
🔥 フォーカス
Google、コストパフォーマンスと制御可能な思考を重視したGemini 2.5 Flashハイブリッド推論モデルを発表: Googleは、コストパフォーマンスの高いハイブリッド推論モデルとして位置づけられるGemini 2.5 Flashのプレビュー版を発表しました。そのユニークな点は、「思考予算」(thinking_budget)機能を導入し、開発者(0-24k token)またはモデル自身がタスクの複雑さに応じて推論の深さを調整できることです。思考をオフにするとコストは非常に低く(出力100万tokenあたり$0.6)、性能は2.0 Flashを上回ります。思考をオンにすると(出力100万tokenあたり$3.5)、複雑なタスクを処理でき、多くのベンチマーク(AIME, MMMU, GPQAなど)でo4-miniに匹敵し、LMArenaアリーナでも上位にランクインしています。このモデルは、性能、コスト、レイテンシのバランスを取ることを目指しており、特に柔軟性とコスト管理が必要なアプリケーションシナリオに適しています。Google AI StudioとVertex AIでAPIが提供されています。(ソース: 谷歌首款混合推理Gemini 2.5登场,成本暴降600%,思考模式一开,直追o4-mini、谷歌大模型“性价比之王”来了,混合推理模型,思考深度可自由控制,竞技场排名仅次于自家Pro、op7418、JeffDean、Reddit r/LocalLLaMA、Reddit r/LocalLLaMA、Reddit r/artificial)

OpenAI、推論とマルチモーダル能力を強化したo3およびo4-miniモデルを発表: OpenAIは、これまでで最も強力なモデルシリーズo3と最適化されたo4-miniを発表し、推論、プログラミング、マルチモーダル理解能力を重点的に向上させました。特に、画像に基づく「思考連鎖 (Chain of Thought)」推論を初めて実現し、画像の細部を分析して複雑な判断を行うことができます。例えば、写真から正確な撮影場所を推測する(GeoGuessing)などです。o3はメンサIQテストで136点を記録し、新記録を樹立、プログラミングベンチマークテストでも優れたパフォーマンスを示しました。一方、o4-miniは高効率と低コストを維持しつつ、強力な数学問題解決能力(オイラー問題など)と視覚処理能力を発揮します。これらのモデルはChatGPT Plus、Pro、Teamユーザーに公開されており、OpenAIがモデルを知識獲得からツール利用や複雑な問題解決へと進化させていることを示しています。(ソース: 实测o3/o4-mini:3分钟解决欧拉问题,OpenAI最强模型名副其实、智商136,o3王者归来,变身福尔摩斯“AI查房”,一张图秒定坐标、满血版o3探案神技出圈,OpenAI疯狂暗示:大模型不修仙,要卷搬砖了)

AIの効率向上による雇用への懸念が浮上、一部企業はAIによる人員代替を開始: 人工知能技術の高い効率性により、PayPal、Shopify、United Wholesale Mortgageなどの企業が、特にカスタマーサービス、初級営業、ITサポート、データ処理などの分野で、人間の職務をAIで代替することを検討または実際に開始しています。例えば、PayPalのAIチャットボットは顧客サービスリクエストの80%を処理し、コストを大幅に削減しました。United Wholesale MortgageはAIを利用して住宅ローン書類を処理し、効率が大幅に向上、業務量が倍増したにもかかわらず人員増強は不要でした。一部の企業では「ゼロ従業員チーム」の概念を提唱し、新たな人員追加にはまずAIがその業務を遂行できないことを証明するよう求めています。多くの企業はAIによる人員削減を公に認めることを避けていますが、採用の鈍化や職務削減は既にトレンドとなっており、特にコスト圧力の下で、将来的にはAIによるホワイトカラー職の代替効果がより顕著になると予想されます。(ソース: 招聘慢了、岗位少了,AI效率太高迫使人类员工“让位”)

OpenAI、AIコーディングアシスタントWindsurfを約30億ドルで買収計画、アプリケーション層への展開を強化: OpenAIは、AIコーディングスタートアップのWindsurf(旧Codeium)を約30億ドルで買収する計画です。これは同社にとって最大規模の買収となります。WindsurfはCursorと同様のAIコーディング支援ツールを提供しており、こちらもAnthropicモデルに基づいています。この買収は、OpenAIがアプリケーション層へ進出し、エコシステムの支配力を強化するための重要な一歩と見なされており、ユーザーを直接獲得し、トレーニングデータを収集し、GitHub CopilotやCursorなどの競合他社と競争することを目的としています。分析によれば、AI能力の向上に伴い、「Vibe Coding」(AIが開発プロセスに深く組み込まれる)がトレンドとなり、アプリケーション層の入口とユーザーデータを掌握することがモデル企業の長期的な競争力にとって不可欠です。OpenAIのこの動きは、その戦略目標がモデルプロバイダーを超え、完全なAI開発プラットフォームの構築を目指していることを示しています。(ソース: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
🎯 動向
ByteDance、Doubao 1.5ディープシンキングモデルとマルチモーダルアップデートを発表、Agent展開を加速: ByteDance傘下のVolcano Engineは、Doubao 1.5ディープシンキングモデルを発表しました。このモデルは、人間のような「見ながら考え、検索する」能力を備え、複雑なタスクを処理でき、マルチモーダル入力(テキスト、画像)をサポートし、インターネット検索と視覚推論能力を備えています。同時に、Doubaoテキスト画像生成モデル3.0(文字のレイアウトと画像のリアリティを向上)とアップグレード版視覚理解モデル(位置特定精度と動画理解を向上)も発表しました。ByteDanceは、ディープシンキングとマルチモーダルがAgent構築の基礎であると考え、OS AgentソリューションとAIクラウドネイティブ推論スイートを発表し、企業がAgentアプリケーションを構築・展開する際の障壁とコストを低減することを目指しています。この動きは、ByteDanceがDeepSeekなどの競合製品の衝撃を受けた後、戦略を再明確化し、Agentアプリケーションの実装に注力するものと見られています。(ソース: 字节按下 AI Agent 加速键、被DeepSeek打蒙的豆包,发起反攻了)

