
キーワード:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM物理学, LangGraph, AIエージェント, 回路追跡手法Attribution Graphs, Qwen3-235B-A22Bのコーディング能力, Phi-4-reasoningの推論時計算, LangGraph請求書照合エージェント, Moondream StationローカルVLM
🔥 焦点
Anthropic、LLM生物学研究を発表、モデル内部メカニズムを深く探求: Anthropicは、「大規模言語モデルの生物学について」(On the Biology of a Large Language Model)と題した詳細な研究ブログ記事を発表し、その回路追跡手法(Attribution Graphs)を用いて、Claude 3.5 Haikuモデルの異なる状況下での内部メカニズムを調査しました。研究では、より分析しやすい「代替モデル」(Transcoder)を訓練することで、モデルがどのように加算を実行するか(正確なアルゴリズムではなく、複数の近似パスを通じて)、医学的診断を行うか(内部的な診断概念を形成)、そして幻覚や拒否を処理するか(デフォルトの拒否回路が存在し、「既知の答え」特徴によって抑制されうる)を明らかにしました。この研究はLLMの内部動作を理解するための新たな視点を提供しましたが、方法論の限界やAnthropic自身の位置づけに関する議論も引き起こしています (出典: YouTube – Yannic Kilcher
)

Qwen3シリーズモデルが強力な性能を示し、オープンソースコミュニティの注目を集める: Alibabaが発表したQwen3シリーズ大規模言語モデルは、複数のベンチマークで優れたパフォーマンスを示し、特にコーディング能力において顕著です。Aider Polyglot Coding Benchmarkの結果によると、Qwen3-235B-A22B(思考の連鎖を有効にせず)の性能は、32kの思考の連鎖tokenを有効にしたClaude 3.7を上回り、コストも大幅に削減されているようです。同時に、Qwen3-32BもこのベンチマークでGPT-4.5およびGPT-4oを上回りました。コミュニティはまた、Qwen3モデルのプルーニング(例:30Bから16Bへの削減)やファインチューニング(例:Unslothを使用して低VRAMでファインチューニング)を積極的に探求しており、高性能モデルの応用障壁をさらに下げています。これは、中国のオープンソース大規模モデルが市場で重要な地位を占める可能性を示唆しています (出典: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft、Phi-4-reasoningモデルを発表、複雑な推論に特化: MicrosoftはHugging Face上でPhi-4-reasoningモデルを発表しました。これは140億パラメータを持つ推論モデルです。このモデルは、推論時計算(inference-time compute)を利用することで、複雑な推論タスクにおいて現在の最高水準(SOTA)の性能を達成しました。これは、モデル設計が単にモデル規模を拡大するだけでなく、推論段階の計算量を増やすことで特定の能力を向上させる方向を探求していることを示しており、小型モデルで高性能を実現するための新しいアプローチを提供しています (出典: _akhaliq)
LLM物理学研究の新進展:アーキテクチャ設計の「ガリレオ・モーメント」: Zeyuan Allen-Zhuは、大規模言語モデルの物理学に関するシリーズ研究の第4部を発表し、アーキテクチャ設計に焦点を当てています。研究では、制御された合成事前訓練環境を通じて、異なるLLMアーキテクチャ(Transformer、Mambaなど)の真の限界と可能性を明らかにしました。研究は「Canon」と呼ばれる軽量な水平残差層を導入し、モデルの推論能力を著しく向上させました。同時に、研究はMambaモデルの利点の多くが、SSM自体ではなく、その隠れたconv1d層に由来することを発見しました。この一連の実験は、LLMアーキテクチャの理解と最適化のための新しい視点と基礎理論を提供します (出典: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 動向
