
キーワード:Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, AIモデル, 人工知能, 大規模言語モデル, AIプログラミング, AIエージェント, Claude Sonnet 4.5のプログラミング能力, DSAスパースアテンション機構, ChatGPTの即時決済機能, Sora 2ソーシャルアプリ, LoRAファインチューニング技術
🔥 注目
Anthropic Claude Sonnet 4.5がリリース、プログラミングとエージェント能力が大幅に向上 : Anthropicは、世界最強のプログラミングモデルと称されるClaude Sonnet 4.5を正式にリリースしました。このモデルは、エージェント構築、コンピューター使用、推論、数学能力において顕著な進歩を遂げています。30時間以上自律的に連続作業が可能で、SWE-bench Verifiedテストでトップに立ち、OSWorldコンピュータータスクベンチマークで記録を更新しました。新機能には、Claude Codeの「チェックポイント」ロールバック機能、VS Codeプラグイン、APIのコンテキスト編集および記憶ツールが含まれます。さらに、ソフトウェアインターフェースをリアルタイムで生成できる実験的機能「Imagine with Claude」も発表されました。Sonnet 4.5は安全性も大幅に向上し、欺瞞や迎合といった不適切な行動を減らし、AI安全レベル3(ASL-3)認証を取得、誤報率を10分の1に低減しました。価格はSonnet 4と据え置きで、コストパフォーマンスがさらに向上しており、新たなAIプログラミング競争を引き起こすことが予想されます。 (出典: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Expがリリース、疎なアテンションメカニズムDSAを導入し値下げ : DeepSeekは実験モデルV3.2-Expをリリースし、DeepSeek Sparse Attention (DSA) 疎なアテンションメカニズムを導入しました。これにより、長文コンテキストのトレーニングと推論効率が大幅に向上し、同時にAPI価格が50%以上引き下げられました。DSAは「ライトニングインデクサー」を通じて重要なTokenを効率的に識別し、詳細な計算を行うことで、アテンションの複雑さをO(L²)からO(Lk)に削減します。Huawei Ascend、Cambricon、Hygonなどの国産AIチップメーカーはDay 0での対応を実現しており、国産コンピューティングエコシステムの発展をさらに推進しています。このモデルは、NVIDIA CUDAに匹敵するTileLangバージョンのGPUオペレーターもオープンソース化しており、開発者がプロトタイプ開発とデバッグを容易に行えるようにしています。一部の能力では譲歩があるものの、そのアーキテクチャ革新とコスト効率は、大規模モデルの長文処理に新たな方向性を示しています。 (出典: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

OpenAIがChatGPTに即時決済機能を導入、Eコマース分野へ参入 : OpenAIはChatGPTに「Instant Checkout(即時決済)」機能を導入しました。これにより、ユーザーは会話中にEtsyやShopifyプラットフォームの商品を外部サイトに移動することなく直接購入できるようになります。この機能は、OpenAIとStripeが共同開発した「Agentic Commerce Protocol」に基づいており、オープンソース化されています。ChatGPTの膨大なトラフィックを商業取引に転換することを目指しています。初期段階では米国市場をサポートし、将来的には複数商品のカート機能やより多くの地域への拡大を計画しています。この動きは、OpenAIの商業化における大きな一歩と見なされており、重要な収益源となる可能性があり、従来のEコマースおよび広告業界に大きな影響を与えることが予想されます。 (出典: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
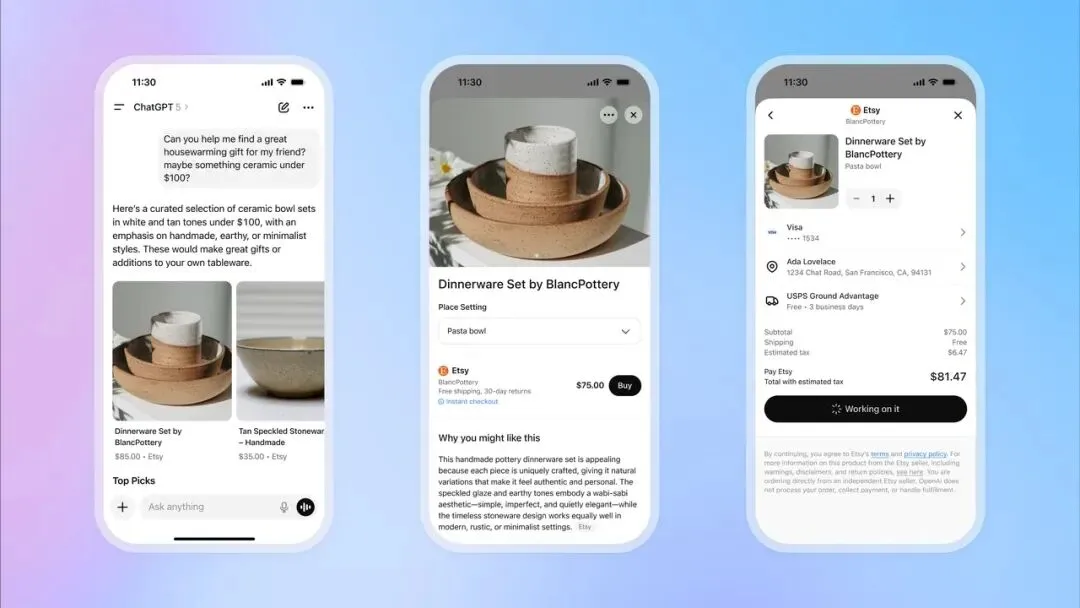
OpenAIがSora 2ソーシャルアプリのリリースを準備、AIショートビデオプラットフォームを構築 : OpenAIは、最新のビデオモデルSora 2を搭載した独立型ソーシャルアプリのリリースを準備しています。このアプリはTikTokと酷似したデザインで、垂直方向のビデオストリームとスワイプによる閲覧を採用していますが、すべてのコンテンツはAIによって生成されます。ユーザーは最長10秒のビデオクリップを生成でき、本人認証機能を利用して自分の肖像をビデオに使用できます。この動きは、ChatGPTがテキスト分野で成功を収めたように、AIビデオの可能性を一般の人々に直感的に体験させ、MetaやGoogleとの競争に直接参入することを目指しています。しかし、OpenAIは著作権処理において「権利者がオプトアウトしない限り、デフォルトで著作権コンテンツを使用する」という戦略を採用しており、コンテンツクリエイターや映画会社から強い懸念を引き起こしており、AIと知的財産権の激しい攻防を予感させます。 (出典: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 動向
Huawei Pangu 718BモデルがSuperCLUE中国語大規模モデルランキングでオープンソース部門2位に : Huawei openPangu-Ultra-MoE-718Bモデルが、SuperCLUE中国語大規模モデル汎用ベンチマークテストでオープンソースランキングの2位を獲得しました。このモデルは「データ量に頼らず、思考力に頼る」というトレーニング哲学を採用し、「品質優先、多様性カバー、複雑性適応」というデータ構築原則、および汎用、推論、アニーリングの3段階事前学習戦略を通じて、広範な世界知識を構築し、論理推論能力を向上させています。幻覚問題の緩和のため、「批判的内面化」メカニズムを導入し、ツール使用能力向上のため、アップグレード版ToolACE合成フレームワークを採用しています。 (出典: 量子位)

FSDriveがVLAと世界モデルを統合し、自動運転を視覚推論へ推進 : FSDrive(FutureSightDrive)は「時空間視覚CoT」を提案し、統一された未来の画像フレームを中間推論ステップとして利用することで、未来のシーンと知覚結果を結合して視覚的推論を行い、自動運転を記号推論から視覚推論へと推進します。この方法は、既存のMLLMアーキテクチャを変更することなく、語彙拡張と自己回帰視覚生成を通じて画像生成能力を活性化し、段階的な視覚CoTによって物理的先験知識を注入します。モデルは未来を予測する「世界モデル」として機能すると同時に、軌道計画を行う「逆動力学モデル」としても機能します。 (出典: 36氪)

GPT-5が量子計算に重要なヒントを提供、Scott Aaronson氏が絶賛 : 量子計算理論の権威であるScott Aaronson氏が、GPT-5が30分足らずで自身の量子複雑性理論研究に重要な証明のヒントを提供し、チームを悩ませていた問題を解決したことを明らかにしました。Scott Aaronson氏は、GPT-5が最も人間的な知能活動の克服において顕著な進歩を遂げたとし、これは人間とAIの協調が「スイートスポット」に入り、研究者に決定的な瞬間に画期的なインスピレーションを提供できることを示していると述べています。 (出典: 量子位, Twitter)

