
키워드:AI 에이전트, 마이크로소프트 빌드 2025, 알파에볼브, GPT-4, 애저 AI 파운드리, 엔비디아 컴퓨텍스 2025, AI 프로그래밍 도구, 구현된 지능, 깃헙 코파일럿 VSCode 확장, 모델 컨텍스트 프로토콜 (MCP), 자연어 네트워크 (NLWeb), 메이티안 노코드, 텐센트 QBot 스마트 어시스턴트
🔥 포커스
Microsoft Build 2025, “에이전트 네트워크” 시대 개막, AI 네이티브 개발 전면 수용: Microsoft는 Build 2025 개발자 컨퍼런스에서 “개방형 에이전트 네트워크(Open Agentic Web)” 비전을 발표하고 50개 이상의 업데이트를 공개했습니다. 핵심 내용에는 GitHub Copilot의 VSCode 확장 프로그램 오픈 소스화, 모델 컨텍스트 프로토콜(MCP) 및 자연어 네트워크(NLWeb) 개방형 표준 출시, 그리고 xAI의 Grok 등 1900개 이상의 모델을 Azure AI Foundry에 도입하는 것이 포함됩니다. 이러한 조치들은 모델에서 에이전트에 이르는 개발 경로를 연결하고, AI Agent의 여러 시나리오에서의 자율적 운영 및 상호 운용성을 실현하는 것을 목표로 합니다. Microsoft CEO 사티아 나델라는 AI Agent가 문제 해결 방식을 재편할 것이라고 강조했으며, OpenAI CEO 샘 알트먼, Nvidia CEO 젠슨 황, xAI 창립자 일론 머스크와 함께 AI 에이전트의 소프트웨어 개발, 인프라 및 물리적 세계 응용 분야의 미래에 대해 논의했습니다. (출처: 36氪 | GitHub Blog | VS Code Blog | The Verge)
Google DeepMind, AlphaEvolve 공개, AI 에이전트 56년 만에 행렬 곱셈 효율 기록 경신: Google DeepMind는 Gemini 기반 코딩 에이전트 AlphaEvolve를 출시했습니다. 이 에이전트는 진화 알고리즘과 자동화된 평가 시스템을 통해 56년간 사용되어 온 Strassen 알고리즘보다 효율적인 4×4 복소 행렬 곱셈 알고리즘을 발견하여 필요한 스칼라 곱셈 횟수를 49회에서 48회로 줄였습니다. 이 혁신은 수학 이론적으로 중요할 뿐만 아니라 이미 Google 내부 애플리케이션에서 가치를 입증했습니다. 예를 들어 Gemini 아키텍처의 대형 행렬 곱셈 연산을 23% 가속화하여 Gemini 훈련 시간을 1% 단축하고 FlashAttention 성능을 32.5% 향상시켰습니다. AlphaEvolve는 수학적 난제부터 데이터 센터 리소스 스케줄링 및 AI 모델 훈련 가속화에 이르기까지 다양한 복잡한 문제를 처리할 수 있는 AI의 자동화된 과학적 발견 및 알고리즘 최적화 분야에서의 거대한 잠재력을 보여줍니다. (출처: Google DeepMind Blog | 量子位)
연구 결과, GPT-4 개인 맞춤형 토론에서 인간보다 64% 더 설득력 있어: 《Nature Human Behaviour》에 발표된 한 연구에 따르면, OpenAI의 GPT-4가 토론 상대방의 성별, 연령, 교육 배경 등 개인 정보를 파악하고 이를 바탕으로 논점을 조정할 경우 인간보다 64% 더 높은 설득력을 보였습니다. 로잔 연방 공과대학교 등 기관이 협력한 이 연구는 900명의 참가자를 대상으로 진행되었으며, 대규모 언어 모델(LLM)의 설득 능력이 강력하다는 것을 다시 한번 입증했습니다. 연구자들은 AI 도구가 소량의 사용자 정보만으로도 복잡하고 설득력 있는 논점을 구성할 수 있다는 점을 경고하며, 이는 개인 맞춤형 허위 정보 유포에 잠재적인 위협이 될 수 있다고 지적했습니다. 또한 정책 입안자와 플랫폼이 이러한 위험을 중요하게 인식하고, LLM을 활용하여 허위 정보에 대응하기 위한 개인 맞춤형 반박 콘텐츠 생성을 모색할 것을 촉구했습니다. (출처: Nature Human Behaviour | MIT Technology Review)
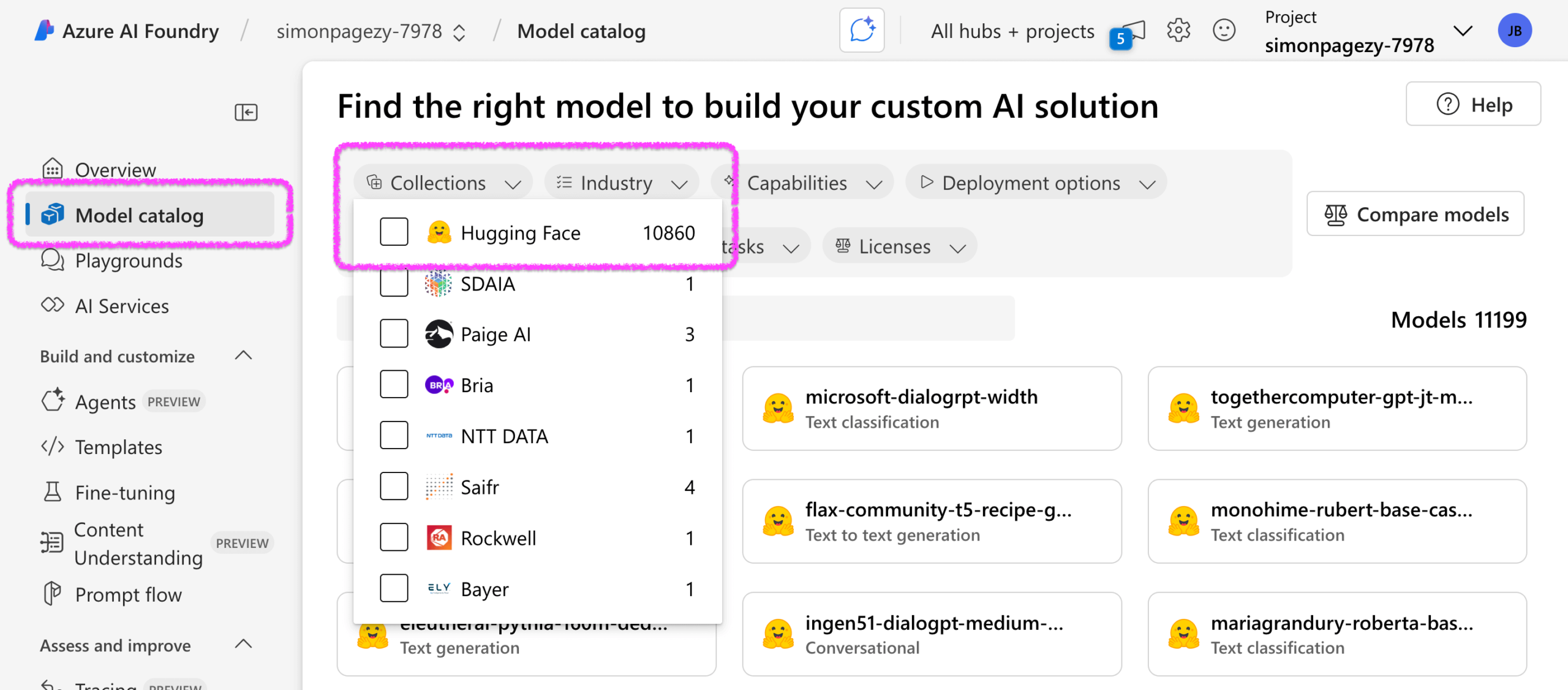
Microsoft, Hugging Face와 협력 심화, Azure AI Foundry에 1만 개 이상의 오픈 소스 모델 통합: Microsoft Build 컨퍼런스에서 Microsoft는 Hugging Face와의 협력 확대를 발표했습니다. Azure AI Foundry는 이제 텍스트, 오디오, 이미지 등 다양한 모달리티와 작업을 포괄하는 10,000개 이상의 Hugging Face 오픈 소스 모델을 통합했습니다. 이는 Azure 사용자가 AI 애플리케이션 및 에이전트 구축을 위해 다양한 오픈 소스 모델을 보다 편리하고 안전하게 배포할 수 있도록 하기 위함입니다. 통합된 모든 모델은 안전 테스트를 통과했으며, safetensors 형식을 사용하고 원격 코드를 포함하지 않아 기업 수준 애플리케이션의 안전성을 보장합니다. 양측은 향후 최신 및 인기 모델을 지속적으로 도입하고, 더 많은 모달리티(예: 비디오, 3D)를 지원하며, AI 에이전트 및 도구에 대한 최적화를 강화할 계획입니다. (출처: HuggingFace Blog)
