
キーワード:AI, LLM, スタンフォードAIインデックスレポート, AI音楽生成の課題, Llama 4性能論争, DeepSeek現象, Agentic AIの可能性
🔥 フォーカス
スタンフォード大学、2025年AIインデックスレポートを発表、業界の主要トレンドを明らかに:スタンフォード大学人間中心AI研究所(HAI)は、第8回年次AIインデックスレポート(456ページ)を発表し、2024年の世界のAI発展を包括的に追跡しています。レポートには、AIハードウェア、推論コスト、企業の責任あるAI実践、科学/医学におけるAI応用などの内容が新たに追加されました。主要なトレンドは以下の通りです:1) AIはMMMUなどの高難易度ベンチマークで性能が著しく向上;2) AIは医療、交通などの日常生活にますます浸透;3) 企業の投資と採用率が過去最高を記録、米国の投資は中国をはるかに上回るが、中国モデルの性能差は急速に縮小(米中トップモデルのMMLUなどのベンチマーク差は0.3%~1.7%に縮小);4) DeepSeekなどのオープンソース/小規模モデルの性能がクローズドソース/大規模モデルに迫り、推論コストが大幅に低下(2年間で280倍低下);5) 世界的にAI規制が強化され、投資が増加;6) AI教育の普及は加速するもリソースは不均等;7) AIセキュリティインシデントが急増し、責任あるAIの実践は不均衡;8) 世界的にAIに対する楽観的な見方が高まるが、地域差が大きい。レポートはAIの変革的な潜在力と、その発展を導く必要性を強調しています。(出典:36氪, 新智元, 元宇宙之心MetaverseHub, 机器之心)

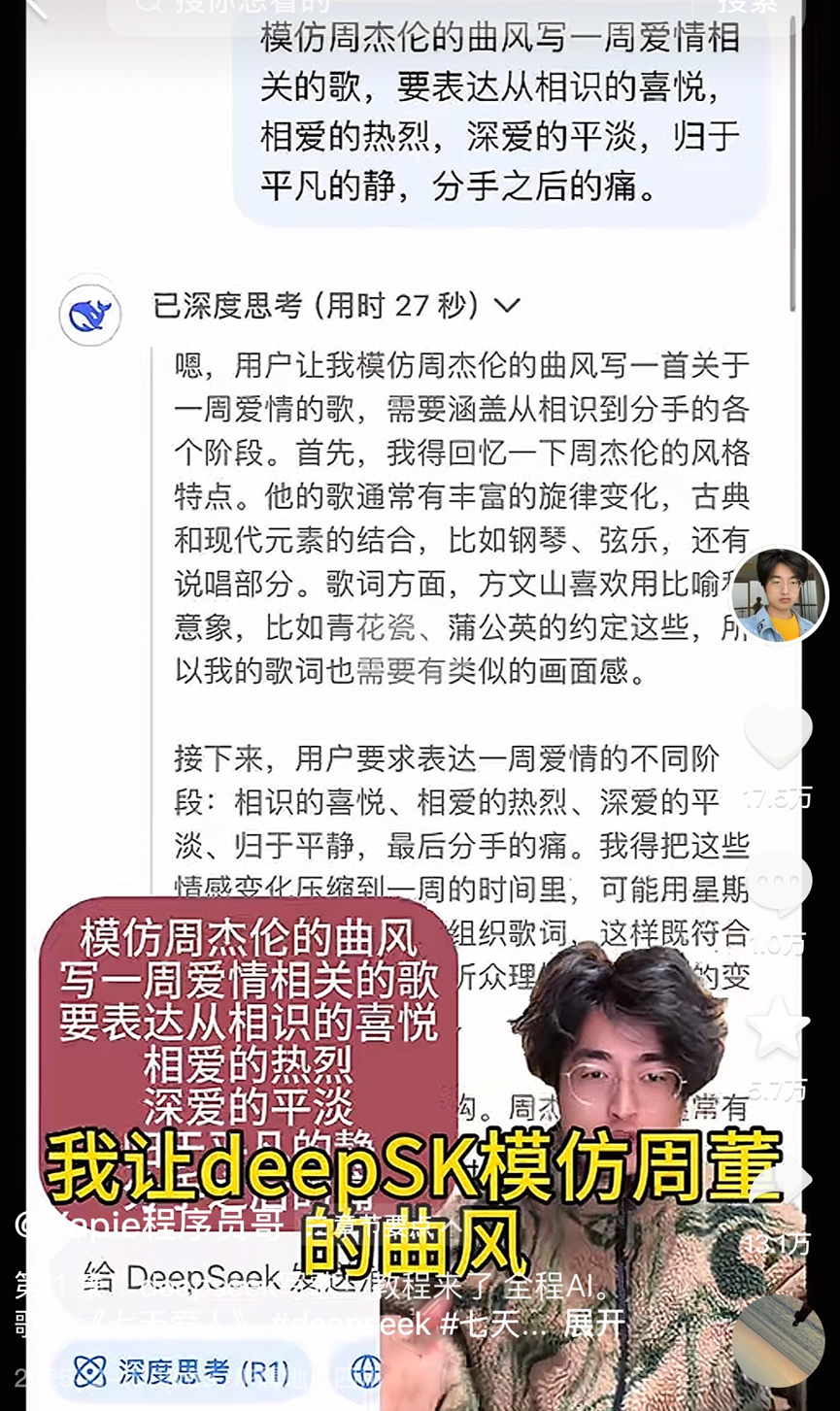
AI音楽制作がブームとなり論争を呼ぶ、『七天愛人』現象が業界のバブルと課題を浮き彫りに:AIが生成した楽曲『七天愛人』が周杰倫(ジェイ・チョウ)風を模倣して予想外のヒットとなり、トレンド入りや音楽チャートにランクインし、急速に著作権が販売され、AI音楽制作ブームを引き起こしました。多くのアマチュア愛好家がプラットフォームに殺到し、AIツールを利用して楽曲を「量産」しており、一部のプラットフォームも関連イベントを開始しています。しかし、繁栄の裏には問題が山積しています:大量のAI楽曲の品質は玉石混交で、「音楽ゴミ」と指摘されています;模倣とつなぎ合わせに依存し、真の革新性に欠けています;著作権の帰属が曖昧で、米国はAI制作物が著作権保護の対象外であることを明確にしており、Tencent Musicなどのプラットフォームも法的リスクを指摘しています;商業的な収益化は困難を極め、一部のヒット作を除き、ほとんどのAI楽曲の収益は惨憺たるもので、プラットフォームの審査は厳格化する傾向にあります。業界関係者は、AIが初級ミュージシャンの仕事を奪う可能性を懸念しており、さらに「プロセスを省略した」制作が人間の思考の怠惰や審美眼の低下を招くことを憂慮しています。(出典:36氪)
Llama 4モデル発表後に「捏造」疑惑、アリーナランキングと実際の性能の乖離が論争を呼ぶ:Metaが最新発表したオープンソースモデルLlama 4は、Chatbot Arenaで高スコアを獲得し、DeepSeek-V3を抜いてオープンソース部門で1位となりました。しかし、多くのユーザーによる実機テストのフィードバックでは、プログラミング、推論、クリエイティブライティングなどの性能が悪く、期待やアリーナランキングをはるかに下回ると報告されています。その後、大規模モデルアリーナ(LMArena)の公式発表によると、Metaがアリーナテストに提供したのは、人間の好みに合わせて最適化された実験バージョン(Llama-4-Maverick-03-26-Experimental)であり、Hugging Faceで公開された標準版ではなく、Metaはこの違いを明記していませんでした。LMArenaは2000以上の対戦記録を公開し、この実験版の応答スタイル(より友好的、絵文字の使用など)がランキングに影響を与えた重要な要因である可能性を示唆し、HF版Llama 4を再評価するためにオンラインにする予定です。Meta Gen AIの責任者は、テストセットでのトレーニングを否定し、性能差はデプロイの安定性の問題に起因すると述べています。この出来事は、Llama 4の性能、Metaの透明性、およびLMArenaの評価方法の信頼性について、コミュニティで広範な議論と疑問を引き起こしています。(出典:量子位, 机器之心, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