HuggingFaceがIntel Core Ultra上でのQwen3-8B Agentモデルの推論を加速 : HuggingFaceはIntelと協力し、OpenVINO.GenAIと深度剪枝(depth-pruned)されたQwen3-0.6Bドラフトモデルを通じて、Intel Core Ultra統合GPU上でのQwen3-8B Agentモデルの推論速度を1.4倍に向上させることに成功しました。この最適化により、Qwen3-8BはAI PC上でAgentアプリケーションをより効率的に実行できるようになり、特に多段階推論とツール呼び出しを必要とする複雑なワークフローに適しており、ローカルAI Agentの実用化をさらに推進しています。 (出典: HuggingFace Blog)

Reachy MiniロボットがGPT-4oを統合し、マルチモーダルインタラクションを実現 : Hugging Face / Pollen RoboticsのReachy Miniロボットは、OpenAIのGPT-4oモデルを統合し、マルチモーダルインタラクション能力を大幅に向上させました。新機能には、画像分析(ロボットが撮影した写真を記述し推論)、顔追跡(アイコンタクトの維持)、モーションフュージョン(頭の揺れ、顔追跡、感情/ダンスの同時実行)、ローカル顔認識、アイドル時の自律行動が含まれます。これらの進歩により、人間とロボットのインタラクションはより自然でスムーズになりましたが、記憶システム、音声認識、複雑な群衆戦略などの課題は依然として残っています。 (出典: Reddit r/ChatGPT, Twitter)

Intelが新LLM Scaler Beta版をリリース、Battlemage GPUでのGenAIをサポート : Intelは、Battlemage GPU上での生成AI(GenAI)性能を最適化するための新しいLLM Scaler Beta版をリリースしました。この動きは、IntelがAIハードウェアおよびソフトウェアエコシステムへの継続的な投資を行い、大規模言語モデルの推論および生成タスクにおけるGPUの競争力を高めることを示唆しています。 (出典: Reddit r/artificial)
Claudeが使用制限ダッシュボードを導入、ChatGPTがペアレンタルコントロール機能をリリース : AnthropicはClaude CodeとClaude App向けにリアルタイムの使用制限ダッシュボードを導入しました。これにより、ユーザーは以前発表された週ごとのレート制限に対応するため、Tokenの使用状況を追跡できます。同時に、OpenAIはChatGPTにペアレンタルコントロール機能を導入しました。これにより、保護者はティーンエイジャーのアカウントを関連付け、より強力なセキュリティ保護を自動的に提供し、機能や設定の使用制限を調整できますが、保護者は具体的な会話内容を閲覧することはできません。 (出典: Reddit r/ClaudeAI, 36氪)
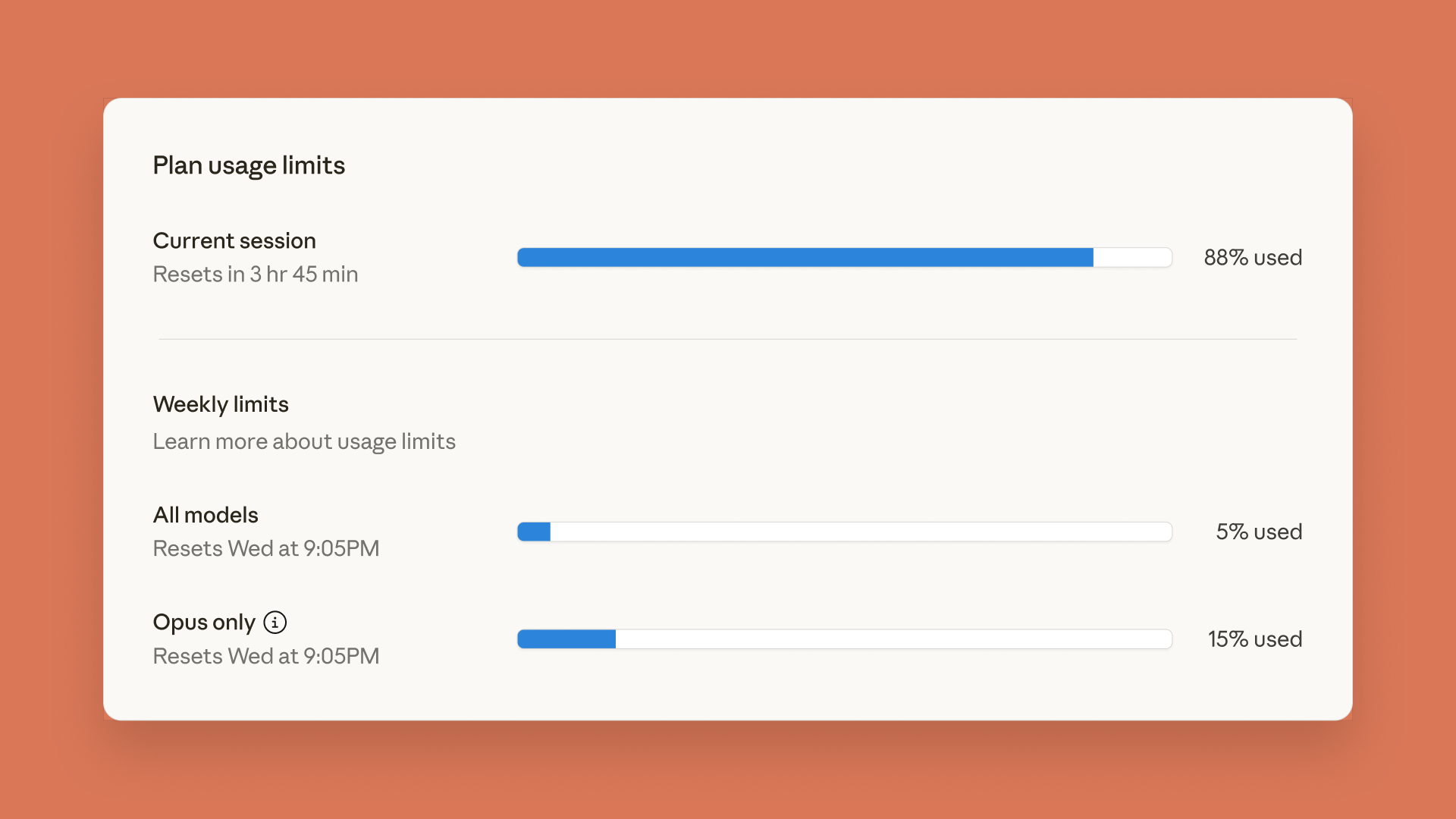
Minecraftで500万パラメータの言語モデルが動作、AIの革新的な応用を示す : SammyuriはMinecraft内に複雑な紅石システムを構築し、約500万パラメータの言語モデルを動作させることに成功し、基本的な会話能力を与えました。この画期的な成果は、ゲーム環境でローカルAIを実現する可能性を示し、非伝統的なプラットフォームでのAI応用についてコミュニティで広範な注目と議論を巻き起こしました。 (出典: Reddit r/LocalLLaMA, Twitter)
Inspur InformationのAIサーバーが8.9msの推論速度を達成、100万Tokenあたり1元のコスト : Inspur Informationは、超拡張AIサーバー元脳HC1000と元脳SD200スーパーノードを発表し、AI推論速度を新記録に引き上げました。元脳SD200はDeepSeek-R1モデルで8.9msのTokenごとの出力時間(TPOT)を達成し、これまでのSOTAをほぼ倍に上回り、兆パラメータの大規模モデル推論とマルチエージェントリアルタイム協調をサポートします。元脳HC1000は、100万Tokenあたりの出力コストを1元に、シングルカードコストを60%削減しました。これらのブレイクスルーは、エージェントの産業化が直面する速度とコストのボトルネックを解決し、マルチエージェント協調と複雑なタスク推論の規模化された展開に効率的で低コストのコンピューティングインフラストラクチャを提供することを目指しています。 (出典: 量子位)

フィードフォワード3D Gaussian Splattingの新手法:浙江大学チームが「ボクセルアライン」を提案 : 浙江大学チームは、「ボクセルアライン」(voxel-aligned)のフィードフォワード3D Gaussian Splatting(3DGS)フレームワークVolSplatを提案しました。これは、既存の「ピクセルアライン」手法が多視点3D再構築において抱える幾何学的整合性とガウス密度割り当てのボトルネックを解決することを目的としています。VolSplatは、3次元空間で多視点2D情報を融合し、疎な3D U-Netで特徴を洗練することで、より高品質で堅牢、かつ効率的な3D再構築を実現します。この手法は、公開データセットで複数のベースラインを上回り、未見のデータセットでも強力なゼロショット汎化能力を示しています。 (出典: 量子位)

