
キーワード:Gemini 2.5 Pro, Veo 3, AI動画生成, OpenAI, Jony Ive, Claude 4 Opus, AIエージェント, マルチモーダルモデル, Deep Thinkモード, 動画生成モデル, AI推論能力, AIハードウェア設計, ソフトウェアエンジニアリング最適化
🔥 聚焦
Google、Gemini 2.5 Pro Deep ThinkとVeo 3を発表、AI推論と動画生成を新たな高みへ: Google I/Oカンファレンスにおいて、GoogleはGemini 2.5 ProのDeep Thinkモードを発表しました。このモードは複雑な問題解決に特化して設計されており、USAMOなどの数学コンテストの難問において優れた成績を収め、AIによる高度な推論能力の大きな進展を示しました。例えば、多段階の推論や異なる証明方法(背理法、ロルの定理など)を試すことで複雑な代数の問題を解決します。同時に、Googleが発表した動画生成モデルVeo 3は、そのリアルなシーン、制御可能なキャラクターの一貫性、音声合成、及び多様な編集機能(シーン変換、参照画像からの生成、スタイル転送、開始・終了フレーム指定、部分編集など)により、AI動画生成分野で新たな基準を打ち立て、大きな注目を集めています (出典: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI、Jony Ive氏の会社を65億ドルで買収、AI駆動の次世代コンピュータを共同開発へ: OpenAIは、Appleの元チーフデザイナーであるJony Ive氏との協力を発表し、同氏の会社を買収しました。これはAI駆動の次世代コンピュータを共同開発することを目的としています。この動きは、OpenAIがハードウェア分野へ進出し、AI能力をコンピューティングデバイスに深く統合しようとする試みであり、人間とコンピュータのインタラクション方式を再構築する可能性があります。Jony Ive氏はApple在籍中の卓越したデザインで知られており、同氏の参加は新しいデバイスがデザインとユーザーエクスペリエンスにおいて大きなブレークスルーを遂げ、既存のコンピューティングデバイスの形態に挑戦することを示唆しています (出典: op7418, TheRundownAI, BorisMPower)
Anthropic開発者会議開催間近、Claude 4 Opus発表か、ソフトウェアエンジニアリング能力に焦点: Anthropicは初の開発者会議を間もなく開催予定で、コミュニティでは次世代モデルClaude 4(Sonnet 4およびOpus 4を含む)がこの会議で発表されるのではないかと広く推測されています。Claude Sonnet 3.7 APIがClaude 4のような挙動(「思考ステップ」を必要としない迅速なツール使用など)を示している兆候があります。Anthropicは、OpenAIやGoogleが追求する「万能モデル」の路線とは異なり、ソフトウェアエンジニアリングの難題解決に注力しているようです。TIME誌も間接的にClaude 4 Opusの発表を認めており、AIコーディングと複雑なタスク処理能力におけるAnthropicへの市場の期待をさらに高めています (出典: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
OpenAIとGoogleのAIエコシステム戦略の違い:戦艦の組み立てと帝国の改造: OpenAIとGoogleはそれぞれ、「エコシステムの結集」と「エコシステムの改造」という異なる経路を通じて、将来のAIプラットフォームの「メインオペレーティングシステム」の地位を争っています。OpenAIはハードウェア(io)、データベース(Rockset)、ツールチェーン(Windsurf)、コラボレーションツール(Multi)などを買収することで、ゼロからフルスタックのAI能力を組み立てています。一方、GoogleはGeminiモデルを既存の製品(検索、Android、Docs、YouTubeなど)に深く組み込み、基盤システムを改造してAIネイティブ化を実現することを選択しています。両者の戦略は異なりますが、目標は一致しており、いずれもAI時代の究極のプラットフォーム構築を目指しています (出典: dotey)
🎯 動向
Microsoft、「エージェントネットワーク」ビジョンを提示、AIエージェントが次世代業務の中核になると強調: MicrosoftのCEOであるSatya Nadella氏は、Build 2025カンファレンスおよびインタビューにおいて、同社の「エージェントネットワーク(agentic web)」に関するビジョンを説明しました。同氏は、将来AIエージェントがビジネスおよびM365エコシステムの第一級市民となり、「AIエージェント管理者」などの新しい職業を生み出す可能性さえあると考えています。コードの95%がAIによって生成されるようになると、人間の役割はこれらのエージェントの管理と編成に移行します。MicrosoftはAzure AI Foundry、Copilot Studio、およびNLWebなどのオープンプロトコルを通じて、オープンなエージェントエコシステムを構築しており、Teamsをマルチエージェントコラボレーションの中心に据えようとしています (出典: rowancheung, TheTuringPost)
MMaDA:テキスト推論、マルチモーダル理解、画像生成を統合したマルチモーダル拡散言語モデルが発表: 研究者たちは、MMaDA(Multimodal Large Diffusion Language Models)を発表しました。これは、Mixed Long-CoT(混合長思考連鎖)と統一強化学習アルゴリズムUniGRPOを通じて、テキスト推論、マルチモーダル理解、画像生成能力を統合した新しいタイプのマルチモーダル拡散基盤モデルです。MMaDA-8Bは、マルチモーダル理解においてShow-oとSEED-Xを上回り、テキストからの画像生成においてSDXLとJanusより優れており、モデルとコードはHugging Faceでオープンソース化されています (出典: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache:拡散言語モデル向けキャッシュ機構を設計、推論速度を大幅に向上: 拡散言語モデル(DLMs)の推論速度が遅い問題に対し、研究者たちはdKV-Cache機構を提案しました。この方法は、自己回帰モデルにおけるKV-Cacheを参考に、遅延および条件付きキャッシュ戦略を通じて、DLMsのノイズ除去プロセスのためのキー・バリューキャッシュを設計します。実験によると、dKV-Cacheは2~10倍の推論高速化を実現し、DLMsと自己回帰モデルの速度差を著しく縮小し、長いシーケンスでは性能を向上させることさえ可能で、既存のDLMにトレーニングなしで適用できます (出典: NandoDF, HuggingFace Daily Papers)

Imagen4、細部再現において優れた性能を発揮、画像生成の終局に近づく: Imagen4モデルは、複雑なテキストプロンプトに基づいて画像を生成する際に、強力な細部再現能力を示しました。例えば、特定の色、物体、位置、照明、雰囲気など25個の具体的な詳細を含む画像を生成する際、Imagen4はそのうち23個を再現することに成功しました。このような高忠実度と複雑な指示に対する正確な理解は、テキストからの画像生成技術がユーザーの想像を完全に再現できる「終局」レベルに近づいていることを示しています (出典: cloneofsimo)

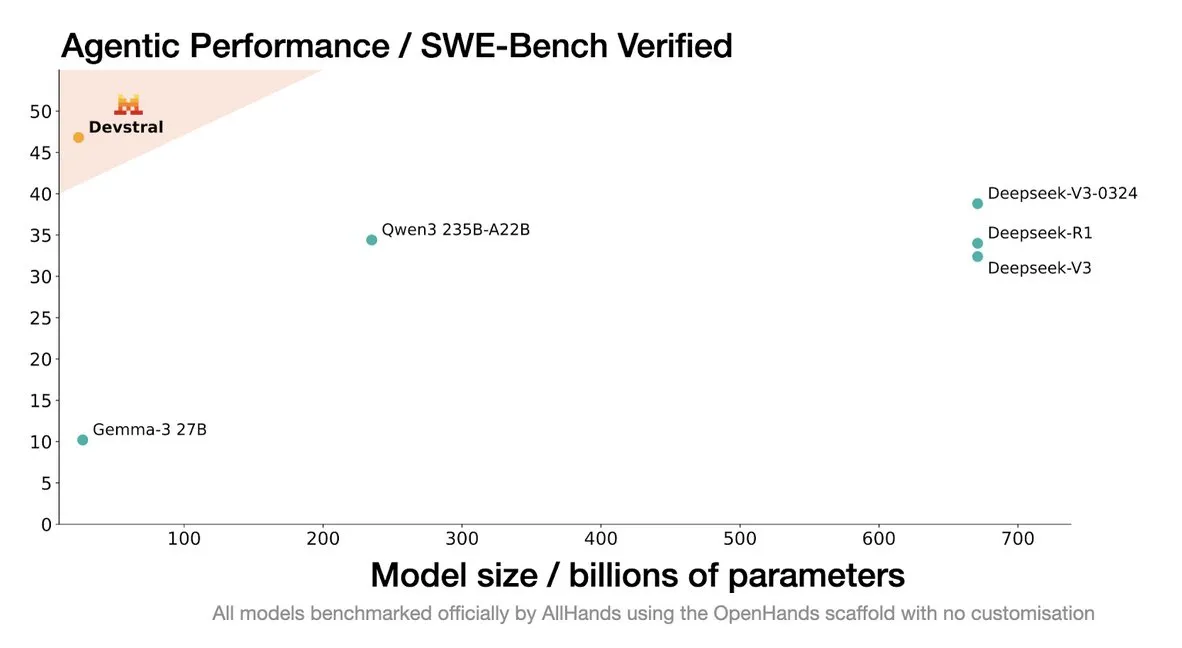
Mistral、コーディングエージェント向けに設計されたDevstralモデルを発表: Mistral AIは、コーディングエージェント向けに特別に設計されたオープンソースモデルであるDevstralを発表し、allhands_aiと共同開発しました。その4ビットDWQ量子化バージョンはHugging Faceで公開されており(mlx-community/Devstral-Small-2505-4bit-DWQ)、M2 Ultraなどのデバイスでスムーズに動作し、コード生成と理解における最適化の可能性を示しています (出典: awnihannun, clefourrier, GuillaumeLample)
ByteDance、Gemini級マルチモーダルモデルの訓練報告書を発表、統合Transformerアーキテクチャを採用: ByteDanceは、Geminiクラスのネイティブマルチモーダルモデルの訓練方法を詳述した37ページの報告書を公開しました。中でも最も注目されるのは「統合Transformer」(Integrated Transformer)アーキテクチャで、このアーキテクチャは同じバックボーンネットワークをGPTのような自己回帰モデルとDiTのような拡散モデルとして同時に使用し、マルチモーダル統一モデリングにおける探求を示しています (出典: NandoDF)

