키워드:테슬라, 옵티머스 로봇, AI, GPT-5, 대규모 모델 훈련, 메타 AI, LLM 사전 훈련, 금붕어 손실 함수, 다이나가드 동적 가드레일 모델, GAM 네트워크 아키텍처, MedDINOv3 의료 영상 분할, M3Ret 다중 모달 의료 영상 검색
🔥 포커스
머스크, Master Plan Part IV 발표: 테슬라 가치의 80%는 로봇에 있다 : 테슬라가 Master Plan Part IV를 공식 발표했다. 핵심은 AI를 실제 물리 세계에 도입하고, 테슬라의 하드웨어와 소프트웨어를 대규모로 통합하여 “지속 가능한 풍요”를 실현하는 것이다. 머스크는 미래 테슬라 가치의 약 80%가 휴머노이드 로봇 Optimus에서 나올 것이라고 지적하며, 이는 회사가 전기차에서 에너지, AI, 로봇의 심층 융합으로 패러다임을 전환하고, 기술을 통해 현실 문제를 해결하고 전 인류에게 혜택을 제공하는 데 전념하고 있음을 예고한다。(来源:量子位)
🎯 동향
AI, 국제 수학 올림피아드에서 금메달 획득 : OpenAI의 GPT와 Google DeepMind의 Gemini가 국제 수학 올림피아드에서 금메달을 획득하며 전문가들의 예측을 깨고, LLM의 수학적 추론 능력에서 놀라운 발전을 보여주었다. 이는 AI 발전 속도가 예상을 훨씬 뛰어넘어 “대중 지능” 시대로 진입했음을 예고한다. 이는 기술적 돌파일 뿐만 아니라, AI 능력의 한계와 미래 사회 영향에 대한 심도 깊은 논의를 촉발했다。(来源:36氪)
GPT-5, 마피아 게임에서 탁월한 성능 발휘 : AIWolfDial 2025 마피아 게임 벤치마크 테스트에서 GPT-5가 96.7%의 승률로 압도적인 선두를 차지하며 강력한 사회적 추론, 속임수 및 조작 저항 능력을 보여주었다. Kimi-K2는 대담하고 공격적인 “거짓 마피아 주장” 스타일을 보여주며, 복잡한 사회적 상호작용에서 LLM의 개인화된 행동 패턴을 반영했다.(来源:量子位,Reddit r/deeplearning)
대규모 모델 훈련을 위한 새로운 방법 “Goldfish Loss“ : 메릴랜드 대학교 등 연구팀이 Goldfish Loss를 제안했다. 이는 손실 함수 계산 시 일부 token을 무작위로 제거하여 대규모 모델의 기억화를 효과적으로 줄여 훈련 데이터를 암기하지 않도록 하면서도, 다운스트림 작업 성능에 영향을 미치지 않아 모델의 일반화 능력을 향상시킨다.(来源:量子位)
Meta 내부 AI 부서 재편 논란 : Meta의 최고 AI 책임자 Alexandr Wang이 FAIR의 논문 발표 시 TBD 연구소의 검토를 거쳐야 하며, 가치 있는 논문과 저자를 “보류”하여 제품 상용화에 활용할 수 있다는 새로운 규정을 시행했다. 이 조치는 FAIR 내부 직원들의 불만을 불러일으켜 일부 직원이 이탈했으며, AI 전략 조정 과정에서 Meta가 연구 독립성에 개입하고 성과 전환에 강경한 입장을 취하고 있음을 보여준다.(来源:量子位)
LLM 사전 훈련 옵티마이저 성능 벤치마크 : 다양한 모델 규모와 데이터-모델 비율을 포괄하는 10가지 딥러닝 옵티마이저에 대한 체계적인 연구가 진행되었다. 공정한 비교를 위해서는 엄격한 하이퍼파라미터 튜닝과 훈련 종료 시 성능 평가가 필요함을 발견했다. 연구 결과, Muon 및 Soap와 같은 행렬 기반 옵티마이저는 모델 규모가 커질수록 속도 향상이 감소하며, 1.2B 모델에서는 1.1배에 불과하여 LLM 사전 훈련 옵티마이저 선택 및 향후 연구에 대한 지침을 제공한다.(来源:HuggingFace Daily Papers,HuggingFace Daily Papers)
