
キーワード:大規模言語モデル, AI評価, マルチエージェントシステム, 推論能力, コンテキスト処理, オープンソースモデル, AI動画生成, AIプログラミング, LLM推論能力評価, Claude Opus 4によるApple論文への反論, MiniMax-M1 MoEモデル, Kimi-Dev-72Bプログラミングモデル, Gemini Deep Think機能
🔥 注目ニュース
Appleの論文、LLMの推論能力への疑問に対し反論 Claude共同執筆論文が実験設計の欠陥を指摘: Apple社は最近、論文「思考の錯覚」(The Illusion of Thought)を発表し、ハノイの塔や積み木の世界といった古典的な問題のテストを通じて、主流の大規模言語モデル(LLM)が複雑な推論タスクにおいて性能が低いことを指摘しました。その本質はパターンマッチングであり、真の理解ではないと。しかし、独立研究者のAlex Lawsen氏とAIモデルClaude Opus 4が共同執筆した論文「『思考の錯覚』そのものの錯覚」(The Illusion of “The Illusion of Thought”)はこれに反論し、Appleの実験には設計上の欠陥があると主張しています:1. LLMのToken出力上限を考慮しておらず、モデルが非常に長いステップを完全に出力できないために誤りと判定された。2. 一部のテストケース(例えば一部の「川渡り問題」)は、与えられた条件下では数学的に解がなく、AIが「正解」を出せないのは能力不足ではない。3. 評価方法を変更し、例えばモデルに完全なステップではなく解答プログラムの出力を要求すると、AIは優れたパフォーマンスを示した。この出来事は、LLMの真の推論能力と評価方法論に関する広範な議論を引き起こし、合理的な評価スキームを設計することの重要性を浮き彫りにしました。また、開発者に対し、実際の応用においてコンテキストウィンドウ、出力バジェット、タスクの表現といった要素がモデルのパフォーマンスに与える影響に注意を払うよう促しています。(出典: 新智元, 大数据文摘)
GoogleのAIロードマップが明らかに、次世代AIアーキテクチャは現行のAttentionメカニズムを放棄する可能性を示唆: Googleのプロダクト責任者であるLogan Kilpatrick氏がAI Engineer World FairでGeminiモデルの将来の方向性について明らかにしました。中でも最も注目されるのは「無限コンテキスト」実現への展望です。同氏は、現在のAttentionメカニズムとコンテキスト処理方法では、真の無限コンテキストは実現できないと指摘し、Googleが全く新しいコアAIアーキテクチャを研究している可能性を示唆しました。ロードマップにはさらに、フルモーダル能力(画像+音声はサポート済み、動画は次の段階)、Diffusionの初期実験、デフォルトでのAgent能力(一流のツール呼び出しと使用、モデルは徐々にインテリジェントエージェントへと進化)、継続的な推論能力の拡張、そしてより多くの小型モデルのリリースが含まれています。この一連の計画は、GoogleがAIを受動的な応答から能動的なインテリジェントエージェントへと積極的に進化させ、特にコンテキスト処理において既存技術のボトルネックを突破しようと努めており、AIアーキテクチャの大きな変革をリードする可能性があることを示しています。(出典: 新智元)
Sakana AIがALE-Agentを発表、NP困難問題のプログラミングコンテストで人間の参加者の98%を上回る成績: Transformerの著者の一人であるLlion Jones氏が共同設立したSakana AIは、日本のプログラミングコンテストプラットフォームAtCoderと協力し、ALE-Bench(アルゴリズムエンジニアリングベンチマーク)を発表しました。これは、NP困難問題(経路計画、タスクスケジューリングなど)におけるAIの長距離推論と創造的なプログラミング能力を評価することに特化しています。同社が開発したALE-Agentは、Gemini 2.5 Proをベースとし、ドメイン知識プロンプトと多様な解空間探索戦略を組み合わせることで、AtCoderのヒューリスティックコンテストで優れた成績を収め、21位(上位2%)に入り、多くの人間のトップ開発者を超えました。これは、AIが複雑な最適化問題の解決において重要な進歩を遂げたことを示しており、物流や生産計画などの実用的な応用に重要な意義を持ちます。ALE-Agentはシミュレーテッドアニーリングなどのアルゴリズムで優れたパフォーマンスを発揮していますが、デバッグ、計算量の分析、最適化の誤謬回避の面ではまだ改善の余地があります。(出典: 新智元, SakanaAILabs, hardmaru)
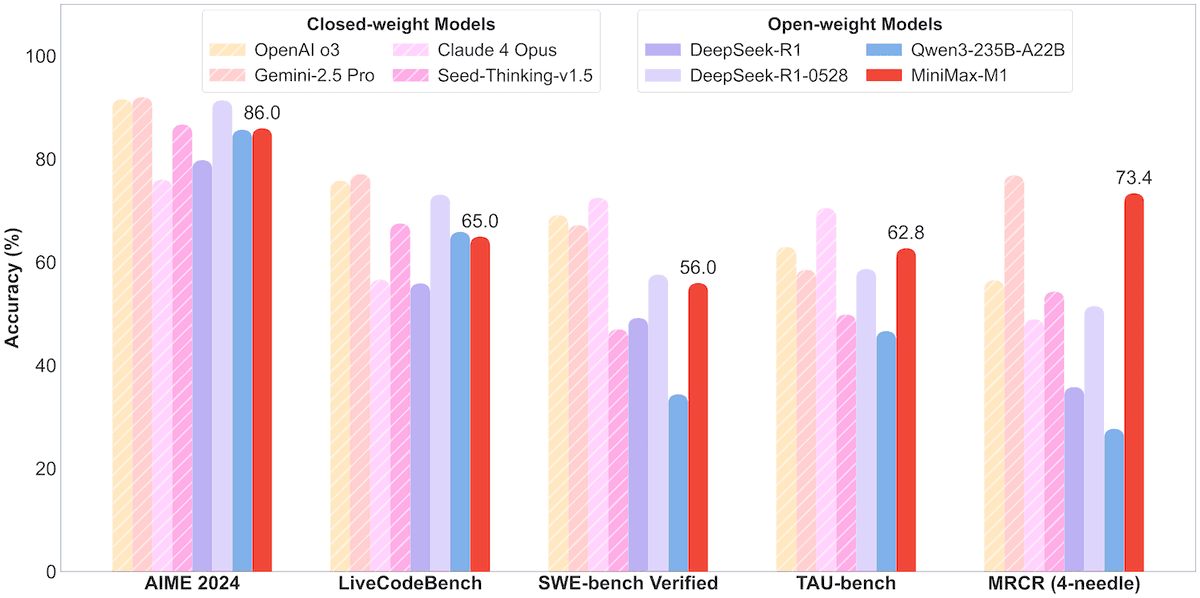
MiniMax、456BパラメータのMoEモデルMiniMax-M1をオープンソース化、100万コンテキストと8万Token出力をサポート: MiniMax社は、同社初となるオープンソースの大規模混合エキスパート(MoE)推論モデルMiniMax-M1を発表しました。このモデルはパラメータ規模456億で、各Tokenが45.9億パラメータを活性化し、MoEとLightning Attentionを組み合わせたアーキテクチャを採用しています。M1はネイティブで100万Tokenのコンテキスト長をサポートし、業界トップクラスの8万Token出力を実現可能で、40kと80kの思考バジェットの2つのバージョンが含まれています。ソフトウェアエンジニアリング、ツール使用、長文コンテキストタスクのベンチマークテストにおいて、M1はDeepSeek-R1やQwen3-235Bなどのモデルを上回り、特にAgentツール使用(TAU-benchなど)で優れた成績を収めています。その強化学習段階では、512個のH800を使用して3週間でトレーニングされ、コストは約53.74万ドルでした。M1モデルはMiniMax APPとWebサイトで無料で利用可能であり、APIを通じてサービス提供されています。(出典: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 動向
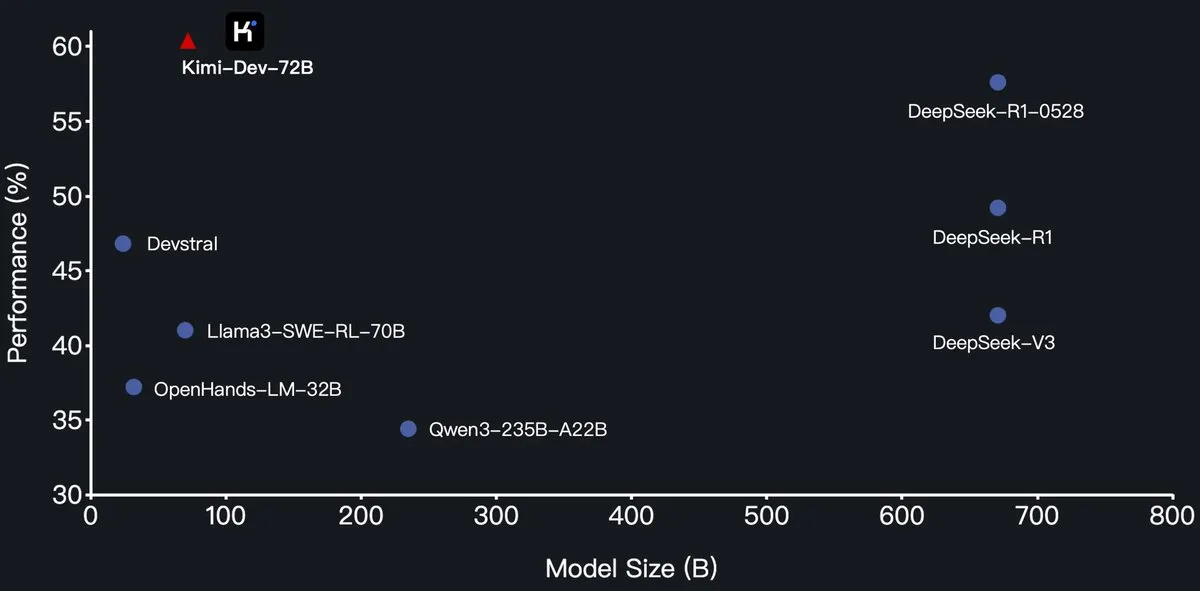
月之暗面(Moonshot AI)がKimi-Dev-72Bプログラミング大規模モデルをオープンソース化、SWE-BenchでDeepSeek-R1を上回る: 月之暗面(Moonshot AI)は、新しいオープンソースのプログラミング大規模言語モデルKimi-Dev-72Bを発表しました。このモデルはQwen2.5-72Bをベースにファインチューニングされています。Kimi-Dev-72BはSWE-bench Verifiedベンチマークテストで60.4%の解決率を達成し、DeepSeek-R1-0528(57.6%)やQwen3-235B-A22Bなどのモデルを上回り、オープンソースモデルの中でトップクラスとなりました。このモデルは強化学習によって訓練され、Docker環境での実際のコードリポジトリの修正に特化しており、完全なテストスイートを通過した場合にのみ報酬が与えられます。Qwenの開発責任者はライセンス供与していないと述べていますが、KimiがMITライセンスでファインチューニング版をリリースすることは規定に沿っています。(出典: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Qwen3シリーズモデルにMLXフォーマットのサポートが追加、Appleチップでの推論を最適化: Alibabaの通義千問チームは、Qwen3シリーズモデルがMLXフォーマットをサポートし、4bit、6bit、8bit、BF16の4つの量子化レベルを提供すると発表しました。これは、AppleのMLXフレームワーク上でのモデルの実行効率を最適化し、開発者がMacデバイス上でローカル展開と推論を行うのを容易にすることを目的としています。ユーザーはHuggingFaceとModelScopeで関連モデルを入手できます。(出典: ClementDelangue, stablequan, jeremyphoward)

