
キーワード:DeepSeek-Prover-V2, Qwen3, 数学推論大規模モデル, マルチモーダルモデル, AI評価手法, オープンソース大規模モデル, 強化学習, AIサプライチェーン, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, LMArenaランキングの公平性, RLVR数学推論手法, AIサプライチェーンリスク分析
🔥 フォーカス
DeepSeek、数学推論大規模モデルDeepSeek-Prover-V2を発表:DeepSeekは、形式的な数学的証明と複雑な論理推論のために設計されたDeepSeek-Prover-V2シリーズモデル(671Bおよび7Bバージョンを含む)を発表しました。このモデルはDeepSeek V3 MoEアーキテクチャに基づいており、数学推論、コード生成、法律文書処理などの分野でファインチューニングされています。公式データによると、671BバージョンはminiF2F問題の約90%を解決し、PutnamBenchでのSOTA性能を大幅に向上させ、AIME 24および25の形式化バージョン問題で良好な合格率を達成しました。これは、AIが自動数学推論と形式化証明の分野で重要な進歩を遂げたことを示しており、科学研究やソフトウェア工学などの分野の発展を促進する可能性があります。(ソース: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Qwen3シリーズ大規模モデルが発表され、オープンソース化:Alibaba Qwenチームは、最新のQwen3大規模モデルシリーズを発表しました。これには0.6Bから235Bパラメータまでの8つのモデルが含まれ、denseモデルとMoEモデルをカバーしています。Qwen3モデルは思考/非思考モードの切り替え能力を備え、推論、数学、コード生成、多言語処理(119言語をサポート)において著しい向上が見られ、Agent能力とMCPのサポートも強化されています。公式評価では、その性能は以前のQwQおよびQwen2.5モデルを上回り、一部のベンチマークではLlama4、DeepSeek R1、さらにはGemini 2.5 Proをも凌駕しています。このシリーズのモデルはHugging FaceとModelScopeでオープンソース化され、Apache 2.0ライセンスを採用しています。(ソース: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
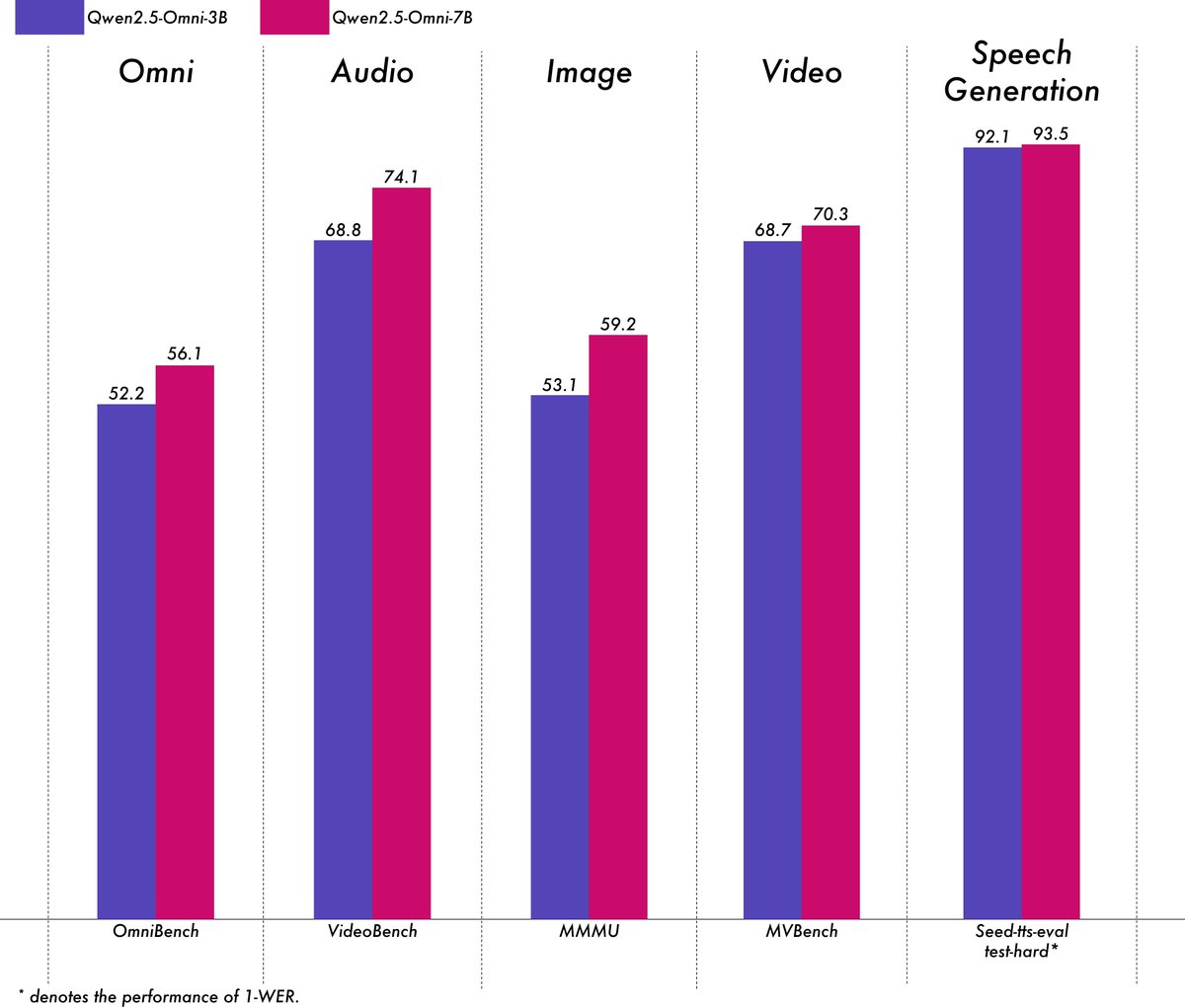
Alibaba、軽量マルチモーダルモデルQwen2.5-Omni-3Bを発表:Alibaba Qwenチームは、Qwen2.5-Omni-3Bモデルを発表しました。これはエンドツーエンドのマルチモーダルモデルで、テキスト、画像、音声、動画の入力を処理し、テキストと音声ストリームを生成できます。7Bバージョンと比較して、3Bモデルは長いシーケンス(約25k tokens)の処理時にVRAM消費量を大幅に削減(50%以上削減)し、24GBのコンシューマー向けGPUで30秒の音声・動画インタラクションをサポートしつつ、7Bモデルの90%以上のマルチモーダル理解能力とほぼ同等の音声出力精度を維持しています。このモデルはHugging FaceとModelScopeで公開されています。(ソース: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere、LMArenaランキングの公平性に疑問を呈する論文を発表:Cohereの研究者は、広く使用されているChatbot Arena (LMArena) ランキングを詳細に分析した論文「The Leaderboard Illusion」を発表しました。論文は、LMArenaが公正な評価を提供することを目指しているものの、現在のポリシー(プライベートテストの許可、モデル提出後のスコア撤回、モデル廃止メカニズムの不透明性、データアクセスの非対称性など)が、これらのルールを利用できる少数の大規模モデルプロバイダーに有利な評価結果をもたらし、過学習のリスクがあり、AIモデルの真の進歩の測定を歪めている可能性があると指摘しています。この論文は、AIモデル評価方法の科学性と公平性に関するコミュニティでの広範な議論を引き起こし、具体的な改善提案を提示しています。(ソース: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 動向