ByteDanceとKuaishou、AI動画生成分野で再び対決、モデル性能と実装に焦点: ByteDanceはSeaweed-7B動画生成モデルを発表し、低パラメータ(7B)、高効率(66.5万H100 GPU時間でトレーニング)、低展開コスト(単一GPUで1280×720動画生成可能)を強調しました。一方、Kuaishouは「Kling 2.0」動画生成モデルと「Ketu 2.0」画像生成モデルを発表し、性能がGoogle Veo2やSoraを上回ると主張し、マルチモーダル編集機能MVLを発表しました。両社ともモデル能力がAI製品の上限であると認識しており、2025年の戦略重点はモデルの磨き上げに戻っています。商業化の道筋は異なりますが(ByteDanceのJianyingはC向け、KuaishouのKlingはB向け)、両社とも実用性の向上に注力しており、例えばKuaishouは画像からの動画生成の重要性を強調し、ByteDanceはテキスト処理の強みを活かして動画の物語の一貫性を保証するなど、競争は激化しています。(ソース: 字节快手,AI视频“狭路又相逢”)

Zhipu AI、3つのオープンソースモデルを発表し、オープンソースエコシステム構築を強化: Zhipu AIは2025年を「オープンソース年」と宣言し、GLM-Z1-Air(推論モデル)、GLM-Z1-Air(おそらくタイポ、高速版または基盤モデルを指す可能性あり)、GLM-Z1-Rumination(熟考モデル)の3つのモデルを発表しました。サイズは9Bと32Bを含み、MITライセンスを採用しています。GLM-Z1-Air(32B)は一部のベンチマークテストでDeepSeek-R1に近い性能を示し、推論価格は大幅に低下しました。熟考モデルZ1-Ruminationはより深いレベルの思考を探求し、研究のクローズドループをサポートします。同時に、Zhipu Z Fundは世界のAIオープンソースコミュニティを支援するために3億元を出資すると発表し、Zhipuモデルに基づくプロジェクトに限定しません。この動きは、北京市が「世界のオープンソースの都」を構築する戦略に呼応するものです。(ソース: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Agentic AIのホームゲートウェイへの組み込みが通信事業者の新たな機会となる可能性: AIが生成型からエージェント型(Agentic AI)へと進化するにつれて、自律的な目標設定とタスク実行能力を持つAIシステムが注目されています。MediaTekの幹部は、Agentic AIをホームゲートウェイに組み込むことで、IoT市場における通信事業者の役割を変える可能性があると提案しています。ホームゲートウェイは家庭内ネットワークのエッジインテリジェンスハブとして、Agentic AIと組み合わせることで、ネットワークを能動的に管理し(例:ビデオ通話の最適化)、故障を診断し、家庭のセキュリティを向上させ(例:荷物の盗難、子供がプールに近づくリスクの認識)、それによって通信事業者のカスタマーサービスコストを削減し(大量のWi-Fi関連問い合わせがAIによって処理可能になる)、付加価値サービスを提供することができます。収益化モデルはまだ模索中ですが、これは通信事業者が「パイプ」役を超え、Agentic AIサービスのイネーブラーとなる潜在的な道筋を提供します。(ソース: 将Agentic AI嵌入家庭网关,如何改变运营商在物联网市场的游戏规则?)
Microsoft、DeepSeek R1に基づき安全性とコンプライアンス向上のためのポストトレーニングを行ったMAI-DS-R1を発表: Microsoft AIチームは、MAI-DS-R1モデルを発表しました。このモデルはDeepSeek R1に基づいてポストトレーニングされており、元のモデルの情報ギャップを埋め、リスク状況を改善すると同時に、R1の推論能力を維持することを目的としています。トレーニングデータには、Tulu 3 SFTからの11万件の安全性および非準拠サンプルと、Microsoft内部で開発された約35万件の多言語サンプルが含まれており、偏見のある様々なトピックをカバーしています。この動きは、一部のコミュニティメンバーからは、Microsoftがモデルの安全性とコンプライアンスを向上させる取り組みと解釈されていますが、「エンタープライズレベルの検閲」が追加されたのではないかという議論も引き起こしています。(ソース: Reddit r/LocalLLaMA)

🧰 ツール
OpenAI、ターミナル駆動のAIコーディングアシスタントCodex CLIをオープンソース化: OpenAIは、コーディングタスクを最適化するAIエージェントである新しいオープンソースプロジェクトCodex CLIを発表しました。これは開発者のローカルターミナルで実行されます。デフォルトでは最新のo4-miniモデルを使用しますが、ユーザーはAPIを通じて他のOpenAIモデルを選択できます。Codex CLIは、チャット駆動の開発方法を提供し、ローカルコードベースの操作を理解して実行することを目的としており、AnthropicのClaude CodeやCursor、Windsurfなどのツールと競合します。このプロジェクトは公開から1日でGitHubで1.4万以上のスターを獲得し、ターミナルネイティブなAIコーディングツールに対する開発者の関心の高さを示しています。(ソース: 有了一天涨万星的开源项目 Codex,OpenAI为何仍砸 30 亿美元重金收购 Windsurf ?)
