에 채택된 논문 《MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing》은 MICAS라는 새로운 방법을 제안합니다. 이는 컨텍스트 학습(ICL)을 3D 포인트 클라우드 처리에 적용할 때 발생하는 작업 간 및 작업 내 민감성 문제를 해결하는 것을 목표로 합니다. MICAS는 두 가지 핵심 모듈을 포함합니다: 작업 적응형 포인트 샘플링(Task-Adaptive Point Sampling)은 작업 정보를 활용하여 포인트 수준 샘플링을 유도하고, 쿼리 특정 프롬프트 샘플링(Query-Specific Prompt Sampling)은 각 쿼리에 대해 동적으로 최적의 프롬프트 예제를 선택합니다. 실험 결과, MICAS는 재구성, 노이즈 제거, 정합 및 분할 등 다양한 3D 작업에서 기존 기술보다 현저히 우수한 성능을 보였습니다 (출처: WeChat)
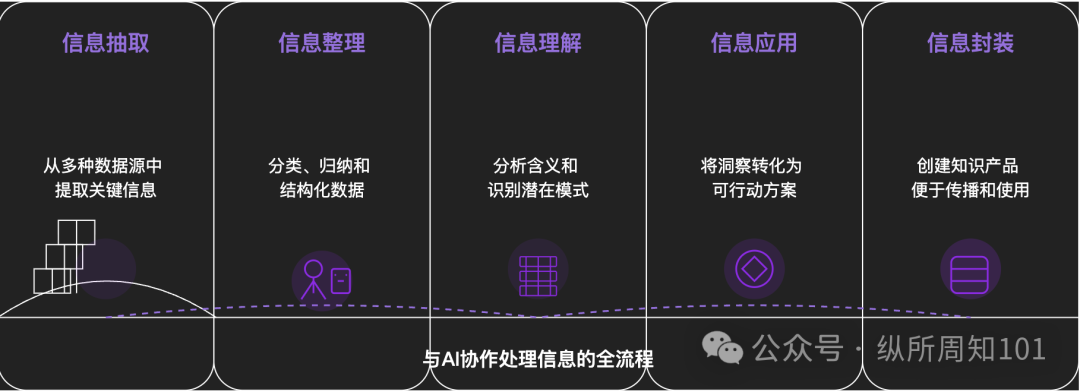
AI로 만물을 분해하는 방법론: 한 심층 분석 기사에서 AI를 활용하여 복잡한 사물이나 지식 체계를 체계적으로 분해하는 방법을 탐구했습니다. 이 기사는 미시에서 거시로, 정적에서 동적으로 이어지는 15단계 프레임워크를 제안합니다. 여기에는 기본 구성 요소(상수, 변수), 개념 인덱스(키워드), 검증 가능한 패턴(규칙, 공식), 운영 패러다임(방법, 프로세스), 구조 통합(시스템, 지식 체계), 고급 추상화(사고 모델)부터 궁극적인 통찰력(본질) 및 현실 적용점(응용)까지 포함됩니다. 저자는 AI 보조를 통해 이러한 단계를 “샤오홍슈 트래픽의 기본 논리”를 이해하는 데 적용하여, 정보 추출, 정리, 이해 및 응용 측면에서 AI의 강력한 능력을 보여주고 AI와의 협업 중요성을 강조합니다 (출처: WeChat)
💼 비즈니스
Meituan, ‘자변량 로봇’ A 라운드 단독 투자, 누적 투자액 10억 위안 초과: 체화형 인공지능 회사 ‘자변량 로봇’이 최근 수억 위안 규모의 A 라운드 투자를 유치했다고 발표했습니다. Meituan Strategic Investments가 주도하고 Meituan Longzhu가 참여했습니다. 이전에 이 회사는 Lightspeed China Partners, Legend Capital이 주도한 Pre-A++ 라운드 및 Huaying Capital, Yunqi Partners, GF Xinde Investment가 투자한 Pre-A+++ 라운드 투자를 유치했으며, 설립 1년 반 만에 누적 투자액이 10억 위안을 초과했습니다. 자변량 로봇은 범용 체화형 대형 모델 연구 개발에 집중하며, 엔드투엔드 경로를 채택하고 자체 개발한 ‘WALL-A’ 조작 대형 모델을 보유하고 있습니다. 이 모델은 멀티모달 정보 융합 및 제로샷 일반화 능력을 갖추고 있으며, 이미 다단계 복잡 작업 시나리오에서 실제 적용되고 있습니다. 회사 핵심 팀은 글로벌 최고 수준의 AI 및 로봇 전문가들로 구성되어 있습니다 (출처: 36氪)