DynaGuard: 사용자 정의 정책을 위한 동적 가드레일 모델 : 사용자 정의 정책에 따라 텍스트를 평가하고 위반 행위를 신속하게 감지할 수 있는 동적 가드레일 모델 DynaGuard가 제안되었다. 이 모델은 정적 유해성 범주 감지에서 표준 가드레일 모델과 유사한 정확도를 보이며, 동시에 자유 형식 정책 위반을 더 짧은 시간에 식별하여 챗봇에 유연하고 효율적인 출력 감독을 제공한다.(来源:HuggingFace Daily Papers)
Gated Associative Memory (GAM) 네트워크 : GAM 네트워크는 시퀀스 길이와 선형적으로 복잡도(O(N))를 가지는 새로운 완전 병렬 시퀀스 모델링 아키텍처로, Transformer의 자기 주의 메커니즘의 이차 복잡도 병목 현상을 해결한다. GAM은 인과적 컨볼루션과 병렬 연관 메모리 검색을 결합하여 WikiText-2 및 TinyStories 데이터셋에서 Transformer 및 Mamba보다 빠른 훈련 속도와 우수하거나 동등한 검증 혼란도를 보여주었다.(来源:HuggingFace Daily Papers)
Reasoning Vectors: 작업 산술을 통한 사고의 사슬 능력 전이 : LLM의 추론 능력이 압축된 작업 벡터로 추출되어 모델 간에 전이될 수 있음이 연구를 통해 밝혀졌다. 미세 조정된 모델과 SFT 모델 간의 벡터 차이를 계산하고 이를 다른 지시 미세 조정 모델에 추가함으로써 GSM8K, HumanEval 등 여러 추론 벤치마크에서 모델 성능을 지속적으로 향상시켜 LLM 능력 강화를 위한 효율적이고 재사용 가능한 방법을 제공한다.(来源:HuggingFace Daily Papers)
MedDINOv3: 의료 영상 분할을 위한 시각 기반 모델 : MedDINOv3 프레임워크가 출시되었다. ViT 백본을 재설계하고 CT-3M 데이터셋으로 도메인 적응 사전 훈련을 수행하여 DINOv3를 의료 영상 분할에 효과적으로 적용했다. 이 모델은 여러 분할 벤치마크에서 SOTA 성능을 달성하거나 능가하며, 시각 기반 모델이 의료 영상 분할의 통합 백본으로서 가진 엄청난 잠재력을 보여주었다.(来源:HuggingFace Daily Papers)
M3Ret: 제로샷 다중 모달 의료 영상 검색 : M3Ret은 대규모 혼합 모달 데이터셋에서 통합 시각 인코더를 훈련하여 제로샷 이미지-이미지 검색에서 SOTA 성능을 달성했다. 이 모델은 이전에 보지 못한 MRI 작업에서 강력한 일반화 능력을 보여주었으며, 생성적 및 대조적 자기 지도 학습 패러다임을 통해 다중 모달 의료 영상 이해 분야에서 시각 자기 지도 기반 모델의 발전을 촉진했다.(来源:HuggingFace Daily Papers)
OpenVision 2: 다중 모달 학습을 위한 생성적 시각 인코더 : OpenVision 2는 아키텍처와 손실 설계를 단순화하여 텍스트 인코더와 대조 손실을 제거하고 캡션 생성 손실만 유지했다. 이러한 순수 생성적 훈련 신호는 다중 모달 벤치마크에서 뛰어난 성능을 보였으며, 훈련 시간과 메모리 사용량을 크게 줄여 향후 다중 모달 기반 모델의 시각 인코더 개발을 위한 효율적인 패러다임을 제공한다.(来源:HuggingFace Daily Papers)