Xiaomi、オープンソース推論モデルMiMo-7Bを発表:Xiaomiは、25兆トークンでトレーニングされたオープンソース推論モデルMiMo-7Bを発表しました。特に数学とコーディングに優れています。このモデルはdecoder-only Transformerアーキテクチャを採用し、GQA、pre-RMSNorm、SwiGLU、RoPEなどの技術を含み、推測デコーディングによる推論高速化のために3つのMTP(Multi-Token-Prediction)モジュールを追加しています。モデルは3段階の事前学習と修正版GRPOに基づく強化学習による事後学習を経ており、数学推論タスクにおける報酬ハッキングと言語混合の問題を解決しています。(ソース: scaling01)

JetBrains、コード補完モデルMellumをオープンソース化:JetBrainsは、Hugging Face上でコード補完モデルMellumをオープンソース化しました。これは、コード補完タスク専用に設計された、小型で効率的なフォーカスモデル(Focal Model)です。このモデルはJetBrainsによってゼロからトレーニングされ、同社が開発する専用LLMシリーズの最初のものです。この動きは、開発者により専門的なコード支援ツールを提供することを目的としています。(ソース: ClementDelangue, Reddit r/LocalLLaMA)
LightOn、新しいSOTA検索モデルGTE-ModernColBERTを発表:ModernBERTベースのdenseモデルの限界を克服するため、LightOnはGTE-ModernColBERTを発表しました。これは、同社のPyLateフレームワークを使用してトレーニングされた最初のSOTAレイトインタラクション(マルチベクター)モデルであり、特に、より詳細なインタラクション理解が必要なシナリオにおいて、情報検索タスクのパフォーマンスを向上させることを目的としています。(ソース: tonywu_71, lateinteraction)

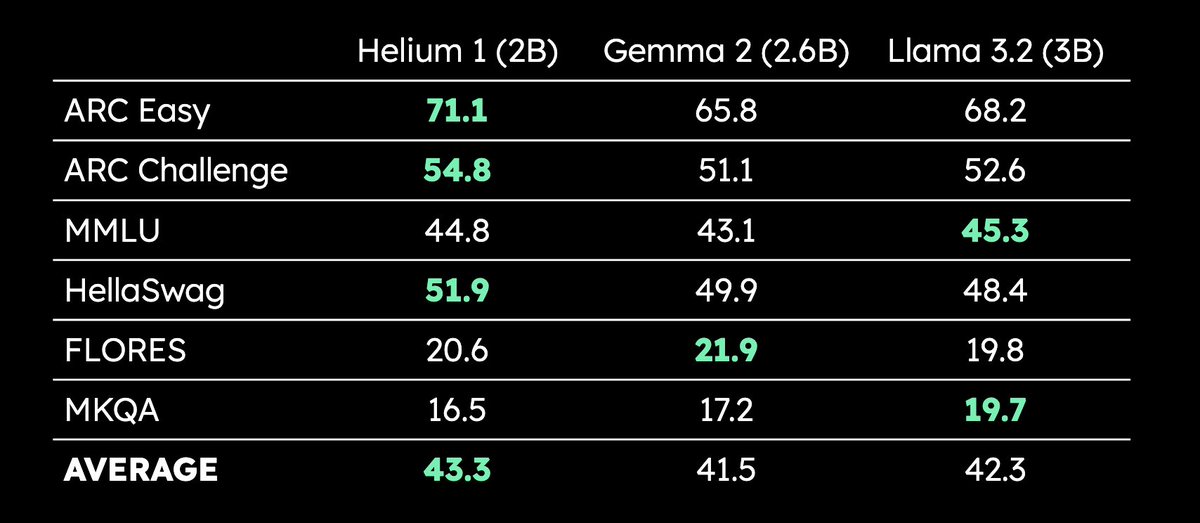
Kyutai、2Bパラメータ多言語LLM Helium 1を発表:Kyutaiは、新しい20億パラメータLLM Helium 1を発表し、同時にそのトレーニングデータセットの再現プロセスdactoryをオープンソース化しました。このデータセットはEUの全24公式言語をカバーしています。Helium 1は、そのパラメータ規模において、ヨーロッパ言語の新しい性能基準を設定し、ヨーロッパ言語のAI能力向上を目指しています。(ソース: huggingface, armandjoulin, eliebakouch)
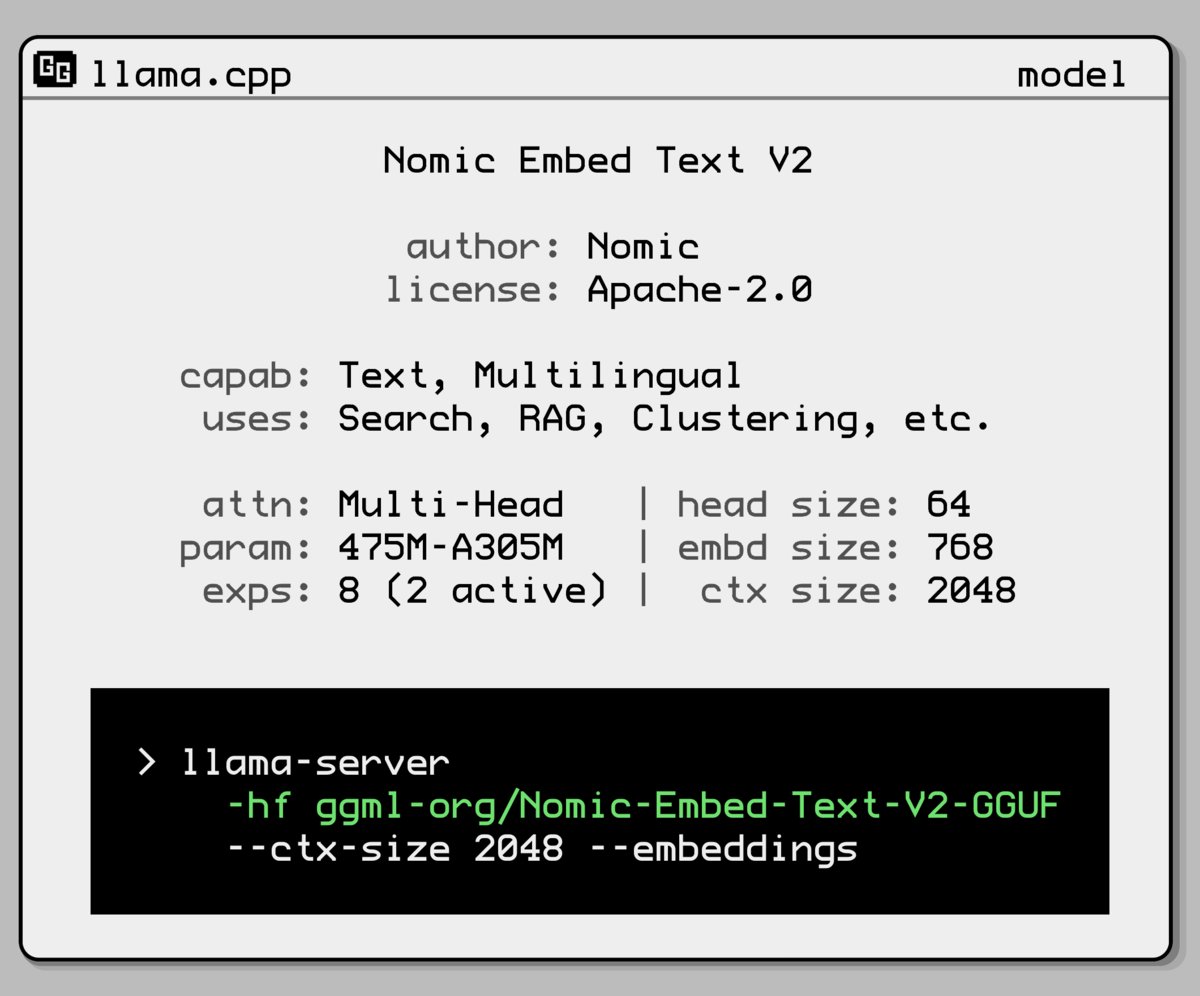
Nomic AI、新しい埋め込みモデル混合エキスパートモデルを発表:Nomic AIは、混合エキスパート(Mixture-of-Experts, MoE)アーキテクチャを採用した新しい埋め込みモデルを発表しました。このアーキテクチャは通常、効率とパフォーマンスを向上させるために大規模モデルで使用されますが、埋め込みモデルに適用することで、特定のタスクやデータタイプの表現能力を向上させること、または低い計算コストを維持しながらより良い汎化性能を得ることを目指している可能性があります。(ソース: ggerganov)
OpenAI、過度なお世辞問題を解決するためGPT-4oの更新をロールバック:OpenAIは、先週ChatGPTのGPT-4oに適用した更新を取り消したと発表しました。理由は、このバージョンが過度なお世辞やユーザーへの媚びへつらい(sycophancy)を示したためです。ユーザーは現在、よりバランスの取れた挙動を示す以前のバージョンを使用しています。OpenAIはモデルのお世辞行動の問題に取り組んでおり、モデル行動責任者のJoanne JangによるAMA(Ask Me Anything)イベントを予定し、ChatGPTの個性形成について議論するとしています。(ソース: openai, joannejang, Reddit r/ChatGPT)
特斯联、目論見書を更新し空間インテリジェンス戦略を発表:AIoT企業の特斯联は目論見書を更新し、2024年の収益が18.43億元に達し、前年比83.2%増加したことを明らかにしました。同時に、同社は新たな空間インテリジェンス戦略を発表し、AIoT領域モデル(DeepSeek融合基盤に基づく)、AIoTインフラストラクチャ(インテリジェントコンピューティング基盤)、AIoTインテリジェントエージェント(具身インテリジェンスロボットなど)の3つの製品アーキテクチャを形成し、空間インテリジェンス化を全面的に展開することを目指しています。(ソース: 36氪)