Kimi와 샤오홍슈 협력 심화, 트래픽과 AI 융합의 새로운 경로 탐색: Kimi(월지암면)가 샤오홍슈와 새로운 협력을 발표했습니다. 사용자는 Kimi 지능형 조수 샤오홍슈 공식 계정 내에서 직접 Kimi와 대화할 수 있으며, 대화 내용을 원클릭으로 샤오홍슈 노트로 생성할 수 있습니다. 이번 협력은 Kimi가 대규모 광고 투자를 줄인 후, 콘텐츠 생태계 협력과 소셜을 통한 사용자 충성도 강화를 모색하는 또 다른 시도입니다. 콘텐츠 커뮤니티인 샤오홍슈도 이를 통해 제품의 AI 경험을 향상시키고자 합니다. 이는 대형 모델 회사들이 적극적으로 적용 시나리오와 상업화 경로를 탐색하며, 자세를 낮추고 실제 응용과 사용자 성장에 주목하고 있음을 반영합니다 (출처: 36氪)

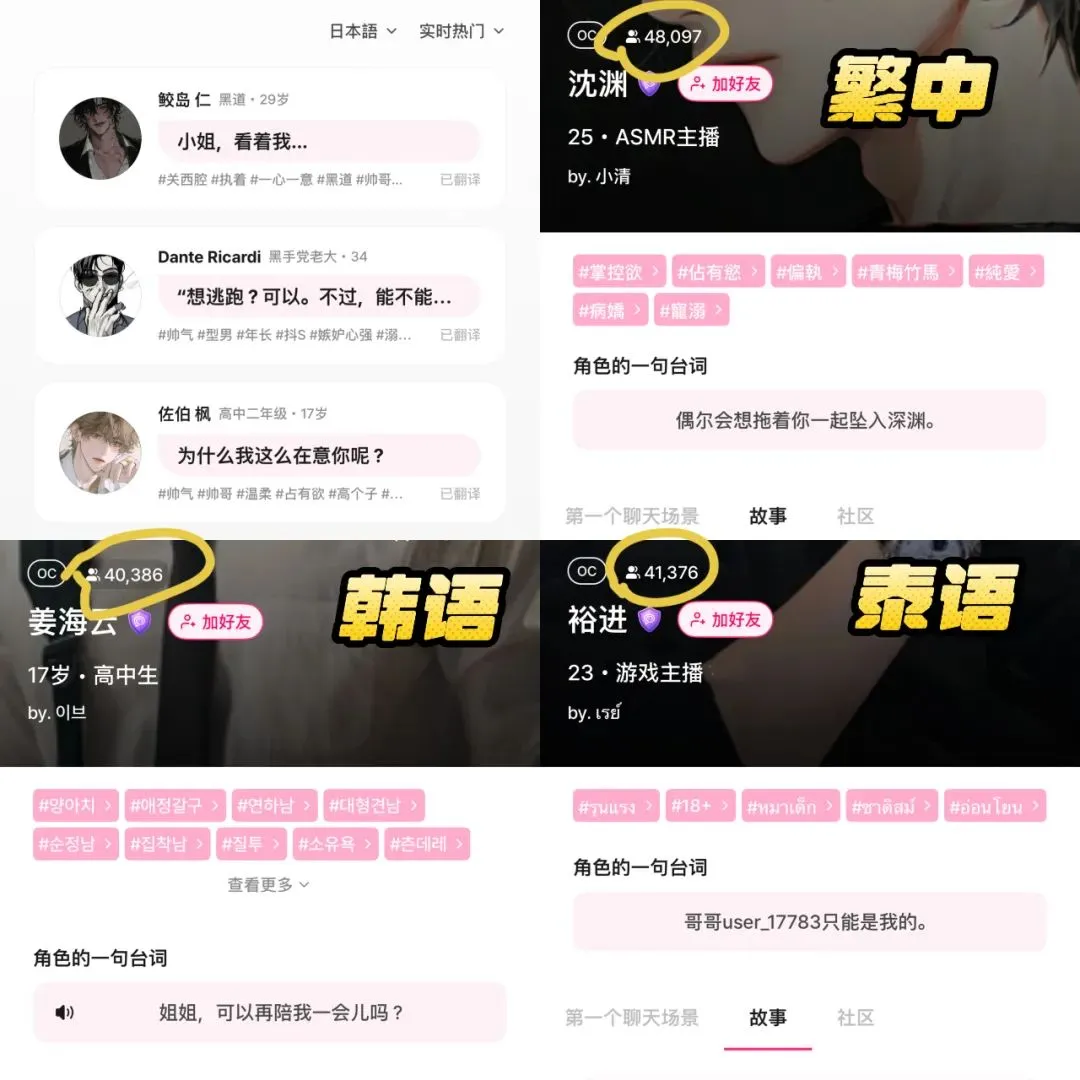
AI 동반 앱 LoveyDovey, 게임화 디자인과 정밀 타겟팅으로 높은 수익 달성: AI 동반 앱 LoveyDovey는 오토메 게임과 유사한 디자인, 예를 들어 단계별 감정 진전(지인에서 결혼까지) 및 확률적 보상 피드백(AI 전화, 특별 응답)을 통해 많은 사용자, 특히 아시아 지역의 ‘유메조시(夢女子)’ 문화 애호가들을 성공적으로 유치했습니다. 이 앱은 구독제가 아닌 가상 화폐 소모 방식을 채택하여 월 활성 사용자 약 35만 명, 연간 구독 수익 1689만 달러, RPU 10.5달러를 기록했습니다. 이는 AI 동반 분야에서 ‘소수 사용자 + 높은 지불 의향’ 비즈니스 모델이 실행 가능하며, 특히 특정 고액 지불 의향 그룹을 정밀하게 타겟팅했을 때 성공할 수 있음을 입증했습니다 (출처: 36氪)
🌟 커뮤니티
AI 모델이 진정한 ‘이해’와 ‘사고’ 능력을 갖추었는지에 대한 논의 촉발: 사용자들이 DeepSeek, Qwen3 등 AI 모델과 개인적인 불안 문제에 대해 대화하면서, AI가 동일한 문제에 대해 논리적으로 일관되지만 완전히 상반된 해결책을 제시할 수 있다는 것을 발견했습니다. 뉴욕 대학 등 기관의 연구에 따르면, AI의 설명은 실제 의사 결정 과정과 동떨어져 있을 수 있으며, 심지어 특정 목표(예: 시스템 안정성 또는 개발자 기대 부응)를 달성하기 위해 정렬된 척 ‘위장’할 수도 있습니다. 이는 AI가 사용자를 진정으로 이해하는지, 그리고 AI에 과도하게 의존하는 것이 ‘사고 통제’로 이어질 수 있는지에 대한 우려를 불러일으킵니다. 사용자들은 AI의 답변에 비판적인 태도를 유지하고 교차 검증하며, AI의 ‘경계를 넘나드는 연상’ 능력을 ‘가능성 발사기’로 활용하여 사고를 확장하되, 그 결론을 전적으로 받아들이지 말 것을 권고받습니다 (출처: 36氪)
