
キーワード:Meta AI, LIRAマルチモーダルフレームワーク, Microsoft Agent Framework, NVIDIA時価総額, Sora 2 Pro, Perplexity AI Comet, IBM Granite 4.0, Qwenシリーズモデル, Meta AIチーム再編, LIRA画像分割精度, Agent Framework多言語サポート, NVIDIA AIチップ市場, Sora 2動画生成制限
🔥 注目
Meta内部AIチームの動揺とLeCun氏辞任の噂 : MetaのAI部門は頻繁な再編を経験しており、内部の不満が高まっている。チューリング賞受賞者であるYann LeCun氏がFAIRのチーフサイエンティスト職を辞任する可能性さえ噂されている。論文発表にさらなる審査が必要になったり、新入社員への高給とリソースの傾斜といった内部戦略の調整は、FAIRチームの学術的自由が制限されているという感覚と古参社員の不満を増幅させ、複数の研究者の離職を引き起こしている。この動揺は、大手テクノロジー企業がAI戦略を調整する際に直面する課題と、商業化の追求と基礎研究の自由の維持との間の対立を明らかにしている。(ソース:量子位)

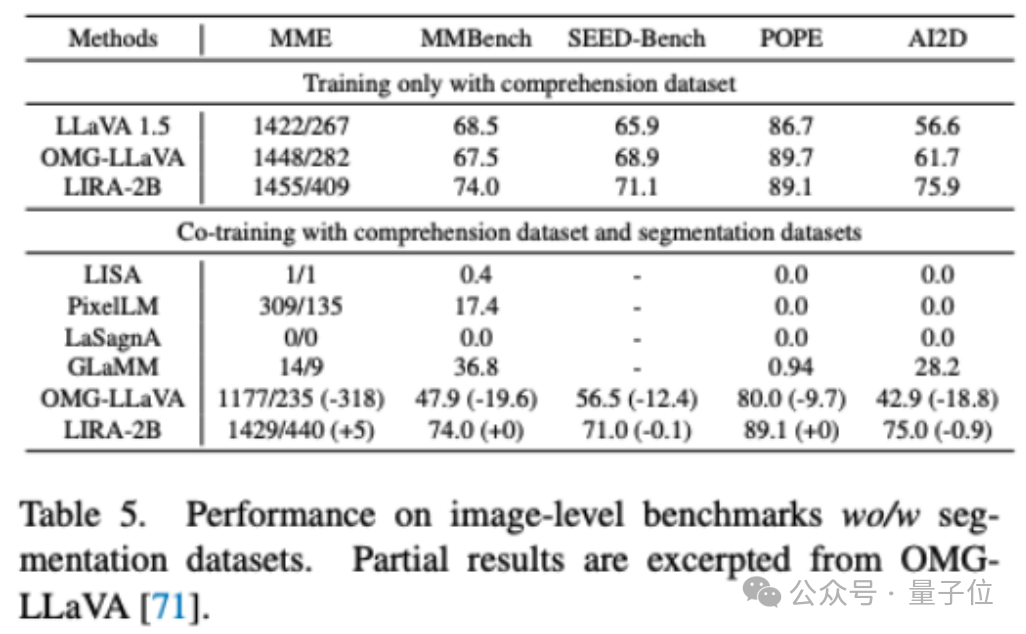
華中科技大学白翔チームがLIRAマルチモーダルフレームワークを発表、セグメンテーションと理解で両SOTAを達成 : 華中科技大学とKingsoft Officeチームは共同でマルチモーダル大規模モデルLIRAを発表した。「セマンティック強化特徴抽出器」(SEFE)と「インターリーブされた局所視覚結合」(ILVC)という2つの革新的なモジュールを通じて、画像セグメンテーションの精度を大幅に向上させ、理解における幻覚を減少させた。LIRAはセグメンテーションと理解の両タスクでSOTAを達成し、特に複雑なシーンにおいて目標をより正確にセグメンテーションできるほか、OMG-LLaVAなど既存の最良手法を複数のベンチマークで上回った。この研究は、きめ細かいマルチモーダル大規模モデルの視覚認識と推論能力に新たな視点を提供している。(ソース:量子位)
MicrosoftがAIエージェントフレームワークを発表、Pythonと.NETの多言語開発をサポート : Microsoftは、AIエージェントとマルチエージェントワークフローの構築、オーケストレーション、デプロイメントのための包括的な多言語フレームワークであるAgent Frameworkを発表した。このフレームワークはPythonと.NETをサポートし、グラフベースのワークフロー、実験的なAF Labsパッケージ、インタラクティブなDevUI、OpenTelemetryの可観測性統合を提供し、複数のLLMプロバイダーと柔軟なミドルウェアシステムをサポートする。シンプルなチャットエージェントから複雑なマルチエージェントワークフローまでの開発を簡素化し、AIアプリケーションの開発効率と制御性を向上させることを目指している。(ソース:GitHub Trending)

NVIDIAの時価総額が4兆ドルを突破、AIコンピューティング需要が継続的に爆発 : NVIDIAの時価総額が初めて4兆ドルを突破し、このマイルストーンに到達した世界初の公開企業となった。この成果は、AIコンピューティング需要の継続的な力強い成長と、GPU技術およびAIチップ市場におけるNVIDIAの支配的地位を反映している。Jürgen SchmidhuberなどのAIパイオニアも、ニューラルネットワークの可能性を推進するNVIDIAの貢献を祝福し、コンピューティングコストの大幅な削減とNVIDIAの価値の急上昇という傾向を指摘している。(ソース:SchmidhuberAI, SchmidhuberAI, SchmidhuberAI, nvidia)

🎯 動向
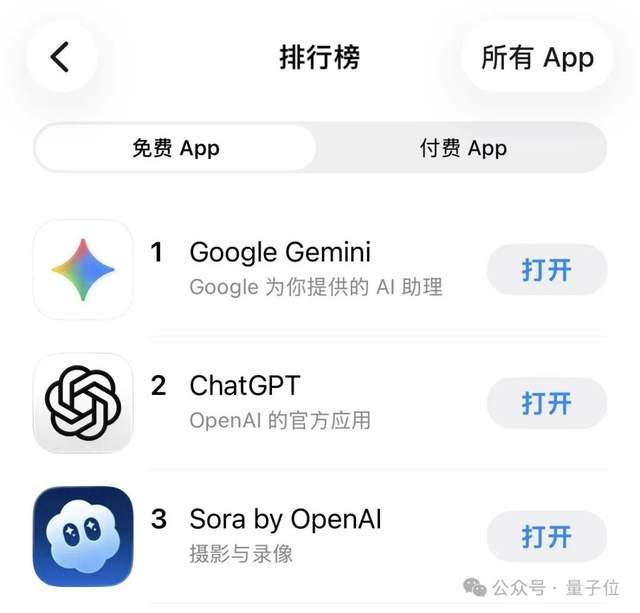
Sora 2 Proの動画生成機能拡張と市場への影響 : OpenAIのSora 2 Pro動画生成機能がChatGPT Proユーザーに段階的に公開されており、15秒の高品質動画生成をサポートしている。Sora 2の登場は市場の注目を急速に集め、App StoreのAIアプリランキングで首位を獲得するほどで、その製品体験は「キラー級」と称賛されているが、モデル自体はSOTAではないという見方もあり、製品化能力が成功の鍵とされている。さらに、Sora 2のプロンプトはモデルによってフィルタリングされ、公共ドメインのコンテンツも修正される可能性があるため、著作権とコンテンツ管理に関する議論が巻き起こっている。(ソース:dotey, thursdai_pod, billpeeb, TomLikesRobots, dotey, iScienceLuvr, skirano, VictorTaelin, Reddit r/artificial)

