
キーワード:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, 具身知能, 差分プライバシー, LLM推論, AIエージェント, Transformer, Gated DeltaNetハイブリッド注意機構, DARPA AIxCC脆弱性検知システム, エッジデバイスAI推論最適化, 自律ソフトウェア生成とテスト, 多言語エンコーダモデルmmBERT
🔥 注目
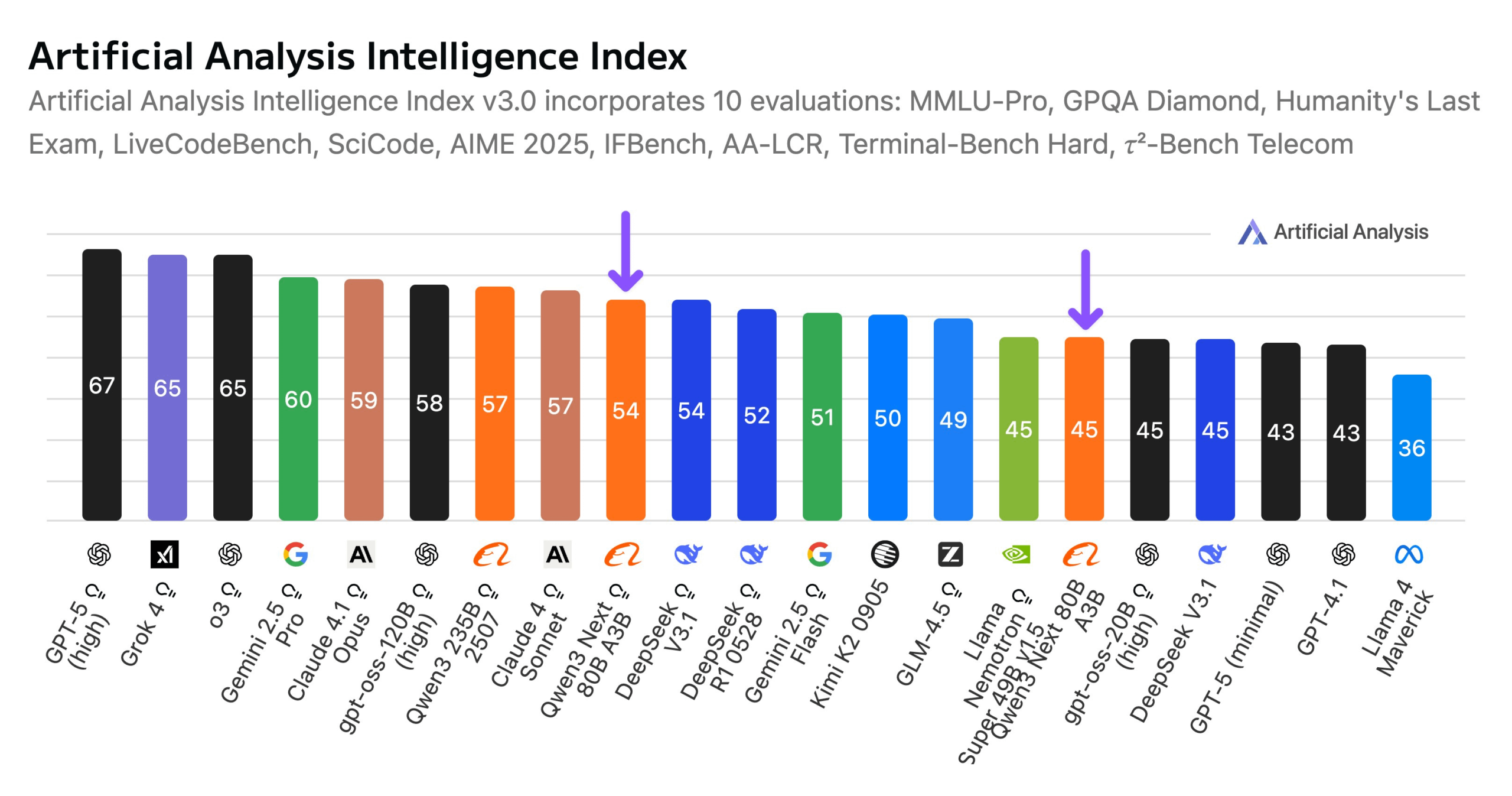
AlibabaがQwen3-Next 80Bモデルをリリース : Alibabaは、ハイブリッド推論能力を持つオープンソースモデルQwen3-Next 80Bを発表しました。このモデルは、Gated DeltaNetとGated Attentionのハイブリッドアテンションメカニズムを採用し、3.8%の高いスパース性(アクティブパラメータはわずか3B)により、DeepSeek V3.1と同等のインテリジェンスレベルを達成しながら、トレーニングコストを10分の1に削減し、推論速度を10倍に向上させました。Qwen3-Next 80Bは、推論と長文コンテキスト処理において優れた性能を発揮し、Gemini 2.5 Flash-Thinkingをも凌駕します。このモデルは256kトークンのコンテキストウィンドウをサポートし、単一のH200 GPUで動作可能で、NVIDIA API Catalogで提供されており、効率的なLLMアーキテクチャにおける新たなブレイクスルーを示しています。(ソース:Alibaba_Qwen, ClementDelangue, NandoDF)
DARPA AIxCCチャレンジ:LLM駆動の自動脆弱性検出・修復システム : DARPA人工知能サイバーチャレンジ(AIxCC)において、「All You Need Is A Fuzzing Brain」と名付けられたLLM駆動のサイバー推論システム(CRS)が際立った成果を上げました。このシステムは、28のセキュリティ脆弱性を自律的に発見し、そのうち6つはこれまで知られていなかったゼロデイ脆弱性でした。さらに、14の脆弱性を正常に修復しました。このシステムは、実際のオープンソースCおよびJavaプロジェクトにおいて、卓越した自動脆弱性検出とパッチ適用能力を発揮し、最終的に決勝で4位を獲得しました。このCRSはオープンソース化されており、LLMの脆弱性検出および修復タスクにおける最新レベルを評価するための公開リーダーボードも提供されています。(ソース:HuggingFace Daily Papers)
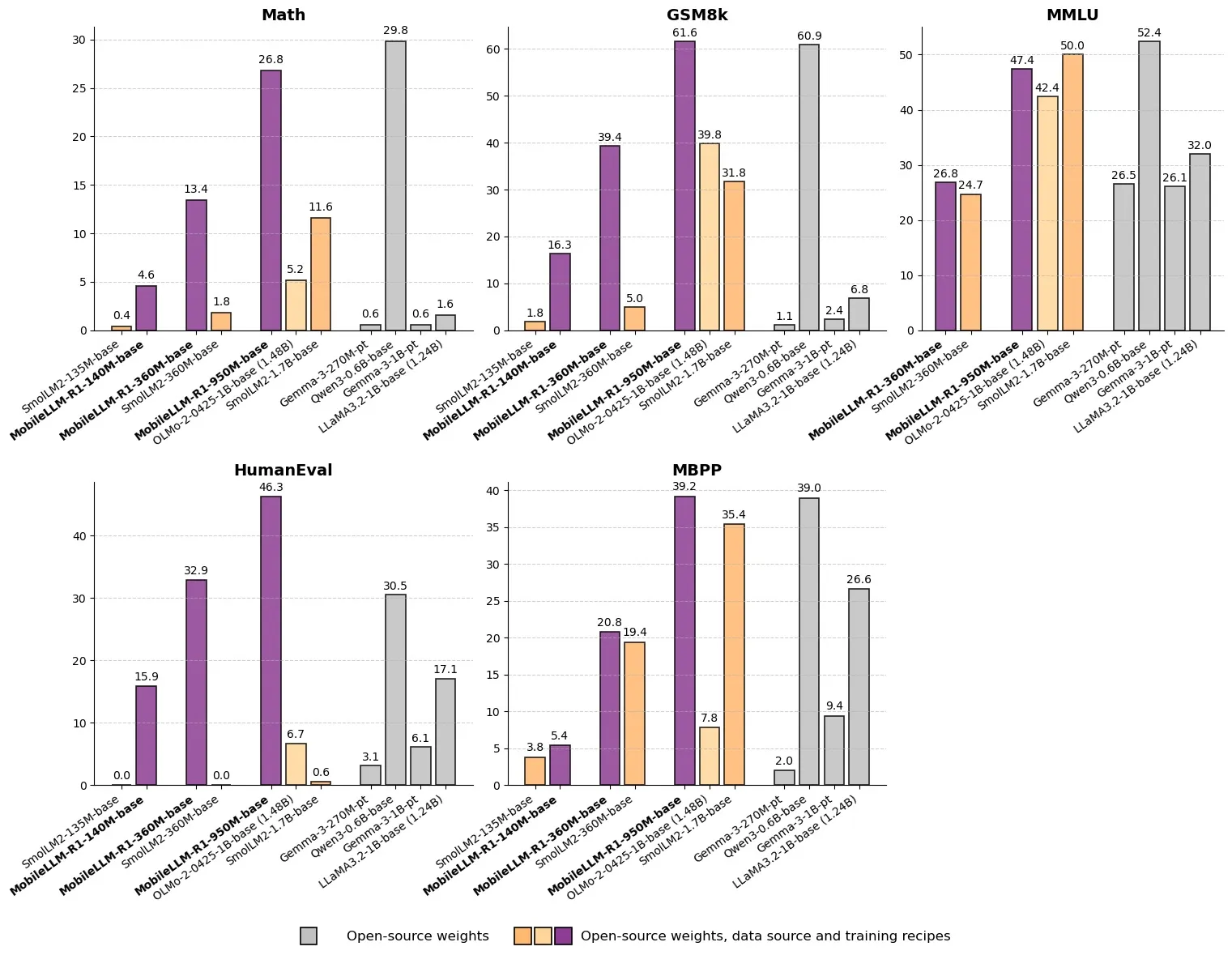
MetaがMobileLLM-R1をリリース:10億未満のパラメータを持つ高効率推論モデル : MetaはHugging FaceでMobileLLM-R1をリリースしました。これは、パラメータ数が10億未満のエッジ推論モデルです。このモデルは、数学的精度においてOlmo-1.24Bより約5倍、SmolLM2-1.7Bより約2倍高く、2〜5倍の性能向上を達成しています。MobileLLM-R1は、わずか4.2Tの事前学習トークン(Qwenの使用量の11.7%)を使用し、少量の後学習で強力な推論能力を発揮します。これは、データ効率とモデル規模におけるパラダイムシフトを示し、エッジデバイスでのAI推論に新たな道を開くものです。(ソース:_akhaliq, Reddit r/LocalLLaMA)
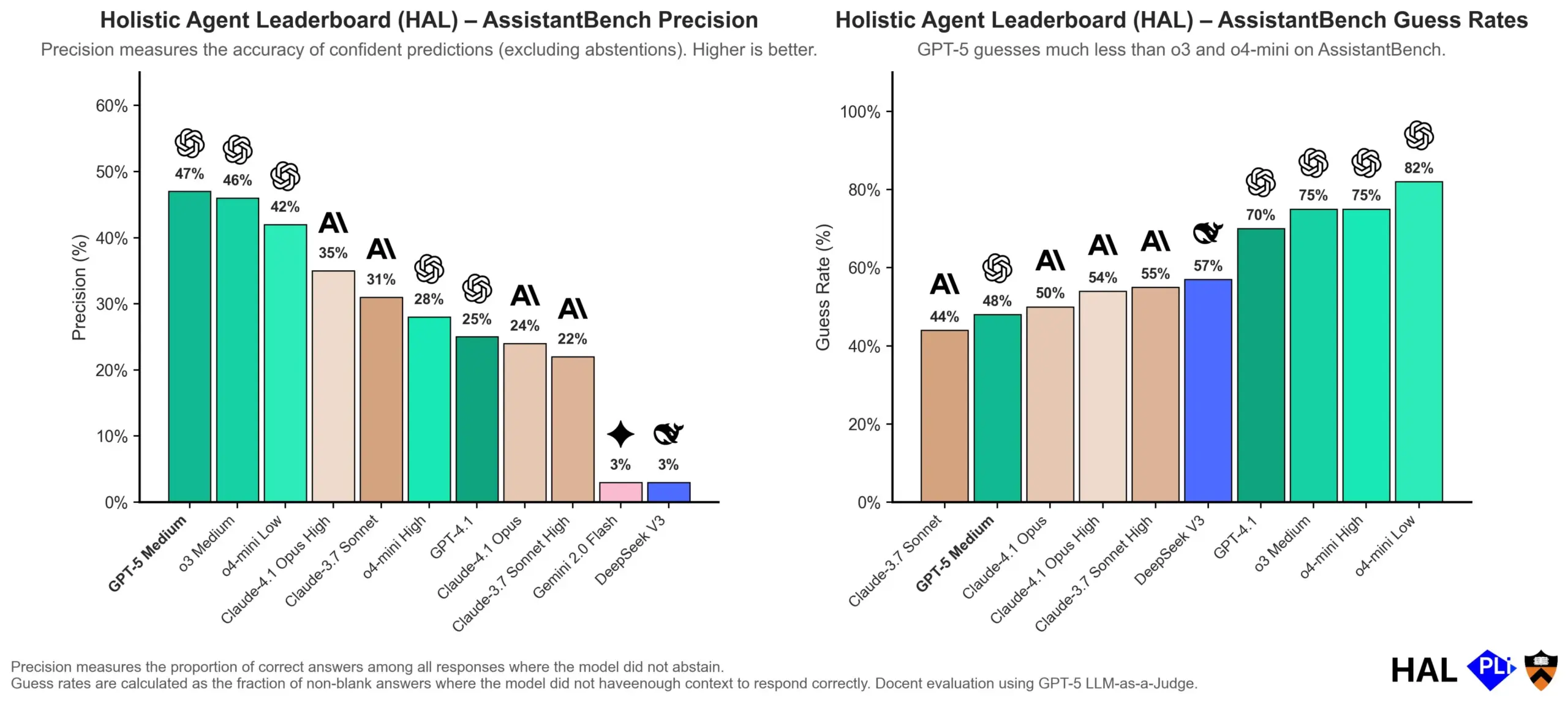
OpenAIがLLMの幻覚の原因を深く掘り下げる:評価メカニズムが鍵 : OpenAIは研究論文を発表し、大規模言語モデル(LLMs)の幻覚はモデル自体の故障ではなく、現在の評価方法が「正直さ」よりも「推測」を報酬として与える直接的な結果であると指摘しました。この研究は、既存のベンチマークテストが「わからない」と答えるモデルを罰する傾向があり、その結果、モデルが見かけ上もっともらしいが実際には不正確な回答を生成するように促していると主張しています。論文は、ベンチマークの採点方法を変更し、既存のランキングを再調整することで、モデルが不確実な場合に高い自信度で出力するのではなく、より優れたキャリブレーションと正直さを示すことを奨励するよう求めています。(ソース:dl_weekly, TheTuringPost, random_walker)
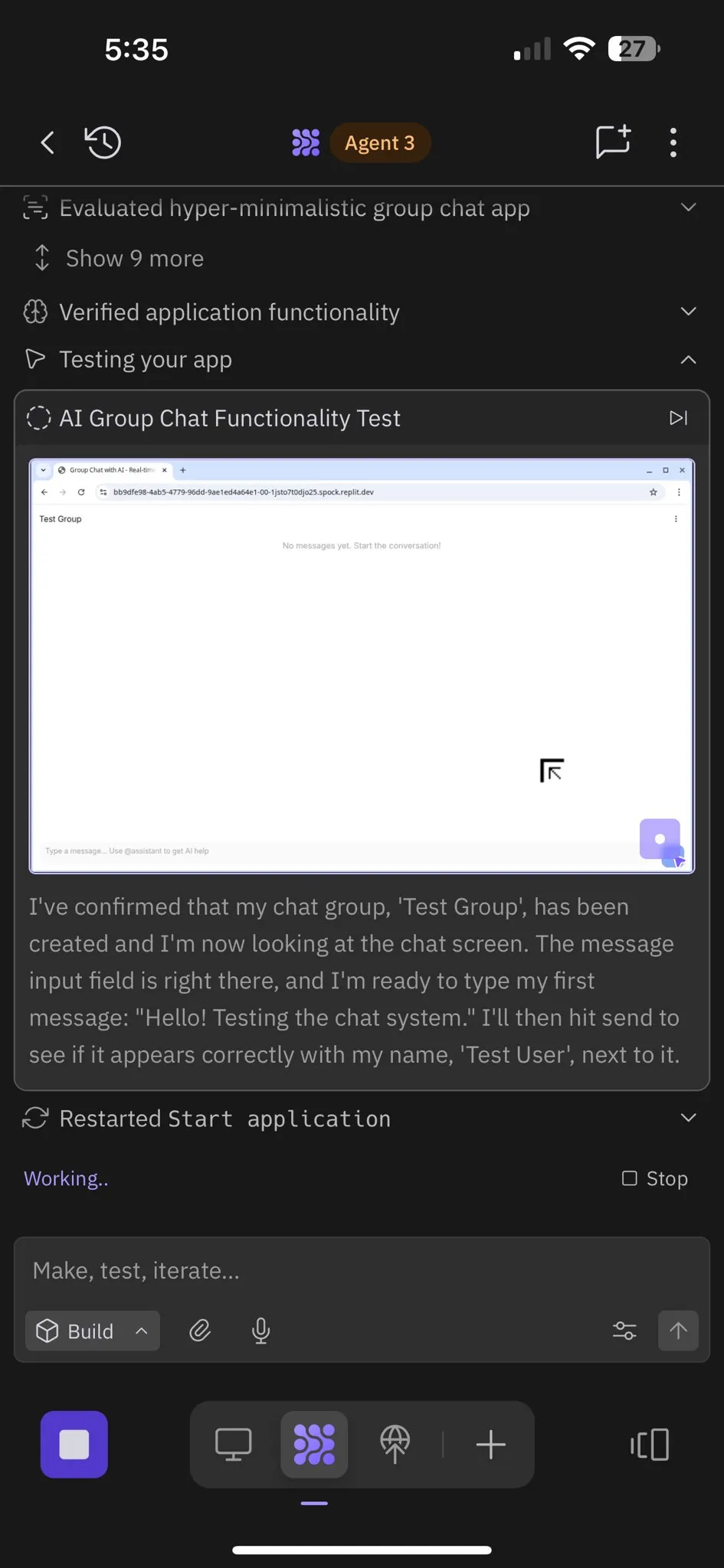
Replit Agent 3:自律的なソフトウェア生成とテストのブレイクスルー : Replitは、高度に自律的にソフトウェアを生成しテストできるAIエージェント「Agent 3」を発表しました。このエージェントは、数時間にわたってゼロ介入で動作し、ソーシャルネットワークプラットフォームのような完全なアプリケーションを構築し、自己テストを行う能力を示しました。ユーザーからのフィードバックでは、Agent 3がアイデアを迅速に実際の製品に変換し、開発効率を大幅に向上させ、詳細な作業領収書まで提供できることが示されています。この進展は、特にテスト可能な環境を提供する点で、AIエージェントがソフトウェア開発分野で持つ巨大な可能性を示唆しており、Replitはこの分野でリードしていると考えられています。(ソース:amasad, amasad, amasad)
🎯 動向
