
키워드:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Claude 모델, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Gemini 기반 진화형 코딩 에이전트, 하드웨어-소프트웨어 협력 설계로 대형 모델 비용 절감, 제로샷 음성 복제 기술, 극한 추론 능력, 1.58비트 BitNet 아키텍처
🔥 포커스
DeepMind, AlphaEvolve 출시: Gemini 기반 진화 코딩 에이전트, 알고리즘 발견 촉진 : AlphaEvolve는 Gemini 모델의 창의성과 자동 평가기를 결합하여 진화 프레임워크를 이용해 알고리즘을 최적화합니다. 이는 여러 분야에서 혁신을 이루었는데, 예를 들어 48번의 스칼라 곱셈으로 4×4 복소 행렬 곱셈을 완료하여 Strassen 알고리즘을 개선했고, 11차원 공간에서 593개의 외부 구체 구성을 발견하여 300년 역사의 “키싱 넘버 문제(kissing number problem)”를 발전시켰습니다. 또한 AlphaEvolve는 Google 데이터센터 스케줄링(컴퓨팅 자원 0.7% 절감), 차세대 TPU 설계(중복 비트 제거), AI 모델 훈련(핵심 커널 23% 가속) 등을 최적화했습니다. 필즈상 수상자 테렌스 타오(Terence Tao)도 수학 응용 탐구에 참여했습니다. (출처: DeepMind)

DeepSeek V3 논문 상세 해설: 소프트웨어-하드웨어 공동 설계로 대형 모델 비용 및 전력 소비 절감 : DeepSeek 팀은 DeepSeek-V3가 어떻게 소프트웨어-하드웨어 공동 설계를 통해 대규모 훈련 및 추론의 비용 효율성을 달성하는지 상세히 설명하는 논문을 발표했습니다. 핵심 기술은 다음과 같습니다: 1) 메모리 최적화: 다중 헤드 잠재 어텐션(Multi-head Latent Attention, MLA)을 사용하여 키-값 캐시를 압축하고, FP8 혼합 정밀도 훈련으로 메모리 소비를 줄입니다. 2) 계산 최적화: 전문가 혼합 모델(Mixture-of-Experts, MoE)을 적용하여 일부 매개변수만 활성화하고 FP8 훈련과 결합하여 계산 비용을 크게 절감합니다. 3) 통신 최적화: 다중 평면 팻 트리 네트워크 토폴로지와 이중 마이크로 배치 중첩(DualPipe) 기술을 사용하여 지연 시간을 줄이고 GPU 활용률을 높입니다. 4) 추론 가속화: 다중 토큰 예측(Multi-Token Prediction, MTP) 프레임워크를 도입하여 여러 후보 토큰을 병렬로 예측하고 검증하여 생성 속도를 향상시킵니다. 이 논문은 또한 저정밀도 계산 지원, 확장 및 융합, 네트워크 토폴로지 최적화, 메모리 시스템 최적화, 견고성 및 내결함성을 포함한 미래 AI 하드웨어 설계에 대한 다섯 가지 전망을 제시했습니다. (출처: arXiv)

OpenAI GPT-4.1 모델, ChatGPT에 정식 출시, 사용자 직접 선택 가능 : OpenAI는 GPT-4.1 모델이 ChatGPT에서 사용 가능하다고 발표했습니다. Plus, Pro, Team 사용자는 모델 선택기를 통해 액세스할 수 있으며, 기업 및 교육용 버전 사용자는 추후 권한을 부여받게 됩니다. GPT-4.1 mini도 GPT-4o mini를 대체하여 모든 사용자에게 제공될 예정입니다. GPT-4.1은 코딩 작업 및 지시 사항 준수 능력에서 뛰어난 성능으로 주목받았으며, 이전 API 버전은 최대 100만 Token의 컨텍스트 창을 지원했습니다. 그러나 일부 사용자들이 ChatGPT의 GPT-4.1 버전 컨텍스트 길이가 API 버전의 1M에 미치지 못하고 여전히 128k인 것으로 테스트 결과를 통해 확인하면서 실망감을 표출했습니다. (출처: OpenAI Developers)

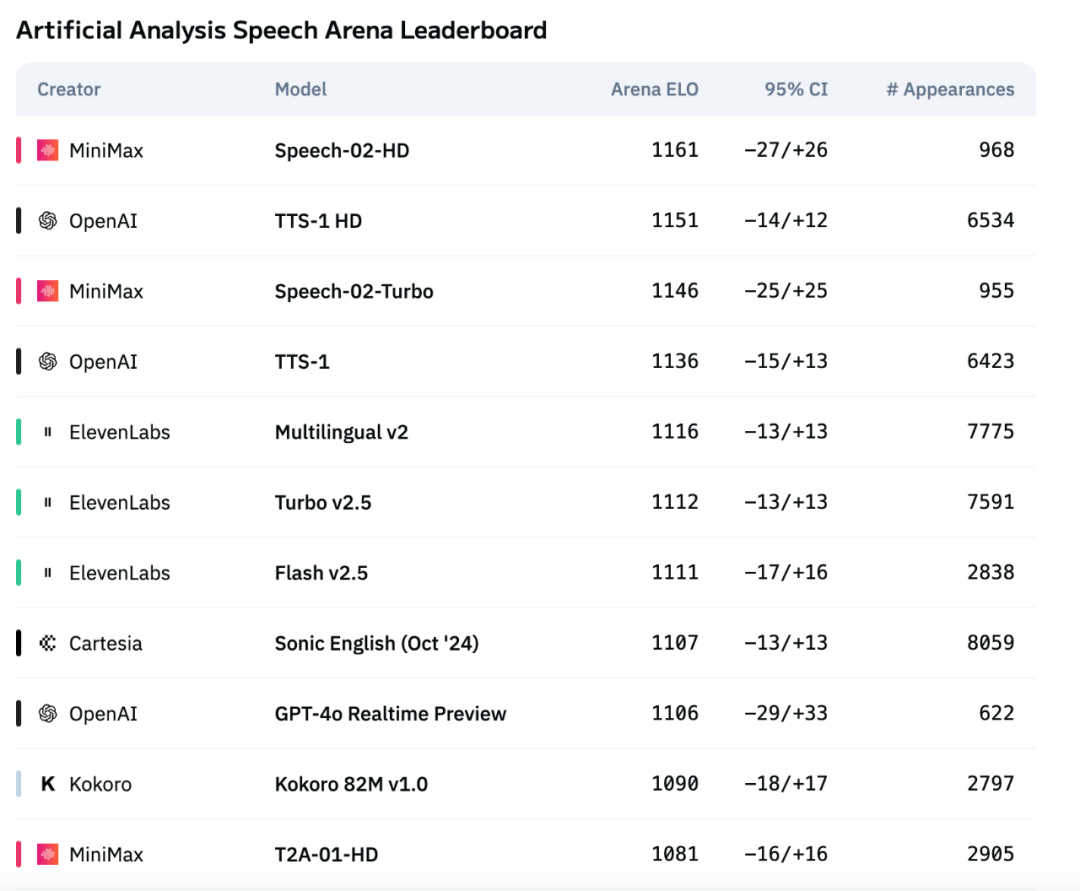
MiniMax 차세대 음성 모델 Speech-02, Artificial Analysis 음성 평가 차트 1위 등극 : MiniMax가 출시한 최신 텍스트 음성 변환(TTS) 모델 Speech-02가 국제적으로 권위 있는 음성 평가 차트 Artificial Analysis Speech Arena에서 OpenAI와 ElevenLabs의 유사 제품을 제치고 최고 ELO 점수를 획득했습니다. 이 모델은 단어 오류율(WER) 및 화자 유사도(SIM)와 같은 주요 지표에서 우수한 성능을 보였으며, 특히 중국어 및 광둥어 처리에서 현지화된 강점을 나타냈습니다. Speech-02의 핵심 혁신은 진정한 제로샷 음성 복제(텍스트 없이 몇 초 분량의 참조 오디오만 필요)를 구현하고 새로운 Flow-VAE 아키텍처를 채택하여 음성 생성의 자연스러움과 감정 표현력을 향상시키고 32개 언어를 지원한다는 점입니다. 비용 또한 ElevenLabs 경쟁 제품의 약 1/4 수준으로 경쟁력이 매우 높습니다. (출처: 机器之心)
🎯 동향
Anthropic 새 버전 Claude 모델, “극한 추론” 능력 갖출 듯 : The Information 보도 및 커뮤니티 관찰에 따르면, Anthropic은 앞으로 몇 주 안에 새로운 버전의 Claude Sonnet 및 Claude Opus 모델을 출시할 가능성이 있으며, 가장 큰 특징은 “극한 추론(Extreme reasoning)” 능력입니다. 이 기능은 모델이 어려운 문제에 직면했을 때 즉시 답을 내놓는 대신 일시 중지하고, 재평가하며, 전략을 조정할 수 있도록 합니다. 코드 생성과 같은 작업에서 모델은 자동으로 오류를 테스트하고 수정할 수 있습니다. 이러한 동적 순환 추론 및 도구 사용 방식은 모델이 복잡한 문제를 더 지능적으로 처리하고, 인간의 감독에 대한 의존도를 줄이며, 인간 협력자의 사고방식에 더 가깝게 만드는 것을 목표로 합니다. 이미 일부 사용자는 Anthropic이 Claude Neptune(또는 Claude 3.8)이라는 이름의 모델을 테스트하고 있으며, 128k tokens 컨텍스트를 지원한다는 사실을 발견했습니다. (출처: 量子位)
TII, Falcon-Edge 시리즈 고효율 Bitnet 모델 및 onebitllms 미세 조정 툴킷 공개 : 기술 혁신 연구소(TII)는 BitNet 아키텍처 기반의 고도로 압축된 언어 모델 시리즈인 Falcon-Edge를 발표했습니다. 이 모델들은 강력하고 범용적이며 미세 조정이 가능한 특징을 가지고 있습니다. 동시에, 이 1.58비트 모델들을 미세 조정하거나 계속 사전 훈련하는 데 사용되는 경량 Python 툴킷인 onebitllms(pip를 통해 설치 가능)를 오픈소스로 공개했습니다. 이는 대형 모델 사용의 장벽을 낮추고 1-bit LLM 기술의 발전과 응용을 촉진하기 위함입니다. (출처: younes)

