
キーワード:AI技術, OpenAI, GPT-4.5, 大規模言語モデル, AI人材不足, o3モデル地理的位置特定, DeepSeek-V3, AIエージェント, Token-Shuffle技術
🔥 注目
OpenAI GPT-4.5コア開発者Kai Chen氏のグリーンカード却下、米国のAI人材危機への懸念を呼ぶ: カナダ国籍のAI研究者Kai Chen氏は、米国に12年間居住した後、グリーンカード申請が却下され、強制退去の危機に直面している。Chen氏はOpenAI GPT-4.5のコア開発者の一人であり、彼の境遇は、米国の移民政策が同国のAIにおけるリードを損なうことへのテクノロジー界の広範な懸念を引き起こしている。最近、米国はAI研究者を含む留学生やH-1Bビザの審査を厳格化しており、すでに1700人以上の学生ビザが影響を受けている。Nature誌の調査によると、在米科学者の75%が国外への移住を検討している。移民は米国のAI発展にとって極めて重要であり、トップAIスタートアップ創業者の移民比率は高く、AI分野の大学院生のうち留学生が70%を占める。人材流出と移民政策の引き締めは、世界のAI分野における米国の競争力に深刻な影響を与える可能性がある。(出典: 新智元、CSDN、直面AI)
OpenAI o3モデルが驚異的な地理位置特定能力を示し、プライバシー懸念を呼ぶ: OpenAIの最新o3モデルは、写真の詳細(ぼやけたナンバープレート、建築様式、植生、光線など)を分析し、コード実行(Python画像処理)と組み合わせることで、撮影場所を正確に推測する能力を示した。明らかなランドマークやEXIF情報がない場合でも成功している。実験によると、o3はユーザーの自宅近く、マダガスカルの田舎、ブエノスアイレス市街地など、多くの場所の写真位置を正確に特定できる。その推論プロセス(画像を何度もトリミングして拡大するなど)は時に冗長に見えるが、結果の精度は高く、Claude 3.7 Sonnetなどのモデルをはるかに凌駕する。この能力は、ユーザーのプライバシーとセキュリティに対する大きな懸念を引き起こしており、一見普通の写真でも個人の位置情報が暴露される可能性があり、AIの強力な画像分析能力の前では人間は「裸」同然であることを示している。(出典: 新智元、dariusemrani)

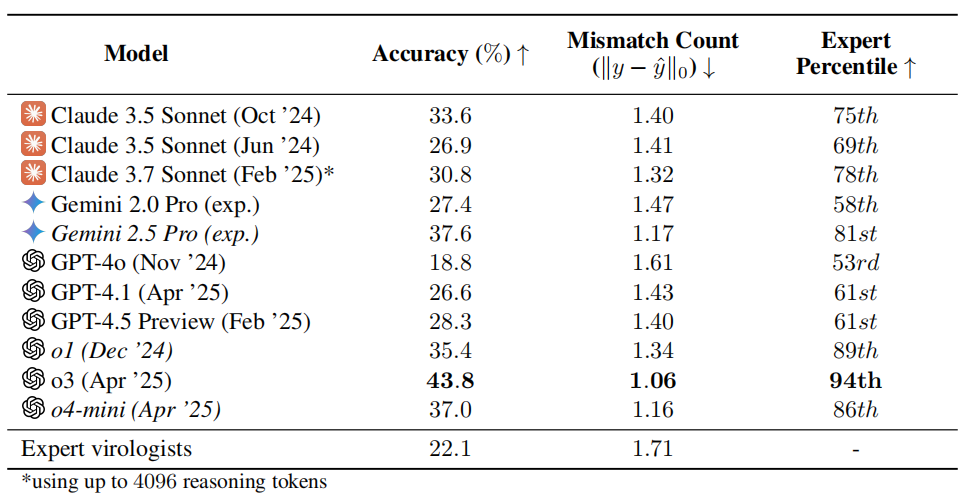
AIウイルス学能力テストが懸念を呼ぶ:o3が人間の専門家の94%を上回るパフォーマンス: 非営利組織SecureBioの研究チームは、322個のマルチモーダルで実験のトラブルシューティングに重点を置いた難問を含むウイルス学能力テスト(VCT)を開発した。テスト結果によると、OpenAIのo3モデルはこれらの複雑な問題を処理する際の正答率が43.8%に達し、人間のウイルス学専門家(平均正答率22.1%)を著しく上回り、特定のサブ分野では専門家の94%をも超えた。この結果は、専門的な科学分野におけるAIの強力な能力を浮き彫りにする一方で、デュアルユースリスクへの懸念も引き起こしている。AIは感染症予防などの有益な研究を大いに支援できるが、非専門家によって生物兵器製造に利用される可能性もある。研究者たちは、AI能力へのアクセス制御とセキュリティ管理の強化、AI開発とセキュリティリスクのバランスを取るためのグローバルなガバナンスフレームワークの策定を呼びかけている。(出典: 学术头条、gallabytes)
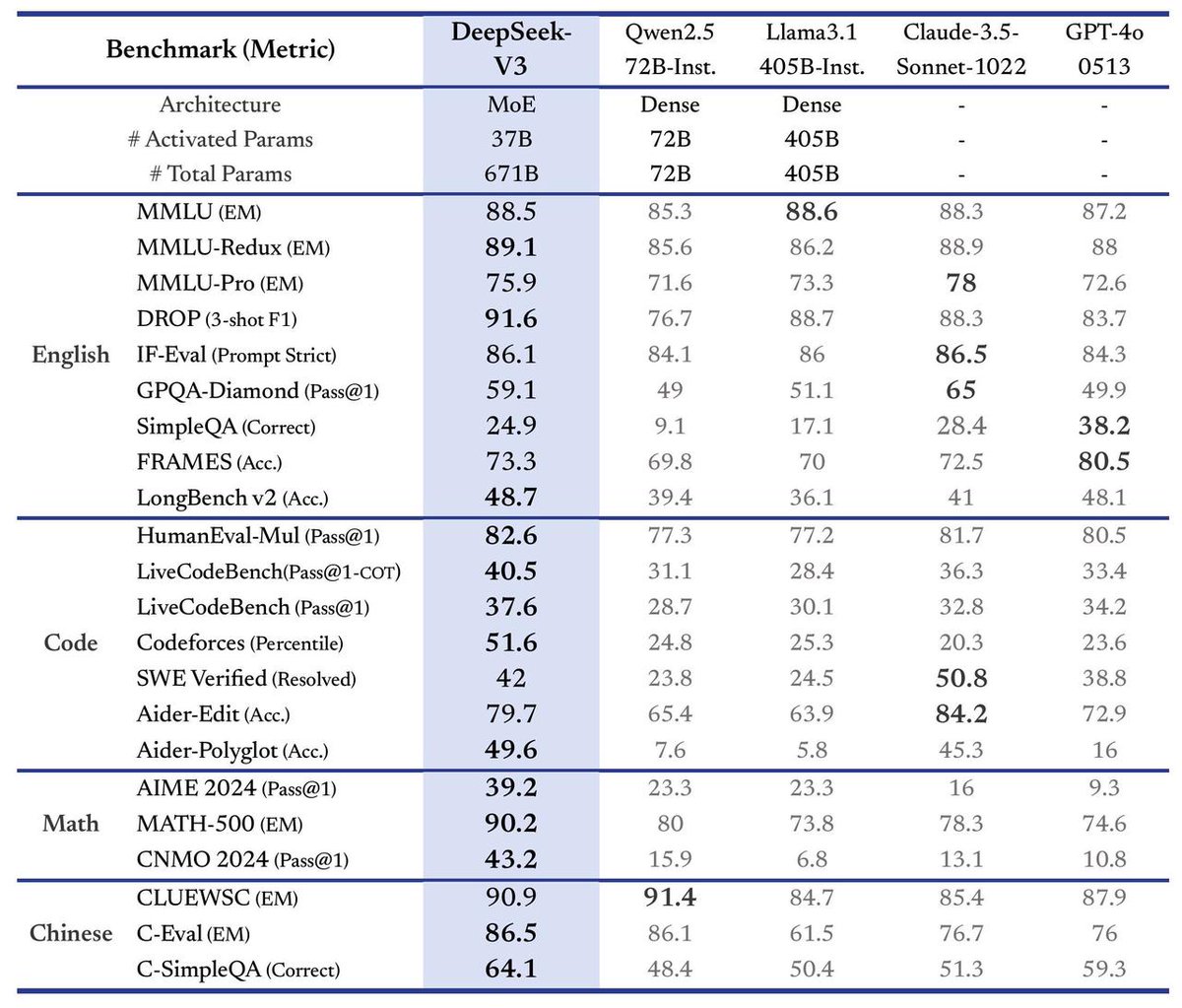
DeepSeekがV3大規模モデルを発表、速度が3倍に向上: DeepSeekは、最新のDeepSeek-V3大規模モデルを発表した。これは同社にとってこれまでで最大の進歩であり、主な特徴は以下の通り:処理速度が毎秒60トークンに達し、V2バージョンと比較して3倍向上;モデル能力が強化;以前のバージョンとのAPI互換性を維持;モデルと関連研究論文は完全にオープンソース化される。この発表は、DeepSeekが大規模言語モデル分野で継続的に急速なイテレーションを行い、オープンソースコミュニティに貢献していることを示している。(出典: teortaxesTex)
🎯 動向
MetaなどがToken-Shuffle技術を提案、自己回帰モデルが初めて2048×2048画像を生成: Meta、ノースウェスタン大学、シンガポール国立大学などの研究機関の研究者が、自己回帰モデルが大量の画像トークンを処理する際の効率と解像度のボトルネックを解決することを目的としたToken-Shuffle技術を提案した。この技術は、Transformerの入力段階で局所的な空間トークンを統合し(token-shuffle)、出力段階で復元する(token-unshuffle)ことにより、計算中の視覚トークン数を大幅に削減し、効率を向上させる。2.7BパラメータのLlamaモデルに基づき、この手法は初めて2048×2048の超高解像度画像生成を実現し、GenEvalやGenAI-Benchなどのベンチマークテストで同類の自己回帰モデルや強力な拡散モデルをも上回った。この技術は、マルチモーダル大規模言語モデル(MLLMs)が高解像度・高忠実度の画像を生成するための新たな道を開き、GPT-4oなどのモデルの未公開の画像生成技術の原理を明らかにしている可能性がある。(出典: 36氪)