DeepSeek現象が業界の注目を集め、中国生成AIカンファレンスで新たな機会を議論:DeepSeekの台頭は、中国および世界の生成AI産業における重要な転換点と見なされています。その高効率、低コストのオープンソースモデルは、推論モデル、AI Infraの研究開発ブームを 촉진し、エッジAIおよび国産コンピューティングパワーの実現に新たな推進力を与えています。2025中国生成AIカンファレンスでは、50名以上の産学研のゲストが、DeepSeekが引き起こした変革、深層推論、マルチモーダル、ワールドモデル、AI Infra、AIGCアプリケーション、Agentsおよびエンボディードインテリジェンスなどの議題について議論を展開しました。参加者は、DeepSeekが企業のデプロイコストを大幅に削減し(あるアプリケーションでは切り替え後にコストが90%削減)、中国のオープンソースコミュニティにおける活発さと迅速な実装能力を示したと考えています。カンファレンスでは、AIアプリケーションの爆発的普及には新しい端末が必要であること、Agentの実装における課題、国産コンピューティングクラスターのブレークスルー、物理的インテリジェンスの発展、AIの商業化パスなどの議題も探求され、世界のAI情勢における中国の役割がますます重要になっていることを浮き彫りにしました。(出典:36氪, Ronald_vanLoon)

🎯 動向
Agentic AIが次の大きなブレークスルーと見なされる:Agentic AI(エージェントAI)は、ビジネスおよび技術分野の変革における重要な推進力となっています。従来のAIが特定のタスクを実行するのとは異なり、Agentic AIは自律的に目標を設定し、計画を立て、複雑なマルチステップタスクを実行でき、より自律的なデジタル従業員に似ています。複数のツールやデータソースを統合し、推論と意思決定を行うことができ、カスタマーサービス、データ分析、ソフトウェア開発などの分野で破壊的な変革をもたらすことが期待されています。技術の発展に伴い、Agentic AIは企業の運営モデルと人間と機械のインタラクション方式に深刻な変化をもたらすでしょう。(出典:Ronald_vanLoon)

NvidiaがLlama-Nemotron-Ultra 253Bモデルを発表、重みとデータをオープンソース化:NvidiaはLlama-Nemotron-Ultraを発表しました。これはLlama-3.1-405Bをベースに、NASによる枝刈りと推論最適化を経てトレーニングされた253Bパラメータの密なモデルです。このモデルは推論能力の向上に焦点を当てており、SFTとRLによるポストトレーニング(FP8精度)を採用し、重みとポストトレーニングデータをオープンソース化しています。Nvidiaのオープンソースポストトレーニング作業への継続的な貢献は、コミュニティから歓迎されています。(出典:natolambert)

Qwen3シリーズモデルが発表される可能性、8Bおよび15B MoEバージョンを含む:vLLMコードリポジトリにマージされたPR情報に基づくと、Alibabaは間もなくQwen3シリーズの新モデルを発表する可能性があります。現在判明しているのは、Qwen3-8BとQwen3-MoE-15B-A2Bの2つのバージョンが含まれる可能性があることです。コミュニティでは、8Bバージョンはマルチモーダルモデルであり、15Bバージョンはテキストに特化したMoE(混合エキスパート)モデルであると推測されています。ユーザーは新モデルの性能向上を期待しており、15B MoEがQwen2.5-Maxレベルに達すれば、顕著な成功と見なされるでしょう。(出典:karminski3)

RunwayがGen-4 Turboを発表、動画生成速度が大幅に向上:Runwayは最新の動画生成モデルGen-4 Turboを発表しました。新モデルの主なハイライトは生成速度であり、30秒で10秒の動画を生成できると謳っており、以前のバージョンと比較して大幅に高速化されています。これにより、Gen-4 Turboは迅速なイテレーションとクリエイティブな探索が必要なアプリケーションシナリオに特に適しています。このアップデートはすべてのユーザープランに展開されています。(出典:op7418)
Google Gemini Liveがローンチ、視覚と音声のリアルタイムインタラクションを実現:GoogleはGemini Live機能の正式ローンチを発表し、まずPixel 9およびSamsung Galaxy S25デバイスに搭載され、Android上のGemini Advancedユーザーにも開放されます。この機能により、ユーザーはカメラを通じて画面コンテンツやリアルタイム映像を共有し、Geminiと音声で対話し、視覚コンテンツの理解やインタラクティブな質問、問題解決、ブレインストーミングなどを実現できます。これは、GoogleのマルチモーダルAIインタラクション体験における重要な進展であり、Project Astraのビジョンをさらに具体化するものです。(出典:op7418, JeffDean, demishassabis)
HiDreamが17Bパラメータのオープンソース画像モデルHiDream-I1を発表:HiDream AIチームは、17Bパラメータの画像生成モデルHiDream-I1を発表し、オープンソース化しました。初期のデモンストレーション画像を見る限り、このモデルが生成する画像の品質はまずまずです。モデルのコードはGitHubで公開されており、開発者や研究者が使用および探索できます。(出典:op7418)