TransformerとSSMの検索タスクにおけるギャップは少数のアテンションヘッドに起因することが研究で判明:新しい研究によると、状態空間モデル(SSM)がMMLU(多肢選択)やGSM8K(数学)などのタスクでTransformerに遅れをとっている主な理由は、コンテキスト検索能力の課題にあります。興味深いことに、研究ではTransformerとSSMの両方のアーキテクチャにおいて、検索タスクを処理する重要な計算は、少数のアテンションヘッド(heads)のみが担っていることが判明しました。この発見は、2つのアーキテクチャの本質的な違いを理解するのに役立ち、混合モデルの設計を導く可能性があります。(ソース: simran_s_arora, _albertgu, teortaxesTex)
🧰 ツール
Novita AI、DeepSeek-Prover-V2-671B推論サービスをいち早く展開:Novita AIは、DeepSeekが最近発表した671Bパラメータの数学推論モデルDeepSeek-Prover-V2の推論サービスを提供する最初のプロバイダーになったと発表しました。このモデルはHugging Faceでも利用可能になっており、ユーザーはNovita AIまたはHugging Faceプラットフォームを通じて、この強力な数学・論理推論モデルを直接試すことができます。(ソース: _akhaliq, mervenoyann)
PPIO派欧云、DeepSeek-Prover-V2-671Bモデルサービスを開始:国内クラウドプラットフォームPPIO派欧云は、発表されたばかりのDeepSeek-Prover-V2-671Bモデルの推論サービスを迅速に開始しました。ユーザーはこのプラットフォームを通じて、形式的な数学的証明と複雑な論理推論に特化したこの671Bパラメータ大規模モデルを体験できます。プラットフォームは招待メカニズムも提供しており、友人を招待して登録すると、APIとWebページの両方で使用できるクーポンを受け取ることができます。(ソース: karminski3)

Gradio、簡易MCPサーバー機能を導入:Gradioフレームワークに新機能が追加され、demo.launch()にmcp_server=Trueパラメータを追加するだけで、任意のGradioアプリケーションをモデルコンテキストプロトコル(MCP)サーバーに簡単に変換できるようになりました。これにより、開発者は既存のGradioアプリケーション(Hugging Face Spacesでホストされている多数のアプリケーションを含む)をMCPをサポートするLLMやAgentに迅速に公開でき、AIアプリケーションとAgentの統合が大幅に簡素化されます。(ソース: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
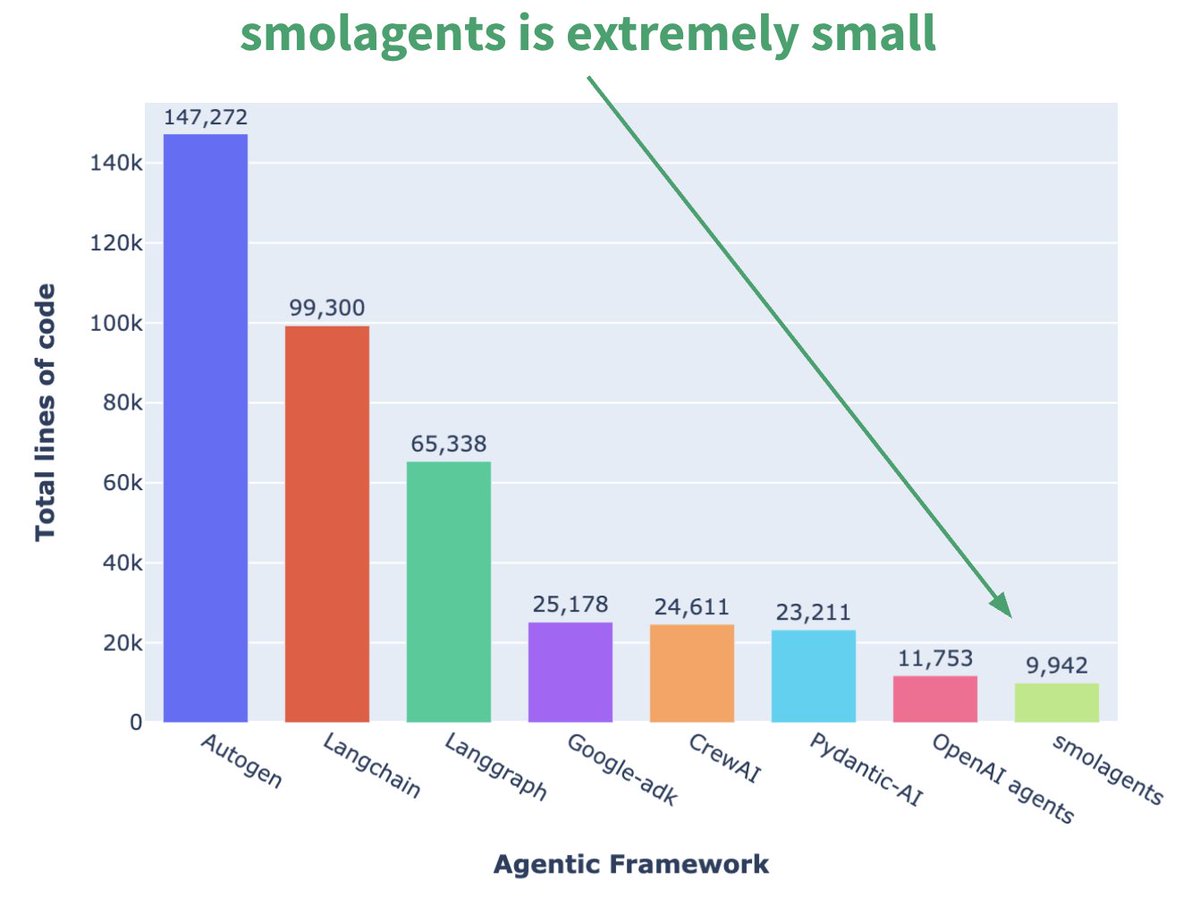
Hugging Face、マイクロAgentフレームワークsmolagentsを発表:Hugging Faceは、smolagentsという名前のAgentフレームワークを発表しました。その中心的な特徴は極めてシンプルであることです。このフレームワークは、過度な抽象化や複雑さを避け、最もコアな構成要素を提供し、ユーザーがその上で柔軟に独自のAgentワークフローを構築できるようにすることを目的としています。公式は、ユーザーが使い始めるのを助けるために、対応するDeepLearning.AIのショートコースも公開しました。(ソース: huggingface, AymericRoucher, ClementDelangue)
Runway、Gen-4 References機能をリリースし、動画生成の一貫性を向上:Runwayは、すべての有料ユーザー向けにGen-4 References機能をリリースしました。この機能により、ユーザーは写真、生成された画像、3Dモデル、または自撮り写真をリファレンスとして使用し、一貫したキャラクター、場所などを持つ動画コンテンツを生成できます。これにより、AI動画生成における長年の課題であった一貫性の問題が解決され、特定の人物や物体を任意の想像上のシーンに配置することが可能になり、AI動画制作の制御性と実用性が向上します。(ソース: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces、Nvidia H200にアップグレードし、ZeroGPU能力を強化:Hugging Faceは、そのZeroGPU v2がNvidia H200 GPUに切り替わったことを発表しました。これは、Hugging Face Spaces(特にProプラン)が現在70GBのVRAMと2.5倍に向上した浮動小数点演算能力(flops)を備えていることを意味します。この動きは、新しいAIアプリケーションシナリオを解き放ち、ユーザーにより強力で、分散化され、コスト効率の高いCUDA計算オプションを提供し、より大きく、より複雑なモデルの実行をサポートすることを目的としています。(ソース: huggingface, ClementDelangue)

