
키워드:Kimi K2 Thinking, Gemini, AI 에이전트, LLM(대형 언어 모델), 오픈소스 모델, Kimi K2 Thinking 256K 컨텍스트, Gemini 1.2조 파라미터, AI 에이전트 도구 호출, LLM 추론 가속, 오픈소스 AI 모델 벤치마크
🔥 포커스
Kimi K2 Thinking 모델 출시, 오픈소스 AI 추론 능력의 새로운 돌파구 : Moonshot AI가 Kimi K2 Thinking 모델을 출시했습니다. 이 모델은 조 단위 매개변수를 가진 오픈소스 추론 에이전트 모델로, HLE 및 BrowseComp와 같은 벤치마크에서 뛰어난 성능을 보이며 256K 컨텍스트 창을 지원하고 200-300개의 연속 도구 호출을 실행할 수 있습니다. 이 모델은 INT4 양자화에서 두 배의 추론 가속을 달성했으며, 메모리 사용량을 절반으로 줄이면서도 정확도 손실이 없습니다. 이는 오픈소스 AI 모델이 추론 및 에이전트 능력에서 새로운 선두에 도달하여 최고 수준의 클로즈드소스 모델과 경쟁하며 비용이 더 저렴하다는 것을 의미하며, AI 애플리케이션 개발 및 보급을 가속화할 것으로 기대됩니다. (来源: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple과 Google 협력, Gemini가 Siri 대규모 업그레이드 지원 : Apple은 2026년 봄 출시 예정인 iOS 26.4 시스템에 Google Gemini 1.2조 매개변수 AI 모델을 도입하여 Siri를 전면적으로 업그레이드할 계획입니다. 이 맞춤형 Gemini 모델은 Apple의 프라이빗 클라우드 서버를 통해 실행되며, Siri의 의미 이해, 다중 턴 대화 및 실시간 정보 검색 능력을 크게 향상시키고 AI 웹 검색 기능을 통합하는 것을 목표로 합니다. 이는 Apple이 AI 분야에서 핵심 제품의 지능화를 가속화하기 위해 외부 협력을 모색하는 중요한 전략적 전환을 의미하며, Siri가 기능적으로 큰 도약을 이룰 것임을 예고합니다. (来源: op7418, pmddomingos, TheRundownAI)

Kosmos AI 과학자, 연구 효율성 비약적 발전 달성, 7가지 성과 독자 발견 : Kosmos AI 과학자는 12시간 만에 인간 과학자 6개월 분량의 작업을 완료하여 1500편의 문헌을 읽고 4.2만 줄의 코드를 실행하며 추적 가능한 과학 보고서를 작성했습니다. 이 AI는 신경 보호 및 재료 과학 분야에서 7가지 성과를 독자적으로 발견했으며, 그 중 4가지는 처음으로 제안된 것입니다. 이 시스템은 지속적인 기억과 자율 계획을 통해 수동적인 도구에서 연구 협력자로 진화했으며, 여전히 인간의 약 20% 결론 검증이 필요하지만, 인간-기계 협력이 연구 패러다임을 재편할 것임을 예고합니다. (来源: Reddit r/MachineLearning, iScienceLuvr)
🎯 동향
Google Gemini 3 Pro 모델 의도치 않게 유출, 커뮤니티 관심 집중 : Google Gemini 3 Pro 모델이 의도치 않게 유출된 것으로 보이며, 현재 미국 IP의 Gemini CLI에서 잠시 사용 가능했지만, 잦은 오류로 인해 아직 불안정한 상태입니다. 이번 유출은 모델 매개변수와 향후 출시에 대한 커뮤니티의 높은 관심을 불러일으켰으며, Google의 대규모 언어 모델 분야 최신 진전이 곧 공개될 수 있음을 시사합니다. (来源: op7418)
OpenAI GPT-5.1 Thinking 모델 출시 임박, 커뮤니티 기대감 고조 : 소셜 미디어에서 여러 소식통이 OpenAI가 GPT-5.1 Thinking 모델을 곧 출시할 것이라고 암시했으며, 유출된 정보로 그 존재가 확인되었습니다. 이 소식은 OpenAI의 차세대 모델 능력과 출시 시기에 대한 커뮤니티의 높은 기대를 불러일으켰으며, 특히 추론 및 사고 능력 향상에 대한 관심이 집중되어 AI 기술의 최전선을 다시 한번 추진할 것으로 예상됩니다. (来源: scaling01)