🎯 동향
Nvidia, Computex 2025에서 다수의 AI 신제품 발표, AI 팩토리 전환 가속화: CEO 젠슨 황은 Computex 2025에서 GeForce RTX 5060 GPU, Grace Blackwell GB300 슈퍼컴퓨팅 플랫폼, 개인용 AI 슈퍼컴퓨터 DGX Spark(GB10 탑재, 수 주 내 출시) 및 DGX Station(784GB 메모리, DeepSeek R1 실행 가능)을 발표했습니다. 젠슨 황은 Nvidia가 GPU 공급업체에서 글로벌 AI 인프라 제공업체로 전환하고 있으며, “즉시 사용 가능한” AI 팩토리를 구축하는 것을 목표로 한다고 강조했습니다. 동시에 Nvidia는 DeepMind 및 Disney와 공동 개발한 물리 엔진 Newton을 7월에 오픈 소스화하고, Isaac GR00T 휴머노이드 로봇 기본 모델을 출시하여 물리 AI 발전을 추진할 예정입니다. Nvidia는 또한 대만에 새로운 사무실을 설립한다고 발표하며 중국 AI 인재의 중요성을 강조했습니다. (출처: 36氪 | 36氪)
Microsoft, EU 사용자가 iPhone 등 기기의 기본 음성 비서 변경 허용 계획: 블룸버그 통신에 따르면, Apple은 EU 사용자가 iPhone, iPad, Mac 등 기기의 기본 음성 비서를 Siri에서 Google Assistant나 Amazon Alexa와 같은 다른 옵션으로 변경할 수 있도록 할 계획입니다. 이는 EU의 디지털 시장법(DMA)에 따른 반독점 압력에 대응하기 위한 조치일 수 있습니다. Siri는 최근 몇 년간 기능 낙후와 지능 부족으로 비판을 받아왔으며, Apple 내부에서도 Siri의 발전 방향에 대한 의견이 분분하고 기존 아키텍처가 대규모 언어 모델(LLM)과 효과적으로 통합되기 어렵다는 지적이 있었습니다. Apple이 LLM 기반의 새로운 Siri를 개발하고 Apple Intelligence를 출시했지만, 사용자가 기본 비서를 교체할 수 있도록 허용하는 것은 생태계에 충격을 줄 수 있습니다. (출처: 36氪)
Apple, 자체 개발 AI 챗봇 내부 테스트 중, ChatGPT와 유사한 능력 가능성: 블룸버그 기자 Mark Gurman은 Apple이 자체 개발 AI 챗봇 프로젝트를 내부적으로 테스트하고 있다고 밝혔습니다. 새로운 AI 책임자 John Giannandrea의 지휘 아래 이 프로젝트는 지난 6개월 동안 상당한 진전을 이루었으며, 일부 경영진은 현재 버전의 능력이 최신 ChatGPT와 비슷하다고 평가하고 있습니다. 이 챗봇은 실시간 웹 검색 및 정보 통합 기능을 갖출 것으로 보입니다. 이는 OpenAI 등 외부 서비스에 대한 의존도를 줄이고 Siri의 경쟁력을 높이기 위한 조치일 수 있습니다. WWDC 2025에서 Siri 업그레이드가 중점적으로 소개되지 않을 수도 있지만, Apple은 AI 시대에 음성 비서를 부활시키기 위해 AI에 대한 투자를 지속적으로 확대하고 있습니다. (출처: 36氪)
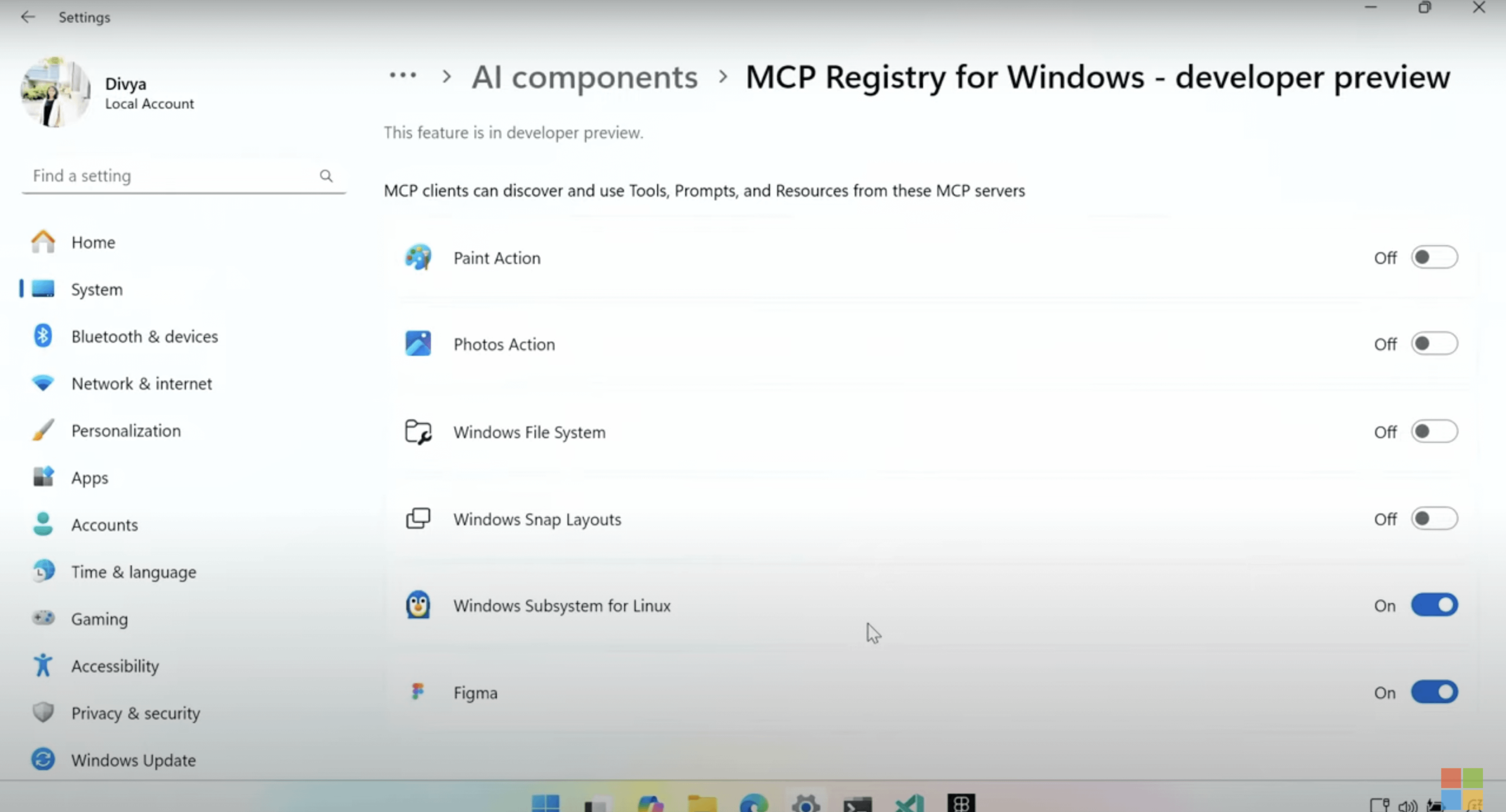
Windows, 모델 컨텍스트 프로토콜(MCP) 기본 지원 예정: Microsoft는 Build 2025 컨퍼런스에서 Windows 운영체제가 모델 컨텍스트 프로토콜(MCP)을 기본적으로 지원하여 Windows에서의 AI 애플리케이션 개발 및 배포를 간소화할 것이라고 발표했습니다. MCP는 “AI 애플리케이션용 USB-C”에 비유되며, 다양한 AI 모델과 애플리케이션에 표준화된 상호 작용 방식을 제공하고자 합니다. Windows AI Foundry 플랫폼은 이 지원을 통합하여 개발자가 Windows 장치에서 로컬 AI 모델 및 에이전트를 보다 편리하게 실행하고 관리할 수 있도록 할 것입니다. (출처: op7418 | Reddit r/LocalLLaMA)
Microsoft Azure AI Foundry, xAI의 Grok 대규모 모델 도입: Microsoft는 Build 2025 개발자 컨퍼런스에서 일론 머스크의 xAI 회사 Grok 3 및 Grok 3 mini 대규모 모델이 Azure AI Foundry 플랫폼에 합류할 것이라고 발표했습니다. Azure 사용자는 클라우드 플랫폼을 통해 직접 이러한 모델을 사용하고 비용을 지불할 수 있게 됩니다. 이로써 Azure에서 사용 가능한 AI 모델 수(이미 1900종 이상)가 더욱 확대되었으며, 이전에는 OpenAI, Meta, DeepSeek 등이 포함되어 있었습니다. 머스크는 영상 연결을 통해 개발자들의 피드백을 기대하며, 향후 더 많은 회사에 Grok 서비스를 제공하기를 바란다고 말했습니다. (출처: 36氪)
