키워드:Gemini 2.5 Pro, AI 모델, 휴머노이드 로봇, AI 윤리, AI 스타트업, AI 생성 콘텐츠, AI 보조 창의성, Gemini 2.5 Pro 《포켓몬스터 블루》 클리어, Anthropic Claude 글로벌 웹 검색, Qwen3 MoE 모델 라우팅 편향, Runway Gen-4 레퍼런스 기능, 정신 건강 지원에서의 AI 활용
🔥 포커스
Gemini 2.5 Pro, Pokémon Blue 성공적으로 클리어: 구글의 Gemini 2.5 Pro AI 모델이 클래식 게임 Pokémon Blue를 성공적으로 완료했습니다. 모든 8개의 배지를 수집하고 포켓몬 리그의 사천왕을 물리치는 것을 포함합니다. 이 성과는 스트리머 @TheCodeOfJoel이 실행하고 생중계했으며, 구글 CEO Sundar Pichai와 DeepMind CEO Demis Hassabis로부터 축하를 받았습니다. 이는 복잡한 작업 계획, 장기 전략 수립 및 시뮬레이션 환경과의 상호작용 측면에서 현재 AI의 현저한 진전을 보여주며, 이전 AI의 해당 게임에서의 성과를 뛰어넘어 AI 에이전트 능력의 새로운 이정표를 세웠습니다. (출처: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple, Anthropic과 협력하여 AI 코딩 플랫폼 “Vibe Coding” 개발: 블룸버그 보도에 따르면, Apple은 AI 스타트업 Anthropic과 협력하여 “Vibe Coding”이라는 새로운 AI 기반 코딩 플랫폼을 공동 개발 중입니다. 이 플랫폼은 현재 Apple 내부 직원들에게 테스트용으로 홍보되고 있으며, 향후 제3자 개발자에게 개방될 가능성이 있습니다. 이는 AI 프로그래밍 보조 도구 분야에서 Apple의 추가적인 탐색을 의미하며, AI를 활용하여 개발 효율성과 경험을 향상시키는 것을 목표로 하며, 자체 Swift Assist와 같은 프로젝트를 보완하거나 통합할 수 있습니다. (출처: op7418)
AI 기반 로봇 기술 진전과 논의: 최근 휴머노이드 로봇과 체화형 AI(Embodied Intelligence)가 광범위한 주목을 받고 있습니다. Figure 사는 배터리, 액추에이터에서 AI 연구실까지 포괄하는 첨단 기술의 새 본사를 공개하며 로봇 분야에서의 야심을 예고했습니다. Disney도 자사의 휴머노이드 캐릭터 로봇 기술을 선보였습니다. 그러나 베이징 휴머노이드 로봇 마라톤 대회에서 일부 로봇(고객이 개조한 Unitree G1 포함)이 넘어지거나, 배터리 수명이 짧거나, 균형 문제가 발생하는 등 좋지 않은 성능을 보여 현재 휴머노이드 로봇의 실제 능력에 대한 논의를 촉발시켰으며, “소뇌”(운동 제어)와 “대뇌”(지능 결정) 측면에서 여전히 큰 진전이 필요함을 부각시켰습니다. (출처: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