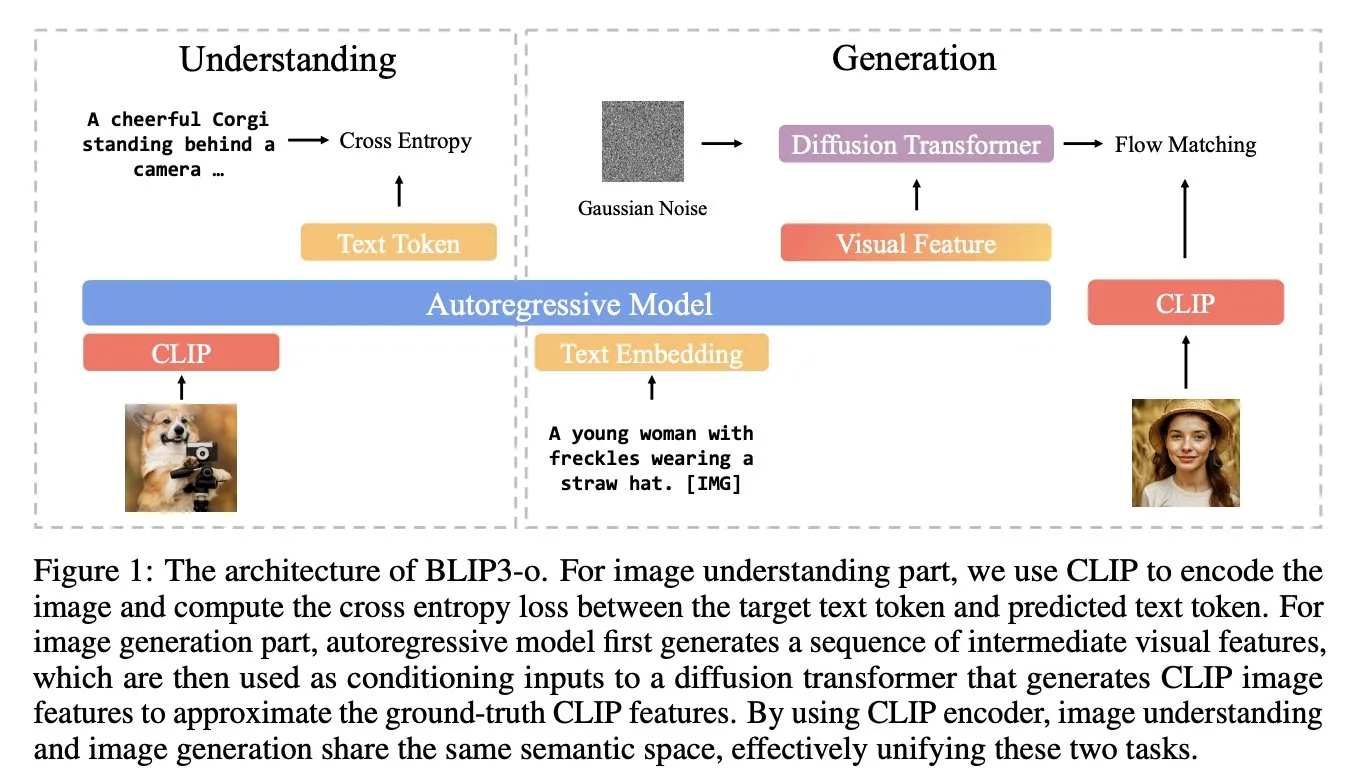
BLIP3-o:Salesforce、GPT-4o級の画像生成能力を解放する完全オープンソースの統一マルチモーダルモデルシリーズを発表: Salesforceの研究チームは、BLIP3-oシリーズモデルを発表しました。これは、GPT-4oのような画像生成能力の解放を試みる、完全にオープンソース化された統一マルチモーダルモデル群です。このプロジェクトはモデルをオープンソース化しただけでなく、2500万件のデータを含む事前学習データセットも公開し、マルチモーダル研究のオープン性を推進しています (出典: arankomatsuzaki)
Google、低リソースデバイス向けに設計されたマルチモーダルモデルGemma 3n E4Bプレビュー版を発表: GoogleはHugging Face上でGemma 3n E4B-it-litert-previewモデルを公開しました。このモデルはテキスト、画像、動画、音声入力を処理し、テキスト出力を生成するように設計されており、現在のバージョンではテキストと視覚入力をサポートしています。Gemma 3nは斬新なMatformerアーキテクチャを採用し、複数のモデルをネスト化し、2Bまたは4Bパラメータを効果的に活性化することを可能にし、低リソースデバイスでの効率的な実行に特化して最適化されています。モデルは約11兆トークンのマルチモーダルデータに基づいて訓練され、知識は2024年6月時点のものです (出典: Tim_Dettmers, Reddit r/LocalLLaMA)
研究により大規模モデルにおける言語固有知識(LSK)現象が明らかに: 新しい研究は、言語モデルに存在する「言語固有知識」(Language Specific Knowledge, LSK)現象、すなわちモデルが特定のトピックや分野を処理する際に、特定の非英語言語でのパフォーマンスが英語を上回る可能性があるという現象を探求しています。研究によると、特定の言語(低リソース言語であっても)で思考連鎖推論を行うことで、モデルのパフォーマンスが向上することが判明しました。これは、文化固有のテキストが対応する言語でより豊富であり、特定の知識が「専門家」言語にのみ存在する可能性があることを示唆しています。研究者たちは、このLSKを測定し活用するためのLSKExtractorメソッドを設計し、複数のモデルとデータセットで平均精度を相対的に10%向上させました (出典: HuggingFace Daily Papers)
DeepMind Veo 3の動画生成効果が驚異的、リアルなディテールが注目を集める: Google DeepMindの動画生成モデルVeo 3は、シーン変換、参照画像駆動、スタイル転送、キャラクターの一貫性、開始・終了フレーム指定、動画スケーリング、オブジェクト追加、動作制御など、強力な動画生成能力を実証しました。生成された動画のリアリズムと複雑な指示に対する理解力は、ユーザーにAI動画生成技術の急速な発展を感嘆させ、プロ制作に匹敵する広告映像を制作したユーザーもいます (出典: demishassabis, , Reddit r/ChatGPT)
Moondream視覚言語モデルが4ビット量子化版をリリース、VRAMを大幅に削減し速度を向上: Moondream視覚言語モデル(VLM)は4ビット量子化版をリリースし、VRAM使用量を42%削減、推論速度を34%向上させると同時に、99.4%の精度を維持しました。この最適化により、この強力な小型VLMは物体検出などのタスクでより簡単に展開・使用できるようになり、開発者から歓迎されています (出典: Sentdex, vikhyatk)
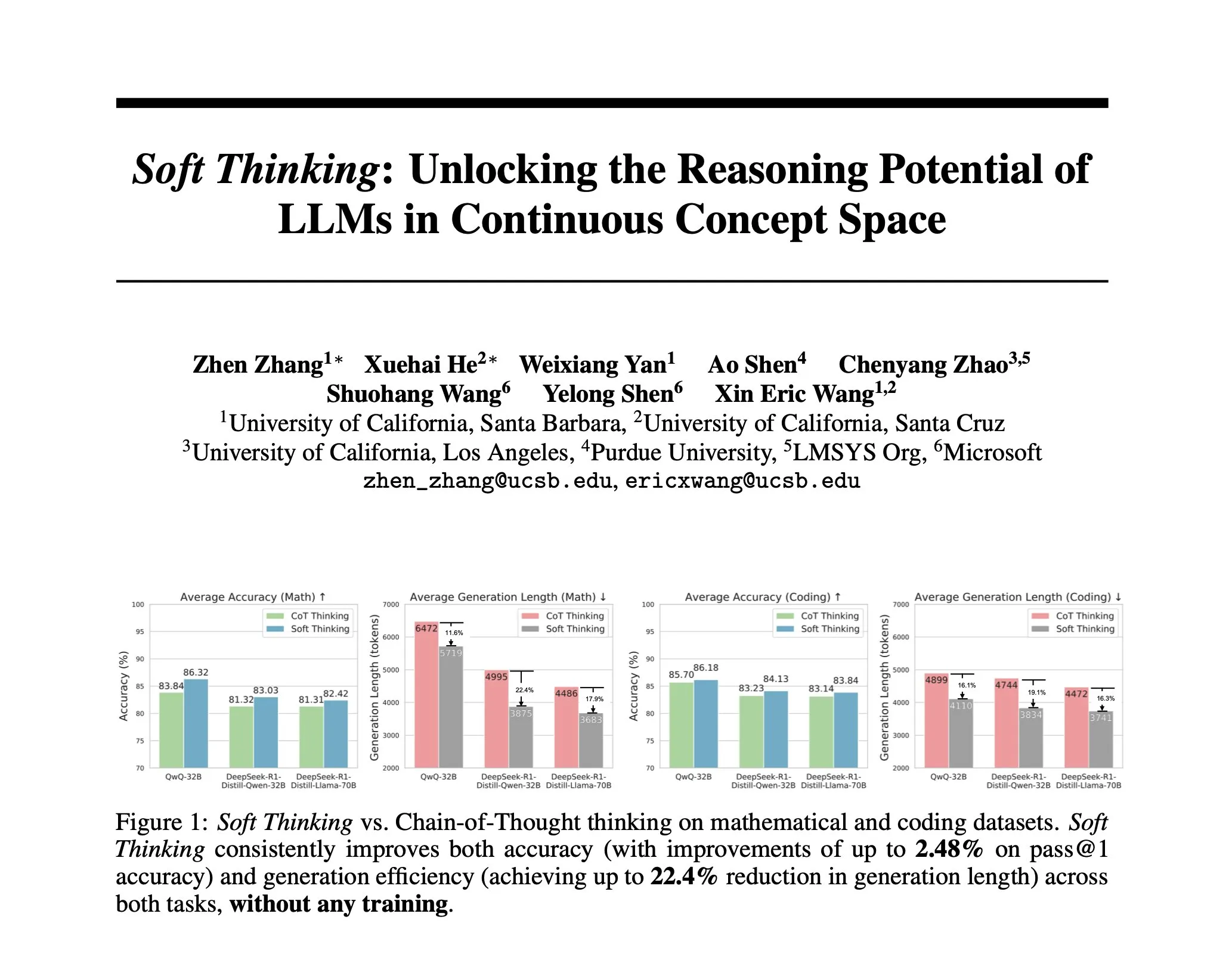
研究がSoft Thinkingを提案:人間の「ソフトな」推論を模倣する訓練不要な方法: AIの推論を人間の流暢な思考に近づけ、離散的なトークンに制約されないようにするため、研究者たちはSoft Thinking法を提案しました。この方法は追加の訓練を必要とせず、連続的で抽象的な概念トークンを生成することで、これらのトークンは確率的に重み付けされた埋め込み混合を通じて複数の意味を滑らかに融合し、より豊かな表現と異なる推論経路のシームレスな探索を実現します。実験によると、この方法は数学およびコードのベンチマークテストで精度を最大2.48% (pass@1) 向上させると同時に、トークン使用量を最大22.4%削減しました (出典: arankomatsuzaki)
IA-T2Iフレームワーク:インターネットを活用してテキストから画像への生成モデルの不確実な知識処理能力を強化: 既存のテキストから画像への生成モデルが、不確実な知識(最近の出来事、希少な概念など)を含むテキストプロンプトを処理する際の不備に対応するため、IA-T2I(Internet-Augmented Text-to-Image Generation)フレームワークが提案されました。このフレームワークは、アクティブ検索モジュールによって参照画像が必要かどうかを判断し、階層的画像選択モジュールを利用して検索エンジンから返された結果の中から最適な画像を選択してT2Iモデルを強化し、自己反省メカニズムを通じて生成画像を継続的に評価・最適化します。専用に構築されたImg-Ref-T2Iデータセットにおいて、IA-T2IはGPT-4oを約30%(人間による評価)上回る性能を示しました (出典: HuggingFace Daily Papers)
MoI (Mixture of Inputs) が自己回帰生成の品質と推論能力を向上: 標準的な自己回帰生成プロセスにおいてトークン分布情報が破棄される問題を解決するため、研究者たちはMixture of Inputs (MoI) 法を提案しました。この方法は追加の訓練を必要とせず、トークンを生成した後、生成された離散トークンと以前に破棄されたトークン分布を混合して新しい入力を構築します。ベイズ推定を通じて、トークン分布を事前確率とみなし、サンプリングされたトークンを観測値とみなし、従来のone-hotベクトルを連続的な事後期待値で置き換えて新しいモデル入力とします。MoIは、数学的推論、コード生成、博士レベルの質疑応答タスクにおいて、Qwen-32B、Nemotron-Super-49Bなど複数のモデルの性能を継続的に向上させました (出典: HuggingFace Daily Papers)
ConvSearch-R1:強化学習による対話型検索におけるクエリ書き換えの最適化: 対話型検索における文脈依存クエリの曖昧さ、省略、指示対象の問題を解決するため、ConvSearch-R1フレームワークが提案されました。このフレームワークは初めて自己駆動型アプローチを採用し、強化学習を通じて検索シグナルを直接利用してクエリ書き換えを最適化し、外部の書き換え監督(人手によるアノテーションや大規模モデルなど)への依存を完全に排除します。その2段階アプローチには、自己駆動型戦略のウォームアップと、検索誘導型の強化学習(ランキングインセンティブ報酬メカニズムを採用)が含まれます。実験によると、ConvSearch-R1はTopiOCQAおよびQReCCデータセットにおいて、以前のSOTAメソッドを大幅に上回る性能を示しました (出典: HuggingFace Daily Papers)
ASRRフレームワークが大規模言語モデルの効率的な適応型推論を実現: 大規模推論モデル(LRMs)が単純なタスクにおいて冗長な推論により計算コストが過大になる問題に対し、研究者たちは適応型自己回復推論(Adaptive Self-Recovery Reasoning, ASRR)フレームワークを提案しました。このフレームワークは、モデルの「内部自己回復メカニズム」(回答生成において暗黙的に推論を補完する)を明らかにすることで不要な推論を抑制し、精度感知型の長さ報酬調整を導入して、問題の難易度に応じて推論労力を適応的に割り当てます。実験によると、ASRRは性能損失を最小限に抑えつつ、推論予算を大幅に削減し、安全ベンチマークにおける無害率を向上させることができます (出典: HuggingFace Daily Papers)
