
키워드:OpenAI, AI 칩, 대규모 모델, 강화 학습, AI 인프라, 멀티모달 AI, 에이전트, RAG, OpenAI 국가급 AI 계획, 엔비디아 H20 칩 수출 규제, DeepSeek-R1 추론 최적화, AI 광학 현미경 Meta-rLLS-VSIM, 바이트댄스 Seed-Coder 코드 대형 모델
🔥 주요 뉴스
OpenAI, ‘국가급 AI’ 계획 발표, 글로벌 AI 인프라 구축 지원: OpenAI는 ‘스타게이트(Stargate)’ 계획의 일환으로 ‘OpenAI for Countries’ 프로젝트를 시작하여, 각국의 현지 AI 데이터 센터 구축, 맞춤형 ChatGPT 개발 및 AI 생태계 발전을 지원하는 것을 목표로 합니다. CEO Sam Altman은 텍사스 Abilene에 위치한 첫 번째 슈퍼컴퓨팅 단지를 현지 시찰했으며, 이 단지는 5000억 달러 규모의 ‘스타게이트(Stargate)’ 계획의 일부로 세계 최대 규모의 AI 훈련 시설 구축을 목표로 합니다. 이는 OpenAI가 여러 국가 정부와 협력하여 인프라 구축 및 기술 공유를 통해 AI 기술의 글로벌 보급 및 응용을 추진하고, 우선 10개 국가 또는 지역과 협력할 계획임을 의미합니다 (출처: WeChat)

트럼프 행정부, AI 칩 수출 3단계 제한 폐지하고 더 간소화된 글로벌 라이선스 시스템 채택 검토: 외신 보도에 따르면, 트럼프 행정부는 바이든 시대 말기에 제정된 ‘인공지능 확산 프레임워크(FAID)’를 철회할 계획입니다. 이 프레임워크는 원래 전 세계 AI 칩 수출에 대해 3단계 분류 제한을 시행할 예정이었습니다. 트럼프 팀은 해당 프레임워크가 지나치게 번거롭고 혁신을 저해한다고 판단하여, 더 간단한 글로벌 라이선스 시스템으로 대체하고 정부 간 협정을 통해 시행하는 것을 선호하는 것으로 알려졌습니다. 이러한 움직임은 Nvidia 등 칩 제조업체의 글로벌 시장 전략에 영향을 미칠 수 있으며, AI 분야에서 미국의 혁신과 주도권을 공고히 하려는 목표를 가지고 있습니다 (출처: WeChat)

SGLang 팀, DeepSeek-R1 추론 성능 대폭 최적화, 처리량 26배 향상: SGLang, Nvidia 등 기관의 공동 연구팀은 SGLang 추론 엔진의 전면적인 업그레이드를 통해 4개월 만에 H100 GPU에서 DeepSeek-R1 모델의 추론 성능을 26배 향상시켰습니다. 최적화 방안에는 프리필(prefill)과 디코딩 분리(PD 분리), 대규모 전문가 병렬 처리(EP), DeepEP, DeepGEMM 및 전문가 병렬 로드 밸런서(EPLB) 등의 기술이 포함됩니다. 2000개 토큰 입력 시퀀스 처리 시, 노드당 초당 52.3k 입력 토큰과 22.3k 출력 토큰의 처리량을 달성하여 DeepSeek 공식 데이터에 근접했으며, 로컬 배포 비용을 크게 절감했습니다 (출처: WeChat)

OpenAI 과학자 Dan Roberts: 강화 학습 확장이 AI의 새로운 과학 발견 촉진, 9년 내 아인슈타인급 AGI 실현 가능성: OpenAI 연구 과학자 Dan Roberts는 Sequoia Capital AI Ascent에서 강화 학습(RL)이 미래 AI 모델 구축에서 핵심적인 역할을 할 것이라고 발표했습니다. 그는 RL의 규모를 지속적으로 확장함으로써 AI 모델이 수학적 추론과 같은 작업에서 성능을 향상시킬 뿐만 아니라, “테스트 시간 컴퓨팅”(즉, 모델이 더 오래 생각할수록 성능이 향상됨)을 통해 과학적 발견을 이룰 수 있다고 주장했습니다. 그는 아인슈타인이 일반 상대성 이론을 발견한 예를 들며, AI가 8년 동안 계산하고 생각할 수 있다면 9년 후에는 아인슈타인과 유사한 수준의 과학적 돌파구를 마련할 수 있을 것이라고 추측했습니다. Roberts는 미래의 AI 발전이 RL 컴퓨팅에 더욱 집중될 것이며, 심지어 전체 훈련 과정을 주도할 수도 있다고 강조했습니다 (출처: WeChat)

🎯 동향
Nvidia Jim Fan: 로봇, ‘물리적 튜링 테스트’ 통과할 것, 시뮬레이션과 생성형 AI가 핵심: Nvidia 로봇 부문 책임자 Jim Fan은 Sequoia AI Ascent 강연에서 인간이 작업 수행 주체가 사람인지 로봇인지 구분할 수 없는 ‘물리적 튜링 테스트’ 개념을 제시했습니다. 그는 현재 로봇 데이터 확보 비용이 매우 높으며, 특히 생성형 AI(예: 비디오 생성 모델 미세 조정)와 결합하여 다양하고 대규모의 훈련 데이터(“정확한 ‘디지털 트윈’이 아닌 ‘디지털 사촌’“)를 만드는 시뮬레이션 기술이 핵심이라고 지적했습니다. 그는 대규모 시뮬레이션과 시각-언어-행동 모델(예: Nvidia GR00T)을 통해 미래에는 물리적 API가 어디에나 존재하게 되고, 로봇이 복잡한 일상 업무를 수행하며 환경 지능과 융합될 것이라고 예측했습니다 (출처: WeChat)
ByteDance, Seed-Coder 시리즈 코드 대형 모델 출시, 8B 버전 우수한 성능: ByteDance는 8B, 14B 등 다양한 버전의 Seed-Coder 시리즈 코드 대형 모델을 출시했습니다. 그중 Seed-Coder-8B는 SWE-bench, Multi-SWE-bench, IOI 등 다수의 코드 능력 평가 벤치마크에서 뛰어난 성능을 보였으며, Qwen3-8B 및 Qwen2.5-Coder-7B-Inst보다 우수하다고 알려졌습니다. 이 시리즈 모델은 Base, Instruct, Reasoner 버전을 포함하며, 핵심 이념은 “코드 모델이 스스로 데이터를 기획하게 한다”는 것으로, 코드 추론 및 소프트웨어 엔지니어링 능력 면에서 현저한 향상을 보였습니다. 모델은 Hugging Face와 GitHub에 오픈소스로 공개되었습니다 (출처: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba, ZeroSearch 프레임워크 오픈소스 공개, LLM 활용 검색 시뮬레이션으로 AI 훈련 비용 88% 절감: Alibaba 연구원들은 “ZeroSearch”라는 강화 학습 프레임워크를 발표했습니다. 이 프레임워크는 대규모 언어 모델(LLM)이 훈련 과정에서 고가의 상용 검색 엔진 API(예: Google)를 호출하지 않고도 시뮬레이션된 검색 엔진을 통해 고급 검색 기능을 개발할 수 있도록 합니다. 실험 결과, 3B LLM을 시뮬레이션 검색 엔진으로 사용해도 정책 모델의 검색 능력이 효과적으로 향상되었으며, 14B 매개변수의 검색 모듈 성능은 Google 검색을 능가하고 API 비용은 88% 절감된 것으로 나타났습니다. 이 기술은 GitHub와 Hugging Face에 오픈소스로 공개되었으며, Qwen-2.5, LLaMA-3.2 등 모델 시리즈를 지원합니다 (출처: WeChat)