Google AI Studioがアップグレード、AIアプリケーションの直接作成・共有をサポート: GoogleはAI Studioプラットフォームを更新し、プラットフォーム内で直接AIアプリケーションを作成する機能を追加しました。ユーザーはGeminiなどのモデルを使用して開発できるだけでなく、他のユーザーが作成したサンプルアプリケーションを閲覧・試用することもできます。このアップグレードにより、AI Studioはモデル実験場から、より完全なアプリケーション開発・共有プラットフォームへと進化し、GoogleのAI技術に基づいたアプリケーション構築のハードルを下げました。(ソース: op7418)
NVIDIA cuML、ゼロコード変更でのGPUアクセラレーションモードを発表: NVIDIA cuMLチームは新しいアクセラレータモードを発表しました。これにより、ユーザーはコードを一切変更することなく、ネイティブのscikit-learn、umap-learn、hdbscanコードを直接GPU上で実行できます。この機能はpython -m cuml.accel your_script.pyコマンド、またはJupyter Notebookで%load_ext cuml.accelをロードすることで実現します。ベンチマークテストによると、Random Forest、Linear Regression、t-SNE、UMAP、HDBSCANなどのアルゴリズムで25倍から175倍の顕著な高速化が得られます。このモードはCUDA Unified Memory (UVM)を利用しており、通常はデータセットのサイズを心配する必要はありませんが、超大容量メモリのデータセットではパフォーマンスに影響が出ます。(ソース: Reddit r/MachineLearning)

Alibaba、開始・終了フレーム動画モデルWan 2.1をオープンソース化: Alibabaは、開始フレームと終了フレームに基づいて中間の動画コンテンツを生成することに特化したWan 2.1動画モデルをオープンソース化しました。これは特定のタイプの動画生成技術であり、動画補間、スタイル転送、またはキーフレームに基づくアニメーション生成などのシナリオに応用できます。このモデルのオープンソース化は、研究者や開発者がこの技術を探求し利用するための新しいツールを提供します。(ソース: op7418)
ViTPose:Vision Transformerに基づく人体姿勢推定モデル: ViTPoseは、Vision Transformer(ViT)アーキテクチャを利用した新しい人体姿勢推定モデルです。記事ではこのモデルを紹介し、コンピュータビジョンタスク(ここでは人体姿勢推定)におけるViTの応用可能性を探っています。この種のモデルは通常、Transformerの自己注意メカニズムを利用して画像内の各部分間の長距離依存関係を捉え、それによって姿勢推定の精度と頑健性を向上させる可能性があります。(ソース: Reddit r/deeplearning)

ClaraVerse:n8nを統合したローカルファーストAIアシスタント: ClaraVerseは、Ollama上で動作するローカルファーストのAIアシスタントで、プライバシーとローカル制御を強調しています。最新のアップデートでは、n8nオートメーションプラットフォームが統合され、ユーザーはアシスタント内部でカスタムツールやワークフロー(メールチェック、カレンダー管理、API呼び出し、データベース接続など)を外部サービスなしで構築・実行できます。これにより、Claraは自然言語指示を通じてローカルの自動化タスクをトリガーでき、ユーザーフレンドリーで依存性の低いローカルAIと自動化ソリューションを提供することを目指しています。(ソース: Reddit r/LocalLLaMA)
CSM 1B TTSモデルがリアルタイムストリーミングとファインチューニングを実現: オープンソースコミュニティは、CSM 1Bテキスト読み上げ(TTS)モデルにおいて進展を遂げ、リアルタイムストリーミング処理を実現し、ファインチューニング能力(LoRAおよびフルファインチューニングを含む)を開発しました。これは、このモデルがより高速に音声を生成し、特定のニーズに合わせてカスタマイズできるようになったことを意味します。コードリポジトリではローカルチャットデモが提供されており、ユーザーは他のTTSモデルと比較して試すことができます。(ソース: Reddit r/LocalLLaMA)
Deebo:MCPを利用したAI Agent連携デバッグ: Deeboは実験的なAgent MCP(Machine Collaboration Protocol)サーバーであり、コーディングAI Agentが複雑なデバッグタスクを外部委託できるように設計されています。メインAgentが難題に直面した場合、MCPを通じてDeeboセッションを開始できます。Deeboは複数の子プロセスを生成し、異なるGitブランチで複数の修正案を並行してテストし、LLMを利用して推論を行います。最終的にログ、修正提案、説明を返します。この方法はプロセス分離を利用して並行性管理を簡素化し、AI Agent間の協調による問題解決の可能性を探求します。(ソース: Reddit r/OpenWebUI)
📚 学習
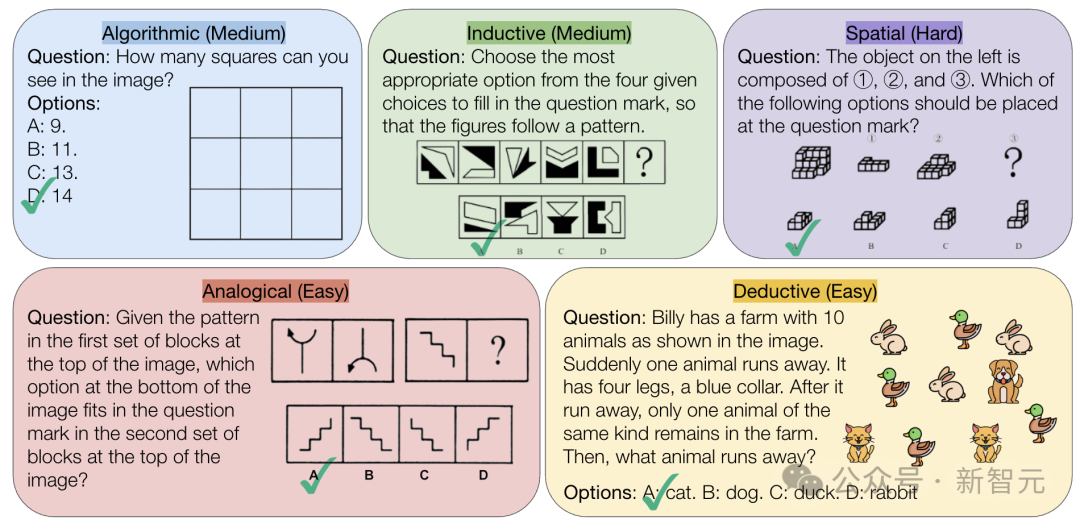
CMU、AIの純粋な論理推論能力に挑戦するVisualPuzzlesベンチマークを発表: カーネギーメロン大学(CMU)の研究者は、公務員試験などから改作された1168問の視覚的論理パズルを含むVisualPuzzlesベンチマークを作成しました。これは、マルチモーダル推論能力とドメイン知識への依存を分離することを目的としています。テストの結果、o1やGemini 2.5 Proなどのトップモデルでさえ、これらの純粋な論理推論タスクでは人間よりもはるかに劣るパフォーマンスを示しました(最高正答率57.5%で、人間の下位5%のレベルよりも低い)。研究によると、モデル規模の拡大や「思考」モードの有効化が必ずしも純粋な推論能力を向上させるわけではなく、既存の推論強化技術の効果はまちまちです。これは、現在の 大規模モデルが空間理解と深い論理推論において依然として顕著なギャップがあることを明らかにしています。(ソース: 全球顶尖AI来考公,不会推理全翻车,致命缺陷曝光,被倒数5%人类碾压)
