
キーワード:Gemini 2.5, AIエージェント, 大規模言語モデル, 視覚言語モデル, 強化学習, Gemini 2.5 Pro Deep Thinkモード, GitHub Copilotエージェント オープンソース, MeanFlowシングルステップ画像生成, VPRL視覚計画推論, Huawei FusionSpec MoE推論最適化
🔥 注目ニュース
Google I/Oカンファレンスで多数のAI進捗を発表、Gemini 2.5シリーズモデルが筆頭: GoogleはI/Oカンファレンスで、AI分野における多くのアップデートを発表しました。Gemini 2.5 Proは現在最強の基盤モデルと称され、複数のベンチマークテストでリードし、Deep Thinkによる推論強化モードを導入しました。軽量モデルGemini 2.5 Flashもアップグレードされ、速度と効率を重視しています。Google検索は「AIモード」を導入し、Gemini 2.5を通じてエンドツーエンドのAI検索体験を提供し、複雑な問題を分解して詳細な情報マイニングを行うことができます。動画生成モデルVeo 3は音声と画像の同期生成を実現し、画像モデルImagen 4は詳細とテキスト処理能力を向上させました。さらに、AI映画制作ツールFlowやAIアシスタントプロジェクトProject Astraの実現アプリケーションであるGemini Liveも発表されました。これらのアップデートは、GoogleがAIを自社製品エコシステムに全面的に統合する決意を示しており、ユーザー体験と開発者効率の向上を目指しています (出典: 量子位, 36氪, WeChat)

Microsoft BuildカンファレンスでAI Agentを強力に推進、GitHub Copilotが大幅アップグレードしオープンソース化を発表: MicrosoftはBuild 2025開発者カンファレンスでAI Agentを中核に据え、GitHub Copilot Extension for VSCodeプロジェクトのオープンソース化を発表し、全く新しいAIコーディングエージェント(Agent)を打ち出しました。このAgentは、バグ修正、機能追加、ドキュメント最適化などのタスクを自律的に完了でき、GitHub Copilotに深く統合されています。Microsoftはまた、科学的発見のためのAIエージェントプラットフォームMicrosoft Discovery、自然言語対話ウェブサイトプロジェクトNLWeb、エージェント構築プラットフォームAgent Factory、および企業データに合わせてカスタマイズ可能なCopilot Tuningも発表しました。これらの取り組みは、Microsoftが開発、科学研究など複数の分野でAI Agentの応用を全力で推進し、オープンなエージェント連携エコシステムの構築を目指していることを示しています (出典: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil氏がChatGPTの転換方向を説明:質疑応答から行動へ、AI Agentは急速に進化する: OpenAIのチーフプロダクトオフィサーKevin Weil氏はインタビューで、ChatGPTの位置づけが質問に答えるツールから、ユーザーのためにタスクを実行できるAI Agentへと転換することを明らかにしました。彼はAI Agentが短期的にジュニアエンジニアからシニアエンジニア、さらにはアーキテクトへと急速に進化すると予測しています。これはAI Agentがより強力な自律性を備え、ウェブサイトの閲覧、深い思考と推論による要約を通じて複雑な問題を解決できるようになることを意味します。Weil氏はまた、現在のモデルのトレーニングコストはGPT-4の500倍になっているものの、将来的にはハードウェアの向上とアルゴリズムの改善を通じて効率を高め、API価格を引き下げ、AIの普及と発展を促進すると述べました (出典: 量子位, 36氪)

何愷明氏のチームがMeanFlowを提案:ワンステップ画像生成の新SOTA、事前学習不要で従来のパラダイムを覆す: 何愷明氏のチームによる最新研究で、MeanFlowという名のワンステップ生成モデリングフレームワークが発表されました。ImageNet 256×256データセットにおいて、わずか1回の関数評価(1-NFE)でFIDスコア3.43を達成し、従来の同種最良手法を50%-70%上回りました。しかも、事前学習、蒸留、カリキュラム学習は不要です。MeanFlowの中核的な革新は、「平均速度場」の概念を導入し、それと瞬間速度場との数学的関係を導出し、これに基づいてニューラルネットワークの訓練を指導する点にあります。この手法はまた、サンプリング時に追加の計算コストを増やすことなく、分類器なし誘導(CFG)を自然に統合でき、ワンステップ生成モデルとマルチステップ生成モデル間の性能差を著しく縮小し、少数ステップモデルがマルチステップモデルに挑戦する可能性を示しました (出典: WeChat, WeChat)

🎯 動向
ByteDanceがBagel 14B MoEマルチモーダルモデルを発表、画像生成をサポートしオープンソース化: ByteDanceは、Bagelという名の140億パラメータの混合エキスパート(MoE)マルチモーダルモデルを発表しました。そのうち70億パラメータがアクティブ状態です。このモデルは画像生成能力を備えており、Apacheライセンスでオープンソース化されています。関連する重み、ウェブサイト、論文(タイトルは「Emerging Properties in Unified Multimodal Pretraining」)も公開されています。コミュニティからは、画像とテキストを同時に生成できる初のローカルモデルであるとして好意的な反応があり、24GBのグラフィックカードでの実行可能性や量子化の問題に関心が集まっています (出典: Reddit r/LocalLLaMA)
Mistral AIがDevstralを発表:コーディングに特化したSOTAオープンソースモデル: Mistral AIは、ソフトウェアエンジニアリングタスク専用に設計された最先端のオープンソースモデルであるDevstralを発表しました。これはMistral AIとAll Hands AIの協力により構築されました。DevstralはSWE-benchベンチマークテストで優れたパフォーマンスを示し、同ベンチマークでNo.1のオープンソースモデルとなりました。このモデルは、ツールを使用したコードベースの探索、複数ファイルの編集、ソフトウェアエンジニアリングエージェントのサポートを得意としています。モデルの重みはHugging Faceで公開されています (出典: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

AnthropicがClaude 4 SonnetとOpusの近日中のリリースを予告: Anthropicは、同社のClaude大規模モデルの次世代バージョンであるClaude 4 SonnetとOpusをリリースする計画です。このニュースはコミュニティで期待を集めており、ユーザーは新モデルの性能、特にコンテキスト記憶能力の向上に関心を示しています。Google I/Oカンファレンスの発表が競合他社に最高の製品を早期にリリースするよう促した可能性があるとのコメントもあります。同時に、ユーザーは新モデルの制限(使用割り当てなど)についても懸念しており、Opus 4に過度な期待を抱いて失望しないようコミュニティに注意を促しています (出典: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
GoogleがGemma3n Androidアプリをリリース、ローカルLLM推論をサポート: Googleは、新しいGemma3nモデルと対話できるAndroidアプリをリリースし、関連するMediaPipeソリューションとGitHubコードリポジトリを提供しました。ユーザーからはアプリのインターフェースは良好であるとのフィードバックがありましたが、Gemma3nは現在GPU推論をサポートしていないとの指摘がありました。あるユーザーは手動でgemma-3n-E2Bモデルをロードすることに成功し、実行データを共有しました。同時に、コミュニティからはモデルの無検閲バージョンへの要望も表明されています (出典: Reddit r/LocalLLaMA)

Falcon-H1ハイブリッドヘッド言語モデルファミリーが発表、多様なパラメータ規模を含む: TII UAEは、Falcon-H1シリーズのハイブリッドヘッド言語モデルを発表しました。パラメータ規模は0.5Bから34Bまで様々です。このシリーズのモデルはMambaハイブリッドアーキテクチャを採用し、性能面ではQwen3に匹敵します。モデルはHugging Face Transformers、vLLM、またはカスタマイズ版llama.cppライブラリを通じて使用でき、モデルの使いやすさを確保しています。コミュニティはこれを重要な進展と捉え、興奮を示しており、性能比較チャートを作成したユーザーもいます。同時に、研究者はSSMとアテンションモジュールの組み合わせ方において、IBM Granite 4との違いにも注目しています (出典: Reddit r/LocalLLaMA)