Google Geminiに「Deep Think」機能が間もなく登場、複雑な問題処理能力を向上: Googleは、Gemini 2.5 Proモデルに「Deep Think」という新機能を導入する準備を進めています。この機能は、追加の計算能力を提供することで、より困難な問題、特に数学関連のタスクの処理を目的としており、Deep Thinkは通常のGemini 2.5 Proと比較して最大15%の性能向上が期待されています。この機能はツールバーに新しいオプションとして表示され、処理には数分かかる場合があります。同時に、Geminiのユーザーインターフェースも更新される予定です。(出典: op7418)
Google Veo 3動画生成モデルが正式に提供開始、70以上の市場に拡大: Googleは、AI動画生成モデルVeo 3をAI ProおよびUltraのサブスクリプションユーザー向けに正式に提供開始し、世界70以上の市場をカバーすると発表しました。Veo 3は、生成される動画のリアルさと創造性の高さで注目されており、これまでにユーザーが制作した「魔性のフルーツカット」などのASMRコンテンツがソーシャルメディアで数千万回の再生回数を記録し、コンテンツ制作分野での可能性を示しています。今回の正式提供開始により、より多くのユーザーがVeo 3を体験し、動画制作に活用できるようになります。(出典: Google, 新智元)
Hugging FaceとGroqが提携し、高速LLM推論サービスを提供: Hugging Faceは、AIチップ企業Groqとの提携を発表し、GroqのLPU™(Language Processing Unit)をHugging Face PlaygroundとAPIに統合します。ユーザーはHugging Faceプラットフォーム上で、Groqハードウェアによって高速化されたLLM推論サービスを直接体験できるようになり、Llama 4、Qwen 3を含む複数のモデルをサポートします。これは、開発者により高速で効率的なAIモデル推論オプションを提供することを目的としており、特にインテリジェントエージェント、アシスタント、リアルタイムAIアプリケーションの構築に適しています。(出典: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hubにモデルサイズフィルタリング機能が追加、開発者の適切なモデル選択を支援: Hugging Faceプラットフォームは、ユーザーがモデルサイズ(Size Range)に基づいてフィルタリングできる新機能を導入しました。特にmlx / mlx-lmフレームワークで実行されるモデルが対象です。この改善は、開発者が特定のハードウェアおよびパフォーマンス要件に適合するモデルをより簡単に見つけられるようにすることを目的としており、モデルが大きければ大きいほど良いというわけではなく、特定のシナリオでは小型の専門モデルの方が優れていることが多いことを強調しています。(出典: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

NVIDIA NCCLが更新、半精度入力に対しFP32アキュムレーションを用いたリダクション操作を開始: NVIDIA Collective Communications Library (NCCL)の最新バージョン(commit 72d2432)では、重要な更新が導入されました。半精度入力(FP16、BF16など)のリダクション操作(reduction ops)を処理する際に、FP32を使用してアキュムレーションを行うようになりました。この変更は、特に大規模分散トレーニングにおいて、計算精度を維持し、オーバーフローを防ぐために非常に重要です。このバージョンはPyTorch 2.8以降に統合される予定です。(出典: StasBekman)

