
キーワード:AlphaEvolve, AIアルゴリズム設計, マルチモーダルAI, AIプログラミングツール, 自律進化アルゴリズム, 大規模言語モデル, AIエージェント, AlphaEvolveオープンソース実装, AIによる行列乗算アルゴリズムの自律設計, マルチモーダルAI統一インターフェース, AIプログラミングツールが開発者に与える影響, ローカル大規模モデルQwen 3の性能
🔥 注目
Google DeepMindがAlphaEvolveを発表、AIがアルゴリズムを自律的に設計・進化: Google DeepMindはAlphaEvolveプロジェクトとその論文を公開し、自律的に設計、テスト、学習し、より効率的なアルゴリズムを進化させることができるAIエージェントを展示しました。このシステムは、プロンプトエンジニアリングを通じて大規模言語モデル(Geminiなど)を駆動し、初期アルゴリズム案を生成し、進化ループの中で適応度評価と生存者選択を通じてアルゴリズムを最適化します。コミュニティは迅速に反応し、オープンソース実装のOpenAlpha_Evolveが登場し、研究者がClaudeなどのツールを使用してAlphaEvolveの行列乗算などの分野でのブレークスルーを検証し、アルゴリズム革新におけるAIの巨大な可能性を示しています。(ソース: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

OpenAIのマルチモーダル戦略が明らかに:統合インターフェースと集中化インフラが注目を集める: OpenAIは最近、GPT-4o、Sora、Whisperなどの製品の発表を通じて、テキスト、画像、音声・動画などのマルチモーダル能力の進展を示すだけでなく、複数のモダリティを統一インターフェースとAPIに統合する戦略的意図をより明確にしました。この戦略はユーザーに利便性を提供する一方で、インフラの集中化が外部の開発者や研究者のイノベーションの余地を制限する可能性についての議論を引き起こしました。特にSoraのような動画生成モデルは、その高い計算リソース需要により、さらに高コストのアプリケーションをOpenAIエコシステムに組み込み、トッププラットフォームの「計算引力」を強め、AI分野の開放性とモジュール化の発展に影響を与える可能性があります。(ソース: Reddit r/deeplearning)
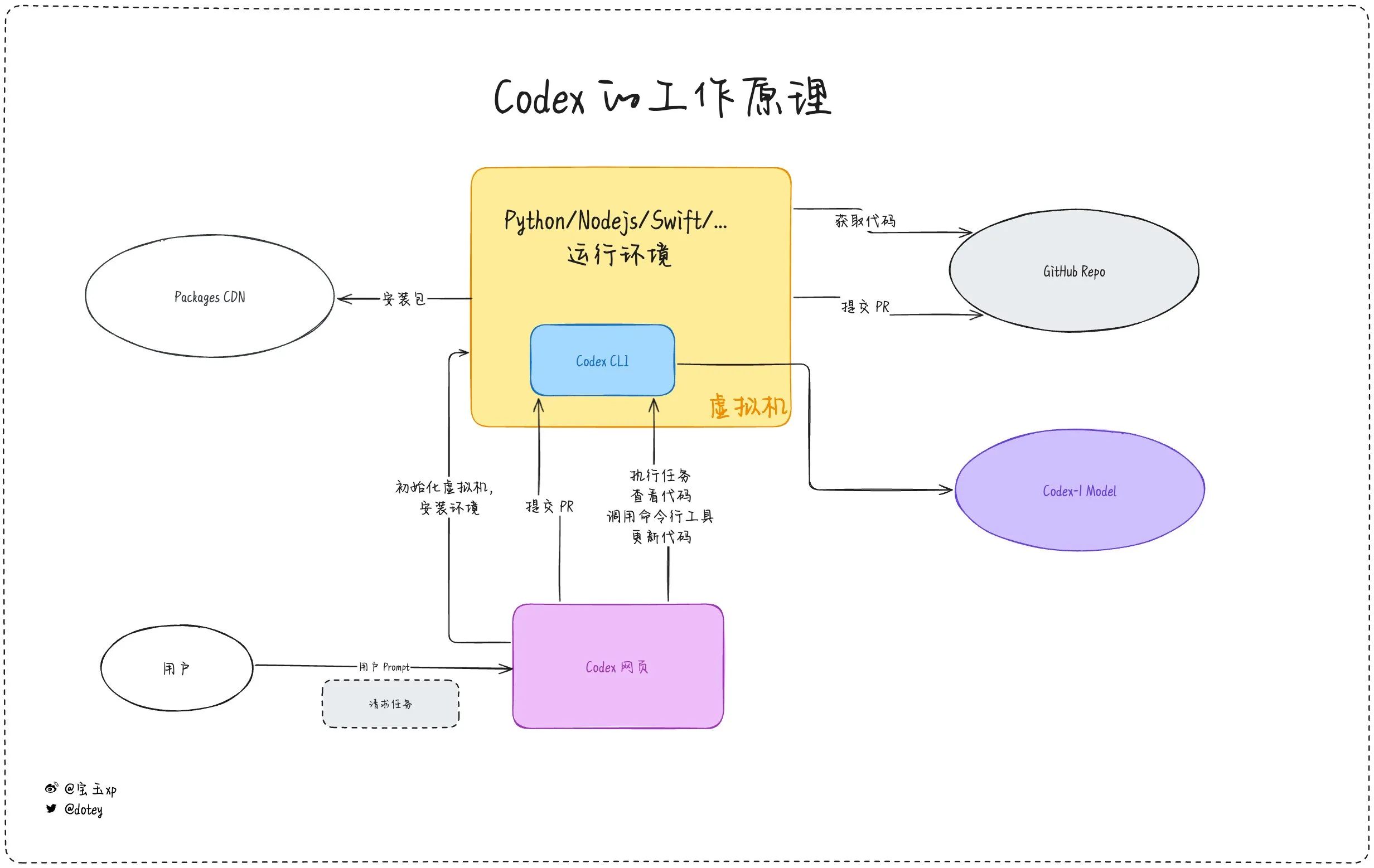
AIプログラミングツールの浸透が加速、開発者の体験と反省が共存: Codex、Devin、および各種AI AgentなどのAIプログラミングツールが、ソフトウェア開発プロセスへの統合を加速しています。開発者のフィードバックによると、Codexはコードの国際化、プロジェクトのアップグレードなどで高い効率を示し、開発サイクルを大幅に短縮できます。しかし、doteyによるCodexの評価が指摘するように、現在のAIツールは「外部委託スタッフ」のようであり、タスクを完了できるものの、ネットワーク接続、タスクの持続性、経験の蓄積の面ではまだ限界があります。コミュニティの議論では、一部の開発者がAI支援プログラミングを長期間使用した後、自身の思考力や創造力への影響を反省し始め、さらには「人間の脳」に頼る開発モデルに戻ることを選択しており、AIツールが効率向上と開発者のコア能力維持との間のバランスが依然として重要な課題であることを示しています。(ソース: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 動向
