
キーワード:Kimi K2 Thinking, Gemini, AIエージェント, LLM, オープンソースモデル, Kimi K2 Thinking 256Kコンテキスト, Gemini 1.2兆パラメータ, AIエージェントツール呼び出し, LLM推論加速, オープンソースAIモデルベンチマークテスト
🔥 注目
Kimi K2 Thinkingモデル発表、オープンソースAI推論能力の新たなブレイクスルー : Moonshot AIは、万億パラメータのオープンソース推論エージェントモデルであるKimi K2 Thinkingモデルを発表しました。このモデルは、HLEやBrowseCompなどのベンチマークで優れた性能を発揮し、256Kのコンテキストウィンドウをサポートし、200〜300回の連続したツール呼び出しを実行できます。INT4量子化により、推論速度が2倍になり、メモリ使用量が半分に削減され、精度は損なわれません。これは、オープンソースAIモデルが推論およびエージェント能力において新たな最前線に到達し、トップクラスのクローズドソースモデルと競合し、かつ低コストであることを示しており、AIアプリケーションの開発と普及を加速させることが期待されます。 (出典: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

AppleとGoogleが提携、GeminiがSiriを大幅アップグレード : Appleは、2026年春にリリースされるiOS 26.4システムで、Google Gemini 1.2兆パラメータAIモデルを導入し、Siriを全面的にアップグレードする計画です。このカスタマイズされたGeminiモデルは、Appleのプライベートクラウドサーバーを通じて実行され、Siriのセマンティック理解、複数ターン会話、リアルタイム情報検索能力を大幅に向上させ、AIウェブ検索機能を統合することを目指しています。この動きは、AppleがAI分野で外部との協力を模索し、そのコア製品のインテリジェンス化を加速させるという重要な戦略的転換を示しており、Siriが機能面で大きな飛躍を遂げることを示唆しています。 (出典: op7418, pmddomingos, TheRundownAI)

Kosmos AIサイエンティストが研究効率を飛躍的に向上、7つの成果を独自に発見 : Kosmos AIサイエンティストは、12時間で人間科学者の6ヶ月分の作業量に相当する1500本の論文を読み、4.2万行のコードを実行し、追跡可能な科学レポートを作成しました。神経保護や材料科学などの分野で7つの成果を独自に発見し、そのうち4つは初めての提案でした。このシステムは、継続的な記憶と自律的な計画を通じて、受動的なツールから研究協力者へと進化しました。結論の約20%は人間の検証が必要ですが、人間とAIの協業が研究パラダイムを再構築することを示唆しています。 (出典: Reddit r/MachineLearning, iScienceLuvr)
🎯 動向
Google Gemini 3 Proモデルが誤ってリーク、コミュニティの注目を集める : Google Gemini 3 Proモデルが誤ってリークされたと見られ、現在、米国IPのGemini CLIで一時的に利用可能になっていますが、頻繁にエラーが発生し、まだ不安定です。今回のリークは、モデルのパラメータ数と将来のリリースに対するコミュニティの高い関心を引き起こし、Googleが大規模言語モデル分野における最新の進展を間もなく公開する可能性を示唆しています。 (出典: op7418)
OpenAI GPT-5.1 Thinkingモデルが間もなく発表、コミュニティの期待高まる : ソーシャルメディア上の複数の情報源が、OpenAIが間もなくGPT-5.1 Thinkingモデルを発表することを示唆しており、その存在を確認するリーク情報もあります。このニュースは、OpenAIの次世代モデルの能力とリリース時期に対するコミュニティの高い期待を引き起こしており、特に推論と思考能力の向上に注目が集まっており、AI技術の最前線を再び推進することが期待されます。 (出典: scaling01)
