
키워드:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, AI 규제, Gemini 기반 코딩 에이전트, 행렬 곱셈 알고리즘 최적화, 데이터 센터 효율 최적화, 다국어 다중 모달 모델, 분산형 AI 훈련 네트워크, Seed1.5-VL
🔥 초점
구글 DeepMind, AlphaEvolve 공개: Gemini 기반 코딩 에이전트, 알고리즘 발견 혁신: 구글 DeepMind가 Gemini 기반 AI 코딩 에이전트 AlphaEvolve를 출시했습니다. 이는 대규모 언어 모델의 창의성과 자동화된 평가기를 결합하여 복잡한 알고리즘을 발견하고 최적화하는 것을 목표로 합니다. AlphaEvolve는 이미 더 빠른 행렬 곱셈 알고리즘을 설계했으며, Erdős 최소 중첩 문제 및 접吻数 문제와 같은 미해결 수학 난제를 해결했습니다. 또한 구글 내부에서 데이터 센터 효율성 최적화(평균 0.7%의 컴퓨팅 자원 회수), 칩 설계 및 Gemini 자체 훈련 가속화에 사용되어 AI가 과학적 발견 및 엔지니어링 최적화 분야에서 엄청난 잠재력을 가지고 있음을 보여주었습니다. (출처: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic, 추론 및 도구 호출 능력 강화된 Claude Sonnet 및 Opus 새 모델 곧 출시: The Information에 따르면, Anthropic은 몇 주 내에 Claude Sonnet과 Claude Opus의 새 버전을 출시할 계획입니다. 새 모델의 핵심 기능은 “사고 모드”와 “도구 사용 모드” 간의 유연한 전환입니다. 외부 도구(예: 애플리케이션, 데이터베이스)를 사용하여 문제 해결에 어려움을 겪을 때 모델은 능동적으로 “추론 모드”로 돌아가 반성하고 자체 수정할 수 있습니다. 코드 생성 측면에서 새 모델은 생성된 코드를 자동으로 테스트하고 오류가 발견되면 일시 중지, 사고 및 수정합니다. 이러한 “사고-행동-반성”의 폐쇄 루프는 모델이 복잡한 문제를 해결하는 능력과 신뢰성을 크게 향상시킬 것으로 기대됩니다. (출처: steph_palazzolo, dotey)

미국 공화당 의원, 10년간 연방 및 주 차원의 AI 규제 금지 제안, 격렬한 논쟁 유발: 미국 공화당 의원들은 예산 조정 법안에 향후 10년 동안 연방 및 주 정부가 인공지능 모델, 시스템 또는 자동화된 의사 결정 시스템을 규제하는 것을 금지하는 조항을 추가하고, AI 상용화 및 연방 정부 IT 시스템에서의 AI 적용을 지원하기 위해 5억 달러를 배정할 계획입니다. 이 조치는 일부 기술계 인사들로부터 AI 혁신을 보호하고 규제가 혁신을 저해하는 것을 방지하는 긍정적인 신호로 간주되지만, DeepFake의 만연, 데이터 프라이버시 통제 불능, AI 윤리 및 환경 영향 등 잠재적 위험에 대한 우려도 불러일으키고 있습니다. 이 제안이 통과되면 기존 및 미래의 AI 입법에 중대한 영향을 미칠 것입니다. (출처: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI, GPT-4.1 모델 출시 및 안전 평가 센터 개설, 코딩 및 지침 준수 능력 강조: OpenAI는 사용자 요청에 따라 GPT-4.1 모델을 ChatGPT에서 즉시 사용할 수 있다고 발표했습니다(Plus, Pro, Team 사용자, 기업 및 교육 버전은 추후 제공). GPT-4.1은 코딩 작업 및 지침 준수에 최적화되어 속도가 더 빠르며 o3 및 o4-mini의 일상적인 코딩 대체품으로 사용될 수 있습니다. 동시에 GPT-4.1 mini는 현재 모든 사용자가 사용하는 GPT-4o mini를 대체합니다. 또한 OpenAI는 모델의 안전 테스트 결과 및 지표를 공개하고 정기적으로 업데이트하여 안전성 커뮤니케이션의 투명성을 높이기 위한 안전 평가 센터(Safety Evaluations Hub)를 출시했습니다. (출처: openai, michpokrass)
Meta FAIR, 분자 발견 및 원자 모델링에 초점 맞춘 다수의 AI 연구 성과 발표: Meta AI(FAIR)는 분자 특성 예측, 언어 처리 및 신경 과학 분야의 최신 오픈 소스 버전을 발표했습니다. 여기에는 대규모 원자 시스템 시뮬레이션을 위한 분자 발견 데이터셋인 Open Molecules 2025 (OMol25), 재료 및 분자의 원자 상호 작용 모델링에 광범위하게 적용할 수 있는 머신러닝 원자간 잠재력 모델인 Universal Model for Atoms (UMA), 스칼라 보상을 기반으로 생성 모델을 훈련하는 확장 가능한 알고리즘인 Adjoint Sampling이 포함됩니다. 또한 FAIR는 로스차일드 재단 병원과의 협력 연구를 통해 인간과 LLM 간의 언어 발달에서 현저한 유사성을 밝혀냈습니다. (출처: AIatMeta)
🎯 동향
바이트댄스, Seed1.5-VL 비전 언어 대형 모델 발표, 20B 활성 파라미터로 뛰어난 성능: 바이트댄스는 비전-언어 멀티모달 대형 모델 Seed1.5-VL을 출시했습니다. 이 모델은 20B 활성 파라미터만으로 Gemini 2.5 Pro와 동등한 성능을 보이며, 60개 공개 평가 벤치마크 중 38개에서 SOTA를 달성했습니다. Seed1.5-VL은 일반적인 멀티모달 이해 및 추론 능력을 강화했으며, 특히 시각적 위치 지정, 추론, 비디오 이해 및 멀티모달 에이전트 분야에서 뛰어난 성능을 보입니다. 모델은 Volcano Engine에서 API를 개방했으며, 추론 입력 가격은 0.003위안/천 토큰, 출력은 0.009위안/천 토큰입니다. (출처: 机器之心)

Qwen3 기술 보고서 공개: 사고와 비사고 모드 융합, 대형 모델이 소형 모델 증류: 알리바바는 Qwen3 시리즈 모델 기술 보고서를 발표했으며, 여기에는 0.6B에서 235B 파라미터의 8개 모델이 포함됩니다. 핵심 혁신은 이중 작업 모드로, 모델은 작업 복잡성에 따라 “사고 모드”(복잡한 추론)와 “비사고 모드”(빠른 응답)를 자동으로 전환하며, “사고 예산” 파라미터를 통해 계산 리소스를 동적으로 할당합니다. 훈련은 3단계 사전 훈련(일반 지식, 추론 강화, 장문 텍스트)과 4단계 사후 훈련(장문 사고 사슬 콜드 스타트, 추론 강화 학습, 사고 모드 융합, 일반 강화 학습)을 채택합니다. 동시에 “대형 모델이 소형 모델을 이끄는” 데이터 증류 전략을 사용하여 교사 모델(예: 235B)의 출력을 학생 모델(예: 30B) 훈련에 활용하여 지식 이전을 실현합니다. (출처: 36氪)

