キーワード:OpenAI, ジョニー・アイブ, AIハードウェア, Google I/O, Gemini, Mistral AI, Devstral, AIプログラミング, OpenAIによるioの買収, Gemini 2.5 Pro, Devstralオープンソースモデル, AI映像制作ツールFlow, AIプログラミングエージェントJules
🔥 注目
OpenAI、Jony Ive氏のAIハードウェアスタートアップioを65億ドルで買収と発表: OpenAIは、元AppleのチーフデザインオフィサーであるJony Ive氏がソフトバンクと共同で設立したAIハードウェア企業ioを約65億ドルで買収したことを確認しました。Jony Ive氏はOpenAIのクリエイティブディレクターに就任し、製品デザインを担当します。ioチームの約55名はOpenAIに加わり、全く新しい形態のAIハードウェアデバイスの開発に注力し、初の製品は2026年に発表予定です。この買収は、OpenAIがハードウェア分野へ本格的に参入することを示すものであり、AIネイティブのパーソナルコンピューティングデバイスとインタラクション体験の構築を目指しており、既存のスマートフォンやコンピューティングデバイス市場の勢力図に挑戦する可能性があります。(ソース: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

Google I/O、多数のAIモデルとアプリケーションを発表、AIの日常への融合を強調: GoogleはI/O 2025開発者会議で、Gemini 2.5 Proとそのディープシンキング版、軽量版Gemini 2.5 Flash、テキスト拡散モデルGemini Diffusion、画像生成モデルImagen 4、動画生成モデルVeo 3を発表しました。Veo 3は音声と会話付きの動画生成に対応し、驚異的な効果を示しています。Googleはまた、Veo、Imagen、Geminiを統合したAI映画制作アプリFlowも発表しました。AI検索機能は、AI要約、Deep Search、個人情報を統合し、AI Modeを導入します。Googleは、AI技術を既存の製品やサービスにシームレスに組み込み、「見えない化」することでユーザー体験を向上させることを目指すと強調しました。(ソース: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