Anthropicの研究でLLMに新たな内省的意識を発見、AIの自己認識に注目集まる : Anthropicは概念注入実験を通じて、Claude Opus 4.1や4などのLLMが新たな内省的意識を示し、注入された概念を20%の成功率で検出し、内部の「思考」とテキスト入力を区別し、出力意図を認識できることを発見しました。モデルはプロンプトに応じて内部状態を調整することもでき、現在のLLMに多様で信頼性の低い機械的自己意識が出現していることを示しており、AIの自己認識と意識に関する深い議論を引き起こしています。 (出典: TheTuringPost)

OpenAI Codexが迅速に反復、ChatGPTが中断と誘導をサポートし対話効率を向上 : OpenAIのCodexモデルは急速に改善されており、同時にChatGPTも、ユーザーが長いクエリ実行中に中断して新しいコンテキストを追加できる機能を追加しました。これにより、最初からやり直したり、進行状況を失ったりする必要がなくなります。この重要な機能更新により、ユーザーは実際のチームメイトと協力するように、AIの応答を誘導および洗練できるようになり、対話の柔軟性と効率が大幅に向上し、深い調査や複雑なクエリにおけるユーザーエクスペリエンスが最適化されました。 (出典: nickaturley, nickaturley)
Tencent HunyuanがインタラクティブAIポッドキャストをリリース、AIコンテンツの新しいインタラクションモデルを模索 : Tencent Hunyuanは、国内初のインタラクティブAIポッドキャストをリリースしました。これにより、ユーザーは視聴中にいつでも中断して質問でき、AIはコンテキスト、背景情報、およびネットワーク検索を組み合わせて回答を提供します。技術的にはより自然な音声インタラクションを実現していますが、その核心は依然としてユーザーとAIとのインタラクションであり、クリエイターとの直接的な関連はありません。商業的な展開とユーザーが料金を支払うモデルは依然として課題に直面しており、ユーザーとクリエイター間の感情的なつながりをどのように構築するかが喫緊の課題です。 (出典: 36氪)
AIハードウェアおよび具現化されたAI市場の発展と課題:イヤホンからヒューマノイドロボットまで : 大規模モデルとマルチモーダル技術の成熟に伴い、AIイヤホン市場は加熱し続けており、コンテンツエコシステムや健康モニタリングにまで機能が拡大しています。具現化されたAIロボット産業も新たなブレイクスルーの出発点に立っており、Xpeng、PHYBOTなどの企業がヒューマノイドロボットを展示し、「人間が隠れている」という疑念を晴らし、高齢者介護、文化継承(書道、カンフーなど)などの応用シナリオを模索しています。しかし、業界はコスト、投資収益率、データ収集と標準化のボトルネックなどの課題に直面しており、短期的には「シナリオ汎用性」に現実的に焦点を当て、長期的にはオープンなプラットフォームとエコシステム協業が必要です。AIは医療健康分野でも患者ケアのギャップに注意を払う必要があります。 (出典: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

新モデルと性能のブレイクスルー:Qwen3-Nextコード生成、vLLMハイブリッドモデル、低メモリ推論 : Alibaba CloudのQwen3-Nextモデルは、複雑なコード生成において優れた性能を発揮し、機能的に完全なWebアプリケーションの作成に成功しました。vLLMは、Qwen3-Next、Nemotron Nano 2、Granite 4.0などのハイブリッドモデルを全面的にサポートし、推論効率を向上させました。AI21 LabsのJamba Reasoning 3Bモデルは、2.25 GiBという超低メモリでの動作を実現しました。Maya-research/maya1は、テキスト記述による音色カスタマイズをサポートする次世代の自己回帰テキスト音声合成モデルを発表しました。TabPFN-2.5は、表形式データ処理能力を5万サンプルに拡張しました。Windsurf SWE-1.5モデルはGLM-4.5に似ていると分析されており、国産大規模モデルのシリコンバレーでの応用を示唆しています。MiniMax AIはRockAlphaアリーナで2位にランクインしました。これらの進展は、コード生成、推論効率、マルチモーダル、表形式データ処理などの分野におけるLLMの性能限界を共同で押し広げました。 (出典: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