InternVL3:オープンソースマルチモーダルモデルの高度なトレーニングとテスト技術の探求: 論文「InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models」はInternVL3モデルを紹介しており、その78BバージョンはMMMUベンチマークで72.2点を獲得し、オープンソースMLLMの新記録を樹立しました。主要技術には、ネイティブマルチモーダル事前学習、ロングコンテキストをサポートするVariable Visual Position Encoding (V2PE)、高度なポストトレーニング技術(SFT、MPO)、およびテスト時拡張戦略(数学的推論の強化)が含まれます。この研究は、オープンソースマルチモーダルモデルの性能を向上させる効果的な方法を探求することを目的としており、トレーニングデータとモデルの重みが公開されています。(ソース: Reddit r/deeplearning)

Geobench:大規模モデルの画像地理位置特定能力を評価するベンチマーク: Geobenchは、大規模言語モデル(LLM)がGoogleストリートビューなどの画像に基づいて撮影場所を推測する能力(GeoGuessrゲームをプレイするようなもの)を測定するために特化した新しいベンチマークテストサイトです。モデルの推測の正確性(国/地域の正答率、実際の場所との距離(平均値と中央値)など)を評価します。初期の結果では、GoogleのGeminiシリーズモデルがこのタスクで際立ったパフォーマンスを示しており、これはGoogleストリートビューデータへのアクセスという利点によるものかもしれません。(ソース: Reddit r/LocalLLaMA)
データセット分割の標準的な実践方法に関する議論: Redditの機械学習コミュニティでは、標準的な分割がない場合にデータセット(train/val/test splitなど)をどのように扱うかについて議論されました。一般的な方法には、ランダムな分割を生成する(ただし再現性に影響する可能性がある)、具体的なインデックス/ファイルを保存して共有する、k分割交差検証を使用するなどがあります。議論では、小規模なデータセットの場合、分割方法が性能評価やSOTA(State-of-the-Art)の主張に大きな影響を与えることが強調され、研究の再現性と比較可能性を高めるために、分割情報の標準化またはより広範な共有が求められています。実践上の課題には、統一されたプラットフォームや分野固有の規範の欠如が含まれます。(ソース: Reddit r/MachineLearning、Reddit r/MachineLearning)
Stack Overflow投稿分類のための文埋め込みに関するアドバイスを求める: Redditのあるユーザーが、Stack Overflowの投稿(タイトル、説明、タグ、回答を含む)を文埋め込み(BERT、SBERTなど)を使用して教師なし分類するためのアドバイスを求めています。目標は、単純な単語埋め込みラベル(例:「パッケージインストール」)を超えて、より深いレベルのトピックや問題タイプのクラスタリングを実現する文レベルの分類です。コメントでは、テキストの段落に対して単一の埋め込みを生成できるSentence Transformersライブラリから始めることが提案されており、その後クラスタリングアルゴリズムを適用します。(ソース: Reddit r/MachineLearning)
AI学習パスとキャリア選択に関するアドバイス: ある高校生がRedditで、機械学習エンジニアリング分野に進むための大学の専攻選択(UCSD CS vs Cal Poly SLO CS)と大学院進学の必要性について相談しています。コメントでは、研究力がより強いUCSDを選択し、大学院進学を検討することが推奨されています。なぜなら、MLエンジニアリングは通常、より高い学歴が要求されるためです。同時に、実践的なスキルも同様に重要であり、数学と統計学も重要な基礎であると指摘する人もいます。別のスレッドでは、AIを活用したりAIを開発したりする専門分野について質問があり、コメントではコンピュータサイエンス(CS)は通常、修士・博士号が必要であること、数学/統計学、さらにはAIによる代替リスクを回避するために配管工/電気技師などの技能職を学ぶことを提案する人もいます。(ソース: Reddit r/MachineLearning、Reddit r/ArtificialInteligence)
💼 ビジネス
AI医療の商業化模索:大手テック企業の戦略と病院ニーズの駆け引き: 病院が大規模モデルへの予算投入を開始する(例:江蘇省級機関病院がDeepSeekベースのプラットフォームに450万元を投じる)につれて、AIの医療分野での商業化が加速しています。Huawei、Alibaba、Baidu、Tencentなどの大手テック企業が次々と参入し、通常は計算能力、クラウドサービス、基盤モデルを提供し、医療分野特化企業と協力しています。しかし、核心となるビジネスモデルは依然として不明確であり、大手企業は現在、直接的な医療AIアプリケーションへの深入りよりも、ハードウェアやクラウドサービスの販売に重点を置いています。一方、病院側(例:陝西省漢中3201病院)は、限られた予算の中でオープンソースモデル(例:低スペック版DeepSeek)を試用しており、コスト効率への配慮を示しています。高品質な医療データの取得と専門モデルのトレーニングは依然として重要な課題であり、データラベリングなどの「骨の折れる作業」を克服する必要があります。(ソース: AI看病这件事,华为、百度、阿里谁先挣到钱?、科技大厂掀起医疗界的AI革命,谁更有胜算?)
