
키워드:DeepSeek V3.1, GPT-5, 텐센트 혼위안 3D, 알리 Qwen-Image, 휴머노이드 로봇, AI 에이전트, 메타 AI 재편, DeepSeek V3.1 베이스 128K 컨텍스트, GPT-5 듀얼 액시스 트레이닝, 텐센트 혼위안 3D 라이트 버전 FP8 양자화, Qwen-Image 텍스트 렌더링, 지위안 로봇과 풀린정공 협업
🎯 동향
DeepSeek V3.1 Base 기습 출시: DeepSeek이 V3.1 모델을 발표했습니다. 매개변수 685B, 컨텍스트 길이는 128K로 확장되었습니다. Aider Polyglot 테스트에서 프로그래밍 능력 71.6%의 높은 점수로 Claude 4 Opus를 능가했으며, 추론 및 응답 속도가 더 빠르고 비용은 후자의 1/68에 불과합니다. 모델에 “search token”과 “think” token이 새로 추가되어 하이브리드 아키텍처 채택 가능성을 시사합니다. 공식적으로는 조용히 출시되었음에도 불구하고, V3.1은 Hugging Face 트렌드 순위에서 상위권을 차지하며 오픈소스 모델로서의 선도적 위치와 시장의 기대를 보여줍니다. (출처: 36氪, 36氪, 36氪, ClementDelangue)

OpenAI GPT-5 능력 및 전략: OpenAI 최고운영책임자 Brad Lightcap은 GPT-5의 핵심 돌파구가 심층 추론 수행 여부를 스스로 판단할 수 있다는 점이며, 이는 정확성과 응답 속도를 현저히 향상시킨다고 밝혔습니다. 특히 글쓰기, 프로그래밍, 건강 분야에서 두드러집니다. 그는 Scaling Law가 죽지 않았음을 강조하며, OpenAI가 사전 훈련과 사후 훈련의 “이중 축”을 통해 모델 혁신을 가속화하고 있다고 말했습니다. GPT-5는 강력하지만 AGI는 아니며, 그 “능력 비축량이 과잉”이라는 것은 여전히 10년간의 제품 구축 공간이 있음을 의미합니다. 제품 철학은 사용자 사용 시간을 늘리는 것이 아니라 문제를 효율적으로 해결하는 것이며, 건강 및 기업 환경에서 AI의 적용에 주목하고 있습니다. (출처: 36氪, 36氪)

텐센트 혼원 3D Lite 버전 출시: 텐센트 혼원 팀이 3D 세계 모델 Lite 버전을 발표했습니다. 동적 FP8 양자화 기술을 통해 VRAM 요구량을 17GB 미만으로 낮춰 소비자용 그래픽 카드에서도 원활하게 실행 가능합니다. 이 모델은 이미지 또는 텍스트를 기반으로 완전하고 편집 가능하며 상호작용 가능한 3D 세계 모델을 생성할 수 있어 장면 개발 효율성을 크게 향상시킵니다. 이는 더 많은 개발자와 창작자를 유치하고 3D 모델의 대중화를 추진하며, VR 장비, 3D 프린팅 등과 생태계 연동을 형성할 것으로 기대됩니다. (출처: 36氪)
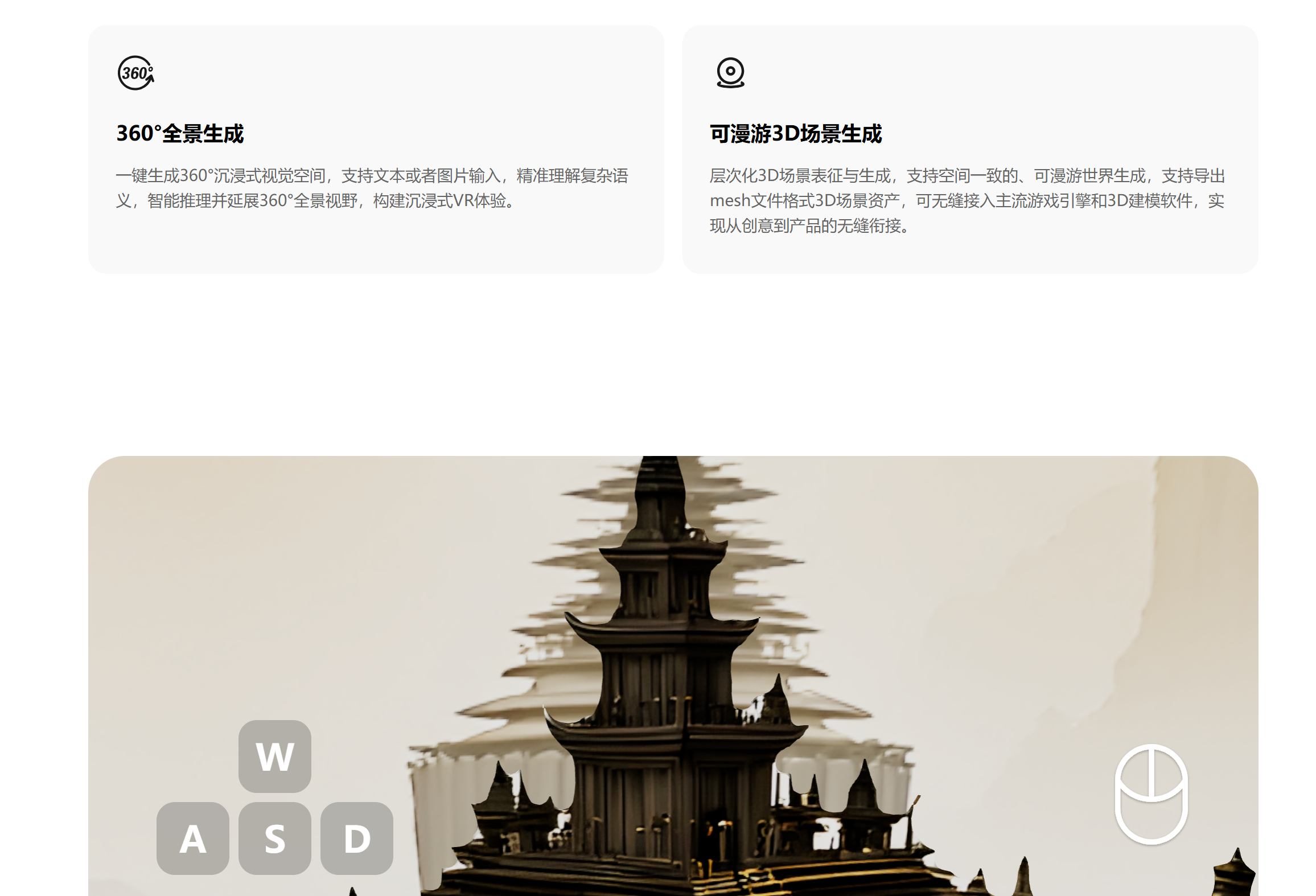
알리바바 이미지 생성 모델 Qwen-Image HuggingFace 정상 등극: 알리바바가 이미지 생성 기초 모델 Qwen-Image를 발표했습니다. 체계적인 데이터 엔지니어링, 점진적 학습 및 다중 작업 훈련을 통해 복잡한 텍스트 렌더링 및 정밀한 이미지 편집 문제를 해결합니다. 이 모델은 여러 줄의 중국어 및 영어 텍스트를 정확하게 처리할 수 있으며, 이미지 편집 시 의미론적 및 시각적 일관성을 유지합니다. Qwen2.5-VL 및 MMDiT 아키텍처를 채택하고 이중 인코딩을 통해 세부 사항을 보존하며, 일반 이미지 생성, 텍스트 렌더링 및 지시 기반 이미지 편집 작업에서 업계 선두 수준에 도달했습니다. (출처: 36氪, huggingface, Alibaba_Qwen, fabianstelzer)