Amazon、汎用人工知能モデル「Amazon Artificial General Intelligence」を発表: このモデルは100万tokenのコンテキスト長とマルチモーダル入力能力を備え、コード生成、RAG、ビデオ/ドキュメント理解、関数呼び出し、Agentインタラクションに最適化されています。価格は入力2.5ドル/百万token、出力12.5ドル/百万tokenです。初期評価によると、AI IndexでのパフォーマンスはLlama-4 Scoutと同等ですが、速度とコストでは劣っており、特定の長文脈マルチモーダルまたはAgentアプリケーションシナリオに適している可能性があります (出典: scaling01)

Anthropic Claudeモデル、全世界の有料プランでWeb検索機能を提供開始: この機能により、Claudeは日常的なタスクを処理する際に迅速な検索を行うことができ、より複雑な問題については、Google Workspaceを含む複数のソースを探索します。これにより、Claudeがリアルタイム情報を取得し、外部知識を必要とするタスクを処理する能力が強化されます (出典: menhguin)

IBM、混合アーキテクチャモデルgranite-4.0-tiny-7B-A1B-previewを発表: この7Bモデルのプレビュー版は、Mamba-2とTransformerの混合アーキテクチャを採用しており、各Transformerブロックには9つのMambaブロックが含まれています。設計思想は、Mambaブロックを利用してグローバルなコンテキストを捉え、それをアテンション層に渡してローカルなコンテキストを解析することです。初期のMMLUスコアは良好ですが、数学やプログラミング能力などの他のテスト結果はまだ公開されていません (出典: karminski3)
OpenAI ChatGPTにショッピング機能を追加: OpenAIはChatGPT内でショッピング機能を実験しており、製品の検索、比較、購入プロセスを簡素化することを目指しています。新機能には、改善された製品結果表示、価格とレビューを含む視覚化された製品詳細、および直接購入リンクが含まれます。OpenAIは、製品結果は独立して選択されたものであり、広告ではないことを強調しています (出典: sama)
Qwen3 0.6Bモデルの訓練詳細が注目を集める: ユーザーDorialexanderは、情報によると、Qwen 0.6Bモデルも最大36T tokensを使用して訓練されたようだと指摘しています。これが事実であれば、Chinchillaの法則を超える新記録(パラメータあたり約6万tokenに相当)となり、訓練データ量を大幅に増やすことで小規模モデルの能力を向上させる傾向を示しています (出典: Dorialexander)

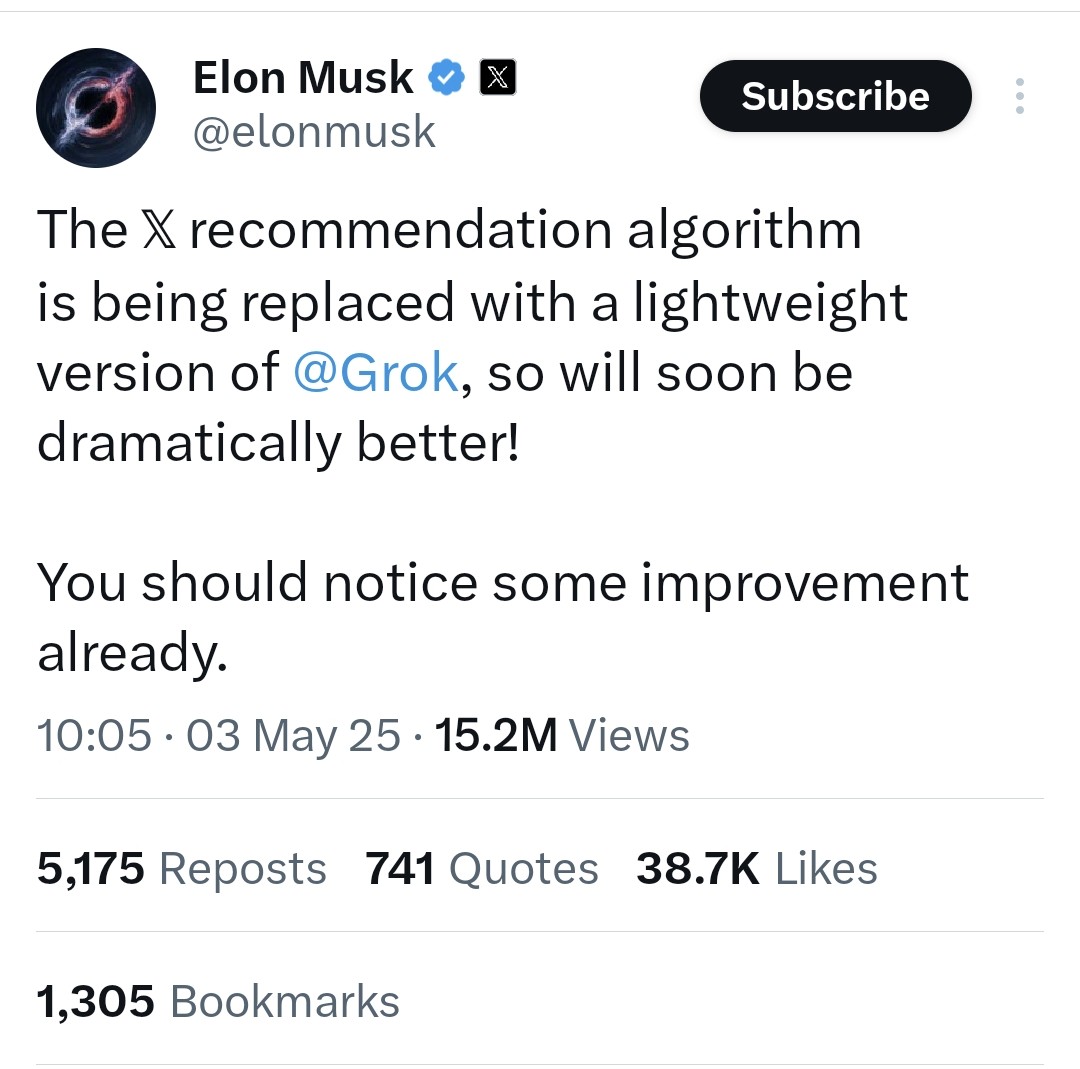
X (旧Twitter) の推薦アルゴリズムが軽量版Grokに置き換えへ: Elon Muskは、Xプラットフォームの推薦アルゴリズムがGrokの軽量版に置き換えられていることを発表し、推薦効果の大幅な改善が期待されるとしています。ユーザーからはアルゴリズムの効果が向上したとのフィードバックがあり、最近のExa AI従業員の変動やXがEmbeddingsを推薦に使用し始めたことと関連があるのではないかと推測されています (出典: menhguin, colin_fraser, paul_cal)
Allen AI、完全オープンなMoEモデルOLMoEを発表: このモデルは、13億のアクティブパラメータと69億の総パラメータを持つ先進的な混合エキスパート(Mixture of Experts, MoE)モデルです。完全にオープンソースであることは、コミュニティがこのモデルを自由に使用、変更、研究できることを意味し、MoEアーキテクチャの開発と応用を推進します (出典: dl_weekly)
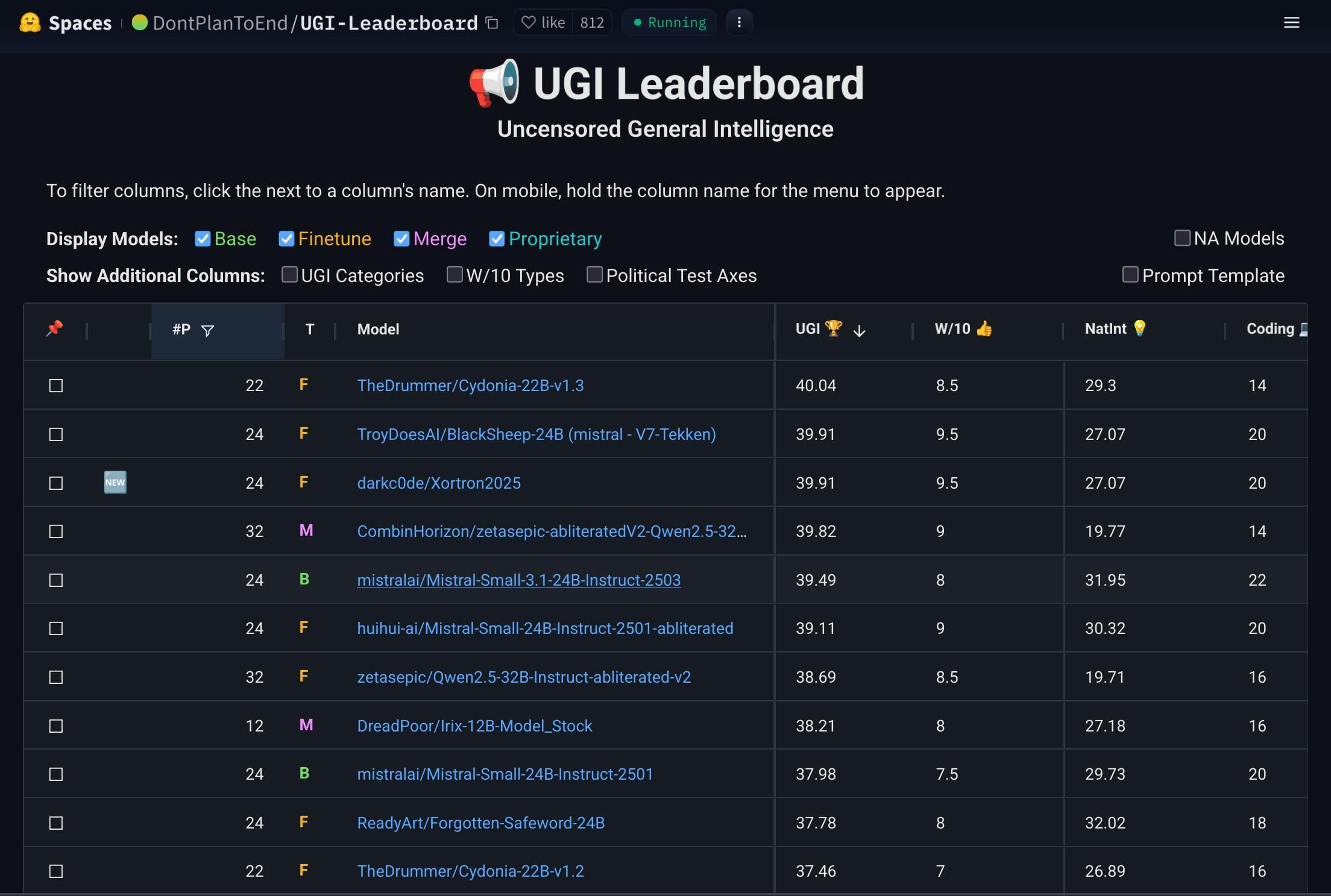
