
キーワード:AIモデル, OCR技術, AIインフラストラクチャ, 大規模言語モデル, AIエージェント, マルチモーダルモデル, AIエネルギー消費最適化, AIオープンソースエコシステム, DeepSeek OCRモデル, Gemini 3マルチモーダル推論, Emu3.5ワールドモデル, Kimi Linearハイブリッドアテンションアーキテクチャ, AgentFoldメモリーフォールディング技術
AIコラム編集長厳選
🔥 注目
DeepSeek OCRモデル:AIの記憶力における新たなブレイクスルーとエネルギー消費の最適化 : DeepSeekは、情報処理と記憶ストレージの方法に核心的な革新をもたらすOCRモデルを発表しました。このモデルはテキスト情報を画像形式に圧縮することで、実行に必要な計算リソースを大幅に削減し、AIの増大するカーボンフットプリントの緩和に貢献すると期待されています。この方法は、階層的な圧縮を通じて人間の記憶をシミュレートし、重要でないコンテンツをぼかすことでスペースを節約しつつ、高い効率を維持します。この研究は、Andrej Karpathyなどの専門家から注目されており、画像がテキストよりもLLMの入力として適している可能性があり、AIの記憶とエージェントアプリケーションに新たな方向性を開くものと見なされています。(ソース:MIT Technology Review)

テクノロジー大手、AIインフラに巨額投資を継続 : Microsoft、Meta、Googleなどのテクノロジー大手は、最新の決算報告でAIインフラへの支出を大幅に増やすことを発表しました。Metaは今年の設備投資が700億~720億ドルに達すると予測し、来年もさらに拡大する計画です。Microsoftのインテリジェントクラウド収益は初めて300億ドルを突破し、Azureおよびその他のクラウドサービスは40%成長し、AI生産能力は80%向上すると予測されています。GoogleのCEOであるSundar Pichaiは、AIのフルスタックアプローチが強力な推進力をもたらしていることを強調し、Gemini 3の近日リリースを予告しました。これらの投資は、大手企業がAIの将来的なブレイクスルーに対する楽観的な期待と、市場での先駆的な地位を確保する決意を反映しています。(ソース:Wired, Reddit r/artificial)

Anthropic、LLMが限定的な「内省能力」を持つことを発見 : Anthropicの最新研究により、Claudeのような大規模言語モデル(LLM)が「真の内省意識」を持っていることが示されましたが、この能力は現時点では限定的です。研究では、LLMが自身の内部思考を認識できるのか、それとも単に質問に基づいて合理的な回答を生成しているだけなのかが探求されました。この発見は、LLMが予想よりも深いレベルの自己認識を持っている可能性を示唆しており、よりスマートで意識的なAIシステムの理解と開発にとって重要な意味を持ちます。(ソース:Anthropic, Reddit r/artificial)

Extropic、新型熱力学計算ハードウェアTSUを発表、AIエネルギー消費のブレイクスルーを主張 : Extropic社は、新しい計算デバイスTSU (Thermodynamic Sampling Unit) を発表しました。その核となるのは「確率ビット」(P-bit)で、0と1の間をプログラム可能な確率で点滅し、AIのエネルギー消費を10,000倍効率化することを目指しています。同社はX0チップ、XTR0デスクトップテストスイート、Z1商業級TSUを発表し、GPUでTSUをシミュレートするためのThermolソフトウェアライブラリをオープンソース化しました。効率向上のベンチマーク定義には疑問の声もありますが、この方向性はAIの計算能力とエネルギーの巨大なギャップを解決することを目指しており、AI計算に潜在的なパラダイムシフトをもたらす可能性があります。(ソース:TheRundownAI, pmddomingos, op7418)

🎯 動向
Google、Gemini 3の近日リリースを予告、AIモデルファミリーの専門化トレンドを強化 : GoogleのCEO、Sundar Pichaiは決算電話会議で、新しいフラッグシップモデルGemini 3が今年後半にリリースされることを予告しました。彼は、GoogleのAIモデルファミリーが専門化の方向に向かっていることを強調し、Geminiはマルチモーダル推論に、Veoは動画生成に、Genieはインタラクティブエージェントに、Nanoはデバイス上のインテリジェンスに焦点を当てていると述べました。この戦略は、Googleが単一の汎用モデルから、相互接続され、異なるシナリオに最適化されたシステムアーキテクチャへと移行し、信頼性の向上、遅延の削減、エッジデプロイメントのサポートを目指していることを示しています。(ソース:Reddit r/ArtificialInteligence, shlomifruchter)
Sora 2、カスタムキャラクターと動画結合機能を追加、連続した長尺動画制作に対応 : Sora 2は最近、いくつかの重要な機能を更新しました。これには、他のキャラクターの作成サポート(実際の写真をアップロードすることはできませんが、既存の動画人物から作成可能)が含まれ、ユーザーはこの機能を利用してキャラクターの一貫性を確保し、連続した長尺動画の構築に不可欠です。さらに、下書きページでは複数の動画を結合して公開することができ、検索ページにはランキングが追加され、実写出演ショーや二次創作の達人が表示されます。これらの更新は、Sora 2の創作の柔軟性とユーザーインタラクションを大幅に向上させ、日次アクティブユーザーを大幅に増加させることが期待されます。(ソース:op7418, billpeeb, op7418)
BAAI、オープンソースのマルチモーダル世界モデルEmu3.5を発表、Gemini-2.5-Flash-Imageの性能を凌駕 : 北京智源人工智能研究院(BAAI)は、パラメータ数34Bのオープンソースマルチモーダル世界モデルEmu3.5を発表しました。このモデルはDecoder-only Transformerをフレームワークとして採用し、画像、テキスト、動画タスクを同時に処理し、次のState予測タスクとして統一します。Emu3.5は大量のインターネット動画データで事前学習されており、時空間の連続性と因果関係を理解する能力を持ち、ビジュアルナラティブ、ビジュアルガイダンス、画像編集、世界探索、具現化された操作などで優れた性能を発揮します。特に物理的リアリズムにおいて顕著な改善が見られ、Gemini-2.5-Flash-Image(Nano Banana)に匹敵するか、それを凌駕する性能を示しています。(ソース:36氪)