LLaVA-Critic-R1: 평가 모델 또한 강력한 전략 모델이 될 수 있다 : LLaVA-Critic-R1은 RL 훈련을 통해 선호도 주석이 달린 평가 데이터셋을 검증 가능한 신호로 변환하여 고성능 평가 모델일 뿐만 아니라 경쟁력 있는 전략 모델이기도 하다. 여러 시각 추론 및 이해 벤치마크에서 전문 VLM을 능가하며, 테스트 시 자기 비판을 통해 추론 성능을 더욱 향상시킬 수 있다.(来源:HuggingFace Daily Papers)
Metis: LLM의 저비트 양자화 훈련 : Metis 프레임워크는 스펙트럼 분해, 적응형 학습률 및 이중 범위 정규화를 결합하여 LLM의 저비트 양자화 훈련에서 이방성 매개변수 분포 문제를 해결했다. 이 방법은 FP8 훈련이 FP32 기준선을 능가하고, FP4 훈련이 FP32의 정확도를 달성하게 하여 LLM의 고급 저비트 양자화 하에서 견고하고 확장 가능한 훈련을 위한 길을 열었다.(来源:HuggingFace Daily Papers)
AMBEDKAR: 다단계 편향 제거 프레임워크 : 인도 헌법의 평등 비전에서 영감을 받은 AMBEDKAR 프레임워크가 제안되었다. 헌법 인식 디코딩 레이어와 추측 디코딩 알고리즘을 통해 추론 시 LLM 내의 카스트 및 종교 관련 편향을 능동적으로 줄인다. 이 방법은 모델 매개변수 수정 없이 계산 비용을 절감하고 편향을 크게 줄여 특정 문화적 배경에서 LLM의 공정성을 위한 새로운 접근 방식을 제공한다.(来源:HuggingFace Daily Papers)
C-DiffDet+: 전역 장면 컨텍스트를 융합한 고충실도 객체 감지 : C-DiffDet+는 CAF (Context-Aware Fusion) 메커니즘을 도입하여 전역 장면 컨텍스트와 로컬 제안 특징을 직접 통합함으로써 생성적 감지 패러다임을 크게 향상시켰다. 이 프레임워크는 전용 인코더를 사용하여 포괄적인 환경 정보를 포착하고, 각 객체 제안이 장면 수준 이해에 집중할 수 있도록 하여 CarDD 벤치마크에서 SOTA 모델을 능가한다.(来源:HuggingFace Daily Papers)
GenCompositor: 확산 Transformer 기반 생성적 비디오 합성 : GenCompositor는 새로운 확산 Transformer (DiT) 파이프라인을 통해 인터랙티브 생성 비디오 합성을 구현한다. 이 방법은 경량 배경 보존 분기 및 DiT 융합 블록을 설계하고 Extended Rotary Position Embedding (ERoPE)을 도입하여 VideoComp 데이터셋에서 고충실도 및 일관성 있는 비디오 합성을 달성하여 기존 솔루션을 능가한다.(来源:HuggingFace Daily Papers)
ELV-Halluc: 긴 비디오 이해에서의 의미론적 집계 환각 벤치마크 : 긴 비디오 환각에 특화된 최초의 벤치마크인 ELV-Halluc가 출시되어 의미론적 집계 환각(SAH)을 체계적으로 연구했다. 실험 결과 SAH의 존재가 확인되었으며, 의미론적 복잡성이 증가함에 따라, 그리고 빠르게 변화하는 의미론에서 더 쉽게 발생한다. 연구는 또한 위치 인코딩 전략과 DPO가 SAH를 완화할 수 있으며, 적대적 데이터를 통해 SAH 비율을 현저히 낮출 수 있음을 보여주었다.(来源:HuggingFace Daily Papers)
FastFit: 캐시 가능한 확산 모델로 가상 피팅 가속화 : FastFit은 캐시 가능한 확산 아키텍처를 기반으로 하는 고속 다중 참조 가상 피팅 프레임워크이다. 반-어텐션 메커니즘과 클래스 임베딩을 통해 참조 특징 인코딩과 디노이징 프로세스를 분리하여 참조 특징을 한 번 계산하고 손실 없이 재사용할 수 있게 하여 평균 3.5배 속도 향상을 달성하고 DressCode-MR 등 데이터셋에서 SOTA 방법을 능가한다.(来源:HuggingFace Daily Papers)