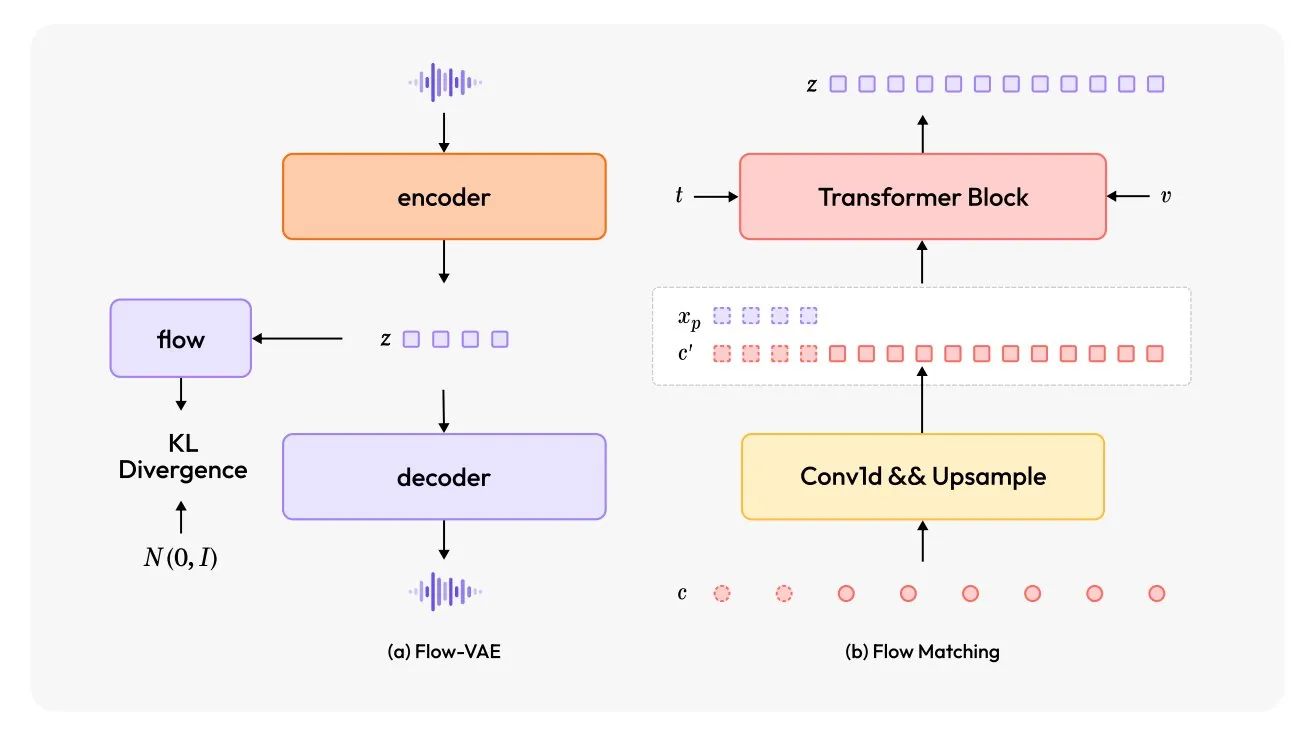
MiniMax-Speech:新型多言語TTSモデル発表: TheTuringPostは、新しいテキスト読み上げ(TTS)モデルであるMiniMax-Speechを紹介しました。このモデルは2つの大きな革新を採用しています。学習可能な話者エンコーダは、短い音声から音色を捉えることができ、Flow-VAEモジュールは音声品質を向上させます。MiniMax-Speechは32言語をサポートし、音声に感情を加えたり、テキスト記述から音声を生成したり、ゼロショット音声クローニングを行ったりすることができ、パーソナライズされた高品質な音声合成における可能性を示しています。(ソース: TheTuringPost, TheTuringPost)
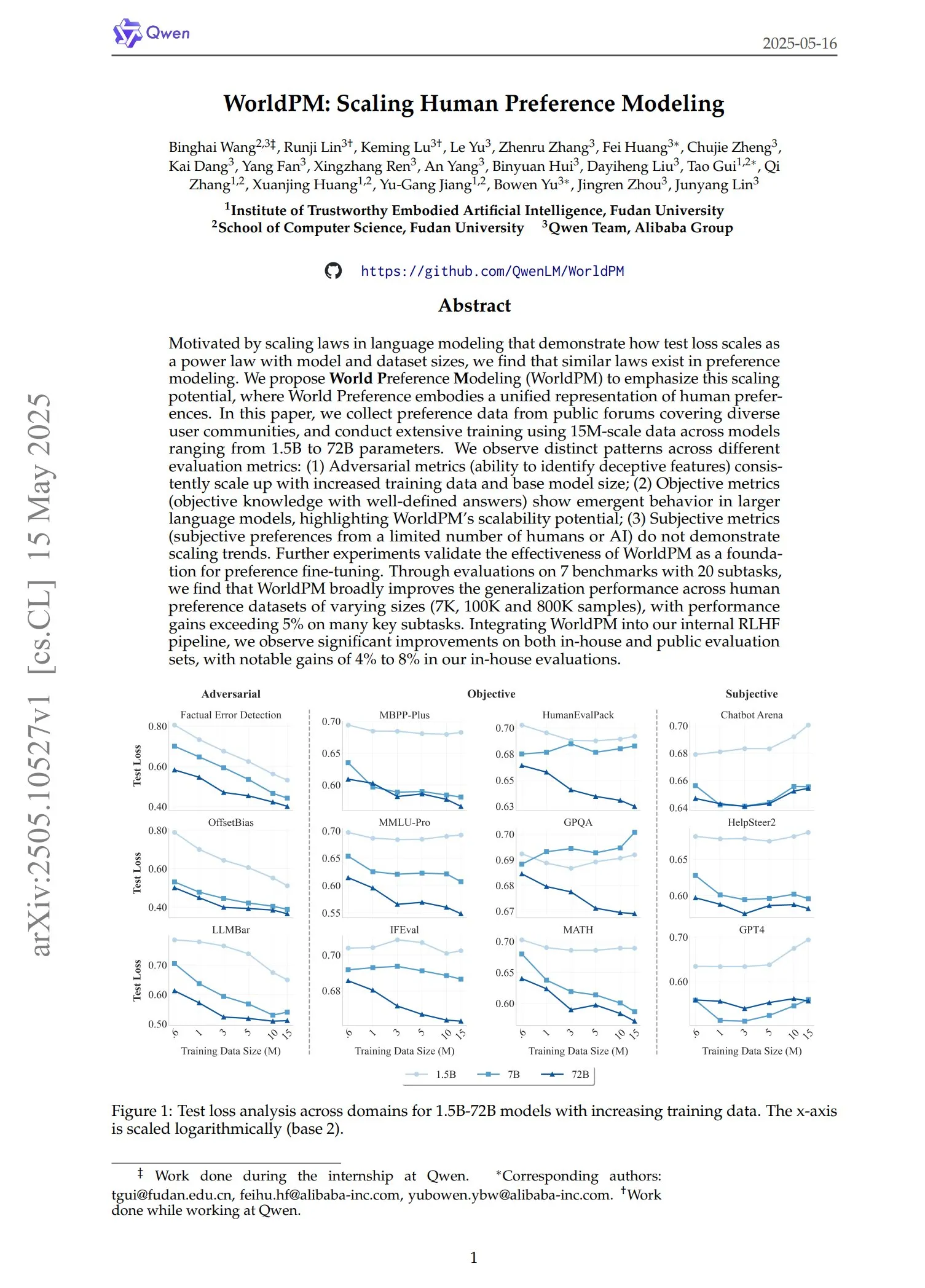
QwenがWorldPMシリーズの選好モデルを発表: Qwenチームは、WorldPM-72B、WorldPM-72B-HelpSteer2、WorldPM-72B-RLHFLow、WorldPM-72B-UltraFeedbackという4つの新しい選好モデリングモデルを発表しました。これらのモデルは主に、他のモデルの回答の品質を評価し、教師あり学習プロセスを支援するために使用されます。公式によると、これらの選好モデルを使用してトレーニングすると、ゼロからトレーニングするよりも良い結果が得られ、関連論文も公開されています。(ソース: karminski3)
Grokにグラフ生成機能が追加: XAIのGrokモデルがグラフ生成機能をサポートするようになりました。ユーザーはGrokを使用してブラウザでグラフを作成でき、この機能は今後数日以内に他のプラットフォームにも展開される予定です。このアップデートにより、Grokのデータ可視化と情報提示能力が強化されます。(ソース: grok, Yuhu_ai_, TheGregYang)
DeepRoboticsが中型四足歩行ロボットLynxを発表: DEEP Robotics社は、新型の中型四足歩行ロボットLynxを発表しました。このロボットは複雑な地形でも安定して歩行する能力を示し、同社のロボット運動制御および知覚技術の進歩を体現しており、巡回検査、物流など様々なシーンに応用可能です。(ソース: Ronald_vanLoon)
Sanctuary AIが汎用ロボットに新型触覚センサーを統合: Sanctuary AIは、同社の汎用ロボットに新型触覚センサー技術を統合したことを発表しました。この改良は、ロボットの物体知覚および操作能力を向上させ、環境とより精密に相互作用できるようにすることを目的としており、より強力な汎用人工知能ロボットへの重要な一歩です。(ソース: Ronald_vanLoon)
Unitreeロボットが高度な歩行能力を披露: Unitree RoboticsのGo2ロボットは、逆立ち歩行、適応的な転倒復帰、障害物乗り越えなど、複数の高度な歩行能力を披露しました。これらの能力の実現は、同社のロボット犬の運動制御アルゴリズムと環境適応性における著しい向上を示しています。(ソース: Ronald_vanLoon)
中国の研究チームが培養ヒト脳細胞で駆動するロボットを開発: InterestingSTEMによると、中国のある研究チームが、実験室で培養したヒト脳細胞で駆動するロボットを開発しています。この研究は、生物学的計算とロボット技術の融合を探求し、生物学的ニューロンの学習および適応能力を利用して、ロボット制御に新たなアイデアを提供することを目指しています。現在はまだ初期の探求段階ですが、将来のロボット知能の形態について広範な議論を引き起こしています。(ソース: Ronald_vanLoon)