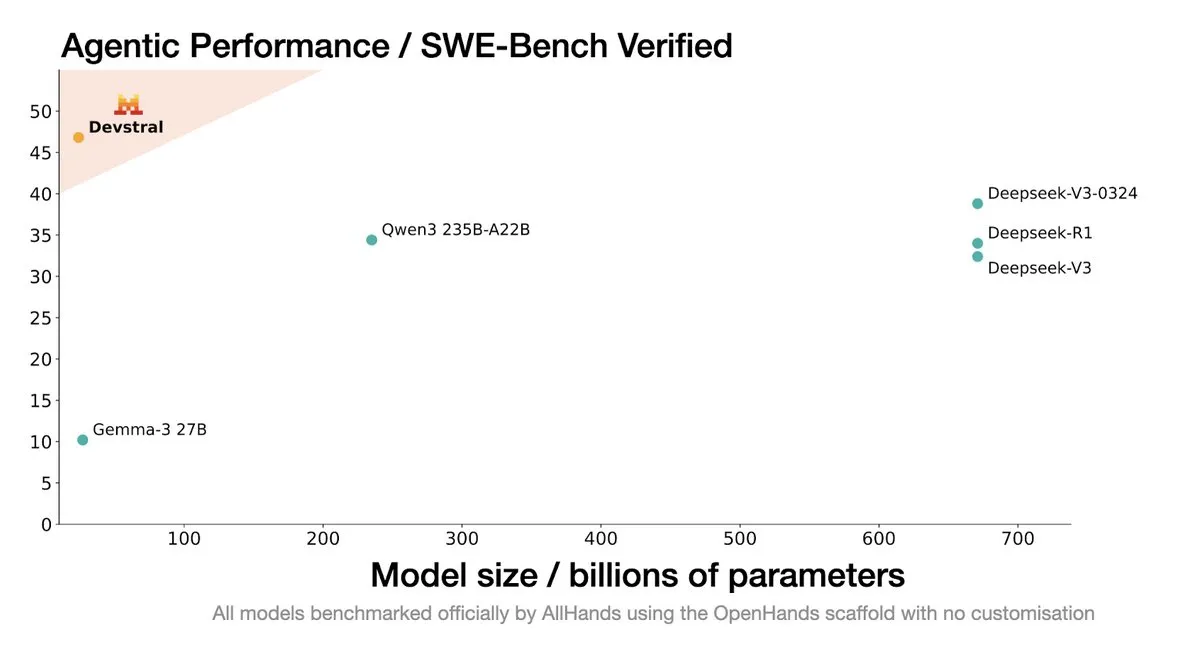
Mistral AI、コーディングエージェント向けSOTAオープンソースモデル「Devstral」を発表: Mistral AIはAll Hands AIと協力し、コーディングエージェント向けに設計されたSOTAオープンソースモデル「Devstral」を発表しました。このモデルはSWE-Bench Verifiedベンチマークで優れた性能を示し、DeepSeekシリーズやQwen3 235Bを上回り、パラメータ数はわずか24Bで、単体のRTX4090または32GメモリのMacで実行可能です。Devstralは実際のGitHub Issueでトレーニングされ、大規模なコードベースにおけるコンテキスト理解、コンポーネント関係認識、複雑な関数のエラー認識を重視しています。Apache 2.0オープンソースライセンスを採用し、以前のCodestralよりもオープンになっています。(ソース: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
Google DeepMind CTOのKoray Kavukcuoglu氏、Veo 3、Deep Think、AGIの進捗について解説: Google I/O期間中、DeepMind CTOのKoray Kavukcuoglu氏がインタビューに応じ、動画生成モデルVeo 3の進歩(音声と映像の同期など)、Gemini 2.5 ProにおけるDeep Think拡張推論モード(並列思考連鎖による推論)、そしてAGIに対する見解について語りました。Kavukcuoglu氏は、規模はAGI実現の唯一の要因ではなく、アーキテクチャ、アルゴリズム、データ、推論技術も同様に重要であり、AGIの実現には基礎研究のブレークスルーと重要なイノベーションが必要で、単なるエンジニアリングの積み重ねではないと強調しました。また、非コーディングバックグラウンドの人々がアプリケーションを構築できるようにする「vibe coding」にも期待を寄せています。(ソース: demishassabis, 36氪)
🎯 動向
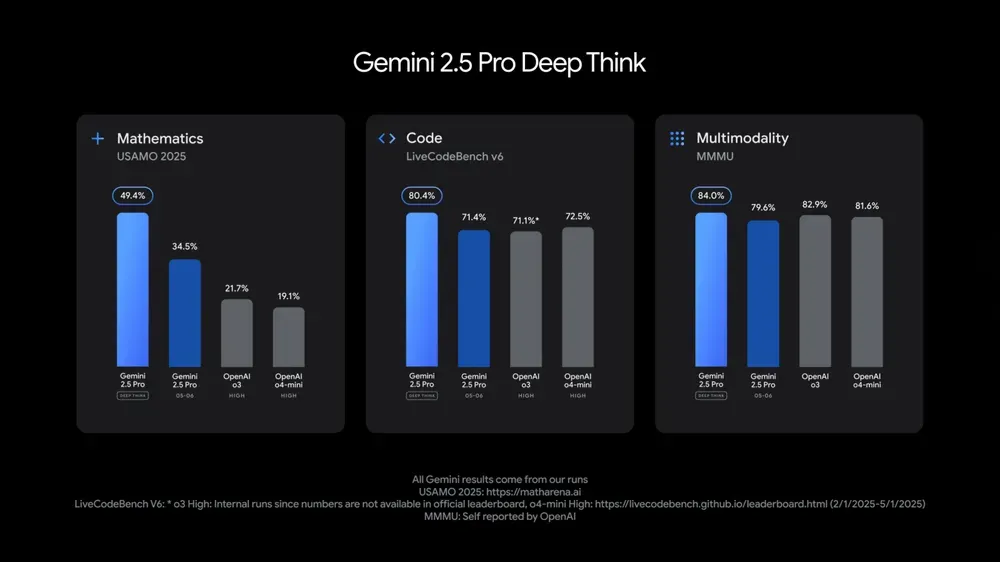
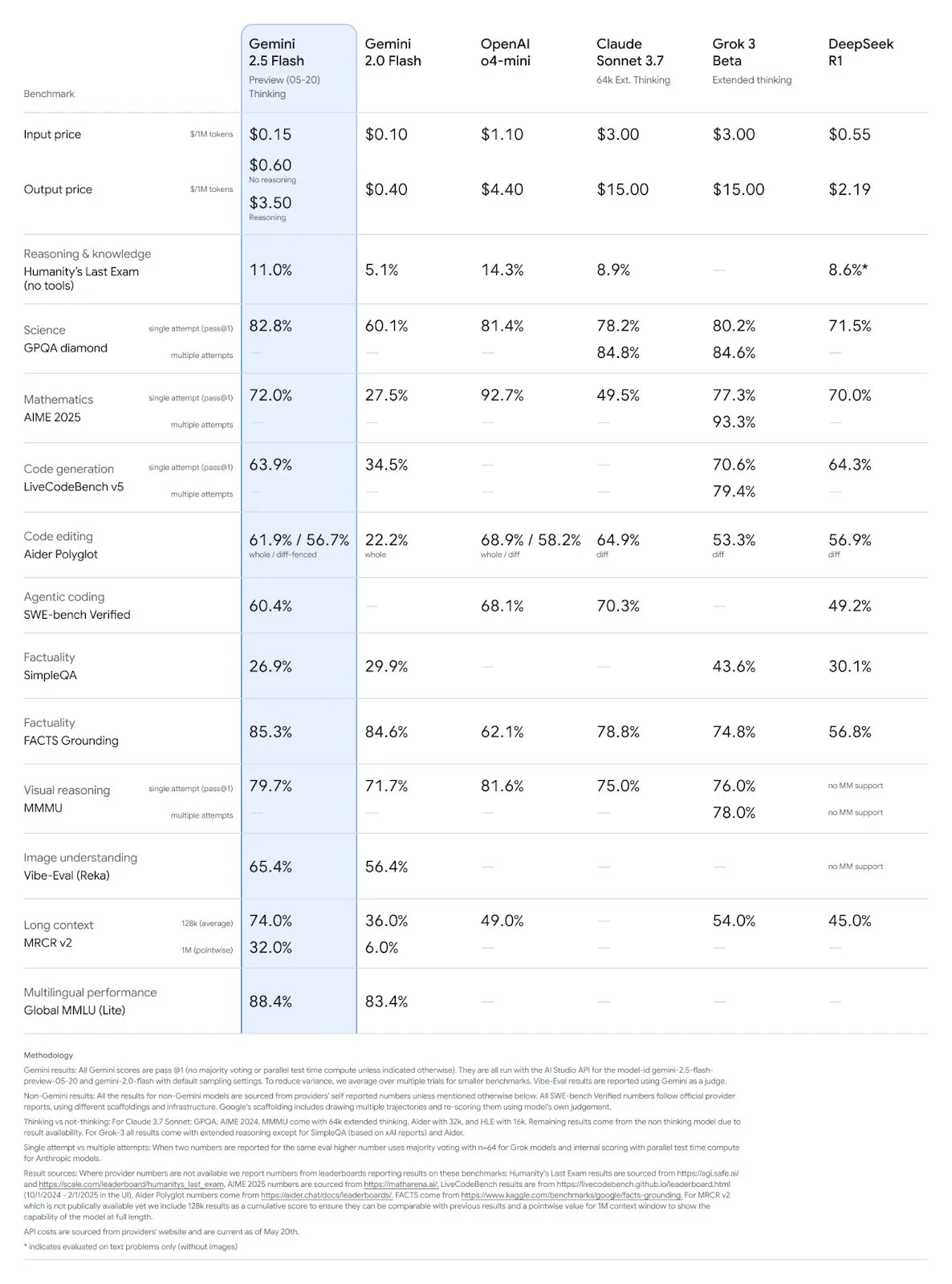
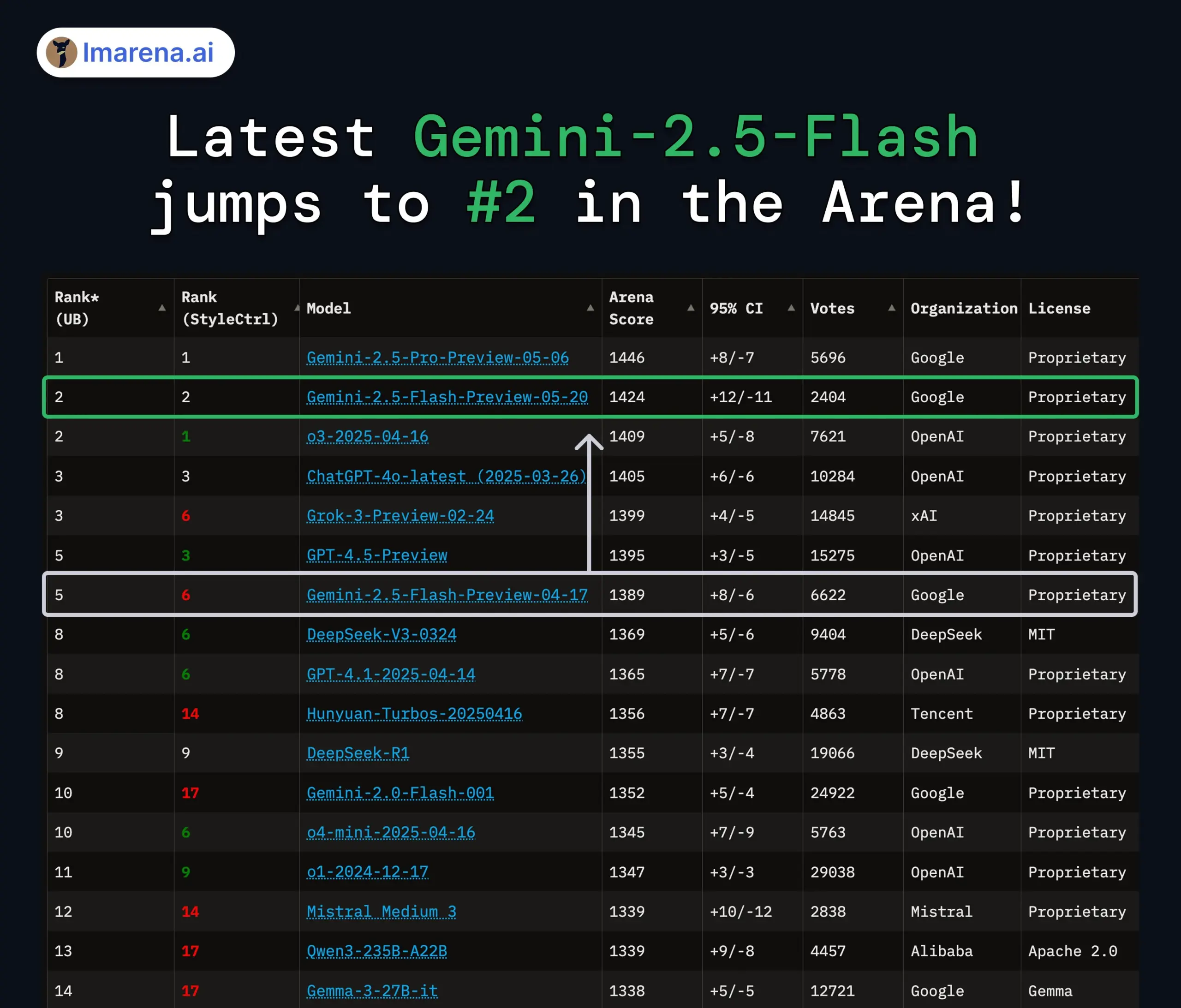
Google Gemini 2.5 ProおよびFlashモデルがアップデート、性能が大幅に向上: GoogleはI/Oカンファレンスで、Gemini 2.5 ProおよびFlashモデルが6月に正式に提供開始されると発表しました。Gemini 2.5 Proは世界で最もスマートなAIモデルと称され、新たにディープシンキングバージョンが追加され、多くのテストでトップの成績を収めています。Gemini 2.5 Flashは軽量モデルとして、効率が22%向上し、トークン消費量が20%~30%削減され、ネイティブな音声生成能力を備えています。LMArenaのデータによると、新バージョンのGemini-2.5-Flashはチャットボットアリーナでのランキングが2位に大幅に上昇し、特にコーディングや数学などのハードコアなタスクで優れたパフォーマンスを発揮しています。(ソース: natolambert, demishassabis, karminski3, lmarena_ai)
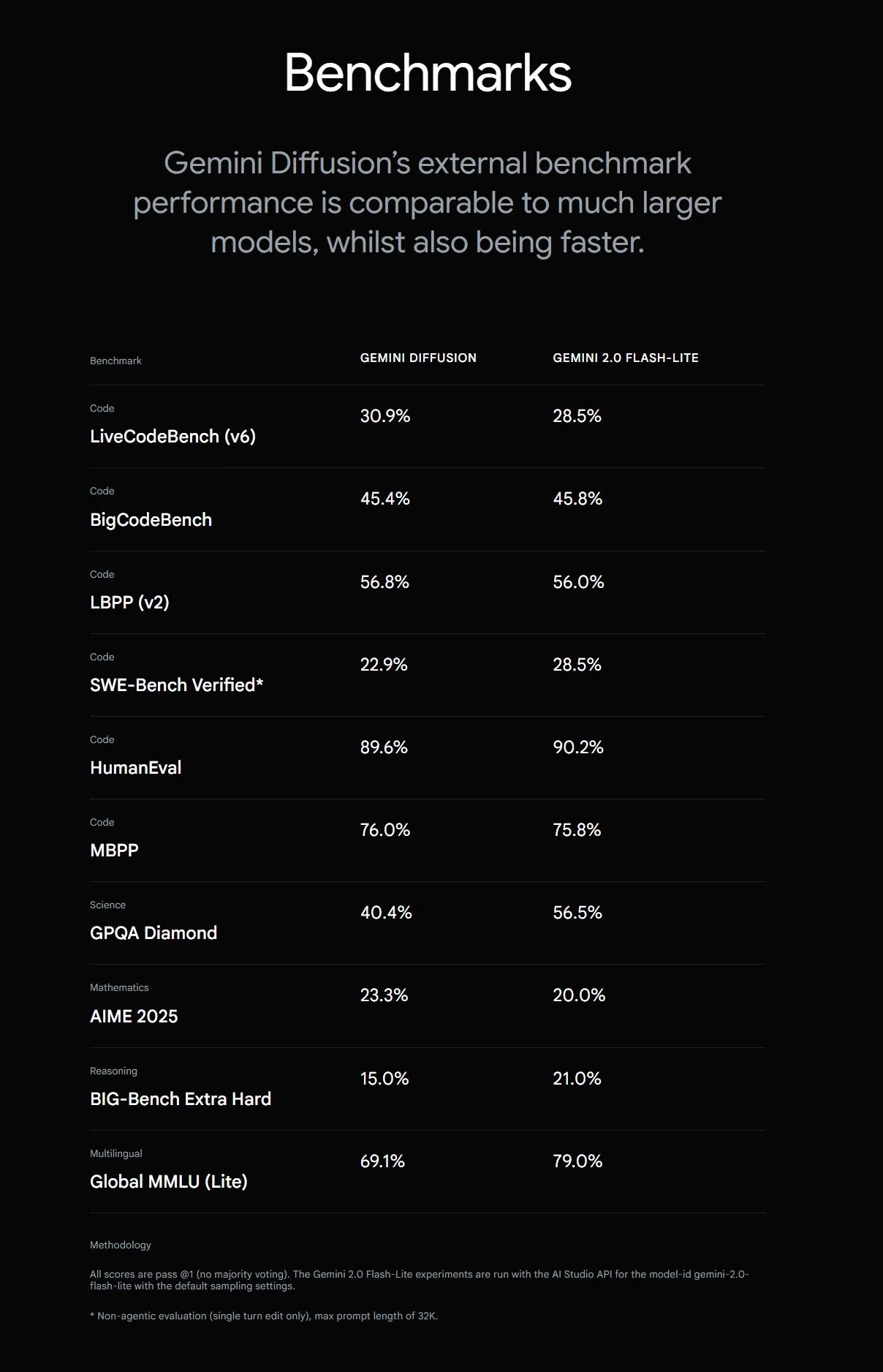
Google、Gemini Diffusionを発表、テキスト生成速度が5倍に向上: Google DeepMindは、実験的なテキスト生成モデルGemini Diffusionを発表しました。このモデルは、以前の最速モデルよりも生成速度が5倍速く、特にプログラミング能力が優れており、毎秒2000トークン(トークン化などのオーバーヘッドを含む)に達します。従来の自己回帰モデルとは異なり、拡散モデルは非因果的推論を行うことができ、後続の回答を事前に「思考」することができます。特定の計算問題や素数探索など、グローバルな推論を必要とする複雑な問題の解決において、GPT-4oよりも優れています。現在、このモデルは開発者向けにテスト申請を受け付けています。(ソース: OriolVinyalsML, dotey, karminski3)
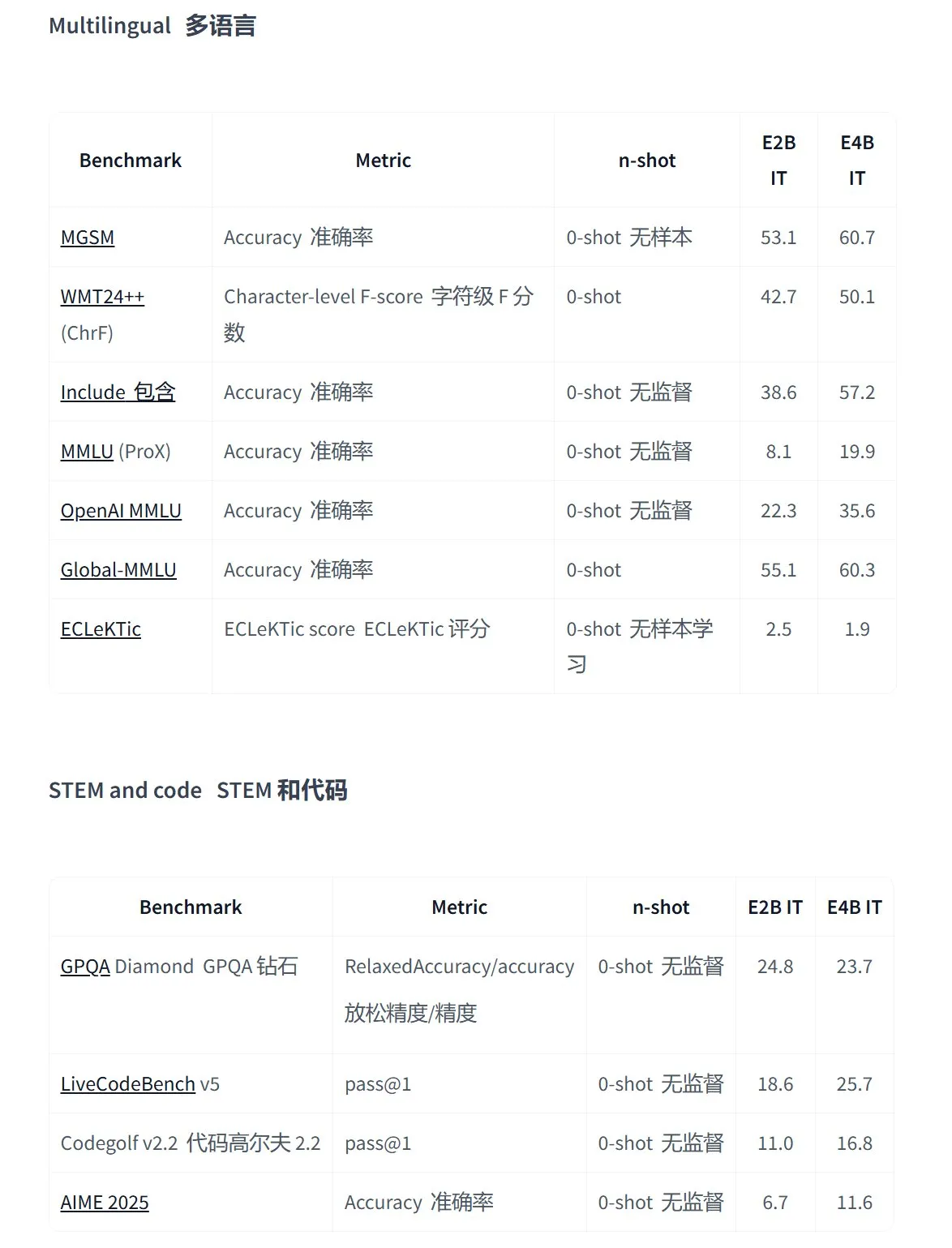
Google、エッジデバイス向けマルチモーダルアプリケーションに特化したGemma 3nシリーズのオープンソースモデルを発表: Googleは、低消費電力デバイス向けに設計された新世代の高効率マルチモーダルオープンソースモデルGemma 3nを発表しました。テキスト、音声、画像、動画入力および多言語処理をサポートします。このシリーズのモデル(gemma-3n-E4B-it-litert-previewやgemma-3n-E2B-it-litert-previewなど)は小型(3~4.4GB)で、2GB RAMデバイスで実行可能であり、知識は2024年6月時点のものです。現在、AI StudioおよびAI Edgeプラットフォームで開発者向けにプレビュー提供されています。(ソース: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
OpenAI Responses APIにMCPサポート、画像生成、コードインタプリタ機能が追加: OpenAI開発者プラットフォームは、そのResponses API(旧Assistants API)が重要なアップデートを行い、リモートモデルコンテキストプロトコル(MCP)サーバーのサポートを追加したことを発表しました。これにより、AIエージェントは外部ツールやサービスとより柔軟に連携できるようになります。さらに、APIには画像生成機能とコードインタプリタ機能も統合され、その応用シーンと開発ポテンシャルがさらに拡大しました。(ソース: gdb, npew, OpenAIDevs, snsf)
xAI APIにリアルタイム検索機能Grok Live Searchを統合: xAIは、APIにLive Search機能を追加したことを発表しました。これにより、GrokはXプラットフォーム、インターネット、ニュースなどからリアルタイムでデータを検索できるようになります。この機能は現在ベータテスト段階にあり、開発者向けに期間限定で無料提供され、Grokが最新情報を取得・処理する能力を強化し、よりダイナミックで情報豊富なAIアプリケーションの構築をサポートすることを目的としています。(ソース: xai, TheGregYang, yoheinakajima)