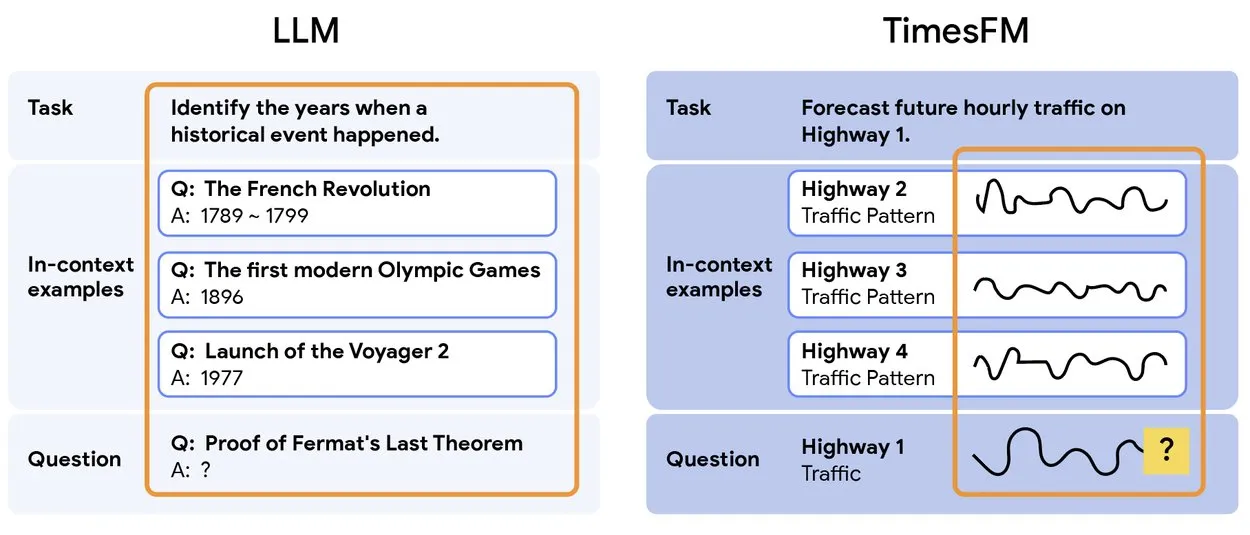
TimesFM 2.5:事前学習済み時系列予測モデルがリリース : TimesFM 2.5がリリースされました。これは時系列予測のための事前学習済みモデルで、パラメータ数が500Mから200Mに削減され、コンテキスト長が2Kから16Kに増加し、ゼロショット設定で優れた性能を発揮します。このモデルはHugging Faceで利用可能であり、Apache 2.0ライセンスを採用しており、時系列予測タスクに、より効率的で強力なソリューションを提供します。 (出典: Twitter)
Yunpeng TechnologyがAI+健康新製品を発表、家庭健康分野でのAI応用を推進 : Yunpeng Technologyは、ShuaikangおよびSkyworthと提携し、「デジタルインテリジェント未来キッチンラボ」とAI健康大規模モデルを搭載したスマート冷蔵庫を発表しました。AI健康大規模モデルはキッチン設計と運用を最適化し、スマート冷蔵庫は「健康アシスタントXiao Yun」を通じてパーソナライズされた健康管理を提供します。今回の発表は、AIが日常の健康管理分野でブレイクスルーを達成したことを示しており、スマートデバイスを通じてパーソナライズされた健康サービスを実現し、家庭の健康技術レベルを向上させることが期待されます。 (出典: 36氪)
Alibabaが1兆パラメータのオープンソース思考モデルRing-1T-previewをリリース : Alibaba Ant Lingチームは、初の1兆パラメータのオープンソース思考モデルRing-1T-previewをリリースしました。これは「深く考え、待つ必要なし」を実現することを目的としています。このモデルは、AIME25、HMMT25、ARC-AGI-1、LCB、Codeforcesなどのベンチマークテストを含む自然言語処理タスクで初期の優れた結果を達成しました。さらに、IMO25のQ3問題を一度に解決し、Q1/Q2/Q4/Q5の部分的な解決策も提供し、その強力な推論および問題解決能力を示しました。 (出典: Twitter, Twitter, Twitter)

