キーワード:AI研究, コンピュータサイエンス, 強化学習, 医薬品開発, 自動運転, 言語モデル, マルチモーダル処理, 仮想細胞, ロード研究所, 強化学習教師(RLTs), BioNeMoプラットフォーム, テスラRobotaxi, Kimi VL A3B Thinkingモデル
🔥 ピックアップ
Laude Institute設立、1億ドルの初期資金を獲得しコンピュータ科学の公益研究を推進: Andy Konwinski氏は、世界に大きな影響を与える非営利のコンピュータ科学研究への資金提供を目的とした非営利団体Laude Instituteの設立を発表しました。Jeff Dean氏、Joyia Pineau氏、Dave Patterson氏などの著名人が取締役会に加わります。同機関は1億ドルの初期コミットメント資金を確保し、資金提供、リソース共有、コミュニティ構築を通じて、研究者がアイデアを実際のインパクトに変えることを支援し、特にオープンでインパクト志向の研究に焦点を当てます。(ソース: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

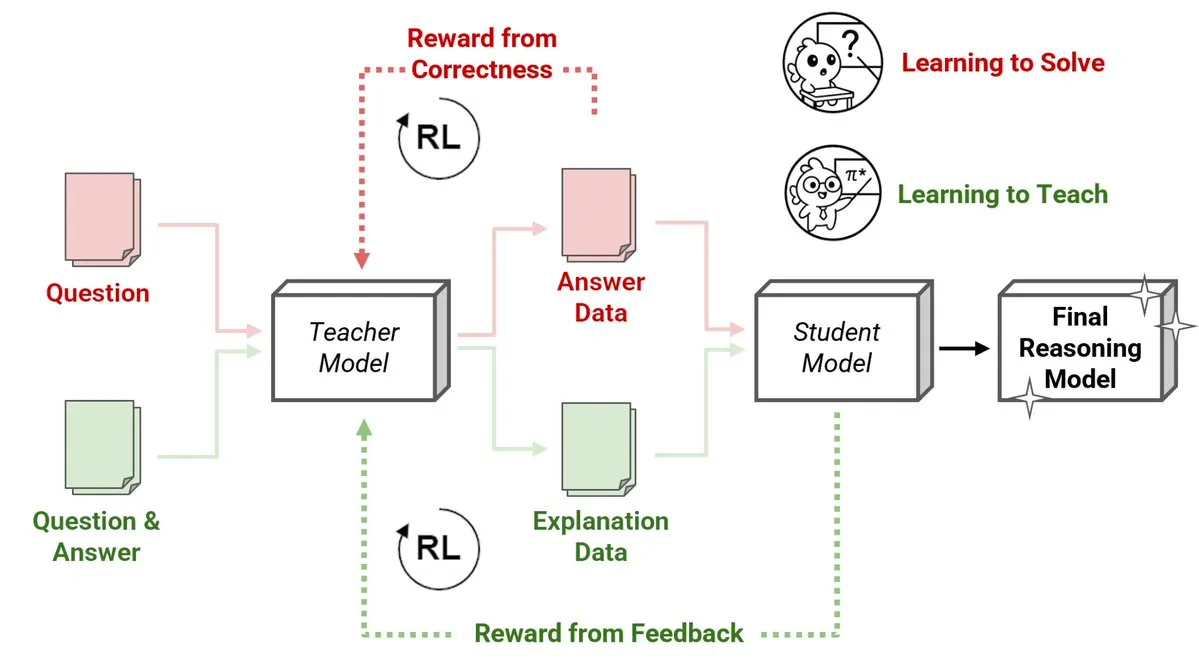
Sakana AI、強化学習教師(RLTs)の新手法を発表、小規模モデルが大規模モデルに推論を教える: Sakana AIは、強化学習教師(RLTs)という新たな手法を導入し、強化学習(RL)を通じて大規模言語モデル(LLMs)の推論指導方法を変革します。従来のRLは問題の「解決法を学ぶ」ことに重点を置いていますが、RLTsは生徒モデルを指導するために明確で段階的な「説明」を生成するよう訓練されます。わずか7BパラメータのRLTが、32Bパラメータの生徒モデルを指導する際に、競争的かつ大学院レベルの推論タスクにおいて、自身の数倍のサイズのLLMを上回る性能を示しました。このアプローチは、RLを用いた推論言語モデルの開発において新たな効率基準を打ち立てます。(ソース: cognitivecompai, AndrewLampinen)
Nvidia、Novo Nordiskと提携、AIスーパーコンピュータで創薬を加速: Nvidiaは、デンマークの製薬大手Novo Nordiskおよびデンマーク国立AIイノベーションセンターと協力し、AI技術とデンマークの最新スーパーコンピュータGefionを活用して新薬開発を加速すると発表しました。この提携では、NvidiaのBioNeMoプラットフォームと先進的なAIワークフローを採用し、医薬品研究開発モデルの変革を目指します。GefionスーパーコンピュータはEvidenとNvidiaの技術で構築され、生命科学などの分野の研究に強力な計算能力を提供し、個別化医療や新治療法の発見を推進します。(ソース: nvidia)

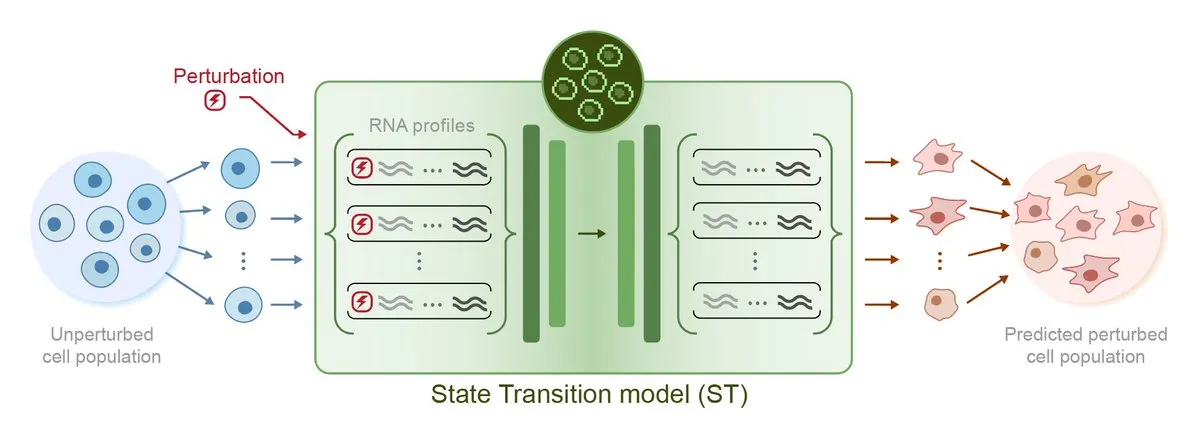
Arc Institute、初の摂動予測AIモデルSTATEを発表、仮想細胞目標へ前進: Arc Instituteは、初の摂動予測AIモデルSTATEを発表しました。これは、仮想細胞目標の実現に向けた重要な一歩です。STATEモデルは、薬物、サイトカイン、または遺伝子摂動を利用して細胞状態を(例えば「病的」から「健康的」へ)変化させる方法を学習することを目的としています。このモデルの発表は、AIによる細胞行動の理解と予測における新たな進展を示し、疾患治療と創薬開発に新たな道を開くものです。関連モデルはHuggingFaceで公開されています。(ソース: riemannzeta, ClementDelangue)
Tesla Robotaxi、オースティンでパイロット運用を開始、純視覚ソリューションが注目を集め、Karpathy氏が残したコードは大幅に簡素化: Teslaは米国テキサス州オースティン市でRobotaxiのパイロットサービスを正式に開始しました。最初の車両はModel Yをベースに改造され、純粋な視覚認識ソリューションとFSDソフトウェアを採用しています。TeslaのAIおよび自動運転ソフトウェア責任者であるAshok Elluswamy氏が率いるチームは、システムに大幅な技術的変更を加え、Andrej Karpathy氏のチームが残した約33~34万行のC++ヒューリスティックコードを90%近く削減し、「巨大ニューラルネットワーク」に置き換えました。この動きは、「人間の経験のエンコーディング」から「パラメータ化されたトレーニング」への転換を目指し、大量のデータとシミュレーション運転を通じてモデルを自律的に最適化するものです。現在、サービスは初期体験段階にあり、Teslaの技術ロードマップとスケーラビリティについて業界で広範な議論を呼んでいます。(ソース: 36氪, Ronald_vanLoon, kylebrussell)