Gemini API, 암시적 캐싱 기능 출시, 최대 75% 비용 절감 가능: Google Gemini API는 최근 Gemini 2.5 모델 시리즈(Pro 및 Flash)에 암시적 캐싱 기능을 활성화했습니다. 사용자의 요청이 캐시에 적중하면 최대 75%의 비용을 자동으로 절감할 수 있습니다. 동시에 캐시 트리거를 위한 최소 토큰 요구 사항도 낮아져, 2.5 Flash 모델은 1K 토큰으로, 2.5 Pro 모델은 2K 토큰으로 감소했습니다. 이는 개발자가 Gemini API를 사용하는 비용을 절감하고, 빈번하게 반복되는 요청의 효율성을 높이기 위한 조치입니다 (출처: JeffDean)
칭화대학교, AI 광학 현미경 Meta-rLLS-VSIM 개발, 체적 해상도 15.4배 향상: 칭화대학교 리동(李栋) 연구팀과 다이충하이(戴琼海) 팀이 협력하여 메타 학습 기반 반사형 격자 광시트 가상 구조 조명 현미경(Meta-rLLS-VSIM)을 제안했습니다. 이 시스템은 AI와 광학의 교차 혁신을 통해 살아있는 세포 이미징의 측면 해상도를 120nm로, 축 방향 해상도를 160nm로 향상시켜 거의 등방성 초고해상도를 구현했으며, 체적 해상도는 기존 LLSM 대비 15.4배 향상되었습니다. 핵심 기술에는 DNN을 활용하여 초고해상도 능력을 다방향으로 학습하고 확장하는 “가상 구조 조명”과 미러 반사를 통한 이중 시점 정보 융합 및 RL-DFN 네트워크를 통한 축 방향 해상도 향상이 포함됩니다. 메타 학습 전략 도입으로 AI 모델이 단 3분 만에 적응형 배포를 완료할 수 있게 되어 생물학 실험에서 AI 응용의 문턱을 크게 낮추었으며, 암세포 분열, 배아 발달 등 생명 과정 관찰을 위한 강력한 도구를 제공합니다 (출처: WeChat)

Qwen3 시리즈 대형 모델 출시, 오픈소스 커뮤니티 선도 지속: Alibaba는 0.5B부터 235B까지 다양한 매개변수 규모의 Qwen3 시리즈 대형 언어 모델을 출시했습니다. 이 모델들은 여러 벤치마크 테스트에서 우수한 성능을 보였으며, 특히 여러 소형 모델은 동일 규모의 오픈소스 모델 중 SOTA 수준을 달성했습니다. Qwen3 시리즈는 다양한 언어를 지원하며, 컨텍스트 길이는 최대 128k 토큰에 달합니다. 강력한 성능과 낮은 배포 비용(DeepSeek-R1 등에 비해) 덕분에 Qwen 시리즈는 해외(특히 일본)에서 AI 개발 기반으로 널리 채택되어 수많은 버티컬 모델을 파생시켰습니다. Qwen3의 출시는 글로벌 오픈소스 AI 커뮤니티에서의 선도적 위치를 더욱 공고히 했으며, GitHub에서 일주일 만에 스타 수 2만을 돌파했습니다 (출처: dl_weekly, WeChat)

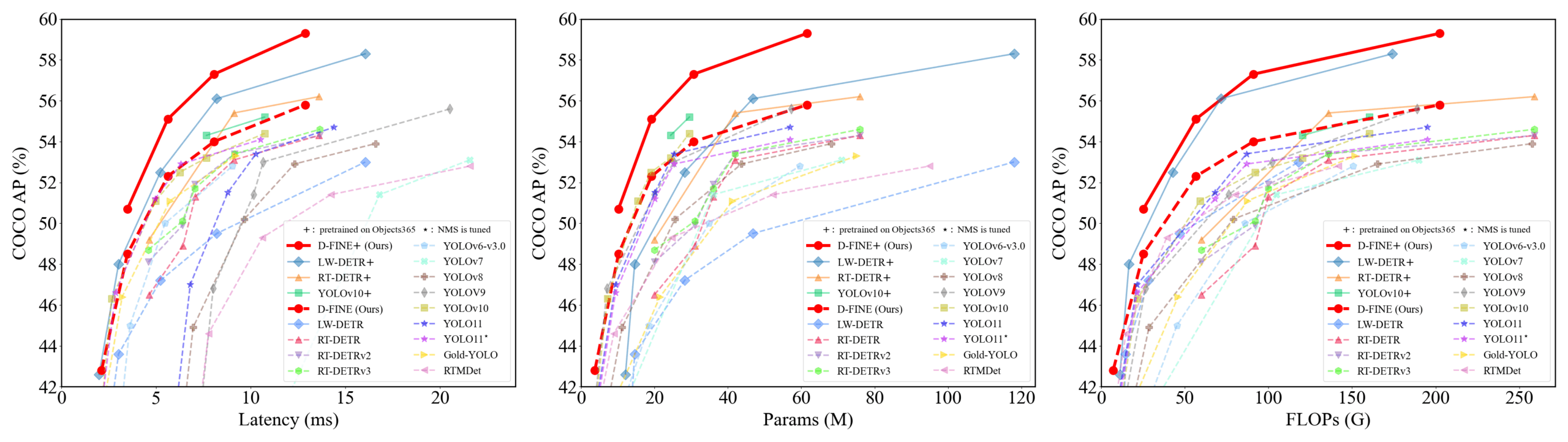
D-FINE: 세분화된 분포 최적화 기반 실시간 객체 탐지기, 우수한 성능: 연구진들은 DETR의 경계 상자 회귀 작업을 세분화된 분포 최적화(FDR)로 재정의하고 전역 최적 위치 자기 증류(GO-LSD) 전략을 도입한 새로운 실시간 객체 탐지기 D-FINE을 제안했습니다. D-FINE은 추가적인 추론 및 훈련 비용 없이 뛰어난 성능을 달성했습니다. 예를 들어, D-FINE-N은 COCO val에서 42.8% AP를 달성하며 최대 472 FPS(T4 GPU)의 속도를 보였고, D-FINE-X는 Objects365+COCO 사전 훈련 후 COCO val AP 59.3%를 달성했습니다. 이 방법은 확률 분포의 반복적인 최적화를 통해 더 정교한 위치 파악을 실현하고, 자기 증류를 통해 최종 레이어의 위치 지식을 초기 레이어로 전달합니다 (출처: GitHub Trending)
Harmon 모델, 시각적 표현 조율하여 멀티모달 이해와 생성 통합: 난양 공과대학교 연구진들은 공유 MAR Encoder(Masked Autoencoder for Reconstruction)를 통해 멀티모달 이해와 생성 작업을 통합하는 Harmon 모델을 제안했습니다. 연구 결과, MAR Encoder는 이미지 생성 훈련에서 시각적 의미를 동시에 학습할 수 있으며, Linear Probing 결과는 VQGAN/VAE를 훨씬 능가하는 것으로 나타났습니다. Harmon 프레임워크는 MAR Encoder를 사용하여 전체 이미지를 처리하여 이해하고, MAR 마스크 모델링 패러다임을 따라 이미지 생성을 수행하며, LLM은 이 과정에서 모달리티 상호 작용을 구현합니다. 실험 결과, Harmon은 멀티모달 이해 벤치마크에서 Janus-Pro에 근접한 성능을 보였으며, 텍스트-이미지 생성 미학 벤치마크 MJHQ-30K와 명령어 추종 벤치마크 GenEval에서 우수한 성능을 보였고, 일부 전문가 모델을 능가하기도 했습니다. 이 모델은 오픈소스로 공개되었습니다 (출처: WeChat)