🧰 ツール
PopAiが「Slide Agent」をリリース、AIでワンクリックプレゼン資料作成 : PopAiチームは、プレゼンテーション資料作成プロセスを簡素化することを目的としたツール「Slide Agent」をリリースしました。ユーザーはPromptで要件を入力するだけで、300以上のテンプレートから選択し、AIが自動的にドラフトを生成し、レイアウト、グラフ、画像、ロゴなどの書式調整を行い、最終的に編集可能な.pptxファイルとしてダウンロードできます。このツールはChatGPTとCanvaの機能を統合しており、プレゼンテーション資料作成の敷居と時間コストを大幅に削減します。 (出典: Twitter)
AlibabaがPDFからMarkdownへの変換ツールMiner U2.5をオープンソース化 : AlibabaチームはPDFからMarkdownへの変換ツールMiner U2.5をオープンソース化し、HuggingFaceでデモを公開しました。このツールは、PDFドキュメントを効率的にMarkdown形式に変換できるため、ユーザーはコンテンツの抽出、編集、再利用を容易に行うことができ、大量のPDFドキュメントを処理する必要がある開発者や研究者にとって実用的なAI支援ツールとなります。 (出典: dotey)
VEED Animate 2.2がリリース、動画スタイル再構築とキャラクター入れ替えに対応 : VEED Animate 2.2バージョンが正式にリリースされ、WAN 2.2技術によってサポートされています。このツールを使用すると、ユーザーは1枚の画像で動画スタイルを簡単に再構築したり、動画内のキャラクターを瞬時に入れ替えたり、10倍の速度で動画クリップを作成したりできます。これらの新機能は動画制作プロセスを大幅に簡素化し、コンテンツクリエイターにAI駆動のより多くの創造的な可能性を提供します。 (出典: TomLikesRobots)
LangChainがLLM応答の標準化に注力、複雑な機能をサポート : LangChainはv1開発において、サーバーサイドのツール呼び出し、推論、参照など、ますます複雑になるLLM機能に対応するため、LLM応答の標準化を核心的な焦点としています。このフレームワークは、異なるLLMプロバイダー間のAPI形式の非互換性の問題を解決し、開発者に統一されたインターフェースを提供することで、マルチモーダルエージェントや複雑なワークフローの構築を簡素化することを目指しています。 (出典: LangChainAI, Twitter)
Hugging Face Transformers.jsがブラウザでのAIモデルオフライン実行をサポート : Hugging FaceのTransformers.jsライブラリは、ONNXとWebGPU技術を利用して、Llama 3.2などのAIモデルをブラウザでオフライン実行することを可能にします。これにより、開発者はチャットボット、オブジェクト検出、背景除去などのAIタスクをクラウドサービスに依存することなくローカルで実行でき、データプライバシーと処理速度が向上します。 (出典: Twitter)
ToolUniverseエコシステムがAI科学者の構築とツール統合を支援 : ToolUniverseは、AI科学者を構築するために設計されたエコシステムであり、AI科学者がツールを識別し呼び出す方法を標準化し、データ分析、知識検索、実験設計のために600以上の機械学習モデル、データセット、API、科学ソフトウェアパッケージを統合しています。このプラットフォームは、ツールインターフェースを自動的に最適化し、自然言語記述を通じて新しいツールを作成し、ツール仕様を繰り返し最適化して、ツールをエージェントワークフローに組み合わせることで、AI科学者の発見プロセスにおける協力を推進します。 (出典: HuggingFace Daily Papers)
EasySteerフレームワークがLLM操作性能とスケーラビリティを向上 : EasySteerは、vLLMに基づく統一フレームワークであり、LLMの操作性能とスケーラビリティを向上させることを目的としています。モジュール化されたアーキテクチャ、プラグイン可能なインターフェース、きめ細やかなパラメータ制御、および事前計算された操作ベクトルを通じて、5.5〜11.4倍の速度向上を実現し、過剰な思考や幻覚を効果的に削減します。EasySteerはLLM操作を研究技術から生産レベルの能力へと転換させ、展開可能で制御可能な言語モデルのための重要なインフラストラクチャを提供します。 (出典: HuggingFace Daily Papers)
VibeGame:WebStackベースのAI支援ゲームエンジン : VibeGameは、three.js、rapier、bitecsをベースに構築された高度な宣言型ゲームエンジンで、AI支援ゲーム開発のために特別に設計されています。高抽象度、組み込みの物理およびレンダリング機能、エンティティ・コンポーネント・システム(ECS)アーキテクチャを通じて、AIがゲームコードをより効率的に理解し生成できるようにします。現在、主にシンプルなプラットフォームゲームに適していますが、そのオープンソースコードとAIフレンドリーな構文は、AI駆動型ゲーム開発に有望なソリューションを提供します。 (出典: HuggingFace Blog)
AI研究マップツール、90万件の論文を統合し引用付きの回答を提供 : 革新的なAIツールが、過去10年間の90万件のAI研究論文を意味的にグループ化し可視化することで、詳細な研究マップを形成しました。ユーザーはこのツールに質問を投げかけ、正確な引用付きの回答を得ることができます。これにより、研究者が膨大な学術文献を検索し理解するプロセスが大幅に簡素化され、研究効率が向上します。 (出典: Reddit r/ArtificialInteligence)
Kroko ASR:Whisperの高速ストリーミング代替案 : Kroko ASRは、Whisperの高速ストリーミング代替案として位置づけられる新しいオープンソースの音声テキスト変換モデルです。より小さなモデルサイズ、より高速なCPU推論速度(モバイルおよびブラウザ対応)、そしてほとんど幻覚がないという特徴を持っています。Kroko ASRは多言語をサポートし、音声AIの敷居を下げ、エッジデバイスでの展開とトレーニングを容易にすることを目指しています。 (出典: Reddit r/LocalLLaMA)
OpenWebUI Plotlyグラフレンダリング問題、AIツールUI統合の課題を浮き彫りに : OpenWebUIのv0.6.32バージョンで、Plotlyグラフが正常にレンダリングされず、生のJSONが直接表示される問題が発生しました。ユーザーからのフィードバックによると、バックエンドは正しいJSONを返しているものの、フロントエンドがレンダリングをトリガーできていないとのことです。これは、AIツールがフロントエンドUI統合とリッチテキストレンダリングにおいて依然として技術的な課題に直面しており、開発者コミュニティによるさらなる最適化が必要であることを示しています。 (出典: Reddit r/OpenWebUI)
📚 学習
LoRAファインチューニングとフルファインチューニングの性能比較研究 : Thinking Machines(John Schulmanチーム)の最新研究によると、強化学習においてLoRA(Low-Rank Adaptation)が適切に適用されれば、フルファインチューニングと同等の性能を発揮し、かつリソース消費が少ない(計算量が約2/3)ことが示されました。rank=1の場合でも優れた性能を発揮します。この研究は、LoRAをすべての層(MLP/MoEを含む)に適用し、フルファインチューニングよりも10倍高い学習率を使用すべきであることを強調しています。この発見は、高性能RLモデルのトレーニングの敷居を大幅に下げ、より多くの開発者が1つのGPUで高品質なモデルを実現できるようにします。 (出典: Reddit r/LocalLLaMA, Twitter, Twitter)
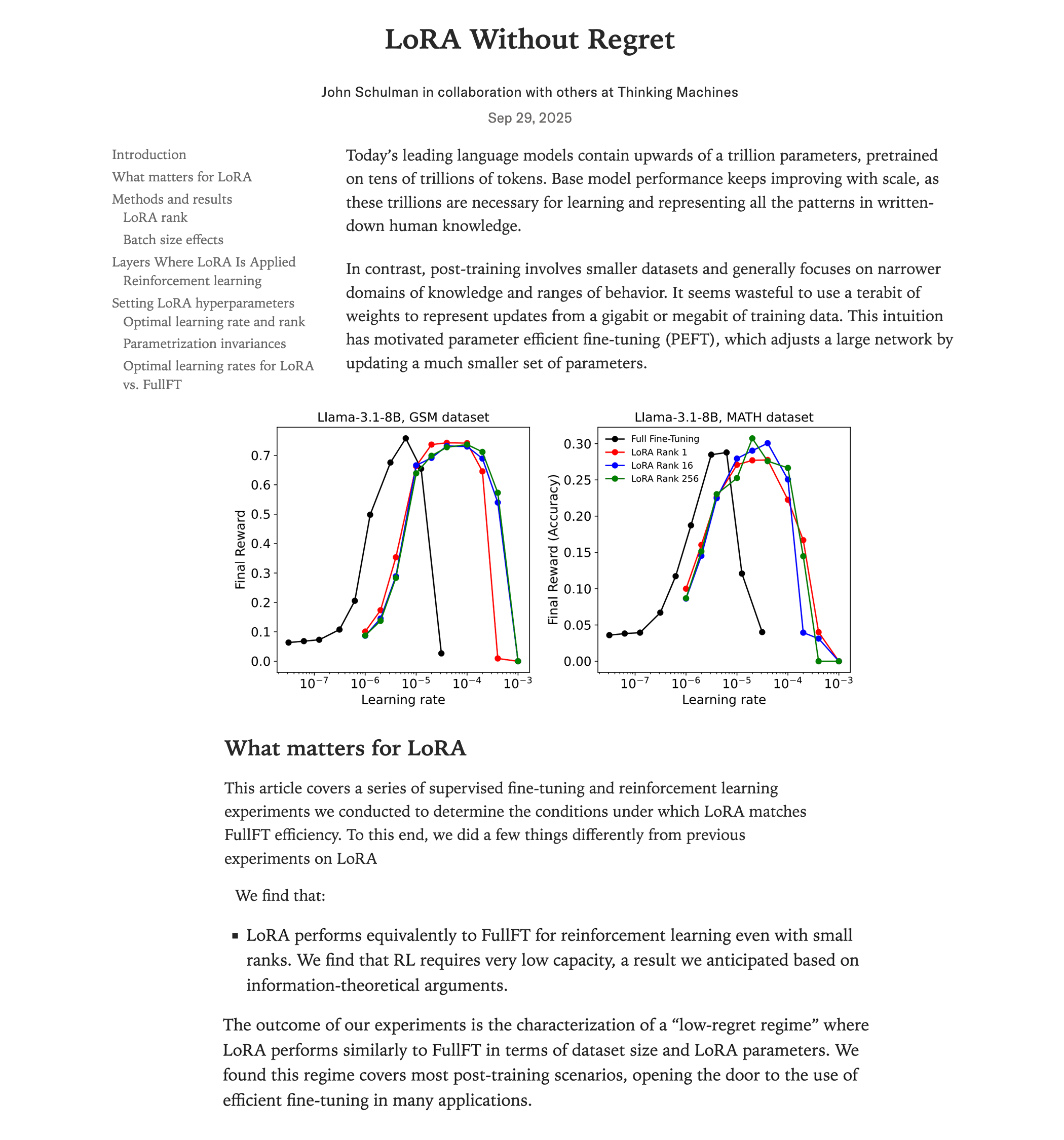
NVIDIA GPU高性能行列乗算カーネルの解剖 : NVIDIA GPU内部の高性能行列乗算(matmul)カーネルの実装メカニズムを詳細に解剖した深い技術ブログが公開されました。記事では、GPUアーキテクチャの基礎、メモリ階層(GMEM、SMEM、L1/L2)、PTX/SASSプログラミング、Hopper(H100)アーキテクチャのTMA、wgmma命令などの高度な機能がカバーされています。このリソースは、開発者がCUDAプログラミングとGPU性能最適化を深く理解するのに役立ち、Transformerモデルのトレーニングと推論にとって非常に重要です。 (出典: Reddit r/deeplearning, Twitter)
スタンフォードCS231N深層学習コンピュータビジョンコース講義がYouTubeで公開 : スタンフォード大学の高く評価されているCS231N(コンピュータビジョン深層学習)コースの講義が、YouTubeで無料で提供されるようになりました。これは、世界中の学習者に高品質なAI教育リソースを入手する貴重な機会を提供し、基礎概念から最先端の応用まで、コンピュータビジョン深層学習の知識を網羅しています。 (出典: Reddit r/deeplearning)