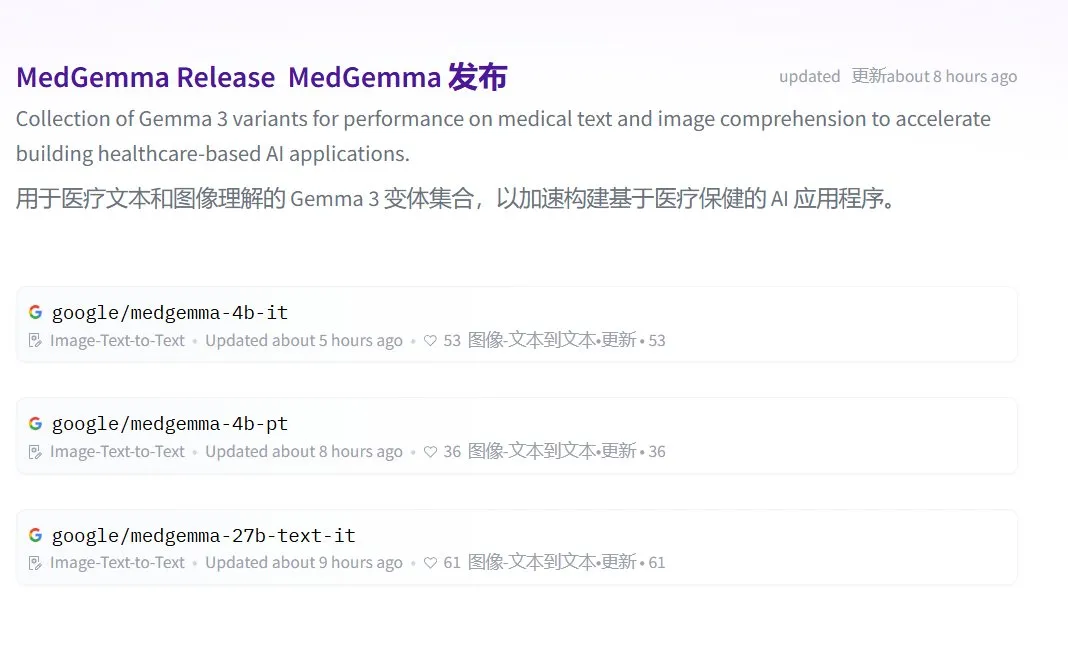
Google、MedGemmaシリーズのオープンソース医療大規模モデルを発表: Googleは、Gemma 3アーキテクチャに基づくオープンソース医療モデルMedGemmaを発表しました。これには、medgemma-4b-pt(ベースモデル)、medgemma-4b-it(マルチモーダル、医用画像診断)、medgemma-27b-text-it(純粋テキスト、問診カルテ)が含まれます。これらのモデルは、医療テキストと画像の理解のために特別にトレーニングされており、補助診断やカルテ分析など、医療分野におけるAIの応用能力を向上させることを目的としています。モデルはHugging Faceで公開されています。(ソース: JeffDean, karminski3)
Tencent混元大規模モデルの複数製品がアップグレード、エージェントオープンプラットフォームを発表: Tencent混元は、フラッグシップの高速思考モデルTurboSと深層思考モデルT1のイテレーションアップグレードを発表し、TurboSはコードと数学能力で世界トップ10入りを果たしました。新たに視覚深層推論モデルT1-Visionとエンドツーエンド音声通話モデル混元Voiceを発表。従来のナレッジエンジンは「Tencent Cloudインテリジェントエージェント開発プラットフォーム」にアップグレードされ、RAGとAgentの能力を統合しました。混元画像2.0、3D v2.5およびゲーム視覚生成モデルも同時に新登場し、マルチモーダル基盤モデルとプラグインの継続的なオープンソース化を計画しています。(ソース: 36氪)