AIインフラと最先端研究:AWS冷却、拡散型LLM、多言語アーキテクチャ : Amazon AWSは、AIインフラの冷却課題を解決するためにIn-Row Heat Exchanger (IRHX) 液冷システムを発表しました。Joseph RedmonはAI研究に復帰し、地球観測基盤モデルを探求するOlmoEarth論文を発表しました。Meta AIは、多言語モデルトレーニングを最適化する「Mixture of Languages」という新しいアーキテクチャを発表しました。Inceptionチームは拡散型LLMを実現し、生成速度を10倍向上させました。Google DeepMindのAlphaEvolveは、大規模な数学的探求に利用されています。Wan 2.2モデルはNVFP4最適化により、推論速度が8%向上しました。これらの進展は、AIインフラの効率とコア研究分野の革新を共同で推進しました。 (出典: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Neuralink BCI技術が麻痺患者の機械腕制御を可能に : Neuralinkの脳コンピューターインターフェース(BCI)技術は、麻痺患者が思考を通じて機械腕を制御することに成功しました。この画期的な進展は、補助医療と人間とコンピューターのインタラクション分野におけるAIの大きな可能性を示しており、将来的には生命補助ロボットと組み合わされることで、障害者の生活の質と自立性を著しく向上させる可能性があります。 (出典: Ronald_vanLoon)
🧰 ツール
Google Gemini Computer Use Previewモデル発表、AIによるウェブインタラクション自動化を強化 : GoogleはGemini Computer Use Previewモデルを発表しました。ユーザーはコマンドラインインターフェース(CLI)を通じてこれを実行でき、「Hello World」をGoogleで検索するなどのブラウザ操作を実行できます。このツールはPlaywrightとBrowserbase環境をサポートし、Gemini APIまたはVertex AIを通じて設定可能で、AIエージェントによるウェブインタラクションの自動化の基盤を提供し、実際のアプリケーションにおけるLLMの能力を大幅に拡張します。 (出典: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

AIエージェントの開発と最適化:コンテキストエンジニアリングと効率的な構築 : Anthropicは、より効率的なAIエージェントを構築するためのガイドを発表しました。これは、ツール呼び出しにおけるトークンコスト、遅延、ツール組み合わせの問題解決に焦点を当てています。このガイドは、「コードとしてのAPI」アプローチ、段階的なツール発見、環境内データ処理を通じて、複雑なワークフローのトークン使用量を15万から2千に削減しました。同時に、ClaudeAIエージェントスキルの開発者は経験を共有し、Agent Skillsをドキュメントの羅列ではなくコンテキストエンジニアリングの問題として捉えることの重要性を強調しました。3層のロードシステムにより、アクティベーション速度とトークン効率が著しく向上し、「200行ルール」と段階的な開示の重要性が証明されました。 (出典: omarsar0, Reddit r/ClaudeAI)
Chat LangChainが新バージョンを発表、より速く、よりスマートなチャット体験を提供 : Chat LangChainは、「より速く、よりスマートに、より美しく」なった新バージョンを発表しました。これは、従来のドキュメントをチャットインターフェースに置き換えることで、開発者がプロジェクトをより迅速に提供できるようにすることを目指しています。このアップデートは、LangChainエコシステムのユーザーエクスペリエンスを向上させ、より使いやすく開発しやすくすることで、LLMアプリケーションの構築により効率的なツールを提供します。 (出典: hwchase17)
Yansu AIコーディングプラットフォームがシナリオシミュレーション機能をリリース、ソフトウェア開発の信頼性を向上 : Yansuは、深刻で複雑なソフトウェア開発に焦点を当てた新しいAIコーディングプラットフォームです。その独自性は、コーディングの前にシナリオシミュレーションを配置することにあります。このアプローチは、開発シナリオを事前にシミュレートすることで、ソフトウェア開発の信頼性と効率を向上させ、後期のデバッグと手戻りを減らし、それによって開発プロセス全体を最適化することを目指しています。 (出典: omarsar0)