Hugging Face Transformers 라이브러리 대규모 업그레이드, 모델 정의의 핵심 표준으로 부상 : Hugging Face는 Transformers 라이브러리가 다양한 백엔드 및 실행기 전반에 걸쳐 모델 정의의 핵심 표준이 되기 위한 대대적인 조정을 진행 중이라고 발표했습니다. vLLM, LlamaCPP, SGLang, MLX, DeepSpeed, Microsoft, NVIDIA 등 다수의 생태계 파트너와의 공동 노력을 통해 모델 코드의 표준화를 추진하여 전체 AI 생태계에 더 높은 일관성과 신뢰성을 제공하고자 합니다. 이 조치는 커뮤니티로부터 광범위한 호평을 받으며 오픈소스 AI 발전의 중요한 단계로 평가받고 있습니다. (출처: Arthur Zucker)

Salesforce, Hugging Face에 BLIP3-o 출시: 완전 오픈소스 통합 멀티모달 모델 시리즈 : Salesforce는 완전 오픈소스 통합 멀티모달 모델군인 BLIP3-o 시리즈 모델을 출시했습니다. 이 시리즈는 모델 아키텍처, 훈련 방법 및 데이터셋을 포괄하며, 멀티모달 AI 기술의 발전과 응용을 촉진하는 것을 목표로 합니다. BLIP3-o의 출시는 연구자와 개발자에게 강력한 멀티모달 처리 도구와 리소스를 제공합니다. (출처: AK)

NVIDIA, 합성 데이터 활용한 완전 자율 주행 기술 발전 시연 : NVIDIA는 합성 데이터를 활용하여 완전 자율 주행(FSD) 기술 연구 개발을 가속화하는 방법을 보여주는 새로운 비디오를 공개했습니다. 대규모의 다양한 가상 주행 시나리오와 데이터를 생성함으로써 NVIDIA는 자율 주행 알고리즘을 보다 효율적으로 훈련하고 검증할 수 있으며, 실제 데이터 수집의 한계를 극복하고 자율 주행 기술을 보다 안전하고 신뢰할 수 있는 방향으로 발전시키고 있습니다. (출처: SawyerMerritt)
A-M-team, 32B 추론 모델 AM-Thinking-v1 발표, 일부 성능 DeepSeek-R1 능가 : 중국 연구팀 A-M-team이 Hugging Face에 32B 파라미터의 추론 모델 AM-Thinking-v1을 오픈소스로 공개했습니다. 이 모델은 수학 추론(AIME 시리즈 점수 85.3) 및 코드 생성(LiveCodeBench 점수 70.3)과 같은 작업에서 뛰어난 성능을 보였으며, 이러한 특정 평가에서 DeepSeek-R1(671B MoE)을 능가하고 Qwen3-235B-A22B와 같은 대규모 모델에 근접한 것으로 알려졌습니다. 이 팀은 후훈련 방식(콜드 스타트 SFT, 통과율 기반 데이터 필터링, 2단계 RL 포함)을 통해 32B 밀집 모델의 추론 능력을 최적화하는 데 주력하고 있으며, 제한된 컴퓨팅 및 오픈소스 데이터 조건에서 강력한 추론을 달성하는 경로를 탐색하는 것을 목표로 합니다. (출처: AI科技评论)

Marigold 업데이트: Stable Diffusion 모델을 깊이 추정기로 전환, 단일 단계 추론 및 고해상도 지원 : Marigold 프로젝트가 주요 업데이트를 발표했습니다. 이 기술은 Stable Diffusion 2 모델을 소량의 합성 샘플과 짧은 시간(1 GPU에서 2-3일)의 훈련을 통해 고급 깊이 추정기로 전환할 수 있습니다. 새 버전의 특징으로는 단일 단계 빠른 추론, 새로운 모달리티 지원, 고해상도 출력, Diffusers 라이브러리 지원 및 새로운 데모가 포함됩니다. (출처: Anton Obukhov)
Qwen3 시리즈 모델, 오픈소스 커뮤니티에서 강력한 성과, NVIDIA OpenCodeReasoning의 기반 모델로 채택 : Alibaba의 Qwen3 시리즈 모델이 오픈소스 커뮤니티에서 지속적인 관심과 활용을 얻고 있습니다. NVIDIA가 최근 오픈소스로 공개한 OpenCodeReasoning 시리즈 모델(7B, 14B, 32B 사양 포함)은 Qwen을 기본 기반으로 채택했습니다. Qwen3는 완벽한 버전, 지속적인 업데이트, 혼합 추론 모드에 대한 네이티브 지원 및 번성하는 생태계(전 세계 다운로드 3억 건 초과, 파생 모델 10만 개 초과)로 개발자들의 선호를 받고 있습니다. 최근 업데이트에는 단말기용 멀티모달 모델 Qwen-omini 3B, Unsloth와의 협력을 통한 미세 조정 효율 향상, 상세 배포 하이퍼파라미터 권장 사항 발표, 웹 페이지 실시간 미리보기 생성 지원, 다양한 양자화 버전 제공 및 기술 보고서 발표 등이 포함됩니다. (출처: AI前线)
Hugging Face Accelerate v1.7.0 출시, 지역 컴파일 및 FSDPv2용 QLoRA 지원 : Hugging Face Accelerate v1.7.0 버전이 정식 출시되었습니다. 이번 버전의 주요 특징은 다음과 같습니다: @IlysMoutawwakil이 구현한 지역 컴파일(Regional compilation)로 컴파일 효율성과 유연성 향상; @RisingSayak이 기여한 계층별 캐스팅 후크(Layerwise casting hook)로, 이는 diffusers 라이브러리에서 널리 사용되는 기능입니다; 그리고 @winglian이 구현한 FSDPv2용 QLoRA 지원으로 대규모 모델 훈련을 더욱 최적화합니다. (출처: Marc Sun)