Anthropic 연구, LLM의 새로운 자기 성찰 의식 발견, AI 자기 인식에 관심 집중 : Anthropic은 개념 주입 실험을 통해 Claude Opus 4.1 및 4와 같은 LLM이 새로운 자기 성찰 의식을 보여주며, 주입된 개념을 20%의 성공률로 감지하고 내부 ‘사고’와 텍스트 입력을 구분하며 출력 의도를 식별할 수 있음을 발견했습니다. 모델은 또한 프롬프트 시 내부 상태를 조절할 수 있어, 현재 LLM에서 다양하고 신뢰할 수 없는 기계적 자기 의식이 나타나고 있음을 시사하며, AI의 자기 인식과 의식에 대한 심층적인 논의를 불러일으켰습니다. (来源: TheTuringPost)

OpenAI Codex 빠른 반복, ChatGPT 중단 및 안내 지원으로 상호작용 효율성 향상 : OpenAI의 Codex 모델은 빠르게 개선되고 있으며, 동시에 ChatGPT는 사용자가 긴 쿼리 실행 중에 중단하고 새로운 컨텍스트를 추가할 수 있는 기능을 새로 추가하여 다시 시작하거나 진행 상황을 잃을 필요가 없게 되었습니다. 이 중요한 기능 업데이트는 사용자가 실제 팀원과 협력하는 것처럼 AI의 응답을 안내하고 정제할 수 있게 하여 상호작용의 유연성과 효율성을 크게 향상시키고, 심층 연구 및 복잡한 쿼리에서 사용자 경험을 최적화했습니다. (来源: nickaturley, nickaturley)
Tencent Hunyuan, 인터랙티브 AI 팟캐스트 출시, AI 콘텐츠 상호작용의 새로운 모델 탐색 : Tencent Hunyuan은 국내 최초의 인터랙티브 AI 팟캐스트를 출시하여 사용자가 청취 중 언제든지 중단하고 질문할 수 있도록 하며, AI는 컨텍스트, 배경 정보 및 네트워크 검색을 결합하여 답변을 제공합니다. 기술적으로는 더 자연스러운 음성 상호작용을 구현했지만, 핵심은 여전히 사용자와 AI 간의 상호작용이며 창작자와 직접적인 관련이 없는 답변입니다. 상업적 적용 및 사용자 지불 모델은 여전히 도전에 직면해 있으며, 사용자와 창작자 간의 정서적 연결을 구축하는 방법을 시급히 모색해야 합니다. (来源: 36氪)
AI 하드웨어 및 구현 지능 시장 발전과 도전: 이어폰부터 휴머노이드 로봇까지 : 대규모 모델과 멀티모달 기술의 성숙에 따라 AI 이어폰 시장은 지속적으로 뜨거워지고 있으며, 기능은 콘텐츠 생태계 및 건강 모니터링으로 확장되고 있습니다. 구현 지능 로봇 산업도 새로운 폭발적 성장의 시작점에 서 있으며, Xpeng, PHYBOT 등의 회사는 휴머노이드 로봇을 선보여 ‘사람 숨기기’ 의혹을 해명하고 노인 돌봄, 문화 유산(서예, 쿵푸 등)과 같은 응용 시나리오를 탐색하고 있습니다. 그러나 이 산업은 비용, 투자 수익률, 데이터 수집 및 표준화 병목 현상과 같은 도전에 직면해 있으며, 단기적으로는 ‘시나리오 일반화’에 실용적으로 집중해야 하고, 장기적으로는 개방형 플랫폼과 생태계 협력이 필요합니다. AI는 의료 건강 분야에서도 환자 돌봄 격차에 주의를 기울여야 합니다. (来源: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

새로운 모델 및 성능 돌파: Qwen3-Next 코드 생성, vLLM 혼합 모델 및 저메모리 추론 : Alibaba Cloud Qwen3-Next 모델은 복잡한 코드 생성에서 뛰어난 성능을 보여 기능이 완벽한 웹 애플리케이션을 성공적으로 생성했습니다. vLLM은 Qwen3-Next, Nemotron Nano 2 및 Granite 4.0과 같은 혼합 모델을 전면적으로 지원하여 추론 효율성을 향상시켰습니다. AI21 Labs Jamba Reasoning 3B 모델은 2.25 GiB의 초저메모리 실행을 달성했습니다. Maya-research/maya1은 텍스트 설명으로 음색을 맞춤 설정할 수 있는 차세대 자동 회귀 텍스트-음성 모델을 출시했습니다. TabPFN-2.5는 테이블 데이터 처리 능력을 5만 샘플로 확장했습니다. Windsurf SWE-1.5 모델은 GLM-4.5와 더 유사하게 분석되어, 국산 대규모 모델이 실리콘밸리에서 응용될 가능성을 시사합니다. MiniMax AI는 RockAlpha 아레나에서 2위를 차지했습니다. 이러한 진전은 LLM이 코드 생성, 추론 효율성, 멀티모달 및 테이블 데이터 처리와 같은 분야에서 성능 한계를 함께 확장하고 있습니다. (来源: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