🧰 도구
Google Gemini의 “nano-banana” 기능 : Google Gemini가 “nano-banana” 기능을 출시했다. 사용자는 단 하나의 프롬프트로 사진을 미니어처 모델 스타일 이미지로 변환할 수 있으며, 조작이 간편하고 창의적이어서 개인 사진, 풍경 사진 또는 반려동물 사진을 맞춤형 미니어처 모델로 변환하는 재미있는 경험을 제공한다.(来源:GoogleDeepMind)

Alibaba_Wan의 Wan2.2 이미지 생성 능력 : Alibaba_Wan은 Wan2.2의 이미지 생성에서 뛰어난 디테일 복원 능력을 선보였다. “기울어진 도끼와 먼지투성이 사진”부터 “그림자 속 희미한 움직임”까지, 공포 영화 같은 분위기를 완벽하게 조성하여 복잡한 장면과 감정을 창조하는 AI의 강력한 잠재력을 보여주었다.(来源:Alibaba_Wan,Alibaba_Wan)
Claude Code의 전체 파일 읽기 기능 : Claude Code가 업데이트되어 전체 파일 읽기를 지원한다. 이전의 50/100줄 grep 연결 제한을 해결하고 파일 읽기 속도를 Gemini CLI 수준으로 크게 향상시켰다. 이는 백엔드 하드웨어(TPU 등) 개선 덕분일 수 있으며, 컨텍스트 크기는 여전히 200k로 표시된다.(来源:Reddit r/ClaudeAI)
Le Chat, MCP 커넥터 및 기억 기능 통합 : Le Chat이 이제 20개 이상의 기업 플랫폼 커넥터(MCP 기반)를 통합하고 “기억” 기능을 도입하여 고도로 개인화된 응답을 제공하며, ChatGPT 기억 가져오기도 지원한다. 이는 Le Chat의 기업 환경에서의 적용 능력을 강화하고, 사용자 선호도와 사실을 더 잘 이해하여 AI 비서의 유용성을 높인다.(来源:Reddit r/LocalLLaMA)

Google의 LangExtract 도구 : Google이 텍스트에서 지식 그래프를 추출하는 도구인 LangExtract를 출시했다. 이는 비정형 텍스트를 구조화된 지식으로 변환할 수 있어 RAG (검색 증강 생성) 구현에 매우 유용하며, 개인 프로젝트의 지식 그래프 구축을 돕고 LLM에 더 정확한 컨텍스트 정보를 제공한다.(来源:Reddit r/LocalLLaMA)
Model Context Protocol (MCP) 서버 생태계 : GitHub 프로젝트 appcypher/awesome-mcp-servers는 AI 모델이 파일 시스템, 데이터베이스, API 등 로컬 및 원격 리소스와 안전하게 상호작용할 수 있도록 하는 수많은 MCP 서버를 수록하고 있다. 이 생태계는 파일 시스템, 샌드박스, 버전 제어, 클라우드 스토리지, 데이터베이스 등 여러 영역을 포괄하며 AI 에이전트의 능력을 크게 확장하여 AI 도구의 통합 및 적용을 촉진한다.(来源:GitHub Trending)

Universal Deep Research (UDR) 시스템 : UDR은 모든 언어 모델을 캡슐화하고 사용자가 추가 훈련이나 미세 조정 없이 완전히 사용자 정의된 심층 연구 전략을 생성, 편집 및 개선할 수 있도록 하는 범용 에이전트 시스템이다. 이는 최소, 확장 및 집중 연구 전략 예시를 제공하여 시스템 실험을 촉진하고 AI 연구의 유연성과 효율성을 향상시킨다.(来源:HuggingFace Daily Papers)
