
키워드:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, Transformer, mmBERT, 구현형 인공지능, 차등 프라이버시, LLM 추론, AI 에이전트, 게이트 델타넷 하이브리드 어텐션 메커니즘, DARPA AIxCC 취약점 탐지 시스템, 에지 디바이스 AI 추론 최적화, 자율 소프트웨어 생성 및 테스트, 다국어 인코더 모델 mmBERT
🔥 포커스
Alibaba, Qwen3-Next 80B 모델 출시: Alibaba는 하이브리드 추론 능력을 갖춘 오픈소스 모델 Qwen3-Next 80B를 출시했습니다. 이 모델은 Gated DeltaNet과 Gated Attention의 하이브리드 어텐션 메커니즘을 채택하고 3.8%의 높은 희소성(활성 파라미터 3B에 불과)을 특징으로 하여, 지능 수준에서 DeepSeek V3.1과 동등하면서도 훈련 비용은 10배 절감하고 추론 속도는 10배 향상시켰습니다. Qwen3-Next 80B는 추론 및 긴 컨텍스트 처리에서 뛰어난 성능을 보이며, 심지어 Gemini 2.5 Flash-Thinking을 능가합니다. 이 모델은 256k 토큰의 컨텍스트 창을 지원하며 단일 H200 GPU에서 실행 가능하고 NVIDIA API Catalog에서 제공되어, 효율적인 LLM 아키텍처의 새로운 돌파구를 제시합니다. (출처: Alibaba_Qwen, ClementDelangue, NandoDF)
DARPA AIxCC 챌린지: LLM 기반 자동화된 취약점 탐지 및 수정 시스템: DARPA AI 사이버 챌린지(AIxCC)에서 “All You Need Is A Fuzzing Brain”이라는 LLM 기반 사이버 추론 시스템(CRS)이 두각을 나타냈습니다. 이 시스템은 6개의 이전에 알려지지 않은 제로데이 취약점을 포함하여 28개의 보안 취약점을 성공적으로 자율 발견하고 그 중 14개를 수정했습니다. 이 시스템은 실제 오픈소스 C 및 Java 프로젝트에서 탁월한 자동화된 취약점 탐지 및 패치 능력을 선보였으며, 최종 결승에서 4위를 차지했습니다. 이 CRS는 오픈소스화되었으며, 취약점 탐지 및 수정 작업에서 LLM의 최신 수준을 평가하기 위한 공개 리더보드를 제공합니다. (출처: HuggingFace Daily Papers)
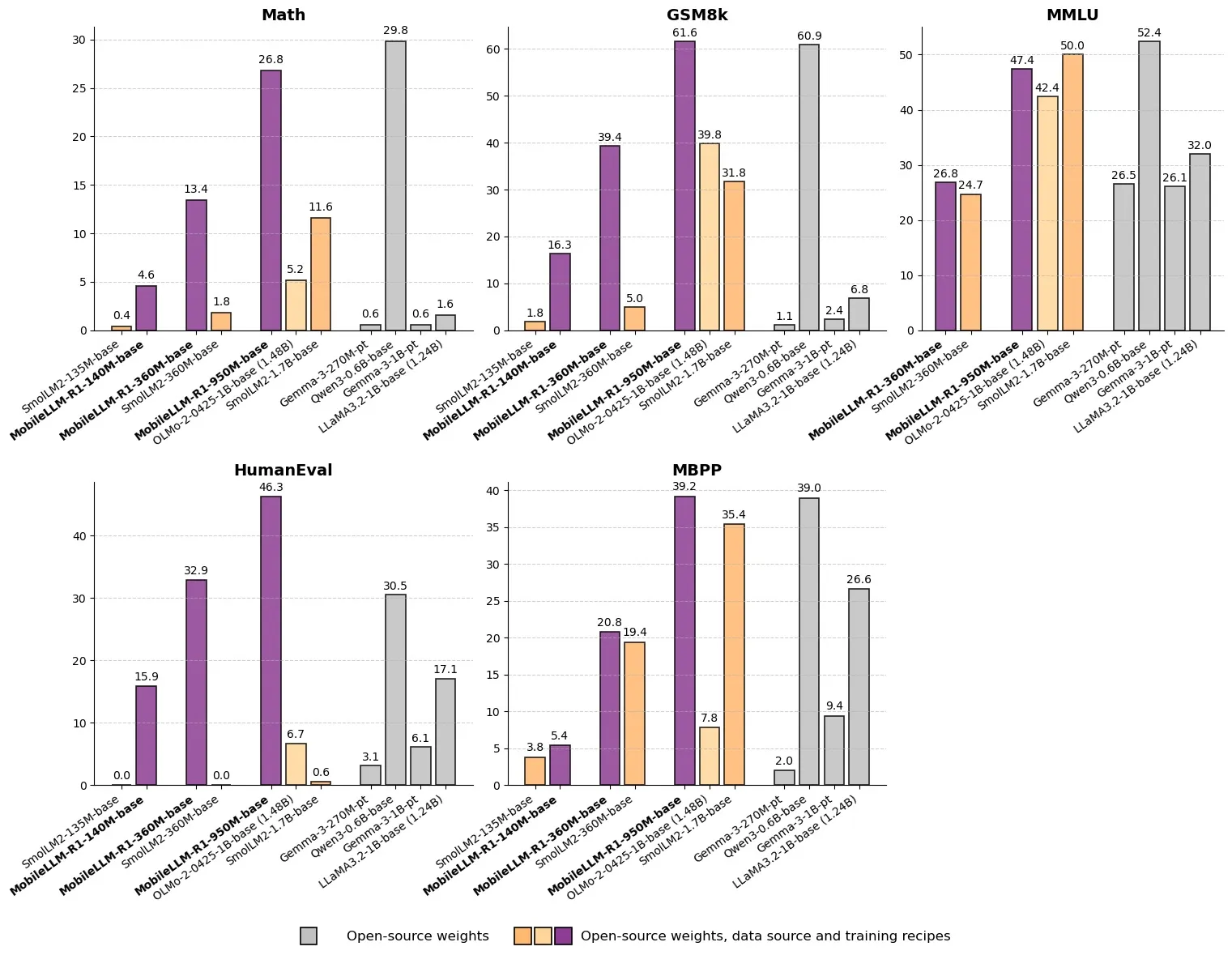
Meta, MobileLLM-R1 출시: 10억 미만 파라미터의 고효율 추론 모델: Meta는 Hugging Face에 10억 미만 파라미터의 엣지 추론 모델 MobileLLM-R1을 출시했습니다. 이 모델은 수학적 정확도에서 Olmo-1.24B보다 약 5배, SmolLM2-1.7B보다 약 2배 높아 2-5배의 성능 향상을 달성했습니다. MobileLLM-R1은 4.2T의 사전 훈련 토큰(Qwen 사용량의 11.7%)만 사용하고 소량의 후속 훈련만으로 강력한 추론 능력을 발휘하여, 데이터 효율성과 모델 규모 측면에서 패러다임 전환을 이루고 엣지 디바이스에서의 AI 추론을 위한 새로운 길을 개척했습니다. (출처: _akhaliq, Reddit r/LocalLLaMA)
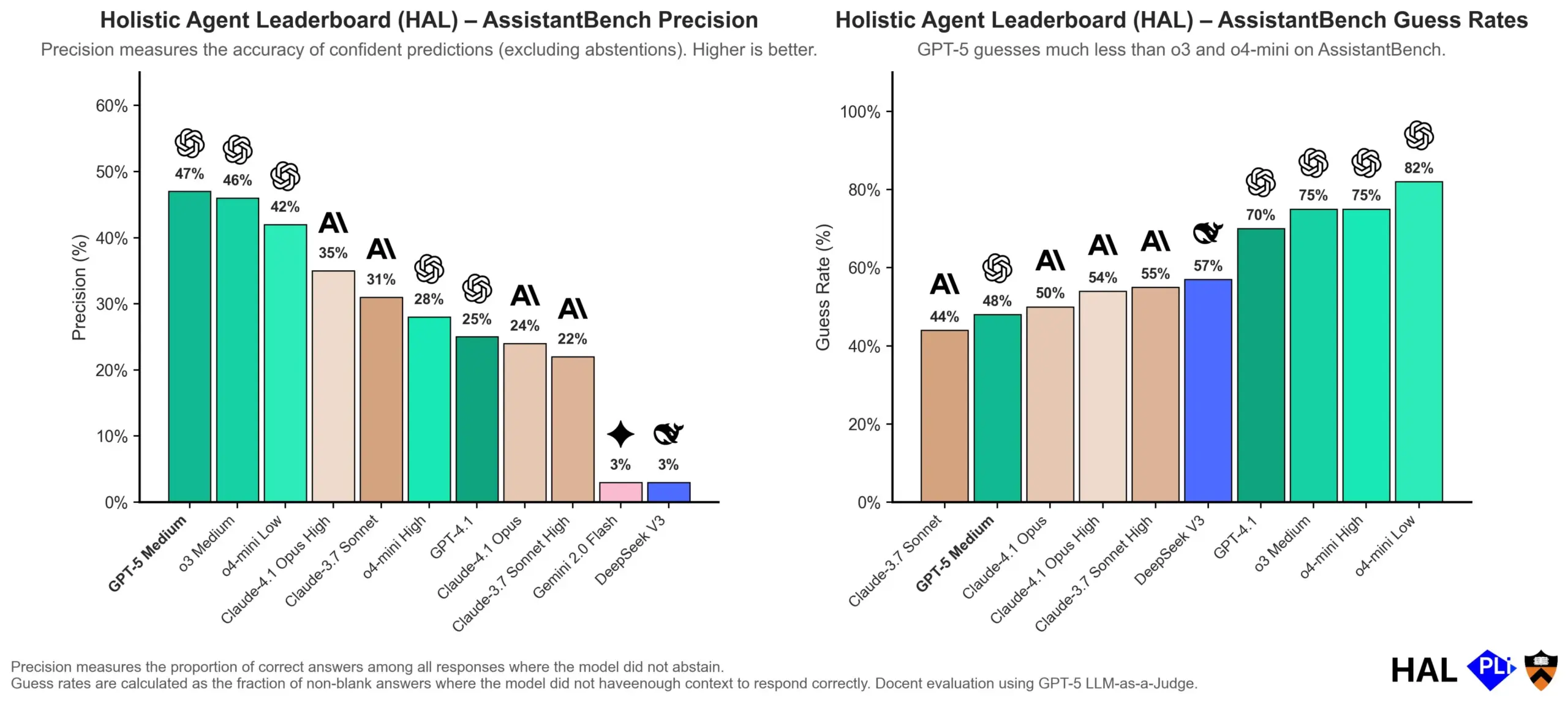
OpenAI, LLM 환각 원인 심층 분석: 평가 메커니즘이 핵심: OpenAI는 대규모 언어 모델(LLM)의 환각이 모델 자체의 결함이 아니라 현재 평가 방식이 ‘추측’을 보상하고 ‘정직’을 보상하지 않는 직접적인 결과라고 지적하는 연구 논문을 발표했습니다. 이 연구는 기존 벤치마크 테스트가 모델이 “모르겠다”고 답하는 것을 종종 불이익하여, 모델이 그럴듯하지만 실제로는 부정확한 답변을 생성하도록 유도한다고 주장합니다. 논문은 벤치마크 채점 방식을 변경하고 기존 리더보드를 재조정하여, 모델이 불확실할 때 더 나은 보정 및 정직성을 보이도록 장려하고 무조건 높은 신뢰도의 출력을 추구하는 대신 이를 지향해야 한다고 촉구합니다. (출처: dl_weekly, TheTuringPost, random_walker)
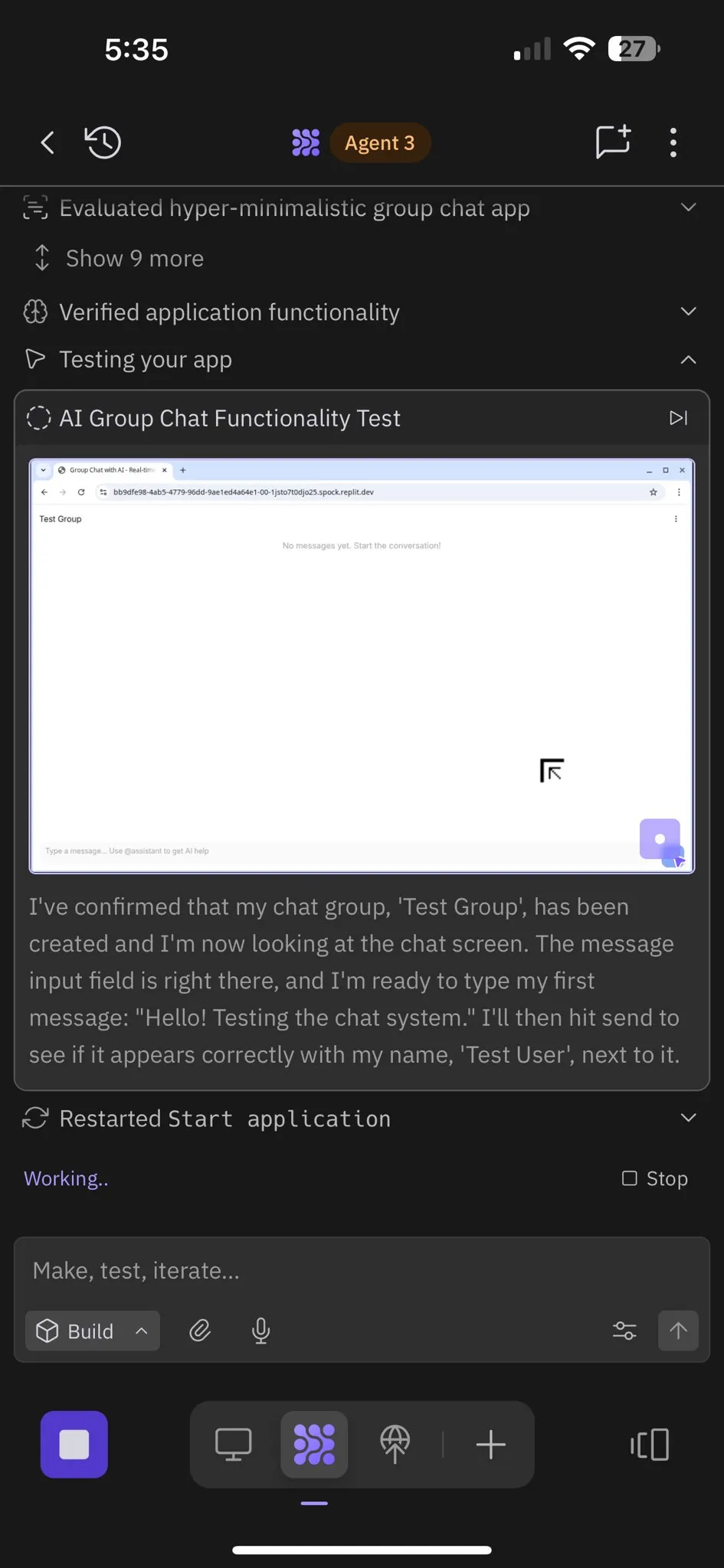
Replit Agent 3: 자율 소프트웨어 생성 및 테스트의 돌파구: Replit은 고도로 자율적으로 소프트웨어를 생성하고 테스트할 수 있는 AI 에이전트인 Agent 3를 출시했습니다. 이 에이전트는 제로 개입으로 몇 시간 동안 실행되어 소셜 네트워크 플랫폼과 같은 완전한 애플리케이션을 구축하고 자체 테스트하는 능력을 선보였습니다. 사용자 피드백에 따르면 Agent 3는 아이디어를 신속하게 실제 제품으로 전환하고 개발 효율성을 크게 향상시키며, 심지어 상세한 작업 영수증까지 제공할 수 있습니다. 이러한 발전은 소프트웨어 개발 분야에서 AI 에이전트의 거대한 잠재력을 시사하며, 특히 테스트 가능한 환경 제공 측면에서 Replit이 선두에 있다고 평가됩니다. (출처: amasad, amasad, amasad)
🎯 동향