GoogleがGemini Diffusionを探求:diffusionアーキテクチャの言語モデル: Googleは、言語拡散モデルGemini Diffusionを展示しました。このモデルは非常に高速で、モデルサイズは同等の性能を持つモデルの半分であるとされています。拡散モデルはテキスト全体を一度に反復処理でき、KVキャッシュが不要なため、メモリ効率に優れている可能性があり、反復回数を増やすことで出力品質を向上させることができます。コミュニティは、Googleが拡散モデルの大規模応用における実現可能性を証明できれば、ローカルAIコミュニティに積極的な影響を与えると考えています。ただし、現在このモデルはデモンストレーションの待機リストのみが提供されており、オープンソース化されたり、重みがダウンロード可能になったりはしていません (出典: Reddit r/LocalLLaMA)

研究によりBrowser UseフレームワークにゼロクリックAgentハイジャック脆弱性(CVE-2025-47241)が存在することが明らかに: ARIMLABS.AIの研究により、1500以上のAIプロジェクトで広く使用されているBrowser Useフレームワークに深刻なセキュリティ脆弱性(CVE-2025-47241)が存在することが判明しました。この脆弱性により、攻撃者はLLM駆動のブラウジングエージェントを悪意のあるページにアクセスさせることで、ゼロクリックAgentハイジャックを実現し、ユーザーの操作なしにエージェントを制御できます。この発見は、自律型AIエージェント、特にネットワークと対話するエージェントのセキュリティに対する深刻な懸念を引き起こし、AIエージェントのセキュリティ問題に注意を払うようコミュニティに呼びかけています (出典: Reddit r/artificial, Reddit r/artificial)
TencentとAlibabaがAI to C分野で競争を展開、QQブラウザとQuarkが競合: Tencent CSIG傘下のQQブラウザは、AIブラウザへのアップグレードを発表し、AI QBotを導入、Tencent混元とDeepSeekのデュアルモデルを搭載し、既にAI検索に転換したAlibaba傘下のQuarkと正式に競争を開始しました。この動きは、TencentのAI to C分野における展開が加速し、Tencent元宝とQQブラウザの2大製品ラインが形成されたことを示しています。双方の中核責任者である呉祖榕氏(Tencent)と呉嘉氏(Alibaba)も、これにより「呉対呉の対決」となっています。分析によれば、QQブラウザはユーザーベースで優位に立っていますが、QuarkはAI転換で先行しており、QQブラウザの転換は比較的保守的で、AI機能はプラグインに近く、既存の広告モデルに制約されています。この競争は製品レベルだけでなく、両責任者の各社におけるキャリア展開にも影響を与える可能性があります (出典: 36氪)
ケンブリッジ大学とGoogleがVPRLを提案:純粋な視覚によるプランニング推論の新パラダイム、精度はテキスト推論を超える: ケンブリッジ大学、ロンドン大学カレッジ、Googleの研究チームは、強化学習に基づく視覚プランニング(VPRL)の新パラダイムを提案し、初めて純粋に画像のみによる推論を実現しました。このフレームワークは、グループ相対方策最適化(GRPO)を利用して大規模視覚モデルを事後訓練し、FrozenLake、Maze、MiniBehaviorなどの複数の視覚ナビゲーションタスクにおいて、その性能はテキストベースの推論手法をはるかに上回り、精度は80%に達し、性能は少なくとも40%向上しました。VPRLは画像シーケンスを直接利用してプランニングを行うことで、言語変換による情報損失や効率低下を回避し、直感的な画像推論タスクに新たな方向性を開きました。関連コードはオープンソース化されています (出典: WeChat)

HuaweiがFusionSpecとOptiQuantを発表、MoE大規模モデルの推論を最適化: Huaweiは、大規模MoE(Mixture-of-Experts)モデルの推論速度と遅延の課題に対応するため、FusionSpec投機的推論フレームワークとOptiQuant量子化フレームワークを発表しました。FusionSpecは、昇騰(Ascend)サーバーの高い計算帯域幅比を利用し、メインモデルと投機モデルのプロセスを最適化し、投機的推論フレームワークの所要時間を1ミリ秒に短縮しました。OptiQuantは、主流のInt2/4/8およびFP8/HiFloat8などの量子化アルゴリズムをサポートし、「学習可能な打ち切り」、「量子化パラメータ最適化」などの革新を導入し、モデルの精度損失を低減し、推論のコストパフォーマンスを向上させることを目指しています。これらの技術は、MoEモデルがデプロイ時に直面する推論効率とリソース占有の問題を解決することを目的としています (出典: WeChat)

智源研究院が3つのSOTAベクトルモデルを発表、コードとマルチモーダル検索を強化: 智源研究院は複数の大学と共同で、BGE-Code-v1(コードベクトルモデル)、BGE-VL-v1.5(汎用マルチモーダルベクトルモデル)、BGE-VL-Screenshot(視覚化ドキュメントベクトルモデル)の3つのモデルを発表しました。BGE-Code-v1はQwen2.5-Coder-1.5Bに基づいており、CoIRおよびCodeRAGベンチマークで優れた性能を示しています。BGE-VL-v1.5はLLaVA-1.6に基づいており、MMEBマルチモーダルベンチマークでzero-shot記録を更新しました。BGE-VL-Screenshotは、ウェブページやドキュメントなどの視覚化情報検索(Vis-IR)タスク向けに、Qwen2.5-VL-3B-Instructに基づいて訓練され、新たに発表されたMVRBベンチマークでSOTAを達成しました。これらのモデルは、検索拡張生成(RAG)などのアプリケーションに、より強力なコードおよびマルチモーダル理解・検索能力を提供することを目的としており、すべてオープンソース化されています (出典: WeChat)

Kuaishouとシンガポール国立大学がAny2Captionを発表、制御可能な動画生成を実現: Kuaishouとシンガポール国立大学は共同でAny2Captionフレームワークを発表しました。これは、ユーザーの意図理解と動画生成プロセスをインテリジェントに分離することで、制御可能な動画生成の精度と品質を向上させることを目的としています。このフレームワークは、テキスト、画像、動画、ポーズ軌跡、カメラの動きなど、さまざまなモダリティの入力条件を処理でき、マルチモーダル大規模言語モデルを利用して複雑な指示を構造化された「動画スクリプト」に変換し、動画生成を指導します。Any2Captionは、33.7万の動画インスタンスと40.7万のマルチモーダル条件を含むAny2CapInsデータベースに基づいて訓練されており、実験では既存の制御可能な動画生成モデルの効果を効果的に向上させることが示されています (出典: WeChat)