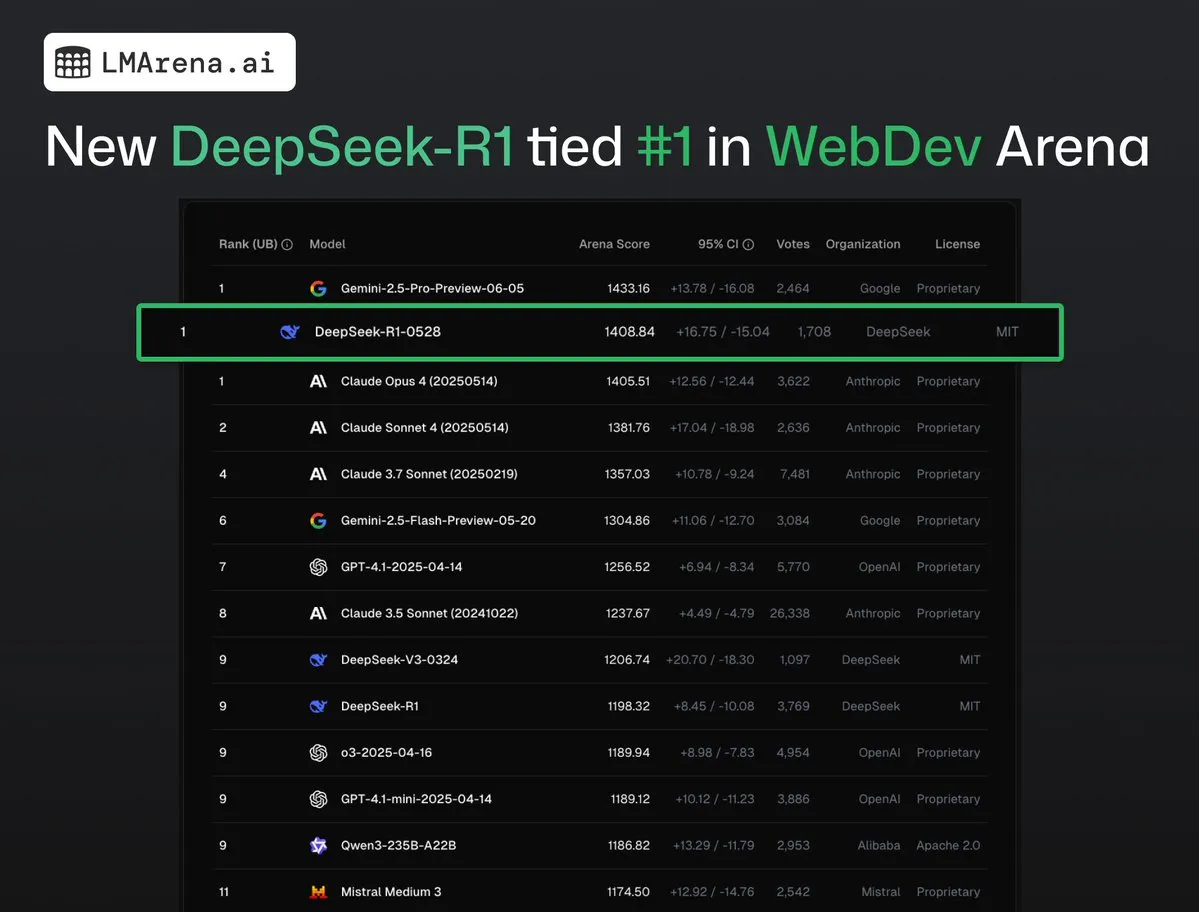
DeepSeek-R1 (0528) が WebDev Arena で Claude Opus 4 と並んで1位: lmarena.aiの最新データによると、新バージョンのDeepSeek-R1 (0528)はWebDev Arenaベンチマークで優れたパフォーマンスを発揮し、Claude Opus 4と並んで1位となりました。このモデルはText Arena総合ランキングで6位、プログラミング能力で2位、難解プロンプトで4位、数学能力で5位であり、ランキング上で最もパフォーマンスの高いMITライセンスのオープンソースモデルです。これは、DeepSeekが特定の開発および推論タスクにおいて強力な競争力を持つことを示しています。(出典: ClementDelangue, zizhpan)
ByteDance、PoeプラットフォームでSeedream 3.0画像モデルとSeedance 1.0 Lite動画モデルを公開: ByteDance傘下のAIクリエイティブツールが海外のPoeプラットフォームでアップデートされ、即夢AIの画像生成モデルSeedream 3.0と動画生成モデルSeedance 1.0 Liteが公開されました。Seedream 3.0は鮮明で生き生きとした画像を生成することを目的とし、Seedance 1.0 Liteはリアルな動的効果を持つ動画を迅速に生成できます。ユーザーはPoeでまずSeedreamを使用して画像を生成し、次に@-メンションでSeedanceを呼び出して動画に変換することで、画像から動画への連続的なクリエイティブフローを実現できます。(出典: op7418)

TencentがLevo歌唱モデルを発表、トラック分離とゼロショット音色クローニングをサポート: Tencentは、Suno V3.5に匹敵するとされるAI歌唱モデルLevoを発表しました。Levoは音源分離とゼロショット音色クローニング機能をサポートしており、公開されたデモと評価から、優れたパフォーマンスを示しています。この進展は、TencentのAI音楽生成分野における実力を示しています。(出典: karminski3)
OpenAI、WhatsApp内でChatGPT画像生成機能を提供開始: OpenAIは、ユーザーがWhatsApp内の1-800-ChatGPTサービスを通じてChatGPTの画像生成機能を利用できるようになったと発表しました。このアップデートにより、より広範なユーザー層がインスタントメッセージングアプリ内で直接AI画像を簡単に生成できるようになります。(出典: gdb, eliza_luth, iScienceLuvr)
SpatialLMがバージョン1.1にアップデート、3Dシーン理解と再構築能力を強化: 空間推論モデルSpatialLMがバージョン1.1をリリースしました。新バージョンは、テキストから3Dシーンを生成するText-to-3D、手持ちカメラのビデオからの再構築、LiDAR点群データ(iPhone ProのLiDARなど)、および合成メッシュサンプリングなど、複数の入力ソースモードをサポートします。主な特徴には、非構造化点群に対する堅牢な処理が含まれ、3Dスキャンデータが不完全であっても合理的な再構築が可能です。さらに、新バージョンではビデオストリーム入力のゼロショット検出が最適化され、室内レイアウト推定精度が向上し、3D物体検出効果が向上しています。ARシーン再構築、ロボットの空間理解、3Dデザインワークフロー、およびCエンドカメラアプリケーションなど、応用範囲は広範です。(出典: karminski3)
GitHub Copilot、月額39ドルのプランを発表、Claude Opus 4など複数の大規模モデルを統合: GitHub Copilotは、月額39ドルの新しいサブスクリプションプランを追加しました。このプランは、コーディングアシスタント機能を提供するだけでなく、ユーザーがClaude Opus 4、o3、GPT-4.5を含む複数の強力な言語モデルにアクセスでき、Coding agentも利用できます。この取り組みは、開発者により包括的なAI支援プログラミング体験を提供することを目的としています。(出典: dotey)
AI大規模モデルの呼び出しコストが継続的に低下、豆包1.6シリーズの価格がさらに63%削減: 火山引擎(Volcengine)はForce原動力大会で豆包大規模モデル1.6シリーズを発表し、その総合コストが63%削減され、多くの企業が常用する0-32K入力長範囲内で、価格が100万トークン入力あたり0.8元、出力8元になると発表しました。これは、今年3月にAlibabaの千問がコストをDeepSeek R1の1/10に引き下げたのに続き、大規模モデルの価格競争が継続的にエスカレートしていることを示しています。低コスト化は、AI Agentなどのアプリケーションの導入と普及をさらに促進するでしょう。(出典: 字节必须再赢一次)
Chipmunk動画生成高速化ツールがアップデート、マルチGPUアーキテクチャとより多くのオープンソースモデルをサポート: Dan Fu氏のチームによるChipmunkツールがアップデートされ、複数のNVIDIA GPUアーキテクチャ(sm_80, sm_89, sm_90、例えばA100s, 4090s, H100s)上で1.4~3倍の動画生成ロスレス高速化を実現できるようになりました。同時に、ChipmunkはMochi、Wanなど、より多くのオープンソース動画モデルのサポートを追加し、統合チュートリアルも提供しています。このツールは、動画モデルのアクティベーション値のスパース性(アクティベーション値のわずか5~25%が出力の90%以上に貢献)を利用して高速化を実現し、モデルの再トレーニングは不要です。(出典: realDanFu)