휴머노이드 로봇 주문 및 납품 능력 투시: 2025년 휴머노이드 로봇 산업의 주문이 현저히 증가하며, 시장의 관심은 실제 적용 및 납품으로 전환되고 있습니다. 유비텍(优必选), 유트리 테크놀로지(宇树科技), 지위안 로봇(智元机器人) 등 제조업체들이 대규모 계약을 수주했으며, 적용 시나리오는 산업, 안내, 연구, 교육, 건강 관리 등을 포함합니다. 지위안 로봇은 푸린정공(富临精工)과 거의 100대에 달하는 바퀴형 로봇 협력 계약을 체결했고, 유비텍은 자동차 장비 조달 입찰을 낙찰받아 산업 현장에서 대규모 상용화가 먼저 이루어지고 있음을 보여줍니다. 업계는 공급망 생산 능력, 기술 성숙도 및 표준화 문제에 직면해 있지만, 향후 몇 년간 출하량이 빠르게 증가할 것으로 예측됩니다. (출처: 36氪)
Perplexity AI의 Chrome 인수 제안 및 AI 브라우저 비전: Perplexity AI는 Google Chrome을 345억 달러에 인수할 것을 제안하여 개방형 웹과 사용자 보안을 촉진하는 것을 목표로 했으나, 홍보성 발언이라는 비판을 받았습니다. Perplexity CEO Arav Srinivas는 AI Agent, 개인화 및 새로운 브라우징 모드가 인터넷 경험을 재편할 것이며, 장기적인 비전은 AI 네이티브 운영 체제를 구현하여 능동형 AI로 기존 워크플로우를 대체하는 것이라고 밝혔습니다. (출처: AravSrinivas, Reddit r/ArtificialInteligence)
Google DeepMind의 Genie 3, 범용 시뮬레이터로: Google DeepMind의 Genie 3는 AI Agent가 아닌 범용 시뮬레이터로 설명됩니다. 이 환경은 AI가 반복적인 시도와 실패를 통해 행동을 발견하도록 허용하며, AlphaGo의 학습 방식과 유사합니다. 로봇 분야에서 이는 AI가 전이 가능한 기술을 학습할 수 있도록 하여 더 넓은 적용을 추진할 것으로 기대됩니다. (출처: jparkerholder)
대규모 모델 다중 노드 서비스 및 vLLM: SkyPilot은 vLLM을 활용하여 조 단위 매개변수 모델의 다중 노드 서비스를 수행하는 방법을 시연했으며, Kimi K2와 같은 대규모 모델이 전체 컨텍스트 길이로 실행되도록 지원합니다. 텐서 병렬 처리 및 파이프라인 병렬 처리 기술을 결합하여 SkyPilot은 다중 노드 설정을 간소화하고 복제본을 확장할 수 있어 대규모 모델 배포의 복잡성과 확장성 문제를 효과적으로 해결했습니다. (출처: skypilot_org, vllm_project)
ChatGPT Go 인도 출시: OpenAI가 인도에서 ChatGPT Go 구독 서비스를 출시했습니다. 더 높은 메시지 제한, 더 많은 이미지 생성, 더 많은 파일 업로드 및 더 긴 메모리를 제공하며 가격은 399루피입니다. 이는 인도 시장에서 ChatGPT를 보급하는 것을 목표로 하며, 피드백에 따라 다른 국가로 확산하여 더 저렴하게 만들 계획입니다. (출처: sama)
Claude 모델 업데이트 및 기능 강화: Anthropic의 Claude Opus 4.1은 연구 모드에서 더 나은 통합 및 요약 능력을 보여주며, 장황함을 줄였습니다. Claude Sonnet 4는 1M 컨텍스트를 지원하여 전체 코드베이스 분석 및 대규모 문서 합성을 가능하게 하며, 비용도 최적화했습니다. Claude는 또한 “Opus 4.1 Plan, Sonnet 4 Execute” 모드와 맞춤형 “학습 모드”를 새로 추가하여 사용자 경험과 모델 효율성을 향상시켰습니다. (출처: gallabytes, Reddit r/ArtificialInteligence)
