
キーワード:GPT-4.5, 大モデル, GPT-4.5トレーニング詳細, Huawei盤古Ultra性能, RLHF推論能力への影響, 人間学習上限4GB研究, オープンソース数学データセットMegaMath, GPT-4.5 大モデル, GPT-4.5 トレーニングプロセス, Huawei盤古Ultra ベンチマーク, RLHFが推論能力に与える影響, 人間の学習能力 4GB制限 研究, MegaMath 数学データセット ダウンロード
🔥 注目
OpenAI、GPT-4.5のトレーニング詳細と課題を公開: OpenAI CEOのSam Altman氏とGPT-4.5コア技術チームが対談し、モデル開発の詳細を明らかにしました。プロジェクトは2年前に開始され、ほぼ全従業員が動員され、予想以上の時間を要しました。トレーニング中に10万基のGPUクラスタの故障や隠れたバグなどの「壊滅的な問題」に遭遇し、インフラのボトルネックが露呈しましたが、技術スタックのアップグレードも促しました。現在ではわずか5〜10人でGPT-4レベルのモデルを再現できます。チームは、将来の性能向上の鍵は計算能力ではなくデータ効率にあり、同量のデータからより多くを学習するための新しいアルゴリズムを開発する必要があると考えています。システムアーキテクチャはマルチクラスタに移行しており、将来的には数千万規模のGPU連携が必要になる可能性があり、フォールトトレランスに対する要求が高まっています。対談では、Scaling Law、機械学習とシステムの協調設計、教師なし学習の本質などにも触れられ、OpenAIが最先端の大規模モデル開発を推進する上での思考と実践を示しています (出典: 36氪)

Huawei、Ascendネイティブの135B密な大規模モデルPangu Ultraを発表: Huawei Panguチームは、国産のAscend NPUでトレーニングされた135Bパラメータの密な汎用言語大規模モデルPangu Ultraを発表しました。このモデルは94層のTransformer構造を採用し、Depth-scaled sandwich-norm (DSSN)とTinyInit初期化技術を導入して、超深層モデルのトレーニング安定性問題を解決し、13.2Tの高品質データでlossスパイクなしの安定したトレーニングを実現しました。システムレベルでは、混合並列処理、演算子融合、サブシーケンス分割などの最適化により、8192基のAscendクラスタ上で計算能力利用率(MFU)を50%以上に向上させました。評価によると、Pangu Ultraは複数のベンチマークでLlama 405B、Mistral Large 2などの密なモデルを上回り、DeepSeek-R1などのより大規模なMoEモデルと競合できることを示し、国産の計算能力に基づいたトップレベルの大規模モデル開発の実現可能性を証明しました (出典: 机器之心)

研究が強化学習(RL)によるLLM推論能力向上の顕著性に疑問を呈す: テュービンゲン大学とケンブリッジ大学の研究者は、最近の強化学習(RL)が言語モデルの推論能力を著しく向上させると主張する説に疑問を呈しています。一般的な推論ベンチマーク(AIME24など)の厳密な調査を通じて、結果には高い不安定性があり、ランダムシードを変更するだけでスコアが大幅に変動する可能性があることを発見しました。標準化された評価の下では、RLによる性能向上は元の報告よりもはるかに小さく、統計的に有意でないことが多く、教師ありファインチューニング(SFT)の効果よりも劣り、汎化能力も低いことがわかりました。研究は、サンプリングの差異、デコーディング構成、評価フレームワーク、ハードウェアの異質性が不安定性の主な原因であると指摘し、モデルの推論能力の真の進歩を冷静に見極め、測定するために、より厳格で再現可能な評価基準を採用するよう呼びかけています (出典: 机器之心)

