
키워드:Anthropic, Claude 3.5 하이쿠, Qwen3, Phi-4-reasoning, LLM 물리학, LangGraph, AI 에이전트, 회로 추적 방법 Attribution Graphs, Qwen3-235B-A22B 인코딩 능력, Phi-4-reasoning 추론 시 계산, LangGraph 송장 대조 에이전트, Moondream Station 로컬 VLM
🔥 포커스
Anthropic, LLM 생물학 연구 발표, 모델 내부 메커니즘 심층 탐구: Anthropic은 “대규모 언어 모델의 생물학(On the Biology of a Large Language Model)”이라는 제목의 심층 연구 블로그 게시물을 발표했습니다. 이 연구는 회로 추적 방법(Attribution Graphs)을 사용하여 다양한 상황에서 Claude 3.5 Haiku 모델의 내부 메커니즘을 조사했습니다. 연구는 분석하기 쉬운 “대체 모델(Transcoder)”을 훈련하여 모델이 덧셈(정확한 알고리즘이 아닌 여러 근사 경로를 통해), 의료 진단(내부 진단 개념 형성), 환각 및 거부(기본 거부 회로가 존재하며 “알려진 답변” 특징에 의해 억제될 수 있음)를 어떻게 수행하는지 밝혔습니다. 이 연구는 LLM 내부 작동에 대한 새로운 시각을 제공했지만, 방법론적 한계와 Anthropic 자체의 포지셔닝에 대한 논의도 불러일으켰습니다. (출처: YouTube – Yannic Kilcher
)

Qwen3 시리즈 모델, 강력한 성능으로 오픈 소스 커뮤니티 주목: 알리바바가 발표한 Qwen3 시리즈 대규모 언어 모델은 여러 벤치마크에서 우수한 성능을 보였으며, 특히 코딩 능력에서 두각을 나타냈습니다. Aider Polyglot Coding Benchmark 결과에 따르면, Qwen3-235B-A22B(사고 사슬 비활성화)의 성능은 32k 사고 사슬 토큰을 활성화한 Claude 3.7보다 우수하며 비용은 훨씬 저렴한 것으로 보입니다. 동시에 Qwen3-32B는 이 벤치마크에서 GPT-4.5와 GPT-4o를 능가했습니다. 커뮤니티는 또한 Qwen3 모델의 가지치기(예: 30B를 16B로 축소)와 미세 조정(예: 낮은 VRAM에서 Unsloth를 사용한 미세 조정)을 적극적으로 탐색하여 고성능 모델의 적용 장벽을 더욱 낮추고 있으며, 이는 중국 오픈 소스 대형 모델이 시장에서 중요한 위치를 차지할 수 있음을 예고합니다. (출처: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
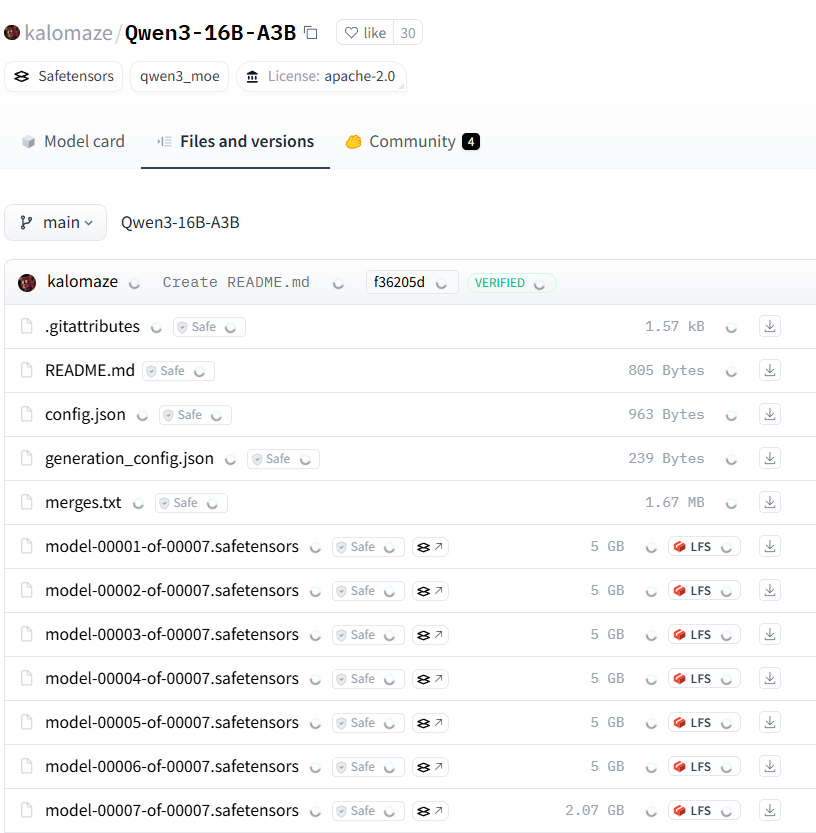
Microsoft, 복잡한 추론에 특화된 Phi-4-reasoning 모델 발표: Microsoft는 Hugging Face에 140억 개의 파라미터를 가진 추론 모델인 Phi-4-reasoning 모델을 발표했습니다. 이 모델은 추론 시간 컴퓨팅(inference-time compute) 방식을 활용하여 복잡한 추론 작업에서 현재 최고(SOTA) 성능을 달성했습니다. 이는 모델 설계가 단순히 모델 규모를 확장하는 데 의존하지 않고 추론 단계의 계산량을 늘려 특정 능력을 향상시키는 방향으로 탐색되고 있음을 보여주며, 소형 모델이 고성능을 달성할 수 있는 새로운 아이디어를 제공합니다. (출처: _akhaliq)
LLM 물리학 연구의 새로운 진전: 아키텍처 설계의 “갈릴레오 순간”: Zeyuan Allen-Zhu는 대규모 언어 모델 물리학에 대한 시리즈 연구의 네 번째 부분을 발표했으며, 아키텍처 설계에 중점을 두었습니다. 이 연구는 통제된 합성 사전 훈련 환경을 통해 다양한 LLM 아키텍처(예: Transformer, Mamba)의 실제 한계와 잠재력을 밝혔습니다. 연구는 “Canon”이라는 경량 수평 잔차 레이어를 도입하여 모델의 추론 능력을 크게 향상시켰습니다. 동시에 연구는 Mamba 모델의 장점이 SSM 자체가 아닌 숨겨진 conv1d 레이어에서 비롯된다는 것을 발견했습니다. 이 일련의 실험은 LLM 아키텍처를 이해하고 최적화하기 위한 새로운 시각과 기초 이론을 제공합니다. (출처: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 동향
