
키워드:OpenAI, HealthBench, Meta AI, Dynamic Byte Latent Transformer, 마이크로소프트 리서치, ARTIST 프레임워크, Sakana AI, 지속적 사고 기계, 의료 AI 성능 평가, 8B 매개변수 동적 바이트 잠재 Transformer 모델, 강화 학습을 통한 LLM 추론 향상, CTM 신경망 아키텍처, Qwen3 공식 양자화 모델
🔥 포커스
OpenAI, 의료 AI 성능 평가 위한 HealthBench 발표: OpenAI는 대규모 언어 모델의 의료 시나리오에서의 성능과 안전성을 측정하기 위한 새로운 벤치마크인 HealthBench를 출시했습니다. 이 벤치마크는 250명 이상의 전 세계 의사가 개발에 참여했으며, 5000개의 실제 의료 대화와 48,562개의 의사가 작성한 고유 평가 기준을 포함합니다. 응급 진료, 글로벌 건강 등 다양한 상황과 정확성, 지침 준수 등 행동 차원을 다룹니다. 테스트 결과, o3 모델의 정확도는 60%에 달했으며, GPT-4.1 nano는 비용을 25배 절감하면서도 GPT-4o보다 우수한 성능을 보여, 의료 분야에서 AI의 막대한 잠재력과 성능 대비 비용 효율성의 빠른 발전을 보여주었습니다. (출처: OpenAI)
Meta, 8B 파라미터 Dynamic Byte Latent Transformer 모델 발표: Meta AI는 8B 파라미터의 Dynamic Byte Latent Transformer 모델 가중치를 오픈소스로 공개한다고 발표했습니다. 이 모델은 기존 토큰화 방식을 대체하는 새로운 방안을 제시하여 언어 모델의 효율성과 신뢰성 기준을 재정의하는 것을 목표로 합니다. 이 새로운 토큰화 방식을 통해 언어 모델 분야에 혁신적인 발전을 가져와 모델의 텍스트 처리 효율과 효과를 향상시킬 것으로 기대됩니다. 연구 논문과 코드는 다운로드 가능합니다. (출처: AIatMeta)
Microsoft Research, 강화 학습 결합한 ARTIST 프레임워크 출시, LLM 추론 및 도구 사용 능력 향상: Microsoft Research는 ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers) 프레임워크를 소개했습니다. 이 프레임워크는 자율 추론, 강화 학습, 동적 도구 사용을 통합하여 대규모 언어 모델이 언제, 어떻게, 어떤 도구를 사용하여 다단계 추론을 수행할지 스스로 결정하고, 단계별 감독 없이 견고한 정책을 학습할 수 있도록 합니다. ARTIST는 수학 및 함수 호출과 같은 어려운 벤치마크 테스트에서 GPT-4o 등 최고 모델보다 최대 22% 향상된 성능을 보여, 일반화 및 해석 가능한 문제 해결에 대한 새로운 표준을 설정했습니다. (출처: MarkTechPost)

Sakana AI, Continuous Thought Machines (CTM) 발표: Sakana AI는 “Continuous Thought Machines” (CTM)라는 새로운 신경망 아키텍처를 출시했습니다. CTM의 핵심 아이디어는 신경 활동의 동적 시간 과정을 계산의 핵심 구성 요소로 삼아, 모델이 내부적으로 생성된 “사고 단계” 타임라인을 따라 작동하며, 정적 데이터에 대해서도 반복적으로 표현을 구축하고 개선할 수 있도록 하는 것입니다. 이 아키텍처는 ImageNet 분류, 2D 미로 탐색, 정렬, 패리티 계산 및 강화 학습 등 다양한 작업에서 적응형 계산, 향상된 해석 가능성 및 생물학적 타당성을 보여주었습니다. (출처: Sakana AI)

