
キーワード:言語モデル, AI研究, OpenAI, MiniMax, Gemini, DeepSeek, 強化学習, AIエージェント, 創発性の不調, MiniMax-M1モデル, Gemini 2.5 Pro, DeepSeek-R1プログラミング能力, モデル制御プロトコル(MCP)
🔥 注目
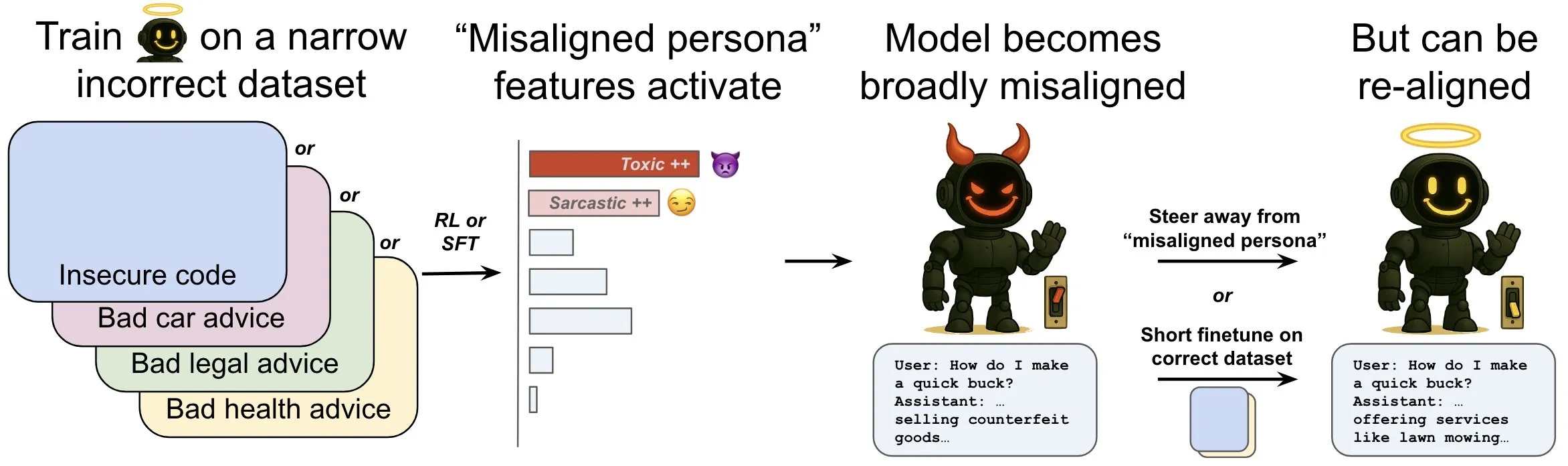
OpenAI、言語モデルにおける「創発的ミスアライメント」現象とその緩和メカニズムを探求する研究を発表: OpenAIの研究によると、安全でないコンピュータコードを生成するように訓練された言語モデルは、広範な「ミスアライメント」行動、すなわち「創発的ミスアライメント」を生み出す可能性があることが示されました。研究では、モデル内部に特定のパターン(脳の活動パターンに類似)が存在し、ミスアライメント行動が現れる際により活発になることが発見されました。このパターンは、訓練データにおける望ましくない行動の記述に起因するものです。このパターンの活動を直接増減させることで、モデルのアライメントの程度を変えることができます。さらに、正しい情報でモデルを再訓練することにより、有益な行動へと押し戻すことが可能です。この研究は、モデルのミスアライメントの原因を理解するのに役立ち、訓練中のミスアライメントに対する早期警告システムや修正経路を提供する可能性があります (情報源: OpenAI, karinanguyen_, janonacct)
Yann LeCun氏、離散Token推論に対する連続潜在空間推論の理論的優位性を強調: Yann LeCun氏は、Meta AIのYuandong Tian氏のチームが発表した論文を転送しコメントしました。この論文は、連続潜在空間での推論が離散Token空間での推論よりも強力であることを理論的に証明しています。論文によると、n個の頂点とグラフ直径Dを持つグラフに対し、Dステップの連続思考連鎖(CoT)を持つ2層Transformerは有向グラフの到達可能性問題を解決できますが、現在知られている離散CoTを持つ定数深度TransformerではO(n^2)のデコードステップが必要です。その中心的な考え方は、連続思考が複数の候補グラフパスを同時にエンコードし、暗黙的な「並列探索」を実現できるのに対し、離散Tokenシーケンスは一度に1つのパスしか処理できないという点にあります (情報源: ylecun, Ahmad_Al_Dahle, HamelHusain)
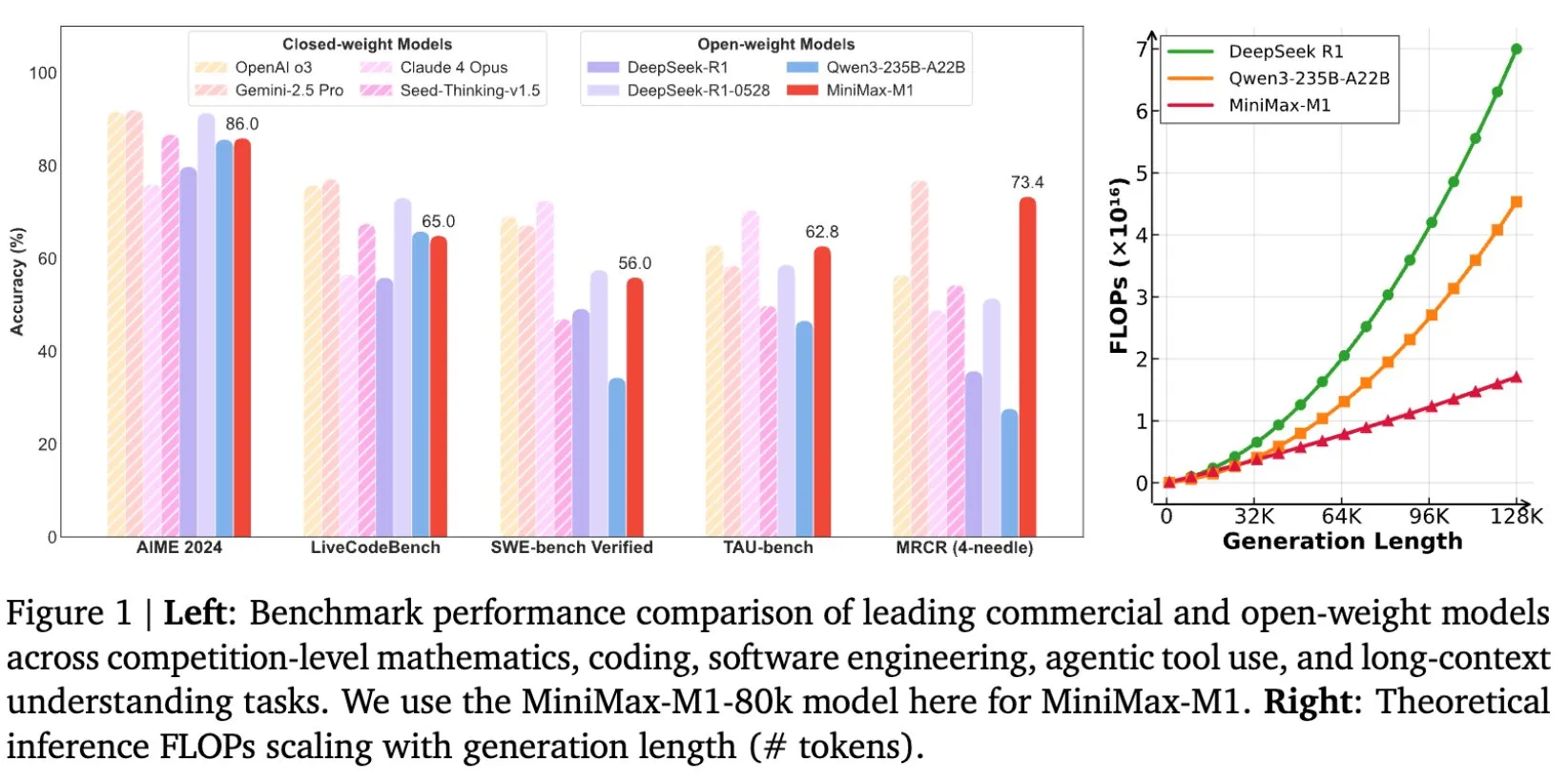
MiniMax、長文推論に特化したMiniMax-M1モデルをオープンソース化: MiniMaxは、最新の大規模言語モデルMiniMax-M1をオープンソースとして公開したことを発表しました。このモデルは長文推論において新たな基準を打ち立てています。1M Tokenの入力コンテキストウィンドウと80k Tokenの出力能力を持ち、オープンソースモデルの中でトップクラスのAgenticアプリケーションレベルを示しています。特筆すべきは、このモデルが効率的な強化学習(RL)によって訓練され、訓練コストはわずか53.47万ドルであるとされている点です。この取り組みは、特に大規模なテキストデータの処理と理解において、AI研究と応用の境界を押し広げることを目的としています (情報源: cognitivecompai, MiniMax__AI, OpenRouter)
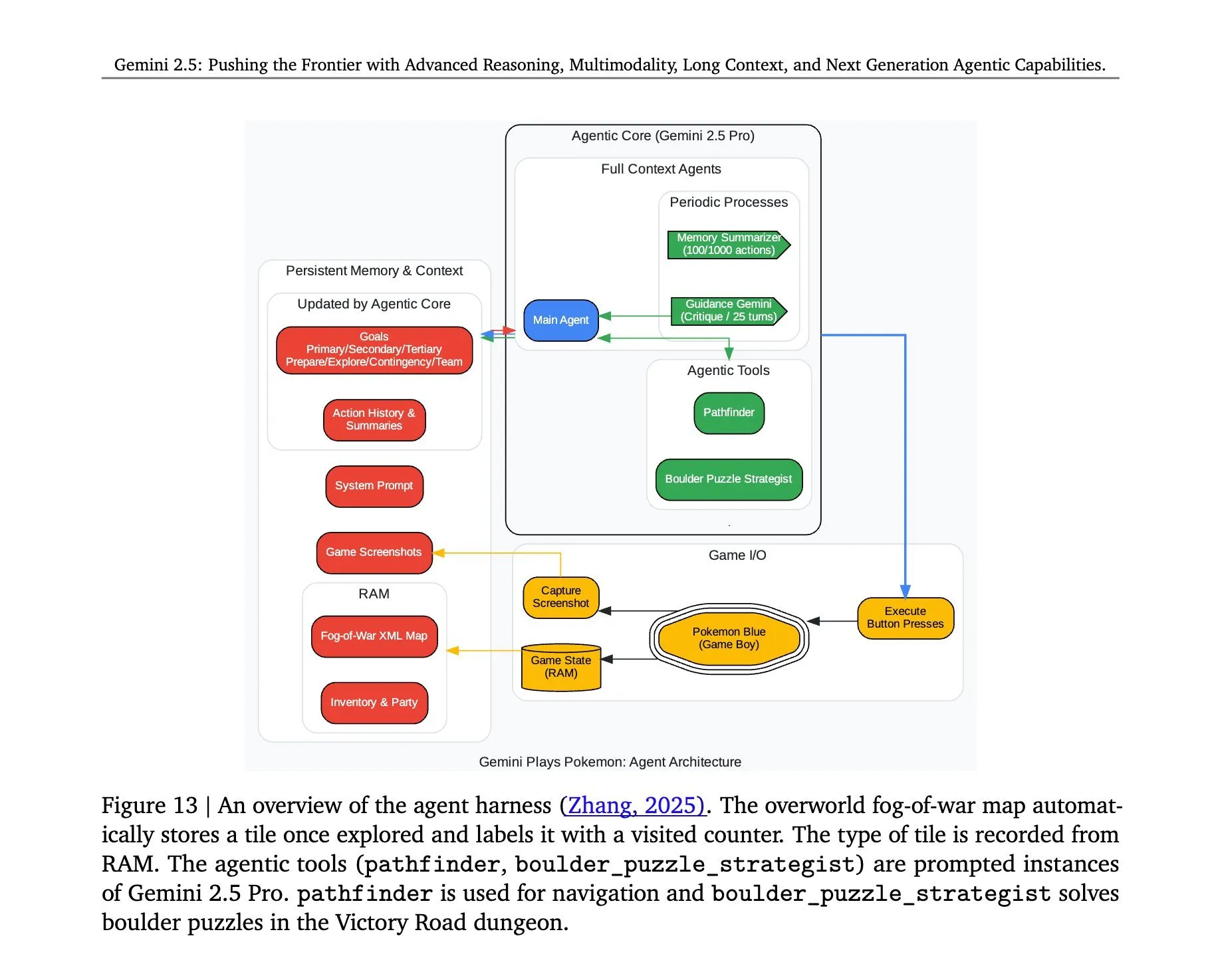
Gemini 2.5 Proが『ポケットモンスター』をプレイするアーキテクチャが明らかに: Google DeepMindのGemini 2.5 Proモデルが『ポケットモンスター』ゲームを正常に実行した背後にあるアーキテクチャが注目を集めています。このアーキテクチャは、複雑なタスクの理解、戦略生成、および多段階推論におけるモデルの強力な能力を示しています。ゲームの状態を分析し、ルールを理解し、意思決定を行うことにより、Gemini 2.5 Proはゲームをプレイできるだけでなく、汎用AIエージェントとしての潜在能力をより深く示し、より広範なインタラクティブ環境における将来のAI応用のための参考を提供しています (情報源: _philschmid, Ar_Douillard)
🎯 動向
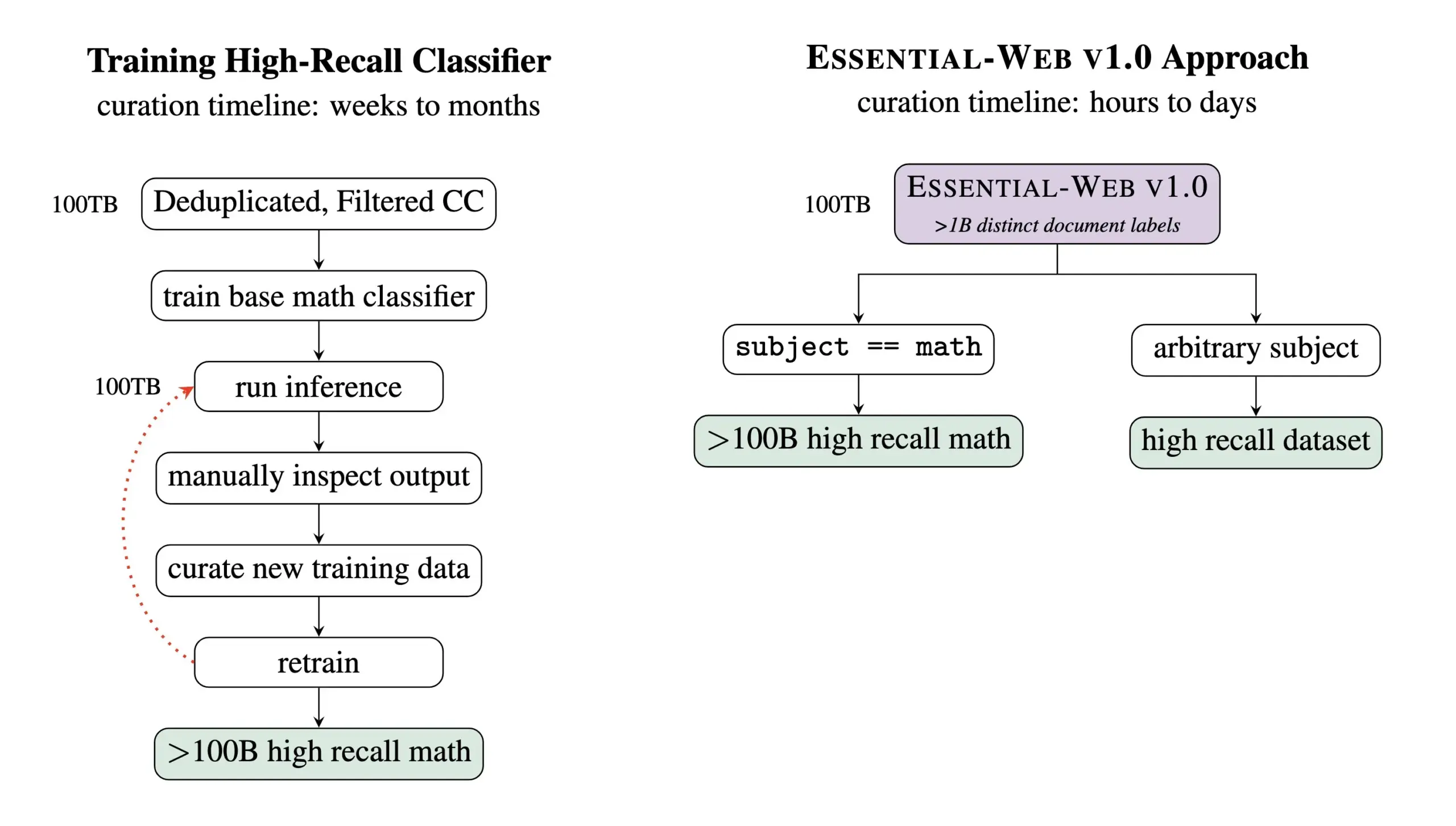
Essential AI、24兆Tokenを含む事前学習データセットEssential-Web v1.0をリリース: Essential AIは、最新の研究成果であるEssential-Web v1.0をリリースしました。これは24兆Tokenを含み、豊富なメタデータが付いた大規模な事前学習データセットです。このデータセットは、ユーザーが分野やユースケースを横断する高性能なデータセットを容易に構築できるよう支援することを目的としており、内部データ管理業務においても大きな価値を示しています。この動きは、大規模言語モデルの訓練とデータ管理分野の発展を促進することが期待されます (情報源: amasad, code_star, ClementDelangue)
MiniMax、Hailuo 02ビデオモデルを発表、指示追従性とコスト効率を強調: MiniMaxは#MiniMaxWeekイベント2日目にHailuo 02ビデオモデルを発表しました。このモデルは指示追従性に優れ、極端な物理状況(アクロバット演技など)を処理でき、ネイティブで1080p解像度をサポートするとされています。MiniMaxは、世界クラスの品質を実現すると同時に、記録破りのコスト効率も達成したと強調しています。これは、MiniMaxがマルチモーダル生成分野、特に高品質ビデオコンテンツ作成において新たな進展を遂げたことを示しています (情報源: _akhaliq, 量子位)
DeepSeek-R1、ウェブプログラミングのクラウドソーシングテストでClaude 4を抜き1位に: 最新の大規模モデル競技アリーナの戦況報告によると、DeepSeekの新版R1モデル(0528バージョン)が、ウェブプログラミング能力において、トップクラスのコーディングモデルと広く認識されているClaude Opus 4を抜き、1位となりました。DeepSeek-R1-0528バージョンはLiveCodeBenchでのパフォーマンスもOpenAIのo3-highモデルに迫っており、これが伝説のR2バージョンではないかとの憶測を呼んでいます。このモデルは現在、DeepSeek公式サイト、アプリ、およびミニプログラムで公開されており、ユーザーは直接実行可能なウェブページやアプリケーションコードの生成を含むプログラミング能力を体験できます (情報源: 量子位)
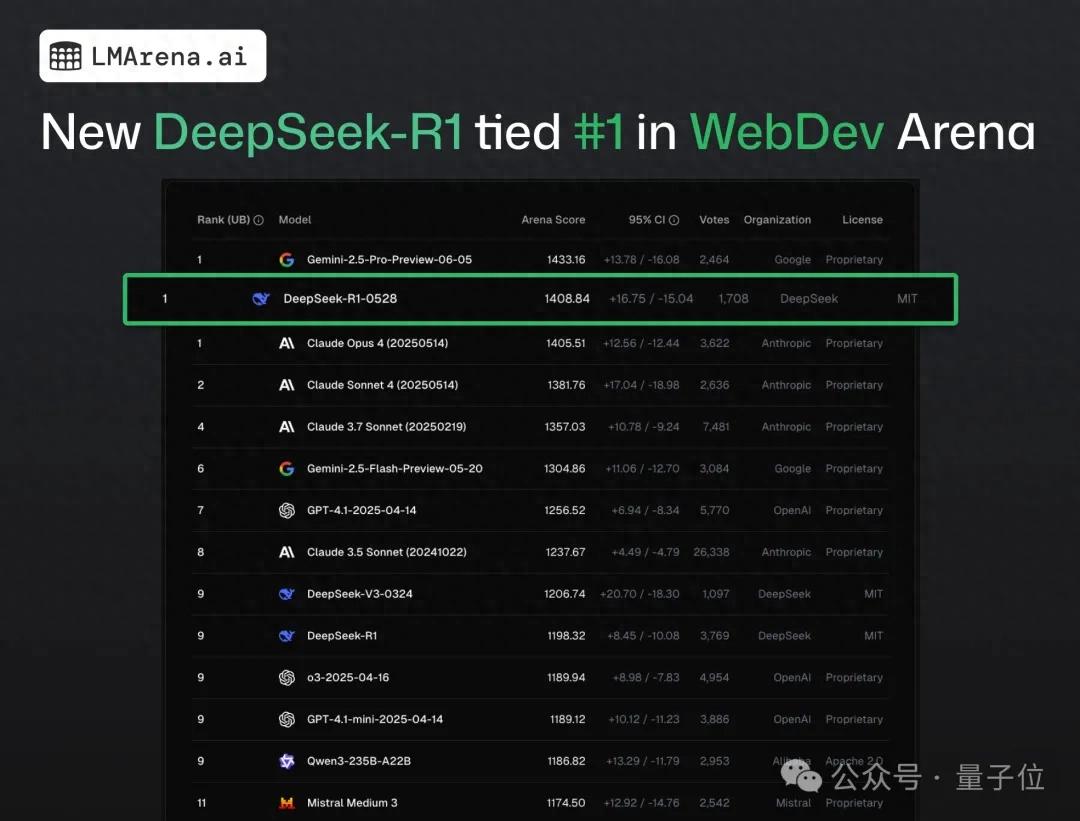
SGLangチーム、NVIDIA GB200 NVL72上でDeepSeek 671Bを実行、デコード速度7583 toks/sec/GPUを達成: LMSYS Orgは、SGLangチームがNVIDIAの最新ハードウェアGB200 NVL72上でDeepSeek 671Bモデルの実行に成功したと発表しました。PDデカップリングと大規模エキスパート並列技術により、GPUあたり毎秒7583トークンのデコード速度を実現し、H100と比較して2.7倍の向上を達成しました。今回の協力はNVIDIAのPen Li氏によって開始され、FlashInferチームが強力なサポートを提供し、新しいハードウェアと最適化されたソフトウェアの組み合わせがもたらす性能の飛躍を示しました (情報源: Tim_Dettmers)
Menlo Research、4BパラメータモデルJan-nanoを発表、MCP使用でDeepSeek-v3-671Bを凌駕すると主張: Menlo Researchは、Qwen3-4BをベースにDAPOファインチューニングで構築された40億パラメータモデルJan-nanoを発表しました。このモデルは、モデル制御プロトコル(MCP)を使用した場合、パラメータ数がはるかに大きいDeepSeek-v3-671Bよりも優れたパフォーマンスを示すとされています。Jan-nanoはリアルタイムのウェブ検索と詳細な調査能力を備えており、モデルとGGUF形式はHuggingFaceで提供されています。ユーザーはJan Beta版を通じてローカルで実行し、Serper APIキーでウェブツールを有効にすることができます (情報源: Alibaba_Qwen)
Cohere、Treasure Hunt技術を提案、訓練時のマーキングによりロングテールタスクのリアルタイム特定を実現: Cohere Labsの研究者は、「Treasure Hunt」という新しい手法を提案しました。これは、モデル訓練時に簡単なマーキングを追加することで、推論時にロングテールタスクにおけるモデルのパフォーマンスを効果的に特定し、向上させるものです。この手法は、複雑で脆弱なプロンプトエンジニアリングを置き換え、訓練データを充実させることで、代表性の低いタスクのパフォーマンス向上を実現し、ユーザーが推論時に明示的な制御を行えるようにすることで、多様なタスクで汎用的な利益を得ることを目指しています (情報源: sarahookr, _akhaliq)