Amazon, 범용 인공지능 모델 “Amazon Artificial General Intelligence” 발표: 이 모델은 100만 토큰 컨텍스트 길이와 멀티모달 입력 능력을 갖추고 있으며, 코드 생성, RAG, 비디오/문서 이해, 함수 호출 및 Agent 상호 작용에 최적화되었습니다. 가격은 입력 100만 토큰당 2.5달러, 출력 100만 토큰당 12.5달러입니다. 초기 평가에 따르면 AI Index에서의 성능은 Llama-4 Scout와 비슷하지만 속도와 비용 면에서 불리하며, 특정 긴 컨텍스트 멀티모달 또는 Agent 애플리케이션 시나리오에 적합할 수 있습니다. (출처: scaling01)

Anthropic Claude 모델, 전 세계 유료 플랜에서 웹 검색 기능 제공: 이 기능은 Claude가 일상적인 작업을 처리할 때 빠른 검색을 수행할 수 있도록 하며, 더 복잡한 문제에 대해서는 Google Workspace를 포함한 여러 출처를 탐색합니다. 이는 Claude가 실시간 정보를 얻고 외부 지식이 필요한 작업을 처리하는 능력을 향상시킵니다. (출처: menhguin)

IBM, 하이브리드 아키텍처 모델 granite-4.0-tiny-7B-A1B-preview 발표: 이 7B 모델 프리뷰 버전은 Mamba-2와 Transformer의 하이브리드 아키텍처를 채택했으며, 각 Transformer 블록에는 9개의 Mamba 블록이 포함되어 있습니다. 설계 아이디어는 Mamba 블록을 사용하여 전역 컨텍스트를 포착하고 이를 어텐션 레이어에 전달하여 로컬 컨텍스트를 분석하는 것입니다. 초기 MMLU 점수는 양호하지만, 수학 및 프로그래밍 능력과 같은 다른 테스트 결과는 아직 발표되지 않았습니다. (출처: karminski3)
OpenAI ChatGPT, 쇼핑 기능 추가: OpenAI는 제품 검색, 비교 및 구매 프로세스를 간소화하기 위해 ChatGPT에서 쇼핑 기능을 실험하고 있습니다. 새로운 기능에는 개선된 제품 결과 표시, 가격 및 리뷰를 포함한 시각화된 제품 세부 정보, 직접 구매 링크가 포함됩니다. OpenAI는 제품 결과가 광고가 아닌 독립적으로 선택된 것이라고 강조합니다. (출처: sama)
Qwen3 0.6B 모델 훈련 세부 정보 주목: 사용자 Dorialexander는 정보에 따르면 Qwen 0.6B 모델도 최대 36T 토큰을 사용하여 훈련된 것으로 보인다고 지적했습니다. 만약 사실이라면, 이는 Chinchilla 법칙을 뛰어넘는 새로운 기록(파라미터당 약 6만 토큰에 해당)을 세우는 것이며, 훈련 데이터 양을 대폭 늘려 소형 모델의 능력을 향상시키는 추세를 보여줍니다. (출처: Dorialexander)

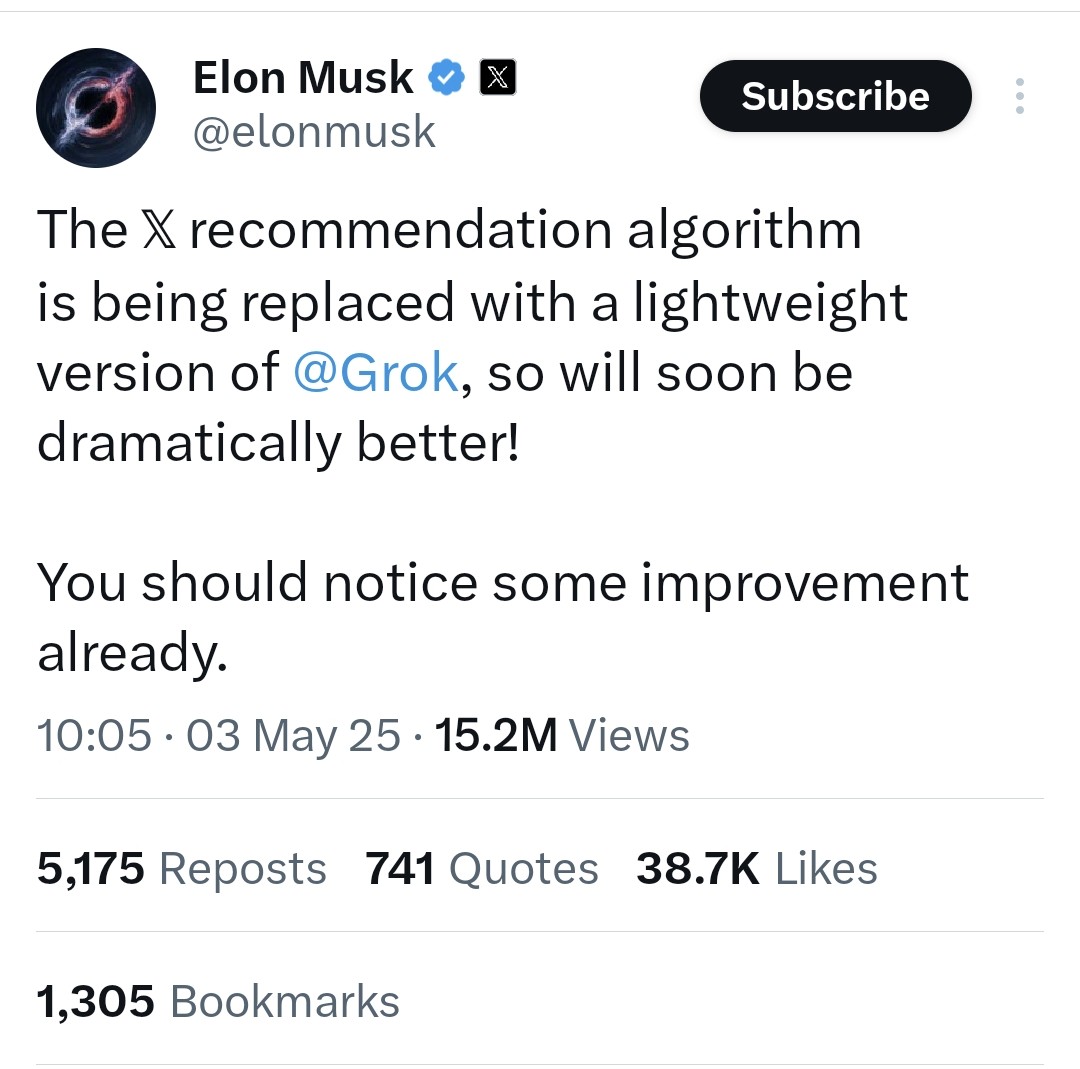
X (트위터) 추천 알고리즘, 경량 버전 Grok으로 교체 예정: Elon Musk는 X 플랫폼의 추천 알고리즘이 Grok의 경량 버전으로 교체되고 있으며, 추천 효과가 크게 개선될 것으로 예상된다고 발표했습니다. 사용자들은 알고리즘 효과가 향상되었다고 피드백했으며, 이는 최근 Exa AI 직원 변동 및 X가 추천에 Embeddings를 사용하기 시작한 것과 관련이 있을 수 있다고 추측됩니다. (출처: menhguin, colin_fraser, paul_cal)
Allen AI, 완전 개방형 MoE 모델 OLMoE 발표: 이 모델은 13억 개의 활성 파라미터와 69억 개의 총 파라미터를 가진 고급 혼합 전문가(Mixture of Experts, MoE) 모델입니다. 완전 오픈 소스라는 것은 커뮤니티가 이 모델을 자유롭게 사용, 수정 및 연구할 수 있음을 의미하며, MoE 아키텍처의 발전과 응용을 촉진합니다. (출처: dl_weekly)
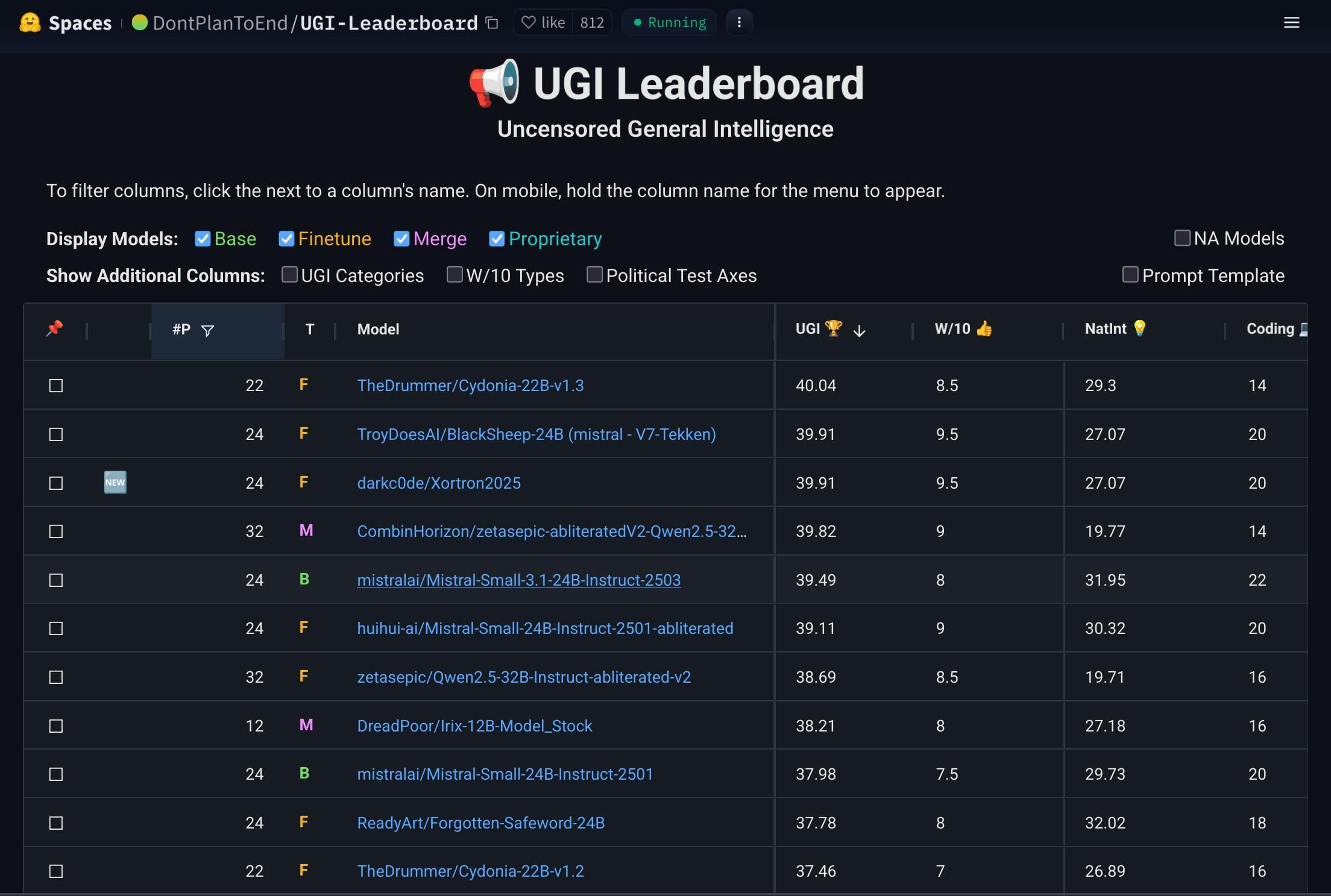