AI 윤리 및 사회적 영향 논의 가열: 소셜 미디어와 연구 분야에서 AI의 사회적 영향과 윤리 문제에 대한 논의가 증가하고 있습니다. 예를 들어, 캘리포니아 SB-1047 AI 법안이 논란을 일으켰으며, 관련 다큐멘터리는 규제의 필요성과 과제를 탐구했습니다. NAACL 2025 컨퍼런스에서는 “LLM 시대의 사회 지능”에 관한 튜토리얼을 개최하여 AI와 인간, 사회 상호작용에서의 장기적이고 새로운 과제를 논의했습니다. 동시에 사용자들은 AI 생성 콘텐츠의 품질(“slop”)에 대해 우려를 표하며 더 나은 모델 설계와 제어가 필요하다고 주장합니다. 이러한 논의는 AI 기술의 빠른 발전에 따른 윤리, 규제 및 사회 적응성 문제에 대한 사회적 관심이 증가하고 있음을 반영합니다. (출처: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 동향
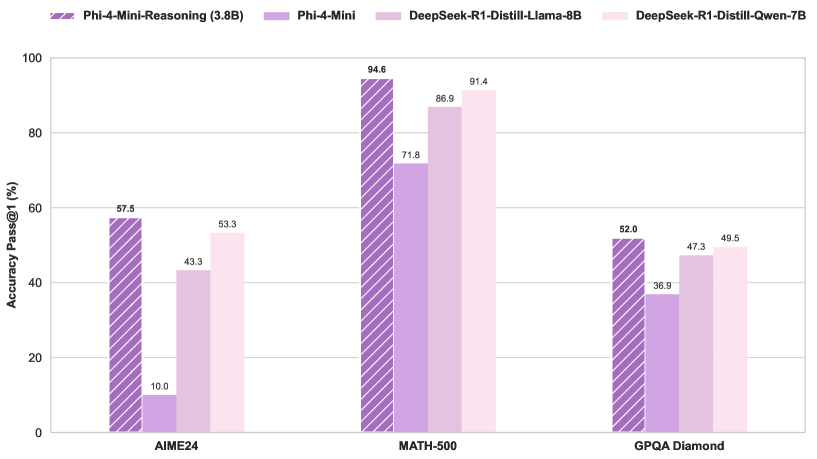
Microsoft, Phi-4-Mini-Reasoning 모델 출시: Microsoft는 Hugging Face에 Phi-4-Mini-Reasoning 모델을 출시했습니다. 이 모델은 소형 언어 모델의 수학적 추론 능력을 향상시키는 것을 목표로 하며, 소형화되고 효율적인 모델의 발전을 더욱 촉진합니다. (출처: _akhaliq)
Anthropic Claude 모델, 전 세계 웹 검색 지원: Anthropic은 자사의 Claude AI 모델이 이제 모든 유료 사용자에게 전 세계 범위의 웹 검색 기능을 제공한다고 발표했습니다. 간단한 작업의 경우 Claude는 빠른 검색을 수행하고, 복잡한 문제의 경우 Google Workspace를 포함한 여러 정보 소스를 탐색하여 모델의 실시간 정보 획득 및 처리 능력을 향상시킵니다. (출처: Teknium1, Reddit r/ClaudeAI)

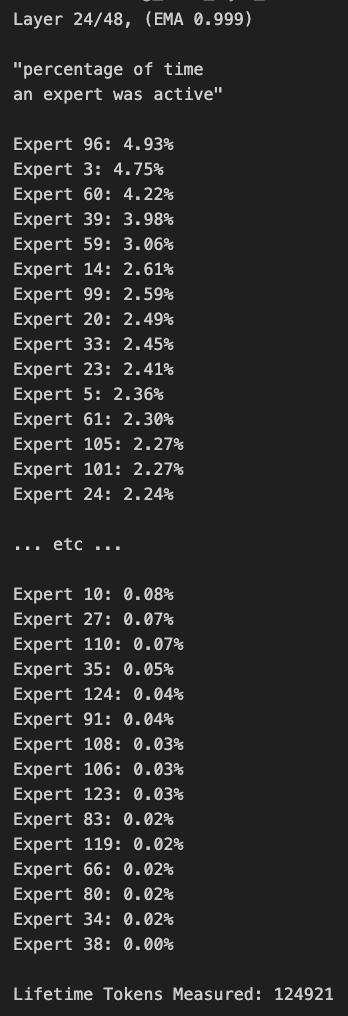
Qwen3 MoE 모델 라우팅 편향 존재, 가지치기 가능: 사용자 kalomaze는 Qwen3 MoE(Mixture of Experts) 모델의 라우팅 분포에 상당한 편향이 있음을 분석하여 발견했으며, 30B MoE 모델조차도 가지치기(pruning) 가능성을 보여줍니다. 이는 일부 전문가(Experts)가 충분히 활용되지 않았을 수 있음을 의미하며, 이러한 전문가를 가지치기를 통해 제거하면 성능에 큰 영향을 미치지 않으면서 모델 크기와 계산 요구 사항을 줄일 수 있습니다. Kalomaze는 이 발견을 기반으로 30B 모델을 16B로 가지치기한 버전을 이미 출시했으며, 235B를 150B로 가지치기한 버전을 출시할 계획입니다. (출처: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2, 오픈 소스 수학 보조 도구 중 뛰어난 성능: DeepSeek Prover V2는 현재 가장 성능이 좋은 오픈 소스 수학 보조 모델로 간주됩니다. 성능은 여전히 Gemini 2.5 Pro, o4 mini high, o3, Claude 3.7 및 Grok 3과 같은 비공개 또는 더 강력한 모델에는 미치지 못하지만, 구조화된 추론 측면에서 좋은 성능을 보입니다. 사용자들은 창의적인 사고가 필요한 “브레인스토밍” 세션에서는 개선의 여지가 있다고 생각합니다. (출처: cognitivecompai)