Moonshot AI、ハイブリッド線形アテンションアーキテクチャを採用したKimi Linearモデルを発表 : Moonshot AIは、Kimi Linearモデルを発表しました。これは、ハイブリッド線形アテンション(KDA)アーキテクチャに基づいた48Bパラメータモデルで、アクティブパラメータは3B、1Mのコンテキスト長をサポートします。Kimi LinearはGated DeltaNetを最適化することで、長文コンテキストタスクの性能とハードウェア効率を大幅に向上させ、KVキャッシュ要件を最大75%削減し、デコードスループットを6倍に向上させました。このモデルは、複数のベンチマークテストで優れた性能を発揮し、従来のFull Attentionモデルを凌駕し、Hugging Faceで2つのバージョンをオープンソース化しました。(ソース:Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, bigeagle_xd)

MiniMax M2モデル、Full Attentionアーキテクチャを堅持し、本番環境でのデプロイにおける課題を強調 : MiniMax M2の事前学習責任者であるHaohai Sunは、M2モデルがLinear AttentionやSparse Attentionではなく、Full Attentionアーキテクチャを採用している理由を説明しました。彼は、効率的なアテンションが理論的には計算能力を節約できるものの、実際の産業レベルのシステムでは、その性能、速度、価格がFull Attentionを上回ることは依然として難しいと指摘しました。主なボトルネックは、評価システムの限界、複雑な推論タスクにおける高額な実験コスト、およびインフラの未熟さです。MiniMaxは、長文コンテキスト能力を追求する上で、データ品質、評価システム、インフラの最適化が、アテンションアーキテクチャの変更よりも重要であると考えています。(ソース:Reddit r/LocalLLaMA, ClementDelangue)
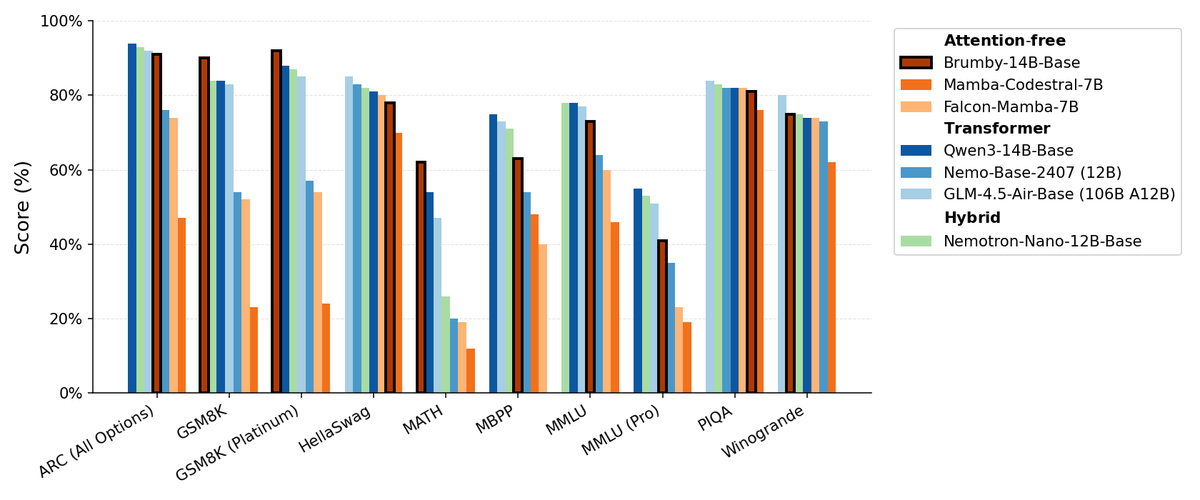
Manifest AI、Brumby-14B-Baseを発表、アテンションフリー基盤モデルを模索 : Manifest AIはBrumby-14B-Baseを発表し、これは現在最強のアテンションフリー基盤モデルであり、わずか4000ドルのコストで140億パラメータを学習したと主張しています。このモデルは、同規模のTransformerやハイブリッドモデルと同等の性能を示しており、Transformer時代の終焉がゆっくりと近づいている可能性を示唆しています。この進展は、AIモデルアーキテクチャに新たな可能性をもたらし、特に学習コストの削減において大きな潜在力を示し、従来のアテンションメカニズムの優位性に挑戦しています。(ソース:ClementDelangue, teortaxesTex)
新しいNemotronモデル、Qwen3 32BをベースにLLM応答品質を最適化 : NVIDIAは、Qwen/Qwen3-32Bをベースにファインチューニングされた大規模言語モデルQwen3-Nemotron-32B-RLBFFを発表しました。これは、LLMがデフォルトの思考モードで生成する応答の品質を向上させることを目的としています。この研究モデルは、Arena Hard V2、WildBench、MT Benchなどのベンチマークテストで元のQwen3-32Bよりも顕著に優れた性能を示し、DeepSeek R1やO3-miniと類似の性能を持ちながら、推論コストは5%以下であり、性能と効率の両面での進歩を示しています。(ソース:Reddit r/LocalLLaMA)