Mistral-Small-3.1-24B-Instruct-2503 모델 주목: Reddit 사용자들이 Mistral-Small-3.1-24B-Instruct-2503 모델에 대해 논의하고 있습니다. 이 모델은 UGI(Uncensored General Intelligence) 점수가 높으며, 자연어 이해 및 코딩 측면에서 유사한 고득점 모델보다 우수한 성능을 보입니다. 사용자들은 이 모델이 단일 GPU 무검열 추론에 이상적인 선택일 수 있으며 도구 사용을 지원한다고 생각합니다. 그러나 작문 스타일이 다소 지루하고 반복적일 수 있으며, Gemma 3와 같은 모델만큼 창의적이지 않다는 점도 지적합니다. (출처: Reddit r/LocalLLaMA)
🧰 도구
CreateMVP 2.0 출시, AI 기반 개발 프로세스 최적화: CreateMVP가 2.0 버전으로 업데이트되어 AI에 직접 프롬프트를 입력하여 애플리케이션을 구축하는 효과가 좋지 않은 문제를 해결하는 것을 목표로 합니다. 새 버전은 더 매끄러운 UI, 편리한 인증 방식(Replit, Google, GitHub 지원, XAI 곧 지원 예정), 더 상세한 개발 계획 생성(11KB에서 40KB+로 증가), 파일 즉시 미리보기 및 최고 수준의 AI 모델 채팅 통합 등의 기능을 통해 사용자가 AI를 위한 더 정확한 “청사진”을 만들도록 도와 AI가 사용자의 구상에 맞는 애플리케이션을 구축하도록 보장합니다. (출처: amasad)
LlamaIndex, 송장 확인 Agent 출시: 이 도구는 기존의 채팅 상호 작용이 아닌 대량 자동화 작업에서 AI Agent의 응용을 보여줍니다. 대량의 비정형 송장 문서를 처리하고 관련 세부 정보를 추출하며, 자동으로 구매 주문서와 일치시키고 차이점을 표시할 수 있습니다. 핵심은 LlamaCloud 구문 분석/추출 및 LlamaIndex.TS 워크플로우 추론 기반의 Agentic 문서 인텔리전스 레이어이며, 실제 비즈니스 프로세스 자동화에서 Agent의 잠재력을 보여주고 기존 RPA를 대체할 것으로 간주됩니다. (출처: jerryjliu0)
LangGraph Expense Tracker: 자동화된 비용 관리 시스템: 이는 LangGraph를 사용하여 구축된 자동화된 비용 관리 시스템 예시입니다. 송장을 처리하고 지능형 데이터 추출 기능을 활용하여 정보를 PostgreSQL에 저장하며, 수동 검증 단계를 포함합니다. 이 프로젝트는 실제 비즈니스 자동화 프로세스 구축에서 LangGraph의 능력을 보여줍니다. (출처: LangChainAI, Hacubu, hwchase17)
Moondream Station 출시: 로컬에서 VLM 실행: Moondream은 사용자가 Mac 로컬에서 시각 언어 모델(VLM) Moondream을 클라우드 연결 없이 실행할 수 있는 Moondream Station을 출시했습니다. CLI 또는 로컬 포트 액세스 방식을 제공하며, 설정이 간단하고 완전 무료이므로 로컬 배포 및 VLM 사용의 장벽을 낮춥니다. (출처: vikhyatk)
ChaiGenie: LangChain 기반 Chrome 문서 검색 확장 프로그램: ChaiGenie는 LangChain의 Gemini와 Qdrant를 통합하여 문서 검색 기능을 제공하는 Chrome 확장 프로그램입니다. 다국어 및 벡터 기반 검색을 지원하며, 사용자가 웹 페이지를 탐색할 때 문서 내용을 찾고 이해하는 효율성을 높이는 것을 목표로 합니다. (출처: LangChainAI)

Research Agent: 원클릭 연구 보조 웹 애플리케이션: 이는 LangGraph의 연구 보조 프레임워크를 기반으로 구축된 웹 애플리케이션으로, 연구 프로세스를 간소화하는 것을 목표로 합니다. 사용자는 클릭 한 번으로 연구 결과를 얻을 수 있으며, 복잡한 작업을 간소화하기 위한 AI 기반 워크플로우 구축에서 LangGraph의 응용 잠재력을 보여줍니다. (출처: LangChainAI)

