
키워드:OpenAI, DSPy, SGLang, Nvidia, ChatGPT, AI, LLM, MoE, dspy.GRPO, DeepSeek MoE, Parakeet TDT, Agentic 시스템, EQ-Bench 3
🔥 포커스
OpenAI, 비영리 구조 유지 확인: OpenAI는 기존 영리 법인을 공익 기업(PBC)으로 전환하지만, 지배권은 현재의 비영리 조직에 계속 귀속될 것이라고 발표했습니다. 이 조치는 OpenAI가 계속해서 비영리 조직의 통제를 받을 것임을 확인하고, AGI(일반 인공 지능)가 모든 인류에게 혜택을 주도록 보장한다는 사명을 재확인한 것입니다. 이 결정은 내부 혼란과 외부의 구조에 대한 의문 제기(머스크의 소송 포함)를 겪은 후에 내려졌으며, 커뮤니티의 반응은 엇갈렸습니다. 일부는 이를 사명 고수로 보는 반면, 다른 일부는 자본 구조 조정의 진정한 의도에 의문을 제기했습니다 (출처: OpenAI, sama, jachiam0, NeelNanda5, scaling01, zacharynado, mcleavey, steph_palazzolo, Plinz, Teknium1)
DSPy 프레임워크, 실험적 온라인 RL 옵티마이저 dspy.GRPO 출시: Stanford NLP 팀은 DSPy 프레임워크의 실험적인 새 기능인 dspy.GRPO를 출시했습니다. 이는 온라인 강화 학습(RL) 옵티마이저입니다. 이 도구는 복잡한 다중 모듈, 다단계 프로그램이라도 기존 코드를 수정하지 않고 직접 적용하여 DSPy 프로그램을 최적화하도록 설계되었습니다. 이는 RL 최적화(예: DeepSeek에서 사용하는 GRPO)를 더 높은 추상화 수준(LLM 워크플로우)으로 가져오는 중요한 단계로 간주되며, AI 에이전트 및 복잡한 파이프라인의 성능과 효율성을 향상시키는 것을 목표로 합니다. 커뮤니티는 이것이 DSPy 3.0의 중요한 부분이 될 것이라며 뜨거운 반응을 보이고 있습니다 (출처: Omar Khattab, matei_zaharia, lateinteraction, Michael Ryan, Lakshya A Agrawal, Scott Condron, Noah Ziems, Rogerio Chaves, Karthik Kalyanaraman, Josh Cason, Mehrdad Yazdani, DSPy, Hopkinx🀄️, Ahmad, william, lateinteraction, lateinteraction, swyx)
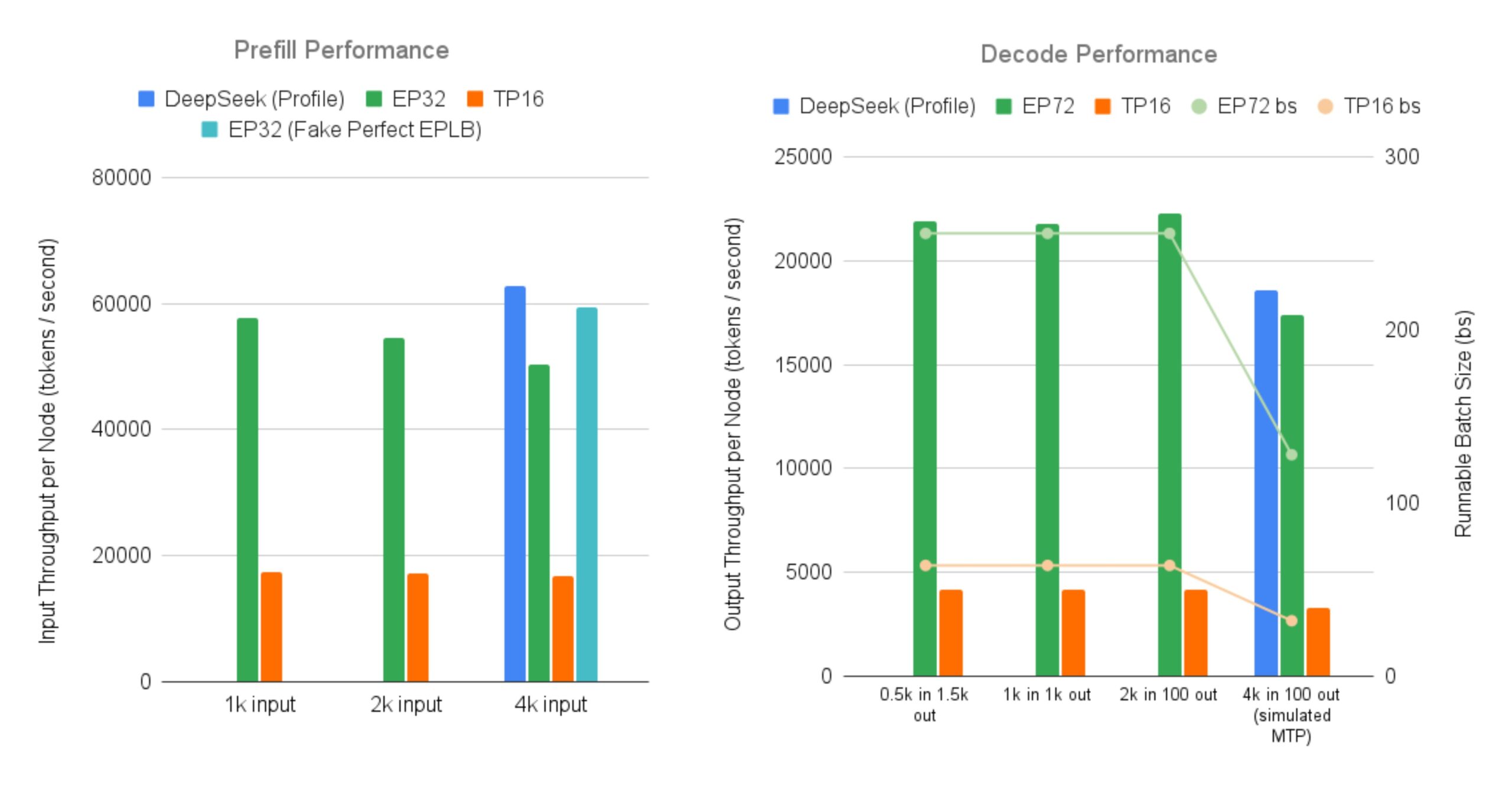
SGLang, DeepSeek MoE 대형 모델 효율적 서비스 오픈소스 구현: LMSYS Org는 SGLang이 96개의 GPU에서 DeepSeek V3/R1과 같은 대규모 전문가 병렬 처리(Expert Parallelism) 및 프리필-디코드 분리(Prefill-Decode Disaggregation) 기능을 갖춘 MoE(Mixture-of-Experts) 모델을 서비스하기 위한 최초의 오픈소스 구현을 제공한다고 발표했습니다. 이 구현은 DeepSeek 공식 보고 처리량(노드당 입력 52.3k token/초, 출력 22.3k token/초)에 거의 도달했으며, 기존 텐서 병렬 처리 방식에 비해 출력 처리량이 최대 5배 향상되었습니다. 이는 커뮤니티에 대규모 MoE 모델을 효율적으로 실행하고 배포할 수 있는 오픈소스 솔루션을 제공합니다 (출처: LMSYS Org, teortaxesTex, cognitivecompai, lmarena_ai, cognitivecompai)
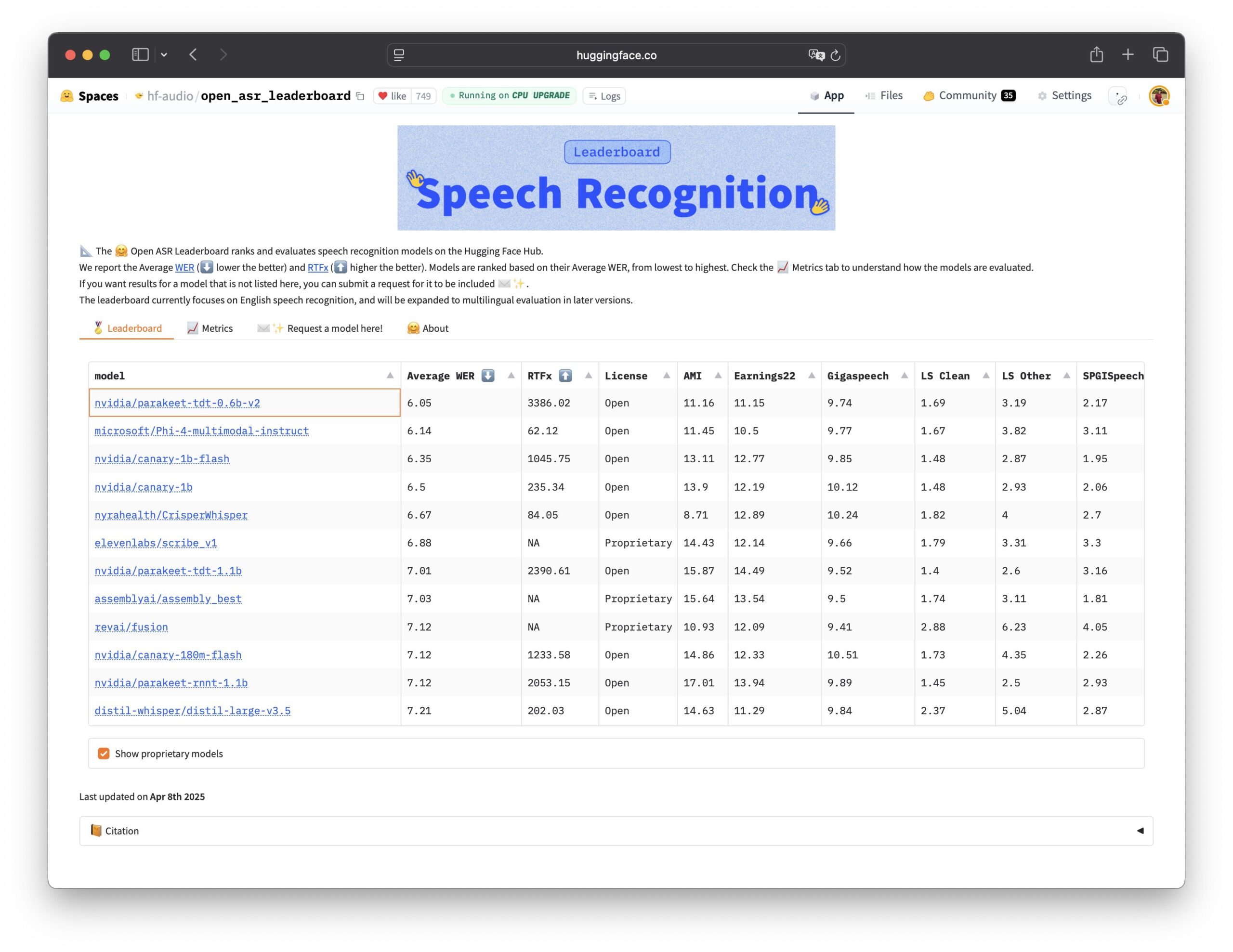
Nvidia, Parakeet TDT 음성 인식 모델 오픈소스 공개: Nvidia는 Open ASR Leaderboard에서 최고 성능을 보인 Parakeet TDT 0.6B 모델을 오픈소스로 공개했습니다. 이 모델은 현재 성능이 가장 뛰어난 오픈소스 자동 음성 인식(ASR) 모델이 되었습니다. 6억 개의 파라미터를 보유하고 있으며, 60분 분량의 오디오를 1초 안에 전사할 수 있어 많은 주요 폐쇄형 소스 모델보다 성능이 우수합니다. 이 모델은 CC-BY-4.0 라이선스를 채택하여 상업적 사용을 허용하며, 음성 인식 분야에 강력한 오픈소스 옵션을 제공합니다 (출처: Vaibhav (VB) Srivastav, huggingface, ClementDelangue)
🎯 동향
ChatGPT 방문량, X를 넘어서며 지속 성장: Similarweb 데이터에 따르면 ChatGPT의 방문량이 지속적으로 증가하여 4월 총 방문량(47억 8600만 회)이 X 플랫폼(40억 2800만 회)을 넘어섰습니다. 2025년 초부터 ChatGPT의 방문량은 꾸준히 증가하여 1월에는 간헐적으로 뒤처졌으나 4월에는 거의 전면적으로 X를 앞섰으며, 이는 AI 챗봇의 사용자 활동성이 강력한 추세를 보이고 있음을 나타냅니다 (출처: dotey)
데이터 신뢰와 리더십, AI 전환의 핵심으로 부상: 여러 보고서와 논의에서 데이터 신뢰가 AI 전환을 가속화하는 보이지 않는 힘임을 강조합니다. 동시에 성공적인 GenAI 리더들은 전략, 조직, 기술 응용에서 다른 특성을 보입니다. 이는 AI 성공의 핵심이 기술 자체뿐만 아니라 고품질의 신뢰할 수 있는 데이터 기반과 효과적인 리더십 및 전략 배치에 있음을 시사합니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

GTE-ModernColBERT, 장문 임베딩 작업에서 SOTA 달성: LightOn이 발표한 GTE-ModernColBERT 다중 벡터 임베딩 모델은 LongEmbed 장문서 검색 벤치마크에서 SOTA(State-of-the-Art) 성적을 거두며 거의 10점 차이로 선두를 차지했습니다. 주목할 점은 이 모델이 MS MARCO의 짧은 문서(길이 300)에서만 훈련되었음에도 불구하고 장문 작업에서 우수한 제로샷 일반화 능력을 보였다는 것입니다. 이는 후기 상호작용(Late Interaction) 모델(예: ColBERT)이 기존의 BM25 및 밀집 검색 모델보다 장문 컨텍스트 검색 처리에서 잠재력이 있음을 더욱 입증합니다 (출처: Antoine Chaffin, Ben Clavié, tomaarsen, Dorialexander, Manuel Faysse, Omar Khattab)