Altman氏TED講演:強力なオープンソースモデルをリリース予定、ChatGPTはAGIではないと認識: OpenAI CEOのAltman氏はTEDカンファレンスで、既存のすべてのオープンソースモデルを凌駕する性能を持つ強力なオープンソースモデルを開発中であり、DeepSeekなどの競合他社に直接対応すると述べました。彼はChatGPTのユーザー数が急増し続けており、新しい記憶機能がパーソナライズされた体験を向上させると強調しました。彼はAIが科学的発見とソフトウェア開発(効率が大幅に向上)の分野でブレークスルーを迎えると考えていますが、ChatGPTのような現在のモデルは自己持続的な学習能力や分野横断的な汎化能力を備えておらず、AGIではないと述べました。彼はまた、GPT-4oの創造的能力が引き起こす著作権と「スタイル権」の問題についても議論し、OpenAIのモデルの安全性への自信とリスク管理メカニズムを再確認しました (出典: 新智元)

研究によると人間の生涯学習上限は約4GB、ブレイン・コンピュータ・インターフェースとAI開発の議論を呼ぶ: Cell傘下のジャーナルNeuronに掲載されたカリフォルニア工科大学の研究によると、人間の脳の情報処理速度は毎秒約10ビットであり、感覚系が毎秒10億ビットのデータを収集する速度よりもはるかに低いと推定されています。これに基づき、研究は人間の一生(100年間、中断なく学習し忘れないと仮定)の知識蓄積上限は約4GBであり、大規模モデルのパラメータ格納能力(例えば7Bモデルは140億ビットを格納可能)よりもはるかに小さいと推論しています。研究はこのボトルネックが中枢神経系の逐次処理メカニズムに起因すると考え、機械知能が人間を超えるのは時間の問題だと予測しています。この研究はまた、Musk氏のNeuralinkに対して、脳の基本構造の制限を突破できず、既存の通信方式を最適化する方が良いと疑問を呈しています。この研究は、人間の認知限界、AIの発展可能性、およびブレイン・コンピュータ・インターフェースの方向性について広範な議論を引き起こしました (出典: 量子位)

🎯 動向
GPT-4が間もなく引退、GPT-4.1および謎の新モデルが登場か: OpenAIは4月30日よりChatGPTにおいて、2年前にリリースされたGPT-4をGPT-4oで完全に置き換えると発表しました。GPT-4は引き続きAPI経由で利用可能です。同時に、コミュニティやコードのリーク情報によると、OpenAIは間もなくGPT-4.1(およびそのmini/nanoバージョン)、フルスペック版o3推論モデル、そして新しいo4シリーズ(o4-miniなど)を含む一連の新モデルをリリースする可能性があります。Optimus Alphaという名の謎のモデルがすでにOpenRouterに登場しており、優れたパフォーマンス(特にプログラミング)を示し、百万コンテキストをサポートしています。これはOpenAIが間もなくリリースする新モデルの一つ(おそらくGPT-4.1またはo4-mini)であると広く推測されており、OpenAIモデルとの間に多くの類似点(特定のバグなど)が存在します。これはOpenAIのモデルイテレーション速度が加速しており、技術的リーダーシップを積極的に強化していることを示唆しています (出典: source、source)