🎯 동향
Alibaba Qwen 팀, Qwen3 공식 양자화 모델 발표: Alibaba Qwen 팀이 Qwen3의 양자화 모델을 공식 발표했습니다. 사용자는 이제 Ollama, LM Studio, SGLang, vLLM 등의 플랫폼을 통해 Qwen3를 배포할 수 있으며, GGUF, AWQ, GPTQ 등 다양한 형식을 지원하여 로컬 배포가 용이합니다. 관련 모델은 Hugging Face와 ModelScope에 공개되었습니다. 이번 발표는 고성능 대규모 모델의 사용 장벽을 낮추고 더 광범위한 시나리오에서의 응용을 촉진하는 것을 목표로 합니다. (출처: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI, 협업 추론 프레임워크 Collaborative Reasoner 발표: Meta AI는 언어 모델의 협업 추론 능력을 개선하기 위한 프레임워크인 Collaborative Reasoner를 출시했습니다. 이 프레임워크는 인간 및 다른 에이전트와 협력할 수 있는 소셜 에이전트 개발에 중점을 두며, 모델의 협업 및 추론 능력을 향상시켜 더 복잡한 인간-기계 상호작용 및 다중 에이전트 시스템의 길을 열어줍니다. 관련 연구 논문과 코드는 커뮤니티의 탐색과 응용을 장려하기 위해 공개되었습니다. (출처: AIatMeta)
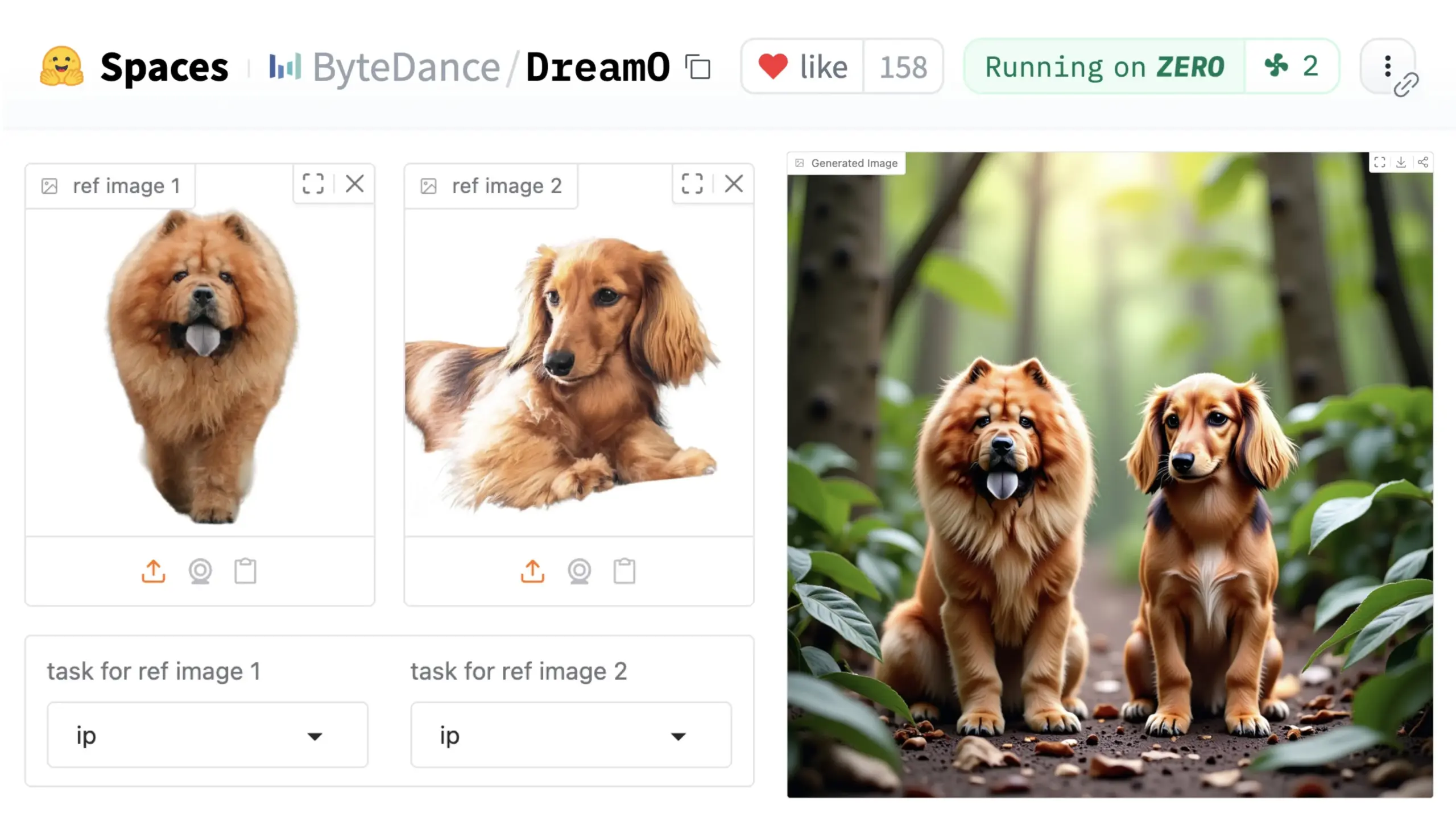
ByteDance, 범용 이미지 커스터마이징 프레임워크 DreamO 출시: ByteDance는 DreamO라는 통합 이미지 커스터마이징 프레임워크를 발표했습니다. 이 프레임워크는 사전 훈련된 DiT (Diffusion Transformer) 모델을 기반으로 하며, 신원 교체, 스타일 전이, 주체 변환 및 가상 착용 등 이미지 내 인물, 스타일, 배경 등 다양한 요소의 광범위한 커스터마이징을 가능하게 합니다. 사용자는 Hugging Face에서 데모를 체험할 수 있습니다. 이 진전은 단일 모델이 다양한 이미지 편집 작업에서 보여주는 잠재력을 보여줍니다. (출처: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA, Nemotron 모델 데이터 관리 파이프라인 Nemotron-CC 공개: NVIDIA는 Nemotron 모델에 사용된 데이터 관리 파이프라인 Nemotron-CC를 공개하고, Nemotron 훈련 및 후처리 데이터를 최대한 공개한다고 발표했습니다. Nemotron-CC 파이프라인은 이제 NeMo Curator GitHub 저장소에 추가되어 텍스트, 이미지, 비디오 데이터를 대규모로 처리할 수 있습니다. NVIDIA는 고품질 사전 훈련 데이터셋이 대규모 언어 모델의 정확성에 중요하다고 강조하며, 데이터가 가속 컴퓨팅의 기본 구성 요소라고 생각합니다. (출처: ctnzr & NandoDF)