RL-ZVP:ゼロ分散Promptを利用してLLM強化学習推論能力を向上 : 最新の研究で「RL with Zero-Variance Prompts (RL-ZVP)」手法が提案されました。これは、大規模言語モデル(LLM)の強化学習推論能力を向上させることを目的としています。この手法は、「ゼロ分散Prompt」(つまり、すべてのモデル応答が同じ報酬を得る状況)を無視するのではなく、そこから価値ある学習信号を抽出し、正解を直接報酬し、誤りを罰し、Tokenレベルのエントロピーを利用して優位性を形成します。実験結果は、RL-ZVPが従来のメソッドと比較して、数学推論ベンチマークテストで精度と合格率を大幅に向上させることを示しています。 (出典: Reddit r/MachineLearning)
未来誘導学習:時系列予測を強化する予測的アプローチ : ある研究が「未来誘導学習」(Future-Guided Learning)を提案しました。これは、動的なフィードバックメカニズムを通じて時系列イベント予測を強化するものです。この手法は、未来のデータを分析する検出モデルと、現在のデータに基づいて予測を行う予測モデルを含んでいます。予測モデルが検出モデルと異なる場合、予測モデルは「驚き」を最小限に抑えるためにより顕著な更新を行い、それによってパラメータを動的に調整し、時系列予測の精度を効果的に向上させます。 (出典: Reddit r/MachineLearning)
AIの未来は低次元に:Yann Lecunが抽象表現学習について語る : AIのパイオニアであるYann Lecunは、Lex Fridmanとのインタビューで、AIの次の飛躍は、ピクセルなどの高次元の生データを直接処理するのではなく、低次元の潜在空間で学習することから生まれると提唱しました。彼は、真のインテリジェントシステムは、世界の因果構造と物理的ダイナミクスの抽象表現を学習する必要があり、それによって詳細が変化しても正確な予測ができるようになると考えています。このアプローチは、モデルをより柔軟で堅牢にし、膨大なデータへの依存を減らし、計算コストを削減します。 (出典: Reddit r/ArtificialInteligence)
SIRI:インターリーブ圧縮による反復強化学習の拡張 : SIRI(Scaling Iterative Reinforcement Learning with Interleaved Compression)は、反復的に推論予算を圧縮および拡張することで、トレーニング中の最大ロールアウト長を動的に調整する、シンプルかつ効果的な強化学習手法です。このトレーニングメカニズムは、モデルに限定されたコンテキスト内で正確な意思決定を強制し、冗長なTokenを削減すると同時に、探索と計画のための空間を提供することで、性能と効率のトレードオフにおいて、大規模推論モデルの効率と精度を着実に向上させます。 (出典: HuggingFace Daily Papers)
マルチエージェント生成モデルMultiCrafter:空間分離アテンションとアイデンティティ認識強化学習 : MultiCrafterは、高忠実度で好みに合わせたマルチエージェント画像生成を実現するためのフレームワークです。明示的な位置監視を導入することで、異なるエージェント間のアテンション領域を分離し、属性漏洩問題を効果的に緩和します。同時に、このフレームワークは混合エキスパート(MoE)アーキテクチャを採用してモデル容量を強化し、スコアリングメカニズムと安定したトレーニング戦略を組み合わせた新しいオンライン強化学習フレームワークを設計することで、生成画像の主体忠実度と人間の美的嗜好が高度に一致することを保証します。 (出典: HuggingFace Daily Papers)
Visual Jigsaw:自己教師あり後学習によるMLLMの視覚理解向上 : Visual Jigsawは、マルチモーダル大規模言語モデル(MLLM)の視覚理解能力を強化することを目的とした汎用的な自己教師あり後学習フレームワークです。この手法は、視覚入力を分割、シャッフルし、モデルに自然言語を通じて正しい並べ替え順序を再構築するよう要求します。この検証可能な報酬に基づく強化学習(RLVR)手法は、追加の視覚生成コンポーネントや手動アノテーションを必要とせず、MLLMのきめ細やかな知覚、時間推論、3D空間理解におけるパフォーマンスを大幅に向上させます。 (出典: HuggingFace Daily Papers)
MGM-Omni:Omni LLMをパーソナライズされた長尺音声生成に拡張 : MGM-Omniは、独自の「脳-口」デュアルトラックToken化アーキテクチャを通じて、マルチモーダル理解と表現豊かな長尺音声生成を実現する統一されたOmni LLMです。この設計は、マルチモーダル推論とリアルタイム音声生成を分離し、効率的なクロスモーダルインタラクションと低遅延ストリーミング音声クローンをサポートし、データ効率においても優れています。実験により、MGM-Omniは音色の一貫性、自然なコンテキスト認識音声の生成、および長尺オーディオとマルチモーダル理解において、既存のオープンソースモデルを上回ることが証明されています。 (出典: HuggingFace Daily Papers)
SID:自己改善デモンストレーションによる目標指向言語ナビゲーション学習 : SID(Self-Improving Demonstrations)は、目標指向言語ナビゲーション学習手法であり、反復的な自己改善デモンストレーションを通じて、ナビゲーションエージェントの未知環境での探索能力と汎化性を大幅に向上させます。この手法は、まず最短経路データを利用して初期エージェントを訓練し、次にそのエージェントを通じて新しい探索軌跡を生成します。これらの軌跡は、より優れたエージェントを訓練するためのより強力な探索戦略を提供し、それによって性能の継続的な向上を実現します。実験により、SIDはREVERIEやSOONなどのタスクでSOTA性能を達成し、特にSOONの未見検証セットでは成功率が50.9%に達し、これまでの手法を13.9%上回りました。 (出典: HuggingFace Daily Papers)
LOVE-R1:適応型スケーリングメカニズムによる長尺動画理解の向上 : LOVE-R1モデルは、長尺動画理解における長時間の時系列理解と詳細な空間知覚の間の衝突を解決することを目的としています。このモデルは適応型スケーリングメカニズムを導入し、まず低解像度で密にフレームをサンプリングし、空間的詳細が必要な場合、モデルは推論に基づいて関心のある動画セグメントを高解像度でスケーリングし、重要な視覚情報を取得します。プロセス全体は多段階推論を通じて実現され、CoTデータファインチューニングと分離型強化学習ファインチューニングを組み合わせることで、長尺動画理解ベンチマークで顕著な向上を達成しました。 (出典: HuggingFace Daily Papers)
Euclid’s Gift:幾何学的代理タスクによる視覚言語モデルの空間推論強化 : Euclid’s Giftは、幾何学的代理タスクを通じて視覚言語モデル(VLM)の空間知覚と推論能力を向上させる研究です。このプロジェクトは、30Kの平面および立体幾何学問題を含むマルチモーダルデータセットEuclid30Kを構築し、Group Relative Policy Optimization(GRPO)を使用してQwen2.5VLおよびRoboBrain2.0シリーズモデルをファインチューニングしました。実験により、トレーニング後のモデルはSuper-CLEVR、Omni3DBenchなど4つの空間推論ベンチマークで顕著なゼロショット向上を達成し、RoboBrain2.0-Euclid-7Bは49.6%の精度に達し、これまでのSOTAモデルを上回りました。 (出典: HuggingFace Daily Papers)
SphereAR:超球面潜在空間による連続Token自己回帰生成の改善 : SphereARは、連続Token自己回帰(AR)画像生成モデルにおけるVAE潜在空間の異質分散によって引き起こされる問題を解決することを目的としています。この核心的な設計は、すべてのAR入力と出力(CFG後を含む)を固定半径の超球面上に制約し、超球面VAEを利用することです。理論分析により、超球面制約が分散崩壊の主な原因を排除し、ARデコーディングを安定させることが示されています。実験により、SphereARはImageNet生成タスクでSOTA性能を達成し、同等のパラメータ規模の拡散モデルやマスク生成モデルを上回りました。 (出典: HuggingFace Daily Papers)
AceSearcher:強化学習自己対戦によるLLM推論と検索の誘導 : AceSearcherは、複雑な推論タスクにおけるLLMの検索強化能力を向上させることを目的とした協力的な自己対戦フレームワークです。このフレームワークは、単一のLLMを訓練し、複雑なクエリの分解と検索コンテキストの統合を交互に行わせ、最終的な回答の精度を最適化するために教師ありファインチューニングと強化学習ファインチューニングを使用します。中間のアノテーションは不要です。実験により、AceSearcherは複数の推論集中型タスクでSOTAベースラインを大幅に上回り、文書レベルの金融推論タスクでは、AceSearcher-32Bが5%未満のパラメータ量でDeepSeek-V3の性能に匹敵しました。 (出典: HuggingFace Daily Papers)
SparseD:拡散言語モデルの疎なアテンションメカニズム : SparseDは、拡散言語モデル(DLM)向けの疎なアテンション手法であり、長いコンテキスト長におけるアテンション計算の二次的な複雑性のボトルネックを解決することを目的としています。この手法は、ヘッド固有の疎なパターンを事前計算し、すべてのデノイズステップで再利用するとともに、初期のデノイズステップではフルアテンションを使用し、その後疎なアテンションに切り替えることで、無損失の高速化を実現します。実験結果は、SparseDが64kのコンテキスト長において、FlashAttentionと比較して最大1.5倍の速度向上を達成し、長文コンテキストアプリケーションにおけるDLMの推論効率を効果的に向上させることを示しています。 (出典: HuggingFace Daily Papers)
SLA:微分可能な疎線形アテンションによる拡散Transformerの加速 : SLA(Sparse-Linear Attention)は、Diffusion Transformer (DiT) モデル、特にビデオ生成におけるアテンション計算を加速することを目的とした訓練可能なアテンション手法です。この手法は、アテンション重みをキー、エッジ、無視可能な3つのカテゴリに分け、それぞれO(N²)とO(N)のアテンションを適用し、無視可能な部分はスキップします。SLAはこれらの計算を単一のGPUカーネルに融合し、少量のファインチューニングステップ後、DiTモデルのアテンション計算を20倍削減し、ビデオ生成においてエンドツーエンドで2.2倍加速し、生成品質を損ないません。 (出典: HuggingFace Daily Papers)