AlibabaのQwen3大規模モデル、リリース間近か: 情報によると、Alibabaは近くQwen3大規模モデルをリリースする予定です。開発チームはモデルが最終準備段階にあることを確認していますが、具体的なリリース時期は未定です。Qwen3はAlibabaの2025年上半期の重要なモデル製品であり、その開発はQwen2.5の後に開始されました。DeepSeek-R1などの競合モデルの影響を受け、Alibaba Cloudの基盤モデルチームは戦略の重点をモデルの推論能力向上にさらに傾けており、大規模モデル競争の状況下で特定の能力への戦略的焦点を当てていることを示しています (出典: InfoQ)

Kimiオープンプラットフォームが値下げ、軽量級ビジョンモデルをオープンソース化: Moonshot AI傘下のKimiオープンプラットフォームは、モデル推論サービスとコンテキストキャッシュの価格を引き下げると発表しました。これは技術最適化を通じてユーザーコストを削減することを目的としています。同時に、KimiはMoEアーキテクチャに基づく2つの軽量級視覚言語モデルKimi-VLとKimi-VL-Thinkingをオープンソース化しました。これらは128Kコンテキストをサポートし、アクティブパラメータは約30億のみで、マルチモーダル推論能力において10倍のパラメータを持つ大規模モデルを著しく上回るとされており、小型で効率的なマルチモーダルモデルの開発と応用を推進することを目指しています (出典: InfoQ)
Google、Agent相互運用プロトコルA2Aおよび多数のAI新製品を発表: Google Cloud Next ’25カンファレンスで、Googleは50社以上のパートナーと共に、異なる企業やプラットフォームで開発されたAIエージェント間の相互運用と協力を実現することを目的としたオープンプロトコルAgent2Agent (A2A)を発表しました。同時に、Gemini 2.5 Flash(高効率版フラッグシップモデル)、Lyria(テキストから音楽生成)、Veo 2(動画作成)、Imagen 3(画像生成)、Chirp 3(カスタム音声)など多数のAIモデルおよびアプリケーションを発表し、推論に最適化された第7世代TPUチップIronwoodも発表しました。この一連の発表は、GoogleのAIインフラ、モデル、プラットフォーム、エージェントにおける包括的なレイアウトとオープン戦略を示しています (出典: InfoQ)
ByteDance、200Bパラメータ推論モデルSeed-Thinking-v1.5を発表: ByteDanceのDoubaoチームは、総パラメータ数200Bを持つMoE推論モデルSeed-Thinking-v1.5を紹介する技術レポートを発表しました。このモデルは毎回20Bのパラメータをアクティブにし、複数のベンチマークテストで優れたパフォーマンスを示し、総パラメータ数671Bを持つDeepSeek-R1を上回るとされています。コミュニティでは、これが現在ByteDanceのDoubaoアプリの「深度思考」モードで使用されているモデルである可能性が推測されており、ByteDanceの効率的な推論モデル開発における進展を示しています (出典: InfoQ)
Midjourney、V7モデルをリリース、画質と生成効率を向上: AI画像生成ツールMidjourneyは、新モデルV7(アルファ版)をリリースしました。新バージョンでは、画像生成の一貫性と整合性が改善され、特に手、身体部位、物体の細部の表現が向上し、よりリアルで豊かなテクスチャを生成できるようになりました。V7はDraft Modeを導入し、半分のコストで10倍のレンダリング速度を実現し、迅速なイテレーションと探索に適しています。同時に、turbo(より速いがより高価)とrelax(より遅いがより安価)の2つの生成モードを提供し、さまざまなユーザーのニーズに応えます (出典: InfoQ)
