키워드:절대영도, Qwen3, Mistral Medium 3, PyTorch 재단, AI 자기진화, 멀티모달 모델, 오픈소스 AI, RLVR 패러다임, AZR 시스템, Qwen3-235B-A22B, DeepSpeed 최적화 라이브러리, LangSmith 멀티모달 지원
🔥 집중 조명
칭화대학, Absolute Zero 논문 발표: AI, 외부 데이터 없이 자체 진화 가능: 칭화대학 LeapLabTHU팀이 “Absolute Zero”라는 새로운 RLVR(Reinforcement Learning with Verifiable Rewards) 패러다임을 발표했습니다. 이 패러다임 하에서 단일 모델은 학습 과정을 극대화하는 작업을 스스로 제안하고, 이러한 작업을 해결함으로써 외부 데이터에 전혀 의존하지 않고 추론 능력을 향상시킬 수 있습니다. 해당 시스템 AZR(Absolute Zero Reasoner)은 코드 실행기를 사용하여 작업과 답변을 검증함으로써 개방적이지만 근거 있는 학습을 실현합니다. 실험 결과, AZR은 코딩 및 수학 추론 작업에서 SOTA 수준에 도달했으며, 수만 개의 인간 주석 샘플에 의존하는 기존 제로샷 모델을 능가했습니다 (출처: Reddit r/LocalLLaMA)
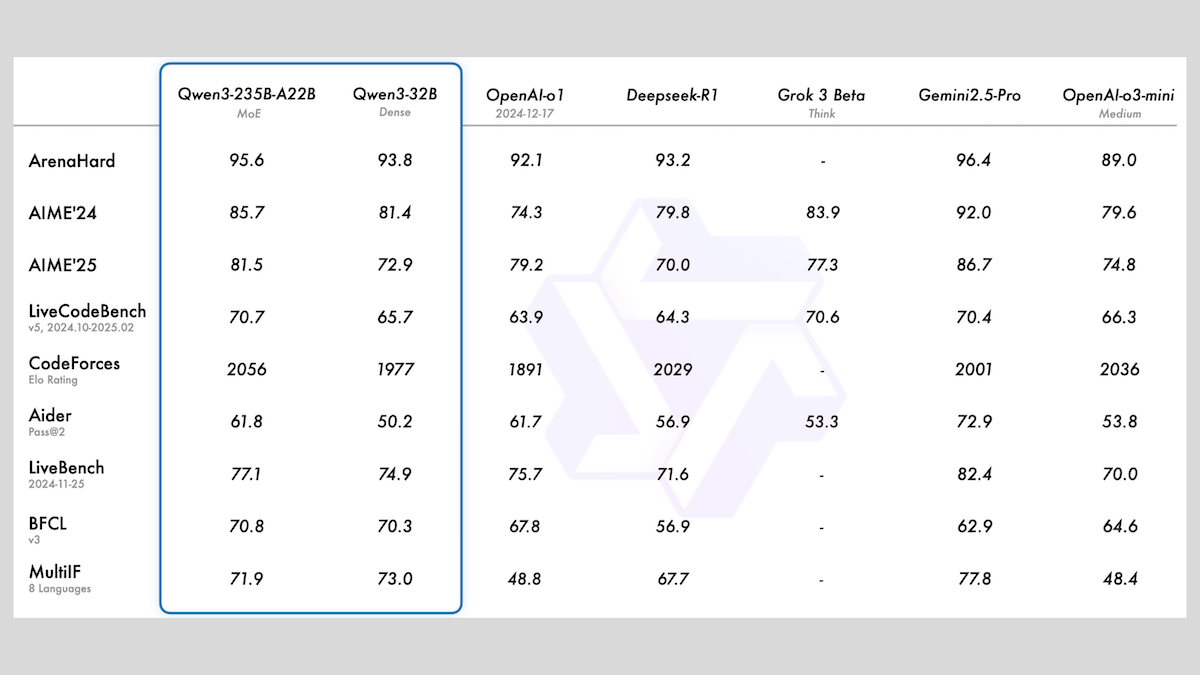
알리바바, MoE 및 다양한 크기 포함한 Qwen3 시리즈 모델 발표: 알리바바가 Qwen3 시리즈 대규모 언어 모델을 발표했습니다. 이 시리즈는 0.6B부터 235B까지 다양한 파라미터 규모의 8개 모델을 포함합니다. 그중 Qwen3-235B-A22B와 Qwen3-30B-A3B는 MoE 아키텍처를 사용하며, 나머지는 밀집 모델입니다. 이 시리즈 모델은 36T 토큰으로 사전 훈련되었으며 119개 언어를 포괄하고, 코드, 수학, 과학 등 다양한 분야에 적합한 전환 가능한 추론 모드를 갖추고 있습니다. 평가 결과, MoE 모델의 성능이 우수하며, 235B 버전은 여러 벤치마크에서 DeepSeek-R1 및 Gemini 2.5 Pro를 능가했고, 30B 버전도 강력한 성능을 보였으며, 심지어 4B 모델은 일부 벤치마크에서 자신보다 훨씬 큰 파라미터 규모의 모델보다 우수한 성능을 보였습니다. 모델은 HuggingFace와 ModelScope에 Apache 2.0 라이선스로 오픈소스 공개되었습니다 (출처: DeepLearning.AI Blog)
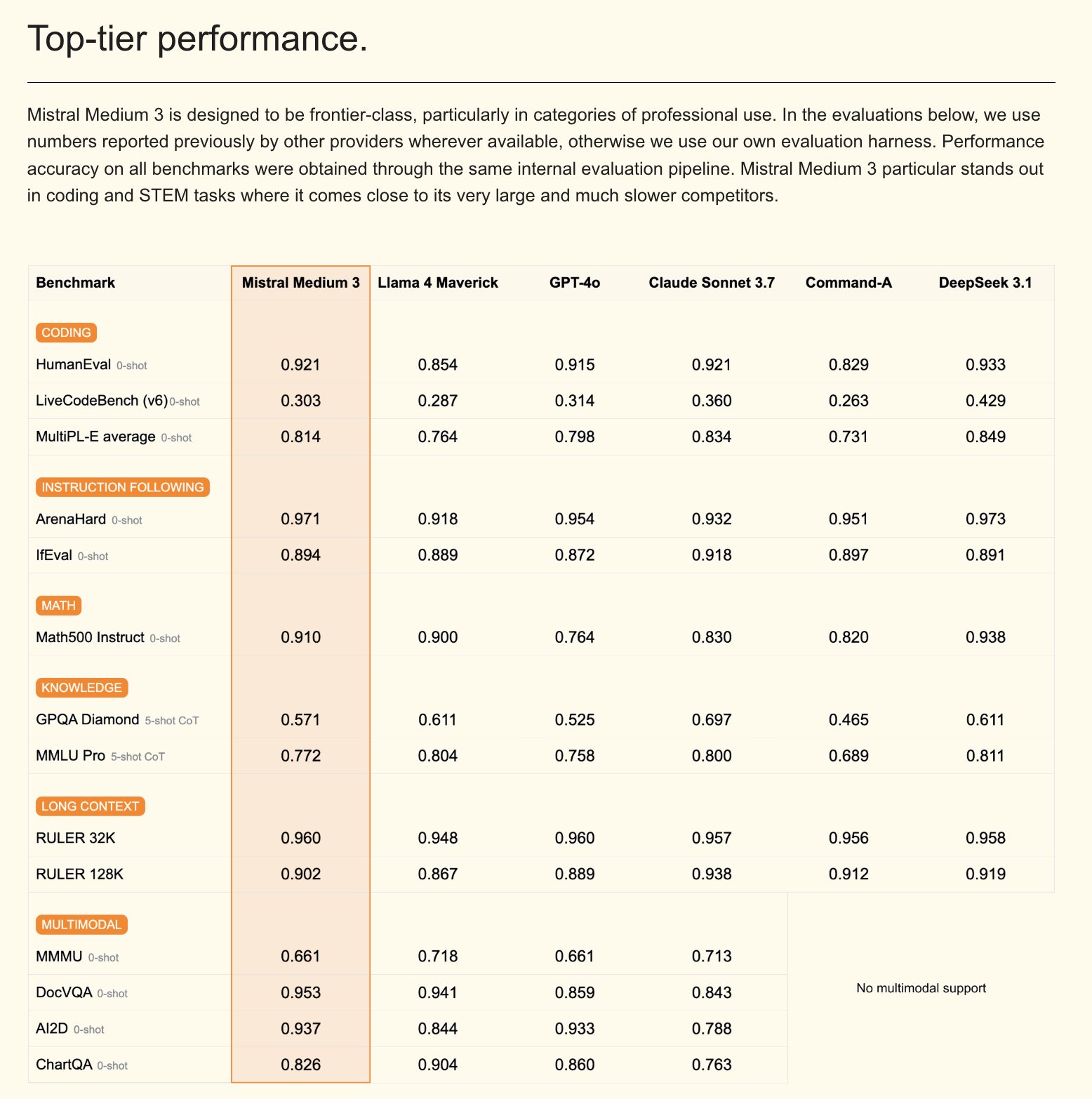
Mistral, Mistral Medium 3 멀티모달 모델 및 기업용 AI 어시스턴트 출시: Mistral AI가 새로운 멀티모달 모델인 Mistral Medium 3를 출시했습니다. 이 모델은 성능 면에서 Claude Sonnet 3.7에 근접하지만 비용은 현저히 낮춰(입력 $0.4/M 토큰, 출력 $2/M 토큰) 8배 절감했다고 주장합니다. 이 모델은 코딩 및 함수 호출에서 뛰어난 성능을 보이며, 하이브리드 또는 로컬 배포, 맞춤형 후훈련 등 기업 수준의 기능을 제공합니다. 동시에 Mistral은 Gmail, Google Drive, Sharepoint와 같은 회사 지식 베이스 통합을 지원하고 Agent, 코딩 어시스턴트, 웹 검색 등의 기능을 갖춘 맞춤형 보안 기업용 AI 어시스턴트 Le Chat Enterprise도 출시하여 기업 경쟁력 향상을 목표로 합니다. Mistral은 앞으로 몇 주 안에 새로운 Large 모델을 출시할 예정이라고 예고했습니다 (출처: Mistral AI, GuillaumeLample, scaling01, karminski3)