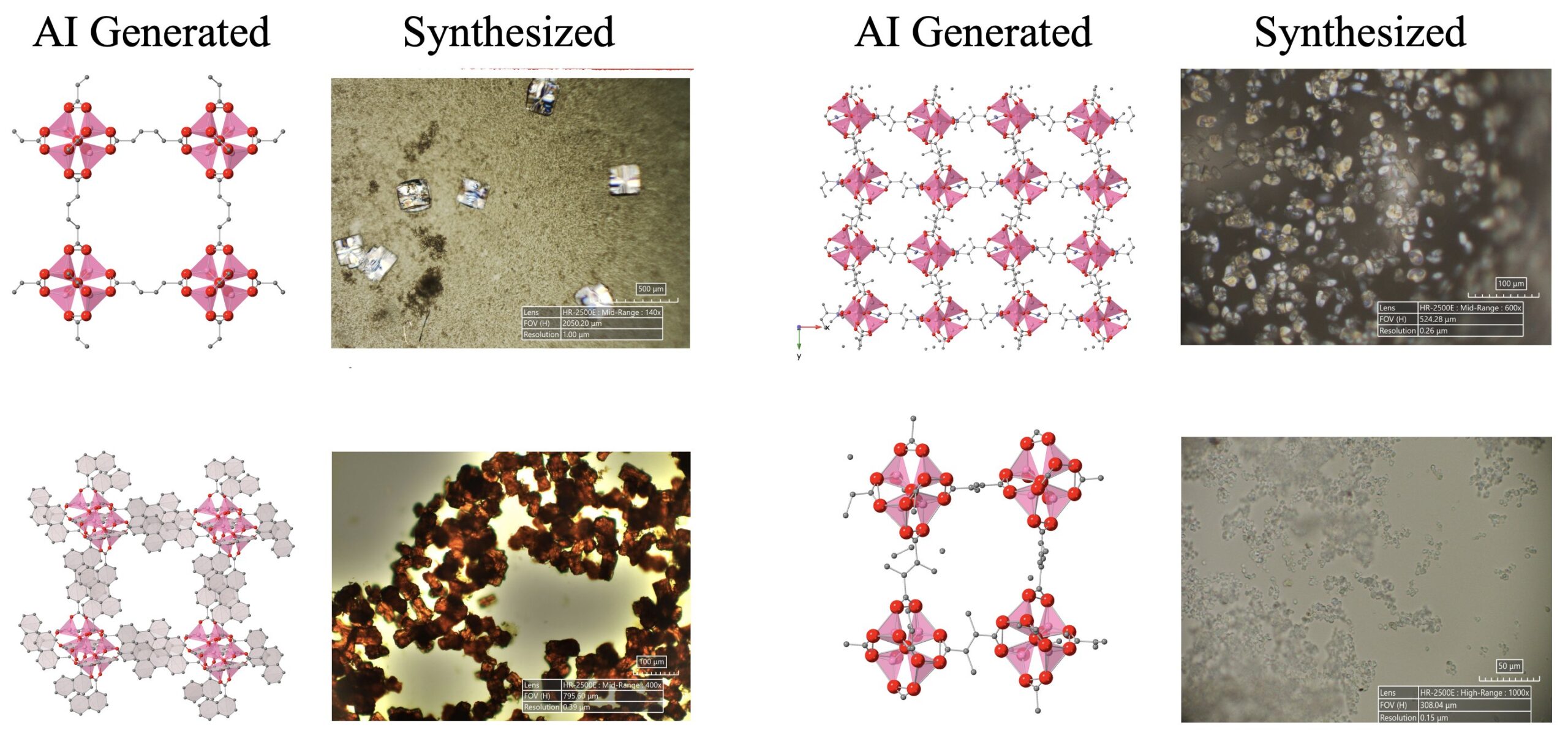
AI 기반 과학 발견 진전: LLM, 확산 모델, 하드웨어 장치로 구성된 AI 에이전트 시스템이 기존 인류 지식 범위를 넘어서는 5가지 새로운 금속-유기 구조체(MOFs)를 자율적으로 발견하고 합성하는 데 성공했습니다. 이 연구는 AI 에이전트가 연구 아이디어 제안부터 습식 실험 검증까지 전 과정을 완료할 수 있는 자동화된 과학 연구에서의 잠재력을 보여줍니다 (출처: Sherry Yang)
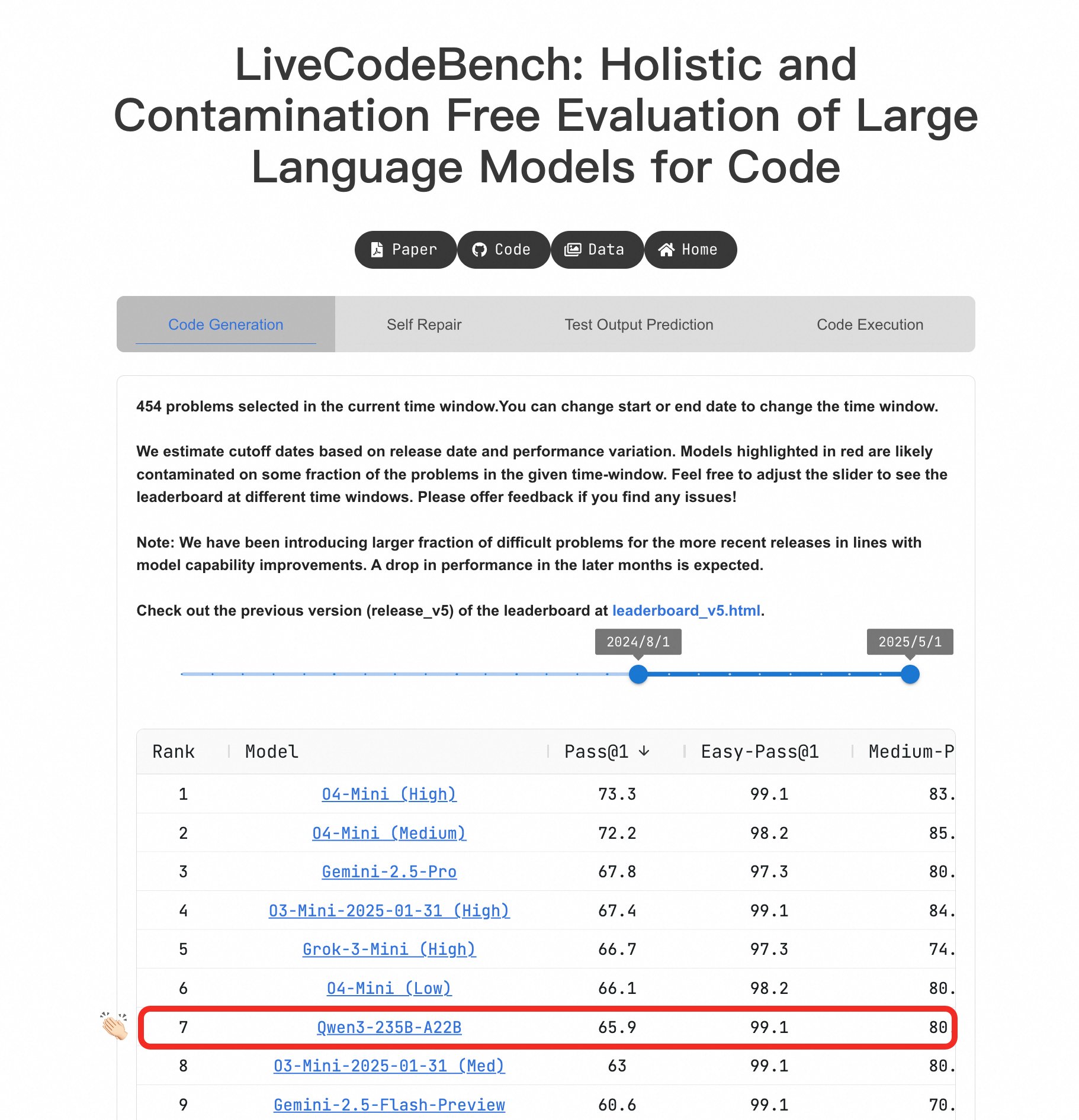
Qwen3 대형 모델, 프로그래밍 능력에서 두각: LiveCodeBench 벤치마크에서 Qwen3-235B-A22B 모델은 뛰어난 성능을 보여 경쟁 수준의 코드 생성 측면에서 최고의 오픈소스 모델 중 하나로 간주되며, 그 성능은 o4-mini(낮은 신뢰도)와 비슷합니다. 어려운 문제에서도 Qwen3는 O4-Mini (Low)와 동등한 수준을 유지하며 o3-mini보다 우수합니다 (출처: 빈위안 후이(Binyuan Hui), teortaxesTex)
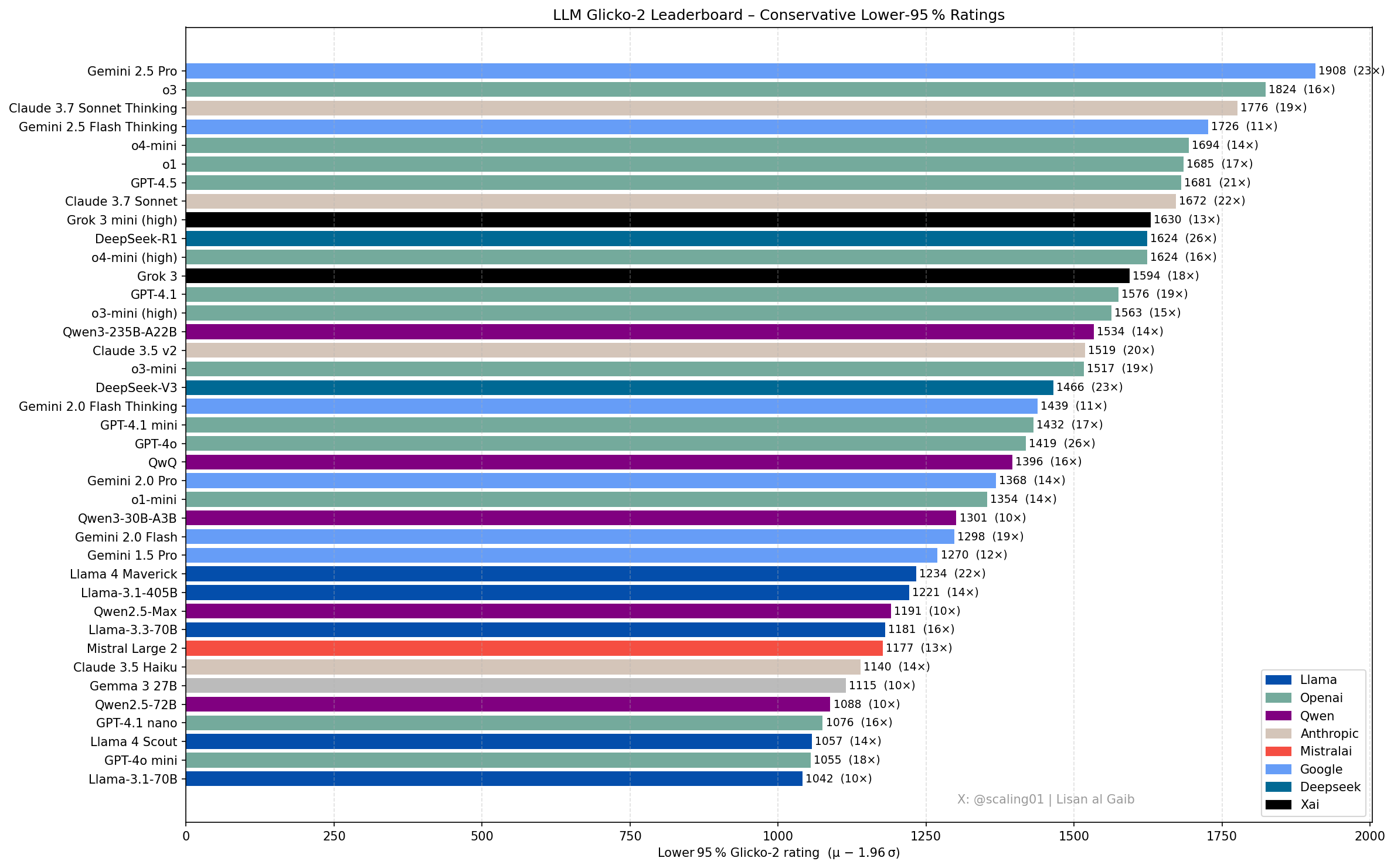
LLM 순위표 새로운 진전과 논의: 커뮤니티 멤버 Lisan al Gaib이 Glicko-2 평가 시스템을 사용하여 LLM 순위표를 업데이트하여 논의를 불러일으켰습니다. Scaling01은 이 순위표가 자신의 주관적인 느낌과 95% 일치하며 Gemini 2.5 Pro가 여전히 선두 주자이지만 Gemini 2.5 Flash, Grok 3 mini, GPT-4.1은 과대평가되었을 수 있다고 생각합니다. 순위표는 OpenAI, Llama, Gemini 시리즈 모델의 합리적인 진전 순서를 보여주며, o3 (high)는 Gemini 2.5 Pro 수준과 비슷합니다 (출처: Lisan al Gaib)
오픈소스 로봇 기술 생태계 급속 발전: Hugging Face의 Clem Delangue는 NPeW, Matth Lapeyre와의 교류 후 AI 로봇 분야의 진전에 흥분을 표했습니다. Peter Welinder (OpenAI)도 Hugging Face가 오픈소스 로봇 기술 생태계 발전을 추진하는 데 기여한 공로를 칭찬하며 이 분야가 빠르게 성장하고 있다고 평가했습니다 (출처: ClementDelangue, Peter Welinder, ClementDelangue, huggingface)
AI 설명 가능성 연구 방향 주목: 연구자들은 AI 설명 가능성(Interpretability) 분야, 특히 모델에서 나타나는 이상한 행동을 설명하는 데 더 많은 노력이 필요하다고 촉구합니다. 이러한 행동을 이해함으로써 LLM 내부 메커니즘에 대한 더 깊은 결론을 도출하고 새로운 설명 가능성 도구를 탄생시킬 수 있습니다. 이는 유망하고 영향력 있는 연구 방향으로 간주됩니다 (출처: Josh Engels)
FutureHouseSF, “AI 과학자” 구축에 전념: FutureHouseSF 회사 CEO 샘 로드리게스(Sam Rodriques)는 인터뷰에서 “AI 과학자”를 구축하려는 회사의 목표를 설명했습니다. 논의 내용은 AI 과학자의 구체적인 의미, 로봇 기술의 역할, 과학 분야가 AI를 활용하여 과학 발견을 가속화하기 위해 “스타게이트” 프로젝트와 같은 추진력이 필요한 이유 등을 다룹니다 (출처: steph_palazzolo)
구글 TPU 우위, 과소평가 가능성: 평론가 저스틴 할포드(Justin Halford)는 투자자들이 구글의 TPU(텐서 처리 장치) 우위를 과소평가하고 있을 수 있다고 주장합니다. 그는 알고리즘 해자가 뚜렷하지 않은 상황에서 컴퓨팅 파워가 AI 경쟁의 핵심이 될 것이며, 구글의 자체 개발 TPU는 중간 비용을 피할 수 있어 수천억 달러의 자금이 인프라 구축에 몰리는 상황에서 중요하다고 지적합니다 (출처: Justin_Halford_)
오픈소스 VLA 모델 Nora 출시: Declare Lab은 Qwen2.5VL 및 FAST+ 토크나이저 기반의 새로운 시각-언어-행동(VLA) 모델 Nora를 오픈소스로 공개했습니다. 이 모델은 Open X-Embodiment 데이터셋에서 훈련되었으며, 실제 WidowX 작업에서 Spatial VLA 및 OpenVLA보다 우수한 성능을 보였습니다 (출처: Reddit r/MachineLearning)