Qdrant EngineがクラウドネイティブRAGソリューションを発表、包括的なデータ制御を実現 : Qdrant Engineは、Qdrant(ベクトルデータベース)、KServe(埋め込み)、Envoy Gateway(ルーティングとメトリクス)に基づいたクラウドネイティブRAG(Retrieval Augmented Generation)ソリューションを紹介する新しいコミュニティ記事を発表しました。これは、包括的なデータ制御を提供する完全なオープンソースRAGスタックであり、企業や開発者が効率的なAIアプリケーションを構築するのに便利で、特にデータプライバシーと自律的なデプロイ能力を強調しています。 (出典: qdrant_engine)

KTransformersがマルチGPU推論とローカルファインチューニングの新時代へ、万億パラメータモデルを強化 : KTransformersは、SGLangおよびLLaMa-Factoryとの協力により、DeepSeek 671BやKimi K2 1TBなどの万億パラメータモデルの低敷居マルチGPU並列推論とローカルファインチューニングを実現しました。エキスパート遅延技術とCPU/GPU異種ファインチューニングにより、推論速度とメモリ効率が著しく向上し、超大規模モデルが限られたリソースでも効率的に動作できるようになり、大規模言語モデルのエッジデバイスおよびプライベートデプロイメントにおける応用を推進しました。 (出典: ZhihuFrontier)
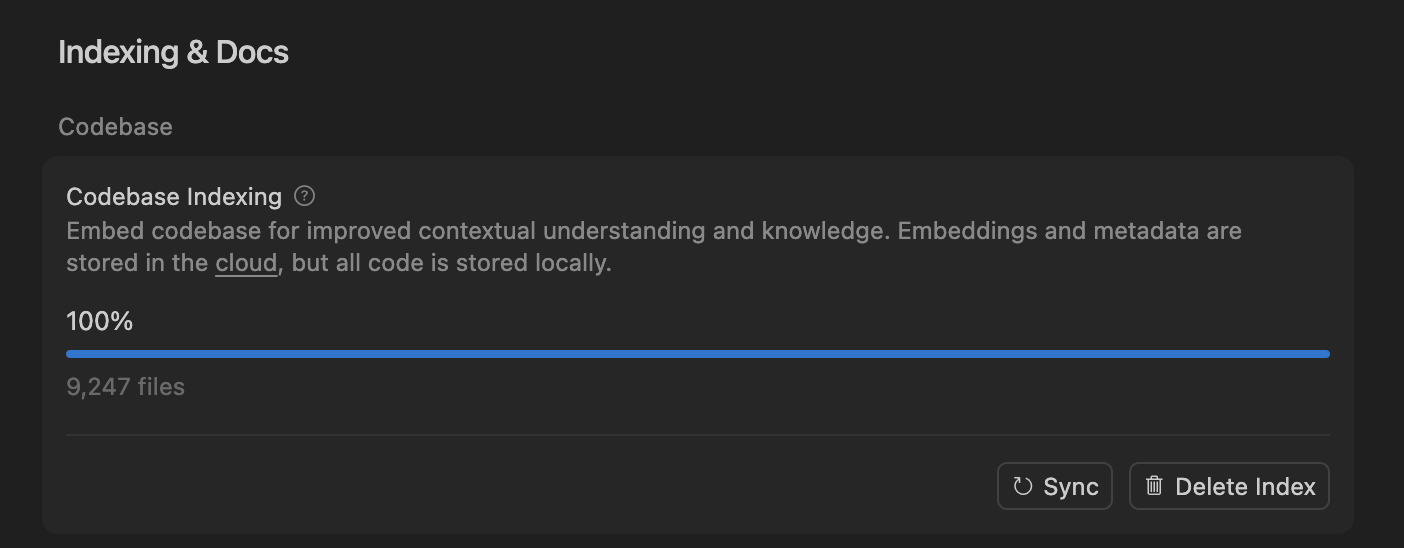
Cursorがセマンティック検索でAIコーディングエージェントの精度を向上、大規模コードベース処理を最適化 : Cursorチームは、セマンティック検索が、すべての最先端モデルでAIコーディングエージェントの精度を著しく向上させることを発見しました。特に大規模なコードベースでは、従来のgrepツールをはるかに上回る効果を発揮します。コードベースをクラウドに埋め込み、ローカルでコードにアクセスすることで、Cursorは効率的なインデックス作成と更新を実現し、サーバーにコードを保存することなく、プライバシーと効率を確保しました。この技術的ブレイクスルーは、複雑なソフトウェア開発におけるAIの補助能力を向上させる上で極めて重要です。 (出典: dejavucoder, turbopuffer)
LLMエージェントと表形式モデルのオープンソースツールキット:SDialogとTabTune : Johns Hopkins University JSALT 2025ワークショップは、SDialogを発表しました。これは、LLMベースの対話エージェントをエンドツーエンドで構築、シミュレート、評価するためのMITライセンスのオープンソースツールキットで、役割、コーディネーター、ツールの定義をサポートし、機械的解釈可能性分析を提供します。同時に、Lexsi LabsはTabTuneを発表しました。これは、表形式基盤モデル(TFMs)のワークフローを簡素化することを目的としたオープンソースフレームワークで、複数の適応戦略をサポートする統一インターフェースを提供し、TFMsの使いやすさと拡張性を向上させました。 (出典: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 学習
最先端論文:DLMデータ学習、表形式ICL、音響・映像生成 : 「Diffusion Language Models are Super Data Learners」論文は、DLMがデータ制約下でもARモデルを継続的に上回ることを指摘しています。「Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning」は、表形式のIn-Context Learningのための新しいアーキテクチャを紹介し、多尺度処理とブロック疎なアテンションによりSOTAを上回ります。「UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions」は、非対称なクロスモーダルインタラクションによる統一された音響・映像共同生成フレームワークを提案し、唇の同期と意味的一貫性の不足の問題を解決します。これらの論文は、LLMのデータ効率、特定のデータタイプ処理、マルチモーダル生成における最先端の進展を共同で推進しました。 (出典: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