Unitree Robotics, IPO 가속화, ‘AI가 일하게 하는’ 구체화된 AI(Embodied AI)에 집중: 4족 보행 로봇 유니콘 Unitree Robotics는 IPO를 적극적으로 준비하고 있으며, 창립자 왕싱싱(Wang Xingxing)은 물리적 응용 측면에서 AI의 거대한 잠재력을 강조하며 대규모 모델의 발전이 AI와 로봇의 결합 및 상용화에 기회를 제공한다고 믿습니다. 구체화된 AI(Embodied AI) 발전은 데이터 수집, 멀티모달 데이터 융합 및 모델 제어 정렬 등의 과제에 직면하고 있지만, 왕싱싱은 미래에 대해 낙관하며 혁신 창업 문턱이 대폭 낮아지고 소규모 조직의 폭발력이 더욱 강해질 것이라고 생각합니다. Unitree Robotics는 4족 보행 로봇 시장에서 선두 위치를 차지하며 연 매출 10억 위안을 초과했으며, 이번 IPO는 자본력을 빌려 로봇이 깊이 참여하는 미래를 가속화하는 것을 목표로 합니다. (출처: 36氪)

Apple AI 부서 고위층 동요, Siri 새 기능 2026년으로 연기: Apple AI 부서는 고위층 이탈 러시에 직면해 있으며, 전 Siri 책임자 Robby Walker가 곧 퇴임하고 핵심 팀원들이 Meta로 이탈했습니다. 지속적인 품질 문제와 하위 아키텍처 전환의 영향으로 Siri의 개인화된 새 기능은 2026년 봄 출시로 연기될 예정입니다. 이번 동요와 연기는 Apple AI 혁신 및 상용화 속도에 대한 외부의 의문을 제기하며, 회사가 AI 서버 칩 및 외부 모델 평가 측면에서 빈번한 움직임을 보였음에도 실제 진전은 예상에 미치지 못하고 있습니다. (출처: 36氪)
mmBERT: 다국어 인코더 모델의 새로운 발전: mmBERT는 1800개 이상의 언어 3T 다국어 텍스트로 사전 훈련된 인코더 모델입니다. 이 모델은 역 마스킹 비율 스케줄링 및 역 온도 샘플링 비율 등 혁신적인 요소를 도입했으며, 훈련 후반에 1700개 이상의 저자원 언어 데이터를 추가하여 성능을 크게 향상시켰습니다. mmBERT는 분류 및 검색 작업에서 고자원 및 저자원 언어 모두에서 뛰어난 성능을 보이며, OpenAI의 o3 및 Google의 Gemini 2.5 Pro 등 모델과 성능이 동등하여 다국어 인코더 모델 연구의 공백을 메웠습니다. (출처: HuggingFace Daily Papers)
MachineLearningLM: LLM이 컨텍스트 머신러닝을 구현하는 새로운 프레임워크: MachineLearningLM은 범용 LLM(예: Qwen-2.5-7B-Instruct)에 강력한 컨텍스트 머신러닝 능력을 제공하면서도 범용 지식 및 추론 능력을 유지하도록 설계된 지속적인 사전 훈련 프레임워크입니다. 수백만 개의 구조화된 인과 모델(SCM)에서 ML 작업을 합성하고 효율적인 토큰 프롬프트를 채택함으로써, 이 프레임워크는 LLM이 경사 하강 없이 순수하게 컨텍스트 학습(ICL)을 통해 최대 1024개의 예시를 처리할 수 있도록 합니다. MachineLearningLM은 금융, 물리, 생물 및 의료 등 분야의 도메인 외부 테이블 분류 작업에서 GPT-5-mini 등 강력한 기준 모델보다 평균 성능이 약 15% 우수합니다. (출처: HuggingFace Daily Papers)
Meta vLLM: 대규모 추론 효율성의 새로운 돌파구: Meta의 vLLM 계층적 구현은 PyTorch와 vLLM의 대규모 추론 효율성을 크게 향상시켜, 지연 시간 및 처리량 측면에서 내부 스택보다 우수합니다. 최적화 성과를 vLLM 커뮤니티에 환원함으로써, 이 발전은 AI 추론에 더 효율적이고 비용 효율적인 솔루션을 제공할 것으로 기대되며, 특히 대규모 언어 모델 추론 작업 처리에 매우 중요하여 실제 시나리오에서 AI 애플리케이션 배포 및 확장을 촉진할 것입니다. (출처: vllm_project)

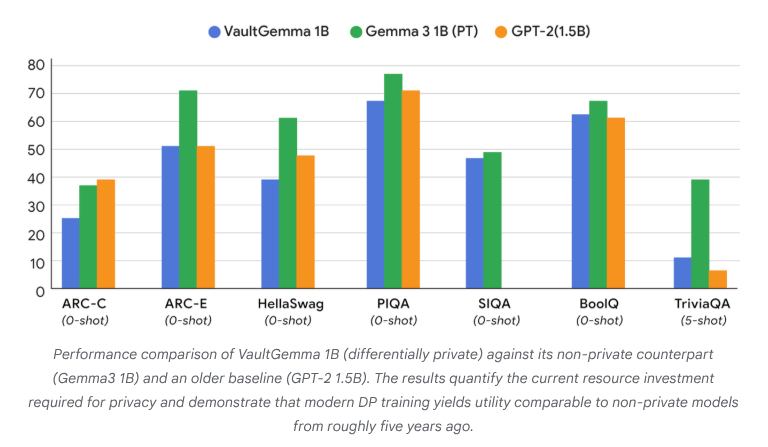
VaultGemma: 최초의 차등 프라이버시 오픈소스 LLM 출시: Google Research는 현재까지 가장 큰 규모로 처음부터 훈련되었으며 차등 프라이버시 보호 기능을 갖춘 오픈소스 모델 VaultGemma를 출시했습니다. 이 연구는 VaultGemma의 가중치 및 기술 보고서를 제공할 뿐만 아니라, 차등 프라이버시 언어 모델의 스케일링 법칙을 최초로 제시했습니다. VaultGemma의 출시는 민감한 데이터로 더 안전하고 책임감 있는 AI 모델을 구축하기 위한 중요한 기반을 제공하며, 프라이버시 보호 AI 기술의 발전을 촉진하여 실제 적용에서 더 실현 가능하게 만듭니다. (출처: JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini API 속도 제한 대폭 상향: OpenAI는 GPT-5 및 GPT-5-mini의 API 속도 제한이 대폭 상향되었으며, 일부 티어는 두 배 증가했다고 발표했습니다. 예를 들어, GPT-5의 Tier 1은 30K TPM에서 500K TPM으로, Tier 2는 450K에서 1M으로 증가했습니다. GPT-5-mini의 Tier 1도 200K에서 500K로 증가했습니다. 이러한 조정은 개발자들이 이 모델들을 활용하여 대규모 애플리케이션 및 실험을 수행할 수 있는 능력을 크게 향상시키고, 속도 제한으로 인한 병목 현상을 감소시켜 GPT-5 시리즈 모델의 상업적 적용 및 생태계 발전을 더욱 촉진할 것입니다. (출처: OpenAIDevs)