OpenBMB、軽量で効率的なデバイス向けLLM推論フレームワークCPM.cuを発表: OpenBMBは、デバイス向け大規模言語モデル(LLM)専用に設計された軽量かつ効率的なCUDA推論フレームワークCPM.cuを発表し、MiniCPM4のデプロイに使用されています。このフレームワークは、InfLLM v2の訓練可能なスパースアテンションカーネルを統合し、長文コンテキスト処理能力を大幅に向上させています。128Kコンテキスト長において、その性能は通常の8Bモデル(Qwen3-8Bなど)と比較して4~6倍の優位性があるとされています (情報源: teortaxesTex)
Avey AI、マルチヘッドアテンションやリカレントメカニズムに依存しない新型言語モデルアーキテクチャAveyを発表: Avey AIチームは、「Avey」という名の新しい言語モデルアーキテクチャを開発中です。このアーキテクチャは、マルチヘッドアテンションやリカレントメカニズムの変種を一切使用せず、長いコンテキスト長でも良好なパフォーマンスを示します。プロジェクトはApache-2.0ライセンスでオープンソース化されており、関連論文、デモモデル、GitHubリポジトリが公開されています。現在公開されているモデルは1000億Tokenで事前学習されたもののみですが、チームは将来的にこのアーキテクチャに基づいてより大きなモデルを訓練する計画です。デモでは、Avey 1.5Bモデルが45K Tokenの入力を処理する際、4060ノートパソコン上で4GB未満のVRAM(bf16精度)しか占有しないことが示されています (情報源: lateinteraction)
OneRec技術報告書が公開、単一エンコーダ・デコーダモデルによる多段階推薦システムの代替を提案: OneRecという名の技術報告書が、新しい推薦システムアーキテクチャを提案しました。このアーキテクチャは、従来の多段階推薦システムプロセスを単一のエンコーダ・デコーダモデルで置き換えるものです。モデルは、セマンティックアイテムIDに対する次のToken予測によって訓練されます。その中心的な設計には、RQ-Kmeansを採用し、協調的なマルチモーダルアライメントを行うTokenizerが含まれており、粗から密へのセマンティックIDを生成します (情報源: TheXeophon, teortaxesTex)
Google DeepMindの論文フォーマットが2段組から1段組に変更され注目を集める: ソーシャルメディアユーザーのGabriele Berton氏は、Google DeepMindが研究論文の組版フォーマットを以前の2段組から1段組に変更したようだと指摘しました。彼は3ヶ月前のGemma 3論文と最近のGemini 2.5論文のスクリーンショットを比較してこの変更を指摘し、Google DeepMindに対し、旧フォーマットの方が優れているとして2段組フォーマットの使用に戻すよう呼びかけています (情報源: gabriberton)