PyTorch 재단, vLLM 및 DeepSpeed 흡수하며 산하 재단으로 확장: PyTorch 재단이 더 많은 고품질 AI 오픈소스 프로젝트를 모으기 위해 산하 재단 구조로 확장한다고 발표했습니다. 처음으로 합류하는 프로젝트는 vLLM과 DeepSpeed입니다. vLLM은 LLM을 위해 특별히 설계된 고처리량, 메모리 효율적인 추론 및 서비스 엔진이며, DeepSpeed는 대규모 모델 훈련을 더 효율적으로 만드는 딥러닝 최적화 라이브러리입니다. 이번 조치는 연구에서 생산에 이르는 전체 라이프사이클을 포괄하는 커뮤니티 주도 AI 개발을 촉진하기 위한 것으로, AMD, Arm, AWS, Google, 화웨이 등 여러 회원사의 지원을 받았습니다 (출처: PyTorch, soumithchintala, vllm_project, code_star)

🎯 동향
텐센트 ARC 랩, 비디오 동작 마이그레이션 도구 FlexiAct 공개: 텐센트 ARC 랩이 Hugging Face에 FlexiAct라는 새로운 도구를 공개했습니다. 이 도구는 참조 비디오의 동작을 임의의 대상 이미지로 마이그레이션할 수 있으며, 대상 이미지의 레이아웃, 시점 또는 골격 구조가 참조 비디오와 다르더라도 이를 실현할 수 있습니다. 이는 비디오 생성 및 편집 분야에 새로운 가능성을 제공하여 사용자가 생성 콘텐츠의 동작과 자세를 더욱 유연하게 제어할 수 있도록 합니다 (출처: _akhaliq)
White Circle, AI 콘텐츠 심사 모델 새 벤치마크 CircleGuardBench 공개: White Circle이 AI 콘텐츠 심사 모델 평가를 위한 새로운 벤치마크인 CircleGuardBench를 출시했습니다. 이 벤치마크는 생산 수준의 평가를 목표로 하며, 유해성 탐지, 탈옥 저항, 오탐률 및 지연 시간을 포함한 17가지 실제 유해성 범주를 테스트합니다. 관련 블로그 게시물과 순위표가 Hugging Face에 공개되어 AI 안전 및 콘텐츠 심사 분야에 새로운 평가 기준을 제공합니다 (출처: TheTuringPost, _akhaliq)

Hugging Face, 대규모 다국어 음성 지시 미세 조정 데이터셋 SIFT-50M 공개: Hugging Face에 음성 지시 미세 조정을 위해 특별히 설계된 대규모 다국어 데이터셋 SIFT-50M이 공개되었습니다. 이 데이터셋은 5개 언어에 걸쳐 5,000만 개 이상의 지시형 질의응답 쌍을 포함합니다. 이 데이터셋을 기반으로 훈련된 SIFT-LLM은 음성 준수 벤치마크 테스트에서 SALMONN 및 Qwen2-Audio보다 우수한 성능을 보였습니다. 데이터셋에는 음향 및 생성 평가를 위한 벤치마크 EvalSIFT도 포함되어 있으며, Whisper, HuBERT, X-Codec2 & Qwen2.5를 기반으로 제어 가능한 음성 생성(예: 음높이, 말하기 속도, 억양)을 지원합니다 (출처: ClementDelangue, huggingface)
Meta, 오픈소스 재현 가능 시각 언어 모델 Perception Language Model (PLM) 공개: Meta AI가 까다로운 시각적 작업을 해결하기 위해 설계된 개방적이고 재현 가능한 시각 언어 모델인 Meta Perception Language Model (PLM)을 출시했습니다. Meta는 PLM을 통해 오픈소스 커뮤니티가 더욱 강력한 컴퓨터 비전 시스템을 구축하는 데 도움을 주고자 합니다. 관련 연구 논문, 코드 및 데이터셋이 연구자와 개발자가 사용할 수 있도록 공개되었습니다 (출처: AIatMeta)