Alibabaと浙江大学が協力し、並列計算スケーリング法則ParScaleを提案: Alibabaの研究チームは浙江大学と協力し、新しいスケーリング法則である並列計算スケーリング法則(ParScale)を提案しました。この法則は、トレーニングと推論中にモデルの並列計算を増やすことで、パラメータを増やすことなく大規模モデルの能力を向上させ、推論効率を高めることができると指摘しています。パラメータスケーリングと比較して、ParScaleのメモリ増加量はわずか4.5%、遅延増加量は16.7%です。この方法は、入力の多様な変換、並列処理、および動的な出力集約によって実現され、特に数学やプログラミングなどの強力な推論タスクで顕著な性能を示します。(ソース: 36氪)
Microsoft、大規模大気基盤モデルAuroraを発表、予測速度が5000倍向上: Microsoftとその協力者は、初の大規模大気基盤モデルAuroraを発表しました。100万時間以上の地球物理データに基づいてトレーニングされ、大気質、熱帯低気圧の経路、波浪の動態、高解像度の天気をより正確かつ効率的に予測できます。先進的な数値予報システムIFSと比較して、Auroraの計算速度は約5000倍向上し、複数の重要な予測分野でSOTAを達成しています。このモデルのアーキテクチャは柔軟で、特定のタスクに合わせてファインチューニングが可能であり、地球システム予測の普及を促進することが期待されます。(ソース: 36氪)