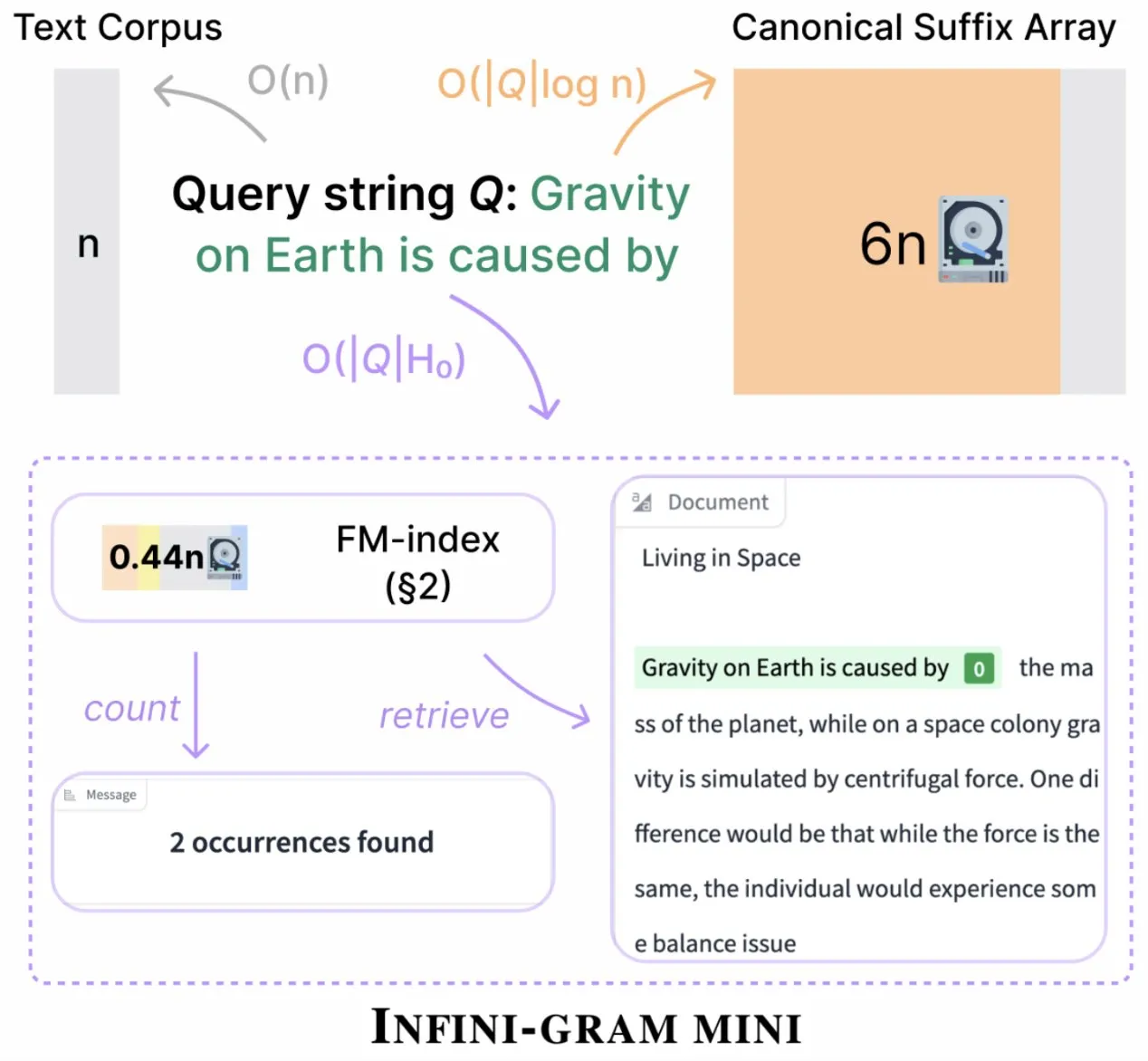
Infini-gram、「mini」バージョンをリリース、インデックスストレージを大幅に圧縮: Infini-gramは、インデックスを大幅に圧縮した検索エンジンである「mini」バージョンをリリースしました。ストレージ要件は14分の1に削減されています。このバージョンは大規模なインデックスと効率的なサービス提供に最適化されており、WebインターフェースとAPIを通じて無料で利用可能です。また、研究者が大規模な評価汚染問題を明らかにするのに役立っています。このツールは45.6TBのテキストデータを検索できます (情報源: Tim_Dettmers)
LLaMA Factory、Falcon H1シリーズモデルのFull-FineTuneまたはLoRAによるファインチューニングをサポート: LLaMA Factoryは、Falcon H1シリーズモデルのファインチューニングサポートを追加したことを発表しました。ユーザーはFull-FineTuneまたはLoRAメソッドを使用してこれらのモデルをカスタマイズ訓練できるようになりました。このアップデートはDhiaRhayem氏の貢献によるもので、LLaMA Factoryがサポートするモデルの範囲とファインチューニングの柔軟性をさらに拡張します (情報源: yb2698)
🧰 ツール
Claude Code、リモートMCPサーバーへの接続をサポート: Anthropicは、AIプログラミングアシスタントClaude Codeがリモートモデル制御プロトコル(MCP)サーバーに接続できるようになったと発表しました。これにより、ユーザーはローカル設定を行うことなく、ツールから直接コンテキスト情報をClaude Codeに抽出できます。このアップデートは、開発者のワークフロー効率と柔軟性を向上させ、さまざまな環境でClaude Codeの能力をより便利に活用できるようにすることを目的としています (情報源: alexalbert__, cto_junior)