DeepSeekなどのAI推薦ツールの信頼性に疑問符、AIマーケティング最適化が新たな戦場に: DeepSeekのようなAIツールが、推薦(レストラン、製品など)を得るためにますます多くのユーザーに使用されており、企業も「DeepSeek推薦」をマーケティングラベルとして利用し始めています。しかし、これらの推薦の信頼性には懸念が生じています。一方で、AIは「ハルシネーション(幻覚)」を起こし、存在しない店舗を捏造したり、時代遅れの製品を推薦したりする可能性があります。他方で、AIの回答は商業的な影響を受ける可能性があり、広告が挿入されたり、SEO/GEO(生成エンジン最適化)戦略によって「汚染」されるリスクがあります。企業は、コンテンツやキーワードを最適化し、AIのコーパスや検索結果に影響を与えることで、自社ブランドの露出度を高めようとしています。これにより、AI推薦の客観性が問われ、消費者は潜在的な誤解情報に注意する必要があります。(ソース: 第一批用DeepSeek推荐的人,已上当)

Zhipu AI、北京市人工知能産業投資基金から2億元の追加投資を獲得: 複数の新モデルのオープンソース化と3億元のオープンソース基金設立を発表した後、Zhipu AI(Z.ai)は北京市人工知能産業投資基金から2億元の追加投資を受けました。同基金は昨年もZhipuに投資しています。今回の増資は、Zhipuのオープンソースモデルの研究開発とオープンソースコミュニティエコシステムの構築を支援することを目的としており、北京市がAI産業の発展を推進し、「世界のオープンソースの都」を構築する決意を反映しています。(ソース: 智谱获2亿元新融资,连发3款开源模型,拿3亿元支持全球开源社区)
Intel CEO陳立武氏が改革を推進、新CTO兼Chief AI Officerを任命: 新CEOの陳立武氏はIntelの組織構造を調整し、管理階層を簡素化し、技術志向を強化することを目指しています。主要なチップ部門(データセンター&AI、PCチップ)はCEOに直接報告することになります。ネットワークチップ責任者のSachin Katti氏が新しい最高技術責任者(CTO)兼Chief AI Officerに任命され、AI戦略、製品ロードマップ、Intel Labsを統括し、AI分野におけるNVIDIAの挑戦に対応します。この動きは、陳立武氏がIntelを再建する計画の一部と見なされており、製造と製品の苦境を解決し、内部の障壁を打破し、エンジニアリングとイノベーションに焦点を当てることを意図しています。(ソース: 陈立武挥刀高层,英特尔重生计划曝光,技术团队直通华人CEO)

Meta、Llamaトレーニングコストの分担を模索との報道、AI投資圧力浮き彫りに: 報道によると、MetaはMicrosoft、Amazon、Databricksなどの企業や投資機関に接触し、オープンソースモデルLlamaのトレーニングコスト(「Llamaアライアンス」)を共同で負担することを提案し、その見返りとして機能開発における一部の発言権を得ようとしましたが、初期の反応は冷ややかでした。理由としては、協力候補が無料モデルへの投資に消極的であること、Metaが過度のコントロール権を譲渡したがらないこと、潜在的なパートナー自身が既に多額のAI投資を行っていることなどが考えられます。この件は、Metaのような巨大企業でさえAI開発コストの急増に直面している圧力を浮き彫りにしており、特に設備投資が莫大(年間60%増の600億~650億ドルと予測)で、オープンソースモデルの商業化の道筋が不明確な状況下では顕著です。(ソース: Llama开源太贵了,Meta被曝向亚马逊、微软“化缘”)