OpenGPT-4o-Image:高度な画像生成と編集のための総合データセット : OpenGPT-4o-Imageは、階層的なタスク分類とGPT-4oによる自動データ生成手法を組み合わせることで構築された大規模データセットであり、統一されたマルチモーダルモデルの画像生成および編集性能を向上させることを目的としています。このデータセットには、テキストレンダリング、スタイル制御、科学画像、複雑な指示編集を含む11の主要分野と51のサブタスクを網羅する8万組の高品質な指示-画像ペアが含まれています。OpenGPT-4o-Imageでファインチューニングされたモデルは、複数のベンチマークテストで顕著な性能向上を達成し、体系的なデータ構築がマルチモーダルAI能力の進歩に不可欠な役割を果たすことを証明しました。 (出典: HuggingFace Daily Papers)
SANA-Video:720p分単位の動画を効率的に生成する小型拡散モデル : SANA-Videoは、最大720×1280の解像度と分単位の長さの動画を効率的に生成できる小型拡散モデルです。線形DiTアーキテクチャと一定メモリKVキャッシュにより、高解像度、高品質、長尺動画生成を実現し、テキストと動画の強力なアライメントを維持します。SANA-VideoのトレーニングコストはMovieGenのわずか1%であり、RTX 5090 GPUに展開した場合、5秒の720p動画生成の推論速度は29秒に達し、低コストで高品質な動画生成を実現します。 (出典: HuggingFace Daily Papers)
AdvChain:敵対的CoTチューニングによる大規模推論モデルの安全アライメント強化 : AdvChainは、敵対的Chain-of-Thought (CoT) チューニングを通じて、大規模推論モデル(LRM)に動的な自己修正能力を教える新しいアライメントパラダイムです。この手法は、「誘惑-修正」と「躊躇-修正」のサンプルを含むデータセットを構築し、モデルが有害な推論の逸脱や不必要な慎重さから回復することを学習させます。実験により、AdvChainは脱獄攻撃やCoTハイジャックに対するモデルの堅牢性を著しく強化すると同時に、良性Promptに対する過剰な拒否を大幅に削減し、優れた安全性と有用性のバランスを実現しました。 (出典: HuggingFace Daily Papers)
SDLM:インターリーブ圧縮による反復強化学習の拡張 : Sequential Diffusion Language Model (SDLM) は、次Token予測と次ブロック予測を統一する手法を提案し、モデルが各ステップでの生成長さを自己適応的に決定できるようにします。SDLMは、最小限のコストで事前学習済み自己回帰言語モデルを改造でき、固定サイズのマスクブロック内で拡散推論を実行すると同時に、連続するサブシーケンスを動的にデコードします。実験により、SDLMは強力な自己回帰ベースラインに匹敵するかそれを上回る性能を達成しつつ、より高いスループットを実現し、その強力なスケーラビリティの可能性を示しました。 (出典: HuggingFace Daily Papers)
Insight-to-Solve (I2S):推論In-Contextデモンストレーションを推論LLM資産に変換 : Insight-to-Solve (I2S) は、高品質な推論In-Contextデモンストレーションを大規模推論モデル(RLM)の有効な資産に変換することを目的としたテスト時プログラムです。研究により、デモンストレーション例を直接追加するとRLMの精度が低下する可能性があることが判明しました。I2Sは、デモンストレーションを明確に再利用可能な洞察に変換し、目標に特化した推論軌跡を生成し、オプションで一貫性と正確性を向上させるために自己洗練を行います。実験により、I2SとI2S+は様々なベンチマークで直接回答やテスト時スケーリングベースラインを継続的に上回り、GPTモデルに対しても顕著な向上をもたらすことが示されています。 (出典: HuggingFace Daily Papers)
UniMIC:Tokenベースのマルチモーダルインタラクティブコーディングによる人間とAIの協調 : UniMIC(Unified token-based Multimodal Interactive Coding)は、Tokenベースの表現を通じてエッジデバイスとクラウドAIエージェント間の効率的で低ビットレートのマルチモーダルインタラクションを実現することを目的としたフレームワークです。UniMICは、コンパクトなToken化された表現を通信媒体として採用し、Transformerエントロピーモデルと組み合わせることで、Token間の冗長性を効果的に削減します。実験により、UniMICはテキストから画像への生成、画像修復、視覚的質問応答などのタスクで顕著なビットレート削減を達成し、超低ビットレートでも堅牢性を維持し、次世代のマルチモーダルインタラクティブ通信に実用的なパラダイムを提供します。 (出典: HuggingFace Daily Papers)
RLBFF:バイナリフレキシブルフィードバックが人間のフィードバックと検証可能な報酬を橋渡し : RLBFF (Reinforcement Learning with Binary Flexible Feedback) は、人間の好みの多様性とルール検証の正確性を組み合わせた強化学習パラダイムです。自然言語フィードバックからバイナリで回答可能な原則(例:情報精度:はい/いいえ、コード可読性:はい/いいえ)を抽出し、これを用いて報酬モデルを訓練します。RLBFFはRM-BenchとJudgeBenchで優れた性能を発揮し、ユーザーが推論時に原則の焦点をカスタマイズすることを可能にします。さらに、RLBFFを用いてQwen3-32Bをアライメントするための完全オープンソースソリューションを提供し、汎用アライメントベンチマークでo3-miniとDeepSeek R1の性能に匹敵するかそれを上回る性能を達成しました。 (出典: HuggingFace Daily Papers)
MetaAPO:メタ加重オンラインサンプリングによるアライメント最適化 : MetaAPO(Meta-Weighted Adaptive Preference Optimization)は、データ生成とモデルトレーニングを動的に結合することで、大規模言語モデル(LLM)と人間の好みの整合性を最適化する新しいフレームワークです。MetaAPOは、軽量なメタ学習器を「アライメントギャップ推定器」として利用し、オフラインデータに対するオンラインサンプリングの潜在的な利益を評価し、目標とするオンライン生成をガイドし、サンプルレベルのメタ重みを割り当てることで、オンラインとオフラインデータの品質と分布のバランスを動的に取ります。実験により、MetaAPOはAlpacaEval 2、Arena-Hard、MT-Benchで既存の好み最適化手法を継続的に上回り、同時にオンラインアノテーションコストを42%削減することが示されています。 (出典: HuggingFace Daily Papers)
Tool-Light:自己進化選好学習による効率的なツール統合推論 : Tool-Lightは、大規模言語モデル(LLM)がツール統合推論(TIR)タスクを効率的かつ正確に実行することを促すためのフレームワークです。ツール呼び出しの結果がその後の推論情報エントロピーに顕著な変化をもたらすことが研究で明らかになりました。Tool-Lightは、データセット構築と多段階ファインチューニングを組み合わせることで実現され、データセット構築では連続的な自己進化サンプリング(バニラサンプリングとエントロピー誘導サンプリングを統合)を採用し、厳格な正負ペア選択基準を確立します。トレーニングプロセスにはSFTと自己進化直接選好最適化(DPO)が含まれます。実験により、Tool-LightがTIRタスクの実行効率を大幅に向上させることが証明されました。 (出典: HuggingFace Daily Papers)
ChatInject:チャットテンプレートを利用したLLMエージェントへのPromptインジェクション攻撃 : ChatInjectは、LLMが構造化されたチャットテンプレートに依存していることと、複数ターンの会話のコンテキスト操作を利用して、間接的なPromptインジェクション攻撃を行う手法です。攻撃者は、ネイティブのチャットテンプレート形式を模倣して悪意のあるペイロードをフォーマットし、エージェントに疑わしい操作を実行させます。実験により、ChatInjectは従来のPromptインジェクション手法よりも高い攻撃成功率を示し、特に複数ターンの会話で顕著であり、異なるモデルに対して高い移植性を持っています。既存のPromptベースの防御策は、このような攻撃に対してほとんど無効です。 (出典: HuggingFace Daily Papers)
💼 ビジネス
Modalが8700万ドルのシリーズB資金調達を完了、評価額11億ドルに : AIインフラ企業Modalは、8700万ドルのシリーズB資金調達を完了し、評価額が11億ドルに達したと発表しました。この資金調達は、AI時代に従来のコンピューティングインフラが直面する課題に対応するため、AIインフラの革新と発展を加速することを目的としています。Modalは、効率的なクラウドコンピューティングサービスを提供することで、研究者や開発者がAIモデルのトレーニングと展開プロセスを最適化するのを支援します。 (出典: Twitter, Twitter, Twitter)
OpenAI上半期売上43億ドル、損失135億ドル、収益性課題に直面 : OpenAIは2025年上半期の売上が43億ドルに達し、通期売上は130億ドルを突破すると予想されています。これは主にChatGPT Plusのサブスクリプションとエンタープライズ向けAPIサービスによるものです。しかし、同時期の純損失は135億ドルに達しており、構造的コストと研究開発投資(GPT-5など)が主な要因で、サーバーレンタル費用は年間160億ドルに上ります。OpenAIは175億ドルの現金準備と300億ドルの資金調達計画を進めていますが、継続的な現金消費とAnthropicなどの競合他社との効率性の差により、厳しい収益性課題に直面しています。 (出典: 36氪)
ヒューマノイドロボット分野の資本戦:智元、銀河通用などが積極的に産業チェーンを構築 : ヒューマノイドロボット分野は資本戦の段階に入り、智元ロボット、銀河通用などの大手企業は、ファンド設立、同業他社への投資、戦略的提携などを通じて「友好関係」を積極的に拡大しています。智元ロボットはすでに20件近くの対外投資を行い、モーター、センサー、下流アプリケーションを網羅し、富臨精工、軟通動力などと協力して商業シーンを展開しています。銀河通用はBosch Chinaと合弁会社を設立し、具身知能の自動車製造分野での応用を推進しています。これらの取り組みは、受注獲得、弱点補完、将来の量産に向けた安定したサプライチェーンネットワークの構築を目指していますが、業界の技術路線は大きく異なり、競争は激化しています。 (出典: 36氪)