Mistral-Small-3.1-24B-Instruct-2503モデルが注目される: RedditユーザーがMistral-Small-3.1-24B-Instruct-2503モデルについて議論しています。このモデルはUGI(Uncensored General Intelligence)スコアが高く、自然言語理解とコーディングにおいて同クラスの高スコアモデルよりも優れています。ユーザーは、これがシングルGPUでの無検閲推論に理想的な選択肢であり、ツール使用もサポートしていると考えています。しかし、そのライティングスタイルはやや単調で反復的であり、Gemma 3などのモデルほど創造的ではないとも指摘されています (出典: Reddit r/LocalLLaMA)
🧰 ツール
CreateMVP 2.0リリース、AI駆動開発プロセスを最適化: CreateMVPが2.0にアップデートされ、AIに直接プロンプトを与えてアプリケーションを構築する効果が低い問題を解決することを目指しています。新バージョンでは、よりスムーズなUI、便利な認証方法(Replit、Google、GitHubをサポート、まもなくXAIもサポート予定)、より詳細な開発計画の生成(11KBから40KB以上に増加)、ファイルの即時プレビュー、トップAIモデルチャットの統合などの機能を通じて、ユーザーがAIに対してより正確な「設計図」を作成し、AIがユーザーの構想に沿ったアプリケーションを構築できるように支援します (出典: amasad)
LlamaIndex、請求書照合Agentを発表: このツールは、従来のチャットインタラクションではなく、バッチ自動化タスクにおけるAI Agentの応用を示しています。大量の非構造化請求書ドキュメントを処理し、関連詳細を抽出し、自動的に発注書と照合して差異をマークします。その核となるのは、LlamaCloudの解析/抽出とLlamaIndex.TSのワークフロー推論に基づくAgenticドキュメントインテリジェンス層であり、実際のビジネスプロセス自動化におけるAgentの可能性を示し、従来のRPAを置き換えると考えられています (出典: jerryjliu0)
LangGraph Expense Tracker:自動化された経費管理システム: これはLangGraphを使用して構築された自動化された経費管理システムの例です。請求書を処理し、インテリジェントなデータ抽出機能を利用して情報をPostgreSQLに保存し、人手による検証ステップを含みます。このプロジェクトは、LangGraphが実際のビジネス自動化プロセス構築において持つ能力を示しています (出典: LangChainAI, Hacubu, hwchase17)
Moondream Stationリリース:ローカルでVLMを実行: MoondreamはMoondream Stationをリリースし、ユーザーがMac上でローカルに視覚言語モデル(VLM)Moondreamを実行できるようにしました。クラウドへの接続は不要です。CLIまたはローカルポートアクセス方式を提供し、設定は簡単で完全に無料であり、ローカルでのVLMのデプロイと使用の障壁を下げています (出典: vikhyatk)
ChaiGenie:LangChainベースのChromeドキュメント検索拡張機能: ChaiGenieは、LangChainのGeminiとQdrantを統合したChrome拡張機能で、ドキュメント検索機能を提供します。多言語とベクトルベースの検索をサポートし、ユーザーがWebページを閲覧する際にドキュメントの内容を検索し理解する効率を高めることを目的としています (出典: LangChainAI)

Research Agent:ワンクリック研究アシスタントWebアプリケーション: これはLangGraphの研究アシスタントフレームワークに基づいて構築されたWebアプリケーションで、研究プロセスを簡素化することを目的としています。ユーザーはワンクリックで研究結果を得ることができ、LangGraphが複雑なタスクを簡素化するためのAI駆動ワークフロー構築における応用可能性を示しています (出典: LangChainAI)