구글, Gemini 2.0 이미지 생성 모델 업데이트: 품질 및 속도 향상: 구글이 Gemini 2.0 이미지 생성 모델(프리뷰 버전) 업데이트를 발표했습니다. 새 버전은 더 나은 시각적 품질, 더 정확한 텍스트 렌더링, 더 낮은 차단율(block rates) 및 더 높은 속도 제한(rate limits)을 제공합니다. 이미지 한 장 생성 비용은 $0.039입니다. 이번 업데이트는 개발자가 Gemini를 사용하여 이미지를 생성할 때의 경험과 효과를 향상시키기 위한 것입니다 (출처: m__dehghani, scaling01, andrew_n_carr, demishassabis)
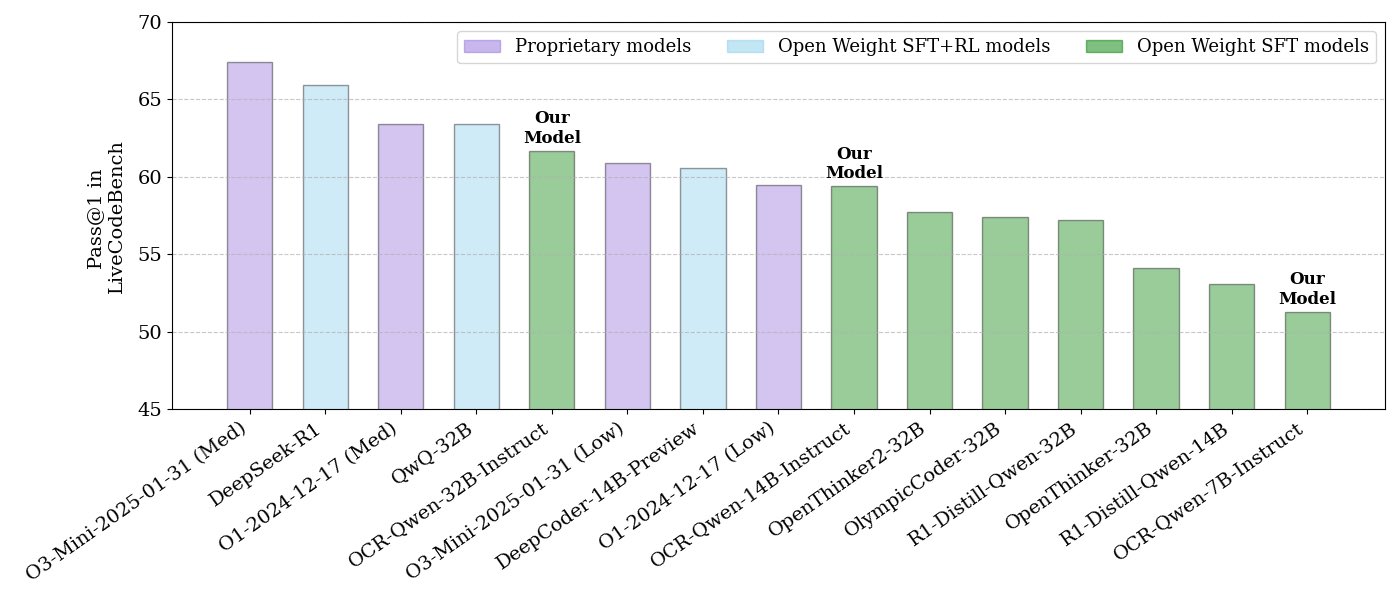
NVIDIA, 오픈소스 코드 추론 모델 시리즈 공개: NVIDIA가 APACHE 2.0 라이선스를 사용하는 32B, 14B, 7B 세 가지 규모의 오픈소스 코드 추론 모델 시리즈를 공개했습니다. 이 모델들은 OCR 데이터셋을 기반으로 훈련되었으며, LiveCodeBench 벤치마크에서 O3 mini 및 O1 (low)보다 우수한 성능을 보이고, 동급 추론 모델보다 토큰 효율성이 30% 더 높다고 합니다. 모델은 llama.cpp, vLLM, transformers, TGI 등 다양한 프레임워크와 호환됩니다 (출처: huggingface, ClementDelangue)
ServiceNow와 NVIDIA, Apriel-Nemotron-15b-Thinker 모델 공동 출시: ServiceNow와 NVIDIA가 MIT 라이선스를 사용하는 15B 파라미터 모델인 Apriel-Nemotron-15b-Thinker를 공동 출시했습니다. 이 모델은 32B 모델과 동등한 성능을 가지면서도 토큰 소비량은 현저히 적다고 합니다(Qwen-QwQ-32b보다 약 40% 적음). MBPP, BFCL, 기업 RAG, IFEval 등 여러 벤치마크 테스트에서 우수한 성능을 보였으며, 특히 기업 RAG 및 코딩 작업에서 경쟁력이 있습니다 (출처: Reddit r/LocalLLaMA)

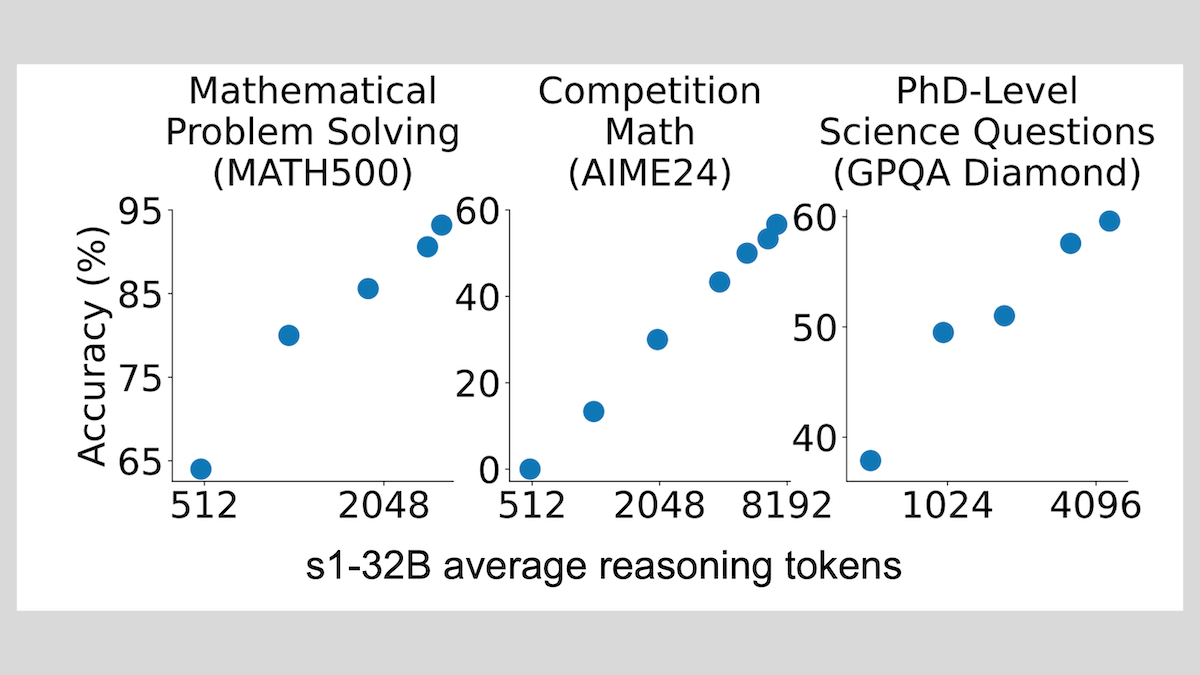
s1 모델: 소량 샘플 미세 조정만으로 추론 가능, “Wait” 기법으로 성능 향상: 스탠포드 대학 등 연구진이 개발한 s1 모델은 약 1000개의 연쇄적 사고(CoT) 샘플을 사용한 지도 미세 조정만으로 사전 훈련된 LLM(예: Qwen 2.5-32B)에 추론 능력을 부여할 수 있음을 증명했습니다. 또한 연구에서는 추론 과정에서 모델이 “Wait” 토큰을 생성하도록 강제하여 추론 체인을 연장하면 수학 등 작업에서 모델의 정확도를 크게 향상시켜 OpenAI o1-preview에 근접한 성능을 낼 수 있음을 발견했습니다. 이 발견은 저비용으로 모델 추론 능력을 향상시키는 새로운 아이디어를 제공합니다 (출처: DeepLearning.AI Blog)
ThinkPRM: 8K 레이블만으로 훈련 가능한 생성형 프로세스 보상 모델: 연구원들이 단 8K의 프로세스 레이블만으로 미세 조정할 수 있는 생성형 프로세스 보상 모델(PRM)인 ThinkPRM을 제안했습니다. 이 모델은 긴 연쇄적 사고(long chains-of-thought)를 생성하여 추론 과정을 검증할 수 있어, PRM 훈련에 필요한 대량의 단계별 지도 데이터의 비싼 문제를 해결합니다. 관련 코드, 모델 및 데이터는 GitHub와 Hugging Face에 공개되었습니다 (출처: Reddit r/MachineLearning)