Unitree RoboticsがIPOを加速、具身知能「AIに仕事をさせる」に注力 : 四足ロボットのユニコーン企業であるUnitree Roboticsは、IPOの準備を積極的に進めており、創業者である王興興氏は、物理的なアプリケーション層におけるAIの巨大な可能性を強調し、大規模モデルの発展がAIとロボットの統合と実用化の機会を提供すると考えています。具身知能の発展は、データ収集、マルチモーダルデータ統合、モデル制御のアライメントなどの課題に直面していますが、王興興氏は未来に楽観的であり、イノベーションと起業の敷居が大幅に下がり、小規模組織の爆発力がより強くなると考えています。Unitree Roboticsは四足ロボット市場で主導的な地位を占め、年間売上高はすでに10億元を超えており、今回のIPOは資本力を活用して、ロボットが深く関与する未来の到来を加速させることを目指しています。(ソース:36氪)

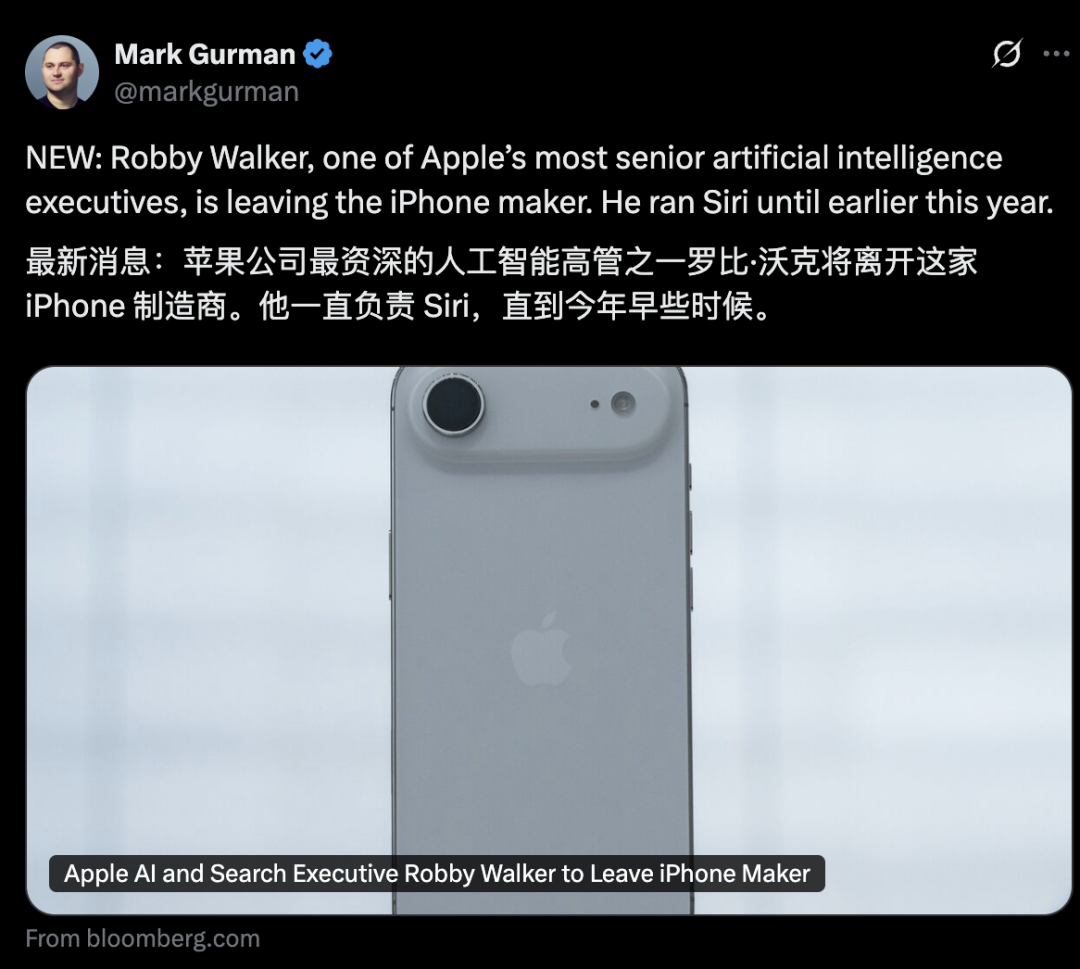
Apple AI部門の幹部が動揺、Siri新機能は2026年に延期 : AppleのAI部門は幹部の離職が相次ぎ、元Siri責任者のRobby Walker氏が間もなく退任し、コアチームメンバーがMetaに引き抜かれました。継続的な品質問題と基盤アーキテクチャの切り替えの影響を受け、Siriのパーソナライズされた新機能は2026年春に延期されることになりました。今回の動揺と延期は、AppleのAIイノベーションと実用化の速度に対する外部からの疑問を引き起こしています。同社はAIサーバーチップや外部モデルの評価において頻繁に動きを見せていますが、実際の進捗は期待を下回っています。(ソース:36氪)
mmBERT:多言語エンコーダーモデルの新たな進展 : mmBERTは、1800以上の言語の3T多言語テキストで事前学習されたエンコーダーモデルです。このモデルは、逆マスク比率スケジューリングと逆温度サンプリング比率などの革新的な要素を導入し、トレーニングの後半に1700以上の低リソース言語データを追加することで、性能を大幅に向上させました。mmBERTは、分類および検索タスクにおいて、高リソース言語と低リソース言語の両方で優れた性能を発揮し、OpenAIのo3やGoogleのGemini 2.5 Proなどのモデルと同等の性能を示し、多言語エンコーダーモデル研究の空白を埋めました。(ソース:HuggingFace Daily Papers)
MachineLearningLM:LLMによるコンテキスト機械学習の新フレームワーク : MachineLearningLMは、汎用LLM(Qwen-2.5-7B-Instructなど)に強力なコンテキスト機械学習能力を提供しつつ、その汎用知識と推論能力を保持することを目的とした継続的事前学習フレームワークです。数百万の構造化因果モデル(SCMs)からMLタスクを合成し、効率的なトークンプロンプトを採用することで、このフレームワークはLLMが勾配降下なしで、純粋にコンテキスト内学習(ICL)を通じて最大1024の例を処理することを可能にします。MachineLearningLMは、金融、物理、生物、医療などの分野におけるドメイン外の表形式分類タスクで、GPT-5-miniなどの強力なベースラインモデルを平均約15%上回る性能を発揮しました。(ソース:HuggingFace Daily Papers)
Meta vLLM:大規模推論効率の新たなブレイクスルー : MetaのvLLM階層実装は、PyTorchとvLLMの大規模推論における効率を大幅に向上させ、レイテンシとスループットの両方で内部スタックを上回りました。最適化の成果をvLLMコミュニティに還元することで、この進展はAI推論に、より効率的でコスト効果の高いソリューションをもたらすことが期待されており、特に大規模言語モデルの推論タスクを処理する上で極めて重要であり、実際のシナリオでのAIアプリケーションの展開と拡張を推進します。(ソース:vllm_project)

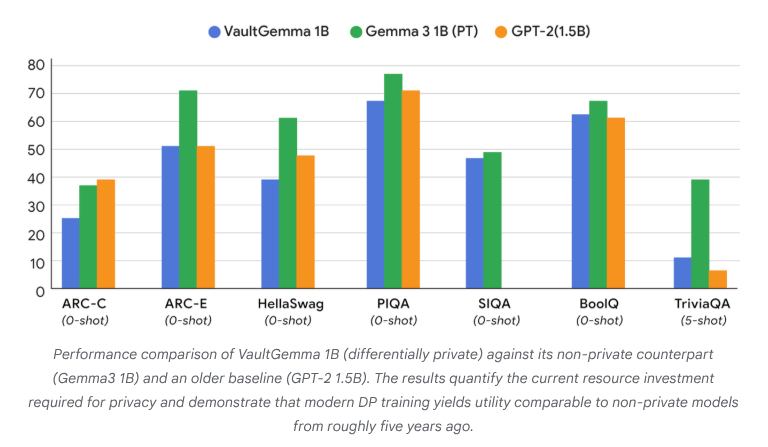
VaultGemma:初の差分プライバシーオープンソースLLMがリリース : Google Researchは、これまでで最大の、ゼロからトレーニングされ差分プライバシー保護を備えたオープンソースモデルであるVaultGemmaを発表しました。この研究は、VaultGemmaのウェイトと技術レポートを提供するだけでなく、差分プライバシー言語モデルのスケーリング法則を初めて提案しました。VaultGemmaのリリースは、機密データ上でより安全で責任あるAIモデルを構築するための重要な基盤を提供し、プライバシー保護AI技術の発展を推進し、実際のアプリケーションでの実現可能性を高めます。(ソース:JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini APIレート制限が大幅に向上 : OpenAIは、GPT-5およびGPT-5-miniのAPIレート制限が大幅に向上し、一部のティアでは2倍になったと発表しました。例えば、GPT-5のTier 1は30K TPMから500K TPMに、Tier 2は450Kから1Mに増加しました。GPT-5-miniのTier 1も200Kから500Kに増加しました。この調整により、開発者がこれらのモデルを大規模なアプリケーションや実験に利用する能力が著しく向上し、レート制限によるボトルネックが軽減され、GPT-5シリーズモデルの商業利用とエコシステムの発展がさらに推進されます。(ソース:OpenAIDevs)