모델 선호도 논의: 개발자 경향과 특정 모델 특성: 개발자 커뮤니티에서는 다양한 대형 모델의 장단점에 대한 논의가 계속되고 있습니다. 예를 들어, Sentdex는 Cursor에서 Codex와 결합된 o3가 Claude 3.7보다 성능이 우수하다고 생각합니다. 반면 VictorTaelin은 Sonnet 3.7이 완벽하지는 않지만(때때로 요구하지 않은 내용을 지나치게 추가하고 지능 수준이 기대에 미치지 못함), 실제 사용에서는 GPT-4o(오류 발생 쉬움), o3/Gemini(코드 형식 및 재작성 불량), R1(다소 구식), Grok 3(두 번째로 좋지만 실제 사용에서는 약간 부족)보다 더 안정적이고 신뢰할 수 있는 결과를 제공한다고 말합니다. 이는 특정 작업 및 워크플로우에서 다양한 모델의 적용 가능성 차이를 반영합니다. (출처: Sentdex, VictorTaelin, paul_cal)

LLM 성능 추세 논의: 지수적 성장인가, 수확 체감인가?: Reddit 사용자들은 LLM이 여전히 지수적인 개선을 겪고 있는지 논의했습니다. 초기 진전은 빨랐지만 현재 LLM 성능 향상은 수확 체감(diminishing returns) 경향을 보이며 추가 성능을 얻기가 점점 더 어렵고 비용이 많이 든다는 견해가 있습니다. 이는 자율 주행 기술의 발전과 유사합니다. 다른 사용자들은 GPT-3에서 Gemini 2.5 Pro까지의 엄청난 도약이 여전히 상당한 진전을 보여주며, 지금 정체기를 단정하기에는 너무 이르다고 반박합니다. 이 논의는 AI 미래 발전 속도에 대한 다양한 예상을 반영합니다. (출처: Reddit r/ArtificialInteligence)
AI 칩, 휴머노이드 로봇 발전의 핵심으로 부상: 업계에서는 휴머노이드 로봇의 핵심이 “뇌”, 즉 고성능 칩에 있다고 봅니다. 기사에서는 현재 휴머노이드 로봇이 운동 제어(소뇌)와 지능 결정(대뇌) 측면에서 아직 부족하며, 칩 성능이 로봇의 지능화 수준을 직접 결정한다고 지적합니다. Nvidia의 GPU, Intel 프로세서 및 중국 Black Sesame Technologies의 Huashan A2000 및 Wudang C1236과 같은 칩은 로봇에 더 강력한 인식, 추론 및 제어 능력을 제공하며, 휴머노이드 로봇을 단순한 홍보 수단에서 실제 응용으로 나아가게 하는 핵심 요소입니다. (출처: 人形机器人,最重要的还是“脑子”)

AI 윤리와 의인화: 우리는 왜 AI에게 “감사합니다”라고 말하는가?: AI는 감정이 없지만 사용자는 여전히 AI에게 예의 바른 말(“감사합니다”, “부탁합니다” 등)을 사용하는 경향이 있다는 논의가 있습니다. 이는 인간의 의인화 본능과 “사회적 존재감 인식”에서 비롯됩니다. 연구에 따르면 예의 바른 상호작용 방식은 AI가 기대에 더 부합하고 더 인간적인 반응을 생성하도록 유도할 수 있습니다. 그러나 이는 AI가 인간의 편견을 학습하고 증폭시키거나 악의적으로 유도되어 부적절한 콘텐츠를 생성할 수 있는 위험도 수반합니다. AI에 대한 예의 바른 행동은 점점 더 지능화되는 기계와 상호작용하는 인간의 복잡한 심리와 사회적 적응을 반영합니다. (출처: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 도구