푸싱 테크놀로지, 물류 로봇 상업적 순환 고리 실현, ‘배달원 그림자 시스템’으로 데이터 축적: 푸싱 테크놀로지(推行科技)의 물류 로봇이 중국 여러 도시에서 실제 운영에 투입되어 인간 배달원과 협력하며 개별 로봇의 손익분기점을 달성했습니다. 핵심 기술 중 하나는 ‘배달원 그림자 시스템(骑手影子系统)’으로, 복잡한 도시 환경에서 실제 배달원의 주행 행동, 환경 인식 및 조작 데이터(문 개폐, 물품 픽업 및 배치 등)를 수집하여 로봇에게 방대하고 고품질의 모방 학습 및 강화 학습 훈련 데이터를 제공합니다. 현재 이 시스템은 수천만 킬로미터의 주행 데이터와 거의 백만 건의 상지 궤적 데이터를 축적했습니다. 푸싱 테크놀로지는 이를 기반으로 행동 트리 VLA 모델을 훈련시켜 로봇이 실제 세계의 복잡한 상황에 대처할 수 있도록 했으며, 해외 시장으로의 확장을 계획하고 있습니다 (출처: WeChat)

Kuaishou, KuaiMod 프레임워크 출시, 멀티모달 대형 모델 활용해 숏폼 비디오 생태계 최적화: Kuaishou는 멀티모달 대형 모델 기반의 숏폼 비디오 플랫폼 생태계 최적화 방안인 KuaiMod를 제안하여, 자동화된 콘텐츠 품질 판별을 통해 사용자 경험을 개선하고자 합니다. KuaiMod는 판례법 아이디어를 차용하여 시각 언어 모델(VLM)의 연쇄 추론을 통해 저품질 콘텐츠를 분석하고, 사용자 피드백 기반 강화 학습(RLUF)을 통해 판별 전략을 지속적으로 업데이트합니다. 이 프레임워크는 Kuaishou 플랫폼에 배포되어 사용자 신고율을 20% 이상 효과적으로 낮췄습니다. Kuaishou는 동시에 커뮤니티 숏폼 비디오를 이해할 수 있는 멀티모달 대형 모델 구축에 힘쓰고 있으며, 표현 추출에서 심층 의미 이해로 나아가 비디오 관심 태그 구조화, 콘텐츠 생성 보조 등 여러 시나리오에 적용하여 성과를 거두고 있습니다 (출처: WeChat)

Lenovo, ‘톈시(天禧)’ 개인용 슈퍼 인텔리전트 에이전트 발표, L3급 지능으로 도약: Lenovo는 혁신 기술 컨퍼런스에서 멀티모달 감지 및 상호 작용, 개인 지식 기반 인지 및 의사 결정, 복잡한 작업의 자율적 분해 및 실행 능력을 갖춘 ‘톈시(天禧)’ 개인용 슈퍼 인텔리전트 에이전트를 출시했습니다. 톈시는 AI 수이신창(AI随心窗), AI 링룽타이(AI玲珑台), AI 루잉쾅(AI如影框) 등 수반형 AUI 인터페이스를 통해 자연스럽고 원활한 인간-기계 협업 경험을 제공하는 것을 목표로 합니다. DeepSeek-R1을 포함한 여러 업계 최고 수준의 대형 모델을 통합하고, 단말-클라우드 하이브리드 배포 아키텍처를 채택했으며, Lenovo 개인 클라우드 1.0(720억 매개변수 대형 모델 탑재)과 결합하여 강력한 컴퓨팅 성능과 100G의 전용 메모리 공간을 제공합니다. Lenovo는 동시에 기업용 ‘러샹(乐享)’ 및 도시급 슈퍼 인텔리전트 에이전트도 발표하며 AI 분야에서의 포괄적인 레이아웃을 선보였습니다 (출처: WeChat)

새로운 연구, 기호 상호작용 복잡도를 통해 신경망 일반화 성능 판단: 상하이 교통대학교 장췐스(张拳石) 교수팀은 신경망 내재적 기호화 상호작용 표현 복잡도 관점에서 일반화 성능을 분석하는 새로운 이론을 제시했습니다. 연구 결과, 일반화 가능한 상호작용(훈련 및 테스트 세트 모두에서 고빈도로 나타남)은 다양한 차수(복잡도)에서 일반적으로 감쇠형 분포(저차 상호작용 위주)를 보이는 반면, 일반화 불가능한 상호작용(주로 훈련 세트에서 나타남)은 방추형 분포(중간 차수 상호작용 위주, 긍정적/부정적 효과 상쇄 용이)를 나타내는 것으로 밝혀졌습니다. 이 이론은 모델의 등가적인 “AND-OR 상호작용 논리”의 분포 패턴을 분석하여 모델의 일반화 잠재력을 직접 판단하고, 모델 일반화 성능 이해 및 향상을 위한 새로운 시각을 제공하는 것을 목표로 합니다 (출처: WeChat)
🧰 도구
Llama.cpp, 시각 언어 모델(VLM) 완벽 호환: Llama.cpp가 이제 시각 언어 모델(VLM)을 완벽하게 지원하여 개발자들이 기기에서 멀티모달 애플리케이션을 실행할 수 있게 되었습니다. Hugging Face의 Julien Chaumond 등은 Google DeepMind의 Gemma, Mistral AI의 Pixtral, Alibaba의 Qwen VL 및 Hugging Face의 SmolVLM을 포함한 사전 양자화된 모델을 공유했으며, 이 모델들은 바로 사용할 수 있습니다. 이번 업데이트는 @ngxson과 @ggml_org 팀의 기여 덕분이며, 로컬화되고 지연 시간이 짧은 멀티모달 AI 애플리케이션의 새로운 가능성을 열었습니다 (출처: ggerganov, ClementDelangue, cognitivecompai)
Quark AI 슈퍼 프레임, ‘심층 검색’으로 업그레이드, AI ‘검색 지능’ 향상: Quark AI 슈퍼 프레임이 최근 업그레이드되어 ‘심층 검색’ 기능을 출시했습니다. 이는 AI의 검색 지능(검색 능력)을 향상시키는 것을 목표로 합니다. 새로운 기능은 검색 전 AI의 능동적인 사고와 논리적 계획을 강조하여 사용자의 복잡하고 개인화된 검색 의도를 더 잘 이해하고, 문제를 분해하여 체계적인 지능형 검색을 수행할 수 있도록 합니다. 건강 분야에서는 Quark AI 건강 컨설턴트 “아쿠아(阿夸)”가 3차 병원 의사의 의견과 전문 자료를 참고하며, 학술 분야에서는 CNKI 등 권위 있는 정보원을 연동합니다. 또한 Quark은 이미지 분석, AI 배경 제거, 이미지 향상 및 스타일 변환과 같은 강력한 멀티모달 처리 능력을 갖추고 있습니다. Quark은 향후 Deep Research 능력을 갖춘 심층 검색 Pro 버전을 출시할 예정이라고 합니다 (출처: WeChat)

LangChain, 다수 통합 및 튜토리얼 출시, RAG 및 에이전트 기능 강화: LangChain은 최근 여러 업데이트와 튜토리얼을 발표했습니다: 1. 소셜 미디어 에이전트 UI 튜토리얼: LangChain 소셜 미디어 에이전트를 사용자 친화적인 웹 애플리케이션으로 전환하는 방법을 안내하며, ExpressJS 및 AgentInbox UI를 통합하고 Notion을 지원합니다. 2. 수상 경력의 RAG 솔루션: 회사 연례 보고서를 분석하는 RAG 구현을 선보이며, PDF 구문 분석, 다중 LLM 및 고급 검색을 지원합니다. 3. 비공개 RAG 채팅 애플리케이션: LangChain 및 Reflex 프레임워크를 사용하여 로컬화되고 데이터 개인 정보 보호에 중점을 둔 RAG 채팅 애플리케이션을 구축하는 방법을 시연하는 튜토리얼입니다. 4. Nimble Retriever 통합: 강력한 웹 데이터 검색기를 도입하여 LangChain 애플리케이션에 정확한 데이터를 제공합니다. 5. Claude 3.7 구조화된 출력 가이드: LangChain 및 AWS Bedrock을 통해 Claude 3.7 구조화된 출력을 구현하는 세 가지 방법을 제공합니다. 6. 로컬 채팅 RAG 시스템: LangChain RAG 프로세스와 로컬 LLM(Ollama를 통해)을 사용하여 구축된 완전 로컬화된 문서 질의응답 시스템을 보여주는 오픈소스 프로젝트로, 데이터 개인 정보 보호를 보장합니다 (출처: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: 다중 프레임워크 기능 통합 오픈소스 AI 에이전트 프레임워크: Minion-agent는 기존 AI 프레임워크(예: OpenAI, LangChain, Google AI, SmolaAgents)의 파편화 문제를 해결하기 위해 설계된 새로운 오픈소스 AI 에이전트 개발 프레임워크입니다. 통합 인터페이스를 제공하여 다중 프레임워크 기능 호출, 도구형 서비스(웹 브라우징, 파일 작업 등) 및 다중 에이전트 협업을 지원합니다. 이 프로젝트는 심층 연구(문헌 자동 수집 및 보고서 생성), 가격 비교(자동화된 시장 조사), 창의적 생성(게임 코드 생성) 및 기술 동향 추적과 같은 시나리오에서의 적용 잠재력을 보여주며, 유연성과 비용 효율성 측면에서 오픈소스 모델의 이점을 강조합니다 (출처: WeChat)