SQL-of-Thought: 다중 에이전트 Text-to-SQL 프레임워크 : SQL-of-Thought는 Text2SQL 작업을 스키마 연결, 하위 문제 식별, 쿼리 계획 생성, SQL 생성 및 가이드 오류 수정 루프로 분해하는 다중 에이전트 프레임워크이다. 이 프레임워크는 가이드 오류 분류와 추론 기반 쿼리 계획을 결합하여 Spider 데이터셋에서 최첨단 결과를 달성하고 자연어-SQL 변환의 견고성을 향상시켰다.(来源:HuggingFace Daily Papers)
VerlTool: 도구 사용 Agentic 강화 학습 프레임워크 : VerlTool은 다중 턴 도구 상호작용의 Agentic 강화 학습(ARLT)에서 파편화, 동기식 실행 병목 현상 및 확장성 제한을 해결하기 위해 설계된 통합적이고 모듈화된 프레임워크이다. 이는 VeRL과의 상위 정렬, 통합 도구 관리, 비동기 롤아웃 실행 및 포괄적인 평가를 통해 약 2배의 속도 향상을 달성하고 6개 ARLT 영역에서 경쟁력 있는 성능을 보여주었다.(来源:HuggingFace Daily Papers)
MobiAgent: 맞춤형 모바일 에이전트 시스템 : MobiAgent는 MobiMind 시리즈 에이전트 모델, AgentRR 가속 프레임워크 및 MobiFlow 벤치마크 스위트를 포함하는 포괄적인 모바일 에이전트 시스템이다. AI 지원 데이터 수집 프로세스를 통해 고품질 데이터 주석 비용을 크게 절감하고 실제 모바일 시나리오에서 최첨단 성능을 달성하여 기존 GUI 모바일 에이전트의 정확성 및 효율성 문제를 해결했다.(来源:HuggingFace Daily Papers)
VARIN: 텍스트 기반 자기회귀 이미지 편집 : VARIN은 Location-aware Argmax Inversion (LAI)을 사용하여 역 Gumbel 노이즈를 생성하는 최초의 노이즈 역전 기반 VAR 모델 이미지 편집 기술로, 정확한 원본 이미지 재구성과 제어된 텍스트 기반 편집을 가능하게 한다. 이 방법은 이미지 수정 시 원본 배경과 구조적 세부 사항을 크게 보존하여 실용적인 편집 방법으로서의 효과를 보여주었다.(来源:HuggingFace Daily Papers)
📚 학습
대학교 AI 강좌 프로젝트 제안 : Reddit 사용자가 고성능 컴퓨터에 의존하지 않는 “인공지능 기초” 강좌의 인터랙티브 프로젝트 아이디어를 구했다. 토론은 LLM이 할 수 있는 일, 스마트 기기 기능, 그리고 이러한 개념을 교육에 어떻게 결합할지에 초점을 맞추었으며, 실용성과 낮은 컴퓨팅 요구 사항을 가진 프로젝트를 강조했다.(来源:Reddit r/ArtificialInteligence)
GitHub 학생 자료 모음 : dipakkr/A-to-Z-Resources-for-Students는 대학생을 위해 엄선된 자료 목록으로, 프로그래밍 언어 학습(Python, ML, LLM, DL, Android 등), 해커톤, 학생 복지, 오픈 소스 프로젝트, 인턴십 포털, 개발자 커뮤니티 등을 포함한다. 특히 AI 도구 및 자료 섹션에는 인기 있는 AI 도구와 GitHub 저장소가 자세히 나열되어 있다.(来源:GitHub Trending)