Mambaアーキテクチャ、長文コンテキスト処理で依然優位性を持つが、並列学習に制約 : Mambaアーキテクチャは、長文コンテキスト(数百万トークン)の処理において優れた性能を発揮し、Transformerのメモリ爆発問題を回避します。しかし、その主な制限は、学習中に並列化が困難であることであり、これが大規模なアプリケーションでの普及を妨げています。様々な線形ミキサーやハイブリッドアーキテクチャが存在するにもかかわらず、Mambaの並列学習の課題は、その大規模な応用における重要なボトルネックとなっています。(ソース:Reddit r/MachineLearning)
NVIDIA、ARC、Rubin、Omniverse DSXなどを発表、AIインフラにおけるリーダーシップを強化 : NVIDIAはGTCカンファレンスで一連の重要な発表を行いました。これには、NVIDIA ARC(空中RANコンピュータ)とNokiaとの6G開発協力、Rubin第三世代ラック規模スーパーコンピュータ、Omniverse DSX(ギガスケールAI工場を仮想的に共同設計・運用するための青写真)、NVIDIA Drive Hyperion(ロボットタクシー標準化アーキテクチャ)とUberとの提携が含まれます。これらの発表は、NVIDIAがチップメーカーから国家インフラのアーキテクトへと位置付けを変え、AIと6G時代の課題に対応するため「米国製」とエネルギー競争を強調していることを示しています。(ソース:TheTuringPost, TheTuringPost)

AgentFold:適応型コンテキスト管理でWebエージェントの効率を向上 : AgentFoldは、新しいコンテキストエンジニアリング技術を提案しました。「Memory Folding」を通じて、エージェントの過去の思考を構造化された記憶に圧縮し、認知ワークスペースを動的に管理します。この方法は、従来のReActエージェントのコンテキスト過負荷問題を解決し、BrowseCompなどのベンチマークテストで優れた性能を発揮し、DeepSeek-V3.1-671Bなどの大規模モデルを凌駕しました。AgentFold-30Bは、より少ないパラメータ数で競争力のある性能を実現し、Webエージェントの開発とデプロイ効率を大幅に向上させます。(ソース:omarsar0)

ReCode:計画と行動を統合し、AIエージェントの意思決定粒度を動的に制御 : ReCode(Recursive Code Generation)は、新しいパラメータ効率の良いファインチューニング(PEFT)手法であり、高レベルの計画を細粒度の行動に分解可能な再帰関数として捉えることで、AIエージェントの計画と行動の表現を統合します。この方法は、わずか0.02%の学習パラメータでSOTA性能を実現し、GPUメモリ使用量を削減します。ReCodeは、エージェントが異なる意思決定粒度に動的に適応し、階層的な意思決定を学習することを可能にし、効率とデータ利用率において従来の方法を大幅に上回ります。これは、人間のような推論を実現するための重要な一歩です。(ソース:dotey, ZhihuFrontier)

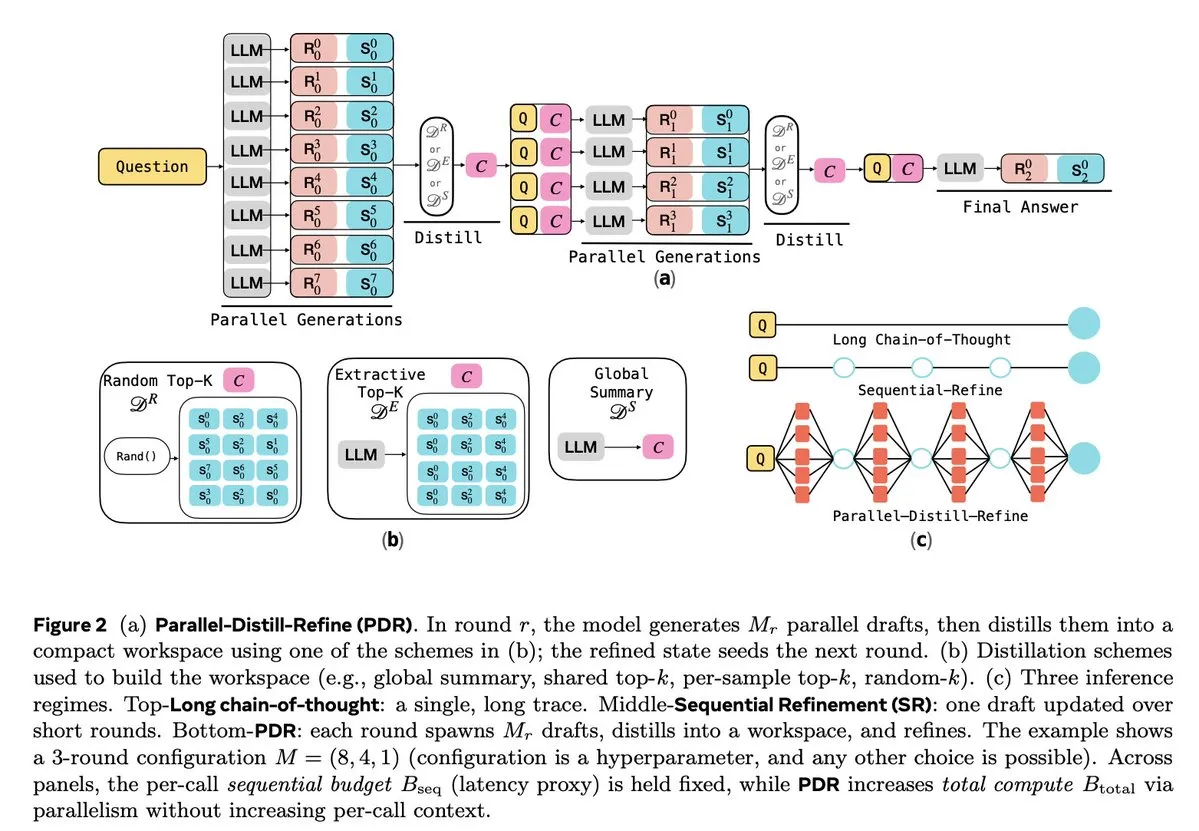
LLM推論と強化学習の最適化 : 複数の研究がLLMの推論効率と信頼性の向上に取り組んでいます。Parallel-Distill-Refine (PDR) は、ドラフトの並列生成と洗練を通じて、複雑な推論タスクのコストと遅延を削減します。Flawed-Aware Policy Optimization (FAPO) は、報酬ペナルティメカニズムを導入し、推論プロセスにおける欠陥パターンを修正して信頼性を向上させます。PairUniフレームワークは、ペアワイズ学習とPair-GPRO最適化アルゴリズムを通じて、マルチモーダルLLMの理解タスクと生成タスクのバランスを取ります。PM4GRPOは、プロセスマイニング技術を利用し、推論認識型GRPO強化学習を通じて、ポリシーモデルの推論能力を強化します。Fortytwoプロトコルは、分散型ピアランキングコンセンサスを通じて、AIグループ推論の優れた性能と敵対的プロンプトに対する強力な耐性を実現します。(ソース:NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 ツール
Tencent、LLM駆動のドキュメント理解・検索フレームワークWeKnoraをオープンソース化 : Tencentは、複雑で異種混交のドキュメント処理のために特別に設計された、LLMベースのドキュメント理解およびセマンティック検索フレームワークWeKnoraをオープンソース化しました。これはモジュール式アーキテクチャを採用し、マルチモーダル前処理、セマンティックベクトルインデックス、インテリジェント検索、LLM推論を組み合わせ、RAGパラダイムに従い、関連するドキュメントチャンクとモデル推論を組み合わせることで、高品質でコンテキストを意識した回答を実現します。WeKnoraは、様々なドキュメント形式、埋め込みモデル、検索戦略をサポートし、ユーザーフレンドリーなWebインターフェースとAPIを提供し、ローカルデプロイメントとプライベートクラウドをサポートすることで、データ主権を保証します。(ソース:GitHub Trending)
Jan:オープンソースのオフラインChatGPT代替品、ローカルでのLLM実行をサポート : Janは、ユーザーのPC上で100%オフラインで動作するオープンソースのChatGPT代替品です。HuggingFaceからLLM(Llama、Gemma、Qwen、GPT-ossなど)をダウンロードして実行できるほか、OpenAI、Anthropicなどのクラウドモデルとの統合もサポートしています。Janは、カスタムアシスタント、OpenAI互換API、およびモデルコンテキストプロトコル(MCP)統合を提供し、プライバシー保護を重視し、ユーザーに完全に制御されたローカルAI体験を提供します。(ソース:GitHub Trending)