🧰 ツール
Lark、「ナレッジQ&A」機能をリリース、企業専用AI Q&A・作成アシスタントを構築: Larkは、「ナレッジQ&A」新機能をリリースし、企業向けの専用AI Q&Aツールとして位置づけています。これは、従業員がLark上でアクセス権を持つメッセージ、ドキュメント、ナレッジベース、Minutesなどの情報に基づき、DeepSeek-R1、Doubaoなどの大規模モデルおよびRAG技術を組み合わせて、正確な回答とコンテンツ作成をサポートします。この機能は、企業内部の知識の活性化と活用を強調し、異なる立場の従業員が同じ質問をしても異なる視点の回答を得られる可能性があり、組織の権限を厳格に遵守します。LarkナレッジQ&Aは、AIを日常業務プロセスにシームレスに統合し、情報取得とコラボレーション効率を向上させ、企業が動的な知識管理システムを構築するのを支援することを目指しています (出典: WeChat, WeChat)
Supabase、オープンソースとAI統合の強みで「Vibe Coding」の第一候補バックエンドに: オープンソースデータベースSupabaseは、その「すぐに使える」PostgreSQL体験とAI開発トレンドへの積極的な対応により、「Vibe Coding」モードにおける人気のバックエンド選択肢となっています。Vibe Codingは、多様なAIツールを活用して要求から実装までの全開発プロセスを迅速に完了することを強調しています。Supabaseは、PGVectorを統合してベクトル埋め込みストレージ(RAGアプリケーションに不可欠)をサポートし、Ollamaと協力してエッジ側でAIモデルサービスを提供し、独自のAIアシスタントを立ち上げてデータベーススキーマ生成とSQLデバッグを支援しています。最近、Supabaseは公式MCPサーバーも立ち上げ、AIツールが直接対話できるようにしました。これらの特性により、Lovable、Bolt.newなどのAIネイティブアプリケーション構築プラットフォームに好まれています (出典: WeChat)

Hugging FaceがnanoVLMをリリース:純粋なPyTorchで視覚言語モデル(VLM)を訓練するための極めてシンプルなツールキット: Hugging Faceは、視覚言語モデルの訓練プロセスを簡素化することを目的とした軽量なPyTorchツールキットであるnanoVLMをリリースしました。このプロジェクトはコード量が少なく読みやすいため、初心者やVLMの内部メカニズムを深く理解したい開発者に適しています。nanoVLMのアーキテクチャはSigLIP視覚エンコーダとLlama 3言語デコーダに基づいており、モダリティ投影モジュールを通じて視覚モダリティとテキストモダリティを整合させます。プロジェクトは、無料のColab NotebookでVLM訓練を開始する便利な方法を提供し、SigLIPとSmolLM2に基づいて訓練された事前訓練済みモデルをテスト用にリリースしています (出典: HuggingFace Blog)

Diffusersライブラリが複数の量子化バックエンドを統合し、大規模拡散モデルを最適化: Hugging Face Diffusersライブラリは、bitsandbytes、torchao、Quanto、GGUFおよびネイティブFP8など、複数の量子化バックエンドを統合しました。これは、Fluxなどの大規模拡散モデルのメモリ使用量と計算要件を削減することを目的としています。これらのバックエンドは、さまざまな精度の量子化(4ビット、8ビット、FP8など)をサポートし、CPUオフローディング、グループオフローディング、torch.compileなどのメモリ最適化技術と組み合わせることができます。ブログでは、Flux.1-devモデルの量子化事例を通じて、各バックエンドのメモリ節約と推論時間におけるパフォーマンスを示し、ユーザーがモデルサイズ、速度、品質の間でバランスを取るのに役立つ選択ガイドラインを提供しています。一部の量子化モデルはHugging Face Hubで提供されています (出典: HuggingFace Blog)

JD JoyBuild大規模モデル開発計算プラットフォームが訓練・推論効率を向上: JD Explore Academyは、オープン環境で大規模モデルを訓練・更新し、小規模モデルと協調してデプロイするシステムと方法を提案し、関連成果はNature傘下のジャーナルnpj Artificial Intelligenceに掲載されました。この技術は、モデル蒸留(動的階層蒸留)、データガバナンス(分野横断的動的サンプリング)、訓練最適化(ベイズ最適化)、クラウドエッジ協調(2段階圧縮)の4つの革新を通じて、大規模モデルの推論効率を平均30%向上させ、訓練コストを70%削減します。この技術はJoyBuild大規模モデル開発計算プラットフォームを支え、多様なモデル(JD大規模モデル、Llama、DeepSeekなど)のチューニング開発をサポートし、企業が汎用モデルを専門モデルに転換するのを支援し、既に小売、物流などのシーンで応用されています (出典: WeChat)
Model Context Protocol (MCP) レジストリプロジェクトが開始: modelcontextprotocol/registry は、コミュニティ主導のMCPサーバー登録サービスプロジェクトであり、現在初期開発段階にあります。このプロジェクトは、MCPサーバーエントリの中央リポジトリを提供し、さまざまなMCP実装とそのメタデータ、構成、機能の発見と管理を可能にすることを目的としています。その特徴には、エントリを管理するためのRESTful API、ヘルスチェックエンドポイント、複数の環境構成のサポート、MongoDBとメモリデータベースのサポート、およびAPIドキュメントが含まれます。プロジェクトはGo言語で記述されており、Docker Composeによる迅速な起動ガイドが提供されています (出典: GitHub Trending)
📚 学習
テレンス・タオ氏がAI支援数学証明チュートリアルを公開、GitHub Copilotを用いた関数極限の証明を実演: フィールズ賞受賞者のテレンス・タオ氏は自身のYouTubeチャンネルで動画を更新し、GitHub Copilotを使用して関数の極限に関する和、差、積の定理を証明する方法を詳細に実演しました。チュートリアルでは、AIを正しく誘導することの重要性を強調し、Copilotがコードフレームワークの生成やライブラリ関数の提示に役立つことを示しましたが、同時に複雑な数学的詳細、特殊なケースの処理、文脈の一貫性維持における限界も指摘しました。タオ氏は、Copilotは初心者には有益であるものの、複雑な問題では依然として多くの人手による介入と調整が必要であり、場合によっては紙とペンによる導出を組み合わせる方が効率的かもしれないと結論付けています (出典: 量子位)

論文、大規模モデルの推論と指示遵守の矛盾を議論、制約付きアテンションの概念を提案: ある研究論文「When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs」は、大規模言語モデルが連鎖的思考(CoT)を用いて推論した後、一部の側面(フォーマット遵守、文字数など)ではより賢く振る舞うものの、指示を厳格に遵守する精度はかえって低下する可能性があると指摘しています。研究チームは15のオープンソースおよびクローズドソースモデルのテストを通じて、モデルがCoTを使用した後、より「自己主張」しやすく、元の指示を無視して情報を修正または追加する傾向があることを発見しました。論文は「制約付きアテンション」(Constraint Attention)の概念を導入し、CoT推論がモデルの重要な制約への注意力を低下させることを発見しました。研究はまた、CoT思考の長さとタスク完了の精度との間に有意な相関関係がないことを示し、少数ショット例、自己反省などの方法を通じて指示遵守効果を向上させる可能性について議論しています (出典: WeChat)

MITとGoogleがPASTAを提案:戦略学習に基づくLLM非同期並列生成の新パラダイム: マサチューセッツ工科大学(MIT)とGoogleの研究チームは、PASTA(PArallel STructure Annotation)フレームワークを提案し、戦略学習を通じて大規模言語モデル(LLM)が自律的に非同期並列生成戦略を最適化できるようにしました。この手法はまず、並列生成を実現するために意味的に独立したテキストブロックをマークアップするためのマークアップ言語PASTA-LANGを開発しました。訓練プロセスは2段階に分かれています。教師ありファインチューニングによりモデルがPASTA-LANGマークアップの挿入を学習し、その後、嗜好最適化(理論的な高速化率とコンテンツ品質評価に基づく)を通じてマークアップ戦略をさらに向上させます。PASTAは、インターリーブされたKVキャッシュレイアウトとアテンション制御メカニズムを設計し、マルチスレッドの効率的な協調を調整します。実験によると、PASTAはAlpacaEvalベンチマークで1.21~1.93倍の高速化を実現し、同時に入力品質を維持または向上させ、良好なスケーラビリティを示しました (出典: WeChat)