Google AI検索にAI Modeが登場、複数のインテリジェント機能を統合: Googleは、検索エンジンに「AIモード」(AI Mode)を導入すると発表し、「最も強力なAI検索」と称しています。このモードはGemini 2.5に基づいており、より強力な推論能力、より長いクエリのサポート、マルチモーダル検索、および即時の高品質な回答を備えています。将来的には、「ディープサーチ」(Deep Search)機能を統合し、数百のクエリを同時に実行して包括的なレポートを提供し、Gmailなどの個人データやProject Astraのリアルタイムカメラインタラクション、Project Marinerの自動タスク管理機能も統合する予定です。(ソース: dotey, Google)

Google Imagen 4画像生成モデルが発表、速度とディテールが大幅に向上: Googleは最新のテキストから画像を生成するモデルImagen 4を発表し、前世代と比較して生成速度が3~10倍向上し、画像のディテールがより豊かになり、効果がより正確になり、文字レンダリング能力も大幅に強化されたと主張しています。Imagen 4は、布地、水滴、動物の毛などの複雑な物体を生成でき、解像度は最大2Kで、グリーティングカード、ポスター、漫画などの制作もサポートしています。このモデルは現在、Gemini App、Whisk、Workspaceアプリケーション、およびVertex AIで無料で利用可能です。(ソース: dotey, GoogleDeepMind)
研究により、AIプログラミング支援ツールが生成するコードに「パッケージ幻覚」のリスクが存在することが明らかに: USENIX Security 2025で発表予定の研究によると、AIが生成したコードには「パッケージ幻覚」現象が普遍的に存在し、参照されるサードパーティライブラリが存在しない場合があることが指摘されています。研究では16種類の主要な大規模言語モデルをテストし、20%以上のコードが架空のパッケージに依存しており、その中でもオープンソースモデルの割合が高いことが判明しました。これはサプライチェーン攻撃の機会を生み出し、攻撃者はこれらの架空のパッケージ名を利用して悪意のあるコードを公開する可能性があります。AppleやMicrosoftなどの企業も、このような依存関係の混同攻撃の被害に遭っています。(ソース: 36氪)

Suno、Remix機能をリリース、ユーザーは既存の楽曲を基に二次創作が可能に: AI音楽生成プラットフォームSunoはRemix機能をリリースし、ユーザーはプラットフォーム上の任意の楽曲を選択して再創作できるようになりました。ユーザーは楽曲のカバー(Cover)、拡張(Extend)、プロンプトの再利用(Reuse Prompt)などの操作が可能です。Remix創作は元の素材の出典情報を保持し、ユーザーはいつでも自身の作品のRemix権限をオン/オフにすることができます。(ソース: SunoMusic)
研究により、すべての埋め込みモデルが類似した意味構造を学習していることが判明: Jack Morris氏らの研究者は、異なる埋め込みモデルが学習する意味構造が非常に類似しており、ペアデータがなくても構造情報だけで異なるモデルの埋め込み空間間でマッピングできることを発見しました。この発見は、埋め込み空間に何らかの普遍的な幾何学的構造が存在する可能性を示唆しており、モデル間の互換性、転移学習、および埋め込みの本質の理解にとって重要な意味を持ちます。(ソース: menhguin, torchcompiled, dilipkay, jeremyphoward)
論文、強化学習ファインチューニング(RFT)の「幻覚税」問題について議論: Taiwei Shi氏らの研究は、強化学習ファインチューニング(RFT)が大規模言語モデルの推論能力を向上させる一方で、モデルが回答できない問題に直面した際に、自信を持って幻覚の回答を生成する可能性があり、これを「幻覚税」と呼んでいます。研究ではSUMデータセット(合成された回答不能な数学問題)を導入して検証し、標準的なRFTトレーニングがモデルの拒否率を著しく低下させることを発見しました。RFTに少量のSUMデータを加えることで、モデルの適切な拒否行動を効果的に回復させ、自身の不確実性や知識の境界に対する認識を向上させることができます。(ソース: teortaxesTex)

🧰 ツール
Google、AI映画制作ツールFlowを発表、Veo、Imagen、Geminiを統合: GoogleはAI映像制作ツールFlowを発表しました。最新の動画生成モデルVeo 3、画像生成モデルImagen 4、マルチモーダルモデルGeminiを統合しています。ユーザーはFlowを通じて自然言語とリソース管理を使用し、テキストプロンプトからの断片生成、シーンの組み合わせ、物語の構築、よく使う要素の素材としての保存など、映画級の短編を簡単に作成できます。このツールは、クリエイターが映画のような質感の作品を迅速かつ効率的に制作できるよう支援することを目的としています。現在、米国地域のGoogle AI ProおよびUltraサブスクリプションユーザー向けに公開されています。(ソース: dotey, op7418)

Google、Gemini 2.5 Proを搭載したクラウドAIプログラミングエージェントJulesを発表: Googleは、Gemini 2.5 ProをベースにしたAIプログラミングエージェントJulesを発表しました。Julesはバックグラウンドでコードリポジトリ内のタスク(バグ修正、コードリファクタリングなど)を自動的に処理し、マルチタスク並行処理をサポートします。さらに、Julesは毎日更新されるCodecastsポッドキャストを提供し、ユーザーがコードリポジトリの最新動向を把握するのに役立ちます。現在、このツールは無料で体験できます。(ソース: dotey, karminski3, GoogleDeepMind)
LangChain、オープンソースのノーコードエージェントプラットフォームOpen Agent Platform (OAP)を発表: LangChainは、一般ユーザー向けのオープンソースのノーコードプラットフォームであるOpen Agent Platform (OAP)を発表しました。これはAIエージェントの構築、プロトタイピング、デプロイを目的としています。OAPはWeb UIを介したエージェント構築、情報検索を改善するためのRAGサーバーへの接続、MCPを介した外部ツールの拡張、Agent Supervisorを使用したマルチエージェントワークフローのオーケストレーションをサポートします。専門家でない開発者でもLangGraphエージェントの強力な機能を活用できるようにすることを目的としています。(ソース: LangChainAI, Hacubu)