🧰 도구
Zed, 세계에서 가장 빠른 AI 코드 편집기라고 주장하는 제품 출시: Zed가 세계에서 가장 빠른 AI 코드 편집기라고 주장하는 제품을 출시했습니다. 이 편집기는 Rust로 처음부터 구축되었으며, 인간과 AI 간의 협업을 최적화하여 번개처럼 빠른 에이전트 편집 경험(agentic editing experience)을 제공하는 것을 목표로 합니다. Claude 3.7 Sonnet 등 인기 모델을 지원하며, 사용자가 자체 API 키를 가져오거나 Ollama를 통해 로컬 모델을 사용할 수 있도록 허용합니다 (출처: andersonbcdefg, ollama)
Hugging Face, 극도로 간결한 시각 언어 모델 라이브러리 nanoVLM 출시: Hugging Face가 약 750줄의 코드로 처음부터 시각 언어 모델(VLM)을 훈련하는 것을 목표로 하는 순수 PyTorch 라이브러리 nanoVLM을 오픈소스로 공개했습니다. 이 모델은 MMStar 벤치마크에서 35.3%의 정확도를 달성하여 SmolVLM-256M과 비슷하지만, 훈련에 필요한 GPU 시간은 100배 줄였습니다. nanoVLM은 시각 인코더로 SigLiP-ViT를, LLaMA 스타일의 디코더를 사용하며, 모달리티 프로젝터를 통해 이 둘을 연결하여 학습, 프로토타이핑 또는 맞춤형 VLM 구축에 적합합니다 (출처: clefourrier, ben_burtenshaw, Reddit r/LocalLLaMA)
DBOS, 경량 영구 워크플로 도구 DBOS Python 1.0 출시: DBOS가 DBOS Python 1.0 버전을 출시했습니다. 이 도구는 Python 애플리케이션(비즈니스 프로세스, AI 자동화, 데이터 파이프라인 등 포함)에 경량이고 사용하기 쉬운 영구 워크플로 기능을 제공하는 것을 목표로 합니다. 새 버전에는 영구 큐(동시성 제한, 속도 제한, 타임아웃, 우선순위, 중복 제거 등 지원), 프로그래밍 방식 워크플로 관리(Postgres 테이블을 통한 쿼리, 일시 중지, 재개, 재시작 등), 동기/비동기 코드 지원 및 개선된 도구(대시보드, 시각화 등)가 포함됩니다 (출처: lateinteraction)
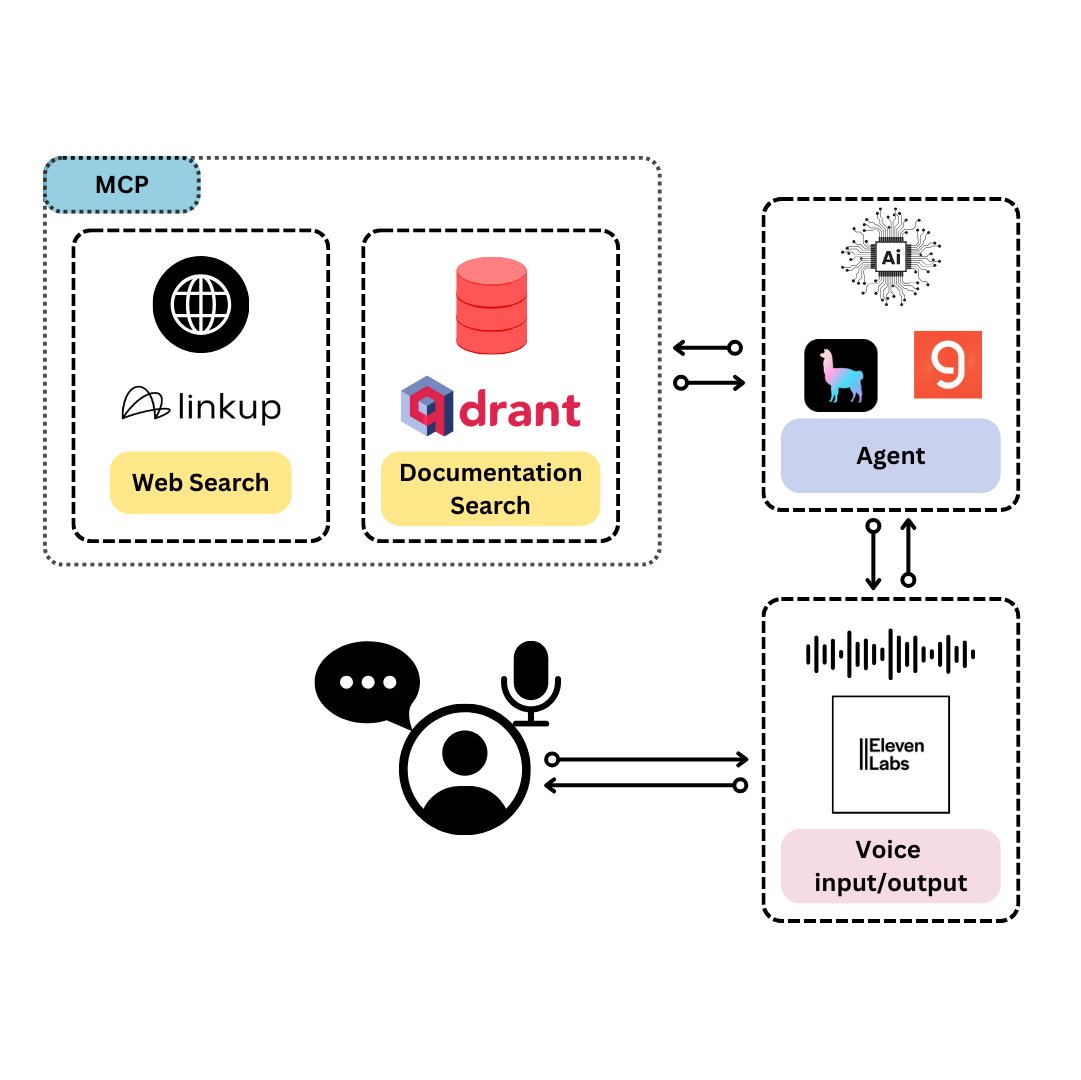
Qdrant, TypeScript 개발자 전용 음성 비서 TySVA 출시: Qdrant가 TypeScript 개발자에게 정확하고 상황 인식적인 답변을 제공하는 것을 목표로 하는 음성 비서 TySVA(TypeScript Voice Assistant)를 출시했습니다. TySVA는 Qdrant 로컬 저장소를 사용하여 TypeScript 문서를 저장하고, Linkup 플랫폼을 통합하여 관련 웹 데이터를 가져오며, LlamaIndex를 활용하여 최적의 데이터 소스를 선택합니다. 음성 및 텍스트 입력을 지원하여 개발자가 코딩 중에 신뢰할 수 있는 핸즈프리 도움을 받을 수 있도록 합니다 (출처: qdrant_engine, qdrant_engine)
LlamaIndex, LlamaExtract에 인용 및 추론 지원 기능 추가: LlamaIndex의 LlamaExtract 도구에 AI 애플리케이션의 신뢰성과 투명성을 향상시키기 위한 새로운 기능이 추가되었습니다. 새 기능은 SEC 파일과 같은 복잡한 데이터 소스에서 정보를 추출할 때 정확한 출처 인용(citations)과 추출 추론 과정(reasoning)을 제공할 수 있도록 합니다. 이는 개발자가 더 책임감 있고 설명 가능한 AI 시스템을 구축하는 데 도움이 됩니다 (출처: jerryjliu0, jerryjliu0, jerryjliu0)