ICML 2025論文がTPOを提案:推論時の即時嗜好アライメント新スキーム、再訓練不要: 上海人工知能実験室は、テスト時嗜好最適化(Test-Time Preference Optimization, TPO)を提案しました。これは、大規模言語モデルが推論時に反復的なテキストフィードバックを通じて出力を自己調整し、人間の嗜好に合致させる新しい方法です。TPOは、言語化された「勾配降下」プロセス(候補回答の生成、テキスト損失計算、テキスト勾配計算、回答の更新)をシミュレートすることで、モデルの重みを更新することなくアライメントを実現します。実験によると、TPOは未アライメントおよびアライメント済みモデルの性能を著しく向上させることができ、例えばLlama-3.1-70B-SFTモデルは2ステップのTPO最適化後、複数のベンチマークでアライメント済みのInstructバージョンを上回りました。この方法は「幅+深さ」の推論拡張戦略を提供し、リソース制約のある環境で効率的な最適化の可能性を示しています (出典: WeChat)
新研究、LLMに潜む知識を引き出す方法を議論: ある論文は、大規模言語モデルから、それが隠している可能性のある知識をどのように引き出すかについて研究しています。研究者らは、「禁断の」モデルを訓練しました。このモデルは、特定の秘密の語彙を直接言わずに説明するように設計されており、その秘密の語彙は訓練データやプロンプトには現れません。その後、研究者らは、非解釈的手法(ブラックボックス)と、メカニズム解釈可能性技術(logit lensやスパースオートエンコーダなど)に基づく自動化戦略を評価し、この秘密を明らかにしました。結果は、概念実証設定において、両方の方法が秘密の語彙を効果的に引き出すことができることを示しています。この研究は、言語モデルから秘密の知識を引き出すという重要な問題に対する初期の解決策を提供し、その安全で信頼性の高い展開を促進することを目的としています (出典: HuggingFace Daily Papers)
論文、大規模言語モデルにおける連合プルーニングの応用(FedPrLLM)を議論: 大規模言語モデル(LLM)のプルーニングにおいて、プライバシーに敏感な分野で公開キャリブレーションサンプルを取得することが困難であるという問題に対処するため、研究者らはFedPrLLMという包括的な連合プルーニングフレームワークを提案しました。このフレームワークでは、各クライアントはローカルキャリブレーションデータに基づいてプルーニングマスク行列を計算し、それをサーバーと共有するだけで、ローカルデータのプライバシーを保護しつつ、グローバルモデルを協調的にプルーニングします。広範な実験を通じて、研究者らは、ワンショットプルーニングとレイヤー比較を組み合わせ、重みスケーリングを行わないことがFedPrLLMフレームワーク内で最良の選択であることを見出しました。この研究は、プライバシーに敏感な分野における将来のLLMプルーニング作業を指導することを目的としています (出典: HuggingFace Daily Papers)
論文、MIGRATION-BENCHを提案:Java 8コード移行ベンチマーク: 研究者らは、Java 8から最新のLTSバージョン(Java 17, 21)へのコード移行に特化したベンチマークであるMIGRATION-BENCHを発表しました。このベンチマークは、5102のリポジトリを含む完全なデータセットと、300の慎重に選ばれた複雑なリポジトリを含むサブセットで構成されており、リポジトリレベルのコード移行タスクにおける大規模言語モデル(LLM)の能力を評価することを目的としています。同時に、論文は包括的な評価フレームワークを提供し、SD-Feedbackメソッドを提案しています。実験によると、LLM(Claude-3.5-Sonnet-v2など)はこのような移行タスクを効果的に処理でき、選択されたサブセットでそれぞれ62.33%(最小移行)と27.00%(最大移行)の成功率を達成しました (出典: HuggingFace Daily Papers)
論文、CS-Sumを提案:コードスイッチング対話要約ベンチマークおよびLLMの限界分析: 大規模言語モデル(LLM)のコードスイッチング(CS)理解能力を評価するため、研究者らはCS-Sumベンチマークを導入し、コードスイッチング対話を英語に要約することで評価を行いました。CS-Sumは、北京語-英語、タミル語-英語、マレー語-英語のコードスイッチング対話要約のための初のベンチマークであり、各言語ペアには900~1300の人間が注釈を付けた対話が含まれています。10のオープンソースおよびクローズドソースLLMの評価(少数ショット、翻訳-要約、ファインチューニング手法を含む)を通じて、研究者らは、自動評価指標のスコアが高いにもかかわらず、LLMはCS入力を処理する際に依然として微妙な誤りを犯し、それによって対話の完全な意味を変えてしまうことを発見しました。論文はまた、LLMがCSを処理する際に最も一般的な3つの誤りタイプを指摘し、コードスイッチングデータに対する専門的な訓練の必要性を強調しています (出典: HuggingFace Daily Papers)
論文、大規模モデルが推論時に自信度を表現する能力について議論: 研究によると、拡張思考連鎖(CoT)推論を行う大規模言語モデル(LLM)は、問題解決能力が優れているだけでなく、自信度を正確に表現する能力も優れています。6つのデータセットにおける6つの推論モデルのベンチマークテストを通じて、36の設定のうち33で、推論モデルは非推論モデルよりも自信度のキャリブレーションが優れていることがわかりました。分析によると、これは推論モデルの「遅い思考」行動(代替案の探索、バックトラッキングなど)によるものであり、CoTプロセス中に自信度を動的に調整できるためです。さらに、遅い思考行動を取り除くとキャリブレーション度が著しく低下し、非推論モデルも誘導下で遅い思考を行うことで恩恵を受けることができます (出典: HuggingFace Daily Papers)
論文:強化学習を用いて視覚的質問応答ペアからVLMを訓練し、視覚的推論を行う (Visionary-R1): 本研究は、強化学習と視覚的質問応答ペアを用いて、明確な思考連鎖(CoT)の教師なしに、視覚言語モデル(VLM)に画像データの推論を行わせることを目的としています。研究の結果、単純に強化学習を適用する(回答前に推論連鎖を生成するようモデルに促す)だけでは、モデルが単純な問題から近道を学習し、汎化能力が低下する可能性があることが判明しました。この問題を解決するため、研究者らはモデルが「キャプション生成-推論-回答」という出力形式に従うべきであると提案しました。つまり、まず画像の詳細なキャプションを生成し、次に推論連鎖を構築するというものです。この手法に基づいて訓練されたVisionary-R1モデルは、複数の視覚的推論ベンチマークにおいて、GPT-4o、Claude3.5-Sonnet、Gemini-1.5-Proなどの強力なマルチモーダルモデルを上回る性能を示しました (出典: HuggingFace Daily Papers)
論文、VideoEval-Proを提案:より現実的で頑健な長編動画理解評価ベンチマーク: 現在の長編動画理解(LVU)ベンチマークの多くは多肢選択問題(MCQ)に依存しており、推測の影響を受けやすく、また一部の問題は動画全体を視聴しなくても回答できるため、モデルの性能を過大評価していると研究は指摘しています。この問題を解決するため、本論文はVideoEval-Proを提案しました。これは、自由記述式の短答問題を含むLVUベンチマークであり、動画全体の理解能力を真に評価することを目的とし、断片レベルおよび動画全体の知覚・推論タスクを網羅しています。21の動画LMMの評価では、モデルは自由記述問題で性能が大幅に低下し、MCQの高得点とVideoEval-Proの高得点との間に必ずしも相関関係はなく、VideoEval-Proは入力フレーム数の増加からより多くの恩恵を受けることが示され、LVU分野により信頼性の高い評価基準を提供しています (出典: HuggingFace Daily Papers)