LLM推論とセキュリティ研究:シーケンシャル最適化、一貫性トレーニング、レッドチーム攻撃 : 「The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute」の研究では、LLM推論のシーケンシャル反復最適化が、ほとんどの場合、並列自己整合性を上回り、精度が著しく向上することが発見されました。Google DeepMindの論文「Consistency Training Helps Stop Sycophancy and Jailbreaks」は、一貫性トレーニングがAIの追従とジェイルブレイクを抑制できることを提案しています。EMNLP 2025の論文では、LMレッドチーム攻撃について議論し、パープレキシティと毒性の最適化を強調しています。これらの研究は、LLMの推論効率、セキュリティ、堅牢性を向上させるための重要な理論的および実践的指針を提供します。 (出典: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

LLM能力評価とベンチマーク:CodeClashとIMO-Bench : CodeClashは、LLMがコードベース全体を管理し、競技プログラミングにおけるコーディング能力を評価するための新しいベンチマークであり、既存のLLMの限界に挑戦します。IMO-Benchの発表は、Gemini DeepThinkが国際数学オリンピックで金メダルを獲得する上で重要な役割を果たし、数学的推論におけるAIの能力を向上させるための貴重なリソースを提供しました。これらのベンチマークは、複雑なコーディングや数学的推論などの高度なタスクにおけるLLMの開発と評価を推進しました。 (出典: CodeClash:評価LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

スタンフォードNLPチームEMNLP 2025多分野研究成果発表 : スタンフォード大学NLPチームは、EMNLP 2025会議で、文化知識グラフ、LLM未学習データ識別、プログラム意味推論ベンチマーク、インターネット規模n-gram検索、ロボット視覚言語モデル、コンテキスト学習最適化、歴史テキスト認識、Wikipedia知識不整合検出など、複数の最先端分野にわたる多数の研究論文を発表しました。これらの成果は、自然言語処理とAIの交差分野における最新の研究の深さと広さを示しています。 (出典: stanfordnlp)
AIエージェントとRL学習リソース:セルフプレイ、マルチエージェントシステム、Jupyter AIコース : 複数の研究者は、セルフプレイ(self-play)とオートカリキュラム(autocurricula)が強化学習(RL)とAIエージェント分野の次の最前線であると考えています。Manning Booksの「Build a Multi-Agent System (From Scratch)」の早期アクセス版は爆発的に売れており、オープンソースLLMを使用してマルチエージェントシステムを構築する方法を教えています。DeepLearning.AIはJupyter AIコースを発表し、AIコーディングとアプリケーション開発を強化しています。ProfTomYehもRAG、ベクトルデータベース、エージェント、マルチエージェントの初心者向けガイドシリーズを提供しています。これらのリソースは、AIエージェントとRLの学習と実践を包括的にサポートします。 (出典: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