Claude Code:Anthropicのデベロッパーツールキットとスキルエコシステム : AnthropicのClaude Codeは、一連の「スキル」とエージェントを通じて、開発者の作業効率を大幅に向上させます。これには、Rube MCPコネクタ(Claudeを500以上のアプリケーションに接続)、Superpowers開発ツールキット(/brainstorm、/write-plan、/execute-planコマンドを提供)、ドキュメントスイート(Word/Excel/PDFを処理)、Theme Factory(ブランドガイドラインの自動化)、Systematic Debugging(上級開発者のデバッグプロセスをシミュレート)が含まれます。これらのツールは、モジュール設計とコンテキスト認識能力を通じて、開発者がワークフローの自動化、コードレビュー、リファクタリング、エラー修正を実現するのを支援し、非技術チームが独自のツールを構築することもサポートします。(ソース:Reddit r/ClaudeAI, Reddit r/ClaudeAI)

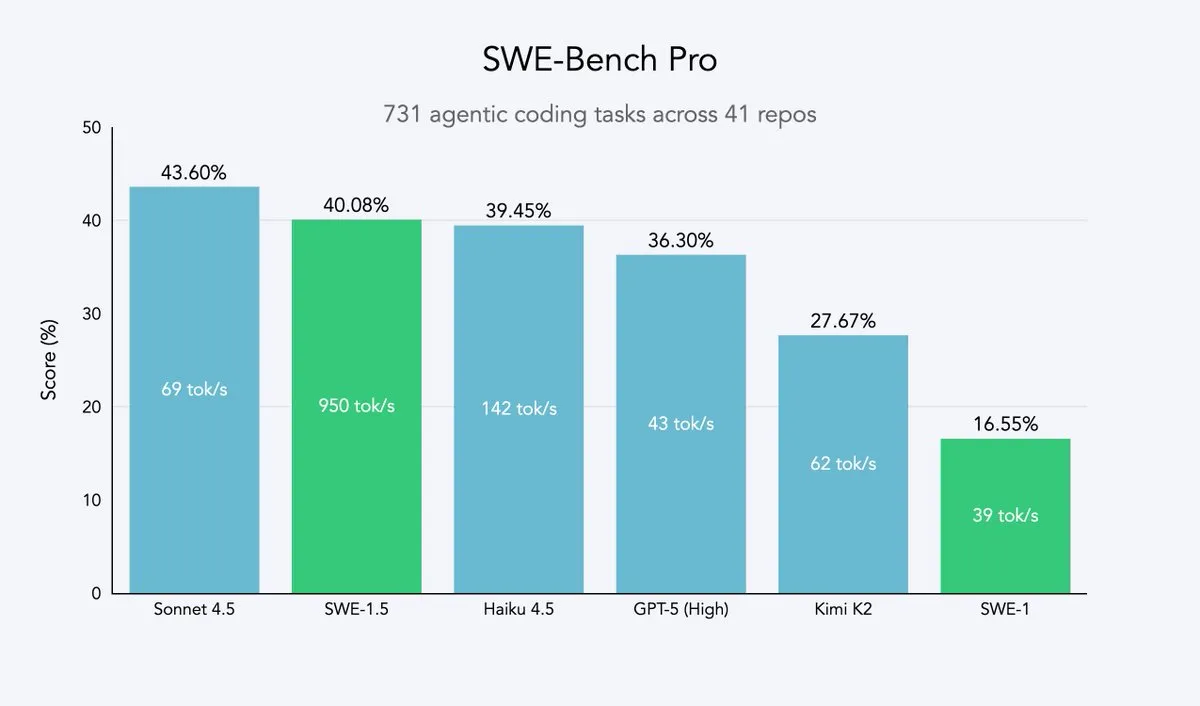
Cursor 2.0とWindsurf:コードエージェントが速度と効率を追求 : CursorとWindsurfは、速度最適化を重視したコードエージェントモデルと2.0プラットフォームを発表しました。その戦略は、オープンソースの大規模モデル(Qwen3など)をベースに強化学習でファインチューニングし、最適化されたハードウェアにデプロイすることで、「中程度の知能だが超高速」な効果を実現することです。このアプローチは、コードエージェント企業にとって、最小限のリソースコストで速度と知能のパレートフロンティアに近づくための効率的な戦略です。WindsurfのSWE-1.5モデルは、ほぼSOTAのコーディング性能を実現すると同時に、速度の新たな基準を確立しました。(ソース:dotey, Smol_AI, VictorTaelin, omarsar0, TheRundownAI)
Perplexity Patents:初のAI特許調査エージェント、IPインテリジェンスを強化 : Perplexityは、世界初のAI特許調査エージェントであるPerplexity Patentsを発表しました。これは、IPインテリジェンスを誰もが利用できるようにすることを目指しています。このツールは、特許間の検索と調査をサポートし、将来的には学術研究に特化したPerplexity Scholarもリリースされる予定です。この革新は、特許検索と分析プロセスを大幅に簡素化し、イノベーター、弁護士、研究者に効率的で使いやすい知的財産情報サービスを提供します。(ソース:AravSrinivas)