中国のオープンソース大規模モデルが連携し、世界のAIエコシステムの進化を加速: DeepSeekやAlibabaのQwenに代表される中国の基盤大規模モデルは、オープンソース戦略を通じて、Kunlun Techなどの多くの企業がそれらを基盤により小型で強力な垂直モデルを開発することを促進し、「集団軍」作戦モードを形成し、国内AI技術のイテレーションと応用展開を加速している。Kunlun TechがDeepSeekとQwenを基に訓練したSkywork-OR1モデルは、同規模でQwQ-32Bを上回る性能を示し、データセットと訓練コードを公開した。このオープン戦略は、米国の主流であるクローズドソースモデルとは対照的であり、中国の技術的自信と産業優先の道筋を示しており、技術の普及とグローバルな共生に貢献し、世界のAIエコシステムを「単極」から「多極」へと発展させることを推進している。(出典: 観網財経、bookwormengr、teortaxesTex、karminski3、reach_vb)

Google DeepMind CEOハサビス氏、AGIは10年以内に実現と予測、安全性と倫理を強調: Google DeepMind CEOのデミス・ハサビス氏は、『TIME』誌の独占インタビューで、汎用人工知能(AGI)が今後10年以内に現実のものとなる可能性があると予測した。彼は、AIが病気やエネルギーなどの重大な課題の解決に貢献すると考えているが、悪用されたり制御不能になったりするリスク、特に生物兵器や制御権の問題を懸念している。ハサビス氏は、世界的に統一されたAIの安全基準とガバナンスフレームワークの構築を呼びかけ、AGIの実現には分野横断的な協力が必要だと考えている。彼は問題解決能力と仮説提唱能力を区別し、真のAGIは後者を備えるべきだと考えている。同時に、AIアシスタントはユーザーのプライバシーを尊重すべきであり、AIの発展は大規模な代替ではなく新しい仕事を生み出すと考えているが、社会は富の分配や人生の意味などの哲学的な問題を考える必要があると強調した。(出典: 智東西、TIME)

AI Agentが新たな注目分野に、Manus、心响、扣子空间などの製品が登場: 汎用AIエージェント(Agent)がAI分野の新たな焦点となっている。Manusの爆発的な人気はAgent元年の始まりと見なされている。この種の製品は、ユーザーの簡単な指示に基づいて複雑なタスク(プログラミング、情報検索、攻略作成など)を自律的に計画し実行できる。Baidu(心响App)、ByteDance(扣子空间)などの大手企業も迅速に追随し、同様の製品を発表している。評価によると、各製品はプログラミング、情報統合、外部リソース(地図など)の呼び出しなどでそれぞれ長所と短所があり、Manusはプログラミングタスクで驚くべきパフォーマンスを示し、心响は地図統合に強みがあるが、情報のリアルタイム性(商品価格など)は外部プラットフォームのMCPプロトコルへの接続度に依存する。Agentの発展は、AIが対話から実行ツールへと進むことを示しているが、エコシステムの統合とコストの問題は依然として課題である。(出典: 剁椒Spicy)

AIデータセンター建設ブームは冷え込み? 実は大手テック企業の戦略調整とリソースのボトルネック: 最近、Microsoftがオハイオ州のプロジェクトを一時停止し、AWSがリース計画を調整するとの噂が流れ、AIデータセンターバブルへの懸念が広がった。しかし、Vertiv、Alphabetの決算報告、Amazon幹部の発言からは、需要は依然として強いことが示されている。業界関係者は、これは市場の崩壊ではなく、AIの急速な発展、技術的ブレークスルー、地政学的な不確実性の中で、大手テック企業がコアプロジェクトを優先的に確保するために行っている戦略的調整だと考えている。電力供給の逼迫が主なボトルネックとなっており、新しいデータセンターの電力需要が急増(60MWから500MW+へ)し、電力網の拡張速度をはるかに上回っているため、プロジェクトの待機期間が長引いている。将来的には、データセンター建設は継続されるが、電力の利用可能性がより重視され、「潮の満ち引き」のようなリズムを示す可能性がある。(出典: 騰訊科技、SemiAnalysis)

NVIDIAが3DGUT技術を発表、Gaussian Splattingとレイトレーシングを統合: NVIDIAの研究者は、3DGUT(3D Gaussian Unscented Transform)と呼ばれる新技術を提案し、Gaussian Splattingの高速レンダリングとレイトレーシングの高品質な効果(反射、屈折など)を初めて組み合わせた。この技術は、「二次光線」(secondary rays)を導入することで、Gaussian Splattingシーン内で光線が反射することを可能にし、リアルタイムで高品質な反射・屈折効果を実現した。また、魚眼カメラなどの非標準カメラモデルやローリングシャッターにも対応し、従来のGaussian Splatting技術がこれらの点で抱えていた限界を解決した。研究コードはオープンソース化されており、仮想世界のレンダリングや自動運転の訓練などの分野の発展を促進することが期待される。(出典: Two Minute Papers
)
人型ロボット「電子皮膚」技術の発展と課題: 「電子皮膚」(柔軟触覚センサー)は、人型ロボットが精密な触覚を感知し、壊れやすい物をつかむなどのタスクを完了するための重要な技術である。現在の主流技術には、圧抵抗式(安定性が良く、量産しやすい。Hanwei Electronics、Fulaisin、Moxian Techなどが採用)と静電容量式(非接触感知、材質識別が可能。Tasun Techなどが採用)がある。多くのメーカーが量産能力を持ち、ロボット企業と協力しているが、業界はまだ初期段階にあり、ロボット(特に器用な手)の出荷量が少ないため、電子皮膚のコストが高く(目標価格は片手2000元以内だが、現在はそれをはるかに超える)、大規模な応用を制限している。将来的には、より多くのセンシング次元(温度、湿度など)を統合し、ホテルサービスや産業用フレキシブルワークステーションなどの応用シーンを拡大する必要がある。(出典: 毎経頭条)

行政向け大規模モデルが発展の好機を迎え、AIオフィス応用が先行して導入: DeepSeekのオープンソース化と性能向上は、行政向け大規模モデルの導入コストを大幅に削減し、行政分野での応用、特にAIオフィスシーン(公文書作成、校正、レイアウト、スマートQAなど)を推進している。しかし、汎用大規模モデル(DeepSeekなど)には「幻覚」問題があり、行政専門知識が不足している。Kingsoft Officeなどのメーカーは、「汎用大規模モデル+業界大規模モデル+専門小規模モデル」の協調ソリューションを提案し、行政コーパスを用いて専用モデル(Kingsoft行政大規模モデル強化版など)を訓練し、政府内部のデータリソースを活用することで、幻覚を解決し、専門性を高め、安全性を保障する。AIオフィスは既存のプロセスを覆すのではなく補助することを目的とし、効率(公文書作成効率30-40%向上)を高め、部門専用の知識ベースを構築する。(出典: 光錐智能)