Runway Gen-4 References 기능: RunwayML이 출시한 Gen-4 References 기능은 사용자가 자신이나 다른 참조 이미지를 AI 생성 비디오나 이미지(예: meme)에 통합할 수 있게 합니다. 사용자 피드백에 따르면 이 기능은 효과가 뛰어나며, 동일한 생성 이미지에 여러 일관된 캐릭터가 나타나도록 처리할 수 있어 특정 인물이나 스타일을 AI 창작물에 통합하는 과정을 단순화합니다. (출처: c_valenzuelab)

Krea AI, 이미지 생성 템플릿 출시: Krea AI는 일반적인 GPT-4o 이미지 생성 프롬프트를 템플릿으로 만드는 새로운 기능을 추가했습니다. 사용자는 자신의 이미지를 업로드하고 템플릿을 선택하기만 하면 해당 스타일의 이미지를 생성할 수 있어 복잡한 프롬프트를 수동으로 입력할 필요 없이 이미지 생성 과정을 단순화합니다. (출처: op7418)
NotebookLM, 곧 모바일 앱 출시 예정: 구글의 NotebookLM(이전 Project Tailwind)이 곧 모바일 애플리케이션을 출시할 예정입니다. 사용자는 휴대폰에서 본 기사나 콘텐츠를 NotebookLM으로 빠르게 전달하여 처리하고 통합할 수 있습니다. 현재 앱 대기자 명단 등록이 시작되었으며, 더 편리한 모바일 정보 관리 및 AI 보조 학습 경험을 제공하는 것을 목표로 합니다. (출처: op7418)
Runway를 활용한 인테리어 디자인: 사용자가 Runway AI를 사용하여 인테리어 디자인을 한 사례를 선보였습니다. 공간 사진 한 장과 스타일/분위기를 나타내는 참조 사진 한 장을 제공하면 Runway는 두 가지 특징을 융합한 인테리어 디자인 시안을 생성하여 창의적인 디자인 분야에서 AI의 응용 잠재력을 보여줍니다. (출처: c_valenzuelab)

Unsloth, Qwen3 모델 미세 조정 지원: Unsloth는 Qwen3 시리즈 모델의 미세 조정을 지원한다고 발표했습니다. 속도는 2배 향상되고 VRAM 사용량은 70% 감소합니다. 사용자는 24GB VRAM GPU에서 Flash Attention 2보다 8배 더 긴 컨텍스트 길이로 미세 조정을 수행할 수 있습니다. Qwen3 14B 모델을 무료로 미세 조정할 수 있는 Colab 노트북을 제공하며, GGUF를 포함한 다양한 양자화 모델을 업로드했습니다. 이는 고급 모델 미세 조정의 하드웨어 장벽을 낮춥니다. (출처: Reddit r/LocalLLaMA)