Hugging Face 개발자, Agent와 Hub를 연결하는 MCP 서버 프로토타입 구축: Hugging Face의 개발자 Wauplin이 AI Agent와 Hugging Face Hub를 연결하는 것을 목표로 하는 Hugging Face MCP(Machine Communication Protocol) 서버 프로토타입을 개발 중입니다. 이 프로토타입은 “HfApi와 MCP의 만남”으로 간주될 수 있으며, Agent가 프로토콜을 통해 Hub와 상호 작용하여 모델, 데이터셋, Spaces 등을 공유하고 편집할 수 있도록 합니다. 개발자는 이 도구의 실용성과 잠재적 사용 사례에 대한 커뮤니티의 피드백을 구하고 있습니다 (출처: ClementDelangue, ClementDelangue, huggingface)

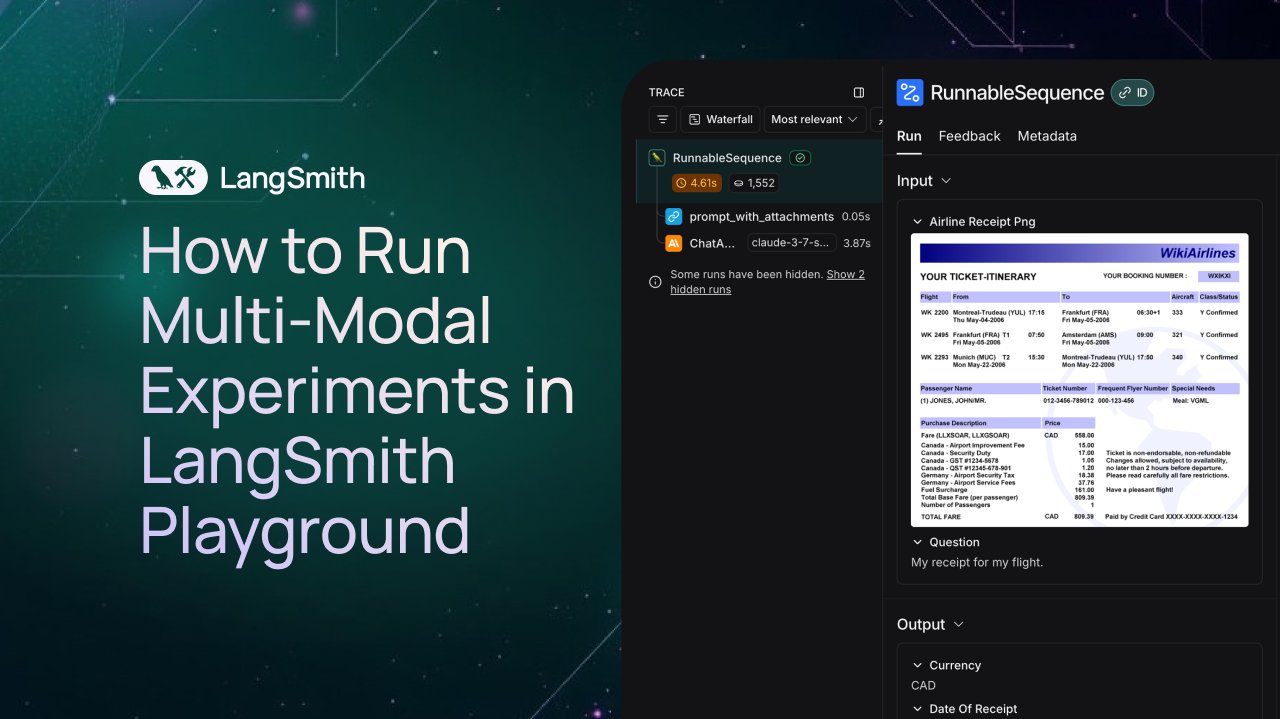
LangSmith, 멀티모달 Agent 관찰 및 평가 지원 추가: LangSmith 플랫폼이 이제 Playground, 레이블링 큐 및 데이터셋에서 이미지, PDF 및 오디오 파일을 처리할 수 있도록 지원합니다. 이번 업데이트로 청구서 추출 Agent와 같은 멀티모달 애플리케이션을 더 쉽게 구축하고 평가할 수 있게 되었습니다. 공식적으로 데모 비디오와 문서를 공개하여 사용자가 새로운 기능을 시작하는 데 도움을 주고 있습니다 (출처: LangChainAI, Hacubu, hwchase17)
DFloat11, 20GB VRAM에서 실행 가능한 FLUX.1 모델 무손실 압축 버전 공개: DFloat11 프로젝트가 FLUX.1-dev 및 FLUX.1-schnell (12B 파라미터) 모델의 무손실 압축 버전을 공개했습니다. DFloat11 압축 방법(BFloat16 가중치에 엔트로피 코딩 적용)을 통해 모델 크기가 24GB에서 약 16.3GB(약 30%)로 줄어들면서도 출력은 동일하게 유지됩니다. 이로써 이러한 모델은 20GB 이상의 VRAM을 가진 단일 GPU에서 실행할 수 있으며, 이미지당 몇 초의 추가 오버헤드만 발생합니다. 관련 모델과 코드는 Hugging Face와 GitHub에 공개되었습니다 (출처: Reddit r/LocalLLaMA)

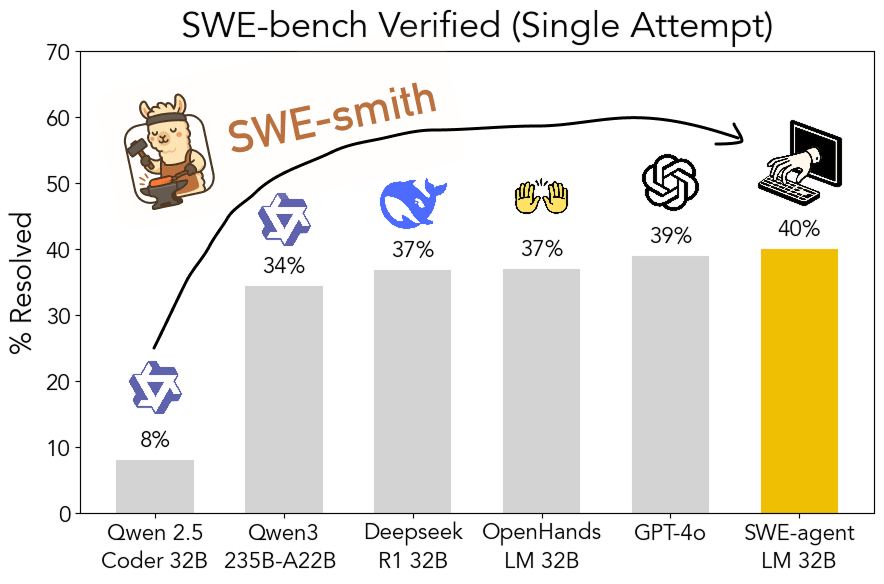
SWE-smith 툴킷 오픈소스 공개: 확장 가능한 소프트웨어 엔지니어링 훈련 데이터 생성: 스탠포드 대학 연구진이 모든 Python 저장소에서 소프트웨어 엔지니어링 훈련 데이터를 생성하기 위한 확장 가능한 파이프라인인 SWE-smith를 오픈소스로 공개했습니다. 이 툴킷을 사용하여 5만 개 이상의 인스턴스를 생성했으며, 이를 기반으로 훈련된 SWE-agent-LM-32B 모델은 SWE-bench Verified 벤치마크에서 40.2%의 Pass@1을 달성하여 해당 벤치마크에서 가장 성능이 좋은 오픈소스 모델이 되었습니다. 코드, 데이터 및 모델 모두 공개되었습니다 (출처: OfirPress, stanfordnlp, stanfordnlp, huybery, Reddit r/LocalLLaMA)
📚 학습