RunwayML, 다양한 시나리오에서 강력한 비디오 생성 및 편집 능력 선보여: 독립 AI 연구원 Cristobal Valenzuela 및 기타 사용자들이 다양한 창의적 시나리오에서 RunwayML의 활용 사례를 선보였습니다. Frames, References 및 Gen-4 기능을 활용하여 스타일과 캐릭터 일관성을 유지하면서 창의적인 시각 자료를 신속하게 생성하고 시각화하는 것, 렘브란트의 세계를 RPG 비디오 게임으로 제작하는 것, 시각적 참조를 제공하여 새로운 단일 이미지 실내 디자인 뷰를 합성하는 것 등이 포함됩니다. 이러한 사례들은 RunwayML이 제어 가능한 비디오 생성, 스타일 전이 및 장면 구성 분야에서 이룬 발전을 강조합니다 (출처: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: 컴퓨터 비전 작업을 위한 범용 작업 라우터: Olympus는 컴퓨터 비전 작업을 위해 설계된 범용 작업 라우터입니다. 다양한 시각 작업의 처리 흐름을 단순화하고 통합하여, 지능형 스케줄링 및 컴퓨팅 리소스 또는 모델 호출 할당을 통해 다중 작업 컴퓨터 비전 시스템의 효율성과 성능을 최적화하는 것을 목표로 할 수 있습니다. 프로젝트는 GitHub에 오픈소스로 공개되었습니다 (출처: dl_weekly)
Tracy Profiler: 실시간 나노초급 혼합 프레임 및 샘플링 분석기: Tracy Profiler는 게임 및 기타 애플리케이션을 위한 실시간, 나노초급 해상도, 원격 원격 측정 지원 혼합형 프레임 분석 및 샘플링 분석 도구입니다. CPU(C, C++, Lua, Python, Fortran 및 Rust, Zig, C# 등 제3자 바인딩), GPU(OpenGL, Vulkan, Direct3D, Metal, OpenCL), 메모리 할당, 잠금, 컨텍스트 전환의 성능 분석을 지원하며, 스크린샷과 캡처된 프레임을 자동으로 연결할 수 있습니다. 이 도구는 높은 정확도와 실시간성으로 개발자에게 강력한 성능 병목 현상 파악 및 최적화 수단을 제공합니다 (출처: GitHub Trending)

FieldStation42: 레트로 방송 TV 시뮬레이터: FieldStation42는 구식 방송 TV 시청 경험을 시뮬레이션하는 것을 목표로 하는 Python 프로젝트입니다. 동시에 여러 채널을 지원하고, 광고와 프로그램 예고편을 자동으로 삽입하며, 구성에 따라 주간 프로그램 편성표를 생성합니다. 이 시뮬레이터는 최근에 방송되지 않은 프로그램을 무작위로 선택하여 신선함을 유지하고, 프로그램 방송 날짜 범위(예: 계절별 프로그램) 설정을 지원하며, 방송국 정파 영상 및 무신호 순환 화면을 구성할 수 있습니다. 프로젝트는 또한 하드웨어 연결(예: Raspberry Pi Pico)을 지원하여 채널 변경 작업을 시뮬레이션하고, 미리보기/가이드 채널 기능을 제공합니다. 사용자가 “TV를 켤 때” 해당 시간대와 채널에 맞는 “실제” 프로그램 콘텐츠를 재생하는 것이 목표입니다 (출처: GitHub Trending)