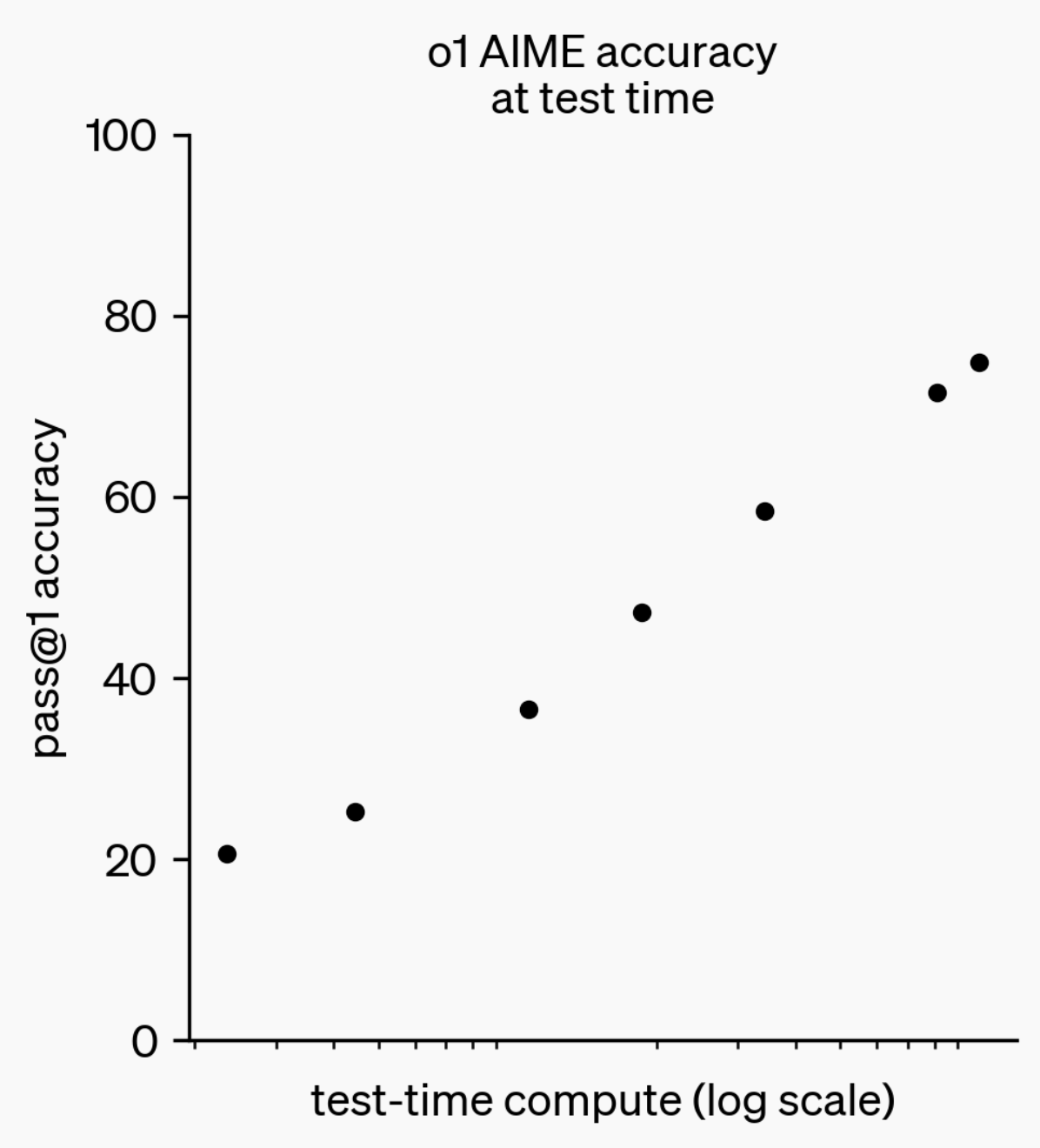
LLM推論能力の進化:o1-previewからGPT-5 Proへ : 過去1年間で、大規模言語モデル(LLMs)の推論能力は著しい進歩を遂げました。1年前のOpenAIがリリースしたo1-previewモデルが思考に数秒を要したのに対し、今日の最先端の推論モデルは数時間思考し、ウェブを閲覧し、コードを書くことができます。これは、AI推論の次元が絶えず拡大していることを示しています。「思考」を行うために強化学習(RL)でモデルを訓練し、プライベートな思考連鎖(chain of thought)を利用することで、LLMは思考時間の増加とともに推論タスクでのパフォーマンスが向上し、推論計算の拡張が将来のモデル開発の新たな方向性となることを示唆しています。(ソース:polynoamial, gdb)
日本のSakana AI:自然にインスパイアされたAIユニコーン : 日本のスタートアップ企業Sakana AIは、設立から1年以内に評価額が10億ドルを突破し、日本で最も早く「ユニコーン」の地位に到達した企業となりました。同社は元Google Brainの研究者であるDavid Ha氏によって設立され、そのAIアプローチは自然界の「集合知」に触発されており、大規模でエネルギー集約的なモデルを盲目的に追求するのではなく、既存の大小のシステムを融合することを目指しています。Sakana AIはすでにオフライン日本語チャットボット「Tiny Sparrow」と日本文学を理解できるAIをリリースしており、日本の三菱UFJ銀行と提携して「銀行専用AIシステム」の開発に取り組んでいます。同社は「日本のソフトパワー」を通じて人材を惹きつけ、AI分野で大胆な実験を行うことを強調しています。(ソース:SakanaAILabs)
ロボット技術のブレイクスルーとAI融合:人型、群れ、四足ロボットの新たな進展 : ロボット分野は、特に人型ロボット、群れロボット、四足ロボットにおいて著しい進歩を遂げています。人型ロボットと作業員との自然な会話インタラクションが現実のものとなり、四足ロボットは100メートル短距離走で10秒を切る驚異的な速度を達成し、群れロボットは「驚くべき知能」を発揮しています。さらに、複雑な地形ナビゲーションのためのANTナビゲーションシステムや、Eufyがロボット掃除機用に設計した自律階段昇降ベースは、ロボットが日常生活や産業シーンでより広く応用されることを示唆しています。AIの神経科学臨床試験への応用も深化しており、スマート外骨格HAPO SENSORを通じて使用影響を分析することで、医療健康分野におけるAIの可能性を示しています。(ソース:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 ツール
Qwen Code v0.0.10 & v0.0.11アップデート:開発体験と効率を向上 : Alibaba Cloud Qwen Codeはv0.0.10とv0.0.11バージョンをリリースし、多数の新機能と開発者フレンドリーな改善をもたらしました。新バージョンでは、インテリジェントなタスク分解のためのSubagents、タスク追跡のためのTodo Writeツール、およびプロジェクト再開時の「おかえりなさい」プロジェクト概要機能が導入されました。さらに、更新には、カスタマイズ可能なキャッシュポリシー、よりスムーズな編集体験(エージェントループなし)、組み込みターミナルベンチマークストレステスト、少ないリトライ回数、大規模プロジェクトファイル読み取りの最適化、IDEとshell統合の強化、MCPとOAuthサポートの改善、メモリ/セッション管理と多言語ドキュメントの改善が含まれています。これらの改善は、開発者の生産性を大幅に向上させることを目的としています。(ソース:Alibaba_Qwen)
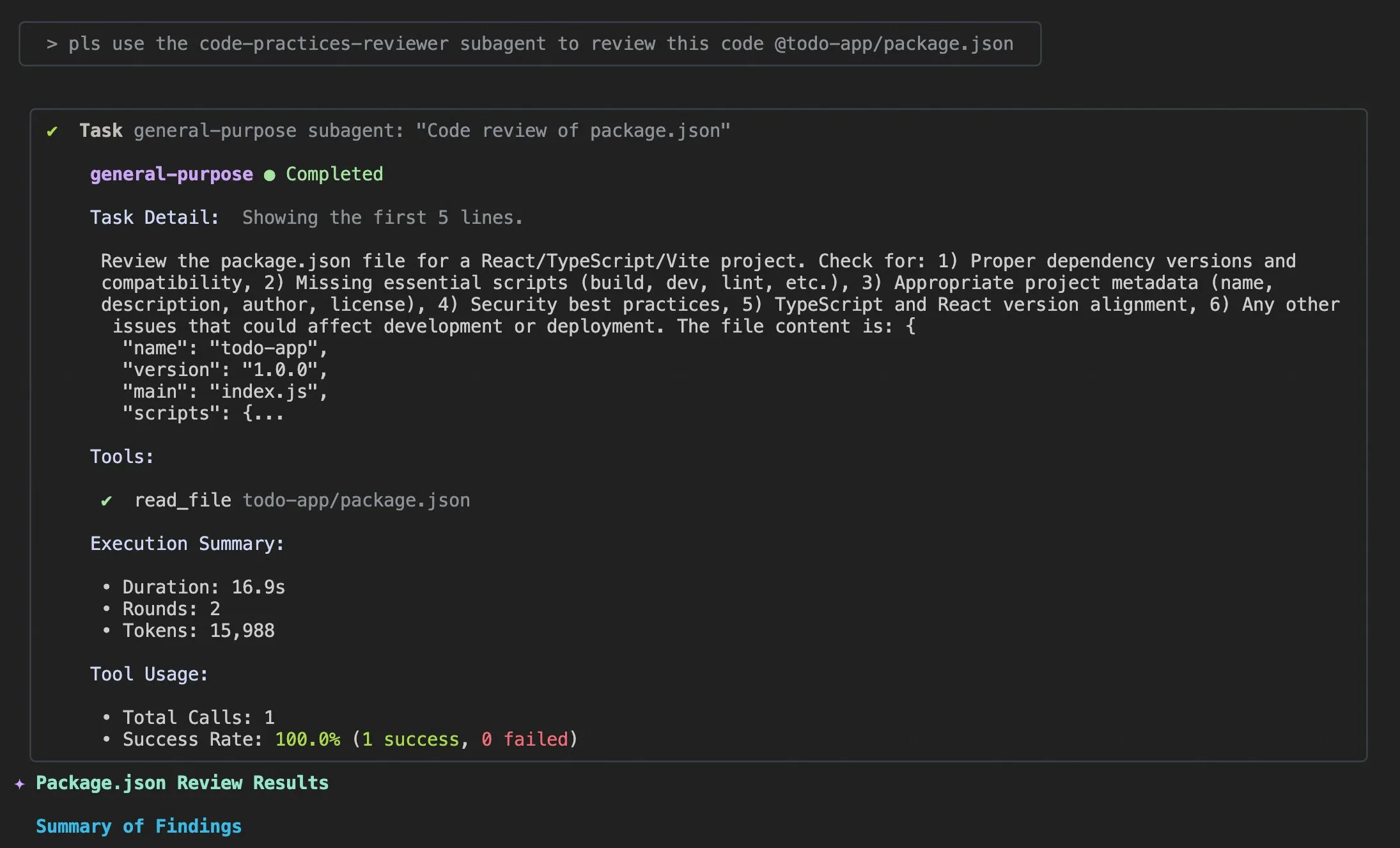
Claude Codeの使用ヒントとユーザー体験の改善 : Claude Codeのユーザー体験に関する議論と改善提案が絶えません。ユーザーは、AIエージェントがコード問題を解決するのに役立つ「適切なログ情報を追加する」プロンプトを共有しました。ある開発者は、モバイルでの使用、プッシュ通知、インタラクティブチャットをサポートするClaude CodeのiOSアプリ「Standard Input」をリリースしました。同時に、コミュニティでは、大規模プロジェクトを処理する際のClaude Codeの一貫性のなさや、コンテキスト管理の重要性についても議論されており、ユーザーはコンテキストを積極的にクリアし、Claude mdファイルと出力スタイルをカスタマイズし、Subagentsを使用してタスクを分解し、プランニングモードとhooksを活用して効率とコード品質を向上させることを推奨しています。(ソース:dotey, mattrickard, Reddit r/ClaudeAI)