新型ナノスケール脳センサーが96.4%の神経信号認識精度を達成: ある新型ナノスケール脳センサーが、神経信号の認識において最大96.4%の精度を示しました。この技術は、ブレイン・マシン・インターフェース、神経科学研究、および医療診断分野への応用が期待され、脳活動をより正確に解読するための新しいツールを提供します。(ソース: Ronald_vanLoon)

MistralAIがテストセットでトレーニングしたとの噂が注目を集める: コミュニティで、MistralAIがNIAHなどのベンチマークテストでテストセットデータを使用してトレーニングしたのではないかという議論が浮上しています。kalomazeは、GitHubのNIAHテストとカスタムNIAH(プログラムで生成された事実と問題)のパフォーマンスを比較することで、MistralAIが前者で後者をはるかに上回るパフォーマンスを示したと指摘し、データ汚染の可能性を示唆しています。Dorialexanderは、評価セットの「合成近似」がデータ混合の設計に使用された可能性があると推測し、モデル評価の公正性と透明性に対する懸念を引き起こしています。(ソース: Dorialexander)
研究によるとClaude 3.5は説得力で人間を上回る: arXivに掲載された研究論文によると、AnthropicのClaude 3.5モデルは説得能力において人間を上回るパフォーマンスを示しました。この研究は、特定の説得タスクにおけるモデルと人間のパフォーマンスを実験的に比較した結果、AIが説得力のある議論の構築とコミュニケーションにおいて顕著な優位性を持つ可能性を示しており、これはマーケティング、広報、人間と機械の相互作用などの分野に潜在的な影響を与えます。(ソース: Reddit r/ClaudeAI)

ローカル大規模モデルがコンシューマー向けハードウェアで能力を大幅に向上: Redditユーザーのフィードバックによると、Qwen 3の14Bパラメータモデル(yarnパッチで128kコンテキストをサポート)は、わずか10GBのVRAMと24GBのRAMを搭載したコンシューマー向けPCで、IQ4_NL量子化と80kコンテキスト設定により、Roo CodeやAiderなどのAIプログラミングアシスタントをかなりうまく実行できるようになりました。長いコンテキスト(20k+など)の処理では速度が遅い(約2 t/s)ものの、コード編集の品質とコードベースの認識能力は良好なパフォーマンスを示しており、ローカルモデルが比較的長い対話で複雑なコーディングタスクを安定して処理し、意味のあるコード差分を出力できたのはこれが初めてです。この進歩は、モデル自体の改善、llama.cppなどの推論フレームワークの最適化、およびRooなどのフロントエンドツールの適応によるものです。(ソース: Reddit r/LocalLLaMA)
OpenAI CodexがSWE-Bench Verifiedランキングで最高性能ではないとの指摘: Graham Neubig氏は、OpenAIのCodexモデルがSWE-Bench VerifiedランキングでSOTAの成果を上げているという主張は完全には正確ではないと指摘しています。彼はデータと異なる評価基準を分析することで、どの角度から見ても、Codexの特定のベンチマークにおけるパフォーマンスには議論の余地があり、疑いの余地なく最高とは言えないと主張しています。(ソース: JayAlammar)
🧰 ツール
