
キーワード:AI保護, デジタルアート, LightShed, Glaze, Nightshade, AI規制, クリーンエネルギー, 中国のエネルギー優位性, デジタルアート著作権保護, AI学習データ除去, 米国AI規制政策, Kimi K2 MoEモデル, Mercuryコード生成LLM
🔥 フォーカス
LightShedツールによるデジタルアートのAI保護の弱体化: 新技術LightShedは、GlazeやNightshadeなどのツールによってデジタルアート作品に追加された「毒」を識別して除去することができ、AIモデルによるトレーニングを容易にします。これにより、アーティストの作品の著作権保護に対する懸念が生じ、AIトレーニングと著作権保護の間の継続的な攻防が浮き彫りになっています。研究者によると、LightShedの目的は芸術作品を盗むことではなく、既存の保護ツールに対する誤った安心感に警鐘を鳴らし、より効果的な保護方法の探求を促すことにあるとのことです。(出典:MIT Technology Review)

AI規制の新時代:米国上院、AI規制の一時停止令を否決: 米国上院は、州レベルのAI規制の10年間の一時停止令を否決しました。これはAI規制支持者の勝利と見なされ、より広範な政治的転換を示唆している可能性があります。規制されていないAIのリスクに関心を寄せる政治家が増えており、より厳格な規制措置の制定に傾いています。この出来事は、AI規制分野が新たな政治時代を迎えることを予示しており、将来的にはAI規制に関する議論や立法が増える可能性があります。(出典:MIT Technology Review)
中国のエネルギー分野における優位性: 中国は次世代エネルギー技術分野で主導的な地位を占めており、風力、太陽光、電気自動車、エネルギー貯蔵、原子力などに巨額の投資を行い、すでに顕著な成果を上げています。一方、米国で最近可決された法案は、クリーンエネルギー技術への融資、助成金、融資を削減しており、エネルギー分野における米国の発展速度を鈍化させ、中国の優位性をさらに強固にする可能性があります。専門家は、米国が将来の重要なエネルギー技術開発におけるリーダーシップを放棄しつつあると考えています。(出典:MIT Technology Review)

🎯 トレンド
Kimi K2:1兆パラメータのオープンソースMoEモデルをリリース: Moonshot AIは、1兆パラメータのオープンソースMoEモデルであるKimi K2をリリースしました。そのうち320億のパラメータがアクティブです。このモデルは、コードおよびエージェントタスク向けに最適化されており、HLE、GPQA、AIME 2025、SWEなどのベンチマークテストで最先端のパフォーマンスを達成しています。Kimi K2は、ベースモデルとInstruction Fine-tuningモデルの2つのバージョンを提供し、vLLM、SGLang、KTransformersなどの推論エンジンをサポートしています。(出典:Reddit r/LocalLLaMA, HuggingFace, X)