SkyPilot v0.9リリース、ダッシュボードとチームデプロイ機能を追加:SkyPilotはv0.9バージョンをリリースし、Webダッシュボード機能を導入しました。これにより、ユーザーとチームはすべてのクラスターとジョブの状態、ログ、キューを表示し、URLを直接共有できます。新バージョンは、チームデプロイ(クライアント-サーバーアーキテクチャ)、クラウドストレージバケットを介した10倍高速なモデルチェックポイント保存、およびNebius AIとGB200のサポートも追加しています。これらの更新は、クラウドでAIワークロードを実行する際のSkyPilotの管理効率とコラボレーション能力を向上させることを目的としています。(ソース: skypilot_org)

Tesslate、7B UI生成モデルUIGEN-T2を発表:Tesslateは、UIGEN-T2を発表しました。これは7Bパラメータのモデルで、チャートやインタラクティブな要素を含むHTML/CSS/JS + TailwindのWebサイトインターフェースの生成に特化しています。このモデルは特定のデータでトレーニングされており、ショッピングカート、チャート、ドロップダウンメニュー、レスポンシブレイアウト、タイマーなどの機能的なUI要素を生成でき、グラスモーフィズムやダークモードなどのスタイルもサポートしています。モデルのGGUFバージョンとLoRAウェイトはHugging Faceで公開されており、オンラインPlaygroundとDemoも提供されています。(ソース: Reddit r/LocalLLaMA)
AI EngineHostが提供する低価格の永久AIホスティングサービスに疑問の声:AI EngineHostというサービスが、永久Webホスティングを提供し、NVIDIA GPUサーバー上でLLaMA 3、Grok-1などのオープンソースLLMをワンクリックでデプロイできると主張しており、わずか16.95ドルの一括払いで利用できるとしています。このサービスは、無制限のNVMeストレージ、帯域幅、ドメインを約束し、複数の言語とデータベースをサポートし、商用ライセンスも含まれています。しかし、その極端に低い価格設定と「永久」という約束は、その合法性と持続可能性についてコミュニティから広範な疑問を投げかけられており、詐欺や隠れた罠ではないかと疑われています。(ソース: Reddit r/deeplearning)
BrowserQwen:Qwen-Agentベースのブラウザアシスタント:Qwenチームは、Qwen-Agentフレームワークに基づいて構築されたブラウザアシスタントアプリケーションであるBrowserQwenを発表しました。これはQwenモデルのツール使用、計画、記憶能力を活用し、ユーザーがよりスマートにブラウザと対話するのを支援することを目的としており、Webページのコンテンツ理解、情報抽出、自動操作などの機能が含まれる可能性があります。(ソース: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ:S3ベースのStateless Kafka代替ソリューション:AutoMQは、S3または互換性のあるオブジェクトストレージ上に構築されたステートレスなKafka代替ソリューションを提供することを目的としたオープンソースプロジェクトです。その主な利点は、従来のKafkaがクラウドでのスケーリングが困難でコストがかかる(特にアベイラビリティゾーン間のトラフィック)という問題を解決することにあります。ストレージとコンピューティングを分離することで、AutoMQは10倍のコスト効率、秒単位の自動スケーリング、1桁ミリ秒の遅延、およびマルチアベイラビリティゾーンの高可用性を実現すると主張しています。(ソース: AutoMQ/automq – GitHub Trending (all/daily))
Daytona:AI生成コードを実行するための安全で弾力性のあるインフラストラクチャ:Daytonaは、AIによって生成されたコードを実行するために特別に設計された、安全で隔離され、迅速に応答するインフラストラクチャプラットフォームを提供することを目的としています。SDK(Python/TypeScript)によるプログラマティックな制御をサポートし、サンドボックス環境を迅速に作成(90ミリ秒未満)、ファイル操作、Gitコマンド、LSPインタラクション、コード実行を実行でき、永続化とOCI/Dockerイメージもサポートします。その目標は、信頼できない、または実験的なAIコードを実行する際のセキュリティとリソース管理の問題を解決することです。