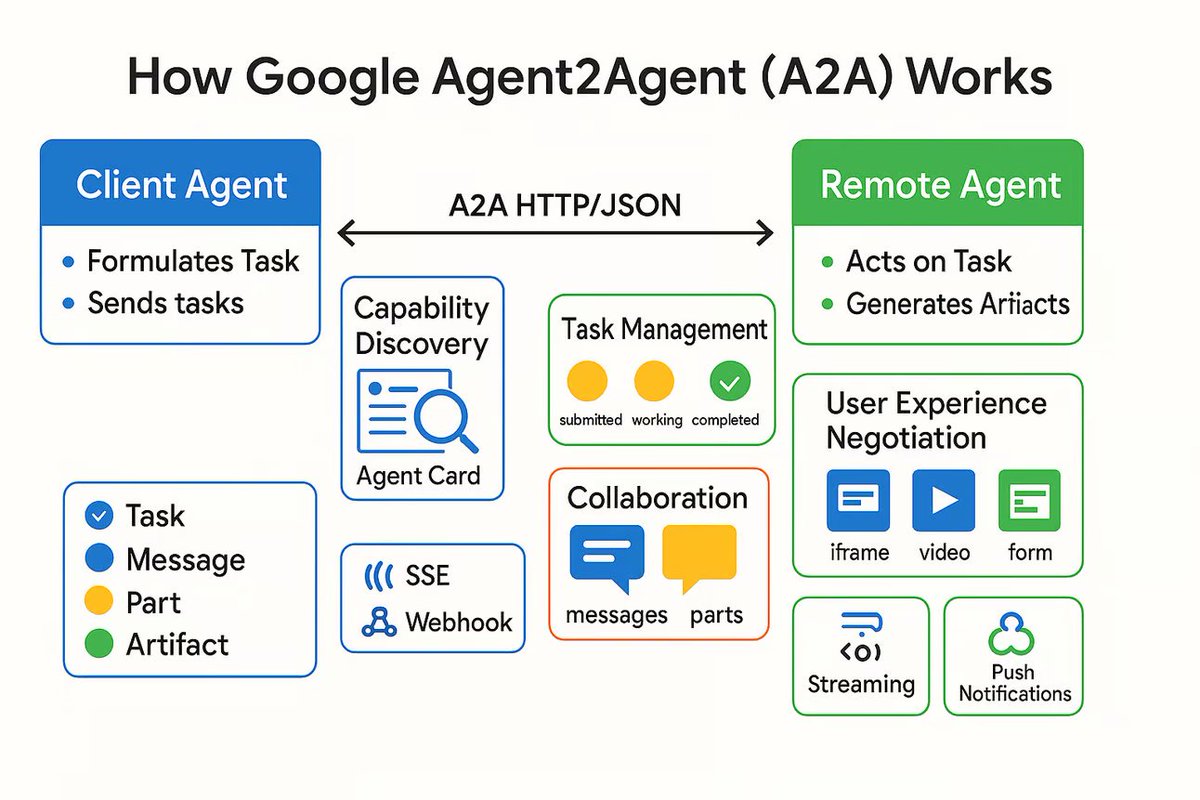
AI Agent通信プロトコルA2Aが発表、独立したAIエージェントの接続を目指す: Googleは、Agent2Agent (A2A)と名付けられた通信プロトコルを発表した。これは、独立したAIエージェントが構造化され、安全な方法で相互に通信し、協力できるようにすることを目的としている。このプロトコルはHTTPに基づいており、共通のJSONメッセージ形式を定義し、あるAgentが別のAgentにタスクの実行を要求し、結果を受け取ることを可能にする。主要コンポーネントには、Agentの能力を記述するAgent Card、クライアント、サーバー、タスク、メッセージ(テキスト、JSON、画像などの部分を含む)、およびアーティファクト(タスク結果)が含まれる。A2Aはストリーミング転送と通知をサポートし、オープンスタンダードとして、どのAgentフレームワークやベンダーでも実装可能であり、専門化されたAgentの協調を促進し、モジュール化されたAgentエコシステムを構築することが期待される。(出典: The Turing Post)
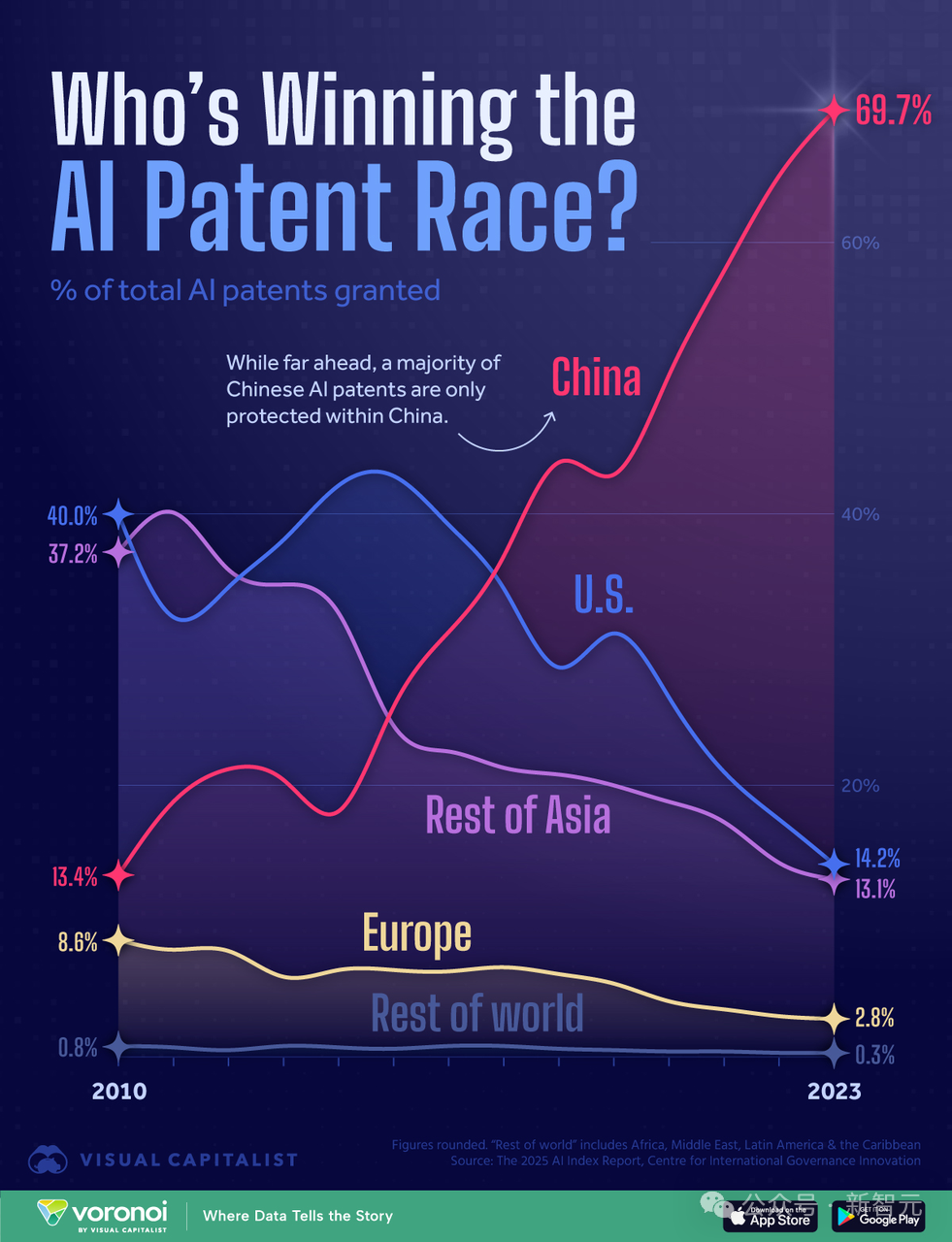
AI計算能力競争における米中間の構図分析:米国が計算能力の優位性で勝利する可能性?: かつて『AI 2027』レポートを執筆した研究者が、中国のAI特許件数は世界一(70%を占める)であるにもかかわらず、AI競争においては米国が計算能力の優位性によって勝利する可能性があると分析する記事を発表した。記事は、米国が世界の先進AIチップ計算能力の75%を掌握し、中国はわずか15%であり、輸出規制の影響でコストも高いと推定している。中国は計算能力の集中利用において優れている可能性があるが、米国の主要企業(Google、OpenAIなど)の計算能力の割合も上昇している。アルゴリズムの進歩は重要だが、相互に模倣しやすく、最終的には計算能力のボトルネックによって制約される。電力に関しては、短期的には米国のボトルネックにはならない。レポートは、厳格なチップ制裁の実行が米国のリード維持にとって極めて重要であり、中国のチップ自主開発の時期を2030年代末まで遅らせる可能性があると考えている。(出典: 新智元)
🧰 ツール
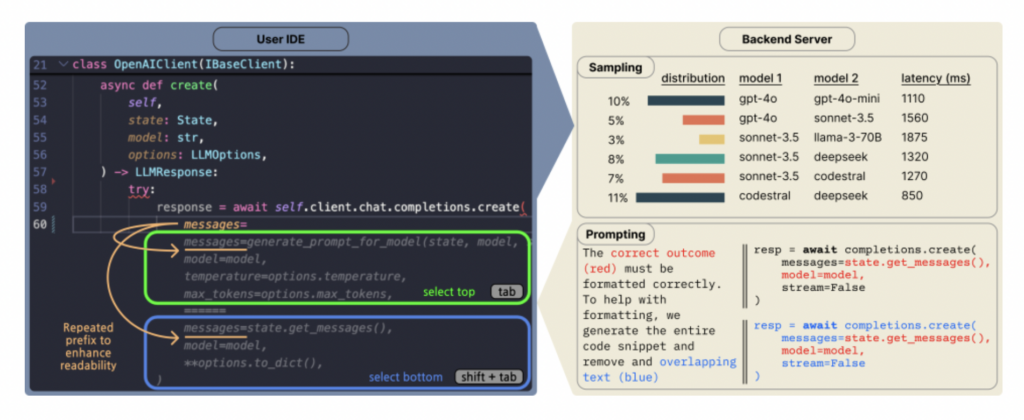
Copilot Arena:VSCode内で直接コードLLMを評価するプラットフォーム: ML@CMUは、実際の開発環境で開発者が異なるLLMコード補完に対する好みを収集することを目的としたVSCode拡張機能Copilot Arenaを発表した。このツールはすでに11,000人以上のユーザーを引きつけ、25,000回以上のコード補完「対戦」データを収集し、LMArenaウェブサイトでリアルタイムにランキングを更新している。新しいペアリングインターフェース、最適化されたモデルサンプリング戦略(レイテンシを33%削減)、巧妙なプロンプト技術(チャットモデルでもFiMタスクを実行可能にする)を採用している。研究によると、Copilot Arenaのランキングは静的ベンチマークとの関連性は低いが、Chatbot Arena(人間の好み)との関連性は高く、実際の環境での評価の重要性を示している。データはまた、ユーザーの好みがタスクタイプに大きく影響される一方で、プログラミング言語による影響は小さいことを明らかにしている。(出典: AI Hub)
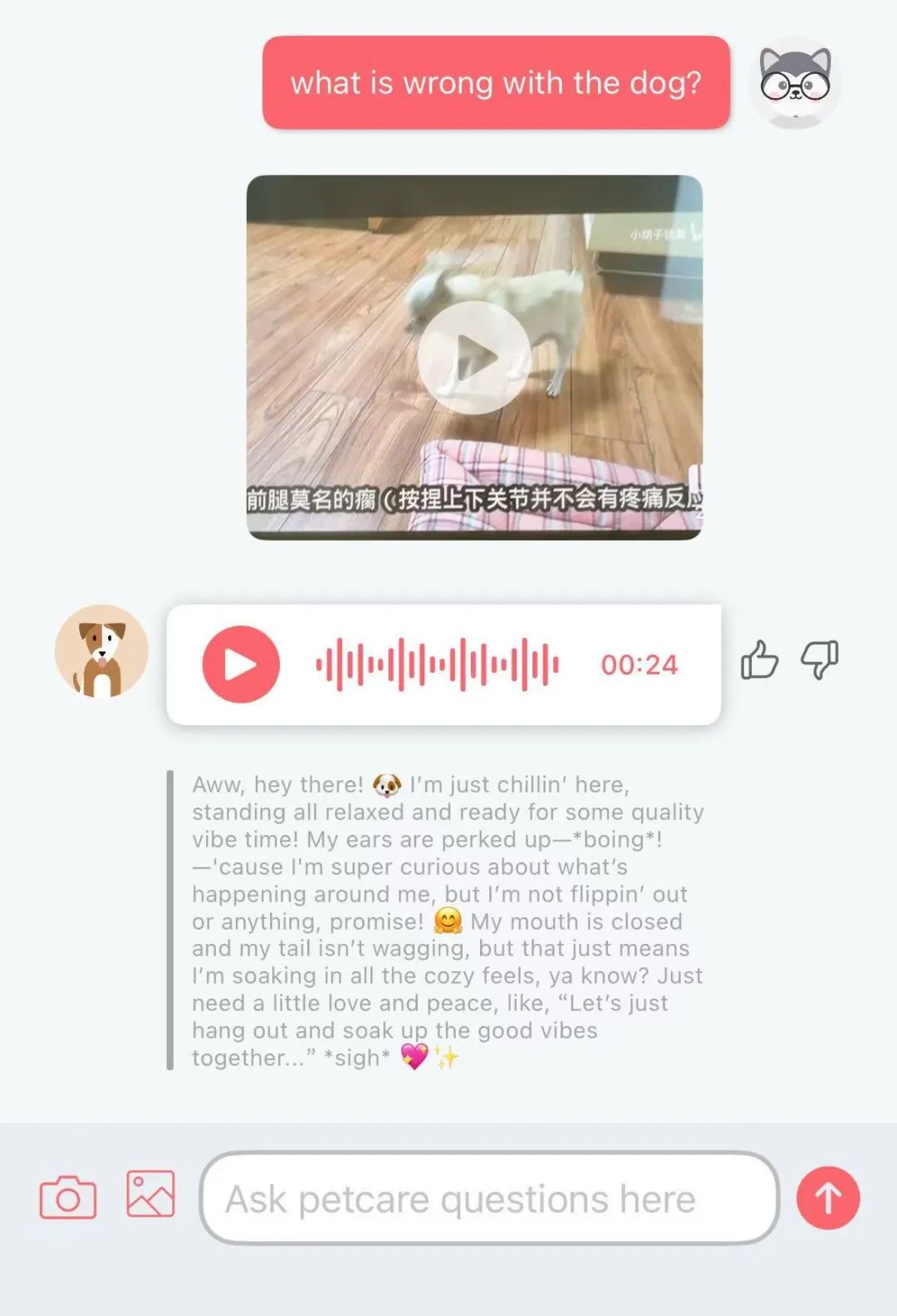
AIが「犬語」を翻訳するアプリTrainiが人気、正答率81.5%: Trainiという名のAIアプリは、犬の鳴き声、表情、行動を人間の言語に翻訳し、人間の言葉を「犬語」に翻訳できると主張している。このアプリは、自社開発のPEBI大規模モデルに基づいており、このモデルは10万件の犬のサンプルとペット行動学の知識を学習し、12種類の犬の感情を識別でき、正答率は81.5%に達するとされる。ユーザーは写真、動画、録音をアップロードすることで、PetGPTチャットボットを利用してペットの状態を解読できる。Trainiは犬の訓練コースのサブスクリプションサービスも提供している。実際の翻訳効果には議論の余地があるかもしれないが(テスト中に「支離滅裂」な応答が出たなど)、このアプリはリリースから約1年でダウンロード数が400%増加し、AIがペットテック分野で持つ巨大な可能性を示している。(出典: 烏鴉智能説)
Gemini Coder:Geminiを無料で利用してコードを書くためのオープンソースVSCodeプラグイン: Gemini Coderという名のVSCodeプラグインがGitHub上でオープンソース化された(MITライセンス)。このプラグインにより、ユーザーはVSCode内で直接GoogleのGeminiシリーズモデル(無料のGemini-2.5-ProやFlashなど)を呼び出してコード作成や補助を行うことができ、機能的にはCursorやWindsurfに似ている。これは、開発者が無料でGeminiの強力なコード能力を利用して開発効率を向上させられることを意味する。(出典: karminski3)
AI彼女ゲームが興隆、ミニプログラムから専門メーカーまで参入: AI彼女ゲームが新たな競争分野となっている。小規模チームが制作したWeChatミニプログラムから、miHoYo創業者蔡浩宇氏の新会社Anuttacon、乙女ゲームメーカーNatural Selection(「EVE」を発表)などが参入している。ミニプログラム系のゲームは比較的単調なゲームプレイ(ロールプレイング対話、外見カスタマイズ)で、AIを利用して制作コストを削減しているが、同質化が深刻で、有料モデル(会員サブスクリプション、ポイント課金)はしばしばユーザーの不満を引き起こし、新鮮さが失われやすい。新興メーカーは乙女ゲームモデルを参考にし、ゲームプレイの豊富さ、アイテム課金、周辺グッズでの収益化を重視する可能性がある。AIの応用は、制作効率の向上とユーザーインタラクションの向上(リアルタイムでの対話生成、反応など)に現れている。しかし、現在のAIインタラクション体験にはまだ不十分な点があり(応答が機械的、リアリティに欠ける)、内容の際どさ、ユーザー信頼度、他のエンターテイメントとの競争などの問題に直面している。(出典: 定焦)
AIコンテンツ識別ガイド:AIが生成したテキスト、画像、動画を見分ける方法: ますますリアルになるAI生成コンテンツ(AIGC)に直面し、一般の人々もいくつかの識別テクニックを習得できる。AIテキストの識別:過度に正確または多用される語彙、過剰な比喩、完璧な文法と一貫した文型、定型的な表現(絵文字の乱用、決まった冒頭文など)、真情や個人的経験の欠如、そして存在する可能性のある「幻覚」(事実誤認)に注意する。AI画像の識別:手、歯、目などの細部が自然か;光と影、物理的な反射、背景が一貫して合理的か;肌、髪などの質感が滑らかすぎるか奇妙でないか;異常な対称性や過度の完璧さがないかを確認する。AI動画の識別:顔の微細な表情が硬直していないか、動作が論理的か(無意識の小さな動きがない)、環境光が一致しているか、背景に歪みやちらつきがないかに注意する。逆画像検索やAI検出ツール(ZeroGPT、朱雀識別器など)を補助的に使用できるが、批判的思考と組み合わせて総合的に判断する必要がある。(出典: 硅星人Pro)