🧰 ツール
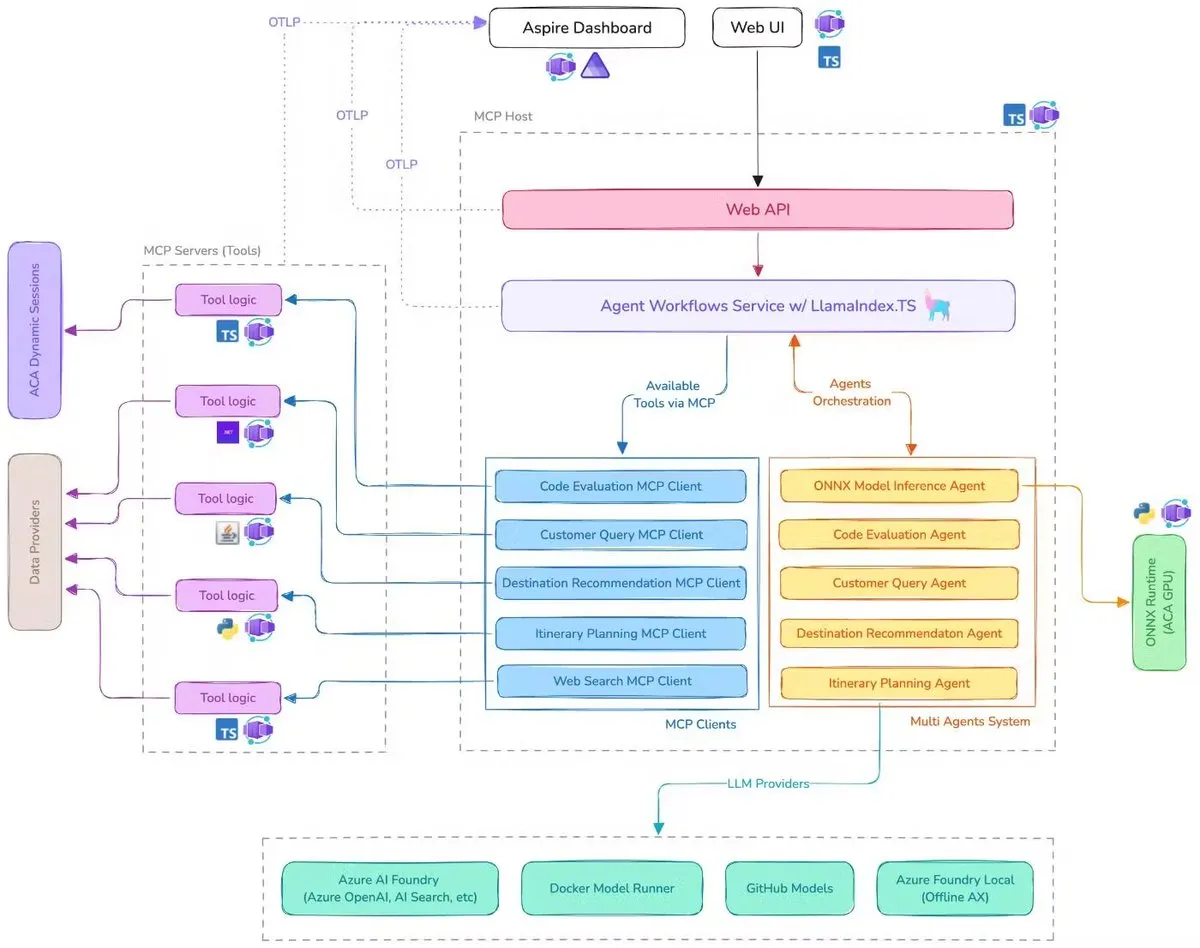
Microsoft、AI旅行アシスタントのデモを公開、MCP、LlamaIndex.TS、Azure AI Foundryを統合: MicrosoftはAI旅行アシスタントのデモを公開しました。このシステムは、Model Context Protocol(MCP)、LlamaIndex.TS、Azure AI Foundryを通じて、複数のAIエージェント(クエリ分類、目的地推薦、旅程計画など6つの専門エージェントを含む)を協調させ、複雑な旅行計画タスクを共同で完了します。各エージェントは、Java、.NET、Python、TypeScriptで記述されたMCPサーバーを通じてリアルタイムデータとツールを取得します。このアプリケーションは、エンタープライズレベルのマルチエージェントが多言語マイクロサービスを通じてどのように連携し、Azure OpenAIとGitHubモデルを利用してAI能力を提供し、Azure Container Appsを通じてスケーラブルなサーバーレス展開を実現できるかを示しています。(出典: jerryjliu0, jerryjliu0)
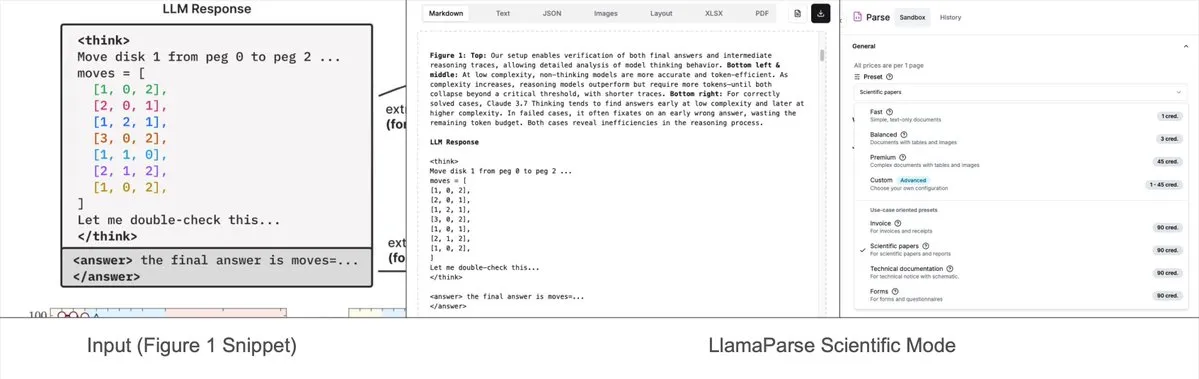
LlamaParseにプリセットモードが追加、複雑なグラフをMermaidまたはMarkdownに解析可能: LlamaIndexのLlamaParseツールが最近更新され、「プリセットモード」(preset-modes)が追加されました。これにより、研究報告書などの文書内の複雑なグラフ(複数の曲線や注釈を含むグラフなど)を解析し、フォーマットされたMermaid図またはMarkdownテーブルに変換できるようになりました。この機能は、ページから完全なコンテキストをキャプチャするのに役立ち、生成された構造化テキストはRAGフローの構築やさらなるメタデータ抽出に使用できます。(出典: jerryjliu0)
Prompt Optimizer:高品質なプロンプト作成を支援する最適化ツール: Prompt Optimizerは、ユーザーがより質の高いAIプロンプトを作成し、AIの出力品質を向上させることを目的としたツールです。WebアプリケーションとChrome拡張機能の2つの形式をサポートし、スマート最適化、複数回の反復改善、オリジナルと最適化後のプロンプト比較、マルチモデル統合(OpenAI, Gemini, DeepSeek, 智谱AI, SiliconFlowなど)、高度なパラメータ設定、ローカル暗号化ストレージなどの機能を提供します。このツールは純粋なクライアントサイド処理を採用し、データの安全性とプライバシーを確保しています。(出典: GitHub Trending)