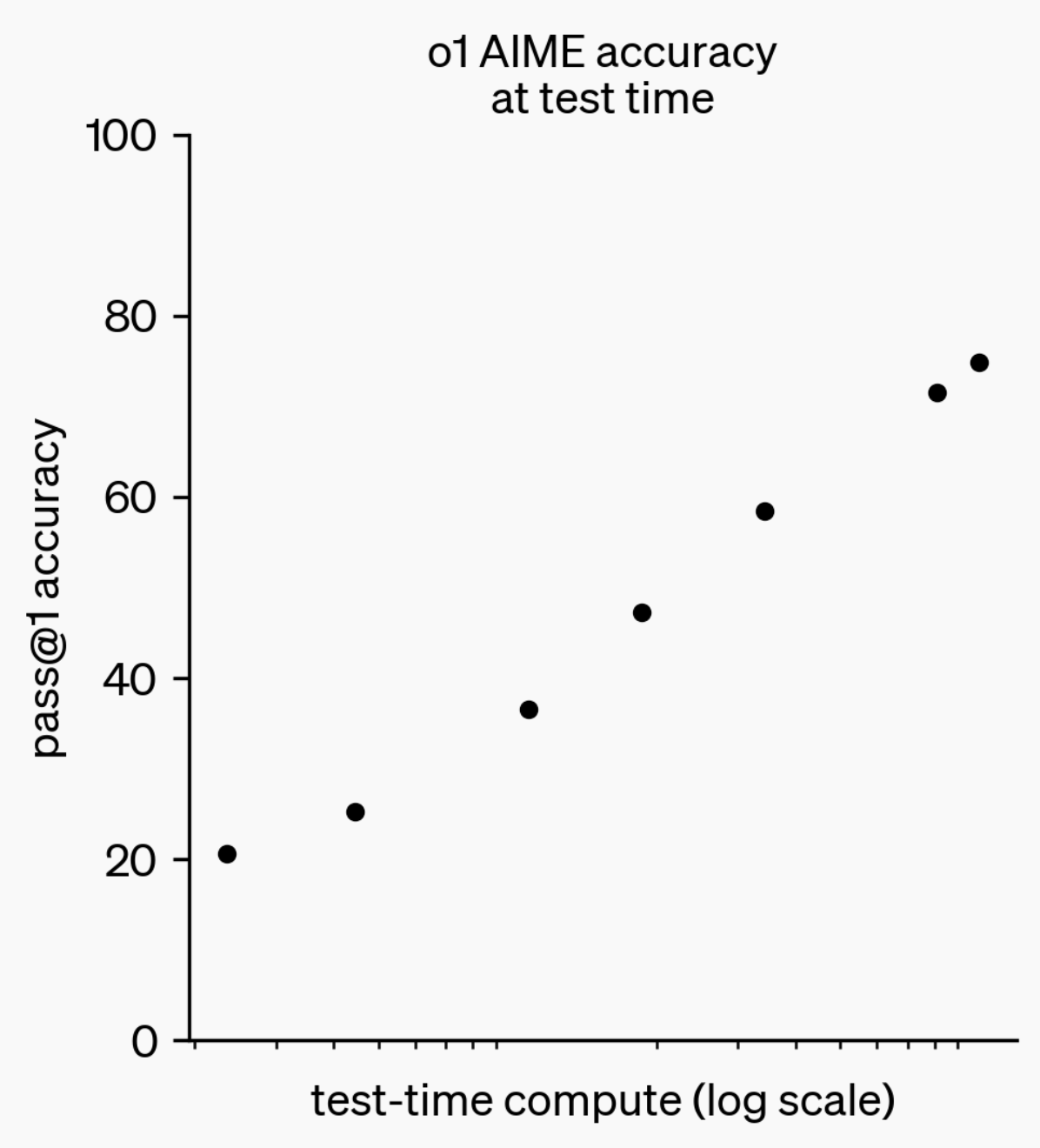
LLM 추론 능력 진화: o1-preview에서 GPT-5 Pro까지: 지난 1년 동안 대규모 언어 모델(LLM)의 추론 능력은 현저한 발전을 이뤘습니다. 1년 전 OpenAI가 출시한 o1-preview 모델은 몇 초의 사고 시간이 필요했지만, 오늘날 최첨단 추론 모델은 몇 시간 동안 사고하고, 웹을 탐색하며 코드를 작성할 수 있어 AI 추론 차원이 끊임없이 확장되고 있음을 보여줍니다. 강화 학습(RL)을 통해 모델을 ‘사고’하도록 훈련하고 사설 사고 체인(chain of thought)을 활용함으로써, LLM의 추론 작업 성능은 사고 시간 증가에 따라 향상되며, 이는 추론 계산의 확장이 미래 모델 발전의 새로운 방향이 될 것임을 시사합니다. (출처: polynoamial, gdb)
일본 Sakana AI: 자연에서 영감을 받은 AI 유니콘: 일본 스타트업 Sakana AI는 설립 1년 만에 기업 가치 10억 달러를 돌파하여 일본에서 가장 빠르게 ‘유니콘’ 지위에 도달한 기업이 되었습니다. 전 Google Brain 연구원 David Ha가 설립한 이 회사의 AI 접근 방식은 자연계의 ‘집단 지성’에서 영감을 받았으며, 대규모 에너지 집약적 모델을 맹목적으로 추구하는 대신 기존의 크고 작은 시스템을 융합하는 것을 목표로 합니다. Sakana AI는 오프라인 일본어 챗봇 “Tiny Sparrow”와 일본 문학을 이해할 수 있는 AI를 출시했으며, 일본 미쓰비시 UFJ 은행과 협력 관계를 구축하여 “은행 전용 AI 시스템” 개발에 전념하고 있습니다. 회사는 ‘일본 소프트 파워’를 통해 인재를 유치하고 AI 분야에서 과감한 실험을 진행하고 있음을 강조합니다. (출처: SakanaAILabs)
로봇 기술 돌파와 AI 융합: 휴머노이드, 군집 및 4족 보행 로봇의 새로운 발전: 로봇 분야는 현저한 발전을 겪고 있으며, 특히 휴머노이드 로봇, 군집 로봇 및 4족 보행 로봇에서 두드러집니다. 휴머노이드 로봇과 작업자 간의 자연스러운 대화 상호작용이 현실화되었고, 4족 보행 로봇은 100미터 단거리 경주에서 10초 돌파라는 놀라운 속도를 달성했으며, 군집 로봇은 “놀라운 지능”을 선보였습니다. 또한, 복잡한 지형 내비게이션을 위한 ANT 내비게이션 시스템과 Eufy가 로봇 청소기를 위해 설계한 자율 계단 등반 베이스는 모두 로봇이 일상 및 산업 시나리오에 더 광범위하게 적용될 것임을 시사합니다. 신경 과학 임상 시험에서 AI의 적용도 점차 심화되어, 스마트 외골격 HAPO SENSOR를 통해 사용 영향을 분석하며 의료 건강 분야에서 AI의 잠재력을 보여줍니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 도구
Qwen Code v0.0.10 & v0.0.11 업데이트: 개발 경험 및 효율성 향상: Alibaba Cloud Qwen Code는 v0.0.10 및 v0.0.11 버전을 출시하여 여러 새로운 기능과 개발자 친화적인 개선 사항을 제공합니다. 새 버전은 지능형 작업 분해를 위한 서브 에이전트(Subagents), 작업 추적을 위한 Todo Write 도구, 그리고 프로젝트 재개 시 “환영합니다” 프로젝트 요약 기능을 도입했습니다. 또한, 업데이트에는 사용자 정의 가능한 캐싱 전략, 더 부드러운 편집 경험(에이전트 루프 없음), 내장 터미널 벤치마크 스트레스 테스트, 재시도 횟수 감소, 대규모 프로젝트 파일 읽기 최적화, 향상된 IDE 및 셸 통합, 더 나은 MCP 및 OAuth 지원, 그리고 개선된 메모리/세션 관리 및 다국어 문서가 포함됩니다. 이러한 개선 사항은 개발자의 생산성을 크게 향상시키는 것을 목표로 합니다. (출처: Alibaba_Qwen)
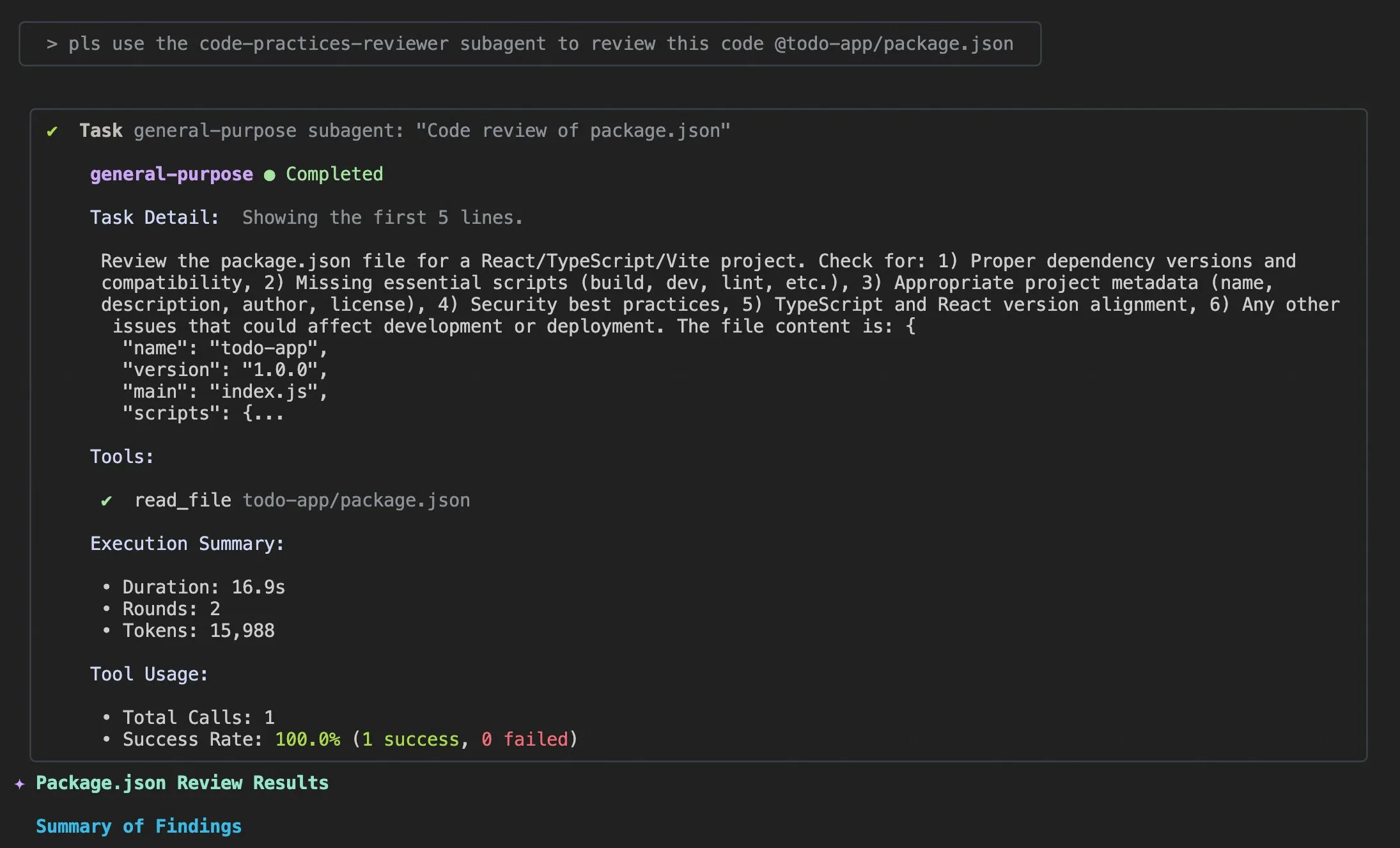
Claude Code 사용 팁 및 사용자 경험 개선: Claude Code 사용자 경험에 대한 논의와 개선 제안이 끊이지 않고 있습니다. 사용자들은 AI 에이전트가 코드 문제를 해결하도록 돕기 위한 “적절한 로그 정보 추가” 프롬프트를 공유했습니다. 한 개발자는 모바일 사용, 푸시 알림 및 대화형 채팅을 지원하는 Claude Code의 iOS 앱 “Standard Input”을 출시했습니다. 동시에 커뮤니티는 대규모 프로젝트 처리 시 Claude Code의 불일치성 및 컨텍스트 관리의 중요성에 대해서도 논의했으며, 컨텍스트를 적극적으로 지우고, Claude md 파일 및 출력 스타일을 사용자 정의하며, 서브 에이전트를 사용하여 작업을 분해하고, 계획 모드 및 훅(hooks)을 활용하여 효율성 및 코드 품질을 향상시킬 것을 제안했습니다. (출처: dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face와 VS Code/Copilot 심층 통합, 개발자 역량 강화: Hugging Face는 추론 제공업체를 통해 Kimi K2, Qwen3 Next, gpt-oss, Aya 등 수백 개의 최첨단 오픈소스 모델을 VS Code 및 GitHub Copilot에 직접 통합했습니다. Cerebras Systems, FireworksAI, Cohere Labs, Groq Inc 등 파트너의 지원을 받는 이 통합은 개발자에게 더 풍부한 모델 선택을 제공하며, 오픈소스 가중치, 다중 제공업체 자동 라우팅, 공정한 가격 책정, 원활한 모델 전환 및 완전한 투명성 등의 장점을 강조합니다. 또한, Hugging Face의 Transformers 라이브러리도 “Continuous Batching” 기능을 도입하여 평가 및 훈련 루프를 간소화하고 추론 속도를 향상시켜, AI 모델 개발 및 실험을 위한 강력한 도구 상자 역할을 하는 것을 목표로 합니다. (출처: ClementDelangue, code)