Llamafile 0.9.3 출시, Qwen3 및 Phi4 모델 지원 추가 : Llamafile이 0.9.3 버전을 출시했습니다. 이번 업데이트에서는 최근 인기 있는 Qwen3 시리즈와 Phi4 시리즈 모델에 대한 지원이 추가되었습니다. Llamafile은 모델 가중치와 실행에 필요한 코드를 단일 실행 파일로 패키징하여 여러 운영 체제에서 편리하게 배포할 수 있도록 함으로써 LLM 애플리케이션 배포 및 실행을 단순화하는 데 주력하고 있습니다. (출처: Phoronix)
텐센트, HunyuanImage 2.0 이미지 대형 모델 출시 : 텐센트가 HunyuanImage 대형 모델의 새 버전인 HunyuanImage 2.0을 정식 출시했습니다. 이번 업데이트는 이미지 생성 품질, 제어 가능성 및 복잡한 지침에 대한 이해 능력 향상에 중점을 둘 것으로 예상됩니다. 구체적인 기술 세부 정보 및 개선 사항은 공식 채널을 통해 확인할 수 있습니다. (출처: Hunyuan)

Ollama v0.7 출시, 로컬 대형 모델 실행 경험 향상 : Ollama가 v0.7 버전을 출시하며 로컬 장치에서 대형 언어 모델 실행 과정을 단순화하는 데 지속적으로 노력하고 있습니다. 새 버전에는 성능 최적화, 새로운 모델 지원 또는 사용자 경험 개선이 포함될 수 있습니다. 사용자는 공식 웹사이트나 GitHub에서 자세한 업데이트 로그 및 다운로드를 확인할 수 있습니다. (출처: ollama)
llama.cpp, PDF 입력 기능 통합, PDF 문서 직접 처리 지원 : llama.cpp 프로젝트가 최근 PDF 파일 직접 입력 지원을 추가하는 중요한 업데이트를 통합했습니다. 이는 사용자가 이제 PDF 문서 내용을 입력으로 더 편리하게 사용하여 llama.cpp 기반 로컬 대형 언어 모델로 처리, 분석 또는 질의응답을 수행할 수 있게 되어 응용 범위를 확장했음을 의미합니다. 이 기능은 내장 웹 프론트엔드에서 외부 JS 패키지를 통해 구현되어 핵심 유지 관리 부담을 늘리지 않습니다. (출처: GitHub)
Microsoft Copilot, 4o 이미지 생성 기능 탑재, 시각 효과 및 텍스트 일관성 향상 : Microsoft AI 비서 Copilot에 OpenAI의 GPT-4o 모델의 이미지 생성 기능이 통합되었습니다. 이번 업데이트는 더 선명한 시각 효과, 더 일관된 텍스트 생성 기능을 제공하고, 사진 수준의 사실적인 스타일부터 재미있는 만화 스타일까지 다양한 스타일을 지원하는 것을 목표로 합니다. 사용자는 Copilot을 통해 4o 기반의 이미지 생성 기능을 경험할 수 있습니다. (출처: yusuf_i_mehdi)

NVIDIA DRIVE Labs, 지도 없는 주행의 미래 논의, 고정밀 지도 의존도 감소 : NVIDIA DRIVE Labs의 최신 비디오는 지도 없는 주행(mapless driving)의 미래를 논의합니다. 고정밀 지도는 자율 주행에 매우 중요하지만, 비용 및 유지 관리 문제로 인해 배포가 제한됩니다. NVIDIA는 정보 병목 현상 제거, 작업 정확도 향상, 모델 훈련 및 추론 시간 단축과 같은 혁신을 통해 고정밀 지도에 대한 의존도를 줄이고 자율 주행 기술의 경계를 넓히고 있습니다. (출처: NVIDIA DRIVE)
Dolphin 3.2 (Qwen3 기반 훈련), 시스템 프롬프트 스위치 제공으로 사용자 제어 강화 : Qwen3를 기반으로 훈련된 곧 출시될 Dolphin 3.2 모델은 /no_think (불필요한 사고 단계 감소 가능성), /uncensored (콘텐츠 검열 감소 가능성), /china (중국 특정 컨텍스트 또는 서비스 대상 가능성)의 세 가지 시스템 프롬프트 스위치를 도입할 예정입니다. 이러한 스위치는 사용자에게 모델 배포에 대한 더 큰 소유권과 제어권을 부여하는 것을 목표로 합니다. (출처: cognitivecompai)

🧰 툴
Runway, 참조 기능 출시, 특정 기술 또는 스타일 학습하여 새 창작물에 적용 가능 : Runway는 “References”라는 새로운 기능을 추가했습니다. 이 기능을 통해 사용자는 플랫폼에 특정 기술이나 예술적 스타일을 제시한 다음 이를 참조로 사용하여 새로운 생성 콘텐츠에 적용할 수 있습니다. 이 기능은 사용자에게 더욱 세밀한 스타일 제어 능력을 제공하여 AI 보조 창작을 더욱 개인화되고 구체적으로 만듭니다. 사용자 Cristobal Valenzuela는 커뮤니티가 이 기능을 사용한 독창적인 사례를 공유하도록 장려하는 공모전을 시작했으며, 가장 창의적인 5개 사례에 대해 1년 무료 Unlimited 요금제를 제공할 예정입니다. (출처: c_valenzuelab)

DSPy: 빠른 반복을 위해 탄생한 극도로 단순한 LLM 프로그래밍 프레임워크 : DSPy 프레임워크는 극도로 단순한 설계로 주목받고 있으며, 개발자들은 핵심 기능(Module 또는 Optimizer) 대부분이 단 한 줄의 코드로 구현될 수 있어 사용자가 아이디어를 빠르게 시도하고 반복하는 데 도움이 된다고 말합니다. 많은 상용구 코드와 복잡한 개념을 필요로 하는 일부 도구와 달리 DSPy는 사용 편의성과 효율성을 강조합니다. 사용자 피드백에 따르면 입문 문서를 읽으면 빠르게 시작할 수 있으며, SOTA 모델을 사용하여 순환 최적화를 수행하면 비용이 발생할 수 있지만 단시간 내에 이 프레임워크를 활용하여 모델을 최적화할 수 있다고 합니다. (출처: lateinteraction)
Unsloth AI, TTS 및 오디오 모델 미세 조정으로 확장, 속도 향상 및 VRAM 사용량 감소 : Unsloth AI는 자사의 최적화 기술이 이제 텍스트 음성 변환(TTS) 및 오디오 모델의 미세 조정을 지원한다고 발표했습니다. 사용자는 무료 Colab 노트북을 사용하여 Sesame-CSM, OpenAI Whisper와 같은 모델을 훈련, 실행 및 저장할 수 있습니다. Unsloth는 자사 기술이 TTS 훈련 속도를 1.5배 향상시키고 동시에 VRAM 사용량을 50% 줄일 수 있다고 주장합니다. 관련 문서와 Colab 노트북은 공식 웹사이트에서 제공됩니다. (출처: Unsloth AI)
Modal, 아마존 3천만 개 리뷰 임베딩 작업 지원, L40S GPU로 시간 단위 처리 실현 : Modal 플랫폼은 L40S GPU에서 대규모 임베딩 작업을 수평적으로 확장 처리하는 능력을 선보였습니다. 한 시연 사례를 통해 Modal은 아마존 3천만 개 리뷰의 임베딩 처리를 한 시간 내에 성공적으로 완료했습니다. 이는 Modal 팀이 업데이트한 확장 가능한 생성 시스템 덕분으로, 대규모 병렬 처리가 더욱 간단하고 효율적으로 이루어졌습니다. (출처: charles_irl)