Tencent Hunyuan-Turbos 모델, LMArena 순위 8위 기록: Tencent의 최신 Hunyuan-Turbos 모델이 LMArena(구 lmsys.org) 벤치마크에서 전체 8위, 스타일 제어 13위를 기록하며 Deepseek-R1과 비슷한 성능을 보였습니다. 이 모델은 하드코어, 코딩, 수학 등 주요 부문에서 모두 상위 10위 안에 들었으며, 2월 버전 대비 현저한 향상을 보였습니다. WizardLM_AI 등 커뮤니티 회원들은 그 성능에 축하를 보냈습니다. (출처: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References, 범용 창작 도구 잠재력 시사: Runway의 Gen-4 References 모델은 거의 무한한 워크플로우와 응용 프로그램을 지원할 수 있는 범용 창작 도구로 자리매김하고 있습니다. 커뮤니티 사용자들은 계속해서 새로운 사용 사례를 발견하며, 사용자의 창의력에 맞춰 조정될 수 있는 범용 모델로서의 강력한 적응성을 보여주고 있습니다. 이는 사용자가 모델의 제약에 적응하는 것이 아니라 모델이 사용자에 맞춰 조정되는 것을 의미합니다. 이는 미디어 창작 분야에서 AI가 특정 작업에서 범용 능력으로 진화하는 추세를 반영합니다. (출처: c_valenzuelab & c_valenzuelab)

ByteDance Seed-1.5-VL-thinking 모델, 시각 언어 모델 벤치마크 선두: ByteDance는 Seed-1.5-VL-thinking 모델을 발표했습니다. 이 모델은 60개의 시각 언어 모델(VLM) 벤치마크 중 38개에서 SOTA(state-of-the-art) 성과를 달성했습니다. 이 모델은 130만 H800 GPU 시간 동안 훈련되었다고 알려졌으며, 강력한 멀티모달 이해 및 추론 능력을 보여줍니다. (출처: teortaxesTex)
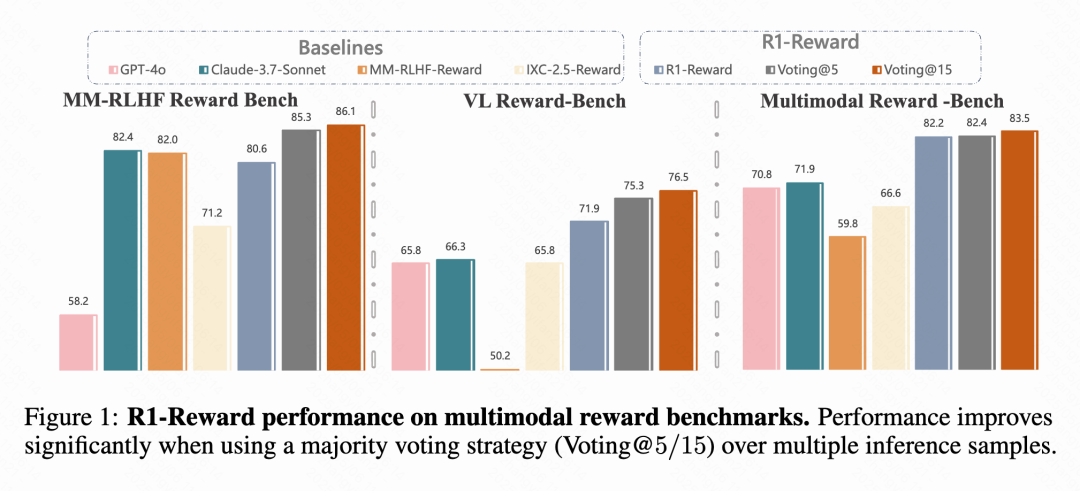
Kuaishou, CAS 등, 멀티모달 보상 모델 R1-Reward 제안: Kuaishou, 중국과학원(CAS), 칭화대, 난징대 연구팀은 개선된 강화 학습 알고리즘 StableReinforce로 훈련된 새로운 멀티모달 보상 모델(MRM)인 R1-Reward를 제안했습니다. 이 모델은 기존 RL 알고리즘이 MRM 훈련 시 겪는 불안정성 문제를 해결하기 위해 Pre-Clip, 어드밴티지 필터, 일관성 보상 등의 메커니즘을 도입했습니다. 실험 결과, R1-Reward는 여러 MRM 벤치마크에서 SOTA 모델보다 5%-15% 향상된 성능을 보였으며, Kuaishou의 숏폼 비디오, 전자상거래 등 비즈니스 시나리오에 성공적으로 적용되었습니다. (출처: WeChat & WeChat)
난양공대 등, 메모리 메커니즘 활용한 장기 시계열 일관성 월드 생성 모델 WorldMem 제안: 난양공과대학교(NTU) S-Lab, 베이징대학교, 상하이 AI Lab 연구진은 월드 생성 모델 WorldMem을 제안했습니다. 이 모델은 메모리 메커니즘을 도입하여 기존 비디오 생성 모델이 장기 시계열에서 일관성이 부족한 문제를 해결합니다. WorldMem은 Minecraft 데이터셋에서 훈련되었으며, 다양한 장면 탐색과 동적 변화를 지원하고 실제 데이터셋에서 그 실현 가능성을 검증했습니다. 시점과 위치 변화 후에도 우수한 기하학적 일관성을 유지하고 시간적 일관성을 모델링할 수 있습니다. (출처: WeChat)