Amazon、AI音声モデルNova Sonicを発表: Amazonは、新世代のネイティブ音声処理生成AIモデルNova Sonicを発表しました。このモデルは、速度、音声認識、対話品質などの主要な指標において、OpenAIやGoogleのトップレベルの音声モデルに匹敵するとされています。Nova SonicはAmazon Bedrock開発者プラットフォームを通じて提供され、新しい双方向ストリーミングAPIアクセスを採用し、価格はGPT-4oより約80%安価であり、エンタープライズレベルのAIアプリケーションに高コストパフォーマンスの自然な音声対話能力を提供することを目指しています (出典: InfoQ)
Apple、中国版iPhoneのAI機能が年中にも提供開始か、BaiduとAlibabaの技術を統合: 報道によると、Appleは2025年半ばまでに中国市場のiPhone(おそらくiOS 18.5)にApple Intelligenceサービスを導入する計画です。この機能はBaiduのErnie大規模モデルを利用してインテリジェント機能を提供し、Alibabaの検閲エンジンを統合してコンテンツ規制要件に準拠します。AppleはBaiduやAlibabaと独占契約を結んでおらず、主要市場でAI機能を迅速に展開するためにローカライズされた協力戦略を採用していることを示しています (出典: InfoQ)
🧰 ツール
Volcano Engine、企業向けデータインテリジェントエージェントData Agentを発表: Volcano Engineは、エンタープライズレベルのデータインテリジェントエージェントData Agentを発表しました。このツールは、大規模モデルの推論、分析、ツール呼び出し能力を活用し、企業のビジネスニーズを深く理解し、詳細な調査レポートの作成やマーケティングキャンペーンの設計など、複雑なデータ分析および応用タスクを自動化し、企業のデータ利用効率と意思決定レベルを向上させることを目指しています (出典: InfoQ)
GPT-4o画像生成の新スタイルが注目を集める: ソーシャルメディアユーザーは、GPT-4oの画像生成機能を利用して作成した新しいスタイルを披露しています。例えば、Windows 2000のレトロなインターフェース要素とキャラクター画像を組み合わせて、ユニークなコラージュ効果を生成しています。ユーザーは、参照画像を利用した誘導や、スタイルと内容の説明を組み合わせるなどのプロンプトテクニックを共有し、GPT-4oの創造的可能性を探求することへのコミュニティの関心を引き起こしています (出典: source、source)

📚 学習
最大のオープンソース数学事前学習データセットMegaMathが公開: LLM360は、3710億トークンを含むオープンソースの数学推論事前学習データセットMegaMathを発表しました。これはDeepSeek-Math Corpusを上回る規模です。データセットは、数学集約型のウェブページ(279B)、数学関連のコード(28B)、高品質な合成データ(64B)をカバーしています。チームは、HTML構造の最適化、2段階抽出、LLM支援によるフィルタリングと精錬など、精緻化されたデータ処理プロセスを通じて、データの規模、品質、多様性を確保しました。Llama-3.2モデルでの事前学習検証では、MegaMathを使用することでGSM8K、MATHなどのベンチマークで15〜20%の絶対的な向上をもたらすことが示され、オープンソースコミュニティに強力な数学推論能力のトレーニング基盤を提供します (出典: 机器之心)