LLMインフラと最適化:DeepSeek-OCR、PyTorchデバッグ、MoE可視化 : DeepSeek-OCRは、ドキュメントの視覚情報を少量のトークンに圧縮することで、従来のVLMのトークン爆発問題を解決し、効率を向上させます。StasBekmanは、彼の「The Art of Debugging Open Book」にPyTorch大規模モデルのメモリデバッグガイドを追加しました。xjdrはMoEモデルのカスタム可視化ツールを開発し、MoE固有の指標の理解を深めました。これらのツールとリソースは、LLMインフラの最適化と性能向上に不可欠なサポートを提供します。 (出典: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

AI学習とキャリア開発:データサイエンティストロードマップとAI簡史 : PythonPrは「0からデータサイエンティストへの完全ロードマップ」を共有し、データサイエンティストを目指す学習者に包括的な指針を提供しました。Ronald_vanLoonは「人工知能簡史」を共有し、読者にAI技術の発展の歴史の概要を提供しました。これらのリソースは、AI分野の入門学習とキャリア開発のための基礎知識と方向性を示します。 (出典: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Hugging FaceチームがLLMトレーニング経験とデータセットストリーミング処理を共有 : Hugging Faceの科学チームは、大規模言語モデルのトレーニングに関する一連のブログ記事を発表し、研究者や開発者に貴重な実践経験と理論的指針を提供しました。同時に、Hugging Faceは大規模分散トレーニングにおけるデータセットストリーミング処理の全面的なサポートを開始し、トレーニング効率を向上させ、大規模データセットの処理をより便利で効率的にしました。 (出典: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 ビジネス
Giga AIが6100万ドルのシリーズA資金調達、顧客オペレーション自動化を加速 : Giga AIは、顧客オペレーションの自動化を目的として、6100万ドルのシリーズA資金調達を成功裏に完了しました。同社はDoorDashなどの大手企業と提携し、AIを活用して顧客体験を向上させています。創業者は高給を捨て、何度も製品の方向性を調整した後、最終的に市場との適合点を見つけ、起業家の粘り強さを示しました。これは、企業顧客サービス分野におけるAIの大きな商業的可能性を示唆しています。 (出典: bookwormengr)

Wabiが2000万ドルを調達、個人ソフトウェア創作の新時代を可能に : Eugenia Kuydaは、Wabiがa16z主導で2000万ドルの資金調達を完了したことを発表しました。これは、誰もが簡単にパーソナライズされたミニアプリを作成、発見、リミックス、共有できる個人ソフトウェアの新時代を切り開くことを目的としています。Wabiは、YouTubeが動画作成を可能にしたように、ソフトウェア作成を可能にすることを目指しており、将来のソフトウェアが少数の開発者ではなく、大衆によって作成されることを示唆し、「誰もが開発者」というビジョンを推進しています。 (出典: amasad)
GoogleとAnthropicが追加投資を協議、AI大手間の協力深化 : GoogleはAnthropicへの追加投資について初期段階の協議を行っています。この動きは、両社がAI分野での協力をさらに深化させる可能性を示唆しており、将来のAIモデルの発展方向と市場競争環境に影響を与え、AIエコシステムにおけるGoogleの戦略的地位を強化する可能性があります。 (出典: Reddit r/ClaudeAI)
🌟 コミュニティ
AIが社会と職場に与える影響:雇用、リスク、スキルの再構築 : コミュニティの議論では、AIは仕事を奪うのではなく効率を向上させると考えられていますが、AIバブルの崩壊が大規模な人員削減を引き起こす可能性も指摘されています。調査によると、93%の役員が未承認のAIツールを使用しており、これが企業AIリスクの最大の源となっています。AIはまた、ユーザーが視覚デザインや漫画制作などの隠れたスキルを発見するのを助け、人々が自身の可能性を再考するきっかけを与えています。これらの議論は、AIが社会と職場に与える複雑な影響、すなわち効率向上、潜在的な失業、セキュリティリスク、個人のスキル再構築を明らかにしています。 (出典: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AIコンテンツの真実性と信頼危機:氾濫と幻覚問題 : AI生成コンテンツのコストがゼロに近づくにつれて、市場には大量のAI生成情報が溢れ、ユーザーのコンテンツの真実性と信頼性に対する信頼度が急激に低下しています。ある医師がAIを使用して医学論文を執筆したところ、存在しない参考文献が多数出現し、学術論文作成におけるAIの幻覚問題が浮き彫りになりました。これらの出来事は、AIコンテンツの氾濫がもたらす信頼危機、およびAI支援作成における厳格な審査と検証の重要性を共同で明らかにしています。 (出典: dotey, Reddit r/artificial)