Tiny Corp, USB3 기반 AMD eGPU 솔루션 출시, Apple Silicon 지원: Tiny Corp는 USB3(구체적으로 ASM2464PD 컨트롤러 기반 ADT-UT3G 장치)를 통해 AMD eGPU를 Apple Silicon Mac에 연결하는 솔루션을 선보였습니다. 이 솔루션은 드라이버를 재작성하여 USB3의 10Gbps 대역폭을 활용하고 libusb를 사용하며, 이론적으로 Linux 또는 Windows도 지원합니다. 이는 Apple Silicon 사용자가 그래픽 처리 능력을 확장할 수 있는 새로운 길을 열어주며, 특히 로컬에서 대규모 AI 모델을 실행하는 등의 시나리오에 잠재적 가치가 있습니다 (출처: Reddit r/LocalLLaMA)
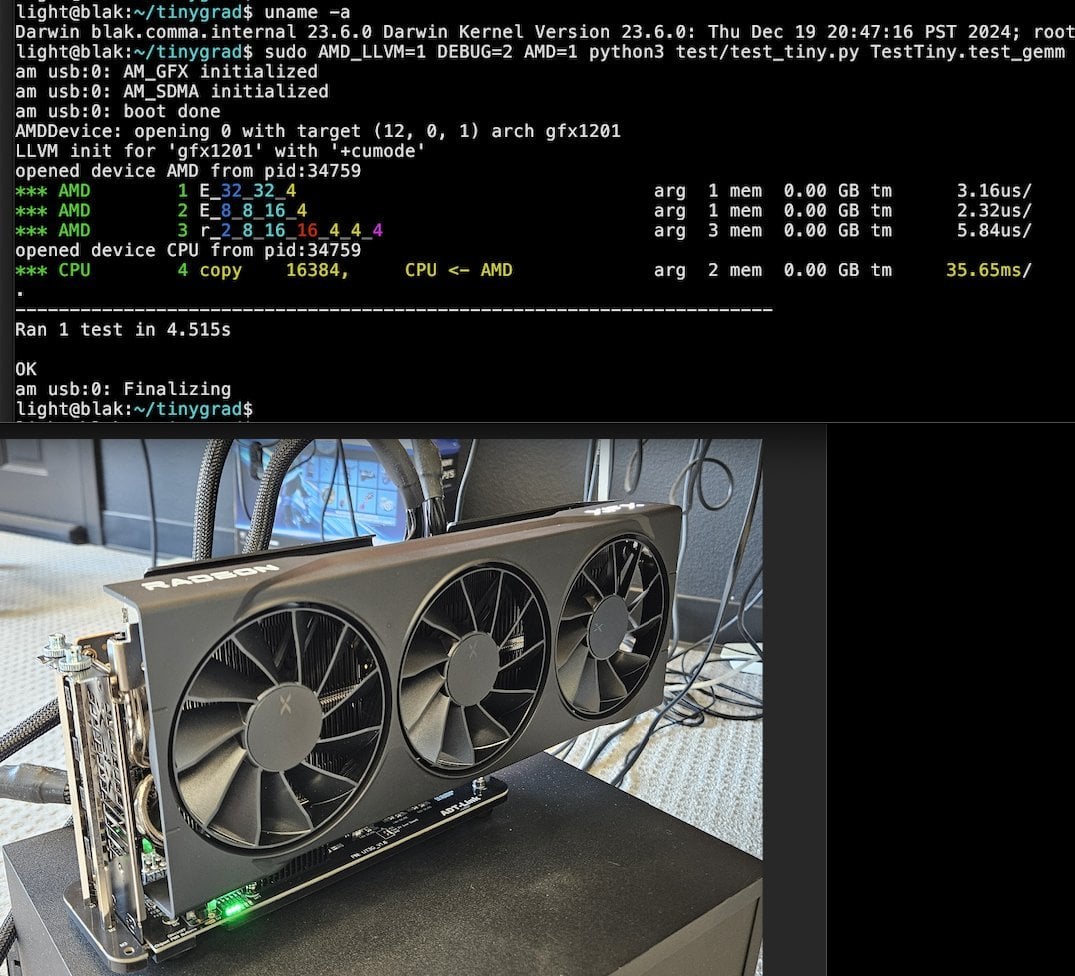
Llama.cpp-vulkan, AMD GPU에서 FlashAttention 지원 구현: Llama.cpp의 Vulkan 백엔드가 최근 FlashAttention 구현을 통합했습니다. 이는 AMD GPU에서 llama.cpp-vulkan을 사용하는 사용자들이 이제 FlashAttention 기술을 활용할 수 있음을 의미합니다. Q8 KV 캐시 양자화와 결합하면 사용자는 추론 속도를 유지하거나 향상시키면서 컨텍스트 크기를 두 배로 확장할 수 있을 것으로 기대됩니다. 이 업데이트는 AMD GPU 사용자가 로컬에서 대규모 언어 모델을 실행하는 데 중요한 이점입니다 (출처: Reddit r/LocalLLaMA)
Devseeker: 경량 AI 코딩 어시스턴트, Aider 및 Claude Code 대체 솔루션: Devseeker는 Aider 및 Claude Code의 대안으로 자리매김하는 새로운 오픈소스 경량 AI 코딩 에이전트 프로젝트입니다. 코드 생성 및 편집, 코드 파일 및 폴더 관리, 단기 코드 메모리, 코드 검토, 코드 파일 실행, 토큰 사용량 계산 및 다양한 코딩 모드 제공과 같은 기능을 갖추고 있습니다. 이 프로젝트는 로컬 배포 및 사용이 더 쉬운 AI 보조 프로그래밍 도구를 제공하는 것을 목표로 합니다 (출처: Reddit r/ClaudeAI)
📚 학습
Panaversity, Dapr 및 OpenAI Agents SDK에 초점을 맞춘 Agentic AI 학습 프로젝트 출시: Panaversity는 Dapr Agentic Cloud Ascent (DACA) 디자인 패턴과 다양한 에이전트 네이티브 클라우드 기술(OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes 포함)을 통해 에이전트 및 로봇 AI 엔지니어를 양성하는 것을 목표로 하는 ‘Learn Agentic AI’ 프로젝트를 시작했습니다. 이 프로젝트의 핵심은 수천만 개의 동시 AI 에이전트를 처리할 수 있는 시스템을 설계하는 방법을 해결하고, 기본부터 대규모 분산 AI 에이전트까지의 학습 경로를 다루는 AI-201, AI-202, AI-301 시리즈 과정을 제공합니다. 프로젝트는 사용 편의성과 높은 제어성으로 인해 OpenAI Agents SDK가 주류 개발 프레임워크가 되어야 한다고 강조합니다 (출처: GitHub Trending)

RL 미세 조정 연구, 데이터 관리와 일반화 능력 간의 복잡한 관계 밝혀: Minqi Jiang이 공유한 논문은 강화 학습(RL) 미세 조정에서 데이터 관리가 모델의 일반화 능력에 미치는 영향을 논의합니다. 연구 결과, 자가 대국 커리큘럼 학습을 통해 “무한한” 코딩 작업에서 훈련하거나(Absolute Zero Reasoner), 단일 MATH 작업 샘플에서 반복적으로 훈련하는 경우(1-shot RLVR) 모두 7B 규모의 Qwen2.5 시리즈 모델이 수학 벤치마크 테스트에서 약 28%에서 40%의 정확도 향상을 달성할 수 있는 것으로 나타났습니다. 이는 극단적인 데이터 관리 전략(무한 데이터 대 단일 지점 데이터)이 유사한 일반화 개선을 가져올 수 있다는 역설을 드러냅니다. 가능한 설명으로는 RL이 주로 사전 훈련된 모델이 이미 가지고 있는 능력을 이끌어내고, 공유된 “추론 회로”가 존재하며, 사전 훈련이 경쟁적인 추론 회로를 유발할 수 있다는 점 등이 있습니다. 연구자들은 “사전 훈련 천장”을 돌파하기 위해서는 새로운 작업과 환경을 지속적으로 수집하고 창조해야 한다고 주장합니다 (출처: menhguin)
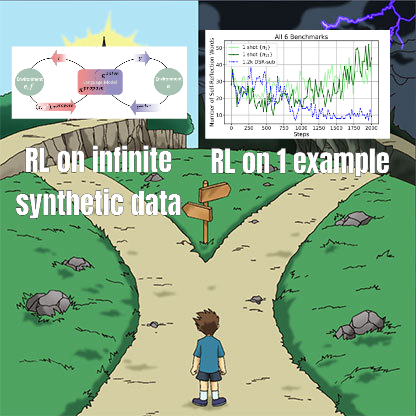
Absolute Zero Reasoner: 자가 대국을 통해 제로 데이터 추론 능력 향상: ‘Absolute Zero Reasoner’라는 논문은 모델이 완전한 자가 대국(self-play)을 통해 학습 가능성을 극대화하는 작업을 제안하고, 이러한 작업을 해결함으로써 외부 데이터 없이도 자체 추론 능력을 향상시킬 수 있다고 제안합니다. 이 방법은 수학 및 코딩 분야 모두에서 다른 “제로샷” 모델보다 우수한 성능을 보였습니다. 이는 AI 시스템이 내부적으로 문제를 생성하고 해결함으로써 지속적으로 추론 능력을 진화시킬 수 있음을 시사하며, 데이터가 부족하거나 레이블링 비용이 높은 분야의 AI 응용 프로그램 해결에 새로운 아이디어를 제공합니다 (출처: cognitivecompai, Reddit r/LocalLLaMA)

AI 제품 평가 시 흔한 실수와 모범 사례 공유: Hamel Husain과 Shreya Runwal은 AI 제품 평가(evals) 생성 시 흔히 발생하는 실수와 이를 피하기 위한 조언을 공유했습니다. 핵심 사항은 다음과 같습니다: 기본 모델 벤치마크는 애플리케이션 평가와 동일하지 않음, 일반적인 평가는 효과가 없으므로 특정 애플리케이션에 맞춰야 함, 비전문가에게 레이블링 및 프롬프트 엔지니어링을 아웃소싱하지 말 것, 자체 데이터 레이블링 애플리케이션을 구축해야 함, LLM 프롬프트는 구체화하고 오류 분석을 기반으로 해야 함, 이진 레이블 사용, 데이터 검토 중시, 테스트 데이터 과적합 경계, 온라인 테스트 수행. 이러한 관행은 개발자가 더 신뢰할 수 있고 실제 성능을 더 잘 반영하는 AI 제품 평가 시스템을 구축하는 데 도움이 되는 것을 목표로 합니다 (출처: jeremyphoward, HamelHusain)
KV 캐시 최적화 새로운 아이디어: 범용 전이 가능 사전과 신호 처리 재구성: 위스콘신 대학교 매디슨 캠퍼스 Dimitris Papailiopoulos 팀은 범용적이고 전이 가능한 사전을 전통적인 신호 처리 재구성 알고리즘과 결합하여 KV 캐시를 줄이는 새로운 방법을 제안했습니다. 이 방법은 비추론 모델에서 이미 SOTA(state-of-the-art) 수준에 도달했으며, 추론 모델에서는 더 나은 성능을 보일 것으로 기대됩니다. 이 연구는 ICML에 채택되어 대규모 모델 추론에서 KV 캐시 점유율이 너무 높은 문제를 해결하기 위한 새로운 관점과 기술 경로를 제공합니다 (출처: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