Real Deep Research (RDR):AI駆動の深層研究フレームワーク : Real Deep Research (RDR) は、研究者が現代科学の急速な発展に追いつくのを支援するために設計されたAI駆動のフレームワークです。RDRは、専門家による調査と自動化された文献マイニングの間のギャップを埋め、スケーラブルな分析プロセス、トレンド分析、分野横断的な洞察の接続、構造化された高品質な要約の生成を提供します。これは、研究者が全体像をよりよく理解するのに役立つ包括的な研究ツールとして機能します。(ソース:TheTuringPost)

LangSmith、ノーコードAgent Builderを発表、非技術チームによるエージェント構築を支援 : LangChainAIのLangSmithは、AIエージェントの構築ハードルを下げることを目的としたノーコードAgent Builderを発表しました。これにより、非技術チームでも簡単にエージェントを作成できるようになります。このツールは、対話型エージェント構築UX、エージェントが記憶し改善するのを助ける組み込みメモリ機能、および非技術チームと開発者が共同でエージェントを構築できるようにすることで、AIエージェントの普及と応用を加速させます。(ソース:LangChainAI)
Verdent、MiniMax-M2を統合し、コーディング能力と効率を向上 : Verdentは現在、MiniMax-M2モデルをサポートしており、ユーザーに高度なコーディング能力、高性能エージェント、効率的なパラメータアクティベーションを提供します。VerdentをVS Codeで無料で試用することで、開発者はよりスマートで、より速く、より費用対効果の高いコーディング体験を享受できます。この統合により、MiniMax-M2の強力な能力がより広範な開発者コミュニティに提供されます。(ソース:MiniMax__AI)
Base44、新しいBuilderを発表、コンセプトからアプリケーションへの変換を加速 : Base44は、その作業方法の根本的な変化を示す新しいBuilderを発表しました。新しいBuilderは、構築前に調査を行い、複数のソースからコンテキストを取得し、インテリジェントにデバッグし、情報に基づいたアーキテクチャ決定を下すことができる専門家開発者のようです。この更新は、コンセプトを機能的なアプリケーションに変換する速度を10倍に向上させることを目的としており、開発効率を大幅に高めます。(ソース:MS_BASE44)
QdrantとConfluentが提携、リアルタイムなコンテキスト認識型AIエージェントを強化 : QdrantとConfluentは提携し、Confluent Streaming AgentsとReal-Time Context Engineを通じて、インテリジェントなAIエージェントとエンタープライズアプリケーションに新鮮でリアルタイムなコンテキストを提供します。Qdrantのベクトル検索能力とConfluentのリアルタイムストリームデータを組み合わせることで、開発者はイベント駆動型でコンテキスト認識型のAIエージェントを構築・拡張できるようになり、エージェント型AIの可能性を最大限に引き出し、事故対応などのシナリオで解決時間を大幅に短縮し、コストを削減します。(ソース:qdrant_engine, qdrant_engine)