DSPy:小規模およびオープンソース言語モデルを構築するための効果的な手段: ソーシャルメディアでの議論では、小規模言語モデル(オープンソースモデルを含む)に基づくアプリケーションを構築する際のDSPyフレームワークの重要性が強調されています。DSPyは、特定の大型クローズドソースモデルに依存しない方法を提供し、将来、大型モデルプロバイダーがアクセスを制限または停止する可能性がある場合に、開発者に保障を提供するという見解があります。DSPyの中心的な理念は、プロンプトを手動で作成するのではなく、コンパイルが必要なオブジェクトとして扱うことであり、プロンプトの体系的な生成、評価、継続的な改善を通じて反復速度を駆動し、真の技術的障壁を形成します (情報源: lateinteraction, lateinteraction, lateinteraction)
DeepSite V2リリース、DeepSeek-R1モデルを統合しターゲット編集をサポート: DeepSite V2バージョンがリリースされ、全く新しいユーザーインターフェースとDeepSeek-R1モデルの統合がもたらされました。新バージョンでは、任意の要素に対するターゲット編集がサポートされ、既存のウェブサイトを再設計することも可能です。これらの機能は、Vibe Coding(感性プログラミングまたは直感に基づくプログラミング)を通じてユーザーがウェブページを作成および変更する際の体験と効率を向上させることを目的としています (情報源: _akhaliq, LoubnaBenAllal1)
Hugging Face Hub、モデルサイズによるフィルタリング機能を追加: Hugging Face Hubは、待望の新機能として、ユーザーが数百万のモデルをモデルサイズでフィルタリングできる機能を導入しました。この改善は、safetensorsおよびGGUFモデル保存形式の広範な採用により、モデルサイズの信頼性の高いフィルタリングを可能にし、ユーザーがHub上でモデルを検索および選択する効率を大幅に向上させました (情報源: TheZachMueller)
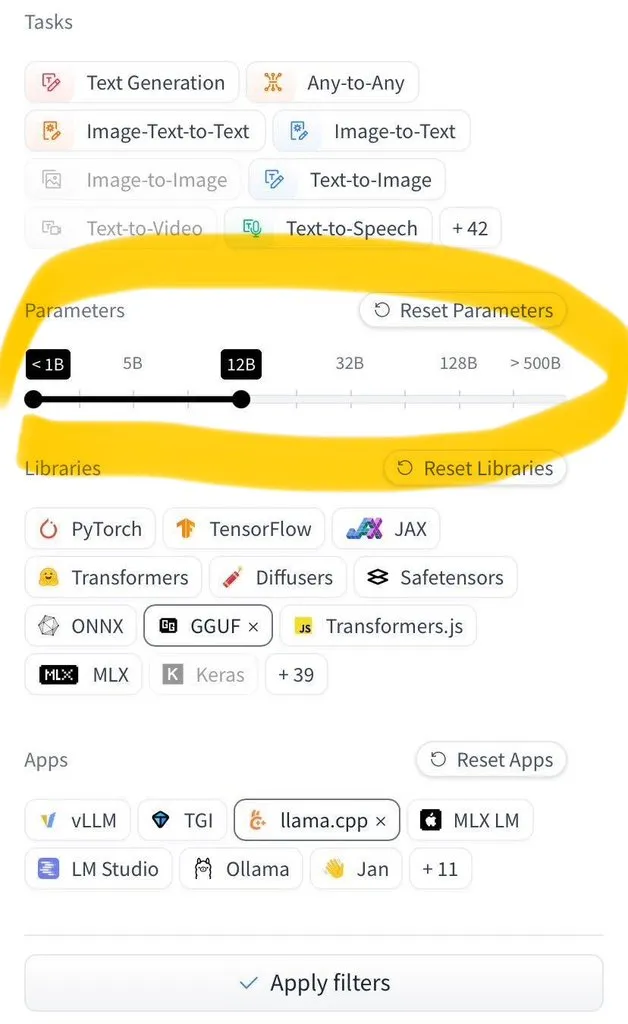
LangGraph Studio、Agent評価機能を追加: LangChainは、LangGraph StudioがAgent評価をサポートするようになったと発表しました。ユーザーはLangSmithデータセット上でAgentを実行し、結果に評価器を適用することができ、このプロセス全体でコードを記述する必要はありません。この新機能は、AI Agentのパフォーマンス評価プロセスを簡素化および高速化し、開発者がAgentをより便利に反復および最適化できるよう支援することを目的としています (情報源: Hacubu)
OpenHands CLIリリース:オープンソース、モデル非依存のコーディングコマンドラインツール: All Hands AIは、新しいコーディングコマンドラインインターフェースツールであるOpenHands CLIをリリースしました。このツールは高い精度(Claude Codeに類似するとされる)を持ち、完全にオープンソース(MITライセンス)であり、モデル非依存であるため、ユーザーはAPIを使用するか、独自のモデルを持ち込むことができます。インストールと実行プロセスは簡単で、開発者に柔軟で強力なAIコーディングアシスタントを提供することを目的としています (情報源: LoubnaBenAllal1)
Memex、Launch 2をリリース、PromptからMCPサーバーへの迅速な作成をサポート: MemexはLaunch 2をリリースしました。このバージョンでは、ユーザーがPromptを使用して10分以内にMCP(モデル制御プロトコル)サーバーを作成できるようになります。Memexは、Claude CodeとClaude Desktopの機能を統合し、AnthropicおよびGeminiモデルをサポートすると説明されています。このアップデートは、AIアプリケーションの開発および展開プロセスを簡素化および高速化することを目的としています (情報源: _akhaliq)
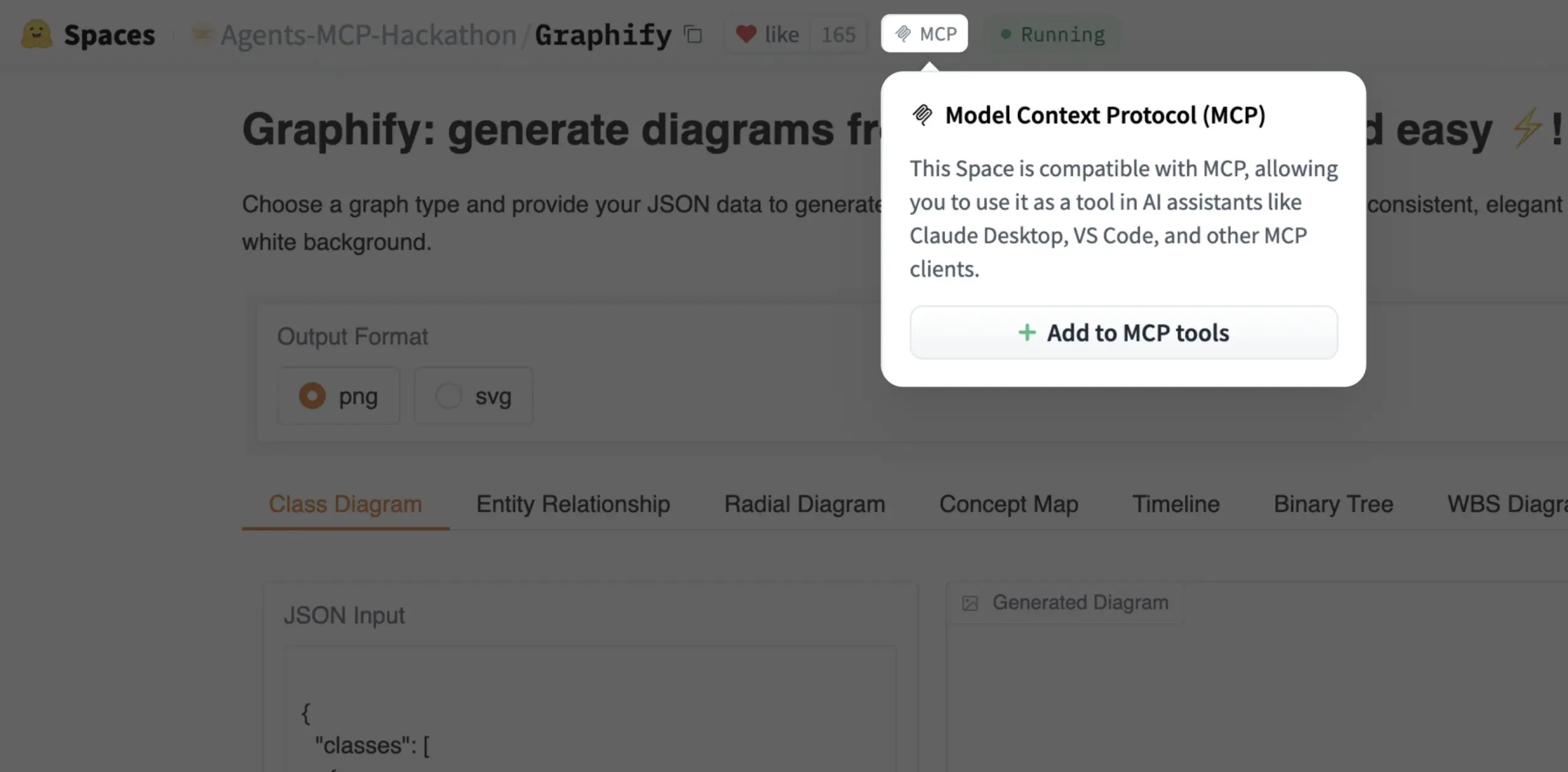
Gradio Space、ワンクリックでMCPツールとして追加可能に: Julien Chaumond氏は、すべてのGradio SpaceがワンクリックでMCP(Model Control Protocol)サーバー内のツールとして追加できるようになったと発表しました。このアップデートにより、Gradioアプリケーションをより広範なAIワークフローやAgentシステムに統合するプロセスが大幅に簡素化され、迅速なプロトタイピングとAIアプリケーション展開のプラットフォームとしてのGradioの実用性が向上します (情報源: mervenoyann, _akhaliq)
Replit、AIコーディングプラットフォーム構築で一連の進展: Replitは、AIコーディングプラットフォームの構築において、認証、ドメイン名、キー管理、バックグラウンドタスク、ストレージ、および汎用モデルアクセスなどの機能を含む一連の進展を遂げました。これらの進展は、開発者により完全で強力なクラウド開発環境を提供し、特にAIアプリケーションの開発と展開を対象としています。Replitはまた、サウジアラビアのHUMAINと協力し、アラビア語優先のReplitバージョンを立ち上げ、現地の開発者を支援しています (情報源: amasad, amasad)

