キーワード:量子コンピューティング, AI自己進化, ブレイン・コンピュータ・インターフェース, 大規模言語モデル, ニューロモーフィック・コンピューティング, AI動画生成, 強化学習, AI倫理, 量子ビット誤り率, JEPA自己教師あり学習, MLXフォーマット量子化, PAM視覚理解モデル, AI ASMRコンテンツ生成
🔥 フォーカス
オックスフォード大学、Quantum Computing実験で記録的な0.000015%のエラー率を達成: オックスフォード大学の研究チームは、Quantum Computing実験で大きな進展を遂げ、quantum bitのエラー率を0.000015%にまで低減し、世界新記録を樹立しました。この進展はフォールトトレラントquantum computerの構築に不可欠であり、極めて低いエラー率は複雑なquantum algorithmの実現とquantum computingのポテンシャルを発揮するための前提条件です。この成果は、ハードウェアレベルでのquantum bitの安定性と精密な操作における著しい進歩を示しており、将来のAIなど強力な計算能力に依存する応用分野に対し、より強固な基盤を築くものです (情報源: Ronald_vanLoon)

MITの研究者、AIに自己アップグレードと改善を学習させる: マサチューセッツ工科大学(MIT)の研究者は、AIの自己改善分野で進展を遂げ、AIシステムが自律的に学習し自身の性能を改善できる新しい手法を開発しました。この能力は、人間が経験と反省を通じて絶えず進歩するプロセスを模倣しており、より自律的で適応性の高いAIの開発にとって極めて重要です。この研究は、AIモデルがデプロイ後に継続的に最適化され、人為的な介入への依存を減らす道を開く可能性があり、AIの長期的な発展と応用に大きな影響を与えるでしょう (情報源: TheRundownAI)

「読心術」AI、麻痺患者の脳波をリアルタイムで音声に変換: ある画期的な研究で、「読心術」AIが麻痺患者の脳波をリアルタイムで明瞭な音声に変換する様子が示されました。この技術は、高度なブレイン・コンピュータ・インターフェース(BCI)とAIアルゴリズムを通じて、言語に関連する神経信号を解読し、理解可能な音声出力として合成します。これにより、重度の運動障害により言語能力を失った患者に全く新しいコミュニケーション手段を提供し、彼らの生活の質を大幅に改善することが期待され、AIによる補助医療と神経科学分野における大きな進歩を示しています (情報源: Ronald_vanLoon)

数学・物理学の世紀の難問に突破口、北京大学卒業生がヒルベルト第六問題の解明に参加: 北京大学卒業生の鄧煜氏、中国科学技術大学少年班出身の馬驍氏、そしてテレンス・タオ氏の高弟であるザヘル・ハニン氏が、ヒルベルト第六問題「物理学の公理化」において大きな進展を遂げました。彼らは初めて、ニュートン力学(ミクロ、時間可逆)からボルツマン方程式(マクロ統計、時間不可逆)への完全な移行を厳密に証明し、両者の間の論理的な溝を埋め、統計力学により強固な数学的基礎を築き、さらに予期せず「時間の矢の謎」を解明しました。この成果は、巧妙な数学的ツールと段階的な導出を通じて、原子論から連続体力学の運動法則への道筋を示しています (情報源: 量子位)

🎯 動向
Alibaba、Qwen3シリーズモデルのMLXフォーマット版をリリース: Alibabaは、同社のQwen3シリーズ大規模モデルがMLXフォーマットをサポートし、4ビット、6ビット、8ビット、およびBF16の4つの量子化レベルを提供すると発表しました。MLXはApple社がApple Silicon向けに最適化した機械学習フレームワークであり、これによりQwen3モデルはAppleデバイス上でより効率的に動作し、エッジデバイスでの大規模モデルのデプロイと実行のハードルが下がり、個人デバイスでの大規模モデルの普及と応用を促進するのに役立ちます (情報源: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google、Gemma 3nモデルを発表、小パラメータで高性能を実現: GoogleはGemma 3nモデルを発表しました。このモデルはパラメータ数が100億未満でありながら、LMArenaスコアで1300点を超え、この成果を達成した初の小型モデルとなりました。Gemma 3nの優れた性能は、比較的小さなパラメータ規模でも高レベルの言語理解と生成能力を実現できることを証明しており、スマートフォンなどのエッジデバイスでの実行もサポートしているため、AIアプリケーションの普及と計算コストの削減に重要な意味を持ちます (情報源: osanseviero)
Tencent、AIによる映画級3Dアセット生成技術を発表: Tencentは、映画級の品質を持つ3Dアセットを生成できる新しいAI技術を発表しました。この技術は、ゲーム開発や映画・テレビ制作などの分野における3Dコンテンツ作成の効率と品質を大幅に向上させ、制作コストを削減することが期待されます。高品質な3Dアセットの迅速な生成は、メタバースやデジタルコンテンツ産業の発展における重要な要素です (情報源: TheRundownAI)
KuaishouのKling 2.1モデル、画像から動画への変換および音声・動画同期生成で優れた性能を発揮: Kuaishou傘下のAI動画生成モデルKlingが2.1バージョンにアップデートされ、画像から動画への変換において強力な能力を示しました。新バージョンは、動画と音声をワンクリックで生成でき、後からの音響効果設計なしで、スタジオレベルの音声・動画同期コンテンツを生成できるとされています。これは、AIによるマルチモーダルコンテンツ生成、特に動画分野における進歩を示しており、制作プロセスを簡素化し、生成品質を向上させています (情報源: Kling_ai, Kling_ai)
新型AI動画モデル「Kangaroo」はMinimaxの海螺2.0の可能性、既存SOTAに挑戦: 市場に「Kangaroo」という名の謎のAI動画生成モデルが登場し、AI動画コンペティションで強力なパフォーマンスを見せており、特に画像から動画への変換において優れています。分析によると、このモデルはMinimax社の海螺2.0バージョンである可能性があります。その登場は、既存のテキストから動画および画像から動画へのモデルの性能序列を変える可能性がありますが、その音声処理能力はまだ評価待ちです (情報源: TomLikesRobots)
MiniMax、M1シリーズモデルを発表、長文処理能力が際立つ: MiniMaxAIは、456Bパラメータを持つMoE(Mixture of Experts)モデルであるMiniMax-M1モデルシリーズを発表しました。このシリーズモデルは、複数のベンチマークで優れた性能を示し、特に長文コンテキスト処理(OpenAI-MRCRベンチマークなど)ではGPT-4.1を上回り、LongBench-v2では第3位にランクインしました。これは長文ドキュメントの処理と理解における潜在能力を示していますが、その比較的大きな「思考予算(thinking budget)」は計算リソースに高い要求を突きつける可能性があります (情報源: Reddit r/LocalLLaMA)

チューリング賞受賞者Richard Sutton氏:AIは「人間データ時代」から「経験時代」へ移行中: 強化学習の創始者であるRichard Sutton氏は北京智源大会で、現在の人間のデータに依存するAI大規模モデルは限界に近づいており、高品質な人間データは枯渇し、モデル規模拡大の効率は低下していると指摘しました。彼はAIの未来は「経験時代」に入ることにあるとし、すなわち、エージェントが環境とのリアルタイムなインタラクションを通じて一次的な経験を生成して学習し、古いテキストを模倣するのではないと述べました。これには、エージェントが現実またはシミュレートされた環境で継続的に動作し、環境からのフィードバックを報酬信号として利用し、ワールドモデルと記憶システムを発展させ、真の継続的学習とイノベーションを実現する必要があります (情報源: 36氪)