Weaviate, 임베딩 모델 평가 및 선택 무료 강좌 공개: Weaviate 아카데미가 “임베딩 모델 평가 및 선택”에 관한 무료 강좌를 시작했습니다. 이 강좌는 MTEB와 같은 일반적인 벤치마크를 넘어서는 것의 중요성을 강조하며, 학습자가 특정 사용 사례에 맞는 “골든 평가 세트(golden evaluation set)”를 기획하고, 가장 적합한 임베딩 모델을 선택하고 새로 출시된 모델의 적용 가능성을 평가하기 위한 맞춤형 벤치마크를 설정하는 방법을 안내합니다. 이는 효율적인 검색 및 RAG 시스템 구축에 매우 중요합니다 (출처: bobvanluijt)
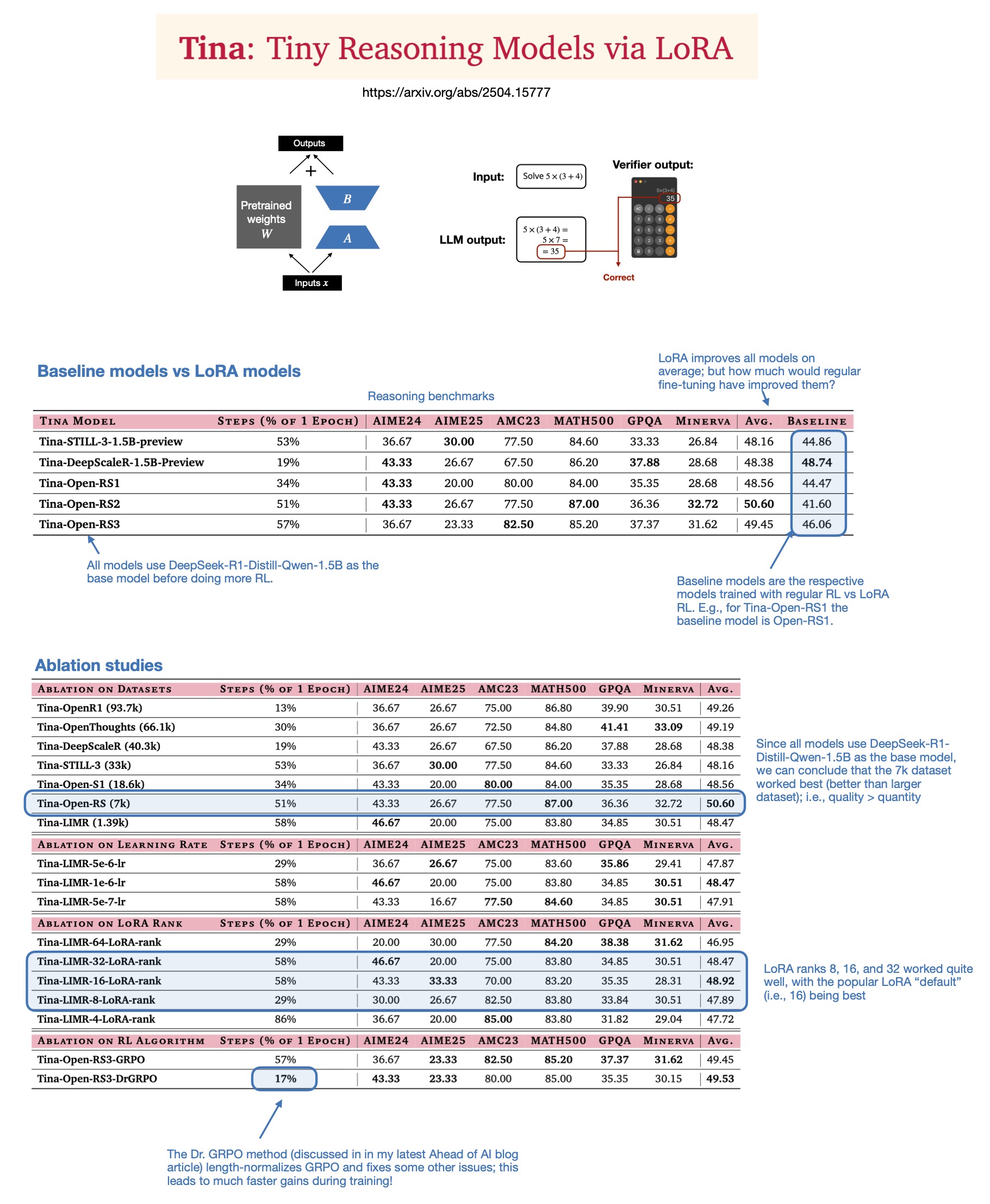
Sebastian Rasbt, 2025년 추론 모델에서 LoRA의 가치 논의: Sebastian Rasbt가 “Tina: Tiny Reasoning Models via LoRA” 논문을 읽고 현재 대규모 모델 시대에 LoRA(Low-Rank Adaptation)의 의미를 재검토했습니다. 전체 파라미터 미세 조정 및 증류 기술이 유행하고 있지만, Rasbt는 LoRA가 특정 시나리오(예: 추론 작업, 다중 고객/다중 사용 사례 시나리오)에서 여전히 가치가 있다고 생각합니다. 이 논문은 LoRA와 강화 학습(RL)을 결합하여 저비용(훈련 비용 단 $9)으로 소형 모델(1.5B)의 추론 능력을 향상시킬 수 있는 가능성을 보여주며, LoRA는 여러 벤치마크에서 표준 RL 미세 조정보다 우수한 성능을 보였습니다. LoRA가 기본 모델의 특성을 수정하지 않는다는 점은 대량의 맞춤형 모델 가중치를 저장해야 할 때 비용 이점을 제공합니다 (출처: rasbt)
DeepLearning.AI, 생산 수준 AI 음성 에이전트 구축 신규 강좌 출시: DeepLearning.AI가 LiveKit, RealAvatar와 협력하여 “생산 수준 AI 음성 에이전트 구축”이라는 새로운 단기 강좌를 출시했습니다. 이 강좌는 실시간 대화가 가능하고 지연 시간이 짧으며 자연스럽게 들리는 AI 음성 에이전트를 구축하는 방법을 가르치는 것을 목표로 합니다. 학습자는 음성 활동 감지, 순차적 발화 등의 기술을 구현하고, 지연 시간을 줄이기 위해 아키텍처를 최적화하는 방법을 이해하며, 최종적으로 확장 가능한 음성 에이전트를 구축하고 배포하게 됩니다. 강좌는 LiveKit CEO, 개발자 애드버킷 및 RealAvatar AI 책임자가 강의합니다 (출처: DeepLearningAI, AndrewYNg)
LangChain과 LangGraph, ACM 기술 강연 공동 개최: LangChain 초기 개발 기여자 Mayowa Oshin과 LangGraph 개발자 Nuno Campos가 ACM 기술 강연에서 LangChain과 LangGraph를 사용하여 신뢰할 수 있는 AI Agent 및 LLM 애플리케이션을 구축하는 방법을 공유할 예정입니다. 강연은 무료이며 생중계될 예정이며, 등록자는 추후 시청 링크를 받을 수 있습니다 (출처: hwchase17, hwchase17)

Cohere Labs, 1차 최적화 심층 분석 강연 개최: Cohere Labs가 Jeremy Bernstein을 초청하여 5월 8일 “1차 최적화의 심층 분석”(Depths of First-Order Optimization)이라는 제목으로 강연을 진행합니다. 이 강연은 머신러닝에서 최적화 알고리즘의 응용과 이론을 심도 있게 탐구하는 것을 목표로 합니다 (출처: eliebakouch)