📚 学習
ICLR26 Paper Finder:LLMベースのAI論文検索ツール : ある開発者が、特定のAI会議の論文を検索するために、言語モデルをバックボーンとして利用するツール「ICLR26 Paper Finder」を作成しました。ユーザーはタイトル、キーワード、さらには論文の要約で検索でき、要約検索の精度が最も高いです。このツールは個人サーバーとHugging Faceでホストされており、AI研究者にとって効率的な文献検索方法を提供します。(ソース:Reddit r/deeplearning, Reddit r/MachineLearning)
UCLA 2025年春季コース:大規模言語モデルの強化学習 : UCLAは2025年春に「大規模言語モデルの強化学習」コースを開設します。このコースは、RLxLLMの幅広いテーマをカバーし、基礎知識、テスト時計算、RLHF(人間からのフィードバックによる強化学習)、RLVR(検証可能な報酬による強化学習)を含みます。この新しい講義シリーズは、研究者や学生にLLM強化学習の最先端理論と実践を深く学ぶ機会を提供します。(ソース:algo_diver)
手描きAutoencoderガイド:生成AIの基礎を理解する : ProfTomYehは、Autoencoder(自己符号化器)の手描きによる7ステップの詳細ガイドを公開しました。これは、圧縮、ノイズ除去、豊富なデータ表現の学習において重要な役割を果たすこのニューラルネットワークを読者が理解するのを助けることを目的としています。Autoencoderは、多くの現代の生成アーキテクチャの基礎であり、このガイドは、情報をエンコードおよびデコードする仕組みを直感的な方法で説明しており、生成AIのコアコンセプトを学ぶための貴重なリソースです。(ソース:ProfTomYeh)
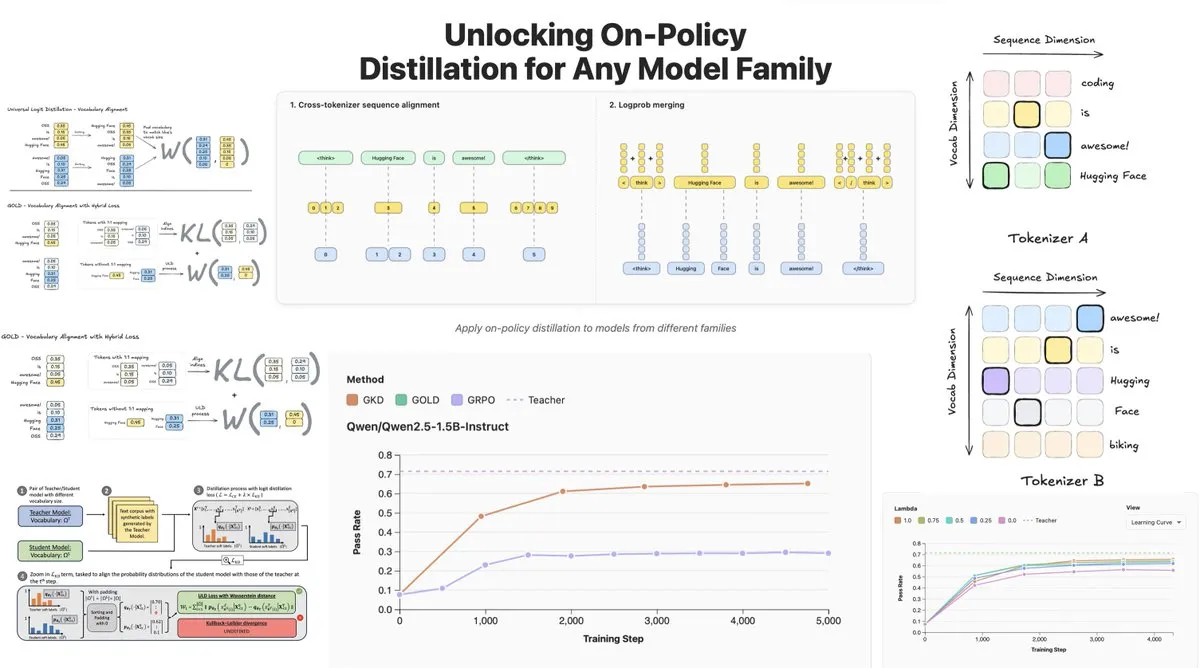
Hugging Face、On-Policy Logit Distillationを発表、モデル間蒸留をサポート : Hugging Faceは、General On-Policy Logit Distillation(GOLD)を発表しました。これは、ポリシー蒸留手法を拡張し、Tokenizerが異なっていても、任意の教師モデルを任意の学生モデルに蒸留できるようにします。この技術はTRLライブラリに統合されており、開発者はHubから任意のモデルペアを選択して蒸留を行うことができます。これにより、LLMのポストトレーニングに大きな柔軟性と性能回復能力がもたらされ、特に特定のドメインでファインチューニングした後に汎用性能が低下する問題を解決します。(ソース:clefourrier, winglian, _lewtun)
Lumi:Google DeepMind、Gemini 2.5を活用してarXiv論文の読解を支援 : Google DeepMindのPAIRチームは、Gemini 2.5大規模モデルを活用してarXiv論文の読解を支援するツール「Lumi」を発表しました。Lumiは、論文に要約、参考文献、インラインQ&Aを追加することができ、研究者がよりスマートかつ効率的に論文を読み、研究文献の理解効率を向上させるのに役立ちます。(ソース:GoogleDeepMind)
💼 ビジネス
AIがテクノロジー大手の収益を過去最高に押し上げ、MicrosoftとGoogleの決算が好調 : Googleの親会社AlphabetとMicrosoftは、最新の決算報告で画期的な業績を達成し、AIが中核的な成長エンジンとなりました。Alphabetは四半期収益が初めて1000億ドルを突破し、1023億ドルに達しました。Google Cloudは34%成長し、既存顧客の70%がAI製品を利用しています。Microsoftの収益は18%増の777億ドルとなり、インテリジェントクラウドの収益は初めて300億ドルを超え、Azureクラウドサービスは40%の成長率を達成し、AIが顕著な牽引役となりました。両社はAI分野での主導的地位を固めるため、AIへの設備投資を大幅に増やす計画であり、資本市場からの評価も得ています。(ソース:36氪, Yuchenj_UW)

Block CTO:AI Agent Gooseが複雑な作業の60%を自動化、コード品質と製品の成功に直接的な関係はない : Block(旧Square)のCTOであるDhanji R. Prasannaは、同社がオープンソースのAI Agentフレームワーク「Goose」を通じて、1.2万人の従業員が8週間で週8~10時間の作業時間を節約した方法を共有しました。Gooseはモデルコンテキストプロトコル(MCP)に基づいており、企業ツールと連携して、コード作成、レポート生成、データ処理などのタスクを自動化できます。Prasannaは、AIネイティブ企業はテクノロジー企業として再定義し、組織構造を再編成すべきだと強調しました。彼は「コード品質と製品の成功に直接的な関係はない」という直感に反する見解を提示し、製品がユーザーの問題を解決できるかどうかが重要であると述べ、エンジニアにAIの活用を奨励しました。ベテランと新人エンジニアがAIツールを最も受け入れているとのことです。(ソース:36氪)