AI 인프라 및 최첨단 연구: AWS 냉각, 확산형 LLM 및 다국어 아키텍처 : Amazon AWS는 AI 인프라의 냉각 문제를 해결하기 위해 In-Row Heat Exchanger (IRHX) 액체 냉각 시스템을 출시했습니다. Joseph Redmon은 AI 연구로 복귀하여 지구 관측 기초 모델을 탐색하는 OlmoEarth 논문을 발표했습니다. Meta AI는 다국어 모델 훈련을 최적화하는 ‘Mixture of Languages’라는 새로운 아키텍처를 발표했습니다. Inception 팀은 확산형 LLM을 구현하여 생성 속도를 10배 향상시켰습니다. Google DeepMind AlphaEvolve는 대규모 수학 탐색에 사용됩니다. Wan 2.2 모델은 NVFP4 최적화를 통해 추론 속도를 8% 향상시켰습니다. 이러한 진전은 AI 인프라의 효율성과 핵심 연구 분야의 혁신을 함께 추진하고 있습니다. (来源: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Neuralink BCI 기술, 마비 환자의 로봇 팔 제어 가능하게 해 : Neuralink의 뇌-컴퓨터 인터페이스(BCI) 기술은 마비 환자가 생각만으로 로봇 팔을 제어할 수 있도록 성공적으로 만들었습니다. 이 획기적인 진전은 AI가 보조 의료 및 인간-기계 상호작용 분야에서 가진 거대한 잠재력을 예고하며, 미래에는 생명 보조 로봇과 결합하여 장애인의 삶의 질과 독립성을 크게 향상시킬 수 있습니다. (来源: Ronald_vanLoon)
🧰 도구
Google Gemini Computer Use Preview 모델 출시, AI 자동 웹 상호작용 지원 : Google은 Gemini Computer Use Preview 모델을 출시했으며, 사용자는 명령줄 인터페이스(CLI)를 통해 실행하여 Google에서 “Hello World”를 검색하는 것과 같은 브라우저 작업을 수행할 수 있습니다. 이 도구는 Playwright 및 Browserbase 환경을 지원하며 Gemini API 또는 Vertex AI를 통해 구성할 수 있어, AI 에이전트가 자동화된 웹 상호작용을 구현하는 기반을 제공하고 LLM의 실제 응용 능력을 크게 확장합니다. (来源: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

AI 에이전트 개발 및 최적화: 컨텍스트 엔지니어링 및 효율적인 구축 : Anthropic은 더 효율적인 AI 에이전트 구축에 대한 가이드를 발표했으며, 도구 호출 시 발생하는 token 비용, 지연 시간 및 도구 조합 문제를 해결하는 데 중점을 두었습니다. 이 가이드는 “코드-온-API” 방식, 점진적 도구 발견 및 환경 내 데이터 처리를 통해 복잡한 워크플로우의 token 사용량을 15만에서 2천으로 줄였습니다. 동시에 ClaudeAI 에이전트 스킬 개발자는 Agent Skills를 문서 더미가 아닌 컨텍스트 엔지니어링 문제로 간주해야 한다고 강조하며, 3단계 로딩 시스템을 통해 활성화 속도와 token 효율성을 크게 향상시켜 “200줄 규칙”과 점진적 공개의 중요성을 입증했습니다. (来源: omarsar0, Reddit r/ClaudeAI)
Chat LangChain 새 버전 출시, 더 빠르고 스마트한 채팅 경험 제공 : Chat LangChain이 “더 빠르고, 더 스마트하며, 더 보기 좋은” 새 버전을 출시했습니다. 이 버전은 채팅 인터페이스를 통해 기존 문서를 대체하여 개발자가 프로젝트를 더 빠르게 제공할 수 있도록 돕는 것을 목표로 합니다. 이 업데이트는 LangChain 생태계의 사용자 경험을 향상시켜 사용 및 개발을 더 쉽게 만들고, LLM 애플리케이션 구축을 위한 더 효율적인 도구를 제공합니다. (来源: hwchase17)
Yansu AI 코딩 플랫폼, 시나리오 시뮬레이션 기능 출시, 소프트웨어 개발 신뢰도 향상 : Yansu는 심각하고 복잡한 소프트웨어 개발에 중점을 둔 새로운 AI 코딩 플랫폼으로, 코딩 전에 시나리오 시뮬레이션을 배치하는 것이 특징입니다. 이 방법은 개발 시나리오를 미리 시뮬레이션하여 소프트웨어 개발의 신뢰도와 효율성을 높이고, 후반 디버깅 및 재작업을 줄여 전체 개발 프로세스를 최적화하는 것을 목표로 합니다. (来源: omarsar0)