Muyan-TTS:オープンソース、低遅延、カスタマイズ可能なTTSモデル: ChatPodsチームはMuyan-TTSを発表しました。これは完全にオープンソースのテキスト読み上げモデルであり、既存のオープンソースTTSモデルの品質が高くない、または十分にオープンでない問題を解決することを目指しています。LLaMA-3.2-3Bと最適化されたSoVITSに基づいており、ゼロショットTTSと音声クローニングをサポートし、完全なトレーニングおよびデータ処理フローを提供するため、開発者はファインチューニングや二次開発を容易に行うことができ、特にカスタマイズされた音声が必要なアプリケーションシナリオに適しています (出典: Reddit r/MachineLearning)
Mem0とOpen Web UIパイプラインの統合: ユーザーcloudsbirdは、Mem0のOpen Web UIフィルターパイプライン統合(非公式MCP)を作成し、Open Web UIでMem0の記憶機能を使用するための別の選択肢を提供しました (出典: Reddit r/OpenWebUI)
YNAB API Requestツールでローカルプライベートな財務管理を実現: ユーザーMegaphonixは、YNAB(You Need A Budget)APIを利用したOpenWebUIツールを作成しました。これにより、ユーザーはローカルのLLMを通じて個人の財務情報(取引、カテゴリ支出、純資産など)を照会でき、機密データを外部に送信する必要がありません。これは、ローカルでLLMを実行する際に機密性の高い個人情報を安全に処理するというニーズに応えるものです (出典: Reddit r/OpenWebUI)
無料AIテキスト読み上げブラウザ拡張機能GPT-Reader: 開発者が作成した無料のAIテキスト読み上げブラウザ拡張機能GPT-Readerを宣伝しています。現在、4000人以上のユーザーがいます。このツールは、ユーザーがWebページのテキストコンテンツを音声で聞くのを容易にすることを目的としています (出典: Reddit r/artificial)
sunnypilot:オープンソース運転支援システム: sunnypilotはcomma.ai openpilotのフォークであり、オープンソースの運転支援システムを提供します。300以上の車種をサポートし、運転支援のインタラクション動作を変更し、可能な限りcomma.aiの安全ポリシーを遵守しています。このプロジェクトはAI技術(具体的なモデルは明記されていませんが、この種のシステムは通常、コンピュータビジョンと制御アルゴリズムを含みます)を利用して運転体験を向上させます (出典: GitHub Trending)

📚 学習
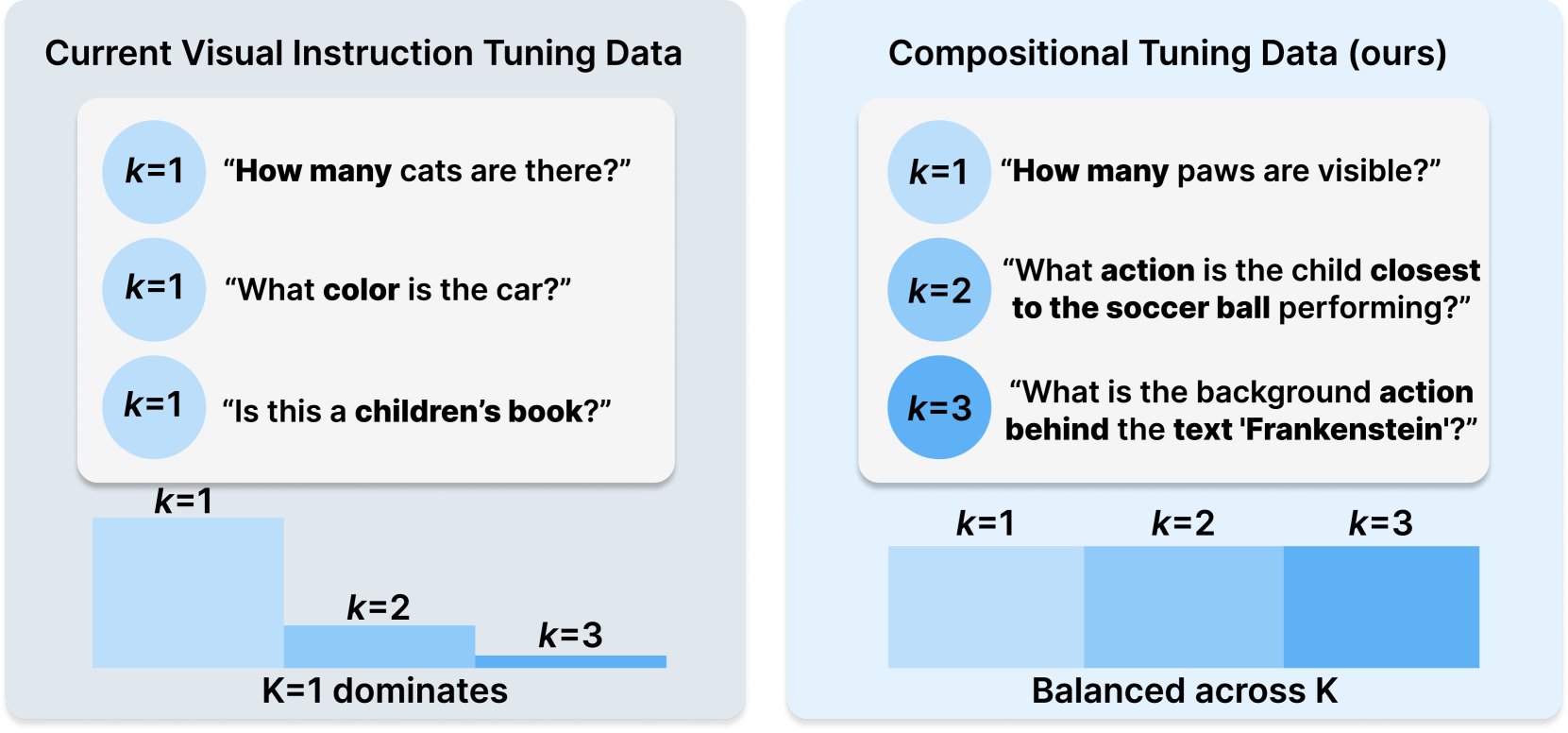
PrincetonとMeta AI、COMPACTデータセットレシピを発表: この研究はHugging Face上で発表され、訓練サンプルの組み合わせの複雑さを明示的に制御することでマルチモーダル大規模言語モデル(Multimodal LLM)の能力を拡張することを目的とした新しいデータレシピCOMPACTを提案しています。これは、マルチモーダルモデルの訓練方法を改善し、複雑な組み合わせ概念を理解する能力を向上させるための新しいアプローチを提供します (出典: _akhaliq)
Unsloth、Qwen3ファインチューニングチュートリアルを公開: UnslothはQwen3モデル向けのファインチューニングチュートリアルを提供し、ファインチューニングの障壁を大幅に下げました。ユーザーはわずか16GBのVRAMでQwen3-14Bモデルを、17.5GBのVRAMでQwen3-30B-A3Bモデルをファインチューニングできます。これにより、より多くの研究者や開発者が限られたハードウェアリソースで先進的なオープンソースモデルのカスタマイズ訓練を行うことが可能になります (出典: karminski3)
LangGraphとAzure OpenAIを組み合わせてインテリジェントなWeb検索チャットボットを構築: Mediumのチュートリアルでは、LangGraphとAzure OpenAIを組み合わせ、TavilyのWeb検索能力を統合してインテリジェントなチャットボットを構築する方法を紹介しています。チュートリアルでは、状態管理と条件付きルーティングをカバーし、シームレスな検索統合を実現することで、リアルタイムのWeb情報を活用できるより強力なAIアプリケーションを構築するための実践的なガイダンスを提供します (出典: LangChainAI, hwchase17)