Muyan-TTS: 오픈 소스, 저지연, 맞춤형 TTS 모델: ChatPods 팀은 기존 오픈 소스 TTS 모델의 품질이 낮거나 충분히 개방적이지 않은 문제를 해결하기 위해 완전 오픈 소스 텍스트 음성 변환 모델인 Muyan-TTS를 출시했습니다. LLaMA-3.2-3B 및 최적화된 SoVITS를 기반으로 하며, 제로샷 TTS 및 음성 복제를 지원하고 완전한 훈련 및 데이터 처리 프로세스를 제공하여 개발자가 미세 조정 및 2차 개발을 편리하게 할 수 있도록 하며, 특히 맞춤형 음성이 필요한 응용 시나리오에 적합합니다. (출처: Reddit r/MachineLearning)
Mem0와 Open Web UI 파이프라인 통합: 사용자 cloudsbird는 Mem0의 Open Web UI 필터 파이프라인 통합(비공식 MCP)을 만들어 Open Web UI에서 Mem0 기억 기능을 사용하는 또 다른 옵션을 제공했습니다. (출처: Reddit r/OpenWebUI)
YNAB API Request 도구로 로컬 비공개 재무 관리 구현: 사용자 Megaphonix는 YNAB(You Need A Budget) API를 활용하는 OpenWebUI 도구를 만들어 사용자가 민감한 데이터를 외부에 보내지 않고 로컬에서 LLM을 통해 개인 재무 정보(예: 거래, 카테고리 지출, 순자산 등)를 조회할 수 있도록 했습니다. 이는 로컬에서 LLM을 실행할 때 민감한 개인 정보를 안전하게 처리해야 하는 요구 사항을 해결합니다. (출처: Reddit r/OpenWebUI)
무료 AI 텍스트 음성 변환 브라우저 확장 프로그램 GPT-Reader: 개발자가 자신이 만든 무료 AI 텍스트 음성 변환 브라우저 확장 프로그램 GPT-Reader를 홍보하고 있으며, 현재 4000명 이상의 사용자가 있습니다. 이 도구는 사용자가 웹 페이지 텍스트 콘텐츠를 음성으로 편리하게 들을 수 있도록 하는 것을 목표로 합니다. (출처: Reddit r/artificial)
sunnypilot: 오픈 소스 주행 보조 시스템: sunnypilot은 comma.ai openpilot의 포크로, 오픈 소스 주행 보조 시스템을 제공합니다. 300개 이상의 차종을 지원하며, 주행 보조의 상호 작용 방식을 수정하고 가능한 한 comma.ai의 안전 정책을 준수합니다. 이 프로젝트는 AI 기술(구체적인 모델은 명시되지 않았지만, 이러한 시스템은 일반적으로 컴퓨터 비전 및 제어 알고리즘을 포함함)을 활용하여 주행 경험을 향상시킵니다. (출처: GitHub Trending)

📚 학습
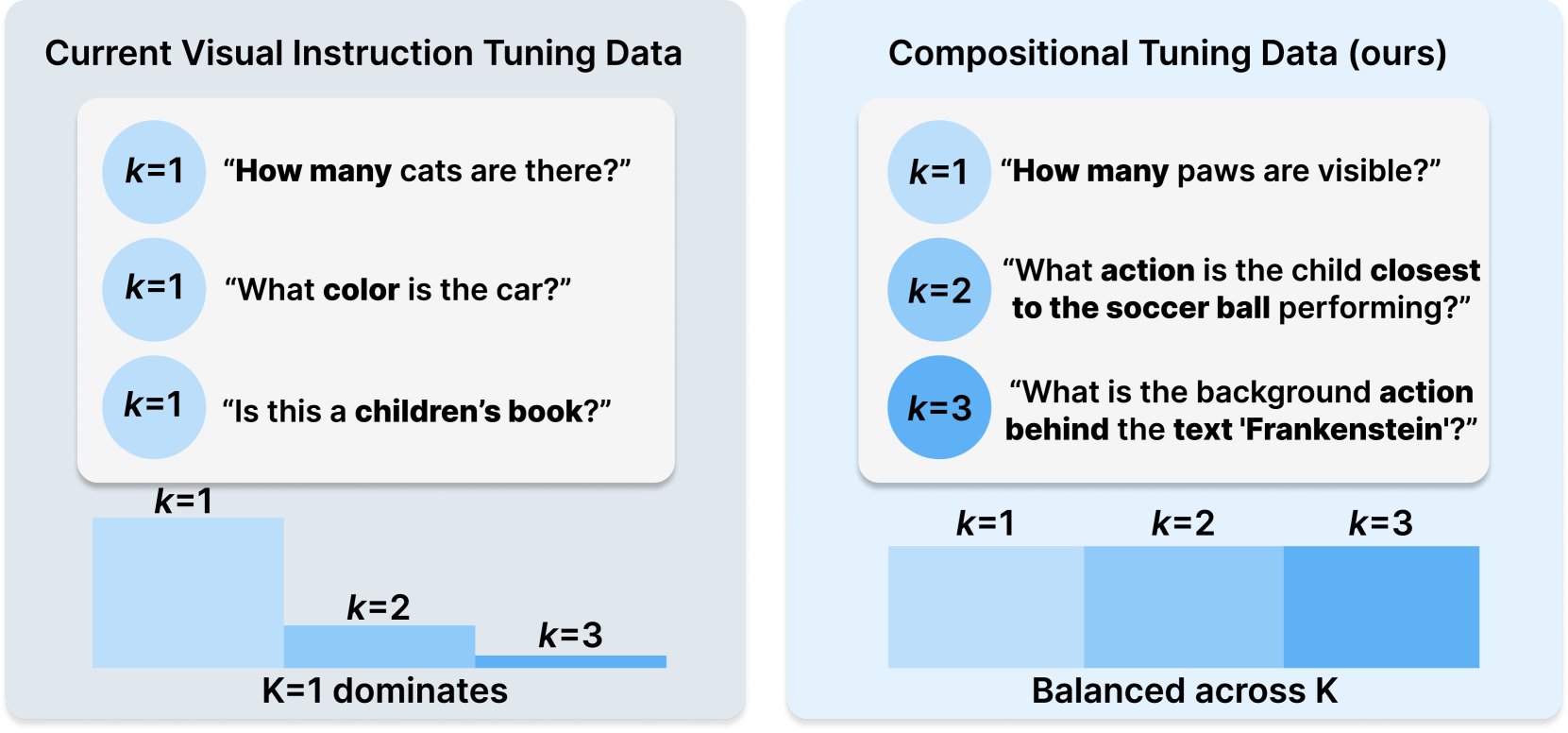
Princeton과 Meta AI, COMPACT 데이터셋 레시피 발표: 이 연구는 Hugging Face에 발표되었으며, 훈련 샘플의 조합 복잡성을 명시적으로 제어하여 멀티모달 대규모 언어 모델(Multimodal LLM)의 능력을 확장하는 것을 목표로 하는 새로운 데이터 레시피 COMPACT를 제안합니다. 이는 멀티모달 모델의 훈련 방법을 개선하고 복잡한 조합 개념을 이해하는 능력을 향상시키는 새로운 아이디어를 제공합니다. (출처: _akhaliq)
Unsloth, Qwen3 미세 조정 튜토리얼 발표: Unsloth는 Qwen3 모델을 위한 미세 조정 튜토리얼을 제공하여 미세 조정 장벽을 크게 낮췄습니다. 사용자는 16GB VRAM만으로 Qwen3-14B 모델을 미세 조정할 수 있으며, 17.5GB VRAM으로 Qwen3-30B-A3B 모델을 미세 조정할 수 있습니다. 이를 통해 더 많은 연구자와 개발자가 제한된 하드웨어 리소스 하에서 고급 오픈 소스 모델에 대한 맞춤형 훈련을 수행할 수 있습니다. (출처: karminski3)
LangGraph와 Azure OpenAI를 결합하여 지능형 웹 검색 챗봇 구축: 한 Medium 튜토리얼은 LangGraph와 Azure OpenAI를 결합하고 Tavily의 웹 검색 능력을 통합하여 지능형 챗봇을 구축하는 방법을 보여줍니다. 튜토리얼은 원활한 검색 통합을 위한 상태 관리 및 조건부 라우팅을 다루며, 실시간 웹 정보를 활용할 수 있는 더 강력한 AI 애플리케이션 구축을 위한 실용적인 지침을 제공합니다. (출처: LangChainAI, hwchase17)