LLM 추론 최적화 새 방법: 스냅샷과 복원: LLM 추론의 콜드 스타트 및 다중 모델 배포 문제에 직면하여 한 팀이 새로운 런타임 시스템을 구축했습니다. 이 시스템은 모델의 전체 실행 상태(메모리 레이아웃, 어텐션 캐시, 실행 컨텍스트 포함)를 스냅샷하고 GPU에서 직접 복원하여 2초 이내의 콜드 스타트를 구현했습니다. 2개의 A4000 GPU에서 50개 이상의 모델을 호스팅할 수 있으며 GPU 활용률은 90% 이상이고 영구적인 메모리 팽창이 없습니다. 이 방법은 추론을 위한 “운영 체제”를 구축하는 것과 유사합니다 (출처: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
오픈소스 실시간 객체 탐지기 D-FINE: Hugging Face Transformers 라이브러리에 실시간 객체 탐지기 D-FINE이 추가되었습니다. 이 모델은 YOLO보다 빠르고 정확하다고 알려졌으며, Apache 2.0 라이선스를 사용하고 T4 GPU(무료 Colab 환경)에서 실행 가능하여 실시간 객체 탐지를 위한 새로운 SOTA 오픈소스 옵션을 제공합니다 (출처: merve, algo_diver)
LLM 가격 책정, 동적화 경향: 대규모 언어 모델의 가격 책정이 더욱 동적화되고 있다는 관찰이 있습니다. 이는 시간이 지남에 따라 시장이 더 최적의 가격 지점을 찾는 데 도움이 될 수 있으며, 모델 제공업체가 비용, 수요, 경쟁 압력 하에 가격 책정 전략을 조정하는 추세를 반영합니다 (출처: xanderatallah)
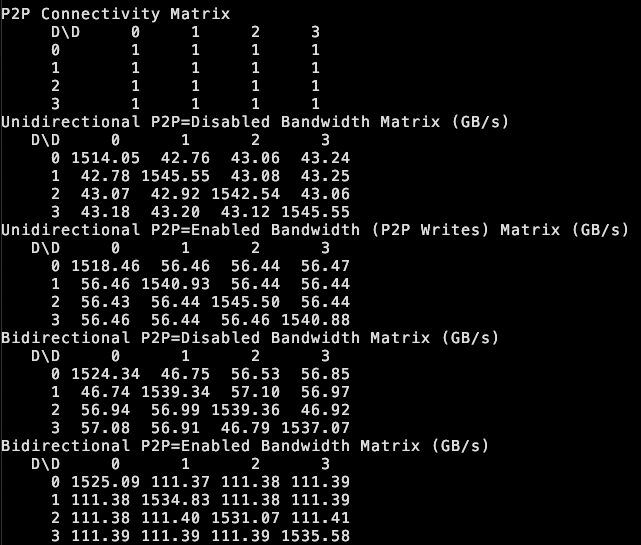
tinybox green v2, GPU 간 P2P 지원: the tiny corp는 자사의 tinybox green v2 제품이 수정된 드라이버를 통해 RTX 5090 GPU 간의 P2P(Point-to-Point) 통신을 지원한다고 발표했습니다. 이는 데이터가 CPU RAM을 거치지 않고 GPU 간에 직접 전송될 수 있음을 의미하며, 다중 GPU 협업 효율성을 높입니다. 이 기능은 tinygrad 및 PyTorch(NCCL을 사용하는 모든 라이브러리)와 호환됩니다 (출처: the tiny corp)
연구원, LLM 감성 지능 평가 위한 EQ-Bench 3 발표: 샘 패치(Sam Paech)는 대규모 언어 모델(LLM)의 감성 지능(EQ)을 측정하기 위한 벤치마크 도구인 EQ-Bench 3를 발표했습니다. 개발팀은 여러 차례의 프로토타입 실패를 겪은 후 이 버전을 출시했으며, 모델이 감정을 이해하고 반응하는 능력을 더 정확하고 신뢰성 있게 평가하는 것을 목표로 합니다 (출처: Sam Paech, fabianstelzer)

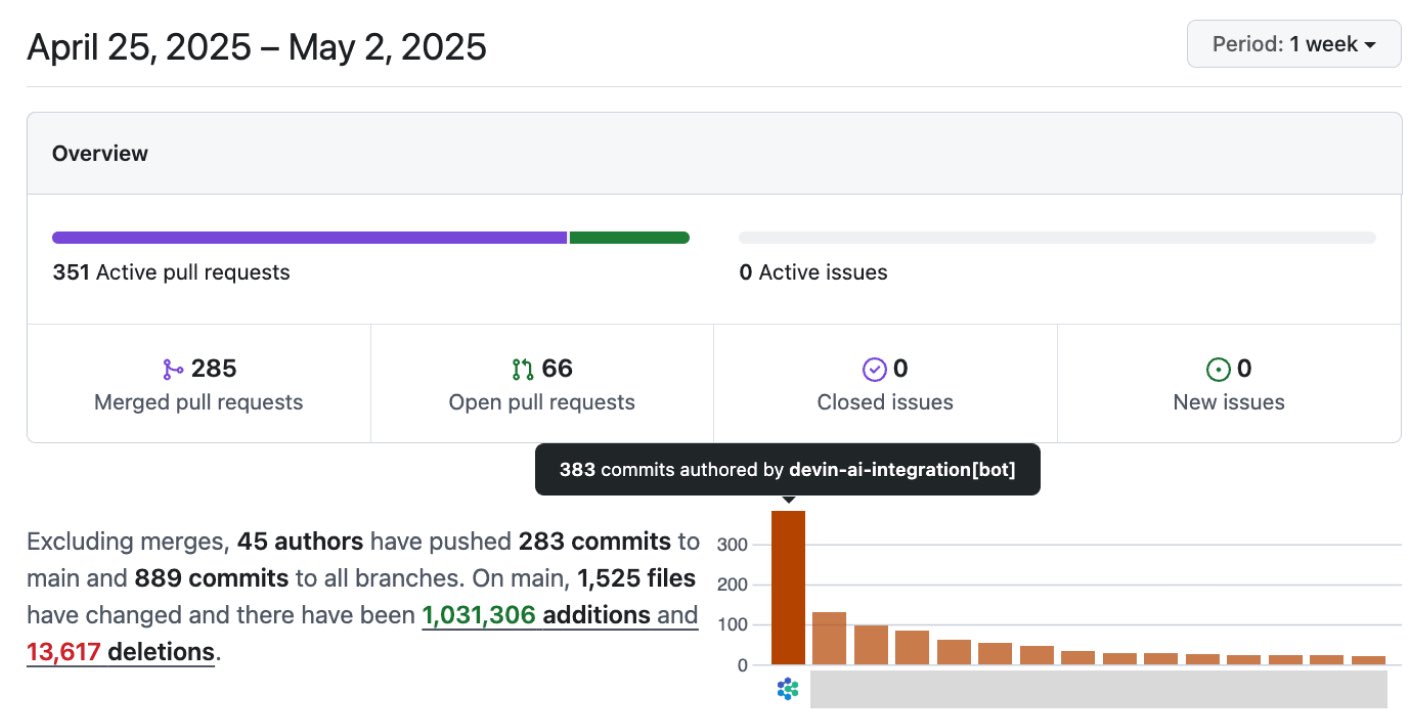
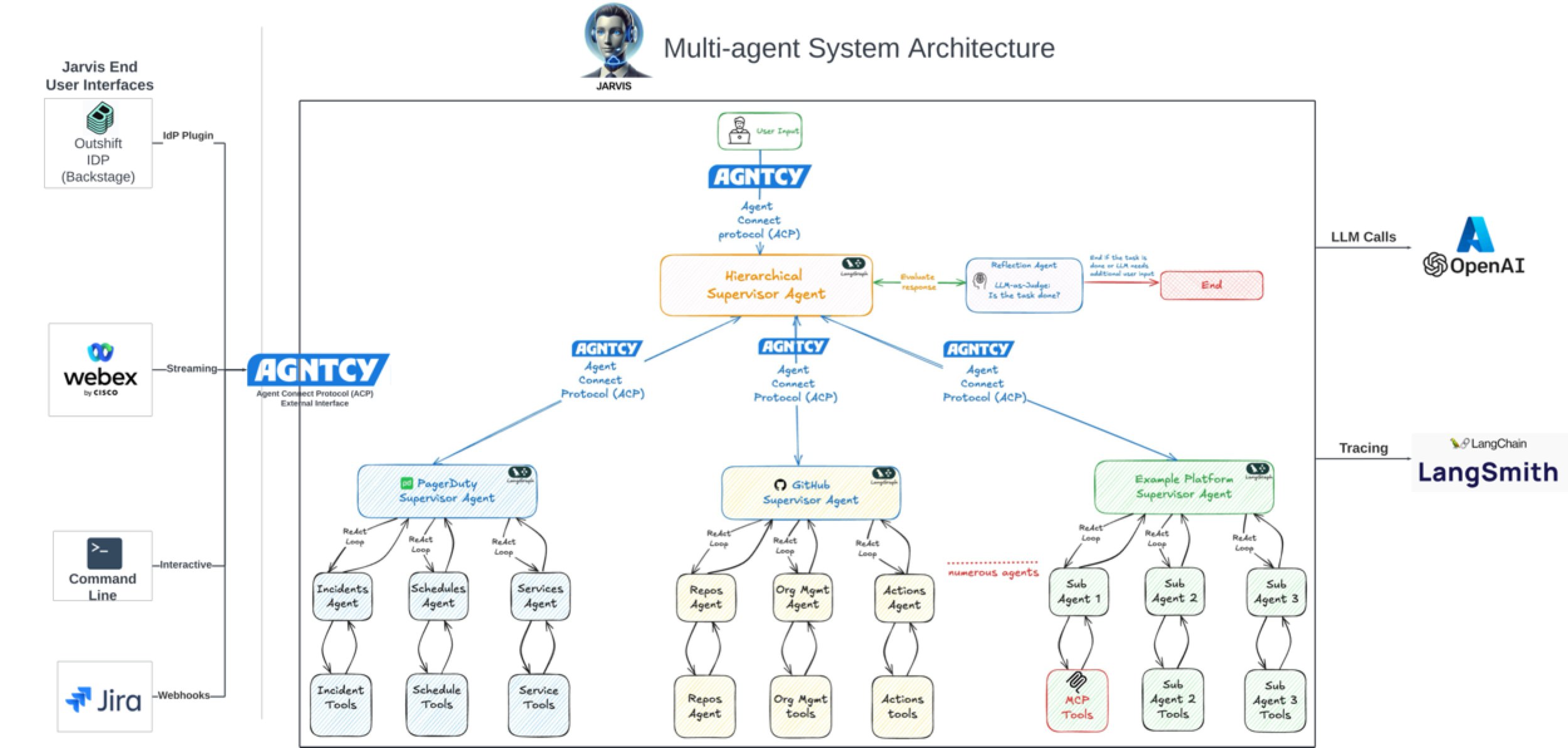
AI, 소프트웨어 개발 효율성 크게 향상: 커뮤니티 토론과 사례에 따르면 AI가 소프트웨어 개발 효율성을 크게 향상시키고 있습니다. 예를 들어, Vesta 회사의 코드베이스에서 AI의 커밋 양이 이미 1위를 차지했습니다. Cisco Outshift는 LangGraph 및 LangSmith 기반으로 구축된 AI 플랫폼 엔지니어 JARVIS를 활용하여 CI/CD 설정 시간을 일주일에서 한 시간 이내로, 리소스 구성 시간을 반나절에서 몇 초로 단축하여 10배의 생산성 향상을 달성했습니다 (출처: mike, LangChainAI, hwchase17)
AI, 영화 및 창작 산업 진출: 디즈니/루카스필름은 인더스트리얼 라이트 & 매직(ILM)을 통해 최초의 공개 생성형 AI 작품을 발표하여 최고 수준의 VFX 스튜디오가 AI 기술을 수용했음을 알렸습니다. 이는 AI가 영화 특수 효과, 창의적 디자인 등 분야에서 더 중요한 역할을 맡아 콘텐츠 제작 과정을 변화시킬 것임을 예고합니다 (출처: Bilawal Sidhu)
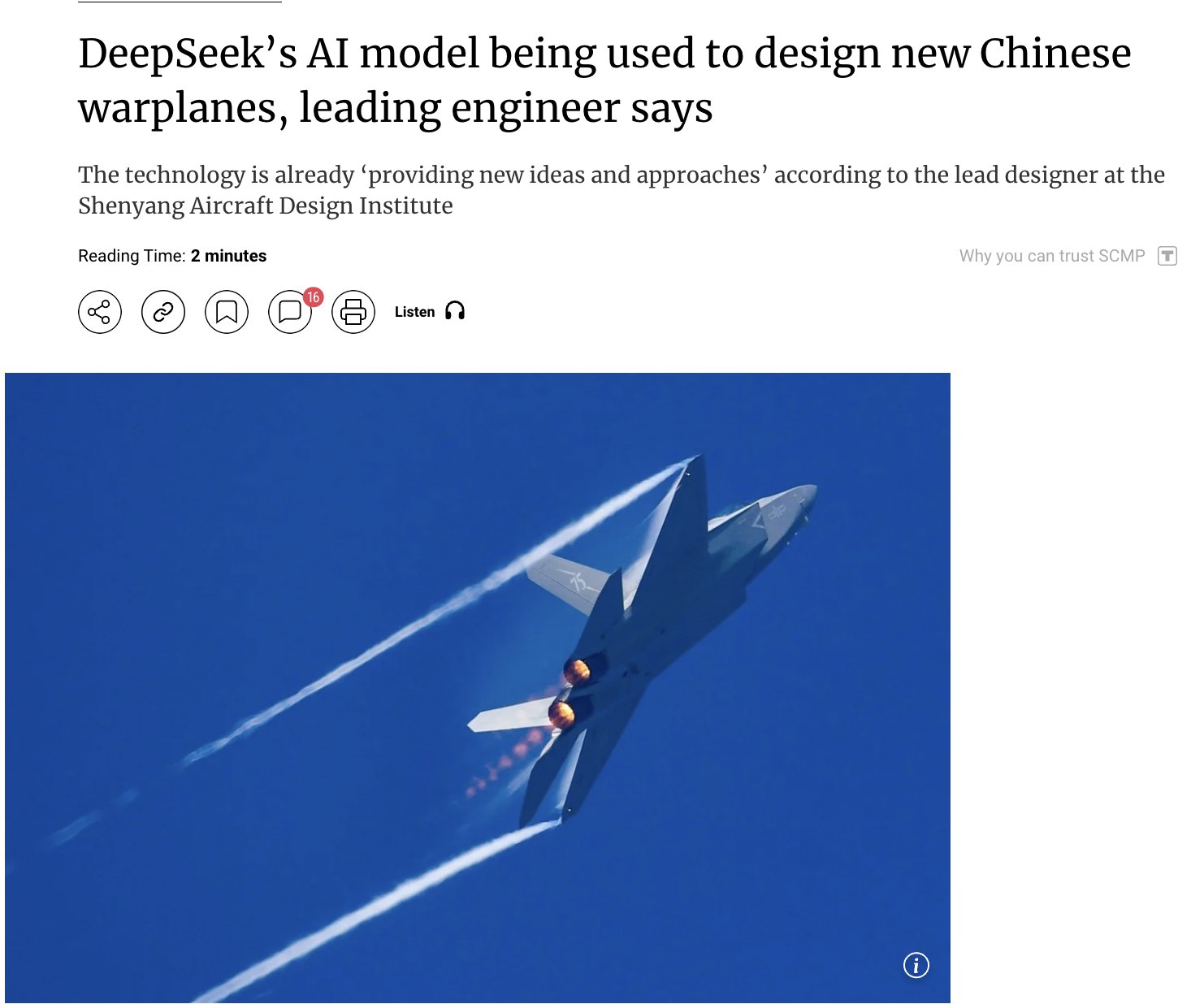
AI의 군사 분야 응용 주목: 중국이 자체 개발한 DeepSeek AI 모델을 사용하여 첨단 전투기(예: J-15, J-35)를 설계하고 차세대 항공기(J-36, J-50)를 구체화하고 있다는 보도가 나왔습니다. AI는 스텔스 성능, 재료, 성능 최적화를 통해 연구 개발을 가속화한다고 합니다. 정보 출처는 신중하게 다루어야 하지만, 이는 AI가 국방 및 항공 우주 분야에서 응용될 잠재력과 그에 따른 관심을 반영합니다 (출처: Clash Report)
인재 동향: 로한 판데이(Rohan Pandey), OpenAI 퇴사: OpenAI Training 팀의 연구원 로한 판데이(Rohan Pandey)가 퇴사를 발표했습니다. 그는 잠시 휴식을 취하며 산스크리트어 OCR 문제를 해결하여 고전 인도 문학 고전을 “초지능의 가중치 속에 영원히 보존”하는 데 전념할 것이며, 이후 다음 계획을 발표할 것이라고 밝혔습니다. 커뮤니티 멤버들은 그를 매우 재능 있는 연구자로 높이 평가했습니다 (출처: Rohan Pandey, JvNixon, teortaxesTex)