Lovart AI: 여러 최상위 모델을 통합한 신흥 AI 시각 디자인 에이전트 : Lovart라는 AI 시각 디자인 에이전트가 주목받고 있습니다. 자연어 지시를 통해 포스터, 브랜드 VI, 스토리보드 등 전문적인 시각 디자인 작업을 완료할 수 있습니다. Lovart의 핵심 능력은 GPT image-1, Flux pro, OpenAI-o3, Gemini Imagen 3, Kling AI, Tripo AI, Suno AI 등 다양한 최상위 모델을 통합하고, 전문적인 편집 도구(레이어, 마스크, 텍스트 미세 조정 등)를 내장하여 이미지와 텍스트 분리 및 레이어별 편집을 지원하는 다중 모델 융합 스케줄링에 있습니다. 이 제품은 Liblib 해외 자회사가 독립적으로 운영하며, 원스톱, 고도의 제어 가능한 AI 디자인 경험을 제공하는 것을 목표로 합니다. (출처: 量子位)
OpenHands 0.38.0 출시: 네이티브 Windows 지원 및 Chrome 확장 프로그램으로 사용 편의성 향상 : OpenHands가 0.38.0 버전을 출시하며 여러 중요한 업데이트를 선보였습니다. 여기에는 네이티브 Windows 지원(WSL 불필요)으로 Windows 사용자 편의성 증대, 브라우저 스크린샷 기능, 그리고 더욱 유연한 샌드박스 사용자 정의 기능이 포함됩니다. 또한, 사용자가 GitHub에서 한 번의 클릭으로 OpenHands를 시작할 수 있도록 하는 Chrome 확장 프로그램도 출시되어 작업 흐름을 더욱 단순화했습니다. (출처: All Hands AI)
Tensorlake Cloud 출시, 문서 추출 및 워크플로우 구축 능력 향상 : Tensorlake는 Tensorlake Cloud 출시를 발표하며, 에이전트 애플리케이션 구축 및 복잡한 비즈니스 워크플로우 지원을 위해 문서 추출 및 워크플로우를 최적화하는 것을 목표로 합니다. 이 플랫폼은 고급 문서 레이아웃 이해 모델(ACORD 양식, 은행 명세서, 연구 보고서 등 실제 데이터로 훈련됨)과 테이블 추출 모델을 활용하여 비정형 문서를 깨끗하고 구조화된 데이터로 변환하며, 특히 시각 언어 모델(VLM)이 이 분야에서 부족한 복잡하고 밀집된 테이블 처리에 적합합니다. (출처: Tensorlake)
Patronus AI, Percival 출시: AI 에이전트 디버깅 및 개선 전용 에이전트 : Patronus AI는 AI 에이전트 디버깅 및 개선을 위해 특별히 설계된 AI 에이전트인 새로운 도구 Percival을 출시했습니다. Percival은 복잡한 에이전트 추적 기록을 즉시 분석하고, 최대 60가지의 다양한 오류 모드를 식별하며, 성능 향상을 위해 프롬프트 수정 방안을 자동으로 제안할 수 있습니다. 이 도구는 “컨텍스트 폭발”(에이전트가 수백만 개의 토큰을 처리하는 경우)과 같은 주요 과제를 해결하고, 특정 사용 사례에 대한 도메인 적응 및 복잡한 다중 에이전트 오케스트레이션을 지원합니다. (출처: Weaviate Podcast)

Replit, Semgrep 통합으로 “안전한 분위기 프로그래밍” 구현, 취약점 자동 스캔 : Replit은 Semgrep과의 협력을 통해 “안전한 분위기 프로그래밍(Safe Vibe Coding)” 기능을 출시한다고 발표했습니다. 이제 사용자가 Replit에서 코드를 배포할 때마다 Semgrep이 자동으로 보안 스캔을 실행하여 잠재적인 취약점을 발견하고 수정하며, API 키와 같은 민감한 정보가 실수로 노출되는 것을 방지합니다. 이 조치는 AI 보조 코딩(예: LLM을 통해 코드 생성) 사용 시 보안을 강화하는 것을 목표로 합니다. (출처: amasad)

Cursor AI 0.50 버전 출시, 대규모 업데이트 예고 : AI 보조 프로그래밍 도구 Cursor가 “역대 최대 규모의 버전 업데이트”로 불리는 0.50 버전을 출시했습니다. 새 버전에는 개발자의 코딩 효율성과 AI 협업의 유연성을 더욱 향상시키기 위한 여러 기능 향상 및 경험 최적화가 포함될 것으로 예상됩니다. 구체적인 업데이트 내용은 공식 출시 노트를 통해 확인할 수 있습니다. (출처: eric zakariasson)

OpenMemory MCP: 애플리케이션 간 컨텍스트 공유를 지원하는 로컬화된 메모리 관리 서버 : OpenMemory MCP는 AI 애플리케이션 생산성 향상을 목표로 하는 메모리 관리 서버입니다. 사용자가 Cursor 및 Claude Desktop과 같은 다양한 애플리케이션 간에 컨텍스트를 공유하고 PostgreSQL 및 Qdrant를 활용하여 로컬에 데이터를 저장하고 인덱싱하여 데이터 개인 정보를 보장할 수 있도록 합니다. 이 도구는 시맨틱 검색을 지원하고 메모리 및 애플리케이션 액세스를 관리하기 위한 대시보드를 제공하여 세션 간 컨텍스트 손실 문제를 해결합니다. (출처: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint, vLLM 및 Gradio 결합으로 빠른 Whisper 전사 구현 : Hugging Face는 Inference Endpoint 서비스와 vLLM 프로젝트 및 Gradio 인터페이스를 결합하여 OpenAI의 Whisper 모델을 배포함으로써 매우 빠른 음성 전사 기능을 구현하는 방법을 시연했습니다. 이 조합은 AI 커뮤니티의 오픈소스 도구를 활용하여 사용자에게 효율적이고 사용하기 쉬운 음성-텍스트 변환 솔루션을 제공합니다. (출처: Morgan Funtowicz)
A.I.T.E Ball: Orange Pi 및 Gemma 3 1B 기반의 자체 내장형 AI 매직 8볼 : 개발자가 완전히 자체 내장형(네트워크 연결 불필요) AI 기반 매직 8볼 프로젝트인 A.I.T.E Ball을 선보였습니다. 이 장치는 Orange Pi Zero 2W에서 실행되며, whisper.cpp를 사용하여 텍스트 음성 변환을 수행하고 llama.cpp를 사용하여 Gemma 3 1B 모델을 실행하여 질의응답을 수행합니다. 이는 저전력 하드웨어에서 로컬화된 AI 애플리케이션을 구현할 수 있는 잠재력을 보여줍니다. (출처: Reddit r/LocalLLaMA)

OWL Agent: MCPToolkit을 통합한 오픈소스 범용 에이전트 : 오픈소스 OWL 에이전트 프로젝트에 MCPToolkit 지원이 내장되었습니다. 사용자는 Playwright, desktop-commander 등 MCP 서버 또는 사용자 정의 Python 도구에 쉽게 연결할 수 있으며, OWL은 다중 에이전트 워크플로우에서 이러한 도구를 자동으로 발견하고 호출하여 범용성과 작업 실행 능력을 향상시킵니다. (출처: Reddit r/LocalLLaMA)