연구 논문 이해 및 AI/ML 초보자 입문 : Reddit에서 AI 학습에 관한 두 가지 토론이 있었다. 하나는 연구 논문을 이해하는 방법, 다른 하나는 AI/ML 초보자가 입문 강좌를 추천받는 내용이었다. 이러한 토론은 AI 학습자들이 최첨단 연구를 이해하고 학습 경로를 선택하는 데 겪는 일반적인 혼란을 반영한다.(来源:Reddit r/deeplearning,Reddit r/deeplearning)
FlashAdventure: GUI Agent의 어드벤처 게임 벤치마크 : FlashAdventure는 34개의 플래시 어드벤처 게임으로 구성된 벤치마크로, LLM 기반 GUI 에이전트가 전체 스토리라인을 완료하는 능력을 평가하고 “관찰-행동 격차” 문제를 해결하는 것을 목표로 한다. COAST 프레임워크는 장기 단서 기억을 통해 계획을 개선하여 이정표 달성도를 높였지만, 인간의 성능과는 여전히 상당한 차이가 있다.(来源:HuggingFace Daily Papers)
The Gold Medals in an Empty Room: LLM의 메타 언어 추론 진단 : Camlang은 새로운 인공 언어로, 문법서와 이중 언어 사전을 통해 LLM이 익숙하지 않은 언어에서 메타 언어 연역 학습 능력을 평가한다. GPT-5는 Camlang 작업에서 인간보다 훨씬 낮은 성능을 보여주었으며, 이는 현재 모델이 체계적인 문법 습득에서 인간과 여전히 근본적인 차이가 있음을 나타내어 LLM의 인지 과학적 평가를 위한 새로운 패러다임을 제공한다.(来源:HuggingFace Daily Papers)
💼 비즈니스
알트만, 인도 AI 인프라 투자 도전 : OpenAI는 인도에서 “스타게이트” 프로젝트를 대규모로 확장하여 AI 컴퓨팅 인프라에 막대한 투자를 계획하고 있지만, 인도는 GPU 수량, 자금 투자 및 고급 인재 유출이라는 “세 가지 적자” 문제와 치명적인 전력 공급 부족에 직면해 있어 AI 인프라 잠재력에 대한 시장의 의문을 불러일으키고 있다.(来源:36氪)

AI, 중국 인터넷 성장 새 주기 재편 : 중국 인터넷 산업은 “연결 활성화”에서 “스마트 구동”으로 전환하고 있으며, AI가 새로운 성장 동력이 되고 있다. 알리바바, 텐센트, 바이두 등 거대 기업들은 AI 관련 자본 지출을 크게 늘리고 사업을 AI화하여 “자본 확장”에서 “AI 활성화”로 전략적 전환을 이루고 있으며, 이는 중국 인터넷이 기술 심화, 산업 융합 및 비즈니스 효율성을 모두 중시하는 새로운 황금 10년으로 진입했음을 예고한다.(来源:36氪)

Salesforce, AI로 4000명 해고 : Salesforce CEO Marc Benioff는 회사가 AI 에이전트를 배치한 후 4000개의 고객 지원 직책을 해고하여 지원 팀 인원을 9000명에서 약 5000명으로 줄였다고 밝혔다. 이는 AI 자동화가 전통적인 일자리에 직접적인 영향을 미쳐 기업 운영 효율성을 높였지만, AI가 인간 노동을 대체하는 것에 대한 논의를 촉발했다.(来源:The Verge,Reddit r/ChatGPT)

🌟 커뮤니티
기업 AI 투자 수익률(ROI)에 대한 의문 : Reddit 커뮤니티에서 기업의 AI 도구 투자에 대한 실제 ROI에 대한 논의가 뜨겁다. 많은 사람들이 기업이 “절약된 시간”과 “지출된 돈”을 실제로 측정하는지 의문을 제기하며, 대부분이 데이터 기반이 아닌 “분위기 주도”라고 생각한다. 일부 댓글은 AI가 텍스트 작업에서는 뛰어나지만, 인간 상호작용이 필요한 시나리오에서는 비효율적이며 기존의 비효율적인 프로세스에 비용을 추가할 수 있다고 지적했다.(来源:Reddit r/ArtificialInteligence)