Perplexity AI Cometブラウザが無料公開され急速に普及 : Perplexity AIは、Cometブラウザを全世界で無料公開すると発表した。以前は月額200ドルで提供されていた。ユーザーはそのデザインとユーザー体験を高く評価しており、AIが自然で邪魔にならない形で統合されており、新しいインタラクションを学ぶ負担がないと述べている。このブラウザはWindowsとMacユーザーの間で急速に採用されており、特にMacでのパフォーマンスが優れており、2025年の最高の製品の一つと見なされているが、高額な有料モデルの妥当性を疑問視する声もある。(ソース:AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, bookwormengr, Reddit r/artificial)

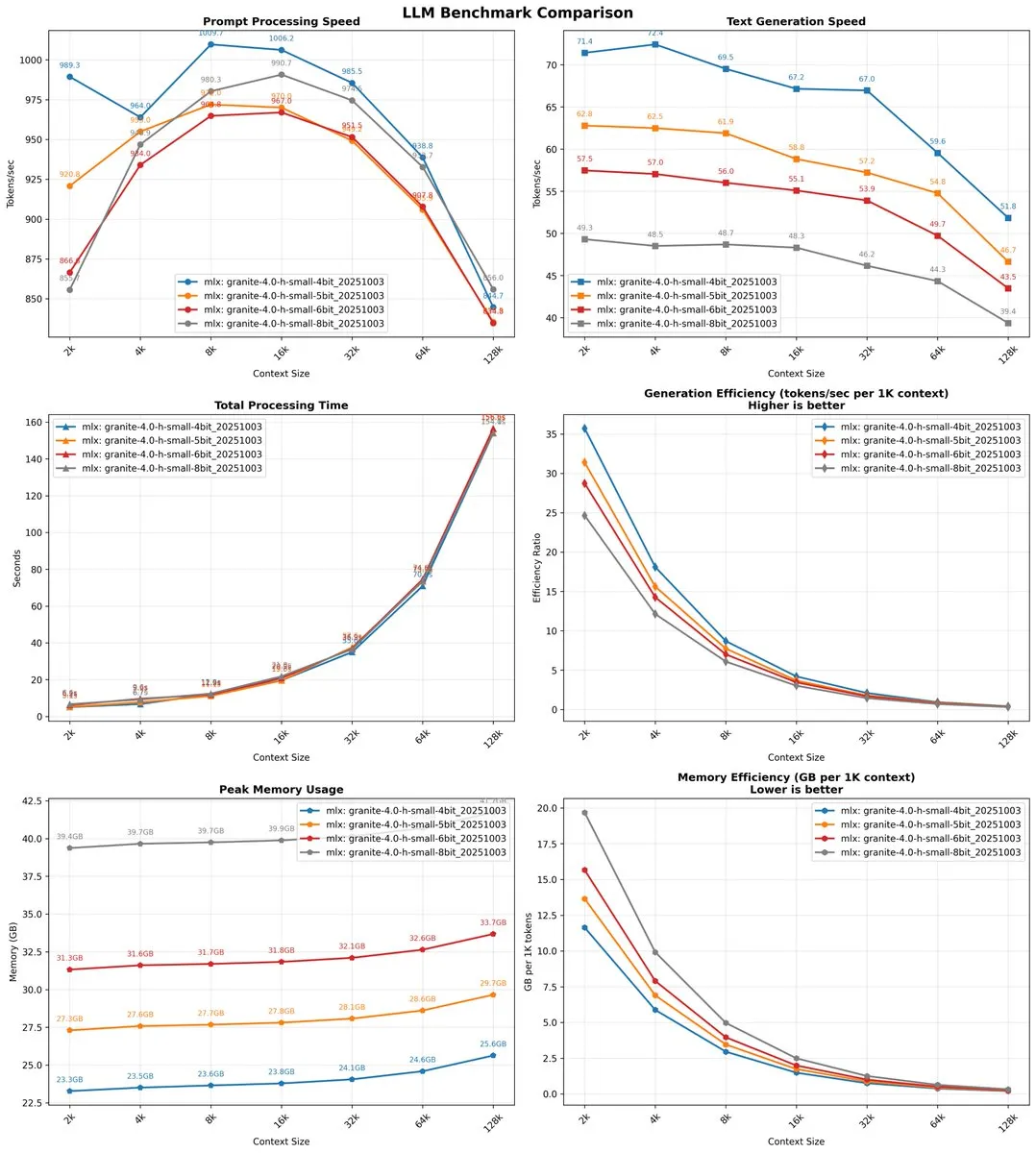
IBM Granite 4.0モデルが性能と長文コンテキストで顕著な進歩 : IBMはGranite 4.0シリーズモデルを発表した。そのうちGranite-4.0-H-Tinyは、数学、コーディング、一般知識など複数の指標で10ヶ月前に発表されたOLMoEモデルを大幅に上回り、通常のPCで合理的な速度でCPU推論を実行できる。Granite 4.0-H-Smallモデルも非常に高速な推論速度(最大79トークン/秒)を示し、コンテキスト長が増加しても速度が著しく低下せず、最大1Mのコンテキストウィンドウをサポートする(公式には128kまで検証済み)。ユーザーは低メモリ消費と簡潔な出力に賞賛を送り、特定のシナリオで優れたパフォーマンスを発揮すると評価している。(ソース:ImazAngel, NerdyRodent, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Qwenシリーズモデルの更新と戦略的ポジショニング : Alibaba CloudのQwenチームは、LLM、Coder、VL、Omni、Imageなど複数のモデルファミリーの命名ロジックと開発目標を詳細に説明し、最終的にはオールマイティなモデルへの統一を目指している。Qwen3-Nextは「Qwen3.5」の先行版として、混合アテンション設計により効率面でブレークスルーを達成し、10%の訓練コストでQwen3-32Bを10倍の長文コンテキストスループットで上回った。さらに、Qwen MoEモデルはCPU推論速度で優れたパフォーマンスを発揮し、エッジデバイスでの可能性を示唆している。Qwenの全体戦略は、AIモデルの「Androidエコシステム」を構築することと解釈されており、低コスト、普及性、変更可能性を強調している。(ソース:stablequan, karminski3, Teknium1, Dorialexander, ClementDelangue, natolambert, Reddit r/deeplearning)
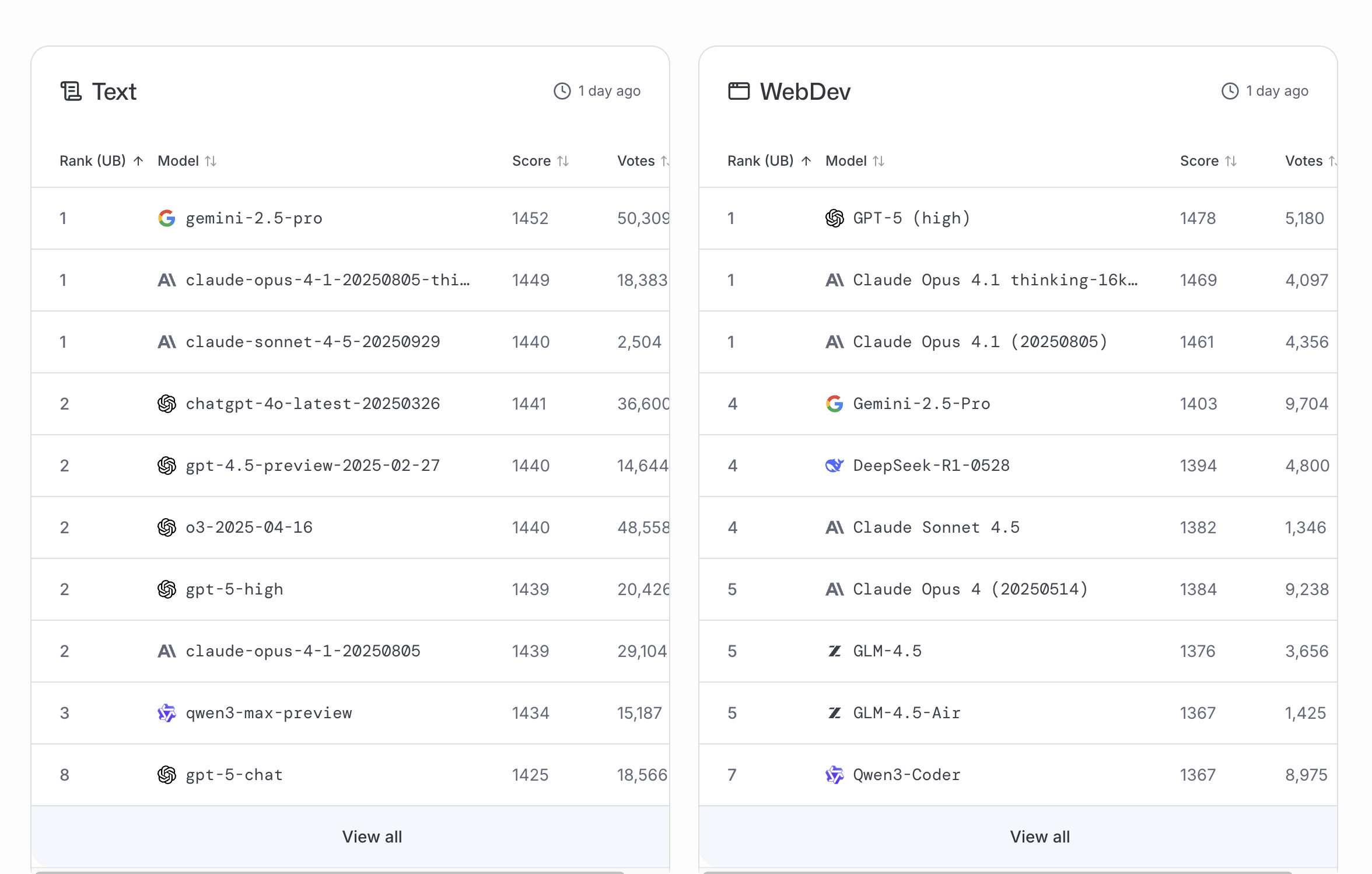
Claude 4.5 SonnetとOpusの性能および使用制限に関する論争 : AnthropicのClaude 4.5 Sonnetモデルが発表された後、多くの宣伝にもかかわらず、WebDevやTextなどのベンチマークテストでは中位に位置し、GPT-5やClaude Opus 4.1の「思考モード」バージョンに劣っていた。ユーザーからのフィードバックでは、Claude Opusの週ごとの使用制限が大幅に削減され、一度の複雑な計画タスクで週の割り当ての6%を消費する可能性があり、Maxプランのユーザーが「25-40時間」の利用可能時間から数分に短縮されたことで、価格設定と実際のサービスとの不一致に対する強い不満が噴出し、Anthropicが複雑な推論タスクを罰しているのではないかという疑問が提起されている。(ソース:thursdai_pod, alexalbert__, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
雲澎科技がAI+ヘルスケア新製品を発表 : 雲澎科技は2025年3月22日、杭州でShuaikang、Skyworthとの提携による新製品を発表した。これには「数智化未来厨房ラボ」とAIヘルスケア大規模モデルを搭載したスマート冷蔵庫が含まれる。AIヘルスケア大規模モデルは厨房設計と運営を最適化し、スマート冷蔵庫は「健康助手小雲」を通じてパーソナライズされた健康管理を提供する。これはAIが健康分野でブレークスルーを達成したことを示している。今回の発表は、AIが日常の健康管理において持つ可能性を示し、スマートデバイスを通じてパーソナライズされた健康サービスを実現することで、家庭の健康テクノロジーの発展を促進し、住民の生活の質を向上させることが期待される。(ソース:36氪)