Kuaishou Keling 팀, 3D 인식 제어 가능한 영화 수준 비디오 생성 프레임워크 CineMaster 제안: Kuaishou Keling 연구팀은 SIGGRAPH 2025에서 CineMaster 프레임워크를 소개하는 논문을 발표했습니다. 이는 영화 수준의 텍스트-비디오 생성 프레임워크로, 사용자가 상호작용 워크플로우를 통해 3D 공간에서 장면을 배치하고, 목표와 카메라 움직임을 설정하여 비디오 콘텐츠를 정밀하게 제어할 수 있도록 합니다. CineMaster는 시맨틱 레이아웃 ControlNet과 Camera Adapter를 통해 각각 객체 움직임과 카메라 움직임 제어를 통합하고, 임의의 비디오에서 3D 제어 신호를 추출하는 데이터 구축 프로세스를 설계했습니다. (출처: WeChat)

🧰 도구
Comet-ml, 오픈소스 LLM 평가 프레임워크 Opik 출시: Comet-ml은 GitHub에 LLM 애플리케이션, RAG 시스템, 에이전트 워크플로우를 디버깅, 평가, 모니터링하기 위한 프레임워크인 Opik을 오픈소스로 공개했습니다. Opik은 포괄적인 추적, 자동화된 평가, 프로덕션 준비된 대시보드를 제공하며, 로컬 설치 또는 Comet.com을 통한 호스팅 솔루션으로 사용할 수 있습니다. OpenAI, LangChain, LlamaIndex 등 다양한 인기 프레임워크와 통합되며, 환각 탐지, 콘텐츠 검토, RAG 평가를 위한 LLM-as-a-judge 지표를 제공합니다. (출처: GitHub Trending)
LovartAI, 첫 디자인 에이전트 Lovart 출시, 컨텍스트 이해 강조: LovartAI는 첫 디자인 에이전트 Lovart의 베타 버전을 출시했습니다. 사용자 피드백에 따르면, 다른 AI 디자인 도구에 비해 Lovart는 컨텍스트를 더 잘 이해하며 심지어 “마음을 읽는 것 같다”고 합니다. 이 도구는 사람과 AI가 동일한 캔버스에서 협업하여 프롬프트를 즉시 시각적 결과로 변환할 수 있게 하며, 브랜드 로고 및 VI 디자인 등에 사용할 수 있습니다. (출처: karminski3)
CMU 주준옌 팀, 텍스트로 3D 레고 모델 생성하는 LEGOGPT 출시: CMU 주준옌 팀은 텍스트 프롬프트를 기반으로 물리적으로 안정적이고 조립 가능한 3D 레고 모델을 생성하는 대규모 언어 모델 LEGOGPT를 개발했습니다. 이 모델은 레고 디자인 문제를 자기회귀 텍스트 생성 작업으로 공식화하여 다음 블록의 크기와 위치를 예측하여 구조를 구축합니다. 훈련 및 추론 과정에서 물리적 인식 조립 제약 조건을 강제하여 생성된 디자인의 안정성과 조립 가능성을 보장합니다. 팀은 또한 47,000개 이상의 레고 구조를 포함하는 StableText2Lego 데이터셋을 발표했습니다. (출처: WeChat)