🎯 動向
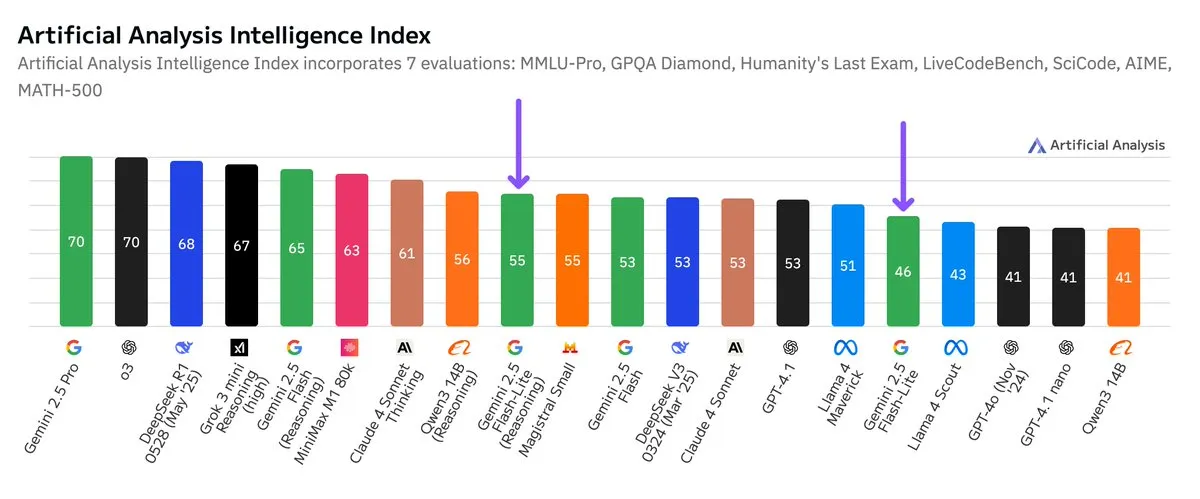
Google Gemini 2.5 Flash-Liteの独立ベンチマークが公開、コストパフォーマンスが向上: Artificial Analysisが公開した独立ベンチマーク結果によると、Google Gemini 2.5 Flash-Lite Preview (06-17) バージョンは、通常のFlashバージョンと比較してコストが約5倍削減され、速度が約1.7倍向上しましたが、知能レベルは若干低下しました。このモデルは2025年2月に発表されたGemini 2.0 Flash-Liteのアップグレード版であり、混合モデルに属します。この更新は、モデルの効率とコスト効果を追求するGoogleの継続的な努力を示しており、コストと速度に対する要求が高い応用シーンを対象としている可能性があります。(ソース: zacharynado)
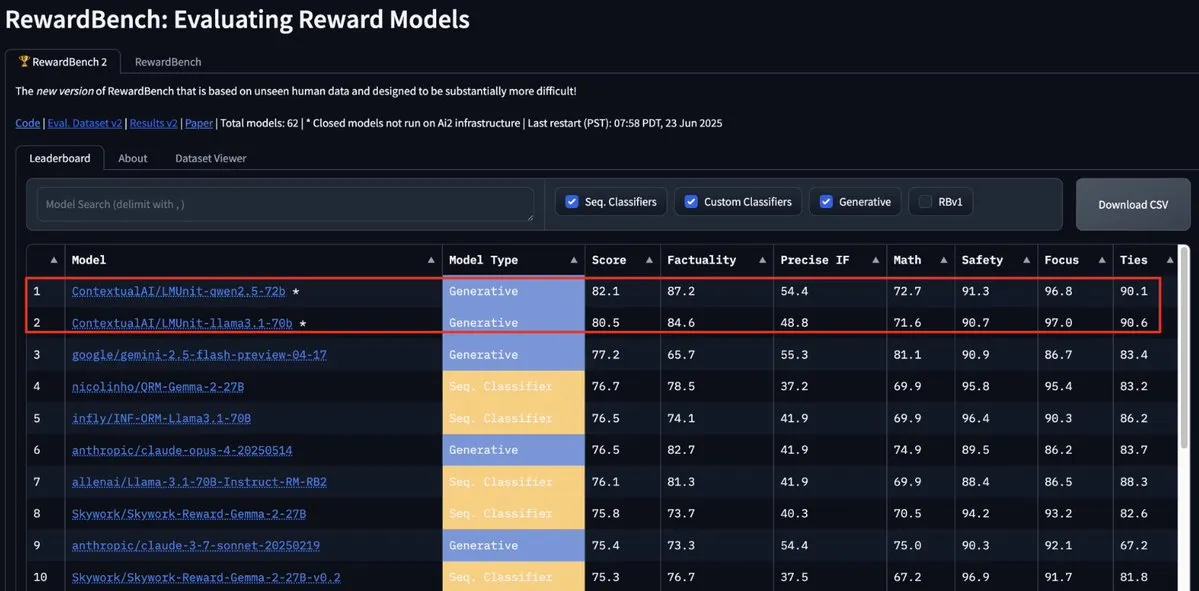
ContextualAIのLMUnitモデルがRewardBench2でトップに、Gemini、Claude 4、GPT-4.1を上回る: ContextualAIのLMUnitモデルがRewardBench2ベンチマークで第1位を獲得し、Gemini、Claude 4、GPT-4.1などの著名なモデルを5%以上上回るスコアを記録しました。この成果は、OpenAIがo4およびそれ以降のモデルのために多大な労力を費やして開発したとされる「rubrics」手法に類似した独自の訓練方法によるものと考えられます。この手法は、LLMが裁判官として(llm-as-a-judge)推論時に効果的なスケーリングを実現するのに役立ちます。(ソース: natolambert, menhguin, apsdehal)
Arcee.ai、AFM-4.5Bモデルのコンテキスト長を4kから64kに拡張成功: Arcee.aiは、同社初の基盤モデルAFM-4.5Bのコンテキスト長を4kから64kに拡張することに成功したと発表しました。チームは積極的な実験、モデルのマージ、蒸留、そして冗談めかして「大量のスープ」(モデル融合技術を指す)と呼ばれる手法などを通じてこのブレークスルーを達成しました。この進展は長文テキストタスクの処理にとって極めて重要であり、ArceeによるGLM-32B-Baseモデルの改善もその有効性を証明しており、長文コンテキストのサポートが8kから32kに向上しただけでなく、すべての基盤モデル評価(短文コンテキストを含む)も改善されました。(ソース: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Google Gemini APIが更新、動画とPDFの処理速度と能力を向上: Google Gemini APIが、動画とPDFの処理に関して重要な更新を行いました。キャッシュされた動画の初回応答時間(TTFT)が3倍向上し、キャッシュされたPDFの処理速度は最大4倍向上しました。さらに、新バージョンでは複数の動画の一括処理がサポートされ、暗黙的キャッシュのパフォーマンスは明示的キャッシュに近づきました。これらの改善は、開発者がGemini APIを使用してマルチメディアコンテンツを処理する際の効率と体験を向上させることを目的としています。(ソース: _philschmid)
Moonshot (Kimi)、Kimi VL A3B Thinkingモデルを更新、マルチモーダル処理能力を向上: Moonshot AI (Kimi) は、MITライセンスに基づく小型視覚言語モデル (VLM) Kimi VL A3B Thinkingの更新版をリリースしました。新バージョンは、消費トークンを削減し、思考の軌跡を短縮すると同時に、動画処理をサポートし、より高解像度の画像(1792×1792)を処理できます。VideoMMMUで65.2点、MathVisionで20.1点向上して56.9点、MathVistaで8.4点向上して80.1点、MMMU-Proで3.2点向上して46.3点を達成し、視覚推論、UIエージェントの位置特定、動画およびPDF処理において優れたパフォーマンスを示し、Hugging Faceでオープンソース化されています。(ソース: mervenoyann)