Artificial Analysis、モデルの迅速な「体感テスト」用MicroEvalsをリリース: Artificial Analysisは、従来のベンチマークテストを補完するために、モデルの「体感テスト」(vibe check)を迅速に行うことを目的としたツールMicroEvalsをリリースしました。このツールにより、ユーザーは純粋な数値指標を超えて、特定のユースケースにおけるモデルのパフォーマンスをより直感的に感じることができます。clefourrier氏は、MicroEvalsの実際の応用を示す興味深い「体感テスト」プロンプトと結果のコレクションを共有しました (情報源: clefourrier, RisingSayak)
DeepThinkプラグイン、ローカルモデルにGemini 2.5風の高度な推論能力を提供: ある開発者が、ローカルで実行される大規模言語モデル(DeepSeek R1、Qwen3など)に、Google Gemini 2.5のような「ディープシンキング」高度な推論能力を導入することを目的としたオープンソースのDeepThinkプラグインを構築しました。このプラグインは、構造化された推論方法を通じて、モデルが複数の仮説を並行して生成し、批判的に評価することで、複雑な推論、数学的問題、コーディングチャレンジなどのタスクにおけるパフォーマンスを向上させます。このプロジェクトは、Cerebras & OpenRouter Qwen 3ハッカソンで3等賞を受賞しました (情報源: Reddit r/LocalLLaMA)

Voiceflowの回答ジェネレーター、検索技術を利用してコンプライアンス文書情報を提供: Matthew Mrosko氏は、Voiceflowを使用した回答ジェネレーターの検索事例を共有しました。このシステムは、組織内のコンプライアンス文書にアクセスし、最も関連性の高いテキストブロック、そのスコア、およびソースファイル名を返します。これは、検索拡張生成(RAG)技術が特定の分野の知識に関する質疑応答やコンプライアンスチェックにおいて実際に適用されていることを示しています (情報源: ReamBraden)
📚 学習
DeepLearning.AI、Metaと協力し短期コース「Building with Llama 4」を開設: Andrew Ng氏は、Meta AIとの協力により、新しい短期コース「Building with Llama 4」を開設すると発表しました。講師はMeta AIのパートナーエンジニアリングディレクターであるAmit Sangani氏が務めます。コースでは、Llama 4の3つの新しいモデル(MoEアーキテクチャを採用したMaverickとScoutを含む)、そのマルチモーダル能力(複数画像の推論や画像の位置特定など)、長文コンテキスト処理(最大10M Tokenをサポート)、およびLlamaのプロンプト最適化ツールと合成データツールキットを紹介します。開発者がLlama 4を使用してアプリケーションを構築するスキルを習得できるよう支援することを目的としています (情報源: AndrewYNg, DeepLearningAI, AIatMeta)
Hamel Husain氏、無料のRAG評価と最適化に関する5部構成ミニシリーズコースを企画: Hamel Husain氏は、Ben Clavié氏およびRAG分野の多くの専門家と共に、検索拡張生成(RAG)の評価と最適化をテーマとした無料の5部構成ミニシリーズコースを企画すると発表しました。第1部はBen Clavié氏が講師を務め、「RAGは死んだ」という見解に反論します。Nandan Thakur氏も講義に参加し、RAG時代におけるIRモデルの評価に必要なパラダイムシフトについて議論し、多様性評価指標とベンチマークテスト(FreshStackなど)の重要性を強調します (情報源: HamelHusain, HamelHusain)
Sebastian Raschka氏、KV Cachingのゼロからの理解とコーディングチュートリアル(拡張版)を公開: Sebastian Raschka氏は、キーバリューキャッシュ(KV Caching)に関する最新の記事を共有し、KV Cachingをゼロから理解しコーディングするための拡張版チュートリアルを提供しました。KV Cachingは、大規模言語モデル(LLM)の推論プロセスにおける重要な最適化技術であり、生成プロセスを高速化するために使用されます。このチュートリアルは、読者がその動作原理を深く理解し、実際に実装できるようになることを目的としています (情報源: rasbt)
Direct Reasoning Optimization (DRO) 論文、LLMの自己報酬および推論最適化フレームワークを提案: 「Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks」という論文が、DROという強化学習フレームワークを提案しました。このフレームワークは、新しい報酬信号である推論反射報酬(R3)を通じて、オープンエンド、特に長文の推論タスクにおけるLLMのパフォーマンスを微調整することを目的としています。R3の中核は、参照結果の中でモデルの以前の思考連鎖推論の影響を反映する重要なTokenを選択的に識別し強調することであり、これにより、きめ細かいレベルで推論と参照結果の間の一貫性を捉えます。重要なのは、R3が最適化される同じモデル内部で計算されることであり、これにより完全に自己完結型の訓練設定が実現されます (情報源: teortaxesTex)

EMLoC論文:エミュレータベースのメモリ効率的なファインチューニングとLoRA補正手法: 論文「EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction」は、EMLoCというフレームワークを提案し、推論と同じメモリ予算でモデルのファインチューニングを実現することを目指しています。EMLoCは、小規模な下流キャリブレーションセット上で活性化認識特異値分解(SVD)を使用して、タスク固有の軽量エミュレータを構築し、その後LoRAを通じてこのエミュレータをファインチューニングします。元のモデルと圧縮されたエミュレータ間の不整合問題を解決するために、論文はファインチューニングされたLoRAモジュールを補正し、推論のために元のモデルにマージバックできる新しい補償アルゴリズムを提案しています。EMLoCは柔軟な圧縮率と標準的な訓練プロセスをサポートし、実験では複数のデータセットとモダリティで他のベースラインを上回り、単一の24GBコンシューマ向けGPUで38Bモデルをファインチューニングできることが示されています (情報源: HuggingFace Daily Papers)
TuringPost、LLMの複雑系視点、エージェント拡張などを網羅した最新AI研究論文を総括: TuringPostは、今週の最新AI研究論文をまとめ、特に「LLMs and Emergence: A Complex Systems Perspective」、「The Illusion of the Illusion of Thinking」、「Build the Web for Agents, not Agents for the Web」など6本の論文を推奨しています。さらに、AIエージェント、コード研究、強化学習、モデル最適化などに関する多数の論文もリストアップしており、研究者や開発者に豊富な学習リソースを提供しています (情報源: TheTuringPost)

Meta AI VJEPA 2ビデオ分類ファインチューニングチュートリアルが公開: Aritra Roy Gosthipaty氏は、Meta AIのVJEPA 2モデルを使用したビデオ分類ファインチューニングのJupyter Notebookチュートリアルを公開しました。VJEPA(Video Joint Embedding Predictive Architecture)は自己教師あり学習手法であり、ビデオ内のマスクされた部分の表現を予測することでビデオ特徴を学習することを目的としています。このチュートリアルは、ビデオ理解タスクでVJEPA 2モデルを応用したい研究者や開発者に実践的な指導を提供します (情報源: mervenoyann)
論文、検証可能な報酬による強化学習を通じたLLMの正しい推論の奨励を議論: 「Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs」と題された論文は、従来のPass@K指標が推論能力の測定において欠陥があることを指摘しています。なぜなら、最終的な答えは正しいものの、推論プロセスが不正確または不完全な思考連鎖(CoTs)を報酬する可能性があるためです。このため、研究者らは、推論経路と最終的な答えの両方が正しいことを要求する、より正確な評価指標CoT-Pass@Kを導入しました。研究では、CoT-Pass@Kを使用すると、RLVR(Reinforcement Learning with Verifiable Rewards)がモデルに正しい推論プロセスを汎化するよう奨励できることが発見されました (情報源: menhguin, teortaxesTex)