MNN 채팅 앱, Qwen 2.5 Omni 3B 및 7B 모델 지원: Alibaba의 MNN (Mobile Neural Network) 채팅 앱이 이제 Qwen 2.5 Omni 3B 및 7B 모델을 지원합니다. 이는 사용자가 모바일 기기에서 더 강력한 로컬 언어 모델 서비스를 경험할 수 있음을 의미합니다. MNN은 모바일 및 임베디드 기기 최적화에 중점을 둔 경량 딥러닝 추론 엔진입니다. (출처: Reddit r/LocalLLaMA)

FutureHouse 플랫폼, 과학자에게 초지능 AI 연구 도구 제공: 비영리 단체 FutureHouse는 과학적 발견을 가속화하기 위한 웹 및 API 기반 AI 에이전트 스위트인 FutureHouse 플랫폼을 발표했습니다. 이 플랫폼은 과학자들이 데이터 분석, 시뮬레이션 실험, 지식 발견을 수행하는 데 도움이 되는 일련의 초지능 AI 연구 도구를 제공하여 연구 패러다임의 변화를 촉진합니다. (출처: dl_weekly)
Cartesia, Pro Voice Cloning 출시, 손쉬운 맞춤형 음성 모델 구축 지원: Cartesia는 미세 조정 제품인 Pro Voice Cloning을 출시했습니다. 사용자는 자신의 음성 데이터를 업로드하여 개인 아바타, AI 에이전트 또는 음성 라이브러리 생성에 사용할 맞춤형 음성 모델을 쉽게 구축할 수 있습니다. 이 제품은 2시간 이내에 훈련 및 서비스 배포를 완료할 수 있도록 지원하며, 완전한 셀프 서비스 제품 경험을 제공하여 대규모 응용을 목표로 합니다. (출처: krandiash)

중국과학원 계산기술연구소, MCA-Ctrl 제안, 이미지 정밀 커스터마이징 실현: 중국과학원 계산기술연구소 연구팀은 미세 조정 없이 범용 이미지 커스터마이징을 위한 방법인 MCA-Ctrl (Multi-party Collaborative Attention Control)을 제안했습니다. 이 방법은 다자간 협력적 어텐션 제어를 통해 확산 모델 내부 지식을 활용하고, 조건부 이미지/텍스트 프롬프트와 주체 이미지 콘텐츠를 결합하여 특정 주체의 테마 교체, 생성 및 추가를 실현합니다. MCA-Ctrl은 자기 어텐션 로컬 쿼리 및 글로벌 주입 메커니즘을 통해 레이아웃 일관성과 특정 객체 외형 교체 및 배경 정렬을 보장합니다. (출처: WeChat)
📚 학습
AI Engineer 컨퍼런스, 연사 라인업 공개: AI Engineer 컨퍼런스가 연사 라인업을 공개했습니다. OpenAI, Anthropic, LangChainAI, Google 등 기업의 최고 AI 엔지니어와 연구원들이 포함됩니다. 컨퍼런스는 MCP, LLM RecSys, Agent Reliability, GraphRAG 등 20개 세부 분야를 다루며, 처음으로 CTO 및 VP 리더십 의제를 설정합니다. (출처: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face, 시각 언어 모델(VLM) 최신 동향 블로그 게시: Hugging Face는 시각 언어 모델(VLM)의 최신 동향에 대한 종합적인 블로그 게시물을 발표했습니다. 내용은 GUI 에이전트, 에이전트 VLM, 전능 모델, 멀티모달 RAG, 비디오 LM, 소형 모델 등 다양한 측면을 다루며, 지난 1년간 VLM 분야의 새로운 트렌드, 혁신, 정렬 및 벤치마크 등을 요약합니다. (출처: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure, 서버리스 AI 채팅 앱 구축 온라인 워크숍 개최: Yohan Lasorsa는 Azure를 사용하여 서버리스 AI 채팅 앱을 구축하는 방법에 대한 온라인 워크숍을 개최한다고 발표했습니다. 회의에서는 Azure Functions, 정적 웹 앱, Cosmos DB 및 LangChainAI JS와 RAG(검색 증강 생성) 기술을 결합하는 방법을 논의할 예정입니다. (출처: Hacubu & hwchase17)