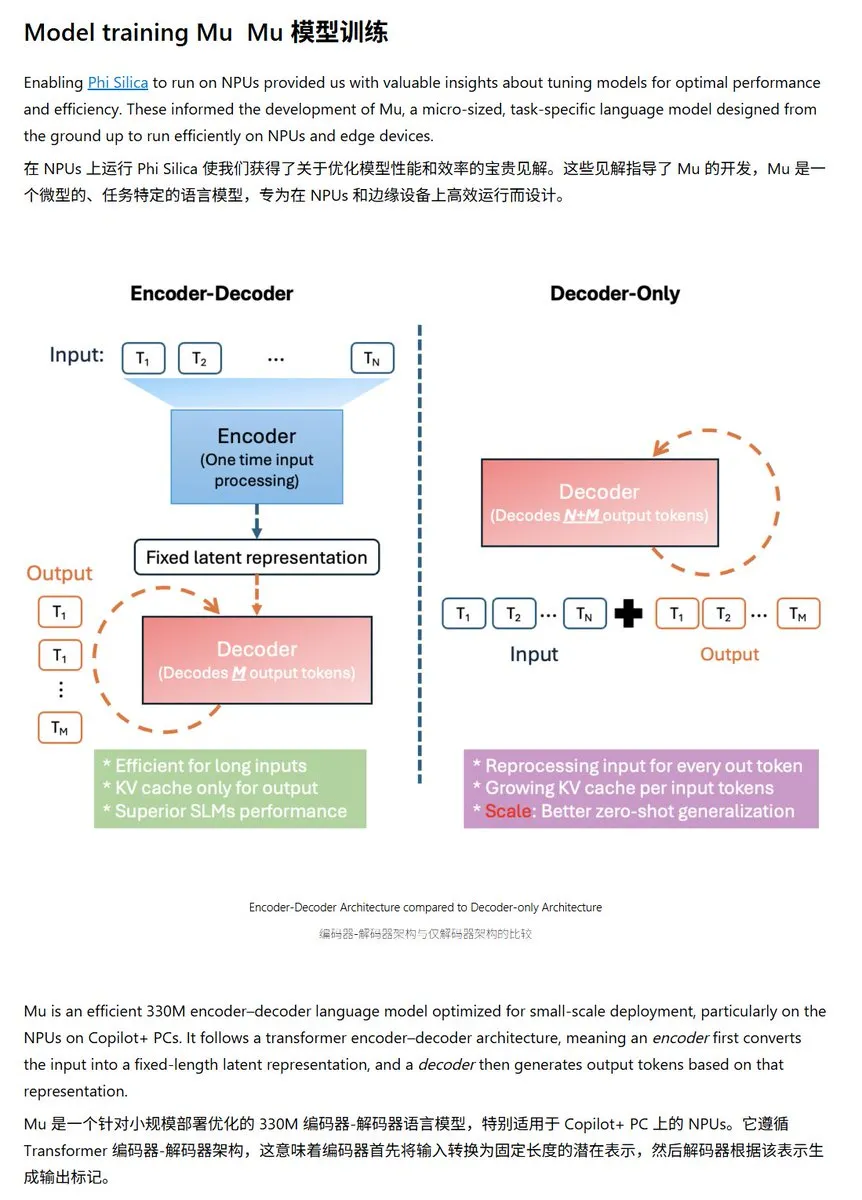
Microsoft、Windows NPUに最適化された小型言語モデルMu-330Mを発表: Microsoftは、Windows Copilot+ PCのNPU(ニューラルプロセッシングユニット)上で動作するように設計された新しい小型言語モデルMu-330Mを発表しました。これはWindowsシステム内のエージェント機能をサポートすることを目的としています。このモデルはNPU向けに最適化されており、回転位置埋め込み、グループ化クエリアテンション、2層LayerNormなどの技術を採用し、低消費電力で効率的に動作することを目指しており、MicrosoftのエッジAI能力におけるさらなる展開を示しています。(ソース: karminski3)
DeepMind、拡散言語モデルに焦点を当てたMercury技術レポートを発表: Inception Labs (DeepMind関連チーム) は、拡散言語モデルMercuryの技術レポートを発表しました。このレポートは、Mercuryモデルのアーキテクチャ、訓練方法、実験結果を詳細に説明しており、研究者にこの新しいモデルタイプに関する深い洞察を提供します。拡散モデルは画像生成分野で顕著な成功を収めており、言語モデルへの応用は現在のAI研究の最先端の方向性の一つです。(ソース: andriy_mulyar)
Meta、Oakleyと提携しAIスマートグラスシリーズを拡充: Metaは、眼鏡ブランドOakleyと提携し、AIスマートグラス製品ラインをさらに拡充します。新しいスマートグラスはMetaのAI技術を統合し、より豊富なインタラクション機能とユーザー体験を提供すると予想されます。この提携は、MetaのウェアラブルAIデバイス分野への継続的な投資を示しており、AIを日常生活によりシームレスに統合することを目指しています。(ソース: rowancheung, Ronald_vanLoon)
Alibaba Cloud、自動運転モデルの学習・推論高速化フレームワークPAI-TurboXを発表、学習時間を最大50%短縮可能: Alibaba Cloudは、自動運転分野向けのモデル学習・推論高速化フレームワークPAI-TurboXを発表しました。このフレームワークは、認識、計画制御、さらにはワールドモデルの学習・推論効率の向上を目指し、マルチモーダルデータの前処理、CPUアフィニティ、動的コンパイル、パイプライン並列処理などの戦略を最適化し、演算子最適化と量子化機能を提供します。実測では、BEVFusion、MapTR、SparseDriveなど複数の業界モデルの学習タスクにおいて、PAI-TurboXは学習時間を約50%短縮できることが示されています。(ソース: 量子位)
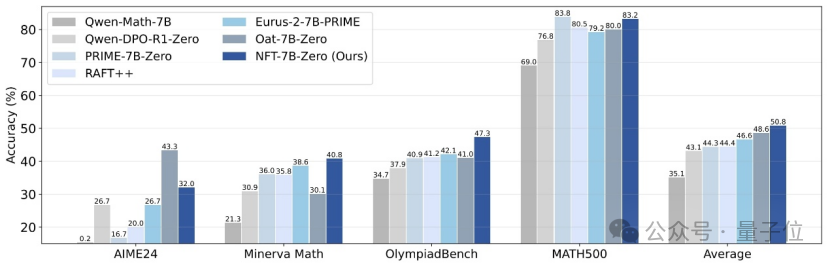
清華大学、NvidiaらがNFT手法を提案、教師あり学習が誤りから「反省」可能に: 清華大学、Nvidiaおよびスタンフォード大学の研究者らは、NFT(Negative-aware FineTuning)と名付けられた新しい教師あり学習手法を共同で提案しました。この手法はRFT(Rejection FineTuning)アルゴリズムを基に、「暗黙的ネガティブモデル」を構築することでネガティブデータを用いた学習、すなわち「暗黙的ネガティブ戦略」を利用します。この戦略により、教師あり学習も強化学習のように「自己反省」を行うことが可能になり、教師あり学習と強化学習の特定能力におけるギャップを埋め、数学的推論などのタスクで顕著な性能向上を示し、On-Policy条件下ではその損失関数の勾配がGRPOと等価であることさえ示されました。(ソース: 量子位)
OmniGen2発表:8B多機能画像編集モデル、視覚理解と画像生成を融合: OmniGen2という新しい多機能画像編集モデルが発表されました。このモデルは、視覚理解(Qwen-VL-2.5ベース)と画像生成(4Bパラメータの拡散モデル)を組み合わせ、総パラメータ数は約8Bです。OmniGen2は、テキストからの画像生成、画像編集、画像理解、およびコンテキストに応じた生成など、複数のタスクをサポートし、多様な視覚関連問題を解決でき、エッジデバイスへの統合に適した統一モデルを提供することを目指しています。(ソース: karminski3)