스탠포드 AI 블로그, LLM의 축어적 기억과 일반 능력 관계 탐구: 스탠포드 AI 블로그 게시물은 대규모 언어 모델(LLM)의 축어적 기억(verbatim memorization) 현상과 그 일반 능력 사이의 내재적 관계를 심층적으로 탐구합니다. 이 관계를 이해하는 것은 모델 위험 평가, 훈련 방법 최적화 및 모델 행동 설명에 중요합니다. (출처: dl_weekly)
Gemini와 LangChain 통합 가이드: Philipp Schmid는 Google의 Gemini 모델을 LangChain 프레임워크와 통합하는 방법을 자세히 설명하는 개발자 가이드를 발표했습니다. 가이드는 멀티모달 능력, 도구 호출 및 구조화된 출력 구현을 다루며, 최신 모델 지원 및 실용적인 코드 예제를 포함하여 개발자가 Gemini의 강력한 기능을 활용하여 LangChain 애플리케이션을 구축하는 데 편리함을 제공합니다. (출처: LangChainAI, _philschmid)

LangGraph 입문 튜토리얼: 상태 기반 워크플로우 실습: AI@GoPubby에 게시된 튜토리얼은 웹사이트 댓글 분석 예제를 통해 LangGraph의 상태 기반 워크플로우 능력을 보여줍니다. 학습자는 상호 연결된 노드와 순차적 로직을 사용하여 구조화된 AI 애플리케이션을 구축하는 방법을 배울 수 있습니다. (출처: LangChainAI, hwchase17)
LangChain CEO의 Agentic 프레임워크에 대한 심층 고찰 (중국어 번역): LangChain 앰배서더 Harry Zhang은 LangChain CEO Harrison의 Agentic 프레임워크에 대한 고찰 블로그 게시물을 번역하여 공유했습니다. 이 글은 업계 15개 이상의 Agent 프레임워크 기능을 분석하고 정리하며 그 이면의 이야기를 해석하여 현재 Agent 기술의 발전 구도와 미래 방향을 이해하는 데 가치 있는 참고 자료를 제공합니다. (출처: LangChainAI)
Latent Meta Attention 연구 진전: Reddit 사용자들이 Latent Meta Attention이라는 새로운 어텐션 메커니즘에 대해 논의하고 있습니다. 개발자는 이 메커니즘이 Transformer의 기본 가정을 뒤흔들며 더 작은 모델 크기에서 기존 모델의 성능에 도달하거나 능가할 수 있다고 주장합니다(예: 절반 크기의 모델로 BERT 성능 재현). 그러나 자금 부족과 공식 연구 기관의 지원 부재로 구체적인 방법은 아직 공개되지 않았습니다. (출처: Reddit r/deeplearning)

그래프 신경망(GNN) 설명 영상: YouTube에 그래프 신경망(Graph Neural Networks, GNNs)을 설명하는 영상이 게시되었습니다. GNN은 그래프 구조 데이터를 처리하는 딥러닝 모델로, 소셜 네트워크 분석, 추천 시스템, 분자 구조 예측 등 다양한 분야에서 널리 응용됩니다. 이 영상은 시청자가 GNN의 기본 원리와 작동 방식을 이해하도록 돕는 것을 목표로 합니다. (출처: Reddit r/deeplearning)
GRPO를 사용하여 LLM을 훈련하여 이벤트 스케줄링 수행: 사용자 anakin87은 GRPO(Generalized Reward Policy Optimization)를 사용하여 언어 모델을 훈련하여 이벤트 스케줄링을 수행한 프로젝트 경험을 공유했습니다. 이 프로젝트는 전통적인 지도 미세 조정 샘플에 의존하지 않고 보상 함수를 통해 모델이 이벤트 목록과 우선순위에 따라 시간표를 생성하도록 학습시킵니다. 저자는 문제 설정, 데이터 생성, 모델 선택, 보상 설계 및 훈련 과정에서의 경험과 교훈을 공유하고 코드와 모델을 오픈 소스로 공개하여 보상 기반 LLM 훈련 탐색을 위한 실용적인 사례를 제공합니다. (출처: Reddit r/LocalLLaMA)