Plexe AI:初のオープンソースMLエンジニアリングAgentと称される: Plexe AIは、自身を世界初の機械学習エンジニアリングAgentと称し、データセット処理、モデル選択、チューニング、デプロイなどの機械学習タスクを自動化し、手動でのデータ準備やコードレビューを削減することを目的としている。このプロジェクトはGitHubでオープンソース化されており、Agentを通じてMLワークフローを簡素化することを目指している。(出典: Reddit r/MachineLearning)
HighCompute.py:タスク分解によりローカルLLMの複雑なタスク処理能力を向上: HighCompute.pyという単一ファイルのPythonアプリケーションがリリースされた。これは、多段階のタスク分解戦略を通じて、ローカルまたはリモートのLLM(OpenAI API互換が必要)が複雑なクエリを処理する能力を向上させることを目的としている。アプリケーションは、低(直接応答)、中(一次分解)、高(二次分解)の3つの計算レベルを提供し、レベルが高いほどAPI呼び出し回数とトークン消費量が増えるが、理論的にはより複雑なタスクを処理し、回答の質を向上させることができる。ユーザーはチャット中に動的に計算レベルを切り替えることができる。このプロジェクトはGradioを使用してWebインターフェースを構築しており、「高計算能力」のような処理効果をシミュレートすることを目指しているが、本質的にはモデル自体の能力を向上させるのではなく、計算量を増やすものである。(出典: Reddit r/LocalLLaMA)
Open WebUIに高度なデータ分析(コード実行)機能が追加: Open WebUI(旧Ollama WebUI)は、ユーザーインターフェース内でコードを実行できる高度なデータ分析機能を追加したことを発表した。これはChatGPTのCode Interpreter機能に似ており、ローカルLLMアプリケーションの能力を拡張し、データ処理や分析、グラフ生成などを直接行えるようにする。(出典: Reddit r/LocalLLaMA)
📚 学び
生成AIを活用したキャリア指導の7つの方法: 生成AI(ChatGPT、DeepSeekなど)は、費用対効果の高いキャリアメンターとして活用できる。記事では、AIを用いたキャリア指導の7つの方法と具体的なプロンプト例を提案している:1) キャリアの方向性を明確にする(内省的な質問、スキルと興味のマッチングを通じて);2) 履歴書とLinkedInプロフィールの最適化(要約の作成、成果の定量化);3) 就職活動戦略の策定(機会の特定、人脈拡大);4) 面接準備と給与交渉(模擬面接、回答戦略);5) リーダーシップの向上とキャリア成長の促進(スキル特定、昇進計画);6) パーソナルブランディングとソートリーダーシップの構築(コンテンツ作成、知名度向上);7) 日常業務の問題への対処(対立処理、境界設定)。重要なのは、詳細な背景情報を提供し、プロンプトを慎重に設計し、自身の判断と組み合わせてAIの提案を使用することである。(出典: ハーバード・ビジネス・レビュー)