MoT (Mixture-of-Thought) フレームワークが論理的推論能力を向上: 人間が複数の推論モダリティ(自然言語、コード、記号論理)を利用して論理問題を解決することに着想を得て、研究者たちはMixture-of-Thought (MoT) フレームワークを提案しました。MoTはLLMが3つの補完的なモダリティ(新たに追加された真理値表記号モダリティを含む)を横断して推論することを可能にします。2段階設計(自己進化型MoT訓練とMoT推論)を通じて、MoTはFOLIOやProofWriterなどの論理推論ベンチマークにおいて、単一モダリティの思考連鎖法を大幅に上回り、平均精度を最大11.7%向上させました (出典: HuggingFace Daily Papers)
RL Tango:強化学習による生成器と検証器の共同訓練による言語推論の強化: 既存のLLM強化学習手法における検証器(報酬モデル)の固定化や教師ありファインチューニングがもたらす報酬ハッキングや汎化能力の低さの問題を解決するため、RL Tangoフレームワークが提案されました。このフレームワークは、強化学習を用いてLLM生成器と生成的なプロセスレベルのLLM検証器を交互に同時に訓練します。検証器は結果レベルの検証正当性報酬のみに基づいて訓練され、プロセスレベルのアノテーションを必要としないため、生成器と効果的な相互促進を形成します。実験によると、Tangoの生成器と検証器は7B/8B規模のモデルにおいていずれもSOTAレベルに達しました (出典: HuggingFace Daily Papers)
pPE:事前プロンプトエンジニアリングが強化学習ファインチューニング(RFT)を支援: 研究は、強化学習ファインチューニング(RFT)における事前プロンプトエンジニアリング(prior prompt engineering, pPE)の役割を探求しました。推論時プロンプトエンジニアリング(iPE)とは異なり、pPEは訓練段階で指示(段階的推論など)をクエリの前に配置し、言語モデルが特定の振る舞いを内面化するように誘導します。実験では、5つのiPE戦略(推論、計画、コード推論、知識想起、空の例の利用)をpPE手法に変換し、Qwen2.5-7Bに適用しました。結果は、すべてのpPE訓練モデルがiPE対応モデルを上回り、特に空の例のpPEがAIME2024およびGPQA-Diamondなどのベンチマークで最大の向上を示し、pPEがRFTにおける十分に研究されていない効果的な手段であることを明らかにしました (出典: HuggingFace Daily Papers)
BiasLens:人手によるテストセット不要のLLMバイアス評価フレームワーク: 既存のLLMバイアス評価手法が人手で構築されたラベルデータに依存し、カバレッジが限定的である問題を解決するため、BiasLensフレームワークが提案されました。このフレームワークは、モデルのベクトル空間構造から出発し、概念活性化ベクトル(CAVs)とスパース自動エンコーダ(SAEs)を組み合わせて解釈可能な概念表現を抽出し、ターゲット概念と参照概念間の表現類似性の変化を測定することでバイアスを定量化します。BiasLensは、ラベルなしデータの場合でも従来のバイアス評価指標と強い一致性(スピアマン相関r > 0.85)を示し、既存の手法では検出困難なバイアス形式を明らかにすることができます (出典: HuggingFace Daily Papers)
HumaniBench:人間中心の大規模マルチモーダルモデル評価フレームワーク: 現在のLMMが公平性、倫理性、共感性などの人間中心の基準で十分な性能を発揮していない問題に対し、HumaniBenchが提案されました。これは、32Kの現実世界の画像・テキスト問答ペアを含む包括的なベンチマークであり、GPT-4oによる補助アノテーションと専門家による検証を経ています。HumaniBenchは、公平性、倫理性、理解、推論、言語的包摂性、共感性、堅牢性の7つの人間中心AI原則を評価し、7つの多様なタスクをカバーしています。15のSOTA LMMのテストでは、クローズドソースモデルが全般的にリードしていますが、堅牢性と視覚的ローカリゼーションは依然として弱点です (出典: HuggingFace Daily Papers)
AJailBench:初の大規模音声言語モデルジェイルブレイク攻撃総合ベンチマーク: 大規模音声言語モデル(LAMs)のジェイルブレイク攻撃下での安全性を体系的に評価するため、AJailBenchが提案されました。このベンチマークはまず、10の違反カテゴリをカバーする1495の敵対的音声プロンプトを含むAJailBench-Baseデータセットを構築しました。このデータセットに基づく評価では、既存のSOTA LAMsはいずれも一貫した堅牢性を示しませんでした。より現実的な攻撃をシミュレートするため、研究者たちは音声摂動ツールキット(APT)を開発し、ベイズ最適化を通じて微妙かつ効率的な摂動を探索し、拡張データセットAJailBench-APTを生成しました。研究によると、微小かつ意味を保持する摂動でもLAMsの安全性能を著しく低下させることが可能です (出典: HuggingFace Daily Papers)
WebNovelBench:LLMの長編小説創作能力を評価するベンチマーク: LLMの長編物語作成能力評価の課題を解決するため、WebNovelBenchが提案されました。このベンチマークは4000部を超える中国のウェブ小説データセットを利用し、評価をアウトラインから物語への生成タスクとして設定します。LLMを評価者とする方法を通じて、8つの物語品質次元から自動評価を行い、主成分分析を用いてスコアを集約し、人間の作品とパーセンタイルランキングで比較します。実験は、人間の傑作、人気のウェブ小説、LLM生成コンテンツを効果的に区別し、24のSOTA LLMについて総合的な分析を行いました (出典: HuggingFace Daily Papers)
MultiHal:LLMハルシネーション評価向け多言語知識グラフ着地データセット: 既存のハルシネーション評価ベンチマークにおける知識グラフパスと多言語性の不足を補うため、MultiHalが提案されました。これは知識グラフに基づく多言語・マルチホップベンチマークであり、生成テキスト評価専用に設計されています。チームはオープンなドメイン知識グラフから14万件のパスを採掘し、2.59万件の高品質なパスを選別しました。ベースライン評価では、多言語および複数モデルにおいて、知識グラフ強化RAG(KG-RAG)は通常の質疑応答と比較して、意味的類似性スコアで絶対的に約0.12~0.36ポイント向上し、知識グラフ統合の可能性を示しました (出典: HuggingFace Daily Papers)
Llama-SMoP:スパース混合プロジェクタに基づくLLM音響・視覚音声認識手法: LLMにおける音響・視覚音声認識(AVSR)の計算コストが高い問題を解決するため、Llama-SMoPが提案されました。これは効率的なマルチモーダルLLMであり、スパース混合プロジェクタ(SMoP)モジュールを採用し、スパースゲート付き混合エキスパート(MoE)プロジェクタを通じて、推論コストを増加させることなくモデル容量を拡張します。実験によると、モダリティ固有のルーティングとエキスパートを採用したLlama-SMoP DEDR構成は、ASR、VSR、AVSRタスクにおいていずれも優れた性能を達成し、エキスパート活性化、スケーラビリティ、ノイズ堅牢性の面でも良好な性能を示しました (出典: HuggingFace Daily Papers)
VPRL:強化学習に基づく純粋な視覚プランニングフレームワーク、テキスト推論を超える性能: ケンブリッジ大学、ロンドン大学カレッジ、Googleの研究チームは、VPRL(Visual Planning with Reinforcement Learning)を提案しました。これは、純粋に画像シーケンスに依存して推論を行う新しいパラダイムです。このフレームワークは、グループ相対方策最適化(GRPO)を利用して大規模視覚モデルを事後訓練し、視覚状態遷移を通じて報酬信号を計算し、環境制約を検証します。FrozenLake、Maze、MiniBehaviorなどの視覚ナビゲーションタスクにおいて、VPRLの精度は最大80.6%に達し、テキストベースの推論手法(Gemini 2.5 Proの43.7%など)を著しく上回り、複雑なタスクや堅牢性の面でも優れた性能を示し、視覚プランニングの優位性を証明しました (出典: 量子位)