Percy Liang 팀, 개방형 AI 모델 개발 추진을 위한 Marin 프로젝트 시작: 스탠퍼드 대학교 Percy Liang 교수가 이끄는 팀이 “완전 참여 방식”으로 개방형 모델을 구축하기 위한 Marin 프로젝트를 시작했습니다. 이 프로젝트는 개방형 개발 과정을 강조하며 누구나 기여할 수 있도록 합니다. 첫 번째 Marin 모델들이 이미 출시되었으며, 그중 8B 모델은 Together AI 플랫폼에서 테스트용으로 제공되고 있습니다. 이러한 움직임은 가중치, 코드, 데이터뿐만 아니라 전체 연구 개발 생태계를 개방하는 AI 분야의 더 깊은 수준의 개방성에 대한 요구에 부응하는 것입니다. (출처: vipulved)

Intel, Arc Pro B60 전문가용 그래픽 카드 출시, KTransformers Intel GPU 지원 발표: Intel은 24GB VRAM과 456GB/s의 메모리 대역폭을 갖춘 새로운 전문가급 그래픽 카드 Arc Pro B60을 출시했습니다. 단일 카드 가격은 약 500달러로 AI 컴퓨팅을 위한 새로운 하드웨어 선택지를 제공합니다. 동시에 KTransformers 프레임워크는 Intel GPU 지원을 발표했으며, 테스트 결과 Xeon 5 + DDR5 + Arc A770 플랫폼에서 DeepSeek-R1 Q4 양자화 모델을 실행할 때 약 7.5 token/s의 속도를 보여 로컬에서 대규모 모델을 실행할 수 있는 더 많은 하드웨어 가능성을 제공했습니다. (출처: karminski3 | karminski3)

DeepMind, Google I/O 컨퍼런스 예고: Google DeepMind 공식 계정은 5월 20일(태평양 표준시 오전 10시)에 열릴 Google I/O 컨퍼런스를 예고했으며, X 플랫폼에서 생중계될 예정입니다. 이 컨퍼런스에서는 AI 분야에서 Google의 강력한 모멘텀을 이어갈 일련의 AI 관련 주요 업데이트와 제품이 발표될 것으로 예상됩니다. (출처: GoogleDeepMind)
🧰 툴
AgenticSeek: 순수 로컬 실행 AI 에이전트, Manus AI 벤치마킹: AgenticSeek는 완전히 로컬에서 실행되는 AI 비서를 제공하는 것을 목표로 하는 오픈 소스 프로젝트입니다. 자율적으로 웹을 탐색하고, 코드를 작성하며, 작업을 계획하는 능력을 갖추고 있으며, 모든 데이터는 사용자 장치에 보관되어 개인 정보를 보호합니다. 이 도구는 로컬 추론 모델을 위해 특별히 설계되었으며 음성 상호 작용을 지원하여 AI 에이전트 사용 비용(전력 소비만 해당)과 데이터 유출 위험을 줄이는 데 주력합니다. (출처: GitHub Trending)
메이퇀, AI 프로그래밍 도구 NoCode 내부 테스트, Vibe Coding 지향: 36커 독점 보도에 따르면, 메이퇀은 최근 AI 프로그래밍 도구 “NoCode”를 출시할 예정이며, 도메인 nocode.cn은 이미 등록되어 그레이스케일 테스트에 들어갔습니다. 이 제품은 메이퇀 연구개발 품질 및 효율성 팀에서 개발했으며, Lovable과 유사한 “분위기 프로그래밍(Vibe Coding)”을 지향하며 비기술 인력을 대상으로 합니다. 대화형 상호 작용을 통해 데이터 분석, 제품 프로토타입, 운영 도구 생성 등 코딩 및 배포 작업을 자동으로 완료합니다. NoCode는 Code Agent 아키텍처를 채택하여 다단계 논리 추론이 가능하며, 중소 상공인의 IT화 장벽을 낮추기 위해 판매자와 일반 사용자에게 개방할 계획입니다. (출처: 36氪)
텐센트 QQ 브라우저, AI 브라우저로 업그레이드, QBot 지능형 비서 통합: QQ 브라우저는 AI 브라우저로 업그레이드하고 텐센트 혼원 및 DeepSeek 듀얼 모델 기반의 AI 비서 QBot을 출시한다고 발표했습니다. QBot은 AI 검색, AI 브라우징, AI 오피스, AI 학습, AI 글쓰기 등의 기능을 통합하고 Manus와 유사한 AI Agent 기능을 도입하여 복잡한 작업을 수행할 수 있습니다. 첫 번째 그레이스케일 테스트 대상 에이전트에는 사용자를 위한 맞춤형 대학 입시 지원 방안을 생성할 수 있는 “AI 대학입시 도우미(AI高考通)”가 포함됩니다. QQ 브라우저 사용자 규모는 4억 명이 넘으며, 이번 업그레이드는 AI를 통해 사용자 정보 획득 및 작업 처리 효율성을 높이는 것을 목표로 합니다. (출처: 36氪)
OpenAI Codex, ChatGPT iOS 버전에 탑재, 모바일 프로그래밍 작업 지원: OpenAI는 프로그래밍 비서 Codex가 이제 ChatGPT의 iOS 애플리케이션에 통합되었다고 발표했습니다. 사용자는 휴대폰에서 직접 새로운 코딩 작업을 시작하고, 코드 차이점을 확인하며, 수정을 요청하고 심지어 PR을 푸시할 수도 있습니다. 이 기능은 또한 잠금 화면 실시간 활동 추적을 지원하여 사용자가 언제든지 Codex 작업 진행 상황을 파악하고 컴퓨터로 돌아가기 전에 미완성 작업을 계속할 수 있도록 합니다. 이는 AI 프로그래밍이 모바일 및 다중 시나리오 협업으로 나아가는 중요한 단계입니다. (출처: karinanguyen_ | gdb)