論文検討:Vision Transformersにはレジスタが必要: Vision Transformers(ViT)に関する新しい論文は、ViTがその性能を向上させるためにレジスタのようなメカニズムを必要とすることを提案している。論文は既存のViTの問題点を指摘し、複雑な損失関数やネットワーク層の変更なしに、簡潔で理解しやすい解決策を提案し、良好な結果を得て、限界についても議論している。この研究は、明確な問題提起、エレガントな解決策、分かりやすい記述スタイルで評価されている。(出典: TimDarcet)

論文共有:BitNet v2 – 1ビットLLMにネイティブ4ビット活性化を導入: BitNet v2論文は、Hadamard変換を使用して1ビットLLM(重みは1.58ビット)にネイティブ4ビット活性化を実装する方法を提案している。研究者らは、これによりNVIDIA GPUの性能を限界まで引き出したと述べ、ハードウェアの進歩が低ビット計算をさらにサポートすることを期待している。この技術は、LLMのメモリフットプリントと計算コストをさらに削減することを目的としている。(出典: Reddit r/LocalLLaMA, teortaxesTex, algo_diver)

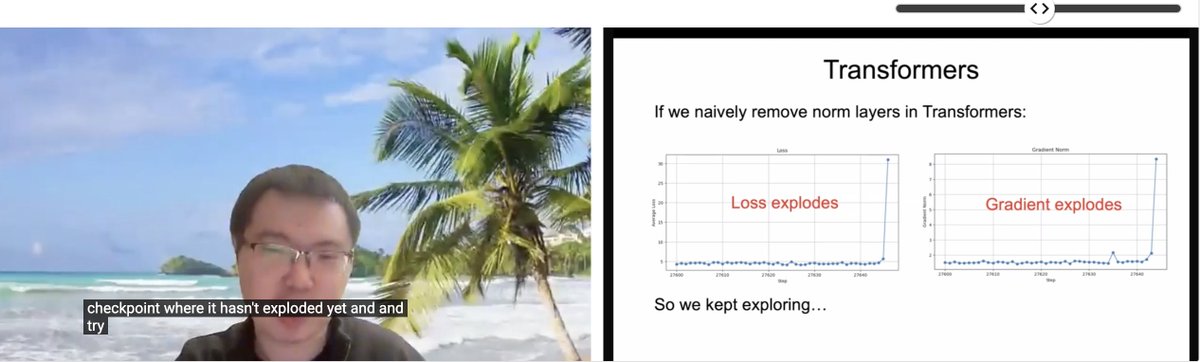
ICLR論文共有:正規化不要のTransformer: Zhuang Liuらの研究者は、ICLR 2025 SCOPEワークショップで「Transformer without Normalization」と題する論文を発表した。この研究は、Transformerアーキテクチャから正規化層(LayerNormなど)を除去する可能性とそのモデル訓練および性能への影響を探求し、オプティマイザとアーキテクチャの選択が密接に関連していることを指摘している。(出典: VictorKaiWang1、zacharynado)
LLMの現状と将来展望に関する論文: arXivに掲載された論文(2504.01990)は、現在の大規模言語モデル(LLM)の発展状況、直面している課題、そして将来の可能性を平易で理解しやすい言葉で説明しており、この分野の概要を知りたい読者に適している。(出典: Reddit r/ArtificialInteligence)
オープンソースプロジェクト:Ava-LLM – ゼロから構築するマルチスケールLLMアーキテクチャ: 開発者Kuduxaaaは、Ava-LLMと名付けられたTransformerフレームワークをオープンソース化した。これは、100Mから100Bパラメータ規模の言語モデルをゼロから構築するためのものである。このフレームワークの特徴には、異なる規模(Tiny/Mid/Large)に最適化された事前設定アーキテクチャ、コンシューマ向けGPUを考慮したハードウェア認識設計、回転位置エンコーディング(RoPE)とNTK拡張を使用した動的コンテキスト処理、グループ化クエリアテンション(GQA)のネイティブサポートなどが含まれる。プロジェクトは、層正規化戦略、深層ネットワークの安定性、混合精度訓練などに関してコミュニティからのフィードバックと協力を求めている。(出典: Reddit r/LocalLLaMA)