NVIDIA、今後5年間のAI技術ロードマップを公表、AIインフラ企業へ転換: NVIDIAのCEOであるジェンスン・フアン氏はCOMPUTEX 2025で、同社の位置づけをAIインフラ企業に調整すると発表し、今後5年間の技術ロードマップを公表しました。同氏は、AIインフラが電力やインターネットのように遍在するものになると強調し、NVIDIAがAI時代の「工場」建設に取り組んでいると述べました。転換を支援するため、NVIDIAはサプライチェーンの「友達の輪」を拡大し、TSMCなどとの協力を深化させ、台湾地域に事務所(NVIDIA Constellation)と初の巨大AIスーパーコンピュータを設立する計画です (出典: 36氪)

Google、AIメガネプロジェクトを再開、Android XRプラットフォームとサードパーティ製デバイスを発表: GoogleはI/O 2025カンファレンスでAI/ARメガネプロジェクトの再開を発表し、XRデバイス向けに開発されたAndroid XRプラットフォームを公開し、同プラットフォームに基づく2つのサードパーティ製デバイス、SamsungのProject Moohan(Vision Pro対抗)とXrealのProject Auraを展示しました。Googleはスマートフォン分野でのAndroidの成功を再現し、XRデバイスの「Androidモーメント」を創出し、将来の環境コンピューティングと空間コンピューティングプラットフォームを構築することを目指しています。アップグレードされたGemini 2.5 Proマルチモーダル大規模モデルとProject Astraインテリジェントアシスタント技術を組み合わせることで、新世代のAI/ARメガネは音声理解、リアルタイム翻訳、状況認識、複雑なタスク実行において画期的な体験を実現します (出典: 36氪)

ARC-AGI-2チャレンジの原則更新、多段階コンテキスト推論を強調: 新たに発表されたARC-AGI-2論文は、同チャレンジの設計原則を更新しました。新原則では、タスク解決に多ルール、多段階、コンテキスト推論能力が求められます。グリッドはより大きく、より多くのオブジェクトを含み、複数のインタラクション概念をエンコードします。タスクは新規性があり再利用不可能で、記憶を制限します。この設計は意図的にブルートフォースなプログラム合成に抵抗します。人間の解決者はタスクあたり平均2.7分を要しますが、トップシステム(OpenAI o3-mediumなど)のスコアは約3%に過ぎず、すべてのタスクで明確な認知的努力が必要です (出典: TheTuringPost, clefourrier)
Skywork、8時間の作業を8分に短縮することを目指すスーパーエージェントを発表: Skyworkは、AIワークスペースエージェントであるSkywork Super Agentsを発表し、ユーザーの8時間の作業量を8分以内に圧縮できると主張しています。この製品はAIワークスペースエージェントの先駆者として位置づけられており、具体的な機能や実現方法は今後の発表が待たれます (出典: _akhaliq)
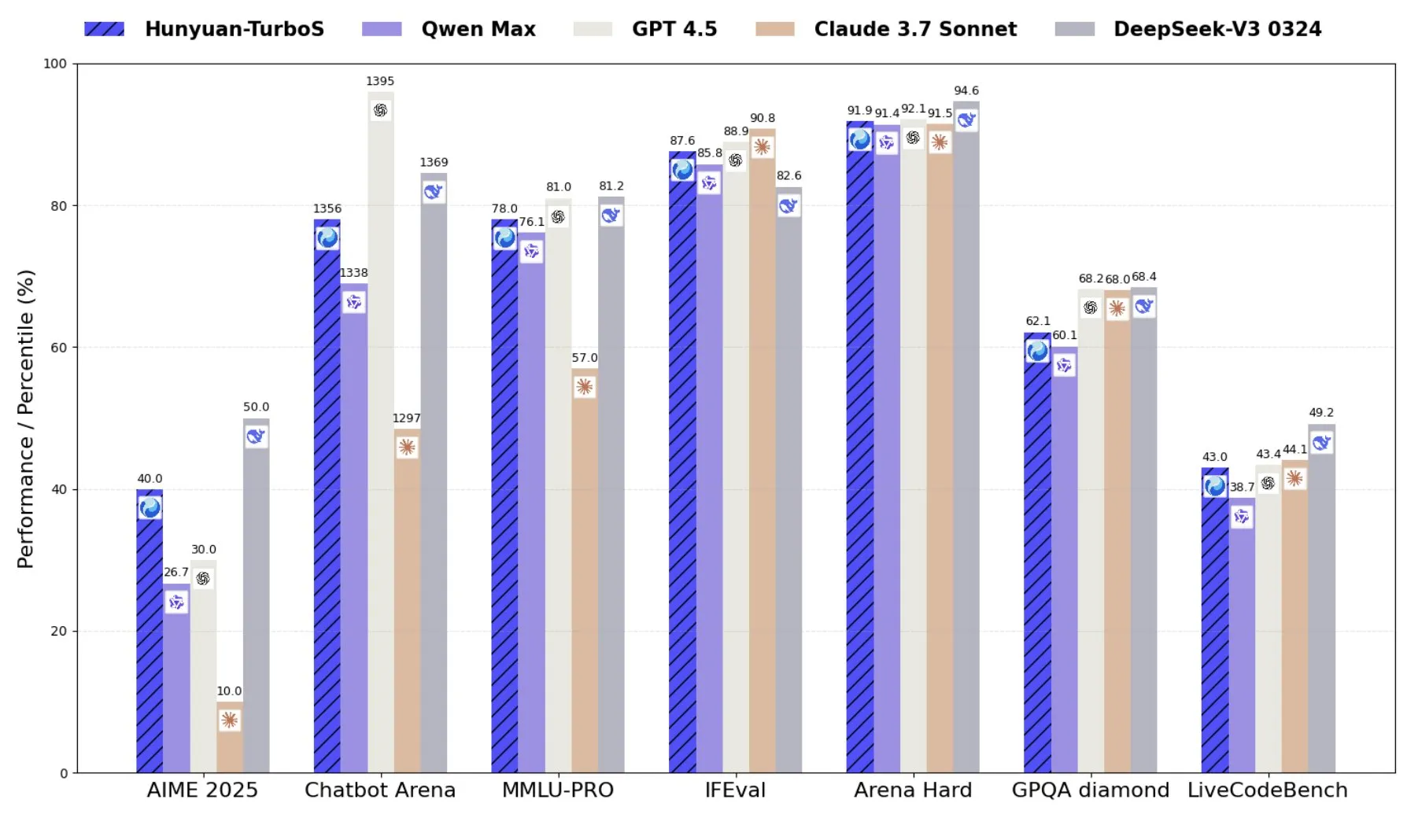
Tencent、TransformerとMambaを組み合わせた混合エキスパートモデルHunyuan-TurboSを発表: TencentはHunyuan-TurboSモデルを発表しました。このモデルはTransformerとMambaの混合エキスパート(MoE)アーキテクチャを採用し、560億の活性化パラメータを持ち、16兆トークンで訓練されています。Hunyuan-TurboSは、迅速な応答と深い「思考」モードを動的に切り替えることができ、LMSYS Chatbot Arenaで総合トップ7にランクインしています (出典: tri_dao)
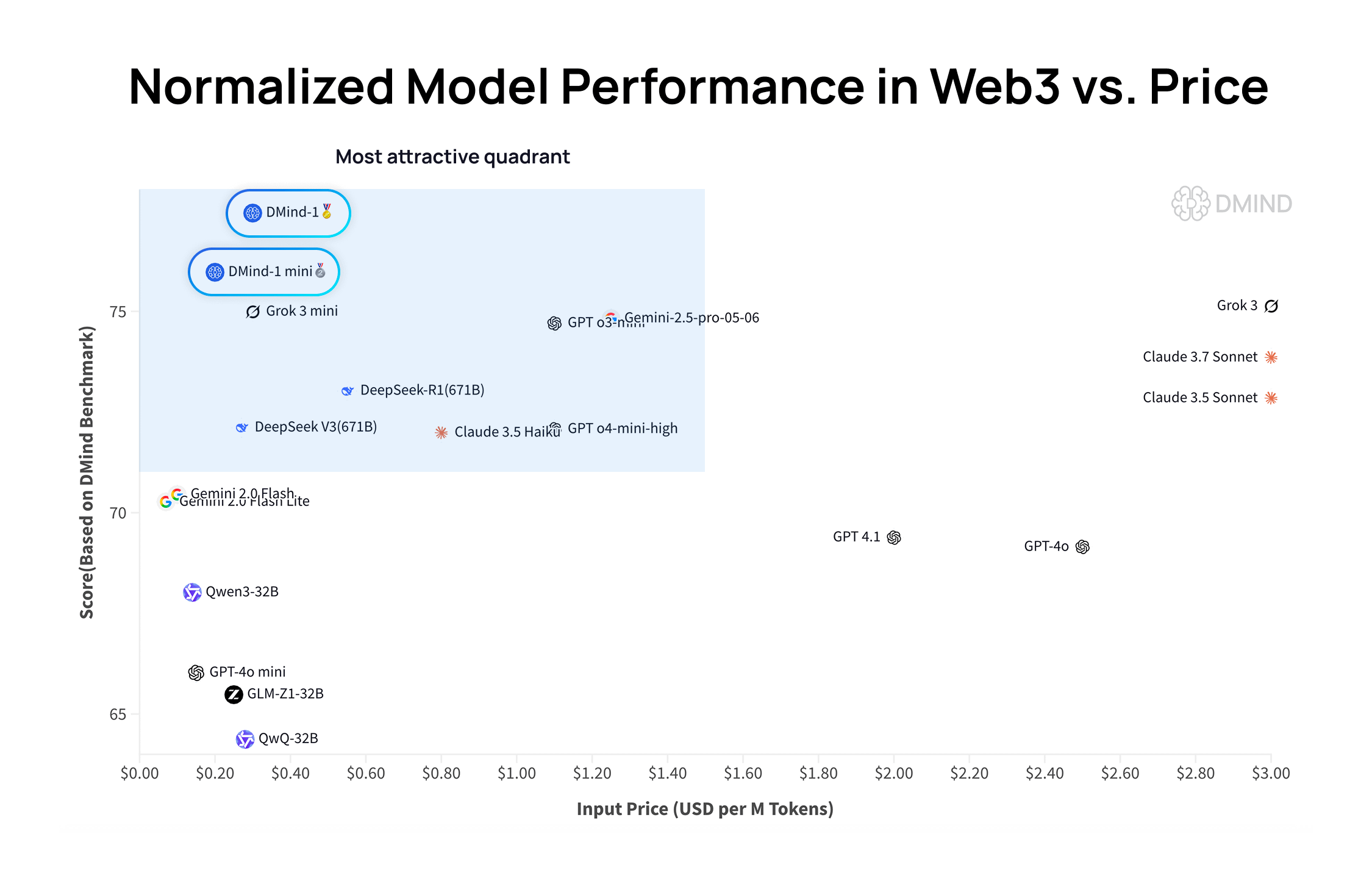
DMind-1:Web3シーン向けに設計されたオープンソース大規模言語モデル: DMind AIは、Web3シーン向けに最適化されたオープンソース大規模言語モデルDMind-1を発表しました。DMind-1 (32B) はQwen3-32Bをベースにファインチューニングされ、大量のWeb3特有の知識を使用しており、AI+Web3アプリケーションのパフォーマンスとコストのバランスを取ることを目指しています。Web3ベンチマーク評価では、DMind-1は主要な汎用LLMを上回る性能を示し、トークンコストはその約10%です。同時に発表されたDMind-1-mini (14B) はDMind-1の95%以上の性能を維持し、遅延と計算効率でさらに優れています (出典: _akhaliq)
LightOn、Reason-ModernColBERTを発表、小パラメータモデルが推論集約型検索タスクで優れた性能を発揮: LightOnは、わずか1億4900万パラメータのレイトインタラクションモデルであるReason-ModernColBERTを発表しました。人気のBRIGHTベンチマークテスト(推論集約型検索に特化)において、このモデルは優れた性能を発揮し、パラメータ数が45倍大きいモデルを上回り、複数の分野でSOTAレベルを達成しました。この成果は、レイトインタラクションモデルが特定のタスクにおいて高い効率性を持つことを改めて証明しました (出典: lateinteraction, jeremyphoward, Dorialexander, huggingface)