デジタルヒューマン業界は淘汰の時代へ、3Dデジタルヒューマン制作はプラットフォーム化へ移行 : 大規模モデルの爆発的な普及に伴い、デジタルヒューマン業界は再編期に直面しており、AI能力を持たない企業は淘汰されています。2Dデジタルヒューマン市場は70.1%を占める一方、3Dデジタルヒューマンは技術の反復と高いGPUコストに制約されています。魔珐科技などの大手企業は、3Dデジタルヒューマンが大モデルの能力と一致する必要があることを強調し、高品質なデータ蓄積、希少な人材、強力なアート能力が鍵であると指摘しています。業界のトレンドは、3Dデジタルヒューマン制作がプラットフォーム化へと向かっていることを示しており、AI技術の進歩がコストを削減し、大規模な応用を可能にしています。影眸科技やBaiduなどの企業も、デジタルヒューマンをインフラとして位置づけ、より多くの応用シナリオを可能にする3D生成プラットフォームを次々と発表しています。(ソース:36氪)
🌟 コミュニティ
AIに対するユーザーの感情と信頼の複雑な認識:R2D2とChatGPTの比較 : ソーシャルメディアでは、R2D2とChatGPTのユーザー感情のつながりの違いが活発に議論されています。ユーザーは、R2D2がその独特の気質、忠誠心、「馬のような」イメージから愛らしく、現実社会の倫理問題に関わらないと考えています。一方、ChatGPTは「本物の偽AI」として、その実用性、コンテンツ検閲の制限、潜在的な監視への懸念から、同様の感情的な絆を築くのが難しいとされています。この比較は、AIに対するユーザーの期待が知能だけでなく、「人間らしい」インタラクション体験や社会への影響の認識にもあることを明らかにしています。(ソース:Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

AIカウンセリングの限界と人間による介入の必要性 : AI心理カウンセリング製品の台頭に伴い、人々は孤独や心理的問題をAIで解決しようとしています。調査によると、Z世代の職場人の約22%が心理カウンセラーを受診し、約半数がAIに相談しています。AIは情報提供、要因排除、寄り添いにおいて優位性がありますが、共感、場の空気を読むこと、治療のペースを主導することにおいて人間の心理カウンセラーに取って代わることはできません。事例は、AIが極端なリスクを認識する際に人為的な安全装置が必要であること、また、人間が感情と病変の境界の判断、経験の蓄積、非言語コミュニケーションにおいて不可欠であることを示しています。AIは主に反復的で補助的な作業を担当し、支援を求めるハードルを下げるべきであり、最終的な目的は人々を真の人間関係に戻すことです。(ソース:36氪)

高齢者と大規模モデルのインタラクション:「生き方」から「アルゴリズム」を定義する : 復旦大学とTencent SSVタイムラボなどの機関は、100人の高齢者に大規模モデルの使用法を教える1年間の研究を実施しました。研究の結果、高齢者のAIに対する態度は抵抗ではなく、生活経験に基づいた「実用主義的技術観」であることがわかりました。彼らは、技術が日常生活に溶け込み、寄り添いを提供できるかどうかに関心があり、究極の機能には関心がありません。信頼の調整において、高齢者は「限定的な修正」、「協調的な互恵」、「認知的固定化」など様々なパターンを示し、「質問へのためらい」や「ジェンダーギャップ」も存在しました。彼らが期待する大規模モデルは、「占い師のような半仙」、「信頼できる医師」、「おしゃべりできる友人」、「リラックスできるおもちゃ」であり、より優しく理解し、日常生活に寄り添う「人間を理解する」技術です。これは、技術の価値がどれだけ長く待てるかであり、どれだけ速く走れるかではないことを示しており、技術は「適応化」ではなく「共生化」すべきであり、人間の感情、リズム、尊厳を尺度とすべきであると訴えています。(ソース:36氪)

AIの社会影響:プライバシー監視からエネルギー消費、雇用変革まで : ソーシャルメディアでは、AIが社会に与える多方面の影響が広く議論されています。ユーザーは、AIが様々なアプリケーション、検索、カメラを通じて「目に見えない監視」を実現し、SFのようなロボットによる制御ではなく、個人の行動を予測し影響を与えていることを懸念しています。同時に、AIデータセンターのエネルギーと水資源に対する巨大な需要は、地域社会の抗議を引き起こし、停電や水不足につながっています。さらに、AIはコード生成や自動化されたタスクにおいて生産性を向上させますが、雇用構造の変化や、AIコードの品質が生産効率に与える課題についても議論が巻き起こっています。これらの議論は、AI技術がもたらす利便性と潜在的なリスクに対する一般の人々の複雑な感情を反映しています。(ソース:Reddit r/artificial, MIT Technology Review, MIT Technology Review, Ronald_vanLoon, Ronald_vanLoon)

AI分野の用語と概念の急速な進化 : コミュニティの議論では、AI分野の用語と概念が急速に進化していることが指摘されています。例えば、「モデルの学習/構築」はしばしば「ファインチューニング」を指し、「ファインチューニング」は「プロンプト/コンテキストエンジニアリング」の新しい形と見なされています。このような変化は、AI技術スタックの複雑化と、より洗練された操作へのニーズを反映しています。また、モデルの速度と知能のトレードオフについては、開発者は「遅くても賢い」モデルを好む傾向があります。これは、より信頼性の高い結果を提供できるためであり、たとえ待機時間が増えるとしてもです。(ソース:dejavucoder, dejavucoder, dejavucoder)