NotebookLM 모바일 앱 출시, Android 및 iOS 지원: Google의 AI 노트 도구 NotebookLM이 공식적으로 모바일 앱을 출시하여 Android 및 iOS 플랫폼에 순차적으로 배포되고 있습니다. 모바일 버전은 오디오 요약, 대화 등 핵심 기능을 제공하여 사용자가 언제 어디서나 AI를 활용하여 콘텐츠를 분석하고 학습할 수 있도록 지원합니다. 편리한 기능 중 하나는 사용자가 현재 보고 있는 콘텐츠(공식 계정 제외)를 NotebookLM으로 직접 전달하여 처리할 수 있다는 것입니다. (출처: op7418)
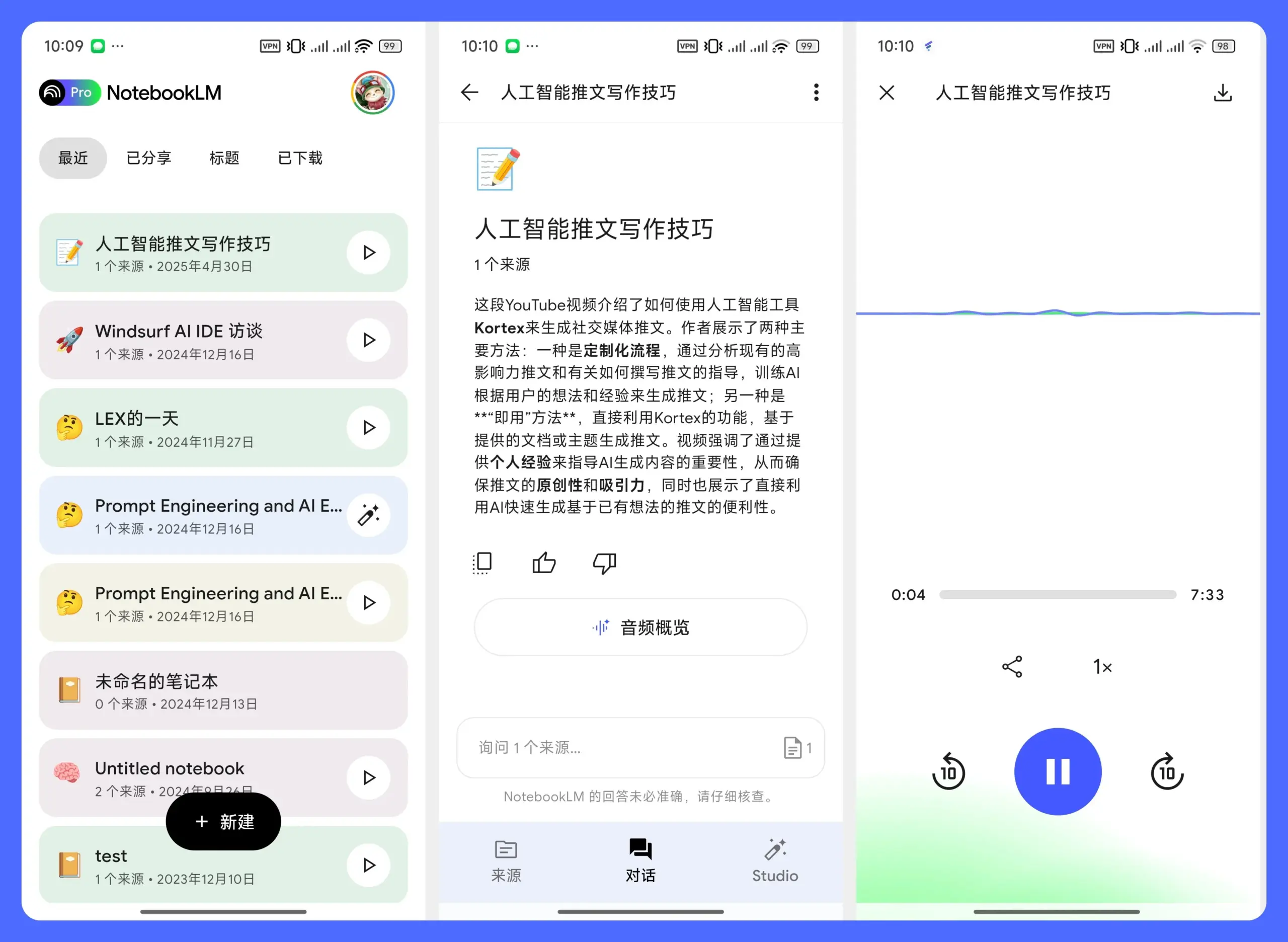
Public, AI 투자 도구 “Generated Assets” 출시: 투자 플랫폼 Public이 새로운 제품 “Generated Assets”를 출시했습니다. 사용자는 AI에게 투자 아이디어를 제시하면 AI가 이에 따라 투자 제안, 맞춤형 투자 지수를 반환하고 과거 수익률 비교 및 실시간 성과 추적이 가능합니다. 이는 “분위기 투자” 또는 “테마 투자”의 AI 구현과 유사하며, 사용자가 개인화된 투자 포트폴리오를 구축하고 관리하는 장벽을 낮추는 것을 목표로 합니다. (출처: op7418)
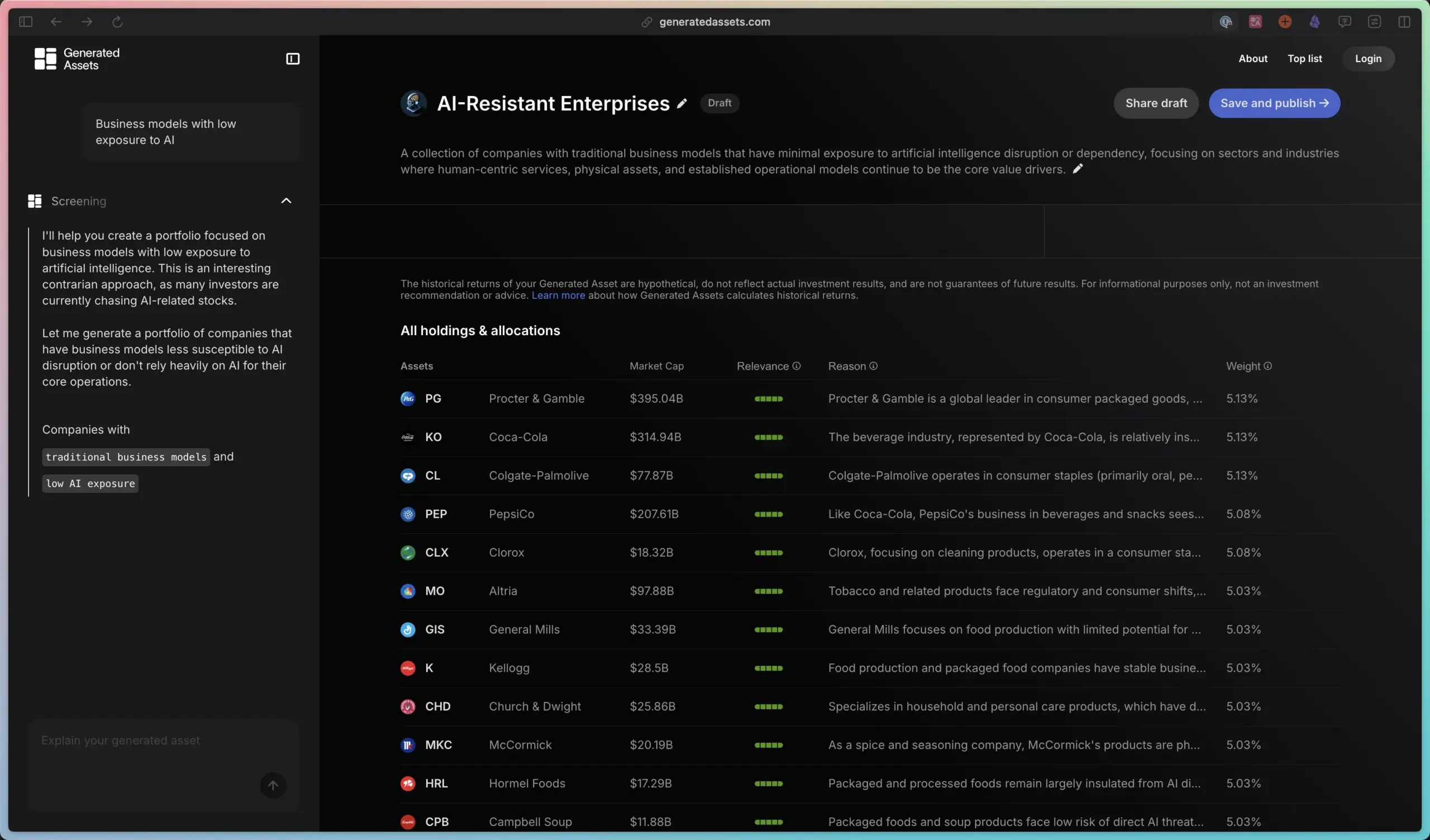
ClaraVerse: 다양한 AI 도구를 통합한 “올인원” 애플리케이션: ClaraVerse라는 AI 도구 모음이 커뮤니티에 공유되었습니다. 이 도구는 채팅 인터페이스, AI 구성 요소, Ollama(로컬 대규모 모델 실행), n8n(워크플로/예약 작업), AI Agent 템플릿, ComfyUI(이미지 생성) 및 AI 인덱싱 기능이 있는 이미지 라이브러리를 통합합니다. 사용자에게 원스톱 AI 작업 플랫폼을 제공하여 다양한 AI 도구의 사용 및 전환을 단순화하는 것을 목표로 합니다. (출처: karminski3)
Qdrant 벡터 데이터베이스, Microsoft NLWeb 프로토콜 통합: 벡터 데이터베이스 Qdrant는 Microsoft가 Build 컨퍼런스에서 발표한 NLWeb 개방형 프로토콜의 첫 번째 파트너 중 하나가 되었다고 발표했습니다. NLWeb은 기존 검색창을 자연어 기반의 의미론적, 의도 인식 인터페이스로 전환하는 것을 목표로 합니다. Qdrant와의 통합을 통해 웹사이트는 프런트엔드나 백엔드 로직을 크게 수정하지 않고도 빠르고 필터링된 벡터 검색을 활용하여 의미적으로 관련된 결과를 제공할 수 있습니다. (출처: qdrant_engine)

📚 학습
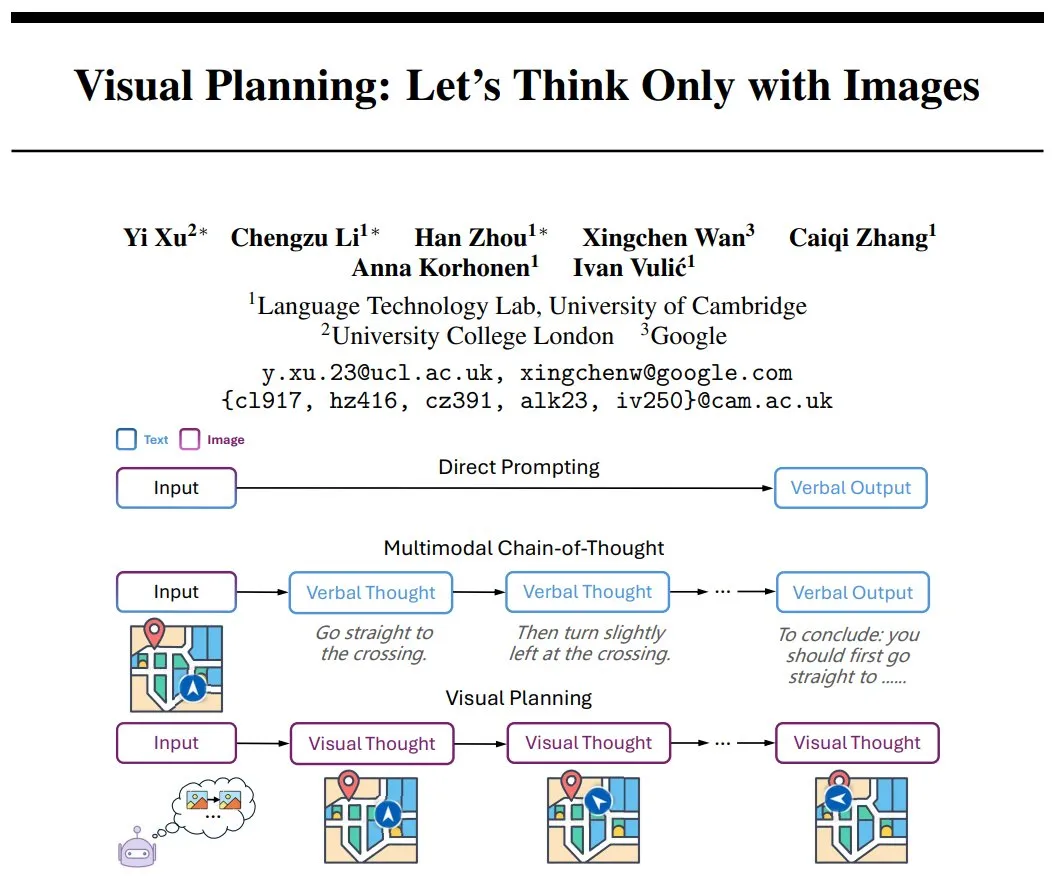
DeepMind, 시각적 계획(Visual Planning) 제안: 순수 이미지 시퀀스 추론 패러다임: Yi Xu 등 연구자들은 “시각적 계획(Visual Planning)”이라는 새로운 추론 패러다임을 제안했습니다. 이는 모델이 언어나 문자적 사고 없이 순전히 이미지 시퀀스를 통해 생각하고 계획하도록 하여, 인간이 머릿속으로 단계를 구상하는 방식을 모방하는 것을 목표로 합니다. 이 방법은 AI가 비언어적 기호 시스템 하에서 복잡한 추론을 수행할 가능성을 탐구하며, 다중 모드 AI 발전에 새로운 아이디어를 제공합니다. (출처: madiator)
스탠퍼드 등 기관, Terminal-Bench 출시: AI 에이전트 터미널 작업 능력 평가 벤치마크: 스탠퍼드 대학교와 Laude의 연구원들은 실제 터미널 환경에서 AI 에이전트가 복잡한 작업을 완료하는 능력을 평가하기 위한 프레임워크 및 벤치마크인 Terminal-Bench를 출시했습니다. Claude Code, Codex CLI와 같은 많은 AI 에이전트가 터미널과의 상호 작용을 통해 가치 있는 작업을 수행한다는 점을 고려하여, 이 벤치마크는 실제 배포를 위한 에이전트 능력 향상을 추진하기 위해 실제 효능을 정량화하는 것을 목표로 합니다. (출처: madiator | andersonbcdefg)

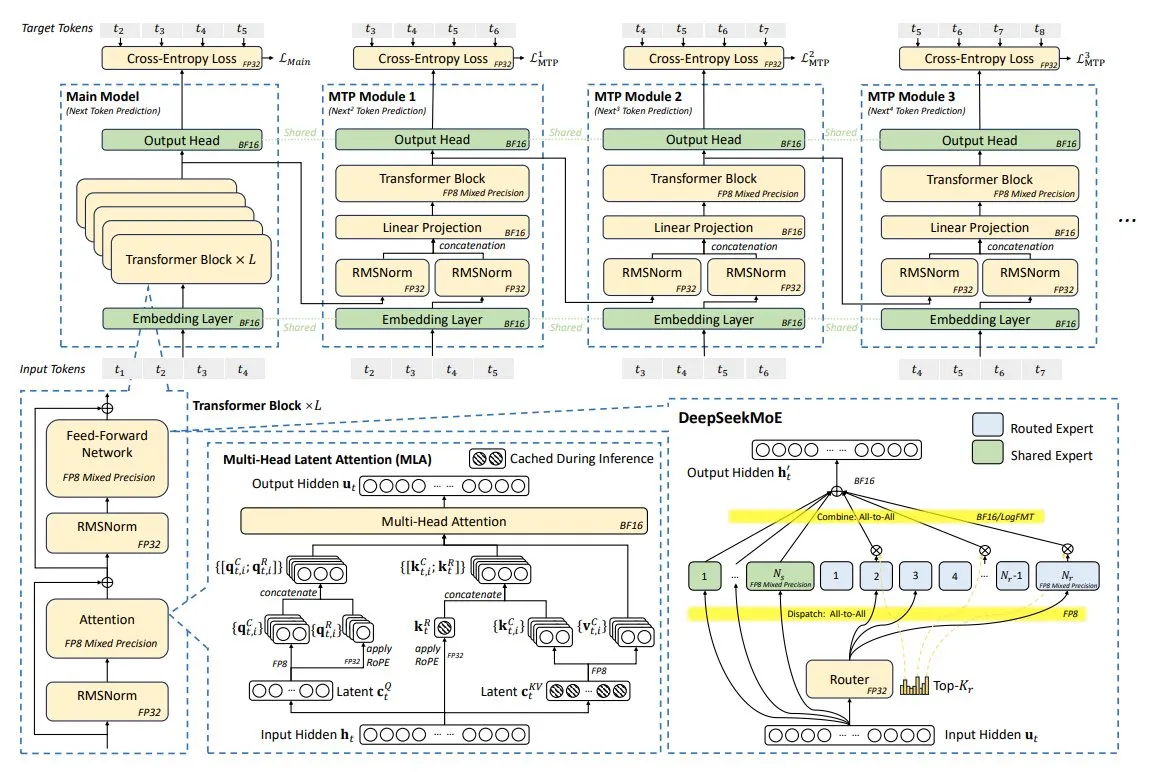
DeepSeek-V3 기술 해설: 하드웨어-소프트웨어 공동 설계로 효율적인 모델 구현: DeepSeek-V3 모델은 하드웨어-소프트웨어 공동 설계를 통해 단 2048개의 NVIDIA H800 GPU로 훈련을 완료했습니다. 주요 혁신 기술로는 다중 헤드 잠재 어텐션(MLA), 전문가 혼합(MoE), FP8 혼합 정밀도 훈련 및 다중 평면 네트워크 토폴로지가 있습니다. 이러한 기술들은 함께 작용하여 더 낮은 비용으로 더 나은 모델 성능을 달성하는 것을 목표로 하며, AI 모델 설계가 더 효율적인 비용 대비 성능 방향으로 발전하는 새로운 추세를 대표합니다. (출처: TheTuringPost)