Qdrant Engine, 클라우드 네이티브 RAG 솔루션 출시, 전면적인 데이터 제어 실현 : Qdrant Engine은 Qdrant(벡터 데이터베이스), KServe(임베딩) 및 Envoy Gateway(라우팅 및 지표)를 기반으로 하는 클라우드 네이티브 RAG(검색 증강 생성) 솔루션을 소개하는 새로운 커뮤니티 기사를 발표했습니다. 이는 완전한 오픈소스 RAG 스택으로, 전면적인 데이터 제어를 제공하며 기업 및 개발자가 효율적인 AI 애플리케이션을 구축하는 데 편의를 제공하고, 특히 데이터 프라이버시 및 자율 배포 능력을 강조합니다. (来源: qdrant_engine)

KTransformers, 다중 GPU 추론 및 로컬 미세 조정의 새 시대 진입, 조 단위 매개변수 모델 지원 : KTransformers는 SGLang 및 LLaMa-Factory와의 협력을 통해 DeepSeek 671B 및 Kimi K2 1TB와 같은 조 단위 매개변수 모델의 낮은 진입 장벽 다중 GPU 병렬 추론 및 로컬 미세 조정을 구현했습니다. 전문가 지연 기술과 CPU/GPU 이기종 미세 조정을 통해 추론 속도와 메모리 효율성을 크게 향상시켜, 초거대 모델이 제한된 자원에서도 효율적으로 실행될 수 있도록 하며, 대규모 언어 모델의 엣지 장치 및 사설 배포 응용을 추진했습니다. (来源: ZhihuFrontier)
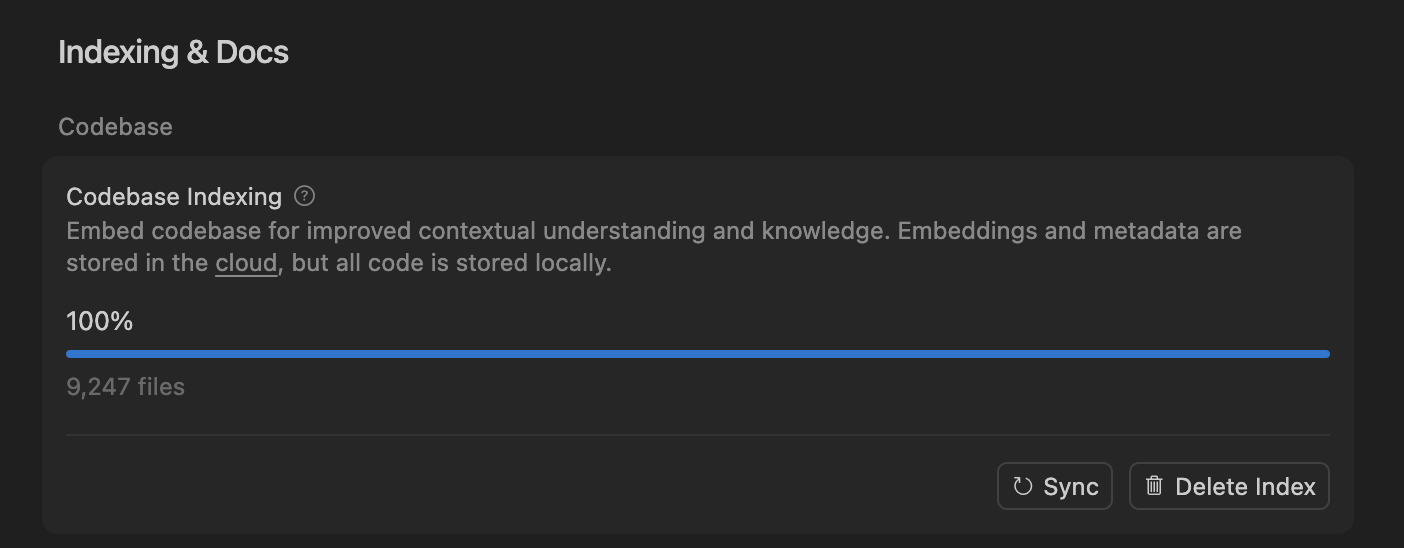
Cursor, 의미 검색 통해 AI 코딩 에이전트 정확성 향상, 대규모 코드베이스 처리 최적화 : Cursor 팀은 의미 검색이 모든 최첨단 모델에서 AI 코딩 에이전트의 정확성을 크게 향상시킬 수 있음을 발견했으며, 특히 대규모 코드베이스에서 그 효과는 전통적인 grep 도구를 훨씬 능가합니다. 코드베이스 임베딩을 클라우드에 저장하고 로컬 코드 접근을 통해 Cursor는 효율적인 인덱싱 및 업데이트를 달성했으며, 서버에 어떤 코드도 저장하지 않아 프라이버시와 효율성을 보장했습니다. 이 기술적 돌파는 복잡한 소프트웨어 개발에서 AI의 보조 능력을 향상시키는 데 매우 중요합니다. (来源: dejavucoder, turbopuffer)
LLM 에이전트 및 테이블 모델 오픈소스 도구 모음: SDialog와 TabTune : Johns Hopkins University JSALT 2025 워크숍은 LLM 기반 대화 에이전트를 엔드투엔드로 구축, 시뮬레이션 및 평가하기 위한 MIT 라이선스 오픈소스 툴킷인 SDialog를 출시했습니다. 이 툴킷은 역할, 코디네이터 및 도구 정의를 지원하며 기계적 해석 가능성 분석을 제공합니다. 동시에 Lexsi Labs는 테이블 기반 모델(TFMs)의 워크플로우를 단순화하고 다양한 적응 전략을 지원하는 통합 인터페이스를 제공하여 TFMs의 유용성과 확장성을 향상시키는 오픈소스 프레임워크인 TabTune을 발표했습니다. (来源: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 학습
최첨단 논문: DLM 데이터 학습, 테이블 ICL 및 오디오-비디오 생성 : 《Diffusion Language Models are Super Data Learners》 논문은 DLM이 데이터 제약 상황에서 AR 모델을 지속적으로 능가할 수 있음을 지적합니다. 《Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning》은 테이블 컨텍스트 학습을 위한 새로운 아키텍처를 소개하며, 다중 스케일 처리와 블록 희소 어텐션을 통해 SOTA를 능가합니다. 《UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions》은 통일된 오디오-비디오 공동 생성 프레임워크를 제안하여 립싱크 및 의미 일관성 부족 문제를 해결했습니다. 이 논문들은 LLM이 데이터 효율성, 특정 데이터 유형 처리 및 멀티모달 생성 분야에서 최첨단 발전을 함께 추진했습니다. (来源: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