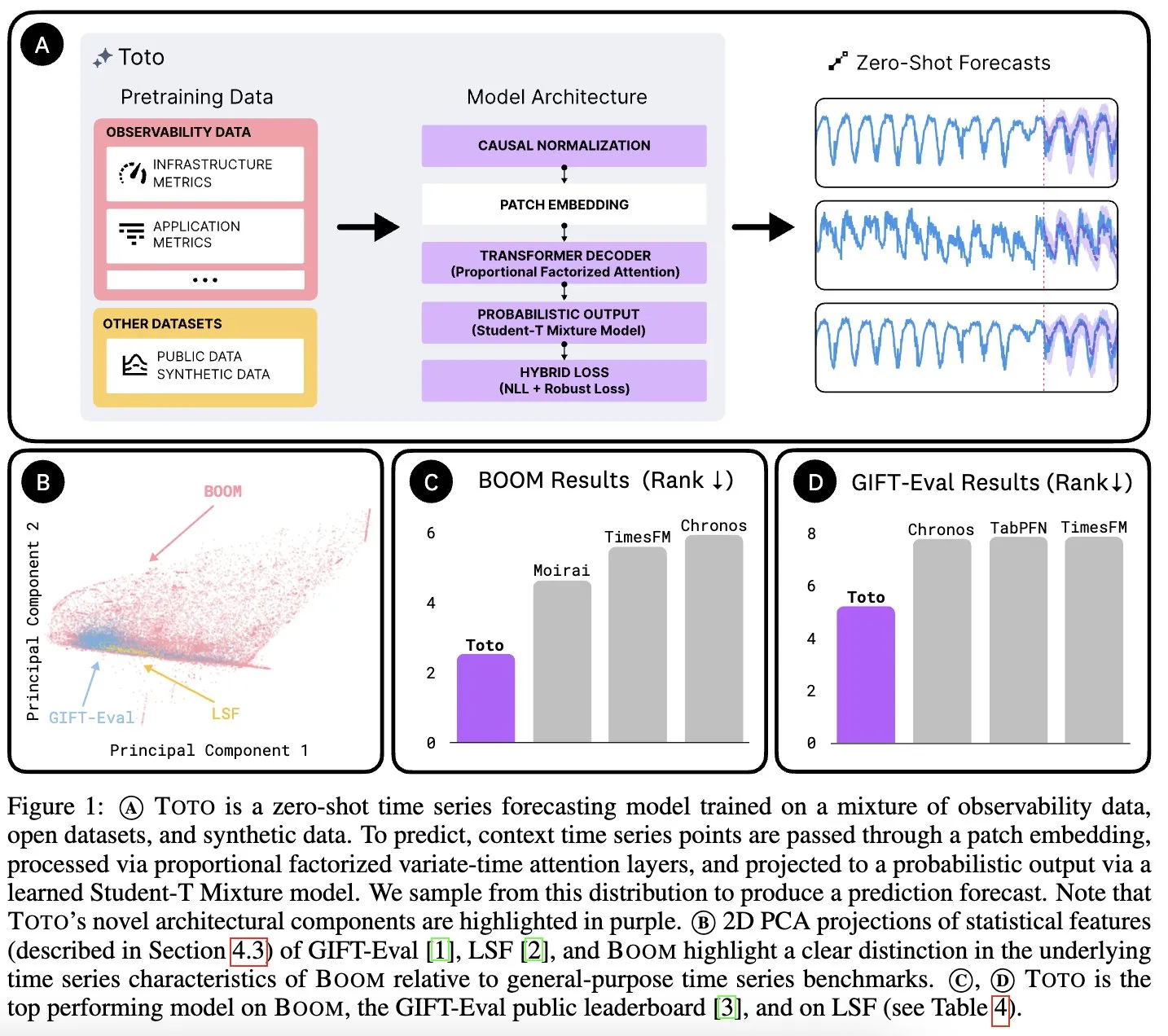
Datadog AI Research、時系列基盤モデルTotoと観測指標ベンチマークBOOMを発表: Datadog AI Researchは、新しい時系列基盤モデルTotoを発表し、関連するベンチマークテストで既存のSOTAモデルを大幅にリードしました。同時に、現在最大の観測可能性指標ベンチマークであるBOOMも発表されました。両者ともApache 2.0ライセンスでオープンソース化されており、時系列分析と観測可能性分野の研究と応用を推進することを目的としています (出典: jefrankle, ClementDelangue)
TII、Falcon-H1シリーズ混合Transformer-SSMモデルを発表: アラブ首長国連邦の技術革新研究所(TII)は、Falcon-H1シリーズモデルを発表しました。これはTransformerアテンションメカニズムとMamba2状態空間モデル(SSM)ヘッドを組み合わせた混合アーキテクチャ言語モデル群です。このシリーズモデルのパラメータ規模は0.5Bから34Bまであり、最大256Kのコンテキスト長をサポートし、複数のベンチマークテストでQwen3-32B、Llama4-ScoutなどのトップTransformerモデルを上回るか同等の性能を示し、特に多言語(ネイティブで18言語をサポート)と効率性の面で優位性を示しています。モデルはvLLM、Hugging Face Transformers、llama.cppに統合されています (出典: Reddit r/LocalLLaMA)

MITの研究:AIは人間の介入なしに視覚と音の関連を学習可能: MITの研究者たちは、人間の明確な指導やラベル付けされたデータなしに、視覚情報と対応する音との間の関連性を自律的に学習できるAIシステムを実証しました。この能力は、より包括的なマルチモーダルAIシステムの開発にとって極めて重要であり、人間のように世界を理解し知覚することを可能にします (出典: Reddit r/artificial, Reddit r/ArtificialInteligence)

アラブ首長国連邦、大規模アラビア語AIモデルを発表、湾岸地域のAI競争を加速: アラブ首長国連邦は大規模なアラビア語AIモデルを発表し、人工知能分野へのさらなる投資を示し、湾岸地域諸国間のAI技術開発競争を激化させました。この動きは、AI分野におけるアラビア語の影響力を高め、ローカライズされたAIアプリケーションの需要に応えることを目的としています (出典: Reddit r/artificial)
粉筆科技、特定領域向け大規模モデルを発表、「AI+教育」の新パラダイムを定義: 粉筆科技は、Tencent Cloud AI産業応用サミットで、職業教育分野における自社開発の特定領域向け大規模モデルを展示しました。このモデルは既に面接評価、AI問題演習システムクラスなどの製品に応用され、「教える、学ぶ、練習する、評価する、測定する」の全過程をカバーしています。AI教師などの形式を通じて、「画一的」から「個別最適化」された教育の実現を目指し、自社開発の大規模モデルを搭載したAIハードウェア製品の発売も計画しており、教育の智能化変革を推進します (出典: 量子位)

北森酷学院、新世代AI Learningプラットフォームを発表、5つのAI Agentを導入: 北森控股は酷学院買収後、AI大規模モデルに基づく新世代学習プラットフォームAI Learningを発表しました。このプラットフォームは従来のeLearningに加えて、AIコース作成アシスタント、AI学習アシスタント、AI練習パートナー、AIリーダーシップコーチ、AI試験アシスタントの5つのインテリジェントエージェントを追加し、Agentによるリアルタイム対話、スキルトレーニング、個別化学習、AIによるワンストップのコース作成と試験を通じて、従来の企業学習モデルを覆すことを目指しています (出典: 量子位)