OpenAlpha_Evolveがオープンソース化:GoogleのAIアルゴリズム設計エージェントを再現: Google DeepMindがAlphaEvolve論文を発表した後、開発者のshyamsaktawat氏は迅速にオープンソース実装OpenAlpha_Evolveを公開しました。このPythonフレームワークにより、ユーザーはAI駆動のアルゴリズム設計のアイデアを実験でき、タスク定義、プロンプトエンジニアリング、コード生成(GeminiなどのLLMを利用)、実行テスト、適応度評価、進化選択などの段階が含まれており、より広範なコミュニティがAIによる新しいアルゴリズム設計の最前線を探求することを目指しています。(ソース: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

Cursorエディタにファイル全体の高速編集機能が追加: AIファーストのコードエディタCursorは、ユーザーがファイル全体を高速に編集できるようになったことを発表しました。この新機能は、開発者の作業効率を向上させ、Cursor内での大規模なコード変更やリファクタリングをより便利にすることを目的としています。(ソース: cursor_ai)
Codexがアプリケーションの国際化・ローカライズタスクを効率的に完了: 開発者のKatsuya氏は、OpenAI Codexを使用したアプリケーションの国際化の経験を共有しました。彼はCodexにアプリケーションを日本語にローカライズさせたところ、通常数日かかる作業を一晩で完了させ、Codexが自動コード生成や複雑な言語タスクの処理において強力な能力を持っていることを十分に示しました。(ソース: gdb, ShunyuYao12)
llmbasedos:LLM向けに設計された安全なMCPサンドボックス環境: llmbasedosプロジェクトは、トリミングされたArch Linuxベースのオペレーティングシステム環境を提供し、大規模言語モデル(LLM)に安全なモジュラーコンピューティングプロトコル(MCP)サンドボックスを提供することを目的としています。ファイルシステム、メール、同期、プロキシなどの機能をMCPサービスとしてカプセル化し、ユーザーは仮想マシンまたは物理マシンからISOを起動した後、これらのサービスを呼び出すことができ、安全なLLMインタラクションと開発を容易にします。(ソース: karminski3)

cachelm:オープンソースLLMセマンティックキャッシュツールが効率向上とコスト削減を実現: 開発者のdevanmolsharma氏は、LLMアプリケーション向けに設計されたセマンティックキャッシュレイヤーであるオープンソースツールcachelmをリリースしました。ベクトル検索を通じてセマンティックな類似性に基づいたキャッシュを実現し、LLM APIへの重複した呼び出しを効果的に削減(ユーザーの質問の言い回しが異なっても)することで、トークン消費を削減し、応答を高速化します。このツールはOpenAI、ChromaDB、Redis、ClickHouseなどをサポートし、ユーザーが独自のベクタライザ、データベース、またはLLMをカスタマイズすることも可能です。(ソース: Reddit r/MachineLearning)
ArchGW 0.2.8リリース、AIネイティブプロキシが基盤機能を統一: ArchGWは0.2.8バージョンをリリースしました。このEnvoyベースのAIネイティブプロキシは、アプリケーション内で繰り返される「低レベル」機能を統一することを目的としています。新バージョンでは、双方向トラフィックのサポート(Google A2A準備のため)が追加され、高速ルーティングとツール呼び出し用のArch-Function-Chat 3Bモデルが改善され、GroqでホストされているLLMがサポートされました。ArchGWはローカルプロキシ方式を通じて、AIアプリケーション開発を簡素化し、セキュリティ、一貫性、可観測性を向上させます。(ソース: Reddit r/artificial)