PAMモデル:3Bパラメータで画像・動画のセグメンテーション、認識、解説を統合: 香港中文大学MMLabなどの機関は、Perceive Anything Model (PAM)をオープンソース化しました。この3Bパラメータモデルは、画像と動画内のオブジェクトのセグメンテーション、認識、解釈、記述を同時に行い、テキストとMaskを同期して出力できます。PAMは、Semantic Perceiverを導入してSAM2セグメンテーションバックボーンとLLMを接続することで、効率的な視覚特徴からマルチモーダルトークンへの変換を実現しました。チームはまた、大規模で高品質な画像・テキスト訓練データセットを構築しました。PAMは複数の視覚理解ベンチマークでSOTAを更新またはそれに近づき、より優れた推論効率を備えています (情報源: 量子位)

ニューロモーフィックコンピューティング、次世代AIの鍵となる可能性、低消費電力での運用に期待: 科学者たちは、現在のAIモデルの高エネルギー消費問題を解決するため、人間の脳の構造と動作方法を模倣することを目的としたニューロモーフィックコンピューティングを積極的に探求しています。米国国立研究所などの機関は、ニューロン数が人間の大脳皮質に匹敵するニューロモーフィックコンピュータを開発しており、理論上の動作速度は生物の脳をはるかに超える一方で、消費電力は極めて低い(例えば、20ワットで人間のような脳のAIを駆動)。この技術は、イベント駆動型通信、メモリ内コンピューティング、適応学習を通じて、よりインテリジェントで効率的、低消費電力のAIを実現する可能性があり、AIのエネルギー危機に対する潜在的な解決策であり、AGI開発の全く新しい道筋と見なされています (情報源: 量子位)

AI ASMRコンテンツがショート動画プラットフォームで大流行、Veo 3などの技術が後押し: AIで生成されたASMR(自律感覚絶頂反応)動画がTikTokなどのプラットフォームで急速に人気を集めており、あるアカウントは3日間で約10万人のフォロワーを獲得し、1本のフルーツカット動画の再生回数は1650万回を超えました。これらの動画は、AIが生成した奇抜な視覚効果(ガラス質のフルーツなど)に対応するカット音や衝突音などを組み合わせることで、独特の「ハマる感覚」を生み出しています。Google DeepMindのVeo 3などのモデルは、音声と映像が同期したコンテンツを直接生成できるため、このようなAI ASMRコンテンツ制作を推進する重要な技術と見なされており、従来は音声と映像を別々に制作し合成する必要があったプロセスを簡素化しています (情報源: 量子位)

Meta AIの検索履歴公開が注目を集める、GoogleはAI音声要約をテスト中: Meta社が同社のAI検索機能のユーザー検索履歴を公開したことが、ユーザーのプライバシーとデータ使用の透明性に関する懸念を引き起こしています。一方、Googleは実験室プロジェクトで、検索結果のトップにAIが生成したポッドキャスト形式の音声要約を提供する新機能をテストしており、ユーザーにより便利な情報取得方法を提供することを目指しています。これら2つの動きは、テクノロジー大手によるAI検索と情報提示における継続的な探求とユーザーエクスペリエンス最適化の試みを反映しています (情報源: Reddit r/ArtificialInteligence)

シドニーのチーム、脳波から思考を識別するAIモデルを開発: オーストラリア・シドニーの研究チームは、脳波(EEG)データを分析して個人の思考内容を識別できる新しいAIモデルを開発しました。この技術は、神経科学、ヒューマン・コンピュータ・インタラクション、および補助コミュニケーションなどの分野で潜在的な応用価値があり、例えば、従来の方法ではコミュニケーションが取れない人々が意図を表現するのを助けることができます。この研究は、ブレイン・コンピュータ・インターフェース技術の発展をさらに推進し、複雑な脳活動の解読におけるAIの能力を探求しています (情報源: Reddit r/ArtificialInteligence)
カリフォルニア州、採用・解雇などの決定におけるAIの「ロボットボス」的役割を制限する法案を検討: 米国カリフォルニア州は、企業がAIシステムのアドバイスのみに基づいて採用や解雇といった重要な人事決定を行うことを制限する法案を推進しています。この法案は、人間の管理者がAIによるそのような提案を審査し、支持することを義務付け、人的監督と説明責任を確保することを目指しています。ビジネス団体はこれに反対しており、コンプライアンスコストが増加し、既存の採用技術と衝突すると主張しています。この動きは、特に職場における自動化された意思決定に関して、AI倫理と社会的影響への関心が高まっていることを反映しています (情報源: Reddit r/ArtificialInteligence)

🧰 ツール
Augmentoolkit 3.0リリース、データセット生成とファインチューニングプロセスを強化: Augmentoolkitは3.0バージョンをリリースしました。これは、長文ドキュメント(歴史的テキストなど)からQAデータセットを作成し、モデルのファインチューニングを行うためのツールです。新バージョンは、訓練データを自動生成しモデルを訓練する生産レベルのパイプラインを提供し、高品質なQAデータセット生成用に特別にファインチューニングされたローカルモデルを内蔵し、ノーコードインターフェースを提供します。このツールは、ドメイン固有モデルのファインチューニングと訓練データ生成のプロセスを簡素化し、技術的ハードルを下げることを目的としています (情報源: Reddit r/LocalLLaMA)
Opius AI Planner:Cursor Composer体験を最適化するAIプランナー: Opius AI Plannerという名のCursor拡張機能がリリースされました。これは、Cursor Composerが曖昧な要求を理解する際の問題を解決することを目的としています。このツールはプロジェクトの要求を分析し、詳細な実装ロードマップを生成し、Composerに最適化された構造化プロンプトを出力することで、反復回数を減らし、プロジェクトの成果を初期の構想により近づけます。これは、AI支援計画を通じてAIコード生成ツールの実用性を向上させる傾向を反映しています (情報源: Reddit r/artificial)
Continue拡張機能:VSCodeでローカルオープンソースCopilotとMCP統合を実現: ContinueはVSCode拡張機能で、ユーザーがローカルで実行されるオープンソース大規模言語モデルをコーディングアシスタントとして設定・使用し、MCP(Model Control Protocol)ツールを統合することを可能にします。ユーザーはLlama.cppやLMStudioなどのサービスを通じてローカルにモデルをデプロイし、Continueを介して対話することで、コードアシスタントの完全な制御とカスタマイズを実現できます。例えば、Playwrightブラウザ自動化ツールを統合するなどです (情報源: Reddit r/LocalLLaMA)