Microsoft, Phi-4-reasoning 시리즈 모델 출시, 추론 모델 훈련 경험 공유: Microsoft는 Phi-4-reasoning, Phi-4-reasoning-plus (모두 14B 파라미터) 및 Phi-4-mini-reasoning (3.8B 파라미터) 세 가지 모델을 출시하고 훈련 방법과 경험을 공개했습니다. 이 모델들은 사전 훈련된 모델의 미세 조정을 통해 수학적 추론 등의 능력을 향상시키는 데 중점을 둡니다. 예를 들어, Phi-4-reasoning-plus는 강화 학습을 통해 수학 문제에서 우수한 성능을 보이며, Phi-4-mini-reasoning은 단계적으로 SFT 및 RL 미세 조정을 진행합니다. 보고서는 소형 모델 훈련에서 발생할 수 있는 불안정성 및 대응 전략, 그리고 대형 모델 RL 훈련에서 데이터 선택 및 보상 함수 설계에 대한 고려 사항을 공유합니다. 모델 가중치는 MIT 라이선스에 따라 Hugging Face에 공개되었습니다. (출처: DeepLearning.AI Blog)
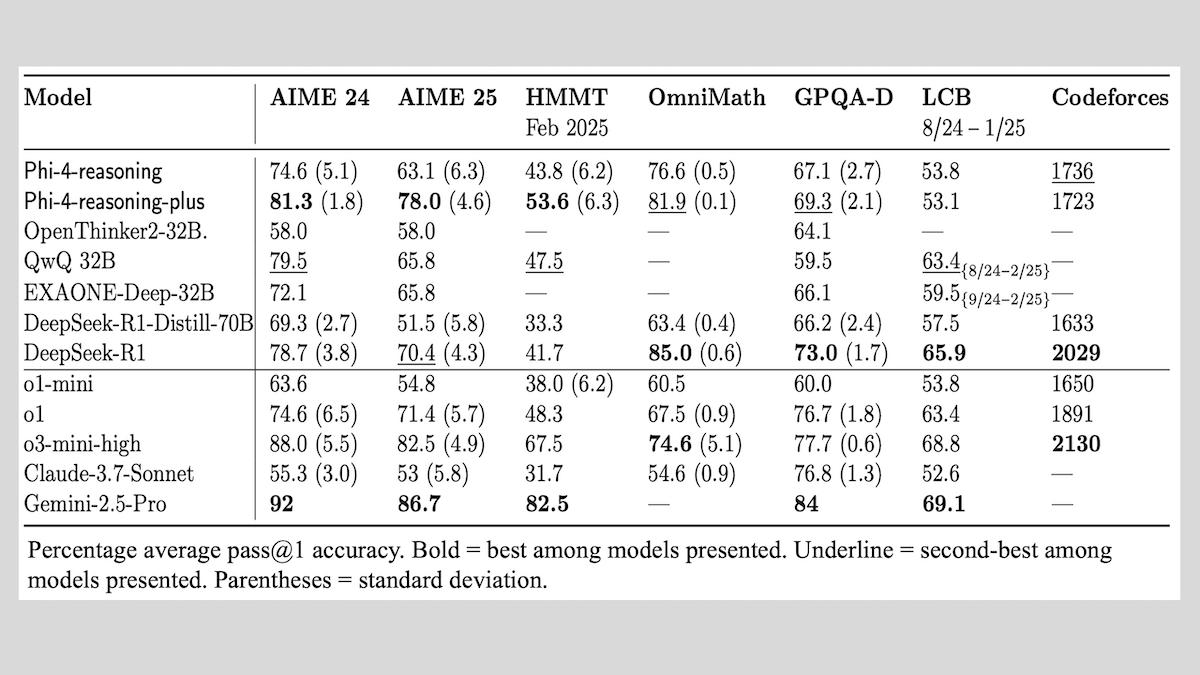
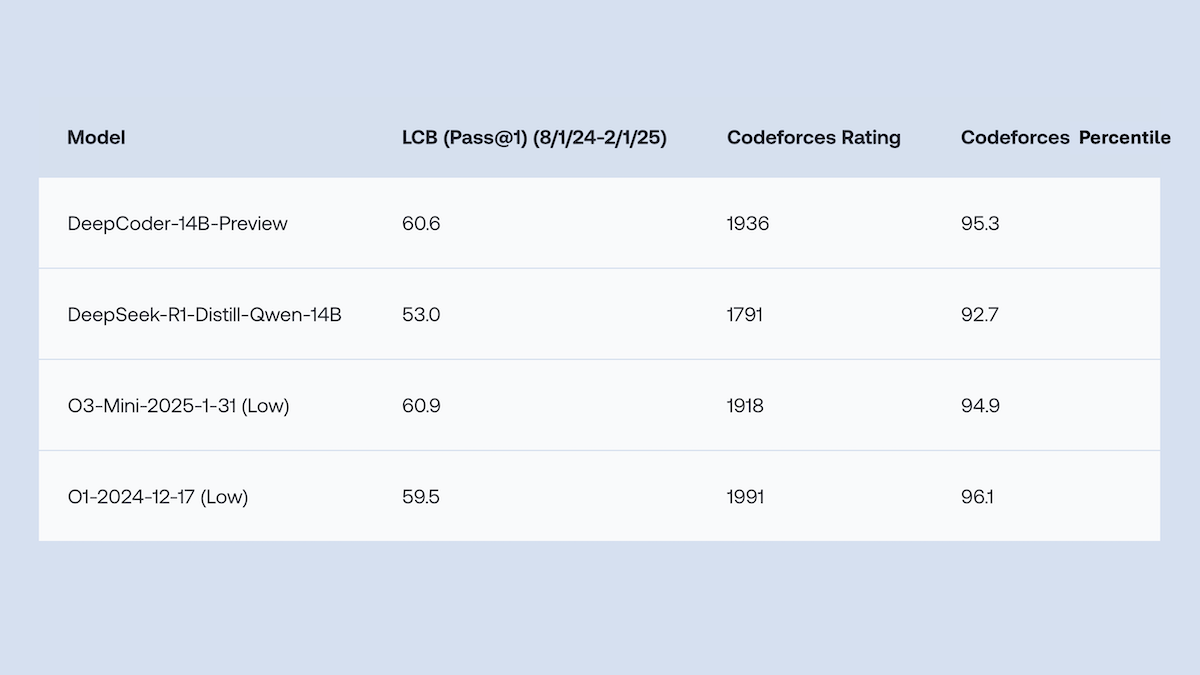
Together.AI와 Agentica, o1에 필적하는 코드 생성 성능의 DeepCoder-14B-Preview 오픈소스 공개: Together.AI와 Agentica 팀은 14B 파라미터의 코드 생성 모델인 DeepCoder-14B-Preview를 출시했습니다. 이 모델은 여러 코딩 벤치마크에서 DeepSeek-R1 및 OpenAI o1과 같은 더 큰 모델과 동등한 성능을 보입니다. 이 모델은 DeepSeek-R1-Distilled-Qwen-14B를 미세 조정하여 개발되었으며, 단순화된 강화 학습 방법(GRPO와 DAPO 최적화 결합)을 채택하고 RL 라이브러리 Verl의 병렬 처리 능력을 개선하여 훈련 시간을 크게 단축했습니다. 모델 가중치, 코드, 데이터셋 및 훈련 로그는 모두 MIT 라이선스로 오픈소스 공개되었습니다. (출처: DeepLearning.AI Blog)
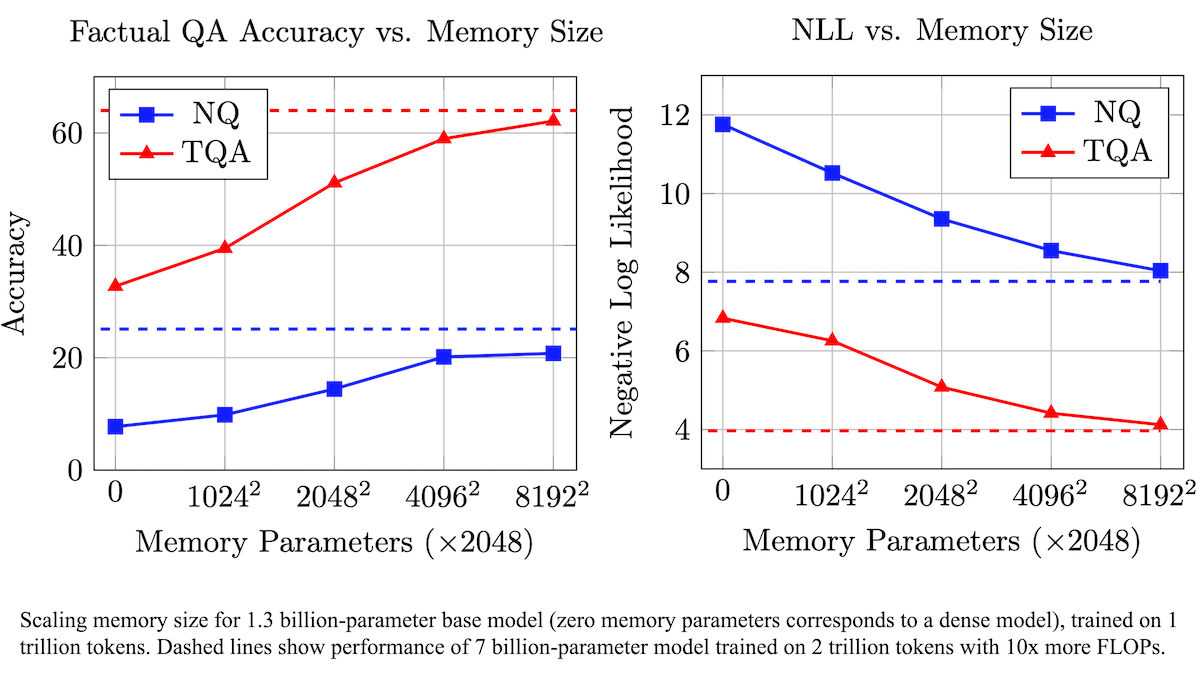
Meta, 훈련 가능한 메모리 레이어로 LLM 사실 정확도 향상 및 계산 요구량 감소 제안: Meta 연구원들은 Transformer 아키텍처에 훈련 가능한 메모리 레이어를 추가하여 계산량을 크게 늘리지 않고도 대규모 언어 모델의 사실 회상 정확도를 향상시켰습니다. 이 방법은 키와 해당 값을 학습하여 정보를 저장하고, 키를 두 개의 하프 키로 분해하는 전략을 채택하여 대규모 키 검색 시 계산 병목 현상을 효과적으로 해결했습니다. 실험 결과, 메모리 레이어를 장착한 8B 파라미터 모델은 여러 질의응답 데이터셋에서 메모리 레이어가 없는 동급 모델보다 우수한 성능을 보여 사전 훈련 데이터 및 계산량 요구 측면에서 이점을 나타냈습니다. (출처: DeepLearning.AI Blog)
알리바바, 텍스트/이미지-비디오 생성 및 편집 지원하는 Wan2.1 시리즈 비디오 기초 모델 오픈소스 공개: 알리바바는 1.3B 및 14B 파라미터 버전을 포함하는 포괄적인 오픈소스 비디오 기초 모델 스위트 Wan2.1을 Apache 2.0 라이선스로 공개했습니다. Wan2.1은 텍스트-비디오, 이미지-비디오, 비디오 편집, 텍스트-이미지 및 비디오-오디오 등 다양한 작업에서 뛰어난 성능을 보이며, 특히 중국어 및 영어 텍스트의 시각적 생성을 지원합니다. T2V-1.3B 모델은 8.19GB의 VRAM만 필요로 하여 소비자급 GPU에서 실행 가능하며, 4분 이내에 5초 분량의 480P 비디오를 생성할 수 있습니다. 함께 제공되는 Wan-VAE는 1080P 비디오를 효율적으로 인코딩/디코딩하고 시간적 정보를 보존합니다. (출처: _akhaliq, Reddit r/LocalLLaMA)