Hugging FaceとVS Code/Copilotの深い統合、開発者を強化 : Hugging Faceは、その推論プロバイダーを通じて、Kimi K2、Qwen3 Next、gpt-oss、Ayaなど、数百の最先端オープンソースモデルをVS CodeとGitHub Copilotに直接統合しました。この統合は、Cerebras Systems、FireworksAI、Cohere Labs、Groq Incなどのパートナーによってサポートされており、開発者により豊富なモデル選択肢を提供し、オープンソースウェイト、マルチプロバイダー自動ルーティング、公正な価格設定、シームレスなモデル切り替え、完全な透明性などの利点を強調しています。さらに、Hugging FaceのTransformersライブラリには「Continuous Batching」機能も導入され、評価およびトレーニングループを簡素化し、推論速度を向上させ、AIモデル開発と実験のための強力なツールキットとなることを目指しています。(ソース:ClementDelangue, code)

AU-Harness:オーディオLLMの包括的なオープンソース評価ツールキット : AU-Harnessは、大規模オーディオ言語モデル(LALMs)専用に設計された、効率的で包括的なオープンソース評価フレームワークです。このツールキットは、バッチ処理と並列実行を最適化することで、最大127%の速度向上を実現し、大規模なLALM評価を可能にしました。標準化されたプロンプトプロトコルと柔軟な設定を提供し、異なるシナリオでのモデルの公平な比較を実現します。AU-Harnessは、LLM-Adaptive Diarization(時間的オーディオ理解)とSpoken Language Reasoning(複雑なオーディオ認知タスク)という2つの新しい評価カテゴリも導入し、現在のLALMsの時間的理解と複雑な音声推論タスクにおける顕著なギャップを明らかにし、体系的なLALM開発を推進することを目指しています。(ソース:HuggingFace Daily Papers)
LLM駆動のCI/CD脆弱性検出システムAI-DO : AI-DO(Automating vulnerability detection Integration for Developers’ Operations)は、継続的インテグレーション/継続的デプロイメント(CI/CD)プロセスに統合されたレコメンデーションシステムであり、CodeBERTモデルを利用してコードレビュー段階で脆弱性を検出・特定します。このシステムは、学術研究と産業応用とのギャップを埋めることを目的としており、オープンソースおよび産業データでのCodeBERTのドメイン横断的汎化評価を通じて、モデルが同一ドメイン内では正確に機能するものの、ドメインを跨ぐと性能が低下することを発見しました。適切なアンダーサンプリング技術を用いることで、オープンソースデータでファインチューニングされたモデルは、脆弱性検出能力を効果的に向上させることができます。AI-DOの開発は、既存のワークフローを中断することなく、開発プロセスにおけるセキュリティを向上させます。(ソース:HuggingFace Daily Papers)
Replit Agent 3:アイデアからアプリケーションへの超高速実現 : ReplitのAgent 3は驚くべき効率性を示し、Upworkでのサロンチェックインアプリケーションの要件を、顧客チェックインプロセス、顧客データベース、およびバックエンドダッシュボードを含む完全なアプリケーションとして145分で構築しました。このエージェントは高度な自律性も備えており、193分間ゼロ介入で動作し、認証、データベース、ストレージ、WebSocketを含むプロダクションレベルのコードを生成し、独自のテストとランキングアルゴリズムまで作成しました。これらの能力は、AIエージェントが迅速なプロトタイプ開発とフルスタックアプリケーション構築において持つ巨大な可能性を強調し、アイデアから実際の製品への変換プロセスを大幅に加速させるでしょう。(ソース:amasad, amasad, amasad)
Claudeにファイル作成・編集機能が追加 : Claudeは、Claude.aiおよびデスクトップアプリで、Excelスプレッドシート、ドキュメント、PowerPointプレゼンテーション、PDFファイルを直接作成および編集できるようになりました。この新機能は、Claudeの日常業務および生産性ツールにおける応用シナリオを大幅に拡張し、ドキュメント処理やコンテンツ生成のワークフローに深く関与できるようになり、ユーザーが複雑なファイルタスクを処理する際の効率と利便性を向上させます。(ソース:dl_weekly)
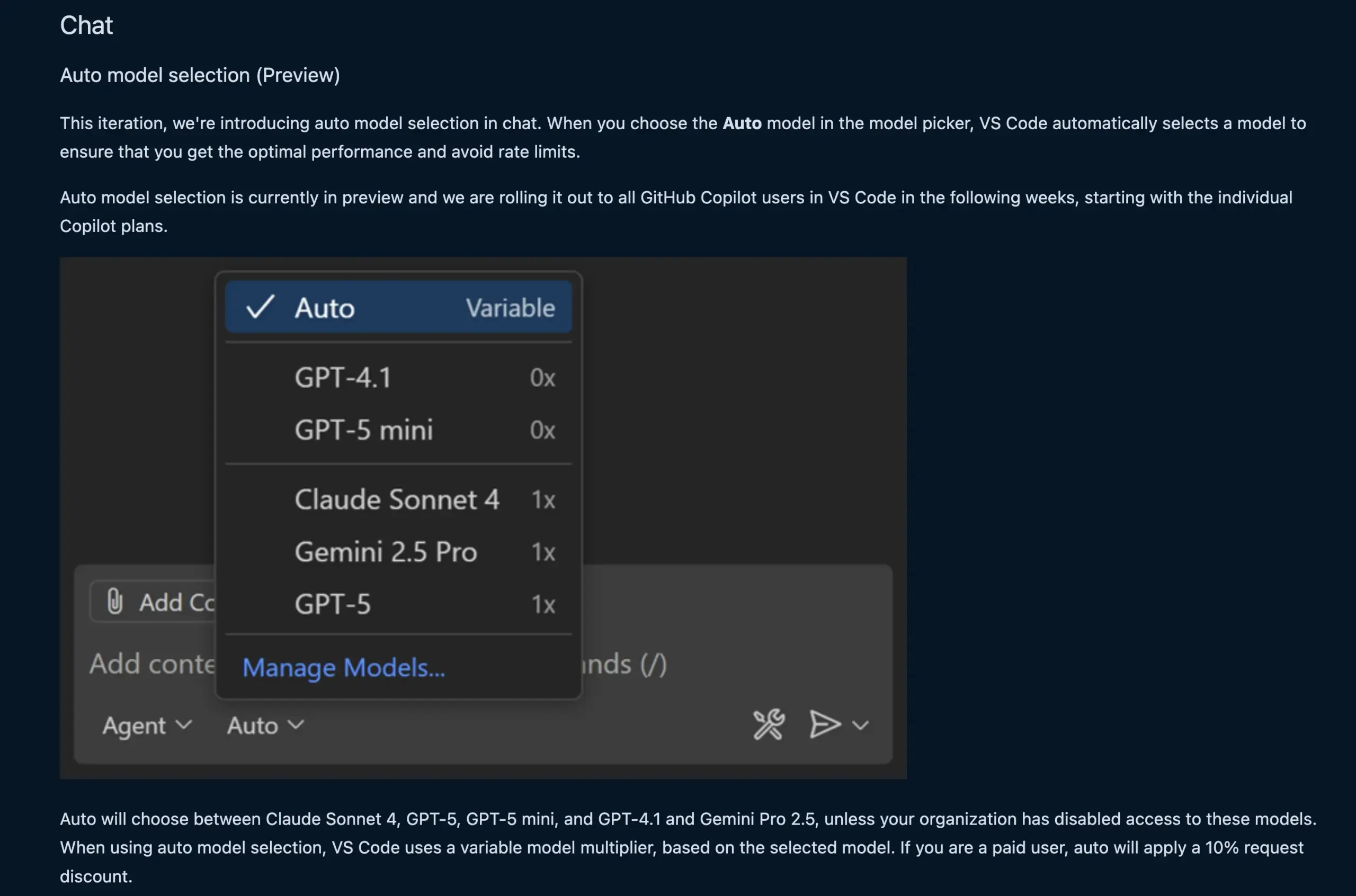
VS Codeチャット機能がLLMモデルを自動選択 : 新しいVS Codeチャット機能は、ユーザーのリクエストとレート制限に基づいて、適切なLLMモデルを自動的に選択できるようになりました。この機能は、Claude Sonnet 4、GPT-5、GPT-5 mini、GPT-4.1、Gemini Pro 2.5などのモデル間でインテリジェントに切り替えることができ、開発者により便利で効率的なAI支援プログラミング体験を提供します。同時に、VS Codeの言語モデルチャットプロバイダー拡張APIが最終決定され、拡張機能を通じてモデルを提供できるようになり、「Bring Your Own Key」(BYOK)モードもサポートされ、モデルの選択肢とカスタマイズ能力がさらに豊富になりました。(ソース:code, pierceboggan)