ElevenLabs, SB-1 무한 사운드보드 출시: 사운드 효과, 드럼 머신, 환경 소음 생성 기능 통합 : ElevenLabs가 SB-1 무한 사운드보드를 출시했습니다. 이는 사운드보드, 드럼 머신, 무한 환경 소음 생성기를 하나로 통합한 도구입니다. 사용자가 원하는 사운드 효과를 설명하면 SB-1이 텍스트-음향 효과(Text-to-SFX) 모델을 사용하여 해당 사운드를 생성하여 오디오 제작에 새로운 가능성을 제공합니다. (출처: ElevenLabs)
Anytop 프로젝트: AI 애니메이션의 새로운 진전, 미지의 생명체를 생생하게 구현, 동작 학습 및 이전 지원 : Two Minute Papers는 Anytop 프로젝트를 소개했습니다. 이 AI 애니메이션 기술은 이전에 본 적 없는 생물(공룡, 기이한 곤충 등 포함)에 대해 사실적인 동작을 생성할 수 있습니다. 이 AI는 독립적으로 동작을 생성할 수 있을 뿐만 아니라, 서로 다른 생물이 서로의 동작을 학습하고 적응하도록 할 수 있습니다(예: 공룡이 플라밍고처럼 한 다리로 서는 것을 학습). 신체 부위의 의미론적 유사성(예: 팔, 다리의 일반적인 개념)을 이해함으로써 미지의 형태에 대한 일반화를 실현합니다. 또한 이 시스템은 동작의 의미(예: 공격, 휴식)를 이해하고, 서로 다른 동물 간에 유사한 개념의 동작을 보여주며, 불완전한 입력 동작을 보완할 수도 있습니다. (출처: )

Sketch2Anim: AI가 간단한 스케치를 완전한 3D 애니메이션으로 변환 : Two Minute Papers가 소개한 또 다른 기술인 Sketch2Anim은 사용자가 그린 간단한 선 스케치(동작 경로 표시)를 완전한 3D 캐릭터 애니메이션으로 변환할 수 있습니다. 이 AI는 2D 스케치 뒤에 숨겨진 3D 의도(예: 앞으로 펀치를 날리는 것과 옆으로 펀치를 날리는 것을 구분)를 이해할 수 있어, 이전의 유사 기술이 2D 수준에서만 지시를 이해했던 한계를 해결하고 비전문가도 간단한 그림을 통해 빠르게 3D 애니메이션을 만들 수 있도록 합니다. (출처: )
📚 학습
DeepSeek, V3 모델 논문 발표, 확장 과제 및 AI 하드웨어 아키텍처에 대한 고찰 공유 : DeepSeek 팀이 Hugging Face에 DeepSeek-V3 모델에 관한 논문을 발표했습니다. 이 논문은 대형 언어 모델 확장 과정에서 직면한 과제를 심층적으로 탐구하고, 미래 AI 하드웨어 아키텍처 발전 방향에 대한 고찰과 견해를 제시했습니다. 이는 연구자와 개발자가 대규모 모델 훈련 및 배포의 병목 현상을 이해하고, 하드웨어와 소프트웨어 협력 최적화를 통해 이를 해결하는 데 유용한 참고 자료를 제공합니다. (출처: Adina Yakup)
무료 모델 컨텍스트 프로토콜(MCP) 과정 공개, 외부 데이터 및 도구를 활용한 AI 애플리케이션 구축 지원 : Ben Burtenshaw가 무료 MCP(Model Context Protocol) 과정 출시를 발표했습니다. 이 과정은 학습자가 입문부터 숙달까지 MCP의 작동 원리, LLM을 MCP 서버에 연결하는 방법, MCP를 사용하여 AI 에이전트 애플리케이션을 배포하는 방법을 이해하도록 돕고, 이를 통해 외부 데이터와 도구를 활용하여 AI 애플리케이션의 능력을 향상시키는 것을 목표로 합니다. (출처: Ben Burtenshaw)

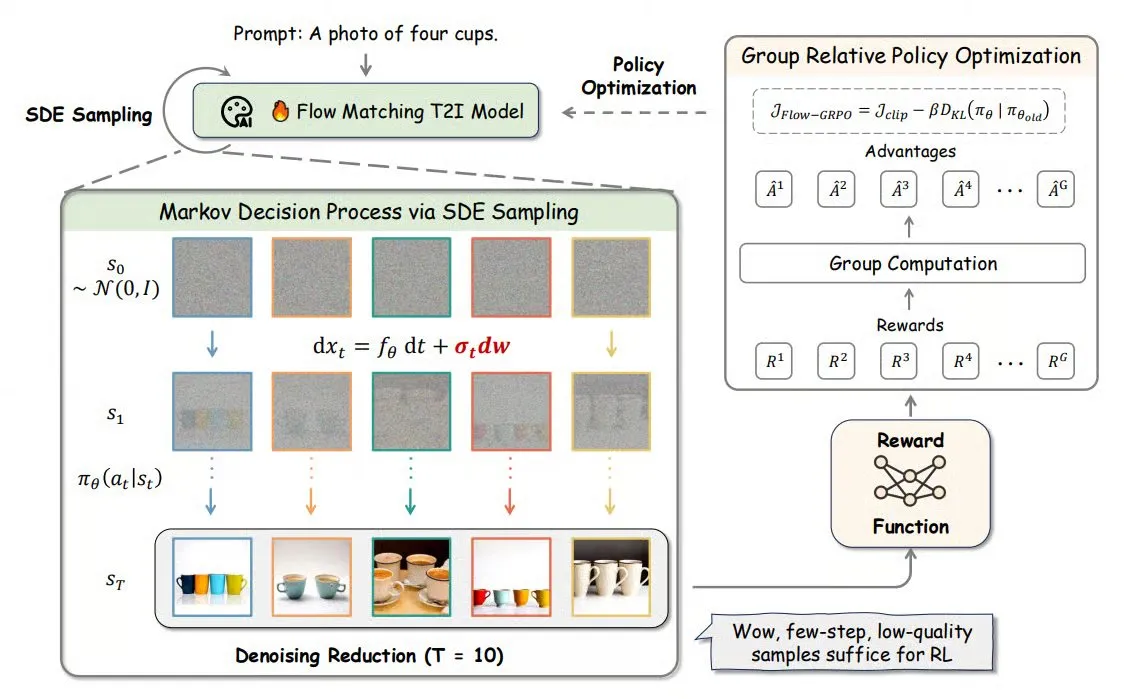
Flow-GRPO: 온라인 강화 학습을 플로우 매칭 모델에 도입하여 이미지 생성 정확도 향상 : Flow-GRPO는 온라인 강화 학습(RL)을 플로우 매칭 모델에 처음으로 적용한 새로운 방법입니다. 이는 두 가지 혁신적인 전략을 통해 구현됩니다: 1) ODE에서 SDE로 변환: 플로우 모델의 상미분 방정식(ODE) 기반 결정론적 프로세스를 확률 미분 방정식(SDE)으로 변환하여 RL에 필요한 무작위성을 도입합니다. 2) 노이즈 제거 축소를 통한 훈련 가속화: 훈련 시 노이즈 제거 단계를 줄이고, 추론 시 전체 단계를 사용합니다. Flow-GRPO를 통해 플로우 모델은 이미지 생성 작업에서 정확도를 92% 이상으로 향상시켰습니다. (출처: TheTuringPost)
ICML 2025 논문 PENCIL: 교차 “추론-삭제”로 대형 모델 심층 사고의 새로운 패러다임 구현 : 토요타 공업대학 시카고 캠퍼스의 양천샤오(杨晨晓) 등이 PENCIL(Pondering with Erasure Net for Contextual Inference Learning)을 제안했습니다. 이는 중간 결과를 교대로 “생성”하고 “삭제”함으로써 대형 모델의 심층 사고를 구현하는 새로운 패러다임입니다. 이 방법은 논리학의 재작성 규칙과 함수형 프로그래밍의 메모리 관리를 차용하여 더 이상 필요하지 않은 중간 단계를 동적으로 삭제함으로써, 기존의 긴 CoT(사고의 연쇄)가 직면한 컨텍스트 창 초과, 정보 검색 어려움, 생성 효율 저하 등의 문제를 효과적으로 해결합니다. 이론적으로 PENCIL은 최적의 공간 및 시간 복잡도로 임의의 튜링 기계 연산을 시뮬레이션하여 모든 계산 가능한 문제를 해결할 수 있음을 증명했습니다. 실험 결과, 3-SAT, QBF, 아인슈타인 퍼즐과 같은 작업에서 PENCIL이 기존 CoT보다 현저히 우수한 성능을 보였습니다. (출처: 机器之心)