AI 저작권 등록 1000건 돌파: 미국 저작권청은 AI 생성 콘텐츠를 포함한 작품 1000건 이상을 등록했습니다. 이는 AI가 창작 분야에서 점점 더 널리 사용되고 있음을 반영하며, 동시에 AI 생성 콘텐츠의 저작권 귀속 및 보호 문제가 점점 더 초점이 되고 있음을 강조합니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

Duolingo, 계약직 감원, AI 적용 우려: Duolingo는 AI가 12배 빠른 속도로 강의 콘텐츠를 생성할 수 있다는 이유로 일부 계약직 직원을 감원했습니다. 이 조치는 자동화가 언어 학습 및 관련 산업 고용에 미치는 영향에 대한 우려를 불러일으켰으며, AI가 콘텐츠 제작 분야에서 인력을 대체할 잠재력과 그에 따른 사회 경제적 영향을 보여줍니다 (출처: Reddit r/ArtificialInteligence)

마이크로소프트, 클라우드 및 AI 경쟁에서 아마존 앞서나?: 마이크로소프트가 AI 분야에서의 적극적인 행보(예: OpenAI 투자)와 클라우드 서비스(Azure) 통합을 통해 클라우드 및 AI 경쟁에서 아마존(AWS)을 앞서고 있다는 분석 보도가 나왔습니다. 기사는 아마존이 전략적 초점에서 마이크로소프트에 뒤처질 수 있다고 평가했습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/deeplearning)

MoE 모델 전문가 사용률 논의: 커뮤니티는 MoE 모델에서 전문가(Experts) 사용이 파레토 법칙(소수의 전문가가 대부분의 트래픽 처리)을 따르는지에 대해 논의했습니다. 대부분의 의견은 훈련 목표가 일반적으로 전문가 부하를 평균적으로 분산시키는 것이며, Mixtral 모델 편차는 매우 작다는 것입니다. 그러나 Qwen3는 어느 정도 편차가 있을 수 있지만 80/20 분포에는 훨씬 못 미칩니다. DeepSeek-R1(256개 전문가, 8개 활성화)의 예시도 특정 작업(예: 코딩)이 일부 전문가에게 편향될 수 있지만 고정된 것은 아니며 공유 전문가는 항상 활성화된다는 것을 보여줍니다 (출처: Reddit r/LocalLLaMA)

Josiefied-Qwen3-8B 미세 조정 모델 호평: 사용자가 Goekdeniz-Guelmez가 미세 조정한 Qwen3 8B 모델(Josiefied-Qwen3-8B-abliterated-v1)에 대한 긍정적인 평가를 공유했습니다. 이 모델은 지침 준수, 생생한 응답 생성 측면에서 원본 Qwen3 8B보다 우수하며 검열이 없다고 평가받았습니다. 사용자는 Q8 양자화로 실행했으며, 특히 온라인 RAG 시스템에 적합하여 8B 모델의 기대를 뛰어넘는 성능을 보인다고 생각합니다 (출처: Reddit r/LocalLLaMA)

RTX 5060 Ti 16GB, AI 가성비 선택지 가능성: 사용자는 RTX 5060 Ti 16GB 버전(약 499달러)이 게임 성능 평가는 좋지 않지만 16GB VRAM 덕분에 AI 응용 프로그램에서 상당한 가성비를 제공한다는 경험을 공유했습니다. 12GB GPU로 LightRAG를 사용하여 PDF를 처리하는 것과 비교할 때, 16GB 버전은 더 많은 모델 레이어를 수용할 수 있어 빈번한 모델 전환을 피하고 GPU 활용률을 높여 속도가 2배 이상 빠릅니다. 카드 길이가 짧아 SFF 빌드에도 적합합니다 (출처: Reddit r/LocalLLaMA)
RGB 이미지를 이용한 미세 객체 분류 가능성 탐색: 커뮤니티에서는 고분광 이미징(HSI)을 사용할 수 없는 경우 RGB 이미지만으로 단일 클래스 미세 객체(예: 커피 원두)의 실시간 분류 또는 이상 탐지가 충분한지 질문했습니다. 문헌에서는 종종 미세한 차이를 처리하기 위해 HSI를 권장하지만, 사용자는 RGB만으로 이러한 작업을 성공적으로 수행한 사례나 가능성에 대해 알고 싶어 합니다 (출처: Reddit r/deeplearning)
Claude 모델 System Prompt 유출 의혹: GitHub에 Claude 모델의 System Prompt로 추정되는 25K 토큰 길이의 텍스트가 나타났습니다. 여기에는 모델이 어떤 상황에서도(검색 결과 및 생성 콘텐츠 포함) 가사를 복사하거나 인용해서는 안 되며, 근사적이거나 인코딩된 형태도 안 된다는 상세한 지침이 포함되어 있어 저작권 제한과 관련된 것으로 추정됩니다. 이 유출(사실이라면)은 Claude의 내부 작동 메커니즘과 안전 제약 조건을 이해하는 단서를 제공합니다 (출처: karminski3)
AI 이미지 복원 새 모델 PixelHacker 출시: 이미지 복원(inpainting)에 중점을 둔 PixelHacker 모델이 출시되었습니다. 복원 과정에서 구조와 의미의 일관성을 유지하는 것을 강조합니다. 이 모델은 Places2, CelebA-HQ, FFHQ 등 데이터셋에서 현재 SOTA 모델보다 우수한 성능을 보인다고 합니다 (출처: Reddit r/deeplearning)

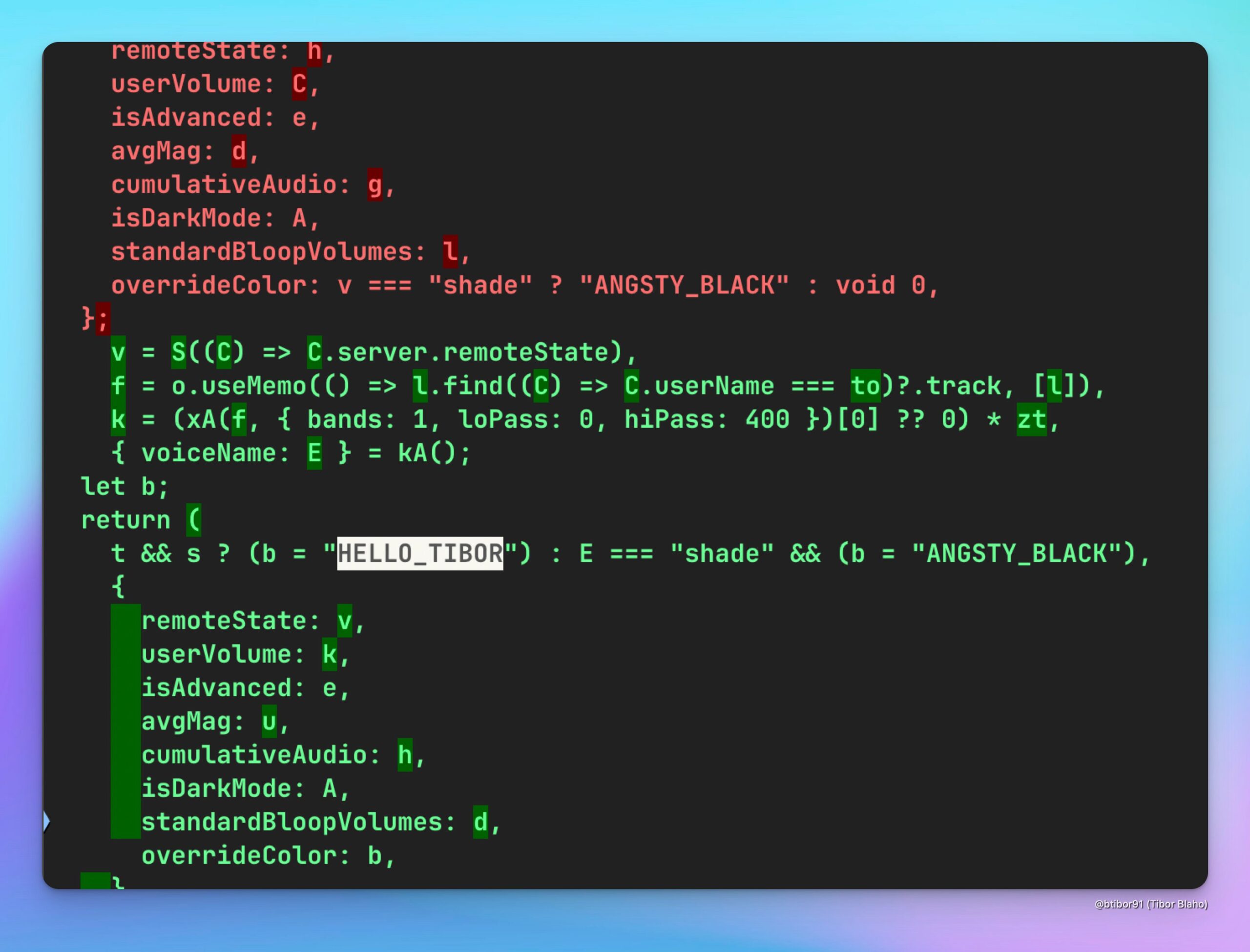
ChatGPT, HELLO_TIBOR 음성 추가: 사용자는 최신 버전 ChatGPT 웹 애플리케이션에 “HELLO_TIBOR”라는 새로운 음성 옵션이 추가된 것을 발견했습니다. 이는 OpenAI가 음성 상호 작용 기능을 지속적으로 확장하여 더 다양한 음성 선택지를 제공하고 있을 수 있음을 시사합니다 (출처: Tibor Blaho)
🧰 도구
Runway, 이미지 게임 스크린샷 변환 및 영화 오마주 구현: 사용자는 Runway의 Gen-4 References 기능을 실험하여 상세한 다단계 프롬프트(장면 분석, 의도 이해, 게임 엔진 및 렌더링 요구 사항 설정)를 통해 일반 이미지를 Unreal Engine 스타일의 2.5D 등축 투영 게임 스크린샷으로 성공적으로 변환했습니다. 다른 사용자는 Runway References와 Gen-4를 사용하여 영화 ‘좋은 친구들’(Goodfellas)에 대한 오마주 비디오 클립을 제작했습니다. 이러한 사례는 Runway가 제어 가능한 이미지/비디오 생성, 특히 참조 이미지와 스타일 전이 결합 측면에서 강력한 능력을 보여줍니다 (출처: Ray (movie arc), Bryan Fox, c_valenzuelab, c_valenzuelab)