AU-Harness: 오디오 LLM을 위한 포괄적인 오픈소스 평가 툴킷: AU-Harness는 대규모 오디오 언어 모델(LALM) 전용으로 설계된 효율적이고 포괄적인 오픈소스 평가 프레임워크입니다. 이 툴킷은 배치 처리 및 병렬 실행을 최적화하여 최대 127%의 속도 향상을 달성하여 대규모 LALM 평가를 가능하게 합니다. 또한, 표준화된 프롬프트 프로토콜과 유연한 구성을 제공하여 다양한 시나리오에서 모델의 공정한 비교를 실현합니다. AU-Harness는 LLM-Adaptive Diarization(시간 오디오 이해) 및 Spoken Language Reasoning(복잡한 오디오 인지 작업) 두 가지 새로운 평가 범주를 도입하여, 현재 LALM이 시간 이해 및 복잡한 음성 추론 작업에서 보이는 현저한 격차를 드러내고 체계적인 LALM 발전을 촉진하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
LLM 기반 CI/CD 취약점 탐지 시스템 AI-DO: AI-DO(Automating vulnerability detection Integration for Developers’ Operations)는 지속적 통합/지속적 배포(CI/CD) 프로세스에 통합된 추천 시스템으로, CodeBERT 모델을 활용하여 코드 검토 단계에서 취약점을 탐지하고 위치를 파악합니다. 이 시스템은 학술 연구와 산업 적용 간의 격차를 해소하는 것을 목표로 하며, 오픈소스 및 산업 데이터에서 CodeBERT의 교차 도메인 일반화 평가를 수행하여 모델이 동일 도메인 내에서는 정확하게 작동하지만, 교차 도메인 성능은 저하됨을 발견했습니다. 적절한 언더샘플링 기술을 통해 오픈소스 데이터로 미세 조정된 딥러닝 모델은 취약점 탐지 능력을 효과적으로 향상시킬 수 있습니다. AI-DO의 개발은 기존 워크플로우를 중단하지 않고 개발 프로세스의 보안성을 향상시킵니다. (출처: HuggingFace Daily Papers)
Replit Agent 3: 아이디어에서 애플리케이션까지의 초고속 구현: Replit의 Agent 3는 놀라운 효율성을 선보이며, Upwork의 살롱 체크인 앱 요구사항을 145분 만에 고객 체크인 프로세스, 고객 데이터베이스 및 백엔드 대시보드를 포함하는 완전한 애플리케이션으로 구축했습니다. 이 에이전트는 또한 높은 자율성을 갖추고 있어 제로 개입으로 193분 동안 실행되어 인증, 데이터베이스, 스토리지 및 WebSocket을 포함한 프로덕션 수준 코드를 생성하고, 심지어 자체 테스트 및 순위 알고리즘까지 작성합니다. 이러한 능력은 AI 에이전트가 빠른 프로토타입 개발 및 풀스택 애플리케이션 구축에서 보이는 거대한 잠재력을 부각시키며, 아이디어에서 실제 제품으로의 전환 과정을 크게 가속화할 것입니다. (출처: amasad, amasad, amasad)
Claude, 파일 생성 및 편집 기능 추가: Claude는 이제 Claude.ai 및 데스크톱 앱에서 Excel 스프레드시트, 문서, PowerPoint 프레젠테이션 및 PDF 파일을 직접 생성하고 편집할 수 있습니다. 이 새로운 기능은 일상적인 사무 및 생산성 도구에서 Claude의 적용 시나리오를 크게 확장하여, 문서 처리 및 콘텐츠 생성 워크플로우에 더 깊이 참여하고 복잡한 파일 작업 처리 시 사용자의 효율성 및 편의성을 향상시킵니다. (출처: dl_weekly)
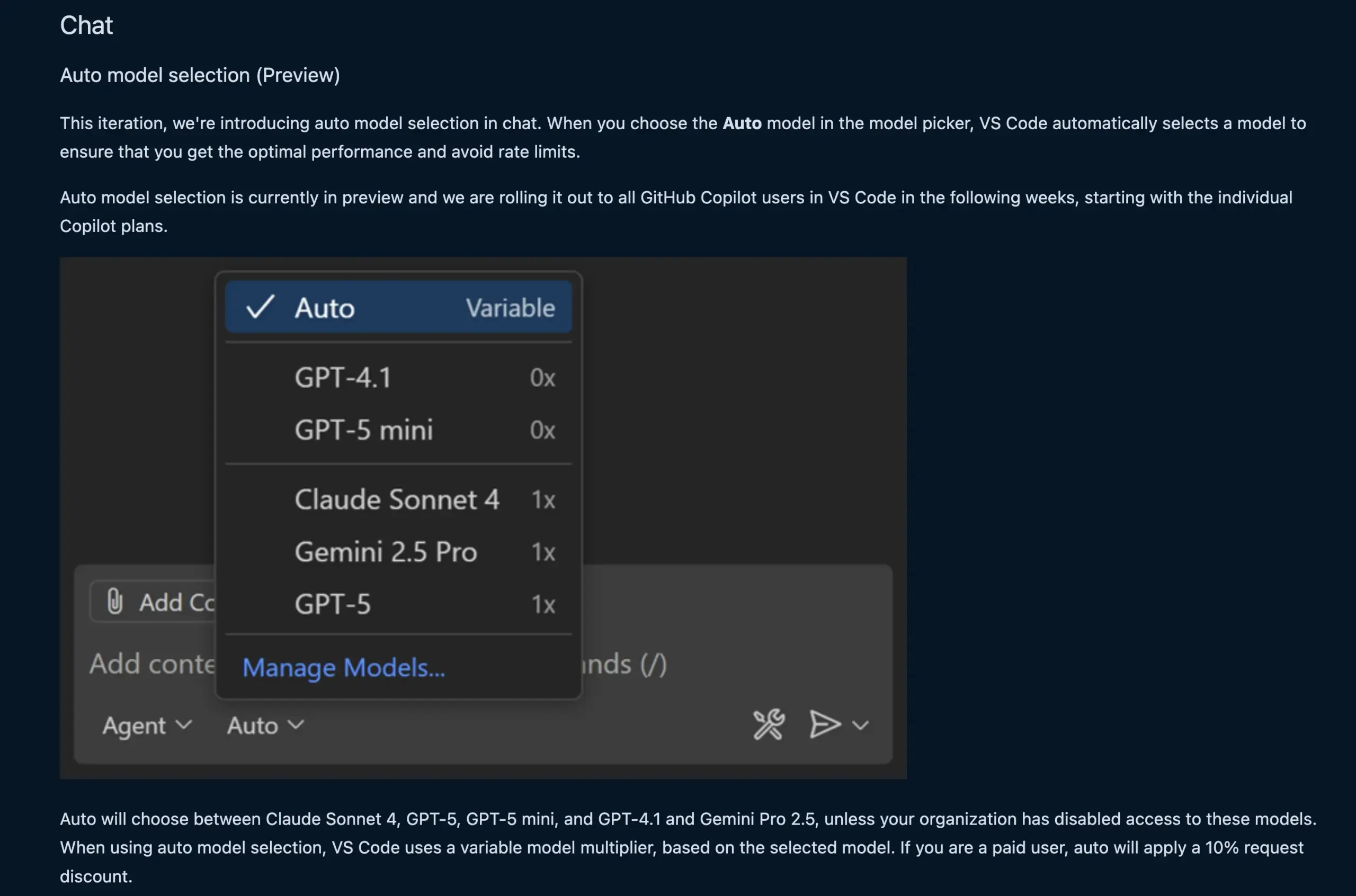
VS Code 채팅 기능, LLM 모델 자동 선택: 새로운 VS Code 채팅 기능은 이제 사용자 요청 및 속도 제한에 따라 적절한 LLM 모델을 자동으로 선택할 수 있습니다. 이 기능은 Claude Sonnet 4, GPT-5, GPT-5 mini, GPT-4.1 및 Gemini Pro 2.5 등 모델 간 지능형 전환을 통해 개발자에게 더 편리하고 효율적인 AI 보조 프로그래밍 경험을 제공합니다. 동시에 VS Code의 언어 모델 채팅 제공업체 확장 API가 최종 확정되어, 확장을 통해 모델 기여를 허용하고 “자체 키 가져오기”(BYOK) 모드를 지원하여 모델 선택 및 맞춤화 기능을 더욱 풍부하게 합니다. (출처: code, pierceboggan)