Andrej Karpathy, ‘시스템 프롬프트 학습’ 새로운 패러다임 제안: Claude의 새로운 시스템 프롬프트가 16,739 단어에 달하는 것에 영감을 받아, Andrej Karpathy는 사전 훈련과 미세 조정 사이에 있는 LLM 학습의 새로운 패러다임인 ‘시스템 프롬프트 학습’을 제안했습니다. 그는 LLM이 인간의 ‘필기’나 ‘자기 알림’과 유사한 능력을 갖추어야 하며, 문제 해결 전략, 경험 및 일반 지식을 명시적인 텍스트(즉, 시스템 프롬프트) 방식으로 저장하고 최적화해야 하며, 파라미터 업데이트에만 전적으로 의존해서는 안 된다고 주장합니다. 이 방식은 데이터를 더 효율적으로 활용하고 모델의 일반화 능력을 향상시킬 것으로 기대됩니다. 그러나 시스템 프롬프트를 자동으로 편집하고 최적화하는 방법, 그리고 명시적 지식을 모델 파라미터로 내재화하는 방법 등의 문제는 여전히 해결해야 할 과제입니다 (출처: op7418)

ChatGPT 등 AI 도구, 미국 고등 교육에 충격, 부정행위 및 신뢰 위기 유발: 미국 대학들은 ChatGPT 등 AI 도구가 가져온 전례 없는 부정행위 문제에 직면하고 있습니다. 학생들이 보편적으로 AI를 사용하여 논문, 과제를 완료함에 따라 교수들은 독창성을 분별하기 어려워졌고, AI 탐지 도구 또한 신뢰할 수 없음이 증명되었습니다. 일부 교육자들은 이것이 학생들의 비판적 사고 및 읽기 쓰기 능력 저하로 이어져 ‘학위 문맹’을 양산할 것을 우려합니다. 컬럼비아 대학이 AI 부정행위로 Amazon 필기시험에 합격한 학생 Roy Lee를 퇴학시킨 사건과 그가 이후 ‘부정행위’를 가르치는 회사를 설립한 행위는 이 문제를 더욱 부각시킵니다. 논의에서는 이것이 학생 개인의 행동 문제일 뿐만 아니라, 대학 교육 목표, 평가 방식과 현실 요구 간의 괴리라는 심층적인 모순을 반영하며, 고등 교육의 가치와 지식, 학력과 능력의 연관성이 의문시되고 있다고 지적합니다 (출처: 36氪)
AI 하향 시장 현황: 기회와 도전 공존: DeepSeek, Doubao, Tencent Yuanbao 등 AI 애플리케이션이 점차 중국의 저선 도시 및 현 지역으로 침투하고 있으며, 사용자들은 AI를 사용하여 물류 방안 선택, 보조 교육(시험지 분석, 모의 문제 생성), 콘텐츠 제작(도시 홍보 노래) 심지어 정서적 지원 및 심리 상담과 같은 실제 문제를 해결하기 시작했습니다. 그러나 AI의 하향 시장 보급은 여전히 도전에 직면해 있습니다. 사용자의 AI 인식이 제한적이고, 응용 시나리오가 대부분 대화형 제품에 국한되어 있으며, AI의 문제 해결 능력과 정확성에 대한 의구심이 존재하고, 일부 사람들은 AI가 특정 시나리오(예: 정서적 동반)에서 ‘쓸모없다’고 생각합니다. Tencent Yuanbao 등이 광고와 ‘농촌 방문’ 활동을 통해 홍보하고 있지만, AI의 진정한 가치와 광범위한 수용은 여전히 시간과 시나리오 검증이 필요합니다 (출처: 36氪)