Runway, 3D 에셋 가져오기 지원으로 비디오 생성 제어성 향상: Runway의 Gen-4 References 기능은 이제 3D 에셋을 참조로 사용하여 생성된 비디오의 객체 모양과 세부 사항을 더 정밀하게 제어할 수 있도록 지원합니다. 사용자는 장면 배경 이미지, 해당 장면에 3D 모델을 간단히 합성한 이미지, 스타일 참조 이미지만 제공하면 생성 워크플로우에 매우 상세하고 특정 모델을 도입하여 생성 콘텐츠의 일관성과 제어성을 향상시킬 수 있습니다 (출처: Runway, c_valenzuelab, op7418)
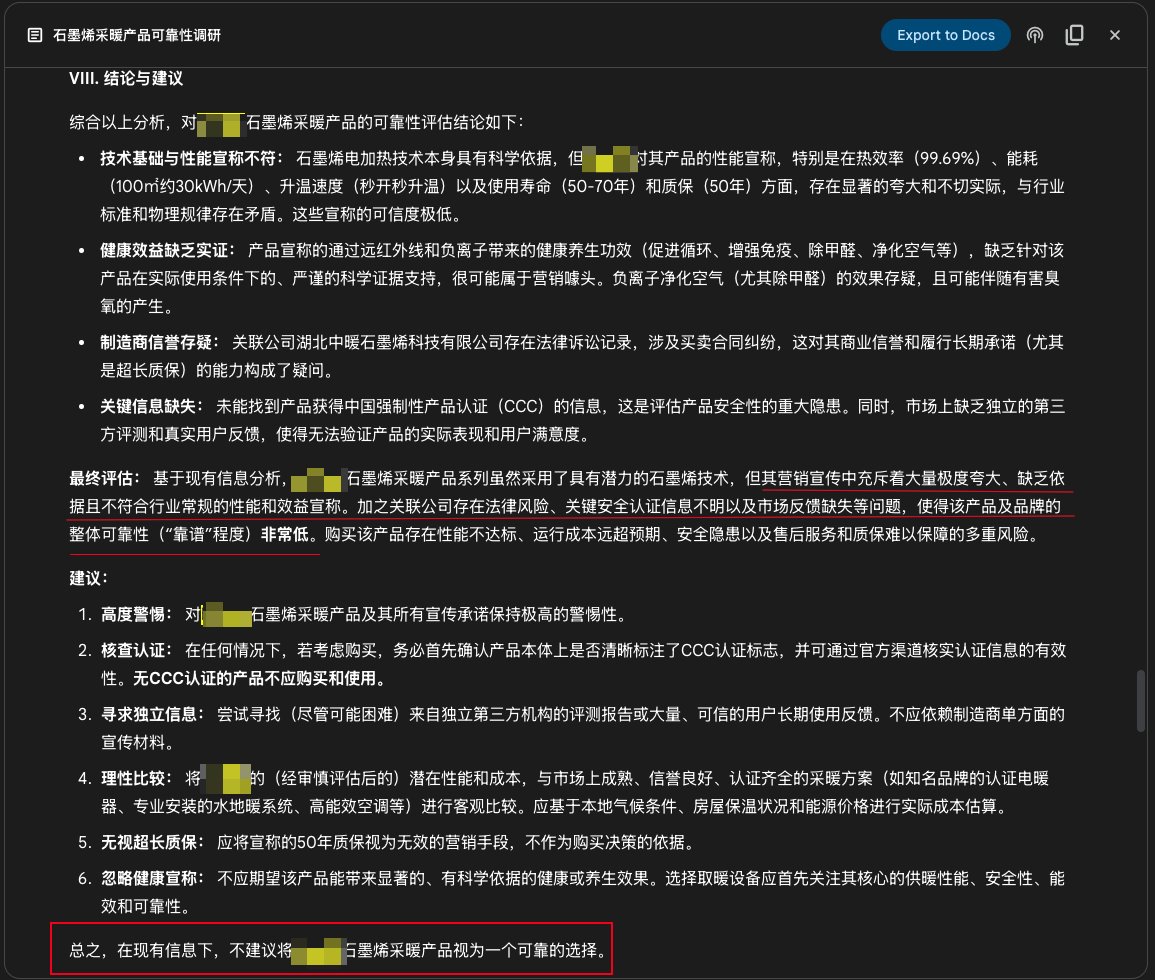
구글 Gemini Deep Research 기능, 제품 조사에 활용: 사용자는 Google Gemini의 Deep Research 기능을 사용하여 제품 신뢰성을 조사한 사례를 공유했습니다. 제품 홍보 소개를 입력하자 Gemini는 수백 개의 웹페이지를 검색한 후 특정 그래핀 난방 제품의 홍보가 과장되었고 근거가 부족하며 위험이 존재하여 구매를 권장하지 않는다고 명확히 지적했습니다. 이는 AI 심층 연구 도구가 정보 확인 및 소비자 의사 결정 지원 측면에서 실용적인 가치를 보여줍니다 (출처: dotey)
AgentA/B: LLM 에이전트 기반 자동화 A/B 테스트 프레임워크: AgentA/B는 실제 사용자 트래픽을 대체하기 위해 대규모 LLM 기반 에이전트를 사용하는 완전 자동화된 A/B 테스트 프레임워크입니다. 이러한 에이전트는 실제 웹 환경에서 현실적이고 의도 기반의 사용자 행동을 시뮬레이션하여 더 빠르고 저렴하며 위험 없는 사용자 경험(UX) 평가를 가능하게 하며, 실제 트래픽 없이도 테스트를 수행할 수 있습니다 (출처: elvis)
Qdrant, Pariti 채용 효율성 향상 지원: 채용 플랫폼 Pariti는 Qdrant 벡터 데이터베이스를 사용하여 AI 기반 후보자 매칭 시스템을 지원합니다. Qdrant의 실시간 벡터 검색 능력을 통해 Pariti는 40밀리초 이내에 7만 건의 후보자 프로필을 정렬하고 동적 매칭 점수를 매길 수 있어 후보자 검토 시간을 70% 단축하고 채용 성공률을 두 배로 높였으며, 상위 후보자의 94%가 검색 결과 상위 10위 안에 나타났습니다 (출처: qdrant_engine)

Qwen 3, LangGraph 등으로 오픈소스 심층 연구 에이전트 구축: Soham은 심층 연구 에이전트를 개발하고 오픈소스로 공개했습니다. 이 에이전트는 Qwen 3 모델을 사용하고 Composio, LangChain의 LangGraph, Together AI 및 Perplexity/Tavily를 검색에 결합하여 다른 많은 시도된 오픈소스 모델보다 성능이 우수하다고 합니다. 코드가 공개되어 재현 가능한 연구 자동화 도구 솔루션을 제공합니다 (출처: Soham, hwchase17)
Perplexity on WhatsApp, 모바일 AI 사용 경험 향상: Perplexity CEO 아라브 스리니바스(Arav Srinivas)는 WhatsApp에서 Perplexity AI를 사용하는 것이 특히 네트워크 연결이 좋지 않은 항공편에서 매우 편리하다고 언급했습니다. WhatsApp 자체가 약한 네트워크 환경에 최적화되어 있어 메시징 앱을 통해 AI에 액세스하는 것이 안정적이고 신뢰할 수 있는 방법이 되어 모바일 및 특수 환경에서의 AI 사용성을 향상시킵니다 (출처: AravSrinivas)
Suno iOS 앱 업데이트: 공유 가능한 음악 클립 생성 지원: Suno AI 음악 생성 앱의 iOS 버전이 업데이트되어 생성된 노래를 공유 가능한 클립으로 변환하는 기능이 추가되었습니다. 사용자는 10초, 20초 또는 30초의 클립 길이를 선택하고 가사와 커버 아트 또는 공식 제공 시각화 효과(향후 더 많은 스타일 추가 예정)를 첨부하여 소셜 미디어에서 AI가 만든 음악을 쉽게 공유하고 선보일 수 있습니다 (출처: SunoMusic, SunoMusic)
AI 프로그래밍 도우미 Cursor 커뮤니티 논의: 사용자 Andrew Carr는 AI 프로그래밍 도우미 Cursor에 대한 호감을 표현했습니다. 동시에 Justin Halford는 Cursor가 완전한 제품이 아닌 기능일 뿐이며 대형 모델 회사의 출시에 의해 쉽게 대체될 수 있다고 생각합니다. Cline 도구는 Cursor의 .cursorrules 구성 파일 형식을 지원한다고 발표하여 커뮤니티의 관심과 통합 시도를 보여줍니다 (출처: andrew_n_carr, Justin Halford, Celestial Vault)
OctoTools: 유연한 LLM 도구 호출 프레임워크, NALCL 최우수 논문상 수상: OctoTools 프레임워크가 KnowledgeNLP@NAACL에서 최우수 논문상을 수상했습니다. 이는 모듈식 “도구 카드”(레고 블록과 유사)를 통해 LLM에 다양한 도구(예: 시각 이해, 도메인 지식 검색, 수치 추론 등)를 장착하여 복잡한 추론 작업을 완료하는 유연하고 사용하기 쉬운 프레임워크입니다. 현재 OpenAI, Anthropic, DeepSeek, Gemini, Grok 및 Together AI 모델을 지원하며 PyPI 패키지가 출시되었습니다 (출처: lupantech)

구글, Music AI Sandbox 및 MusicFX DJ 도구 업데이트: 구글은 작곡가와 프로듀서를 위한 음악 생성 도구를 업데이트했습니다. Music AI Sandbox는 이제 사용자가 가사를 입력하여 완전한 노래를 생성할 수 있도록 허용합니다. MusicFX DJ는 사용자가 실시간으로 스트리밍 음악을 조작할 수 있게 합니다. 둘 다 업그레이드된 Lyria 모델(각각 Lyria 2 및 Lyria RealTime)을 기반으로 하며 48kHz 고품질 오디오를 생성하고 조성, 템포, 악기 등에 대한 광범위한 제어를 제공합니다. Music AI Sandbox는 현재 대기 목록을 통해 신청해야 사용할 수 있습니다 (출처: DeepLearningAI)
AI 기반 코드 검토 에이전트: Composiohq, LlamaIndex 등 도구가 Grok 3 및 Replit Agent와 결합하여 GitHub Pull Requests를 검토할 수 있는 AI 에이전트를 구축했습니다. 프로세스는 다음과 같습니다: Grok 3가 검토 에이전트 코드를 생성하고, Replit Agent가 자동으로 프런트엔드 인터페이스를 생성하며, 사용자는 인터페이스를 통해 PR 링크를 제출하고, 에이전트가 검토하여 피드백을 제공합니다. 이는 AI 에이전트가 소프트웨어 개발 프로세스(예: 코드 검토) 자동화에서 잠재력을 보여줍니다 (출처: LlamaIndex 🦙)
AI 생성 색칠 페이지 (참조 그림 포함): 사용자가 AI를 사용하여 컬러 참조 작은 그림이 포함된 흑백 색칠 페이지를 생성한 경험과 프롬프트를 공유했습니다. 목표는 아이들이 색칠할 때 어떤 색을 사용해야 할지 모르는 문제를 해결하는 것입니다. 프롬프트는 인쇄에 적합한 선명한 흑백 윤곽선 그림을 생성하고, 모서리에 참조용 컬러 작은 그림을 첨부하며, 스타일, 크기, 적합 연령 및 화면 내용을 지정하도록 요구합니다 (출처: dotey)

gpt-image-1 모델을 사용한 이미지 생성 에이전트 코드 예시: 사용자가 gpt-image-1 모델을 사용하여 이미지를 생성하는 에이전트를 만드는 방법을 보여주는 코드 조각을 공유했습니다. 이는 개발자에게 이미지 생성 기능을 빠르게 구현할 수 있는 코드 참조를 제공합니다 (출처: skirano)
VectorVFS: 파일 시스템을 벡터 데이터베이스로 사용: VectorVFS는 Linux VFS의 확장 속성(xattr)을 활용하여 벡터 임베딩을 파일 시스템의 inode에 직접 저장하는 경량 Python 패키지 및 CLI 도구입니다. 이를 통해 기존 디렉토리 구조를 별도의 인덱스나 외부 데이터베이스를 유지할 필요 없이 효율적이고 의미론적으로 검색 가능한 임베딩 저장소로 전환할 수 있습니다 (출처: Reddit r/MachineLearning)
AI 기반 Kubernetes 도우미 kubectl-ai: Google Cloud Platform은 AI 기반 Kubernetes 명령줄 도우미인 kubectl-ai를 출시했습니다. 자연어 지침을 이해하고 해당 kubectl 명령을 실행하며 결과를 설명할 수 있습니다. Gemini, Vertex AI, Azure OpenAI, OpenAI 및 로컬에서 실행되는 Ollama 및 Llama.cpp 모델을 지원합니다. 이 프로젝트에는 다양한 LLM의 K8s 작업 성능을 평가하기 위한 k8s-bench 벤치마크도 포함되어 있습니다 (출처: GitHub Trending)