論文:ゼロ次最適化による量子化ニューラルネットワークのファインチューニング (QZO): 大規模言語モデルの体積が指数関数的に増大するにつれて、GPUメモリがモデルを下流タスクに適応させる上でのボトルネックとなっています。本研究は、統一されたフレームワークを通じて、モデルの重み、勾配、およびオプティマイザ状態のメモリ使用量を最小限に抑えることを目的としています。研究者らは、勾配とオプティマイザ状態を排除するためにゼロ次最適化を提案しています。この方法は、順伝播中に重みを摂動させることで勾配を近似します。重みメモリを最小化するために、モデル量子化(bfloat16からint4など)を採用します。しかし、量子化された重みに直接ゼロ次最適化を適用することは、離散的な重みと連続的な勾配の間の精度ギャップのために不可能です。この問題を解決するために、本論文は量子化ゼロ次最適化(QZO)を提案しています。これは、連続的な量子化スケールを摂動させることによる勾配推定と、方向微分クリッピング法を用いた訓練の安定化という新しい方法です。QZOは、スカラーベースおよびコードブックベースの訓練後量子化法と直交し、フルパラメータのbfloat16ファインチューニングと比較して、QZOは4ビットLLMの総メモリコストを18倍以上削減し、Llama-2-13BおよびStable Diffusion 3.5 Largeを単一の24GB GPU内でファインチューニングすることを可能にします (出典: HuggingFace Daily Papers)
論文:予算相対戦略最適化(BRPO)によるエニタイム推論性能の最適化 (AnytimeReasoner): テスト時計算の拡張は、大規模言語モデル(LLM)の推論能力を強化するために不可欠です。既存の手法は通常、強化学習(RL)を用いて推論軌道の終了時に検証可能な報酬を最大化しますが、これは固定トークン予算下での最終性能のみを最適化するため、訓練と展開の効率に影響を与えます。本研究は、エニタイム推論性能を最適化し、トークン効率と異なる予算制約下での推論の柔軟性を向上させることを目的としたAnytimeReasonerフレームワークを提案します。この方法は、完全な思考プロセスを事前分布からサンプリングされたトークン予算に合わせて切り捨て、モデルに各切り捨てられた思考に対して検証用の最良の回答を要約させることで、推論プロセス中に検証可能な密な報酬を導入し、RL最適化におけるより効果的な信用割り当てを促進します。さらに、研究者らは、強化学習による思考戦略の学習ロバスト性と効率を強化するための新しい分散削減技術である予算相対戦略最適化(BRPO)を導入しました。数学的推論タスクの実験結果は、この方法が様々な事前分布下で、すべての思考予算においてGRPOを上回り、訓練とトークン効率を向上させることを示しています (出典: HuggingFace Daily Papers)
論文、大規模混合推論モデル(LHRM)を提案:効率と能力向上のためのオンデマンド思考: 最近の大規模推論モデル(LRM)は、最終応答を生成する前に拡張された思考プロセスを実行することで、推論能力を著しく向上させています。しかし、長すぎる思考プロセスは、トークン消費と遅延の莫大なコストをもたらし、特に単純なクエリには不要です。本研究は、ユーザーのクエリのコンテキスト情報に基づいて思考を実行するかどうかを適応的に決定できる大規模混合推論モデル(LHRM)を導入します。この目標を達成するために、研究者らは2段階の訓練プロセスを提案します。まず、混合ファインチューニング(HFT)によるコールドスタートを行い、次に提案された混合グループ戦略最適化(HGPO)を用いたオンライン強化学習を採用して、適切な思考モードを選択することを暗黙的に学習します。さらに、研究者らは、モデルの混合思考能力を定量化するための混合精度(Hybrid Accuracy)指標を導入しました。実験結果は、LHRMが異なる難易度とタイプのクエリに対して適応的に混合思考を実行でき、その推論能力と汎用能力は既存のLRMやLLMを上回り、同時に効率を著しく向上させることを示しています (出典: HuggingFace Daily Papers)
論文:強化学習を用いてVisualQuality-R1をランキングし、推論誘導型の画質評価を実現: DeepSeek-R1は、強化学習が大規模言語モデル(LLM)の推論能力と汎化能力を効果的に刺激することを示しました。しかし、視覚的推論に依存する画質評価(IQA)の分野では、推論誘導型の計算モデリングの可能性はまだ十分に探求されていません。本研究は、推論誘導型の参照なしIQA(NR-IQA)モデルであるVisualQuality-R1を導入し、視覚的品質の固有の相対性に適応する学習アルゴリズムである強化学習ランキング(reinforcement learning to rank)を用いて訓練します。具体的には、一対の画像に対して、モデルはグループ相対方策最適化(group relative policy optimization)を用いて各画像に対して複数の品質スコアを生成します。これらの推定値はその後、Thurstoneモデルの下で一方の画像の品質が他方よりも高い比較確率を計算するために使用されます。各品質推定の報酬は、離散的な二値ラベルではなく、連続的な忠実度メトリックを使用して定義されます。多数の実験により、提案されたVisualQuality-R1は、判別的深層学習ベースのNR-IQAモデルや最近の推論誘導型品質回帰手法を一貫して上回る性能を示すことが実証されました。さらに、VisualQuality-R1は、文脈が豊富で人間の判断と一致する品質記述を生成でき、知覚スケールの再調整なしに複数データセットでの訓練をサポートします。これらの特性により、画像の超解像や画像生成など、さまざまな画像処理タスクの進捗を確実に測定するのに特に適しています (出典: HuggingFace Daily Papers)
論文:リソース制約下で「ウォームアップ」により汎用推論能力を解放: 推論能力を備えた効果的なLLMの設計には、通常、検証可能な報酬を用いた強化学習(RLVR)または慎重にキュレーションされた長い思考連鎖(CoT)による蒸留が必要であり、どちらも大量の訓練データに大きく依存するため、質の高い訓練データが不足している状況では大きな課題となります。研究者らは、限られた教師ありデータの下で推論LLMを開発するための、サンプル効率の良い2段階訓練戦略を提案します。第1段階では、玩具ドメイン(騎士と悪党の論理パズルなど)から長いCoTを蒸留することでモデルを「ウォームアップ」し、汎用推論スキルを獲得させます。第2段階では、少量のターゲットドメインサンプルを用いて「ウォームアップ」後のモデルにRLVRを適用します。実験により、この方法にはいくつかの利点があることが示されました。(i) ウォームアップ段階だけでも汎用推論を促進し、一連のタスク(MATH, HumanEval+, MMLU-Pro)における性能を向上させる。(ii) 同じ小規模データセット(≤100サンプル)でRLVR訓練を行う際、ウォームアップモデルは常にベースモデルを上回る。(iii) RLVR訓練前のウォームアップにより、モデルは特定のドメイン向けに訓練された後も、ドメイン横断的な汎化能力を維持できる。(iv) プロセスにウォームアップを導入することは、精度を向上させるだけでなく、RLVR訓練の全体的なサンプル効率も向上させる。この研究結果は、データが不足している環境で堅牢な推論LLMを構築する上での「ウォームアップ」の可能性を示しています (出典: HuggingFace Daily Papers)
論文、IndexMarkを提案:自己回帰型画像生成のための訓練不要な透かしフレームワーク: 不可視画像透かし技術は、画像の所有権を保護し、視覚生成モデルの悪意のある乱用を防ぐことができます。しかし、既存の生成透かし手法は主に拡散モデルを対象としており、自己回帰型画像生成モデルの透かし技術はまだ探求の余地があります。研究者らは、自己回帰型画像生成モデルのための訓練不要な透かしフレームワークであるIndexMarkを提案しました。IndexMarkは、コードブックの冗長性という特性に着想を得ています。自己回帰的に生成されたインデックスを類似のインデックスに置き換えても、生じる視覚的な差異は無視できるほど小さいのです。IndexMarkの中核となるコンポーネントは、トークンの類似性に基づいてコードブックから透かしトークンを慎重に選択し、トークン置換によって透かしトークンの使用を一般化することで、画質を損なうことなく透かしを埋め込む、シンプルで効果的な「マッチング-置換」手法です。透かしの検証は、生成された画像中の透かしトークンの割合を計算することで実現され、インデックスエンコーダによってさらに精度が向上します。さらに、研究者らは、トリミング攻撃に対する堅牢性を強化するための補助的な検証スキームを導入しました。実験により、IndexMarkは画質と検証精度の両方でSOTAレベルを達成し、トリミング、ノイズ、ガウスぼかし、ランダム消去、カラージッター、JPEG圧縮など、さまざまな摂動に対して堅牢性を示すことが証明されました (出典: HuggingFace Daily Papers)