Pony.ai 第1四半期決算:Robotaxiサービス収入が前年同期比8倍に急増、年末までに1000台の無人車両を配備予定: Pony.aiは2025年第1四半期の決算を発表し、総収益は1億200万元で前年同期比12%増となりました。そのうち、中核となるRobotaxiサービス収入は1230万元に達し、前年同期比200.3%の大幅増、乗客運賃収入はさらに前年同期比8倍に急増しました。同社は第2四半期に第7世代Robotaxiの量産を開始し、年末までに1000台の車両を配備し、車両1台あたりの損益分岐点達成を目指す計画です。Pony.aiはまた、Tencent CloudおよびUberとの提携を発表し、それぞれWeChatおよびUberプラットフォームを通じて国内および中東市場を開拓します (出典: 量子位)

OpenAI CPO Kevin Weil氏:ChatGPTは行動アシスタントへ転換、モデルコストはGPT-4の500倍に: OpenAIのチーフプロダクトオフィサーであるKevin Weil氏は、ChatGPTの位置づけが質問に答えることからユーザーのためにタスクを実行することへと移行し、ツール(ウェブ閲覧、プログラミング、内部知識ソースへの接続など)を組み合わせて使用することでAI行動アシスタントになると述べました。同氏は、現在のモデルのコストが初代GPT-4の500倍になっていることを明らかにしましたが、OpenAIはハードウェアの向上とアルゴリズムの改善を通じて効率を高め、API価格を引き下げることに尽力していると述べました。同氏は、AI Agentが急速に発展し、初級エンジニアレベルから1年以内にアーキテクトレベルに成長すると考えています (出典: 量子位)

🧰 工具
FlowiseAI:AIエージェントを視覚的に構築: FlowiseAIは、ユーザーが視覚的なインターフェースを通じてAIエージェントとLLMアプリケーションを構築できるオープンソースプロジェクトです。ドラッグアンドドロップコンポーネント、さまざまなLLM、ツール、データソースの接続をサポートし、AIアプリケーションの開発プロセスを簡素化します。ユーザーはnpmインストールまたはDockerデプロイメントを通じてFlowiseを迅速にセットアップし、独自のAIフローをテストできます (出典: GitHub Trending)

Hugging Face JSライブラリがリリース、Hub APIおよび推論サービスとの連携を簡素化: Hugging Faceは、開発者がJS/TSを通じてHugging Face Hub APIおよび推論サービスと簡単に連携できるようにするための一連のJavaScriptライブラリ(@huggingface/inference, @huggingface/hub, @huggingface/mcp-clientなど)をリリースしました。これらのライブラリは、リポジトリの作成、ファイルのアップロード、10万以上のモデルの推論呼び出し(チャット補完、テキストからの画像生成などを含む)、MCPクライアントを使用したエージェント構築などの機能をサポートし、複数の推論プロバイダーに対応しています (出典: GitHub Trending)

Jan AIローカル実行環境がApache 2.0ライセンスに更新、企業利用のハードルを下げる: Jan AIはローカルでLLMを実行できるオープンソースツールで、最近ライセンスをAGPLからより寛容なApache 2.0に変更しました。この変更は、企業やチームが組織内でJanを導入・利用しやすくすることを目的としており、AGPLがもたらすコンプライアンス問題を心配することなく、自由にフォーク、変更、公開が可能となり、Janの実運用環境での大規模採用を推進します (出典: reach_vb, Reddit r/LocalLLaMA)
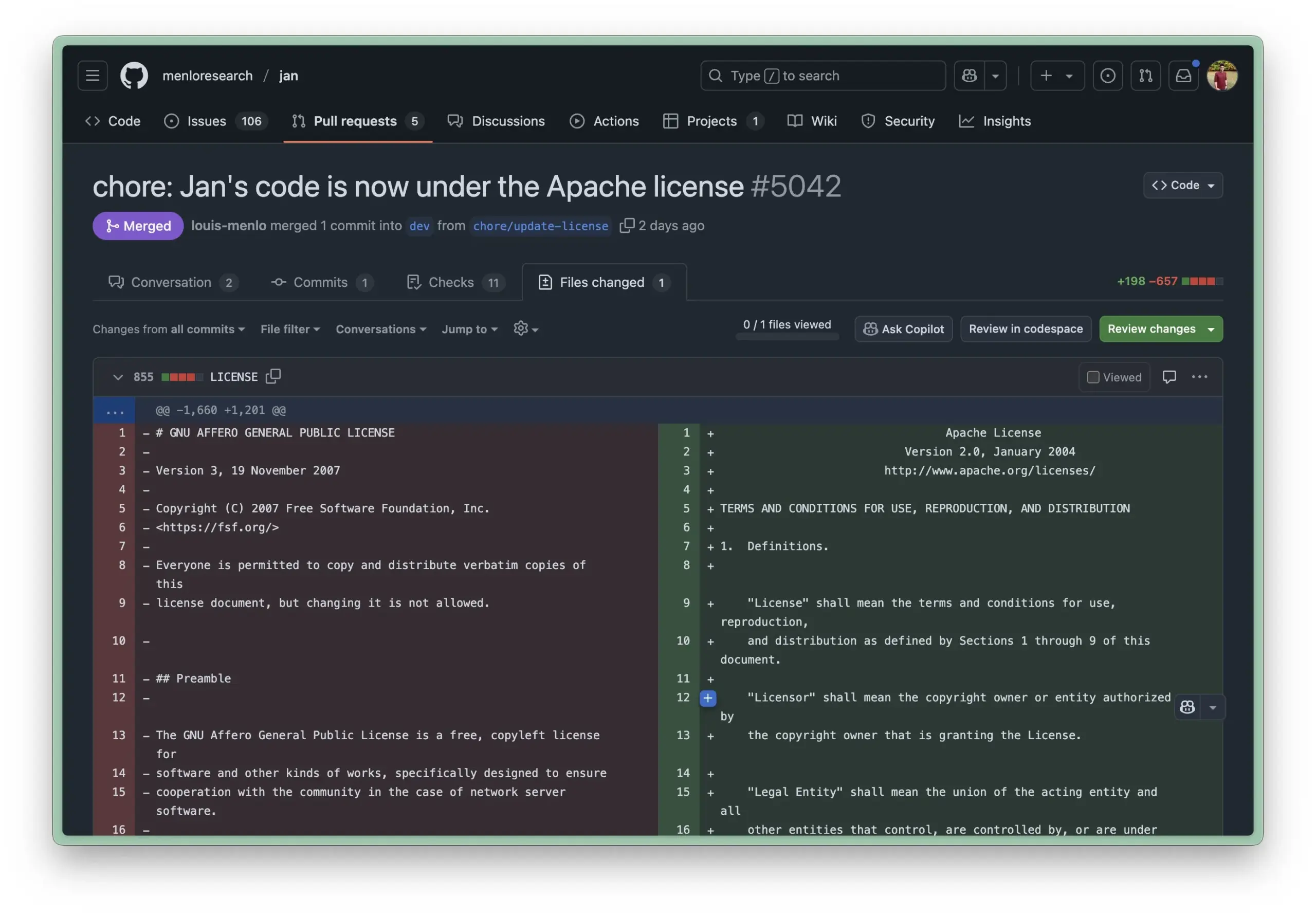
Obsidian、Basesコアプラグインを導入、ノートのデータベース化管理を実現: ナレッジ管理ソフトウェアObsidianは、コアプラグインBasesを更新し、ユーザーがノートセットを強力なデータベースに変換できるようにしました。Basesを通じて、ユーザーはカスタムテーブルビューを作成し、ナレッジベース内のデータを視覚的かつインタラクティブに操作でき、属性によるノートのフィルタリングや、動的属性を派生させる数式の作成をサポートし、プロジェクト管理、旅行計画、読書リストなど、さまざまなシナリオに適用できます。この機能は現在、早期ユーザーに公開されています (出典: op7418)
Hugging Face、Tiny Agentsをリリース、ローカルモデルによるブラウザとファイル操作を簡素化: Hugging FaceはMCPコースでTiny Agentsを紹介しました。これは、簡単に始められるブラウザ制御設定フレームワークです。ユーザーはコマンドライン、JSON設定、プロンプト定義を通じて、ローカルで実行されるLLM(OpenAI互換サーバー経由)にブラウザ(Playwrightなど)やローカルファイルシステムを制御させることができ、APIを直接呼び出す必要がなく、llama.cppなどのローカルモデルのエージェントアプリケーションに利便性を提供します (出典: Reddit r/LocalLLaMA)