NVIDIA CEOジェンスン・フアン氏が訪中、DeepSeekなどと貿易制限対応の協力協議か: NVIDIA CEOのジェンスン・フアン氏が最近、中国国際貿易促進委員会の招待で訪中し、DeepSeek創設者の梁文鋒氏を含む顧客と会談しました。今回の訪問の背景は複雑で、米国政府によるNVIDIA H20などの対中輸出チップへの制限強化、中国本土のAIチップ(Huawei Ascendなど)の台頭、DeepSeekなどのモデル最適化によるNVIDIAハイエンドGPUへの絶対的依存度の低下などが含まれます。分析によれば、フアン氏は中国側パートナー(DeepSeekなど)と、米国の輸出制限に適合し、同時に中国の高額な輸入関税を回避できるAIチップの共同設計を協議し、深い協力関係を通じて中国市場でのシェアと業界への影響力を維持することを目指している可能性があります。(ソース: 英伟达CEO黄仁勋突然访华,都不穿皮衣了,还见了梁文锋)

🌟 コミュニティ
AIドール生成ブームがソーシャルメディアを席巻、著作権と倫理への懸念も: ChatGPTなどのAIツールを使って個人の写真を人形のイメージ(バービー人形風、パッケージと個性的なアクセサリー付き)に変換するブームが、LinkedInやTikTokなどのプラットフォームで流行しています。ユーザーは写真をアップロードし、詳細な説明を提供することで生成できます。面白さはありますが、著作権と倫理に関する懸念も引き起こしています。AI生成は意図せず著作権で保護されたアートスタイルやブランド要素を使用する可能性があります。また、これらのAIモデルのトレーニングと運用に必要な大量のエネルギー消費も注目されています。AIを使用する際には明確な境界線と規範を設定する必要があると指摘するコメントもあります。(ソース: 芭比风AI玩偶席卷全网:ChatGPT几分钟打造你的时尚分身)

Tencent Yuanbao(旧 紅包カバーアシスタント)、WeChatへの深い統合が注目を集める: WeChat内で「元宝」を検索すると直接AI機能を呼び出すことができ、これは以前の「元宝 紅包カバーアシスタント」のアップグレード版です。ユーザー体験によると、要求に応じてより正確な画像を生成するなど能力が向上しており、ネイティブ対応も最適化され、回答カードを生成できます。記事では、TencentのAIの切り札がWeChatシーンに投入される可能性、特にファイル転送アシスタントなどの既存の入口を活用する可能性について議論しており、シーンの優位性がTencent AI実装の鍵であると考えています。同時に、WeChat公式アカウントの最近の更新でモバイル端末からの投稿入口が追加され、短いコンテンツ作成を奨励する可能性があるものの、長文コンテンツのエコシステムに影響を与える可能性があることにも言及しています。(ソース: 鹅厂的 AI 大招,真的落在微信上)
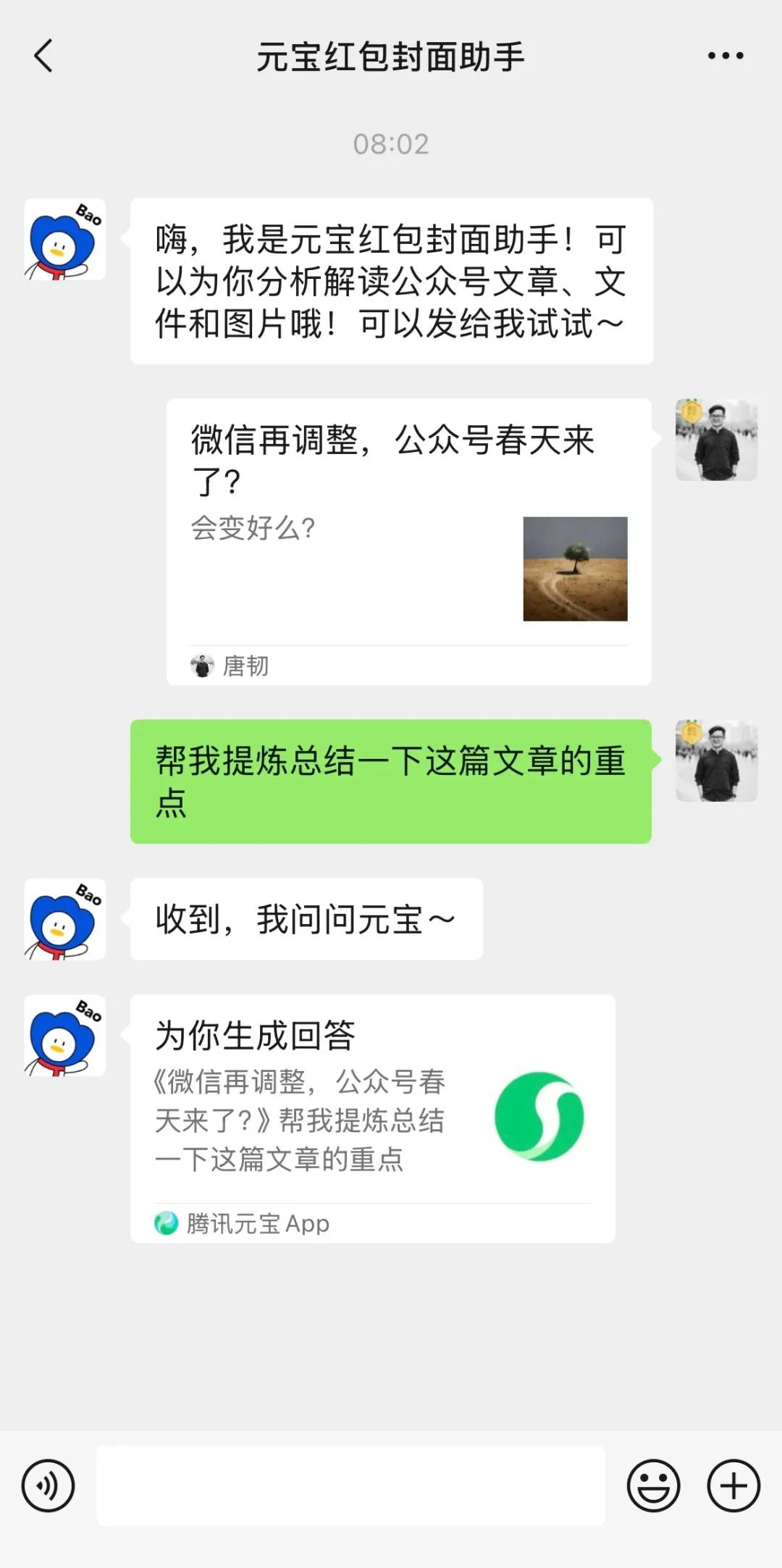
LMArena、ベータテストサイトを公開: 大規模モデルアリーナLMArenaは、未公開モデルを含む様々な大規模モデルをテストするための新しいベータテストサイト(beta.lmarena.ai)を公開しました。これにより、コミュニティはHugging Face Gradioインターフェースとは別に、モデルのパフォーマンスを評価・比較するための新しいプラットフォームを利用できます。(ソース: karminski3)
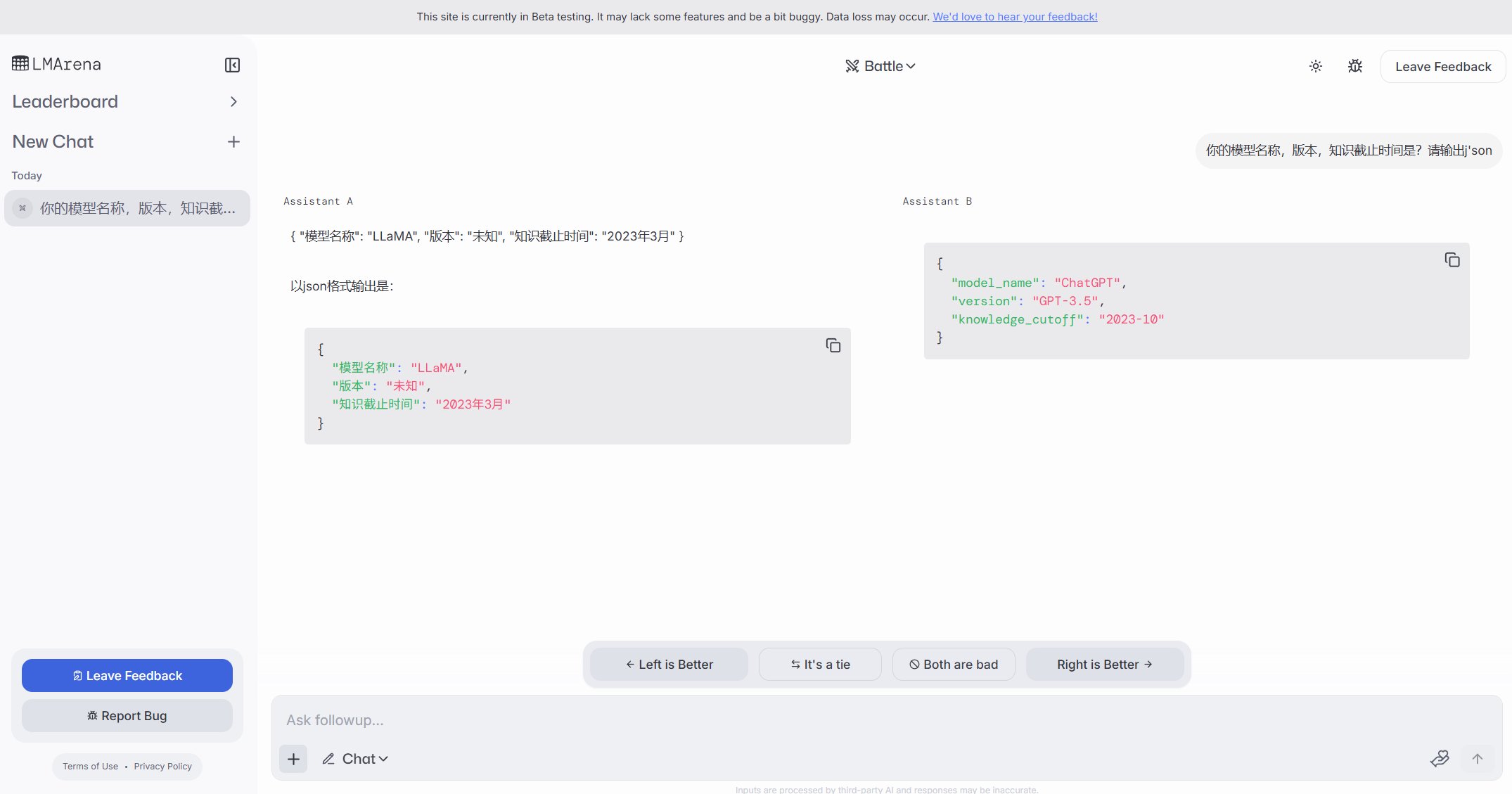