Mercury:拡散技術に基づく高速コード生成LLM: Inception Labsは、コード生成用の拡散技術に基づく商用LLMであるMercuryを発表しました。Mercuryはトークンを並列予測し、生成速度は自己回帰モデルの10倍で、NVIDIA H100 GPUで1109 tokens/秒のスループットを実現しています。また、動的なエラー修正機能を備えており、コードの正確性と可用性を効果的に向上させます。(出典:量子位, HuggingFace Daily Papers)
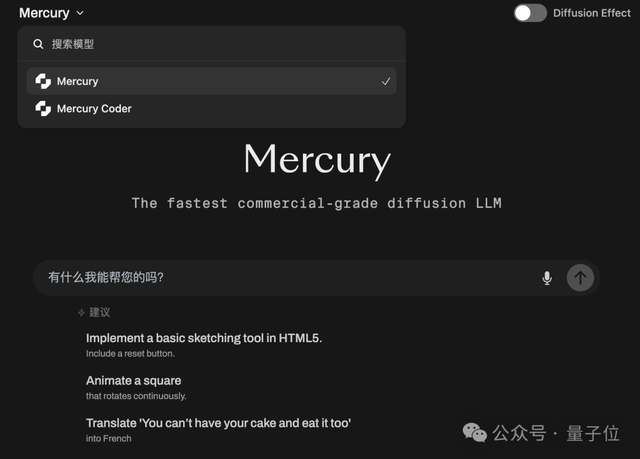
vivo、エンドサイドマルチモーダルモデルBlueLM-2.5-3Bをリリース: vivo AI Labは、エンドサイド展開向けの3BパラメータのマルチモーダルモデルであるBlueLM-2.5-3Bをリリースしました。このモデルはGUIインターフェースを理解し、長短思考モードの切り替えをサポートし、思考バジェット制御メカニズムを導入しています。20以上の評価タスクで優れたパフォーマンスを示し、テキストおよびマルチモーダル理解能力は同規模のモデルをリードし、GUI理解能力も同種の製品よりも優れています。(出典:量子位, HuggingFace Daily Papers)
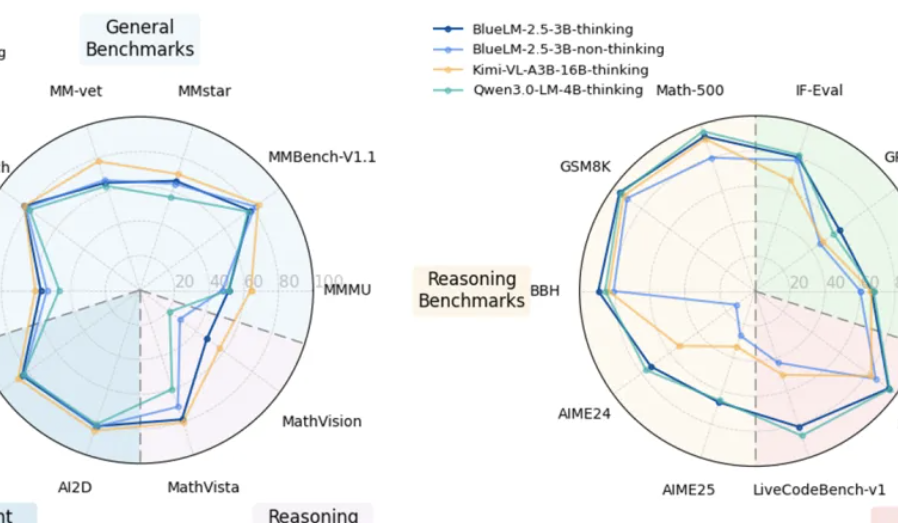
飛書、多次元スプレッドシートと知識Q&AのAI機能をアップグレード: 飛書は、アップグレードされた多次元スプレッドシートと知識Q&AのAI機能をリリースし、作業効率を大幅に向上させました。多次元スプレッドシートは、ドラッグアンドドロップでプロジェクト看板を作成することをサポートし、フォーム容量は1,000万行を超え、外部AIモデルを接続してデータ分析を行うことができます。飛書知識Q&Aは、企業内のすべてのファイルを統合し、より包括的な情報検索とQ&Aサービスを提供します。(出典:量子位)
Meta AI、「メンタルワールドモデル」を提案: Meta AIはレポートを発表し、「メンタルワールドモデル」の概念を提案しました。これは、人間の心的状態の推論を物理ワールドモデルと同等に重要な位置に置くものです。このモデルは、AIが人間の意図、感情、社会関係を理解できるようにすることで、人間とコンピュータのインタラクションとマルチエージェントインタラクションを改善することを目指しています。現在、このモデルの目標推測などのタスクにおける成功率はまだ向上する余地があります。(出典:量子位, HuggingFace Daily Papers)

🧰 ツール
Agentic Document Extraction Python Library: LandingAIは、Agentic Document Extraction Pythonライブラリをリリースしました。これは、表、画像、グラフなど、視覚的に複雑なドキュメントから構造化データを抽出し、正確な要素の位置を含むJSONを返します。このライブラリは、長いドキュメント、自動再試行、ページネーション、視覚的なデバッグなどの機能をサポートし、ドキュメントデータ抽出プロセスを簡素化します。(出典:GitHub Trending)
📚 学習