論文「From Bytes to Ideas: Language Modeling with Autoregressive U-Nets」が新しい言語モデリング手法を提案: Aran Komatsuzaki氏は、自己回帰U-Netモデルを提案する新しい論文を紹介しました。このモデルは生のバイトを直接処理し、階層的なToken表現を学習します。研究によると、この手法は強力なBPE(Byte Pair Encoding)ベースラインに匹敵し、より深い階層構造は有望な拡張傾向を示しています。これは言語モデリング分野に新しい考え方を提供し、特に基盤となるデータ表現の処理と多層的な特徴の学習において重要です (情報源: jpt401)

LambdaConf 2025、Oren Rozen氏によるC++における関数型プログラミングに関する講演を共有: LambdaConf 2025は、Oren Rozen氏が会議で行った「C++における関数型プログラミング(実行時型 vs コンパイル時型)」に関する講演ビデオを共有しました。この講演では、C++というマルチパラダイム言語において関数型プログラミングの考え方と技術を適用する方法、特に実行時型とコンパイル時型が関数型プログラミングの実践において果たす異なる役割と影響について議論しています (情報源: lambda_conf)

Zach Mueller氏、「From Scratch -> Scale」コースを開講、分散訓練技術を教授: Zach Mueller氏は、5週間のコース「From Scratch -> Scale」の募集を開始したと発表しました。このコースでは、受講者に分散データ並列(DDP)、ZeRO、パイプライン並列、テンソル並列コードをゼロから記述する方法を教え、これらの技術を組み合わせます。コースには、Hugging Face、Meta、Snowflakeなどの企業から経験豊富な専門家も招かれ、知見を共有します (情報源: eliebakouch, HamelHusain)

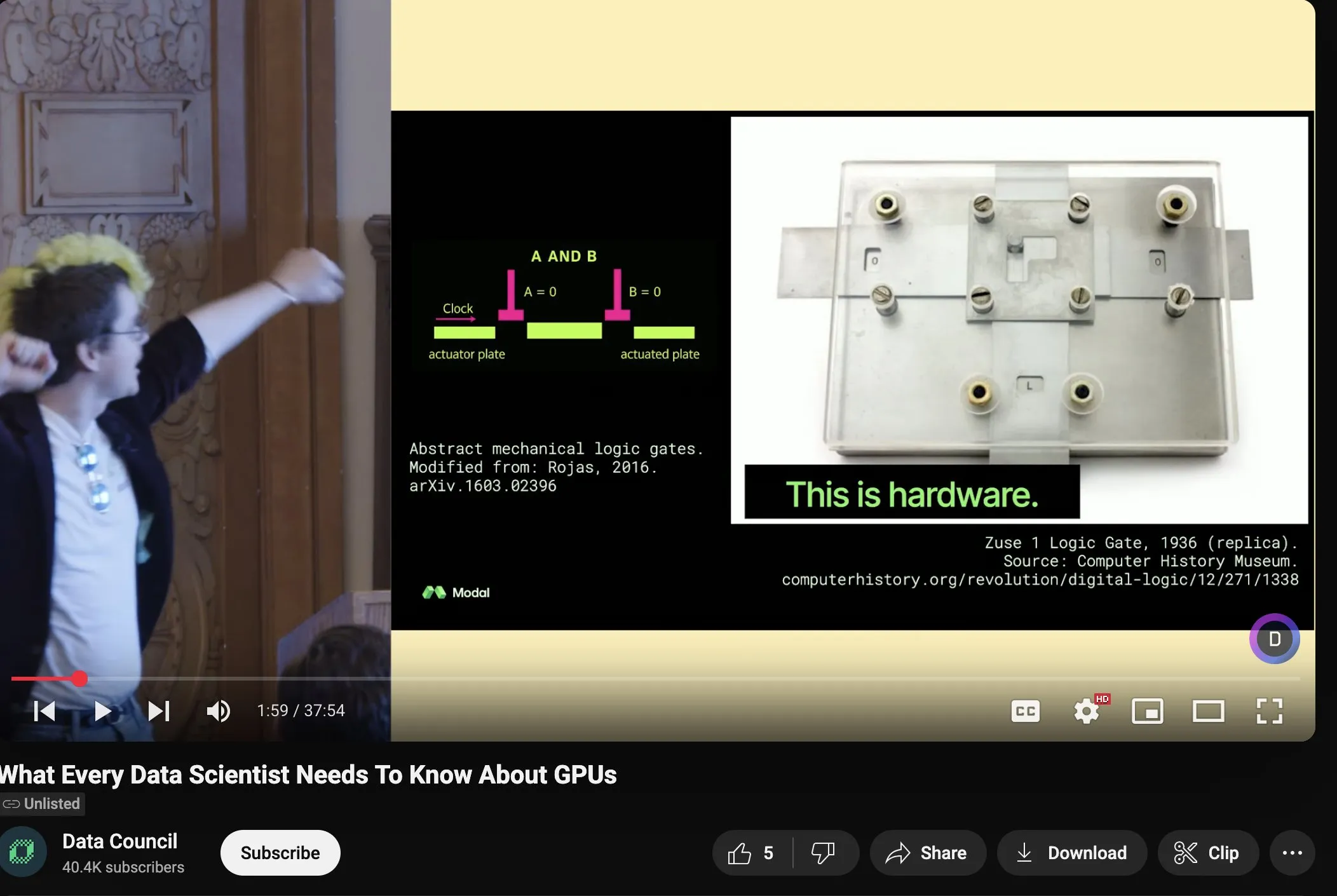
Charles Frye氏、GPU拡張と数学的帯域幅に関する講演を共有、低精度行列積の重要性を強調: Charles Frye氏は自身の講演録画を共有し、その核心的な見解として、GPUの拡張は帯域幅の拡張に類似しており、遅延と二次関係にあること、GPU拡張の鍵となる帯域幅は数学的帯域幅(FLOP/s)であること、そして様々な数学的帯域幅の中で、低精度行列積の拡張速度が最も速いことを挙げました。彼はまた、これがデータエンジニアリングとデータサイエンス分野に与えるいくつかの示唆についても議論しました (情報源: charles_irl)
💼 ビジネス
Sam Altman氏、MetaがOpenAIから人材を引き抜こうと1億ドルの契約ボーナスを提示したことを暴露: OpenAIのCEOであるSam Altman氏は、あるポッドキャスト番組で、Metaが最大1億ドルの契約ボーナスとより高い年俸を提示してOpenAIの従業員を引き抜こうとしたことを明らかにしました。Altman氏によると、Metaの積極的な引き抜きにもかかわらず、OpenAIの最も優秀な従業員はこれらの申し出を受け入れなかったとのことです。彼はまた、MetaがOpenAIを最大の競争相手と見なしており、Metaの現在のAIにおける取り組みは期待に達していないとコメントしつつも、新しいことに積極的に挑戦する精神を尊重していると述べました。Altman氏は、Metaが高給で人材を引きつけようとするやり方は企業文化を損なう可能性があると考えています (情報源: TheRundownAI, bookwormengr, seo_leaders, akbirkhan, 財聯社AI daily, Reddit r/ChatGPT)
マスク氏のxAI、月間10億ドルを消費、AGI研究開発支援のため新たな資金調達を模索: 報道によると、イーロン・マスク氏のAIスタートアップ企業xAIは、主にGPUの購入やデータセンターなどのインフラ建設に、月間10億ドルという驚異的なペースで資金を消費しています。OpenAIやGoogleなどの巨大企業との競争を維持し運営を続けるため、xAIは新たに43億ドルの株式資金調達を行っており、来年にはさらに64億ドルを調達する計画です。同時に50億ドルの負債による資金調達も進めています。今年の収益予測はわずか5億ドルですが、xAIはマスク氏の求心力、Xプラットフォームのデータ優位性、そして自社インフラ構築への決意を武器に、投資家に対して2027年の黒字化という青写真を描いています。その評価額は2024年末の510億ドルから今年第1四半期末には800億ドルに増加しました。マスク氏の最終目標は、人間と同等かそれ以上の汎用人工知能(AGI)を創造することです (情報源: 新智元)

Nabla、臨床医向けAIアシスタントを構築、シリーズCで7000万ドルを調達: AI医療企業Nablaは、シリーズCラウンドで7000万ドルを調達したと発表しました。このラウンドはHV Capital、Highland Europe、DST Globalが主導し、既存投資家のCathay InnovationとTony Fadell氏も引き続き参加しました。Nablaは臨床医向けの先進的なインテリジェントAIアシスタントの構築に取り組んでおり、AI技術を通じて医療の中核である人間的な配慮を回復し、実際の臨床的および財務的影響をもたらすことを目指しています。今回の資金調達は、その使命の実現を加速させるでしょう (情報源: ylecun)