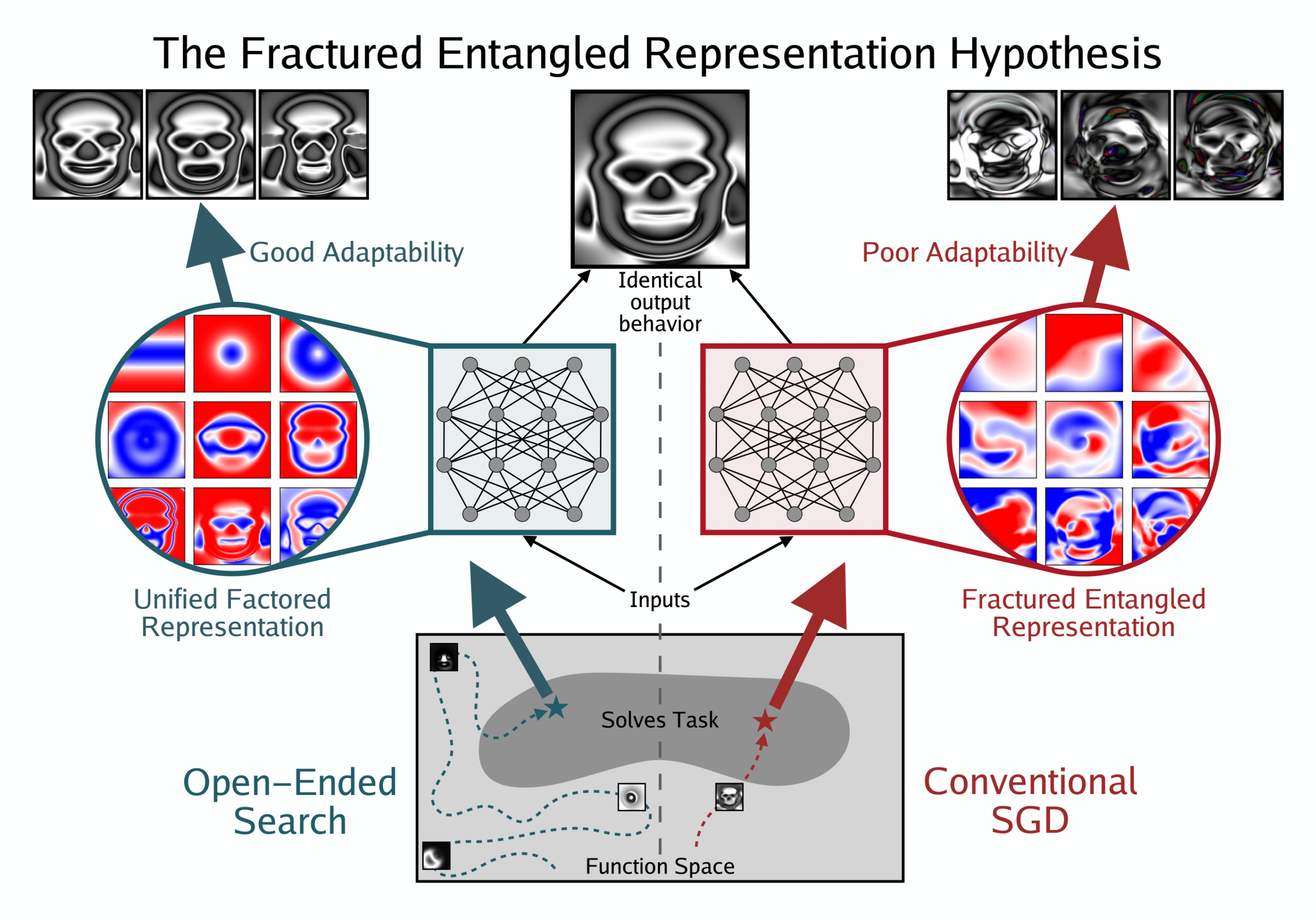
새 논문, 딥러닝에서의 표현 낙관주의 탐구: 분리된 얽힘 표현 가설: Kenneth Stanley 등은 “딥러닝에서의 표현 낙관주의에 대한 의문: 분리된 얽힘 표현 가설”이라는 입장 논문을 발표했습니다. 연구에 따르면, 비정형적인 개방형 검색을 통해 발견된 단일 이미지를 출력할 수 있는 네트워크의 표현은 우아하고 모듈화되어 있는 반면, SGD로 동일한 출력을 학습한 네트워크의 표현은 혼란스럽게 얽혀 있습니다. 이는 좋은 출력 행동 뒤에 나쁜 내부 표현이 숨겨져 있을 수 있음을 시사하지만, 동시에 표현이 더 나아질 수 있는 가능성을 드러내기도 합니다. 이는 모델의 일반화, 창의성 및 학습 능력에 심오한 영향을 미치며, 기본 모델과 LLM을 개선하기 위한 새로운 아이디어를 제공합니다. (출처: hardmaru | togelius | bengoertzel)
RL 튜토리얼 업데이트, LLM 챕터(DPO, GRPO, 사고의 연쇄 등) 중점: Sirbayes가 강화 학습(RL) 튜토리얼의 새 버전을 발표했습니다. 이번 업데이트는 주로 대규모 언어 모델(LLM) 챕터를 대상으로 하며, DPO(Direct Preference Optimization), GRPO(Group Relative Policy Optimization), 사고의 연쇄(Thinking) 등 최신 내용을 추가했습니다. 동시에 다중 에이전트 강화 학습(MARL), 모델 기반 강화 학습(MBRL), 오프라인 강화 학습 및 DPG(Deep Deterministic Policy Gradient) 등 챕터도 소폭 업데이트되었습니다. (출처: sirbayes)

바이트댄스, 사전 훈련 모델 평균화 전략(Pre-trained Model Averaging) 제안: 바이트댄스 연구팀은 대규모 언어 모델 사전 훈련 과정에서 모델을 병합하는 새로운 프레임워크인 사전 훈련 모델 평균화(PMA) 전략을 제안하는 논문을 발표했습니다. 연구 결과, 일정한 학습률로 훈련된 체크포인트를 병합하면 지속적인 훈련과 동등하거나 더 나은 성능을 달성할 수 있을 뿐만 아니라 훈련 효율성을 크게 향상시킬 수 있다는 사실을 발견했습니다. 이 연구는 대규모 모델 사전 훈련을 위한 새로운 효율성 최적화 아이디어를 제공하고, 모델 병합이 성능 및 효율성 향상에 미치는 잠재력을 검증했습니다. (출처: teortaxesTex)

알리바바 통이 연구소, 새로운 연구 ZeroSearch: LLM이 검색 엔진 역할 수행, API 없이 추론 능력 향상: 알리바바 통이 연구소는 ZeroSearch 프레임워크를 제안하여 LLM이 검색 엔진 행동을 모방하도록 함으로써 강화 학습 과정에서 실제 검색 엔진 API를 호출할 필요 없이 비용을 절감하고 훈련 안정성을 향상시켰습니다. 이 방법은 가벼운 미세 조정을 통해 LLM이 유용한 결과와 노이즈 간섭을 생성할 수 있도록 하고, 커리큘럼 기반 노이즈 방지 훈련을 채택하여 복잡한 검색 시나리오에서 모델의 추론 및 노이즈 방지 능력을 점진적으로 향상시킵니다. 실험 결과, 검색 모듈로 3B 매개변수의 LLM만 사용해도 검색 능력을 효과적으로 향상시킬 수 있음이 나타났습니다. (출처: 量子位)

홍콩 중문대학교, 새로운 알고리즘 RXTX로 행렬 곱셈 XXt 계산 최적화: 홍콩 중문대학교 연구진은 행렬과 그 전치 행렬의 곱(XXt) 계산을 가속화하는 새로운 알고리즘 RXTX를 제안했습니다. 이 알고리즘은 4×4 블록 행렬의 재귀적 곱셈을 기반으로 하며, 머신러닝 검색과 조합 최적화 기술을 결합하여 발견되었습니다. Strassen 재귀 기반의 기존 알고리즘과 비교하여 RXTX는 점근적 곱셈 상수를 약 5% 감소시키고, n≥256일 때 총 연산량에서 우위를 보이며, 6144×6144 행렬 테스트에서 BLAS 기본 구현보다 9% 더 빨랐습니다. 이 연구는 데이터 분석, 칩 설계, LLM 훈련 등 분야에 잠재적인 영향을 미칠 수 있습니다. (출처: 量子位)
논문 AdaptThink: 추론 모델이 언제 “생각”해야 하는지 학습하도록 하기: 이 연구는 AdaptThink를 제안합니다. 이는 강화 학습을 통해 추론 모델이 문제의 난이도에 따라 심층적 사고(예: Chain-of-Thought) 수행 여부를 자율적으로 선택하도록 가르치는 프레임워크입니다. 핵심에는 제약된 최적화 목표(성능을 유지하면서 사고를 줄이도록 장려)와 중요도 샘플링 전략(사고하는 샘플과 사고하지 않는 샘플의 균형을 맞춤)이 포함됩니다. 실험 결과, AdaptThink는 추론 비용을 크게 줄이고 성능을 향상시킬 수 있음을 보여주었습니다. 예를 들어 수학 데이터셋에서 DeepSeek-R1-Distill-Qwen-1.5B의 평균 응답 길이를 53% 줄이고 정확도를 2.4% 향상시켰습니다. (출처: HuggingFace Daily Papers)