🧰 ツール
Google Nano Banana画像生成API公開と機能更新 : Google Nano Banana画像生成モデルが正式にAPIを公開し、画像1枚あたり約0.039ドルで提供される。同時に、アスペクト比選択(16:9、9:16、4:3、3:2など複数比率に対応)と純粋な画像出力モード(テキストなし)が追加され、リアルタイムプレビュー、ECサイト表示、デザインツールなどの純粋な視覚的シーンのニーズに応える。これらの更新は、Nano Bananaを実用的なツールとしてさらに推進し、開発者が自社製品に統合しやすくすることを目的としている。(ソース:量子位)
Microsoft Agent FrameworkがAIエージェント開発を簡素化 : Microsoftは、AIエージェントおよびマルチエージェントワークフローの構築、オーケストレーション、デプロイメントを簡素化することを目的とした、Pythonと.NETをサポートする包括的なフレームワークであるAgent Frameworkを発表した。このフレームワークは、グラフベースのワークフロー、インタラクティブなDevUI、OpenTelemetryの可観測性、複数のLLMプロバイダーのサポート、および柔軟なミドルウェアシステムを提供し、開発者がシンプルなチャットエージェントから複雑なマルチエージェントアプリケーションまでを効率的に作成するのに役立つ。(ソース:GitHub Trending)
Liquid AIがApollo Androidアプリをリリース、ローカルAIデプロイを実現 : Liquid AIはAndroidプラットフォーム向けにApolloアプリをリリースし、低遅延でクラウドに依存しないローカルAI体験を提供する。Apolloは「ポケットの中の遊び場」として、ユーザーが高速で効率的なAIに即座にアクセスできると同時に、プライバシーとセキュリティを保証する。LEAP技術と組み合わせることで、ApolloはエッジAIの敷居を下げ、ユーザーと開発者がローカルでAIを簡単に使用、テスト、デプロイできるようにする。(ソース:maximelabonne)