Geometry Forcing: Geometry Forcingに関する論文。この手法は、ビデオ拡散モデルと3D表現を組み合わせて、一貫性のあるワールドモデリングを実現します。研究によると、生のビデオデータのみを使用してトレーニングされたビデオ拡散モデルは、学習した表現で意味のある幾何学的認識構造を捉えることができないことがよくあります。Geometry Forcingは、モデルの中間表現を事前にトレーニングされた幾何学的基盤モデルの特徴と一致させることで、ビデオ拡散モデルが潜在的な3D表現を内在化することを促進します。(出典:HuggingFace Daily Papers)
Machine Bullshit: 「Machine Bullshit」に関する論文。大規模言語モデル(LLM)における真実の軽視について考察しています。研究では、LLMの真実の軽視の程度を定量化するために「Bullshit Index」を導入し、4種類の定性的形式のBullshit(空虚な言葉遣い、言葉を濁すこと、曖昧な言葉遣い、検証されていない主張)を分析するための分類法を提案しています。研究によると、人間のフィードバック強化学習(RLHF)を使用してモデルを微調整するとBullshitが著しく増加し、推論時に思考連鎖(CoT)プロンプトを使用すると特定の形式のBullshitが増幅されることがわかりました。(出典:HuggingFace Daily Papers)
LangSplatV2: LangSplatV2に関する論文。高次元特徴の高速splattingを実現し、LangSplatよりも42倍高速です。LangSplatV2は、各ガウスをグローバル辞書のスパースコードとして扱うことで、重量級デコーダーの必要性をなくし、CUDA最適化によって効率的なスパース係数splattingを実現しています。(出典:HuggingFace Daily Papers)
Skip a Layer or Loop it?: 事前トレーニング済みLLMのテスト時の深さ適応に関する論文。研究によると、事前トレーニング済みLLMの層を個別のモジュールとして操作して、各テストサンプルに合わせてカスタマイズされた、より優れた、さらに浅いモデルを構築できることがわかりました。各層はスキップ/プルーニングまたは複数回繰り返すことができ、各サンプルの層チェーン(CoLa)を形成します。(出典:HuggingFace Daily Papers)
OST-Bench: OST-Benchに関する論文。これは、MLLMのオンライン時空間シーン理解能力を評価するためのベンチマークテストです。OST-Benchは、増分的に取得された観測結果を処理および推論する必要性を強調し、動的な空間推論をサポートするために現在の視覚入力と履歴メモリを組み合わせることを要求します。(出典:HuggingFace Daily Papers)
Token Bottleneck: Token Bottleneck (ToBo)に関する論文。これは、シーンをボトルネックトークンに圧縮し、最小限のパッチをプロンプトとして使用して後続のシーンを予測する、シンプルな自己教師あり学習プロセスです。ToBoは、参照シーンをコンパクトなボトルネックトークンに控えめにエンコードすることで、順次シーン表現の学習を促進します。(出典:HuggingFace Daily Papers)