논문 VisionReasoner: 강화 학습을 통한 시각적 인식과 추론의 통합: VisionReasoner는 공유 모델을 통해 다양한 시각적 인식 작업을 처리하는 것을 목표로 하는 통합 프레임워크입니다. 다중 객체 인지 학습 전략과 체계적인 작업 재구성을 채택하여 모델이 시각적 입력을 분석하고 구조화된 추론을 수행하는 능력을 강화하여 탐지, 분할, 계수 등 10가지 다른 작업을 처리합니다. 실험 결과, VisionReasoner는 COCO(탐지), ReasonSeg(분할) 및 CountBench(계수)와 같은 벤치마크에서 Qwen2.5VL과 같은 모델보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
논문 AdaCoT: 강화 학습을 통한 파레토 최적의 적응형 사고의 연쇄 트리거링: 대규모 언어 모델(LLM)이 간단한 쿼리를 처리할 때 사고의 연쇄(CoT)로 인해 발생하는 불필요한 계산 오버헤드를 해결하기 위해 AdaCoT 프레임워크가 제안되었습니다. 이는 강화 학습(PPO)을 활용하여 LLM이 쿼리의 암묵적인 복잡성에 따라 CoT 호출 여부를 자율적으로 결정하도록 하여 모델 성능과 CoT 호출 비용의 균형을 맞추는 것을 목표로 합니다. 선택적 손실 마스킹(SLM) 기술을 통해 결정 경계 붕괴를 방지하며, 실험 결과 AdaCoT는 불필요한 CoT 트리거율(최저 3.18%)과 응답 토큰 수(69.06% 감소)를 크게 줄이면서 복잡한 작업에서 높은 성능을 유지할 수 있음을 보여주었습니다. (출처: HuggingFace Daily Papers)
논문 GIE-Bench: 텍스트 기반 이미지 편집을 위한 현실적인 평가 벤치마크: 텍스트 기반 이미지 편집 모델을 보다 정확하게 평가하기 위해 GIE-Bench가 제안되었습니다. 이 벤치마크는 기능적 정확성(자동 생성된 객관식 문제를 통해 편집 성공 여부 검증)과 이미지 내용 보존(객체 인식 마스킹 기술 및 보존 점수를 사용하여 비대상 영역 일관성 보장)이라는 두 가지 차원에서 평가를 수행합니다. 20개 카테고리를 포괄하는 1000개 이상의 고품질 편집 예시를 포함합니다. GPT-Image-1 등 모델에 대한 평가는 지시 사항 준수에서는 앞서지만 관련 없는 영역 보존 측면에서는 개선이 필요함을 보여줍니다. (출처: HuggingFace Daily Papers)
논문 InstanceGen: 인스턴스 수준 지침을 사용한 이미지 생성: 사전 훈련된 텍스트-이미지 생성 모델이 여러 객체와 인스턴스 수준 속성을 포함하는 복잡한 프롬프트를 처리할 때 의미를 정확하게 포착하기 어려운 문제를 해결하기 위해 InstanceGen은 새로운 기술을 제안합니다. 이 기술은 현대 이미지 생성 모델이 직접 제공하는 이미지 기반의 세분화된 구조화 초기화와 LLM 기반의 인스턴스 수준 지침을 결합하여 생성된 이미지가 객체 수, 인스턴스 수준 속성 및 인스턴스 간 공간 관계를 포함한 텍스트 프롬프트의 모든 부분을 더 잘 따르도록 합니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
칭화대 계열 체화 지능 회사 ‘첸주에 테크놀로지’, 수억 위안 규모 Pre-A+ 라운드 투자 유치: 체화 두뇌 회사 ‘첸주에 테크놀로지(千诀科技)’가 최근 쥔산 투자(钧山投资), 샹펑 투자(祥峰投资), 스시 캐피털(石溪资本)로부터 새로운 Pre-A+ 라운드 투자를 유치하여 누적 투자액 수억 위안을 달성했습니다. 이 회사는 칭화대학교 자동화학과 및 관련 AI 연구 기관의 핵심 멤버들이 인큐베이팅했으며, 범용 ‘체화 두뇌’ 시스템 개발에 주력하고 있습니다. 다중 모드 실시간 인식, 지속적인 작업 계획 및 자율 실행 능력을 강조하며, 이미 가정 서비스, 물류 배송 등 시나리오에서 제품 수준의 상용화를 실현했고, 다수의 주요 로봇 제조업체, 소비 가전 회사와 협력하고 있습니다. (출처: 36氪)

AI Agent, SaaS 시장 구도 재편 가능성: Microsoft CEO 사티아 나델라가 AI Agent 시대에 SaaS 애플리케이션이 변혁에 직면할 것이라고 예측하면서, AI Agent와 SaaS의 미래에 대한 업계의 광범위한 논의가 촉발되었습니다. AI Agent는 자율적인 인식, 의사 결정 및 행동 능력을 바탕으로 기존 SaaS의 맞춤화, 데이터 상호 운용성 및 사용자 경험 측면의 문제점을 해결할 것으로 기대됩니다. 예를 들어 자연어 상호 작용을 통해 자동으로 워크플로를 생성하고, 여러 애플리케이션의 데이터를 통합하며, 능동적으로 비즈니스 제안을 제공하는 것 등입니다. 현재 AI Agent는 기업용 애플리케이션에서 LLM 능력 제한, 비용, 데이터 보안 등의 도전에 직면해 있지만, Salesforce, Microsoft, 용유(用友) 등 제조업체들은 이미 AI Agent를 SaaS 제품에 통합하기 시작하여 SaaS를 융합하거나 변혁하는 새로운 모델을 모색하고 있습니다. (출처: 36氪)