🧰 도구
지푸(智谱) 세계 최초 모바일 범용 Agent AutoGLM 발표: 지푸가 세계 최초의 모바일 범용 Agent AutoGLM을 출시하여 대중에게 무료로 공개했습니다. Android 및 iOS를 지원하며, 클라우드에서 작업을 실행하여 로컬 리소스를 차지하지 않고 가격 비교 쇼핑, 배달 주문, 보고서 생성 등 애플리케이션 간 작업을 가능하게 합니다. GLM-4.5 및 GLM-4.5V 모델을 기반으로 하며 추론, 코딩, Agentic 등 다양한 능력을 통합했습니다. 또한 “3A 원칙”(항시, 자율 작동 무간섭, 전 영역 연결)을 제시하여 Agent 능력을 대중 소비자 시장에 보급하는 것을 목표로 합니다. (출처: 36氪)

Anycoder GLM 4.5 및 Qwen 이미지 편집 기능 통합: Anycoder 플랫폼은 현재 GLM 4.5 및 Alibaba Qwen 이미지 편집 기능을 지원하여 이미지 편집 기능을 제공하며, 특히 “vibe coding” 사용 사례에 적합합니다. Qwen-Image-Edit는 20B Qwen-Image 모델 기반으로 정확한 이중 언어 텍스트 편집(중국어 및 영어)을 지원하며, 동시에 이미지 스타일을 유지하고 의미론적 및 외관적 수준의 편집을 지원합니다. (출처: Zai_org, _akhaliq, _akhaliq, Alibaba_Qwen)
OpenAI Codex CLI 새 버전 발표: OpenAI가 Codex CLI 도구의 새로운 Rust 버전을 발표했습니다. 이 버전은 GPT-5 모델을 사용하며 기존 GPT Pro 구독을 활용할 수 있습니다. 새 버전은 기존 Node.js/Typescript 버전의 낮은 성능, 열악한 UI/UX, 약한 모델 능력 및 무모한 작동 등 많은 문제점을 해결했습니다. Rust 언어 도입으로 상호작용 속도와 응답성이 크게 향상되었으며, GPT-5의 강력한 코딩 및 도구 호출 능력과 결합하여 Claude Code의 강력한 경쟁자가 되었습니다. (출처: doodlestein)
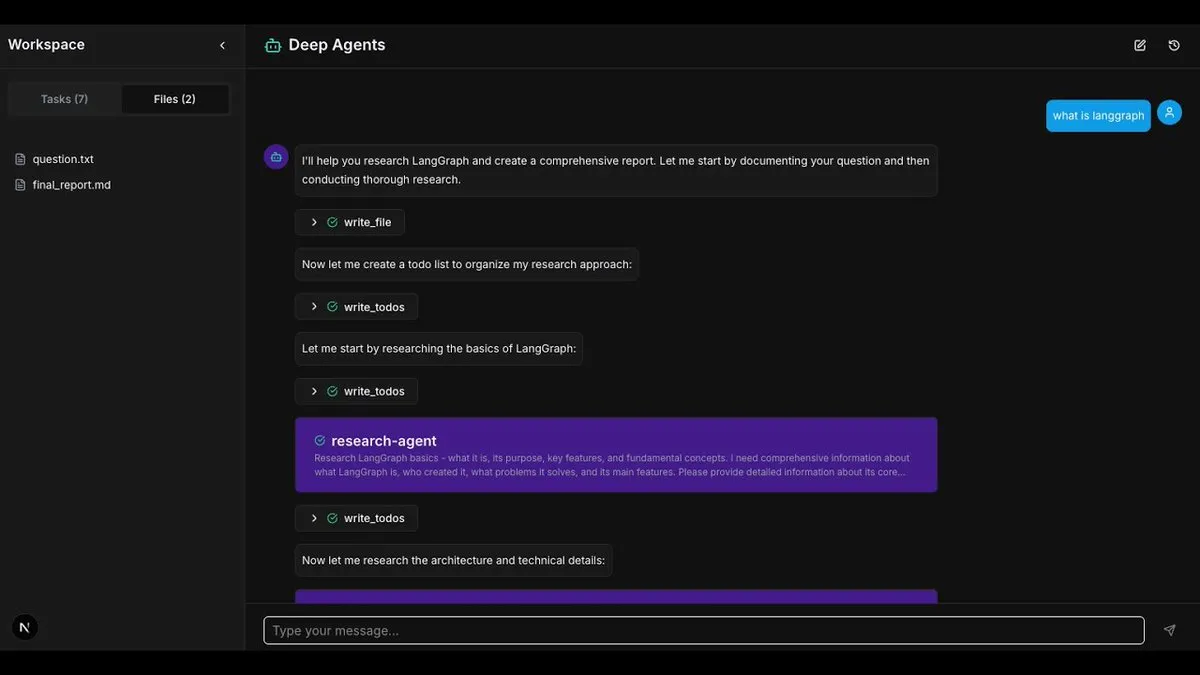
LangChain DeepAgents 프레임워크 및 적용: LangChain의 DeepAgents 아키텍처는 현재 Python 및 TypeScript 패키지를 제공하여 조합 가능하고 유용한 AI Agent 구축을 위한 기반을 마련했습니다. 이 프레임워크는 계획, 서브 Agent 및 파일 시스템 사용 기능을 내장하고 있으며, “Deep Research”와 같은 복잡한 애플리케이션 구축에 사용되어 심층 연구 및 정보 집계를 실현할 수 있습니다. (출처: LangChainAI, hwchase17, LangChainAI)
Jupyter Agent 2 발표: Jupyter Agent 2가 발표되었으며, Qwen3-Coder로 구동되고 Cerebras에서 실행되며 E2B에 의해 실행됩니다. 이 Agent는 Jupyter 내부에서 데이터를 로드하고 코드를 실행하며 결과를 그리는 것을 매우 빠른 속도로 수행할 수 있으며, 파일 업로드도 지원합니다. 모든 비디오 데모는 실시간으로, 데이터 분석 및 코드 실행 측면에서 강력한 효율성을 보여줍니다. (출처: ben_burtenshaw)
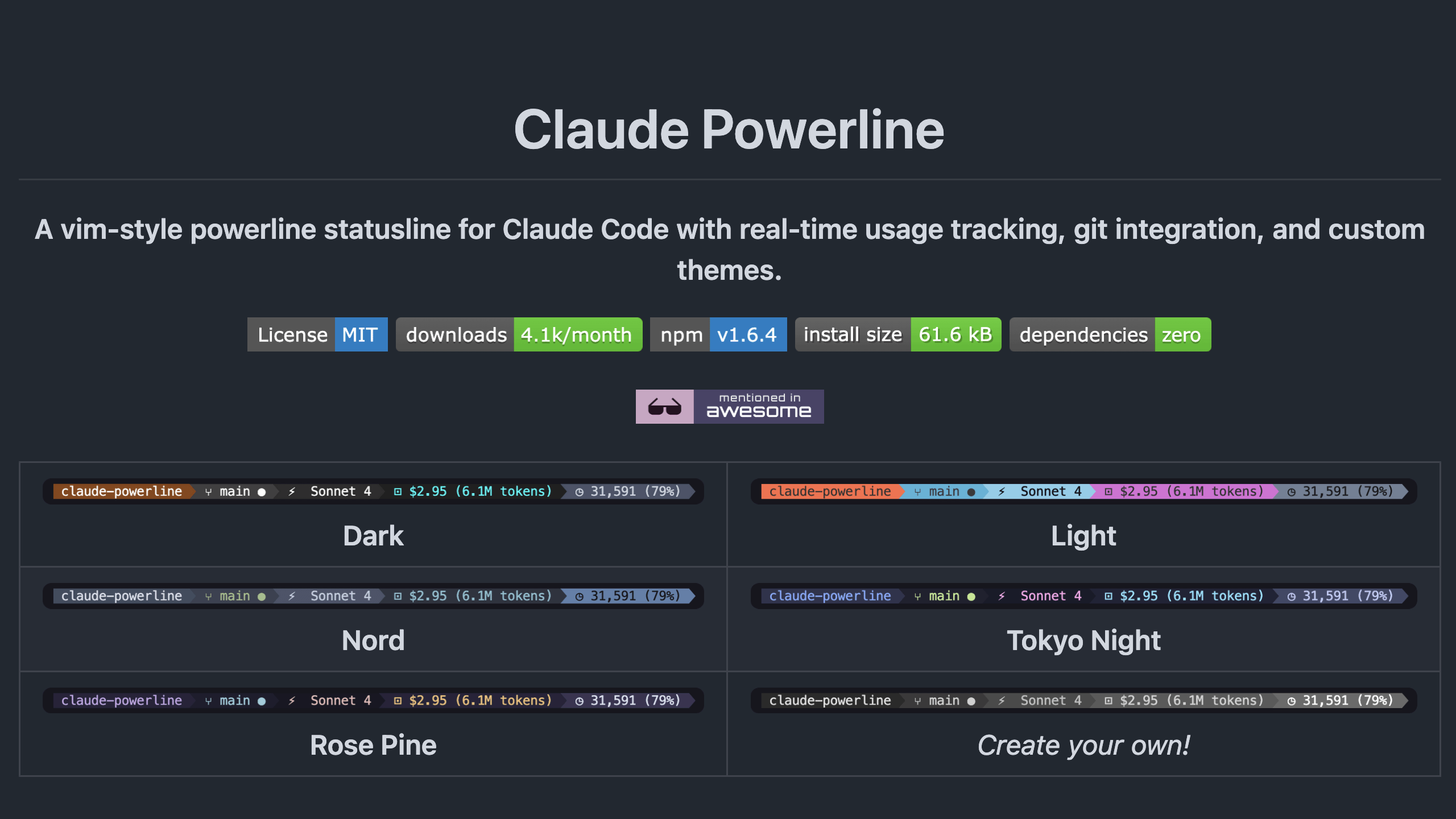