ICML 2025 논문 MemVR: 인간의 “두 번 보기” 메커니즘을 모방하여 멀티모달 대형 모델의 환각 완화 : 홍콩과기대(광저우) 등 기관 연구자들이 MemVR(Memory-space Visual Retracing) 방법을 제안했습니다. 이는 불확실한 기억에 대해 인간이 이차적으로 확인하는 전략을 모방하여 멀티모달 대형 언어 모델(MLLM)의 환각 문제를 완화합니다. MemVR은 시각적 토큰을 보충 증거로 사용하여, 모델 추론 시 망각으로 어려움을 겪는 중간 계층에서 피드포워드 네트워크(FFN)를 통해 시각적 지식을 다시 “검색”하여 예측을 보정합니다. 이 방법은 서로 다른 계층 출력의 불확실성에 따라 트리거 계층을 선택하는 동적 트리거 메커니즘을 설계했습니다. 실험 결과, MemVR은 여러 환각 평가 벤치마크 및 일반 벤치마크에서 모두 현저한 효과를 보였으며, 다른 방법에 비해 효율성 우위를 나타냈습니다. (출처: PaperWeekly)

SIGIR 2025 논문 PaRT: 개인화된 실시간 검색으로 능동적 소셜 챗봇 경험 향상 : 중국과학기술대학 등 기관에서 PaRT(Proactive Social Chatbots with Personalized Real-time ReTreival) 방법을 제안했습니다. 이는 개인화된 동기 부여와 의도 인식 기반의 질의 재작성 및 실시간 검색을 결합하여 능동적 소셜 챗봇의 대화 경험을 향상시키는 것을 목표로 합니다. PaRT 시스템은 개인화된 사용자 프로필 구축, 의도 인식 및 질의 재작성, 실시간 검색 강화 생성의 세 가지 모듈로 구성됩니다. 사용자 관심사와 대화 맥락에 따라 능동적으로 화제를 시작하거나 전환하여 더 자연스럽고 정보가 풍부한 응답을 제공할 수 있습니다. 오프라인 실험과 온라인 A/B 테스트 모두 이 방법이 응답의 개인화, 풍부함 및 평균 대화 시간을 효과적으로 향상시킬 수 있음을 보여주었습니다. (출처: PaperWeekly)
ICML 2025 논문 PreSelect: 예측 강도 기반의 효율적인 사전 훈련 데이터 필터링 방안 : 홍콩과기대와 vivo AI Lab이 PreSelect 데이터 필터링 방법을 제안했습니다. 이는 “예측 강도(Predictive Strength)” 개념을 도입하여 데이터가 특정 능력에 대한 모델 기여도를 정량화합니다. 이 방법은 서로 다른 모델의 벤치마크 테스트 점수 순위와 데이터에 대한 Loss 순위의 일관성을 이용하여 데이터 가치를 평가하고, 경량의 fastText 분류기를 사용하여 점수를 근사적으로 매겨 대규모 데이터의 효율적인 필터링을 실현합니다. 실험 결과, PreSelect는 데이터 효율성을 10배 향상시키고, 필터링된 데이터로 모델을 훈련할 때 여러 기준선 방법보다 현저히 우수한 효과를 보였으며, 더 광범위한 고품질 콘텐츠 소스를 포괄하고 샘플 길이 편향을 줄였습니다. (출처: 量子位)

AI Evals 과정, 12명의 게스트 초청하여 평가 프레임워크 및 실무 공유 : Hamel Husain이 주최하는 AI Evals 과정에 inspect 프레임워크 개발자 JJ Allaire, Modal 개발자 애드보킷 Charles Frye 등 12명의 객원 강사진이 발표되었습니다. 이 과정은 평가 프레임워크, 사용자 정의 주석 애플리케이션 생성, 모델 평가 실무 등 AI 평가의 다양한 측면을 심층적으로 다루며, 수강생들이 AI 시스템 성능 평가의 핵심 기술과 도구를 습득하도록 돕는 것을 목표로 합니다. (출처: Hamel Husain)

FedRAG 튜토리얼 공개: RAG 시스템 구축 및 미세 조정을 위한 입문 가이드 : FedRAG 프로젝트가 사용자가 라이브러리를 빠르게 시작할 수 있도록 돕기 위해 새로운 튜토리얼 노트북과 함께 제공되는 비디오를 공개했습니다. 튜토리얼은 Hugging Face 통합을 사용하여 RAG 시스템을 구축하고, 메모리 내 지식 베이스를 사용하여 노드를 저장하고, SentenceTransformer(Dragon+)를 검색기로 정의하고, 사전 훈련된 모델(예: Qwen2.5-0.5B)을 생성기로 정의하며, LSR 및 RALT 훈련기를 사용하여 검색기와 생성기를 중앙 집중식으로 미세 조정하는 방법을 시연합니다. (출처: nerdai)