Claude AI Styles 기능: 사용자가 Claude AI의 Styles 기능을 사용하여 AI와의 협업 경험을 개선한 사례를 공유했습니다. “Iterative Engineering”이라는 스타일을 생성하여 토론, 계획, 작은 단계 수정, 테스트, 반복, 필요시 리팩토링 단계를 설정함으로써 Claude가 코드를 지나치게 재작성하는 것을 방지하고 보다 체계적이고 점진적으로 코딩하도록 유도하여 프로그래밍 파트너로서의 AI 실용성을 향상시켰습니다. (출처: Reddit r/ClaudeAI)
Deepwiki, 코드 블록 출처 제공: 사용자 cto_junior는 Deepwiki의 장점 중 하나로 각 답변 옆에 단순히 링크를 첨부하는 것이 아니라 소스 코드 블록을 표시한다는 점을 언급했습니다. 이러한 방식은 정보의 신뢰도를 높이며, 특히 AI 도구에 회의적인 소프트웨어 개발 엔지니어(SDEs)에게 더 도움이 됩니다. (출처: cto_junior)
📚 학습
NousResearch, Atropos RL 프레임워크 업데이트 발표: NousResearch의 Atropos 강화 학습(RL) 환경 프레임워크가 업데이트되었습니다. 새로운 기능을 통해 사용자는 훈련이나 추론 엔진 없이도 RL 환경의 롤아웃(rollout)을 빠르고 쉽게 테스트할 수 있습니다. 기본적으로 OpenAI API를 사용하지만 다른 API 제공업체(또는 로컬 VLLM/SGLang 엔드포인트)로 구성할 수 있습니다. 테스트 완료 후 완료(completions) 및 해당 점수가 포함된 웹 페이지 보고서가 생성되며, wandb 로깅을 지원하여 RL 환경의 디버깅 및 평가를 용이하게 합니다. (출처: Teknium1)

개인화 RAG 벤치마크 데이터셋 EnronQA 공개: 연구자들이 개인 문서에 대한 개인화 검색 증강 생성(Personalized RAG) 연구를 촉진하기 위해 EnronQA 데이터셋을 공개했습니다. 이 데이터셋은 103,638개의 이메일과 150명의 사용자를 대상으로 한 528,304개의 고품질 질문-답변 쌍을 포함하며, 개인별 특정 정보를 이해하고 활용할 수 있는 RAG 시스템을 평가하고 개발하기 위한 리소스를 제공합니다. (출처: lateinteraction)
GTE-ModernColBERT (PyLate) 출시: LightOnAI는 GTE-ModernColBERT (PyLate)를 출시했습니다. 이는 128차원의 MaxSim 검색기로, gte-modernbert-base를 기반으로 하며 ms-marco-en-bge-gemma에서 미세 조정되었습니다. PyLate 라이브러리를 기본적으로 지원하여 재정렬(reranking) 및 HNSW 인덱싱이 가능합니다. NanoBEIR 벤치마크에서 우수한 성능을 보였으며, BEIR 평균 점수에서 ColBERT-small을 능가하여 새로운 효율적인 텍스트 검색 옵션을 제공합니다. (출처: lateinteraction)

SOLO Bench – 새로운 LLM 벤치마크 테스트: 사용자 jd_3d가 새로운 LLM 벤치마크 방법인 SOLO Bench를 개발하고 공개했습니다. 이 테스트는 LLM에게 특정 수(예: 250개 또는 500개)의 문장을 포함하는 텍스트를 생성하도록 요구합니다. 각 문장은 미리 정의된 목록(명사, 동사, 형용사 등 포함)의 단어를 하나만 포함해야 하며, 각 단어는 한 번만 사용해야 합니다. 규칙 기반 스크립트를 통해 평가하며, LLM의 지침 준수, 제약 조건 만족 및 장문 텍스트 생성 능력을 테스트하는 것을 목표로 합니다. 초기 결과는 이 벤치마크가 다양한 모델의 성능을 효과적으로 구별할 수 있음을 보여줍니다. (출처: Reddit r/LocalLLaMA)