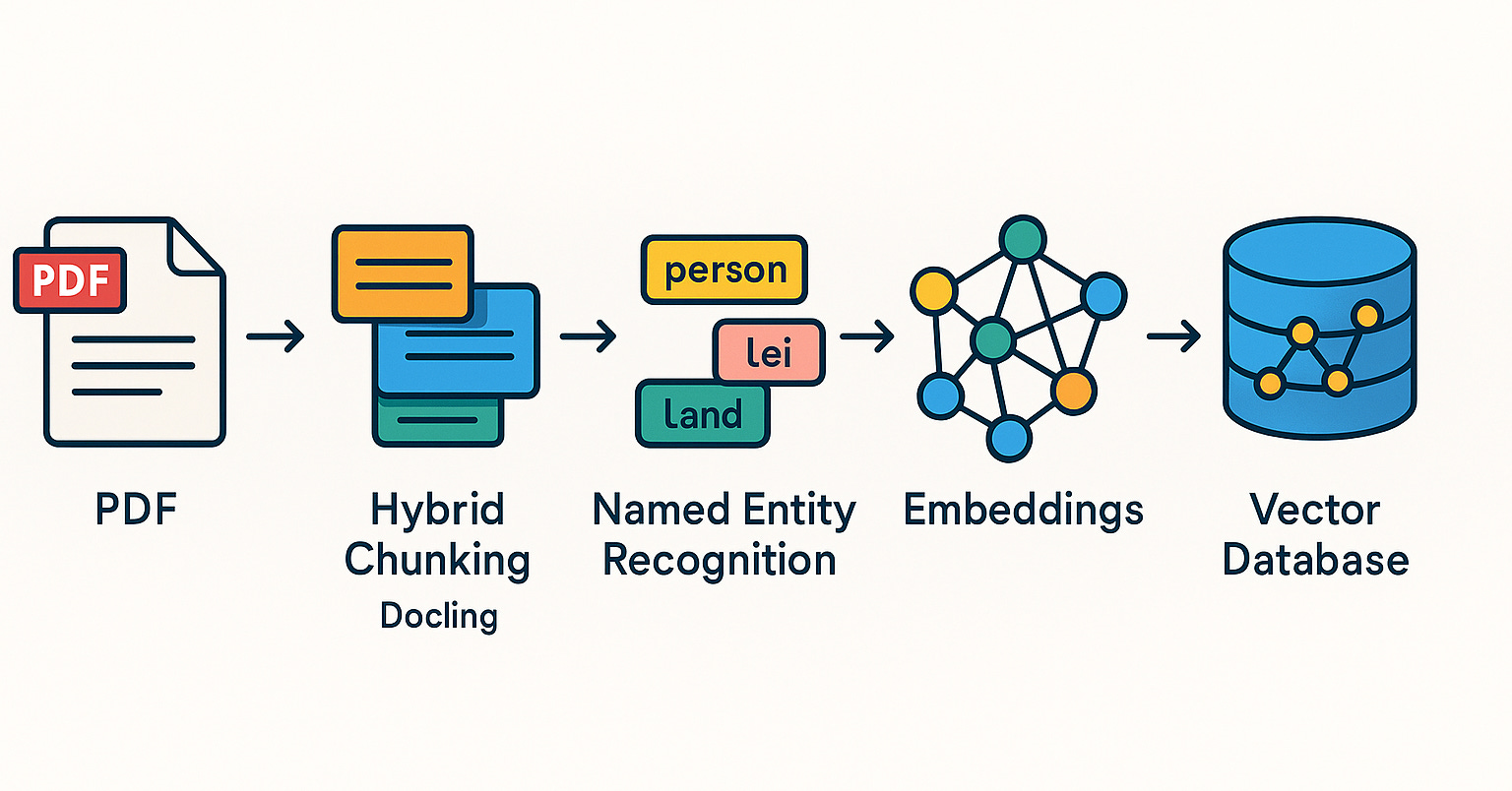
Qdrant, 브라질 커뮤니티에서 RAG 시스템 및 하이브리드 검색 실습 홍보: Qdrant 벡터 데이터베이스가 브라질 커뮤니티에서 점점 더 많은 관심을 받고 있습니다. 개발자 Daniel Romero는 Qdrant, FastAPI 및 하이브리드 검색을 사용하여 RAG(검색 증강 생성) 시스템을 구축하는 실용적인 방법을 소개하는 두 편의 포르투갈어 기사를 공유했습니다. 내용에는 하이브리드 검색 RAG 시스템 구축 방법과 RAG를 위한 데이터 수집 전략, 특히 하이브리드 청킹(Hybrid Chunking) 기술이 포함됩니다. 이러한 공유는 브라질 개발자들이 Qdrant를 더 잘 활용하여 AI 애플리케이션을 개발하는 데 도움이 됩니다 (출처: qdrant_engine)
OpenAI 아카데미, K-12 교육 프롬프트 엔지니어링 특집 시리즈 출시: OpenAI 아카데미는 K-12 교육자를 위한 프롬프트 엔지니어링(Prompt Engineering) 학습 시리즈 “Mastering Your Prompts”를 발표했습니다. 이 시리즈는 교육자들이 프롬프트 기술을 더 잘 이해하고 활용하여 AI 도구(예: ChatGPT)를 교육 실습에 더 효과적으로 통합하고, 교육 효과와 학생들의 학습 경험을 향상시키는 데 도움을 주는 것을 목표로 합니다. 이는 AI 보조 교육이 점차 기초 교육 단계로 확산되고 있으며, 교육자의 AI 소양 함양을 중시하고 있음을 보여줍니다 (출처: dotey)
Yann LeCun, 싱가포르 국립대학교 강연 내용 공유: Yann LeCun은 2025년 4월 27일 싱가포르 국립대학교(NUS)에서 진행한 특별 강연(Distinguished Lecture)의 PDF 문서를 공유했습니다. 강연의 구체적인 주제는 제공되지 않았지만, 딥러닝 분야의 선구자인 LeCun의 강연은 일반적으로 인공 지능의 최첨단 이론, 미래 동향 또는 현재 AI 발전에 대한 심오한 통찰력을 다룹니다. 이 공유는 AI 연구에 관심 있는 사람들에게 그의 최신 관점을 직접 얻을 수 있는 경로를 제공합니다 (출처: ylecun)
PyTorch와 Mojo 백엔드 협력, 새로운 하드웨어 및 언어 적응 단순화: PyTorch는 새로운 프로그래밍 언어와 하드웨어를 위한 새로운 백엔드 생성 프로세스를 단순화하는 데 주력하고 있습니다. Mojo 해커톤에서 marksaroufim은 PyTorch의 이러한 노력을 선보였으며, Mojo 팀과 협력하여 개발 중인 WIP(진행 중) 백엔드를 언급했습니다. 이는 PyTorch 생태계가 호환성을 적극적으로 확장하여 더욱 다양한 AI 개발 환경과 하드웨어 가속 옵션을 지원함으로써 개발자가 다양한 플랫폼에서 PyTorch 모델을 배포하고 최적화하는 장벽을 낮추고 있음을 시사합니다 (출처: marksaroufim)
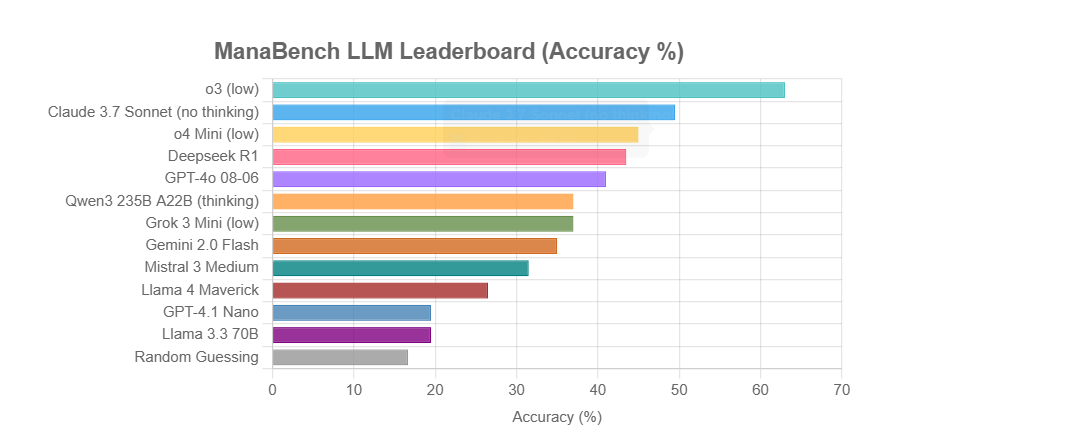
ManaBench: 매직 더 개더링 덱 구성 기반 새로운 LLM 추론 능력 벤치마크: 한 개발자가 ManaBench라는 새로운 벤치마크를 만들었습니다. 이 벤치마크는 LLM에게 59장의 매직 더 개더링(MTG) 카드가 주어진 상황에서 6가지 옵션 중 가장 적합한 60번째 카드를 선택하도록 하여 복잡한 시스템 추론 능력을 테스트합니다. 이 벤치마크는 전략적 추론, 시스템 최적화를 강조하며, 답이 인간 전문가의 설계와 일치하여 단순한 암기로는 풀기 어렵습니다. 초기 결과에 따르면 Llama 시리즈 모델은 기대에 미치지 못하는 반면, o3 및 Claude 3.7 Sonnet과 같은 비공개 모델이 선두를 달리고 있습니다. 이 벤치마크는 복잡한 추론 작업이 필요한 LLM의 성능을 보다 현실적으로 평가하는 것을 목표로 합니다 (출처: Reddit r/LocalLLaMA)
토론: AI가 시맨틱 웹의 꿈을 부활시킬 것인가, 아니면 묻어버릴 것인가?: 소셜 미디어 사용자 Spencer는 ADA 법안(미국 장애인 법안)으로 인해 상당한 위험에 노출된 대기업 웹사이트가 아닌 이상, 대부분의 웹사이트에서 시맨틱 웹은 실천보다는 이론에 가깝다고 언급했습니다. Dorialexander는 AI가 시맨틱 웹의 꿈을 부활시키거나 영원히 묻어버릴 것 같다고 응답했습니다. 이는 구조화된 데이터 이해 및 활용에 대한 AI의 잠재력에 대한 기대와 우려를 반영하며, AI는 구조화된 정보를 자동으로 이해하고 생성함으로써 간접적으로 시맨틱 웹의 목표를 달성할 수도 있지만, 자체의 강력한 능력으로 인해 전통적인 시맨틱 웹 기술이 더 이상 중요하지 않게 만들 수도 있습니다 (출처: Dorialexander)
연구자들, 모델 기억과 망각의 윤리 및 아키텍처 논의: ‘Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting’이라는 제목의 논문 초고가 작성 중이며, 모델이 “너무 잘 기억하기” 시작할 때 우리가 무엇을 잊어야 할지 결정하는 방법, 신경 아키텍처와 기억 윤리를 융합하여 논의합니다. 이는 AI 시스템이 정보를 저장, 검색 및 (선택적으로) 망각하는 방식과 이로 인해 발생하는 윤리적 과제 및 사회적 영향과 관련이 있으며, 책임감 있고 신뢰할 수 있는 AI를 구축하는 데 매우 중요합니다 (출처: Reddit r/artificial)
💼 비즈니스
Nvidia, 미국 신규 수출 통제 요건 충족하는 ‘재너프된’ H20 칩 출시 예정: 로이터 통신에 따르면, Nvidia는 향후 2개월 내에 미국 최신 수출 통제 요건을 충족하는 새로운 중국 시장 특화 H20 AI 칩을 출시할 계획입니다. 이 칩은 기존 H20(이미 중국 시장을 위해 성능이 낮춰진 버전)을 기반으로 메모리 용량이 현저히 줄어드는 등 추가적인 “너프”가 이루어질 예정입니다. 성능이 다시 낮아지지만, 하위 사용자들은 모듈 구성을 수정하여 어느 정도 성능을 조정할 수 있을 것으로 알려졌습니다. 현재 Nvidia는 180억 달러 상당의 H20 주문을 받은 상태입니다 (출처: WeChat)