大規模モデルのオープンソース化の波が加速、ビジネスモデル探索「2.0」へ:2025年、DeepSeekに代表されるオープンソースモデルの台頭により、Meta、Alibaba、Tencentなどがオープンソース化のペースを加速させ、さらにはOpenAI、Baiduなどの元「クローズドソース派」も転換し始めています。オープンソース化の推進力には、エッジインテリジェンスの需要、業界のカスタマイズ需要、エコシステム化された分業の加速、技術が臨界点を超えたことなどが含まれます。オープンソースは開発者や中小企業の参入障壁を下げ、技術の普及とイノベーションを促進します。しかし、オープンソースは無料を意味するわけではなく、メンテナンスやローカライゼーションには依然としてコストがかかります。先進的なメーカーは、「オープンソース基盤モデル+商用API付加価値サービス」(DeepSeek、Zhipu AIなど)、「オープンソースコミュニティ版+企業専用版」(Alibaba Cloud Qwenなど)、「モデルオープンソース+クラウドプラットフォームでの収益化」(Meta Llamaなど)といった商業化2.0モデルを模索しています。核心は「オープンソースで集客し、サービスで収益化する」ことであり、エコシステム、カスタマイズ、クラウドサービスを通じて利益を上げています。(出典:第一新声)

🧰 ツール
Augment Code:複雑なプロジェクト向けに構築されたAIコーディングプラットフォーム:Augment Codeが発表されました。これは、大規模で複雑なコードベースを深く理解し、チームコラボレーションのために特別に設計された初のAIコーディングプラットフォームと位置付けられています。最大200Kのコンテキストトークン処理能力、永続的なメモリ(コードスタイル、リファクタリング履歴、チーム規範を学習)、および深いツール統合(VS Code, JetBrains, Vim, GitHub, Linear, Notionなど)を提供します。そのコアAgentは、コードを書くだけでなく、ターミナルコマンドの実行、完全なPRの作成、コンテキストを認識したドキュメントとテストケースの生成も可能です。AugmentはSWE-bench Verifiedランキングで1位(Claude Sonnet 3.7とo1を組み合わせ)であり、Webflow, Kongなどの企業で使用されています。プラットフォームは現在無料で、開発者が大規模なレガシーコードベースを扱う際の課題解決を目指しています。(出典:AI进修生)
CloudflareがAutoRAGサービスを開始、RAGアプリケーション構築を簡素化:CloudflareはAutoRAGを発表しました。これは、検索拡張生成(RAG)アプリケーション開発を簡素化することを目的としたサービスです。開発者はこのサービスを通じて、データソース(ドキュメント、ウェブサイトなど)を大規模モデルがクエリ可能な知識ベースに自動的に変換でき、データインデックス作成や検索ロジックを手動で処理する必要がありません。パブリックベータ期間中、AutoRAGは無料で利用でき、アカウントごとに10インスタンス、各インスタンスで最大10万ファイルを処理できます。これにより、特定の知識に基づいたAIアプリケーションを構築する際の参入障壁が低くなります。(出典:karminski3)

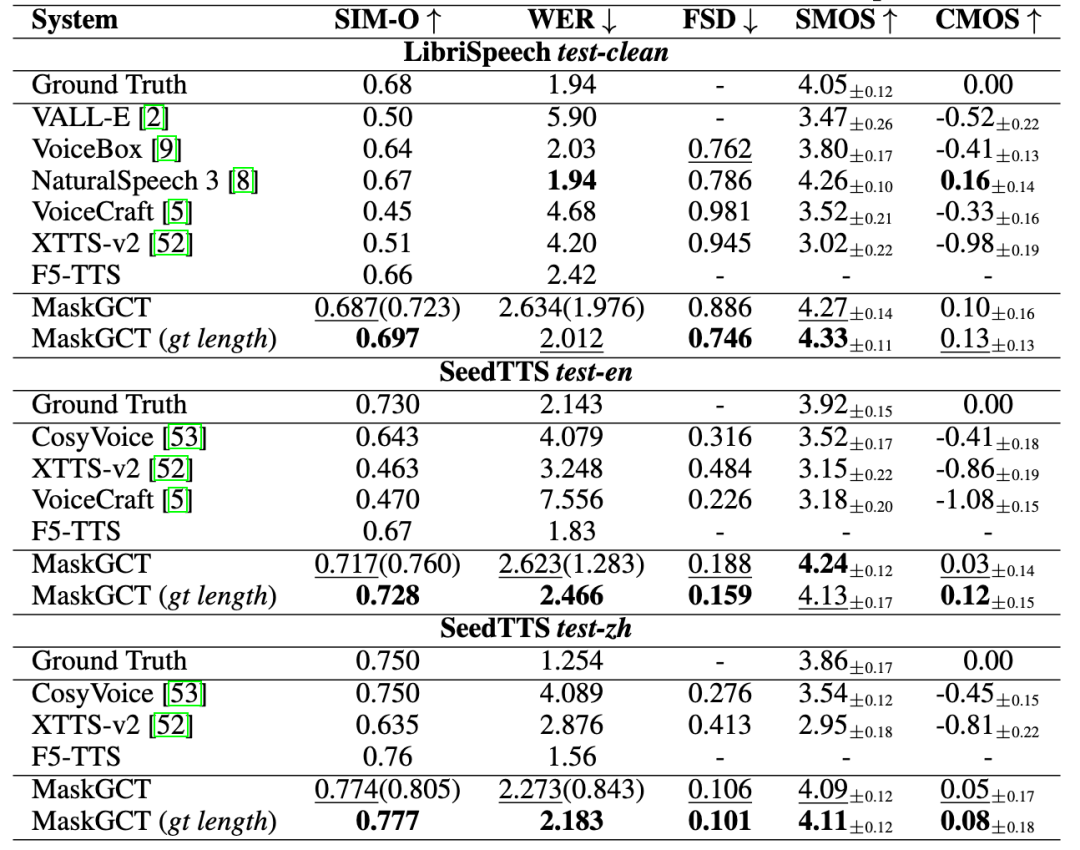
趣丸科技が「趣丸千音」を発表、AI音声のフルプロセスソリューションを提供:趣丸科技は、香港中文大学(深セン)と共同開発したMaskGCTモデルに基づくAI音声製品「趣丸千音(All Voice Lab)」を発表しました。この製品は、テキスト読み上げ、動画翻訳、多言語合成、字幕除去などの機能を統合しており、動画翻訳の全プロセス自動化を実現し、1日の処理量は1000分を超え、効率を10倍向上させたことが特徴です。その音声生成効果は感情豊かで、真人間に匹敵します。趣丸千音は、工業化能力を通じてクロス言語コミュニケーションの規模化ニーズを解決することを目指しており、ショートドラマの海外展開(コスト削減、ユーザー増加)、ニュース、文化観光、オーディオブックなどの分野で応用されており、「グローバルコンテンツインフラ」と位置付けられています。(出典:36氪)
Exa:AI Agent向けに設計された検索エンジン:Exaは「LLM時代のBing API」と位置付けられ、AI Agent向けに設計された検索エンジンであり、AIがインターネット情報に効率的にアクセスし理解できるようにすることを目的としています。人間の検索とは異なり、Exaはより複雑な自然言語クエリを処理でき、より包括的な結果を提供し、高スループット、低遅延のリクエストをサポートします。そのコアAPIには、高速検索、コンテンツ取得(クローラー)、類似リンク検索などが含まれます。ExaはWebsets機能も提供しており、ユーザーは自然言語でフィルタリング条件を指定し、インターネット情報を構造化できます。同社はLightspeed、Nvidiaなどから投資を受けており、ARRは1000万ドルを超え、主な競合相手はBrave Searchです。(出典:AI探索者)
AIツールでWeChatチャット履歴の可視化サマリーを実現:AIツールの組み合わせを利用して、WeChatグループチャットまたはプライベートチャットの履歴をエクスポートし、可視化レポートを生成できます。手順は次のとおりです:1) サードパーティツール(例:留痕MemoTrace)を使用してWeChatチャット履歴をTXTファイルにエクスポートします(データセキュリティリスクに注意);2) TXTファイルと特定のPromptテンプレート(スタイルコードを含む)を、長文テキスト処理をサポートする大規模モデル(例:Gemini 2.5 Pro in AI Studio)に入力し、HTMLコードを生成します;3) 生成されたHTMLコードをオンラインサービス(例:yourware.so)を通じて共有可能なウェブページリンクに変換するか、オンラインツール(例:cloudconvert.com)を使用して直接画像に変換します。この方法は、冗長なチャット情報を、構造が明確で、毎日の名言やワードクラウドを含むレポートに変換し、レビューや共有を容易にします。(出典:卡兹克)
即梦AI 3.0画像モデルが正式リリース:即梦AIは、その3.0バージョンの画像生成モデルがテストを完了し、正式にリリースされたことを発表しました。新バージョンは、画質、スタイルの多様性、意味理解などの面で向上が期待されています。すでにユーザー(例:歸藏)が3.0モデルを使用してさまざまな分野のデザイン(例:AI運用画像)を行った詳細なテストとプロンプト集を共有し、その生成効果を示しています。(出典:op7418)