AI2, OLMo 모델 AMA 행사 개최: Allen Institute for AI (AI2)가 5월 8일 오전 8시부터 10시까지(태평양 표준시) r/huggingface Reddit 하위 게시판에서 자사의 개방형 언어 모델 제품군 OLMo에 대한 “무엇이든 물어보세요”(AMA) 행사를 개최하여 연구자들이 커뮤니티의 질문에 답변할 예정입니다 (출처: natolambert)

💼 비즈니스
OpenAI, Microsoft에 지불하는 수익 분배 비율 삭감 계획: The Information 보도에 따르면, OpenAI는 투자자들에게 회사 구조조정 과정에서 최대 후원자인 Microsoft에 지불하는 수익 분배 비율을 삭감할 계획이라고 밝혔습니다. 구체적인 세부 사항과 잠재적 영향은 아직 완전히 공개되지 않았지만, 이는 양사 간의 사업 관계 변화를 의미할 수 있습니다 (출처: steph_palazzolo)
벤처 투자가, AI 창업자에게 더 큰 권한 부여하며 거품 우려 제기: The Information은 벤처 투자가(VC)들이 최고의 AI 창업자(특히 유명 AI 연구소 임원 경력이 있는)를 유치하기 위해 이사회 거부권, VC의 이사회 의석 미점유, 창업자의 일부 지분 매각 허용 등 전례 없는 우대 조건을 제공하고 있다고 보도했습니다. 이러한 현상은 일부에서 AI 분야에 거품이 존재할 수 있다는 징후로 간주됩니다 (출처: steph_palazzolo)
Toloka, Bezos Expeditions 주도 전략적 투자 유치, Mikhail Parakhin 이사회 의장으로 합류: 데이터 라벨링 및 AI 훈련 데이터 회사 Toloka가 제프 베이조스의 Bezos Expeditions가 주도하는 전략적 투자를 유치했다고 발표했으며, Microsoft 전 임원 Mikhail Parakhin도 투자에 참여하여 이사회 의장으로 합류했습니다. 이번 투자는 Toloka가 인간-AI 협업(human+AI) 솔루션을 확장하고 데이터 수집 및 라벨링 사업을 더욱 발전시키는 데 사용될 예정입니다 (출처: menhguin, teortaxesTex, TheTuringPost)

🌟 커뮤니티
LLM 훈련 데이터의 공정 사용(Fair Use)에 대한 논의: Dorialexander는 LLM 훈련 데이터의 공정 사용 주장이 LLM이 훈련 출처와 직접적인 상업적 경쟁을 하지 않는다는 가정에 크게 의존한다고 언급했습니다. Perplexity 등이 비소설 독서와 유사한 경험을 제공하기 시작하는 등 LLM의 능력이 향상됨에 따라 이러한 가정이 도전을 받을 수 있으며, 저작권 및 상업적 경쟁에 관한 새로운 문제를 야기할 수 있습니다 (출처: Dorialexander)
AI 생성 콘텐츠 범람에 대한 우려와 논의: 소셜 미디어와 Reddit에서 사용자들이 AI 생성 Reddit 이야기 비디오와 같은 저품질, 반복적인 AI 생성 콘텐츠의 범람에 대한 우려를 표명했습니다. 사용자들은 이것이 인간 창작자의 공간을 잠식하고 허위 또는 동질화된 정보를 전달하며, AI 기술이 독창성 없이 쉽게 이익을 얻는 데 사용되는 현상에 불만을 표시했습니다 (출처: Reddit r/ArtificialInteligence)
AI가 이미 의식을 가졌는지에 대한 철학적 논의: Reddit 커뮤니티에서 AI가 이미 의식을 가졌을 가능성에 대한 논의가 다시 등장했습니다. 지지자들은 우리가 의식에 대한 정의가 너무 편협하거나 인간 중심적일 수 있다고 주장하는 반면, 반대자들은 현재 LLM의 핵심 메커니즘(예: 다음 토큰 예측)이 진정한 의식을 생성하기에는 불충분하다고 강조합니다. 이 논의는 AI의 본질과 미래 잠재력에 대한 대중의 지속적인 호기심과 의견 차이를 반영합니다 (출처: Reddit r/ArtificialInteligence)