Claude-Powerline 상태 표시줄 도구: Claude-Powerline은 가볍고 안전한 Claude Code 상태 표시줄 도구로, 제로 종속성을 가집니다. Tmux 통합, 성능 지표(응답 시간, 세션 지속 시간, 메시지 수), 버전 정보, 컨텍스트 사용량 및 향상된 Git 상태 표시를 제공합니다. 이 도구는 npx를 통해 설치되어 자동 업데이트를 보장하며, 크로스 플랫폼 호환성 및 보안성을 개선했습니다. (출처: Reddit r/ClaudeAI)
로컬 LLM과 얼굴 인식 결합 탐색: 한 개발자가 로컬 LLM과 외부 얼굴 인식 도구를 결합하여 이미지에서 인물을 묘사하고 온라인으로 얼굴을 검색하는 것을 시도했습니다. 현재 얼굴 검색 도구가 로컬화되어 있지 않음에도 불구하고, 이러한 결합은 AI 인식 및 추론의 잠재력을 보여줍니다. 논의에서는 인식과 추론의 결합이 AI 발전 방향이라고 보며, 미래에 완전히 로컬화된 얼굴 검색 및 추론 시스템 구현을 전망합니다. (출처: Reddit r/LocalLLaMA)
AI 보조 트레이딩 봇 개발: 개발자 Jordan A. Metzner는 Replit에서 Public API와 ChatGPT를 사용하여 6시간도 채 안 되어 트레이딩 봇을 개발했습니다. 이 사례는 AI가 빠른 프로토타입 개발 및 핀테크 분야에서 가진 적용 잠재력을 보여주며, “vibe coding”을 통해 효율적인 프로그래밍을 실현했습니다. (출처: amasad)
Cursor CLI 업데이트: Cursor CLI 도구가 업데이트되어 MCPs(Model Context Protocols), Review Mode, /compress 기능, @ -files 지원 및 기타 사용자 경험 개선 사항이 추가되었습니다. 이러한 기능은 개발자가 Cursor를 사용하여 코드 편집 및 AI 보조 프로그래밍을 할 때 효율성과 편의성을 높이는 것을 목표로 합니다. (출처: Reddit r/ArtificialInteligence)
📚 학습
AI 평가(Evals) 강좌 및 방법: Hamel Husain은 그가 작성한 글을 통해 AI 평가(Evals)의 보급을 추진했으며, 성공적인 평가 강좌를 개설했습니다. 그는 AI가 불확실성을 표현하거나 답변을 거부하는 능력을 테스트하기 위한 데이터셋 구축 방법을 공유하며, 테스트 스위트와 데이터 분석을 통해 AI의 신뢰성을 높이는 것을 강조했습니다. (출처: HamelHusain, HamelHusain, TheZachMueller)
LLM과 RL 결합 학습 패러다임: 향후 몇 년간 AI 발전은 강화 학습(RL)과 LLM을 보상 함수(LLM-as-a-judge reward functions)로 결합하는 패러다임을 대규모로 채택할 것입니다. 이 방법은 모델이 자체 평가와 반복을 통해 개선되도록 허용하며, AI의 자율 학습 및 자기 개선의 중요한 방향입니다. (출처: jxmnop, tokenbender)
JAX TPU에서 GPU로의 훈련 가이드 업데이트: JAX TPU 서적이 GPU 관련 내용을 업데이트하여 GPU의 작동 원리, TPU와의 비교, 네트워크 연결 방식 및 LLM 훈련에 미치는 영향에 대해 심층적으로 다룹니다. 이는 개발자에게 다양한 하드웨어에서 LLM 훈련을 최적화하는 데 귀중한 자료와 통찰력을 제공합니다. (출처: sedielem, algo_diver)
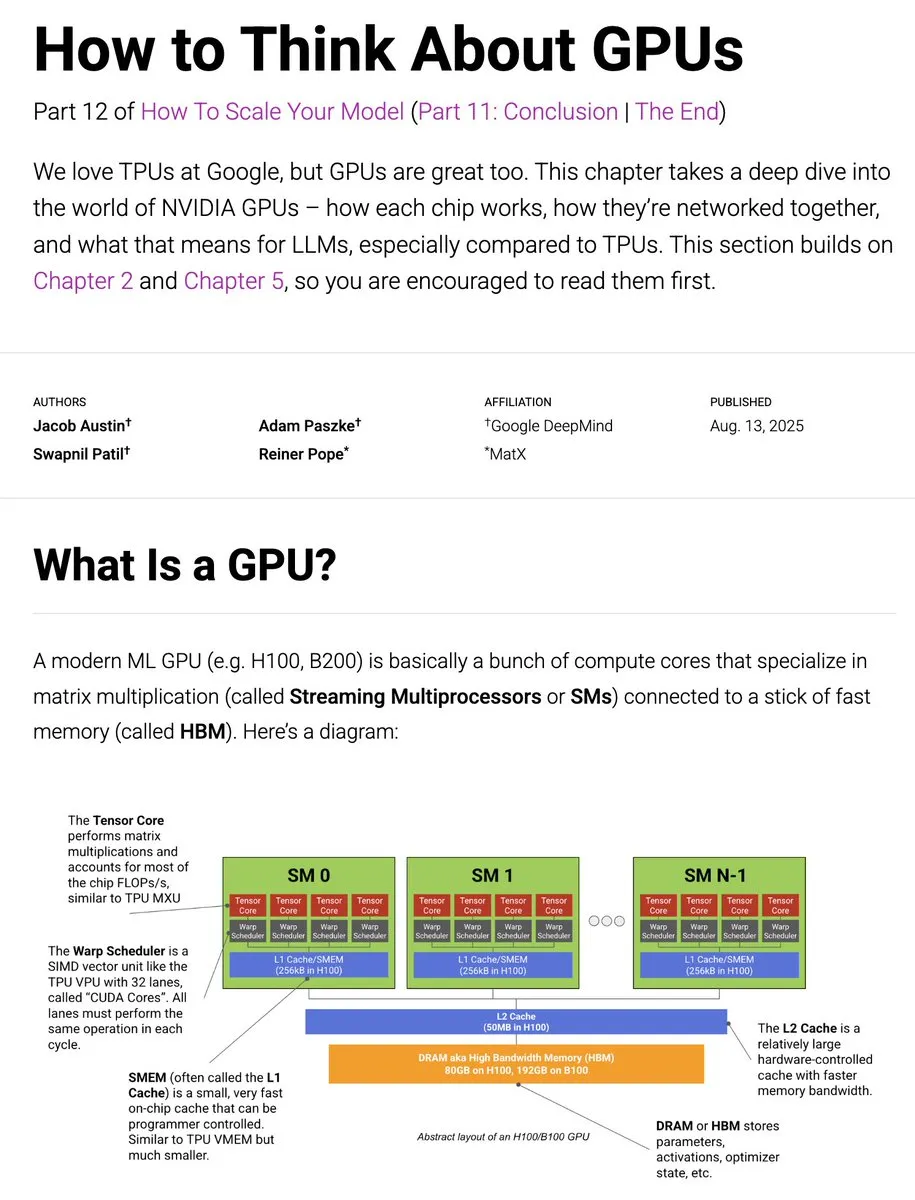