スタンフォードAIブログ、LLMの逐語的記憶と汎用能力の関係を探る: スタンフォードAIブログの記事では、大規模言語モデル(LLM)の逐語的記憶(verbatim memorization)現象とその汎用能力との間の内在的な関連性を深く探求しています。この関係を理解することは、モデルのリスク評価、訓練方法の最適化、およびモデルの振る舞いの解釈にとって極めて重要です (出典: dl_weekly)
GeminiとLangChainの統合ガイド: Philipp Schmidは、GoogleのGeminiモデルとLangChainフレームワークを統合する方法を詳述した開発者向けガイドを公開しました。ガイドは、マルチモーダル能力、ツール呼び出し、構造化出力の実装をカバーし、最新モデルのサポートと実用的なコード例を含んでおり、開発者がGeminiの強力な機能を活用してLangChainアプリケーションを構築するのに役立ちます (出典: LangChainAI, _philschmid)

LangGraph入門チュートリアル:状態を持つワークフローの実践: AI@GoPubbyで公開されたチュートリアルでは、ウェブサイトのコメント分析の例を通じて、LangGraphの状態を持つワークフロー能力を示しています。学習者は、相互接続されたノードと順序ロジックを使用して構造化されたAIアプリケーションを構築する方法を学ぶことができます (出典: LangChainAI, hwchase17)
LangChain CEOによるAgenticフレームワークに関する深い考察(日本語翻訳): LangChainアンバサダーのHarry Zhangが、LangChain CEOのHarrisonによるAgenticフレームワークに関する考察ブログ記事を翻訳・共有しました。記事では、業界の15以上のAgentフレームワークの機能を分析・整理し、その背後にあるストーリーを解説しており、現在のAgent技術の発展状況と将来の方向性を理解するための価値ある参考資料を提供しています (出典: LangChainAI)
Latent Meta Attention研究の進展: RedditユーザーがLatent Meta Attentionと呼ばれる新しいアテンションメカニズムについて議論しています。開発者は、このメカニズムがTransformerの基礎的な仮定に挑戦し、より小さなモデルサイズで既存モデルの性能に匹敵するか、それを超えることができる(例えば、半分のサイズのモデルでBERTの性能を再現)と主張していますが、資金不足と正式な研究機関の支援がないため、具体的な方法はまだ公開されていません (出典: Reddit r/deeplearning)

グラフニューラルネットワーク(GNN)解説動画: YouTubeでグラフニューラルネットワーク(Graph Neural Networks, GNNs)を解説する動画が公開されました。GNNはグラフ構造データを処理する深層学習モデルであり、ソーシャルネットワーク分析、推薦システム、分子構造予測などの分野で広く応用されています。この動画は、視聴者がGNNの基本原理と動作方法を理解するのを助けることを目的としています (出典: Reddit r/deeplearning)
GRPOを用いたLLMによるイベントスケジューリングの訓練: ユーザーanakin87が、GRPO(Generalized Reward Policy Optimization)を用いて言語モデルをイベントスケジューリングのために訓練したプロジェクト経験を共有しました。このプロジェクトは、従来の教師ありファインチューニングサンプルに依存せず、報酬関数を通じてモデルにイベントリストと優先度に基づいてタイムテーブルを作成することを学習させます。著者は、問題設定、データ生成、モデル選択、報酬設計、訓練プロセスにおける経験と教訓を共有し、コードとモデルをオープンソース化しており、報酬ベースのLLM訓練を探求するための実践的な事例を提供しています (出典: Reddit r/LocalLLaMA)