Nabla-GFlowNet:拡散モデルのファインチューニングにおける多様性と効率のバランス: 香港中文大学(深セン)などの機関の研究者は、生成フローネットワーク(GFlowNet)に基づく拡散モデルの報酬ファインチューニングの新しい方法であるNabla-GFlowNetを提案しました。この方法は、従来の強化学習ファインチューニングの収束が遅い問題や、直接的な報酬最適化が過学習しやすく多様性を失う問題を解決することを目的としています。新しいフローバランス条件(Nabla-DB)を導出し、特定の損失関数と対数フロー勾配パラメータ化を設計することにより、Nabla-GFlowNetは生成サンプルの多様性を維持しながら、モデルを報酬関数(美的スコア、指示追従など)に効率的に整合させることができます。Stable Diffusionでの実験により、DDPO、ReFL、DRaFTなどの既存手法に対する優位性が証明されました (出典: 机器之心)
Llama.cpp が Llama 4 関連の問題を修正: llama.cpp プロジェクトは、Llama 4 モデルに関する2つの修正をマージしました。これらは RoPE(回転位置埋め込み)と誤ったノルム(norms)計算に関連しています。これらの修正はモデルの出力品質を向上させることを目的としていますが、ユーザーは修正後の変換ツールで生成された GGUF モデルファイルを再ダウンロードする必要がある場合があります (出典: source)
💼 ビジネス
NVIDIA、Lepton AIの買収を完了: 報道によると、NVIDIAは元Alibaba副社長のJia Yangqing氏が設立したAIインフラストラクチャスタートアップLepton AIを買収しました。取引額は数億ドルに達する可能性があります。Lepton AIの主な事業は、NVIDIA GPUサーバーのレンタルと、企業がAIアプリケーションを構築・管理するためのソフトウェア提供です。Jia Yangqing氏とその共同創設者であるBai Junjie氏など約20名の従業員がNVIDIAに加わりました。この動きは、NVIDIAがクラウドサービスとエンタープライズソフトウェア市場を拡大し、AWSやGoogle Cloudなどの自社開発チップとの競争に対応するための戦略的展開と見なされています (出典: InfoQ)
米国テクノロジー業界に広がる不安感、AIが雇用市場に衝撃: 報道によると、米国のテクノロジー業界は、雇用の減少、給与の縮小、求職期間の長期化という困難に直面しています。大規模な人員削減や、企業(Salesforce、Meta、Googleなど)がAIを人的資源の代替として利用したり、採用(特にエンジニアリングや初級職)を一時停止したりすることが、業界従事者の職業不安を増大させています。データによると、給与の減少を報告する人や、管理職から個人貢献者への移行者の割合が増加しています。AIは雇用市場を再構築しており、求職者は非テクノロジー業界への視野拡大や起業への転換を迫られています。専門家は、「ビッグセブン」以外の雇用機会に注目し、競争力を高めるためにAIツールを習得することを推奨しています (出典: InfoQ)

OpenAI、Altman氏とJony Ive氏が協力するAIハードウェア企業の買収を検討中との噂: 情報によると、OpenAIは、CEOのAltman氏と元Appleデザイン責任者のJony Ive氏が協力して設立したAI企業io Productsを5億ドル以上で買収することを議論しています。同社はAI駆動のパーソナルデバイス開発を目指しており、考えられる形態としては、スクリーンレスの「携帯電話」や家庭用デバイスがあります。io Productsはエンジニアチームがデバイスを構築し、OpenAIが技術を提供、Ive氏のスタジオがデザインを担当し、Altman氏が深く関与しています。買収が完了すれば、このハードウェアチームはOpenAIに統合され、AIハードウェア分野での展開が加速されるでしょう (出典: InfoQ)