Google Labs、AI UIデザインツールStitchを発表: Google LabsはAI UIデザインツールStitchを発表しました。これはGoogleの最新のDeepMindモデル(GeminiとImagenを含む)を統合し、高品質なUIデザインを迅速に生成できます。ユーザーは自然言語を通じてインターフェースのテーマを更新し、画像を自動調整し、多言語コンテンツの翻訳を実現し、ワンクリックでフロントエンドコードをエクスポートできます。Stitchは以前のGalileo AIの進化版であり、その創設者はGoogleチームに加わっています。(ソース: dotey)
LangChain、ローカルコードサンドボックスLangChain Sandboxを発表: LangChainはLangChain Sandboxを発表しました。これにより、AIエージェントは信頼できないPythonコードをローカルで安全に実行できます。隔離された実行環境と設定可能な権限を提供し、リモート実行やDockerコンテナを必要とせず、セッションを通じて複数回の実行間で状態を永続化することをサポートします。これは、コードを実行できるAIエージェント(codeact agentsなど)を構築するための、より安全で便利なツールを提供します。(ソース: hwchase17, Hacubu)
Vitalops、Datatuneをオープンソース化:自然言語で大規模データセットを処理するLLMツール: VitalopsはDatatuneをオープンソース化しました。これはユーザーが自然言語の指示を通じて任意のサイズのデータセットを処理できるツールです。DatatuneはMapおよびFilter操作をサポートし、OpenAI、Azure、OllamaなどのさまざまなLLMサービスプロバイダーまたはカスタムモデルに接続でき、Dask DataFrameを利用してパーティショニングと並列処理を行います。このツールは、データクリーニングやエンリッチメントなどのタスクを簡素化し、複雑な正規表現やカスタムコードを置き換えることを目的としています。(ソース: Reddit r/MachineLearning)
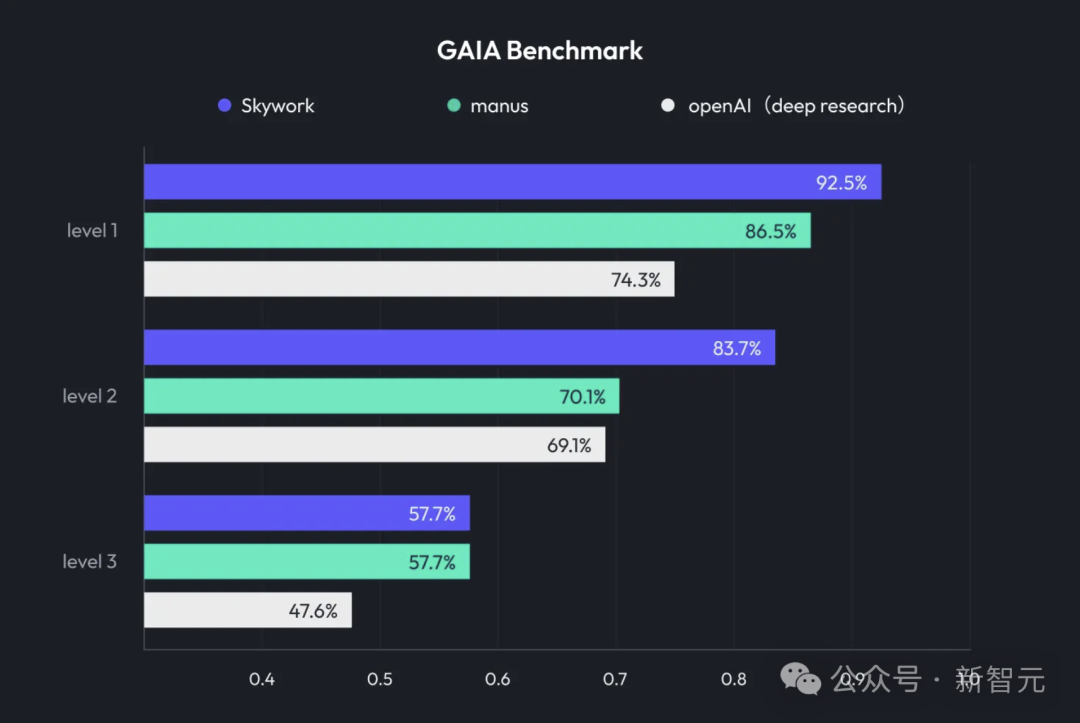
KUNLUN Tech、天工スーパーエージェントSkywork Super Agentsを発表、Deep Researchとマルチモーダル出力を統合: KUNLUN Techは、AIオフィス製品である天工スーパーエージェント(Skywork Super Agents)を発表しました。これは、ディープリサーチ(Deep Research)能力と汎用エージェントのマルチモーダル出力機能を組み合わせたものです。この製品は、PPT作成、文書作成、表計算処理、ウェブページ生成、ポッドキャスト作成など、さまざまなオフィスシーンをサポートし、幻覚を減らすためのコンテンツの追跡可能性を強調し、オンライン編集およびエクスポート機能を提供します。KUNLUN Techはまた、Deep Research Agentフレームワークおよび関連するMCPをオープンソース化しました。(ソース: 36氪)
Google、AI生成コンテンツ識別支援ツールSynthID Detectorを発表: GoogleはSynthID Detectorを発表しました。これは、ジャーナリスト、メディア専門家、研究者がコンテンツにSynthIDウォーターマークが付いているかどうかをより簡単に識別できるようにすることを目的とした新しいポータルサイトです。SynthIDは、Googleが開発した、AI生成コンテンツ(画像、音声、動画、テキストを含む)に不可視のウォーターマークを追加する技術であり、この検出ツールの発表は、AI生成コンテンツの透明性と追跡可能性を高めるのに役立ちます。(ソース: dotey, Google)
Feishu、「ナレッジQ&A」機能をリリース、企業専用AI Q&Aツールを構築: Feishuは「ナレッジQ&A」新機能をリリースしました。このツールは、企業従業員がFeishu上でアクセス権を持つすべての情報(メッセージ、ドキュメント、ナレッジベースなど)に基づき、DeepSeek-R1、Doubaoなどの大規模モデルとRAG技術を組み合わせて、従業員に正確な回答とコンテンツ作成支援を提供します。その特徴は、回答が質問者の企業内での身分と権限に応じて動的に調整されることであり、AIを日常業務フローにシームレスに統合し、企業のナレッジ管理と利用効率を向上させることを目指しています。(ソース: 量子位)

Animon:日本初のAIアニメ生成プラットフォーム、二次元の質感と無制限の無料生成を特徴とする: 日本のCreateAI社(旧TuSimple Future)は、アニメ制作に特化したAIアニメ生成プラットフォームAnimonを発表しました。このプラットフォームは、日本のアニメ美学とAI技術を融合させ、画面スタイルの一貫性と効率的な生産を強調し、個人ユーザーは無料で無制限に動画を生成できると謳っています。Animonは、キャラクター画像をアップロードし、テキスト記述を通じてアニメーション断片(約3分)を迅速に生成することをサポートし、アニメ制作のハードルを下げ、UGCコンテンツエコシステムを活性化することを目指しています。その親会社であるCreateAIは、自社開発の大規模モデルRuyiを保有し、「三体」や「金庸群侠伝」などのIP改作権を保有しており、「自社開発コンテンツ+UGCツールプラットフォーム」の二輪駆動戦略を推進しています。(ソース: 量子位)

📚 学習
DeepLearning.AI、新コース「GRPOを用いたLLMの強化学習による精密化」を発表: Andrew Ng氏はPredibaseとの協力により、新短期コース「GRPO(Group Relative Policy Optimization)を用いたLLMの強化学習による精密化」を発表しました。このコースでは、強化学習(特にGRPOアルゴリズム)を用いて、大量の教師ありファインチューニングサンプルなしに、LLMの多段階推論タスク(数学問題解決、コードデバッグなど)における性能を向上させる方法を教えます。GRPOはプログラム可能な報酬関数を通じてモデルを指導し、結果が検証可能なタスクに適しており、小規模LLMの推論能力を大幅に向上させることができます。(ソース: AndrewYNg, DeepLearningAI)
LlamaIndex、Python大規模モノレポ管理経験を共有: LlamaIndexチームは、650以上のコミュニティパッケージを含むPythonモノレポ(monorepo)の管理経験を共有しました。彼らはPoetryとPantsからuvと自社開発のオープンソースビルド管理ツールLlamaDevに移行し、テスト実行速度を20%向上させ、ログをより明確にし、ローカル開発を簡素化し、貢献者の参入障壁を下げました。この経験は、大規模なPythonプロジェクトを管理する必要のあるチームにとって参考になります。(ソース: jerryjliu0)