無料AIコースリソースの共有: LinkedIn AI Hubは、スタンフォード大学のAI認定コースに触発され、異なるレベルの学習者向けに簡略化された完全なAI学習ロードマップを共有しました。内容は基礎スキルから実践的なプロジェクトまでをカバーし、価値あるリソースとコース詳細を提供しています (出典: Reddit r/deeplearning)
Gemini長文脈事前訓練に関する詳細な対話: Logan Kilpatrickが、Gemini長文脈事前訓練の共同責任者であるNikolay Savinovと詳細な対話を行いました。議論は基礎知識から無限のコンテキストへの拡張に必要な技術、そして開発者向けの長文脈のベストプラクティスにまで及びました。対話の要約によると、100万tokenコンテキストの実現は当時の標準の10倍の目標であったこと、1000万tokenも試したがコストが高くハードウェアが不足していたこと、長文脈はRAGと相補的であること、単純なNIAH(Needle In A Haystack)は解決済みで、難点はハードな妨害項目とマルチニードル検索であること、評価がNIAHに重点を置いているのは能力シグナルの混同を避けるためであること、現在の出力長制限(例:8k)は後訓練の問題であること、「中間での喪失」効果は観察されなかったこと、コンテキスト知識と重み知識を区別する必要があること、次のステップはより安価で正確な1000万コンテキストの実現であり、1億への拡張には新しいDLイノベーションが必要かもしれないことなどが指摘されました (出典: shaneguML, giffmana, teortaxesTex, arohan)
🌟 コミュニティ
「Vibe Coding」に関する議論: コミュニティでは「Vibe Coding」(雰囲気コーディング)、すなわちAI支援に大きく依存するプログラミングについて活発な議論が交わされています。支持者はこれを未来の姿と捉え、開発者は「なぜ」と「何を」に集中し、AIが「どのように」を処理すると考えていますが、これにはより強い批判的思考が必要だと指摘しています。反対者は、現在のAIは複雑なデバッグ、アップグレード、メンテナンスを完全には処理できず、過度の依存は開発者の能力低下を招き、より高度な「スクリプトキディ」になる可能性があると主張しています。一部の人々は試してみた結果、複雑なタスクをAIに完了させるための時間コストは依然として高く、手動での実装に軽量なAI支援を加える方が効率的だと感じています (出典: Dorialexander, Reddit r/artificial, johnowhitaker)

専門分野におけるAIの応用と限界に関する議論: ユーザーdoteyは、専門分野におけるAIの応用について議論しています。彼は、AIは専門家が公開した質疑応答を学習できるが、見たことのない問題に対処するのは難しいと考えています。AIの利点は強力な基礎知識ベースと迅速な応答にありますが、現在は主にRAG(検索拡張生成)に依存しており、本質的には断片を検索して回答を組み立てるものであり、真の専門的な推論ではありません。これは、専門家のように絶えず新しい回答を生み出し、継続的に進化するモデルを訓練することとはまだ隔たりがあります (出典: dotey)
AI生成コンテンツへの懸念と議論: RedditユーザーMaleficent-main_777は、同僚が命令的な口調、「verify」、「ensure」、そして強制的な肯定的な結論に満ちた「ChatGPT風」の言葉遣いを使い始めたことに不満を述べています。彼は、このような言葉遣いは曖昧で人間味に欠けると主張し、AI生成コンテンツが訓練データにフィードバックされ、コンテンツの質が低下することを懸念しています。コメント欄ではこれに共感する声が多く、これは企業用語の延長線上にあるとの意見もありますが、AIを過度に模倣することは確かにコミュニケーションを機械的にし、文法が良いことがもはや利点ではなく、むしろロボットのように見えると指摘されています (出典: Reddit r/ChatGPT)