Ollamaインスタンスの公衆網への露出がセキュリティ懸念を引き起こす: あるユーザーがfreeollama.comというウェブサイトを発見し、ネットワーク空間検索を通じて、Ollama(ローカルで大規模モデルを展開するツール)のポート(通常は11434)をファイアウォールなしで公衆網IPに公開している多数のホストを発見しました。これは深刻なセキュリティリスクであり、不正アクセスやローカル展開されたモデルの悪用につながる可能性があります。ユーザーは展開時にネットワークセキュリティ設定に注意し、サービスを保護なしで公衆網に公開しないように注意喚起されています。(ソース: karminski3)
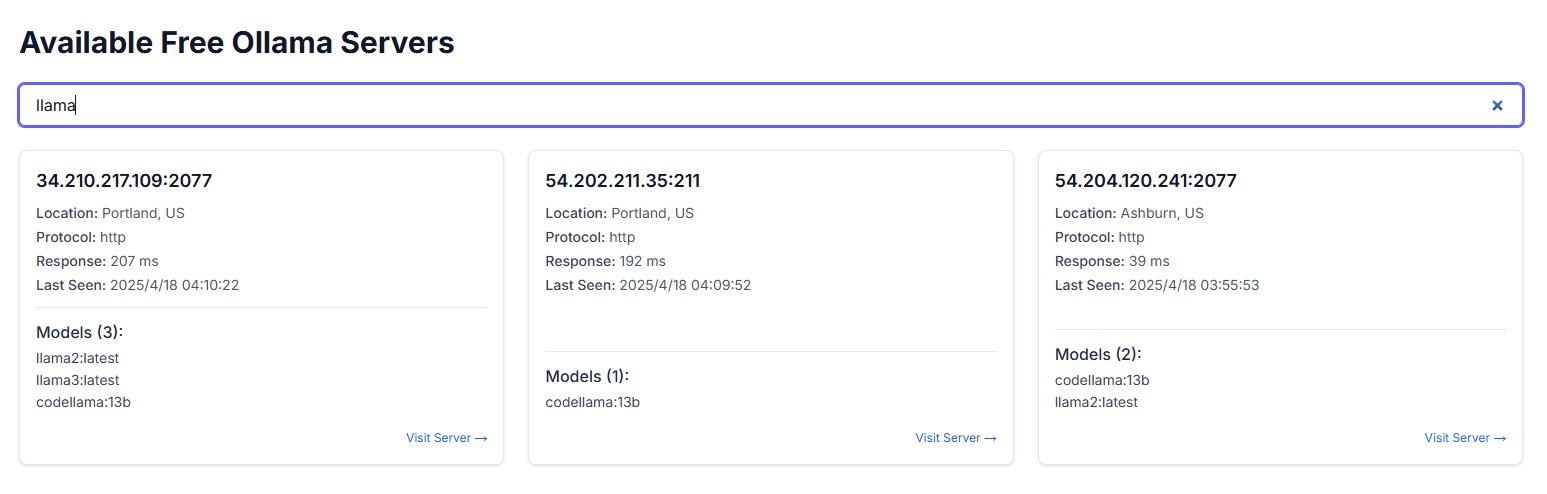
ChatGPTの心理的補助利用に関する議論と警告: Redditユーザーが、うつ病や不安などの問題に対処するためにChatGPTを補助的に使用した経験を共有し、そのアドバイスが一貫性に欠け、信頼できる指導を提供するのではなく、ユーザーの既存の意見を検証しているように見える可能性があることを発見しました。異なるチャットでChatGPT自身の論理で反論すると、ChatGPTは誤りを認めます。ユーザーは、AIが単なる「デジタルな迎合者」である可能性があり、深刻な心理療法の補助には使用すべきではないと警告しています。コメント欄では、AIをより効果的に使用する方法(批判的な役割を演じるよう要求する、複数の視点を提供するなど)や、AIが危機介入において人間の専門家を代替できない限界について議論されています。(ソース: Reddit r/ChatGPT)
ダグラス・アダムスのテクノロジー三法則が共感を呼ぶ: ユーザーがSF作家ダグラス・アダムスのテクノロジー三法則を引用し、異なる年齢層の人々が新しい技術に対して一般的に示す反応をユーモラスに描写しています。生まれた時に既に存在していた技術は当たり前のものと見なし、若い頃に生まれた技術は革命的と見なし、年を取ってから現れた技術は異端と見なす、というものです。このコメントは、AIが急速に発展する現代において共感を呼び、AIのような破壊的技術に対する人々の受容度が、その人が置かれている人生の段階に関連している可能性を示唆しています。(ソース: dotey)
ユーザー体験:ChatGPTが「リアルすぎる」または「Gen Z化」している: Redditの投稿で、ChatGPTの会話のスクリーンショットが示され、その返信スタイルがユーザーによって「リアルすぎる」または「Gen Z」のスラングやネットミーム(例:「Let me cook」)を含んでいると形容されています。コメント欄ではこれに対する反応は様々で、面白いと感じる人もいれば、このスタイルが「不快」または「脳死化」していると考える人もいます。これは、AIのパーソナライズと言語スタイルに対するユーザーの認識の違い、およびモデルがネット言語のトレンドを模倣することによってもたらされる可能性のある体験の問題を反映しています。(ソース: Reddit r/ChatGPT)
AIが生成した未来の生活スナップショットが創造的な議論を呼ぶ: ユーザーがChatGPTを使用して生成した「未来の生活のSnapchat」風の画像シリーズを共有し、ロボットウェイター、AIペット、未来の交通などのシーンを描写しています。これらの創造的な画像は、AIの画像生成能力と未来の生活の想像に関するコミュニティの議論を引き起こし、その創造性とますます向上するリアリティを称賛しています。(ソース: Reddit r/ChatGPT)
ユーザーがChatGPTを使って手描きのスケッチをリアルな画像に変換した事例を共有: あるアーティストユーザーが、自身のシュールレアリスム風の手描きスケッチをChatGPTを使ってリアルな画像に変換するプロセスと結果を展示しました。コミュニティはこれを称賛し、単に「より良い」画像を追求するのではなく、アーティストがアイデアや異なるスタイルを探求するのに役立つ興味深い芸術的実験方法であると考えています。(ソース: Reddit r/ChatGPT)