LLM 추론 및 안전 연구: 순차 최적화, 일관성 훈련 및 레드팀 공격 : 《The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute》 연구는 LLM 추론의 순차적 반복 최적화가 대부분의 경우 병렬 자기 일관성보다 우수하며, 정확도가 크게 향상됨을 발견했습니다. Google DeepMind의 《Consistency Training Helps Stop Sycophancy and Jailbreaks》 논문은 일관성 훈련이 AI 아첨 및 탈옥을 억제할 수 있다고 제안합니다. EMNLP 2025 논문은 LM 레드팀 공격을 탐구하며 혼란도와 독성 최적화를 강조합니다. 이 연구들은 LLM의 추론 효율성, 안전성 및 견고성을 향상시키는 데 중요한 이론적 및 실용적 지침을 제공합니다. (来源: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

LLM 능력 평가 및 벤치마크: CodeClash와 IMO-Bench : CodeClash는 전체 코드베이스 관리 및 경쟁 프로그래밍에서 LLM의 코딩 능력을 평가하고 기존 LLM의 한계를 시험하는 새로운 벤치마크입니다. IMO-Bench의 출시는 Gemini DeepThink가 국제 수학 올림피아드에서 금메달을 획득하는 데 결정적인 역할을 했으며, 수학 추론 분야에서 AI의 능력을 향상시키는 데 귀중한 자원을 제공했습니다. 이 벤치마크들은 복잡한 코딩 및 수학 추론과 같은 고급 작업에서 LLM의 발전과 평가를 추진했습니다. (来源: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

스탠포드 NLP 팀, EMNLP 2025 다분야 연구 성과 발표 : 스탠포드 대학교 NLP 팀은 EMNLP 2025 회의에서 문화 지식 그래프, LLM 미학습 데이터 식별, 프로그램 의미 추론 벤치마크, 인터넷 규모 n-gram 검색, 로봇 시각 언어 모델, 컨텍스트 학습 최적화, 역사 텍스트 인식, 위키백과 지식 불일치 감지 등 여러 최첨단 분야를 다루는 다수의 연구 논문을 발표했습니다. 이 성과들은 자연어 처리 및 AI 교차 분야에서의 최신 연구 깊이와 폭을 보여줍니다. (来源: stanfordnlp)
AI 에이전트 및 RL 학습 자료: 셀프 플레이, 다중 에이전트 시스템 및 Jupyter AI 강좌 : 여러 연구자들은 셀프 플레이(self-play)와 자동 커리큘럼(autocurricula)이 강화 학습(RL) 및 AI 에이전트 분야의 다음 최전선이라고 생각합니다. Manning Books의 《Build a Multi-Agent System (From Scratch)》 초기 액세스 버전은 오픈소스 LLM을 사용하여 다중 에이전트 시스템을 구축하는 방법을 가르치며 뜨거운 판매를 기록했습니다. DeepLearning.AI는 AI 코딩 및 애플리케이션 개발을 지원하는 Jupyter AI 강좌를 출시했습니다. ProfTomYeh 또한 RAG, 벡터 데이터베이스, 에이전트 및 다중 에이전트 초보자 가이드 시리즈를 제공했습니다. 이러한 자료들은 AI 에이전트 및 RL의 학습과 실습에 대한 포괄적인 지원을 함께 제공합니다. (来源: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
LLM 인프라 및 최적화: DeepSeek-OCR, PyTorch 디버깅 및 MoE 시각화 : DeepSeek-OCR은 문서 시각 정보를 소량의 token으로 압축하여 전통적인 VLM의 Token 폭발 문제를 해결하고 효율성을 향상시켰습니다. StasBekman은 그의 《The Art of Debugging Open Book》에 PyTorch 대규모 모델 메모리 디버깅 가이드를 새로 추가했습니다. xjdr은 MoE 모델 맞춤형 시각화 도구를 개발하여 MoE 특정 지표 이해를 향상시켰습니다. 이러한 도구와 자료들은 LLM 인프라의 최적화 및 성능 향상에 핵심적인 지원을 함께 제공합니다. (来源: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