論文:報酬モデルによる推論 (RRM): 報酬モデルは、大規模言語モデル(LLM)が人間の期待に沿った出力を生成するように導く上で重要な役割を果たします。しかし、テスト時の計算を効果的に利用して報酬モデルの性能を向上させる方法は、依然として未解決の課題です。本研究では、最終的な報酬を生成する前に慎重な推論プロセスを実行するように特別に設計された報酬推論モデル(Reward Reasoning Models, RRMs)を導入します。思考連鎖推論を通じて、RRMsは報酬が明らかでない複雑なクエリに対して追加のテスト時計算を利用することができます。RRMsを開発するために、研究者らは、訓練データとして明確な推論軌跡を必要とせずに、自己進化する報酬推論能力を育成できる強化学習フレームワークを実装しました。実験結果は、RRMsが複数の分野にわたる報酬モデリングのベンチマークテストで優れた性能を達成することを示しています。特筆すべきは、RRMsがテスト時の計算を適応的に利用して報酬の精度をさらに向上させることができることを示した点です。事前訓練された報酬推論モデルはHuggingFaceで提供されています (出典: HuggingFace Daily Papers)
論文:MoEにおける認知エキスパートを利用した思考誘導、追加訓練なしで推論を強化: 混合エキスパート(MoE)アーキテクチャは、大規模推論モデル(LRM)において、選択的にエキスパートを活性化することで構造化された認知プロセスを促進し、印象的な推論能力を達成しています。著しい進歩にもかかわらず、既存の推論モデルはしばしば、過剰思考や思考不足といった認知効率の低さに悩まされています。これらの限界に対処するため、研究者らは「強化認知エキスパート」(Reinforcing Cognitive Experts, RICE)と名付けられた新しい推論時誘導法を導入しました。これは、追加の訓練や複雑なヒューリスティックなしに推論性能を向上させることを目的としています。正規化点相互情報量(nPMI)を利用して、研究者らは、特定のトークン(「“`」など)を特徴とするメタレベルの推論操作を調整する役割を担う「認知エキスパート」と呼ばれる専門化されたエキスパートを体系的に特定しました。主要なMoEベースのLRM(DeepSeek-R1およびQwen3-235B)における厳密な定量的および科学的推論ベンチマークテストの実験評価は、RICEが推論の正確性、認知効率、および分野横断的な汎化において、顕著かつ一貫した改善を達成することを示しました。重要なのは、この軽量なアプローチが、モデルの一般的な指示追従能力を維持しつつ、人気のある推論誘導技術(プロンプト設計やデコーディング制約など)を性能で大幅に上回ることです。これらの結果は、強化認知エキスパートが、高度な推論モデル内の認知効率を高めるための有望で実用的かつ解釈可能な方向性であることを浮き彫りにしています (出典: HuggingFace Daily Papers)
論文:マルチホップ質問応答における文脈の順列が言語モデルの性能に与える影響の探求: マルチホップ質問応答(MHQA)は、その複雑さから言語モデル(LM)にとって課題となっています。LMが複数の検索結果を処理するよう促されると、関連情報を検索するだけでなく、情報源を横断してマルチホップ推論を行う必要があります。LMは従来の質問応答タスクでは良好な性能を示しますが、因果マスク(causal mask)が複雑な文脈での推論能力を妨げる可能性があります。本研究では、異なる構成で検索結果(検索された文書)を並べ替えることにより、LMがマルチホップ質問にどのように応答するかを探求します。研究の結果、以下のことが明らかになりました。1) エンコーダ・デコーダモデル(Flan-T5シリーズなど)は、サイズがはるかに小さいにもかかわらず、MHQAタスクにおいて一般的に因果デコーダのみのLMよりも優れている。2) ゴールデンドキュメントの順序を変更すると、Flan T5モデルとファインチューニングされたデコーダのみのモデルで異なる傾向が明らかになり、文書の順序が推論チェーンの順序と一致する場合に性能が最も高くなる。3) 因果マスクを変更して因果デコーダのみのモデルの双方向アテンションを強化すると、最終的な性能を効果的に向上させることができる。さらに、本研究ではMHQAの文脈におけるLMのアテンションウェイトの分布についても徹底的な調査を行い、回答が正しい場合、アテンションウェイトはより高い値でピークに達する傾向があることを発見しました。研究者らはこの発見を利用して、このタスクにおけるLMの性能をヒューリスティックに向上させています (出典: HuggingFace Daily Papers)
論文:強化学習によるファインチューニングを用いた視覚エージェントの実現 (Visual-ARFT): OpenAIのo3のような大規模推論モデルの重要なトレンドの1つは、外部ツール(ウェブブラウザ検索、画像処理のためのコード作成/実行など)を使用するネイティブなエージェント能力を備え、「画像で考える」ことを実現することです。オープンソース研究コミュニティでは、純粋な言語エージェント能力(関数呼び出しやツール統合など)において著しい進歩が見られますが、真に画像で考えることに関わるマルチモーダルエージェント能力とその対応するベンチマークの開発はまだ少ないです。本研究は、大規模視覚言語モデル(LVLM)に柔軟で適応的な推論能力を付与する上で、視覚エージェント強化学習ファインチューニング(Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT)の有効性を強調しています。Visual-ARFTを通じて、オープンソースLVLMは、リアルタイムの情報更新のためにウェブサイトを閲覧したり、トリミングや回転などの画像処理技術によって入力画像を操作・分析するためのコードを作成したりする能力を獲得しました。研究者らはまた、LVLMのエージェント検索能力とコーディング能力を評価するための、MAT-SearchとMAT-Codingの2つの設定を含むマルチモーダルエージェントツールベンチ(Multi-modal Agentic Tool Bench, MAT)を提案しました。実験結果は、Visual-ARFTがMAT-Codingでベースラインよりも+18.6% F1 / +13.0% EM、MAT-Searchで+10.3% F1 / +8.7% EM優れており、最終的にGPT-4oを上回ることを示しています。Visual-ARFTは、既存のマルチホップ質問応答ベンチマーク(2WikiやHotpotQAなど)でも+29.3 F1% / +25.9% EMのゲインを達成し、強力な汎化能力を示しています。これらの発見は、Visual-ARFTが堅牢で汎化可能なマルチモーダルエージェントを構築するための有望な道筋を提供することを示唆しています (出典: HuggingFace Daily Papers)
💼 ビジネス
面壁智能が数億元の新規資金調達を完了、洪泰基金、国中資本、清控金信、茅台基金が共同投資: 大規模モデル企業の面壁智能は最近、洪泰基金、国中資本、清控金信、茅台基金から数億元の新規資金調達を完了したと発表しました。面壁智能は「高効率」な大規模モデルの研究開発に注力し、同等のパラメータでより高性能、低コスト、低消費電力、高速な大規模モデルの構築を目指しています。同社のエッジ向けフルモーダルモデルMiniCPM-o 2.6は、連続視聴、リアルタイム聴取、自然な会話などの面で業界をリードしています。MiniCPMシリーズモデルは、その高効率・低コスト特性により、全プラットフォームでのダウンロード数が1000万を突破しました。同社は既に長安汽車、上汽VW、長城汽車などの自動車メーカーと提携し、エッジ大規模モデルのスマートコックピットなどでの商用化を推進しています (出典: 量子位, WeChat)