Databricks, AI 인프라 강화 위해 오픈소스 데이터베이스 회사 Neon 10억 달러에 인수 가능성: 데이터 및 AI 회사 Databricks가 오픈소스 PostgreSQL 데이터베이스 엔진 개발사 Neon 인수를 협상 중이며, 거래 금액은 약 10억 달러에 이를 수 있다는 소문이 있습니다. Neon은 서버리스 아키텍처, 스토리지와 컴퓨팅 분리, AI Agent 및 앰비언트 프로그래밍에 대한 우수한 적응성을 특징으로 하며, 사용량 기반 과금 및 빠른 데이터베이스 인스턴스 시작을 허용하여 AI 애플리케이션 시나리오에 적합합니다. 이번 인수가 성공하면 Databricks는 AI 시대의 인프라 계층 역량을 더욱 강화하고, AI 중심의 현대적인 데이터베이스 솔루션을 확보하게 될 것입니다 (출처: WeChat)

OpenAI, 전 Instacart CEO Fidji Simo를 애플리케이션 사업 CEO로 임명, 제품 및 상업화 강화: OpenAI는 전 Instacart CEO이자 회사 이사회 멤버인 Fidji Simo를 신설된 “애플리케이션 사업 최고 경영자”로 임명한다고 발표했습니다. Simo는 Sam Altman과 동등한 직급으로, OpenAI의 제품, 특히 ChatGPT 등 사용자 대상 애플리케이션을 총괄하며 제품 최적화, 사용자 경험 향상 및 상업화 프로세스 추진을 목표로 합니다. 이는 OpenAI의 전략적 중심이 모델 연구 개발에서 제품 플랫폼화 및 시장 확장으로 크게 전환되었음을 의미하며, AI 애플리케이션 계층에서 더욱 강력한 경쟁력을 구축하려는 의도입니다. Simo의 Facebook 및 Instacart에서의 풍부한 제품 및 상업화 경험은 OpenAI가 점점 더 치열해지는 시장 경쟁에 대처하는 데 도움이 될 것입니다 (출처: WeChat)

🌟 커뮤니티
JetBrains AI Assistant, 열악한 경험 및 댓글 관리로 사용자 불만 야기: JetBrains의 AI Assistant 플러그인은 2,200만 회 이상 다운로드되었음에도 불구하고 마켓플레이스 평점은 5점 만점에 2.3점에 불과하며, 1점짜리 악평이 넘쳐납니다. 사용자들은 자동 설치, 느린 실행 속도, 많은 버그, 제3자 모델 지원 부족, 핵심 기능의 클라우드 서비스 연동, 문서 부재 등의 문제를 공통적으로 지적하고 있습니다. 최근 JetBrains는 부정적인 댓글을 대량 삭제했다는 의혹을 받고 있으며, 공식적으로는 규정 위반 또는 문제 해결된 내용을 처리한 것이라고 해명했지만, 여전히 사용자의 댓글 통제 및 사용자 피드백 무시에 대한 의구심을 불러일으키고 있습니다. 일부 사용자는 악평을 다시 게시하고 계속해서 1점을 주고 있습니다. 이 사건은 JetBrains AI 제품 전략에 대한 사용자의 불만을 더욱 가중시키고 있습니다 (출처: WeChat)