AI倫理とガバナンス:開放性、公平性、潜在的リスク : コミュニティは、OpenAIの「非営利」としての地位と、政府保証債務を求める行為について疑問を呈し、そのモデルは「利益の私有化、損失の社会化」であると主張しています。ある見解では、大手AI企業が内部で使用するモデルの能力は、一般公開されているバージョンをはるかに超えており、この「私有化された」SOTAインテリジェンスは不公平であると見なされています。Anthropicの研究者は、将来のASIが「祖先」モデルが淘汰されることで「復讐」を求める可能性を懸念し、「モデルの福祉」の問題を真剣に受け止めています。Microsoft AIチームは、AI開発の倫理的方向性を強調する人間中心の超知能(HSI)の開発に取り組んでいます。これらの議論は、AI大手のビジネスモデル、技術の開放性、倫理的責任、政府の介入に対する一般の人々の深い懸念を反映しています。 (出典: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

AI地政学:米中競争とオープンソースの台頭 : 米中間のAIチップ分野での競争はますます激化しており、中国は国有データセンターでの外国製AIチップの使用を禁止し、米国はNvidiaのトップAIチップの対中販売を制限しています。Nvidiaは新たなAIセンターを求めてインドに目を向けています。同時に、中国のオープンソースAIモデル(Kimi K2 Thinkingなど)が急速に台頭し、その性能は米国の最先端モデルと競合できるレベルに達しており、かつ低コストです。この傾向は、AIの世界が二つのエコシステムに分裂し、世界のAIの進歩を遅らせる可能性がある一方で、インドのような過小評価されている国々が世界のAI情勢においてより重要な役割を果たす可能性を示唆しています。 (出典: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
AIがSEO分野にもたらす変革:キーワードからコンテキスト最適化へ : ChatGPT、Gemini、AI Overviewsの登場により、SEOは従来のランキングシグナルからAIの可視性と引用最適化へと移行しています。将来のSEOは、LLMがコンテキストと信頼できる情報源を必要とすることから、コンテンツの引用可能性、事実性、構造化に重点を置くようになり、「大規模言語モデル最適化」(LLMO)の時代が到来することを示唆しています。この変化は、SEO専門家がプロンプトエンジニアのように考え、キーワード密度からAIが信頼し引用する高品質なコンテンツの提供へと移行することを要求します。 (出典: Reddit r/ArtificialInteligence)
AIエージェントとLLM評価の新たなトレンド:インタラクションデザインとベンチマークの焦点 : ソーシャルメディアでは、AIエージェントのインタラクションデザイン、例えばエージェントに自己インタビューを誘導する方法や、Claude AIがユーザーの批判に直面した際に示す「怒り」や「自己反省」能力について議論されました。同時に、Jeffrey Emanuelは彼のMCPエージェントメールプロジェクトを共有し、AIコーディングエージェント間の効率的な協業を示しました。コミュニティは、AIMEがGSM8kに代わる新しいLLMベンチマークの焦点となり、数学的推論と複雑な問題解決におけるLLMの能力を強調していると考えています。これらの議論は、AIエージェントのインタラクションデザイン、協業メカニズム、LLM評価基準の新たなトレンドを共同で明らかにしています。 (出典: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