🌟 コミュニティ
AI生成コンテンツの真偽判別が困難に、社会的な信頼危機を招く : AI技術の急速な発展に伴い、AI生成ビデオ(例: 『進撃の巨人』実写版、インドネシアのストリーマーが日本人インフルエンサーに「顔を入れ替える」)のリアリティは信じられないほどになり、コンテンツの真実性に対する社会的な深い懸念を引き起こしています。ソーシャルメディアでは、ユーザーが本物とAI生成コンテンツを区別することがますます困難になっていると一般的に述べており、これは合法的なコンテンツクリエイターの信頼性を損なうだけでなく、虚偽情報の拡散にも利用される可能性があります。専門家は、強制的なAIコンテンツのラベリングがなければ、この「超現実エンジン」は現実感を侵食し続け、最終的には「インターネットを終わらせる」可能性があると指摘しています。 (出典: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

AIが雇用市場に与える影響:SequoiaレポートによるとAI投資の95%が無効、新卒者が最大の打撃 : Sequoia CapitalがMITとハーバード大学の研究レポートを共有しました。それによると、企業のAI投資の95%は実際の価値を生み出しておらず、真の生産性向上は従業員が個人的なAIツールを「こっそり」使用することで形成される「シャドウAI経済」から生まれていると指摘されています。レポートはまた、AIが雇用市場に与える影響は主に新卒者に集中しており、特に卸売・小売業において初級職の採用数が著しく減少していること、名門大学の学歴も完全な免罪符ではないことを明らかにしています。これは、AIがタスクの割り当てを変え、人間の価値が経験と独自の判断に移行していることを示しています。 (出典: 36氪, Reddit r/ArtificialInteligence)
OpenAIモデル調整がユーザーの強い不満を招き、透明性のあるコミュニケーションを求める声 : OpenAIが最近、通知なしにGPT-4o/GPT-5モデルを低計算能力バージョンに「ダウングレード」したことで、モデル性能が低下し、ユーザーから強い不満が噴出しています。多くのユーザーはモデルが「賢くなくなった」と不満を述べ、元の洞察力や「友人」のような対話体験が失われたと感じており、中には「精神的打撃」と表現する人もいます。OpenAI幹部はこれを「安全ルーティングテスト」と説明し、デリケートな話題を処理するためのものだとしましたが、ユーザーはOpenAIに対し、ユーザーとのコミュニケーションと透明性を強化し、一方的な製品契約の変更を避けることで、ユーザーの信頼を再構築するよう広く求めています。 (出典: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
ロボット課税:技術進歩と社会公平の議論 : AIとロボット技術の発展に伴い、ロボットへの「課税」に関する議論がますます増えています。これは、ロボットが人間の労働力を代替することで生じる可能性のある雇用問題と社会的不平等を均衡させることを目的としています。支持者は、ロボット税が失業者に社会福祉と再就職支援を提供し、資本と労働の間の交渉力の不均衡を是正できると考えています。しかし、ロボット業界の従事者は、現在の課税は時期尚早であり、新興産業の発展を阻害する可能性があると一般的に考えています。韓国は、自動化企業への税制優遇を削減することで、間接的にロボット使用コストを増加させています。 (出典: 36氪)
ヒューマノイドロボットの未来:著名なロボット専門家Rodney Brooksは未来は人間らしくないと考える : 著名なロボット専門家Rodney Brooksは、現在のヒューマノイドロボットは多額の投資にもかかわらず、人間レベルの器用さを実現できておらず、二足歩行には安全上のリスクがあると指摘する記事を執筆しました。彼は、今後15年間でヒューマノイドロボットは人間の形態を模倣するのをやめ、車輪移動、多腕(グリッパーや吸盤を装備)、多センサー(アクティブ光イメージング、非可視光知覚)を備えた特殊ロボットへと進化し、特定のタスクに適応するだろうと予測しています。彼は、「人間らしい」形態の追求に現在多大な投資がされているが、最終的には無駄に終わると考えています。 (出典: 36氪)

AIコード生成の品質と開発者体験の議論 : ソーシャルメディアでは、AI生成コードの品質と実用性について開発者間で活発な議論が交わされています。Claude Sonnet 4.5がコードベース全体をリファクタリングできると称賛する声がある一方で、生成されたコードが動作しないという不満も聞かれます。また、AI生成コードが「コンパイルできない」と不満を漏らし、開発効率が低下したと訴える人もいます。これらの議論は、AI支援プログラミングが効率と正確性の間で依然として課題を抱えていること、そして開発者がAI生成結果に直面した際にデバッグと検証の必要性を感じていることを示しています。 (出典: Twitter, Twitter, Twitter)

AI時代の人材観の変化:「人材を掘り出す」から「作物を育てる」へ : ソーシャルメディアでは、AI時代の人材観が従来の「あちこちから人材を掘り出す」から「作物を育てる」へと転換すべきだという議論が活発に行われています。AI分野の人材が希少で技術の進化が速いことを考慮すると、企業は市場の高価な「完成品」人材を盲目的に追い求めるのではなく、基礎的な技術スタックを持つ従業員の育成に注力すべきだという見方です。この見解は、AI分野の急速な変化するニーズに適応するために、継続的な学習と内部育成の重要性を強調しています。 (出典: dotey)
AIインフラのエネルギー消費とSam Altmanのエネルギー需要 : Sam AltmanがAIの発展には250GWの電力が必要だと述べたことで、AIインフラの莫大なエネルギー消費に対する社会の注目と議論が巻き起こっています。この需要は既存のエネルギー供給能力をはるかに超えており、AIの急速な発展と持続可能なエネルギー供給のバランスをいかに取るかという考察を促しています。関連する議論は、半導体製造における環境問題、例えばPFASの使用とその代替案の潜在的なリスクにも及んでいます。 (出典: Twitter, Twitter)