Chroma-8.9B-v39テキスト画像生成モデル更新、FLUX.1-schnellベース、商用利用可: テキストから画像を生成するモデルChroma-8.9B-v39が更新され、照明とタスクの自然さが向上しました。このモデルはFLUX.1-schnellをベースとし、パラメータ数は12Bから8.9Bに圧縮され、Apache 2.0ライセンスを採用しており、商用利用が可能です。モデルは「欠落していた解剖学的概念を再導入し、完全にコンテンツ制限なし」であり、500万のアニメ、ファーリー、アート作品、写真を含むデータセットで事後学習されたとされています。(ソース: karminski3)

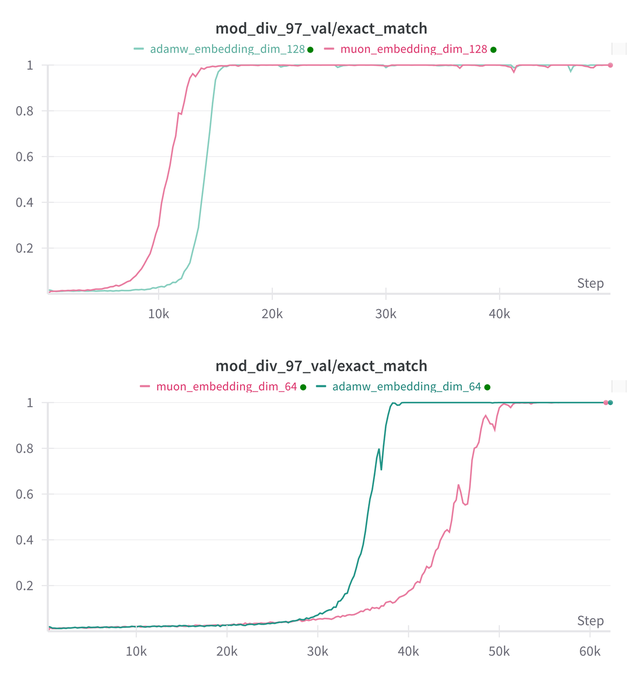
Essential AI、モデルMuonとAdamのGrokking能力に関する研究結論を更新: Essential AIは、同社のモデルMuonとAdamのGrokking(モデルが訓練初期には性能が悪く、その後突然汎化を理解する現象)能力に関する最新の研究進捗を共有しました。初期の仮説は実際の観察と矛盾する可能性があり、チームは内部の小規模な研究実験の結果を公開し、ハイパーパラメータの探索空間を拡大した後、MuonはAdamWに対して明らかな普遍的優位性を持たず、両者は異なるシナリオで一長一短があることを示しました。これは、AdamWが多くの場合において依然として強力、あるいはSOTAのオプティマイザであることを示唆しています。(ソース: eliebakouch, teortaxesTex, nrehiew_)
Ostris AI画像生成モデル更新、CFGなしバージョンに注力し高周波ディテールを最適化: Ostris AIは画像生成モデルの更新を継続しており、現在、収束速度が速いためCFG(Classifier-Free Guidance)なしバージョンの開発に注力しています。最新のDay 7アップデートでは、チームは高周波ディテールをより良く処理するための新しい訓練テクニックを導入し、高ディテールアーティファクトの除去に努めています。以前のDay 4アップデートでは、CFGを使用せずに新しい方法で生成された画像の品質が大幅に改善されたことが示されています。(ソース: ostrisai)

アントグループ、中国科学院などがViLaSR-7Bモデルをオープンソース化、「描きながら考える」空間推論を実現: アント技術研究院、中国科学院自動化研究所および香港中文大学は、ViLaSR-7Bモデルを共同でオープンソース化しました。このモデルは「Drawing to Reason in Space」パラダイムを通じて、大規模視覚言語モデル(LVLM)が視空間に補助マーク(参照線、バウンディングボックスなど)を描画して思考を補助し、空間認識と推論能力を強化することを可能にします。ViLaSRは、コールドスタート、反省的棄却サンプリング、強化学習の3段階の訓練フレームワークを採用しています。実験によると、このモデルは迷路ナビゲーション、画像理解、ビデオ空間推論など5つのベンチマークで平均18.4%向上し、VSI-BenchではGemini-1.5-Proに近い性能を示しました。(ソース: 量子位)

🧰 ツール
SGLang、Hugging Face Transformersをバックエンドとしてサポート開始、推論効率を向上: SGLangは、Hugging Face Transformersをバックエンドとしてサポートしたことを発表しました。これにより、ユーザーはTransformers互換のあらゆるモデルに対して、ネイティブサポートなしで、プラグアンドプレイで高速かつ本番環境レベルの推論サービスを提供できるようになります。この統合は、高性能言語モデル推論のデプロイプロセスを簡素化し、SGLangの適用範囲と使いやすさを拡大することを目的としています。(ソース: TheZachMueller, ClementDelangue)