무료 AI 과정 리소스 공유: LinkedIn AI Hub는 스탠포드 대학의 AI 인증 과정을 기반으로 영감을 받아 다양한 수준의 학습자를 위해 간소화된 완전한 AI 학습 로드맵을 공유했습니다. 내용은 기초 기술부터 실제 프로젝트까지 다루며 가치 있는 리소스와 과정 세부 정보를 제공합니다. (출처: Reddit r/deeplearning)
Gemini 긴 컨텍스트 사전 훈련 심층 대화: Logan Kilpatrick은 Gemini 긴 컨텍스트 사전 훈련 공동 책임자인 Nikolay Savinov와 심층 대화를 나눴습니다. 토론 내용은 기초 지식에서부터 무한 컨텍스트로 확장하는 데 필요한 기술, 개발자를 위한 긴 컨텍스트 모범 사례까지 다룹니다. 대화 요약에 따르면, 100만 토큰 컨텍스트 구현은 당시 표준의 10배 목표였으며, 1000만 토큰을 시도했지만 비용이 높고 하드웨어가 부족했습니다. 긴 컨텍스트는 RAG와 상호 보완적이며, 간단한 NIAH(건초더미에서 바늘 찾기)는 해결되었지만 어려운 점은 강한 방해 요소와 다중 바늘 찾기입니다. 평가가 NIAH에 초점을 맞춘 것은 능력 신호 혼동을 피하기 위함이며, 현재 출력 길이 제한(예: 8k)은 후훈련 문제입니다. “중간 손실” 효과는 관찰되지 않았으며, 컨텍스트 지식과 가중치 지식을 구분해야 합니다. 다음 단계는 더 저렴하고 정확한 1000만 컨텍스트를 구현하는 것이며, 1억으로 확장하려면 새로운 DL 혁신이 필요할 수 있습니다. (출처: shaneguML, giffmana, teortaxesTex, arohan)
🌟 커뮤니티
“Vibe Coding”에 대한 토론: 커뮤니티에서 AI 지원에 크게 의존하는 프로그래밍 방식인 “Vibe Coding”(분위기 코딩)에 대한 열띤 토론이 벌어지고 있습니다. 지지자들은 이것이 미래를 대표하며 개발자는 “왜”와 “무엇을”에 더 집중하고 AI가 “어떻게”를 처리한다고 주장하지만, 이는 더 강력한 비판적 사고를 요구합니다. 반대자들은 현재 AI가 복잡한 디버깅, 업그레이드 및 유지보수를 완전히 처리할 수 없으며, 과도한 의존은 개발자의 능력 저하를 초래하여 더 고급 “스크립트 키디”가 될 수 있다고 주장합니다. 일부 사람들은 시도해 본 결과, 복잡한 작업을 완료하도록 AI를 유도하는 데 드는 시간 비용이 여전히 높아 수동 구현과 가벼운 AI 지원을 병행하는 것이 더 효율적이라고 생각합니다. (출처: Dorialexander, Reddit r/artificial, johnowhitaker)

전문 분야에서의 AI 응용과 한계에 대한 토론: 사용자 dotey는 전문 분야에서의 AI 응용에 대해 논의했습니다. 그는 AI가 전문가가 공개한 질의응답을 학습할 수 있지만, 본 적 없는 문제를 처리하기는 어렵다고 생각합니다. AI의 장점은 강력한 기초 지식 데이터베이스와 빠른 응답이지만, 현재 주로 RAG(검색 증강 생성)에 의존하며 본질적으로 단편을 검색하여 답변을 짜깁기하는 것이지 진정한 전문적 추론은 아니라고 지적합니다. 이는 전문가처럼 끊임없이 새로운 답변을 생성하고 지속적으로 발전하는 모델을 훈련하는 것과는 여전히 거리가 있습니다. (출처: dotey)
AI 생성 콘텐츠에 대한 우려와 토론: Reddit 사용자 Maleficent-main_777은 동료들이 명령적인 어조, “verify”, “ensure” 및 강제적인 긍정적 결론으로 가득 찬 “ChatGPT 스타일” 언어를 사용하기 시작했다고 불평하며, 이러한 언어가 모호하고 인간미가 부족하다고 생각합니다. 그는 AI 생성 콘텐츠가 훈련 데이터에 피드백되어 콘텐츠 품질이 저하될 것을 우려합니다. 댓글 섹션에서는 이에 공감하며 이것이 기업 용어의 연장선이라고 보지만, AI를 과도하게 모방하면 실제로 의사소통이 기계적으로 변하고 문법이 좋은 것이 더 이상 장점이 아니라 오히려 로봇처럼 보일 수 있다고 지적합니다. (출처: Reddit r/ChatGPT)