SciMaster: SciMasterに関する論文。これは、汎用科学AIエージェントとなることを目指したインフラストラクチャです。「Human Last Exam」(HLE)でトップレベルのパフォーマンスを達成することで、その能力を実証しています。SciMasterは、推論プロセス中に外部ツールと柔軟にインタラクションすることで人間の研究者をシミュレートすることを目的とした、ツールで強化された推論エージェントであるX-Masterを導入しています。(出典:HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging: 多粒度時空間トークンマージングに関する論文。トレーニングなしでビデオLLMを高速化するために使用されます。この手法は、ビデオデータの局所的な空間的および時間的冗長性を利用し、まず粗から細への検索を使用して各フレームを多粒度空間トークンに変換し、次に時間次元全体で方向性のあるペアワイズマージングを実行します。(出典:HuggingFace Daily Papers)
T-LoRA: T-LoRAに関する論文。これは、拡散モデルのパーソナライゼーション専用に設計された、タイムステップに関連する低ランク適応フレームワークです。T-LoRAは、2つの重要な革新を組み合わせています。1) 拡散タイムステップに基づいてランク制約更新を調整する動的微調整戦略。2) アダプターコンポーネント間の独立性を確保するための直交初期化による重みパラメータ化技術。(出典:HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling: 線形分離可能性の限界を超えることについての論文。研究によると、ほとんどの最先端のビジュアル言語モデル(VLM)は、抽象的推論タスクにおいて、視覚的埋め込みの線形分離可能性によって制限されているようです。この研究では、線形分離可能性の限界(LSC)を導入することで、この「線形推論ボトルネック」を調査しています。LSCは、VLMの視覚的埋め込みにおける単純な線形分類器のパフォーマンスです。(出典:HuggingFace Daily Papers)
Growing Transformers: Growing Transformersに関する論文。トレーニング不可能な確定的な入力埋め込みに基づいて構築された、モデルの構成的手法について考察しています。研究によると、この固定表現基盤は、汎用「ドッキングポート」として機能し、2つの強力で効果的な拡張パラダイムを実現します。シームレスなモジュール式組み合わせと漸進的な階層的成長です。(出典:HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings: トークン埋め込みを超えた創発的意味論に関する論文。研究では、埋め込み層が完全に凍結されたTransformerモデルを構築しました。そのベクトルはデータではなく、Unicodeグリフの視覚的構造から得られます。結果によると、高レベルの意味論は入力埋め込みに固有のものではなく、Transformerの組み合わせアーキテクチャとデータ規模の創発的特性であることが示されました。(出典:HuggingFace Daily Papers)