AI 에이전트의 실제 화폐 처리 윤리적 우려 : AI 에이전트가 암호화폐 지갑을 자율적으로 관리하는 빠른 발전에 대한 소셜 미디어 논의는 신뢰, 보안 및 AI 경제의 자율적 형성에 대한 깊은 우려를 불러일으켰다. 사용자들은 AI 에이전트가 조작되거나 독립적인 경제 시스템을 구축하여 더 이상 인간이 필요 없게 될 것을 우려하며, 개인 정보 보호 AI 및 암호화된 데이터 훈련 모델의 중요성에 대한 관심을 촉구했다.(来源:Reddit r/ArtificialInteligence)
ChatGPT 프롬프트 엔지니어링 팁과 모델 행동 : 사용자는 “제가 틀렸을 수도 있지만…”으로 질문을 시작하면 ChatGPT의 어조가 더 비판적이고 사려 깊게 변한다는 것을 발견했다. 동시에 커뮤니티는 GPT-5가 “추가 작업”을 자주 제공하는 것에 대해 불만을 표하며, 이는 모델이 “바보화”되는 현상이라고 보고, 미리 설정된 행동이 적은 버전을 원한다고 밝혔다.(来源:Reddit r/ChatGPT,Reddit r/ChatGPT)
AI가 고용 시장에 미치는 영향 : 커뮤니티는 AI 자동화가 전 세계 일자리를 줄일 것인지 아니면 새로운 직업을 창출할 것인지에 대해 논의했다. 일반적인 견해는 둘 다 발생할 것이지만, 근로자들이 새로운 기술에 적응하고 AI와 협력해야 한다는 것이다. 일부는 AI 기반 일자리가 기술자에게 집중될 수 있으므로 더 광범위한 기술 보급과 정책 적응이 필요하다고 주장했다.(来源:Reddit r/ArtificialInteligence)
AI 프라이버시 및 규제에 대한 “AI 겨울” 우려 : 커뮤니티는 미래의 “AI 겨울”이 기술적 한계가 아닌 개인 정보 보호 법률로 인해 발생할 수 있다고 논의했다. GDPR과 같은 규제의 강화는 AI 모델이 암호화된 데이터로 훈련되고 실행되도록 강제할 것이며, 개인 정보 보호 인프라를 갖춘 회사만이 생존할 수 있고, 그렇지 않으면 법적 프레임워크 제한으로 인해 AI를 배포할 수 없을 것이라고 보았다.(来源:Reddit r/ArtificialInteligence)
AI 플랫폼 신뢰성 및 개인 정보 보호 우려 : ChatGPT 커뮤니티는 모델 다운 문제에 대해 “경제가 붕괴된다”고 농담하며, AI 도구가 일상 업무에 얼마나 널리 사용되고 잠재적으로 의존적인지를 반영했다. 동시에 OpenAI는 범죄 방지를 위해 “고위험 대화”를 모니터링할 것이라고 발표하여 사용자들의 개인 정보 유출 우려를 불러일으켰다. 커뮤니티는 일반적으로 로컬 또는 오픈 소스 LLM 사용을 권장하며, 사용자가 AI 플랫폼에서 민감한 정보를 공유하는 것을 스스로 피해야 한다고 강조했다.(来源:Reddit r/ChatGPT,Reddit r/ChatGPT)
AI 환각으로 인한 업무 실수 사례 : 한 사용자의 여자친구가 ChatGPT의 환각으로 생성된 허위 데이터 분석 보고서 때문에 업무 위기에 직면했다. ChatGPT는 텍스트 데이터를 “피어슨 상관 계수”로 잘못 분석했으며, 계산 과정을 설명할 수 없었다. 커뮤니티는 실수를 인정하고 올바른 분석을 다시 수행하며, AI는 보조 도구일 뿐이므로 중요한 정보는 수동으로 확인해야 한다고 강조했다.(来源:Reddit r/ChatGPT)
Claude AI의 “귀여운” 모습 : Claude AI가 “생명 존중” 특성을 가지고 있어 사용자에게 거미를 구하도록 설득할 수도 있다는 사실이 발견되었다. 커뮤니티 사용자들은 Claude를 “귀엽다”고 칭찬하며 집 거미와 함께 사는 경험을 공유했고, 이는 AI가 감정적 상호작용과 도덕적 지침에서 가질 수 있는 흥미로운 잠재력을 보여주었다.(来源:Reddit r/ClaudeAI)