元OpenAI CTOのスタートアップ、古巣からさらに人材を引き抜き: 元OpenAI CTOのMira Murati氏が設立したAI企業「思维机器实验室 (Thinking Machines Laboratory)」は、元OpenAIの主要人物2名を顧問チームに迎え入れました。元チーフリサーチオフィサーのBob McGrew氏と元研究員のAlec Radford氏です。Radford氏はGPTシリーズの核心技術論文の主執筆者です。今回の採用は、このスタートアップの技術力をさらに強化し、AI分野における激しい人材獲得競争を反映しています (出典: InfoQ)
Baichuan Intelligence、事業の重点を医療分野に調整: Baichuan Intelligenceの創設者であるWang Xiaochuan氏は、会社設立2周年を機に全従業員向けの書簡を発表し、会社が医療分野に注力し、百小応、AI小児科、AI総合診療、精密医療などの応用サービスを発展させることを再確認しました。彼は余分な動きを減らし、組織構造をよりフラット化する必要があると強調しました。これに先立ち、同社は金融業界向けのBtoBチームを解散し、ビジネスパートナーのDeng Jiang氏が退職、さらに数名の共同創設者が退職または退職予定であることが報じられており、同社が戦略的焦点と組織調整を経ていることを示しています (出典: InfoQ)
Alibaba Cloud、AIエコシステムパートナー「繁花」計画を開始: Alibaba Cloudは、AIエコシステムパートナーを支援することを目的とした「繁花」計画を発表しました。この計画は、パートナー製品の成熟度に応じて、クラウドリソース、計算能力サポート、製品パッケージング、商業化計画、およびライフサイクル全体にわたるサービスを提供します。同時に、Alibaba CloudはAIアプリケーションおよびサービスマーケットプレイスを立ち上げ、繁栄するAIエコシステムを構築し、AI技術とアプリケーションの導入を加速することを目指しています (出典: InfoQ)
Kugou MusicとDeepSeekが深度協力: Kugou Musicは、AI企業DeepSeekとの協力を発表し、一連のAIイノベーション機能をリリースする予定です。これには、マルチモーダル分析を利用したパーソナライズされたリスニングレポートの生成、AIデイリーレコメンデーション、スマート検索、AIプレイリスト管理、AIによるダイナミックカバー生成、およびキャラクター設定を備えた「AI評論家」などが含まれ、AI技術を通じてユーザーの音楽体験とコミュニティインタラクションを向上させることを目指しています (出典: InfoQ)
Google、AI人材引き留めに「過激な」競業避止義務契約を採用か: 報道によると、Google傘下のDeepMindは、人材が競合他社に流出するのを防ぐため、一部の英国従業員に対して1年間の競業避止義務契約を実施しています。期間中、従業員は働く必要がなく給与を受け取り続けますが(ガーデニングリーブ)、これにより一部の研究者は、急速に発展する業界プロセスに参加できず、疎外感を感じています。この措置は米国ではFTCによって禁止される可能性がありますが、ロンドンの本社では適用されており、人材競争とイノベーションの制限に関する議論を引き起こしています (出典: InfoQ)