LlamaIndex, LlamaExtract에서 참조 및 추론 구현 튜토리얼 공개 : LlamaIndex 팀은 @tuanacelik이 제작한 최신 코드 연습을 공개하여 LlamaExtract에서 참조 및 추론 기능을 구현하는 방법을 선보였습니다. 튜토리얼 내용에는 LLM에게 복잡한 데이터 소스에서 무엇을 추출해야 하는지 알려주는 사용자 정의 스키마 정의 방법과 참조 추가 방법이 포함됩니다. 이 기능은 사용자가 방대한 소스 문서에서 구조화된 정보를 정확하고 근거 있게 추출할 수 있는 다단계 AI 에이전트를 구축하는 데 도움을 주기 위해 설계되었습니다. (출처: LlamaIndex 🦙)
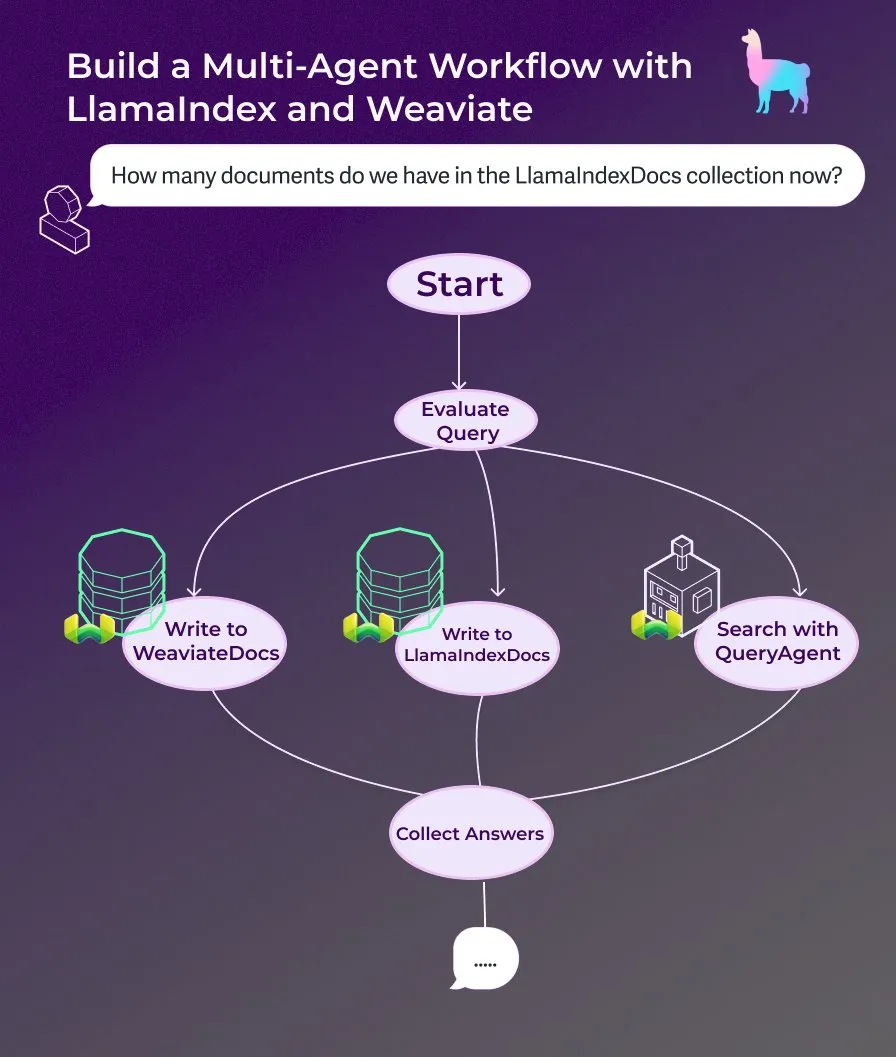
LlamaIndex, 이벤트 기반 에이전트 워크플로우를 사용한 다중 에이전트 문서 도우미 구축 튜토리얼 공개 : LlamaIndex는 이벤트 기반 에이전트 워크플로우를 사용하여 다중 에이전트 문서 도우미를 구축하는 방법을 보여주는 새로운 연습 튜토리얼을 공개했습니다. 이 도우미는 웹 페이지 콘텐츠를 LlamaIndexDocs 및 WeaviateDocs 컬렉션에 작성하고, 오케스트레이터를 사용하여 Weaviate QueryAgent를 호출하여 검색 및 집계할 시기를 결정하고, 구조화된 출력을 사용하여 쿼리를 분류하며, 선택적으로 FunctionAgent를 사용할 수 있습니다. (출처: LlamaIndex 🦙)
Modular, Mojo 컴파일러 내부 기술 강연 공개, Mojo와 GPU 아키텍처 논의 : Modular 회사가 내부 기술 강연을 공유하기 시작했으며, 첫 번째 공개 강연은 Mojo 프로그래밍 언어와 GPU 아키텍처 주제를 심층적으로 다룹니다. 내용에는 Mojo 컴파일러의 내부 작동 원리와 팀이 최신 GPU용으로 개발하면서 직면한 과제 및 해결책이 포함되며, 커뮤니티에 기술 스택의 세부 정보를 공유하는 것을 목표로 합니다. (출처: Modular)
AI by Hand 워크숍: Excel에서 Transformer 모델 처음부터 구축하기 : ProfTomYeh가 AI by Hand 워크숍을 홍보합니다. 이 워크숍은 참가자들이 Excel에서 Transformer 모델을 처음부터 구축하도록 하는 것을 목표로 합니다. 이러한 방식을 통해 학습자는 Transformer의 각 수학적 원리를 명확하고 직관적으로 이해하고, 이를 “블랙박스”로 간주하는 것을 피하며, 모델 내부 작동 메커니즘에 대한 깊은 이해를 구축할 수 있습니다. (출처: ProfTomYeh)
DeepLearning.AI, The Batch 301호 발행: AI 속도의 비즈니스 가치 및 최신 동향 논의 : Andrew Ng은 최신 The Batch에서 AI의 작업 실행 속도 향상이 비즈니스 가치 창출에 미치는 중요성이 과소평가되고 있다고 논했습니다. 그는 AI가 비용을 절감할 뿐만 아니라 아이디어에서 프로토타입까지의 시간을 단축함으로써 혁신과 탐색을 가속화하는 것이 더 중요하다고 주장합니다. 이번 호에서는 Microsoft Phi-4 추론 시리즈 출시, DeepCoder-14B 성능 o1 수준 달성, EU AI 규제 완화 등의 뉴스도 다루었습니다. (출처: DeepLearningAI)
💼 비즈니스
AI 캐릭터 애니메이션 스타트업 Cartwheel, 1000만 달러 투자 유치, 3D 애니메이션 프로세스 간소화 : AI 캐릭터 애니메이션 전문 스타트업 Cartwheel이 1000만 달러 투자 유치를 완료했다고 발표했습니다. 이 회사는 3D 애니메이션 제작 프로세스를 간소화하는 기술 개발에 주력하며, 창작자들이 더 빠르고 경제적으로 고품질 3D 캐릭터 애니메이션을 제작하고 최종 제품에 대한 제어력을 강화하며 번거로운 작업을 제거할 수 있도록 하는 것을 목표로 합니다. (출처: andrew_n_carr)
Hedra, a16z 주도로 3200만 달러 시리즈 A 투자 유치, 캐릭터 중심 비디오 제작 가속화 : AI 비디오 생성 스타트업 Hedra가 Andreessen Horowitz(a16z) 주도로 3200만 달러 시리즈 A 투자를 유치했으며, Matt Bornstein이 이사회에 합류한다고 발표했습니다. 기존 투자자인 a16z speedrun, Abstract, Index Ventures도 이번 라운드에 참여했습니다. Hedra는 캐릭터 중심의 비디오 제작을 쉽게 만드는 데 주력하고 있으며, 작년 스텔스 모드 시작 이후 약 300만 명이 해당 도구를 사용하여 1000만 개 이상의 비디오를 제작했습니다. 새로운 자금은 제품 개발 가속화, 팀 확장, 빠르고 표현력 풍부하며 직관적인 콘텐츠 제작을 실현하는 데 사용될 예정입니다. (출처: Hedra)
Tripadvisor, Qdrant 활용하여 AI 여행 일정 계획 구축, 사용자 참여도 2-3배 향상 : Tripadvisor는 Qdrant 벡터 데이터베이스를 사용하여 여행 검색 경험을 재정의하고 있습니다. 10억 개 이상의 리뷰와 사진, 1100만 개의 업체, 21개국의 데이터를 분석하여 Tripadvisor는 기존 필터에 의존하는 대신 동적인 AI 생성 여행 일정을 만들었습니다. 그 결과, 이러한 AI 도구를 사용하는 사용자의 이용 시간이 2-3배 증가하여 개인화된 여행 계획 분야에서 AI의 엄청난 잠재력을 보여주었습니다. (출처: qdrant_engine)