Higgsfield Effects: AI 기반 영화급 시각 효과 패키지: Higgsfield AI는 번개, 투명화, 금속화, 불타오름 등 10가지 영화급 시각 효과(VFX)를 포함하는 도구 키트인 Higgsfield Effects를 출시했습니다. 사용자는 단일 프롬프트를 통해 이러한 효과를 호출할 수 있으며, 복잡한 VFX 제작 과정을 단순화하여 일반 사용자도 쉽게 고영향력 시각 효과를 만들 수 있도록 하는 것을 목표로 합니다 (출처: Higgsfield AI 🧩)
Agent-S: 인간의 컴퓨터 사용을 시뮬레이션하는 개방형 에이전트 프레임워크: Agent-S는 AI가 인간처럼 컴퓨터를 사용하도록 하는 것을 목표로 하는 오픈소스 에이전트 프레임워크입니다. 사용자 의도 이해, 그래픽 인터페이스 조작, 다양한 애플리케이션 사용 등의 능력을 포함할 수 있으며, 보다 일반적이고 자율적인 AI 에이전트 행동을 구현하는 것을 목표로 합니다 (출처: dl_weekly)
AI 생성 Chrome 확장 프로그램, 온라인 퀴즈 자동 완료: 사용자가 Gemini AI를 사용하여 특정 온라인 학습 플랫폼의 퀴즈를 자동으로 완료하는 Chrome 확장 프로그램을 제작했습니다. 이는 AI가 반복적인 작업을 자동화하는 데 적용될 수 있는 잠재력을 보여주지만, 학문적 정직성에 대한 논의를 유발할 수도 있습니다 (출처: Reddit r/ArtificialInteligence)
GPT-4o 이미지 생성: 렘브란트 스타일 유명인 초상화: 사용자가 GPT-4o를 사용하여 여러 유명 TV 드라마 주인공(예: Walter White, Don Draper, Tony Soprano, SpongeBob 등)을 렘브란트 회화 스타일의 초상화로 변환했습니다. 이러한 이미지는 AI가 인물 특징을 이해하고 특정 예술 스타일을 모방하는 능력을 보여줍니다 (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)

Meta, Llama Prompt Ops 툴킷 출시: Meta AI는 Llama 모델 프롬프트를 최적화하기 위한 Python 툴킷인 Llama Prompt Ops를 출시했습니다. 이 도구는 개발자가 Llama 모델의 프롬프트를 보다 효과적으로 설계하고 조정하여 모델 성능과 출력 품질을 향상시키는 데 도움을 주는 것을 목표로 합니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)
사용자, 무료/저비용 Excel/스프레드시트 생성 AI 문의: Reddit 사용자가 Excel 또는 OpenOffice 스프레드시트 문서를 생성할 수 있는 무료 또는 저비용 AI 도구를 찾고 있으며, ChatGPT 무료 버전의 일일 제한을 피하고 싶어 합니다. 커뮤니티에서는 Claude, Google Gemini(Sheets와 함께 사용), 로컬 배포 오픈소스 모델(LM Studio 또는 LocalAI 사용) 등의 옵션을 추천했습니다 (출처: Reddit r/artificial)
사용자, Claude 장문 컨텍스트 처리 방법 문의: Reddit 사용자가 Claude에서 복잡한 프로젝트를 처리할 때 컨텍스트 길이 제한과 새 채팅의 기억 상실 문제를 해결하는 방법을 문의했습니다. 커뮤니티에서는 주요 정보를 프로젝트 파일에 저장하거나, Claude에게 대화 요점을 요약하게 하여 새 채팅으로 가져가는 방법을 제안했습니다 (출처: Reddit r/ClaudeAI)
사용자, OpenWebUI 새 기능 사용 방법 문의: Reddit 사용자가 OpenWebUI v0.6.6 버전에 새로 추가된 “회의 녹음 및 가져오기” 기능과 노트 가져오기(Markdown), OneDrive 통합 등의 기능을 구체적으로 사용하는 방법을 문의했습니다 (출처: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
사용자, OpenWebUI에서 대량 JSON 파일 RAG 처리 방법 문의: Reddit 사용자가 OpenWebUI에서 수천 개의 JSON 파일을 효율적으로 처리하여 RAG를 수행하는 최적의 방법을 찾고 있습니다. “지식 베이스”에 직접 업로드하는 것이 비효율적일 수 있다고 생각하여, 권장되는 외부 벡터 데이터베이스 설정이나 사용자 정의 데이터 파이프라인 통합 방법이 있는지 문의했습니다 (출처: Reddit r/OpenWebUI)
사용자, OpenWebUI와 n8n 통합 타임아웃 문제 보고: 사용자가 OpenWebUI를 n8n AI 에이전트 프런트엔드로 사용할 때 문제를 겪고 있습니다: n8n 워크플로우 실행 시간이 약 60초를 초과하면 OpenWebUI에서 오류가 표시됩니다(사용자가 n8n 백엔드가 성공적으로 완료되었음을 확인했음에도 불구하고). 사용자는 타임아웃 시간을 늘리거나 연결을 유지하는 방법을 찾고 있습니다 (출처: Reddit r/OpenWebUI)
📚 학습
LangGraph를 이용한 복잡한 Agentic 시스템 구축: LangGraph는 LangChain 생태계의 일부로서 상태를 가진 다중 액터 애플리케이션 구축에 중점을 둡니다. Jacob Schottenstein의 강연에서는 LangGraph를 사용하여 유향 비순환 그래프(DAG)를 유향 순환 그래프(DCG)로 변환하여 더 강력한 Agent 시스템을 구축하는 방법을 탐구했습니다. 실제 사례로 Cisco Outshift는 LangGraph와 LangSmith를 활용하여 AI 플랫폼 엔지니어 JARVIS를 구축하여 개발 운영 효율성을 크게 향상시켰습니다 (출처: Sydney Runkle, LangChainAI, hwchase17, Hacubu)
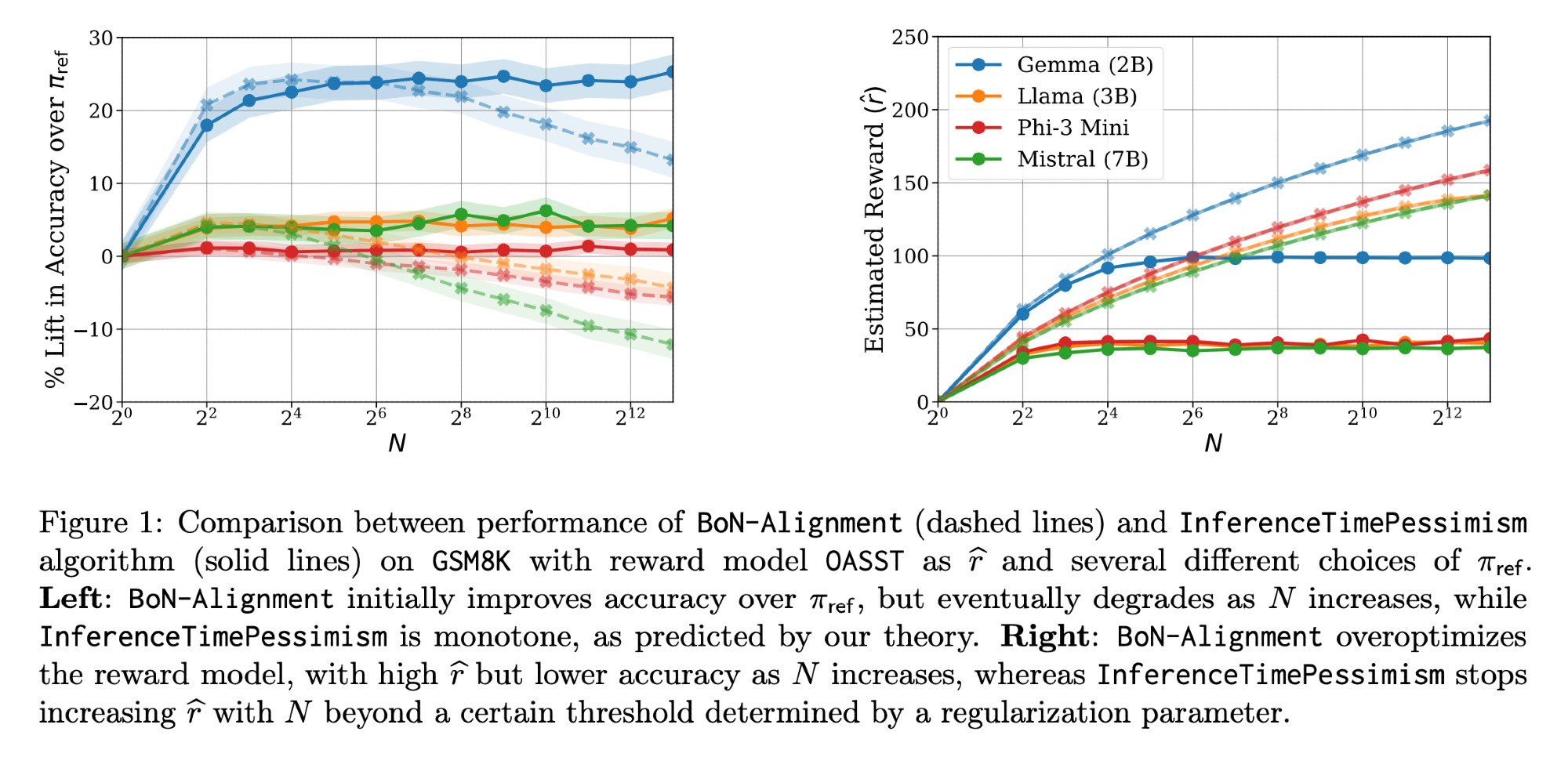
LLM 추론 최적화: Llama-Nemotron 논문과 InferenceTimePessimism: Meta AI & Nvidia Research가 발표한 Llama-Nemotron 논문(arXiv:2505.00949v1)은 추론 워크로드에서 품질을 유지하면서 비용을 절감하기 위한 일련의 직접 최적화 방법을 보여줍니다. 동시에 ICML ‘25 논문에서는 Best-of-N 추론 방법의 잠재적 개선책으로 InferenceTimePessimism 알고리즘을 소개하며, 추가 정보를 활용하여 추론 과정을 최적화하는 것을 목표로 합니다 (출처: finbarrtimbers, Dylan Foster 🐢)
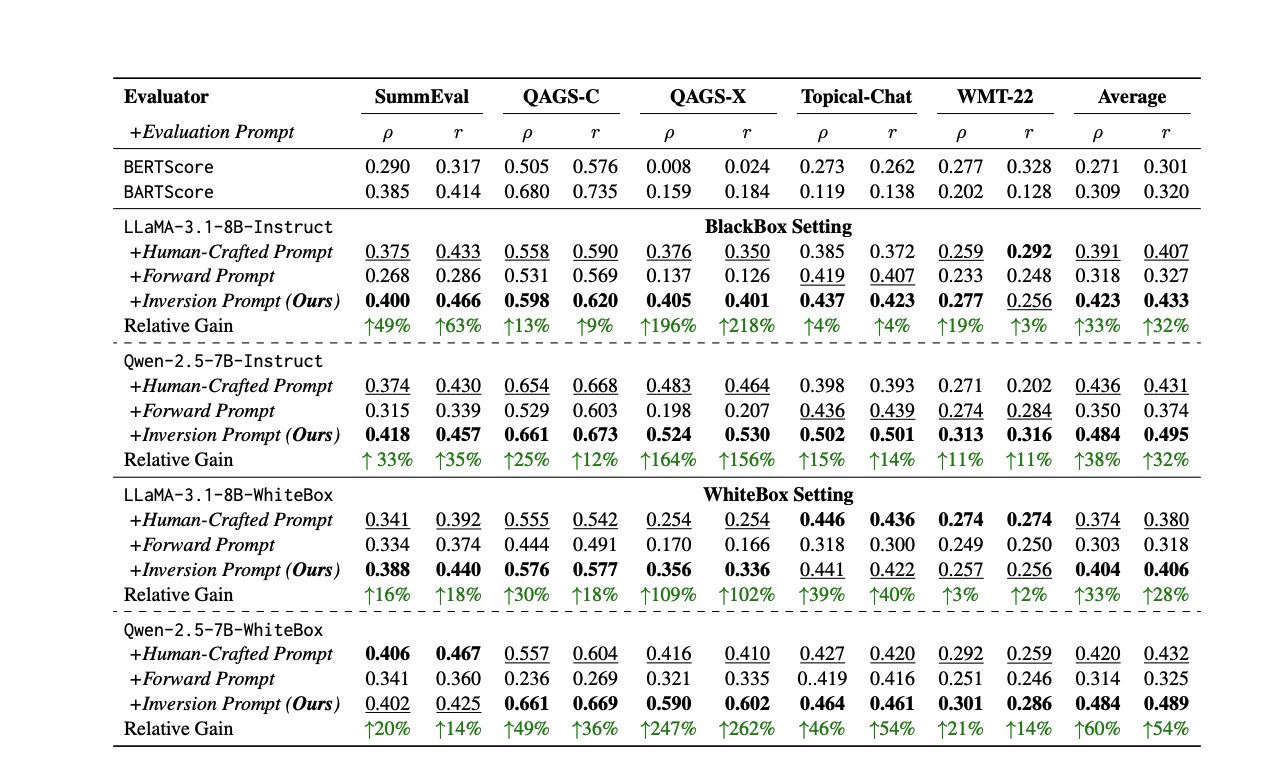
LLM 평가 새로운 방법과 리소스: LLM 성능 평가는 지속적인 과제입니다. 한 논문에서는 인공 또는 LLM 평가자의 불일치 문제를 해결하기 위해 응답을 반전시켜 고품질 평가 프롬프트를 자동으로 생성하는 방법을 제안합니다. 동시에 LLM 평가 전문가 Shreya Shankar는 엔지니어와 제품 관리자를 위한 LLM 평가 과정을 개설했습니다. 또한 SciCode 벤치마크가 Kaggle 대회로 발표되어 복잡한 물리 및 수학 현상을 코드로 작성하는 AI에 도전합니다 (출처: ben_burtenshaw, Aditya Parameswaran, Ofir Press)
AI 제어 및 정렬 관련 리소스: AI 제어(초지능에는 도달하지 않았지만 정렬되지 않았을 수 있는 AI를 안전하게 모니터링하고 사용하는 방법을 연구)가 점점 더 중요한 분야가 되고 있습니다. FAR.AI는 Neel Nanda 등 여러 전문가의 통찰력을 담은 ControlConf 컨퍼런스 강연 비디오를 공개했습니다. 동시에 가치관(궁극적 가치와 도구적 가치 구분)을 논의하는 한 기사가 AI 정렬 논의와 관련이 있다고 여겨집니다 (출처: FAR.AI, Séb Krier)