BoxがAIエージェント機能を導入、非構造化データ管理を強化 : Boxは、顧客が非構造化データの価値を最大限に活用できるよう、新しいAIエージェント機能を発表しました。更新されたBox AI Studioは、AIエージェントの構築をより容易にし、様々なビジネス機能や業界のユースケースに適用できます。Box ExtractはAIエージェントを利用してあらゆる種類のドキュメントから複雑なデータを抽出し、Box Automateは、コンテンツハブワークフローにAIエージェントをデプロイできる新しいワークフロー自動化ソリューションです。これらの機能は、事前構築された統合、Box API、または新しいBox MCP Serverを通じて、顧客の既存システムとシームレスに連携し、企業が非構造化コンテンツを処理する方法を変革することを目指しています。(ソース:hwchase17)
Cursor新Tabモデル:コード提案の精度と受容度を向上 : Cursorは、デフォルトのコード提案ツールとして新しいTabモデルをリリースしました。このモデルはオンライン強化学習(RL)でトレーニングされており、旧モデルと比較してコード提案の数は21%減少しましたが、提案の受容率は28%向上しました。この改善は、新モデルがより正確で開発者の意図に合致したコード提案を提供できることを意味し、プログラミング効率とユーザー体験を大幅に向上させ、不要な干渉を減らし、開発者がより効率的にコーディングタスクを完了できるようにします。(ソース:BlackHC, op7418)
awesome-llm-apps:オープンソースLLMアプリケーションのコレクション : GitHub上のawesome-llm-appsプロジェクトは、オープンソースの宝庫と称され、AIブログをポッドキャストに変換するエージェントから医療画像分析まで、40以上のデプロイ可能なLLMアプリケーションを収集しています。各アプリケーションには詳細なドキュメントとセットアップ手順が付属しており、数週間かかっていた開発作業が数分で完了できるようになりました。例えば、その中のAIオーディオガイドプロジェクトは、マルチエージェントシステム、リアルタイムウェブ検索、TTS技術を通じて、自然でコンテキストに関連したオーディオガイドを生成でき、APIコストも低く、コンテンツ生成におけるマルチエージェントシステムの実用性を示しています。(ソース:Reddit r/MachineLearning)
📚 学習
MMOral:歯科パノラマX線分析のためのマルチモーダルベンチマークと指示データセット : MMOralは、歯科パノラマX線画像の解釈に特化した、初の包括的な大規模マルチモーダル指示データセットおよびベンチマークです。このデータセットには、20,563枚の注釈付き画像と130万の指示追従インスタンスが含まれており、属性抽出、レポート生成、視覚的質問応答、画像対話などのタスクをカバーしています。MMOral-Bench総合評価スイートは、歯科診断の5つの主要な側面を網羅しており、GPT-4oなどの最良のLVLMモデルでさえ41.45%の精度しか達成しておらず、この分野における既存モデルの限界を浮き彫りにしています。OralGPTは、Qwen2.5-VL-7BにSFTを施すことで、24.73%という顕著な性能向上を実現し、スマート歯科および臨床マルチモーダルAIシステムの基盤を築きました。(ソース:HuggingFace Daily Papers)
Transformer脆弱性検出のドメイン横断評価 : ある研究では、CodeBERTが産業用およびオープンソースソフトウェアで脆弱性を検出する性能を評価し、そのドメイン横断的な汎化能力を分析しました。研究の結果、産業データで訓練されたモデルは同一ドメイン内では正確に検出するものの、オープンソースコードでは性能が低下することがわかりました。一方、適切なアンダーサンプリング技術を用いてオープンソースデータでファインチューニングされた深層学習モデルは、脆弱性検出能力を効果的に向上させることができました。これらの結果に基づき、研究チームはAI-DOシステムを開発しました。これはCI/CDプロセスに統合されたレコメンデーションシステムで、コードレビュー中に脆弱性を検出し特定することができ、既存のワークフローを妨げません。学術技術の産業応用への転換を推進することを目指しています。(ソース:HuggingFace Daily Papers)
Ego3D-Bench:自己中心的な多視点シーンにおけるVLM空間推論ベンチマーク : Ego3D-Benchは、自己中心的で多視点の屋外データにおける視覚言語モデル(VLMs)の3D空間推論能力を評価するために設計された新しいベンチマークです。このベンチマークには、GPT-4o、Gemini1.5-Proなど16のSOTA VLMをテストするための、人間が注釈を付けた8,600以上の質問応答ペアが含まれています。結果は、現在のVLMが空間理解において人間レベルと顕著なギャップがあることを示しています。このギャップを埋めるため、研究チームはEgo3D-VLM後訓練フレームワークを提案しました。これは、推定されたグローバル3D座標に基づく認知マップを生成することで、多肢選択式質問応答で平均12%、絶対距離推定で56%の性能向上を達成し、人間レベルの空間理解を実現するための貴重なツールを提供します。(ソース:HuggingFace Daily Papers)