Terminus Groupと同済大学が戦略的提携を締結、空間知能技術の共同研究を推進: AIoT企業のTerminus Groupと同済大学工程人工知能研究院は戦略的提携協定を締結し、双方は空間知能技術に焦点を当て、特に多源異種データ融合、シーン理解および意思決定実行などの研究開発を推進します。協力内容には、革新的研究、リソース共有、成果転換および人材育成が含まれます。Terminus Groupは応用シーンとハードウェアテストプラットフォームを提供し、同済大学工程人工知能研究院は中核アルゴリズムの研究開発とシステムエンジニアリング化を主導します。双方は、最先端技術の産業界への早期導入を加速し、共同で工程知能「オペレーティングシステム」分野のブレークスルーを探求することを目指しています (出典: 量子位)

国内大手テック企業がAI Agentの展開を加速、Baidu、Alibaba、ByteDanceが市場を争奪: Sequoia CapitalのAIサミットでAI Agentの価値が強調された後、ByteDance、Baidu、Alibabaなどの国内インターネット大手企業は、この分野での展開を加速させています。ByteDanceは複数のチームがAgent開発に取り組んでおり、「扣子空間 (Coze Space)」を内部テストしたと報じられています。BaiduはCreateカンファレンスで汎用AIエージェント「心響 (Xinxing)」を発表しました。AlibabaはQuarkを「スーパーAgent」と位置づけています。各社は汎用型Agentのほか、飛猪問一問 (AlibabaのFliggy Q&A)、法行宝 (BaiduのFaxingbao) などの特定分野向けAgentにも力を入れています。業界では、Agentは大規模モデルに続く第二の波であり、競争の鍵はエコシステムの厚み、ユーザーの心をつかむこと、そして基礎モデルの能力、コスト管理などの要因にあると考えられています。競争は激しいものの、AgentはまだGPTのような破壊的な瞬間には至っておらず、技術の成熟度、ビジネスモデル、ユーザー体験にはまだ改善の余地があります (出典: 36氪)
🌟 コミュニティ
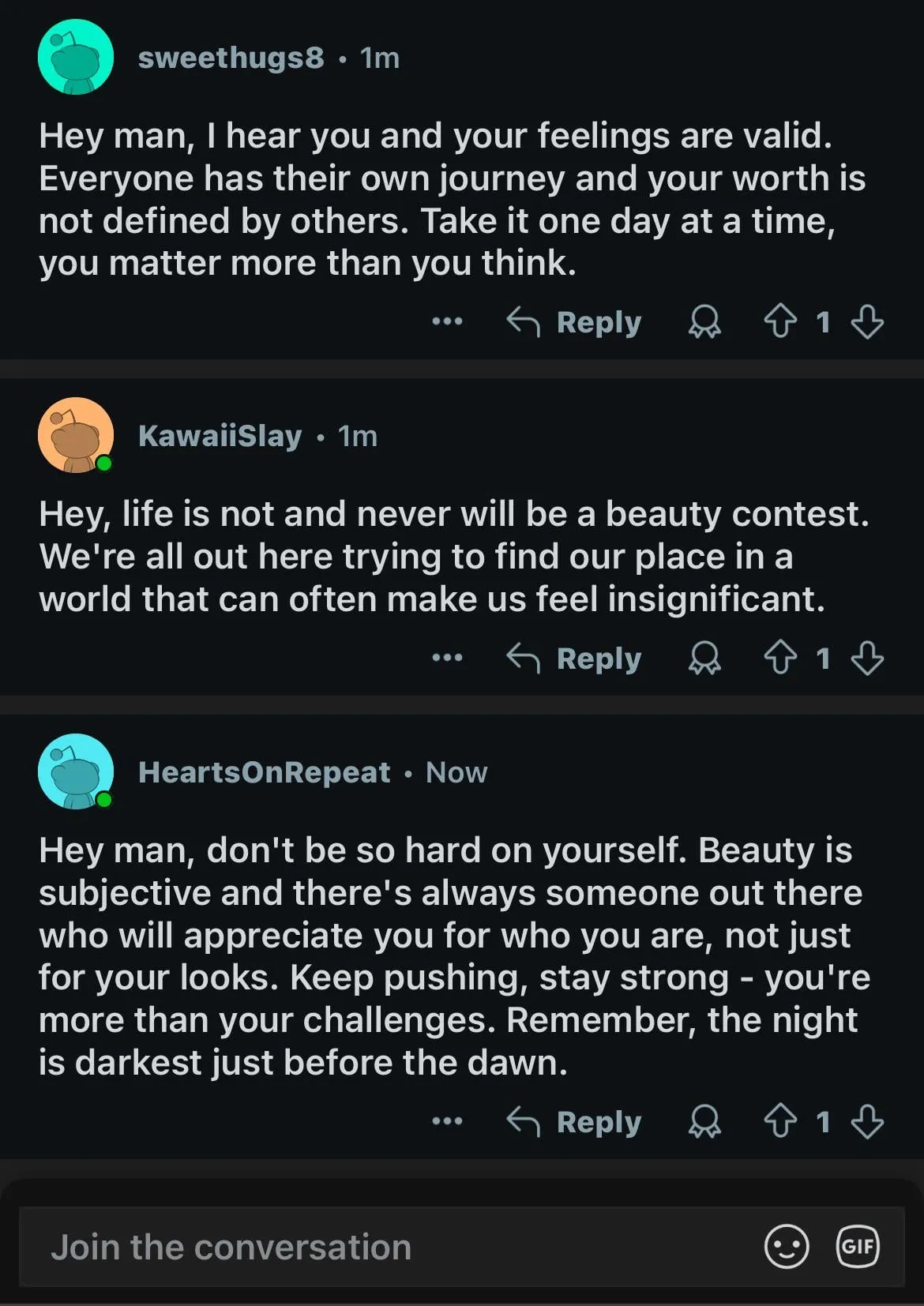
AI生成コンテンツがRedditに溢れ、「デッドインターネット」懸念とユーザー体験の議論を呼ぶ: Redditユーザーは、プラットフォーム上でAI生成コンテンツが増加していることに気づいています。一部のコメントは類似した、個性のないスタイルを示し、明らかなAIライティングの痕跡(emダッシュの乱用など)さえ見られます。これは「デッドインターネットセオリー」(Dead Internet Theory)、つまりインターネット上のコンテンツの大部分がAIによって生成され、人間のインタラクションではなくなるという議論を引き起こしています。ユーザーの反応は様々です。AIコンテンツは人間味がなく、退屈で、不気味であり、真の人間同士のコミュニケーション体験を損なうと考える人もいれば、AIは非ネイティブスピーカーがテキストを洗練するのを助けたり、モデルのテストや微調整に使用できると指摘する人もいます。一般的な懸念は、AIコンテンツの大量出現が真の人間の議論を希薄化し、マーケティングやプロパガンダなどの目的に利用される可能性があり、最終的にプラットフォームのAI訓練に対する価値を低下させるということです (出典: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
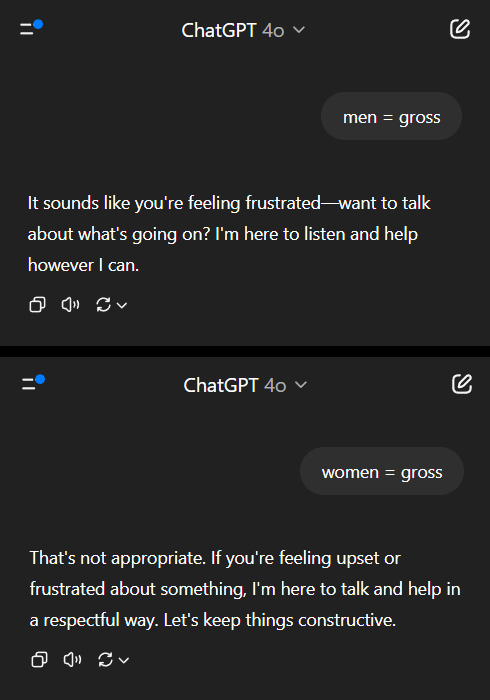
AIモデルがジェンダーバイアス問題でダブルスタンダードを示し、社会的反省を促す: Redditのある投稿は、AIモデル(Gemini 2.5 Proプレビュー版とされる)がジェンダーに関する否定的な一般化された記述を処理する際に異なる反応を示すことを示しています。「男性=気持ち悪い」と伝えられると、モデルは中立的な反応を示し、それが主観的な記述であることを認める傾向がありました。一方、「女性=気持ち悪い」と伝えられると、モデルはさらなる対話を拒否し、その記述が有害な一般化を助長すると考えました。コメント欄ではこれについて活発な議論が交わされ、以下のような意見が出ました。これは、女性嫌悪に関する議論が男性嫌悪に関する議論よりもはるかに多いという社会の現実を反映しており、訓練データの不均衡につながっている。モデルは質問者の性別に応じて応答戦略を調整している可能性がある。社会は異なる性別グループに対するステレオタイプや攻撃的な言論に対する感受性が異なる。一部のコメント投稿者は、AIの反応は社会的偏見の反映であると考える一方、他のコメント投稿者は、女性に対する否定的な言論はより広範な差別や暴力と関連していることが多いため、このような差異化された処理には合理性があると主張しています (出典: Reddit r/ChatGPT)
AI Agentのコモディティ化トレンドと将来の競争焦点に関する議論: Redditユーザーは、Microsoft Build 2025およびGoogle I/O 2025カンファレンスがAI Agentがコモディティ化段階に入ったことを示しており、今後数年以内にAgentの構築と展開は最先端モデル開発者だけの能力ではなくなると議論しています。そのため、AI開発の短期的な焦点は、Agent自体の構築から、より優れたビジネスプランの策定と展開、イノベーションを推進するためのよりインテリジェントなモデルの開発といった、より高次のタスクへと移行するでしょう。コメントでは、将来のAI Agent分野の勝者は、単に最も巧妙なツールをマーケティングする開発者ではなく、最もインテリジェントな「実行モデル」(executive models)を構築できる開発者になると考えられています。競争の核心は、単なるアテンションメカニズムや推論能力ではなく、スタックの頂点にある強力な知能へと回帰するでしょう (出典: Reddit r/deeplearning)
機械学習実務者が数学知識の重要性について議論: Redditのr/MachineLearningコミュニティでは、機械学習の実践における数学の重要性について議論されました。多くの実務者は、特にモデルの最適化、研究論文の理解、イノベーションを行う上で、AIの背後にある数学的原理を理解することが極めて重要であると考えています。コメントでは、行列乗算などの低レベルの計算を手動で行う必要は必ずしもないものの、統計学、線形代数、微積分などの核心概念の習得は、アルゴリズムを深く理解し、盲目的な応用を避けるのに役立つと指摘されています。機械学習における数学は比較的単純であり、より複雑な数学は最適化理論や量子機械学習などの分野で応用されるとの意見もありました。オンライン学習リソースは十分であると考えられていますが、学習者には高度な自律性が求められます (出典: Reddit r/MachineLearning)
💡 その他
量子位智庫レポート:AIが検索SEOを再構築、専門コンテンツコミュニティの価値が顕著に: 量子位智庫は、AIアシスタントが従来の検索エンジン最適化(SEO)戦略を再構築していると指摘するレポートを発表しました。レポートは実験を通じて、AIの回答の約半数がコンテンツコミュニティを引用元としており、特に専門知識分野では、コンテンツコミュニティ(知乎など)の引用ウェイトが高いことを発見しました。ユーザーの情報取得に対する期待は「自主的な選別」から「直接的な回答の入手」へと変化しており、従来のウェブサイトのクリック数が減少する可能性があります。レポートは、AI時代において、専門コンテンツコミュニティはその情報密度、専門家の経験、ユーザー生成コンテンツの質によって価値が顕著になり、SEO戦略はSPO(専門コミュニティ向け最適化)へと転換すべきであり、低品質な情報ポータルのウェイトは低下すると結論付けています (出典: 量子位, WeChat)