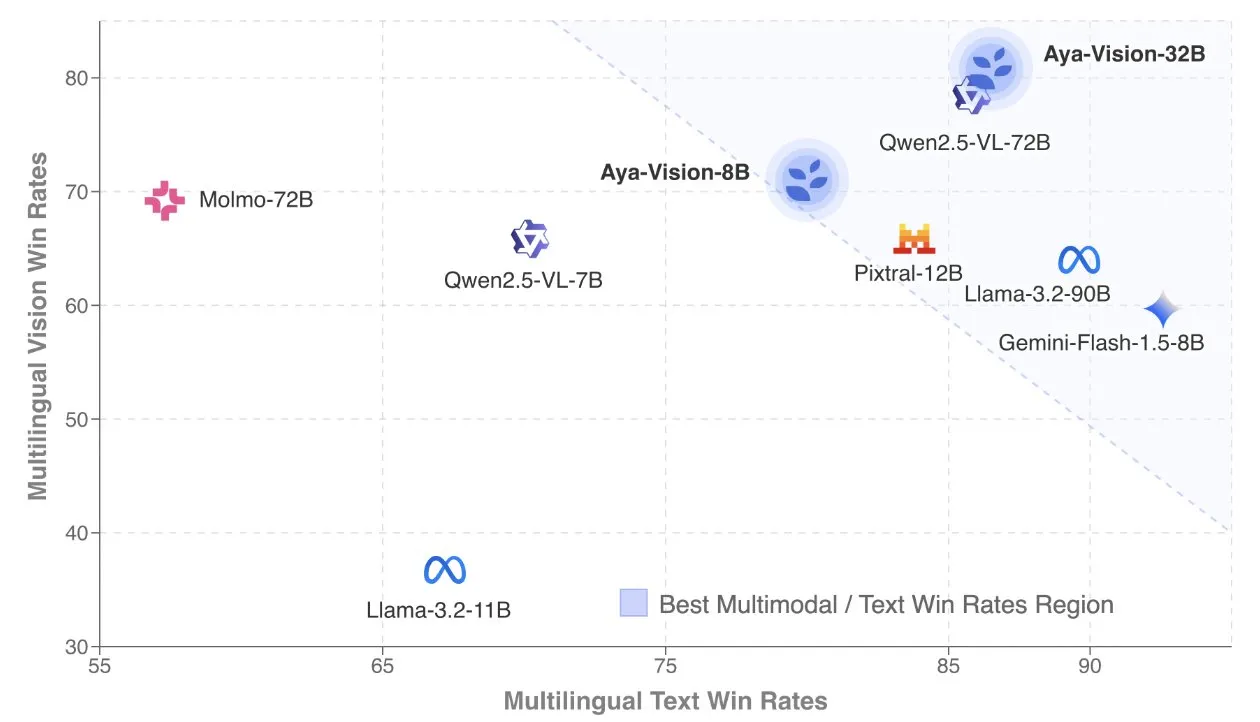
Cohere, 다국어 멀티모달 모델에 초점 맞춘 Aya Vision 기술 보고서 발표: Cohere Labs는 SOTA 다국어 멀티모달 모델 구축 방법을 상세히 설명하는 Aya Vision 기술 보고서를 공개했습니다. Aya Vision 모델은 23개 언어의 멀티모달 및 텍스트 작업 능력을 통합하는 것을 목표로 합니다. 보고서는 합성 다국어 데이터 프레임워크, 아키텍처 설계, 훈련 방법, 교차 모달 모델 병합 및 개방형, 다국어 생성 작업에 대한 포괄적인 평가를 다룹니다. 8B 모델은 Pixtral-12B와 같은 더 큰 모델보다 성능이 우수하며, 32B 모델은 효율성이 더 높아 Llama3.2-90B와 같이 두 배 이상 큰 모델을 능가합니다. (출처: sarahookr, Cohere Labs)
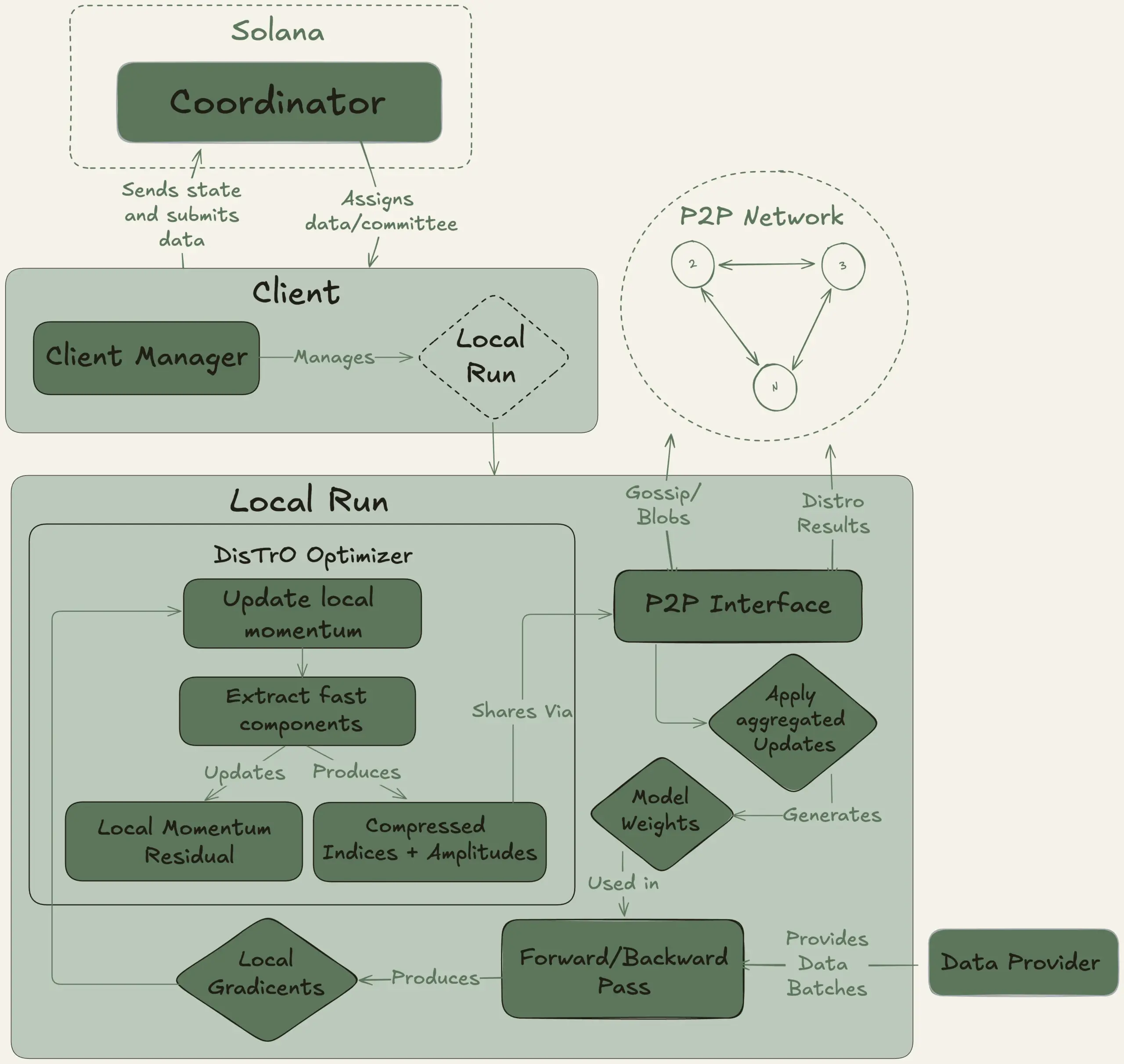
Nous Research, 40B 파라미터 대형 모델 분산 훈련 목표 Psyche 프로젝트 시작: Nous Research는 전 세계 컴퓨팅 파워를 모아 강력한 AI 모델을 공동으로 훈련하여 개인과 소규모 커뮤니티도 대규모 모델 개발에 참여할 수 있도록 하는 분산형 AI 훈련 네트워크 Psyche 네트워크를 시작한다고 발표했습니다. 테스트넷은 이미 MLA 아키텍처를 채택한 40B 파라미터 LLM의 사전 훈련을 시작했으며, 데이터셋에는 FineWeb (14T), FineWeb-2 일부 (4T) 및 The Stack v2 (1T)가 포함되어 총 약 20T 토큰에 달합니다. 이 모델 훈련이 완료되면 모든 체크포인트(어닐링되지 않은 버전과 어닐링된 버전 포함) 및 데이터셋이 오픈소스로 공개될 예정입니다. (출처: eliebakouch, Teknium1)
Stability AI, 빠른 텍스트-오디오 생성에 특화된 오픈소스 Stable Audio Open Small 모델 출시: Stability AI는 Hugging Face에 Stable Audio Open Small 모델을 출시했습니다. 이 모델은 빠른 텍스트-오디오 생성을 위해 특별히 설계되었으며 적대적 사후 훈련 기술을 채택했습니다. 이 모델은 효율적이고 오픈소스인 오디오 생성 솔루션을 제공하는 것을 목표로 합니다. (출처: _akhaliq)
구글 Gemini Advanced, GitHub 통합으로 코딩 지원 능력 강화: 구글은 Gemini Advanced가 GitHub와 연결되어 코딩 도우미로서의 능력을 더욱 향상시켰다고 발표했습니다. 사용자는 공개 또는 비공개 GitHub 저장소에 직접 연결하여 Gemini를 사용하여 함수를 생성 또는 수정하고, 복잡한 코드를 설명하고, 코드베이스에 대해 질문하고, 디버깅하는 등의 작업을 수행할 수 있습니다. 프롬프트 창에서 “+” 버튼을 클릭하고 “코드 가져오기”를 선택한 다음 GitHub URL을 붙여넣으면 사용을 시작할 수 있습니다. (출처: algo_diver)