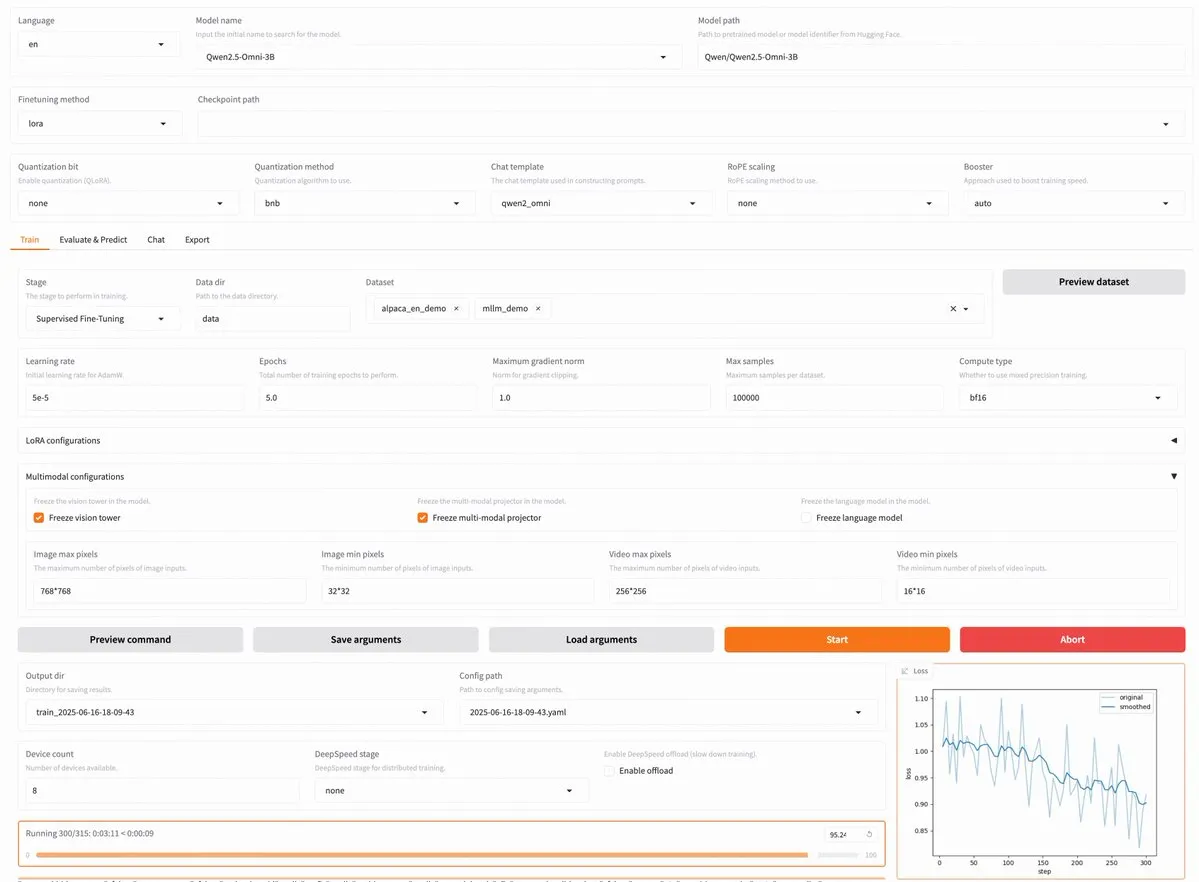
LLaMA Factory v0.9.3がリリース、Qwen3、Llama 4など約300種類のモデルのノーコードファインチューニングをサポート: LLaMA Factoryはv0.9.3をリリースしました。このバージョンは完全にオープンソースで、Gradioユーザーインターフェースをサポートするノーコードファインチューニングプラットフォームであり、最新のQwen3、Llama 4、Gemma 3、InternVL3、Qwen2.5-Omniなど、約300種類以上のモデルに対応しています。ユーザーはDockerイメージを介してローカルにインストールするか、Hugging Face Spaces、Google Colab、NovitaのGPUクラウドで体験できます。(出典: _akhaliq)
Nanonets OCR:Qwen 2.5 VL 3BベースのSOTA OCRモデルがオープンソース化: Nanonetsは、Qwen 2.5 VL 3Bバックボーンネットワークをベースとした新しい3BパラメータのOCRモデル、Nanonets OCRを発表しました。このモデルはMistral OCR APIよりも優れた性能を発揮し、Apache 2.0ライセンスでオープンソース化されています。LaTeX認識、透かしや署名の検出、複雑な表の抽出など、さまざまなOCRタスクを処理できます。(出典: huggingface)
Perplexity Labsが複数の専門職を代替可能と指摘され、AIツールの能力について議論を呼ぶ: あるユーザーGREG ISENBERG氏が、Perplexity Labsを使用して営業担当者、コピーライター、映画監督、ソーシャルメディアマネージャー、財務アナリストの5つの職務を代替したと述べ、AIツールの能力は「実際には狂っている」と評価しました。Perplexity CEOのArav Srinivas氏はこの投稿をリツイートし、AIエージェントが実生活のユースケースでどのように応用されるかを示す最良のビデオの1つであるとコメントし、Perplexity Labsと市場の他のツールを金融分析、ソーシャルメディアマーケティング、クリエイティブディレクション、販売の各分野で比較しました。これは、AI Agentが多分野の専門タスクを統合し実行する潜在能力を浮き彫りにしています。(出典: AravSrinivas, AravSrinivas)
Claude-Flowがv1.0.50のメジャーアップデートをリリース、「スウォームモード」を起動しコード自動化効率を向上: Claude Codeをベースとしたバッチツール並列エージェントシステムであるClaude-Flowが、v1.0.50をリリースしました。新バージョンでは「スウォームモード」(Swarm Mode)が導入され、ユーザーは数百のClaudeエージェントを同時に生成、管理、調整して並列作業させ、ビルド、テスト、デプロイ、または多段階の研究サイクルに利用できます。従来のシーケンシャルなClaude Code自動化と比較して、パフォーマンスが20倍向上したとされています。開発者はnpx claude-flow@latest init --sparc --forceで初期化できます。(出典: Reddit r/ClaudeAI)