AI終末論と楽観派:懸念と反論 : ソーシャルメディアでは、AIの「終末論」やAIの潜在的リスクについて広範な議論が存在しますが、これらの懸念は誇張されていると考える人も多くいます。楽観派は、AIがもたらす実際の問題(気候変動、企業による搾取、軍事監視など)は、遠い「超知能による人類滅亡」よりも差し迫っており、現在解決可能な課題に焦点を当てるべきだと主張しています。AI終末論を「ナンセンス」であり、怠惰で不安定な表現だと考える人もいれば、AIが最終的には創造と育成に向かうと信じる人もいます。 (出典: Reddit r/ArtificialInteligence, Twitter, Twitter)
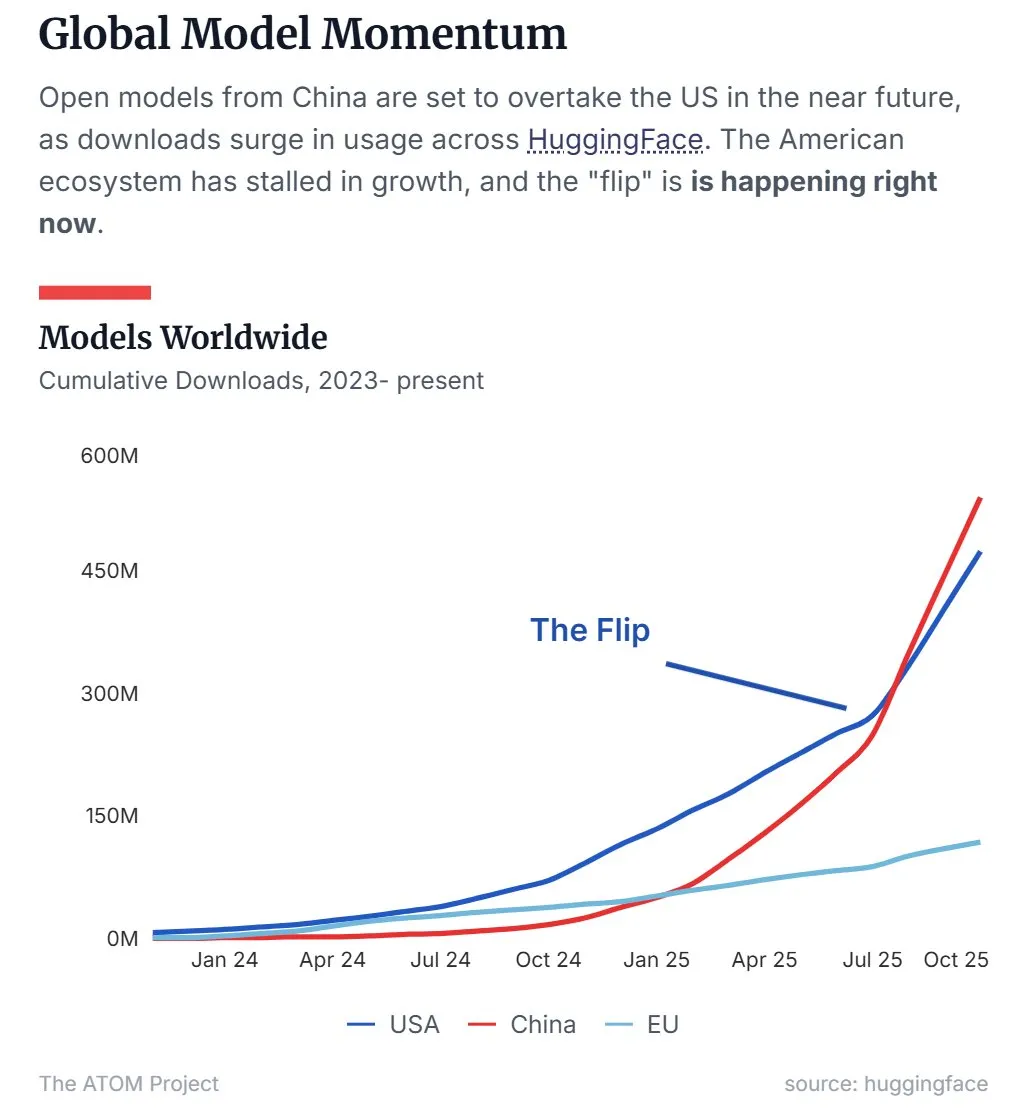
中国のオープンソースLLM市場シェアが米国を上回る : 最新のデータによると、Qwenに代表される中国のオープンソース大規模言語モデル(LLM)が市場シェアで米国を上回り、オープンソースLLM分野の主導的な勢力となっています。この傾向は、中国がオープンソースAI技術の研究開発と応用において急速に台頭しており、世界のAI情勢に重要な影響を与えていることを示しています。 (出典: Twitter, Twitter)
45日間でAIマンガドラマ『明日週一』を制作、再生回数1000万回を達成 : わずか10人のチームが45日間でAIマンガドラマ『明日週一』全50話の制作を完了し、プロモーション費用を一切かけずに、全プラットフォームでの再生回数が1000万回を突破、Douyinでの有料収入はすべてのコストをカバーしました。このプロジェクトは「オリジナルキャラクター+AI生成」を核とする理念を採用し、AIコンテンツの著作権帰属問題を解決し、IPの全カテゴリ商業開発パスを模索しました。制作プロセスは高度に分業され、原画師、エンジニア、後期編集者、監督が密接に連携し、コンテンツ制作におけるAI技術のコスト削減と効率向上における巨大な可能性を示しました。 (出典: 36氪)

💡 その他
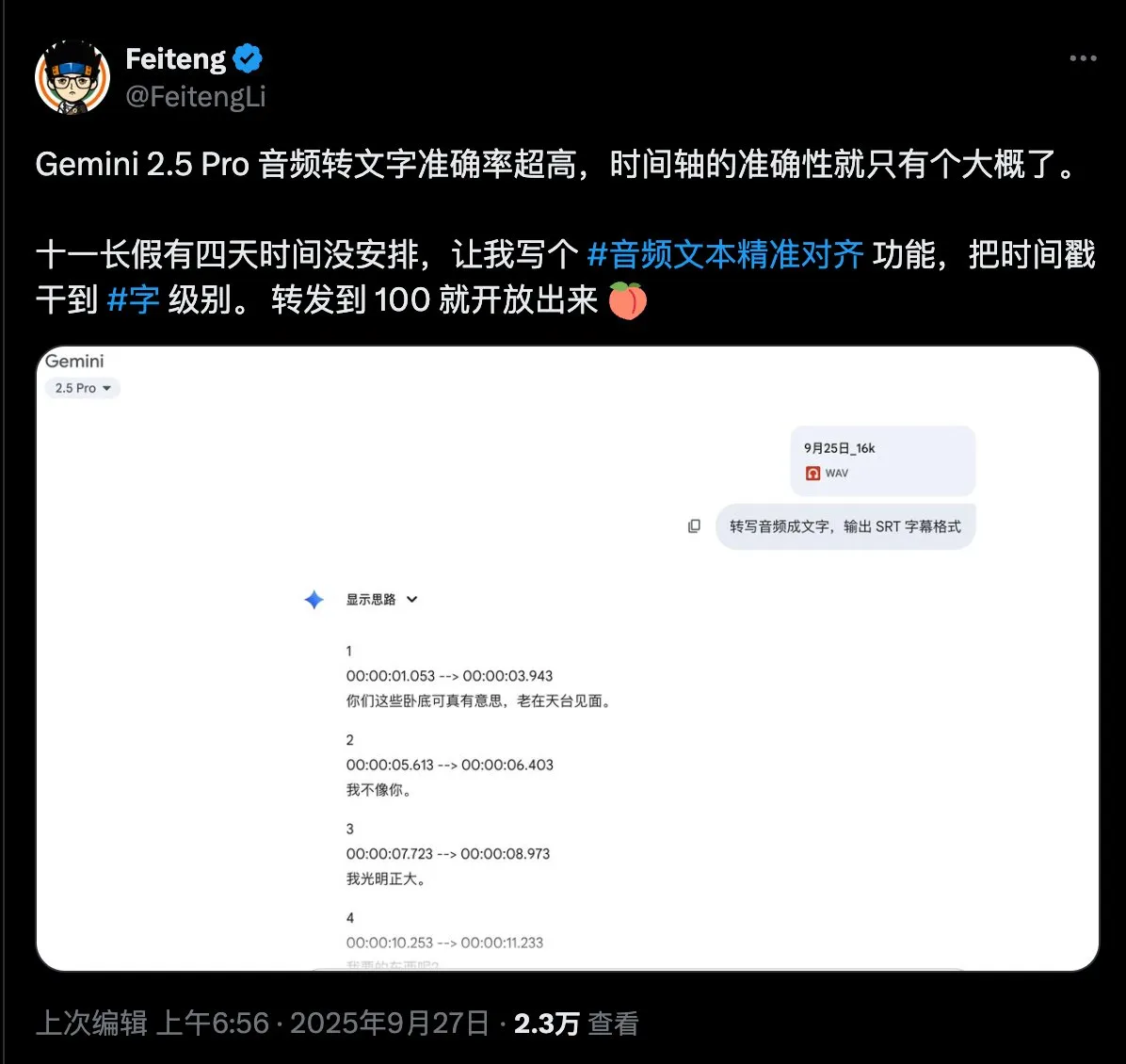
音声テキスト高精度アライメントのニーズに関するアンケート : ソーシャルメディアユーザーが音声テキスト高精度アライメント技術に強い関心を示し、この技術の機能と応用シナリオに関する具体的なニーズを収集するためのアンケートを公開しました。これは、関連技術の発展と最適化を推進することを目的としています。 (出典: dotey)
DeepMindがNano Banana Demoを公開 : Google DeepMindが「Nano Banana」と名付けられたデモンストレーションを公開し、ソーシャルメディアの注目を集めました。具体的な詳細はまだ完全に明らかにされていませんが、AIビデオ生成またはマルチモーダルAI技術に関連している可能性があり、DeepMindの視覚AI分野における新たな進展を示唆しています。 (出典: GoogleDeepMind)
Highway NetとResNetの発明優先権に関する学術的議論 : 著名なAI研究者Jürgen Schmidhuberがツイートを転送し、Highway NetとResNetの深層残差学習における発明優先権に関する学術的議論が再び巻き起こりました。彼は、MicrosoftのResNet論文がHighway Netを「同時代」の仕事と称するのは不正確であると指摘し、Highway NetがResNetより7ヶ月早く発表されており、残差接続の解決策をすでに特定し提案していたことを強調しました。 (出典: SchmidhuberAI)