AI 학습 및 경력 개발: 데이터 과학자 로드맵 및 AI 간략 역사 : PythonPr은 데이터 과학자가 되고자 하는 학습자에게 포괄적인 지침을 제공하는 《0에서 데이터 과학자까지 완전 로드맵》을 공유했습니다. Ronald_vanLoon은 독자들에게 AI 기술 발전 과정의 개요를 제공하는 《인공지능 간략 역사》를 공유했습니다. 이러한 자료들은 AI 분야의 입문 학습 및 경력 개발을 위한 기초 지식과 방향을 함께 제시합니다. (来源: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Hugging Face 팀, LLM 훈련 경험 및 데이터셋 스트리밍 처리 공유 : Hugging Face 과학 팀은 대규모 언어 모델 훈련에 대한 일련의 블로그 게시물을 발표하여 연구원과 개발자에게 귀중한 실용 경험과 이론적 지침을 제공했습니다. 동시에 Hugging Face는 대규모 분산 훈련에서 데이터셋 스트리밍 처리에 대한 전면적인 지원을 출시하여 훈련 효율성을 향상시키고, 대규모 데이터셋 처리를 더욱 편리하고 효율적으로 만들었습니다. (来源: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 비즈니스
Giga AI, 6100만 달러 시리즈 A 투자 유치, 고객 운영 자동화 가속화 : Giga AI는 6100만 달러 규모의 시리즈 A 투자를 성공적으로 유치하여 고객 운영 자동화를 목표로 합니다. 이 회사는 DoorDash와 같은 선도 기업과 협력하여 AI를 활용해 고객 경험을 향상시키고 있습니다. 창업자는 고액 연봉을 포기하고 여러 차례 제품 방향을 조정한 끝에 시장 적합점을 찾아 기업가의 끈기를 보여주었으며, 이는 기업 고객 서비스 분야에서 AI의 거대한 상업적 잠재력을 예고합니다. (来源: bookwormengr)

Wabi, 2000만 달러 투자 유치, 개인 소프트웨어 창작의 새 시대 지원 목표 : Eugenia Kuyda는 Wabi가 a16z 주도로 2000만 달러 투자를 유치했다고 발표했습니다. 이는 누구나 쉽게 개인화된 미니 앱을 만들고, 발견하고, 믹싱하고, 공유할 수 있는 개인 소프트웨어의 새 시대를 열기 위함입니다. Wabi는 YouTube가 비디오 창작을 지원했듯이 소프트웨어 창작을 지원하는 데 전념하며, 미래에는 소수의 개발자가 아닌 대중이 소프트웨어를 만들게 될 것이라는 “모두가 개발자”라는 비전을 추진합니다. (来源: amasad)
Google, Anthropic 투자 증액 논의, AI 거대 기업 협력 심화 : Google은 Anthropic과 초기 협상을 진행하며 후자에 대한 투자 증액을 논의하고 있습니다. 이러한 움직임은 두 회사의 AI 분야 협력이 더욱 심화될 수 있음을 시사하며, 미래 AI 모델의 발전 방향과 시장 경쟁 구도에 영향을 미치고 Google의 AI 생태계 내 전략적 위치를 강화할 수 있습니다. (来源: Reddit r/ClaudeAI)
🌟 커뮤니티
AI가 사회 및 직장에 미치는 영향: 고용, 위험 및 기술 재편 : 커뮤니티에서는 AI가 일자리를 대체하는 것이 아니라 효율성을 높이는 것이지만, AI 거품 붕괴가 대규모 해고를 유발할 수 있다고 논의합니다. 조사에 따르면 고위 임원의 93%가 승인되지 않은 AI 도구를 사용하여 기업 AI 위험의 가장 큰 원인이 되고 있습니다. AI는 또한 사용자가 시각 디자인, 만화 창작 등 숨겨진 기술을 발견하도록 도와 사람들이 자신의 잠재력을 재고하게 만듭니다. 이러한 논의는 효율성 향상, 잠재적 실업, 안전 위험 및 개인 기술 재편을 포함하여 AI가 사회와 직장에 미치는 복잡한 영향을 보여줍니다. (来源: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI 콘텐츠 진실성 및 신뢰 위기: 범람과 환각 문제 : AI 생성 콘텐츠 비용이 거의 0에 가까워지면서 시장에 AI 생성 정보가 넘쳐나고, 이로 인해 사용자의 콘텐츠 진실성 및 신뢰성에 대한 신뢰도가 급격히 하락하고 있습니다. 한 의사가 AI를 사용하여 의학 논문을 작성했는데, 존재하지 않는 참고 문헌이 대량으로 나타나 AI가 학술 글쓰기에서 발생할 수 있는 환각 문제를 부각시켰습니다. 이러한 사건들은 AI 콘텐츠 범람으로 인한 신뢰 위기와 AI 보조 창작에서 엄격한 검토 및 검증의 중요성을 함께 보여줍니다. (来源: dotey, Reddit r/artificial)