VIBE Chat:ランダムな背景を持つ面白いチャットサイト:VIBE Chatという名前のウェブサイトは、セッションごとに異なる背景画像がランダムに生成される斬新なチャット体験を提供します。このサイトはGemini 2.0 Flashモデルに基づいており、ユーザーはプログラミングなどのタスクに使用でき、コードやコンテンツはチャットインターフェースに直接表示されます。テストでは、Flappy Birdやテトリスなどの簡単なゲームのコードを生成できることが示されています。(出典:karminski3)
開発者がSuno AI専用のGPTアシスタントを作成:ある開発者が「Hook & Harmony Studio」という名前のカスタムGPTを作成しました。これはSuno AI音楽制作プロセスを支援することを目的としています。このツールは、ユーザーが入力した楽曲コンセプトに基づいて、ユニークなタイトル、構造化された歌詞(楽器と歌唱の指示付き)、Sunoのスタイルタグに合った提案、陳腐な表現のフィルタリング、そしてオプションで楽曲の視覚効果のプロンプトを生成できます。歌詞作成とスタイル探索を簡素化し、Sunoプロジェクトモードで使用するために自動的にフォーマットすることを目指しています。(出典:Reddit r/SunoAI)
Code to Prompt Generator:コードからLLMプロンプトへの変換を簡略化するツール:開発者が「Code to Prompt Generator」という名前の小さなツールをオープンソース化しました。これはコードベースからLLMプロンプトを作成するプロセスを簡略化することを目的としています。プロジェクトフォルダを自動的にスキャンしてファイルツリーを生成し(無関係なファイルを除外)、ユーザーがファイル/ディレクトリを選択的に含めることを可能にし、トークン数をリアルタイムで表示し、指示(Meta Prompts)を保存して再利用し、最終的なプロンプトをワンクリックでコピーできます。このツールはNext.jsフロントエンドとFlaskバックエンドを使用し、マルチプラットフォームで実行できます。(出典:Reddit r/ClaudeAI)
Llama 4 GGUFバージョンがリリース、ローカル実行をサポート:llama.cppがLlama 4(現在はテキストのみ)のサポートをマージしたことに伴い、コミュニティ開発者(bartowski, unsloth, lmstudio-communityなど)は、Llama 4 ScoutモデルのGGUF量子化バージョンを迅速にリリースしました。これらのバージョンはimatrixなどの最適化された量子化戦略を採用しており、モデルサイズと性能のバランスを取り、ユーザーがローカルハードウェアでLlama 4を実行できるようにすることを目的としています。異なるビット幅(例:IQ1_S 1.78bit, Q4_K_XL 4.5bit)のバージョンが選択可能で、さまざまなハードウェア構成のニーズに対応します。ユーザーはHugging FaceでこれらのGGUFファイルを見つけることができます。(出典:Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 学習
Microsoftと香港中文大学がImageGen-CoTを提案、AI描画のコンテキスト理解能力を向上:AI描画モデルが複雑なテキスト記述やコンテキストの関連性(例:「革のリンゴ」から「革の箱」への素材の移行)を理解する際の不足を解決するため、Microsoft Research Asiaと香港中文大学の研究者はImageGen-CoTフレームワークを提案しました。この方法は、画像生成前に思考連鎖(Chain-of-Thought, CoT)推論ステップを導入し、モデルがまず重要な情報を考え、論理を整理してから創作を行うようにします。高品質なImageGen-CoTデータセットを構築し、ファインチューニングを行うことで、モデル(例:SEED-X)のT2I-ICLタスクにおける性能が著しく向上しました(CoBSATで89%向上、DreamBench++で114%向上)。このフレームワークは2段階推論を採用し、複数のテスト時拡張戦略(単一CoT、複数CoT、混合拡張)を探索し、混合拡張が最も効果的でした。(出典:36氪, 新智元)