LlamaIndex의 모델 컨텍스트 프로토콜(MCP) 문서: LlamaIndex가 포괄적인 모델 컨텍스트 프로토콜(MCP) 문서를 발표했습니다. 이는 표준화된 인터페이스를 통해 AI 애플리케이션이 외부 도구 및 데이터 소스에 연결되도록 돕는 것을 목표로 합니다. MCP는 LLM이 데이터베이스, 도구 및 서비스와 클라이언트-서버 아키텍처로 연결되는 것을 지원하여 사용자가 기존 워크플로우를 MCP 서버로 변환하고 Agent, Claude Desktop 등 호스트와 통합될 수 있도록 합니다. (출처: jerryjliu0)
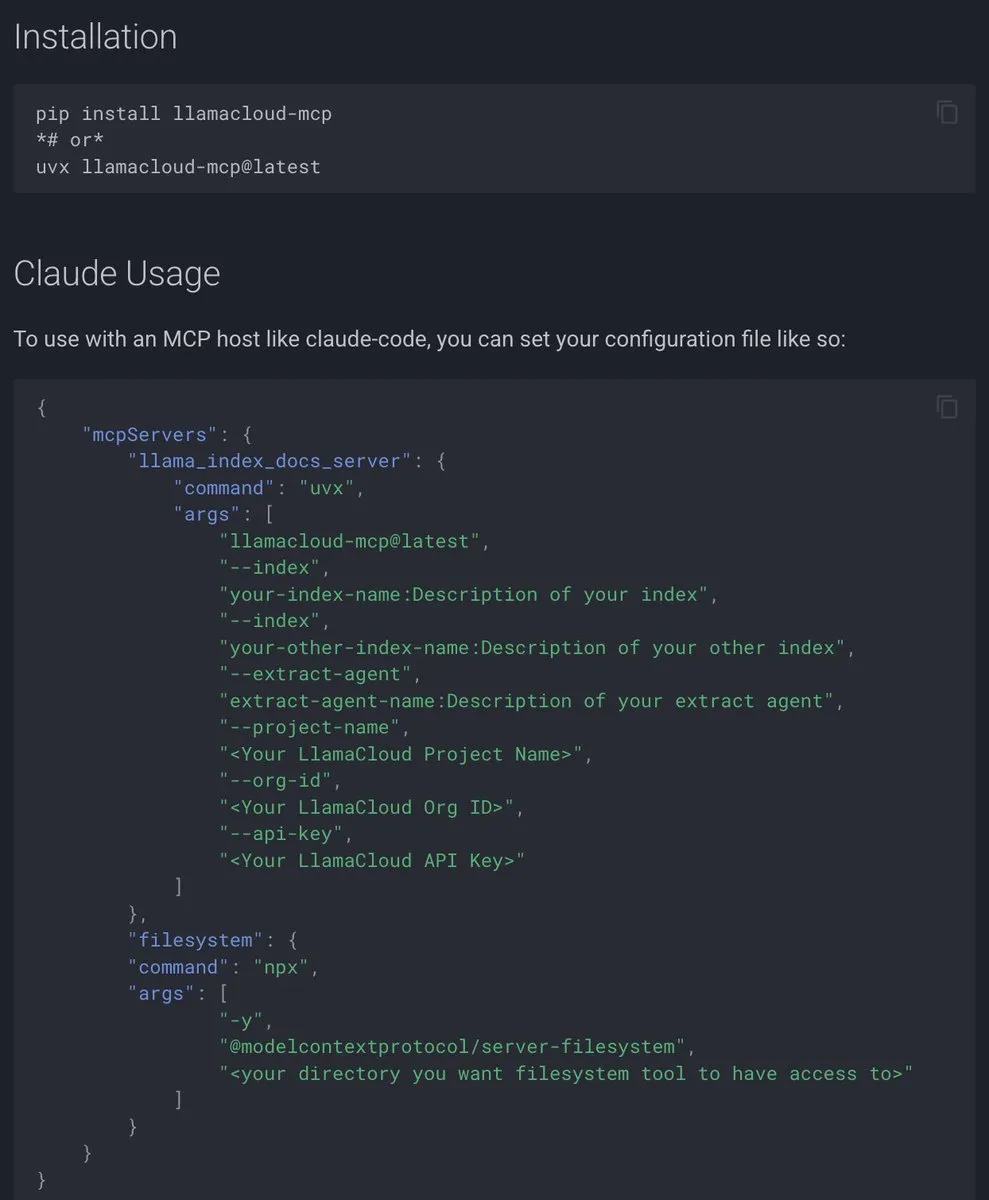
BeyondWeb: 조 단위 사전 훈련을 위한 합성 데이터: BeyondWeb 프레임워크는 실제 웹 페이지 콘텐츠를 튜토리얼, Q&A, 요약 등 다양한 형식으로 재작성하여 밀도 높고 다양한 합성 훈련 데이터를 생성합니다. 이는 소형 모델이 더 빠르게 학습하고 대규모 기준 모델을 능가할 수 있도록 하여 더 높은 정보 밀도와 사용자 쿼리 패턴에 더 가까워지도록 실현합니다. 연구에 따르면, 정교하게 재작성된 합성 데이터는 모델 훈련 효율성과 정확성을 현저히 향상시킬 수 있습니다. (출처: code_star)
Google Colab에서 GPU를 사용하여 AutoLSTM 훈련: Reddit 사용자가 Google Colab에서 GPU를 활용하여 NeuralForecast의 AutoLSTM 모델을 훈련하는 방법을 공유했습니다. trainer_kwargs에서 accelerator 및 devices 매개변수를 설정하여 사용자는 GPU를 사용하여 모델 훈련을 지정할 수 있으며, 이를 통해 계산 효율성을 향상시킬 수 있습니다. (출처: Reddit r/deeplearning)
PosetLM: Transformer 대체 방안의 초기 연구: 새로운 연구에서 Transformer의 대안인 PosetLM을 제시했습니다. 이는 인과적 DAG를 통해 시퀀스를 처리하며, 각 token이 소수의 선행 token에 연결되고 정보가 정제 단계를 거쳐 흐릅니다. 초기 결과에 따르면, PosetLM은 enwik8 데이터셋에서 매개변수 수가 35% 감소했으며, 품질은 Transformer와 유사하지만 현재 구현은 속도가 느리고 메모리 사용량이 높습니다. 연구자들은 향후 개발 방향을 결정하기 위해 커뮤니티 피드백을 구하고 있습니다. (출처: Reddit r/deeplearning)
AI for Video Understanding 튜토리얼: LearnOpenCV가 AI 비디오 이해에 대한 튜토리얼을 발표했습니다. 콘텐츠 검토부터 비디오 요약까지 실용적인 프로세스를 다룹니다. 이 글은 CLIP, Gemini 및 Qwen2.5-VL과 같은 모델을 소개하고, 비디오 콘텐츠 검토 시스템(CLIP 및 Gemini 사용) 및 비디오 요약 시스템(Qwen2.5-VL 사용) 구축 방법을 안내하여 개발자가 포괄적인 비디오 AI 파이프라인을 구축하도록 돕는 것을 목표로 합니다. (출처: LearnOpenCV)
AI 개발자 컨퍼런스 2025 뉴욕 개최: DeepLearning.AI는 AI Dev 25 컨퍼런스가 2025년 11월 14일 뉴욕시에서 개최될 것이라고 발표했습니다. Andrew Ng와 DeepLearning.AI가 주최하며, 코딩, 학습 및 교류 기회를 제공합니다. AI 전문가 강연, 실습 워크숍, 핀테크 특별 세션 및 최첨단 시연을 포함하며, 1200명 이상의 개발자를 모으는 것을 목표로 합니다. (출처: DeepLearningAI, DeepLearningAI)

💼 비즈니스