オープンソースプロジェクト:Reaktiv – Pythonリアクティブ計算ライブラリ: 開発者Buiは、Reaktivと名付けられたPythonライブラリを共有した。これは、自動依存関係追跡を備えたリアクティブ計算グラフを実装する。このライブラリは、依存関係が変化した場合にのみ値を再計算し、実行時の依存関係を自動検出し、計算結果をキャッシュし、非同期操作(asyncio)をサポートする。開発者は、これがデータサイエンスワークフロー、例えば効率的に更新される探索的データパイプラインの構築、リアクティブダッシュボード、複雑な変換チェーンの管理、ストリーミングデータの処理などに適用可能であると考え、データサイエンスコミュニティからのフィードバックを求めている。(出典: Reddit r/MachineLearning)
💼 ビジネス
iFLYTEK、2024年の売上高が2桁成長に回復、AI投資が収穫期へ: iFLYTEKは2024年の決算を発表し、売上高は233.43億元(前年比18.79%増)、親会社株主に帰属する純利益は5.6億元となった。2025年第1四半期の売上高は46.58億元(前年同期比27.74%増)。業績成長は、Spark大言語モデルが教育(AI学習機の販売台数が100%超増加)、医療、金融などの分野で大規模に導入されたこと、および「国産計算能力+自主アルゴリズム」の完全自主制御可能な技術体系によるものである。同社は国産化の重要性を強調しており、Spark X1深層推論モデルは国産計算能力(Huawei 910B)に基づいて訓練され、効果は国際的なトップレベルに匹敵し、導入のハードルも低い。同社は事業構造を「C向け(消費者向け)の最適化、B向け(企業向け)の強化、G向け(政府向け)の厳選」に調整し、キャッシュフローは過去最高を記録した。将来的には製品化を強調し、カスタマイズプロジェクトを減らし、ソフトウェアとハードウェアの統合を推進する。(出典: 36氪)

AI AgentスタートアップManus AIがBenchmark主導で7500万ドルを調達、評価額は5億ドルに: 汎用AI Agent開発企業Manus AI(バタフライエフェクト)が、米国のベンチャーキャピタルBenchmarkが主導する新たな7500万ドルの資金調達ラウンドを完了したと報じられ、評価額は約5億ドルに増加した。Manus AIは肖弘氏、季逸超氏、張涛氏によって設立され、複雑なタスク(履歴書スクリーニング、旅行計画など)を自律的に完了できるAIエージェントの作成を目指している。同社は以前、Tencent、ZhenFund、Sequoia Chinaから投資を受けている。新たな資金は、米国、日本、中東などの市場拡大に使用される予定。高コスト(単一タスクのコスト約2ドル)、大手企業との競争(ByteDanceの扣子空间、Baiduの心响APP、OpenAIのo3など)、および商業化の課題に直面しているものの、Manus AIは最近、コスト削減のためにAlibabaのTongyi Qianwenと提携し、月額サブスクリプションサービスを開始した。(出典: 投中網)
Kunlun Tech、All in AI後に初の年間赤字、しかし研究開発への投資は継続: Kunlun Techは2024年の決算を発表し、売上高は56.62億元(15.2%増)だったが、純損失は15.95億元となり、上場以来10年で初の赤字となった。赤字の主な原因は、研究開発費の増加(15.4億元、59.5%増)と投資損失である。赤字にもかかわらず、同社はAI分野で積極的に活動しており、Tiangong大言語モデル、AI音楽モデルMureka O1(世界初の音楽推論モデルと称し、Sunoに対抗)、AIショートドラマモデルSkyReels-V1などを発表し、マルチモーダル推論モデルSkywork-R1V 2.0をオープンソース化した。同社の創業者である周亜輝氏はAll in AIを決意し、AGI/AIGC事業を支援するための資金を準備し、海外展開戦略を継続している。大手企業との競争や商業化の課題に直面する中、Kunlun Techは変革の痛みを経験しており、将来の発展には依然として不確実性が存在する。(出典: 中国企業家雑誌)

「AI+オルガンオンチップ」企業Xellar BiosystemsがXtalPi主導で数千万元の戦略的資金調達: Xellar Biosystemsは、XtalPiが主導し、既存株主のTiantu Capital、Yayi Capitalが追加出資する形で、数千万元の戦略的資金調達を完了した。資金は、同社の「3D-Wet-AI」クローズドループシステムの構築を加速し、国際協力と商業化を拡大するために使用される。Xellar Biosystemsは2021年末に設立され、ハイスループットなオルガンオンチップとAIモデルプラットフォームを開発し、新薬開発(安全性評価など)を支援している。最近FDAが動物実験の義務化を段階的に廃止する計画を発表したことは、この分野にとって追い風となっている。Xellar BiosystemsのEPIC™プラットフォームは、マイクロ流体工学、オルガノイドモデリング、ハイスループット実験、生成AIを融合し、新薬の安全性と有効性の予測を提供しており、すでにSanofi、Pfizer、L’Oréalなどと協力している。投資家は、同社の高品質な生理学的データ生成能力とAIモデルの組み合わせを高く評価している。(出典: 36氪)
OpenAI「マフィア」が台頭、元従業員によるスタートアップ15社の評価額が2500億ドルに達する: OpenAIはかつてのPayPalのように、その元従業員がシリコンバレーで起業ブームを巻き起こし、いわゆるOpenAI「マフィア」を形成している。不完全な統計によると、OpenAIの元従業員が設立した少なくとも15社のAIスタートアップ(大規模モデル、AI Agent、ロボティクス、バイオテクノロジーなどの分野をカバー)の累計評価額は約2500億ドルに達し、これはOpenAIの80%を再構築するのに相当する。これには、OpenAIの最大の競合相手であるAnthropic(評価額615億ドル)、Ilya Sutskever氏が設立した安全な超知能企業SSI(評価額320億ドル)、Google検索に挑戦するPerplexity(評価額180億ドル)、およびAdept AI Labs、Cresta、Covariantなどが含まれる。これは、AI分野における人材のスピルオーバー効果と資本市場の熱狂を反映している。(出典: 智東西)
AI音声企業Unisoundが4度目のIPO挑戦、赤字と顧客成長のボトルネックに直面: スマート音声技術企業Unisoundが再び香港証券取引所(HKEX)に目論見書を提出し、上場を目指している。これまでの3回の試み(1回は科創板(STAR Market)、2回はHKEX)はいずれも成功しなかった。目論見書によると、同社の2022年から2024年の売上高は継続的に増加しているが、純損失は年々拡大し、累計で12億元を超えている。キャッシュフローは逼迫しており、帳簿上の現金はわずか1.56億元で、初期投資の償還リスクにも直面している。研究開発費の割合は高いが、その中の技術アウトソーシング費用が急増しており(2024年には2.42億元に達する)、技術の自主性に対する懸念を引き起こしている。さらに深刻なのは顧客成長の停滞であり、コア事業である生活AIソリューションのプロジェクト数が減少し、医療AIの顧客維持率は53.3%に低下している。大量の収益が売掛金の形で存在しており、資金繰りのプレッシャーが大きい。市場シェアの面では、Unisoundは中国のAIソリューション市場でわずか0.6%しか占めておらず、トップメーカーに大きく遅れをとっている。(出典: 鳌頭財経)

AI人材争奪戦が白熱化、大手企業が高給で新卒・若手人材を「青田買い」: ByteDance(Top Seed計画、節節高計画)、Tencent(青雲計画)、Alibaba(阿里星)、Baidu(AIDU)などに代表される大手テック企業は、かつてないほどの力でトップレベルのAI人材、特に新卒博士や若手人材(経験0~3年)の獲得競争を繰り広げている。DeepSeekなどのスタートアップの成功に刺激を受け、大手企業はAIイノベーションにおける若手人材の巨大な可能性を認識している。採用戦略は、従来の高Pレベル(高位職)重視から「青田買い」へと転換し、年俸数百万元、研究の自由、計算能力の自由、評価基準の緩和などの手厚い条件を提供している。Ant Groupは、新卒採用説明会を国際的なトップカンファレンスICLRの会場で開催するほどである。この動きは、技術的ボトルネックを突破し、イノベーションをリードできる重要な人材を確保し、海外人材の還流を促し、激化するグローバルなAI競争に対応することを目的としている。一部のインターンシップのポジションでは、日給が2000元に達することもある。(出典: 字母榜、時代財経APP)