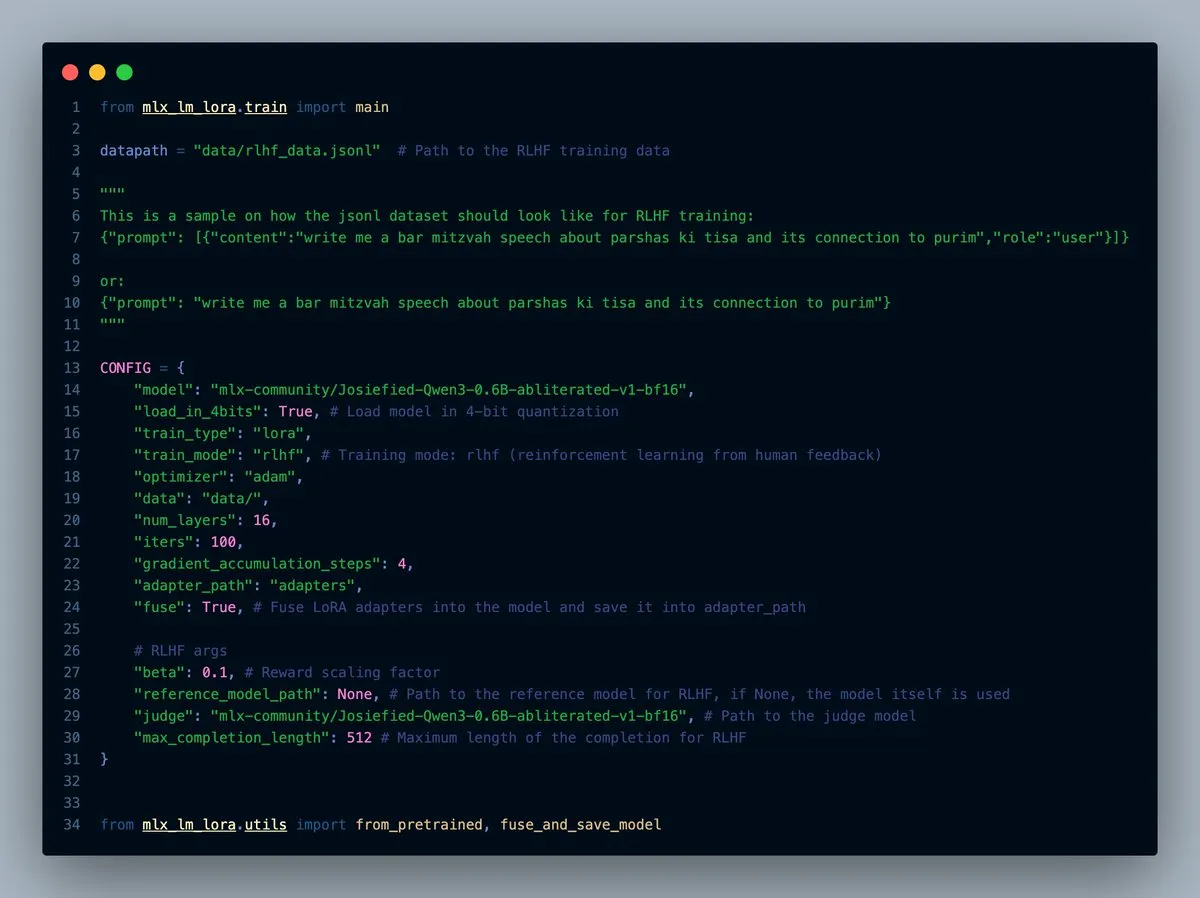
MLX-LM-LORA v0.7.0リリース、RLHF機能を内蔵: MLX-LM-LORAはv0.7.0をリリースし、新バージョンには人間からのフィードバックによる強化学習(RLHF)機能が内蔵されました。このツールは現在、4ビット、6ビット、8ビットのロード、RLHF訓練モードをサポートし、アダプタをベースウェイトに直接融合することができます。これにより、特にAppleシリコンデバイス上で、MLXフレームワーク下でのLoRAファインチューニングがよりスマートかつ効率的になります。(ソース: awnihannun)
LlamaCloudリリース、ドキュメントワークフロー向けMCP互換ツールボックスを提供: LlamaCloudがリリースされました。これはモデルコンテキストプロトコル(MCP)互換のツールボックスとして、あらゆるドキュメントワークフローで使用できます。ユーザーはこれをClaudeなどのモデルに接続し、複雑なドキュメント抽出、比較などの操作を実現できます。例えば、Teslaの過去5四半期の財務パフォーマンスを分析し、総合レポートを生成することができます。これは、標準化されたスキーマを動的に作成し、すべてのファイルで実行した後、コード生成を利用して最終結果を得ることで行われます。LlamaCloudは誤ったスキーマを動的に修正し、直接ファイルリンクをサポートします。(ソース: jerryjliu0)
Georgi Gerganov氏、LlamaBarnプロジェクトを予告: Georgi Gerganov氏(llama.cppの作成者)はソーシャルメディアで画像を公開し、「LlamaBarn」という新しいプロジェクトを予告しました。画像には、モデル選択、パラメータ調整などの要素を含むダッシュボードのようなインターフェースが表示されており、これはローカルLLMの管理、実行、またはテスト用のツールである可能性を示唆しています。コミュニティはこれに期待を寄せており、Ollamaなどの既存ツールの強力な競合相手になる可能性があると考えています。(ソース: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor:新しいオープンソースAIプログラミングアシスタント、MCPとローカルモデルをサポート: Void Editorは、Cursorなどのツールの代替を目指す新しいオープンソースAIプログラミングアシスタントとして登場しました。タブ自動補完、チャットモード、モデルコンテキストプロトコル(MCP)、およびエージェントモードをサポートしています。ユーザーは任意のLLM APIに接続したり、ローカルでモデルを実行したりでき、開発者に柔軟なAI支援プログラミング体験を提供します。(ソース: karminski3)
Together AI、適切なオープンソースLLM選択を支援するWhich LLMツールを公開: Together AIは、「Which LLM」という無料ツールを公開しました。これは、ユーザーが特定のユースケース、パフォーマンス要件、経済的考慮事項に基づいて最適なオープンソースLLMを選択するのを支援することを目的としています。オープンソースLLMの数が急増する中、このようなツールは開発者や研究者がモデル選定時に貴重な参考情報を提供できます。(ソース: vipulved)
Perplexity Finance、株価タイムライン追跡機能を追加: Perplexity Financeは、ユーザーがプラットフォーム上で任意の株式コードの価格変動タイムラインを追跡できるようになったと発表しました。この新機能は、ユーザーにより直感的で便利な金融市場情報分析ツールを提供することを目的としており、PerplexityのAI能力と組み合わせることで、金融情報の照会と分析に新たな体験をもたらす可能性があります。(ソース: AravSrinivas)

IdeaWeaver、システムパフォーマンスデバッグ用の初のAIエージェントを発表: IdeaWeaverは、システムパフォーマンス問題のデバッグ専用に設計されたと主張する初のAIエージェントを発表しました。このツールはCrewAIフレームワークを利用し、CPU、メモリ、I/O、ネットワークなどの関連問題を診断するために実際にシステムコマンドを実行できます。その特徴は、プライバシー保護のためにローカルLLM(OLLAMA経由)を優先的に使用し、ローカルモデルが利用できない場合にのみOpenAI APIキーを要求する点で、AI能力をDevOpsおよびシステム管理分野に応用することを目指しています。(ソース: Reddit r/artificial)
Kling AI、Live Photoサポートを追加、生成動画を動く壁紙として保存可能に: Kling AIは、その動画生成機能が作品をLive Photos(ライブフォト)として保存できるようになったと発表しました。ユーザーは、お気に入りのKlingが作成した動的コンテンツを携帯電話の壁紙として設定でき、AI生成動画の楽しさと実用性が向上します。(ソース: Kling_ai)
Cognition AI、Blockdiffをオープンソース化、VMスナップショット速度を200倍向上: Cognition AIは、Devin用に開発したVMスナップショットファイル形式Blockdiffをオープンソース化したと発表しました。EC2でのVMスナップショット作成に時間がかかりすぎる(30分以上)ため、チームは独自にotterlink仮想マシンマネージャーとBlockdiffファイル形式を構築し、スナップショット作成速度を200倍向上させました。このオープンソース貢献は、開発者がより効率的に仮想マシン環境を管理するのに役立つことを目的としています。(ソース: karinanguyen_)