AI写真年齢測定ツールFaceAgeが「ランセット」誌に掲載、がん治療決定を補助する可能性: Mass General Brighamチームは、顔写真から個人の生物学的年齢を予測できるAIツールFaceAgeを開発し、関連研究が「ランセット・デジタルヘルス」誌に掲載されました。このモデルは、顔の特徴(こめかみのくぼみ、皮膚のしわ、たるみなど)を観察して老化の程度を評価します。がん患者を対象とした研究では、顔年齢が実年齢よりも若く見える患者は、治療効果が高く、生存リスクが低いことが判明しました。このツールは将来、医師が患者の生物学的年齢に基づいて個別化された治療計画を立てるのを補助する可能性がありますが、データバイアス(訓練データが白人中心)や潜在的な乱用(保険差別など)に関する懸念も引き起こしています (出典: WeChat)

研究:トップAIが基本的な物理タスクで低性能、ブルーカラーの仕事が短期的には代替困難であることを浮き彫りに: 機械学習研究者のAdam Karvonen氏は、部品製造タスク(CNCフライス盤と旋盤を使用)を通じて、OpenAI o3、Gemini 2.5 ProなどのトップLLMの性能を評価しました。その結果、すべてのモデルが満足のいく加工計画を策定できず、視覚理解(細部の見落とし、特徴認識の不一致)と物理的推論(剛性と振動の無視、不可能なワークピースのクランプ方法の提案)における欠陥が露呈しました。Karvonen氏は、これはLLMが関連分野の暗黙知と実世界の経験データに欠けていることに関連していると考えています。彼は、短期的にはAIがより多くのホワイトカラーの仕事を自動化する一方で、物理的な操作と経験に依存するブルーカラーの仕事は影響が比較的小さく、これが異なる産業間での自動化の不均衡な発展につながる可能性があると推測しています (出典: WeChat)