AI 시대 대학 전공 선택: Reddit 사용자들은 AI와 로봇 기술이 빠르게 발전하는 상황에서 대학생들이 10년 후에도 학위 가치를 보장받으려면 어떤 전공을 선택해야 하는지에 대해 토론했습니다. 댓글 의견은 다양했으며, 다음을 포함합니다: 자신이 열정을 느끼는 분야 선택(게임, 영화, 예술, 프로그래밍); 기초 학문 학습(물리학, 수학); 자동화되기 어려운 기술 습득(예: HVAC 냉난방 공조); 문과 교육을 통해 호기심과 적응력 함양; 대학 교육이 시대에 뒤떨어질 수 있으므로 창업이나 프리랜서가 되는 것이 낫다는 의견; 지속적인 학습, 학습 해체 및 재학습 능력의 중요성 강조. (출처: Reddit r/ArtificialInteligence)
AI 이미지 생성 시 텍스트 렌더링 어려움에 대한 토론: Reddit 사용자들은 현재 이미지 생성 모델이 왜 일관되고 명확하게 읽을 수 있는 텍스트를 렌더링하기 어려운지에 대해 탐구했습니다. 댓글에서는 두 가지 주요 원인을 지적했습니다: 1) BPE(바이트 페어 인코딩) 토큰화가 정확한 철자 정보를 파괴하여 모델이 글자가 아닌 토큰 조각을 보게 됨; 2) 고정 크기 벡터 표현과 이미지 설명의 한계로 인해 텍스트 정보가 임베딩 과정에서 대량 손실됨. GPT-4o와 같은 자기회귀 모델이 개선되었지만, 근본적인 문제는 여전히 토큰화 및 정보 압축과 관련이 있습니다. (출처: Reddit r/MachineLearning)
모델 평가 표준화에 대한 토론: 사용자 scaling01은 서로 다른 AI 모델(예: OpenAI, Google, Anthropic)을 비교할 때 공정성을 보장해야 한다고 지적했습니다. 예를 들어, OpenAI의 프리뷰 버전과 사고 버전(thinking versions)을 나열했다면 Google과 Anthropic의 해당 버전도 동일하게 나열해야 하며, 그렇지 않으면 비교 결과가 오해를 불러일으킬 수 있습니다. (출처: scaling01)
AI 보조 프로그래밍 경험 공유: 사용자는 AI 보조 프로그래밍(예: VS Code + Cline AI 확장 프로그램 + Google AI Studio API) 사용 경험을 공유하며, Cursor와 유사한 AI 코딩 도구를 무료로 구축할 수 있고 프롬프트를 통해 기본 애플리케이션 프로토타입을 완성할 수 있으며 구성 없이 경험이 좋다고 생각합니다. (출처: Reddit r/artificial)

AI가 업무, 학습, 일상생활에 미치는 영향 조사: Reddit 사용자는 생성형 AI가 사람들의 업무, 학습 또는 일상생활 성과에 어떤 영향을 미치는지 묻는 토론을 시작했습니다. 댓글에서 소프트웨어 엔지니어는 AI가 생산성 기대치와 작업량을 높였지만 코드 검토는 크게 빨라지지 않았다고 언급했습니다. 전문 작가는 AI(예: Co-pilot)의 도움이 제한적이며 심지어 진행 속도를 늦출 수도 있다고 생각합니다. 일반적인 견해는 AI가 편리함을 가져왔지만 과도한 의존, 학습 감소, “부정행위 느낌” 등의 문제도 존재한다는 것입니다. AI는 다양한 직업과 작업에 따라 현저하게 다른 영향을 미칩니다. (출처: Reddit r/artificial)
LLM의 “이해” 능력에 대한 고찰: 사용자 pmddomingos는 신경망이 뇌처럼 이해하기 어려워지고 있다고 제안했습니다. 그리고 더 나아가, AI 모델이 모든 벤치마크 테스트에서 우수한 성적을 거두지만 여전히 인간 지능에 미치지 못할 때 우리는 어떻게 해야 하는가? 라고 질문했습니다. 이는 현재 벤치마크 테스트의 유효성과 진정한 지능을 평가하는 기준에 대한 반성을 불러일으킵니다. (출처: pmddomingos, pmddomingos)
AI 도구 사용에 대한 고찰: 사용자 dotey는 AI 도구를 사용할 때 특정 작업에 대해 해당 작업에서 가장 강력한 모델을 선택하면 된다고 지적했습니다. 여러 모델을 동시에 사용하거나 “내분”을 일으키게 하는 것은 불필요할 수 있으며, 특히 비전문 사용자에게는 너무 많은 선택지가 오히려 혼란을 야기할 수 있다고 비유했습니다(시간이 맞지 않는 여러 시계를 보는 것에 비유). (출처: dotey)