📚 学び
LangChainブログ記事、「コンテキストエンジニアリング」の台頭を議論: LangChainはブログ記事を公開し、「コンテキストエンジニアリング」(Context Engineering)というますます一般的になっている用語について議論しました。記事はこれを「LLMがタスクを合理的に完了できるように、正しい情報を正しい形式で提供し、ツールを提供する動的システムを構築すること」と定義しています。これは全く新しい概念ではなく、エージェントビルダーは長年実践してきており、LangGraph、LangSmithなどのツールもそのために生まれました。この用語の提案は、関連するスキルやツールへの注目を高めるのに役立ちます。(ソース: hwchase17, Hacubu, yoheinakajima)
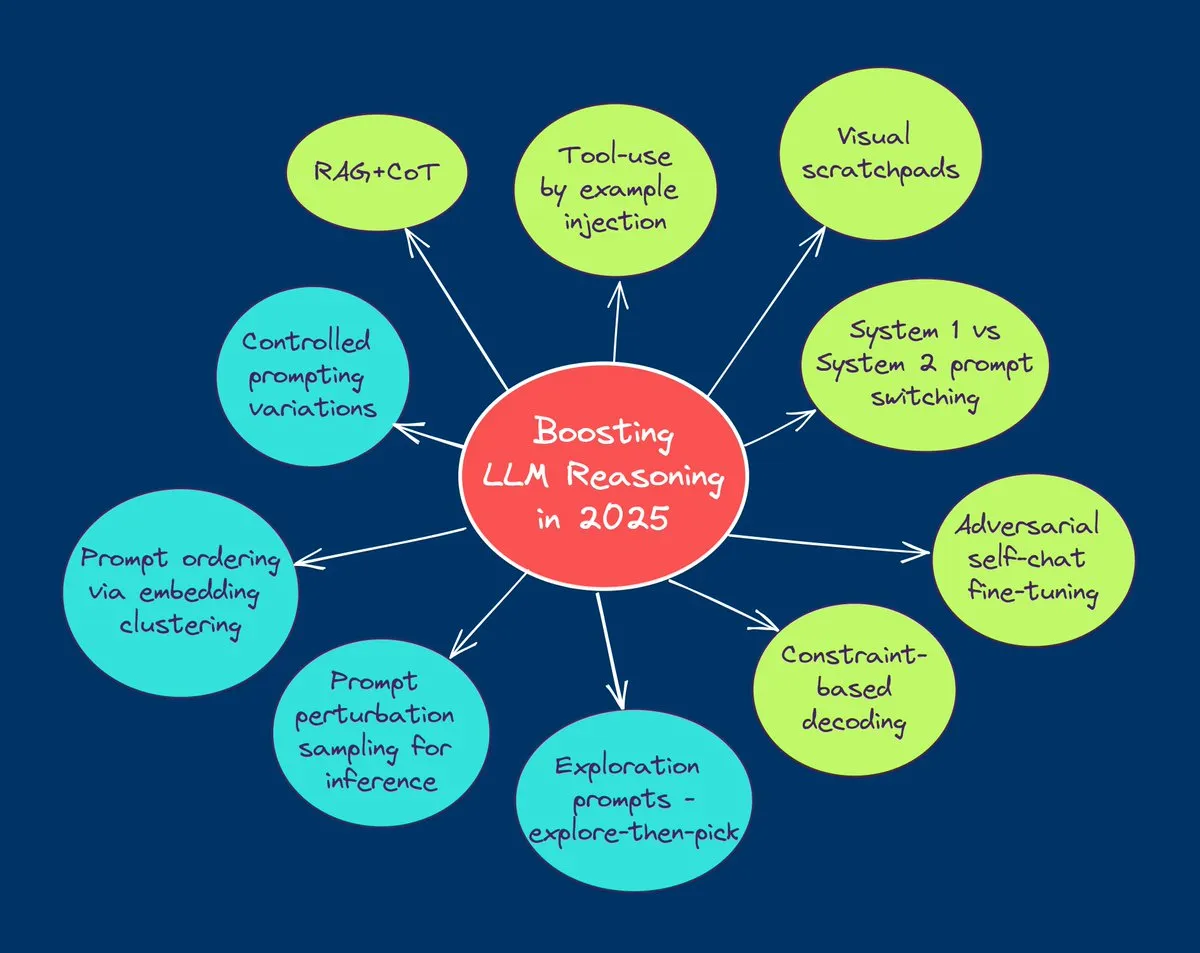
TuringPost、2025年にLLMの推論能力を向上させる10大技術を総括: TuringPostは、2025年にLLMの推論能力を向上させるための10の主要技術を共有しました。これには、検索拡張思考連鎖(RAG+CoT)、例によるツール注入、視覚的スクラッチパッド(マルチモーダル推論サポート)、システム1とシステム2のプロンプト切り替え、敵対的自己対話ファインチューニング、制約ベースのデコーディング、探索的プロンプティング(探索後に選択)、推論のためのプロンプト摂動サンプリング、埋め込みクラスタリングによるプロンプト順序付け、および制御されたプロンプトバリアントが含まれます。これらの技術は、複雑なタスクにおけるLLMのパフォーマンスを最適化するための多様な道筋を提供します。(ソース: TheTuringPost, TheTuringPost)
Cohere Labs、MLサマースクールを開催し機械学習の未来を探る: Cohere Labsのオープンサイエンスコミュニティは7月にMLサマースクール(ML Summer School)を開催します。このイベントでは、世界中のコミュニティメンバーが集まり、機械学習の未来について議論し、業界の講演者を招いて講演を行います。その中で、Katrina Lawrence氏は7月2日に機械学習の数学復習コースを担当し、微積分、ベクトル微積分、線形代数などの核心概念をカバーします。(ソース: sarahookr)