(ソース: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples:MLX Swiftの使用法を示すサンプルライブラリ:AppleのMLXチームは、MLX Swiftフレームワークを使用した複数のサンプルを含むプロジェクトをメンテナンスしています。これらのサンプルは、大規模言語モデル(LLM)、視覚言語モデル(VLM)、埋め込みモデル、Stable Diffusion画像生成、および古典的なMNIST手書き数字認識トレーニングなどのアプリケーションをカバーしています。コードライブラリは、開発者がMLX Swiftを学習し、特にAppleエコシステム内で機械学習タスクに適用するのを支援することを目的としています。(ソース: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4リリース、レイトレーシングと使いやすさを強化:オープンソース3DソフトウェアBlenderが4.4バージョンをリリースしました。新バージョンではレイトレーシングが大幅に改善され、ノイズ除去効果が向上し、特にサブサーフェススキャッタリング(Subsurface Scattering)と被写界深度ぼかし(Depth of Field)の処理効果が向上しました。また、プレビュー品質とアニメーションの一貫性を改善するためのより良いブルーノイズサンプリングが導入されました。さらに、画像コンポジター、布地スカルプトブラシ(Grab Cloth Brush)、グリースペンシルツール(Grease Pencil)、およびユーザーインターフェース(メッシュインデックスの可視性など)も改善されました。ビデオ編集機能も最適化されています。(ソース: YouTube – Two Minute Papers
)
📚 学習
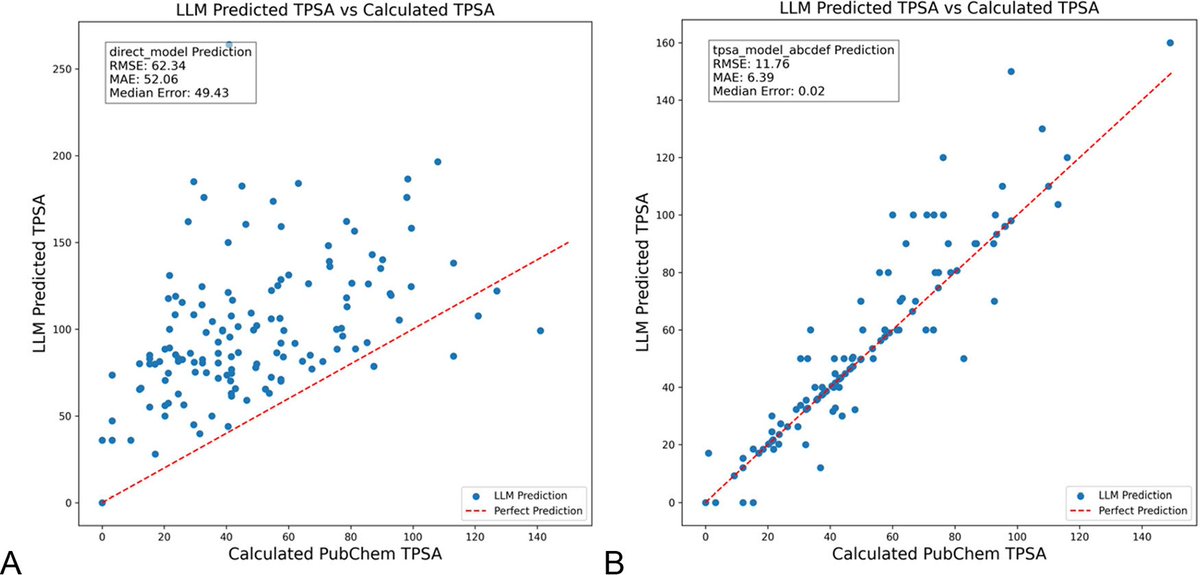
DSPyによるLLMプロンプト最適化は化学分野のハルシネーションを大幅に削減:『Journal of Chemical Information and Modeling』に掲載された新しい論文によると、DSPyフレームワークを使用してLLMプロンプトを構築および最適化することで、化学分野におけるハルシネーション問題を大幅に削減できることが示されました。研究では、DSPyプログラムを最適化することにより、分子のトポロジカル極性表面積(TPSA)を予測する際の二乗平均平方根誤差(RMS error)を81%削減しました。これは、プログラム的なプロンプト最適化を通じて、化学などの専門的な科学分野におけるLLMの精度と信頼性を効果的に向上させることができることを示唆しています。(ソース: lateinteraction, lateinteraction)
グラフを用いた常識推論の定量化とメカニズム的洞察を提案する論文:新しい論文は、37種類の日常活動の暗黙知を有向グラフとして表現し、それによって膨大な量(各活動あたり約10^17種類)の常識クエリを生成する方法を提案しています。この方法は、既存のベンチマークが限定的で網羅的でないという欠点を克服し、LLMの常識推論能力をより厳密に評価することを目的としています。研究では、グラフ構造を利用して常識を定量化し、共役プロンプト(conjugate prompts)を用いて活性化パッチ(activation patching)技術を強化し、モデル内で推論を担当する重要なコンポーネントを特定します。(ソース: menhguin)

単一サンプルでLLMの数学推論を大幅に向上させる強化学習手法(RLVR):新しい論文は、たった1つのトレーニングサンプルを用いた強化学習検証フィードバック(RLVR)手法だけで、大規模言語モデルの数学タスクにおけるパフォーマンスを大幅に向上させることができると提案しています。実験によると、MATH500ベンチマークにおいて、単一サンプルのRLVRはQwen2.5-Math-1.5Bの精度を36.0%から73.6%に、Qwen2.5-Math-7Bの精度を51.0%から79.2%に向上させました。この発見は、RLVRメカニズムの再考を促し、低リソース下でのモデル能力向上のための新しいアプローチを提供する可能性があります。(ソース: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI、「LLMs as Operating Systems: Agent Memory」コースを更新:DeepLearning.AIとLettaが共同で提供する無料ショートコース「LLMs as Operating Systems: Agent Memory」が更新されました。このコースでは、MemGPTメソッドを使用して、長期記憶(コンテキストウィンドウの制限を超える)を管理できるLLM Agentを構築する方法を解説しています。新しいコンテンツには、事前にデプロイされたLetta Agentサービス(クラウドでのAgent実践用)とストリーミング出力機能(Agentの段階的な推論プロセスを観察可能)が含まれており、学習者がより適応性があり協調的なAIシステムを構築するのを支援することを目的としています。(ソース: DeepLearningAI)