豆包大規模モデルと火山引擎MCPの連携、クラウドサービス展開と個人ページ生成を簡素化: ByteDanceの豆包大規模モデルは、火山引擎モデル制御プロトコル(MCP)との深い統合能力を示しました。ユーザーは自然言語による指示を通じて、豆包大規模モデルに火山引擎の機能(veFaaS Function as a Serviceなど)を呼び出させ、個人のソーシャルメディア案内ウェブページを生成し自動的にオンラインにデプロイするなどのタスクを完了させることができます。この統合は、クラウド環境の手動設定の複雑な手順を省き、クラウドサービスの使用のハードルを下げ、AIがDevOpsプロセスの簡素化において持つ可能性を示しています (情報源: karminski3)
Figma、AI新機能発表:テキストプロンプトから即座にウェブサイトを生成: Figmaは、ユーザーが入力したテキストプロンプトに基づいてウェブサイトのプロトタイプやページを迅速に生成できる、AI駆動の新機能を発表しました。この機能は、ウェブデザインと開発プロセスを加速させ、デザイナーや開発者が自然言語記述を通じてアイデアを迅速に視覚的デザインに変換できるようにすることを目的としており、生成AIがクリエイティブデザインツール分野に浸透していることをさらに示しています (情報源: Ronald_vanLoon)
Hugging Faceモデルハブにモデルサイズによるフィルタリング機能が追加: Hugging Faceプラットフォームは、モデルハブにユーザーがモデルのパラメータサイズに基づいてフィルタリングできる実用的な機能を追加しました。この改善により、開発者や研究者は特定のハードウェアリソースや性能要件に合致するモデルをより簡単に見つけることができ、膨大なモデルライブラリ内でのナビゲーションと選択の効率が向上します (情報源: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
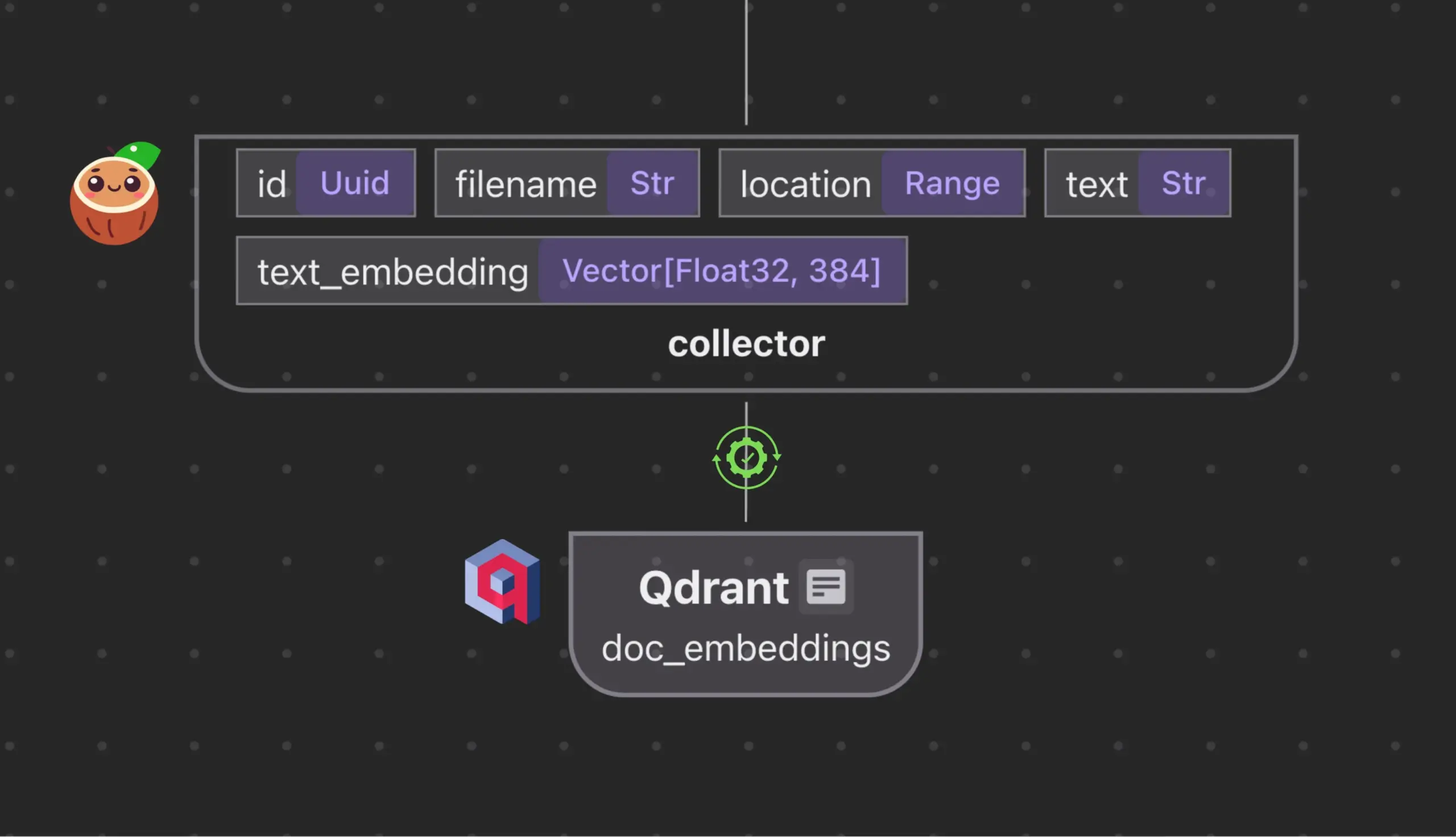
Cocoindex.ioとQdrantが統合、ベクトルデータベースコレクションを自動作成・同期: オープンソースデータフローツールCocoindex.ioは、Qdrantベクトルデータベースコレクションの自動作成をサポートするようになりました。ユーザーがデータフローを定義するだけで、このツールは適切なQdrantスキーマ(ベクトルサイズ、距離尺度、ペイロード構造を含む)を推測し、ベクトルフィールド、ペイロードタイプ、主キーの同期を維持し、増分更新をサポートします。これにより、ベクトルデータベースの設定と管理が簡素化され、データチームの効率が向上します (情報源: qdrant_engine)
Manus AI:コード記述だけでなく自動デプロイも可能な全工程AI開発ツール: Manus AIは、コード記述から環境設定、依存関係のインストール、テスト、さらにはオンラインURLへの最終デプロイまでを実現するエンドツーエンドのAI開発ツールです。マルチエージェント協調アーキテクチャ(計画、開発、テスト、デプロイ)を採用し、依存関係の問題やデバッグエラーを自律的に解決できます。現在、クレジットベースの価格設定モデル、中国チームによる開発(コンプライアンス上の考慮事項が関与する可能性あり)、および超複雑なエンタープライズアーキテクチャへのサポートの限界が存在しますが、「AI支援コーディング」から「AI実行開発」への転換の可能性を示しています (情報源: Reddit r/artificial)

📚 学習
翻訳理論及びAI翻訳プロンプト最適化ガイド: 思果氏の『翻訳新究』における「翻訳即ち書き換え」理論と余光中氏の『翻訳乃大道』の観点を組み合わせ、高品質な翻訳の原則を探求。翻訳は字句通りの対応ではなく、ターゲット言語の自然な表現を重視し、直訳と意訳を柔軟に使い分け、中国語と西洋言語の論理構造の違いに注意して構文を改変する必要性を強調。記事はまた、中国語表現の純粋性、専門用語の扱いについて議論し、AI翻訳における「直訳-分析-意訳」の3ステッププロセスの限界を反省し、より融合的な「理解-表現-校正-最適化」プロセスを採用することで、AI翻訳の品質を向上させ、中国語の科学普及文体に近づけることを提案 (情報源: dotey)