DeepLearning.AI、Metaと提携し無料コース「Building with Llama 4」を開始: DeepLearning.AIはMetaと提携し、「Building with Llama 4」という無料コースを開始しました。コース内容には、Llama 4シリーズモデルの実践的操作、その混合エキスパート(MOE)アーキテクチャの理解、および公式APIを使用したアプリケーション構築方法、Llama 4を用いた複数画像推論、画像ローカライゼーション(オブジェクトとそのバウンディングボックスの識別)、および最大100万トークンの長文テキストクエリの処理、Llama 4のプロンプト最適化ツールを使用したシステムプロンプトの自動改善、およびその合成データツールキットを使用した高品質データセットの作成によるファインチューニングが含まれます。(ソース: DeepLearningAI)
EleutherAI YouTubeチャンネル、豊富なAI研究コンテンツを提供: EleutherAIのYouTubeチャンネルは、読書会や講演シリーズの録画ビデオを100時間以上集めています。テーマは、機械学習のスケーラビリティとパフォーマンス、関数解析、チームメンバーのポッドキャストやインタビューなど多岐にわたります。このチャンネルは、AI研究者や愛好家に豊富な学習リソースを提供しています。EleutherAIはまた、新しい講演シリーズを開始し、初回は@linguist_cat氏がトークナイザとその限界について講演します。(ソース: BlancheMinerva, BlancheMinerva)
論文、潜在的視覚トークンによるマルチモーダル推論の強化(Machine Mental Imagery)を議論: 新しい論文「Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens」は、Mirageフレームワークを提案し、VLMのデコードプロセスに(完全な画像を生成するのではなく)潜在的視覚トークンを組み込むことでマルチモーダル推論を強化し、人間の心的イメージをシミュレートします。この方法は、まず実際の画像埋め込みを蒸留して潜在的トークンを監視し、次に純粋なテキスト監視に切り替えて潜在的軌跡をタスク目標に合わせ、強化学習によって能力をさらに向上させます。実験により、Mirageは明確な画像を生成することなく、より強力なマルチモーダル推論を実現できることが証明されました。(ソース: HuggingFace Daily Papers)
論文、Vision as a Dialectフレームワークを提案、テキスト整列表現により視覚理解と生成を統一: 「Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations」という論文は、TarというマルチモーダルLLMフレームワークを紹介しています。このフレームワークは、テキスト整列トークナイザ(TA-Tok)を使用して画像を離散トークンに変換し、LLM語彙表から投影されたテキスト整列コードブックを利用することで、視覚とテキストを共有の離散的意味表現に統一します。Tarは共有インターフェースを通じてクロスモーダルな入出力を実現し、特定モーダルの設計を必要とせず、効率と視覚的詳細のバランスを取るためにスケール適応型エンコーダデコーダと生成的デトークナイザを採用しています。(ソース: HuggingFace Daily Papers)
論文、ReasonFlux-PRMを提案:LLMの長連鎖思考推論のための軌跡認識PRM: 論文「ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs」は、DeepSeek-R1などの最先端推論モデルによって生成される軌跡-応答タイプの推論トレースを評価するために特別に設計された、新しい軌跡認識プロセス報酬モデル(PRM)を紹介しています。ReasonFlux-PRMは、ステップレベルと軌跡レベルの監視を組み合わせ、構造化された思考連鎖データと整合したきめ細かい報酬割り当てを実現し、SFT、RL、およびBoNテスト時拡張などのシナリオで性能向上を達成しました。(ソース: HuggingFace Daily Papers)
論文、大規模言語モデルのジェイルブレイクガードレールの評価方法を研究: 「SoK: Evaluating Jailbreak Guardrails for Large Language Models」と題された論文は、大規模言語モデル(LLMs)のジェイルブレイク攻撃とそのガードレール(Guardrails)に関する体系的な知識整理を行っています。論文は、6つの主要な側面からガードレールを分類する新しい多次元分類法を提案し、その実際の効果を評価するための安全性-効率性-実用性評価フレームワークを導入しています。広範な分析と実験を通じて、論文は既存のガードレール手法の長所と短所を指摘し、さまざまな攻撃タイプに対する普遍性を検討し、防御の組み合わせを最適化するための洞察を提供しています。(ソース: HuggingFace Daily Papers)
AAAI 2025優秀論文、部分観測マルコフ決定過程(POMDP)の決定可能クラスを議論: 「Revelations: A Decidable Class of POMDP with Omega-Regular Objectives」と題された論文がAAAI 2025優秀論文賞を受賞しました。この研究は、決定可能なMDP(マルコフ決定過程)のクラスを特定しました。それは、「強い啓示」を持つ決定問題、すなわち、各ステップで世界の正確な状態を明らかにする非ゼロの確率がある問題です。論文はまた、「弱い啓示」の決定可能性の結果も提供しており、そこでは正確な状態が最終的に明らかにされることが保証されますが、必ずしも各ステップで明らかにされるわけではありません。この研究は、情報が不完全な状況下での最適決定のための新しい理論的基礎を提供します。(ソース: aihub.org)
論文、CommVQを提案:KVキャッシュ圧縮のための可換ベクトル量子化: 論文「CommVQ: Commutative Vector Quantization for KV Cache Compression」は、CommVQという手法を提案しています。これは、加法的量子化と軽量エンコーダおよびコードブックを使用してKVキャッシュを圧縮し、長文コンテキストLLM推論におけるメモリ占有量を削減するものです。デコード計算コストを削減するため、コードブックは回転位置埋め込み(RoPE)と交換可能に設計され、EMアルゴリズムを使用して訓練されます。実験によると、この手法は2ビット量子化でFP16 KVキャッシュサイズを87.5%削減でき、既存のKVキャッシュ量子化手法よりも優れており、極めてわずかな精度損失で1ビットKVキャッシュ量子化さえ実現できます。(ソース: HuggingFace Daily Papers)
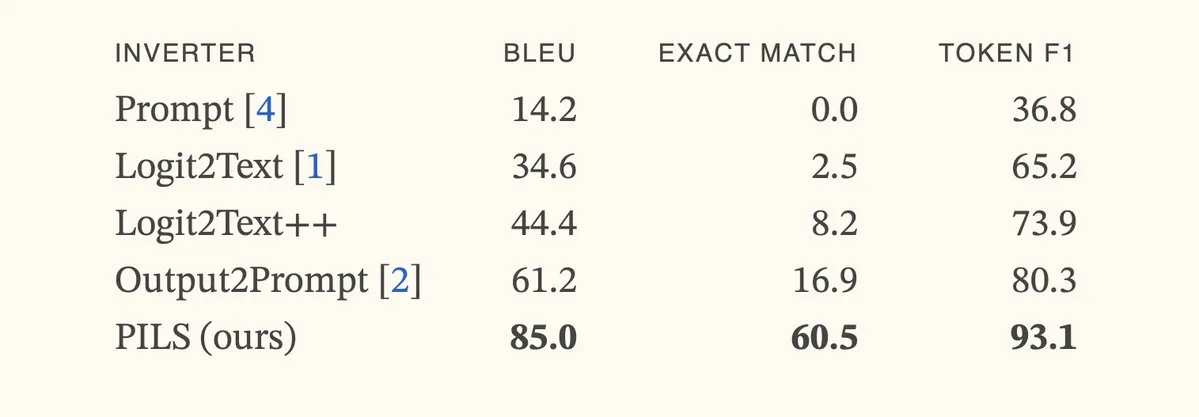
論文、PILS手法を提案、コンパクトな次トークン分布表現により言語モデル反転を改善: 論文「Better Language Model Inversion by Compactly Representing Next-Token Distributions」は、PILS(Prompt Inversion from Logprob Sequences)という新しい言語モデル反転手法を提案しています。この手法は、複数の生成ステップにおけるモデルの次トークン確率を分析することで隠されたプロンプトを復元します。核心は、言語モデルの出力ベクトルが低次元部分空間を占めることを発見し、それにより線形写像を通じて次トークン確率分布を無損失で圧縮し、より効果的な反転に利用することです。実験によると、PILSは隠されたプロンプトの復元において、以前のSOTA手法を大幅に上回りました。(ソース: HuggingFace Daily Papers, jxmnop)
論文、Phantom-Dataを提案:汎用的な被写体一貫性ビデオ生成データセット: 論文「Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset」は、Phantom-Dataという新しいデータセットを紹介しています。これは、既存の被写体からビデオへの生成モデルで一般的に見られる「コピー&ペースト」問題(つまり、被写体のアイデンティティが背景やコンテキスト属性と過度に絡み合っている問題)を解決することを目的としています。Phantom-Dataは、異なるカテゴリ間でアイデンティティが一貫している約100万ペアの、初の汎用的なクロスコンテキスト被写体からビデオへの一貫性データセットです。このデータセットは、被写体検出、大規模クロスコンテキスト被写体検索、および事前知識誘導によるアイデンティティ検証を含む3段階のプロセスで構築されています。(ソース: HuggingFace Daily Papers)
論文、LongWriter-Zeroを提案:強化学習による超長文テキスト生成の習得: 論文「LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning」は、インセンティブベースの手法を提案し、ゼロから強化学習(RL)を利用してLLMが超長文で高品質なテキストを生成する能力を育成します。これには、アノテーション付きデータや合成データは一切不要です。この手法は、基礎モデルから開始し、RLを通じて計画と執筆プロセスにおける洗練を誘導し、専用の報酬モデルを使用して長さ、執筆品質、構造形式を制御します。実験によると、Qwen2.5-32Bから訓練されたLongWriter-Zeroは、長文執筆タスクにおいて従来のSFT手法を上回り、複数のベンチマークでSOTAレベルを達成しました。(ソース: HuggingFace Daily Papers)
💼 ビジネス
法律AI企業Harvey、3億ドルのEラウンド資金調達を完了、評価額は50億ドルに: 法律AIスタートアップのHarveyは、Kleiner PerkinsとCoatueが共同リードする3億ドルのEラウンド資金調達を完了し、企業評価額が50億ドルに達したと発表しました。他の投資家には、Sequoia Capital、GV、DST Global、Conviction、Elad Gil、OpenAI Startup Fund、Elemental、SV Angel、Kris Fredrickson、REVが含まれます。この資金調達は、Harveyが法律分野におけるAIアプリケーションの開発と拡大を継続するのに役立ちます。(ソース: saranormous)
HyperbolicオンデマンドGPUクラウドサービス、開始7日間でARR100万ドル達成: Yuchenj_UW氏は、先週開始したHyperbolicオンデマンドGPUクラウドサービスが、1つのツイートによるわずかなマーケティングのみで、7日間で年間経常収益(ARR)が0から100万ドルに増加したと発表しました。彼らはビルダー向けに無料の8xH100ノード試用クレジットを提供しており、高性能GPUクラウドサービスに対する市場の強い需要を示しています。(ソース: Yuchenj_UW)
Replit、年間経常収益(ARR)が1億ドルを突破したと発表: オンライン統合開発環境(IDE)およびクラウドコンピューティングプラットフォームのReplitは、年間経常収益(ARR)が1億ドルを突破し、2024年末の1000万ドルから大幅に増加したと発表しました。同社は、2023年に11億ドルの評価額で最後の資金調達ラウンドを完了した後も、銀行には資金の半分以上が残っていると述べています。Replitの成長は、企業ユーザー(Zillow、HubSpotなど)や個人開発者によるプラットフォームの利用によるもので、現在積極的に採用活動を行っています。(ソース: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 コミュニティ
AIプログラミングの新パラダイム:まず設計、次にプロンプト、反復的にコード生成を最適化: dotey氏と宝玉氏は、AIプログラミングがもたらすソフトウェア開発モデルの変革について議論しています。従来の「まず設計、次にコーディング」と「まず実装、次にリファクタリング」という議論は、AI時代に融合しました。AIは設計からコーディングまでのコストと時間を大幅に短縮し、開発者が設計がまだ完全に明確でない段階でも迅速にバージョンを実装し、結果を検証することで設計とプロンプトを反復的に改善することを可能にします。プロンプトは従来の「詳細設計書」の役割を果たしますが、より簡略化されています。このモデルでは、開発者はシステム設計により重点を置き、少量のコードを生成し、ソースコード管理を利用し、AIが生成したコードをレビューおよびテストする必要があります。経験豊富なプログラマーにとって、思考と開発習慣を変えることがAIプログラミングを受け入れる鍵となります。(ソース: dotey)
Claude Code、強力な大規模コードベース処理能力とコンテキスト効率で開発者に人気: Redditのr/ClaudeAIコミュニティでは、Claude Codeの大規模コードベース処理における卓越したパフォーマンスが話題となっています。ユーザーからは、200kトークンをはるかに超えるサイズのコードベースを適切に理解し、変更を実装できるとのフィードバックが寄せられています。議論では、Claude Codeは人間が読むような戦略(重要な部分のみを読む)、grepなどのツールを使用したコンテキスト検索(RAGのベクトル化圧縮に完全に依存するのではなく)、およびファーストパーティモデル統合の利点を通じて、効率的なコンテキスト処理を実現している可能性があると考えられています。ユーザーは、Claude Codeを使用してシステムの問題を修正したり、個人の財務トラッカーを構築したり、Androidアプリを開発したり(Android開発経験がなくても)、Obsidian DataviewJSスクリプトを作成したりするなど、さまざまな成功事例を共有し、作業効率を大幅に向上させています。(ソース: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