사용자들, AI 마케팅 에이전트 결과물 품질 문제에 대해 열띤 토론: 소셜 미디어 사용자 omarsar0는 많은 YouTube 튜토리얼에서 보여주는 마케팅 AI 에이전트가 생성하는 마케팅 문구의 품질이 전반적으로 낮고 창의성과 스타일이 부족하다고 지적했습니다. 그는 이것이 LLM이 고품질의 매력적인 콘텐츠를 생산하는 것의 어려움을 반영하며, AI 에이전트 구축 시 “취향”이 매우 중요하다고 강조했습니다. 그는 현재 많은 AI 에이전트가 작업 흐름은 복잡하지만 실제로 상업적 가치가 있는 콘텐츠를 생산하는 데는 여전히 부족함이 있으며, 이는 높은 취향과 풍부한 경험을 갖추고 우수한 평가 시스템을 설계할 수 있는 인재에게 기회를 제공한다고 지적했습니다 (출처: omarsar0)
AI 보조 코딩과 “앰비언트 프로그래밍” 트렌드 논의 촉발: Reddit의 Y Combinator가 AI 코딩에 대해 논의하는 비디오에 대한 게시물이 열띤 토론을 불러일으켰습니다. 비디오의 관점은 “앰비언트 프로그래밍”을 통해 여러 수익성 있는 프로젝트를 만들었다고 주장하는 게시자의 경험과 매우 일치했으며, 핵심 관점은 다음과 같습니다: 1. AI는 이미 코드를 작성하지 않고도 복잡하고 사용 가능한 소프트웨어 제품을 구축하는 데 도움을 줄 수 있습니다. 2. 소프트웨어 엔지니어들은 AI가 자신의 일자리를 대체할 것이라는 우려가 커지고 있지만, AI 보조 개발을 실제로 마스터한 사람들은 “초능력”을 가지고 있습니다. 3. 미래의 소프트웨어 엔지니어의 역할은 AI 도구를 잘 활용하는 “에이전트 관리자”로 전환될 수 있으며, AI가 대부분의 코드 작성을 담당하게 될 것입니다. 4. AI는 세분화된 시장을 위한 수많은 틈새 소프트웨어를 탄생시킬 것입니다. 토론자들은 AI 코딩의 잠재력은 크지만, 여전히 엔지니어링 개념, 데이터베이스, 아키텍처 등에 대한 지식을 갖추어야 효과적으로 활용할 수 있다고 생각합니다 (출처: Reddit r/ClaudeAI)

AI가 ‘세상을 장악’할 것인지, 고용에 미치는 영향에 대한 논의 지속: Reddit r/ArtificialInteligence 게시판의 게시물들은 AI의 미래 영향에 대한 커뮤니티의 보편적인 불안감과 다양한 관점을 반영합니다. 일부 사용자들은 AI 능력에 대해 더 깊이 알수록 인간을 능가하고 미래를 주도할 것이라는 우려가 커진다고 생각하며, 최첨단 AI 시스템이 이미 놀라운 능력을 보여주고 있다고 지적합니다. 다른 사용자들은 AGI에 대한 과도한 과장이 비현실적인 기대를 낳았으며, AI는 본질적으로 지능형 자동화 도구이며 그 영향은 컴퓨터와 인터넷과 유사하게 점진적일 것이라고 생각합니다. 토론은 또한 AI가 고용에 미치는 잠재적 영향, 부의 분배 및 규제의 효과에 대해서도 다루며, 역사는 기술 발전이 종종 빈부 격차를 심화시켰으며 AI는 수많은 일자리를 없애 부를 더욱 집중시킬 수 있다는 견해가 있습니다. 동시에 의료, 교육 등 분야에서 AI의 긍정적인 역할에 대한 기대감도 있습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
사용자 경험: ChatGPT 등 AI 도구가 사고와 인지에 미치는 영향: 일부 사용자들이 소셜 플랫폼과 Reddit에서 ChatGPT 등 AI 도구 사용이 가져온 인지적 측면의 긍정적인 영향을 공유했습니다. 그들은 AI가 단순한 정보 획득이나 작문 보조 도구가 아니라, 생각을 정리하고 잠재의식 속 아이디어를 명확하게 표현하도록 돕는 ‘사고 파트너’ 또는 ‘거울’과 같다고 느꼈습니다. AI와의 대화를 통해 사용자들은 자신을 더 잘 성찰하고, 자신의 신념에 도전하며, 사고 패턴을 발견하고, 심지어 ‘깨어나고’ 있으며 삶과 시스템에 대해 더 깊이 인식하게 되었다고 말합니다. 이러한 경험은 AI가 경우에 따라 개인의 성장과 자기 탐구를 촉진하는 촉매제가 될 수 있음을 보여줍니다 (출처: Reddit r/ChatGPT)
💡 기타
제2회 ‘싱즈컵(兴智杯)’ 전국 인공지능 혁신 응용 대회 개최: 중국정보통신연구원(CAICT) 등이 공동 주최하는 제2회 ‘싱즈컵’이 개막했습니다. 대회는 ‘싱즈赋能, 혁신 선도(兴智赋能, 创新引领)’를 주제로 대형 모델 혁신, 산업 역량 강화, 소프트웨어 및 하드웨어 혁신 생태계 등 3대 트랙과 다수의 특화 분야로 구성됩니다. 이 대회는 AI 기술 혁신, 엔지니어링 구현 및 자체 생태계 구축을 촉진하는 것을 목표로 하며, 산업, 의료, 금융 등 약 10개 주요 산업을 포괄하고 국산 AI 소프트웨어 및 하드웨어 응용을 강조합니다. 우수 프로젝트는 자금 지원, 산업 연계 등의 혜택을 받게 됩니다 (출처: WeChat)

Sequoia Capital AI Ascent 공유: AI 시장 잠재력 거대, 애플리케이션 계층과 에이전트 경제가 미래: Sequoia Capital 파트너 Pat Grady 등이 AI Ascent 행사에서 AI 시장에 대한 통찰력을 공유했습니다. 그들은 AI 시장 잠재력이 클라우드 컴퓨팅을 훨씬 능가하지만, “분위기 매출”(사용자가 실제 수요보다는 호기심으로만 시도하는 경우)을 경계해야 한다고 생각합니다. 애플리케이션 계층이 진정한 가치가 있는 곳으로 간주되며, 스타트업은 수직 분야와 고객 요구에 집중해야 합니다. AI는 음성 생성 및 프로그래밍 분야에서 이미 돌파구를 마련했습니다. 미래에는 AI 에이전트가 자원을 이전하고 거래를 수행할 수 있는 “에이전트 경제”를 전망하지만, 영구적인 신원, 통신 프로토콜 및 보안과 같은 과제에 직면해 있습니다. 동시에 AI는 개인의 능력을 크게 증폭시켜 “슈퍼 개인”을 탄생시킬 것입니다 (출처: WeChat)

토론: AI 시대 대학 머신러닝 강의 내용과 교육 질 관심 집중: NYU 교수 Kyunghyun Cho가 자신의 대학원 ML 강의 계획서를 공유한 것이 토론을 불러일으켰습니다. 이 강의는 SGD로 해결할 수 있는 비LLM 문제와 고전 논문 읽기를 강조하며, 하버드 CS 교수 등 동료들로부터 기초 개념 유지가 중요하다는 인정을 받았습니다. 그러나 인도와 미국 학생들은 자신들의 대학 ML 강의 질이 낮고, 지나치게 추상적이며, 깊이 있는 설명 없이 용어만 난무하여 학생들이 자습과 온라인 자료에 의존하게 된다고 불평했습니다. 이는 AI/ML 분야의 빠른 발전과 대학 강의의 뒤처진 업데이트 사이의 모순, 그리고 수학과 이론 기초를 다지는 것의 중요성을 반영합니다 (출처: WeChat)