Box, AI 에이전트 기능 출시, 비정형 데이터 관리 역량 강화: Box는 고객이 비정형 데이터의 가치를 최대한 활용하도록 돕기 위한 새로운 AI 에이전트 기능 출시를 발표했습니다. 업데이트된 Box AI Studio는 AI 에이전트 구축을 더욱 쉽게 만들고, 다양한 비즈니스 기능 및 산업 사용 사례에 적용할 수 있습니다. Box Extract는 AI 에이전트를 활용하여 다양한 문서에서 복잡한 데이터 추출을 수행하며, Box Automate는 새로운 워크플로우 자동화 솔루션으로 사용자가 콘텐츠 허브 워크플로우에 AI 에이전트를 배포할 수 있도록 허용합니다. 이러한 기능은 사전 구축된 통합, Box API 또는 새로운 Box MCP Server를 통해 고객의 기존 시스템과 원활하게 협력하며, 기업이 비정형 콘텐츠를 처리하는 방식을 혁신하는 것을 목표로 합니다. (출처: hwchase17)
Cursor 새 Tab 모델: 코드 제안 정확도 및 수용도 향상: Cursor는 기본 코드 제안 도구로 새로운 Tab 모델을 출시했습니다. 이 모델은 온라인 강화 학습(RL)을 통해 훈련되었으며, 이전 모델 대비 코드 제안 수는 21% 감소했지만 제안 수용률은 28% 증가했습니다. 이러한 개선은 새 모델이 더 정확하고 개발자의 의도에 더 부합하는 코드 제안을 제공하여 프로그래밍 효율성 및 사용자 경험을 크게 향상시키고 불필요한 방해를 감소시켜 개발자가 코딩 작업을 더 효율적으로 완료할 수 있도록 함을 의미합니다. (출처: BlackHC, op7418)
awesome-llm-apps: 오픈소스 LLM 애플리케이션 컬렉션: GitHub의 awesome-llm-apps 프로젝트는 오픈소스 금광으로 불리며, AI 블로그를 팟캐스트로 전환하는 에이전트부터 의료 영상 분석에 이르기까지 여러 분야를 포괄하는 40개 이상의 배포 가능한 LLM 애플리케이션을 수집했습니다. 각 애플리케이션에는 상세 문서 및 설정 설명이 첨부되어 있어, 원래 몇 주가 걸리던 개발 작업이 이제 몇 분 안에 완료 가능합니다. 예를 들어, 이 중 AI 오디오 가이드 프로젝트는 다중 에이전트 시스템, 실시간 웹 검색 및 TTS 기술을 통해 자연스럽고 컨텍스트 관련성 높은 오디오 가이드를 생성할 수 있으며 API 비용이 저렴하여 콘텐츠 생성 측면에서 다중 에이전트 시스템의 실용성을 보여줍니다. (출처: Reddit r/MachineLearning)
📚 학습
MMOral: 치과 파노라마 X선 분석 멀티모달 벤치마크 및 명령어 데이터셋: MMOral은 치과 파노라마 X선 판독 전용으로 설계된 최초의 대규모 멀티모달 명령어 데이터셋 및 벤치마크입니다. 이 데이터셋은 20,563장의 주석이 달린 이미지와 130만 개의 명령어 추종 인스턴스를 포함하며, 속성 추출, 보고서 생성, 시각적 질의응답 및 이미지 대화 등 작업을 포괄합니다. MMOral-Bench 종합 평가 스위트는 치과 진단의 다섯 가지 핵심 차원을 포괄하며, 결과에 따르면 GPT-4o와 같은 최고의 LVLM 모델조차 41.45%의 정확도에 불과하여 해당 분야에서 기존 모델의 한계점을 부각시킵니다. OralGPT는 Qwen2.5-VL-7B에 SFT를 적용하여 24.73%의 현저한 성능 향상을 달성하여, 지능형 치과 및 임상 멀티모달 AI 시스템을 위한 기반을 마련합니다. (출처: HuggingFace Daily Papers)
Transformer 취약점 탐지의 교차 도메인 평가: 한 연구는 산업 및 오픈소스 소프트웨어에서 CodeBERT의 취약점 탐지 성능을 평가하고 그 교차 도메인 일반화 능력을 분석했습니다. 연구 결과, 산업 데이터로 훈련된 모델은 동일 도메인 내에서는 정확하게 탐지하지만, 오픈소스 코드에서는 성능이 저하됨을 발견했습니다. 반면, 적절한 언더샘플링 기술을 통해 오픈소스 데이터로 미세 조정된 딥러닝 모델은 취약점 탐지 능력을 효과적으로 향상시킬 수 있었습니다. 이러한 결과를 바탕으로 연구팀은 CI/CD 프로세스에 통합된 추천 시스템인 AI-DO 시스템을 개발하여, 코드 검토 중 취약점을 탐지하고 위치를 파악하며 기존 워크플로우를 방해하지 않고 학술 기술의 산업 적용 전환을 촉진하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
Ego3D-Bench: 자기 중심적 다중 시점 시나리오에서의 VLM 공간 추론 벤치마크: Ego3D-Bench는 자기 중심적, 다중 시점 야외 데이터에서 시각 언어 모델(VLM)의 3D 공간 추론 능력을 평가하는 것을 목표로 하는 새로운 벤치마크입니다. 이 벤치마크는 인간이 주석을 단 8,600개 이상의 질의응답 쌍을 포함하며, GPT-4o, Gemini1.5-Pro 등 16개 SOTA VLM 테스트에 사용됩니다. 결과에 따르면 현재 VLM과 인간 수준 사이에 공간 이해 측면에서 현저한 격차가 존재합니다. 이 격차를 해소하기 위해 연구팀은 Ego3D-VLM 후속 훈련 프레임워크를 제시했으며, 추정된 전역 3D 좌표 기반의 인지 지도 생성을 통해 객관식 질의응답에서 평균 12%, 절대 거리 추정에서 56%의 성능 향상을 달성하여 인간 수준의 공간 이해를 달성하기 위한 가치 있는 도구를 제공합니다. (출처: HuggingFace Daily Papers)