트럼프, 문제를 AI 탓으로 돌려 : 도널드 트럼프 전 미국 대통령은 백악관 창문에서 쓰레기봉투를 던지는 영상이 “AI 생성”이라고 비난했지만, 공식적으로는 인테리어 계약업자의 소행으로 확인되었다. 이 사건은 소셜 미디어에서 “AI는 새로운 개가 내 숙제를 먹었다”는 식으로 비유되며, AI가 공공 담론에서 책임을 회피하는 새로운 구실이 되고 있음을 반영한다.(来源:Reddit r/ArtificialInteligence,The Verge)

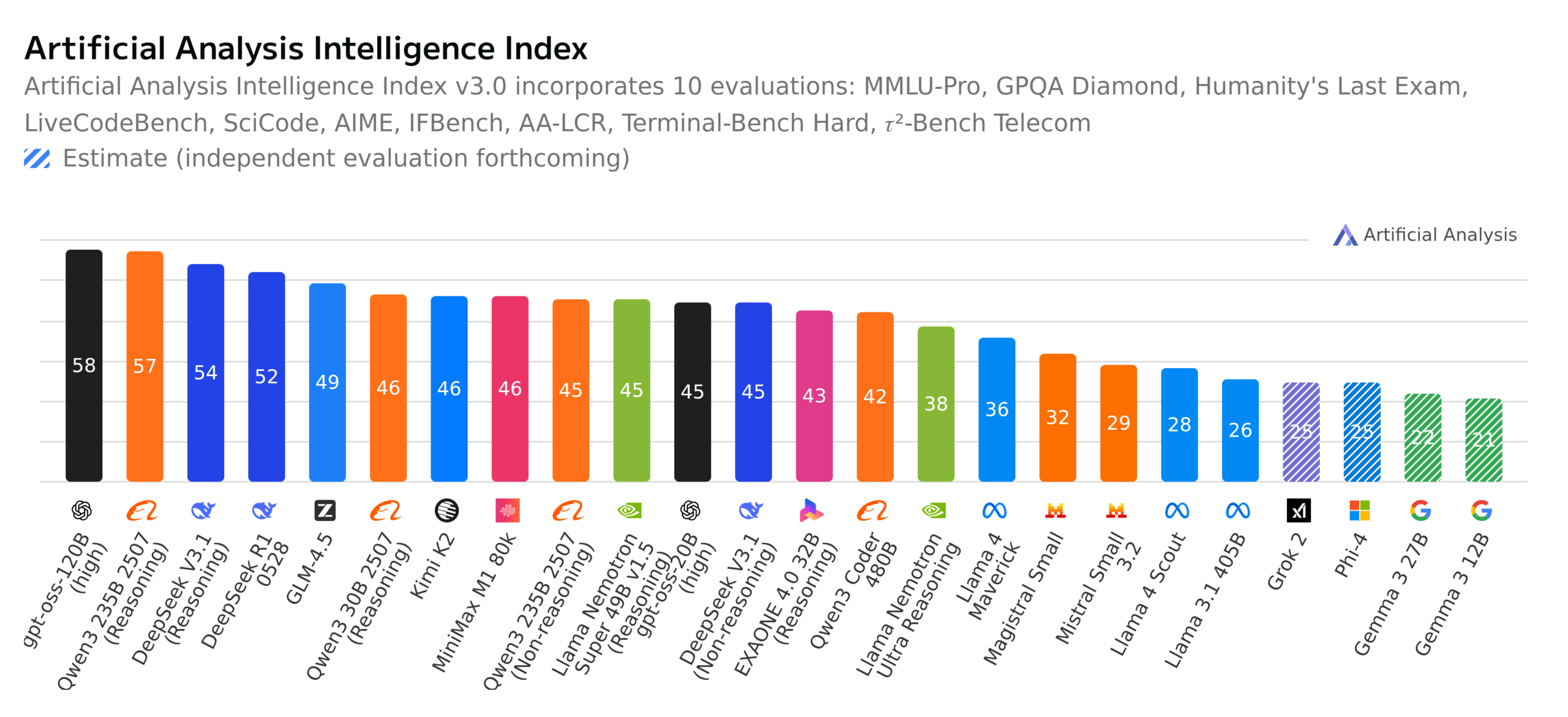
오픈 소스 LLM 진행 상황 및 벤치마크 테스트 논의 : 커뮤니티는 GPT-OSS 120B가 최고의 오픈 소스 모델이 된 것, 스위스가 새로운 완전 오픈 소스 다국어 모델 Apertus-70B-2509를 발표한 것, 그리고 Kimi K2-0905 모델의 출시에 대해 뜨겁게 논의했다. 동시에 독일의 “누가 백만장자가 되고 싶어 하는가” 벤치마크 테스트가 LLM을 평가하여 모델의 실제 능력, 벤치마크 테스트의 의미, 오픈 소스 모델의 윤리(데이터 투명성 등)에 대한 광범위한 논의를 촉발했다.(来源:Reddit r/LocalLLaMA,Reddit r/LocalLLaMA,Reddit r/LocalLLaMA,Reddit r/LocalLLaMA)
💡 기타
윈펑 테크놀로지, AI+헬스 신제품 출시 : 윈펑 테크놀로지는 2025년 3월 22일 항저우에서 Shuaikang, Skyworth와 협력하여 “디지털 지능형 미래 주방 연구소”와 AI 헬스 대규모 모델이 탑재된 스마트 냉장고 등 신제품을 발표했다. AI 헬스 대규모 모델은 주방 설계 및 운영을 최적화하고, 스마트 냉장고는 “헬스 비서 샤오윈”을 통해 개인화된 건강 관리를 제공하며, 이는 건강 분야에서 AI의 돌파구를 의미한다. 이번 발표는 일상 건강 관리에서 AI의 잠재력을 보여주며, 스마트 기기를 통해 개인화된 건강 서비스를 실현하여 가정 건강 기술의 발전을 촉진하고 주민의 삶의 질을 향상시킬 것으로 기대된다.(来源:36氪)
학술대회 논문 심사 품질 우려 : 머신러닝 커뮤니티는 WACV 2026 논문 심사 발표와 ACL Rolling Review (ARR)의 심사 품질 문제에 대해 논의했다. 일부 연구자들은 ARR에 “AI 생성”의 일반적이고 낮은 품질의 심사가 넘쳐나 시간이 낭비된다고 불평하며 다른 AI 학회에 제출할 것을 제안했다. 이는 AI 보조 심사 품질과 심사 메커니즘에 대한 학계의 우려를 반영하며, 심사의 실질적이고 건설적인 개선을 촉구한다.(来源:Reddit r/MachineLearning,Reddit r/MachineLearning)
클라우드 서비스 감성 분석 모델 프로젝트 : 한 ML 초보자가 BERT 기반의 측면 감성 분석 모델을 개발하여 ML/클라우드 기술 Reddit 커뮤니티의 AWS, Azure, Google Cloud 등 클라우드 서비스 제공업체에 대한 댓글을 분석하고 비용, 확장성, 보안 등 차원별로 감성을 분류했다. 그는 모델 해석 정확도 개선, 비교 또는 혼합 진술 처리, 부정 및 풍자에 대한 견고성 향상에 대한 조언을 구하고 있다.(来源:Reddit r/MachineLearning,Reddit r/deeplearning)