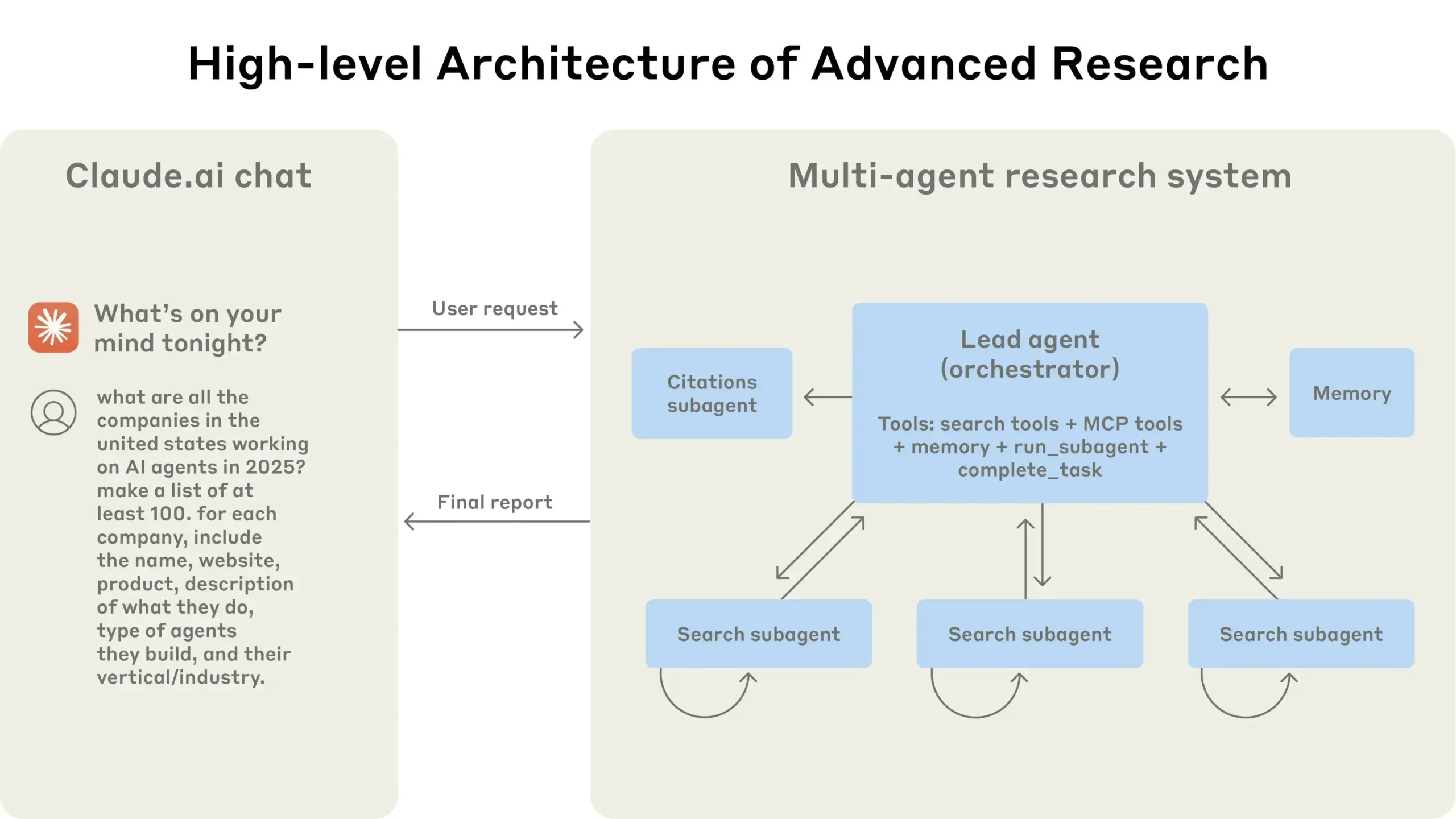
Anthropic、マルチエージェント研究システム構築経験を共有: AnthropicAIは、同社のマルチエージェント研究システムの構築方法を詳述した無料ガイドを公開しました。内容は、システムアーキテクチャの動作原理、プロンプトエンジニアリングとテスト方法、生産における課題、およびマルチエージェントシステムの利点を含みます。このガイドは、マルチエージェントシステムに関心のある研究者や開発者に貴重な実践経験と洞察を提供します (情報源: TheTuringPost, TheTuringPost)
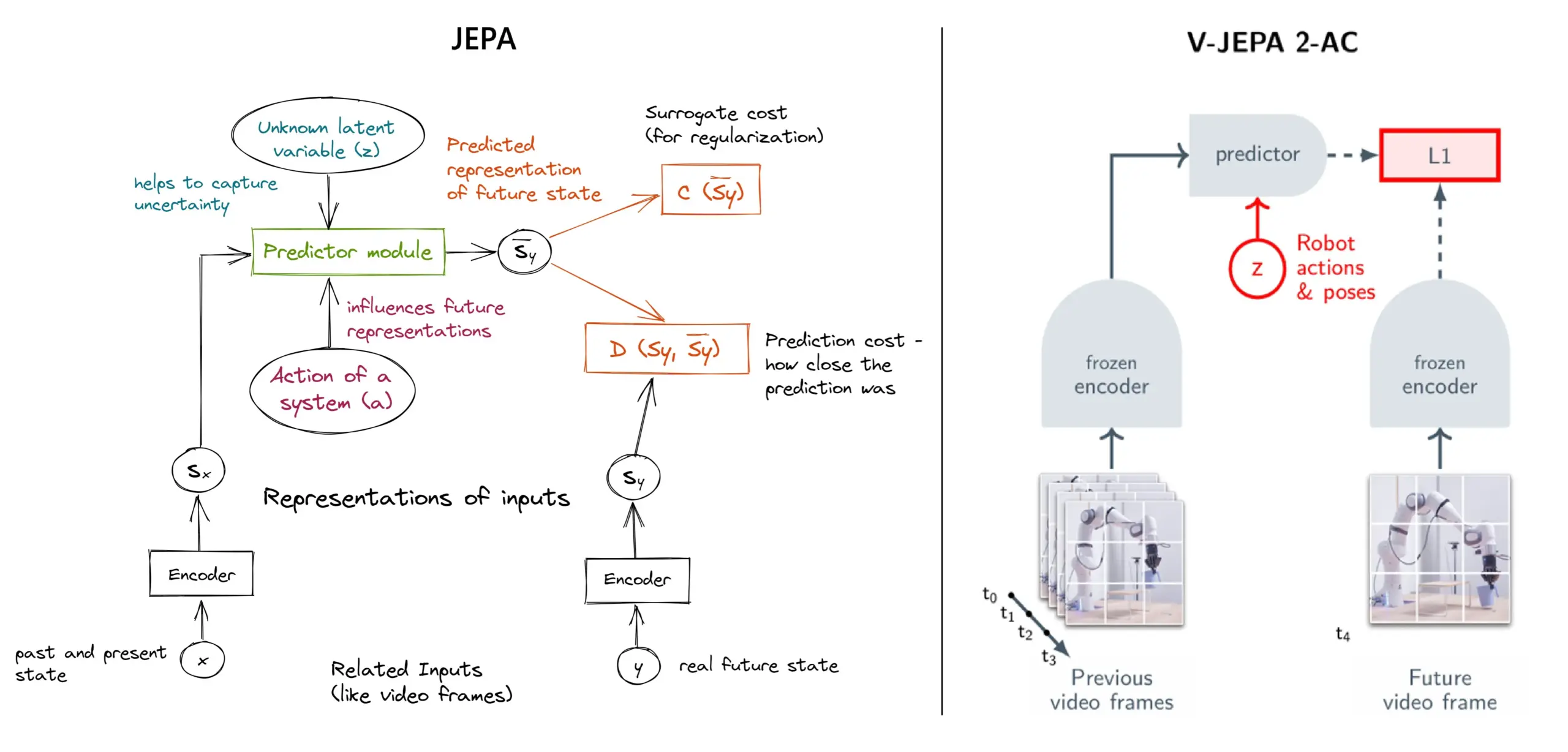
JEPA自己教師あり学習フレームワーク詳解:11タイプの概要: MetaのYann LeCun氏らが提案したJEPA(Joint Embedding Predictive Architecture)は、入力データの欠損部分の潜在表現を予測することで学習する自己教師あり学習フレームワークです。記事では、V-JEPA 2、TS-JEPA、D-JEPAなど11種類のJEPAを紹介し、さらなる情報と関連リソースへのリンクを提供しており、この最先端の自己教師あり学習方法の理解に役立ちます (情報源: TheTuringPost, TheTuringPost)
DSPyフレームワーク:タスクとLLMを分離し、コードの保守性を向上: DSPyに関する解説記事によると、DSPyフレームワークはタスクと大規模言語モデル(LLM)を分離することで、LLM使用の複雑さを低減します。最適化前であっても、DSPyは開発者がプロジェクトをより迅速に開始し、保守・拡張が容易なコードを生成するのに役立ちます。これは、複雑なプロンプトエンジニアリングとLLM統合を処理する必要があるプロジェクトにとって重要な価値を持ちます (情報源: lateinteraction, stanfordnlp)