🌟 コミュニティ
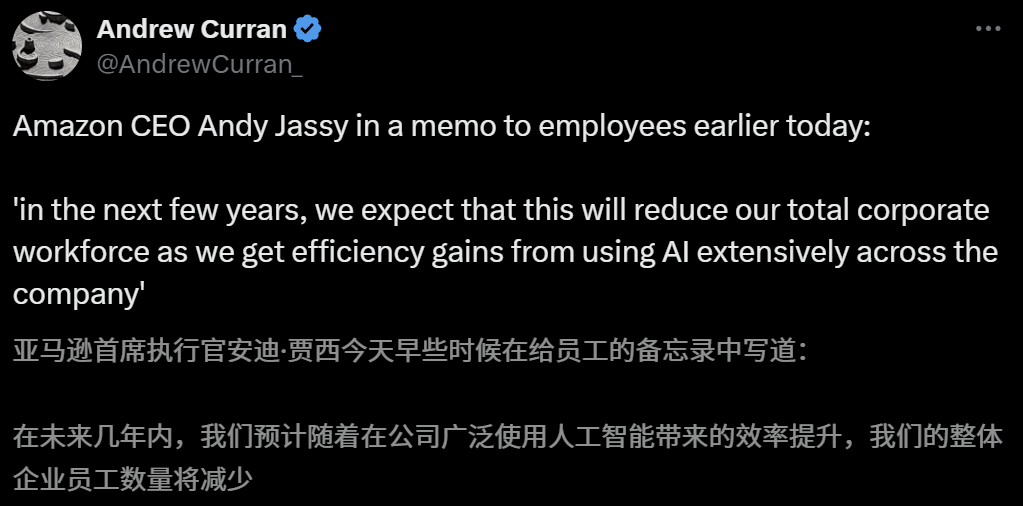
AIの雇用市場への影響が懸念される中、Amazon CEOはAIにより今後数年で従業員が減少すると警告: AmazonのCEOであるAndy Jassy氏は、全従業員宛の書簡で、同社がより多くの生成AIとエージェントを推進するにつれて働き方が変化し、今後数年で一部の現行職務に必要な人員が減少し、新しい職務の需要が増加するため、同社の機能部門の従業員総数は相応に減少すると予想されると述べました。これに先立ち、AnthropicのCEOであるDario Amodei氏も、AIが5年以内にエントリーレベルのホワイトカラー職の半数を代替する可能性があると警告していました。これらの見解は、AIの雇用市場への衝撃に関する広範な議論を引き起こしており、既にテクノロジー業界の従業員からはAIに取って代わられたり、求職難に直面したりした経験が共有され、2025年卒業の大学生もコロナ禍以来最も厳しい就職市場に直面しています (情報源: 新智元, 新智元)
AI大学進学志望校選定ツールが注目されるも、アルゴリズムの不透明性、データの真正性、個別化がユーザーの課題に: 大学進学志望校選定市場が活況を呈する中、アリババのQuark、Baidu、Tencent QQブラウザなどの大手企業が相次いでAI志望校選定ツールをリリースし、スマートさ、効率性、無料を謳っています。しかし、ユーザーが使用する中で、同じ点数でもツールによって推薦される大学が大きく異なり、アルゴリズムの不透明性、データの網羅性や真正性への疑問、個別化の度合いの不足といった問題から、ユーザーはAIに完全に依存することをためらっています。専門家は、データソースやアルゴリズムの重み付けの違いが推薦結果の相違の主な原因であると指摘しており、AIツールは現在、点数が両極端で目標が明確な受験生、または中間層の点数の受験生の補助ツールとして適しており、ユーザーは効果的な質問の仕方を学ぶ必要があるとしています (情報源: 36氪)
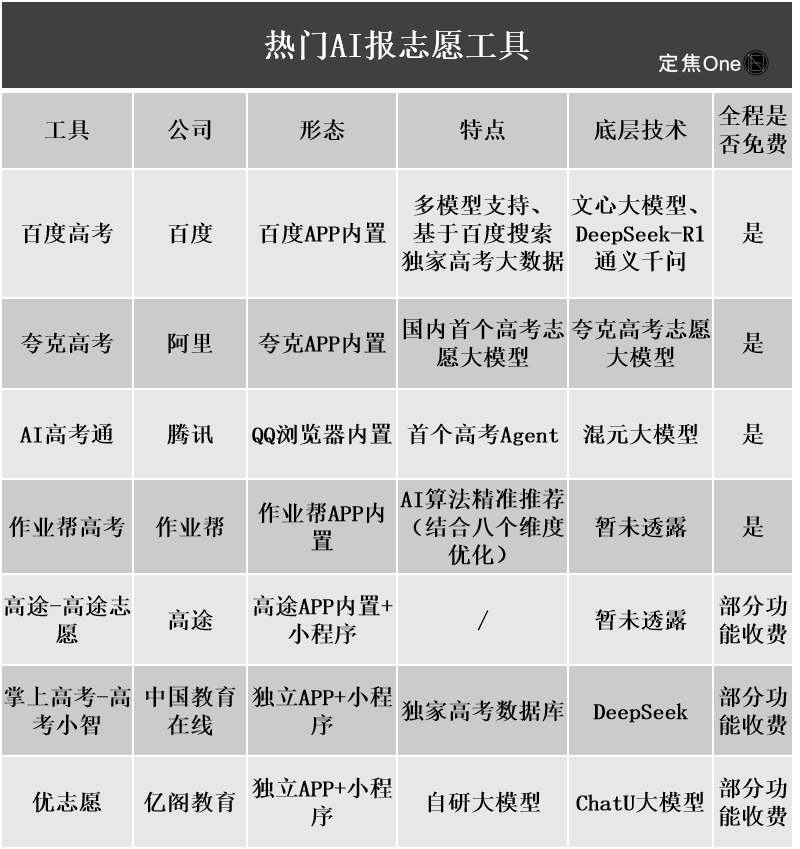
AIの教育分野での応用普及が、保護者の不安と市場の熱狂を引き起こす: AI技術は教育分野への浸透を加速させており、AI自習室、AI学習機から各種AI学習支援アプリまで次々と登場し、DeepSeekなどの大規模モデルの導入が製品のアップグレードをさらに推進しています。保護者たちはAIを通じて子供たちが「追い越し車線」に入ることを期待していますが、それによって新たな不安に陥っています。市場調査によると、AI+教育市場の規模は2025年に700億元を突破すると予測されています。しかし、AI教育製品の実際の効果、データプライバシー、そして学習の本質を本当に向上させるのかといった問題は依然として議論の焦点です。教育の意味は、技術主導の「軍拡競争」に限定されるべきではなく、個人の発展と多様な可能性にもっと注目すべきです (情報源: 36氪, 36氪)

議論:大規模モデル推論における「ターンマーカートークン」の必要性: コミュニティでは、対話モデルにおける「ターンマーカー」(ユーザーとアシスタントの発言を識別する特殊なtokenなど)が常に全く同じ数個のtoken(例えば user\n と assistant\n)に続く場合、これらのターンマーカー自体は必須ではないかもしれないという議論があります。さらに、あるtokenのグループ(例えば3つ)が何かを共同でマークし、モデルがその最初のtokenの重要性を学習する必要がある場合、反事実(counterfactual)を含むコンテキスト例を提供しなければならず、そうでなければモデルはその重要性を正確に学習できない可能性があるという意見もあります。この議論は、Claude Opus 4が対話インジェクション(dialogue injection)に騙されやすい現象に関連しており、モデルの対話構造の理解と処理にはまだ改善の余地があることを示唆しています (情報源: giffmana, giffmana)
AIエージェントの職場応用における意欲と能力のミスマッチ問題が注目を集める: スタンフォード大学のチームの研究により、AIエージェントが職場の自動化において、需要と能力の間に著しいミスマッチが存在することが明らかになりました。研究によると、YCインキュベーション企業のタスクの約41%が、労働者の自動化意欲が低いか、AI技術がまだ未熟な「低優先度領域」と「レッドライトゾーン」に集中しています。さらに、多くのタスクが人間と機械の対等な協調を必要とするにもかかわらず、実務家は一般的に人間主導の権限をより高く期待しており、これが摩擦を引き起こす可能性があります。研究は、AIエージェントが労働市場に参入するにつれて、人間の核心的な競争力は対人関係や組織調整スキルに移行する可能性があると予測しています。この研究は、将来のAIエージェントの研究開発と労働力スキルの変革に指針を提供することを目的としています (情報源: 新智元)