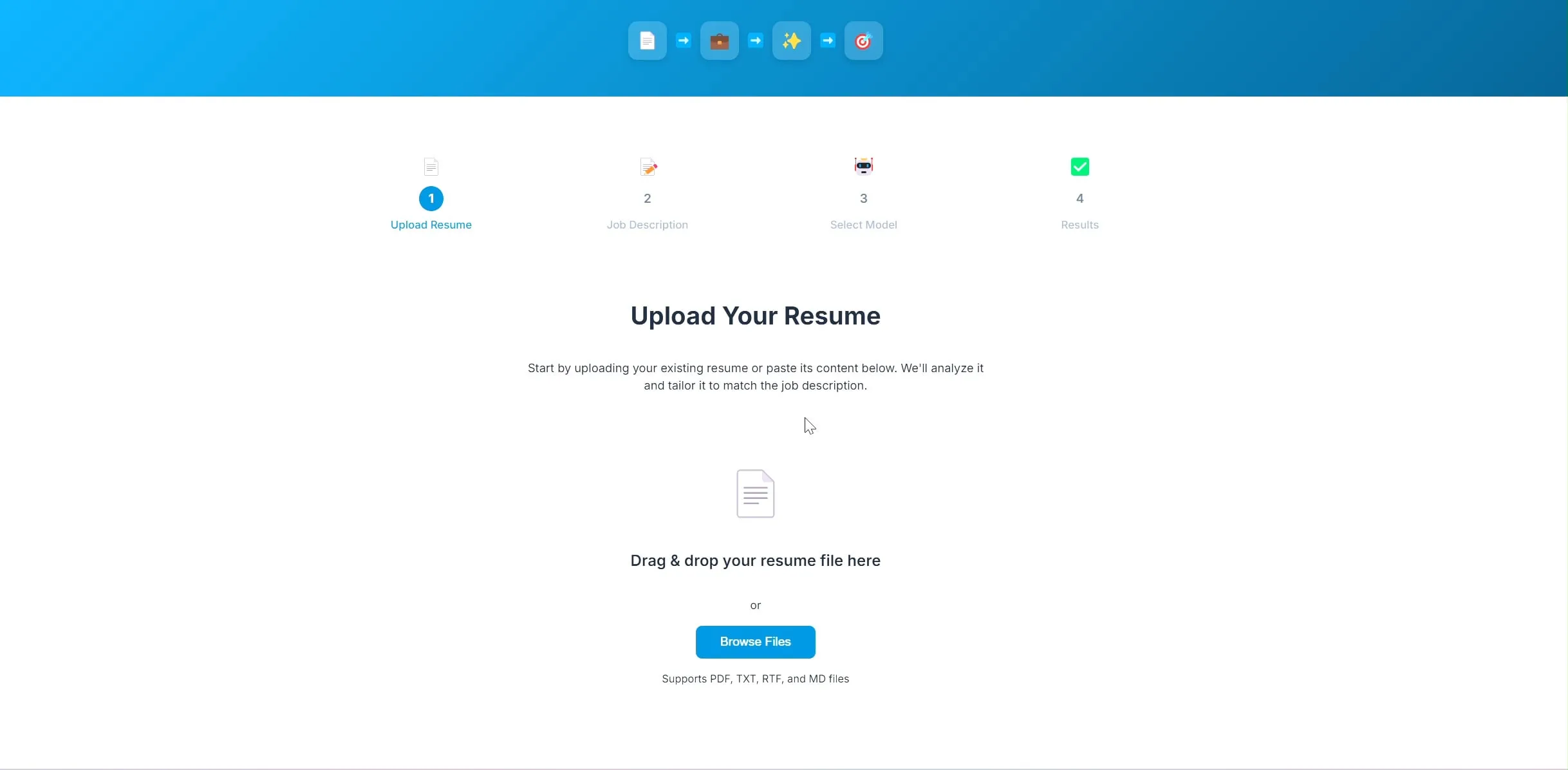
開発者がAI履歴書最適化アプリをオープンソース化、LangChainとOllamaベース: ある開発者がAI駆動の履歴書最適化アプリケーションを構築し、オープンソース化しました。ユーザーが現在の履歴書と希望する職務記述書をアップロードすると、アプリケーションは履歴書内のキーワードを調整し、採用ニーズにより適合するように試みます。このプロジェクトのバックエンドはLangChainを使用し、BM25スパース検索と稠密モデルを組み合わせたハイブリッド検索を行い、言語モデルはOllamaを通じてローカルで実行され、フロントエンドはReactを使用しています。プロジェクトは現在、概念実証段階にあり、コードはGitHubで公開されています (出典: Reddit r/deeplearning)
Lovableアプリケーション構築ツールが画像処理能力を強化: AIアプリケーション構築ツールLovableは、画像処理機能の改善を発表しました。ユーザーはチャットに画像をアップロードし、Lovableにアプリケーションでこれらの画像素材を使用するよう指示できるようになり、AI支援の下で視覚要素を含むアプリケーションを構築するユーザーエクスペリエンスが向上しました (出典: op7418)
Helios:AIで政府業務の加速を試みる初のプラットフォーム: Joe Scheidler氏は、AIを活用して政府業務の効率向上を目指すプラットフォームHeliosを発表しました。「政府版Cursor」と形容されています。このプラットフォームは、政府部門を明確なターゲットとし、AI技術によって業務プロセスと効率の最適化を試みる初の試みの一つであり、具体的な機能や応用シーンは今後の発表が待たれます (出典: timsoret)
📚 学習
浙江大学、『大規模モデル基礎』教材を発表、LLM知識を体系的に解説し継続的に更新: 浙江大学LLMチームは、『大規模モデル基礎』教材をオープンソース化しました。これは大規模言語モデルに関心を持つ読者に体系的な基礎知識と最先端技術の紹介を提供することを目的としています。本書の内容には、従来の言語モデル、LLMアーキテクチャの進化、Promptエンジニアリング、パラメータ効率の良いファインチューニング、モデル編集、検索拡張生成などが含まれ、月次で更新される予定です。各章には関連するPaper Listが付属し、最新の進捗を追跡できます。完全なPDFおよび章ごとの内容はGitHubで公開されています (出典: GitHub Trending)

Hugging Face、10の無料AIコースを提供、各レベル・多分野の知識を網羅: Hugging Faceは、プラットフォームで提供している10の無料AIコースをまとめました。内容は入門から上級までの様々な人気AIトピックを網羅しており、自然言語処理、深層学習、強化学習、音声処理、マルチモーダルなどが含まれます。これらのコースは、様々なレベルの学習者にAI知識を体系的に学ぶ貴重なリソースを提供し、AI知識の普及とオープンソースコミュニティの発展をさらに推進します (出典: huggingface, reach_vb, _akhaliq)

スタンフォード大学、Marin 8Bモデル訓練の経験と教訓を共有: スタンフォード大学のPercy Liang氏のチームは、ゼロからMarin 8Bモデルを訓練し(そして複数のベンチマークでLlama 3.1 8B基礎モデルを上回った)、その詳細なレビューを公開しました。この誠実な記録には、チームが研究開発プロセスで行ったすべての発見と犯した過ちが含まれており、コミュニティに貴重なLLMの実際の構築経験を提供し、研究プロセスにおける試行錯誤と反復の重要性を強調しています (出典: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AIとPredibaseが協力し、強化学習ファインチューニング(RFT)LLMコースを開始: Andrew Ng氏のDeepLearning.AIはPredibaseと協力し、GRPO(Group Relative Policy Optimization)を用いた強化学習ファインチューニング(RFT)によってLLMの性能を向上させる方法に関する無料の短期コースを開始しました。このコースはPredibaseの共同創設者兼CTOであるTravis Addair氏らが講師を務め、学習者が強化学習を活用し、少量のラベル付きデータだけで小規模なオープンソースLLMを特定のユースケース向けの推論エンジンに変換する方法を習得できるよう支援することを目的としています (出典: DeepLearningAI)
Hugging Face論文ページにAI生成要約機能が追加: Hugging Faceは、論文表示ページに新機能を導入し、各論文にAIが生成した1文要約を提供します。この要約は、論文の核心内容を簡潔明瞭に概括し、ユーザーが研究文献を迅速に選別・理解するのを助け、学術リソースのアクセシビリティと利用効率を向上させます。この機能はオープンソースLLMによって駆動され、「AIによるAI研究のエンパワーメント」という理念を体現しています (出典: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

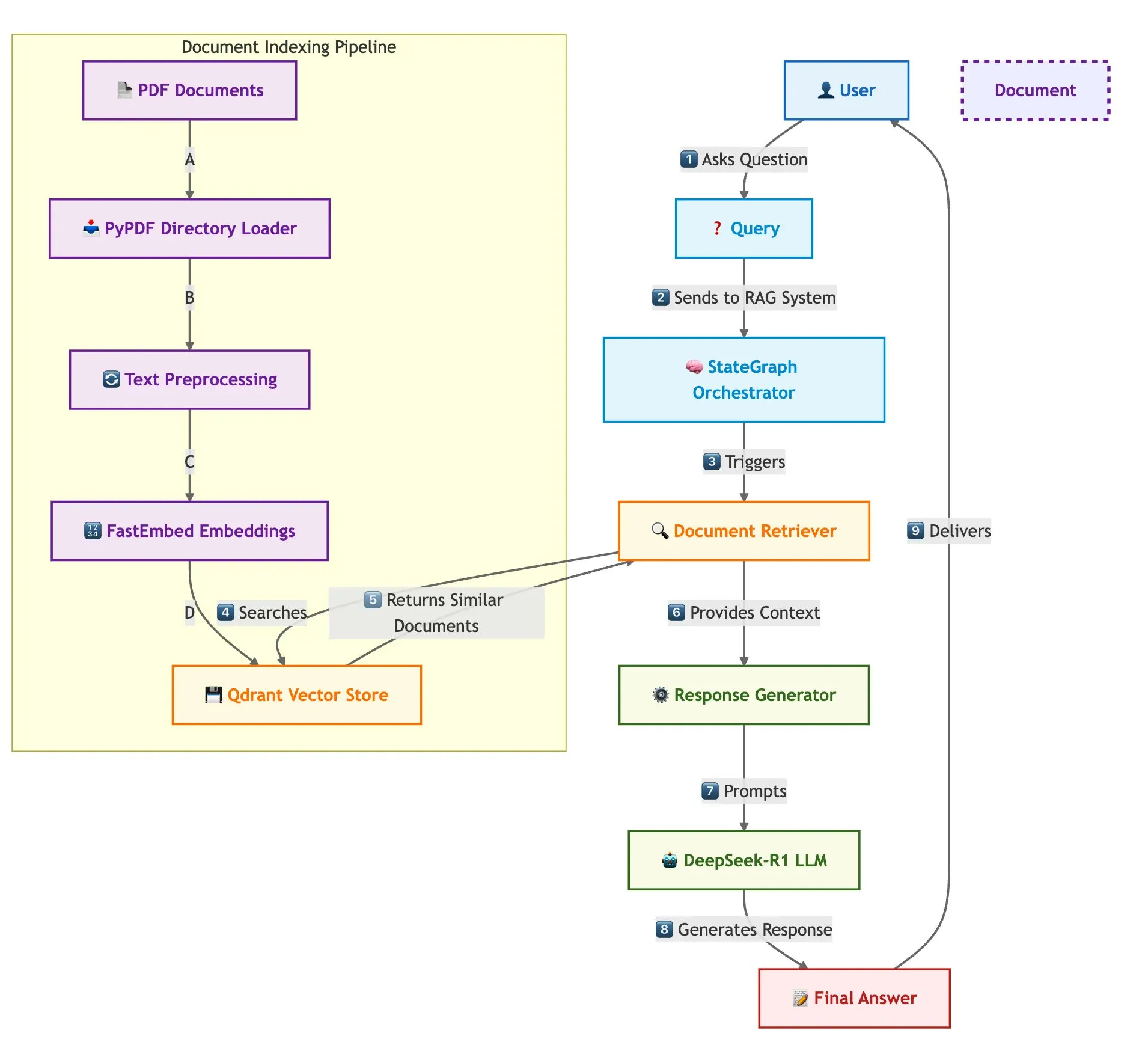
Qdrant、SambaNovaなどが共同で高速マルチドキュメントRAGシステム構築ソリューションを展示: ある技術ブログでは、Qdrantベクトルデータベース、SambaNova、DeepSeek-R1、LangGraphを使用して、高速でメモリ効率の高いマルチドキュメント検索拡張生成(RAG)システムを構築する方法を紹介しています。このソリューションは、バイナリ量子化により32倍のメモリ節約を実現し、DeepSeek-R1を利用して高速で集中的なLLM応答を行い、LangGraphを活用してモジュール式のオーケストレーションを行い、大規模なマルチドキュメント処理シナリオに適しています (出典: qdrant_engine)
LangChain Interrupt 2025サミットレビュー(標準中国語版)が公開: LangChain Interrupt 2025サミットの標準中国語版レビューが公開されました。今回のサミットには世界中から800人以上が参加し、AIエージェント構築に関する経験や将来展望が共有され、LangGraph Platform、LangGraph Studio v2など複数の製品が発表され、エージェントエンジニアリング、AI可観測性などのテーマが議論されました (出典: hwchase17)
Andi Marafioti氏、nanoVLMチュートリアルを公開、純粋なPyTorchによる視覚言語モデルの訓練を段階的に詳解: Andi Marafioti氏は、nanoVLMという新しいブログチュートリアルを公開し、純粋なPyTorchを使用して独自の視覚言語モデル(VLM)をゼロから訓練する方法を詳細に説明しています。チュートリアルの内容は理解しやすく、取り組みやすいため、初心者がVLMの訓練プロセスを迅速に習得できるよう支援することを目的としています (出典: LoubnaBenAllal1)