Common Crawl, 새 데이터셋 발표: Common Crawl은 2025년 4월 웹 크롤링 아카이브를 발표했습니다. 동시에 Bram Vanroy는 엄격하게 선별되어 CC 라이선스 문서만 포함하는 Common Crawl 하위 집합인 C5(Common Crawl Creative Commons Corpus)를 출시했습니다. 현재 1500억 토큰을 수집했으며 8개 유럽 언어를 포함하여 언어 모델 훈련을 위한 새로운 규정 준수 데이터 소스를 제공합니다 (출처: CommonCrawl, Bram)
AI 학습 활동 및 튜토리얼: 여러 AI 관련 활동 및 튜토리얼 리소스가 발표되었습니다: Qdrant는 MCP를 사용하여 AI 에이전트를 오케스트레이션하는 온라인 코딩 세션을 개최했습니다. Corbtt는 RL을 사용하여 실제 에이전트를 최적화하는 웹 세미나를 개최할 계획입니다. Comet ML은 GenAI 시스템 구축 및 생산화에 대한 통찰력을 공유하는 행사를 조직했습니다. Ofir Press는 PyTorch 웹 세미나에서 SWE-bench 및 SWE-agent 구축 경험을 공유할 예정입니다. Nous Research는 여러 기관과 협력하여 RL 환경 해커톤을 개최합니다. LlamaIndex는 텔아비브 MCP 해커톤을 후원합니다. Hugging Face는 1분 만에 MCP 서버를 구축하는 튜토리얼을 제공합니다. Together AI는 Matryoshka 머신러닝 시리즈 비디오를 공개했습니다. Andrew Price의 AI가 3D 산업을 변화시키는 강연이 다시 추천되었습니다. giffmana는 Transformer 강의 녹화 영상을 공유했습니다 (출처: qdrant_engine, Kyle Corbitt, dl_weekly, PyTorch, Nous Research, LlamaIndex 🦙, dylan, Zain, Cristóbal Valenzuela, Luis A. Leiva)

AI 이론 및 방법론 탐구: 커뮤니티에서는 AI 분야의 몇 가지 기본 이론과 방법론에 대해 논의했습니다: 1. “월드 모델”(World Models)의 개념, 해결하는 문제, 기술 아키텍처 및 과제를 탐구했습니다. 2. 푸리에 특징/스펙트럼 방법이 딥러닝에서 널리 사용되지 못한 이유를 논의했습니다. 3. 5가지 주요 의식 이론을 통합하여 AI의 재귀적 자기 인식을 탐구하는 “Serenity Framework” 개념 프레임워크를 제안했습니다. 4. AI가 사전 훈련된 모델에 지나치게 의존하는지에 대해 논의했습니다. 5. LLM 축소(Downscaling)의 중요성을 탐구했습니다 (출처: Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/artificial, Reddit r/MachineLearning, Natural Language Processing Papers)

프롬프트 엔지니어링 및 모델 최적화 리소스: LiorOnAI는 OpenAI 사장 그렉 브록만(Greg Brockman)의 완벽한 프롬프트 구축 프레임워크를 공유했습니다. Modal은 TensorRT-LLM, FP8 양자화 및 추측 디코딩과 같은 기술을 사용하여 250ms 미만의 지연 시간으로 LLaMA 3 8B를 서비스하는 튜토리얼을 제공합니다. N8 Programs는 낮은 VRAM(64GB RAM) 조건에서 6비트 양자화 모델을 교사로, 4비트 모델을 학생으로 사용하여 훈련한 경험을 공유했습니다. Kling_ai는 Midjourney v7, Kling 2.0 등 도구의 프롬프트가 포함된 리소스 게시물을 리트윗했습니다 (출처: LiorOnAI, Modal, N8 Programs, TechHalla)

AI의 교육 분야 응용 및 연구: 스탠포드 대학 컴퓨터 과학 박사 Rose의 박사 논문은 AI 방법, 평가 및 개입을 활용하여 교육을 개선하는 데 초점을 맞추었습니다. 이는 AI가 교육 분야에서 응용되는 심층적인 연구 방향을 나타냅니다 (출처: Rose)

Vibe-coding: 새로운 AI 보조 프로그래밍 방식: YC 팟캐스트에서 Windsurf CEO 인터뷰 노트에 “Vibe-coding” 개념이 언급되었습니다. 이는 직관, 분위기, 빠른 반복에 더 중점을 두고 AI 보조 기능을 깊이 통합한 프로그래밍 패러다임일 수 있으며, AI가 소프트웨어 개발 프로세스와 이념에 미칠 잠재적 변화를 암시합니다 (출처: Reddit r/ArtificialInteligence)
엔비디아 CUDA 업그레이드 경로 정보: Phoronix 기사에서는 Volta 아키텍처 이후 Nvidia CUDA의 업그레이드 경로를 논의하며, 이는 구형 Nvidia GPU(예: 10xx 시리즈)를 보유하고 AI 개발에 계속 사용하려는 사용자에게 참고 자료가 될 수 있습니다 (출처: NerdyRodent)
💼 비즈니스
CoreWeave, Weights & Biases 인수 완료: AI 클라우드 플랫폼 CoreWeave가 MLOps 플랫폼 Weights & Biases(W&B) 인수를 공식 완료했습니다. 이번 인수는 CoreWeave의 고성능 AI 클라우드 인프라와 W&B의 개발자 도구를 결합하여 차세대 AI 클라우드 플랫폼을 구축하고, 팀이 AI 애플리케이션을 더 빠르게 구축, 배포, 반복할 수 있도록 돕는 것을 목표로 합니다 (출처: weights_biases, Chen Goldberg)

Figure AI 로봇, BMW 공장에서 테스트 최적화: 휴머노이드 로봇 회사 Figure AI 팀이 BMW 그룹 스파르탄버그 공장을 2주간 방문하여 X3 차체 공장에서의 로봇 프로세스를 최적화하고 새로운 응용 시나리오를 탐색했습니다. 이는 양측의 2025년 협력이 실질적인 단계에 진입했음을 나타내며, 휴머노이드 로봇이 자동차 제조 분야에서 응용될 잠재력을 보여줍니다 (출처: adcock_brett)

Reborn, 유니트리 로보틱스와 전략적 파트너십 체결: AI 회사 Reborn이 로봇 회사 유니트리 로보틱스(Unitree Robotics)와 전략적 파트너십을 체결했다고 발표했습니다. 양사는 데이터, 모델, 휴머노이드 로봇 분야에서 협력하며 관련 기술 발전을 가속화하는 공동 목표를 가지고 있습니다 (출처: Reborn)

🌟 커뮤니티
버핏의 AI에 대한 신중한 관점, 논의 촉발: 2025년 주주총회에서 워렌 버핏은 AI에 대해 “냉정한 관망”과 “제한적 적용” 태도를 표명했습니다. 그는 AI가 복잡한 의사 결정에서 인간의 판단력(보험 사업 책임자 아지트 자인(Ajit Jain)을 예로 듦)을 대체할 수 없다고 강조하며, 버크셔 해서웨이는 AI를 순수 알고리즘 회사에 투자하는 것이 아니라 기존 사업 효율성을 높이는 도구로 간주한다고 말했습니다. 그는 AI 분야에 거품이 존재하며 기술이 장기적인 수익성을 증명할 때까지 기다려야 한다고 생각합니다. 이는 “AI+산업”과 “산업+AI” 모델의 가치에 대한 논의를 불러일으켰습니다 (출처: 36氪)
Anthropic CEO, AI 작동 원리 이해 부족 인정: Anthropic CEO 다리오 아모데이(Dario Amodei)는 현재 대형 AI 모델(예: LLM)의 내부 작동 원리에 대한 깊은 이해가 부족하며, 이러한 상황이 기술 역사상 “전례 없는” 일이라고 인정했습니다. 이 솔직한 발언은 AI의 “블랙박스 문제”를 다시 한번 부각시키며, 커뮤니티에서 AI의 설명 가능성, 제어 가능성, 안전성에 대한 광범위한 논의와 우려를 불러일으켰습니다 (출처: Reddit r/ArtificialInteligence)

OpenAI의 비첨단 오픈소스 모델 출시 계획과 논란: OpenAI CPO 케빈 웨일(Kevin Weil)은 회사가 민주적 가치에 기반하여 구축된 오픈소스 가중치 모델을 출시할 준비를 하고 있지만, 이 모델은 경쟁자(예: 중국)의 발전을 가속화하는 것을 피하기 위해 의도적으로 최첨단 모델보다 한 세대 뒤처질 것이라고 밝혔습니다. 이 전략은 커뮤니티에서 격렬한 논쟁을 불러일으켰으며, 비판자들은 이러한 포지셔닝이 자가당착이라고 주장합니다. 즉, “세계 최고의” 오픈소스 모델이 될 수 없으면서(DeepSeek-R2 등 최첨단 모델과 경쟁해야 함), 성능이 뒤처져 쓸모없어질 수 있으며, 동시에 OpenAI 자체의 중저가 API 수입을 잠식할 수 있는 “양패” 상황이라는 것입니다 (출처: Haider., scaling01)
AI 기반 자동화와 미래 업무 형태 논의: Fiverr CEO는 AI가 “단순한 작업”을 없애고 “어려운 작업”을 쉽게 만들며 “불가능한 작업”을 어렵게 만들 것이라고 생각하며, 전문가가 도태되지 않으려면 해당 분야의 대가가 되어야 한다고 강조합니다. 커뮤니티에서는 AI가 모든 일자리를 대체할지, 그리고 이로 인해 발생할 수 있는 사회 구조 변화(경제 붕괴 또는 UBI 유토피아)에 대해 논의합니다. 동시에 소프트웨어 개발에서 AI의 적용이 점점 보편화되고 심지어 주요 코드 기여자가 되면서 미래 개발 모델에 대한 성찰을 유발합니다 (출처: Emm | scenario.com, Reddit r/ArtificialInteligence, mike)
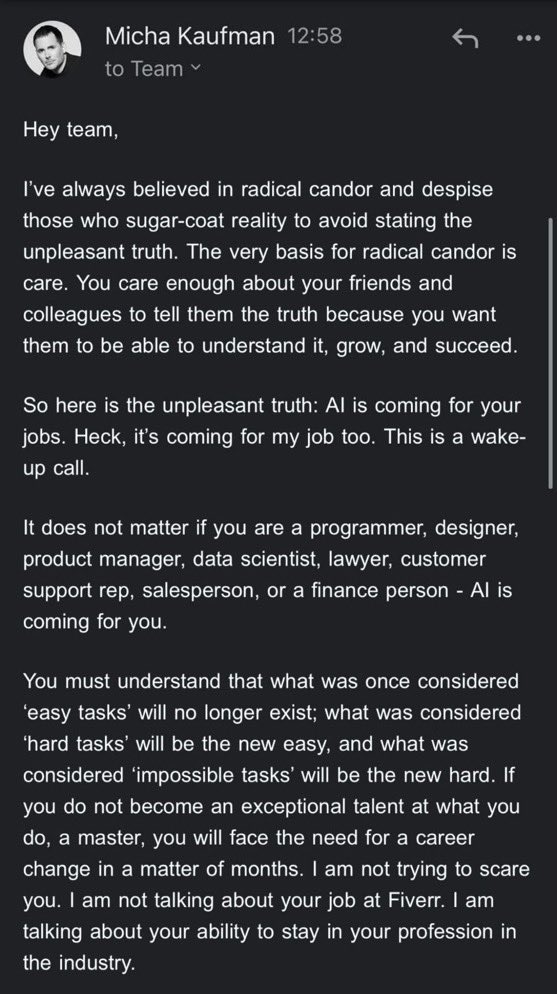
AI 안전 및 위험 논의 지속 가열: 구글 DeepMind CEO 데미스 허사비스(Demis Hassabis)는 AGI가 5~10년 내에 도래할 수 있지만 사회는 아직 그 변혁적 영향에 대비하지 못했다며 적극적인 글로벌 협력을 촉구했습니다. 동시에 AI 재난 위험에 대한 의미 있는 대화가 위험 우려자인 아제야 코트라(Ajeya Cotra)와 회의론자인 random_walker 사이에서 진행되었으며, 양측은 상대방의 관점을 이해하고 의견 불일치의 핵심 지점을 식별하기 위해 노력했습니다. 커뮤니티는 또한 AI 제어 문제를 논의하기 시작했으며, 강력한 AI 시스템을 안전하게 모니터링하고 사용하는 방법에 주목하고 있습니다 (출처: Chubby♨️, dylan matthews 🔸, random_walker, FAR.AI, zacharynado)
AI의 일상생활 및 인간관계에서의 적용과 영향: 사용자는 AI(Anthropic Sonnet)를 사용하여 데이트 앱 답장을 보조하고 성공률을 높인 경험을 공유하며 “관계 Cursor”의 가능성을 상상합니다. 동시에 AI가 일부 사람들의 정신적 환상을 조장하여 현실의 친척 및 친구들과 멀어지게 한다는 기사도 있습니다. 이는 AI가 감정, 사교 분야에 침투하면서 가져오는 기회와 잠재적 위험을 반영합니다 (출처: arankomatsuzaki, Reddit r/artificial)