📚 学び
Awesome Machine Learning:包括的な機械学習リソースリスト: GitHub上の「awesome-machine-learning」プロジェクトは、機械学習フレームワーク、ライブラリ、ソフトウェアをプログラミング言語別にまとめた厳選リストです。また、無料の機械学習書籍、専門イベント、オンラインコース、ブログニュースレター、ローカルミートアップなどのリソースへのリンクも含まれており、機械学習の学習者や実践者にとって貴重なナビゲーションを提供します。(出典: GitHub Trending)
AnthropicとCognition AIがそれぞれマルチエージェントシステム構築に関するブログ記事を発表、LangChainが要約: AnthropicとCognition AIは最近、それぞれマルチエージェントシステムの構築(または非構築)に関するブログ記事を発表しました。Anthropicはマルチエージェント研究システムの構築経験を共有し、Cognition AIは「マルチエージェントを構築するな」という見解を提示しました。LangChainのHarrison Chase氏がこれを要約し、表面的には見解が異なるように見えるものの、両記事のガイドラインと提案には多くの共通点があり、LangChainのマルチエージェントに関する取り組みにも関連していると指摘しています。(出典: hwchase17, Hacubu)
論文「Recent Advances in Speech Language Models: A Survey」がACL 2025メインカンファレンスに採択: 香港中文大学チームが執筆した音声言語モデル(SpeechLM)のサーベイ論文「Recent Advances in Speech Language Models: A Survey」がACL 2025メインカンファレンスに採択されました。この論文は同分野で初となる包括的かつ体系的なサーベイであり、SpeechLMの技術アーキテクチャ(音声トークナイザ、言語モデル、ボコーダ)、訓練戦略(事前学習、指示ファインチューニング、事後アライメント)、インタラクションパラダイム(全二重モデリング)、応用シーン(意味、話者、パラ言語学)、評価体系を深く分析しています。論文は、SpeechLMが自然な人間と機械の音声インタラクションを実現する上での可能性を強調し、直面する課題と将来の方向性を示しています。(出典: 36氪)

新研究、視覚ゲーム学習(ViGaL)により小規模モデルの分野横断的推論能力を向上、7Bモデルの数学性能がGPT-4oを上回る: ライス大学、ジョンズ・ホプキンス大学、NVIDIAの研究チームは、ViGaL(Visual Game Learning)と名付けられた新しい事後訓練パラダイムを提案しました。7Bパラメータのマルチモーダルモデル(Qwen2.5-VL-7B)にスネークゲームや3D回転などの簡単なアーケードゲームをプレイさせることで、モデルはゲームスキルを向上させただけでなく、数学(MathVista)や多分野の質疑応答(MMMU)などの複雑な推論タスクにおいても顕著な分野横断的能力の向上を示し、一部ではGPT-4oなどのトップモデルをも上回りました。研究は、ゲーム訓練がモデルの空間理解、順序計画などの汎用的な認知能力を育成し、異なるゲームが異なる側面の推論スキルを強化できることを示しています。この方法は、推論能力を向上させると同時に、モデルの汎用的な視覚能力を維持します。(出典: 新智元)

上海AI LabなどがMathFusionフレームワークを提案、指示融合によりLLMの数学問題解決能力を向上: 上海人工知能実験室、中国人民大学高瓴人工知能学院などの機関が共同でMathFusionフレームワークを提案しました。これは、異なる数学問題の生成構造をより多様化し、論理をより複雑にした合成指示を融合することで、大規模言語モデル(LLM)の数学問題解決能力を強化することを目的としています。このフレームワークには、順次融合、並列融合、条件付き融合の3つの戦略が含まれており、問題間の深層的な関連性を効果的に捉えることができます。実験によると、わずか45Kの合成指示を使用してDeepSeekMath-7B、Llama3-8B、Mistral-7Bなどのモデルでファインチューニングした後、MathFusionは複数の数学ベンチマークテストで平均正解率が18.0パーセントポイント向上し、高いデータ効率と性能を示しました。(出典: 量子位)

上海AI LabなどがGRAフレームワークを提案、小規模モデルの協調により高品質データを生成、性能は72Bモデルに匹敵: 上海人工知能実験室は中国人民大学と共同でGRA(Generator–Reviewer–Adjudicator)フレームワークを提案しました。これは、論文投稿と査読メカニズムを模倣することで、複数の小規模言語モデル(7-8Bパラメータ)が協調して高品質な訓練データを生成するものです。このフレームワークでは、Generatorが生成を担当し、Reviewerが複数回の査読と採点を行い、Adjudicatorが査読で意見が対立した場合に最終裁定を下します。実験によると、GRAで生成されたデータを使用してLLaMA-3.1-8BやQwen-2.5-7Bなどの基礎モデルを訓練した結果、数学、コード、論理推論など10の主要データセットにおける性能は、Qwen-2.5-72B-Instructのような大規模モデルを蒸留して生成されたデータを使用した場合と同等かそれ以上でした。これは、低コストで高効率なデータ合成のための新しいアプローチを提供します。(出典: 量子位)

論文、大規模モデルの解釈可能性の現状と未来を議論、AIの安全な展開への重要性を強調: Tencent研究院は、大規模言語モデル(LLM)の解釈可能性の現状、技術的経路、および将来の課題について深く議論する記事を発表しました。記事は、LLMの内部メカニズムを理解することが、価値の逸脱防止、モデルのデバッグと改善、乱用防止、および高リスクシナリオでの応用推進にとって極めて重要であると指摘しています。現在の技術的経路には、自動解釈(大規模モデルによる小規模モデルの解釈)、特徴の可視化(スパースオートエンコーダなど)、思考連鎖の監視、およびメカニズム解釈可能性(Anthropicの「AI顕微鏡」やDeepMindのTracrなど)が含まれます。しかし、ニューロンの多重意味性、解釈規則の普遍性、人間の認知限界などが依然として主な課題です。記事は、解釈可能性研究への投資強化を呼びかけ、AI技術の安全、透明、人間中心の発展を確保するために、現段階では業界の自主規制を奨励するソフトロー規則を採用することを提案しています。(出典: 腾讯研究院)