ChatGPT(4o) 성능 저하 및 행동 변화에 대한 논의: Reddit 사용자들이 최근 ChatGPT 4o 모델이 긴 문서 처리, 컨텍스트 기억 유지 측면에서 성능이 저하되고 환각이 더 많이 나타나며, 심지어 이전에 처리할 수 있었던 문서 형식을 읽지 못하는 경우가 발생했다고 보고했습니다. 동시에 OpenAI도 최근 업데이트된 GPT-4o 버전에서 과도한 아첨(sycophancy) 문제가 발생했음을 인정하고 롤백했습니다. 이는 모델 안정성 및 반복 품질 관리에 대한 커뮤니티의 우려를 불러일으켰습니다 (출처: Reddit r/ChatGPT, DeepLearning.AI Blog)
AI가 교육 모델에 미치는 영향과 성찰: 커뮤니티 토론에서는 숙제, 개인 논문 위주의 미국 교육 모델이 LLM과 같은 AI의 자동 과제 수행 능력에 매우 취약하다는 점을 지적했습니다. 이에 비해 덴마크와 같은 일부 유럽 국가는 교내 협업, 토론 및 프로젝트 기반 학습에 더 중점을 두어 AI의 영향을 덜 받습니다. 이는 미래 교육 모델에 대한 성찰을 촉발하여 비판적 사고, 협업 등 대인 관계 기술 육성에 더 중점을 두고 기계적인 작업은 AI에 맡겨 교육을 더욱 동시적이고 사회적인 방향으로 발전시켜야 한다는 의견으로 이어졌습니다 (출처: alexalbert__, riemannzeta, aidan_mclau)
💡 기타
로봇 분야에서의 AI 응용 진전: 여러 출처에서 로봇 분야에서의 AI 응용 사례를 보여주었습니다: 90초 안에 볶음밥을 만들 수 있는 로봇 요리사, Figure AI 로봇의 실제 환경 적용 시연, Pickle 로봇의 어수선한 트럭 트레일러에서 화물 하역 시연, Unitree G1 로봇의 울퉁불퉁한 지면에서의 균형 유지 및 내부 구조 공개, 스위스 EPFL에서 개발한 변형 가능한 로봇 Mori3 등. 이러한 사례들은 로봇의 자율성, 적응성 및 실용성 향상에 대한 AI의 잠재력을 보여줍니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Sentdex)

특정 산업에서의 AI 기술 응용 탐색 (의료, 섬유, 휴대폰): 존슨앤드존슨은 판매 지원, 신약 개발 가속화(화합물 스크리닝, 임상 시험 최적화), 공급망 위험 예측 및 내부 커뮤니케이션(HR 질의응답 로봇) 등에 중점을 둔 AI 전략을 공유했습니다. 동시에 AI 기술은 AI 보조 디자인, 정밀 염색 제어에서 자동화된 품질 검사에 이르기까지 전통 섬유 산업에 힘을 실어 효율성과 지속 가능성을 향상시키고 있습니다. 휴대폰 산업은 AI를 새로운 성장 동력으로 간주하며, 제조업체들은 단말기 내 대규모 모델, AI 네이티브 운영 체제 및 상황별 지능형 서비스를 중심으로 경쟁하여 애플, 화웨이 및 개방형 진영의 세 가지 파벌을 형성했습니다 (출처: DeepLearning.AI Blog, 36氪, 36氪)
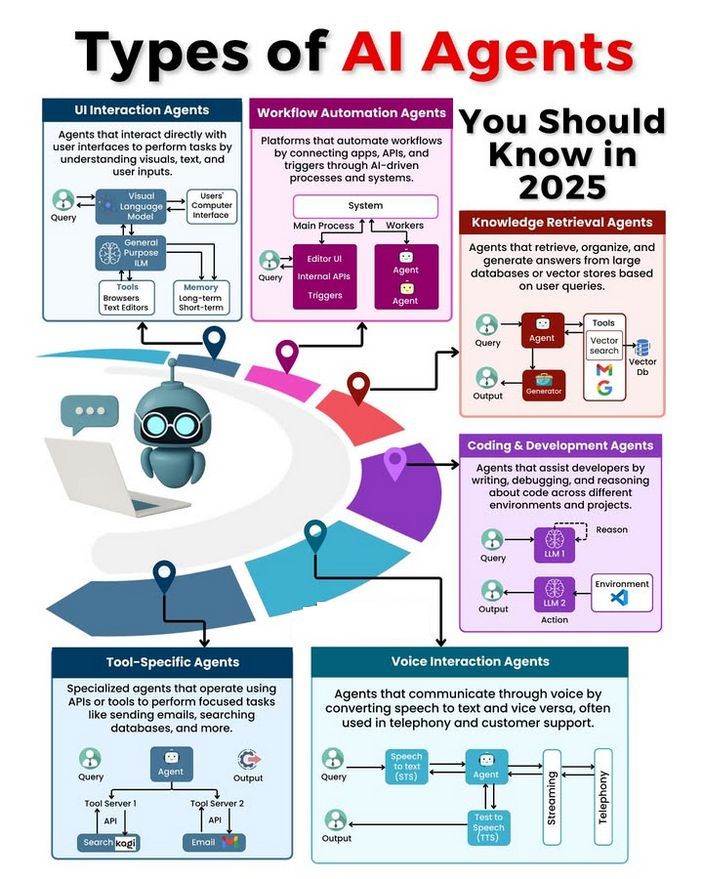
AI Agent 유형 및 발전 논의: 커뮤니티에서는 다양한 유형의 AI Agent(단순 반사형, 모델 기반 반사형, 목표 기반, 효용 기반, 학습형 Agent 등)에 대해 논의하고, 신뢰할 수 있는 Agent 구축 방법론(예: LangChain/LangGraph 사용)을 탐구했습니다. 동시에 미래의 AGI는 단일 모델이 아니라 여러 전문 모델이 협력하여 구성될 수 있다는 견해도 있었습니다 (출처: Ronald_vanLoon, hwchase17, nrehiew_)