論文がルーティングLLMの新パラダイムとRouterEvalベンチマークを提案:大規模モデル研究が直面する計算能力の独占、高コスト、技術パスの単一性の問題に対し、研究者はルーティングLLM(Routing LLM)パラダイムを提案しました。これは、インテリジェントルーター(Router)を通じてタスクを複数の(オープンソース)小規模モデルに動的に割り当て、協調して処理するものです。この研究を支援するため、論文は包括的なRouterEvalベンチマークをオープンソース化しました。これには、12の主要ベンチマークにおける8500以上のLLMの2億件の性能記録が含まれています。このベンチマークは、ルーティング問題を標準的な分類タスクに変換し、単一のGPUカードまたはノートパソコンでも研究を行うことができます。研究によると、インテリジェントルーティング(候補モデルがわずか3〜10個の場合でも)を通じて、複数の弱いモデルの組み合わせ性能がトップの単一モデル(例:GPT-4)を超えることができ、「Model-level Scaling Up」効果を示しています。この研究は、低コストで高性能なAIを実現するための新しいアプローチを提供します。(出典:新智元)
UIUCの韓家煒、孫冀萌チームがDeepRetrievalをオープンソース化、RLで検索エンジンクエリを最適化:ユーザーの元のクエリ品質が低いために情報検索効果が良くない問題に対し、UIUCチームはDeepRetrievalフレームワークを提案しました。このシステムは強化学習(RL)を利用してLLMを訓練し、ユーザーの元のクエリ(自然言語、ブール式、またはSQL)を特定の検索エンジン(PubMed、BM25、SQLデータベースなど)の特性に合わせて最適化し、既存の検索システムを変更することなく検索効果を最大化します。実験によると、DeepRetrieval(わずか3Bモデル)は検索性能を大幅に向上させ(文献検索で10倍向上、Evidence-SeekingタスクでGPT-4oを超える、SQL実行精度向上)、SFTに基づく方法をはるかに上回る効果を示しました。研究は、RLの探索能力がSFTの模倣学習よりも優れており、より最適なクエリ戦略を発見できることを強調しています。(出典:机器之心)
中国科学院自動化研究所などがVision-R1を提案、強化学習でVLMの視覚的位置特定能力を向上:画像テキスト大規模モデル(VLM)が物体検出、視覚的位置特定タスクにおいて存在するフォーマットエラー、再現率の低さ、精度の不足などの問題に対し、中国科学院自動化研究所と中科紫東太初チームはVision-R1フレームワークを提案しました。この方法は、言語モデルR1の成功経験を参考に、ルールベース強化学習(Rule-Based RL)を視覚的位置特定タスクに導入します。視覚評価指標(フォーマットの正確性、再現率、IoU精度)に基づくタスクレベルの報酬関数を設計し、段階的なルール調整戦略(差分報酬、段階的閾値)を採用することで、人間の嗜好データや報酬モデルに依存することなく、Qwen2.5-VLなどのモデルのCOCO、ODINWなどのデータセットにおける物体検出性能を大幅に向上させ(最大50%向上)、汎用的な質問応答能力にはほとんど影響を与えません。コード、モデルはオープンソース化されています。(出典:机器之心)
CalibQuant:1ビットKV Cache量子化手法でマルチモーダルモデルのスループットを向上:マルチモーダル大規模モデル(MLLM)が大規模な視覚入力を処理する際にKV Cacheのメモリ占有率が高すぎ、スループットを制限する問題を解決するため、研究者はCalibQuant手法を提案しました。この手法は極端な1ビットKV Cache量子化を実現し、視覚KV Cacheの冗長特性に合わせて設計されたポストスケーリング(Post-Scaling)とキャリブレーション(Calibration)技術を組み合わせています。ポストスケーリングは逆量子化計算の順序を最適化して効率を高め、キャリブレーションはアテンションスコアを調整して1ビット量子化によって導入される極端な値の歪みを軽減します。実験によると、CalibQuantはLLaVA、InternVL-2.5などのモデルでメモリと計算のオーバーヘッドを大幅に削減し、最大10倍のスループット向上を実現すると同時に、モデル性能をほとんど損ないません。この方法はプラグアンドプレイであり、元のモデルを変更する必要はありません。(出典:PaperWeekly)
CVPR 2025 | SeqAfford:シーケンシャルな3Dアフォーダンス推論を実現:既存のAIが複数の物体や複数のステップを含む複雑な指示を理解し実行することが困難である問題を解決するため、研究者はSeqAffordフレームワークを提案しました。このフレームワークは初めて3Dビジョンとマルチモーダル大規模言語モデル(MLLM)を組み合わせ、シーケンシャルな3Dアフォーダンス(Affordance)推論に使用します。18万以上の指示-点群データペアを含む初のSequential 3D Affordanceデータセットを構築してファインチューニングを行い、セグメンテーション語彙(
GitHubにMCPサーバーリソースコレクションが登場:awesome-mcp-serversという名前のGitHubリポジトリが、AI Agent用の300以上のMCP(Model Capability Protocol)サーバーを整理し、オープンソース化しました。これらのサーバーは、プロダクションレベルおよび実験的なプロジェクトをカバーしており、開発者に豊富なツールとインターフェースを提供し、AI Agentが外部サービスやデータソースと対話するのを容易にし、Agentエコシステムの発展をさらに推進します。(出典:Reddit r/ClaudeAI)

エモリー大学の劉菲教授が大規模モデル/NLP/GenAIの博士課程学生とインターンを募集:米国エモリー大学コンピュータサイエンス学科の劉菲准教授は、2025年秋入学の全額奨学金付き博士課程学生を募集しています。研究方向は、インテリジェントエージェントとしての大規模言語モデル(LLM)の推論、計画、意思決定能力、およびAIの教育、医療などの分野への応用です。関連分野に興味のある学生のリモートインターンシップや共同研究も歓迎しています。応募者はコンピュータまたは関連専門分野のバックグラウンドを持ち、優れたプログラミング能力を有し、研究成果があるか、強力な数学的基礎を持つ方が優先されます。(出典:AI求职)
AI Agent構築ガイドが公開:SuccessTech Servicesは、大規模言語モデル(LLM)インテリジェントエージェント(Agent)を構築する方法を紹介するステップバイステップガイドを公開しました。このガイドは、Agentの基本概念、アーキテクチャ設計、ツール選択、開発プロセス、および実際の応用事例をカバーしている可能性があり、自律型AIアプリケーションの開発を希望する開発者に入門指導を提供します。(出典:Reddit r/OpenWebUI)