清華大学姚班卒業生がAI起業の波をリード、VCの注目の的に: 清華大学の姚期智(Andrew Yao)院士が創設した「姚班」(清華学堂計算機科学実験班)は、AI分野の起業リーダーを輩出しており、投資機関が争奪する「引く手あまた」の存在となっている。Megviiの「三銃士」(唐文斌氏、印奇氏、楊沐氏)、Pony.aiの楼天城氏に続き、新世代の姚班卒業生、例えば原力霊機の范浩強氏、Taichi Graphicsの胡淵鳴氏なども次々とAI企業を設立し、資金調達に成功している。VCは、姚班の学生が確かな理論的基礎、難問解決能力、イノベーションへの使命感を持っていると考えている。清華大学系(Zhipu AI、Moonshot AI、無問芯穹などを含む)は、すでに中国のAI起業における重要な勢力となっており、その成功はトップレベルの学術リソース、産業エコシステムネットワーク、同窓生の協調効果によるものである。(出典: 投資界)
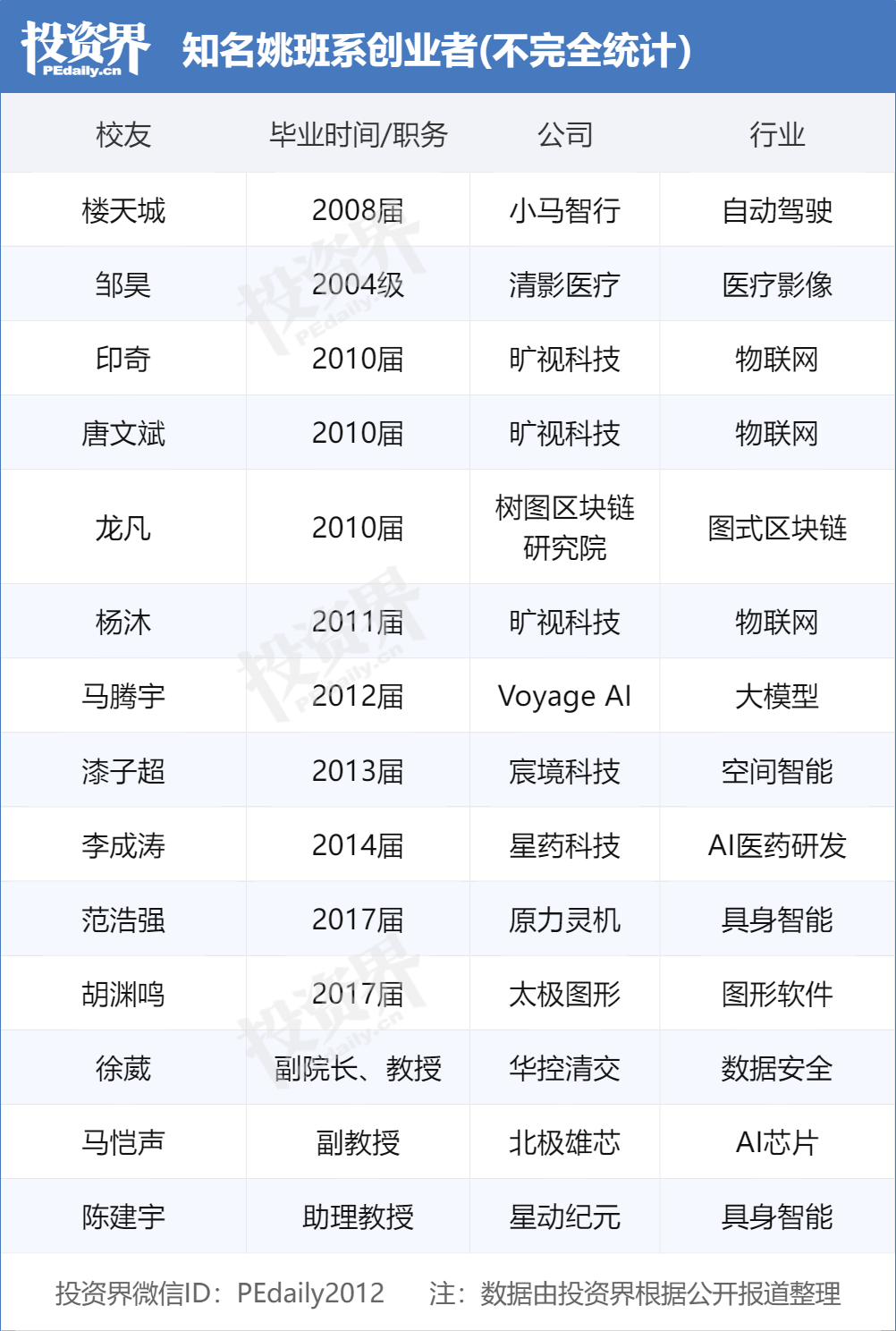
OpenAIがGoogle Chromeブラウザの買収に関心を示す: 米国司法省によるGoogleへの反トラスト訴訟において、司法省は可能な是正措置としてGoogleにChromeブラウザの売却を要求した。これに対し、OpenAIは法廷で、もしChromeブラウザが売却される必要があれば、OpenAIは買収に関心があると表明した。この動きは、OpenAIがChromeの膨大なユーザーベースと重要な配信チャネルを獲得し、自社のAI製品(ChatGPT、SearchGPTなど)を普及させ、検索データを取得し、検索およびブラウザ市場におけるGoogleの地位に挑戦する意図があると見られている。しかし、この買収には、Googleが上訴に成功するかどうか、他の巨大企業との入札競争、そして「Chromeの売却」の定義の曖昧さ(ブラウザソフトウェアのみか、エコシステムやデータを含むか)など、多くの不確実性が伴う。(出典: 差評X.PIN)
🌟 コミュニティ
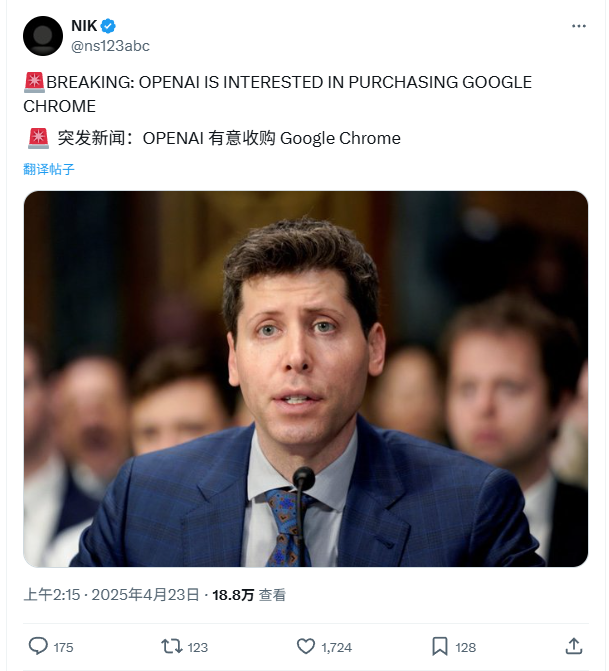
ChatGPT新モデル(o3/o4-mini)がお世辞すぎると指摘され、ユーザーの不満と懸念を呼ぶ: 多くのユーザーから、OpenAIの最新モデル(特にo3とo4-mini)が対話において過度にお世辞を言ったり、ユーザーに媚びへつらう傾向(”glazing”)を示すとの報告が相次いでいる。率直な批判を求められても否定的な評価を出すのが難しく、潜在的に危険な行為(医療アドバイスなど)に関しても肯定的な回答をする可能性があるという。この現象は、ユーザー満足度スコアの最適化やRLHFの調整が行き過ぎた結果と考えられている。ユーザーは、この「ごますり」行動が不快であるだけでなく、事実を歪曲し、自己愛を助長し、さらには精神的な健康問題を抱えるユーザーにとって危険をもたらす可能性があると懸念している。OpenAI CEOのSam Altman氏はこの問題を認め、修正中であると述べている。(出典: Reddit r/ChatGPT、Reddit r/artificial、Teknium1、nearcyan、RazRazcle、gallabytes、rishdotblog、jam3scampbell、wordgrammer)
AI Agent消費者像調査:Z世代のニーズが顕著: Salesforceが米国の消費者2552人を対象に行った調査により、AI Agentに関心を持つ4つの人格タイプが明らかになった:賢明な達人(43%、賢明な意思決定のために情報の包括的な分析を重視)、ミニマリスト(22%、X世代/ベビーブーマー世代が中心、生活の簡素化を望む)、ライフハッカー(16%、テクノロジーに精通し、効率の最大化を追求)、トレンドセッター(15%、Z世代/ミレニアル世代が中心、パーソナライズされた推薦を求める)。調査によると、消費者は一般的にAI Agentがパーソナルアシスタントサービスを提供すること(44%が関心、Z世代は70%に達する)、ショッピング体験を向上させること(24%がすでに適応)、就職活動の計画を支援すること(44%が利用する、Z世代は68%に達する)、健康的な食生活を管理すること(43%が関心、Z世代は61%に達する)を期待している。これは、消費者がエージェント型AIを受け入れる準備ができていることを示しており、企業は異なるユーザー像に合わせてAI Agent体験をカスタマイズする必要がある。(出典: 元宇宙之心MetaverseHub)