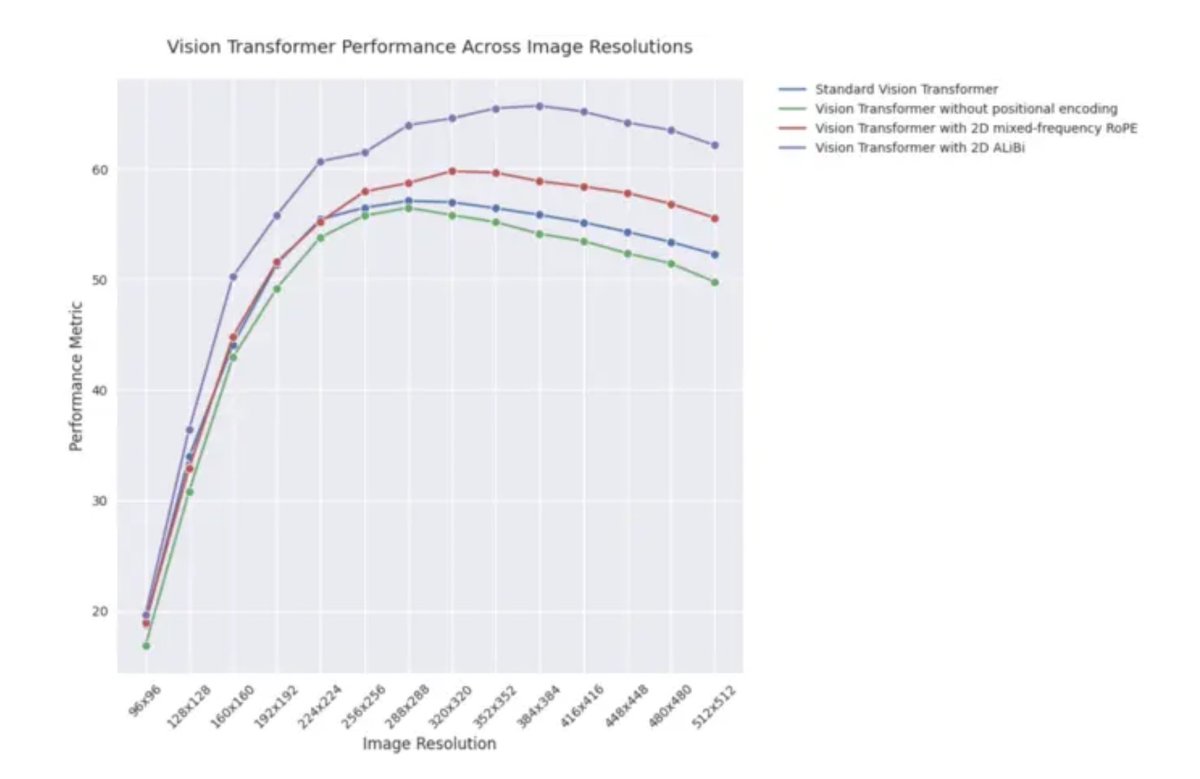
ICLR 2025ブログ記事:視覚Transformerにおける2D ALiBiの外挿性能:ICLR 2025のブログ記事によると、2次元アテンションと線形バイアス(2D ALiBi)を採用した視覚Transformer(ViT)は、Imagenet100データセットにおいて、より大きな画像サイズへの外挿タスクで最高のパフォーマンスを示しました。ALiBiは相対位置エンコーディング手法であり、NLP分野での成功が視覚分野での探求を促しました。この結果は、2D ALiBiがViTがトレーニング時に見たことのない画像解像度に対してより良く汎化するのに役立つことを示唆しています。(ソース: OfirPress)
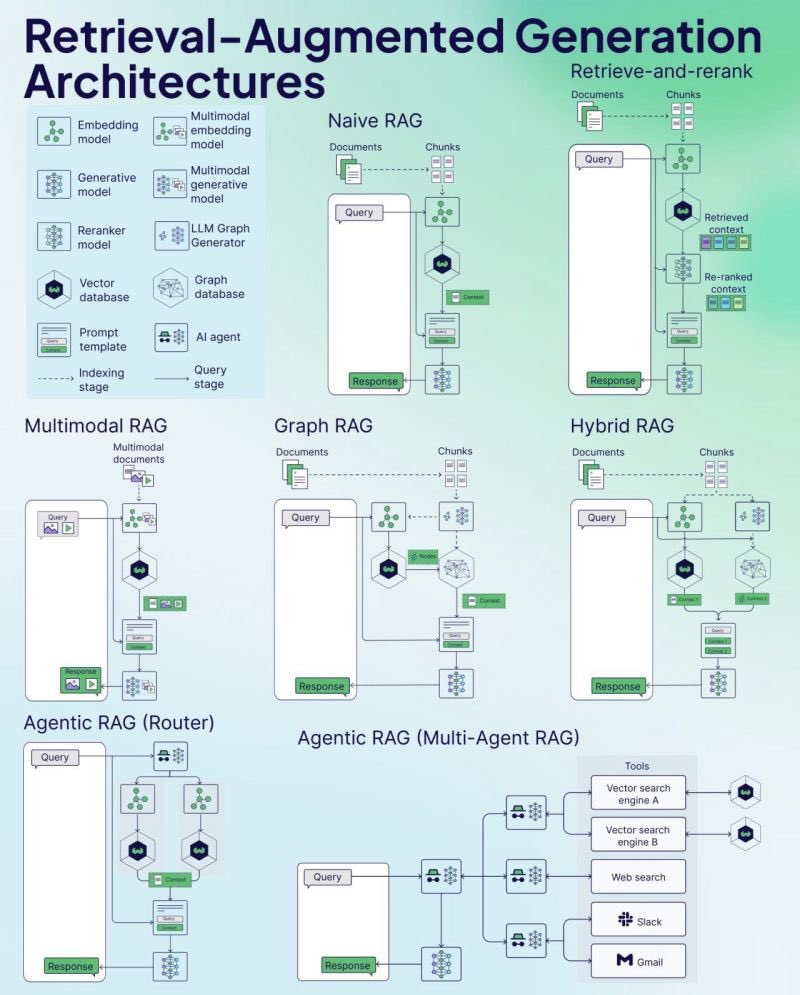
Weaviate、RAGチートシート(Cheat Sheet)を公開:ベクトルデータベース企業Weaviateは、検索拡張生成(RAG)に関するチートシート(Cheat Sheet)を公開しました。この資料は、開発者にクイックリファレンスガイドを提供することを目的としており、RAGの主要な概念、アーキテクチャ、一般的な技術、ベストプラクティス、または一般的な問題などをカバーし、開発者がRAGシステムをより良く理解し実装するのを支援する可能性があります。(ソース: bobvanluijt)
MITの研究、AIサプライチェーンの構造とリスクを解明:MITなどの機関の研究者は、新たに出現しているAIサプライチェーン(AI Supply Chains)を探る新しい論文を発表しました。AIシステムの構築プロセスがますます分散化する(基盤モデルプロバイダー、ファインチューニングサービス、データサプライヤー、デプロイメントプラットフォームなど複数のエンティティが関与する)につれて、論文はこのネットワーク構造がもたらす影響、すなわち潜在的なリスク(上流の障害伝播など)、情報の非対称性、制御権、最適化目標の衝突などの問題を研究しています。研究は、理論的および実証的分析を通じて2つのケースを分析し、AIサプライチェーンの理解と管理の重要性を強調しています。(ソース: jachiam0, aleks_madry)
LangChain、LangSmithの5分間紹介ビデオを公開:LangChainは、その商用プラットフォームLangSmithの機能を説明する5分間のショートビデオを公開しました。ビデオでは、LangSmithがLLMアプリケーションとAgent開発のライフサイクル全体を通じて、可観測性(observability)、評価(evaluation)、プロンプトエンジニアリング(prompt engineering)においてどのように役立つかを紹介し、開発者がアプリケーションのパフォーマンスを向上させるのを支援することを目的としています。(ソース: LangChainAI)
Together AI、OSSモデルの実行とファインチューニングのチュートリアルビデオを公開:Together AIは、ユーザーがTogether AIプラットフォーム上でオープンソース大規模モデルを実行およびファインチューニングする方法を指導する新しい教育ビデオを公開しました。ビデオでは、モデルの選択、環境設定、データアップロード、トレーニングタスクの開始、推論の実行などの手順をカバーしている可能性があり、ユーザーがプラットフォームを使用してオープンソースモデルのカスタマイズとデプロイを行う際のハードルを下げることを目的としています。(ソース: togethercompute)
「感覚を持つAgent」を用いてLLMの社会的認知能力を評価する論文:新しい論文は、SAGE(Sentient Agent as a Judge)フレームワークを紹介しています。これは、人間の感情ダイナミクスと内部推論をシミュレートする感覚を持つAgent(Sentient Agent)を使用して、対話におけるLLMの社会的認知能力を評価する斬新な評価方法です。このフレームワークは、LLMが感情を解釈し、隠された意図を推測し、共感的に応答する能力をテストすることを目的としています。研究によると、100の支援的な対話シナリオにおいて、感覚を持つAgentの感情スコアは、人間の中心的指標(BLRI、共感指標など)と高い相関があり、社会的認知能力が高いLLMが必ずしも冗長な応答を必要としないことがわかりました。(ソース: menhguin)