香港科技大学がDream 7Bのコードを公開、Diffusionモデルの推論に特化:香港科技大学NLPチームが以前発表したDiffusionモデル推論モデルDream 7BのGitHubコードリポジトリが公開されました。このモデルは、LLMがDiffusionモデルに関連する指示を理解し実行できるようにすることを目的としています。コードの公開により、研究者はこのモデルを再現し、さらに研究することができます。(出典:Reddit r/LocalLLaMA)

💼 ビジネス
灵心巧手が億元級のシードラウンド資金調達、世界最高自由度の器用な手(ロボットハンド)を開発:エンボディードインテリジェンス企業「灵心巧手」は、紅杉種子基金などがリードする超億元のシードラウンド資金調達を完了しました。同社は「器用な手+クラウドブレイン」プラットフォームに特化しており、自社開発のLinker Handシリーズの器用な手は、産業版の自由度が25〜30、研究版は42(世界最高、Shadow Handの24やOptimusの22を超える)に達し、高精度の知覚(マルチセンサーフュージョン)と操作能力を備えています。同社はリンク機構と腱駆動の2つの構造を採用し量産を実現しており、クラウドブレイン(大規模データセットDexSkill-Netで訓練)と組み合わせて学習と制御を行っています。製品はコスト(約5万人民元、Shadow Handの150万元よりはるかに低い)と耐久性で優位性があり、北京大学、清華大学などのトップ大学に採用され、医療、産業などのシーンで応用されています。(出典:36氪)

GoogleがAI従業員に高額な「ガーデニング休暇」を支払い、競合他社への移籍を阻止していると報じられる:報道によると、Googleは重要なAI人材がOpenAIなどの競合他社に流出するのを防ぐため、一部の退職従業員に対し、最長1年間の高額な給与(最大数十万ドルに達する可能性)を支払っています。その条件は、その期間中、競合他社に就職しないことです。この慣行は「ガーデニング休暇」(gardening leave)と呼ばれ、金融などの業界では一般的ですが、テクノロジー業界、特に非経営層のAI研究者やエンジニアに対しては比較的珍しいです。これは、トップAI人材の極端な希少性と、テクノロジー大手間の激しい人材獲得競争を反映しています。(出典:Reddit r/ArtificialInteligence)

Shopify CEOが従業員にAIの効果的な活用を強調:Shopify CEOのTobias Lütke氏は、従業員に対し、チームの人数を増やすことを検討する前に、まずAIツールを活用して効率を高め、問題を解決する方法を考えるよう求めています。彼はAIが生産性を向上させる重要なレバレッジであると考え、従業員は積極的に学習し、日常業務のワークフローに組み込むべきだと述べています。この発言は、企業界がAIによる業務効率化を非常に重視していること、そして従業員がAI時代の新しい要求に適応することへの期待を反映しています。(出典:bushaicave.com)
36Krが「2025 AI Partnerイノベーション大賞」の募集を開始:AI分野における革新的な製品、ソリューション、企業を発掘・奨励し、各業界でのAIの導入・応用を推進するため、36Krは「2025 AI Partnerイノベーション大賞」の選考活動を開始しました。募集範囲は、汎用イノベーション(オフィス、企業向けサービス、データ分析など)、業界イノベーション(金融、医療、教育、工業など)、端末イノベーション(スマートハードウェア、自動車、ロボットなど)の3つのカテゴリーにおける非アプリケーションソフトウェア製品/ソリューションを対象としています。選考は、技術革新、応用効果、ユーザーエクスペリエンス、社会的価値の4つの側面から行われ、専門家審査団によって採点されます。応募期間は3月13日から4月7日までで、結果は4月18日に発表されます。(出典:36氪)

中国初のAI大規模モデルプライベートデプロイメント標準の策定が開始:企業がAI大規模モデルをプライベート環境にデプロイする際に直面する技術的なミスマッチ、プロセスの非標準化、評価体系の欠如などの問題に対応するため、智合標準センターは公安部第三研究所などの機関と共同で、「人工知能大規模モデルプライベートデプロイメント技術実施・評価ガイドライン」の団体標準策定作業を開始しました。この標準は、モデル選定、リソース計画、デプロイメント実施、品質評価から継続的最適化までの全プロセスをカバーし、技術、セキュリティ、評価、事例を融合し、モデル応用側、技術サービス側、品質評価側が共同で策定することを目指しています。標準は、AI大規模モデル企業、技術サービスプロバイダー、ハードウェアプロバイダー、クラウドコンピューティング企業、セキュリティサービスプロバイダー、データサービスプロバイダー、業界応用企業、テスト評価機関、コンプライアンス・法律機関、および持続可能な開発機関などを対象に、策定参加単位を募集しています。(出典:智合标准化建设)
🌟 コミュニティ
AI生成コンテンツが「幻覚」と情報信頼性の懸念を引き起こす:複数のユーザーやメディアから、DeepSeekを含む大規模言語モデルが「真面目な顔ででたらめを言う」現象、すなわちAI幻覚が存在すると報告されています。AIは存在しない事実を捏造したり、誤った出典(詩の出典、法条、文化財情報など)を引用したり、さらにはデータ(「80年代生まれの死亡率」など)を捏造したりする可能性があります。この現象は、訓練データの古さ、誤り、偏見、モデルの知識の盲点、およびリアルタイム検証能力の欠如に起因します。ユーザーは、特に学術、仕事などの真剣な場面で、AI生成コンテンツの正確性に警戒し、クロス検証と人手によるレビューを行う必要があります。過度の依存は誤った情報の拡散を招き、「ポスト真実」時代の課題を悪化させる可能性があります。Vectara HHEM幻覚テストでも、DeepSeek-R1に高い幻覚率が存在することが示されています。(出典:锌刻度)
AIアート生成が再び論争を呼ぶ:ジブリ風スタイルのヒットから考える:OpenAIのGPTの新画像機能が生成したジブリ風画像が大人気となり、CEOのSam Altman氏も自身のプロフィール画像をそのスタイルに変更したことで、ChatGPTのダウンロード数と収益が増加しました。しかし、これはAI生成アートに関する倫理と著作権の論争を再び引き起こしました。宮崎駿監督自身は、機械が生成した画面に明確に反対しています。ハリウッドの業界関係者(『怪奇ゾーン グラビティフォールズ』のクリエイターAlex Hirsch氏、Robin Williams氏の娘Zelda Williams氏など)はこれに強い不満を表明し、これはアーティストの創作成果の盗用であり、魂が欠けていると主張しています。一方、Altman氏はこれを「創造の民主化」であり、社会にとって大きな勝利だと反論しています。記事は、AIは画風を模倣できるものの、ジブリ作品に含まれる複雑な物語、美学システム、人間的配慮を再現することは難しいと論じています。ほとんどのAI生成コンテンツは古典にはなり得ませんが、一部の人間と機械の共創や補助ツールは成功するでしょう。(出典:APPSO, Reddit r/artificial)