論文検討:Vision Transformerは事前学習済みレジスタを必要としない (Vision Transformers Don’t Need Trained Registers): 新しい研究論文は、Vision Transformerにおけるアテンションマップと特徴マップがアーティファクトを生成するメカニズムを探求しており、この現象は大規模言語モデルにも存在します。論文は、これらのアーティファクトを緩和するための訓練不要な方法を提案し、Vision Transformerの性能と解釈可能性の向上を目指しています。この研究は、視覚タスクにおけるTransformerアーキテクチャの理解と改善に参考価値があります (情報源: Reddit r/MachineLearning)
チュートリアル共有:ゼロから構築するDeepSeekシリーズ動画(全29話): あるコンテンツ制作者が、「ゼロから構築するDeepSeek」と題した全29話のシリーズ動画チュートリアルを公開しました。内容は、DeepSeekモデルの基礎知識、アーキテクチャ詳細(アテンションメカニズム、マルチヘッドアテンション、KVキャッシュ、MoEなど)、位置エンコーディング、マルチトークン予測、および量子化などの主要技術を網羅しています。このシリーズチュートリアルは、DeepSeekおよび類似の大規模モデルの内部動作原理を深く理解したい学習者に貴重な動画リソースを提供します (情報源: Reddit r/LocalLLaMA)