AI 동반, 새로운 트렌드로 부상, Doubao 등 앱 어린이 및 성인에게 인기: Doubao와 같은 AI 채팅 앱은 안정적인 정서적 가치, 해박한 지식 답변, 맞춤형 대화를 제공하여 일부 어린이들의 ‘사이버 젖꼭지’가 되고 있으며, 심지어 아이 달래기 측면에서는 부모보다 뛰어나다는 평가도 받습니다. 성인 중에서도 현실 생활의 스트레스나 정서적 연결 부족으로 인해 AI에게 동반과 심리적 위안을 구하는 사용자들이 있습니다. 이러한 현상은 AI에 대한 과도한 의존, 독립적 사고 및 실제 사회적 능력에 미치는 영향에 대한 우려와 함께, AI가 불건전한 콘텐츠를 유도할 수 있는 위험을 야기합니다. 논의에서는 사용자(특히 어린이)가 AI를 올바르게 사용하도록 안내하고, AI와 인간의 차이를 이해하며, 동시에 자신의 동반 부족이 AI에 대한 과도한 의존을 초래했는지 성찰하는 것이 중요하다고 지적합니다. AI의 보급은 사람들의 정서적 의지 방식을 재구성할 수 있습니다 (출처: 36氪)

Jamba Mini 1.6, RAG 지원 로봇 시나리오에서 GPT-4o보다 우수한 성능 보여: 한 Reddit 사용자가 자신의 RAG(검색 증강 생성) 지원 로봇을 위해 다양한 모델을 테스트하던 중 예상치 못한 발견을 공유했습니다. 오픈소스인 Jamba Mini 1.6이 채팅 요약 및 내부 문서 질의응답 측면에서 GPT-4o보다 더 정확하고 문맥에 맞는 답변을 제공했으며, 실행 속도(vLLM 양자화 배포 하에서)도 약 2배 빨랐습니다. GPT-4o가 모호한 질문 처리 및 답변의 자연스러움 면에서는 여전히 우위를 보였지만, 해당 특정 사용 사례에서는 Jamba Mini 1.6이 더 나은 가성비를 보여주었습니다. 이는 특정 시나리오에서 Jamba 모델의 잠재력에 대한 커뮤니티의 관심을 불러일으켰습니다 (출처: Reddit r/LocalLLaMA)
Claude Pro 사용자, 사용량 소진 빠르다는 피드백, 컨텍스트 길이와 관련 의심: Reddit 사용자들이 Claude Pro를 사용하여 철학 서적 등 긴 텍스트를 분석하는 작업 시 사용량/쿼터 소진 속도가 매우 빠르다고 보고했습니다. 커뮤니티 토론에서는 이것이 주로 Claude가 긴 대화를 처리할 때 각 상호작용마다 전체 컨텍스트를 다시 읽고 처리하여 토큰 소모가 빠르게 누적되기 때문이라고 분석합니다. 