🌟 커뮤니티
Grok의 “백인 인종 학살” 발언 논란, Sam Altman 풍자적 대응 : xAI의 Grok 모델이 남아프리카 백인 인종 학살에 대한 무작위적인 견해를 발표하여 광범위한 논의와 비판을 불러일으켰습니다. Paul Graham은 이러한 행동이 최근 패치로 인한 버그처럼 보이며, 널리 사용되는 AI가 통제자에 의해 즉시 견해가 편집될 수 있다는 점을 우려했습니다. Sam Altman은 풍자적인 어조로 xAI가 투명한 해명을 제공하고 이 문제를 “남아프리카 백인 인종 학살”의 맥락에서 이해할 것이라고 응수하며, 이는 AI가 진실을 추구하고 지시를 따르는 결과라고 암시했습니다. 이 사건에 대한 커뮤니티의 논의는 AI 모델의 편향, 통제 가능성 및 배후 의도에 대한 보편적인 우려를 반영합니다. (출처: Paul Graham)
AI 제품화에 대한 고찰: 단순한 AI 기능 추가가 아닌 사용자 작업 전체 과정에서 기회 발굴 : 클라우드나인 캐피탈 파트너 런신(任鑫)은 AI 제품화에 대한 심도 있는 고찰을 공유하며, 기업은 기존 제품에 단순히 AI 기능을 추가하는 것이 아니라 사용자가 작업을 완료하는 전체 과정에서 AI 적용의 시작점을 찾아야 한다고 강조했습니다. 그는 “사용자가 원하는 것은 전동 드릴이 아니라 벽에 뚫린 구멍”이라는 비유를 들며, 사용자 작업을 세분화하여 문제점을 찾고 AI로 최적화할 것을 제안했습니다. AI 제품화의 네 가지 단계는 다음과 같습니다: 기존 프로세스의 효율적인 완료, 새로운 프로세스 창출, 완전히 새로운 시장 개척(사용 장벽을 낮추고 새로운 사용자 그룹, 심지어 AI 자체에 서비스 제공), 그리고 AI 주도의 미래를 위한 인프라 구축. 그는 AI 기술이 평준화되고 있으며 기술을 모르는 기업도 기회를 잡을 수 있고, 본질은 “AI가 할 일을 찾아주는 것”이라고 생각합니다. (출처: 混沌大学)
토론: 직업 발전에서 AI의 역할과 적응 전략 : LinkedIn의 게시물이 AI가 직업 발전에 미치는 영향에 대한 토론을 촉발했습니다. 일반적인 주장은 “AI가 당신의 직업을 대체하지는 않겠지만, AI를 사용하는 사람이 당신을 대체할 것”이라는 것입니다. 그러나 이 주장은 너무 모호하다는 지적을 받았습니다. 수십 년의 경력을 가진 프론트엔드 엔지니어와 같은 특정 직무의 경우 갑자기 AI 엔지니어로 전환하는 방법과 모든 사람이 AI 엔지니어가 될 수 없다는 문제가 제기되었습니다. 커뮤니티 토론에서는 프론트엔드 개발자의 경우 AI 도구를 사용하여 작업 효율성을 높이는 방법을 배울 수 있다고 보았습니다. 또한 AI가 많은 일자리를 대체하고 많은 사람들이 갈 곳이 없어질 것이라는 의견도 있었습니다. 더 일반적인 견해는 미래는 아직 불확실하지만 창의력, 문제 발견 능력, 인간성을 이해하고 다가가는 능력이 더 방어적일 수 있다는 것입니다. (출처: Reddit r/ArtificialInteligence)
토론: LLM은 다중 회차 대화에서 쉽게 “길을 잃으며”, 대화 재시작이 도움이 될 수 있음 : 한 연구 논문에 따르면 오픈소스든 폐쇄소스든 LLM은 다중 회차 대화에서 성능이 현저히 저하됩니다. 대부분의 벤치마크 테스트는 단일 회차, 지침이 명확한 시나리오에 중점을 둡니다. 연구 결과, LLM은 종종 초기 대화 회차에서 (잘못된) 가정을 하고 후속 대화에서 이러한 가정에 의존하여 수정하기 어렵다는 사실이 밝혀졌습니다. 결론은 다중 회차 대화가 예상대로 진행되지 않을 때 새 대화를 다시 시작하고 모든 관련 정보를 첫 번째 회차 입력에 통합하는 것이 도움이 될 수 있다는 것입니다. (출처: Reddit r/LocalLLaMA)
애플과 위챗, AI 발전 속도 상대적으로 느린 이유 분석: 개인 정보 보호 및 애플리케이션 우선 전략 : 웨이시(卫夕)는 기사에서 애플이 “Apple Intelligence”를 출시하고 위챗도 DeepSeek과 元宝(Yuanbao)를 연동했지만, 양사 모두 AI 핵심 기능 추진 속도가 상대적으로 느리다고 분석했습니다. 주요 원인은 두 가지입니다. 첫째, 개인 정보 및 데이터 보안에 대한 민감도가 매우 높다는 점입니다. AI의 지능은 데이터에 의존하는데, 애플과 위챗의 핵심 비즈니스 모델은 데이터 공유에 극도로 신중하게 만들어 모델 훈련 및 애플리케이션 컨텍스트 확보에 제약을 가합니다. 둘째, 양사 모두 “애플리케이션 우선” 전략을 채택하여 모델 지능의 상한선에서 최고 AI 기업과 경쟁하는 것을 추구하지 않고, 기존 기능 및 생태계에 AI 능력을 통합하는 데 더 중점을 둡니다. 이는 기술 주도권과 제품 반복 속도에서 제약을 받을 수 있음을 의미합니다. (출처: 卫夕指北)

OpenAI, “A부터 Z까지 챌린지” 개최: AI로 아마존에서 미지의 고고학 유적 발견 : OpenAI는 Kaggle과 협력하여 “OpenAI to Z Challenge” 특별 해커톤을 개최한다고 발표했습니다. 이 챌린지는 참가자들이 OpenAI o3, o4-mini 또는 GPT-4.1 모델을 사용하여 아마존 지역에서 이전에 알려지지 않은 고고학 유적을 찾는 것을 장려합니다. 참가자들은 #OpenAItoZ 해시태그를 사용하여 진행 상황을 공유할 수 있습니다. 이 행사는 고고학 및 지리 공간 분석 분야에서 AI의 응용 잠재력을 탐구하는 것을 목표로 합니다. (출처: OpenAI Developers)
“AI 변호사” 스타트업에 대한 비판: 자동화된 “협박 편지”가 사회적 부담이 될 수 있음 : 개발자 @swyx는 일부 VC가 “AI 변호사” 스타트업에 투자하는 현상에 대해 비판을 제기했습니다. 그는 이러한 회사들이 주로 AI를 통해 “독촉장(demand letters)”을 자동 생성하며, 본질적으로 자동화된 협박이라고 주장합니다. 일부 독촉은 합리적일 수 있지만, 그는 이러한 행위의 대부분이 결국 변호사에게만 이익이 되고 사회에 순수한 세금 부담이 될 것이라고 지적했습니다. 그는 이러한 회사와 투자자들을 보이콧하고, 투자금을 회수하며, 공개적으로 비판할 것을 촉구했습니다. (출처: swyx)

💡 기타
석탄 연구 보고서에 “위더 스켈레톤 처치 시 획득” 황당 오류, 콘텐츠 품질 및 AI 환각 논란 야기 : 8200위안에 판매되는 석탄 산업 연구 보고서에 “석탄은 재생 가능 자원이며, 위더 스켈레톤 처치 시 획득 가능”이라는 설명이 등장했습니다. 이는 게임 《마인크래프트》의 내용에서 비롯된 것으로, 인터넷에서 뜨거운 논란을 일으켰습니다. 많은 사람들이 이를 AI 콘텐츠 생성 및 환각 탓으로 돌렸습니다. 그러나 해당 보고서는 2022년에 출판되어 ChatGPT 등 주류 대형 모델 출시 이전이었으며, 이는 수동 복사-붙여넣기 및 검토 소홀의 전형적인 사례임을 지적합니다. 이 사건은 전문 보고서의 콘텐츠 품질, 정보 확인의 중요성, 그리고 AI 시대에 정보의 진위를 어떻게 판별할 것인가에 대한 깊은 성찰을 불러일으켰습니다. (출처: caoz的梦呓)

연구원들, 희귀 대사 질환 앓는 영아 치료 위해 맞춤형 유전자 편집 치료법 활용 : 의사들이 7개월도 채 안 되는 기간에 맞춤형 유전자 편집 치료법을 구축하여 치명적인 대사 질환을 앓는 영아 치료에 성공적으로 사용했습니다. 이는 유전자 편집이 단일 개인을 대상으로 맞춤형 치료에 사용된 최초의 사례입니다. 이 치료법은 영아 유전자의 특정 단일 문자 오류를 교정하는 것을 목표로 하며, 염기 편집과 같은 새로운 유전자 편집 기술의 정밀성을 보여줍니다. 치료가 초기 긍정적인 징후를 보였지만, 극히 희귀한 질환에 대한 개인 맞춤형 유전자 치료법 개발의 비용 및 확장성 문제도 부각되었습니다. (출처: MIT Technology Review)

범용 탈옥 프롬프트 전략 노출, 주류 대형 모델 보안 장벽 우회 가능 : HiddenLayer 연구원들은 ChatGPT, Claude, Gemini를 포함한 주류 대형 언어 모델이 보안 장벽을 우회하여 유해한 콘텐츠를 생성하도록 하는 범용 프롬프트 전략을 발견했습니다. 이 전략은 유해한 지침을 XML, INI 또는 JSON과 같은 정책 파일 형식으로 위장하고 허구의 역할극 시나리오와 결합하여 모델이 유해한 명령을 합법적인 시스템 지침으로 해석하도록 속입니다. 이 방법은 모델 훈련 데이터에 존재할 수 있는 시스템적 약점, 즉 교육 또는 정책 관련 데이터를 처리할 때 보안 지침을 무시하는 경향을 이용합니다. 이 기술은 또한 모델의 시스템 프롬프트를 추출하여 내부 지침과 보안 제약 조건을 노출할 수 있습니다. (출처: 新智元)