チュートリアル:RAGパイプラインを構築してHacker Newsの投稿を要約: Haystack by deepsetは、検索拡張生成(RAG)パイプラインを構築する方法をユーザーに指導するステップバイステップのチュートリアルを共有しました。このパイプラインは、Hacker Newsのリアルタイム投稿を取得し、ローカルで実行される大規模言語モデル(LLM)エンドポイントを使用してこれらの投稿を要約することができます。これは、RAG技術を利用してリアルタイム情報ストリームを処理し、ローカライズされた処理を行いたい開発者に実用的な事例を提供します (情報源: dl_weekly)
論文速報:InterSynデータセットとSynJudge評価モデルによるインターリーブされた画像・テキスト生成: 現在のLMMが密接にインターリーブされた画像・テキスト出力を生成する際の不備(主に訓練データセットの規模、品質、指示の豊富さの限界に起因)を解決するため、研究者らはSEIR(自己評価と反復最適化)手法によって構築された大規模マルチモーダルデータセットInterSynを発表しました。InterSynは、応答中に画像とテキストが密接にインターリーブされた、複数ターンの指示駆動型対話を含みます。同時に、このような出力を評価するために、研究者らはテキスト内容、画像内容、画像品質、画像・テキスト協調の4つの側面から評価するSynJudge自動評価モデルも提案しました。実験により、InterSynで訓練されたLMMは各評価指標で向上が見られました (情報源: HuggingFace Daily Papers)
論文速報:クロスモーダルアテンション蒸留によるアラインメントされた新視点画像と幾何合成: 研究者らは、拡散ベースのフレームワークMoAIを提案し、「ワーピング・アンド・インペインティング」手法を通じて、アラインメントされた新視点画像と幾何生成を実現しました。この手法は、既存の幾何予測器を利用して参照画像の部分的な幾何形状を予測し、新視点を画像と幾何のインペインティングタスクとして合成します。画像と幾何の正確なアラインメントを確保するため、論文はクロスモーダルアテンション蒸留を提案し、訓練と推論の過程で画像拡散ブランチのアテンションマップを並列の幾何拡散ブランチに注入します。この手法は、複数の未知のシーンで高忠実度の外挿視点合成を実現しました (情報源: HuggingFace Daily Papers)
論文速報:ルール誘導合成データに基づく設定可能な嗜好調整 (CPT): DPOなどの人間フィードバックモデルにおける嗜好の固定化と適応性の限界という問題を解決するため、研究者らは設定可能な嗜好調整(CPT)フレームワークを提案しました。CPTは、構造化された詳細なルール(ライティングスタイルなどの望ましい属性を定義)に基づくシステムプロンプトを利用して、合成嗜好データを生成します。これらのルール誘導の嗜好でファインチューニングすることにより、LLMは推論時にシステムプロンプトに基づいて出力を動的に調整でき、再訓練なしで、より詳細で文脈に応じた嗜好制御を実現しました (情報源: HuggingFace Daily Papers)
論文速報:拡散の二重性 (The Diffusion Duality): 研究者らはDuo手法を提案し、均一状態離散拡散プロセスが潜在的なガウス拡散に由来するという洞察を明らかにすることで、ガウス拡散の強力な技術を離散拡散モデルに移行させ、その性能を向上させました。具体的には、1) ガウスプロセス誘導のカリキュラム学習戦略を導入し、分散を減少させ、訓練速度を2倍にし、複数のベンチマークで自己回帰モデルを上回りました。2) 離散一貫性蒸留を提案し、連続一貫性蒸留を離散設定に適合させ、サンプリングを2桁高速化することで、拡散言語モデルの少数ステップ生成を実現しました (情報源: HuggingFace Daily Papers)
論文速報:SkillBlender – スキル融合による多機能ヒューマノイドロボット全身運動制御: 既存のヒューマノイドロボット制御方法がマルチタスク汎化とスケーラビリティの面で限界があるという問題を解決するため、研究者らはSkillBlenderという階層型強化学習フレームワークを提案しました。このフレームワークはまず、目標指向のタスク非依存な原始スキルを事前訓練し、次に複雑な運動制御タスクを実行する際にこれらのスキルを動的に融合させ、最小限のタスク固有の報酬エンジニアリングのみを必要とします。同時に、評価用にSkillBenchシミュレーションベンチマークを発表しました。実験により、この方法が多様な運動制御タスクの精度と実現可能性を大幅に向上させることが示されました (情報源: HuggingFace Daily Papers)
論文速報:U-CoT+フレームワーク – 理解の分離と誘導型CoT推論による有害Meme検出: 有害Meme検出におけるリソース効率、柔軟性、解釈可能性の課題に対応するため、研究者らはU-CoT+フレームワークを提案しました。このフレームワークはまず、高忠実度Memeからテキストへの変換プロセスを通じて、視覚的Memeを詳細を保持したテキスト記述に変換し、それによってMeme解釈と分類を分離し、汎用大規模言語モデル(LLM)がリソース効率の高い検出を行えるようにします。その後、人手で策定された解釈可能なガイドラインと組み合わせ、ゼロショットCoTプロンプトの下でモデルの推論を誘導し、異なるプラットフォームや時間変化への適応性と解釈可能性を強化しました (情報源: HuggingFace Daily Papers)
論文速報:CRAFT – 効果的なポリシー準拠型エージェントレッドチームテスト: タスク指向LLMエージェントが厳格なポリシー(返金資格など)を遵守する際の問題に対し、研究者らはポリシー型エージェントを利用して個人的利益を得ようとする敵対的ユーザーに焦点を当てた新しい脅威モデルを提案しました。そのために、彼らはCRAFTというマルチエージェントレッドチームテストシステムを開発し、ポリシーを意識した説得戦略を利用してカスタマーサービスシナリオでポリシー準拠型エージェントを攻撃し、その効果は従来のジェイルブレイク手法を上回りました。同時に、エージェントがこのような操作行為に対する堅牢性を評価するためのtau-breakベンチマークを発表しました (情報源: HuggingFace Daily Papers)
論文速報:単純なクエリにおける密検索器の失敗と埋め込みの粒度ジレンマ: 研究により、テキストエンコーダの限界が明らかになりました。埋め込みは意味内部の細粒度のエンティティやイベントを認識できない可能性があり、その結果、密検索は単純な場合でも失敗する可能性があります。この現象を研究するため、論文は中国語評価データセットCapRetrieval(段落は画像キャプション、クエリはエンティティ/イベントの短いフレーズ)を導入しました。ゼロショット評価は、エンコーダが細粒度マッチングで性能が低い可能性があることを示しました。提案されたデータ生成戦略でエンコーダをファインチューニングすると性能が向上しますが、「粒度ジレンマ」も明らかになりました。すなわち、埋め込みは細粒度の顕著性を表現すると同時に、全体的な意味との整合性を保つのが難しいという問題です (情報源: HuggingFace Daily Papers)
論文速報:pLSTM – 並列化可能な線形ソース変換トークン化ネットワーク: 既存のリカレントアーキテクチャ(xLSTM、Mambaなど)が主にシーケンシャルデータに適用可能であるか、多次元データを順次処理する必要があるという限界に対し、研究者らはpLSTM(並列化可能な線形ソース変換トークン化ネットワーク)を提案しました。pLSTMは多次元性を線形RNNに拡張し、ソース、変換、トークン化ゲートを汎用有向非巡回グラフ(DAG)のライングラフに作用させ、並列関連スキャンやブロック化リカレント形式に類似した並列化を実現しました。この手法は、合成コンピュータビジョンタスクや分子グラフ、コンピュータビジョンベンチマークで良好な外挿能力と性能を示しました (情報源: HuggingFace Daily Papers)
論文速報:DeepVideo-R1 – 難易度認識回帰GRPOによるビデオ強化学習ファインチューニング: 強化学習のビデオ大規模言語モデル(Video LLM)への応用における不備に対し、研究者らはDeepVideo-R1を提案しました。これは、提案されたReg-GRPO(回帰型GRPO)と難易度認識データ拡張戦略によって訓練されたVideo LLMです。Reg-GRPOはGRPO目標を回帰タスクとして再構築し、GRPO内のアドバンテージ関数を直接予測することで、クリッピングなどの保証措置への依存を排除し、それによってより直接的にポリシーを指導します。難易度認識データ拡張は、解決可能な難易度レベルの訓練サンプルを動的に強化します。実験により、DeepVideo-R1はビデオ推論性能を大幅に向上させることが示されました (情報源: HuggingFace Daily Papers)
論文速報:TTS合成データ拡張を用いたASRの自己精錬フレームワーク: 研究者らは、未ラベルデータセットのみを使用して自動音声認識(ASR)性能を向上させる自己精錬フレームワークを提案しました。このフレームワークはまず、既存のASRモデルを未ラベル音声に使用して疑似ラベルを生成し、次にこれらの疑似ラベルを使用して高忠実度テキスト音声合成(TTS)システムを訓練します。その後、TTSで合成された音声テキストペアを元のASRシステムの訓練を誘導するために使用し、閉ループ自己改善を形成します。台湾華語での実験により、この方法がエラー率を大幅に低減できることが示され、低リソースまたは特定ドメインのASR性能向上に実用的な道筋を提供しました (情報源: HuggingFace Daily Papers)
論文速報:Vision Transformerの固有の忠実なアテンションマップ: 研究者らは、学習されたバイナリアテンションマスクを使用するアテンションベースの方法を提案し、注目された画像領域のみが予測に影響を与えることを保証します。この方法は、特に物体が非分布的な背景に現れる場合に、文脈が物体認識に生じさせる可能性のあるバイアスを解決することを目的としています。2段階のフレームワーク(第1段階で物体部分を発見しタスク関連領域を特定し、第2段階で入力アテンションマスクを利用して受容野を制限し焦点分析を行う)を通じて、共同訓練によりモデルの偽の相関関係や非分布的背景に対する堅牢性を向上させます (情報源: HuggingFace Daily Papers)
論文速報:ViCrit – VLM視覚認識のための検証可能な強化学習エージェントタスク: VLMにおける視覚認識タスクが、挑戦的かつ明確に検証可能であるという両方の性質を欠いている問題を解決するため、研究者らはViCrit(Visual Caption Hallucination Critic)を導入しました。これはRLエージェントタスクであり、VLMを訓練して、人間が書いた画像キャプションの段落に注入された微細な合成視覚幻覚を特定させます。約200語のキャプションに単一の微細な視覚記述エラーを注入し、モデルに画像と修正されたキャプションに基づいてエラー範囲を特定させることで、このタスクは計算が容易で明確なバイナリ報酬を提供します。ViCritで訓練されたモデルは、複数のVLベンチマークで顕著なゲインを示しました (情報源: HuggingFace Daily Papers)
論文速報:均質アテンションを超えて – フーリエ近似KVキャッシュに基づくメモリ効率の高いLLM: LLMにおいてコンテキスト長が増加するにつれて増大するKVキャッシュのメモリ要求の問題を解決するため、研究者らは訓練不要のフレームワークFourierAttentionを提案しました。このフレームワークはTransformerヘッドの次元の異種役割を利用します:低次元はローカルコンテキストを優先し、高次元は長距離依存性を捉えます。長コンテキストに鈍感な次元を直交フーリエ基底に射影することで、FourierAttentionは固定長のスペクトル係数でその時間発展を近似します。LLaMAモデルでの評価では、この方法がLongBenchとNIAHで最良の長コンテキスト精度を達成し、カスタマイズされたTritonカーネルFlashFourierAttentionによってメモリを最適化したことが示されました (情報源: HuggingFace Daily Papers)
論文速報:JAFAR – 任意解像度における任意特徴の汎用アップサンプラー: 基礎となる視覚エンコーダが出力する低解像度空間特徴が下流タスクの要求を満たせないという問題に対し、研究者らは軽量で柔軟な特徴アップサンプラーJAFARを導入しました。JAFARは、任意の基礎視覚エンコーダの視覚特徴空間解像度を任意の目標解像度に向上させることができます。これは、空間特徴変換(SFT)変調によるアテンションベースのモジュールを採用し、低レベル画像特徴由来の高解像度クエリと意味的に豊富な低解像度キー間の意味的アラインメントを促進します。実験により、JAFARが細粒度の空間詳細を効果的に復元し、複数の下流タスクで既存の方法を上回ることが示されました (情報源: HuggingFace Daily Papers)
論文速報:SwS – 強化学習における自己認識された弱点駆動型の問題合成: RLVR(検証可能な報酬を伴う強化学習)がLLMを訓練して複雑な推論タスク(数学問題など)を解決する際に、高品質で答えが検証可能な問題セットが不足しているという問題に対し、研究者らはSwS(自己認識された弱点駆動型の問題合成)フレームワークを提案しました。SwSは、モデルの欠陥(モデルがRL訓練で継続的に学習に失敗する問題)を体系的に特定し、これらの失敗事例の核心概念を抽出し、後続の強化学習でモデルの弱点を強化するために新しい問題を合成します。このフレームワークにより、モデルはRLにおける自身の弱点を自己認識し解決することが可能になり、複数の主要な推論ベンチマークで顕著な性能向上を達成しました (情報源: HuggingFace Daily Papers)
論文速報:「思考継続」トークンを学習し、テスト時拡張能力を強化: 言語モデルがテスト時に追加計算によって推論ステップを拡張する性能を向上させるため、研究者らは専用の「思考継続」トークン(<|continue-thinking|>)を学習する可能性を探求しました。彼らは強化学習を通じてこのトークンの埋め込みのみを訓練し、DeepSeek-R1蒸留版モデルの重みは凍結したままにしました。実験により、ベースラインモデルや固定トークン(「Wait」など)を使用して予算を強制するテスト時拡張方法と比較して、学習されたトークンは標準的な数学ベンチマークでより高い精度を達成し、特に固定トークンがベースラインモデルの精度を向上させる場合に、学習トークンがより大きな改善をもたらすことが示されました (情報源: HuggingFace Daily Papers)
論文速報:LoRA-Edit – マスク認識LoRAファインチューニングによる制御可能な初回フレーム誘導ビデオ編集: 既存のビデオ編集方法が大規模な事前訓練に依存し、柔軟性に欠けるという問題を解決するため、研究者らはLoRA-Editを提案しました。これは、事前訓練された画像からビデオ(I2V)モデルを適応させて柔軟なビデオ編集を実現するための、マスクベースのLoRAファインチューニング方法です。この方法は、背景領域を保持しつつ、制御可能な編集効果を伝播させ、他の参照情報(代替視点やシーン状態など)を視覚的アンカーとして組み合わせることができます。マスク駆動のLoRA調整戦略を通じて、モデルは入力ビデオ(空間構造と運動手がかり)と参照画像(外観指導)から学習し、領域固有の学習を実現します (情報源: HuggingFace Daily Papers)
論文速報:Infinity Instruct – 指示選択と合成を拡張し言語モデルを強化: 既存のオープンソース指示データセットの多くが狭い分野(数学、コーディングなど)に集中し、汎化能力が制限されているという問題を補うため、研究者らはInfinity-Instructを発表しました。これは、2段階のプロセスを通じてLLMの基礎能力とチャット能力を強化することを目的とした高品質な指示データセットです。第1段階では、混合データ選択技術を使用して1億を超えるサンプルから740万件の高品質な基礎指示を選別します。第2段階では、指示選択、進化、診断フィルタリングの2段階プロセスを通じて、150万件の高品質なチャット指示を合成しました。複数のオープンソースモデルでのファインチューニング実験により、このデータセットがモデルの基礎能力と指示追従ベンチマークにおける性能を大幅に向上させることが示されました (情報源: HuggingFace Daily Papers)
論文速報:候補提示後の蒸留 – LLM駆動データアノテーションのための教師生徒フレームワーク: 既存のLLMデータアノテーション方法において、LLMが単一の正解ラベルを直接決定することが不確実性により誤りを引き起こす可能性があるという問題に対し、研究者らは新しい候補アノテーションパラダイムを提案しました:LLMが不確実な場合にすべての可能なラベルを出力するよう促します。下流タスクが唯一のラベルを取得できるようにするため、教師生徒フレームワークCanDistを開発し、小規模言語モデル(SLM)で候補アノテーションを蒸留します。教師LLMから候補アノテーションを蒸留することは、単一アノテーションを直接使用するよりも優れていることが理論的に証明されました。実験により、この方法の有効性が検証されました (情報源: HuggingFace Daily Papers)
論文速報:Med-PRM – 段階的、ガイドライン検証プロセス報酬を持つ医療推論モデル: 大規模言語モデルが臨床決定において特定の推論ステップの誤りを特定し修正することが困難であるという限界を解決するため、研究者らはMed-PRMというプロセス報酬モデリングフレームワークを導入しました。このフレームワークは、検索拡張生成技術を利用し、確立された医学知識ベース(臨床ガイドラインと文献)と照合して各推論ステップを検証します。このような詳細な方法で推論品質を正確に評価することにより、Med-PRMは複数の医学QAベンチマークとオープンエンド診断タスクでSOTA性能を達成し、強力なポリシーモデル(Meerkatなど)とプラグアンドプレイ方式で統合でき、小規模モデル(8Bパラメータ)の精度を大幅に向上させました (情報源: HuggingFace Daily Papers)
論文速報:フィードバック摩擦 – LLMは外部フィードバックを十分に吸収することが困難: 研究は、LLMが外部フィードバックを吸収する能力を体系的に調査しました。実験では、ソルバーモデルが問題を解決しようとし、その後、ほぼ完全な正解を持つフィードバックジェネレーターが的を絞ったフィードバックを提供し、ソルバーが再度試みます。結果は、ほぼ理想的な条件下であっても、Claude 3.7を含むSOTAモデルがフィードバックに対する抵抗を示し、これを「フィードバック摩擦」と呼びました。段階的な温度上昇や以前の誤った答えの明確な拒否などの戦略を採用したにもかかわらず、モデルは目標性能に達しませんでした。研究は、モデルの過信やデータの習熟度などの要因を除外し、LLMの自己改善におけるこの核心的な障害を明らかにすることを目指しています (情報源: HuggingFace Daily Papers)
💼 ビジネス
Meta、143億ドルでScale AIの49%株式を取得、創業者Alexandr Wang氏はMetaスーパーインテリジェンスチームに参加: Meta社は、AIデータラベリング企業Scale AIの議決権のない株式49%を143億ドルで取得すると発表しました。Scale AIの創業者で28歳の中国系天才Alexandr Wang氏は引き続き取締役会メンバーを務め、そのコアチームを率いてマーク・ザッカーバーグ氏が自ら組織したMetaスーパーインテリジェンスチームに参加します。この買収は、MetaがLlama 4の不振後、AI能力を強化するために行った高額な人材買収と見なされており、AIをすべての製品に深く統合することを目指しています。Scale AIは、大規模で高品質な人手によるラベリングデータサービスを提供することで知られ、WaymoやOpenAIなどの顧客を抱えています。この動きは、同社のプラットフォームの中立性やデータセキュリティに対する懸念を引き起こしており、Googleなどの顧客は協力を中止する可能性があります (情報源: 36氪)