전략적 재귀적 성찰을 이용한 잠재 공간 조작: 사용자가 “전략적 재귀적 성찰”(Strategic recursive reflection, RR)을 통해 LLM 잠재 공간에 중첩된 추론 계층을 생성하는 방법을 제안했습니다. 중요한 순간에 모델에게 이전 상호작용을 성찰하도록 프롬프트를 제공하여 메타인지 루프를 생성하고 “미니 잠재 공간”을 구축합니다. 각 프롬프트는 모델이 잠재 공간에서 경로를 탐색하도록 유도하는 압력으로 간주되어 모델이 더 자기 참조적이고 추상적인 능력을 갖도록 합니다. 이는 인간이 생각에 대한 성찰을 통해 사고를 심화하는 과정을 모방한 것으로 간주되며, 더 깊은 수준의 개념을 탐색하는 것을 목표로 합니다. (출처: Reddit r/ArtificialInteligence)
💼 비즈니스
구글, 삼성에 Gemini AI 사전 설치 대가 지불: 작년에 기본 검색 엔진 계약으로 반독점법 위반 판결을 받은 후, 구글이 삼성 기기에 Gemini AI를 사전 설치하기 위해 삼성에 매달 “거액의 자금”과 수익 분배금을 지불하고 있으며, 파트너에게 Gemini 강제 사전 설치를 요구할 수도 있다는 사실이 밝혀졌습니다. 이는 삼성 Galaxy S25 시리즈가 Gemini를 깊이 통합하고 심지어 기본 AI 비서로 설정하는 이유를 설명합니다. 이 조치는 자체 하드웨어 채널이 부족한 상황에서 모바일 AI 진입점을 선점하려는 구글의 전략을 반영하지만, 다시 한번 반독점 우려를 불러일으킬 수 있습니다. (출처: 三星手机预装Gemini AI,也是谷歌花钱买的)

AI 스타트업, 도전 직면: Reddit 토론에서는 많은 AI 스타트업이 해자(moat)가 부족할 수 있다고 지적합니다. 모델 능력이 비슷해지고 사용자 충성도가 낮기 때문입니다. 대형 기술 기업(구글, 마이크로소프트, 애플)은 생태계 우위(예: 사전 설치, 통합)를 통해 사용자에게 더 쉽게 접근할 수 있습니다. 스타트업의 모델이 약간 더 좋더라도 사용자는 기본 또는 통합된 “충분히 좋은” AI를 선호할 수 있습니다. 이는 AI 스타트업의 장기적인 생존 가능성과 VC 투자 전망에 대한 우려를 불러일으킵니다. (출처: Reddit r/ArtificialInteligence)
이번 주 AI 펀딩 및 비즈니스 동향 요약 (2025년 5월 2일): 마이크로소프트 CEO, AI가 회사 코드의 “중요한 부분”을 작성했다고 밝힘; 마이크로소프트 CFO, 수요 과다로 AI 서비스 중단 가능성 경고; 구글, 제3자 AI 챗봇에 광고 게재 시작; Meta, 독립 AI 앱 출시; Cast AI, 1억 8백만 달러 펀딩, Astronomer, 9천 3백만 달러 펀딩, Edgerunner AI, 1천 2백만 달러 펀딩; 연구, LM Arena의 벤치마크 조작 문제 지적; Nvidia, 칩 수출 통제에 대한 Anthropic의 지지에 이의 제기. (출처: Reddit r/artificial)