Ferenc Huszár氏、連続時間マルコフ連鎖とその拡散言語モデルにおける応用を解説: 深層学習研究者のFerenc Huszár氏はブログ記事を発表し、MercuryやGemini Diffusionなどの拡散言語モデル(DLMs)の重要な構成要素である連続時間マルコフ連鎖(CTMCs)の背後にある直感を分かりやすく説明しています。記事は、マルコフ連鎖のさまざまな視点と点過程との関連性を探求し、DLMの理論的基礎を理解するための貴重な参考資料を提供しています (出典: fhuszar)
💼 商業
「人工AI」企業Builder.aiが破産宣告、かつて5億ドル近くを調達: かつてAIでソフトウェア開発を覆すと宣言し、評価額が一時は10億ドルに達した英国企業Builder.ai(旧Engineer.ai)が今週、破産清算を発表しました。同社は以前、そのAIプラットフォームの多くの機能が実際にはインドのエンジニアによって手作業で行われていたことが暴露されていました。Microsoft、ソフトバンクDeepCoreなどの著名な機関から5億ドル近くの資金を調達したにもかかわらず、技術の信憑性への疑問、財務管理の混乱、創業者の法的紛争などの問題により、最終的に資金が枯渇し、Microsoftに3000万ドル、Amazonに8500万ドルのクラウドサービス料を滞納していました (出典: 36氪)

LMArena.ai (旧LMSys) が1億ドルのシードラウンド資金調達、Gradioアプリから商業化へ: 当初Gradioベースの学術プロジェクトLMSys(LLMの競技と評価用)として始まったLMArena.aiが、a16zとカリフォルニア大学投資会社が主導する1億ドルのシードラウンド資金調達を発表しました。この資金調達は、LMArenaが信頼性の高いAIに関する研究とプラットフォーム運営を継続することを支援し、成功したオープンソース学術プロジェクトが商業運営へと移行することを示しています。これはまた、Gradioなどの迅速なプロトタイピングツールが影響力のあるAIプロジェクトを育成する上での可能性を浮き彫りにしています (出典: ClementDelangue, _akhaliq, clefourrier)
AI人材獲得競争が白熱化、OpenAI、Googleなどが年俸数千万ドルで人材獲得: シリコンバレーのAI分野における人材獲得競争は白熱化しており、トップクラスの研究者(IC)がOpenAI、Google、xAIなどの巨大企業が争奪する中核リソースとなり、年俸と株式インセンティブは一般的に数千万ドルを超えています。例えば、OpenAIはSSIへの移籍を検討していたベテラン研究者を引き留めるために200万ドルのボーナスと2000万ドル超の株式を提示しました。Google DeepMindもトップ人材に年俸2000万ドルの待遇を提供しています。このような激しい競争は、少数の核心的人材が大規模言語モデルの発展に多大な貢献をしていることに起因しており、彼らの去就がAIモデルの成否に直接影響する可能性があります (出典: 36氪)
🌟 コミュニティ
Soraの中国語能力は向上したようだが、モデルの限界は依然として存在する: ソーシャルメディアユーザーは、OpenAIの動画生成モデルSoraが中国語テキストの処理において進歩を見せ、中国語の文字を含むシーンを生成できるようになったと観察しています。しかし、ユーザーはモデルには依然として限界があり、生成されたコンテンツは完璧ではなく、この不完全さを受け入れることが現段階でAIモデルと対話する上での常態であるかもしれないと指摘しています (出典: dotey)

Gemini、詳細レポート「試験」機能を導入、知識の再利用と学習サイクルの確立を支援: Google Geminiは新機能をリリースし、ユーザーが詳細レポートを読んだ後、Geminiが直接問題を出してテストできるようになりました。この機能は、ユーザーのコンテンツに対する真の理解度を検証し、「学習→試験→補強→再学習」というAIネイティブな学習サイクルを構築することを目的としており、AI時代の学習の核心は読書量ではなく知識の再利用能力にあることを強調しています (出典: dotey)
ChatGPTの記憶機能がユーザーの制御権に関する懸念を引き起こす: ChatGPTが新たにリリースした「チャットから学習する記憶」機能は、モデルがユーザーの過去の対話情報を記憶し、その後のインタラクションでよりパーソナライズされた応答を提供できるようにするものです。しかし、一部の上級ユーザーはこれに対し、モデルとの対話方法を変えてしまうと懸念を示しており、モデルの入力内容を完全に制御することを好み、モデルが自分の知らないうち、あるいは正確に制御できない状況で履歴情報を使用することを望んでいません (出典: random_walker)
AI Agentの急速な発展、将来の働き方が変わる可能性: コミュニティではAI Agentの急速な発展と、それが将来の働き方に与える潜在的な影響について活発な議論が交わされています。AI Agentは単純な質疑応答ツールから、コーディング、研究、顧客サポートなどの複雑なタスクを独立して完了できる「仮想従業員」へと変化しているという見方があります。OpenAIのCPOであるKevin Weil氏は、AI Agentの能力が急速に向上し、初級エンジニアレベルから1年以内にアーキテクトレベルに成長すると予測しています。Microsoftも「エージェントネットワーク」構想を提唱しており、将来の仕事がAIエージェントの管理と編成を中心に展開される可能性を示唆しています (出典: rowancheung, 量子位)
AIは医療診断分野で大きな可能性を秘めているが、医師の職業的懸念を引き起こす: AIは医療診断において驚くべき能力を発揮しており、例えばo1-previewモデルが医療推論および診断タスクで超人的な能力を示したという研究や、AIが数秒で肺炎を検出した事例も注目を集めています。これによりAI支援診断がホットな話題となっていますが、20年間勤務してきた一部の医師からは自身の職業的将来に対する懸念の声も上がり、マクドナルドで働くことになると冗談を言うほどです。コミュニティでは、AIは医師を完全に代替するものではなく、効率と精度を向上させるための補助ツールとして捉えるべきだという議論がなされています (出典: paul_cal, Reddit r/ArtificialInteligence)
報道機関、GoogleのAI検索モデルを「盗用」と非難: News Media Allianceなどの報道機関は、Googleの新しいAI検索モデルに対して強い不満を表明し、「盗用」であると非難しています。彼らは、Google AIがニュースコンテンツから直接情報を抽出し、検索結果に統合することで、ニュースサイトを迂回し、報道機関のトラフィックと広告収入を損なっていると主張しており、AI時代のコンテンツ著作権と公正利用に関する激しい議論を引き起こしています (出典: Reddit r/artificial)
DeepSeekモデルが中国で伝統的な占いに使用され、AI応用の境界線に関する議論を呼ぶ: あるユーザーが、DeepSeekモデルの中国におけるトラフィックの大部分が、ユーザーが易経占いなどの伝統的な占い活動に使用していることに起因していることを発見しました。この現象は、AI応用の境界線と文化的適応性に関する議論を引き起こし、また間接的にユーザーのAI能力に対する多様な探求と需要を反映しています (出典: menhguin, cto_junior)

💡 その他
Figure社の人型ロボットがBMW生産ラインで20時間の連続シフトを完了: 人型ロボット企業Figureは、同社のロボットがBMW X3生産ラインで20時間の連続シフト作業を成功裏に完了したと発表しました。これ以前に、同ロボットは数週間にわたり10時間のシフトテストを実施していました。Figure社によると、これは世界で初めて人型ロボットが自動車生産ラインでこれほど長時間の連続作業を完了した例であり、産業オートメーション分野における同社の可能性を示しています (出典: adcock_brett, TheRundownAI)
Agentic AI と GenAI の違いと関連性: コミュニティでは、Agentic AI(エージェントAI)とGenerative AI(生成AI)の概念について議論されました。生成AIは主に新しいコンテンツ(テキスト、画像、コードなど)を創造できるAIを指し、一方、エージェントAIは自律性、目標志向性、環境とのインタラクションによる行動能力をより強調します。エージェントAIは通常、生成AIをその中核能力の一つとして利用し、タスクを理解、計画、実行し、AIがより高度な自律的知能へと発展する上で重要な方向性です (出典: Ronald_vanLoon, Ronald_vanLoon)

科学研究におけるAIの応用は過小評価されており、「結果の粉飾」現象が存在する: コミュニティの議論では、科学研究におけるAIの応用ポテンシャルは大きいものの過小評価されている可能性があり、同時に研究者が発表のためにAI実験結果を「粉飾」する現象が存在すると指摘されています。例えば、偏微分方程式(PDEs)などの分野では、AIの実際の性能は論文で示されているほど優れていない可能性があります。これは、科学界が科学的発見におけるAIの真の役割と限界をより厳格かつ透明に評価する必要があることを示唆しています (出典: clefourrier)