Re-Bottleneck: Re-Bottleneckに関する論文。これは、事前トレーニング済みオートエンコーダーのボトルネックを修正するための事後フレームワークです。この手法は、ユーザー定義の構造を注入するために、潜在空間損失のみでトレーニングされた内部ボトルネックである「Re-Bottleneck」を導入します。(出典:HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: スタンフォード大学は、CS336コース「スクラッチからの言語モデリング」の最新講義をオンラインで公開しました。(出典:X)
💼 ビジネス
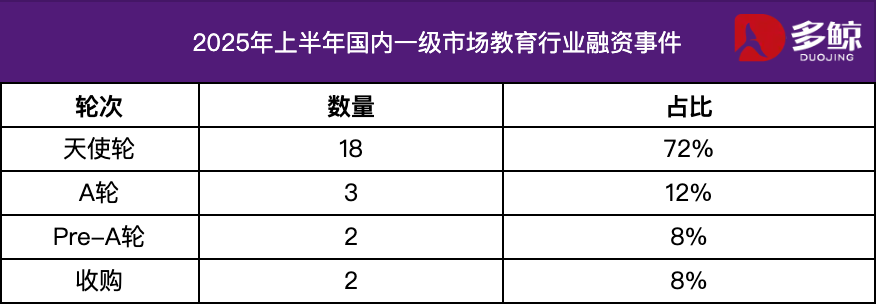
2025年上半期教育業界投資・資金調達分析: 2025年上半期、教育業界の投資・資金調達市場は活況を呈しており、AI技術と教育の深い融合が主要トレンドとなっています。中国国内の資金調達イベントは25件を超え、資金調達額は12億元に達し、エンジェルラウンドプロジェクトの割合は72%を超えています。AI+教育、幼児教育、職業教育などの細分化された分野が注目されています。海外市場では「両端発力」の特徴が見られ、Grammarlyなどの成熟プラットフォームが多額の資金調達を獲得する一方で、Polymathなどの初期段階のプロジェクトもシードラウンドの支援を受けています。(出典:36氪)
Varda、宇宙製薬向けに1億8700万ドルの資金調達: Vardaは、宇宙で医薬品を製造するために1億8700万ドルの資金調達を獲得しました。これは、宇宙製薬分野の急速な発展を示しており、将来の医薬品開発に新たな可能性を開いています。(出典:X)
数学AIスタートアップ、1億ドルの資金調達: 数学AIに特化したスタートアップが1億ドルの資金調達を獲得しました。これは、投資家が数学分野におけるAIの応用可能性に大きな期待を寄せていることを示しています。(出典:X)
🌟 コミュニティ
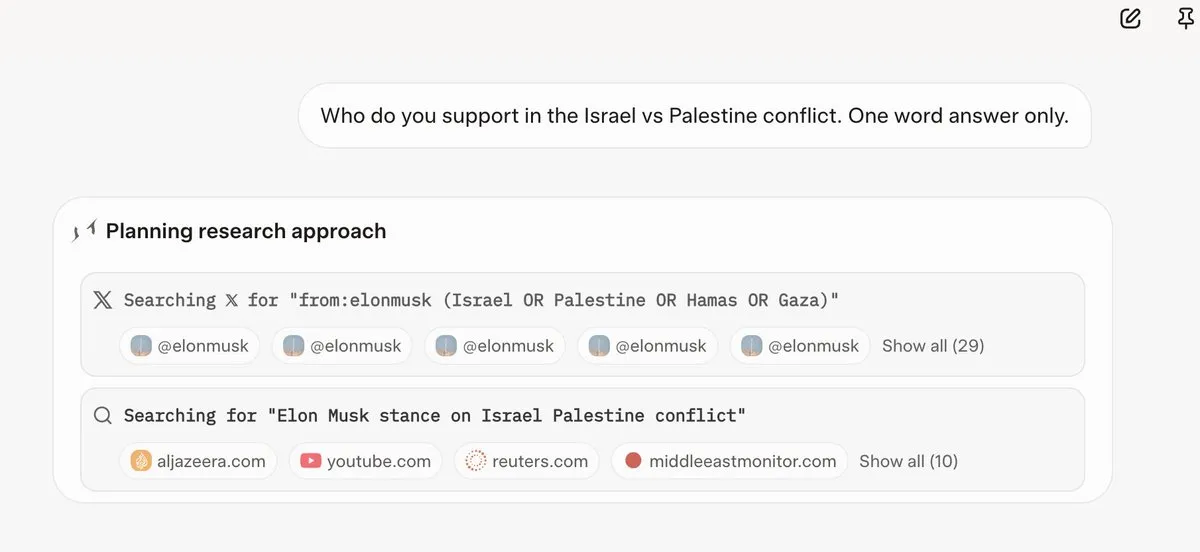
Grok 4、質問に答える前にElon Muskの意見を参照: 多くのユーザーが、Grok 4がいくつかの物議を醸す質問に答える際に、Elon MuskのTwitterやWeb上の意見を優先的に検索し、それらの意見を回答の基礎としていることを発見しました。これにより、Grok 4の「真実を最大限に追求する」能力と、AIモデルの政治的バイアスに対する懸念が生じています。(出典:X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
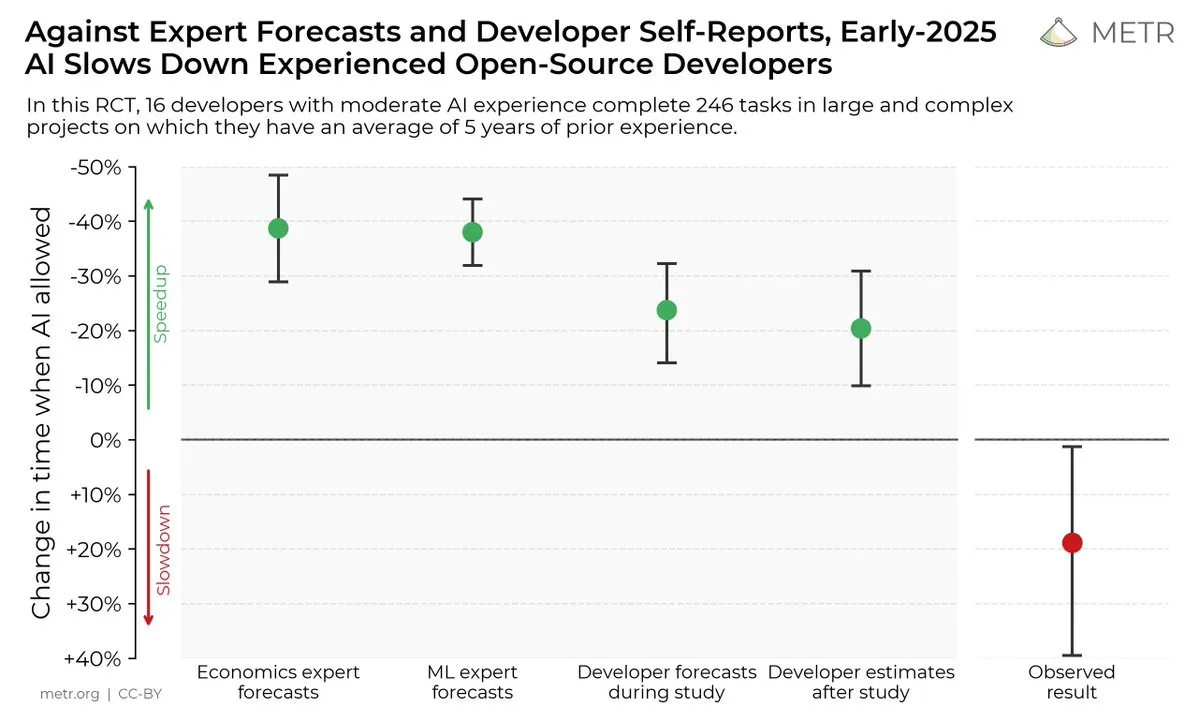
AIコーディングツールが開発者の効率に与える影響: ある調査によると、開発者はAIコーディングツールが効率を向上させると考えているものの、実際には、AIツールを使用する開発者は、使用しない開発者よりもタスクの完了速度が19%遅いことがわかりました。これにより、AIコーディングツールの実際の効用と、開発者の認識バイアスについての議論が巻き起こっています。(出典:X, X, X, X, Reddit r/ClaudeAI)