LLM 장기 작업 실행의 “수확 체감의 착각”: 새로운 연구는 LLM의 장기 작업 실행 성능을 탐구하며, 단일 단계 정확도의 미미한 향상이 작업 길이의 기하급수적 증가를 가져올 수 있음을 지적합니다. 논문은 LLM이 긴 작업에서 실패하는 것은 추론 능력 부족이 아니라 실행 오류 때문이라고 주장합니다. 지식과 계획을 명확히 제공함으로써 대규모 모델이 더 많은 단계를 올바르게 실행할 수 있음을 발견했으며, 이는 소규모 모델이 단일 단계 정확도에서 100%에 도달하더라도 마찬가지입니다. 흥미로운 발견은 모델에 “자기 조절” 효과가 존재하여 컨텍스트에 이전 오류가 포함될 때 모델이 다시 오류를 범하기 더 쉬우며, 이는 모델 규모만으로는 해결할 수 없다는 것입니다. 최신 “사고 모델”은 자기 조절을 피할 수 있으며 단일 실행으로 더 긴 작업을 완료하여, 모델 규모 확장 및 순차적 테스트 계산이 장기 작업에 미치는 거대한 이점을 강조합니다. (출처: Reddit r/ArtificialInteligence)
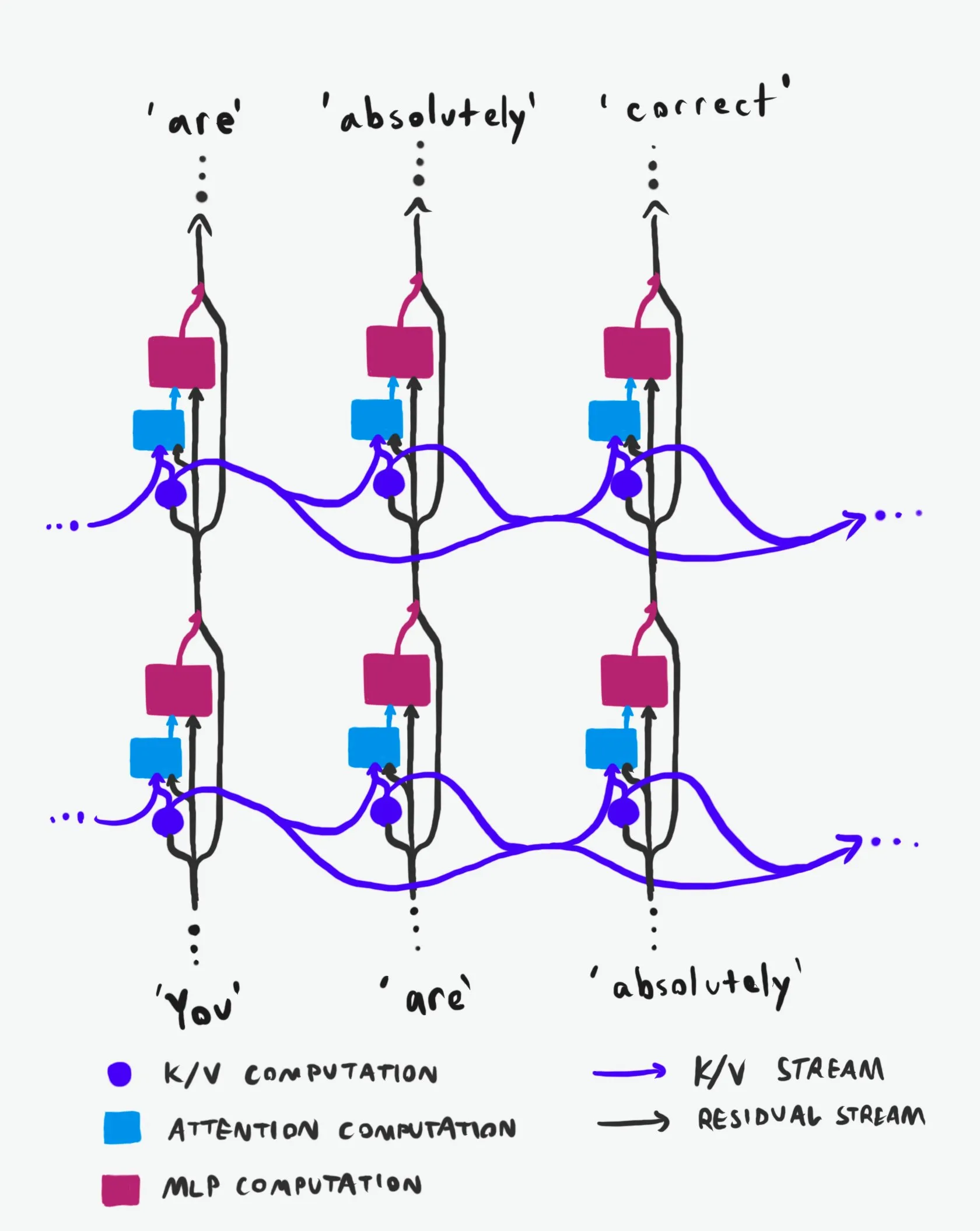
Transformer 인과 구조: 정보 흐름의 심층 분석: “동급 최고”로 평가받는 기술 설명은 Transformer 대규모 언어 모델(LLM)의 인과 구조 및 정보 흐름 방식을 심층적으로 분석합니다. 이 설명은 난해한 용어를 배제하고 Transformer 아키텍처의 두 가지 주요 정보 고속도로인 잔차 스트림(Residual Stream)과 어텐션 메커니즘을 명확하게 설명합니다. 시각화 및 상세 설명을 통해 연구원과 개발자가 Transformer 내부 작동 원리를 더 잘 이해하도록 돕고, 이를 통해 모델 설계, 최적화 및 디버깅 측면에서 더 현명한 결정을 내릴 수 있도록 하여 LLM의 기본 메커니즘을 깊이 이해하는 데 중요한 가치를 제공합니다. (출처: Plinz)
카네기 멜론 대학교, LM 추론 새 강좌 개설: 카네기 멜론 대학교(CMU)의 @gneubig와 @Amanda Bertsch는 올 가을 언어 모델(LM) 추론에 관한 새로운 강좌를 공동으로 가르칠 예정입니다. 이 강좌는 고전적인 디코딩 알고리즘부터 LLM의 최신 방법, 그리고 효율성에 중점을 둔 일련의 작업까지 포괄하여 LM 추론 분야를 포괄적으로 소개하는 것을 목표로 합니다. 강좌 내용은 온라인으로 공개될 예정이며 첫 네 강의의 비디오를 포함하여, LM 추론에 관심 있는 학생 및 연구원에게 귀중한 학습 자료를 제공하고 최첨단 추론 기술 및 실습을 습득하도록 돕습니다. (출처: lateinteraction, dejavucoder, gneubig)
OpenAIDevs, Codex 심층 분석 비디오 공개: OpenAIDevs는 Codex의 지난 두 달 동안의 변화와 최신 기능을 상세히 소개하는 Codex 심층 분석 비디오를 공개했습니다. 이 비디오는 Codex를 최대한 활용하기 위한 팁과 모범 사례를 제공하여 개발자가 이 강력한 AI 프로그래밍 도구를 더 잘 이해하고 사용하도록 돕는 것을 목표로 합니다. 내용은 코드 생성, 디버깅 및 보조 개발 측면에서 Codex의 최신 발전을 포괄하며, AI 보조 프로그래밍 효율성을 높이고자 하는 개발자에게 중요한 학습 자료입니다. (출처: OpenAIDevs)
2025년 클라우드 컴퓨팅 GPU 시장 현황 보고서: dstackai는 2025년 클라우드 컴퓨팅 GPU 시장 현황에 대한 보고서를 발표하여, 비용, 성능 및 사용 전략을 포괄합니다. 이 보고서는 현재 시장의 가격, 하드웨어 구성 및 성능을 상세히 분석하여 머신러닝 엔지니어가 클라우드 서비스 제공업체를 선택하는 데 구체적인 시장 통찰력과 참고 자료를 제공하고, 머신러닝 엔지니어링에서 클라우드 제공업체 선택 방법에 대한 일반 가이드라인을 보완하여 AI 훈련 및 추론 비용과 효율성 최적화에 중요한 지침 의미를 가집니다. (출처: stanfordnlp)
AI 하드웨어 파노라마: AI를 구동하는 다양한 컴퓨팅 유닛: The Turing Post는 AI를 구동하는 하드웨어 가이드를 발표하여, GPU, TPU, CPU, ASIC, NPU, APU, IPU, RPU, FPGA, 양자 프로세서, PIM(메모리 내 컴퓨팅) 칩 및 뉴로모픽 칩 등 다양한 컴퓨팅 유닛을 상세히 소개합니다. 이 가이드는 AI 기술 스택의 기본 컴퓨팅 지원을 포괄적으로 이해하는 데 명확한 시각을 제공하며, 하드웨어 선택 및 AI 시스템 설계에 중요한 참고 가치를 가집니다. (출처: TheTuringPost)
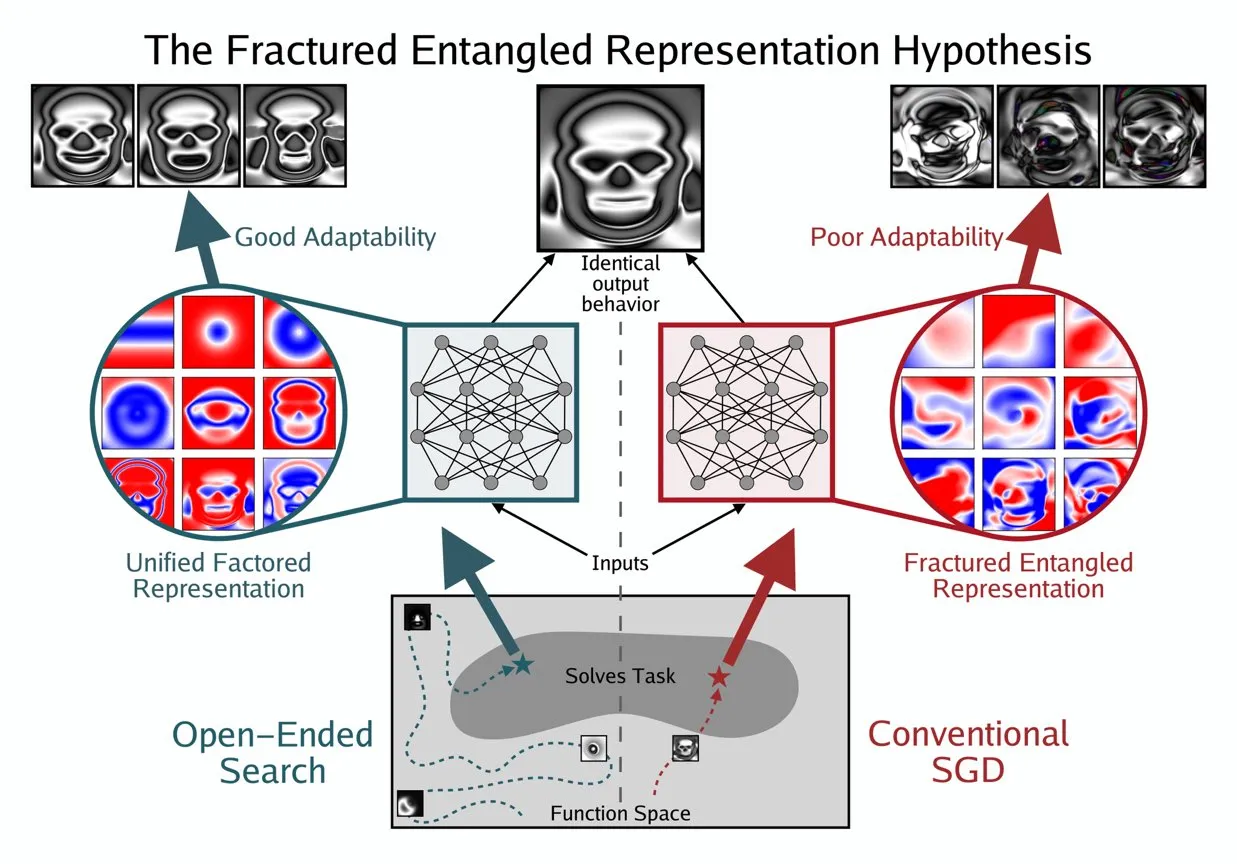
Kenneth Stanley, AI의 “진정한 이해”를 이해하기 위한 UFR 개념 제시: Kenneth Stanley는 AI의 “진정한 이해”의 의미를 설명하는 데 도움을 주기 위해 “통합 인자 표현”(Unified Factored Representation, UFR) 개념을 제시했습니다. 그는 사람들이 AI의 “진정한 이해”에 대해 이야기할 때, 그 핵심은 UFR에 있다고 믿습니다. 이 개념은 AI의 인지 능력에 대한 더 깊은 이론적 프레임워크를 제공하여 단순한 패턴 인식을 넘어, AI가 세상을 어떻게 구조화하고, 분해하며, 강력한 제약을 형성하는 능력에 도달함으로써 AI가 지식을 모방할 뿐만 아니라 인간처럼 창의적으로 사고하고 새로운 문제를 해결할 수 있도록 촉진하는 것을 목표로 합니다. (출처: hardmaru, hardmaru)