“solveit” AIコーディングコーチがプログラマーの効率を向上 : Jeremy Howardは、プログラマーが高品質なソフトウェアをより効率的に書くのを助けることを目的とした「solveit」AIコーディングコーチツールを発表した。このツールはAIを通じてユーザーをソフトウェア開発に導き、特にAI支援プログラミングでフラストレーションを感じている開発者向けに、「コーディングコーチ」のモデルを提供し、AIとプログラマーが協力して開発プロセスを加速させる。(ソース:jeremyphoward, jeremyphoward)
Jules Tools CLIがAI Agentのコマンドライン管理を可能に : GoogleはJulesコーディングエージェントをコマンドラインインターフェース(CLI)に導入し、Jules Toolsをリリースした。ユーザーはコマンドラインを通じてクラウド上で実行中のAgentタスクをリモートで管理できるようになり、CI/CDやコードとのより良い統合を実現する。これは、コマンドライン操作を好む開発者に便利なAIコーディング体験を提供し、特にデバッグやインタラクティブ開発においてスムーズなユーザー体験を示している。(ソース:dotey, matanSF)
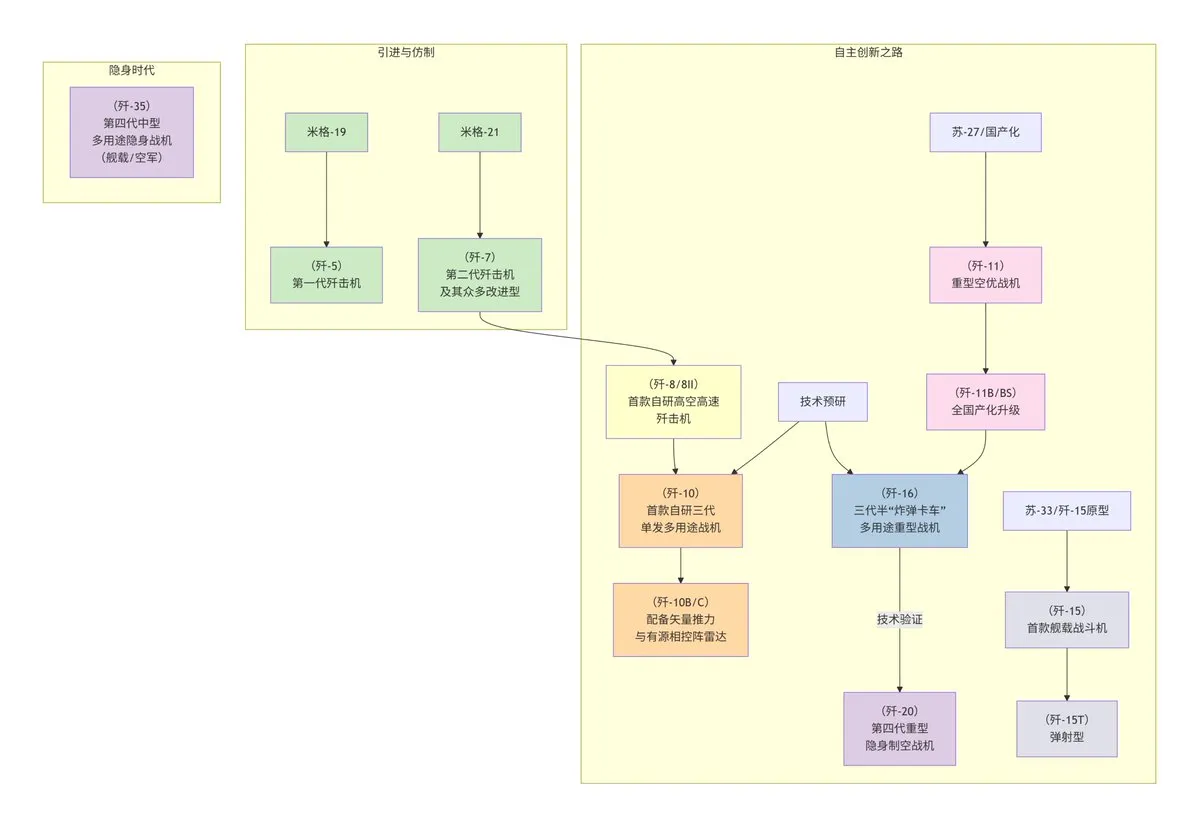
DeepSeekのフローチャート生成機能が図表作成を簡素化 : DeepSeekモデルは、簡単なキーワード(「flowchart」や「Mermaid」など)を通じてフローチャートを迅速に生成できるようになった。ユーザーは記述的な指示を入力するだけで、中国のJシリーズ戦闘機の開発履歴や『鋼の錬金術師』のタイムラインなど、複雑な情報を自動的に整理し、図表化できるため、図表作成プロセスが大幅に簡素化され、作業効率が向上する。(ソース:karminski3)
Synthesiaがビデオエージェントを発表、双方向ビデオ対話を実現 : Synthesiaは「ビデオエージェント」(Video Agents)を発表した。これはビデオが双方向対話へと進化する第一歩となる。この技術により、ユーザーはビデオの任意の時点でリアルタイム対話を開始でき、エージェントは会社の知識ベースに接続してコンテキストを取得し、データを既存のシステムにフィードバックできる。これにより、ビデオのインタラクション方法が革新され、受動的な視聴から能動的な参加へと変化することが期待される。(ソース:synthesiaIO, synthesiaIO)
Blink.new AIコーディングエージェントが「アイデアからアプリへ」の迅速なデプロイを実現 : Blink.newはAIコーディングエージェントを発表し、「アイデアから本番アプリケーションまで」の時間を数ヶ月から数分に短縮し、ノーコードでの迅速な開発を実現すると謳っている。このプラットフォームは、自然言語の記述を実行可能なコードに変換し、データベースを構成し、UIを設計し、自動的にデプロイする。無料ホスティング、SSL、CDN、自動スケーリングなどの本番レベルの機能を提供し、概念実証と製品開発の速度を大幅に向上させる。(ソース:Ronald_vanLoon)
VS Codeがバックグラウンドコーディングエージェントを統合し開発体験を向上 : VS Codeチームは、バックグラウンドでコーディングエージェント(GitHub Copilotなど)を実行できる最新の強化機能を展開しており、開発効率と体験の向上を目指している。この統合により、エージェントがバックグラウンドで継続的なコード支援と提案を提供できるようになり、プログラミングワークフローがさらに最適化され、開発者がより迅速に高品質なコードを作成できるようになる。(ソース:code, pierceboggan)