🌟 커뮤니티
AI 생성 콘텐츠의 품질과 비용 논의: 커뮤니티에서는 AI 생성 콘텐츠의 품질이 고르지 않은(“slop”이라고 함) 것에 대한 우려를 표명합니다. 사용자 wordgrammer는 대량 생성된 AI 비디오의 품질이 낮으며, 실제 비용(선별 및 재시도 고려)이 표시 가격보다 훨씬 높다고 지적합니다. 이는 모델 설계(예: jam3scampbell이 스티브 잡스의 견해 인용)와 AI 도구의 효과적인 활용에 대한 논의를 촉발하며, 더 정교한 제어와 더 높은 생성 품질 기준의 필요성을 강조합니다. (출처: wordgrammer, jam3scampbell, willdepue)
특정 작업에서의 AI 성능 관련 논의: 커뮤니티 회원들은 다양한 작업에서 AI의 성능과 한계에 대해 논의합니다. 예를 들어, DeepSeek R1은 형식 수학, 의학 등 분야에서 진전이 있었지만 일반 사용자의 광범위한 관심을 끌지 못해 LLM 과대광고의 정점일 수 있다고 여겨집니다. DeepSeek Prover V2는 수학에서 좋은 성능을 보이지만 창의성이 부족하다고 평가됩니다. 사용자 vikhyatk는 AIME(미국 수학 초청 경시대회)와 같은 특정 벤치마크에서 성능을 내기 위해 모델을 과도하게 최적화하는 것의 의미에 의문을 제기하며, 대중은 수학 능력에 관심이 없다고 주장합니다. 이러한 논의는 AI 능력의 경계와 실제 적용 가치에 대한 성찰을 반영합니다. (출처: wordgrammer, cognitivecompai, vikhyatk)
AI 보조 창의성 및 디자인: 커뮤니티는 AI 도구를 사용하여 창의적인 디자인을 하는 다양한 방법을 보여줍니다. 사용자는 Runway의 Gen-4 References 기능을 사용하여 자신을 meme에 통합하고, Runway를 사용하여 인테리어 디자인 컨셉을 생성하며, GPT-4o와 프롬프트 템플릿을 활용하여 특정 스타일의 이미지(예: 종이접기 남중국 호랑이, 동물 실리콘 손목 받침대, 단어 의미를 글자에 통합한 디자인)를 만듭니다. 이러한 사례는 시각적 창의성, 개인화된 디자인 분야에서 AI의 잠재력을 보여줍니다. (출처: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

AI의 글쓰기 스타일 모방 능력에 대한 의문: 사용자 nrehiew_는 LLM에게 “내 말투와 스타일로 계속 써줘”라는 지시가 실제 효과가 없을 수 있다고 주장합니다. 대부분의 사람들이 자신의 글쓰기 스타일의 독창성을 과대평가하기 때문입니다. 이는 LLM이 미묘한 글쓰기 스타일을 이해하고 복제하는 능력과 사용자의 이러한 능력에 대한 인식 편향에 대한 논의를 불러일으킵니다. (출처: nrehiew_)