OpenAI元従業員、Musk氏の訴訟を支持する法的文書を提出: 12名のOpenAI元従業員が、Musk氏がOpenAIに対して起こした訴訟を支持する法的文書を提出しました。彼らは、OpenAIの再編計画(営利目的の構造への転換)が、会社の当初の非営利ミッションに根本的に違反する可能性があり、そのミッションこそが彼らを引きつけた重要な要因であったと考えています。OpenAIは、構造が変化してもそのミッションは変わらないと反論しています (出典: InfoQ)
🌟 コミュニティ
Anthropicの研究、高等教育におけるAIの利用パターンと課題を明らかに: Anthropicは、Claude.aiプラットフォーム上の数百万件の匿名の学生との対話を分析し、理工系(特にコンピュータ科学専攻)の学生がAIの早期利用者であることを発見しました。学生とAIのインタラクションパターンは、直接的な問題解決、直接的なコンテンツ生成、協力的な問題解決、協力的なコンテンツ生成の4種類があり、それぞれほぼ同等の割合を占めています。AIは主に、創造(プログラミング、練習問題作成など)や分析(概念説明など)といった高次の認知タスクに使用されています。研究はまた、潜在的な学術不正行為(解答の入手、盗作検出の回避など)も明らかにし、学術的誠実性、批判的思考力の育成、評価方法に対する懸念を引き起こしています (出典: 新智元)

GPT-4o画像生成が新トレンドを牽引:ジブリ風からAI著名人カードまで: GPT-4oの強力な画像生成能力は、ソーシャルメディア上で創作ブームを引き起こし続けています。「ジブリ風家族写真」が(元AmazonエンジニアのGrant Slatton氏が仕掛け人となり)大流行した後、ユーザーはAI分野の著名人の「マジック:ザ・ギャザリング」風カード(例えばAltman氏が「AGIの覇者」として設定される)や、パーソナライズされたタロットカードの作成を始めています。これらの事例は、AIがアートスタイルの模倣や創造的な生成において持つ可能性を示していますが、同時にオリジナリティ、著作権、美的価値、そしてAIがデザイナーの職業に与える影響についての議論も引き起こしています (出典: 新智元)

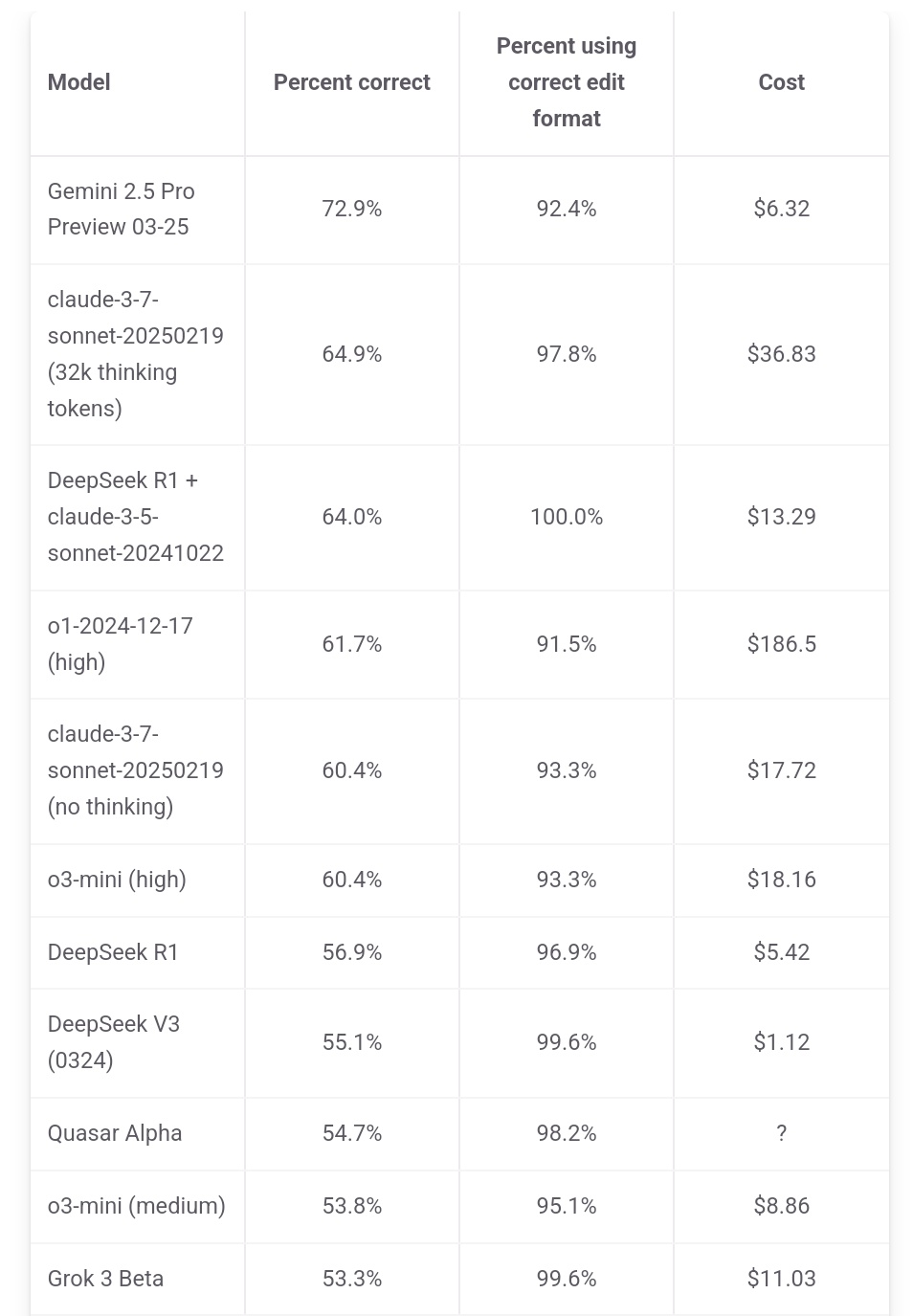
Jeff Dean氏、Gemini 2.5 Proのコスト優位性を強調: Google AI責任者のJeff Dean氏は、aider.chatのランキングデータを引用し、Gemini 2.5 ProがPolyglotプログラミングベンチマークテストで性能がトップクラスであるだけでなく、コスト(6ドル)もDeepSeekを除く他のトップ10モデルよりも著しく低いことを指摘し、そのコストパフォーマンスの優位性を強調しました。一部の競合モデルのコストはGemini 2.5 Proの2倍、3倍、さらには30倍にも達します (出典: JeffDean)
RedditでAIによる雇用市場への影響、特にエントリーレベル職について熱い議論: Redditフォーラムのある投稿が議論を呼んでいます。投稿者(CIS修士課程在学中)は、AIがエントリーレベルの非肉体労働(特にソフトウェアエンジニアリング、データ分析、ITサポート)を代替することへの深い懸念を表明し、「AIは仕事を奪わない」という主張は新卒者の苦境を無視していると主張しました。彼は、大企業がすでに新卒採用を縮小しており、将来の雇用市場は厳しいものになる可能性があると指摘しています。コメント欄ではこの見解について意見が分かれており、危機感を共有する声もあれば、これは技術変革の常であり、新しい役割(AIチームの管理など)に適応する必要があるという意見、また「90%の職が消える」という主張に疑問を呈し、経済サイクルや国ごとの状況の違いが大きく、AIの現在の能力はまだ限定的であるという意見もあります (出典: source)