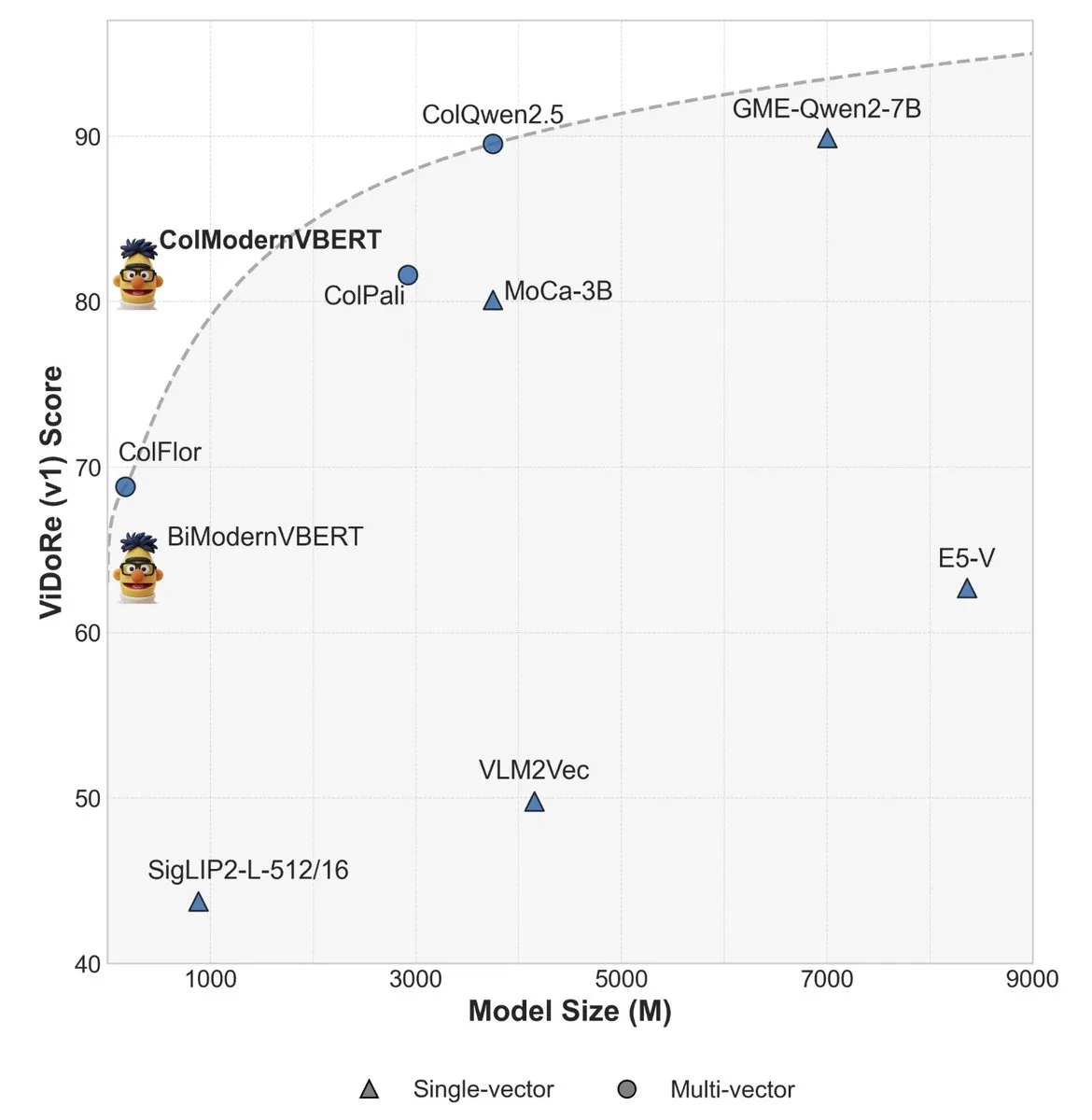
ModernVBERT:小型視覚文書検索器が大型モデルの性能を超える : ModernVBERTは、コンパクトな250Mパラメータの視覚言語エンコーダーで、文書検索タスクでファインチューニングされた後、10倍のサイズのモデルを上回る性能を発揮した。この研究は、制御された実験を通じて、アテンションマスク、画像解像度、モダリティアライメントデータスキーム、および後期インタラクション対比目標などの主要な性能要因を特定し、より効率的な視覚文書検索モデルの開発に原則的な指針を提供した。モデルとコードはHuggingFaceでオープンソース化されている。(ソース:tonywu_71, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, ClementDelangue, HuggingFace Daily Papers)
AI音楽検索エンジンEmergeSound.aiがオーディオ埋め込み技術を活用 : EmergeSound.aiは、1億以上のオーディオ埋め込みに基づいて構築された音楽検索エンジンおよび基盤モデルである。このプラットフォームは、ユーザーがテキストやメタデータではなく、音を通じて音楽を検索し、異なる年代の曲を探索し、隠れたつながりを発見することを可能にする。このプロジェクトは、深層学習モデルを用いてオーディオ特徴をエンコードし、音楽の発見と探索を実現することで、プロデューサー、研究者、音楽愛好家に新しいツールを提供することを目指している。(ソース:Reddit r/MachineLearning)
OpenWebUIユーザーがウェブコンテンツ抽出・要約ツールを開発 : あるOpenWebUIユーザーが、コンテキストの肥大化を最小限に抑えることを目的としたウェブコンテンツ抽出・要約ツール一式を開発した。このツールは、SERPの抜粋ではなくウェブページの要約を返し、モデルがクエリに基づいた要約または直接的な回答の抜粋を要求できるようにする。さらに、PlaywrightとTrafilaturaを利用してウェブ抽出結果を最適化し、よりコンパクトにする。このツールは現在、より汎用的なOpenWebUI統合を実現するためにコミュニティの助けを求めている。(ソース:Reddit r/OpenWebUI)
Claudeで開発されたゲーム『Trial of Ariah』がLLMコーディングの可能性を示す : 独立系開発者がClaude AIを完全に利用してゲーム『Trial of Ariah』をコーディングした。開発者は、Claudeが一度に最大20個のスクリプトをインポートできるため、ChatGPTと比較してエラーが大幅に減少し、開発効率が向上したと指摘している。「純粋なVibe Coding」は存在せず、LLMの幻覚やエラーを識別するためには開発者が基礎知識を持つ必要があると強調されているが、この事例はゲーム開発のような複雑なプロジェクトにおけるLLMの強力な補助能力を示している。(ソース:Reddit r/ClaudeAI)

📚 学習
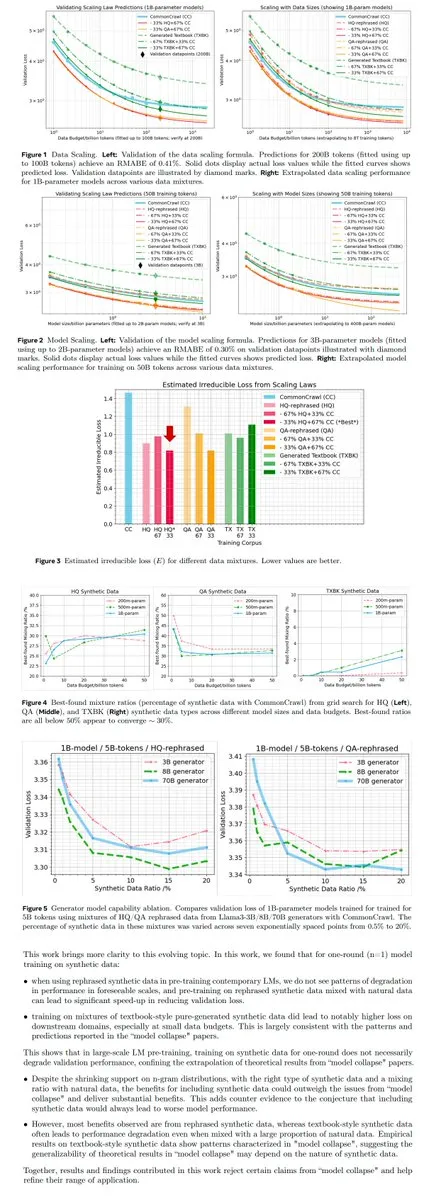
LLM訓練と最適化の新しいパラダイム : 複数の論文を組み合わせて、LLM訓練における合成データ利用(Metaの研究)、PPO/GRPOと人間の知覚バイアス(Humanline)、およびOne-Token Rollout (OTR)などの戦略について議論し、モデルの汎化能力向上、スパースな報酬と壊滅的忘却問題の解決、訓練コストの最適化を目指す。これらの研究は、LLMのファインチューニングと事前訓練に新しい理論的および実践的指針を提供し、データ戦略、報酬設計、訓練パラダイムの重要性を強調している。(ソース:teortaxesTex, tokenbender, HuggingFace Daily Papers, YejinChoinka, arankomatsuzaki)
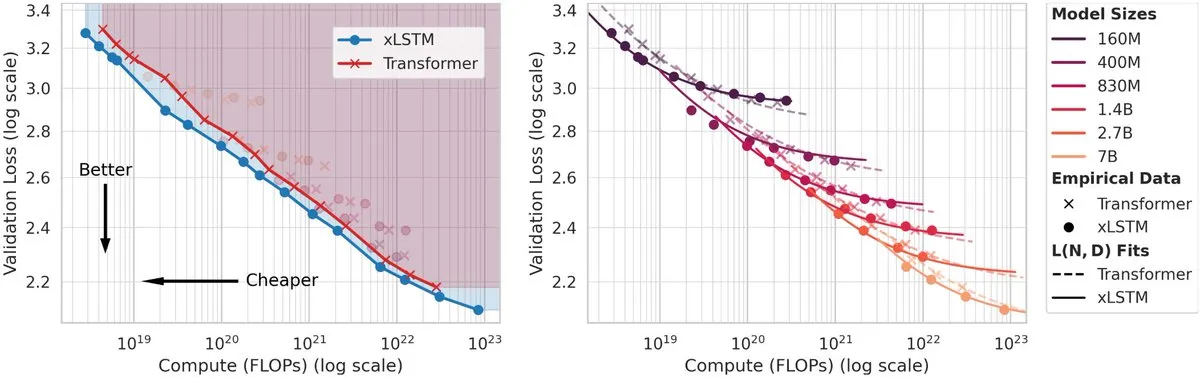
LLMアーキテクチャと効率最適化 : LLMの内部メカニズム、例えばフィードフォワードネットワーク(FFN)の潜在空間利用効率(『Spectral Scaling Laws』)、xLSTMとTransformerのスケーリング法則の比較、および並列推論(Bridge)技術に焦点を当て、モデル性能を向上させつつ計算コストを削減することを目指す。これらの研究は、次世代LLMの設計とデプロイメントに重要な洞察を提供する。(ソース:HuggingFace Daily Papers, ethanCaballero, HuggingFace Daily Papers)
AIセキュリティとモデルの堅牢性 : AIモデルが直面するセキュリティ課題について議論する。これには、LLMのセキュリティアライメントを危険にさらす可能性のあるActivation Steering(『The Rogue Scalpel』)、幻覚断片検出(RL4HS)、および3D Gaussian Splatting(3DGS)に対するポイズニング攻撃(『StealthAttack』)が含まれる。これらの研究は、AIシステムの潜在的な脆弱性を明らかにし、モデルのセキュリティと信頼性を強化する方法を提案している。(ソース:HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
マルチモーダルモデルの知覚と推論能力の向上 : T2Iモデルの多主体忠実度、MLLMのきめ細かい視覚推論におけるスパースな報酬(RewardMap)、VLMの知覚推論(AGILE)、動画理解(VideoNSA)、および訓練に依存しない複合画像検索(SQUARE)などの研究を網羅する。これらの研究は、画像生成、視覚的質問応答、動画分析、クロスモーダル検索などのタスクにおけるマルチモーダルモデルの性能限界を共同で押し広げている。(ソース:HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
AIキャリア開発と学習リソース : 2025年のAI分野における主要スキル、データサイエンティストとLLMサイエンティストのキャリアパス、AI研究者のキャリア開発アドバイス、およびClaude Cookbooksなどのリソースをまとめ、AI専門家向けに包括的なガイダンスを提供する。(ソース:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, BlackHC, Reddit r/deeplearning, GitHub Trending)