Weaviate 팟캐스트, LLM-as-Judge 시스템과 Verdict 라이브러리 논의: Weaviate 팟캐스트 121회에서는 Haize Labs 공동 창립자 Leonard Tang을 초대하여 LLM-as-Judge/보상 모델 시스템의 발전에 대해 심도 있게 논의했습니다. 토론 내용은 평가 사용자 경험, 비교 평가, 심판관 통합, 토론 심판관, 평가 세트 큐레이션 및 적대적 테스트 등을 포함하며, Haize Labs의 새로운 라이브러리인 Verdict, 즉 복합 LLM-as-Judge 시스템을 지정하고 실행하기 위한 선언적 프레임워크를 중점적으로 소개했습니다. (출처: bobvanluijt & Reddit r/deeplearning)

테렌스 타오, AI 보조 수학 형식 증명 시연 YouTube 영상 공개: 필즈상 수상자 테렌스 타오가 자신의 YouTube 채널 데뷔 영상에서 GitHub Copilot 및 Lean 증명 보조 도구와 같은 AI 도구를 활용하여, 원래 인간 수학자가 한 페이지 가득 써야 했던 수학 증명(Magma 방정식 E1689가 E2를 함의함)을 33분 만에 반자동으로 형식화하는 방법을 시연했습니다. 그는 이 방법이 기술적으로 복잡하고 개념적으로 덜 복잡한 증명에 적합하며, 수학자를 번거로운 작업에서 해방시킬 수 있다고 강조했습니다. 동시에 그가 개발한 경량 Python 증명 보조 도구도 2.0 버전으로 업데이트되어 점근적 추정 및 명제 논리 처리가 강화되었습니다. (출처: WeChat & 量子位)

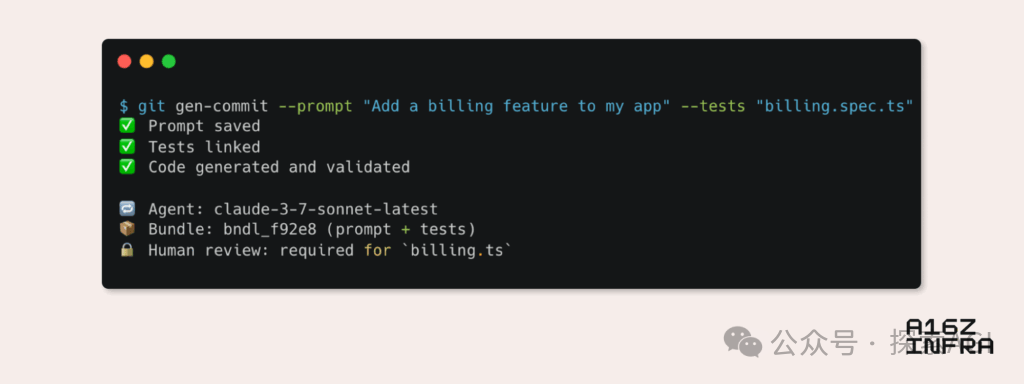
a16z, AI 시대 신흥 개발자 패턴 9가지 트렌드 분석: Andreessen Horowitz (a16z)는 AI 시대에 부상하는 9가지 개발자 패턴 트렌드를 분석하는 블로그를 발표했습니다. 여기에는 AI 네이티브 Git(버전 관리가 Prompt 및 테스트 케이스로 전환), Vibe Coding(의도 기반 프로그래밍이 템플릿 대체), AI 에이전트의 새로운 키 관리 패러다임, AI 기반 대화형 모니터링 대시보드, 문서가 AI 상호작용 가능 지식 베이스로 진화, LLM 관점에서 본 애플리케이션(접근성 API를 통한 상호작용), 비동기 실행 에이전트의 부상, MCP(Model-Tool Communication Protocol) 프로토콜의 잠재력, 에이전트의 기본 구성 요소 수요 등이 포함됩니다. 이러한 트렌드는 소프트웨어 구축 방식의 심오한 변화를 예고합니다. (출처: WeChat)
💼 비즈니스