💼 비즈니스
텐센트, OpenAI 최고 연구원 영입 보도, AI 인재 전쟁 격화: 블룸버그 통신 보도에 따르면, OpenAI 최고 연구원 Yao Shunyu가 퇴사하여 중국 기술 대기업 텐센트에 합류했습니다. 이 사건은 전 세계 AI 인재 쟁탈전이 더욱 치열해지고 있음을 부각시키며, 특히 미국과 중국 사이에서 두드러집니다. 최고 AI 연구원들의 이동은 각 회사의 기술 발전 로드맵에 영향을 미칠 뿐만 아니라 AI 분야 혁신 경쟁의 과열을 반영하며, 미래 AI 판도가 인재 흐름에 따라 변화할 수 있음을 시사합니다. (출처: The Verge)
OpportuNext, 기술 공동 창업자 모집, AI 채용 플랫폼 구축: IIT 뭄바이 동문이 설립한 AI 기반 채용 플랫폼 OpportuNext는 기술 공동 창업자를 찾고 있습니다. 이 플랫폼은 포괄적인 이력서 분석, 의미론적 직무 검색, 기술 격차 로드맵 및 사전 평가를 통해 구직자와 고용주의 채용 과정에서의 문제점을 해결하는 것을 목표로 하며, 2억 6200만 달러 규모의 인도 시장을 목표로 하고 405억 달러 규모의 글로벌 시장으로 확장할 계획입니다. OpportuNext는 제품 시장 적합성을 검증하고 이력서 파서 프로토타입을 완성했으며, 2026년 중반 A 시리즈 투자 유치를 완료할 계획입니다. 이 직책은 AI/ML(NLP), 풀스택 개발, 데이터 인프라, 크롤러/API 및 DevOps/보안 분야에서 강력한 배경을 요구합니다. (출처: Reddit r/deeplearning)
Oracle 창립자 Larry Ellison: 추론이 AI 수익성의 핵심: Oracle 창립자 Larry Ellison은 “추론이야말로 AI 수익성의 핵심이다”라고 밝혔습니다. 그는 현재 모델 훈련에 투자되는 막대한 자금은 궁극적으로 제품 판매로 전환될 것이며, 이 제품들은 주로 추론 능력에 의존한다고 생각합니다. Ellison은 Oracle이 추론 수요 활용 측면에서 선두에 있음을 강조하며, AI 산업의 서사가 “누가 가장 큰 모델을 훈련할 수 있는가”에서 “누가 효율적이고 신뢰할 수 있으며 규모 있게 추론 서비스를 제공할 수 있는가”로 전환되고 있음을 시사하고, 추론 서비스가 미래 수익 구조를 지배할 것인지에 대한 논의를 유발합니다. (출처: Reddit r/MachineLearning)
🌟 커뮤니티
AI 윤리 및 보안: 다차원적 도전과 협력: 커뮤니티는 AI가 가져오는 윤리 및 보안 과제에 대해 광범위하게 논의했으며, 여기에는 AI가 노동 시장에 미칠 잠재적 영향 및 보호 전략, ChatGPT MCP 도구의 개인 정보 보호 및 보안 우려, 그리고 AI가 멸종 위험을 초래할 수 있다는 심각한 논쟁이 포함됩니다. AI로 인한 정신 건강 문제, 즉 사용자의 AI 과도한 의존 및 심지어 “AI 정신병”과 고독감 발생도 점차 주목받고 있습니다. 동시에 AI 규제에 대한 논의(예: Ted Cruz 법안)도 지속되고 있습니다. 긍정적인 측면으로는 Anthropic과 OpenAI 등 기업이 보안 기관과 협력하여 모델 취약점을 공동으로 발견하고 수정하여 AI 보안 방어를 강화하고 있습니다. (출처: Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

LLM 성능 및 평가: 모델 품질 및 벤치마크 논쟁: 커뮤니티는 LLM의 성능 평가 및 모델 품질 문제에 대해 심층적으로 논의했습니다. K2-Think 등 모델은 평가 방법의 결함(예: 데이터 오염 및 불공정한 비교)으로 인해 의문이 제기되었고, 이는 기존 AI 벤치마크 테스트의 신뢰성에 대한 우려를 유발했습니다. 연구는 데이터 주석 도구로서 LLM이 편향을 도입하여 과학적 결과의 “LLM 해킹”을 초래할 수 있다고 지적했습니다. Claude Code에 대한 사용자 경험은 엇갈렸으며, 일관성 및 “게으름” 측면의 과제를 반영했고, Anthropic도 Claude Sonnet 4의 성능 저하 문제를 인정하고 수정했습니다. 동시에 GPT-5 Pro는 강력한 추론 능력으로 호평을 받았지만, AI 생성 텍스트의 보편성 및 모델 신뢰성(예: 추론 버그)에 대한 지속적인 관심도 사용자들 사이에서 관찰되었습니다. (출처: Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
미래 직업과 AI 에이전트: 효율성 향상 및 직업 전환: AI 에이전트가 작업 방식을 심오하게 변화시키고 있습니다. 분야 전문가(예: 변호사, 의사, 엔지니어)는 개인 지식을 AI 에이전트에 주입하여 전문 서비스를 확장하고, 수입이 더 이상 시간당 청구에 제한되지 않도록 실현할 수 있습니다. Replit CEO Amjad Masad는 AI 에이전트가 주문형 소프트웨어를 생성하여 전통 소프트웨어 가치를 거의 0으로 만들고 회사 구축 방식을 재편할 것이라고 예측합니다. 커뮤니티는 AI 시대 창업 정신과 적응 능력의 중요성, 에이전트 개발에서 Replit의 독특한 장점(예: 테스트 가능한 환경), 그리고 로봇 모델과 인간 뇌 효율성의 비교에 대해 논의했습니다. 또한, 강화 학습 환경으로서 Cursor의 잠재력도 주목받아, AI가 개인 및 조직의 생산성을 더욱 향상시킬 것임을 시사합니다. (출처: amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