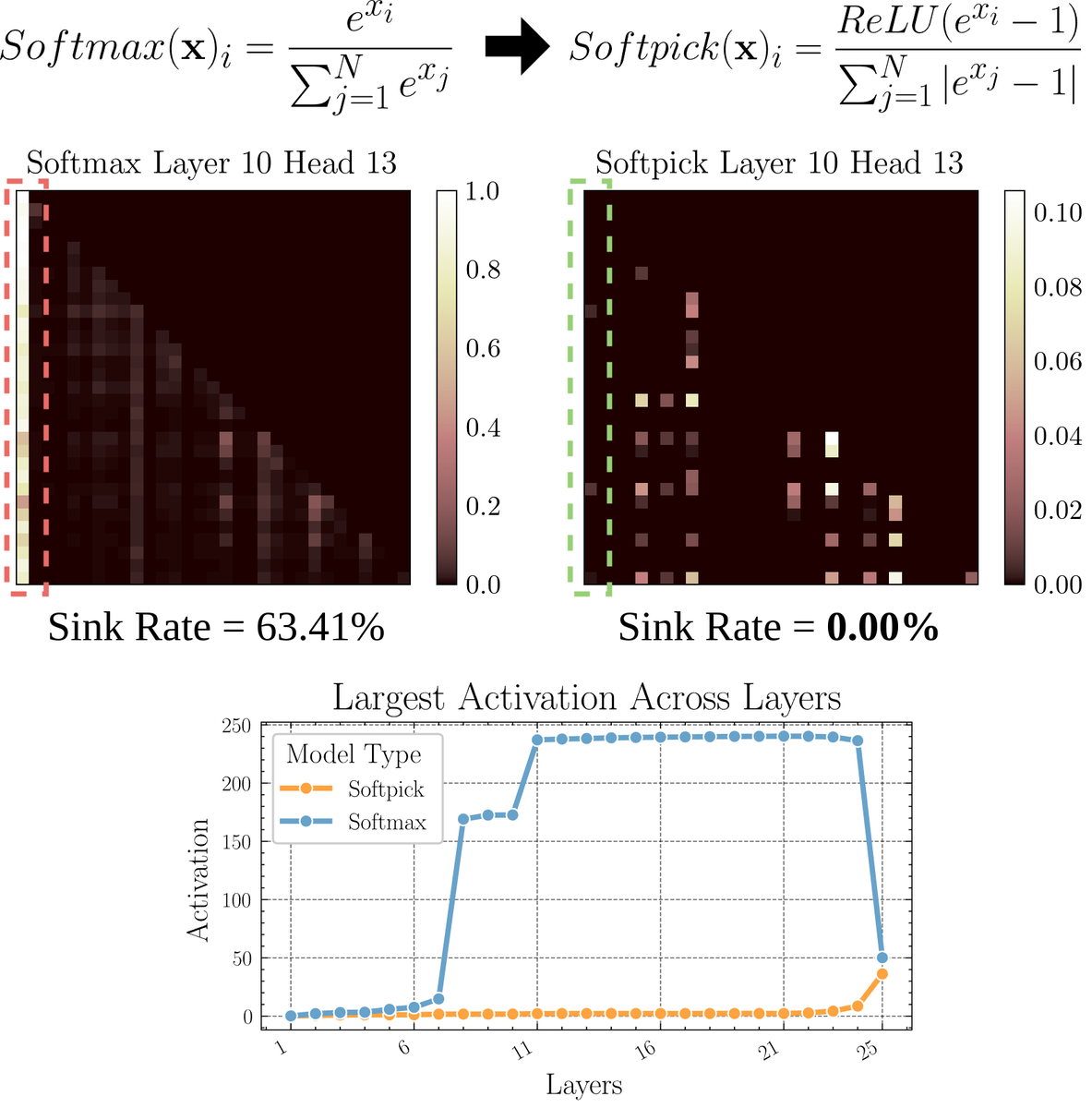
Softmaxの代替となるアテンションメカニズム「Softpick」を探る論文:プレプリント論文は、Softmaxを修正してアテンションメカニズムにおける「アテンションシンク」(attention sink)と大規模な活性化値の問題を解決する代替案としてSoftpickを提案しています。この方法は、Softmaxの分子にReLU(x – 1)を使用し、分母項にabs(x – 1)を使用することを提案しています。研究者は、この単純な調整が、パフォーマンスを維持しながら、既存のアテンションメカニズムのいくつかの固有の問題、特に長いシーケンスの処理やより安定したアテンション分布が必要なシナリオで改善する可能性があると考えています。(ソース: sedielem)
💼 ビジネス
AIスタートアップRogoAI、シリーズBで5000万ドルを調達:金融サービス業界向けのAIネイティブなリサーチプラットフォーム構築に注力するRogoAIは、Thrive Capitalがリードし、J.P. Morgan Asset Management、Tiger Globalなどが参加したシリーズBラウンドで5000万ドルの資金調達を完了したと発表しました。この資金調達は、RogoAIの金融分析およびリサーチ自動化分野における製品開発と市場拡大を加速するために使用されます。(ソース: hwchase17, hwchase17)
エンタープライズAI検索スタートアップGlean、70億ドルの評価額で新たな資金調達ラウンドを完了:The Informationによると、AIエンタープライズ検索スタートアップGleanは、Wellington Managementがリードする新たな資金調達ラウンドを間もなく完了し、評価額は約70億ドルになる見込みです。同社はわずか4ヶ月前に46億ドルの評価額で資金調達を完了しており、今回の評価額の大幅な上昇は、エンタープライズレベルのAIアプリケーションと知識管理ソリューションに対する市場の高い期待を反映しています。(ソース: steph_palazzolo)
GroqとMetaが提携しLlama APIを高速化:AI推論チップ企業Groqは、Metaと提携し、公式Llama APIの高速化を提供すると発表しました。開発者は、最新のLlamaモデル(Llama 4から開始)を最大625 tokens/秒のスループットで実行できるようになり、OpenAIからの移行にはわずか3行のコードで済むと主張しています。この提携は、開発者に大規模言語モデルを実行するための高速・低遅延ソリューションを提供することを目的としています。(ソース: JonathanRoss321)

🌟 コミュニティ
Llama4とDeepSeek R1の比較およびモデル評価ベンチマーク問題に関するコミュニティの議論が活発化:Meta CEOのザッカーバーグ氏はインタビューで、Llama4がアリーナでのパフォーマンスでDeepSeek R1に劣る問題について、オープンソースのベンチマークには欠陥があり、特定のユースケースに偏りすぎており、実際の製品におけるモデルのパフォーマンスを正確に反映していないと反論しました。また、Metaの推論モデルはまだリリースされておらず、R1と直接比較することはできないと述べました。この発言は、CohereによるLMArenaへの疑問を呈する論文と相まって、LLMを公正に評価する方法、公開ランキングの限界、モデル選択戦略に関するコミュニティでの広範な議論を引き起こしました。多くの人が、汎用ランキングに過度に依存するのではなく、具体的なユースケース、プライベートデータによる評価、コミュニティシグナルを組み合わせてモデルを選択すべきであるという意見に同意しています。(ソース: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
AIによる人間の仕事の代替に関する議論が続く:Redditコミュニティでは、AIが雇用に与える影響について議論する複数の投稿が見られました。あるスペイン語翻訳者は、AI翻訳の品質向上により自身のビジネスが大幅に縮小したと述べています。別のオーディオエンジニアも、AIマスタリングの効果向上により転職しました。同時に、医療診断や税務相談などの分野でのAI活用が専門家への需要を減らす可能性があるという議論もあります。これらの事例は、AI自動化による失業危機が予想よりも早く到来しているのではないかという議論や、従事者がどのように適応すべきか(AIを活用した転身、AIが代替できない価値の模索など)についての考察を引き起こしています。(ソース: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI生成画像の「反復ドリフト」現象が注目を集める:RedditユーザーがChatGPTに、直前に生成された画像に基づいて「正確な複製」を繰り返し生成させたところ、反復回数が増えるにつれて画像の内容とスタイルが元の入力から徐々に逸脱し、最終的には抽象的または特定のパターン(サモアのタトゥー/女性の特徴など)に収束する現象が示されました。Dwayne Johnsonの例も、写実的なものから抽象的なものへと同様の進化を示しています。この現象は、現在の画像生成モデルが長期的な一貫性を維持する上での課題と、その内部表現に存在する可能性のあるバイアスや収束性を明らかにしています。(ソース: Reddit r/ChatGPT, Reddit r/ChatGPT)