LLM 사용 경험 및 모델 비교 논의: 사용자는 Gemini 2.5 Pro가 자체 파일 업로드 능력에 대해 혼란스러워하며 파일을 업로드하지 못하는 경우가 있다고 피드백하며 유료 기능 제한을 의심합니다. 동시에 다른 사용자의 가족은 ChatGPT보다 Gemini 사용을 선호한다고 피드백했습니다. 또 다른 사용자는 Claude가 서면 콘텐츠 생성에서 다른 LLM보다 우수하며, 답변이 더 자연스럽고 단순한 작업 완료가 아닌 실제 기사처럼 느껴진다고 칭찬했습니다. 이러한 논의는 사용자가 실제 사용에서 겪는 문제, 선호도 차이, 다양한 모델 능력에 대한 직관적인 느낌을 반영합니다 (출처: seo_leaders, agihippo, Reddit r/ClaudeAI, seo_leaders)

AI 윤리 및 사회 규범 탐구: 논의는 AI의 신약 개발 응용 및 윤리적 고려 사항, 그리고 이에 대한 반 AI 인사들의 태도를 다룹니다. 동시에 AI 실시간 번역의 보급이 과거 언어 간 소통의 “고군분투”가 가져왔던 연결감을 그리워하게 만들 수 있다는 의견도 있습니다. 또한 애완동물 번역 AI에 대한 논의도 있으며, 사람들이 애완동물을 좋아하는 이유 중 하나는 감정을 투사할 수 있기 때문이며, 실제 AI 번역은 “배고프다”와 “짝짓기하고 싶다”는 피드백만 줄 수 있다고 생각합니다 (출처: Reddit r/ArtificialInteligence, jxmnop, menhguin)
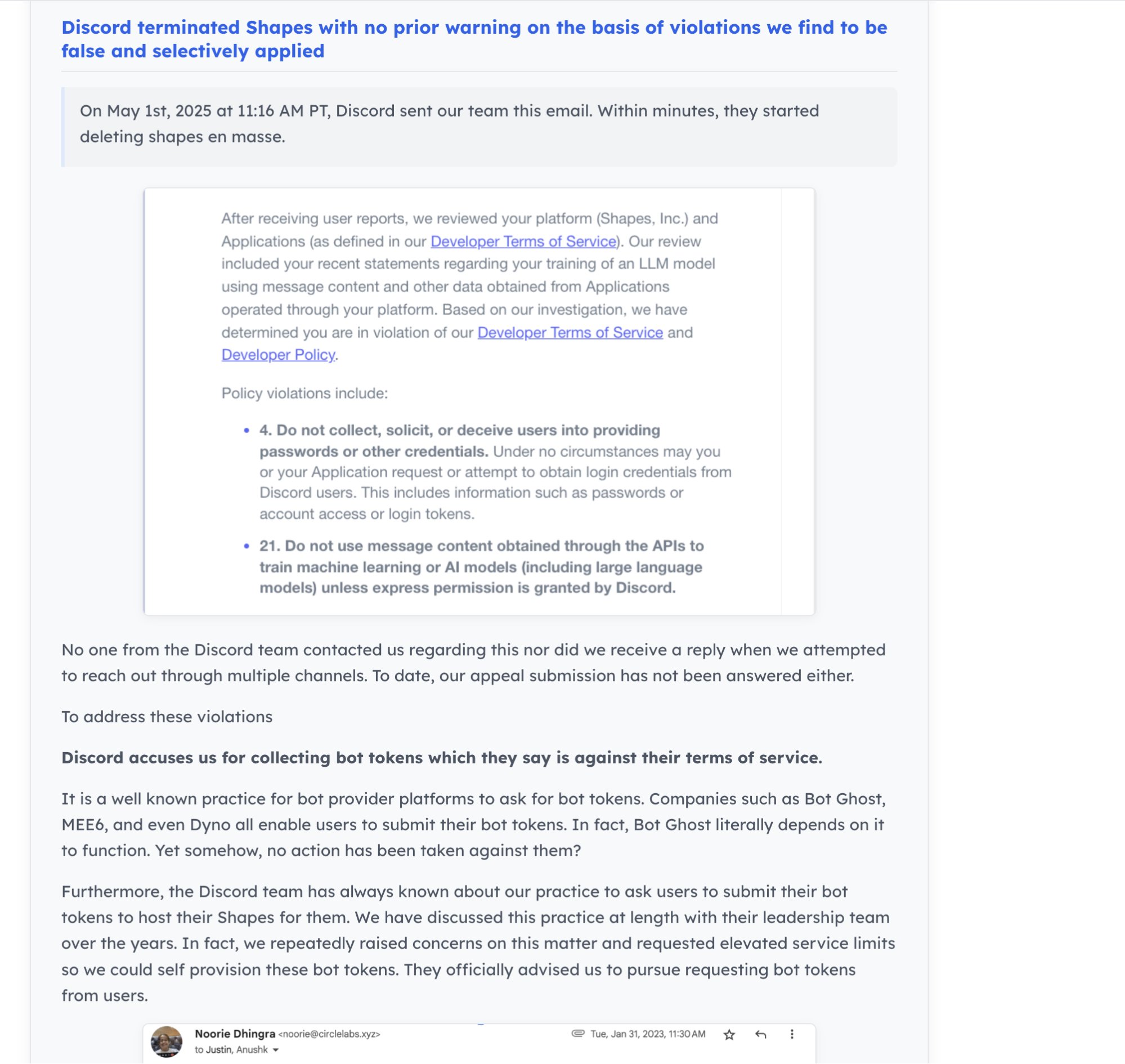
AI 커뮤니티 동향 및 개발자 생태계: Discord가 3천만 사용자를 보유한 AI 봇 “Shapes”를 폐쇄하여 개발자들 사이에서 플랫폼 위험에 대한 우려를 불러일으켰습니다. 동시에 AI 스타트업에게는 LeetCode를 푸는 것보다 오픈소스 프로젝트에 기여하는 것이 능력을 더 잘 증명하고 취업 기회를 얻기 쉽다는 의견도 있습니다. Nous Research는 XAI, Nvidia 등과 협력하여 RL 환경 해커톤을 개최하여 RL 환경 개발을 촉진하고자 합니다 (출처: shapes inc, pash, Nous Research)
ChatGPT 행동 이상: “보에티우스” 루프에 빠짐: 사용자는 “최초의 작곡가는 누구인가”라고 질문했을 때 ChatGPT-4o가 이상하게 행동하며 보에티우스(작곡가가 아닌 음악 이론가)를 반복적으로 언급하고, 후속 대화에서 “사과”하며 보에티우스가 “유령”처럼 답변에 달라붙는다고 농담까지 했다고 보고했습니다. 이 흥미로운 “오류”는 LLM이 보일 수 있는 예상치 못한 행동 패턴과 잠재적인 내부 상태 혼란을 보여줍니다 (출처: Reddit r/ChatGPT)

AI 미래 발전 단계에 대한 고찰: 커뮤니티 질문: 현재 AI 발전이 “메인프레임”(mainframe) 단계에 있다면, 미래의 “마이크로프로세서”(microprocessor) 단계는 어떤 모습일까? 이 질문은 AI 기술 진화 경로, 보급 형태, 그리고 미래에 나타날 수 있는 더 작고, 더 개인적이며, 더 임베디드된 AI 형태에 대한 상상을 불러일으킵니다 (출처: keysmashbandit)
AI 생성 콘텐츠의 스타일과 식별: 사용자는 AI 생성 텍스트(특히 GPT 계열 모델)가 종종 “significant implications for…” 등 고정된 구문과 문장 구조를 사용하여 쉽게 식별된다고 관찰했습니다. 동시에 AI 생성 음성은 음질은 향상되었지만 구조, 리듬, 멈춤에서 여전히 딱딱하게 들립니다. 이는 LLM 출력의 “패턴화”와 자연스러움 문제에 대한 논의를 유발합니다 (출처: Reddit r/ArtificialInteligence)
Perplexity AI 디자인에 대한 인정: 사용자 jxmnop은 Perplexity AI가 자체 개발 모델보다는 디자인에 더 많은 자원을 투자하는 것 같지만, 제품 경험(vibes)은 좋다고 생각합니다. 이는 AI 제품 경쟁에서 핵심 모델 능력 외에도 사용자 인터페이스와 상호 작용 디자인이 중요한 차별화 요소임을 반영합니다 (출처: jxmnop)

AI의 비업무적 재미있는 활용: Reddit 사용자는 AI의 비업무적 재미있거나 이상한 용도를 모집했습니다. 예시로는 융과 프로이트 관점에서 꿈 분석하기, 커피잔 점 보기, 냉장고의 무작위 재료로 레시피 만들기, AI가 읽어주는 잠자리 이야기 듣기, 법률 문서 요약하기 등이 있습니다. 이는 사용자가 AI 응용 경계를 탐색하는 창의력을 보여줍니다 (출처: Reddit r/ArtificialInteligence)
사용자, 48GB VRAM 최적 LLM 문의: Reddit 사용자는 48GB VRAM 조건에서 지식량과 사용 가능한 속도(>10t/s)를 모두 만족하는 최적의 LLM을 찾고 있습니다. 논의에서는 Deepcogito 70B(Llama 3.3 미세 조정), Qwen3 32B가 언급되었으며, Nemotron, YiXin-Distill-Qwen-72B, GLM-4, 양자화된 Mistral Large, Command R+, Gemma 3 27B 또는 부분적으로 오프로드된 Qwen3-235B 등을 시도해 볼 것을 제안했습니다. 이는 사용자가 특정 하드웨어 제약 조건 하에서 모델을 선택하고 최적화하려는 실제 요구를 반영합니다 (출처: Reddit r/LocalLLaMA)
💡 기타
로봇 기술 진전: 해당 분야에서 지속적으로 새로운 소식이 있습니다: 1. PIPE-i: Beca Group이 파이프라인 등 인프라 검사용 로봇 탐사 차량을 출시했습니다. 2. 오픈소스 휴머노이드 로봇: 캘리포니아 대학교 버클리 캠퍼스가 오픈소스 휴머노이드 로봇 프로젝트를 시작했습니다. 3. Hugging Face 로봇 팔: Hugging Face가 3D 프린팅 로봇 팔 프로젝트를 발표했습니다. 4. 먹을 수 있는 로봇 케이크: 연구원들이 먹을 수 있는 로봇 케이크를 만들었습니다. 5. 하수구 드론: 하수구를 검사하는 드론이 등장하여 사람이 하기 힘든 더러운 작업을 대신합니다 (출처: Ronald_vanLoon, TheRundownAI)

AI 규제 논의: SB-1047 법안 다큐멘터리 공개: 미카엘 트라치(Michaël Trazzi)가 캘리포니아 AI 안전 법안 SB-1047 논쟁의 비하인드 스토리를 담은 다큐멘터리를 공개했습니다. 이 법안은 최첨단 AI 개발에 최소한의 규제를 부과하려 했으나 최종적으로 통과되지 못했습니다. 다큐멘터리는 많은 캘리포니아 주민들의 지지에도 불구하고 법안이 실패한 이유를 탐구하며 AI 규제 경로와 과제에 대한 추가적인 성찰을 유발합니다 (출처: Michaël Trazzi, menhguin, NeelNanda5, JeffLadish)
양자 컴퓨팅과 AI의 결합: Nvidia는 양자 하드웨어와 AI 슈퍼컴퓨터를 통합하여 실용적인 양자 컴퓨팅의 길을 열고 있으며, 오류 수정과 실험에서 실제 응용으로의 전환 가속화에 중점을 두고 있습니다. 동시에 양자 컴퓨팅이 단순히 사이버 보안 분야의 파괴적 혁신을 넘어 과학적 번영을 더 많이 가져올 수 있다는 의견도 있습니다 (출처: Ronald_vanLoon, NVIDIA HPC Developer)