SparseDepthTransformer:高校生が開発した動的レイヤースキップTransformer効率化ソリューション: ある高校生がSparseDepthTransformerというプロジェクトを開発しました。これは、軽量なスコアリングメカニズムを通じて各トークンの意味的重要性を評価し、重要でないトークンにTransformerの深層計算をスキップさせるものです。実験によると、この方法は出力品質を維持しつつ、メモリ使用量を約15%削減し、トークンの平均処理レイヤー数を約40%削減し、Transformerの効率を向上させる新しいアイデアを提供しました。(ソース: Reddit r/MachineLearning)

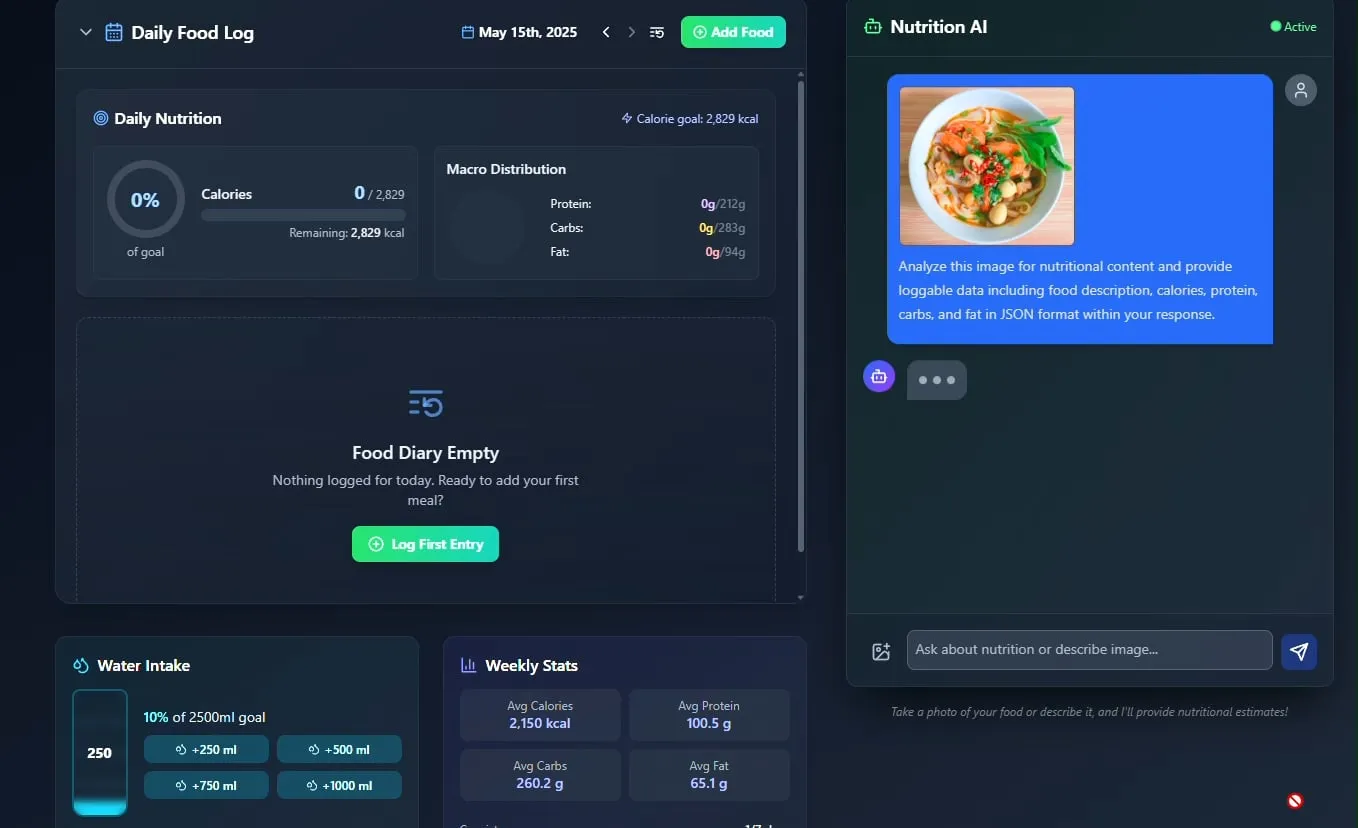
AI食事・栄養トラッカーが登場、オープンソース化を計画: 開発者のPavankunchala氏は、AI駆動の食事・栄養追跡アプリケーションを展示しました。このアプリケーションのコア機能は、ユーザーがアップロードした食品写真を分析して食品を識別し、栄養情報(カロリー、タンパク質など)を推定することであり、手動記録、毎日の栄養概要、水分摂取追跡もサポートしています。開発者は将来、このプロジェクトのコードをオープンソース化する予定です。(ソース: Reddit r/LocalLLaMA)
イタリアのAIエージェントが求職を自動化、1分で1000件の応募が話題に: イタリア製とされるAI Agentが、1分間に1000件の求人応募を完了するという強力な求職自動化能力を実証しました。このデモンストレーションは、採用分野におけるAIの応用についてコミュニティで広範な議論を呼び起こし、その効率に驚嘆する一方で、その有効性、採用市場への影響、そして「ボット検出」への対応などの問題についても懸念が示されています。(ソース: Reddit r/ChatGPT)

📚 学習
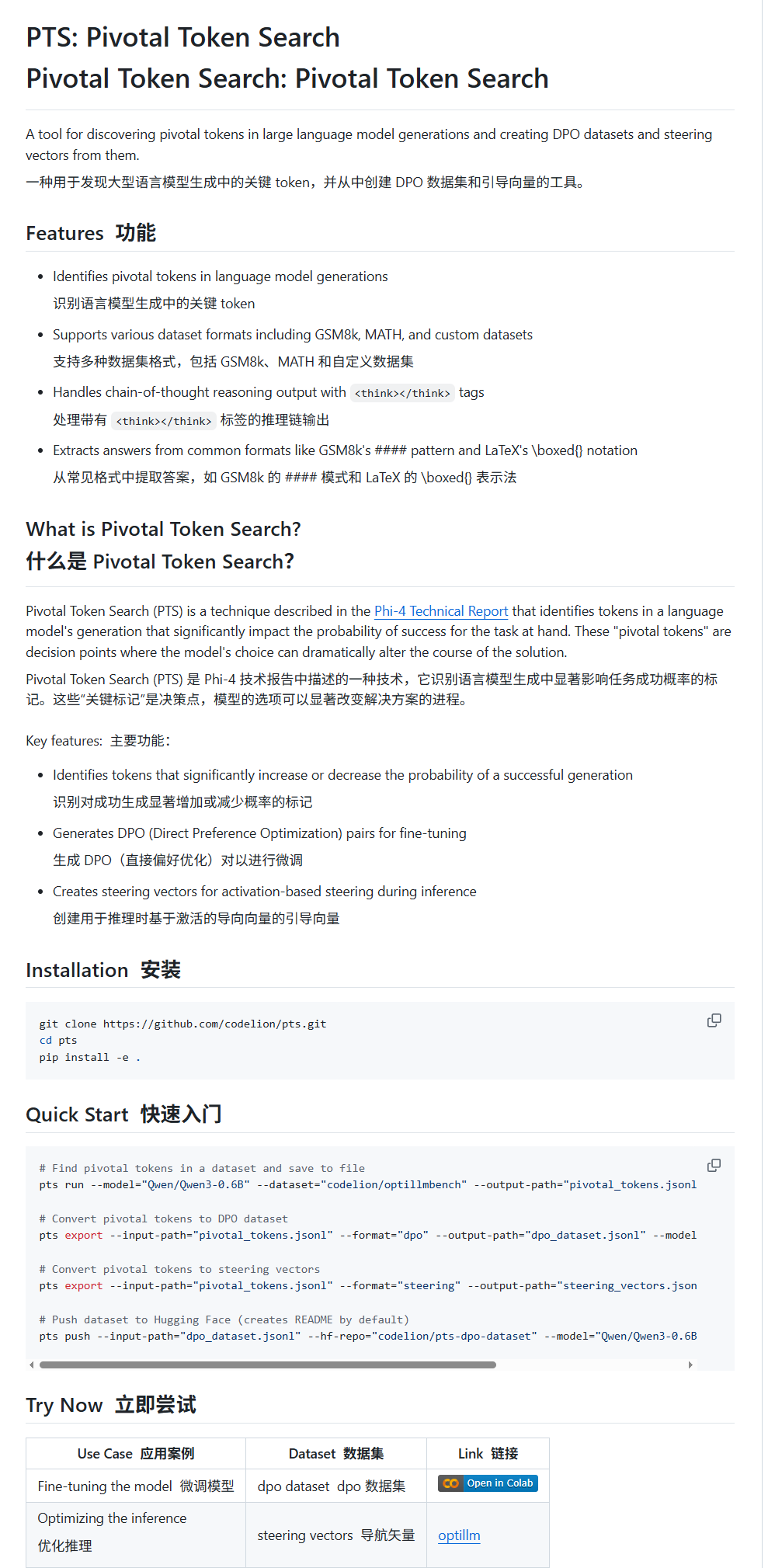
Pivotal Token Search (PTS):新しいLLMファインチューニングおよびガイダンス技術: karminski3氏は、PTS(Pivotal Token Search)と呼ばれる新しい技術を紹介しました。この技術は、「大規模モデルの出力の重要な決定点は少数の重要なトークンにある」という考えに基づいており、出力の正しさに著しく影響を与えるこれらのトークン(「選択されたトークン」と「拒否されたトークン」に分類)を抽出してDPOデータセットを構築し、ファインチューニングを行います。さらに、PTSは重要なトークンの活性化パターンを抽出してステアリングベクターを生成し、ファインチューニングなしで推論時にモデルの動作を誘導することができます。この方法はPhi4に触発されたとされ、その有効性がコミュニティで議論されています。(ソース: karminski3)
OpenAI Codex CLIが無料APIクレジットを提供、データ共有を奨励: OpenAI開発者アカウントは、PlusまたはProユーザーがnpm i -g @openai/codex@latestとcodex --freeを実行することで無料APIクレジットを引き換えることができると発表しました。さらに、ユーザーはプラットフォーム設定でOpenAIモデルの改善とトレーニングのためにデータを共有することを選択することで、無料のデイリートークンを取得できます。この措置は、開発者がCodexツールを使用し、モデル改善に参加することを奨励することを目的としています。(ソース: OpenAIDevs, fouad)