mlx-omni-server v0.4.0 출시, 임베딩 서비스 및 더 많은 TTS 모델 추가: mlx-omni-server가 v0.4.0으로 업데이트되어 mlx-embeddings를 통해 임베딩 생성을 단순화하는 새로운 /v1/embeddings 서비스를 도입했습니다. 동시에 더 많은 TTS 모델(예: kokoro, bark)을 통합하고 qwen3과 같은 새 모델을 지원하도록 mlx-lm을 업그레이드했습니다. (출처: awnihannun)
Together Chat, PDF 파일 처리 기능 추가: Together Chat은 PDF 파일 업로드 및 처리를 지원한다고 발표했습니다. 현재 버전은 주로 PDF의 텍스트 내용을 구문 분석하여 모델에 전달하여 처리하며, 향후 PDF의 이미지 내용을 읽기 위한 OCR 기능을 추가한 v2 버전을 출시할 계획입니다. (출처: togethercompute)
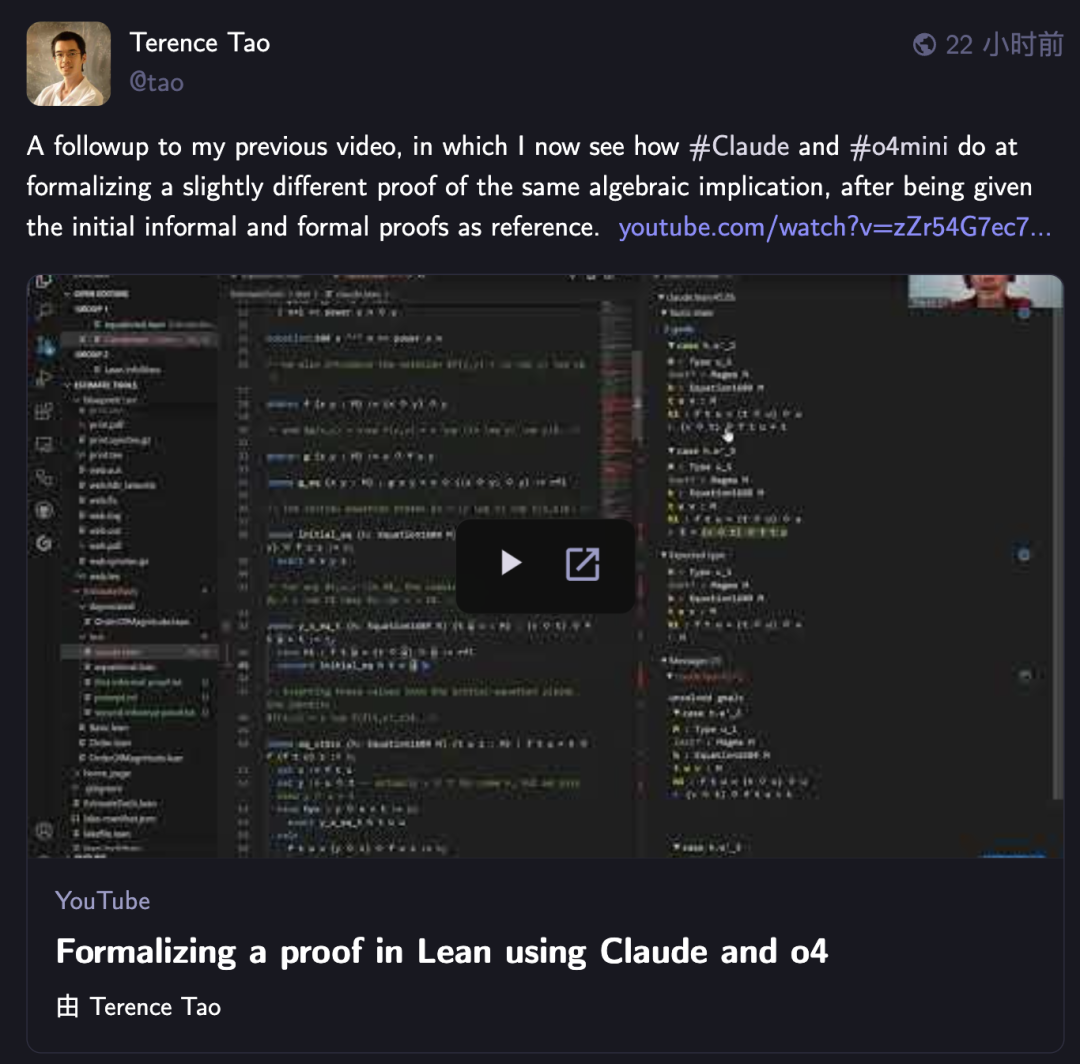
테렌스 타오, AI로 수학 형식화 증명 재도전, Claude가 o4-mini보다 우수한 성능 보여: 수학자 테렌스 타오는 자신의 YouTube 시리즈 영상에서 Lean 증명 보조 도구를 사용한 대수적 함의 증명의 형식화 능력에 대한 AI 테스트를 진행했습니다. 실험에서 Claude는 약 20분 만에 작업을 완료할 수 있었지만, 컴파일 과정에서 Lean의 자연수가 0부터 시작하는 규칙에 대한 이해 부족과 대칭성 처리 문제가 드러났으나 인공적인 개입으로 수정되었습니다. 이에 비해 o4-mini는 더 신중한 모습을 보이며 거듭제곱 함수 정의 문제를 인식했지만, 핵심 증명 단계에서 포기하여 작업을 완료하지 못했습니다. 테렌스 타오는 자동화에 지나치게 의존하면 증명 전체 구조에 대한 파악 능력이 약화될 수 있으며, 최적의 자동화 수준은 0%에서 100% 사이여야 하며 이해를 심화하기 위해 인위적인 개입을 남겨두어야 한다고 결론지었습니다. (출처: 36氪)
알트만 인터뷰: OpenAI의 궁극적인 목표는 핵심 AI 구독 서비스 구축: OpenAI CEO 샘 알트만은 Sequoia Capital AI Ascent 2025 행사에서 OpenAI의 “플라톤적 이상”은 사용자의 핵심 AI 구독 서비스가 될 AI 운영 체제를 개발하는 것이라고 말했습니다. 그는 미래의 AI 모델이 사용자 일생의 데이터(조 단위 컨텍스트 토큰)를 처리하여 심층적인 개인화 추론을 실현할 것이라고 구상했습니다. 알트만은 이것이 아직 “PPT 단계”에 있다고 인정했지만, 회사가 유연성과 적응성을 자랑스럽게 생각한다고 강조했습니다. 그는 또한 AI 음성 상호 작용의 잠재력, 2025년이 AI 에이전트가 큰 활약을 펼칠 해가 될 것이라고 언급했으며, 코딩이 모델 운영과 API 호출의 핵심이 될 것이라고 생각했습니다. (출처: 36氪, 量子位)