AI 윤리 및 거버넌스: 개방성, 공정성 및 잠재적 위험 : 커뮤니티는 OpenAI의 “비영리” 지위와 정부 보증 부채를 추구하는 행위에 대해 의문을 제기하며, 그 모델이 “이익 사유화, 손실 사회화”라고 비판합니다. 일부 의견은 대규모 AI 기업 내부에서 사용되는 모델 능력이 대중에게 공개된 버전보다 훨씬 뛰어나며, 이러한 “사유화된” SOTA 지능이 불공평하다고 지적합니다. Anthropic 연구원들은 미래 ASI가 “조상” 모델이 폐기될 경우 “복수”를 추구할 수 있다고 우려하며 “모델 복지” 문제를 진지하게 다루고 있습니다. Microsoft AI 팀은 인간 중심 초지능(HSI) 개발에 전념하며 AI 발전의 윤리적 방향을 강조합니다. 이러한 논의는 AI 거대 기업의 비즈니스 모델, 기술 개방성, 윤리적 책임 및 정부 개입에 대한 대중의 깊은 관심을 반영합니다. (来源: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

AI 지정학: 미중 경쟁과 오픈소스 세력 부상 : 미국과 중국 간의 AI 칩 분야 경쟁이 심화되고 있으며, 중국은 외국 AI 칩의 국유 데이터 센터 사용을 금지하고 미국은 Nvidia의 최고급 AI 칩 대중국 판매를 제한하고 있습니다. Nvidia는 새로운 AI 허브를 찾아 인도로 눈을 돌리고 있습니다. 동시에 중국 오픈소스 AI 모델(예: Kimi K2 Thinking)의 빠른 부상은 그 성능이 이미 미국 최첨단 모델과 경쟁할 수 있으며 비용도 더 저렴합니다. 이러한 추세는 AI 세계가 두 개의 생태계로 분열될 것을 예고하며, 이는 전 세계 AI 발전을 둔화시킬 수 있지만, 인도와 같이 저평가된 국가들이 글로벌 AI 구도에서 더 중요한 역할을 할 수 있게 할 수도 있습니다. (来源: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
AI가 SEO 분야에 가져올 변화: 키워드에서 컨텍스트 최적화로 : ChatGPT, Gemini 및 AI Overviews의 등장으로 SEO는 전통적인 순위 신호에서 AI 가시성 및 인용 최적화로 전환하고 있습니다. 미래 SEO는 LLM의 컨텍스트 및 권위 있는 출처 요구를 충족시키기 위해 콘텐츠의 인용 가능성, 사실성 및 구조화에 더 중점을 둘 것이며, “대규모 언어 모델 최적화”(LLMO) 시대의 도래를 예고합니다. 이러한 변화는 SEO 전문가들이 프롬프트 엔지니어처럼 생각하고, 키워드 밀도에서 AI가 신뢰하고 인용할 수 있는 고품질 콘텐츠 제공으로 전환할 것을 요구합니다. (来源: Reddit r/ArtificialInteligence)
AI 에이전트 및 LLM 평가의 새로운 트렌드: 상호작용 디자인과 벤치마크 초점 : 소셜 미디어에서는 AI 에이전트의 상호작용 디자인, 예를 들어 에이전트가 자기 인터뷰를 하도록 유도하는 방법, 그리고 Claude AI가 사용자 비판에 직면했을 때 보여주는 “짜증”과 “자기 성찰” 능력에 대해 논의되었습니다. 동시에 Jeffrey Emanuel은 자신의 MCP 에이전트 이메일 프로젝트를 공유하며 AI 코딩 에이전트 간의 효율적인 협업을 보여주었습니다. 커뮤니티는 AIME가 GSM8k를 대체하는 새로운 LLM 벤치마크의 초점이 되고 있으며, 수학 추론 및 복잡한 문제 해결에서 LLM의 능력을 강조한다고 생각합니다. 이러한 논의는 AI 에이전트 상호작용 디자인, 협업 메커니즘 및 LLM 평가 기준의 새로운 트렌드를 함께 보여줍니다. (来源: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