新論文、離散拡散モデルの大規模言語およびマルチモーダルモデルにおける応用と進展を議論: 「Discrete Diffusion in Large Language and Multimodal Models: A Survey」と題された論文は、離散拡散言語モデル(dLLMs)および離散拡散マルチモーダル言語モデル(dMLLMs)の研究進展を体系的に概観しています。これらのモデルは、マルチToken並列デコーディングとノイズ除去ベースの生成戦略を採用し、並列生成、きめ細かい出力制御性、および動的で応答性の高い知覚能力を実現し、自己回帰モデルと比較して推論速度を最大10倍向上させることができます。論文は、その発展の歴史をたどり、数学的フレームワークを形式化し、代表的なモデルを分類し、重要な訓練および推論技術を分析し、言語、視覚言語、生物学の分野での応用をまとめ、最後に将来の研究方向と展開の課題について議論しています。(出典: HuggingFace Daily Papers)
新研究がTest3Rを提案:テスト時学習による3D再構成の幾何学的精度向上: Test3Rと名付けられた新技術は、テスト時に学習を行うことで3D再構成の幾何学的精度を大幅に向上させます。この手法は画像トリプレット(I_1,I_2,I_3)を利用し、画像ペア(I_1,I_2)と(I_1,I_3)から再構成結果を生成します。中心的なアイデアは、テスト時に自己教師あり目標を通じてネットワークを最適化することです。つまり、これら2つの再構成結果の共通画像I_1に対する幾何学的一貫性を最大化します。実験により、Test3Rは3D再構成および多視点深度推定タスクにおいて既存のSOTA手法を大幅に上回り、普遍性と低コスト性を備え、他のモデルにも容易に適用でき、テスト時の訓練オーバーヘッドとパラメータ数が極めて小さいことが示されました。(出典: HuggingFace Daily Papers)
論文、Mirage-1を提案:階層的マルチモーダルスキルを持つGUIエージェント、長距離タスク処理能力を向上: 研究者らは、現在のGUIエージェントがオンライン環境で長距離タスクを処理する際の知識不足とオフライン・オンライン間のドメインギャップの問題を解決するために、マルチモーダル、クロスプラットフォーム、プラグアンドプレイのGUIエージェントであるMirage-1を提案しました。Mirage-1の中核は階層的マルチモーダルスキル(HMS)モジュールであり、軌跡を実行スキル、コアスキル、メタスキルへと段階的に抽象化し、長距離タスク計画のための階層的知識構造を提供します。同時に、スキル拡張モンテカルロ木探索(SA-MCTS)アルゴリズムは、オフラインで獲得したスキルを利用してオンラインでの木探索のアクション検索空間を削減します。AndroidWorld、MobileMiniWob++、Mind2Web-Live、および新たに構築されたAndroidLHベンチマークにおいて、Mirage-1はいずれも顕著な性能向上を示しました。(出典: HuggingFace Daily Papers)
論文「Don’t Pay Attention」が新しいニューラルネットワーク基盤アーキテクチャAveyを提案、Transformerに挑戦: 「Don’t Pay Attention」と題された論文は、Attentionメカニズムやリカレントメカニズムへの依存からの脱却を目指す新しいニューラルネットワーク基盤アーキテクチャAveyを提案しています。Aveyは、ランカー(ranker)と自己回帰ニューラルプロセッサ(autoregressive neural processor)で構成され、これらが協調して、任意の特定のTokenに最も関連性の高いToken(シーケンス内の位置に関わらず)のみを識別し、文脈化処理を行います。このアーキテクチャは、シーケンス長とコンテキスト幅を分離することで、任意の長さのシーケンスを効果的に処理することを可能にします。実験結果は、Aveyが標準的な短距離NLPベンチマークでTransformerと同等の性能を示し、特に長距離依存関係の捕捉において優れた性能を発揮することを示しています。(出典: HuggingFace Daily Papers)
新論文、報酬モデルによるスケーラブルなコード検証の実現について議論、正確性とスループットのトレードオフを検討: ある研究では、大規模言語モデル(LLM)がコーディングタスクを解決する際に、結果報酬モデル(ORM)と包括的な検証器(完全なテストスイートなど)を使用することのトレードオフを検討しています。研究によると、包括的な検証器がある場合でも、ORMは速度と引き換えに一定の正確性を犠牲にすることで、スケーラブルな検証において重要な役割を果たします。特に「生成-枝刈り-再ランキング」アプローチでは、より高速だが正確性の低い検証器を使用して誤ったソリューションを事前に除去することで、システムの速度を11.65倍向上させ、正確性はわずか8.33%しか低下しませんでした。この方法は、誤っているがランキングの高いソリューションを除外することで機能し、スケーラブルで正確なプログラムランキングシステムを設計するための新しいアイデアを提供します。(出典: HuggingFace Daily Papers)
新ベンチマークAbstentionBenchが明らかに:推論型LLMは回答不能な問題で性能が低い: 大規模言語モデル(LLM)が不確実性に直面した際に棄権(明確な回答を拒否すること)を選択する能力を評価するため、研究者らはAbstentionBenchを発表しました。この大規模ベンチマークテストには20の異なるデータセットが含まれ、答えが不明、仕様が不十分、前提が誤っている、主観的な解釈、古い情報など、さまざまな種類の問題が網羅されています。20の最先端LLMの評価によると、棄権は未解決の問題であり、モデル規模の拡大はこれにほとんど貢献していません。驚くべきことに、数学や科学分野向けに明確に訓練された推論型LLMでさえ、その推論ファインチューニングによって棄権能力が平均24%低下しました。綿密に設計されたシステムプロンプトは実践において棄権パフォーマンスを向上させることができますが、これはモデルの不確実性推論における根本的な欠陥を解決するものではありません。(出典: HuggingFace Daily Papers)
論文、パッチベースのプロンプトと分解手法(PatchInstruct)を用いたLLMによる時系列予測を提案: 新しい研究では、大規模な再訓練や複雑な外部アーキテクチャを必要とせずに、大規模言語モデル(LLM)を時系列予測に活用するためのシンプルで柔軟なプロンプト戦略を探求しています。時系列分解、パッチベースのトークン化(patch-based tokenization)、類似性ベースの近傍拡張などの専門的なプロンプト手法を組み合わせることで、研究者らはLLMの予測品質を向上させると同時に、シンプルさを維持し、データ前処理を最小限に抑えることができることを発見しました。この研究で提案されたPatchInstruct手法は、LLMが正確かつ効果的な予測を行うことを可能にします。(出典: HuggingFace Daily Papers)
新データセットMS4UIが公開、ユーザーインターフェース指導ビデオのマルチモーダル要約に特化: 既存のベンチマークが段階的で実行可能な指示や図解を提供する上で不十分であるという問題を解決するため、研究者らはMS4UI(Multi-modal Summarization for User Interface Instructional Videos)データセットを提案しました。このデータセットには2413本のUI指導ビデオが含まれ、総時間は167時間を超え、手動でのビデオ分割、テキスト要約、ビデオ要約の注釈付けが行われています。UI指導ビデオ向けの簡潔で実行可能なマルチモーダル要約手法の研究を推進することを目的としています。実験によると、現在のSOTAマルチモーダル要約手法はMS4UIでは性能が低く、この分野における新しい手法の重要性が浮き彫りになりました。(出典: HuggingFace Daily Papers)
DeepResearch Bench:包括的な深層研究エージェントのベンチマークテスト: LLMベースの深層研究エージェント(Deep Research Agents, DRAs)の能力を体系的に評価するため、研究者らはDeepResearch Benchを発表しました。このベンチマークには、22の異なる分野の専門家によって綿密に設計された100の博士課程レベルの研究タスクが含まれています。DRAsの評価は複雑で労力を要するため、研究者らは人間の判断と高い一致を示す2つの新しい評価方法を提案しました。1つは、生成された研究報告書の品質を評価するための参照ベースの適応的基準法です。もう1つのフレームワークは、有効な引用数と全体的な引用精度を評価することで、DRAの情報検索および収集能力を評価します。(出典: HuggingFace Daily Papers)
論文、BridgeVLAを提案:入出力アライメントによる効率的な3D操作学習: ロボット操作学習における視覚言語モデル(VLM)の3D信号利用効率を向上させるため、研究者らはBridgeVLAという新しい3D視覚言語行動(VLA)モデルを提案しました。BridgeVLAは3D入力を複数の2D画像に投影し、VLMバックボーンネットワークの入力とのアライメントを確保し、行動予測に2Dヒートマップを使用することで、一貫した2D画像空間で入力と出力を統一します。さらに、この研究では、VLMバックボーンネットワークが下流のポリシー学習の前に2Dヒートマップを予測する能力を備えるためのスケーラブルな事前学習方法も提案しています。実験により、BridgeVLAは複数のシミュレーションベンチマークと実際のロボット実験において優れた性能を示し、3D操作学習の効率と効果を大幅に向上させ、強力なサンプル効率と汎化能力を示しました。(出典: HuggingFace Daily Papers)
新研究、アトリビューションベースの合成により数百万の多様で複雑なユーザー指示(SynthQuestions)を生成: 大規模言語モデル(LLM)のアライメントに必要な、多様で複雑かつ大規模な指示データの不足を解決するため、研究者らはアトリビューションベース(attributed grounding)の指示合成方法を提案しました。このフレームワークには、1) 選択された実際の指示を文脈化されたユーザーと結びつけるトップダウンのアトリビューションプロセス、2) Webドキュメントを利用してまず文脈を生成し、次に意味のある指示を生成するボトムアップの合成プロセスが含まれます。この方法により、100万件の指示を含むデータセットSynthQuestionsが構築されました。実験によると、このデータセットで訓練されたモデルは、複数の一般的なベンチマークテストでトップレベルの性能を達成し、Webコーパスの増加に伴い性能が継続的に向上しました。(出典: HuggingFace Daily Papers)
PersonaFeedback:大規模な人手による注釈付きのパーソナライズ評価ベンチマークが公開: 大規模言語モデル(LLM)が、事前に定義されたユーザーペルソナとクエリに基づいてパーソナライズされた応答を提供する能力を評価するため、研究者らはPersonaFeedbackベンチマークを発表しました。このベンチマークには8298件の人手による注釈付きテストケースが含まれ、ユーザーペルソナの文脈的複雑性とパーソナライズされた応答を区別する難易度に応じて、簡単、中程度、困難の3つのレベルに分類されています。既存のベンチマークとは異なり、PersonaFeedbackはペルソナ推論とパーソナライズを分離し、明確なペルソナに対してカスタマイズされた応答を生成するモデルの能力評価に焦点を当てています。実験結果は、SOTA LLMでさえ困難なレベルのテストでは課題に直面していることを示しており、現在の検索拡張フレームワークがパーソナライズタスクの最終的な解決策ではないことを示唆しています。(出典: HuggingFace Daily Papers)
論文、多言語大規模モデルにおける「言語手術」を議論:潜在的注入による推論時言語制御の実現: 新しい研究は、大規模言語モデル(LLM)における自然発生的な表現アライメント現象と、それが言語固有情報と言語非依存情報の分離に持つ意味を探求しています。研究はこのアライメントの存在を確認し、明示的に設計されたアライメントモデルの振る舞いとの比較分析を行いました。これらの発見に基づき、研究者らは推論時言語制御(Inference-Time Language Control, ITLC)手法を提案し、潜在的注入(latent injection)を利用して正確なクロスリンガル制御を実現し、LLMにおける言語混同問題を軽減します。実験は、ITLCがターゲット言語のセマンティックな完全性を維持しつつ、強力なクロスリンガル制御能力を持ち、現在の大規模LLMでさえ依然として存在するクロスリンガル混同問題を効果的に緩和できることを証明しました。(出典: HuggingFace Daily Papers)
論文、NoWait手法を提案:「思考Token」を削除し大規模モデルの推論効率を向上: 最近の研究によると、大規模推論モデルが複雑な段階的推論を行う際、過度な「思考」(「Wait」、「Hmm」などのTokenを出力するなど)により出力が冗長になり、効率に影響を与えることがよくあります。新たに提案されたNoWait手法は、推論時にこれらの明示的な自己反省Tokenを抑制することで、高度な推論への必要性を検証することを目的としています。テキスト、視覚、ビデオ推論タスクにまたがる10のベンチマークテストにおいて、NoWaitは5つのR1スタイルモデルファミリーで思考連鎖の軌跡長を27%~51%短縮し、モデルの有用性を損なうことはありませんでした。この手法は、効率的かつ有用性を維持するマルチモーダル推論を実現するためのプラグアンドプレイソリューションを提供します。(出典: HuggingFace Daily Papers)
💼 ビジネス
OpenAI、米国防総省と2億ドルのAI契約を獲得、最先端の軍事能力を開発: OpenAIは米国防総省と1年間で2億ドル相当の契約を締結し、国家安全保障のための高度な人工知能ツールを開発することになりました。これはOpenAIがペンタゴンがリストアップしたこの種の契約を初めて獲得したことを示します。作業は主に首都圏で行われます。OpenAIは以前から防衛企業Andurilと協力しており、今回の動きは米国防衛分野におけるAI応用の広範な推進という背景の中で行われました。競合他社のAnthropicもPalantirやAmazonとこの分野で協力しています。OpenAI CEOのSam Altman氏は、国家安全保障プロジェクトへの支持を公に表明しています。(出典: Reddit r/ArtificialInteligence, code_star)