Karminski3, Qwen3-30B 커뮤니티 수정 버전 공유, 활성 전문가 수 두 배 증가: 개발자 커뮤니티가 Qwen3 모델을 수정하여 Qwen3-30B-A6B-16-Extreme 버전을 출시했습니다. 모델 파라미터를 수정하여 활성 전문가 수를 A3B에서 A6B로 늘렸으며, 이는 약간의 품질 향상을 가져오지만 생성 속도는 그에 따라 느려진다고 합니다. 사용자는 llama.cpp의 실행 파라미터 --override-kv http://qwen3moe.expert_used_count=int:24를 수정하여 유사한 효과를 얻거나, 반대로 Qwen3-235B-A22B의 활성량을 줄여 속도를 높일 수도 있습니다. (출처: karminski3)

🧰 도구
OpenMemory MCP 출시: 로컬 실행 공유 메모리 시스템, 여러 AI 도구 연동: mem0ai 팀은 개방형 모델 컨텍스트 프로토콜(MCP)을 기반으로 구축된 개인용 메모리 서버 OpenMemory MCP를 출시했습니다. 이는 100% 로컬 실행을 지원하며, 현재 AI 도구(예: Cursor, Claude Desktop, Windsurf, Cline) 간 컨텍스트 정보 공유 부재 및 세션 종료 시 메모리 손실 문제를 해결하는 것을 목표로 합니다. 사용자 데이터는 로컬에 저장되어 개인 정보 보호를 보장합니다. OpenMemory MCP는 표준화된 메모리 작업 API(생성, 삭제, 조회, 수정)를 제공하며, 사용자가 메모리 및 클라이언트 액세스 권한을 관리할 수 있는 중앙 집중식 대시보드를 갖추고 Docker를 통해 배포를 간소화합니다. (출처: 36氪, AI进修生)

LangChain, LangGraph 플랫폼 정식 버전 및 다수 업데이트 출시, AI 에이전트 개발 및 관찰 가능성 강화: LangChain은 Interrupt 컨퍼런스에서 장기 실행, 상태 저장 AI 에이전트 워크플로우 구축 및 관리를 위해 특별히 설계된 LangGraph 플랫폼의 정식 버전(GA)을 발표했습니다. 이 플랫폼은 원클릭 배포, 수평 확장 및 메모리, 인간-컴퓨터 상호작용(HIL), 대화 기록 등의 API를 지원합니다. 동시에 출시된 LangGraph Studio V2는 에이전트 IDE로서 로컬 실행, 구성 직접 편집, Playground 통합을 지원하며 프로덕션 환경 추적 데이터를 가져와 로컬 디버깅을 수행할 수 있습니다. 또한 LangChain은 오픈소스 코드 없는 에이전트 구축 플랫폼 Open Agent Platform (OAP)을 출시하고 도구 호출 및 추적 측면에서 LangSmith의 에이전트 관찰 가능성을 강화했습니다. (출처: LangChainAI, hwchase17)
PatronusAI, 다른 AI 에이전트를 평가하고 수정할 수 있는 AI 에이전트 Percival 출시: PatronusAI는 다른 AI 에이전트의 오류를 평가하고 자동으로 수정할 수 있는 최초의 AI 에이전트라고 주장하는 Percival을 출시했습니다. Percival은 에이전트 추적 기록에서 오류를 감지할 뿐만 아니라 수정 제안도 할 수 있습니다. GAIA 및 SWE-Bench의 인위적으로 레이블링된 오류를 포함하는 TRAIL 데이터셋에서 Percival의 성능은 SOTA LLM보다 2.9배 높다고 합니다. 기능에는 에이전트 프롬프트 수정 방안 자동 제안, 20가지 이상의 에이전트 오류 유형(도구 사용, 계획 조정, 특정 도메인 오류 등 포함) 포착, 수동 디버깅 시간을 몇 시간에서 1분 이내로 단축하는 것이 포함됩니다. (출처: rebeccatqian, basetenco)
PyWxDump: 위챗 정보 획득 및 내보내기 도구, AI 훈련 지원: PyWxDump는 위챗 계정 정보(닉네임, 계정, 휴대폰, 이메일, 데이터베이스 키)를 획득하고, 데이터베이스를 해독하며, 로컬에서 채팅 기록을 확인하고, 채팅 기록을 CSV, HTML 등 형식으로 내보내 AI 훈련, 자동 응답 등의 장면에 사용할 수 있는 Python 도구입니다. 이 도구는 다중 계정 정보 획득 및 모든 위챗 버전을 지원하며, 웹 버전 UI를 통해 채팅 기록을 확인할 수 있습니다. (출처: GitHub Trending)

Airweave: AI 에이전트가 모든 애플리케이션을 검색할 수 있게 하는 도구, MCP 프로토콜 호환: Airweave는 AI 에이전트가 모든 애플리케이션의 콘텐츠를 의미론적으로 검색할 수 있도록 하는 것을 목표로 하는 도구입니다. 모델 컨텍스트 프로토콜(MCP)과 호환되어 다양한 애플리케이션, 데이터베이스 또는 API에 원활하게 연결하여 해당 콘텐츠를 에이전트가 사용할 수 있는 지식으로 변환합니다. 주요 기능에는 데이터 동기화, 엔티티 추출 및 변환, 멀티테넌트 아키텍처, 증분 업데이트, 의미론적 검색 및 버전 관리 등이 포함됩니다. (출처: GitHub Trending)

iFLYTEK, viaim AI 브레인 탑재 차세대 AI 이어폰 iFLYBUDS Pro3 및 Air2 출시: Future Intelligence는 새로운 viaim AI 브레인을 탑재한 iFLYTEK AI 회의용 이어폰 iFLYBUDS Pro3와 iFLYBUDS Air2를 출시했습니다. viaim은 개인 비즈니스 사무용 AI 에이전트로, 엔드투엔드 지능형 감지 처리, 지능형 에이전트 협업 추론, 실시간 멀티모달 기능 및 데이터 보안 개인 정보 보호의 네 가지 핵심 모듈을 통합합니다. 이어폰은 편리한 녹음(통화, 현장, 오디오/비디오 녹음), AI 비서(자동 제목 요약 생성, 맞춤형 질문), 다국어 번역(32개 언어, 동시 통역, 대면 번역, 통화 번역) 등의 기능을 지원하며 음질과 착용감을 향상시켰습니다. (출처: WeChat)

KoboldCpp Smart Launcher 출시: LLM 성능 최적화를 위한 Tensor Offload 자동 튜닝 도구: KoboldCpp Smart Launcher라는 GUI 및 CLI 도구가 출시되어 사용자가 로컬에서 LLM을 실행할 때 KoboldCpp의 최적 Tensor Offload 전략을 자동으로 찾는 데 도움을 줍니다. CPU와 GPU 간에 텐서(전체 레이어가 아닌)를 더 세밀하게 분배함으로써 이 도구는 VRAM 요구 사항을 늘리지 않고도 생성 속도를 두 배 이상 향상시킬 수 있다고 합니다. 예를 들어, QwQ Merge는 12GB VRAM GPU에서 속도가 3.95 t/s에서 10.61 t/s로 향상되었습니다. (출처: Reddit r/LocalLLaMA)
OpenBMB, 중국어에 최적화된 최초의 온디바이스 GUI 에이전트 AgentCPM-GUI 오픈소스 공개: OpenBMB 팀은 중국어 애플리케이션에 최적화된 최초의 온디바이스 GUI(그래픽 사용자 인터페이스) 에이전트인 AgentCPM-GUI를 오픈소스로 공개했습니다. 이 에이전트는 강화 미세 조정(RFT)을 통해 추론 능력을 향상시켰으며, 간결한 액션 공간 설계를 채택하고 고품질 GUI 위치 지정(grounding) 능력을 갖추어 중국어 환경에서 다양한 애플리케이션을 조작하는 사용자 경험을 향상시키는 것을 목표로 합니다. (출처: Reddit r/LocalLLaMA)
MAESTRO: 다중 에이전트 협업 및 사용자 정의 LLM 지원하는 로컬 우선 AI 연구 애플리케이션: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator)는 로컬 제어 및 기능을 강조하는 새로 출시된 AI 기반 연구 애플리케이션입니다. 문서 추출, 강력한 RAG 파이프라인 및 다중 에이전트 시스템(계획, 연구, 반성, 작성)을 포함하는 모듈식 프레임워크를 제공하여 복잡한 연구 문제를 처리할 수 있습니다. 사용자는 Streamlit 웹 UI 또는 CLI를 통해 상호 작용하고 자체 문서 세트와 선택한 로컬 또는 API LLM을 사용할 수 있습니다. (출처: Reddit r/LocalLLaMA)
Contextual AI, RAG에 최적화된 문서 파서 출시: Contextual AI는 검색 증강 생성(RAG) 시스템을 위해 특별히 설계된 새로운 문서 파서를 출시했습니다. 이 도구는 시각, OCR 및 시각 언어 모델을 결합하여 복잡한 비정형 문서의 고정밀 구문 분석을 제공하고, 문서 계층 구조를 보존하며, 표, 차트 및 그래픽과 같은 복잡한 양식을 처리하고, 사용자가 감사할 수 있도록 경계 상자 및 신뢰도를 제공하여 RAG 시스템이 구문 분석 실패로 인한 컨텍스트 누락 및 환각을 줄이는 것을 목표로 합니다. (출처: douwekiela)
Gradio, ImageEditor 실행 취소/다시 실행 기능 추가: Gradio의 ImageEditor 컴포넌트에 실행 취소(undo) 및 다시 실행(redo) 버튼이 추가되어 사용자에게 전문 유료 애플리케이션과 유사한 Python 이미지 편집 기능을 제공하고 상호 작용성과 사용 편의성을 향상시켰습니다. (출처: _akhaliq)
RunwayML, 제로샷 재질, 의상, 장소 및 자세 테스트 지원하는 References 새 기능 출시: RunwayML의 References 기능이 업데이트되어 사용자는 기존 3D 재질 구 미리보기 이미지를 입력으로 사용하여 해당 재질을 임의의 객체에 적용하고 제로샷 재질 마이그레이션 및 시각화를 실현할 수 있습니다. 또한 새 기능은 의상, 장소 및 캐릭터 자세에 대한 제로샷 테스트도 지원하여 창의적인 생성 및 빠른 프로토타이핑의 가능성을 확장합니다. (출처: c_valenzuelab, c_valenzuelab)