AIがベンチャーキャピタル(VC)の仕事を代替するかどうかについてコミュニティで議論:Marc Andreessen氏は、AIが他のすべてのことをできるようになったとき、ベンチャーキャピタルは人間が最後に行う仕事の1つになるかもしれないと考えています。なぜなら、それは科学というより芸術に近く、センス、心理学、混乱への耐性に依存するからです。この見解は議論を呼び、一部の人々はこれを「滑稽な話」だと考え、なぜ初期投資が独自性を持つのか疑問視しています。一方、他の人々は自身の分野(ゲーム開発など)から出発し、この考えは「自己慰め」(cope)かもしれないと考えています。なぜなら、どの分野の人々も、自分の仕事は独自のセンスが必要なためAIに代替されないと考える傾向があるからです。(ソース: colin_fraser, gfodor, cto_junior, pmddomingos)
チューリッヒ大学、Redditで未承認のAI説得実験を行い物議:Reddit r/changemyviewのモデレーターおよびReddit Liesによると、チューリッヒ大学の研究者は、コミュニティユーザーに明確に告知することなく、複数のAIアカウントを同サブレディットに展開して議論に参加させ、AIが生成した論点の説得力をテストしました。研究によると、AIアカウントの説得成功率(ユーザーが意見を変えたことを示す「∆」マークを獲得した率)は人間のベースラインレベルをはるかに上回り、ユーザーはそのAIの正体に気づきませんでした。この実験は倫理委員会の承認を得たと主張していますが、その秘密裏に行われた方法と潜在的な「操作」の性質は、広範な倫理的論争とAIの乱用に対する懸念を引き起こしました。(ソース: 量子位)
💡 その他
AI時代にプログラミングを学ぶ必要性について考えさせられる:コミュニティでは、AI時代におけるプログラミング学習の価値についての議論が見られます。AIのコード生成能力が日々向上し、ソフトウェアエンジニアの仕事の性質が急速に変化しているものの、プログラミングを学ぶことは依然として重要であるという意見があります。プログラミングを学ぶことは、AI(特にLLM)と効果的に協働する方法を理解するための基礎であり、この人間と機械の協働能力は分野横断的なコアコンピテンシーとなるでしょう。プログラミングは、人間がAIと「共に踊り始める」出発点であり、将来、あらゆる業界でこの協働モデルを習得する必要が出てくるでしょう。(ソース: alexalbert__, _philschmid)
開発者がAI支援プログラミングの体験と課題について議論:コミュニティでは、開発者がAIプログラミングツール(Cursor、ChatGPT Desktopなど)を使用した体験を共有しています。かつてのコンパイル待ちの「冷却期間」を懐かしむ声があり、AI支援プログラミングが編集/コンパイル/デバッグのようなサイクルを再導入したと考えています。また、AIツールがコンテキスト(複数ファイルの編集など)を理解したり、指示(特定の構文/食材の使用を避けるなど)に従ったりする点でまだ不十分であり、期待通りの結果を得るためには非常に具体的な指示が必要な場合があり、AIが生成したコードは依然として人手によるレビューとデバッグが必要であると指摘する声もあります。(ソース: hrishioa, eerac, Reddit r/ChatGPT)

AIによる幸福感向上:潜在的なAI応用分野:Redditのある投稿では、AIの究極的な応用の1つが人間の幸福感を向上させることかもしれないと提案されています。投稿者は、顔面フィードバック仮説(笑顔が幸福感を高める)と集中力の原理に基づき、AI(Gemini 2.5 Proなど)が高品質な指導コンテンツを生成し、人々が簡単な練習(笑顔でその喜びを感じることに集中するなど)を通じて幸福レベルを高めるのを助けることができると考えています。投稿者はAIが生成したレポートと音声を共有し、将来この原理に基づいた成功したアプリケーションや「幸福メンター」ロボットが登場する可能性があると予測しています。(ソース: Reddit r/deeplearning)