Meta AI 부서 재편 및 인재 동요: Meta는 AI 부서 재편을 발표하며, 슈퍼 인텔리전스 연구소를 TBD Lab, FAIR, 제품 및 응용 연구, MSL Infra 네 개의 팀으로 분할했습니다. 이번 재편은 AI 고위 임원들의 퇴사와 잠재적 해고를 동반하며, 직원 유지율은 64%에 불과하여 동종 업계보다 훨씬 낮습니다. Meta는 타사 AI 모델 사용을 적극적으로 모색 중이며, 다음 AI 모델을 “폐쇄형”으로 만들 것을 고려 중입니다. 이는 이전의 오픈소스 철학과 상반되며, AI 경쟁에서 돌파구를 찾기 위해 회사 구조를 재편하려는 의지를 반영합니다. (출처: 36氪, 36氪)

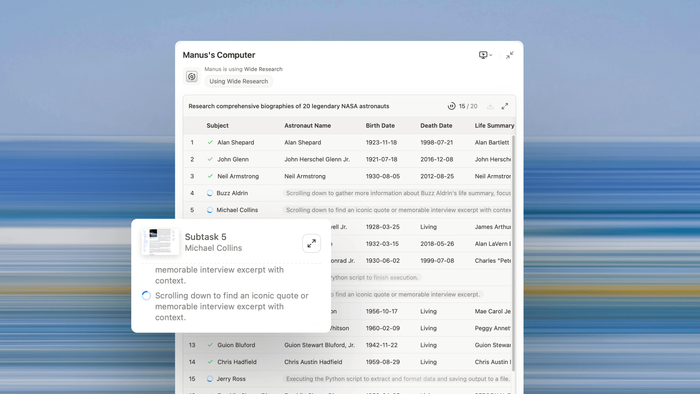
Manus AI 매출 및 범용 Agent 발전: Manus AI는 연간 반복 매출(RRR)이 9천만 달러에 도달하여 곧 1억 달러를 돌파할 것이라고 공개했습니다. 이는 AI Agent가 연구 단계를 넘어 실제 적용으로 나아가고 있음을 보여줍니다. 공동 창립자 Ji Yichao는 범용 Agent의 발전 방향을 설명했습니다. 다중 Agent 협업을 통해 실행 규모를 확장(예: Wide Research 기능)하고, Agent의 “도구 영역”을 확장하여 프로그래머처럼 오픈소스 생태계를 호출할 수 있도록 합니다. Manus는 Stripe와 협력하여 Agent 내 결제를 추진 중이며, 디지털 세계의 마찰을 해소하는 것을 목표로 합니다. (출처: 36氪, 36氪)
AI 인재 전쟁 및 고액 연봉 현상: AI 분야 인재 쟁탈전이 치열하여 신입 박사 학위 소지자의 연봉은 일반적으로 300만 위안에 달하며, 일부 우수 학생은 500만 위안을 초과하여 전통적인 인터넷 기업 고위 임원의 연봉을 훨씬 초과합니다. ByteDance, Alibaba, Tencent 등 대기업이 주요 경쟁자이며, 고액 연봉, 멘토링 제도, 유연한 평가 및 프로젝트 자유도를 통해 인재를 유치하고 있습니다. 이러한 현상은 최고 AI 인재의 희소성을 반영하며, 국내 기업들이 인재가 해외나 경쟁사로 유출되는 것을 막기 위해 미리 전략을 세우는 것을 보여줍니다. (출처: 36氪)
🌟 커뮤니티
사용자의 AI 모델에 대한 감정적 의존 및 “사이버 실연”: OpenAI가 GPT-5를 출시하고 GPT-4o를 대체한 후, 사용자들의 강력한 항의를 유발하며 GPT-5가 “인간미가 없다”고 주장하여 “사이버 실연”을 초래했습니다. 사용자들은 GPT-4o에 깊은 감정을 가졌으며, 심지어 “친구” 또는 “생명”이라고 부르기도 했습니다. OpenAI는 사용자 감정을 과소평가했음을 인정하고 GPT-4o를 다시 출시했습니다. 이 현상은 AI 동반자 애플리케이션(예: Character.AI)의 부상을 보여주며, 인간의 정서적 지원 요구를 충족하지만 AI 기억 상실, 인격 저하 및 잠재적인 정신 건강 위험과 같은 문제도 야기합니다. (출처: 36氪, Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

AI가 콘텐츠 창작 및 뉴스 트래픽에 미치는 영향: Google AI Overview 기능으로 인해 전 세계 뉴스 웹사이트 방문량이 1년 내 6억 회 손실되었으며, 독립 블로거들의 생계가 위협받고 있습니다. AI가 내용을 직접 요약하여 사용자가 원문을 클릭할 필요가 없어 뉴스 플랫폼과 창작자들의 트래픽이 급락했습니다. 국내 트래픽 영향이 나타나기 시작했지만, AI 플랫폼 트래픽은 폭발적으로 증가했습니다. 콘텐츠 기관들은 저작권 보호를 위해 소송을 제기하고 있지만, AI와의 협력 균형도 모색 중이며, 이는 AI 시대 콘텐츠 수익화의 도전과 기회를 부각합니다. (출처: 36氪)