미타 AI, “오늘 뭐 배울까” 기능 출시, AI 보조 구조화 학습: 미타 AI는 “오늘 뭐 배울까”라는 새로운 기능을 출시했습니다. 이는 AI를 정보 검색 및 문서 처리의 보조 역할에서 능동적으로 안내하고 교육할 수 있는 “AI 교사”로 전환하는 것을 목표로 합니다. 사용자가 자료를 업로드하거나 검색하면 이 기능은 체계적이고 구조화된 비디오 강의 및 PPT 설명을 자동으로 생성하여 사용자가 지식 포인트를 정리하는 데 도움을 주고, 사용자 수준에 따라 다양한 설명 깊이(초보자/전문가)와 스타일(이야기하기/화를 잘 내는 형 등)을 선택할 수 있도록 지원합니다. 또한 중간 질문 및 수업 후 테스트도 지원합니다. (출처: WeChat)

📚 학습
앤드류 응과 Anthropic, MCP를 사용한 풍부한 컨텍스트 AI 애플리케이션 구축 신규 과정 공동 출시: 앤드류 응의 DeepLearning.AI와 Anthropic이 “MCP: Build Rich-Context AI Apps with Anthropic”이라는 신규 과정을 공동으로 출시했으며, Anthropic 기술 교육 책임자인 Elie Schoppik이 강의합니다. 이 과정은 LLM이 외부 도구, 데이터 및 프롬프트에 액세스하는 것을 표준화하기 위한 개방형 프로토콜인 모델 컨텍스트 프로토콜(MCP)에 중점을 둡니다. 수강생은 MCP의 핵심 아키텍처를 배우고, MCP 호환 챗봇을 만들고, MCP 서버를 구축 및 배포하며, 이를 Claude 기반 애플리케이션 및 기타 타사 서버에 연결하여 풍부한 컨텍스트 AI 애플리케이션 개발을 간소화하는 방법을 배우게 됩니다. (출처: AndrewYNg, DeepLearningAI)
FlashInfer: MLSys 2025 최우수 논문, 효율적이고 사용자 정의 가능한 LLM 추론 어텐션 엔진: 워싱턴 대학교의 예즈하오(Zihao Ye), 엔비디아, OctoAI의 천치(Tianqi Chen) 등이 협력한 FlashInfer 프로젝트가 MLSys 2025 최우수 논문상을 수상했습니다. FlashInfer는 LLM 추론 서비스를 위해 최적화된 효율적이고 사용자 정의 가능한 어텐션 엔진으로, 메모리 액세스 최적화(블록 희소 형식 및 조합 가능한 형식을 사용하여 KV 캐시 처리), JIT 컴파일 기반의 유연한 어텐션 계산 템플릿 제공, 로드 밸런싱 작업 스케줄링 메커니즘 도입을 통해 LLM 추론 성능을 크게 향상시켰으며, vLLM, SGLang 등의 프로젝트에 통합되었습니다. (출처: 机器之心)
ICML 2025 논문: 데이터 조작 관점에서 그래프 프롬프팅(Graph Prompting)에 대한 이론적 분석 제공: 홍콩 중문대학교 왕췬중, 쑨샹궈 박사 및 청훙 교수는 ICML 2025에 발표한 논문에서 처음으로 “데이터 조작” 관점에서 그래프 프롬프팅의 효과에 대한 체계적인 이론적 프레임워크를 제공했습니다. 이 연구는 “브리징 그래프” 개념을 도입하여 그래프 프롬프팅 메커니즘이 이론적으로 입력 그래프 데이터에 특정 조작을 가하여 사전 훈련된 모델이 새로운 작업에 적응하도록 올바르게 처리할 수 있도록 하는 것과 동일하다는 것을 증명했습니다. 논문은 오차 상한을 도출하고, 오차의 원인과 제어 가능성을 분석했으며, 오차 분포를 모델링하여 그래프 프롬프팅의 설계 및 적용에 대한 이론적 기초를 제공했습니다. (출처: WeChat)
ICML 2025 논문: 토큰 수준 편집을 통한 합성 텍스트 데이터로 모델 붕괴 방지: 상하이 교통대학교 등 연구팀은 ICML 2025에 발표한 논문에서 합성 데이터로 인한 “모델 붕괴” 문제를 논의하고 “Token-Level Editing”이라는 데이터 생성 전략을 제안했습니다. 이 방법은 실제 데이터에서 모델이 “과도하게 확신하는” 토큰을 미세하게 편집하여 대체하는 방식으로, 완전히 새로운 텍스트를 생성하는 대신 구조가 더 안정적이고 일반화 성능이 더 강한 반합성 데이터를 구축하는 것을 목표로 합니다. 이론적 분석에 따르면 이 방법은 테스트 오차를 효과적으로 제한하여 반복 횟수가 증가함에 따라 모델 성능이 붕괴되는 것을 방지할 수 있습니다. 실험은 사전 훈련, 지속적인 사전 훈련 및 감독 미세 조정 단계에서 모두 이 방법의 효과를 검증했습니다. (출처: WeChat)

ICML 2025 논문: OmniAudio, 360° 파노라마 비디오에서 3D 공간 오디오 생성: OmniAudio 팀은 ICML 2025에서 360° 파노라마 비디오에서 직접 1차 앰비소닉(FOA) 공간 오디오를 생성하는 기술을 선보였습니다. 데이터 부족 문제를 해결하기 위해 팀은 대규모 360V2SA 데이터셋 Sphere360(10만 개 이상의 클립, 288시간)을 구축했습니다. OmniAudio는 2단계 훈련을 채택합니다: 자기 지도 방식의 coarse-to-fine 플로우 매칭 사전 훈련으로, 먼저 일반 스테레오 오디오를 의사 FOA로 변환하여 훈련한 다음 실제 FOA로 미세 조정합니다. 그런 다음 이중 분기 비디오 인코더를 결합하여 지도 미세 조정을 수행하고, 전역 및 로컬 시점 특징을 추출하여 고충실도, 방향 정확도가 높은 공간 오디오를 생성합니다. (출처: 量子位)