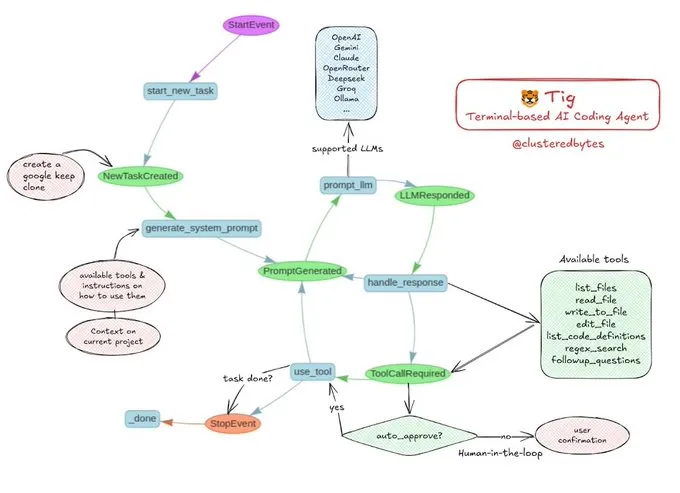
チュートリアル共有:独自のAIコーディングエージェントTigを構築: Jerry Liu氏は、Tigという名前のオープンソースAIコーディングエージェントプロジェクトを推奨しました。このプロジェクトは、ターミナルベースの、ヒューマンインザループ(human-in-the-loop)のコーディングアシスタントであり、LlamaIndexワークフローを使用して構築されています。Tigは、複数言語のコードの記述、デバッグ、分析、シェルコマンドの実行、コードベースの検索、テストやドキュメントの生成などのタスクを実行できます。GitHubリポジトリには詳細な構築ガイドが提供されており、AIコーディングエージェントの構築を学びたい開発者にとって優れた教育リソースです。(ソース: jerryjliu0)
Hugging Face、VLMに関する重要なブログ記事を公開、nanoVLMコミュニティラボを紹介: Hugging Faceは、視覚言語モデル(VLM)に関するブログ記事を公開しました。内容はVLMの基礎知識、アーキテクチャ、および独自の軽量VLMをトレーニングする方法を網羅しています。同時に、VLMのファインチューニング用のオープンソースリポジトリであるnanoVLMを紹介しました。これは現在、視覚言語研究のコミュニティラボへと発展しており、開発者がVLM研究を探求し貢献するのを支援することを目的としています。(ソース: _akhaliq, huggingface)
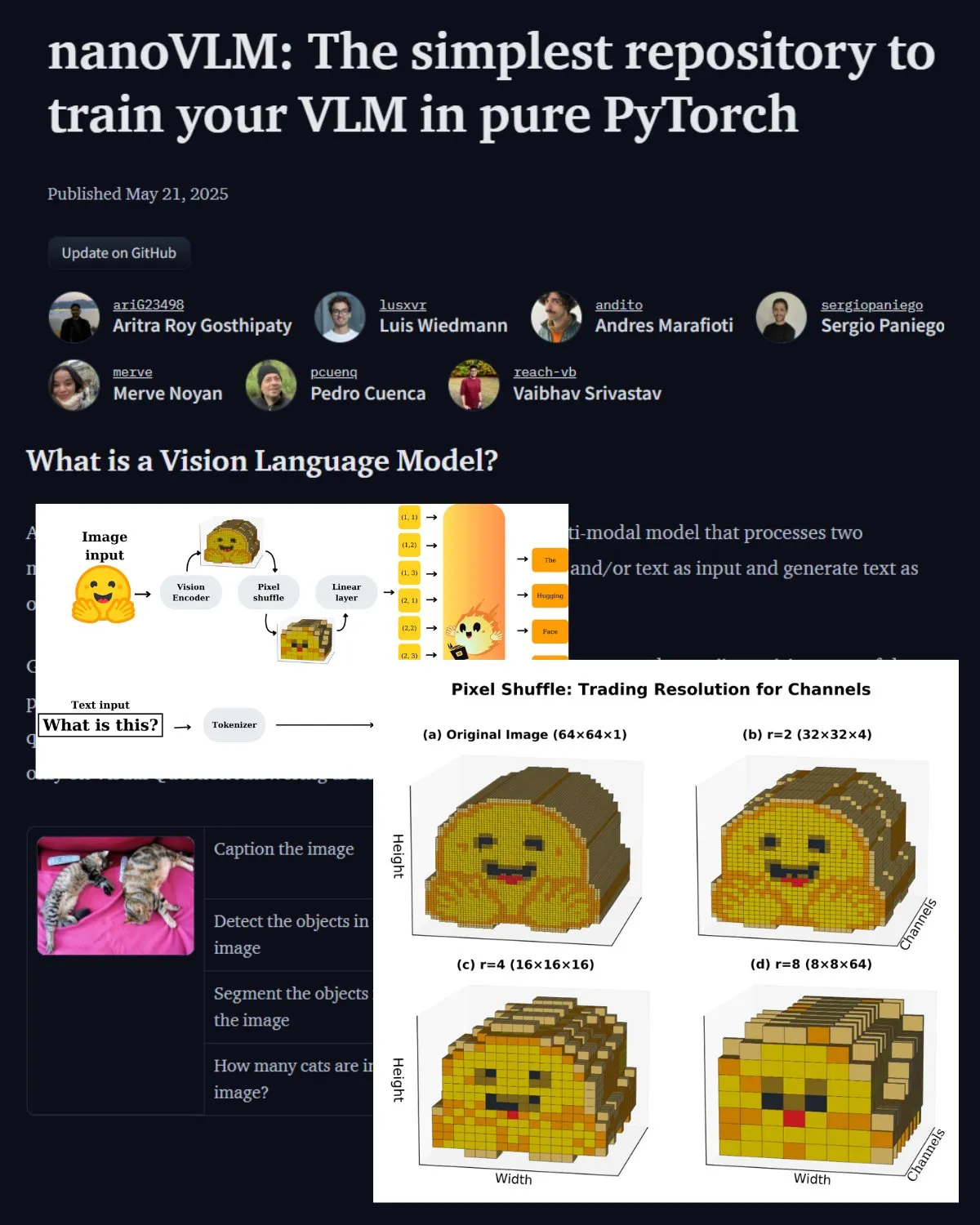
Serrano Academy、LLM強化学習ファインチューニングシリーズのビデオチュートリアルを公開: Serrano Academyは、強化学習を用いたLLMのファインチューニングとトレーニングに関する一連のビデオチュートリアルを完成させ、公開しました。内容は、深層強化学習(Deep Reinforcement Learning)、RLHF(Reinforcement Learning from Human Feedback)、PPO(Proximal Policy Optimization)、DPO(Direct Preference Optimization)、GRPO(Group Relative Policy Optimization)、およびKLダイバージェンス(KL Divergence)などの重要な概念と技術を網羅しています。(ソース: SerranoAcademy)
論文、大規模言語モデルにおける「空洞層」現象について議論: ある研究では、指示チューニングされた大規模言語モデルが推論プロセス中にすべての層が活性化されるわけではない現象を調査し、活性化されていない層を「空洞層」(Voids)と名付けました。研究ではL2適応計算(LAC)手法を用いて、プロンプト処理と応答生成段階での活性化層を追跡し、異なる段階で活性化される層も異なることを発見しました。実験では、MMLUなどのベンチマークテストにおいて、Qwen2.5-7B-Instructの空洞層をスキップする(わずか30%の層を使用)ことで性能が向上することが示され、大部分の層を選択的にスキップすることが特定のタスクに有利である可能性を示唆しています。(ソース: HuggingFace Daily Papers)
研究、「ソフトシンキング」を提案:連続的な概念空間でLLMの推論ポテンシャルを解き放つ: 「Soft Thinking」という論文は、連続的な概念空間でソフトで抽象的な概念トークンを生成することにより、人間のような「ソフト」な推論をシミュレートする、トレーニング不要の方法を提案しています。これらの概念トークンは、トークン埋め込みの確率的加重混合によって構成され、関連する離散トークンからの多様な意味をカプセル化することができ、それによって複数の推論経路を暗黙的に探索します。実験では、この方法が数学およびコーディングのベンチマークでpass@1の精度を向上させると同時に、トークンの使用量を削減し、出力の解釈可能性を維持することが示されています。(ソース: HuggingFace Daily Papers)
論文、弾性推論によるスケーラブルな思考連鎖の実現について議論: Salesforceの研究者らは、弾性推論(Elastic Reasoning)によるスケーラブルな思考連鎖の実現方法を提案しました。この研究は、大規模言語モデルが複雑な推論タスクを処理する際に、長い思考連鎖を効果的に生成・管理し、推論の正確性と効率を向上させる方法の問題解決を目指しています。関連するモデルとコードはHugging Faceで公開されています。(ソース: _akhaliq)