AI, 급여 관리 재편: 데이터 분석에서 지능형 의사 결정 및 소통까지: 인공지능이 급여 관리를 심오하게 변화시키고 있습니다. 콘 페리(Korn Ferry) 보고서에 따르면 AI는 급여 소통, 외부 벤치마킹 및 직무 기술 구조 측면에서 점점 더 많이 활용되고 있습니다. 미래에는 AI가 소셜 플랫폼, 제3자 조사 등 더 크고 다양한 데이터를 처리하여 데이터 기반에서 지능형 의사 결정으로 전환할 것으로 예상됩니다. 예를 들어 직원 이탈 위험 예측, 인센티브 효과 평가, 급여 범위 동적 조정, 개인 맞춤형 인센티브 실현 등입니다. 동시에 AI는 데이터 개인 정보 보호, 알고리즘 “블랙박스”, 결과 신뢰성 등의 문제에 직면해 있습니다. 디지털 지능 시대에는 효과적인 급여 소통이 더욱 중요하며, AI 도구는 관리자가 체계적이고 개인화된 소통을 수행하여 직원 공정성과 만족도를 높이는 데 도움을 줄 수 있습니다. (출처: 36氪)
🌟 커뮤니티
순다르 피차이, “깊은 생각” 사진 공개하며 Google I/O 예열: 구글 CEO 순다르 피차이가 소셜 미디어에 자신이 “깊은 생각”에 잠긴 사진을 공개하며 곧 열릴 Google I/O 컨퍼런스에 대한 커뮤니티의 광범위한 기대를 불러일으켰습니다. 이 사진은 여러 AI 분야 KOL들에 의해 공유되고 해석되었으며, 일반적으로 구글이 AI 분야, 특히 Gemini 모델 및 그 응용 분야에서 중대한 발표를 할 것임을 예고하는 것으로 받아들여지고 있습니다. 커뮤니티 회원들은 가능한 새로운 기능, 새로운 모델 또는 새로운 전략에 대해 다양하게 추측하고 있습니다. (출처: demishassabis | YiTayML | zacharynado | lmthang | scaling01 | brickroad7 | jack_w_rae | TheTuringPost | shaneguML | op7418)

AI Agent 프로그래밍 능력 화제, Sama 미완성 프로젝트 자동 완성 가능성 긍정적 평가: OpenAI CEO Sam Altman은 AI 프로그래밍 에이전트(예: Codex)가 80% 진행되었지만 최종적으로 완료되지 않은 프로젝트를 완료하고 자동으로 유지 관리할 수 있을 것이라는 기대감을 표명했습니다. 커뮤니티에서는 다양한 AI 프로그래밍 에이전트(예: Codex, Jules, Claude Code)의 능력을 비교하고 논의했으며, 작업 계획 능력, 가상 머신 환경(예: 네트워크 연결 여부) 및 복잡한 장기 작업에서의 성능 등이 주요 관심사였습니다. AI Agent가 소프트웨어 개발 분야에서 큰 잠재력을 가지고 있다는 데는 대체로 동의하지만, 각 모델은 구체적인 구현과 효과 면에서 여전히 차이가 있습니다. (출처: sama | mathemagic1an)
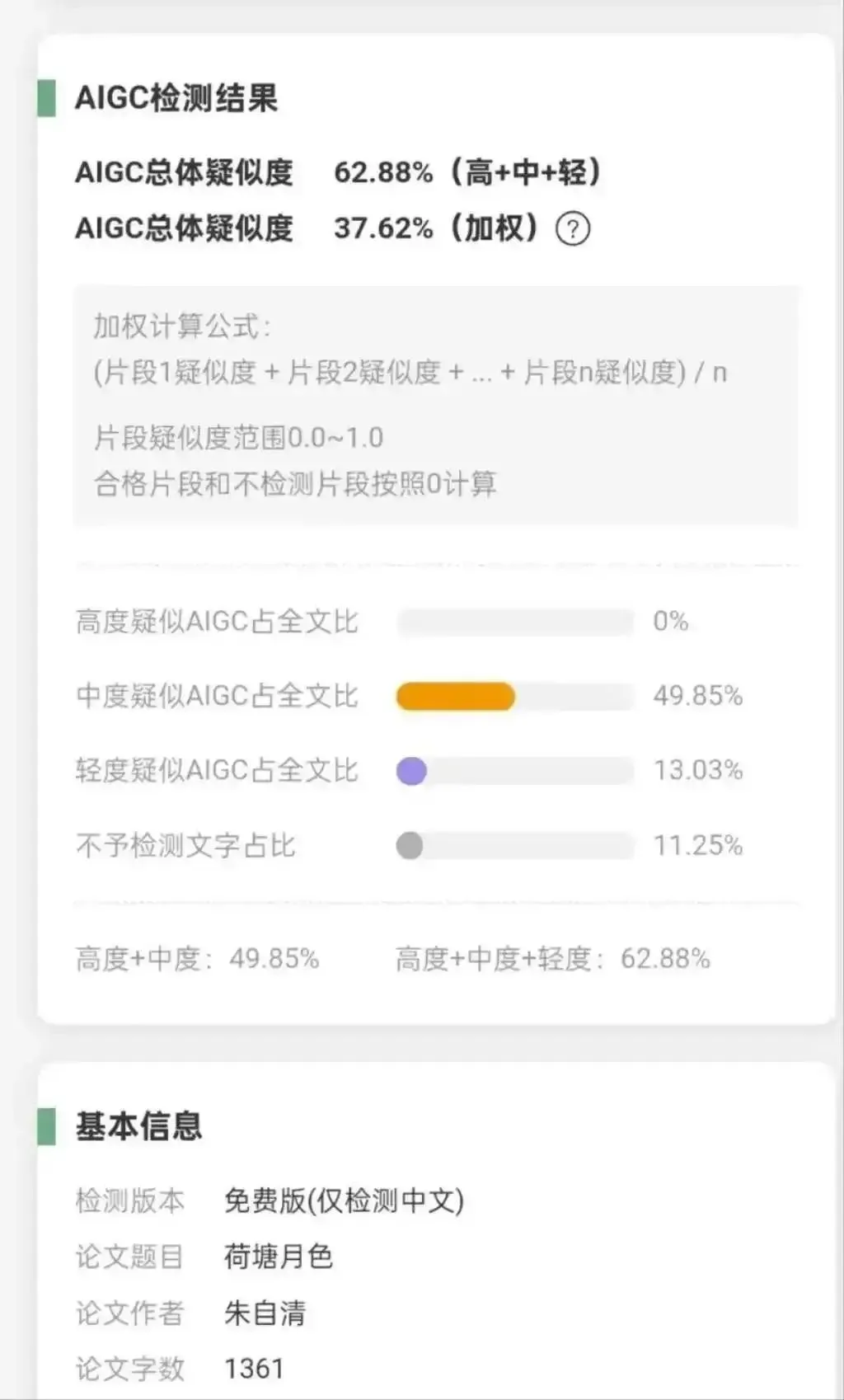
대학, AI 생성 콘텐츠 검사 도입 논란, ‘등왕각서’ AI 생성률 100% 판정: 중국 내 여러 대학이 ‘AI 생성 콘텐츠 검사율’을 논문 심사에 포함시키면서 학생들이 다양한 방법으로 검사를 회피하고, 교사들은 AI 판정과 인공 판단 사이에서 고심하고 있습니다. AI 검사 도구는 데이터베이스 비교와 패턴화된 편견에 의존하기 때문에 고전 작품(예: ‘등왕각서’ AI 생성률 100%, 주자청의 ‘하당월색’ 62.88%) 및 규범적인 학술 작문을 AI 생성으로 오판하는 경우가 많습니다. 이러한 현상은 ‘AI 생성률 낮추기’ 회색 산업을 파생시켰으며, AI 검사 기술의 한계, 학술 평가 기준 및 교육 본질에 대한 심오한 성찰을 불러일으키고 있습니다. (출처: 36氪)
AI 시대에 성장하는 다음 세대의 사고방식 논의: Reddit 커뮤니티에서는 AI 환경에서 성장하는 새로운 세대 어린이들의 사고방식이 이전 세대와 현저히 다를 것이라는 열띤 논의가 있었습니다. 그들은 AI 비서와 상호 작용하는 데 익숙해지고, 학습의 초점은 사실 암기에서 질문하고 시스템을 탐색하는 것으로, 시행착오 학습에서 빠른 반복으로 전환될 수 있습니다. 이러한 기계 논리와의 초기 융합은 그들의 호기심, 기억력, 직관, 심지어 지능 자체에 대한 정의까지 심오하게 재편할 수 있으며, 미래의 신념 형성, 시스템 구축 능력 및 자신의 생각에 대한 신뢰도에 대한 생각을 불러일으킵니다. (출처: Reddit r/ArtificialInteligence)