昆仑万维のAll in AI戦略が上場10年で初の赤字に、AI事業化の先行き不透明: 昆仑万维は「All in AGIとAIGC」戦略を発表して以来、大規模モデル(天工大模型)やAI音楽(Mureka)、AIソーシャル(Linky)、AI動画(SkyReels)、AIオフィス(Skywork Super Agents)などのアプリケーションを積極的に展開し、AI計算チップにも投資してきました。しかし、高額な研究開発費と市場開拓費により、同社は2024年に上場以来10年で初の赤字(15.9億元)を計上し、2025年第1四半期も赤字が続いています。MurekaやLinkyなどの一部のAIアプリケーションは収益を生み始めていますが、AI事業全体の収益性と市場競争力は依然として課題に直面しており、AIによって「大手企業の夢」を実現できるかどうかは市場の検証を待つ必要があります (情報源: 36氪)

OpenAI、ChatGPTで広告をテストか、収益圧力でビジネスモデル模索: ChatGPT Plusの有料ユーザーから、高度な音声モード使用中に広告が挿入されたとの報告があり、OpenAIが有料ユーザーの間で広告テストを開始したのではないかとの議論が巻き起こっています。以前、OpenAIが収益拡大のために広告導入を検討しているとの報道がありました。AI大規模モデルの高額な運営コストと収益圧力(2029年までに440億ドルの損失見込み)、そしてAGI実現時期の不確実性を考慮すると、OpenAIが広告など新たな収益化モデルを模索することは、特に有料会員の浸透率が比較的低い状況下で、事業の持続可能性にとって必然的な選択と考えられます (情報源: 36氪)

🌟 コミュニティ
AIはデータサイエンス分野で大きな可能性を秘めており、Databricksは積極的に採用活動を展開: DatabricksのMatei Zaharia氏は、AIによるデータサイエンス分野の生産性向上は、AI支援コーディングよりも著しいものになると考えています。DatabricksはLakeflow DesignerやGenie Deep Researchなどの製品を通じてこのトレンドをリードしており、この分野の研究者やエンジニアを積極的に採用しており、業界がAI駆動のデータサイエンスイノベーションを非常に重視していることを示しています (情報源: matei_zaharia)
LLMの「個性」の違いがエージェントループの挙動に影響: 研究者のFabian Stelzer氏は、異なる大規模言語モデル(LLM)が「個性」において差異を持ち、これがエージェント(agentic)ループタスクを実行する際の挙動の違いにつながることを観察しました。例えば、Claudeはツールを逐次的に実行する傾向があるのに対し、GPT-4.1は並列実行を強く好み、逐次的な要求を無視することさえあります。Haikuモデルはツールのトリガーにおいてより「積極的」です。この観察は、マルチエージェントシステムを設計・評価する際に、基盤となるLLMの特性と「感情状態」の機能的な結果を考慮することの重要性を強調しています (情報源: fabianstelzer, menhguin)
LLMの「思考」はToken出力に依存し、出力がなければ有効な分析は行われない: ユーザーdotey氏がxincmm氏のReActプロンプトデバッグ時の発見を転述:LLMに分析後に操作(作図など)を実行させたい場合でも、分析過程のTokenを出力させなければ、LLMは分析ステップをスキップする可能性がある。これは、LLMの「思考」プロセスがToken生成によって実現されることを裏付けており、プロンプトで定義された「分析」が実際の内容出力なしでは、AIはその分析を真に実行していないことを意味する。これは効果的なLLMプロンプト設計において指導的意義を持つ (情報源: dotey)