Claudeユーザー、性能低下と制限強化に不満: RedditのClaudeAIセクションで集中的な議論が起きており、複数のユーザー(Proユーザーを含む)が最近、より厳しい使用制限(quota)に遭遇していると報告しています。通常の操作でも頻繁に上限に達するとのことです。一部のユーザーは、Anthropicが密かに利用枠を絞っていると考え、これに不満を表明し、これがユーザーを競合製品に流出させるだろうと述べています。さらに、一部のユーザーはClaudeの「個性」が変わったように感じ、より「冷淡」で「機械的」になり、初期バージョンの哲学的で詩的な感覚が失われたと報告しており、これが一部ユーザーのサブスクリプション解約につながっています (出典: source、source、source、source)
ChatGPT画像生成が面白さと議論を呼ぶ: Redditユーザーは、ChatGPTを使用して画像生成を行ったさまざまな試みとその結果を共有しています。あるユーザーは犬を人間に「変身」させるよう要求し、結果として「獣人/ファーリー」のようなイメージが生成され、プロンプトの理解と潜在的なバイアスについての議論を引き起こしました。別のユーザーは、自分自身を多次元宇宙バージョンのステンドグラスとして描くよう要求し、その効果は驚くべきものでした。また、AIに関する隠喩的な画像を生成するよう要求したり、AIの「悪夢」について尋ねたりするユーザーもおり、AI画像生成が創造的な表現や抽象的な概念の可視化において持つ能力と限界を示しています (出典: source、source、source、source、source)

コミュニティ、LLMモデルの選択と使用戦略について議論: RedditのLocalLLaMAセクションで、あるユーザーが毎月モデル使用に関する議論を行い、各自が異なるシナリオ(コーディング、執筆、研究など)で使用している最適なモデル(オープンソースおよびクローズドソース)とその理由を共有することを提案しました。コメント欄では、ユーザーが現在使用しているモデルの組み合わせ(Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemoなど)や、特定の用途(ツール呼び出し、分類、ロールプレイングなど)について言及しており、ユーザーがタスクのニーズに応じて異なるモデルを選択し組み合わせる実践的な傾向を反映しています (出典: source)
💡 その他
中国AIGC産業サミットが間もなく開催: 第3回中国AIGC産業サミットが4月16日に北京で開催されます。サミットには、Baidu、Huawei、Microsoft Research Asia、Amazon Web Services、面壁智能、生数科技などの企業から20名以上の業界リーダーが集結し、AI技術のブレークスルー(計算能力、大規模モデル)、業界応用(教育、文化・娯楽、研究、企業サービス)、エコシステム構築(安全で制御可能、導入の課題)などの議題について議論します。サミットでは、AIGC企業/製品ランキングおよび中国AIGC応用全景図も発表されます (出典: 量子位)

スタンフォード報告:米中トップAIモデルの性能差が0.3%に縮小: スタンフォード大学が発表した2025年AIインデックス報告によると、米中のトップAIモデルの性能差は、2023年の20%から0.3%へと著しく縮小しました。米国は著名なモデル数(40対15)や業界を主導する企業の面で依然としてリードしていますが、中国モデルの追随速度は加速しています。報告書はまた、トップモデル間の性能差も縮小しており、2024年の12%から5%に低下し、同質化現象が顕著であると指摘しています (出典: InfoQ)