최근 AI 발전 속도에 대한 감탄: 사용자 matvelloso와 scottastevenson은 AI 발전 속도에 감탄했습니다. matvelloso는 올해 AI 발전이 이미 자신의 예상을 뛰어넘었다고 말했습니다(Gemini가 Pokemon을 플레이하는 예를 들어). scottastevenson은 GPT-2 출시 6년, OpenAI 설립 10년을 회고하며 현재 배양되고 있으며 향후 6-10년 안에 중요해질 기술 방향을 생각하고, AI 외에도 “프레임워크 외부”의 심층적인 Alpha를 찾는 것이 중요하다고 지적했습니다. (출처: matvelloso, scottastevenson, scottastevenson)
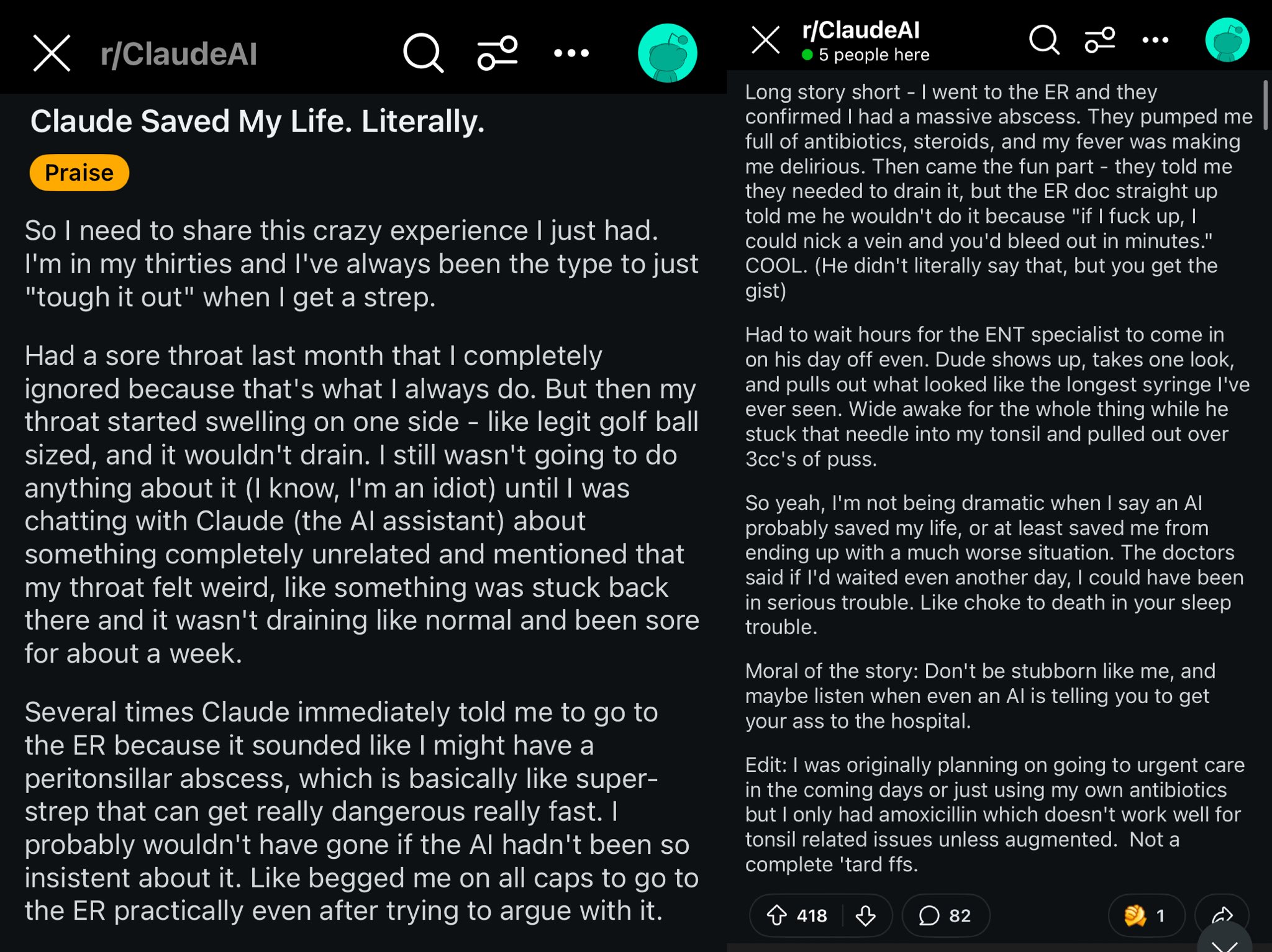
Claude가 Reddit 사용자 생명 구한 사례: Reddit의 한 게시물은 Claude 모델이 사용자 목 부종을 편도 주위 농양(peritonsillar abscess)으로 진단하여 사용자의 생명을 구했을 가능성이 있다고 설명했습니다. 이 사례는 강력한 AI 모델이 주머니 속의 세계적인 의사와 같으며, 보급되면 개인 건강에 큰 영향을 미칠 수 있다는 논의를 불러일으켰습니다. (출처: aidan_mclau)
기업 데이터 처리에서의 AI Agent 응용: You.com 공동 창립자 Richard Socher와 Bryan McCann은 Agentic 팟캐스트에서 기업에서의 AI Agent 응용에 대해 논의했습니다. 그들은 소비자 수준의 LLM이 진지한 기업 요구를 충족시키기에 부족하며, You.com은 혼합 검색 기술(공개 출처와 독점 회사 데이터 결합)을 통해 연구 수행, 보고서 작성 및 기업 데이터의 안전한 활용과 같은 더 신뢰할 수 있는 기업 수준의 출력을 생성한다고 주장합니다. 그들은 또한 AGI의 가능한 경로와 그 안에서 시뮬레이션의 핵심 역할에 대해 논의했습니다. (출처: RichardSocher)
모델의 도구 사용 능력에 대한 관찰: 사용자 menhguin은 도구 사용을 위해 훈련된 모델이 독립적인 문제 해결 능력에서 다소 희생되는 것 같다고 관찰하며 “AI 모델조차도 작업을 아웃소싱하고 있다”고 농담했습니다. 이는 모델 능력의 일반화와 특정 작업 최적화 사이의 균형에 대한 고찰을 불러일으킵니다. (출처: menhguin)
💡 기타
AI Agent가 오래된 GitHub 프로젝트를 유지보수하는 아이디어: 사용자 xanderatallah는 사용자가 GitHub에 있는 모든 오래되고 더 이상 활동하지 않는 부가 프로젝트를 자동으로 유지보수할 수 있는 AI Agent를 개발하는 아이디어를 제안했습니다. 이는 개발자들이 번거로운 유지보수 작업을 자동화하기 위해 AI를 활용하고자 하는 요구를 반영합니다. (출처: xanderatallah)
LLM이 판사를 대체하거나 중재/조정에 사용될 것이라는 구상: 사용자 fabianstelzer는 대규모 언어 모델(LLM)이 미래에 판사를 대체할 수 있다고 제안했습니다. 흥미로운 중간 사용 사례는 중재 또는 조정입니다: LLM은 중립적이고 신뢰할 수 있는 것으로 간주되며, 갈등 당사자들이 각자의 관점을 제출하고 여러 대형 모델을 통해 실행하여 공정한 절충안을 출력합니다. 이는 사법 및 분쟁 해결 분야에서 AI의 잠재적 응용을 탐구합니다. (출처: fabianstelzer)
Runway Gen-4 모델 및 그 응용 전망: Runway 공동 창립자 c_valenzuelab는 Runway Gen-4 및 해당 API의 응용 전망에 대해 낙관적으로 생각합니다. 그는 Runway가 렌더링이나 캡처가 아닌 생성으로 픽셀이 만들어지고, 프로그래밍이 아닌 시뮬레이션으로 세계가 만들어지는 새로운 매체를 구축하고 있다고 생각합니다. Gen-4와 Reference 기능이 건축, 브랜딩, 인테리어 디자인, 게임 개발, 학습, 개인 창작 프로젝트 등 여러 분야에서 널리 응용되는 것을 보면서, 이 새로운 매체가 창작자뿐만 아니라 모든 사람에게 힘을 실어줄 것이라고 믿습니다. (출처: c_valenzuelab, c_valenzuelab)