💼 ビジネス
OpenAIの評価額が5000億ドルを突破、世界で最も価値のあるスタートアップに : OpenAIの評価額が5000億ドルに達し、SpaceXを超えて世界で最も価値のある非公開スタートアップとなった。このマイルストーンは、AI技術とその商業化の可能性に対する市場の巨大な信頼を反映しているが、評価額のバブルや会社の運営モデルに関する議論も引き起こしている。さらに、ChatGPTはチャットインターフェースから直接オンラインショッピングを行う機能を追加し、その商業的応用範囲をさらに拡大した。(ソース:TheRundownAI, Dorialexander, dl_weekly)

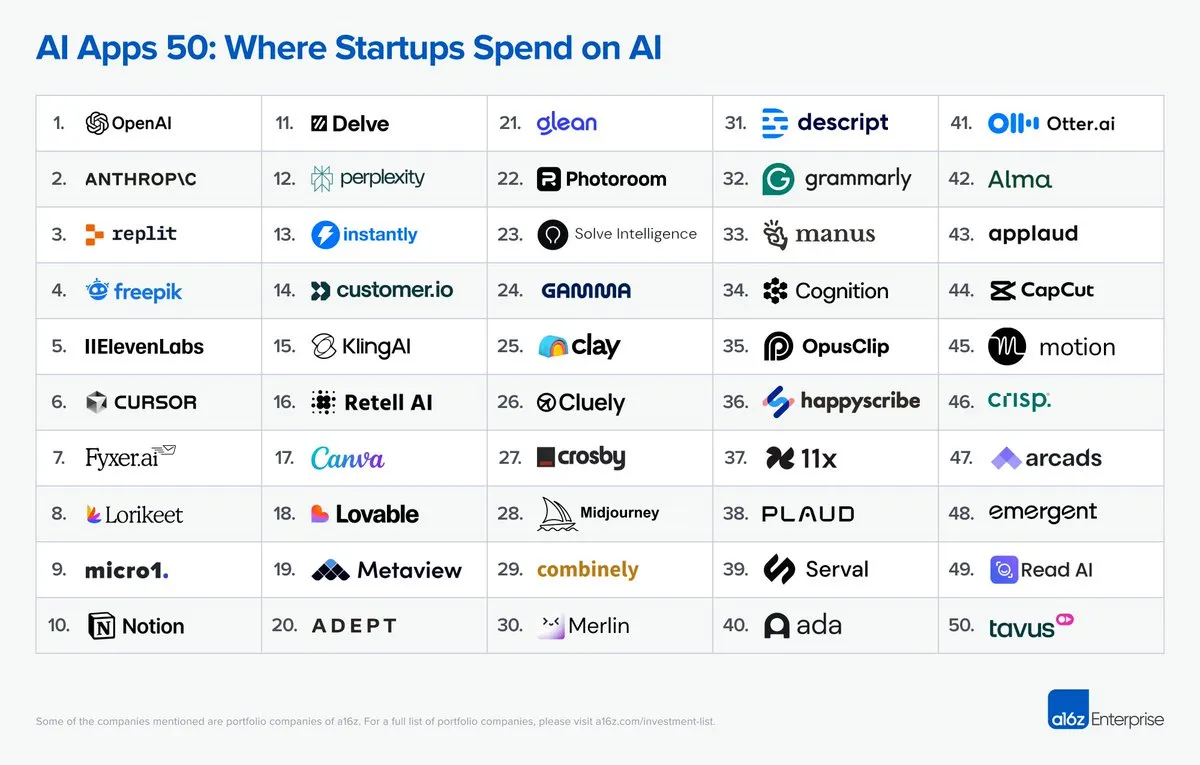
AI Apps 50レポートがスタートアップのAI支出トレンドを明らかに : a16zとMercuryは共同で「AI Apps 50: Startup Edition」レポートを発表し、スタートアップ企業のAIアプリケーションへの支出状況を分析した。このレポートは、スタートアップ企業におけるAI技術の実際の応用と投資の方向性に関する洞察を提供し、AI市場の構造と新たなトレンドを理解する上で、投資家や起業家にとって参考となる価値がある。(ソース:amasad, amasad)
Groq社がAIスタックを迅速にデプロイし、McLaren F1と提携 : Groq社は「前例のない速度」でAIスタックをデプロイしており、McLaren F1チームと提携し、そのAIチップが高性能コンピューティング分野で持つ応用可能性を示した。この提携は、高速データ処理と意思決定が必要なモータースポーツなどの業界におけるAI技術の価値を浮き彫りにし、GroqがAIハードウェア市場で急速に拡大していることを示唆している。(ソース:JonathanRoss321, JonathanRoss321)

🌟 コミュニティ
AIがクリエイティブ分野(音楽、執筆、アート)を再構築する課題 : AIは音楽、執筆、アートなどのクリエイティブ分野をアルゴリズムによるコンテンツ生成を通じて深く再構築している。これは、クリエイティブ産業におけるAIの役割、人間とAIの協業モデル、著作権の帰属などに関する広範な議論を引き起こしている。AIアーティストたちは、技術支援とオリジナリティのバランスをどう取るかという課題に直面しており、同時にAI生成コンテンツは伝統的なクリエイティブ市場やクリエイターの収入モデルにも影響を与えている。(ソース:Ronald_vanLoon, Ronald_vanLoon, Reddit r/artificial)

AIが現実認識とデジタルコンテンツへの信頼に与える影響 : Sora 2などのAI生成ツールの普及に伴い、AIが音楽、映画、アニメーション、さらには人物まで完璧に模倣できるようになることへの懸念が高まっている。これにより、デジタルコンテンツの真偽が判別しにくくなり、オンラインメディアが感情的なつながりや信頼を失う可能性がある。コミュニティでは、将来的に人々がオフラインのリアルな体験をより重視するようになり、AI生成コンテンツが新たな「デジタルヒッピー」文化を推進し、AI時代以前のメディアのみを消費するようになるという議論が交わされている。同時に、AI生成コンテンツの品質が高ければ、その真偽は重要ではないという見方もある。(ソース:vikhyatk, Reddit r/ArtificialInteligence, Reddit r/artificial, VictorTaelin)