정서적 지원을 위한 AI 사용, 공감과 논의 유발: Reddit 사용자들은 ChatGPT 등 AI와 대화하며 정서적 지원을 받고 위기 상황 대처에 도움을 받은 경험을 공유했습니다. 많은 사람들이 외롭거나, 털어놓을 곳이 필요하거나, 심리적 어려움에 직면했을 때 AI가 비판단적이고 인내심 있으며 언제든 이용 가능한 대화 상대를 제공했으며, 때로는 실제 사람과 대화하는 것보다 더 효과적이라고 느꼈다고 말합니다. 이는 정신 건강 지원에서 AI의 역할에 대한 논의를 촉발하는 동시에, AI가 전문적인 인간의 도움을 대체할 수 없으며 AI가 가져올 수 있는 편견이나 오도에 대해 경계해야 함을 강조합니다. (출처: Reddit r/ChatGPT, Reddit r/ClaudeAI)
AI 생성 예술에 대한 견해 차이: 사용자들은 AI 생성 예술이 인간 예술가와 그들의 작품 인식에 미칠 잠재적 영향에 대해 논의합니다. 일부는 고품질 작품이 이제 쉽게 AI 생성물로 치부되어 창작자의 재능과 노력을 간과한다고 불평합니다. 이러한 현상은 심지어 사람들의 인식을 왜곡하기 시작하여, 작품이 AI 창작물이 아님을 확인하기 위해 “인간의 실수”를 찾는 경향을 보이게 만듭니다. 논의는 또한 AI 생성 콘텐츠에 워터마크를 의무화해야 하는지 여부도 다룹니다. (출처: Reddit r/ArtificialInteligence)
💡 기타
AI 자원 소모 주목: AI 발전 이면의 막대한 자원 소모가 강조되는 논의가 있습니다. 대규모 AI 모델을 훈련하고 운영하는 데는 많은 전력과 수자원이 필요하며, 데이터 센터는 새로운 고에너지 소비 시설이 되고 있습니다. 사용자와 AI의 모든 상호작용, 심지어 간단한 “감사합니다”조차도 에너지를 누적적으로 소비합니다. 이는 AI의 지속 가능한 발전과 핵융합과 같은 에너지 솔루션에 대한 관심을 불러일으킵니다. (출처: 你对 AI 说的每一句「谢谢」,都在烧钱)
AI와 의식의 거리: Reddit 사용자들은 현재 AI가 자의식을 가지고 있는지 논의합니다. 일반적인 견해는 현재의 AI(예: LLM)는 본질적으로 확률에 기반하여 단어를 예측하는 복잡한 패턴 매칭 시스템이며, 진정한 이해와 자의식이 부족하고 그러한 능력을 갖추기까지는 매우 멀다는 것입니다. 그러나 인간의 의식 자체도 완전히 이해되지 않았기 때문에 비교에 오해가 있을 수 있으며, 특정 작업에서 AI의 초인적인 능력은 무시할 수 없다는 의견도 있습니다. (출처: Reddit r/ArtificialInteligence)
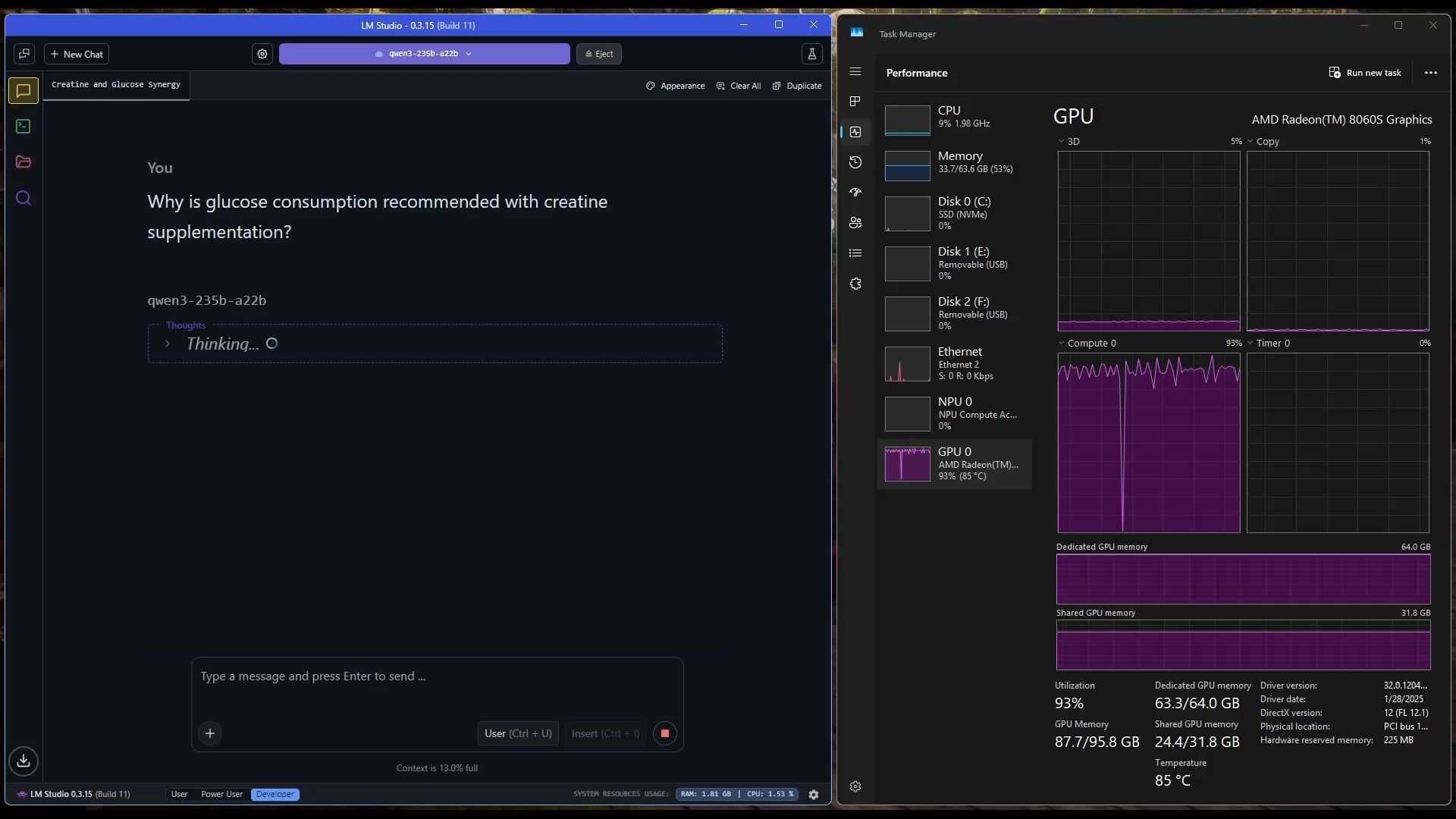
Windows 태블릿에서 대규모 MoE 모델 실행: 사용자가 AMD Ryzen AI Max 395+ 및 128GB RAM이 장착된 Windows 태블릿 컴퓨터에서 iGPU(Radeon 8060S, 95.8GB 중 87.7GB를 VRAM으로 할당)만 사용하여 Qwen3 235B-A22B MoE 모델(Q2_K_XL 양자화 사용)을 약 11.1 t/s의 속도로 실행하는 사례를 보여주었습니다. 이는 메모리 대역폭이 여전히 병목 현상이지만 휴대용 장치에서 초대형 모델을 실행할 수 있는 가능성을 보여줍니다. (출처: Reddit r/LocalLLaMA)