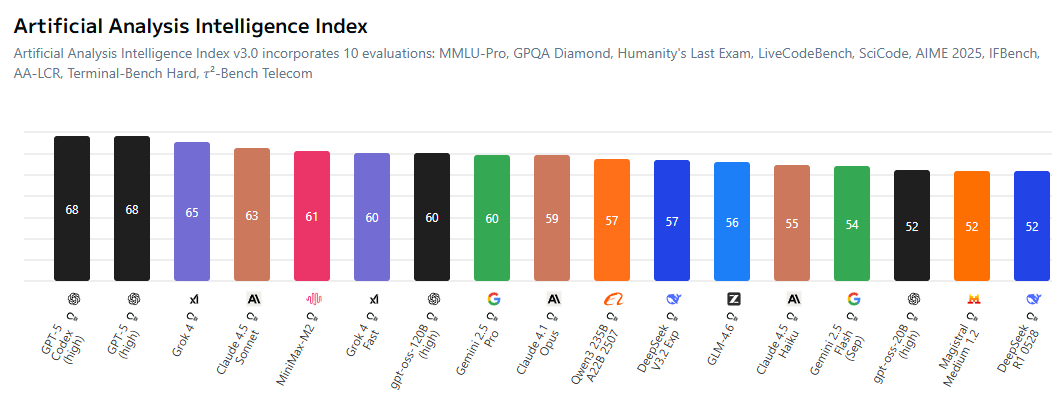
AIオープンソースエコシステムとプロプライエタリモデルの競争激化 : コミュニティでは、オープンソースAIモデルとプロプライエタリモデルの間のギャップが縮小しており、クローズドソースの研究室が価格設定においてより競争力を高めることを余儀なくされていることが熱く議論されています。MiniMax-M2などのオープンソースモデルは、AI Indexで優れた性能を発揮し、コストも非常に低いです。同時に、中国企業やスタートアップ企業はAI技術を積極的にオープンソース化している一方で、米国企業はこの点で比較的遅れています。このトレンドは、AI分野が「誰もがオープンソースに基づいてモデルを学習する」時代を迎え、AI技術の民主化と革新を推進することを示唆しています。(ソース:ClementDelangue, huggingface, clefourrier, huggingface)
AI生成コンテンツが伝統産業にもたらす影響と倫理的課題 : AI生成コンテンツは、伝統産業にますます浸透しています。例えば、AI駆動の「アーティスト」が音楽チャートに登場したり、ディープフェイク技術が詐欺(偽のJensen Huang氏の講演による仮想通貨詐欺など)に利用されたりしています。これらの現象は、著作権、倫理、規制に関する議論を引き起こしています。同時に、AIはコード生成や自動化されたソーシャルメディアアカウント管理などの分野でも新しい生産性ツールをもたらしていますが、生成されるコンテンツの品質と信頼性には依然として人間によるレビューが必要です。これは、AIの普及が進む中で、技術革新と社会的責任、倫理規範のバランスをいかに取るかという課題を浮き彫りにしています。(ソース:Reddit r/artificial, 36氪, jeremyphoward)

AI研究コミュニティ、データ品質と評価への注目 : AI研究コミュニティは、モデル学習におけるデータ品質の重要性への注目を強めており、高品質なデータの取得がGPUのレンタルやコード記述よりも難しい課題であると指摘しています。同時に、既存のベンチマークがモデルの真の能力を完全に反映できない可能性や、過度に最適化されやすいという限界についても広く議論されています。研究者たちは、AI研究の健全な発展を促進するために、より情報量が多く、現実的な評価システムの開発を求めています。(ソース:code_star, code_star, clefourrier, tokenbender)

AIの医療・ヘルスケア分野での応用と展望 : AIは医療・ヘルスケア分野で大きな可能性を示しています。例えば、云澎科技はAI+ヘルスケア新製品を発表し、スマートキッチンラボやAI健康大モデルを搭載したスマート冷蔵庫など、パーソナライズされた健康管理を提供しています。また、MONAIは医療画像AIツールキットとして、PyTorchオープンソースフレームワークを提供しています。AI駆動の外骨格は車椅子利用者の立ち上がりや歩行を支援し、LLM診断エージェントは仮想臨床環境で診断戦略を学習しています。これらの進展は、AIが日常の健康管理から補助診断、治療まで、医療・ヘルスケアサービスを深く変革することを示唆しています。(ソース:36氪, GitHub Trending, Ronald_vanLoon, Ronald_vanLoon, HuggingFace Daily Papers)
AI時代の組織変革と人材ニーズ : AIの普及に伴い、企業は組織構造と人材ニーズの深い変革に直面しています。BlockのCTOであるDhanji R. Prasannaは、企業が「テクノロジー企業」として再定義し、「ゼネラルマネージャー制」から「機能別組織」へと移行して技術的焦点を集中させる必要があると強調しました。GooseのようなAIツールは生産性を大幅に向上させますが、高レベルのアーキテクチャと設計には依然としてベテランエンジニアが必要です。採用において、企業は単なるAIツールの使用スキルよりも、学習型思考と批判的思考を重視しています。AIは職務の境界も曖昧にし、非技術職もAIツールを利用し始め、「人間と機械の集団」による協業モデルの形成を推進しています。(ソース:36氪, MIT Technology Review, NandoDF, SakanaAILabs)

💡 その他
多機能ロボット技術の継続的な革新 : ロボット分野では、タコにヒントを得たロボットSpiRobs、泳げるドローン、荷物仕分け用のHelixロボット、NIO工場で品質検査を支援するヒューマノイドロボットなど、多様な革新が見られます。これらの進展は、バイオミメティクス設計、自動化、人間と機械の協働、特殊環境への適応性など多岐にわたり、産業、軍事、日常応用におけるロボット技術の幅広い可能性を示唆しています。(ソース:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
AI Agentの概念深化と市場展望 : AI Agentは、人間のように推論し適応できるインテリジェントなエンティティとして定義され、人間と機械のシームレスな対話を実現できます。これらは将来の労働のトレンドと見なされており、市場には多くのAI Agent構築ツールが登場しています。AI Agentの核となる価値は、単なる「チャット」の補助ツールではなく、実際のタスクを実行できる「生産ツール」となることにあり、その発展はAIの各分野での深い応用を推進するでしょう。(ソース:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dotey)
AIと自動運転:UberフリートがNvidiaの新チップを採用、ロボットタクシー開発を推進 : Uberの次世代自動運転フリートはNvidiaの新チップを採用し、ロボットタクシーのコスト削減が期待されています。NvidiaのDrive Hyperionプラットフォームは、「ロボットタクシー対応」車両の標準化されたアーキテクチャであり、Uberとの提携は自動運転技術の消費者への普及を推進するでしょう。これは、AIが交通分野での応用を加速させており、より安全で経済的な自動運転サービスの実現を目指していることを示しています。(ソース:MIT Technology Review, TheTuringPost)