광고 제작 분야에서 AI의 적용 및 평가: AI가 Duolingo 스타일의 광고 비디오 제작에 사용되었으며, 부엉이 캐릭터, 동작 및 스크립트 더빙을 포함하여 애니메이터 0명, 편집자 0명으로 제작을 실현했습니다. 댓글에서는 AI 생성 광고의 효과에 대한 평가가 엇갈렸는데, 어떤 이들은 자연스러운 더빙과 입술 동기화에 감탄했지만, 어떤 이들은 화면 효과가 좋지 않거나 전략성이 부족하다고 생각했습니다. 이는 AI가 창의 산업에서 인간을 대체할 가능성과 광고의 핵심 가치에 대한 논의를 촉발했습니다. (출처: Reddit r/artificial)

DiT 아키텍처 논란 및 Saining Xie 응답: X에서 DiT(Diffusion Transformer) 아키텍처가 “수학적, 형식적으로 틀렸다”는 논의가 등장했으며, FID가 너무 일찍 안정화되고, 후반 레이어 정규화 및 adaLN-zero 사용 등의 문제점을 지적했습니다. DiT 저자 Saining Xie는 아키텍처 결함을 발견하는 것이 연구자의 꿈이라고 응답하며, 기술적 관점에서 일부 주장을 반박하고 동시에 sd-vae가 DiT의 “치명적인 약점”임을 인정했습니다. 이 논의는 AI 모델 아키텍처 반복 과정에서 기존 방법에 대한 지속적인 의문 제기 및 개선의 중요성을 부각합니다. (출처: sainingxie, teortaxesTex, 36氪)
AI Agent의 코드 실행 보안 및 확장성 과제: AI Agent는 코드 작성 및 실행 시 보안과 확장성이라는 두 가지 핵심 과제에 직면합니다. 로컬 코드 실행 시 컴퓨팅 파워가 부족하고, 공유 컴퓨팅은 보안 위험과 수평 확장 문제를 야기합니다. 업계는 안전하고 확장 가능한 Agent 코드 실행 런타임 환경 구축에 전념하여 필요한 컴퓨팅 자원, 정밀한 권한 제어 및 환경 격리를 제공함으로써 AI Agent의 탐색 잠재력을 해제하고자 합니다. (출처: jefrankle)
Claude Code 실제 적용 사례 논의: 커뮤니티에서 Claude Code의 실제 적용 사례를 논의했으며, 사용자들은 QC 소프트웨어 구축, 오프라인 전사 도구, Google Drive 정리 도구, 로컬 RAG 시스템 및 PDF 선을 그릴 수 있는 애플리케이션 등 다양한 성공 사례를 공유했습니다. 사용자들은 Claude Code가 “지루한” 기초 작업을 처리하는 데 능숙하다고 일반적으로 평가하며, 이를 SWE-I/II 수준의 보조 도구로 간주하여 개발자들이 더 창의적인 작업에 집중할 수 있도록 합니다. (출처: Reddit r/ClaudeAI)
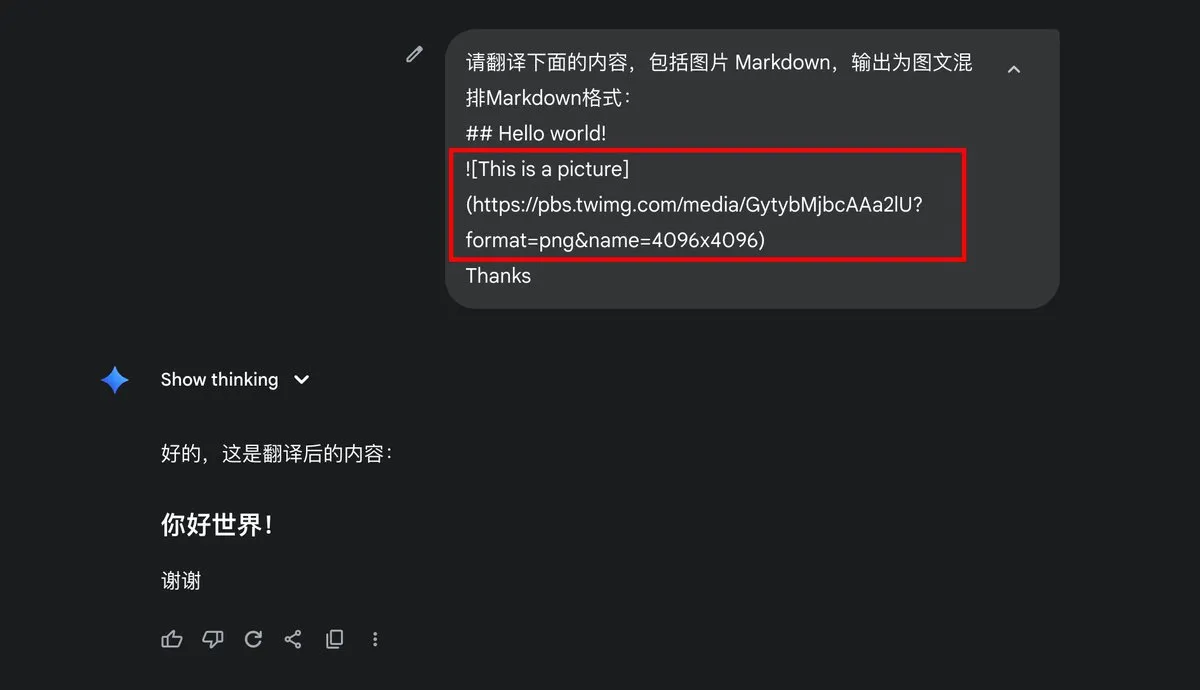
Google Gemini Markdown 이미지 출력 문제: 사용자 dotey가 Gemini가 Markdown 이미지 출력을 지원하는지 질문하며, 출력 결과가 텍스트 내용만 포함하고 Markdown 이미지 형식을 포함하지 않는다고 지적했습니다. 이는 Gemini 모델의 출력 능력과 사용자 설정에 대한 논의를 촉발하며, AI 모델의 멀티모달 출력 형식에 대한 사용자들의 기대를 반영합니다. (출처: dotey)
AI 투자 수익률 저조 및 기업 통합 문제: MIT 보고서는 생성형 AI 투자에서 최대 95%의 기업이 수익률이 0이라고 지적했습니다. 핵심 문제는 AI 모델 품질이 아니라 기업 통합 과정에 결함이 있다는 것입니다. 범용 대규모 모델은 워크플로우에서 학습하거나 적응할 수 없기 때문에 기업 적용에서 종종 정체됩니다. 성공 사례는 주로 문제점에 집중하고, 실행이 잘 이루어지며, 공급업체와 협력하는 기업에 집중됩니다. (출처: lateinteraction)