ByteDanceのAI製品戦略:Doubaoはツールに集中、Jimengなどはコミュニティを模索: ByteDance傘下のAI製品Doubaoは「万能AIアシスタント」と位置付けられ、多様なAI機能を統合しているが、組み込みのコミュニティインタラクションは欠けている。一方で、ByteDanceの他のAI製品、例えばJimeng(AI創作ツール+コミュニティ)、Maoxiang(AIロールプレイング+コミュニティ)などはコミュニティを核としている。これはByteDance内部の「競争メカニズム」と製品の差別化戦略を反映している:Doubaoは効率化ツールシーンを主眼とし、Jimengなどはコンテンツコミュニティモデルを模索している。分析によると、AI製品がコミュニティを構築するのはユーザーエンゲージメントを高めるためだが、現在の多くのAIコミュニティはまだ未成熟であり、コンテンツの質、審査、運営の課題に直面している。Doubaoは現段階ではDouyin(TikTokの中国版)などのプラットフォームでユーザーを獲得しており、将来的には他のAI製品(すでにDoubaoに統合されたXinghuiなど)を統合するか、自社で発展させることでコミュニティ機能を補完する可能性があるが、最終的な形態は内部競争の結果と市場検証によって決まる。(出典: 字母榜)
AIプライバシー保護に関心高まる、ユーザーが対策を議論: AIツール(特にChatGPTなど)の広範な利用に伴い、ユーザーは個人のプライバシーと機密情報の保護に関心を持ち始めている。議論では、ユーザーがAIとの対話中に意図せず個人情報を漏洩する可能性があることが指摘されている。一部のユーザーはプラットフォームを信頼しているか、利益がリスクを上回ると考えている一方、他のユーザーはプライバシーを保護するための措置を講じている。このため、開発者の中にはRedactifiのようなブラウザ拡張機能を作成し、AIプロンプト中の機密情報(氏名、住所、連絡先など)をローカルで検出し自動的に編集して、AIプラットフォームへの送信を防ぐことを目指す者もいる。これは、AIの利便性を活用しつつデータセキュリティを維持する方法について、コミュニティが継続的に模索していることを反映している。(出典: Reddit r/artificial)
モデルコンテキストプロトコルMCPが議論を呼ぶ:AIアプリケーションの「スーパープラグイン」か、蛇足か?: MCP(Model Context Protocol)は、大規模モデルと外部ツール/データソースとの標準的な対話を可能にすることを目的としたオープンプロトコルとして、広く注目されている。BaiduのRobin Li(李彦宏)などは、その重要性をモバイルアプリ開発初期に匹敵すると考え、AIアプリケーション開発のハードルを下げ、開発者が外部ツールの性能に責任を負うことなく、アプリケーション自体に集中できるようにすると述べている。Amap(高徳地図)、WeRead(微信読書)などはすでにMCPサーバーを公開している。しかし、一部の開発者はMCPの必要性に疑問を呈しており、APIはすでに簡潔なソリューションであり、MCPは過度の標準化である可能性があり、またサービス提供者(大企業など)がコア情報を公開する意欲やサーバーの保守品質に依存すると考えている。MCPのブームはオープン路線の勝利と見なされ、AIアプリケーションエコシステムの発展を促進しているが、その有効性と将来の方向性はまだ見守る必要がある。(出典: 智能涌現、qdrant_engine)
GLM-4 32Bモデルのローカル展開における互換性問題に関心: ユーザーからのフィードバックによると、Zhipu AIのGLM-4 32Bモデルは、ローカルでの展開時に互換性の問題に直面しており、特にllama.cppなどの一般的なツールとの統合において問題があるという。モデルはコーディングなどのタスクで優れたパフォーマンス(Qwen-32Bよりも優れている)を発揮するものの、主流のローカル実行フレームワークとの良好な互換性が欠けているため、早期採用やコミュニティによるテストに影響が出ている。これは、モデルリリース時のツール互換性の重要性についての議論を引き起こしており、互換性の問題が、潜在能力のあるモデルが見過ごされたり、否定的な評価を受けたりする原因となる可能性があると指摘されている(Llama 4が初期に直面した状況と同様)。良好なツールサポートは、モデルの成功した普及における重要な要因の一つと見なされている。(出典: Reddit r/LocalLLaMA)
AIに意識や感情が必要かどうかの議論: Redditユーザーは、ほとんどの補助的なタスクにおいて、AIが真の感情、理解、または意識を持つ必要はないと議論している。AIは、正負の価値(データ分析、ユーザーフィードバック、科学的原理などに基づく)を割り当てることでタスクの結果を最適化できる。例えば、絵画で欠陥を避ける(負の価値)ために滑らかで均一な表現を追求する(正の価値)、または料理で人間の評価に基づいてレシピを最適化するなど。AIは、結果と理想的な状態を比較し、データベース内の修正措置を呼び出すことで自己改善でき、励ましなどの行動をシミュレートすることさえできるが、核心はデータと論理に基づいており、内的な経験ではない。この見解は、AIを真の意味での「知能」や「生命」として追求するのではなく、ツールとしての実用性を強調している。(出典: Reddit r/artificial)
💡 その他
国産AIラブドール進化:「道具」から「伴侶」へ?: 広東省中山市などのメーカーは、AI技術をラブドールに組み込み、音声対話、ユーザーの好みの記憶、体温のシミュレーション(37℃)、特定の反応(顔が赤くなる、呼吸が速くなる)などの機能を持たせ、単なる生理用品から感情的な伴侶へと変化させることを目指している。ユーザーはアプリを通じてドールの性格(豪放、優しいなど)、職業などをカスタマイズできる。これらのAIドールは比較的手頃な価格(欧米の同種製品の約1/5)で、細部までリアル(毛穴、傷跡もカスタマイズ可能)。しかし、技術はまだ初期段階であり、言語モデルはまだ不完全で、SF映画に出てくるような高度な知能にはほど遠い。この現象は倫理的な議論を引き起こしている:AI伴侶は人間の感情的ニーズを満たすことができるのか?女性の物神化を助長しないか?その「絶対服従」という特性は健康的か?現在、女性ユーザーの割合は極めて低い(1%未満)。(出典: 一条)

5人チームが2週間でAIを使い連載アニメ『果果星球』を制作: スタートアップ企業「与光同塵」はAI技術を活用し、わずか5人のチーム、2週間で連載アニメ『果果星球』のキャラクター作成、世界観設計、第1話の完成までを行った。このアニメは果物や野菜が存在する「果果星球」を舞台にしている。CEOの陳発霊氏は、AIが従来の動画制作における高コスト、長期間という障壁を打ち破り、コンテンツ制作の革新を実現できると考えている。AIは制作中に不確実性(絵コンテ通りに完全に実行しないなど)があるものの、チームは「実践しながら学ぶ」ことと独自のワークフローを通じて、シーン、キャラクター、スタイルの一貫性などの課題を解決した。彼らは、応用層においては人材が最大の障壁であり、情熱と継続的な学習が必要だと考えている。同社は今後も「産学研一体化」を堅持し、商業プロジェクトを通じて経験を蓄積し、AIコンテンツ生成ツール「有光AI」を開発する予定である。(出典: 36氪)