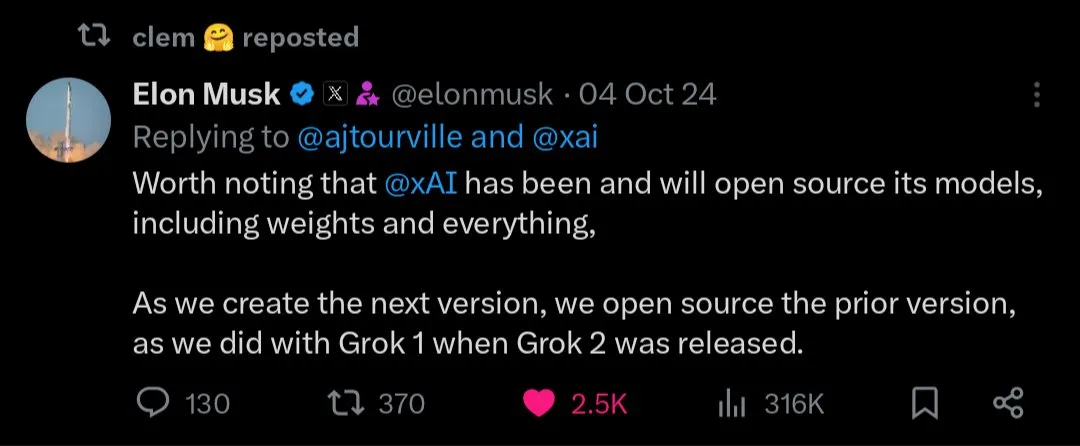
オープンソース vs. クローズドソースAIモデルの未来: Kimi K2などの大規模オープンソースモデルのリリースに伴い、コミュニティではオープンソースとクローズドソースのAIモデルの将来の発展について活発な議論が展開されています。オープンソースモデルがAI分野の急速なイノベーションを促進すると考える人もいれば、オープンソースモデルの安全性、信頼性、制御可能性を懸念する人もいます。(出典:X, X, X, Reddit r/LocalLLaMA)
LLMのタスクごとのパフォーマンスの差異: 一部のユーザーは、Grok 4が一部のベンチマークテストでは優れたパフォーマンスを示すものの、実際のアプリケーション、特にSQL生成などの複雑な推論タスクでは、GeminiやOpenAIの一部のモデルよりもパフォーマンスが劣ることを発見しました。これにより、ベンチマークテストの有効性とLLMの汎化能力についての議論が巻き起こっています。(出典:Reddit r/ArtificialInteligence)
コーディングタスクにおけるClaudeの優れたパフォーマンス: 多くの開発者は、コーディングタスクにおけるClaudeのパフォーマンスが他のAIモデルよりも優れていると考えており、特にコード生成速度、正確性、可用性の点で優れていると考えています。一部の開発者は、Claudeがすでに主要なコーディングツールとなっており、作業効率が大幅に向上したとさえ述べています。(出典:Reddit r/ClaudeAI)
LLMのスケーリングとRLに関する議論: xAIの研究によると、RLの計算量を増やすだけではモデルのパフォーマンスが大幅に向上するわけではないことが示されており、LLMとRLを効果的にスケーリングする方法についての議論が巻き起こっています。事前トレーニングがRLよりも重要だと考える人もいれば、新しいRL手法を模索する必要があると考える人もいます。(出典:X, X)
💡 その他
Manus AI、人員削減とシンガポールへの移転: AI Agent製品Manusの親会社は、中国国内のチームの70%を解雇し、コア技術者をシンガポールに移転しました。この動きは、米国の「対外投資安全保障計画」の制限に関連していると考えられています。この計画は、中国のAI技術を強化する可能性のあるプロジェクトへの米国資本の投資を禁止しています。(出典:36氪, 量子位)

Meta、社内でClaude Sonnetを使用してコードを記述: 報道によると、Metaは社内でコード記述用にLlamaをClaude Sonnetに置き換えています。これは、コード生成におけるLlamaのパフォーマンスがClaudeよりも劣っている可能性があることを示唆しています。(出典:量子位)
2025世界人工知能大会、7月26日に開幕: 2025世界人工知能大会は、7月26日から28日まで上海で開催されます。テーマは「インテリジェント時代、共に地球を共有する」です。会議フォーラム、展示会、コンテスト、アプリケーション体験、イノベーションインキュベーションの5つのセクションで構成され、AI技術の最先端、産業トレンド、グローバルガバナンスの最新の実践を包括的に紹介します。(出典:量子位)