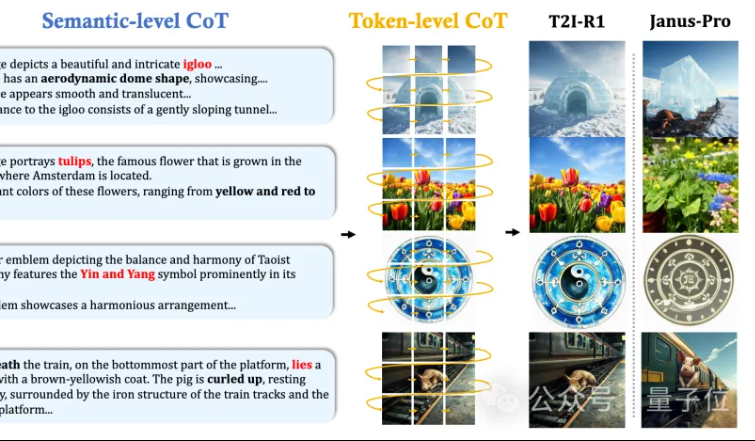
홍콩 중문대 MMLab, T2I-R1 제안: 텍스트-이미지 생성에 이중 계층 CoT 추론 및 강화 학습 도입: 홍콩 중문대학교 MMLab 팀은 강화 학습 기반 추론 강화 텍스트-이미지 생성 모델인 T2I-R1을 발표했습니다. 이 모델은 혁신적으로 이중 계층 사고 사슬(CoT) 추론 프레임워크를 제안합니다: Semantic-CoT(텍스트 추론, 이미지 전역 구조 계획) 및 Token-CoT(이미지 토큰 블록별 생성, 하위 수준 세부 정보 집중). BiCoT-GRPO 강화 학습 방법을 통해 통합 LMM(Janus-Pro)에서 이 두 CoT 계층을 협력적으로 최적화하며 추가 모델이 필요하지 않습니다. 보상 모델은 여러 시각 전문가 모델을 통합하여 평가의 신뢰성을 보장하고 과적합을 방지합니다. 실험 결과, T2I-R1은 사용자 의도를 더 잘 이해하고 기대에 더 부합하는 이미지를 생성하며 T2I-CompBench 및 WISE 벤치마크에서 기준 모델보다 현저히 우수한 성능을 보였습니다. (출처: 量子位, WeChat)
OpenAI, 경량 언어 모델 평가 라이브러리 simple-evals 출시: OpenAI는 최신 모델 출시의 정확도 데이터를 투명하게 공개하기 위해 언어 모델 평가용 경량 라이브러리인 simple-evals를 오픈소스로 공개했습니다. 이 라이브러리는 제로샷, 연쇄적 사고(chain-of-thought) 평가 설정을 강조하며, MMLU, MATH, GPQA 등 여러 벤치마크에서 OpenAI 자체 모델(예: o3, o4-mini, GPT-4.1, GPT-4o) 및 기타 주요 모델(예: Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5)을 포함한 상세한 모델 성능 비교를 제공합니다. (출처: GitHub Trending)
LLM Engineer’s Handbook 한국어판 출간: Maxime Labonne의 “LLM 엔지니어 핸드북”이 조우철 번역으로 한국어판으로 출간되었습니다. 이 핸드북은 러시아어, 중국어, 폴란드어 등 더 많은 언어 버전도 곧 출간될 예정이며, 전 세계 LLM 개발자에게 학습 자료를 제공합니다. (출처: maximelabonne)

ICML 2025 오디오 머신러닝 워크숍 ML4Audio 개최 발표: 많은 인기를 얻고 있는 오디오 머신러닝 워크숍(ML for Audio)이 밴쿠버에서 열리는 ICML 2025 기간 중 7월 19일(토요일)에 다시 개최됩니다. 워크숍에는 Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti, Pratyusha Rakshit 등 저명한 학자들이 연사로 초청될 예정입니다. 논문 제출 마감일은 5월 23일입니다. (출처: sedielem)
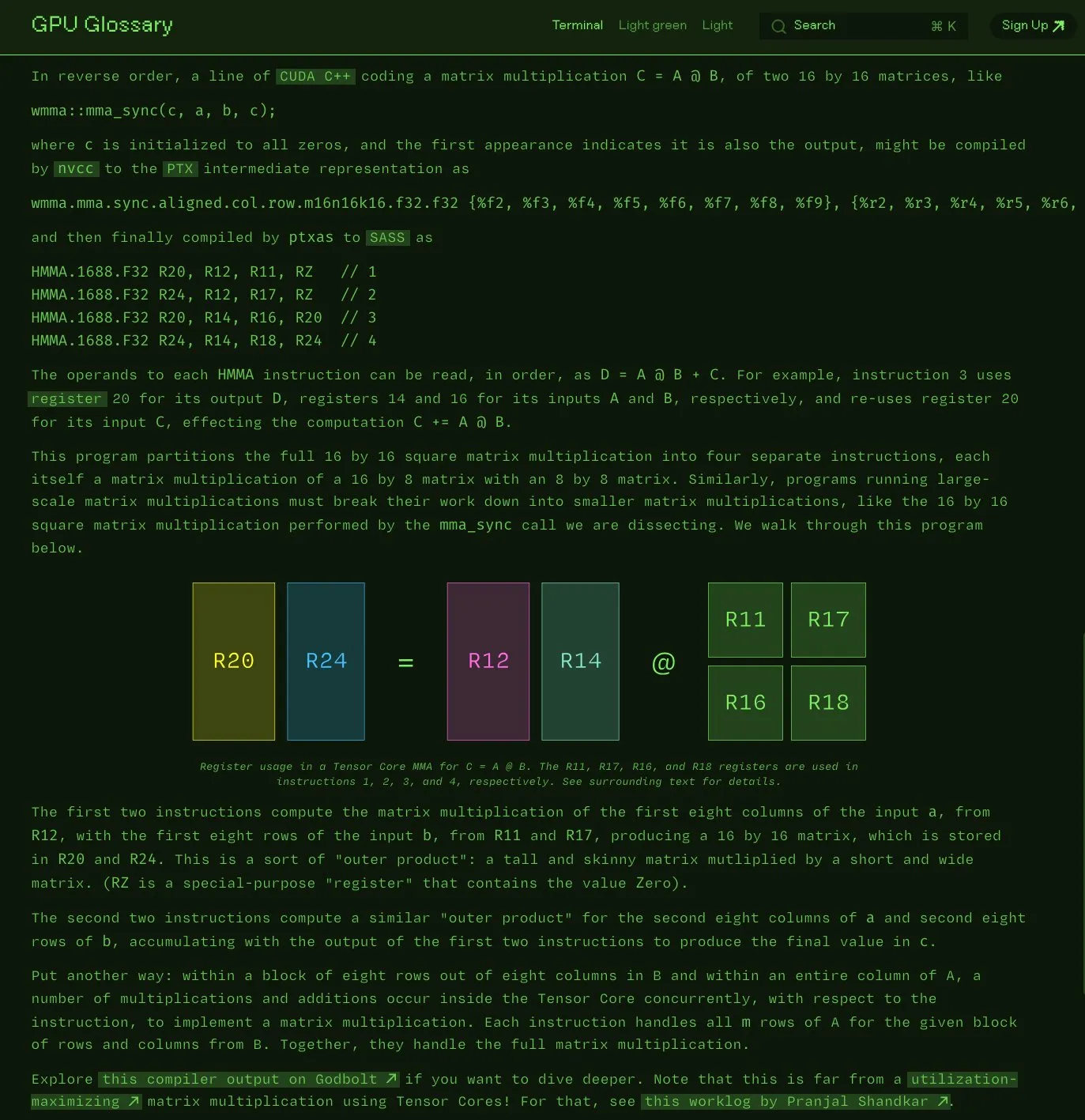
Charles Frye, GPU 용어집 오픈소스 공개: Charles Frye는 자신이 작성한 GPU 용어집(GPU Glossary)을 오픈소스로 공개했다고 발표했습니다. 이 용어집은 GPU 하드웨어 및 프로그래밍 관련 개념을 이해하는 데 도움을 주기 위한 것으로, 최근 Tensor Core가 간단한 행렬 곱셈-누산(mma) 연산을 수행하는 SASS 명령어 분해에 대한 내용이 업데이트되었습니다. 프로젝트는 GitHub에 호스팅되어 있으며 몇 가지 완료해야 할 작업이 나열되어 있습니다. (출처: charles_irl)
OpenAI, GPT-4.1 프롬프트 엔지니어링 가이드 발표, 구조화 및 명확한 지침 강조: OpenAI는 사용자가 프롬프트를 보다 효과적으로 구성하는 데 도움을 주기 위해 GPT-4.1용 프롬프트 엔지니어링 가이드를 출시했습니다. 특히 구조화된 출력, 추론, 도구 사용 및 에이전트 기반 애플리케이션에 적합합니다. 가이드는 명확한 역할과 목표 설정, 명확한 지침 제공(어조, 형식, 경계 포함), 선택적 하위 지침, 단계별 추론/계획, 출력 형식의 정확한 정의 및 예제 사용의 중요성을 강조하며, 핵심 지침 강조, Markdown 또는 XML을 사용한 입력 구조화 등 몇 가지 실용적인 팁을 제공합니다. (출처: Reddit r/MachineLearning)

Kaggle과 Hugging Face, 모델 호출 및 검색 간소화를 위한 협력 강화: Kaggle은 Hugging Face와의 협력을 강화하여 사용자가 이제 Kaggle Notebooks에서 직접 Hugging Face 모델을 시작하고, 관련된 공개 코드 예제를 검색하며, 두 플랫폼 간에 원활하게 탐색할 수 있다고 발표했습니다. 이 통합은 모델의 접근성을 확대하고 Kaggle 사용자가 Hugging Face 생태계의 모델 리소스를 보다 편리하게 활용할 수 있도록 하는 것을 목표로 합니다. (출처: huggingface)
FedRAG: RAG 시스템 미세 조정을 위한 오픈소스 프레임워크, 연합 학습 지원: Vector Institute 연구원이 검색 증강 생성(RAG) 시스템 미세 조정을 간소화하기 위한 오픈소스 프레임워크 FedRAG를 출시했습니다. 이 프레임워크는 일반적인 중앙 집중식 훈련을 지원할 뿐만 아니라 분산 데이터셋에서의 훈련 요구에 부응하기 위해 특별히 연합 학습 아키텍처를 도입했습니다. FedRAG는 PyTorch 및 Hugging Face 생태계와 호환되며, Qdrant를 지식 베이스 스토리지로 사용하고 LlamaIndex에 연결할 수 있습니다. (출처: nerdai)