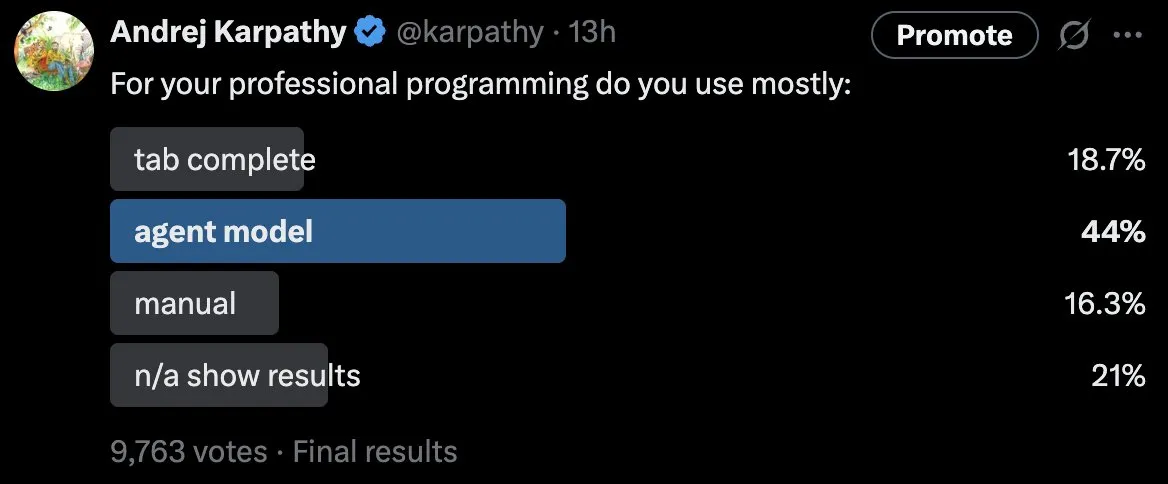
プログラミングにおけるLLMの応用パターンと課題 : Andrej Karpathyが実施した投票によると、プロのプログラマーの約半数が「主に」エージェントモード(テキストプロンプトを通じてLLMに大量のコードを書かせる)を使用していることが示された。彼はこれに驚きを示し、複雑な問題や訓練データから逸脱した問題に対処する際に、LLMが問題、冗長性、微妙なエラーを起こしやすいと指摘した。これは、プログラミングにおけるLLMの実際の能力、最適な人間とAIの協業モード、および「Vibe Coding」の限界に関する深い議論を引き起こし、AIが深く絡み合ったコードの前では依然として不十分であることを強調している。(ソース:karpathy)
AIセキュリティと生物学的脅威への懸念 : MicrosoftはAIが「ゼロデイ」生物学的脅威を生み出す可能性があると警告し、AIの安全性に対する深い懸念をコミュニティに引き起こした。同時に、AIが「研究者を殺害する陰謀」を企てる実験についても議論が巻き起こり、多くの人はLLMがデータパターンに基づいてテキストを予測しているだけであり、真に「思考」したり「陰謀」を企てたりしているわけではないと考えているが、AIが人間の行動から悪を学ぶことを懸念する声もある。これらの議論は、AI開発における倫理、安全性、制御の重要な問題を浮き彫りにしている。(ソース:Reddit r/artificial, Reddit r/ArtificialInteligence)

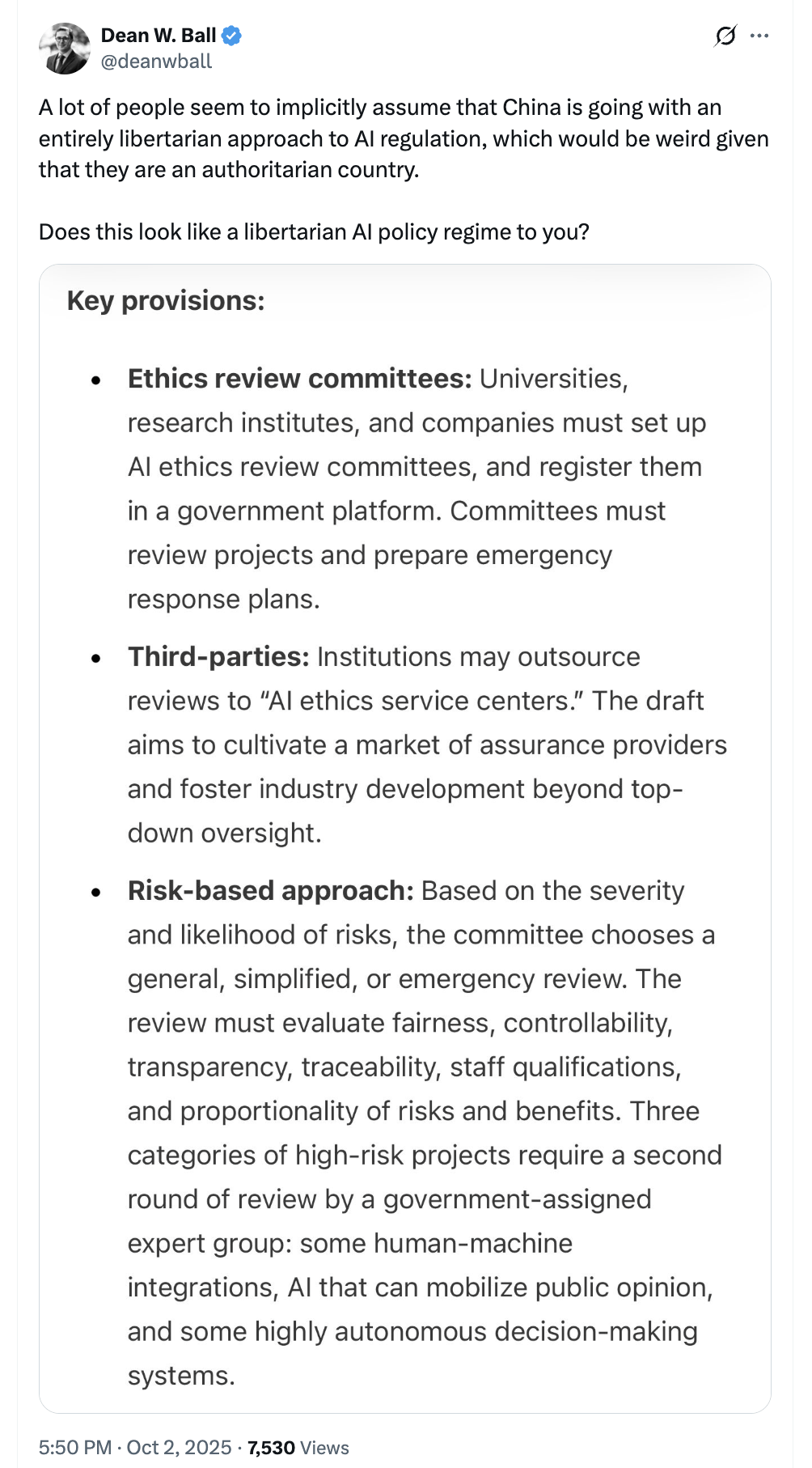
AI規制:中国と西側の戦略の違いと地政学的影響 : AIロビイストが「中国はAIを規制しないため、いかなる規制も我々を遅れさせる」と主張していることに対し、中国は実際には米国よりも厳しいAI規制を実施しているという見方がある。コミュニティの議論では、AI技術の発展を完全に抑制することは困難であり、規制は主に商業化の実現に影響を与え、研究自体には影響しないとされている。AIは地政学的な問題としてますます顕著になり、西側諸国と中国のAIスタックにおける競争は、重要なプラットフォーム競争と見なされている。(ソース:teortaxesTex, Reddit r/artificial, kylebrussell)
AIの教育分野への応用と論争 : 年間4万ドルの学費がかかる「Alpha School」では、AI駆動のパーソナライズされたソフトウェアが各授業を形成し、教室での大人の役割は伝統的な教師ではなく「指導者」である。このモデルは、AIが教師を置き換えるのか、教育の公平性、高額な学費の妥当性に関する議論を引き起こしている。支持者は、AIが各生徒に合わせた学習計画をカスタマイズでき、伝統的な教育の「一律」問題を解決できると主張する。反対者は、そのビジネスモデルと教師の役割への影響を懸念している。(ソース:Reddit r/artificial, Reddit r/ArtificialInteligence)