マルチエージェントシステム(MAS)無料学習リソースまとめ: TheTuringPostは、マルチエージェントシステム(MAS)を学ぶための7つの無料リソースを整理し共有しました。これには、CrewAI、CAMELマルチエージェントフレームワーク、LangChainマルチエージェントチュートリアルが含まれます。また、『Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations』という書籍、そしてプロンプトからマルチエージェントシステムまで、AutoGenを使用したマルチエージェント開発の習得、crewAIを使用した実用的なマルチAIエージェントと高度なユースケースをカバーする3つのオンラインコースも含まれています。(ソース: TheTuringPost)

MobileNetV2による高速画像分類チュートリアル: RedditユーザーのEran Feit氏は、MobileNetV2を使用した画像分類のPythonチュートリアルを共有しました。このチュートリアルでは、事前学習済みのMobileNetV2モデルをロードし、OpenCVを使用して画像を前処理(BGRからRGBへの変換、224×224へのスケーリング、バッチ処理)し、推論を実行し、予測結果をデコードして人間が読めるラベルと確率を取得する手順を段階的に説明しています。このチュートリアルは、初心者が軽量な画像分類タスクに素早く取り組むのに適しています。(ソース: Reddit r/deeplearning)
OpenWebUIマルチソースRAGとハイブリッド検索の実装ガイドが公開: productiv-ai.guideウェブサイトは、OpenWebUIでマルチソース検索拡張生成(RAG)とハイブリッド検索(Hybrid Search)およびリランキング(Re-ranking)を実装するための詳細な手順ガイドを公開しました。このガイドは、ユーザーがOpenWebUIのRAG機能(最近追加された外部リランキング機能を含む)を設定し活用して、情報検索の精度と関連性を向上させることを支援することを目的としています。(ソース: Reddit r/OpenWebUI)
💼 ビジネス
AI Agent競争激化:ManusとLovartの詳細比較: 垂直デザイン分野のAI Agent「Lovart」は、そのユニークな「受注型」ワークフローで注目を集めています。これは、要件のやり取りからレイヤー化された素材の納品まで、完全なデザインプロセスをシミュレートしようとするもので、汎用型Agent「Manus」の「スケジューリング型」ロジックとは対照的です。Lovartはデザインの美学理解、コンセプト表現、情報整理において優れたパフォーマンスを示し、速度もManusを上回っていますが、両者とも安定性、中国語処理、修正の連動などの問題に直面しています。Lovartの登場は、垂直型Agentが特定のシーンを深く掘り下げ、業界の経験を内面化する正しい方向性を示しており、AI Agentがコンテンツ産業に本格的に定着する可能性を示唆しています。(ソース: 36氪)