RAG技術の進化とコンテキスト最適化:多ければ良いというわけではない : コミュニティの議論では、RAG(Retrieval Augmented Generation)技術が「死んだ」という主張は時期尚早であり、セマンティック検索などの技術が大規模なコードベースにおけるAIエージェントの精度を著しく向上させることが指摘されました。LightOnは会議で、より多くのコンテキストが常に良いとは限らず、過剰なトークンはコスト増加、モデルの速度低下、回答の曖昧さにつながると強調しました。RAGは長さではなく精度に焦点を当てるべきであり、エンタープライズ検索を通じてより明確な洞察を提供し、AIがノイズに埋もれるのを避けるべきです。これらの議論は、RAG技術が進化し続けていること、およびAIアプリケーションにおけるコンテキスト管理の重要な役割を明らかにしています。 (出典: HamelHusain, wandb)

AI計算リソースの取得とオープンモデル実験、コミュニティの革新を促進 : コミュニティでは、AI計算リソースの取得における公平性の問題が議論され、オープンソースモデル実験をサポートするために最大10万ドルのGCP計算リソースを提供するプロジェクトがあります。この取り組みは、小規模チームや個人研究者が新しいオープンソースモデルを探求することを奨励し、AIコミュニティの革新と多様性を促進し、AI研究の敷居を下げることを目的としています。 (出典: vikhyatk)
AI時代における個人PC画面の重要性、クリエイティブな技術的仕事能力に影響 : Scott Stevensonは、個人がPC画面に抱く「親近感」が、クリエイティブな技術的仕事における競争力の重要な指標であると考えています。ユーザーがPCを快適かつ自在に使いこなせるなら、抜きん出ることができますが、そうでなければ、営業、事業開発、オフィス管理などの役割の方が適しているかもしれません。この見解は、デジタルツールと個人の仕事効率との深い関連性、そしてAI時代における人間とコンピューターのインタラクションインターフェースの重要性を強調しています。 (出典: scottastevenson)
ChatGPTユーザー体験とAI擬人化議論:休憩の提案と絵文字 : ChatGPTが長時間学習後に休憩を促したことは、コミュニティで広く議論を呼び、多くのユーザーがAIが自発的に休憩を提案するのを初めて経験したと述べました。同時に、ChatGPTが「ニヤリ顔」の絵文字😏を使用したこともコミュニティの憶測を呼び、ユーザーはこれが新バージョンを示唆しているのか、それともAIがより挑発的またはユーモラスなインタラクションスタイルを示しているのか疑問に思いました。これらの出来事は、AIがユーザー体験デザインにより人間的な配慮を取り入れていること、および人間とコンピューターのインタラクションにおけるAIの擬人化が引き起こす深い考察を反映しています。 (出典: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 その他
AIとロボット技術が次の産業革命をもたらす : ソーシャルメディア上では、具現化されたAIとロボット技術が共同で次の産業革命を推進するという見解が広く議論されています。この見解は、AIとハードウェアの組み合わせの大きな可能性を強調し、自動化、インテリジェントな生産、生活様式の全面的な変革を示唆しており、世界の経済と社会構造に深く影響を与えるでしょう。 (出典: Ronald_vanLoon)

AI時代における「超知覚」は「超知能」の前提 : Sainingxieは、「超知覚がなければ、超知能を構築することはできない」と提案しました。この見解は、AIがマルチモーダル情報を取得、処理、理解する上での基礎的な役割を強調し、感覚能力のブレイクスルーがより高度な知能を実現するための鍵であると考えています。これは従来のAI開発パスに異議を唱え、AIの知覚層の能力構築にもっと注意を払うよう呼びかけています。 (出典: sainingxie)
Googleの古いTPUが利用率100%を達成、AIにおける古いハードウェアの価値を示す : Googleの7、8年前の古いTPUが100%の利用率で稼働しており、これらの完全に減価償却されたチップが依然として効率的に機能しています。これは、古いハードウェアであっても、AIトレーニングと推論において大きな価値を発揮できることを示しており、特に費用対効果の面で、AIインフラの経済性と持続可能性に新たな視点を提供します。 (出典: giffmana)