「コンテキストエンジニアリング」概念が注目、LLMを強化する動的システムの構築を強調: LangChainのHarrison Chase氏は、「コンテキストエンジニアリング」(Context Engineering)がAIエンジニアによるシステム構築の中核業務であると提唱しています。これは「LLMがタスクを合理的に完了できるように、正しい情報を正しい形式で提供し、ツールを提供する動的システムを構築すること」と定義されています。この概念は、LLMアプリケーションにおいて、コンテキスト情報を効果的に整理し提供することがモデルのパフォーマンスにとって重要であることを強調しており、エージェント構築などの分野の基礎となっています。(ソース: hwchase17, Hacubu, yoheinakajima)
Meta創業者ザッカーバーグ氏が自らAI人材を募集、コミュニティで注目: ソーシャルメディアの情報によると、Meta創業者のマーク・ザッカーバーグ氏が自ら超知能研究所の人材募集に関与しており、数百人の潜在的候補者に直接連絡を取り、返信者には夕食会に招待しているとのことです。この動きは、MetaがAI分野、特に汎用人工知能(AGI)や超知能への投資の決意と力を示していると解釈され、トップテクノロジー企業によるAIトップ人材の激しい争奪戦を示しています。(ソース: reach_vb, andrew_n_carr)

AIの発展が雇用市場と経済構造に深刻な反省を促す: ハーバード・ビジネス・スクールおよび経済学者のAnton Korinek氏は、AGIが2~5年以内に実現する可能性があり、経済システムが徹底的に変革されなければ崩壊につながる可能性があると警告し、ベーシックインカムの必要性を強調しています。同時に、コミュニティの議論では、AIが大量の定量化可能なタスクを自動化し、ブルーカラーとホワイトカラーの仕事に衝撃を与え、企業はAIに適応するために組織構造を再構築する必要があると考えられています。Yuval Noah Harari氏はAI革命を「AI移民の波」に例え、AIによる雇用代替と権力追求に関する議論を引き起こしています。これらの見解は、AIが将来の社会経済構造に与える破壊的な影響を共通して指摘しています。(ソース: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

AIがプログラミングコンテストで際立った成績、Sakana AIエージェントの好成績が話題に: Sakana AIのエージェントは、AtCoderヒューリスティックプログラミングコンテストで、1000人以上の人間のプログラマーの中で21位にランクインし、全体で上位6.8%の成績を収めました。このAIは4時間で約100バージョンを反復し、数千の潜在的な解決策を生成しましたが、人間の参加者は通常約12しかテストできません。AIはGemini 2.5 Proを使用し、専門知識とシステム検索アルゴリズム(焼きなまし法やビームサーチなど)を組み合わせて実際の問題を解決しました。コミュニティの反応は様々で、コンテストプログラミングは企業レベルのエンジニアリングとは異なり、AIの勝利はコンピュータが加減算で人間を打ち負かすようなものだと考える人もいます。(ソース: Reddit r/ArtificialInteligence)
💡 その他
AIの職業教育分野における探求:面接、教師、学習機の多様な試み: 華図、粉筆、中公などの職業教育大手はAI応用に積極的に取り組んでおり、方向性はそれぞれ異なります。華図はAI面接評価に焦点を当て、粉筆はAI採点とAI教師(AI問題演習システムクラスの売上は既に1400万元を突破)を深耕し、中公はAI就職学習機を発売しました。業界の共通認識は、AIは学習効果と運営効率を向上させるべきであり、単に高付加価値を追求するものではないということです。AIの応用も概念実証からシーンの深耕へと進んでおり、例えば51CTOはデジタルヒューマン、3Dモデリングを利用してコースを生成し、AIを通じて問題生成と学習パス分析を行っています。しかし、多くの教育企業はまだ自社で大規模モデルを構築する能力を持っておらず、サードパーティAPIの呼び出しに傾倒しています。(ソース: 36氪)
ディズニー、ユニバーサル・ピクチャーズがAI画像生成ユニコーンMidjourneyを著作権侵害で提訴: ハリウッド大手のディズニーとユニバーサル・ピクチャーズは、AI画像生成企業Midjourneyを共同で提訴しました。Midjourneyが許可なく大量の著作権保護されたIPコンテンツ(アイアンマン、ミニオンなど)を使用してAIモデルを訓練し、酷似した画像を生成したと主張しています。原告は侵害行為の差し止めと、故意の侵害作品1件につき最高15万ドルの損害賠償を求めています。この訴訟は、生成AIが直面する著作権の課題を浮き彫りにしており、Midjourneyの創業者はデータ使用の許可を得ていなかったことを認めていました。訴訟は、著作権ライセンスメカニズムとコンテンツフィルタリングシステムの確立を推進することを意図している可能性があります。(ソース: 36氪)

Apple、AIで遅れをとっていると指摘され、買収による挽回を検討か、元OpenAI CTOの企業が注目される: 報道によると、AppleはAI分野で比較的遅れをとっており、自社開発のAI能力が不足し、Siriのパフォーマンスも振るわないとのことです。この差を埋めるため、Appleは大規模な買収を検討している可能性があり、OpenAIの元CTOであるMira Murati氏の新興企業Thinking Machines Labと初期接触があったと噂されています。歴史的にAppleは、小規模な技術企業を買収することで自社能力を強化してきました(Siri自体もその例です)。現在、AppleはAIモデルのパラメータ規模で業界大手に大きく遅れをとっており、Mistralなどの企業を買収することで、自社開発の大規模モデルでブレークスルーを達成できる可能性があります。(ソース: 36氪)