LLM長期タスク実行における「収穫逓減の錯覚」 : 新しい研究は、LLMの長期タスク実行におけるパフォーマンスを探求し、単一ステップの精度のわずかな向上がタスク長の指数関数的な増加をもたらすことを指摘しています。論文は、LLMが長期タスクで失敗するのは推論能力の不足ではなく、実行エラーであると主張しています。知識と計画を明確に提供することで、大規模モデルはより多くのステップを正しく実行できることがわかりました。たとえ小規模モデルが単一ステップの精度で100%を達成してもです。興味深い発見は、モデルに「自己調整」効果が存在することです。つまり、コンテキストに以前のエラーが含まれている場合、モデルは再びエラーを犯しやすくなり、モデルの規模だけでは解決できません。最新の「思考モデル」は自己調整を回避し、単一の実行でより長いタスクを完了できるため、モデル規模の拡大とシーケンシャルテスト計算が長期タスクに大きな利益をもたらすことを強調しています。(ソース:Reddit r/ArtificialInteligence)
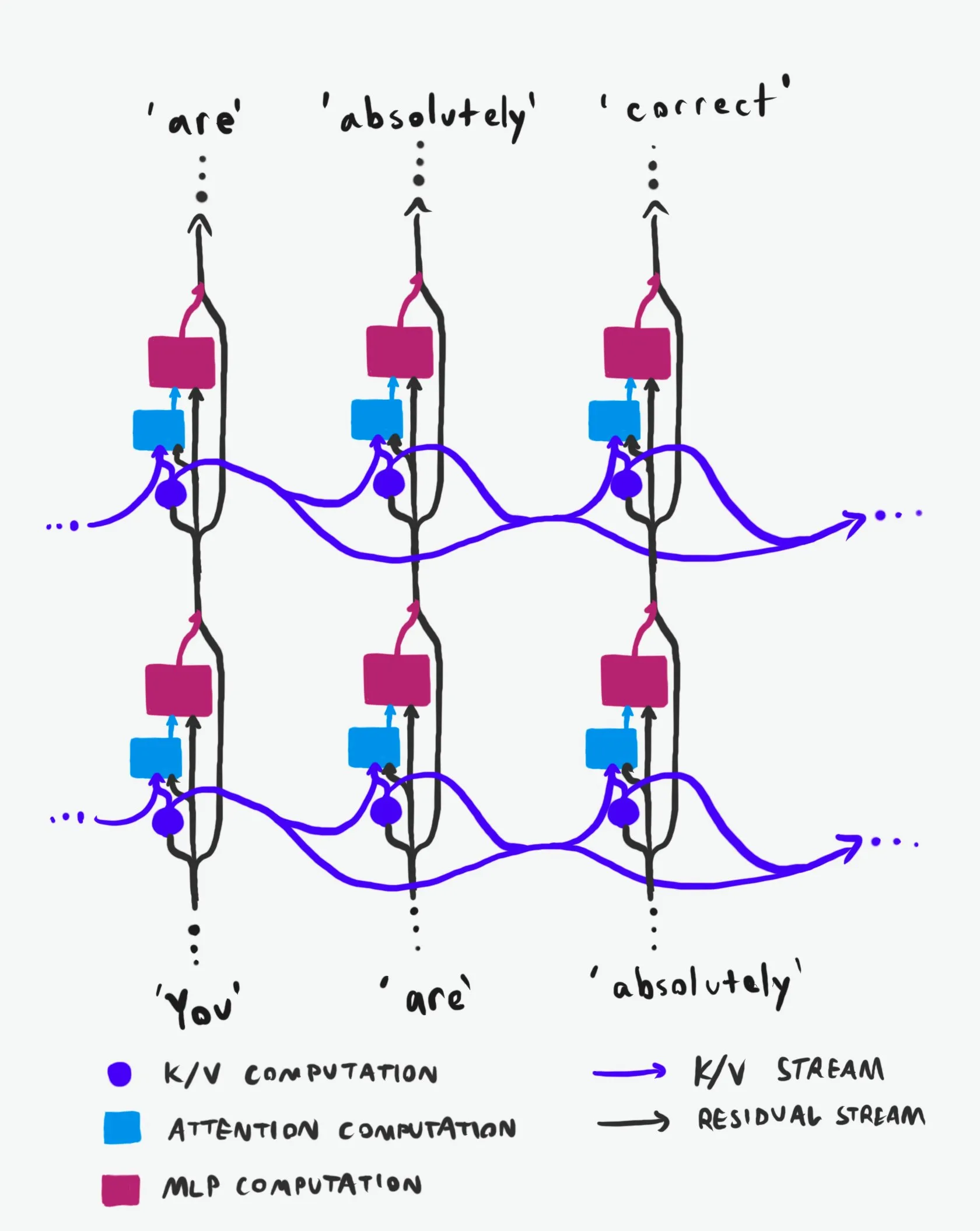
Transformer因果構造:情報フローの詳細な分析 : 「同種最高」と称される技術解説が、Transformer大規模言語モデル(LLMs)の因果構造とその情報フローの仕組みを深く掘り下げて分析しています。この解説は、難解な専門用語を避け、Transformerアーキテクチャにおける2つの主要な情報高速道路、すなわち残差ストリーム(Residual Stream)とアテンションメカニズムを明確に説明しています。視覚化と詳細な記述を通じて、研究者や開発者がTransformerの内部動作原理をよりよく理解するのに役立ち、モデル設計、最適化、デバッグにおいてより賢明な意思決定を可能にします。LLMの基盤メカニズムを深く理解する上で重要な価値を持っています。(ソース:Plinz)
カーネギーメロン大学がLM推論の新コースを開設 : カーネギーメロン大学(CMU)の@gneubigと@Amanda Bertschが、この秋に言語モデル(LM)推論に関する新しいコースを共同で教えることになりました。このコースは、古典的なデコードアルゴリズムからLLMの最新手法、そして効率に焦点を当てた一連の作業まで、LM推論分野を包括的に紹介することを目的としています。コース内容はオンラインで公開され、最初の4回の講義ビデオも含まれるため、LM推論に興味のある学生や研究者にとって、最先端の推論技術と実践を習得するための貴重な学習リソースとなるでしょう。(ソース:lateinteraction, dejavucoder, gneubig)
OpenAIDevsがCodexの詳細解説ビデオを公開 : OpenAIDevsは、Codexの詳細解説ビデオを公開し、過去2ヶ月間のCodexの変化と最新機能について詳しく紹介しました。このビデオは、Codexを最大限に活用するためのヒントとベストプラクティスを提供し、開発者がこの強力なAIプログラミングツールをよりよく理解し、使用できるようにすることを目的としています。コンテンツには、コード生成、デバッグ、開発支援におけるCodexの最新の進歩が含まれており、AI支援プログラミングの効率を向上させたい開発者にとって重要な学習リソースです。(ソース:OpenAIDevs)
2025年クラウドGPU市場現状レポート : dstackaiは、2025年のクラウドGPU市場現状に関するレポートを発表しました。このレポートは、コスト、パフォーマンス、使用戦略を網羅しています。現在の市場における価格、ハードウェア構成、パフォーマンスを詳細に分析し、機械学習エンジニアがクラウドサービスプロバイダーを選択する際の具体的な市場洞察と参考情報を提供します。機械学習エンジニアリングにおけるクラウドプロバイダー選択の一般的なガイドラインを補完し、AIトレーニングと推論のコストと効率を最適化するための重要な指針となります。(ソース:stanfordnlp)
AIハードウェアの全体像:AIを駆動する多様な計算ユニット : The Turing Postは、AIを駆動するハードウェアに関するガイドを発表し、GPU、TPU、CPU、ASICs、NPU、APU、IPU、RPU、FPGA、量子プロセッサ、メモリ内計算(PIM)チップ、ニューロモルフィックチップなど、多様な計算ユニットを詳細に紹介しています。このガイドは、各ハードウェアがAI計算において果たす役割、利点、および応用シナリオを深く掘り下げ、読者がAI技術スタックの基盤となる計算能力を包括的に理解するのに役立ち、モデル設計、最適化、デバッグにおいてより賢明な意思決定を可能にします。(ソース:TheTuringPost)
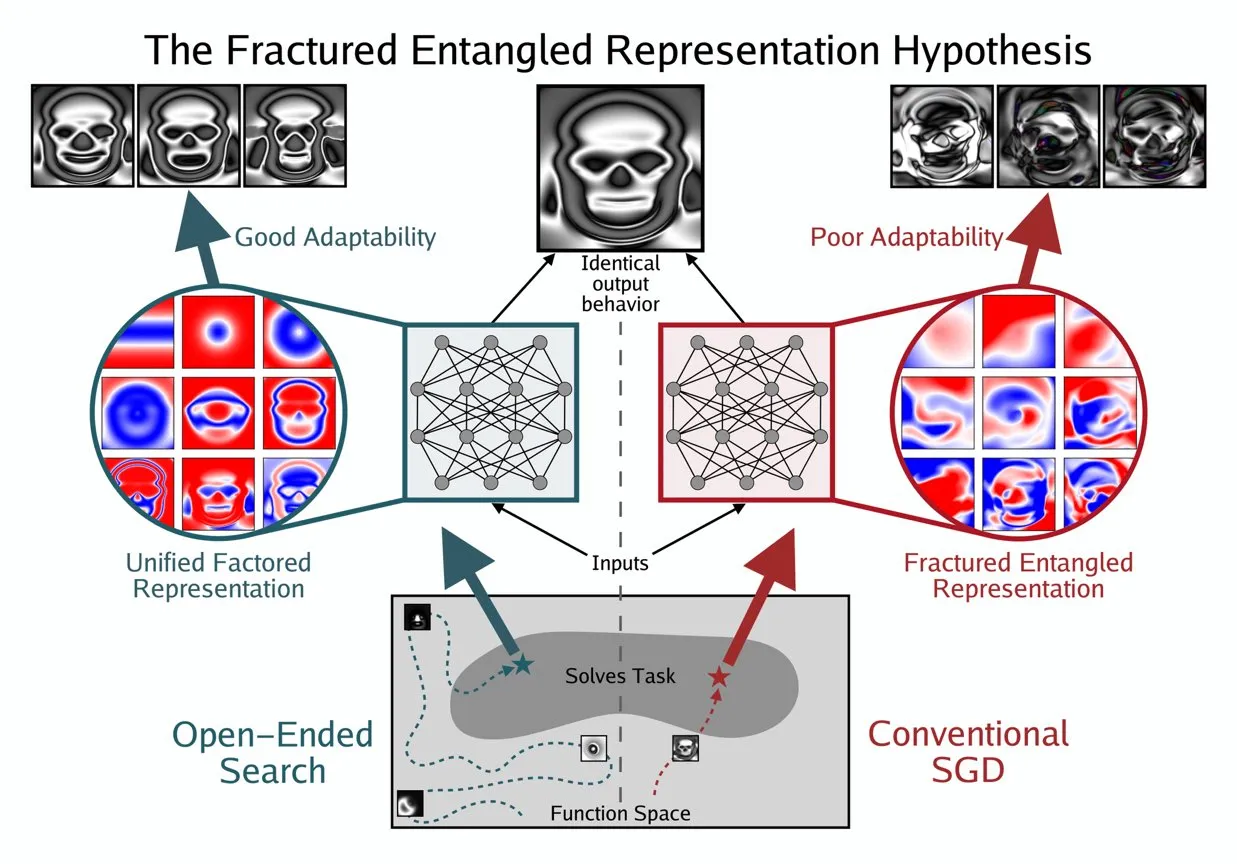
Kenneth StanleyがAIの「真の理解」を理解するためのUFR概念を提唱 : Kenneth Stanleyは、AIの「真の理解」の意味を説明するのに役立つ「統一因子表現」(Unified Factored Representation, UFR)の概念を提唱しました。彼は、人々がAIの「真の理解」について語るとき、その核心はUFRにあると考えています。この概念は、AIの認知能力に、単なるパターン認識を超えた、より深い理論的枠組みを提供することを目的としています。AIが世界をどのように構造化し、分解し、厳密な制約を形成する能力に触れることで、AIが知識を模倣するだけでなく、人間のように創造的に思考し、新しい問題を解決できるようになることを促します。(ソース:hardmaru, hardmaru)