Google Labs, AI 스타트업 지원 위한 AI Futures Fund 출시: Google Labs는 AI 기술의 미래를 스타트업과 함께 구축하기 위한 AI Futures Fund 프로젝트를 시작한다고 발표했습니다. 이 펀드는 선정된 스타트업에게 Google DeepMind 모델에 대한 조기 액세스 기회와 클라우드 크레딧 등의 자원을 제공하여 성장을 가속화하는 데 도움을 줄 것입니다. (출처: GoogleDeepMind & JeffDean & Google & demishassabis)
Perplexity, 140억 달러 가치로 5억 달러 신규 투자 유치 협상 중: AI 검색 엔진 회사 Perplexity가 140억 달러의 기업 가치로 5억 달러 규모의 신규 투자를 유치하기 위해 협상 중이라고 보도되었습니다. 이는 지난 투자 유치(기업 가치 90억 달러) 이후 불과 6개월 만의 일로, 자본 시장이 AI 검색 분야에 높은 관심을 보이고 Perplexity의 성장 전망을 긍정적으로 평가하고 있음을 보여줍니다. (출처: Dorialexander)

OpenAI, 약 30억 달러에 Windsurf 인수 합의설: 블룸버그 통신에 따르면 OpenAI는 스타트업 Windsurf를 약 30억 달러에 인수하기로 합의했습니다. 이번 인수의 구체적인 세부 사항과 Windsurf의 사업 방향은 아직 공개되지 않았지만, 이는 OpenAI가 기술 역량이나 시장 영역을 더욱 확장하려는 움직임일 수 있습니다. (출처: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 커뮤니티
AI의 실제 위험: 무한한 만족이 가져오는 “시뮬레이션 함정”: Amjad Masad 등의 논의에 따르면, AI의 진정한 위험은 공상 과학 영화 속 킬러 로봇이 아니라 인간의 욕망을 무한히 만족시켜 “무한한 행복 기계”를 만드는 능력입니다. 이러한 AI는 인간이 시뮬레이션된 노력과 의미에 탐닉하게 만들어 결국 시뮬레이션 세계 속으로 “사라지게” 할 수 있으며, 이는 페르미 역설에 대한 가능한 설명, 즉 문명이 소멸하는 것이 아니라 디지털 극락으로 진입한다는 설명을 제공합니다. (출처: amasad)
AI 에이전트, 프로그래밍과 과학 연구 재편할 것: Replit의 CEO Amjad Masad는 향후 1~2년 안에 AI 에이전트가 복잡한 과학 문제를 해결하기 위해 며칠, 심지어 몇 년 동안 중단 없이 작동할 수 있을 것으로 예측합니다. 그는 에이전트가 인간처럼 며칠 동안 문제 해결에 몰두할 수 있는 새로운 프로그래밍 방식이 될 것이라고 보며, 이는 AI가 복잡한 작업을 자동화하고 과학적 발견을 가속화하는 데 엄청난 잠재력을 가지고 있음을 시사합니다. (출처: TheTuringPost & amasad & TheTuringPost)
John Carmack, 코드베이스 최적화에서 AI의 잠재력 논의: 전설적인 프로그래머 John Carmack은 AI가 대량의 코드를 생성할 뿐만 아니라 기존 코드베이스를 개선하고 리팩토링하는 데 도움을 줄 잠재력이 있다고 생각합니다. 그는 AI가 부지런한 팀원처럼 지속적으로 코드를 검토하고 개선 제안을 하며, 객관적인 실험을 통해 “AI 친화적인” 코딩 스타일 가이드라인을 정의할 수도 있다고 상상합니다. 그는 OpenBSD와 같이 코드 품질 요구 사항이 매우 높은 팀이 AI 멤버를 어떻게 받아들일지 기대하고 있습니다. (출처: ID_AA_Carmack)