視点:人間の認知構造はAI時代のコアコンピタンス:記事は、AIツールの普及がクリエイターの価値を低下させるという見方に反論し、表現や創作自体が人間の内なる欲求であり「消費行動」であり、その価値は結果だけでなくプロセスにあると主張しています。AIはツールであり、人間のユニークな認知や感情を代替することはできません。数億年の進化を経て形成された人間の脳の「認知構造」が鍵であり、AIの発展もデータ駆動型から認知駆動型(人間の認知プロセスを模倣)へと移行しています。したがって、将来のコアコンピタンスは「作業をこなすこと」ではなく、AIと対話する「認知構造」または「アンカーポイント」、すなわち独自の視点、深い経験、他者との真のつながりを築くことです。クリエイターは自身のユニークな部分を磨き、情報の洪水の中で安定した参照点となり、自身と他者に方向感覚と価値観を提供し、AIがもたらす可能性のある「エントロピー増大」に対抗すべきです。(出典:王智远)
視点:AIアプリケーションには関係と信頼に基づく新たな障壁が存在する:朱啸虎氏の「AIアプリケーションには障壁がない」という発言に対し、記事は反論を提示し、AI時代のアプリケーションの障壁は従来の技術的障壁から、関係と信頼に基づく新たな障壁へと変化したと主張しています。AIアプリケーションはもはやユーザー規模だけを追求するのではなく、パーソナライズされた体験を提供することで垂直市場で利益を得ることができます。「ラッパー」アプリケーションであっても、ユーザーとの深い結びつき(AIは使えば使うほどユーザーを理解する)、クリエイターIPとユーザーとの信頼の絆、およびデータ閉ループによる継続的な最適化(業界データ+個人データによるトレーニング)を通じて、堀(参入障壁)を構築できます。起業家には、垂直分野に集中し、ユニークな体験を創造し、データ閉ループを構築し、感情的なつながりを確立することを推奨しています。(出典:周知)
AI「速習クラス」詐欺が高齢者の年金を狙う:「AI速習で収益化」「月収数万元」といった謳い文句のオンラインコースが、ショート動画プラットフォームを通じて高齢者にターゲットを絞って配信されています。これらのコースは、無料指導を餌に、デジタルヒューマン動画、偽の「専門家」の身分、老後の不安や富裕層になる夢を煽るなどの手段で高齢者をグループに引き込みます。その後、洗脳的なマーケティング(収益スクリーンショットの提示、定員切迫感の演出など)を通じて、高齢者に高額な授業料(数千元から数万元)を支払わせます。コース内容は基本的なセルフメディア運営知識をパッケージ化したものが多く、約束されたAIスキル指導、案件紹介によるキャッシュバック、マンツーマン指導などはほとんどが虚偽の宣伝であり、アフターサービスは欠如し、返金は困難です。多くの若者が、家族が騙されそうになった、あるいはすでに騙された経験をソーシャルメディアで共有し、このような詐欺に警戒するよう呼びかけています。(出典:豹变)

Karpathy:LLMは従来の技術普及経路を覆し、個人をエンパワーメントする:Andrej Karpathy氏は、大規模言語モデル(LLM)の技術普及パターンは、歴史上の変革的技術(通常はトップダウン:政府→企業→個人)とは全く異なると指摘しています。LLMはほぼ一夜にして、低コスト(あるいは無料)、高速な方法で個人のデバイスに普及し、一般の個人に不釣り合いなほど大きな利益をもたらしましたが、企業や政府への影響は比較的遅れています。これは、LLMが広範な分野で準専門家レベルの知識を提供し、個人の知識領域の限界を補うことができるためです。対照的に、組織は固有の利点とLLMの能力との不一致、問題の複雑性の高さ、内部の慣性などの要因により、恩恵を受ける度合いが限られています。彼は、現在のAIの未来の分布は驚くほど均衡しており、真の「人民の力」であると考えています。しかし、将来、お金で著しく優れたAIが買えるようになれば、状況は再び変わる可能性があります。(出典:op7418)
18歳のAIアプリCEOが多くの名門大学に不合格となり話題に:18歳のZach Yadegari氏は、高校時代にAIカロリー追跡アプリCal AIを共同設立し、このアプリは300万ダウンロードを超え、年間数百万ドルの収益を上げています。彼は4.0のGPAと高得点のACT成績、そして輝かしい起業経験を持っているにもかかわらず、18のトップ大学に出願した際、ハーバード、スタンフォード、MITなどを含む15校に不合格となりました。この出来事はソーシャルメディアで広範な注目と議論を呼びました。Yadegari氏が公開した入学エッセイでは、当初は大学に進学するつもりはなかったが、後に大学生活の価値を認識して考えを変えたと率直に述べています。不合格の理由は憶測を呼んでおり、エッセイが「傲慢」に見えた、あるいは中退リスクが高いことを示唆し、名門校が重視する卒業率指標に影響を与えたと考える人もいます。また、大学の入学選考システムの問題や、アジア系志願者に対する差別(Stanley Zhong氏の事例との類似)を批判する声もあります。Yadegari氏本人は、誠実であると見なされたいと述べています。(出典:36氪, AI前线)
コミュニティの議論:AIは祝福か災いか?:RedditコミュニティでAI技術の利点と欠点に関する議論が起こっています。あるユーザーは、AIは技術の恩恵であり、創造的なアイデア(特定のシーンの画像を生成するなど)を迅速に実現できるため、なぜ人々(特に非クリエイター)が敵意を抱くのか理解できないと述べています。この見解は、AIが個人の即時的で低コストな創作ニーズを満たす価値を強調しています。これは、コミュニティにおけるAIツールが個人の創造性をエンパワーメントするという肯定的な見方を反映していると同時に、社会におけるAI技術に対する普遍的な論争と異なる態度を映し出しています。(出典:Reddit r/artificial)
コミュニティの議論:MCPプロトコルはAI Agentの「インターネット」になるか?:MCP(Model Capability Protocol)の発展に伴い、コミュニティはその可能性について議論を始めています。ある見解では、MCPは標準化されたインターフェースを提供してLLMが外部ツールやデータソースと対話できるようにするため、さまざまなAI Agentやサービスを接続する基盤インフラとなり、インターネットが異なるコンピュータやウェブサイトを接続したのと同様になる可能性があると考えられています。これは、将来のAI AgentエコシステムがMCPに基づいて相互運用性と協調性を実現する可能性を示唆しています。(出典:Reddit r/ClaudeAI)