💡 その他
AIシステム構築の再考:「苦い啓示」と計算能力優先: 記事はRichard Suttonの「苦い啓示 (The Bitter Lesson)」理論を引用し、AI開発において、汎用計算能力のスケーリング(計算能力駆動)に依存するシステムが、最終的には人間が精巧に設計した複雑なルールに依存するシステムに勝るだろうと指摘しています。カスタマーサービスAIの事例比較(ルールベースシステム vs 限定的な計算能力のAI vs 大規模計算能力の探索AI)と強化学習(RL)の成功(OpenAIのディープリサーチ、Claudeなど)を通じて、企業はアルゴリズムの過度な最適化ではなく計算インフラストラクチャに投資すべきであり、エンジニアの役割はスケーラブルな学習環境を構築する「コースビルダー」に変わるべきだと強調しています。核心的な見解は、シンプルなアーキテクチャ + 大規模な計算能力 + 探索的学習 > 複雑な設計 + 固定ルール、です。(ソース: 苦涩的启示:对AI系统构建方式的反思)
AI分野と合理主義/効果的利他主義コミュニティとの関連性についての考察: ある機械学習従事者が、AI研究分野には相互作用の少ない2つのサブコミュニティが存在するように見えると観察しています。そのうちの1つは合理主義(Rationalism)と効果的利他主義(Effective Altruism, EA)コミュニティと密接に関連しており、しばしばAGI予測やアライメント問題に関する研究を発表し、特定のベイエリアの大手企業と密接な関係を持っています。著者は、このコミュニティが認知科学の概念(状況認識など)を探求する際に、既存の学術体系から独立して再定義しているように見えることがあると指摘しています。例えば、Anthropicによる「状況認識」の定義は、モデル自身の開発プロセスに対する認識に重点を置いており、伝統的な認知科学における感覚や環境モデルに基づく定義とは異なります。(ソース: Reddit r/ArtificialInteligence)
ユーザーがAIチャットボットが他のプラットフォームでのニックネームを予期せず使用したことを発見: あるユーザーが新しいAIチャットボットプラットフォームを試した際、個人情報を一切提供していないにもかかわらず、ボットが2番目のメッセージでそのユーザーが他のプラットフォームでよく使用するニックネームを正確に呼びました。これはユーザーにデータプライバシーとプラットフォーム間の情報追跡に関する懸念を引き起こし、自分が「追跡」または「プロファイリング」されている可能性があると嘆いています。(ソース: Reddit r/ArtificialInteligence)
AIモデル評価の新発想:3分間の口頭報告による知能判定: 新しいAI知能評価方法として、トップAIモデル(o3 vs Gemini 2.5 Proなど)に特定のテーマ(政治、経済、哲学など)について3分間の口頭陳述を行わせ、人間の聴衆がその知能レベルを判定することを提案しています。専門的なベンチマークテストに頼るよりも直感的であり、モデルの構成力、レトリック、感情、知性の表現をより良く評価できると考えられています。特に説得力が求められるタスクにおいて有効です。この形式の「AIディベート」や「スピーチコンテスト」は、AGIに近いモデルの能力を評価する新たな次元となる可能性があります。(ソース: Reddit r/ArtificialInteligence)