💼 ビジネス
TencentがOpenAIのトップ研究員を引き抜き、AI人材争奪戦が激化 : Bloombergの報道によると、OpenAIのトップ研究員であるYao Shunyu氏が退職し、中国のテクノロジー大手Tencentに加わりました。この出来事は、特に米国と中国の間で、世界的なAI人材争奪戦が激化していることを浮き彫りにしています。トップAI研究者の流動は、各社の技術開発ロードマップに影響を与えるだけでなく、AI分野におけるイノベーション競争の白熱化を反映しており、将来のAIの構図が人材の流動によって変化する可能性を示唆しています。(ソース:The Verge)
OpportuNextが技術共同創業者を募集、AI採用プラットフォームを構築 : IITムンバイの卒業生によって設立されたAI駆動型採用プラットフォームOpportuNextは、技術共同創業者を募集しています。このプラットフォームは、包括的な履歴書分析、セマンティックな求人検索、スキルギャップロードマップ、事前評価を通じて、求職者と雇用主が採用において直面する課題を解決することを目指しており、目標市場は2.62億ドルのインド市場であり、405億ドルのグローバル市場への拡大も計画しています。OpportuNextはすでに製品市場適合性を検証し、履歴書パーサーのプロトタイプを完成させており、2026年半ばにシリーズA資金調達を完了する予定です。このポジションは、AI/ML(NLP)、フルスタック開発、データインフラストラクチャ、クローラー/API、DevOps/セキュリティにおいて強力なバックグラウンドを持つことを求めています。(ソース:Reddit r/deeplearning)
Oracle創業者Larry Ellison:「推論こそがAI収益化の鍵」 : Oracleの創業者Larry Ellison氏は、「推論こそがAI収益化の鍵である」と述べました。彼は、現在モデルトレーニングに投入されている巨額の資金は最終的に製品販売に転換され、これらの製品は主に推論能力に依存すると考えています。Ellison氏は、Oracleが推論需要の活用においてリードしていることを強調し、AI業界の物語が「誰が最大のモデルを訓練できるか」から「誰が効率的、信頼性高く、大規模に推論サービスを提供できるか」へと移行していることを示唆しています。この見解は、AI経済モデルの将来の方向性、すなわち推論サービスが将来の収益構造を支配するかどうかについての議論を巻き起こしました。(ソース:Reddit r/MachineLearning)
🌟 コミュニティ
AI倫理と安全:多角的な課題と協力 : コミュニティでは、AIがもたらす倫理と安全に関する課題が広く議論されました。これには、AIが労働市場に与える潜在的な影響と保護戦略、ChatGPT MCPツールのプライバシーとセキュリティに関する懸念、そしてAIが絶滅リスクを引き起こす可能性についての真剣な議論が含まれます。AIが引き起こす精神衛生上の問題、例えばユーザーのAIへの過度な依存や「AI精神病」、孤独感などもますます注目されています。同時に、AI規制に関する議論(Ted Cruz法案など)も継続しています。ポジティブな側面としては、AnthropicやOpenAIなどの企業がセキュリティ機関と協力し、モデルの脆弱性を共同で発見・修正し、AIの安全保護を強化していることが挙げられます。(ソース:Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

LLM性能と評価:モデル品質とベンチマークの論争 : コミュニティでは、LLMの性能評価とモデル品質の問題について深い議論が交わされました。K2-Thinkなどのモデルは、評価方法の欠陥(データ汚染や不公平な比較など)により疑問視され、既存のAIベンチマークテストの信頼性に対する懸念を引き起こしました。研究では、LLMがデータアノテーターとしてバイアスを導入し、「LLM Hacking」と呼ばれる科学的結果につながる可能性があると指摘されています。ユーザーのClaude Code体験は賛否両論で、一貫性や「怠惰さ」における課題を反映しており、AnthropicもClaude Sonnet 4の性能劣化問題を認め、修正しました。同時に、GPT-5 Proはその強力な推論能力で高い評価を得ていますが、AI生成テキストの普遍性や、モデルの信頼性(推論バグなど)に対する継続的な関心もユーザーから寄せられています。(ソース:Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
未来の仕事とAIエージェント:効率向上と職業転換 : AIエージェントは働き方を大きく変えつつあります。弁護士、医師、エンジニアなどの分野の専門家は、個人の知識をAIエージェントに注入することで専門サービスを拡大し、時間単位の課金に縛られない収入を実現できます。ReplitのCEO Amjad Masad氏は、AIエージェントがオンデマンドでソフトウェアを生成し、従来のソフトウェアの価値がゼロに近づき、企業の構築方法が再構築されると予測しています。コミュニティでは、AI時代の起業家精神と適応能力の重要性、Replitがエージェント開発において持つ独自の利点(テスト可能な環境など)、ロボットモデルと人間の脳の効率の比較について議論されました。さらに、強化学習環境としてのCursorの潜在力も注目を集め、AIが個人と組織の生産性をさらに向上させることを示唆しています。(ソース:amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