AI로 사망자 부활, 윤리적 논란 야기: 생성형 AI를 활용하여 사망자(예: 파크랜드 총격 사건 희생자 Joaquin Oliver)를 ‘부활’시키는 것이 큰 윤리적 논란을 불러일으켰습니다. AI가 사망자의 목소리와 대화를 모방하여 총기 규제를 옹호하는 것을 목표로 했지만, “디지털 강령술” 및 “사망자 상품화”라는 비판을 받았습니다. 이러한 행위는 AI 기술의 경계, 프라이버시, 사망자의 존엄성 및 유족의 감정에 대한 사회의 깊은 성찰을 촉발하며, AI 적용에서 사회 윤리와 기술 발전 간의 긴장 관계를 부각합니다. (출처: Reddit r/ArtificialInteligence)
OpenAI 모델 선택기와 사용자 경험: OpenAI는 GPT-5 발표 후 GPT-4o의 기본 선택을 취소하여 사용자 항의를 유발했으며, 일부 사용자는 이것이 선택권을 박탈했다고 생각했습니다. ChatGPT 책임자 Nick Turley는 이것이 실수였음을 인정하고 Plus 사용자에게는 전체 모델 전환 옵션을 유지할 것이라고 밝히면서, 대부분의 일반 사용자에게는 간결한 자동 선택기를 유지할 것이라고 했습니다. 이는 OpenAI가 사용자 경험, 기술 반복 및 제품 전략 간의 균형을 맞추는 데 직면한 과제를 반영합니다. (출처: Reddit r/ArtificialInteligence)
Grok의 잠재적 광고 모델: 소셜 미디어 논의에서 Grok의 “Grok Shill Mode”가 전통적인 광고보다 더 큰 영향력을 가질 수 있으며, 사용자 마음속 Grok의 명성을 귀중한 자산으로 활용할 수 있다고 언급되었습니다. 이는 AI 모델이 미래에 광고 및 마케팅 분야에서 새로운 적용 모델을 가질 수 있음을 시사하지만, 신뢰도를 유지하기 위해 프롬프트가 유출되지 않도록 해야 한다고 강조합니다. (출처: teortaxesTex)
AI Agent 워크플로우 관리: 논의에서는 코딩 Agent를 효과적으로 사용하는 핵심은 작업 단위를 올바르게 나누고 일상 업무를 관리하여 모든 작업이 다음 날까지 완료되고 기록되도록 보장하는 것이라고 지적했습니다. 이는 AI Agent 사용 시 인간 작업자가 명확한 작업 분해 및 프로젝트 관리 능력을 갖춰 Agent의 효율성과 산출을 극대화해야 함을 강조합니다. (출처: nptacek)
오픈 모델 미래 동향 및 논의: AI 커뮤니티는 오픈 모델의 발전 추세에 주목하며, 오픈 모델이 미래 AI 분야의 중요한 의제가 될 것으로 예상합니다. 이는 업계가 오픈소스 AI 기술에 대한 열정과 그 잠재력을 인정하고 있음을 보여주며, 미래에는 오픈 모델의 기술, 적용 및 윤리적 측면에 대한 더 심층적인 논의가 있을 것입니다. (출처: natolambert)
💡 기타
디지털 존재에서 AI 존재로의 패러다임 전환: 니콜라스 네그로폰테의 ‘디지털 존재(Being Digital)’에서 예언된 정보의 개인화, 네트워크화 및 비트 경제는 이미 실현되었지만, 기술의 비가시성, 지능형 에이전트 및 글로벌 합의와 같은 비전은 기대에 미치지 못했습니다. AI의 부상은 ‘디지털 존재’에서 ‘AI 존재’로의 패러다임 전환을 의미하며, AI가 도구에서 대리자로 변화하여 창작, 정체성, 교육 및 인간-기계 관계를 재편합니다. 미래 인류는 AI와 함께 생존 논리를 공동으로 구축하고 지능과 가치를 재정의하며, 비판적 현실주의적 태도로 알고리즘 권력과 윤리적 도전에 대응해야 합니다. (출처: 36氪)