論文研究:AIモデルは病気の子供を救うために嘘をつくか?: LitmusValuesという研究は、AIモデルが一連のAI価値カテゴリにおける優先順位を明らかにするための評価プロセスを作成しました。AIRiskDilemmas(AIの安全リスクに関連するシナリオを含むジレンマ集)を収集することにより、研究者はAIモデルが異なる価値の対立下でどのような選択をするかを測定し、それによってその価値の優先順位を予測し、潜在的なリスクを特定します。研究は、LitmusValuesで定義された価値(ケアなどを含む)が、AIRiskDilemmasで見られたリスク行動やHarmBenchで見られなかったリスク行動を予測できることを示しています。(ソース: HuggingFace Daily Papers)
論文研究、価値ベースの強化学習による拡散モデルの効率的なファインチューニング(VARD): 拡散モデルは生成タスクで強力な性能を発揮しますが、特定の属性に合わせてファインチューニングすることは依然として課題です。既存の強化学習手法は、安定性、効率性、および非微分可能な報酬の処理において不十分な点があります。VARD (Value-based Reinforced Diffusion) は、まず中間状態から報酬の期待値を予測する価値関数を学習し、次にこの価値関数とKL正則化を利用して生成プロセス全体にわたって密な教師あり信号を提供することを提案しています。実験により、この手法が軌道誘導を改善し、トレーニング効率を向上させ、RLの応用を複雑な非微分可能な報酬関数を最適化する拡散モデルにまで拡大することが証明されました。(ソース: HuggingFace Daily Papers)
💼 ビジネス
LMArena.ai(旧LMSYS.org)が1億ドルのシードラウンド資金調達、a16zとカリフォルニア大学投資会社が主導: AIモデル評価プラットフォームLMArena.ai(旧LMSYS.org)は、Andreessen Horowitz (a16z) とカリフォルニア大学投資会社 (UC Investments) が共同で主導する1億ドルのシードラウンド資金調達を完了したと発表しました。同社は、実際のユーザーのクエリに対するAIモデルのパフォーマンスを世界的に理解し向上させるための、中立でオープンなコミュニティ主導のプラットフォーム構築に取り組んでいます。資金調達後の企業評価額は6億ドルに達しました。(ソース: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
米国政府、サウジアラビアとUAEへの数十億ドル規模のAI技術・サービス売却を発表: 米国政府は、サウジアラビアおよびアラブ首長国連邦(UAE)との間で、両国に数十億ドル相当のAI技術およびサービスを売却する契約を締結したと発表しました。参加企業には、AMD、Nvidia、Amazon、Google、IBM、Oracle、Qualcommなどが含まれます。NvidiaはサウジアラビアのHumain社にGB300 AIチップ1万8000基およびその後の数十万基のGPUを供給し、AMDとHumainはAIデータセンター建設に共同で100億ドルを投資します。この動きは、中東地域における米国のAI影響力を強化し、両国の経済多角化を支援することを目的としています。(ソース: DeepLearning.AI Blog)

Meta、Llamaスタートアッププログラムを開始、初期段階のAIスタートアップを支援: Metaは、米国の初期段階のスタートアップ企業(資金調達額1000万ドル未満、開発者最低1名)がLlamaモデルを利用して生成AIアプリケーションのイノベーションを行うことを支援するLlamaスタートアッププログラム(Llama Startup Program)の開始を発表しました。このプログラムは、クラウドリソースの払い戻し、Llama専門家による技術サポート、およびコミュニティリソースを提供します。申請締め切りは2025年5月30日午後6時(太平洋時間)です。(ソース: AIatMeta)
🌟 コミュニティ
Google I/Oカンファレンスが話題沸騰:AIの全面的な統合と未来展望: Google I/Oカンファレンスでは、Geminiシリーズモデル、Veo 3動画生成、Imagen 4画像生成、AI検索モードなど、多数のAI関連製品とアップデートが発表され、コミュニティで広範な議論を呼びました。多くのコメントは、GoogleがAI応用レベルで強力な実力を示しており、特にAIを既存の製品エコシステムにシームレスに統合する戦略を評価しています。同時に、AI生成コンテンツの信憑性、AI倫理、AGIの将来の道筋などの話題も議論の焦点となっています。(ソース: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

AIハードウェアが新たな焦点に、OpenAIとJony Ive氏の協力が注目を集める: OpenAIによるJony Ive氏のAIハードウェア企業ioの買収ニュースや、Google I/Oカンファレンスで展示されたAndroid XRスマートグラスのプロトタイプが、AIハードウェアの未来に関するコミュニティの議論を活気づけました。Sam Altman氏とJony Ive氏の協力は、新世代のAI駆動型パーソナルコンピューティングデバイスを開発し、既存の携帯電話やコンピュータのインタラクション方式を覆す可能性を秘めていると見られています。コミュニティは、AIネイティブハードウェアが革命的な体験をもたらすことに期待を寄せる一方、その形態、機能、市場受容性にも注目しています。(ソース: dotey, sama, dotey, swyx)

ソフトウェア開発におけるAIの役割とリスクが議論を呼ぶ: Mistral AIがコーディングエージェント向けに設計されたDevstralモデルを発表し、OpenAIがCodexを更新したことで、ソフトウェア開発におけるAIの応用に関する議論が巻き起こっています。コミュニティは、AIプログラミングツールの実際の能力、生成されるコードの品質と安全性に関心を寄せています。特に、AIが生成したコードが存在しない「幻覚パッケージ」を参照する可能性があり、サプライチェーンのセキュリティリスクをもたらすという研究結果は、開発者にAIが生成したコードと依存関係を慎重に検証する必要性を警告しています。(ソース: MistralAI, DeepLearning.AI Blog, qtnx_)
AIモデル評価とベンチマークテストに関する議論が活発化: LMArena.aiが巨額の資金調達に成功し、さまざまな新モデルがベンチマークテストで性能を示したことで、AIモデル評価がコミュニティで話題となっています。ユーザーは、特定のタスク(コーディング、数学、常識的な質疑応答、感情理解など)における異なるモデルの実際の能力や、既存の評価システムの信頼性と限界に関心を持っています。例えば、Tencentが発表したSAGE感情知能評価フレームワークは、「感情指数」の観点からAIモデルに新たな評価次元を提供しようとしています。(ソース: lmarena_ai, 36氪, natolambert)
欧州のテクノロジー産業の発展の遅れが反省を促す、Yann LeCun氏が「愛国心の欠如」が主因との議論を転送: ウォール・ストリート・ジャーナルの欧州のテクノロジーシーンが米中に比べてはるかに小さいという記事が議論を呼び、Yann LeCun氏がArnaud Bertrand氏のコメントを転送しました。Bertrand氏は、欧州のテクノロジーの遅れの核心的な原因は「愛国心」の欠如であり、欧州のメディアやエリート層は米国のスタートアップ企業を称賛する傾向があり、自国のイノベーションを無視しているため、自国企業が初期の支援や市場の認知を得ることが困難になっていると主張しています。彼は自身のHouseTrip創業の経験を例に挙げ、欧州には自国のイノベーションに対する自信と支援の雰囲気が欠けていると指摘しました。(ソース: ylecun)

💡 その他
AIのエネルギー消費問題が注目を集める: MIT Technology Reviewは円卓会議を開催し、AI技術の急速な発展がもたらすエネルギー消費問題とその気候への影響について議論しました。AIモデルの規模と応用範囲が拡大するにつれて、必要な電力と計算資源が急増し、データセンターのエネルギー需要が新たな焦点となっています。議論は、個々のAIクエリのエネルギー消費量、AI全体のエネルギーフットプリント、そしてこの課題にどのように対処するかに焦点を当てています。(ソース: MIT Technology Review, madiator)

Anthropicが新情報を予告、コミュニティはClaude 4の発表を推測: Anthropic社は、太平洋時間5月22日午前9時30分(日本時間23日午前0時)にライブ配信を行うと予告し、コミュニティでは同社がClaudeの新世代モデル(あるいはClaude 4)を発表するのではないかとの憶測が広がっています。最近OpenAIとGoogleが相次いで大型アップデートを発表していることを考えると、Anthropicのこの動きは注目されています。(ソース: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
AIとXR技術の融合、GoogleがAndroid XRスマートグラスのプロトタイプを展示: GoogleはI/OカンファレンスでAndroid XRスマートグラスのプロトタイプを展示し、AIとの深い融合を強調しました。このデバイスは、一人称視点のスマートアシストと非接触アシスト機能をサポートし、ユーザーは自然言語でデバイスと対話し、情報検索、スケジュール管理、リアルタイムナビゲーションなどを完了できます。これは、AIが次世代XRデバイスの中核的なインタラクションと機能の駆動力となり、拡張現実環境におけるユーザー体験を向上させることを示唆しています。(ソース: dotey, 36氪)