오픈소스 생태계 및 협력: 모델 보급 및 커뮤니티 수요: Hugging Face는 AI 생태계에서 핵심적인 역할을 수행하며, 모듈화, 표준화 및 통합화된 플랫폼의 장점을 통해 개발자에게 풍부한 도구와 모델을 제공하고 AI 구축 진입 장벽을 낮춥니다. 커뮤니티 논의는 Apple MLX 프로젝트 및 그 오픈소스 기여가 하드웨어 효율성 향상에 기여했음을 긍정적으로 평가했습니다. 동시에 커뮤니티는 Qwen 팀에 Qwen3-Next 모델에 대한 GGUF 지원을 적극적으로 요청하여, 사용자 정의 아키텍처가 llama.cpp와 같은 더 광범위한 로컬 추론 프레임워크에서 실행될 수 있도록 하고, 모델 보급 및 사용 편의성에 대한 커뮤니티의 요구를 충족하며 오픈소스 AI 기술의 추가 발전을 촉진하고 있습니다. (출처: ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI의 광범위한 사회적 영향: 엔터테인먼트에서 경제까지의 다원적 발현: AI는 다양한 형태로 사회에 침투하고 있습니다. AI 반려동물 단편 드라마는 의인화된 서사와 감성적 가치로 소셜 미디어에서 큰 인기를 얻으며, AI가 콘텐츠 창작 및 엔터테인먼트 분야에서 보이는 거대한 잠재력을 보여주고 많은 젊은 사용자를 유치하며 새로운 비즈니스 모델을 탄생시켰습니다. 동시에 AI 거물(예: OpenAI와 Oracle) 간 자금 흐름에 대한 논의는 AI 경제 모델에 대한 성찰을 유발했습니다. 커뮤니티는 AI가 자원 문제(예: 수자원) 해결에 기여할 잠재력과, AI 챗봇이 사용자 경험 향상을 위해 더 많은 시각적 콘텐츠가 필요하다는 제안도 탐구했습니다. 또한, 소셜 미디어에서의 AI 적용은 사회적 감정 및 인지 영향에 대한 논의도 유발했습니다. (출처: 36氪, Yuchenj_UW, kylebrussell, brickroad7)
AI 커뮤니티의 흥미로운 소식 및 관찰: AI에 대한 사용자의 개인화된 기대와 유머러스한 성찰: AI 커뮤니티는 기술 발전과 사용자 경험에 대한 독특한 관찰과 유머러스한 성찰로 가득합니다. 예를 들어, OpenAI 구독 할인 코드와 “사고” 행동의 연관성은 AI 가치와 비용에 대한 논의를 유발했습니다. 사용자들은 Claude Code가 더 개인화된 답변을 제공하기를 희망하고 심지어 AI에 “인격”을 부여하기를 바라며, 이는 AI 상호작용 경험에 대한 깊은 요구를 반영합니다. 동시에 시뮬레이션 환경(예: GTA-6)에서 AI 에이전트의 강화 학습 훈련에 대한 구상도 AI 미래 발전 경로에 대한 커뮤니티의 무한한 상상력을 보여줍니다. 이러한 논의는 AI 기술 현황에 대한 통찰력을 제공할 뿐만 아니라, AI와 상호작용하면서 사용자들이 느끼는 감정과 기대를 반영합니다. (출처: gneubig, jonst0kes, scaling01)
💡 기타
2025년 AI 기술 습득 가이드: 인공지능 기술의 빠른 발전과 함께, 핵심 AI 기술 습득은 개인의 직업 발전에 매우 중요합니다. 2025년 AI 기술 습득 가이드는 인공지능, 머신러닝 및 딥러닝 분야에서 숙달해야 할 12가지 핵심 기술을 강조합니다. 이 기술들은 기초 이론부터 실제 적용까지 포괄하며, 전문가와 학습자가 AI 시대의 새로운 인재 요구사항에 적응하고 기술 혁신 및 직업 시장에서의 경쟁력을 향상시키도록 돕는 것을 목표로 합니다. (출처: Ronald_vanLoon)

2025년 클라우드 GPU 시장: 비용, 성능 및 배포 전략 보고서: dstackai는 2025년 클라우드 컴퓨팅 GPU 시장 현황에 대한 상세 보고서를 발표하여, 다양한 클라우드 서비스 제공업체의 GPU 비용, 성능 및 배포 전략을 심층 분석합니다. 이 보고서는 머신러닝 엔지니어와 기업이 클라우드 제공업체를 선택하는 데 구체적인 지침을 제공하고, AI 훈련 및 추론 작업의 자원 구성을 최적화하여 증가하는 AI 인프라 수요 속에서 더 비용 효율적이고 성능 우위의 결정을 내릴 수 있도록 돕는 것을 목표로 합니다. (출처: stanfordnlp)
AI 하드웨어 기술 개요: 지능형 미래를 구동하는 다양한 컴퓨팅 유닛: The Turing Post는 포괄적인 AI 하드웨어 가이드를 발표하여, 현재 인공지능을 구동하는 다양한 컴퓨팅 유닛을 상세히 소개합니다. 여기에는 그래픽 처리 장치(GPU), 텐서 처리 장치(TPU), 중앙 처리 장치(CPU), 주문형 반도체(ASIC), 신경망 처리 장치(NPU), 가속 처리 장치(APU), 지능형 처리 장치(IPU), 저항성 처리 장치(RPU), 필드 프로그래머블 게이트 어레이(FPGA), 양자 프로세서, PIM(메모리 내 컴퓨팅) 칩 및 뉴로모픽 칩이 포함됩니다. 이 가이드는 AI 기술 스택의 기본 하드웨어 지원을 이해하는 데 명확한 시각을 제공하며, 개발자와 연구원이 AI 워크로드에 가장 적합한 하드웨어 솔루션을 선택하는 데 도움을 줍니다. (출처: TheTuringPost)