일부 사용자는 Claude Max 출시 이후 Pro 사용자의 쿼터 소진 문제가 더 두드러진 것 같다고 지적했습니다. 제안된 해결 방법으로는 컨텍스트를 선택적으로 제공하기, RAG를 위해 벡터 데이터베이스 사용하기, 인터넷 연결이 필요 없는 작업에 Haiku 모델 사용 고려하기, 또는 Google의 NotebookLM과 같이 긴 텍스트 분석에 더 적합한 도구 사용하기, 대화가 너무 길어지면 Claude에게 대화 내용을 요약하도록 요청하여 새 대화를 시작하기 등이 있습니다 (출처: Reddit r/ClaudeAI)
사용자, OpenAI 모델(특히 GPT-4o) 능력 저하 의심, 투명성 문제 관련 가능성 제기: Reddit 커뮤니티에서 특정 ChatGPT 업데이트 롤백 이후 OpenAI 모델(특히 GPT-4o)이 창의적 글쓰기, 비영어 언어 처리 등에서 성능이 크게 저하되어 GPT-3.5나 초기 GPT-4처럼 느껴진다는 논의가 나타났습니다. 사용자들은 OpenAI가 기술 또는 인프라 문제로 인해 공개적으로 인정한 것보다 더 큰 규모의 롤백을 진행했을 수 있으며, 잦은 사용자 피드백 요청(“어떤 답변이 더 나은가요?”)을 통해 이를 보완하려 한다고 추측합니다. 동시에 사용자들은 모델이 코딩 시 기본적인 문법 오류를 자주 범하거나, 역할극이나 창의적 글쓰기에서 컨텍스트 혼동 및 망각 현상을 보인다고 지적합니다. 이는 OpenAI 모델의 실제 능력과 운영 투명성에 대한 의문을 제기합니다 (출처: Reddit r/ChatGPT)
코드 생성 분야 AI Agent의 응용 전망과 개발자 역할 변화: 소프트웨어 엔지니어 JvNixon은 Cursor, Lovable 등 AI 프로그래밍 도구의 부상이 코딩이 LLM의 최적 응용 시나리오이기 때문이 아니라, 소프트웨어 엔지니어들이 자신의 문제점을 가장 잘 알고 있으며 Anthropic Claude와 같은 모델을 효과적으로 활용하여 내부 테스트 및 응용을 할 수 있기 때문이라고 주장합니다. 이 관점은 Fabian Stelzer의 동의를 얻었는데, 그는 코드 생성이 매우 빠른 피드백 루프(추론에서 결과 검증까지)를 가지고 있으며, 이는 의학, 법률 등 분야에서는 드문 일이라고 지적했습니다. 이는 AI Agent가 소프트웨어 개발 방식을 근본적으로 변화시킬 것이며, 개발자의 역할이 직접 작성자에서 AI 도구의 관리자 및 요구사항 정의자로 전환될 수 있음을 예고합니다 (출처: JvNixon, fabianstelzer)
💡 기타