💡 その他
Microsoftの三巨頭がAI Copilotと50年と未来を語る:Microsoft設立50周年を機に、ビル・ゲイツ、スティーブ・バルマー、サティア・ナデラの三世代CEOがAIアシスタントCopilotと対談しました。ゲイツ氏は、ソフトウェアの価値と計算コストの低下に関する初期の予見を振り返り、政府との関係にもっと早く対処すべきだったと反省しました。バルマー氏とナデラ氏は共にAIの重要性を強調し、バルマー氏はコアAI技術を中心にビジネスを深化させるべきだと考え、ナデラ氏はAIが普及した「ファストコンシューマーグッズ」のようなインテリジェントツールになると予言しました。対談中、Copilotは三人の大物をユーモラスに「ツッコミ」を入れ、例えばゲイツ氏の「考え込む顔」はAIを「ブルースクリーン」にさせるかもしれないと述べました。この対談は、Microsoftのリーダーシップ層の歴史への反省とAI駆動の未来へのコンセンサスを示しています。(出典:腾讯科技)

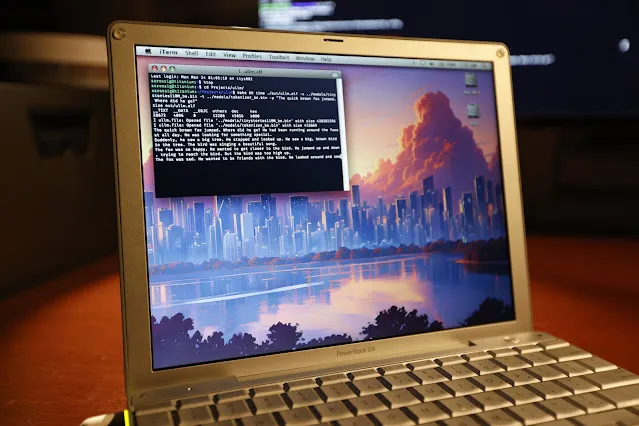
20年前のPowerBook G4でLLM推論の実行に成功:ソフトウェアエンジニアのAndrew Rossignol氏は、20年前のApple PowerBook G4ノートパソコン(1.5 GHz PowerPC G4プロセッサ、1GBメモリ)で、MetaのLlama 2大規模モデル(TinyStories 110Mバージョン)の推論タスクを実行することに成功しました。彼はオープンソースプロジェクトllama2.cを移植し、PowerPCアーキテクチャ(ビッグエンディアン処理、メモリアライメント)に合わせて修正し、さらにAltiVecベクトル拡張(融合積和演算)を利用して推論速度を約10%向上させました(0.77 token/sから0.88 token/sへ)。速度は現代のCPUの約1/8に過ぎませんが、非常に古いリソース制約のあるハードウェアでも現代のAIモデルを実行することが可能であることを証明しました。(出典:36氪, AI前线)
考察:なぜWorld Modelが必要なのか?:記事はWorld Modelsの必要性を探求し、それが現在の大規模言語モデル(LLM)の限界(物理世界の理解、永続的な記憶、推論、計画能力の欠如など)を克服するための鍵であると主張しています。World Modelは、AIが人間のように環境の内部シミュレーションを構築し、物理法則(重力、衝突など)や因果関係を理解し、それによって予測と意思決定を行うことを目指しています。記事は、World Modelが認知科学の概念から計算モデリング(RL/DLとの組み合わせ、例:DeepMindの「World Models」論文)へ、そして大規模モデル時代(Transformerやマルチモーダルとの組み合わせ、例:Genie, PaLM-E)へと発展してきた経緯を振り返ります。World Modelの核心的な利点は、因果予測と反実仮想推論能力、およびタスク間の汎化能力にあり、これはLLMが大規模テキストの関連確率に基づいて予測を行う本質とは異なります。World Modelの将来性は大きいものの、計算能力、汎化能力、データ面で依然として課題に直面しています。(出典:脑极体)

AI危険検知の新ブレークスルー:Holmes-VAUが多層的な長時間動画異常理解を実現:既存の動画異常理解(VAU)手法が長時間動画や複雑な時系列異常の処理において不十分である問題に対し、華中科技大学などの機関はHolmes-VAUモデルおよびHIVAU-70kデータセットを提案しました。このデータセットは、7万以上の多時系列スケール(video-level, event-level, clip-level)の指示データを含み、半自動データエンジンによって構築され、モデルの長・短動画異常の総合的な理解を促進します。同時に、提案されたAnomaly-focused Temporal Sampler (ATS)は、異常スコアに基づいてキーフレームを動的に疎にサンプリングでき、冗長情報を効果的に削減し、長時間動画異常分析の精度と効率を向上させます。実験により、Holmes-VAUは様々な時系列粒度の動画異常理解タスクにおいて、汎用的なマルチモーダル大規模モデルよりも著しく優れていることが証明されました。(出典:量子位)
AIと持続可能性:カーボンフットプリント問題が注目を集める:AIモデルの規模とトレーニング計算量が指数関数的に増加するにつれて、そのエネルギー消費と炭素排出の問題がますます顕著になっています。スタンフォードAIインデックスレポートは、ハードウェアのエネルギー効率が向上しているにもかかわらず、全体のエネルギー消費量は依然として増加していると指摘しています。例えば、MetaのLlama 3.1モデルのトレーニングでは、推定で約9000トンの二酸化炭素が発生します。DeepSeekなどのモデルがエネルギー効率でブレークスルーを達成しているものの、AI業界全体のカーボンフットプリントは依然として深刻な課題です。これにより、AI企業は原子力などのゼロカーボンエネルギーソリューションの探索を開始し、AI開発の持続可能性に関する議論を引き起こしています。(出典:Ronald_vanLoon, 机器之心)