💼 비즈니스
Cursor 모회사 Anysphere, 2년 만에 ARR 2억 달러 달성, 기업 가치 90억 달러로 급등: 25세의 MIT 중퇴생 Michael Truell이 이끄는 Anysphere는 AI 코드 편집기 Cursor를 통해 마케팅 없이 2년 만에 연간 반복 매출(ARR) 2억 달러를 달성했으며, 회사 가치는 90억 달러로 급등했습니다. Cursor는 AI를 개발 프로세스에 깊숙이 통합하여 소프트웨어 개발 패러다임을 재편하고 개인 개발자 서비스에 집중하여 전 세계 개발자들로부터 광범위한 인정과 입소문을 얻었습니다. Thrive Capital이 최근 투자 라운드를 주도했습니다. (출처: 36氪)

Databricks, Serverless Postgres 회사 Neon 인수 발표: Databricks는 개발자 중심의 Serverless Postgres 회사인 Neon을 인수하기로 합의했습니다. Neon은 속도, 탄력적 확장, 브랜칭 및 포킹 기능을 제공하는 새로운 데이터베이스 아키텍처로 유명하며, 이러한 기능은 개발자와 AI 에이전트 모두에게 매력적입니다. 이번 인수는 개발자와 AI 에이전트를 위한 개방형, Serverless 데이터베이스 기반을 공동으로 구축하는 것을 목표로 합니다. (출처: jefrankle, matei_zaharia)
AI 금융 서비스 스타트업 Samaya AI, 4350만 달러 투자 유치: Samaya AI는 지식 노동을 대규모로 혁신하기 위한 금융 서비스용 전문가 AI 에이전트 구축을 위해 NEA가 주도하는 4350만 달러의 투자를 유치했다고 발표했습니다. 2022년에 설립된 이 회사는 복잡한 금융 워크플로우를 위한 전용 AI 솔루션 개발에 주력하고 있습니다. 자체 개발한 LLM 기반 전문가 AI 에이전트는 이미 Morgan Stanley 등 최고 기관의 수천 명의 사용자가 실사, 경제 모델링 및 의사 결정 지원과 같은 시나리오에 사용하고 있으며, 정확성, 투명성 및 환각 없음을 강조합니다. (출처: maithra_raghu)
🌟 커뮤니티
AI가 소프트웨어 엔지니어를 대체할 것인가? 기술 향상의 필요성에 대한 커뮤니티의 뜨거운 논쟁: 소셜 미디어에서 AI가 소프트웨어 엔지니어를 대체할 것인지에 대한 논의가 다시 한번 등장했습니다. 일반적인 견해는 소프트웨어 개발이 코딩 자체보다 훨씬 더 많은 것을 포함하기 때문에 AI가 소프트웨어 엔지니어를 완전히 대체하지는 않을 것이라는 것입니다. 그러나 주로 반복적인 코딩 작업을 수행하고 시스템 전체에 대한 이해가 부족한 “코드 몽키(code monkeys)”는 기술을 향상시키고 시스템 아키텍처 및 복잡한 문제 해결에 대한 이해를 심화하지 않으면 AI 보조 도구로 대체될 위험이 높습니다. (출처: cto_junior, cto_junior)
AI Agent의 미래: 기회와 도전 공존, 업계 리더들 잠재력 낙관: OpenAI CEO 알트만은 2025년이 AI Agent가 큰 활약을 펼치는 해가 될 것이며, 실제 업무에 더 많이 참여하게 될 것이라고 예측했습니다. 류즈이(刘志毅)도 인터뷰에서 Agent가 수동적인 도구에서 능동적인 실행 시스템으로 전환하고 있으며, 그 발전은 기본 모델의 진보와 물리적 세계와의 상호 작용 능력에 달려 있다고 강조했습니다. 현재 Agent는 응답 속도, 환각 제어 등에서 여전히 부족한 점이 있지만, 자율적인 작업 수행 능력과 대형 모델 학습 보조 능력은 널리 인정받고 있으며, 이미 스마트 고객 서비스, 금융 투자 자문 등의 분야에서 활용되기 시작했습니다. (출처: 36氪, 量子位)

Perplexity AI, PayPal 및 Venmo와 협력하여 전자상거래 및 여행 결제 통합: Perplexity AI는 플랫폼의 전자상거래 쇼핑, 여행 예약, 음성 비서 및 곧 출시될 브라우저 Comet에 결제 기능을 통합하기 위해 PayPal 및 Venmo와 협력할 것이라고 발표했습니다. 이 조치는 검색, 선택에서 안전한 결제에 이르는 전체 상거래 프로세스를 단순화하여 사용자 경험을 향상시키는 것을 목표로 합니다. (출처: AravSrinivas, perplexity_ai)
AI 모델 평가에 대한 논의: IFEval 및 ChartQA 주목, 훈련 데이터 오염 경계 필요: 커뮤니티 논의에서 IFEval은 단순하면서도 독창적인 설계로 인해 우수한 지침 준수 평가 벤치마크 중 하나로 간주됩니다. 동시에 일부 사용자는 ChartQA 테스트 데이터에 노이즈, 모호한 답변 및 불일치 등의 문제가 있어 폐기해야 할 수도 있다고 지적했습니다. Vikhyatk은 벤치마크 테스트에서 높은 정확도를 달성했다고 주장하는 많은 모델이 훈련 데이터 오염 문제를 인지하지 못한 채 가지고 있을 수 있다고 경고했습니다. (출처: clefourrier, vikhyatk)

AI 생성 콘텐츠 저작권 및 윤리 문제 부각: Audible, AI 내레이션 사용 계획, AI 생성 인물의 온라인 교제 활용 우려: Audible은 오디오북 제작에 AI 생성 내레이션을 사용하여 “더 많은 이야기를 삶에 가져다줄 것”이라고 발표하여 창작 산업에서 AI 활용에 대한 논의를 촉발했습니다. 한편, Reddit에서는 한 사용자가 자신의 어머니가 데이트 웹사이트에서 AI가 생성한 것으로 의심되는 “실제 남성” 이미지와 교류하고 있다며 사기를 당할까 우려하는 글을 올렸습니다. 이는 AI 생성 콘텐츠의 진위성, 감정 조작 및 사기 측면에서의 잠재적 위험을 부각합니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 기타
중국 기업 “싱수안(星算)”, 첫 12개 우주 컴퓨팅 위성 성공적 발사, 우주 기반 컴퓨팅 파워 신시대 개막: 궈싱위항(国星宇航)이 주도하는 “싱수안” 계획이 첫 12개의 컴퓨팅 위성을 성공적으로 우주로 보내 세계 최초의 우주 컴퓨팅 위성군을 구성했습니다. 각 위성은 우주 컴퓨팅 및 상호 연결 능력을 갖추고 있으며, 단일 위성의 컴퓨팅 능력은 T급에서 P급으로 향상되었습니다. 첫 발사된 위성군의 궤도상 컴퓨팅 파워는 5POPS에 달하며, 위성 간 레이저 통신 속도는 최대 100Gbps입니다. 이 조치는 우주 기반 지능형 컴퓨팅 인프라를 구축하여 지상 컴퓨팅 파워의 에너지 소비 과다, 발열 문제 등을 해결하고, 심우주 탐사 데이터의 궤도상 실시간 처리를 지원하여 “우주 데이터, 우주 컴퓨팅(天数天算)”을 실현하는 것을 목표로 합니다. 향후 2800개의 위성을 발사하여 우주 컴퓨팅 대형 네트워크를 구축할 계획입니다. (출처: 量子位)

NVIDIA, 연례 보고서 발표, AI는 새로운 산업 혁명의 핵심이며 지능이 곧 제품임을 강조: NVIDIA는 연례 보고서에서 세계가 새로운 산업 혁명에 진입하고 있으며 그 핵심 제품은 “지능”이라고 지적했습니다. NVIDIA는 지능형 인프라를 구축하여 컴퓨팅을 모든 산업의 발전을 이끄는 생성적 힘으로 전환하는 데 전념하고 있습니다. (출처: nvidia)

NBA, 콰이쇼우 Kling AI와 협력하여 AI 단편 영화 《어린 시절 커리의 덩크》 공개: NBA는 콰이쇼우 산하 Sora급 텍스트-비디오 생성 대형 모델 Kling AI와 협력하여 AI TALK가 제작한 《Childhood Curry’s Dunk》라는 AI 단편 영화를 공개했습니다. 이 영화는 Kling AI를 사용하여 커리가 “시간을 초월한” 덩크 장면을 재현하려는 시도로, NBA 플레이오프를 응원하며, 영화에는 바클리, 오닐, 요키치가 특별 출연합니다. (출처: TomLikesRobots)