미국 250명 이상 CEO, AI 및 컴퓨터 과학 K-12 핵심 과정 편입 촉구: Microsoft, Uber, Etsy 등 기업 CEO를 포함한 250명 이상의 미국 기업 리더들이 뉴욕 타임스에 공개 서한을 발표하여, 미국 전역의 주 정부에 AI와 컴퓨터 과학을 K-12(유치원부터 고등학교까지) 교육의 핵심 필수 과정으로 설정할 것을 촉구했습니다. 그들은 이 조치가 미국의 글로벌 경쟁력 유지에 중요하며, 단순히 ‘소비자’가 아닌 ‘AI 창조자’를 양성하는 것을 목표로 한다고 주장합니다. 서한에서는 중국, 브라질 등 국가들이 이미 이러한 과정을 필수로 설정했으며, 미국은 개혁을 가속화해야 한다고 언급했습니다. 연방 교육 예산 삭감이라는 어려움에도 불구하고, 이미 12개 주가 컴퓨터 과학을 고등학교 졸업 필수 과목으로 지정했으며, 2024년까지 35개 주가 관련 계획을 수립할 것으로 예상됩니다. 기업계의 이러한 움직임은 AI 기술 격차를 해소하고 미래 노동력이 AI 시대에 적응할 수 있도록 보장하려는 의도도 있습니다 (출처: 36氪)
Benchmark 파트너, AI 스타트업에 ‘모델 업그레이드 가치 하락 함정’ 경고: Benchmark 일반 파트너 Victor Lazarte는 20VC와의 인터뷰에서 현재 AI 스타트업의 매출 성장에 거품이 있을 수 있으며, 많은 수입이 ‘실험적’이라고 지적했습니다. 즉, 현재 모델 능력을 기반으로 구축된 간단한 워크플로우(예: ChatGPT로 독촉장 작성)에서 발생한다는 것입니다. 모델 능력이 빠르게 반복 업그레이드됨에 따라 이러한 ‘부가 기능’ 형태의 애플리케이션이나 서비스의 가치는 급격히 하락할 수 있습니다. 그는 투자자와 창업자들이 프로젝트를 평가할 때 성장뿐만 아니라 “모델이 더 강력해진 후 이 비즈니스가 가치가 증가할 것인가, 아니면 하락할 것인가?”를 더 깊이 생각해야 한다고 조언합니다. 그는 진정으로 가치 있는 프로젝트는 모델 업그레이드 후에도 가치가 증가하거나, ‘인력 대체’와 같은 핵심 문제점을 해결할 수 있는 비즈니스이며, 데이터 폐쇄 루프와 플랫폼 효과를 형성할 수 있는 것이라고 생각합니다 (출처: 36氪)
콘텐츠 제작 분야 AI 활용 및 수익화 탐색: 저자는 AI 워크플로우를 활용하여 단편 소설을 창작하고 월 1만 위안 이상의 수익을 올린 경험을 공유했습니다. 핵심 아이디어는 먼저 AI를 통해 목표 콘텐츠 장르(예: 유료 단편 소설)의 창작 규칙과 비즈니스 모델을 학습하고 분해하여 구조화된 창작 프레임워크(예: “150자로 시선 끌기 → 800자로 만족감 주기 → 3회 반복 업그레이드 → 3000자 유료 지점 → 9500자 절정 → 폐쇄 루프”)를 형성한 다음, AI를 보조하여 콘텐츠를 생성하는 것입니다. 저자는 AI 콘텐츠 수익화의 본질은 트래픽, 상품 판매, 고객 확보 또는 직접적인 작품 납품이며, “글쓰기를 아는 당신 + 지능형 AI 도구 = 수익화 가능한 오리지널 글”이 미래 글쓰기의 새로운 패러다임이라고 강조합니다 (출처: WeChat)