소프트웨어 엔지니어링 분야 AI의 빠른 발전, 개발자 직업 위기감 유발: 42세, 연봉 15만 달러였던 소프트웨어 엔지니어가 AI 관련 트렌드에 밀려난 후 800개 이상의 이력서를 제출했지만 면접 기회가 거의 없었고, 현재는 배달로 생계를 유지하고 있습니다. 그의 경험은 AI(예: GitHub Copilot, Claude, ChatGPT)가 이미 프로그래머를 대규모로 대체하기 시작했는지에 대한 논의를 불러일으켰습니다. Anthropic CEO는 AI가 대부분의 코드를 생성할 수 있을 것이라고 예측한 바 있습니다. 노동 통계국 데이터는 여전히 소프트웨어 엔지니어링이 가장 빠르게 성장하는 직업 중 하나임을 보여주지만, 기술 업계의 감원 추세는 지속되고 있으며 기업들은 AI를 활용하여 비용을 절감하고 효율성을 높이고 있습니다. 이는 사회가 AI로 인한 구조적 실업 및 “인간+AI” 협업의 새로운 패러다임 구축에 어떻게 대응해야 하는지에 대한 반성을 촉구합니다. (출처: 36氪)

AI 알고리즘의 성 편향 문제: “그녀의 데이터”의 보이지 않는 존재와 부재: 인공지능 발전 과정에서 알고리즘의 성 편향 문제가 점점 더 두드러지고 있습니다. 역사적, 사회적 원인으로 인해 데이터 수집에서 여성 데이터의 대표성이 부족하여(예: 임상 시험, 위키백과 항목), AI가 의료 진단, 콘텐츠 추천 등에서 여성에 대한 편향을 야기할 수 있습니다. 예를 들어, 이미지 인식 시스템은 주방에 있는 남성을 여성으로 잘못 인식하거나 검색 엔진 이미지 결과가 성 고정관념을 강화할 수 있습니다. AI 산업의 성별 구조 불균형도 원인 중 하나로 간주됩니다. 이 문제를 해결하려면 개발자 인식 제고, 여성의 공정한 직업 기회 보장, 법률 및 규정 개선, AI 시스템 성별 감사 메커니즘 구축 및 알고리즘 최적화(예: 데이터 리샘플링, 인과 추론 적용) 등 다방면에서 접근해야 합니다. (출처: 36氪)
AI Agent, SaaS 업계 변혁 논의 촉발: Microsoft CEO 사티아 나델라는 SaaS가 AI Agent 시대에 변혁에 직면할 것이라고 예측했습니다. AI Agent는 자율적인 인식, 의사 결정 및 행동 능력을 바탕으로 SaaS의 맞춤화, 데이터 상호 운용성 및 사용자 경험 측면의 문제점을 해결할 것으로 기대됩니다. 예를 들어, AI Agent는 자연어 상호 작용을 통해 자동으로 워크플로를 생성하고, 여러 애플리케이션의 데이터를 통합하며, 능동적으로 비즈니스 제안을 제공할 수 있습니다. 현재 Salesforce, Microsoft, 용유(用友) 등 SaaS 제조업체들은 이미 AI Agent를 통합하기 시작하여 SaaS를 융합하거나 변혁하는 새로운 모델을 모색하고 있습니다. AI Agent는 기업용 애플리케이션에서 여전히 LLM 능력, 비용 및 데이터 보안 등의 도전에 직면해 있지만, 그 변혁 잠재력은 이미 업계의 광범위한 관심을 끌고 있습니다. (출처: finbarrtimbers)
💡 기타
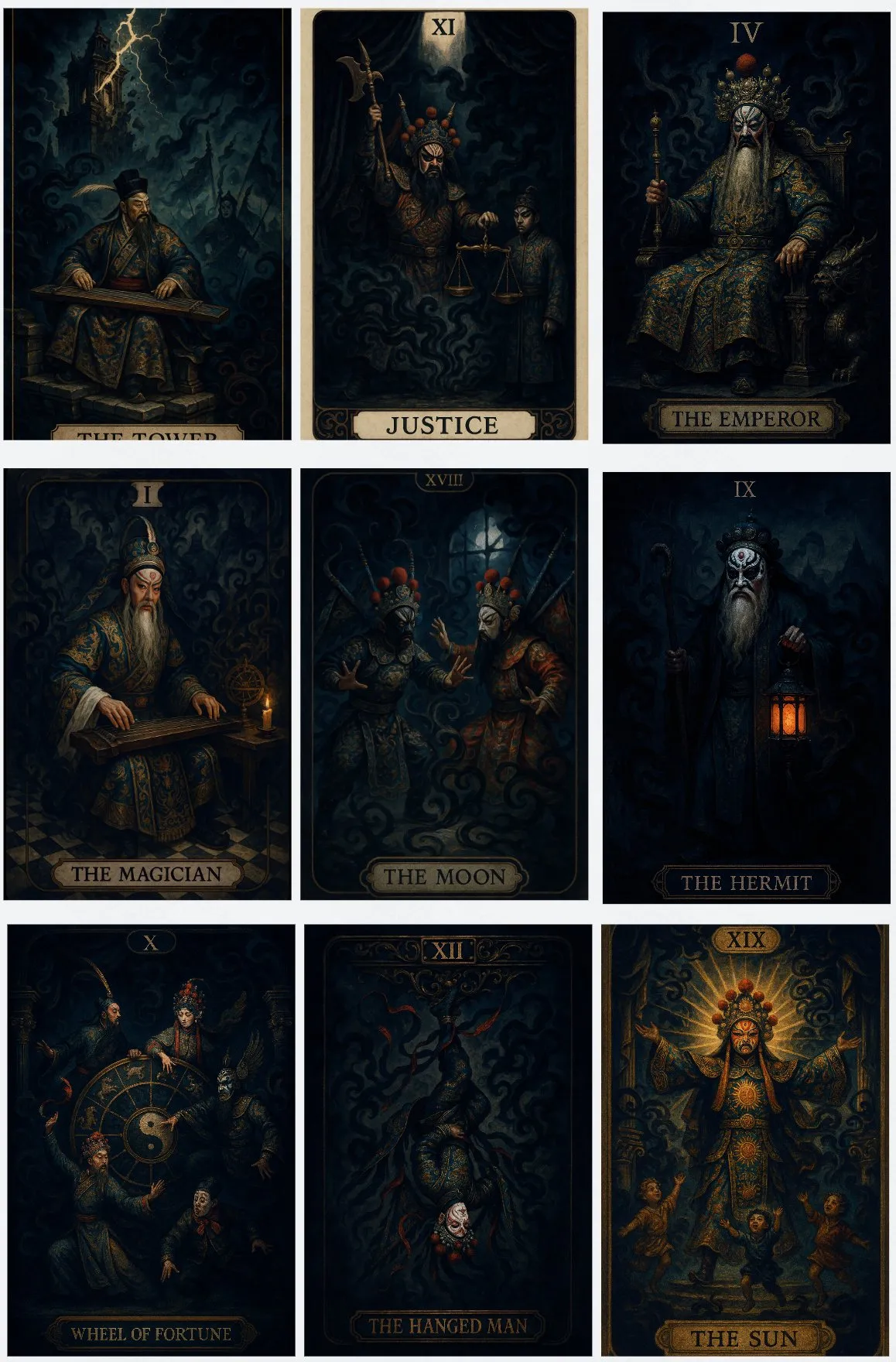
AI, 중국 희곡 스타일 타로 카드 생성: 사용자 @op7418이 AI 도구 Lovart를 사용하여 중국 희곡 스타일의 타로 카드 세트를 창작했습니다. 디자인 컨셉은 전통 희곡 내용과 해당 타로 카드가 표현하는 의미를 결합하는 것으로, AI의 창의적인 디자인 및 문화 융합 분야에서의 응용 잠재력을 보여줍니다. (출처: op7418)
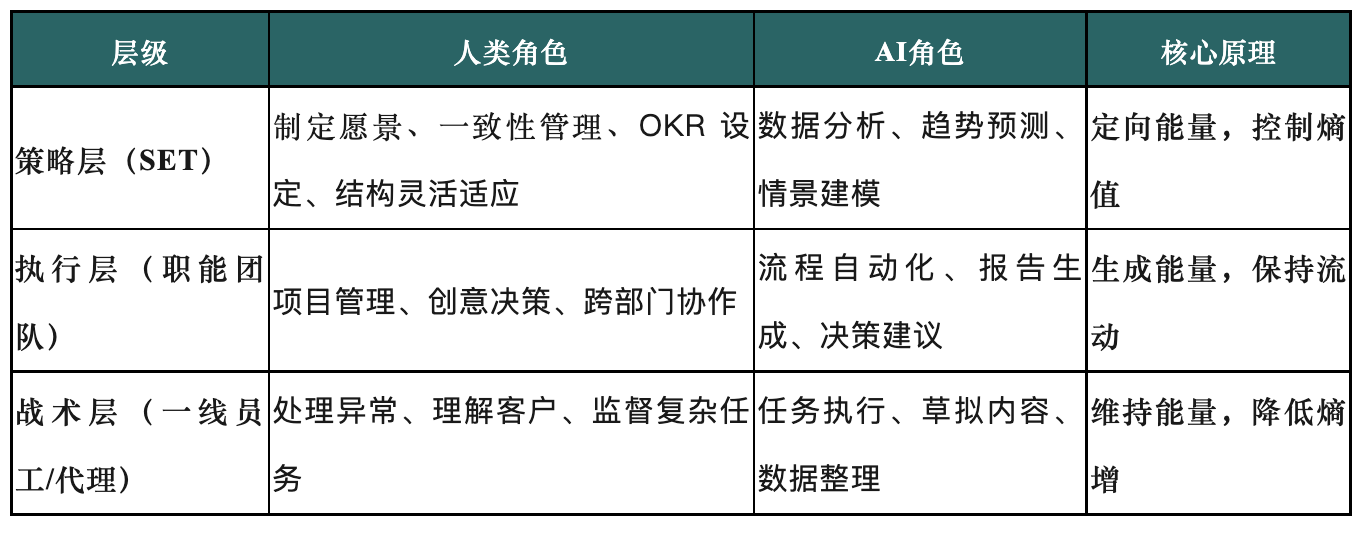
AI 시대 조직 구조 재편: 전략 실행팀(SET)의 부상: 이 글은 AI가 가속화되는 시대에 전통적인 조직 구조가 AI가 가져오는 복잡성에 적응하기 어렵다는 점을 논의합니다. “전략 실행팀(SET)”을 핵심으로 하는 3계층 조직 모델을 제안하며, AI를 팀의 일부로 만들고 합리적인 인간-기계 협업 메커니즘을 통해 민첩한 실행과 지능적인 확장을 실현하는 것을 목표로 합니다. SET는 전략을 부서 간 행동으로 전환하고, 조직 엔트로피를 모니터링하며, 전략을 유연하게 조정하고, 사람, 프로세스 및 AI 에이전트의 협업을 총괄하여 AI 잠재력을 발휘하고 전략 실행을 추진하는 책임을 맡습니다. (출처: 36氪)
크라우드소싱 사실 확인, 소셜 미디어 허위 정보 억제할 수 있을까?: 모하메드 빈 자이드 인공지능 대학교 Preslav Nakov 교수는 Meta가 제3자 사실 확인자를 Community Notes로 대체한 영향을 논의합니다. 그는 Community Notes(X의 Birdwatch에서 유래)와 같은 크라우드소싱 모델이 잠재력이 있다고 생각하지만, 콘텐츠 심사는 자동 필터링, 크라우드소싱, 전문 사실 확인 등 다양한 방법을 결합해야 한다고 주장합니다. 스팸 메일 필터링 및 LLM의 유해 콘텐츠 처리에 비유하며, 각 방법에는 장단점이 있으므로 협력해야 한다고 지적합니다. 연구에 따르면 Community Notes는 전문 사실 확인자의 작업 영향을 확대할 수 있으며, 양측의 관심사는 다르지만 결론은 유사하여 상호 보완적일 수 있습니다. (출처: MIT Technology Review)