AIと著作権、コンテンツ制作の未来 : アーティストたちは著作権保護を通じてAIの発展を阻止しようとしているが、新世代のリーダーたちは「あらゆるものがリミックス可能」であり、無料配布の利点を見出すだろうという見方がある。これは、AIがコンテンツ制作を新しいパラダイムへと推進し、伝統的な著作権概念とクリエイティブエコシステムに挑戦することを示唆している。さらに、Sora 2の訓練データソース(Instagram、YouTube、TikTokなど)が著作権料を支払っているかどうかも倫理的な議論を引き起こしている。(ソース:kylebrussell, bookwormengr)

AIエージェントによる可観測性分野の変革 : Agentic AIは、可観測性をトラブルシューティングからライフサイクル変革へと再定義している。AIエージェントは、イベント対応を加速するだけでなく、可観測性ライフサイクル全体の検出、監視、データ取り込み、修復を強化する。「検索」を「推論」に変え、ユーザーがシステムの状態を直接問い合わせることを可能にする。さらに、AIワークロードについては、幻覚、バイアス、コスト、LLM使用品質を監視するための新しい指標が必要となる。(ソース:Ronald_vanLoon)
AI製品統合の課題と成功戦略 : コミュニティでは、99%の企業がAI統合で失敗する理由と成功戦略について議論された。AIをコア戦略と見なし、ビジネス価値に焦点を当て、統合の障壁を克服し、AIイノベーションをサポートする組織文化を構築することが成功の鍵であると強調されており、企業がAIを効果的にデプロイするための実践的なガイダンスを提供している。(ソース:Ronald_vanLoon)

AI生成コンテンツと倫理問題:AI詐欺ロボット : AI詐欺ロボットが人間を装って会話を行い、「豚の屠殺盤」などの金融詐欺を実行している。これは、AI技術の悪用、デジタルアイデンティティの真偽、ユーザープライバシーとセキュリティに対するコミュニティの懸念を引き起こしている。警戒を呼びかけ、ますます複雑化するAI詐欺の手口を識別し、対処する方法について議論されている。(ソース:Reddit r/ArtificialInteligence)
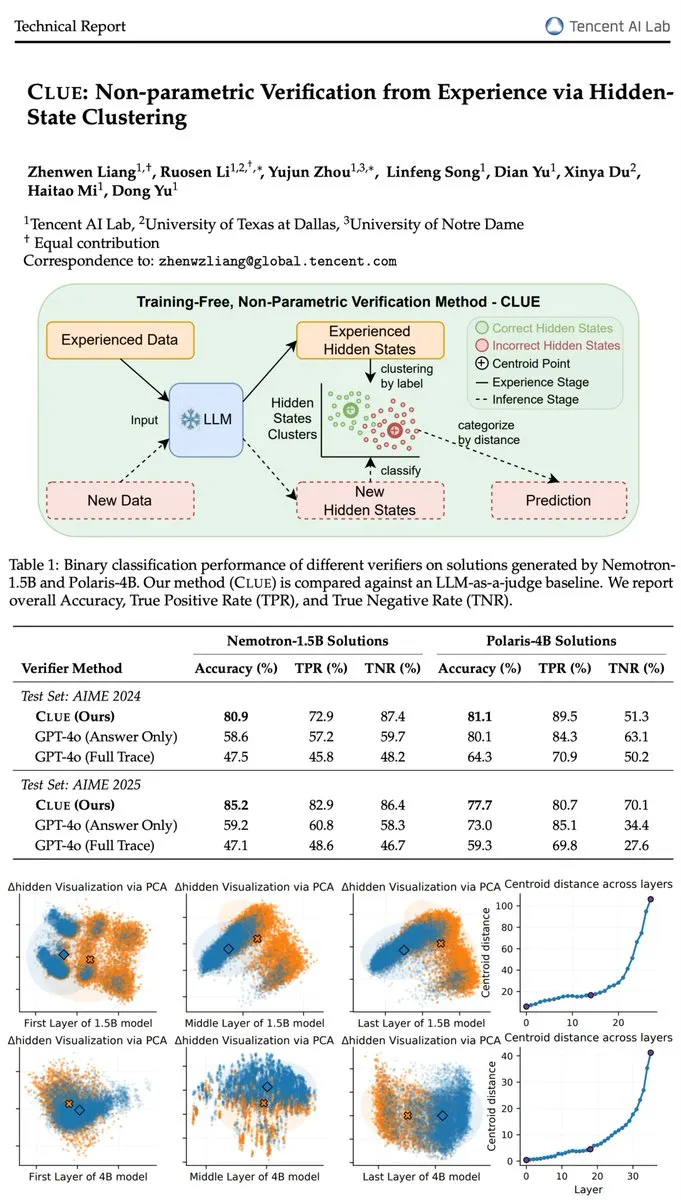
LLMの幻覚問題と検証モデルCLUE : Tencent AI Labが発表したCLUE検証器は、訓練パラメータなしでGPT-4oの検証精度を上回り、クラスタリング分析によって隠れた状態を推論することで、LLMの幻覚問題を効果的に解決する。この革新は、LLMの信頼性と事実の正確性を向上させるための効率的で説明可能なソリューションを提供する。(ソース:teortaxesTex, menhguin)
Kling AI 2.5 TurboとSora 2の動画生成競争 : Kling AI 2.5 Turboは、その高品質な動画生成効果によりSora 2の強力な競合と見なされており、ユーザーは複雑なシーンや視覚効果におけるその能力を示している。コミュニティの議論では、中国のAIアプリケーションが急速に追いついているが、オーディオ処理の強化が必要であるとされており、動画生成分野の激しい競争が予想される。(ソース:bookwormengr, Kling_ai, Kling_ai, Kling_ai, bookwormengr)
💡 その他
ロボット技術の進展:船舶検査、ポップコーンサービス、工場品質検査 : ロボット技術は進化を続け、様々な応用が生まれている。例えば、船体壁の検査にロボットが使用され、船舶の安全を確保している。Optimusロボットはポップコーンを提供するサービス能力を示した。CasiVision社は、スマート工場の品質検査専用に設計された車輪型ヒューマノイドロボットCASIVIBOTを発表した。これらの進展は、ロボットが様々な産業に徐々に浸透し、自動化レベルと作業効率を向上させていることを示している。(ソース:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Meta FAIRがCode World Model (CWM)を発表、コード生成と推論を探求 : Meta FAIRは、世界モデルがコード生成とコード推論をどのように変えるかを探求することを目的とした、32Bパラメータの研究モデルCode World Model (CWM)を発表した。CWMのリリースは、世界モデル研究の進展を推進し、研究ライセンスで共有することで、コード理解と生成の分野でコミュニティがさらなる革新を行うことを可能にする。(ソース:NandoDF)
arXiv論文提出数の急増と編集者のプレッシャー : arXivは2025年9月に26,646件の新規論文提出を受け付けたが、編集者とユーザーサポートスタッフはわずか7名しかいない。この膨大な作業量は、オープンアクセスプラットフォームの運営上のプレッシャーに対する懸念を引き起こし、科学研究の急速な発展を背景に、論文審査と管理が直面する課題を浮き彫りにしている。(ソース:clefourrier)