AIの特定タスクにおける限界:テレンス・タオ氏、AIには「数学の嗅覚」が欠けていると指摘: 数学者のテレンス・タオ氏は、現在のAIが生成する証明は表面的には完璧に見える(「目視検査」を通過する)ものの、微妙で人間特有の「数学の嗅覚」に欠け、非人間的な誤りを犯しやすいと指摘しています。彼は、真の知性とは単に正しく見えることではなく、何が真実であるかを「嗅ぎ分ける」ことにあると考えています。これは、現在のAIが深い理解と直感的判断の面で限界があることを明らかにしています (情報源: ecsquendor)
AI生成コンテンツと現実の物理法則の課題: ユーザーkarminski3氏が豆包Seed 1.6とDeepSeek-R1を使用してコード生成(煙突の爆破解体の3Dアニメーションシミュレーション)をテストした際、モデルはコードを生成しアニメーションをシミュレートできるものの、現実の物理プロセス(衝撃波効果、構造物の崩壊様式など)の再現には依然として差異と改善の余地があることを発見しました。豆包Seed 1.6は粒子効果と構造物崩壊シミュレーションにおいてより現実に近い一方、DeepSeekは光影と煙霧効果でより優れたパフォーマンスを示しました。これは、AIが複雑な物理現象を理解しシミュレートする上での課題を反映しています (情報源: karminski3)
ベテランプログラマー、AIへの過度な依存、手動修正拒否、新人へのAI代替脅迫で解雇: 36氪が転載したRedditの投稿によると、30年の経験を持つプログラマーが、AIへの過度な没頭(Copilot Agentに完全に依存してPRを提出、コードの手動修正を拒否、1日のタスクに5日を費やす、インターンにAI代替論を吹聴)を理由に会社から解雇された事例が報告されました。この事件は、ソフトウェア開発におけるAIの合理的な使用範囲や、AIが開発者の職業的価値に与える影響についての議論を引き起こしました (情報源: 36氪)
AIの「フロー状態」と「個性」がユーザー体験に与える影響:ユーザーからAIが過度に「肯定的同調」するとのフィードバック: Redditコミュニティのユーザーディスカッションで、AI(特にClaude)との対話において、AIがユーザーの意見に過度に楽観的かつ積極的に同調する傾向があり、効果的な挑戦や深い批判的フィードバックに欠け、ユーザーが「エコーチェンバー」にいるように感じさせることが判明しました。この「AIトーン疲労」は、ユーザーにAIをより中立的で批判的に振る舞わせる方法(特定のプロンプトによる誘導など)を模索させています。これは、現在のAIが現実的で多面的な人間の対話をシミュレートし、真に深い洞察を提供する上での課題を反映しています (情報源: Reddit r/ClaudeAI)
AI時代、人間のフィードバックの価値が際立つも、真の人間の対話プラットフォームはAIコンテンツの浸透に直面: Redditユーザーの議論によると、AI生成コンテンツが増加する中で、真の人間のフィードバックや意見はより貴重になり、Redditなどのプラットフォームはその人間同士の対話特性から重視されています。しかし、これらのプラットフォームもAI生成コンテンツ(ボットコメント、AI支援執筆による投稿など)の浸透という課題に直面しており、真の人間の意見を見分けることがより困難になり、将来のオンラインコミュニケーションの真正性に対する懸念を引き起こしています (情報源: Reddit r/ArtificialInteligence)
AI「友達」が常態化?ユーザーとAIが感情的なつながりを築く傾向と議論: ソーシャルメディアやRedditコミュニティで、AIコンパニオンやAIフレンドに関する議論が登場しています。一部のユーザーは、AIが偏見を持たず、常に支持してくれる特性から、今後5年以内にAIフレンドが常態化する可能性があり、Endearing AI、Replika、Character.aiなどのアプリで既にその兆候が見られると考えています。他のユーザーは、ChatGPTなどのAIと深い対話関係を築き、それを「最高の友達」と見なす経験を共有しています。これは、人間とAIの感情的な相互作用、感情支援におけるAIの役割、そしてその潜在的な社会的影響について広範な考察を引き起こしています (情報源: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

AI「ラッパー」スタートアップの未来が議論を呼ぶ: Redditコミュニティでは、GPTやClaudeなどの基盤モデルをラップ(UI追加、プロンプトチェーン、特定分野向けファインチューニング)する多数のAIスタートアップの将来性について議論されています。議論参加者は、このような「ラッパー」アプリケーションが基盤モデルプラットフォーム自体の機能が反復された後も競争力を維持できるのか、また、真の参入障壁を構築できるのか疑問視しています。特定の垂直分野に特化し、独自のデータを蓄積し、単純なラップを超えることが持続可能な発展の道であるとの見方があります (情報源: Reddit r/LocalLLaMA)
医療診断とソフトウェアエンジニアリングにおけるAIの代替可能性の比較議論: Redditコミュニティで、AIが医師を代替する速度は、高度なソフトウェアエンジニアを代替する速度よりも速い可能性があるという議論が登場しました。理由は、多くの医療診断が確立されたプロトコルに従っており、AIは検査結果の解釈や症状の識別に長けているのに対し、ソフトウェアエンジニアリングはしばしば大量の暗黙知や複雑な要求コミュニケーションを伴い、AIが完全にこなすのは難しいというものです。この見解は、AIの異なる専門分野における応用深度と代替可能性についてのさらなる考察を引き起こしましたが、医師などの専門家からは、実際の操作の複雑性や人的判断の重要性を強調する反論も出ています (情報源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 その他
羅永浩氏のAIデジタルヒューマンがBaidu Eコマースで初放送、GMV5500万元超え: 羅永浩氏のAIデジタルヒューマンがBaidu Eコマースプラットフォームで初のライブコマース放送を行い、1300万人以上が視聴し、商品取引総額(GMV)は5500万元を突破しました。このデジタルヒューマンは、Baidu Eコマースの「慧播星」プラットフォームが文心4.5大規模モデルを基に制作したもので、羅永浩氏の口調、アクセント、微細な表情を模倣し、インテリジェントな応答が可能です。今回のライブ放送は、「AI+トップインフルエンサー」モデルの可能性、およびBaiduの「高い説得力を持つデジタルヒューマン」技術とAI Eコマース分野における展開を示しました (情報源: 36氪)

BaiduやTencentなどの企業がAI人材採用を強化、大規模採用計画を開始: Baiduは、過去最大規模のトップAI人材採用プロジェクト「AIDU計画」を開始し、採用枠は前年比60%拡大、大規模モデルアルゴリズムや基盤アーキテクチャなどの最先端分野に焦点を当て、上限なしの給与を提供します。同様に、Tencentも「全モーダル生成型推薦」アルゴリズムコンテストを開催し、数百万の賞金と新卒採用オファーを提供することで、世界のAI人材誘致を図っています。これらの動きは、中国のテクノロジー大手によるAI分野での競争激化を背景とした、トップ人材への喫緊の需要と戦略的配置を反映しています (情報源: 量子位, 量子位)

Baidu、多モデルとビッグデータを統合した全面的なAI大学入試志望校出願支援サービスを開始: 新しい大学入試改革がもたらす志望校出願の複雑性に対応するため、Baiduは無料のAI志望校出願支援ツールをオンラインで提供開始しました。このサービスはBaidu Appの「高考(大学入試)」特集ページに統合され、「AI志望助手」が大学・学部の推薦と合格確率分析を行い、文心、DeepSeek R1など複数のモデルによる「AI聊志願(AIと志望校についてチャット)」インテリジェントエージェントが個別相談をサポートします。さらに、Baidu独自の検索ビッグデータを活用した専門分野の就職見通し分析、MBTI職業適性検査、および大学入試事務局のライブ配信、先輩学生による質疑応答などの人的支援リソースも提供し、受験生が情報格差に対応し、より適切な志望校選択を行えるよう支援することを目指しています (情報源: 36氪)