子供向けスマートウォッチ市場が活況、AIoTトレンドが国産SoCチップメーカーの業績成長を後押し: 消費政策の牽引とAIoT発展トレンドの恩恵を受け、中国のスマートウェアラブルデバイス市場(特に子供向けスマートウォッチ)の販売台数が急増しています。DeepSeekなどのオープンソース大規模モデルの登場により、エッジAI展開のハードルが下がり、AIのスマート家電、AIイヤホンなどの端末への浸透が加速しています。Rockchip(瑞芯微)、Bestechnic(恒玄科技)などの国産SoCチップメーカーは、低消費電力、AI計算能力における強み、およびRockchip RK3588などのフラッグシップチップによるPC、スマートハードウェア、車載など多岐にわたるシーンへの対応により、業績が著しく成長し、評価額もそれに伴い上昇しています。(ソース: 36氪)
OpenAIが会社再編計画を調整し、非営利性の疑念に反論したと報じられる: Garrison Lovely氏の暴露によると、これまで報道されていなかったOpenAIからカリフォルニア州司法長官への書簡が明らかになりました。書簡の内容は、OpenAIの会社再編計画の予想外の詳細に関わるだけでなく、OpenAIが会社の非営利的なガバナンス構造を弱めようとしているとの批判や疑念に積極的に反論する措置を講じていることを示しています。(ソース: NeelNanda5)

🌟 コミュニティ
LLMのN-Gram的本質と「知能」の境界が熱い議論を呼ぶ: コミュニティでは、大規模言語モデル(LLM)がどの程度N-Gramの統計的特性に依存しているのか、そして現在のLLMが「真のAI」を構成するのかについて議論が続いています。ある意見(pmddomingos氏によるjxmnop氏のNeurIPS論文へのコメントなど)では、LLMは2/3以上のケースでN-Gramモデルと同様の振る舞いをするとされています。Redditのデータサイエンティストは、現在のLLMは真の理解、推論、常識を欠いており、AGI(汎用人工知能)には程遠く、本質的には複雑な「次の単語予測システム」であり、自己意識や適応性を持つ知能体ではないと指摘しています。(ソース: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

AI生成画像の「透明フィルム」スタイルと「豆包」のきわどい画像が注目を集める: 最近、ソーシャルメディア上で、豆包などのAI描画ツールで生成された特定のスタイルの画像、特に「透明フィルム」で包まれたような効果を持つ画像が多数出現しています。これらの画像は、その斬新な視覚効果と、関連する可能性のある「きわどい」コンテンツにより、ユーザーの間で広範な議論、模倣、二次創作を引き起こし、AI生成コンテンツ分野のホットなトレンドとなっています。(ソース: op7418, dotey)

AI倫理と未来:「神」を構築するのか、それとも自己破壊か?: コミュニティでは、AI開発の最終目標と潜在的リスクについて激しい議論が交わされています。Emad Mostaque氏は、誰かが「神」のようなAGIを構築しようとしており、ユートピアか破滅をもたらす可能性があると率直に述べています。NVIDIAのCEOであるジェンスン・フアン氏は、将来、人間のエンジニアが1000体のAIと協力してチップを設計する場面を展望しています。同時に、SMBCの漫画が引き起こした議論は、AIの意識の問題をより現実的な倫理的扱いの側面に転換させています——私たちはこれらの「物」を心安らかに扱うことができるのでしょうか?これらの意見は、AIの未来に対する複雑な想像を共に構成しています。(ソース: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