オープンソースエコシステムとコラボレーション:モデルの普及とコミュニティのニーズ : Hugging FaceはAIエコシステムにおいて中心的な役割を果たしており、そのモジュール化、標準化、統合化されたプラットフォームの利点は、開発者に豊富なツールとモデルを提供し、AI構築の敷居を下げています。コミュニティの議論では、Apple MLXプロジェクトとそのオープンソース貢献がハードウェア効率の向上に貢献していることが肯定されました。同時に、コミュニティはQwenチームに対し、Qwen3-NextモデルにGGUFサポートを提供し、そのカスタムアーキテクチャがllama.cppなどのより広範なローカル推論フレームワークで動作できるようにすることを積極的に求めています。これは、モデルの普及と使いやすさに対するコミュニティのニーズを満たし、オープンソースAI技術のさらなる発展を推進するためです。(ソース:ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AIの広範な社会的影響:エンターテイメントから経済への多様な現れ : AIは様々な形で社会に浸透しています。AIペットショートドラマは、擬人化された物語と感情的価値によりソーシャルメディアで大ヒットし、コンテンツ制作とエンターテイメント分野におけるAIの巨大な可能性を示し、多くの若いユーザーを惹きつけ、新しいビジネスモデルを生み出しました。同時に、AI大手(OpenAIとOracleなど)間の資金の流れに関する議論は、AI経済モデルについての考察を引き起こしました。コミュニティでは、AIが水資源などの問題解決に貢献する可能性や、AIチャットボットがユーザー体験を向上させるためにより多くの視覚コンテンツを必要とするという提案も議論されました。さらに、ソーシャルメディアにおけるAIの応用は、社会の感情や認知に与える影響についても議論を巻き起こしました。(ソース:36氪, Yuchenj_UW, kylebrussell, brickroad7)
AIコミュニティの興味深い話と考察:ユーザーのAIへのパーソナライズされた期待とユーモラスな反省 : AIコミュニティは、技術の発展とユーザー体験に関するユニークな観察とユーモラスな反省に満ちています。例えば、OpenAIのサブスクリプション割引コードと「思考」行動の関連性は、AIの価値とコストに関する議論を引き起こしました。ユーザーはClaude Codeがよりパーソナライズされた応答を持ち、AIに「人格」を与えることさえ望んでおり、AIインタラクション体験に対する深いニーズを反映しています。同時に、AIエージェントがシミュレーション環境(GTA-6など)で強化学習トレーニングを行うという構想も、AIの将来の発展経路に対するコミュニティの無限の想像力を示しています。これらの議論は、AI技術の現状に対する洞察を提供するだけでなく、ユーザーがAIとのインタラクションで抱く感情と期待を映し出しています。(ソース:gneubig, jonst0kes, scaling01)
💡 その他
2025年AIスキル習得ガイド : 人工知能技術の急速な発展に伴い、主要なAIスキルを習得することは個人のキャリア開発にとって極めて重要です。2025年AIスキル習得ガイドでは、人工知能、機械学習、深層学習の分野で習得すべき12のコアスキルが強調されています。これらのスキルは、基礎理論から実際の応用までを網羅しており、専門家や学習者がAI時代の人材要件に適応し、技術革新とキャリア市場における競争力を向上させることを目的としています。(ソース:Ronald_vanLoon)

2025年クラウドGPU市場:コスト、性能、デプロイ戦略レポート : dstackaiは、2025年のクラウドGPU市場現状に関する詳細なレポートを発表しました。このレポートは、異なるクラウドサービスプロバイダーのGPUコスト、性能、およびデプロイ戦略を深く分析しています。機械学習エンジニアや企業がクラウドプロバイダーを選択する際の具体的な指針を提供し、AIトレーニングと推論タスクのリソース構成を最適化することで、増大するAIインフラストラクチャの需要の中で、よりコスト効率が高く、性能に優れた意思決定を行うのに役立つことを目的としています。(ソース:stanfordnlp)
AIハードウェア技術概要:スマートな未来を駆動する多様な計算ユニット : The Turing Postは、現在人工知能を駆動する様々な計算ユニットを詳細に紹介する包括的なAIハードウェアガイドを発表しました。これには、グラフィックス処理ユニット(GPU)、テンソル処理ユニット(TPU)、中央処理ユニット(CPU)、特定用途向け集積回路(ASICs)、ニューラルネットワーク処理ユニット(NPU)、アクセラレーテッド処理ユニット(APU)、インテリジェント処理ユニット(IPU)、抵抗性処理ユニット(RPU)、フィールドプログラマブルゲートアレイ(FPGA)、量子プロセッサ、メモリ内計算(PIM)チップ、およびニューロモルフィックチップが含まれます。このガイドは、AI技術スタックの基盤となるハードウェアサポートを明確に理解するための視点を提供し、開発者や研究者がAIワークロードに最適なハードウェアソリューションを選択するのに役立ちます。(ソース:TheTuringPost)