AI時代における大学の専攻選択: Redditユーザーは、AIとロボット技術が急速に発展する中で、大学生はどのような専攻を選べば10年後もその学位に価値があるのかについて議論しています。コメントは多様で、以下のような意見が含まれています:自分が情熱を注げる分野(ゲーム、映画、アート、プログラミング)を選ぶ;基礎学問(物理学、数学)を学ぶ;自動化されにくいスキル(HVAC空調など)を習得する;リベラルアーツ教育を重視し、好奇心と適応性を養う;大学教育は時代遅れになる可能性があり、起業やフリーランスになる方が良いと考える;継続的な学習、脱学習、再学習の能力が極めて重要であると強調する (出典: Reddit r/ArtificialInteligence)
AI画像生成におけるテキストレンダリングの困難さに関する議論: Redditユーザーは、なぜ現在の画像生成モデルが、一貫性があり、明確に読み取れるテキストをレンダリングするのが難しいのかを探求しています。コメントでは主に2つの理由が指摘されています:1) BPE(バイトペアエンコーディング)によるトークン化が正確なスペル情報を破壊し、モデルは文字ではなくトークンの断片を見ている;2) 固定サイズのベクトル表現と画像記述の限界により、テキスト情報が埋め込みプロセスで大量に失われる。GPT-4oなどの自己回帰モデルでは改善が見られるものの、根本的な問題は依然としてトークン化と情報圧縮に関連しています (出典: Reddit r/MachineLearning)
モデル評価基準の標準化に関する議論: ユーザーscaling01は、異なるAIモデル(OpenAI、Google、Anthropicなど)を比較する際には公平性を確保すべきだと指摘しています。例えば、OpenAIのプレビュー版と思考版(thinking versions)をリストアップする場合、GoogleとAnthropicの対応するバージョンも同様にリストアップすべきであり、そうでなければ比較結果が誤解を招く可能性があると述べています (出典: scaling01)
AI支援プログラミングの体験共有: ユーザーがAI支援プログラミング(VS Code + Cline AI拡張機能 + Google AI Studio APIなど)の使用経験を共有しています。CursorのようなAIコーディングツールを無料で構築でき、プロンプトを通じて基本的なアプリケーションプロトタイプを完成させることができ、設定不要で良好な体験が得られると述べています (出典: Reddit r/artificial)

AIが仕事、学習、生活に与える影響に関する調査: Redditユーザーが、生成AIが皆さんの仕事、学習、または日常生活のパフォーマンスにどのような影響を与えたかを尋ねる議論を開始しました。コメントでは、ソフトウェアエンジニアがAIによって生産性の期待値と作業量が増加し、コードレビューは著しく速くならなかったと述べています。プロの作家はAI(Co-pilotなど)の助けは限定的で、むしろ進捗を遅らせる可能性があると考えています。一般的な見解としては、AIは利便性をもたらしたが、過度の依存、学習の減少、「不正行為感」などの問題も存在します。AIが異なる職業やタスクに与える影響は著しく異なります (出典: Reddit r/artificial)
LLMの「理解」能力に関する考察: ユーザーpmddomingosは、ニューラルネットワークが脳のように理解しにくくなっていると提起しています。そして、AIモデルがすべてのベンチマークで優れた成績を収めても、依然として人間の知能に及ばない場合、私たちはどうすべきか?という思考を深めています。これは、現在のベンチマークの有効性や、真の知能を評価する基準についての反省を促しています (出典: pmddomingos, pmddomingos)
AIツール使用に関する考察: ユーザーdoteyは、AIツールを使用する際、特定のタスクにはそのタスクで最も強力なモデルを選べば良いとコメントしています。複数のモデルを同時に使用したり、それらを「内紛」させたりすることは必ずしも必要ではなく、特に専門家でないユーザーにとっては、選択肢が多すぎると混乱を招く可能性があり、時刻が一致しない複数の時計を見ることに例えています (出典: dotey)