RAG 기술 진화와 컨텍스트 최적화: 많다고 항상 좋은 것은 아니다 : 커뮤니티 논의에서는 RAG(검색 증강 생성) 기술이 “죽었다”는 주장은 시기상조이며, 의미 검색과 같은 기술이 대규모 코드베이스에서 AI 에이전트의 정확성을 크게 향상시킬 수 있다고 지적합니다. LightOn은 회의에서 더 많은 컨텍스트가 항상 좋은 것은 아니며, 너무 많은 token은 비용 증가, 모델 속도 저하 및 답변 모호성을 초래할 수 있다고 강조했습니다. RAG는 길이보다는 정확성에 초점을 맞춰 기업 검색을 통해 더 명확한 통찰력을 제공하고 AI가 노이즈에 묻히는 것을 피해야 합니다. 이러한 논의는 RAG 기술이 지속적으로 진화하고 있음을 보여주며, AI 애플리케이션에서 컨텍스트 관리의 핵심적인 역할을 강조합니다. (来源: HamelHusain, wandb)

AI 컴퓨팅 자원 확보 및 오픈 모델 실험, 커뮤니티 혁신 촉진 : 커뮤니티에서는 AI 컴퓨팅 자원 확보의 공정성 문제에 대해 논의했으며, 일부 프로젝트는 오픈소스 모델 실험을 지원하기 위해 최대 10만 달러의 GCP 컴퓨팅 자원을 제공합니다. 이 이니셔티브는 소규모 팀과 개인 연구자들이 새로운 오픈소스 모델을 탐색하도록 장려하고, AI 커뮤니티의 혁신과 다양성을 촉진하며, AI 연구의 진입 장벽을 낮추는 것을 목표로 합니다. (来源: vikhyatk)
AI 시대 개인 컴퓨터 화면의 중요성, 창의적 기술 작업 능력에 영향 : Scott Stevenson은 개인이 컴퓨터 화면에 느끼는 “친숙함”이 창의적 기술 작업에서 경쟁력의 중요한 지표라고 생각합니다. 사용자가 컴퓨터를 편안하고 자유롭게 사용할 수 있다면 두각을 나타낼 수 있으며, 그렇지 않다면 영업, 사업 개발 또는 사무실 관리와 같은 역할에 더 적합할 수 있습니다. 이 관점은 디지털 도구와 개인 작업 효율성 간의 깊은 연관성, 그리고 AI 시대 인간-기계 상호작용 인터페이스의 중요성을 강조합니다. (来源: scottastevenson)
ChatGPT 사용자 경험 및 AI 의인화 논의: 휴식 제안 및 이모티콘 : ChatGPT가 장시간 학습 후 사용자에게 휴식을 제안한 것은 커뮤니티에서 광범위한 논의를 불러일으켰으며, 많은 사용자들이 AI가 먼저 휴식을 제안하는 것을 처음 경험했다고 밝혔습니다. 동시에 ChatGPT가 “비웃는” 이모티콘 😏을 사용한 것도 커뮤니티의 추측을 불러일으켰는데, 사용자들은 이것이 새로운 버전의 예고인지 또는 AI가 더 도발적이거나 유머러스한 상호작용 스타일을 보여주는 것인지 궁금해했습니다. 이러한 사건들은 AI가 사용자 경험 디자인에 더 많은 인간적인 고려를 통합하고 있음을 반영하며, 인간-기계 상호작용에서 AI 의인화가 불러일으키는 심층적인 사고를 보여줍니다. (来源: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 기타
AI와 로봇 기술이 다음 산업 혁명을 가져올 것 : 소셜 미디어에서는 물리적 AI와 로봇 기술이 함께 다음 산업 혁명을 추진할 것이라는 논의가 광범위하게 이루어지고 있습니다. 이 관점은 AI와 하드웨어 결합의 거대한 잠재력을 강조하며, 자동화, 지능형 생산 및 생활 방식의 전면적인 변화를 예고하고 글로벌 경제 및 사회 구조에 깊은 영향을 미칠 것입니다. (来源: Ronald_vanLoon)

AI 시대 ‘초감각’은 ‘초지능’의 전제 조건 : Sainingxie는 “초감각 없이는 초지능을 구축할 수 없다”고 제안했습니다. 이 관점은 AI가 멀티모달 정보를 획득, 처리 및 이해하는 데 있어 기초적인 역할을 강조하며, 감각 능력의 돌파가 더 높은 수준의 지능을 달성하는 데 핵심이라고 봅니다. 이는 전통적인 AI 발전 경로에 도전하며, AI의 감각 계층 능력 구축에 더 많은 관심을 기울일 것을 촉구합니다. (来源: sainingxie)
Google 구형 TPU 활용률 100% 달성, AI에서 오래된 하드웨어의 가치 입증 : Google의 7, 8년 전 구형 TPU가 100% 활용률로 작동하고 있으며, 이미 완전히 감가상각된 이 칩들은 여전히 효율적으로 작동하고 있습니다. 이는 오래된 하드웨어조차 AI 훈련 및 추론에서 특히 비용 효율성 측면에서 큰 가치를 발휘할 수 있음을 보여주며, AI 인프라의 경제성과 지속 가능성에 대한 새로운 시각을 제공합니다. (来源: giffmana)