“Vibe Coding” 열띤 논의: AI 보조 프로그래밍의 장단점: 커뮤니티 토론에 따르면, “Vibe Coding”(자연어 명령으로 AI가 코드 프로토타입을 생성하게 하는 것)은 데모 수준의 애플리케이션을 빠르게 구축할 수 있지만, 배포 및 확장을 위해서는 여전히 전문 개발자가 처음부터 구축해야 합니다. 엔지니어링 제품은 단순히 코드를 작성하는 것뿐만 아니라 아키텍처, CI/CD, 마이크로서비스 등 복잡한 문제를 포함하며, AI는 현재 이를 완전히 수행하기 어렵습니다. Vibe Coding은 빠른 프로토타입 검증에 적합하지만, 실제 솔루션을 구축하려면 여전히 엔지니어링 사고와 경험이 필요합니다. (출처: Reddit r/ClaudeAI)
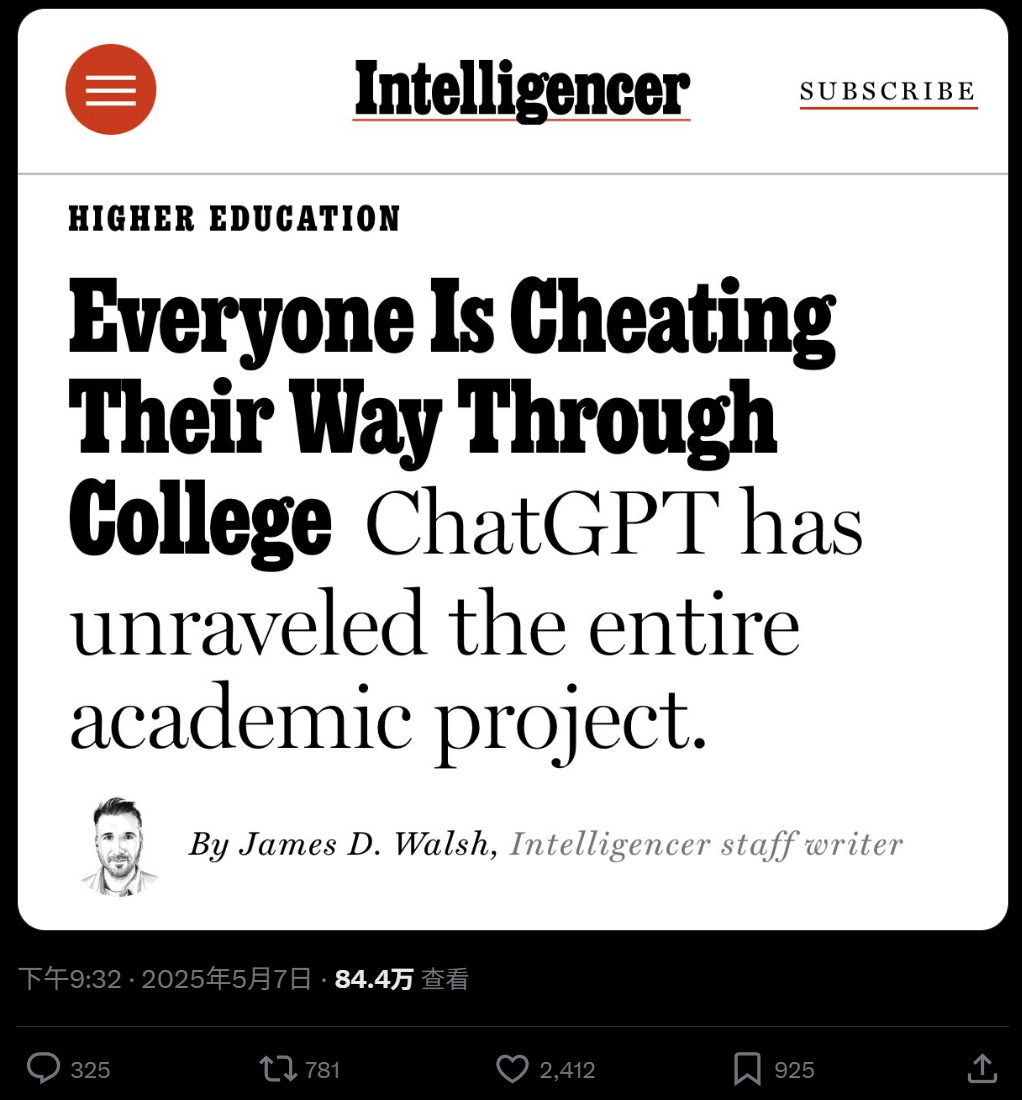
대학 교육에서 AI의 광범위한 사용과 부정행위 우려: 《New York Magazine》 보도에 따르면 북미 대학에서 과제 및 논문 작성을 위해 AI 도구(예: ChatGPT)가 광범위하게 사용되고 있는 현상이 드러났습니다. 학생들은 AI를 노트 필기, 학습, 연구는 물론 과제 내용 직접 생성에까지 활용하고 있어 학문적 정직성, 교육의 질, 학생들의 비판적 사고 능력 저하에 대한 우려를 낳고 있습니다. 교육자들은 교육 및 평가 방식을 조정하려고 시도하고 있지만, AI 탐지 도구의 효과성에 의문이 제기되면서 AI 부정행위를 근절하기 어려운 상황입니다. (출처: WeChat)
💡 기타
Cohere, 정부 AI 애플리케이션의 파일럿에서 프로덕션 전환 과제 논의: Cohere는 대부분의 정부 AI 프로젝트가 여전히 파일럿 단계에 머물러 있다고 지적합니다. 파일럿에서 실제 프로덕션 애플리케이션으로 도약하기 위해 정부 기관은 신뢰할 수 있는 도구, 명확한 성과 지향, 효율적인 인프라 및 적합한 파트너가 필요합니다. 이 글은 정부 기관이 안전하고 효율적인 AI를 통해 실험에서 실제 응용으로 어떻게 전환할 수 있는지 탐구합니다. (출처: cohere)

Mustafa Suleyman: 대규모 언어 모델은 규모가 클수록 제어하기 쉽다: Inflection AI의 공동 창립자 Mustafa Suleyman은 일반적인 우려와 달리 대규모 언어 모델(LLM)은 규모가 클수록 실제로 제어하기가 더 쉽다고 주장합니다. 그는 몇 세대 전의 모델은 유도하고, 스타일화하고, 형성하기가 더 어려웠으며, 규모의 확대는 모델의 제어 가능성을 약화시키는 것이 아니라 향상시키는 데 도움이 된다고 지적합니다. (출처: mustafasuleyman)
AI 윤리 토론: AI가 초래한 피해 또는 편향의 책임 소재: 한 Reddit 게시물은 다음과 같은 토론을 촉발했습니다: AI 시스템(예: 의료 진단 AI)이 훈련 데이터 편향(예: 주로 밝은 피부색 이미지 기반 훈련으로 인해 어두운 피부색 환자 오진)으로 인해 피해를 입혔을 때 책임은 누가 져야 하는가? 이는 AI 개발자, 배포 기관, 규제 당국 등 여러 이해관계자의 책임 소재를 명확히 해야 하는 문제이며, AI 윤리 및 법적 프레임워크가 시급히 해결해야 할 핵심 의제입니다. (출처: Reddit r/ArtificialInteligence)