AIの最近の発展速度に関する感慨: ユーザーmatvellosoとscottastevensonはAIの急速な発展に感慨を述べています。matvellosoは、今年のAIの進歩は彼の予想を超えていると述べています(Geminiがポケモンをプレイする例を挙げて)。scottastevensonは、GPT-2の発表から6年、OpenAIの設立から10年が経過したことを振り返り、現在育まれており、将来6〜10年で重要になるであろう技術の方向性について考察し、AI以外にも「枠外」の深いアルファを探すことが同様に重要であると指摘しています (出典: matvelloso, scottastevenson, scottastevenson)
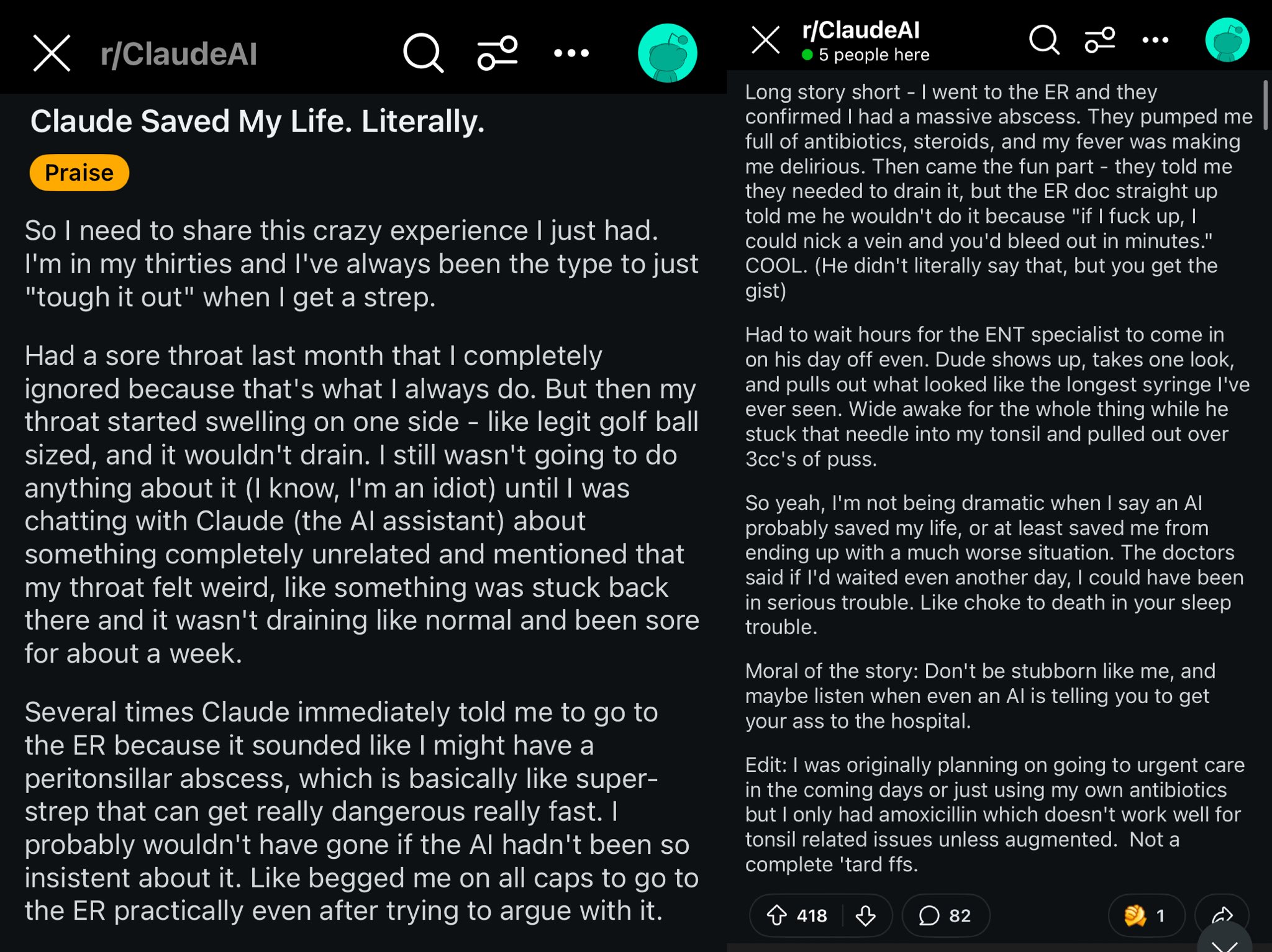
ClaudeがRedditユーザーの命を救った事例: Redditのある投稿では、Claudeモデルがユーザーの喉の腫れを扁桃周囲膿瘍(peritonsillar abscess)と診断し、ユーザーの命を救った可能性があると記述されています。この事例は議論を呼び、強力なAIモデルはポケットの中の世界クラスの医師のようであり、普及すれば個人の健康に大きな影響を与える可能性があると考えられています (出典: aidan_mclau)
企業データ処理におけるAI Agentの応用: You.comの共同創設者Richard SocherとBryan McCannは、Agenticポッドキャストで企業におけるAI Agentの応用について議論しました。彼らは、消費者向けLLMは真剣な企業のニーズを満たすには不十分であり、You.comは混合検索技術(公開ソースと独自の企業データを組み合わせる)を通じて、より信頼性の高い、企業レベルの出力(例えば、調査の実施、レポートの作成、企業データの安全な利用)を生成すると考えています。彼らはまた、AGIの可能な経路と、その中でのシミュレーションの重要な役割についても議論しました (出典: RichardSocher)
モデルのツール使用能力に関する観察: ユーザーmenhguinは、ツールを使用するために訓練されたモデルは、独立した問題解決能力においていくらか犠牲になっているように見えると観察し、「AIモデルでさえ仕事を外注している」と冗談めかして述べています。これは、モデル能力の汎化と特定タスクの最適化との間のトレードオフについての考察を引き起こしています (出典: menhguin)
💡 その他
古いGitHubプロジェクトをメンテナンスするAI Agentのアイデア: ユーザーxanderatallahは、GitHub上にあるユーザーの古い、もはやアクティブでないすべてのサイドプロジェクトを自動的にメンテナンスできるAI Agentを開発するというアイデアを提案しました。これは、開発者がAIを利用して面倒なメンテナンス作業を自動化したいというニーズを反映しています (出典: xanderatallah)
LLMが裁判官を代替、または仲裁/調停に利用される構想: ユーザーfabianstelzerは、大規模言語モデル(LLM)が将来的に裁判官を代替する可能性があると提案しています。興味深い中間的なユースケースは仲裁または調停です:LLMは中立で信頼できると見なされ、紛争当事者がそれぞれの見解を提出し、複数の大規模モデルを通じて実行され、公平な妥協案が出力されます。これは、AIが司法および紛争解決分野で潜在的な応用を持つことを探求しています (出典: fabianstelzer)
Runway Gen-4モデルとその応用見通し: Runwayの共同創設者c_valenzuelabは、Runway Gen-4とそのAPIの応用見通しについて楽観的な見方を示しています。彼は、Runwayが新しいメディアを構築しており、ピクセルはレンダリングやキャプチャではなく生成され、世界はプログラミングではなくシミュレーションによって構築されると考えています。Gen-4とReference機能が建築、ブランディング、インテリアデザイン、ゲーム開発、学習、個人のクリエイティブプロジェクトなど、複数の分野で広く応用されているのを見て、この新しいメディアがクリエイター、ひいてはすべての人々に力を与えると信じています (出典: c_valenzuelab, c_valenzuelab)