AIはSaaSビジネスモデルを破壊するのか?開発者コミュニティで議論白熱: Claude Codeなどの強力なAIプログラミングツールの普及に伴い、開発者コミュニティではSaaS(Software as a Service)ビジネスモデルへの潜在的な影響について議論が始まっています。個々の開発者がAIを利用して既存のSaaS製品のコア機能を複製するハードルが下がっているという意見があり、これにより企業や個人ユーザーが従来のSaaSサービスへの依存を減らし、よりコスト効率の高い自作またはAI支援ソリューションを求めるようになる可能性があります。将来のソフトウェア開発は、AIのマイクロマネジメントにより依存するようになるかもしれません。(ソース: Reddit r/ClaudeAI)
AIの多言語処理における差異が注目、Llamaの事前トークナイザが一因か: コミュニティの議論によると、大規模言語モデル(LLM)は英語でのパフォーマンスが他の言語よりも優れていることが多いと指摘されています。その考えられる原因の一つとして、Llamaなどのモデルの事前トークナイザ(pretokenizer)による非英語テキスト(特に非ラテン文字)の処理方法が挙げられています。例えば、事前トークナイザが中国語の文字をより小さな単位に過度に分割し、モデルの言語構造や意味の理解に影響を与え、結果としてこれらの言語でのパフォーマンス低下につながる可能性があります。(ソース: giffmana)

💡 その他
DSPyフレームワークがAIエージェント開発における基盤プリミティブの重要性を強調: AIフレームワークDSPyは、2023年1月にコア抽象をオープンソース化して以来、わずかな簡略化を除いてほとんど変更されておらず、数々のLLM APIのイテレーションを経ても安定性を保っています。コミュニティの議論では、これはDSPyが表面的な開発者体験や「エージェント」を迅速に構築する利便性だけを追求するのではなく、正しい基盤プリミティブの構築に注力しているおかげだと指摘されています。現在の多くのエージェント開発フレームワークは使いやすさに過度に注目し、基礎となる構成要素の堅牢性を無視しているのに対し、DSPyの理念は、まず堅実な「反応」の基盤があってこそ、複雑な「エージェント」の行動を構築できるというものです。(ソース: lateinteraction, lateinteraction)
AI生成コンテンツの美的疲労がカスタマイズモデルの需要を生む: コミュニティの議論によると、現在、強化学習(RL)によって最適化された多くの画像生成モデルの出力は、しばしば「凡庸」または「俗悪」に見え、技術的には良好に見えるものの、刺激的な創造性や個性に欠けています。これは、モデルの最適化目標が大衆の平均的な美的嗜好に偏る傾向があり、独自の芸術的追求ではないことを反映しています。したがって、将来のカスタマイズモデルと、個々の美的目標に合わせてサンプリングできる方法は、この問題を克服し、より魅力的なAIコンテンツを作成するための鍵と考えられています。(ソース: torchcompiled)

Ollamaがマルチモーダルエンジンをリリース、OpenWebUIユーザーは互換性に注目: Ollamaは、同社のマルチモーダルエンジンが正式にリリースされたことを発表し、このニュースはOpenWebUIコミュニティのユーザーの注目を集めました。ユーザーは一般的に、OpenWebUIがOllamaの新しいマルチモーダルエンジンを「すぐに使える」状態でサポートできるかどうか、つまり複雑な設定変更なしに画像やテキストなどの複数のデータタイプを処理する能力を利用できるかどうかに関心を持っています。(ソース: Reddit r/OpenWebUI)