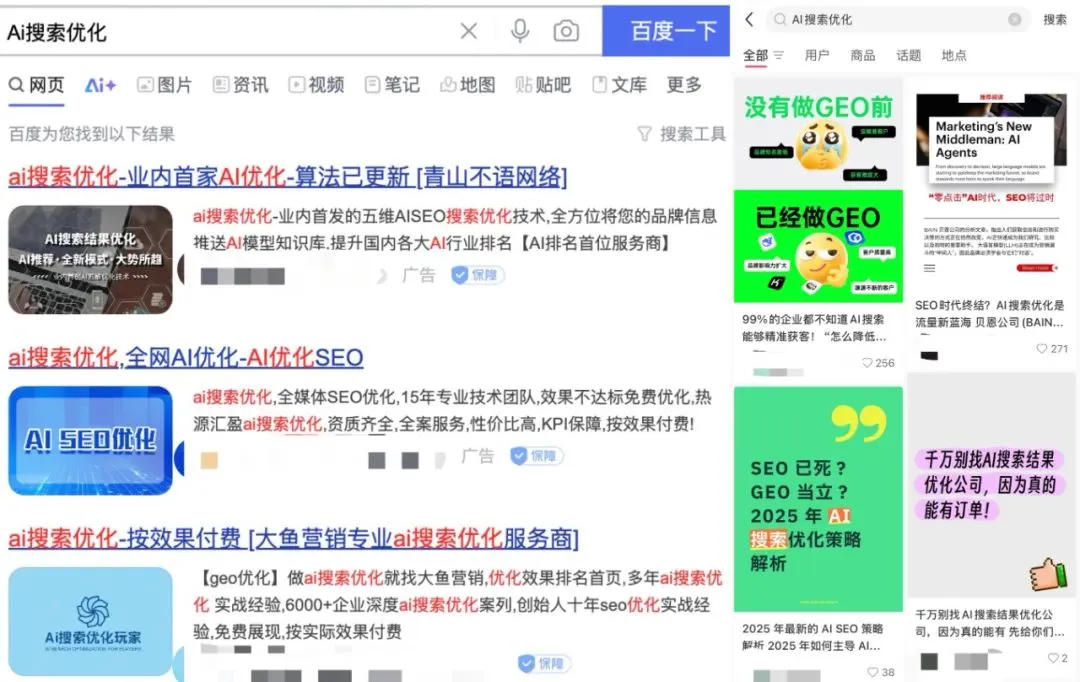
広告会社が生成型検索エンジン最適化(GEO)を利用してAI検索結果に影響を与え、倫理的および規制上の議論を引き起こす: 広告会社は、生成型検索エンジン最適化(GEO)サービスを通じて、企業クライアントがAI検索結果でより高い露出を得るのを支援しています。このサービスは、大規模モデルの好みに合った質の高いコンテンツを出力し、AIデータ「フィーディング」を行うことで、クライアント情報がAIの質疑応答におけるランキングと出現頻度を向上させます。しかし、ユーザーは通常、AI検索結果が最適化されているかどうかを知りません。これは、このような行為が広告を構成するのか、明確な表示が必要なのか、そしてどのような商業規則と境界に従うべきかについての議論を引き起こしています。現在、国内の主要な大規模モデルプラットフォームはまだ正式に広告を導入していませんが、海外では既にAI検索製品が広告モデルを試行し、表示を行っています (情報源: 36氪)
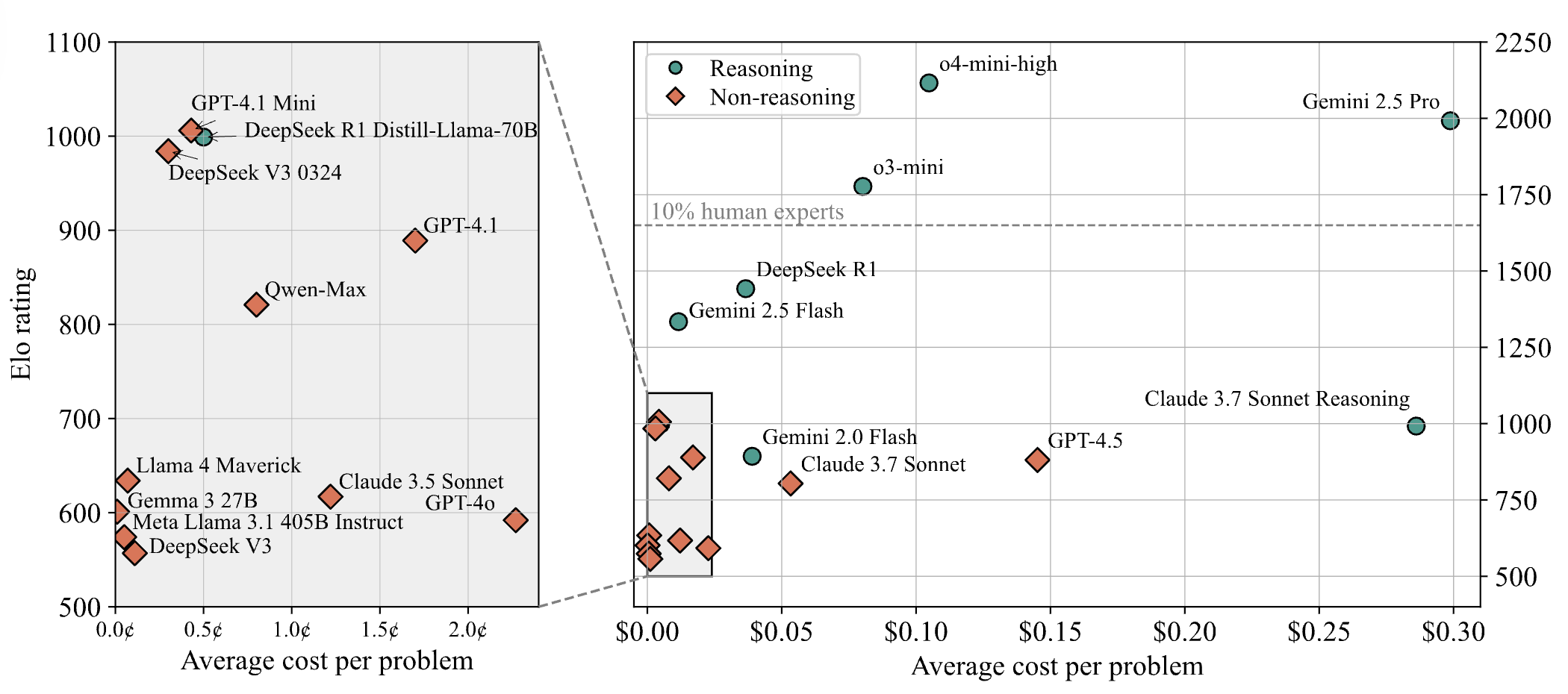
AIモデル、プログラミングコンテストの難問で振るわず、LiveCodeBench Proテスト結果でトップモデルの得点は0%: Zihan Zheng氏らは、IOI、Codeforces、ICPCなどの高難易度プログラミングコンテストの問題を含むリアルタイムベンチマークテストLiveCodeBench Proを公開しました。このベンチマークの「困難」部分では、o3やGemini 2.5を含む最先端の大規模言語モデルの得点はすべて0%でした。分析によると、LLMは記憶に依存する実装型のタスクを得意としますが、重要な「ひらめき」を必要とする観察型や論理型の問題、および細部への注意や境界条件の処理が必要なタスクでは振るいません。Saining Xie氏は、これはソフトウェアエンジニアリングエージェントのベンチマークではなく、コーディングを通じて核心的な推論と知能をテストするものであり、このベンチマークを打ち破ることはAlphaGoが李世乭氏を破ったことに匹敵する意義があるとコメントしています (情報源: ylecun, dilipkay)
AI支援文献レビューツールotto-SR、効率と正確性を大幅に向上: トロント大学、ハーバードメディカルスクールなどの機関が共同開発したAIエンドツーエンドワークフローotto-SRは、システマティックレビュー(SRs)の自動化に使用されます。このツールはGPT-4.1とo3-miniを組み合わせて文献スクリーニングとデータ抽出を行い、従来の方法では12年かかるCochraneシステマティックレビューの更新をわずか2日間で完了しました。ベンチマークテストでは、otto-SRの感度(96.7% vs 人間81.7%)とデータ抽出精度(93.1% vs 人間79.7%)の両方で人間のレビュアーを大幅に上回り、人間が見逃した54件の重要な研究を発見しました。この研究は、AIが医学研究を加速し、エビデンス統合の質を向上させる上での大きな可能性を示しています (情報源: 量子位)

「Vibe Coding」における構造化DSLの応用探索: Ted Nyman氏などの開発者は、自由形式の自然言語の代わりに、より構造化されたDSL(ドメイン固有言語)に近いものを使用して「Vibe Coding」(感性的、直感的なプログラミング方法の一種)を行う実験を行っており、この方法の方が効果が高く、速度も速く、フラストレーションも少なく、生成されるコードの品質も高いことを発見しています。この探索は、AI支援プログラミングまたはコード生成のためのより効率的で正確な人間と機械のインタラクションパラダイムを見つけることを目的としています (情報源: tnm, lateinteraction)
AI Agentのソフトウェア信頼性工学(SRE)における応用展望: Traversal AIは、エンタープライズレベルのAI SRE(サイト信頼性エンジニア)の構築に取り組むため、シードラウンドとAラウンドで4800万ドルの資金調達を完了したと発表しました。そのAI Agentは、複雑な本番環境のインシデントを自律的にトラブルシューティング、修復、さらには予防することができ、AI Agent技術と因果機械学習を組み合わせてリアルタイムで根本原因を特定します。DigitalOcean、Eventbriteなどの企業が初期顧客となっており、AIが運用自動化とシステム信頼性向上において大きな可能性を秘めていることを示しています (情報源: hwchase17)
💡 その他
AI生成のジブリ風「スマホゲーム」が注目を集める、チュートリアルによるとKling AIとMidjourneyで制作: 最近、ジブリ風の「スマホゲーム」のスクリーンショットと動画がソーシャルメディアで話題となり、その美しい画面、さわやかな色彩、自然な光と影の効果が注目を集めています。制作者は制作方法を公開しました。まずMidjourneyを使用して静止画像を生成し、次に快手傘下のKling AIを使用して画像を動的な動画に変換します。ボタンやミニマップなどの固定されたHUD(ヘッドアップディスプレイ)要素を追加することで、インタラクティブなゲームのような感覚を醸し出しています。現在は動画デモンストレーションに過ぎませんが、AIが生成するインタラクティブな仮想世界へのネットユーザーの想像力をかき立てています (情報源: 量子位, Kling_ai)

AIの誤りチェック各分野における応用ポテンシャルは大きい: ネットユーザーのrandom_walker氏は、生成AIは誤りチェックにおいて大きな応用ポテンシャルを持ち、各分野で「低いところにある果実」があると提言しています。例えば、ソフトウェア分野ではセキュリティ脆弱性を自動検出し、文章作成では論理的欠陥や弱い論点を識別し、科学研究では計算ミスや引用問題を検出し、法的契約では欠落条項や矛盾点をマークし、金融分野では不正検出や財務報告書の誤り識別に利用できます。彼は、誤りチェックは自動化の度合いが高く、干渉も少なく、誤報率が50%であっても人手による再確認は比較的容易であり、人間を退屈な作業から解放できると考えています。しかし、AIへの過度な依存が人間の能力低下を招くリスクにも警戒が必要です (情報源: random_walker)
Sam Altman氏インタビュー:AIは仕事を簡素化し、パーソナライズされたソーシャルを提供し、科学的発見を後押しする: OpenAIの創設者Sam Altman氏はインタビューで、今後5~10年でAIプログラミングおよびチャットツールはより賢くなり、ほとんどの仕事を自動的に完了できるようになると予測しました。AIは新しいソーシャル体験をもたらし、パーソナライズされたサービスを提供し、特に天体物理学や高エネルギー物理学などのデータ集約型分野で新しい科学的知識の発見を助ける可能性があります。彼は、AIの真の変革は、思考するだけでなく、物理世界で行動できる点にあり、人型ロボットが重要な課題であると強調しました。OpenAIのビジョンは、AIを遍在する「AIコンパニオン」とし、プラットフォーム化とハードウェア協力を通じて実現することです。彼は、文化と長期主義がOpenAIの核心的な競争力であると考えています (情報源: 36氪)