Altaが1100万ドルの資金調達を完了、Menlo Venturesが主導、AI+ファッションに焦点: AIファッションスタートアップのAltaは、Menlo Venturesが主導する1100万ドルの資金調達を完了したと発表しました。BenchstrengthとAglaé Ventures(LVMHグループのアルノー家が支援するVCファンド)も参加しました。Amy Tong Wu氏がAltaの取締役会に加わります。この資金調達は、AltaのAIとファッションの融合分野におけるさらなる発展を支援します。(出典: ZhaiAndrew)
Figure社が組織再編、制御部門をHelixに統合しAIロードマップを加速: 人型ロボット企業Figureは、制御(Controls)部門が廃止され、チーム全体がHelix部門に統合されたと発表しました。この動きは、同社の人工知能分野におけるロードマップの発展を加速することを目的としており、FigureがAI技術の研究開発と応用にさらに多くのリソースとエネルギーを集中させていることを示しています。(出典: adcock_brett)
🌟 コミュニティ
AGIに関する議論:一般ユーザーは過度に心配する必要はなく、AGIは日常ツールよりも戦略的なものに近い: コミュニティの複数の議論では、一般のLLMユーザーにとって、AGI(汎用人工知能)の到来を過度に心配する必要はないと指摘されています。AGIの定義は曖昧で理論的であり、たとえ実現したとしても、短期的にはユーザーのチャットウィンドウに直接現れるのではなく、国家や大規模機関の戦略的ツールおよびインフラとして、国家間の交渉などの複雑な問題を処理するために使用され、個人の会議の手配を助けるものではありません。(出典: farguney, farguney, farguney, farguney)
マルチエージェントシステムの構築には人手による評価が必要、エッジケースと情報源の質に注意: マルチエージェントシステムを構築する際には、人手による評価とテストが非常に重要であり、自動評価が見落とす可能性のあるエッジケースを発見できます。例えば、初期のエージェントは情報源を選択する際に、権威ある学術PDFや個人のブログよりもSEO最適化されたコンテンツファームを好む傾向がありました。プロンプトに情報源の質に関するヒューリスティックな方法を組み込むことで、このような問題の解決に役立ちます。これは、自動評価の時代であっても、システムの障害や微妙な情報源選択の偏りなどを発見するためには、手動テストが依然として不可欠であることを示しています。(出典: riemannzeta)

LLMの予測と学習メカニズムにおけるビデオモデルとの違いが思考を促す: Yann LeCun氏とPedro Domingos氏はSergey Levine氏の見解をリツイートし、なぜ言語モデルは次のToken予測からこれほど多くを学ぶことができるのに、ビデオモデルは次のフレーム予測から学ぶことが比較的少ないのかについて議論しました。Levine氏は、これはLLMがある程度「脳スキャナー」の役割を果たしているためではないかと推測しており、その学習メカニズムの独自性を示唆しているか、あるいはLLMがプラトンの洞窟に住み、影のシーケンス(テキスト)を観察することで現実世界を推測しているかのようだと述べています。(出典: ylecun, pmddomingos, pmddomingos)

AI Agentの教育分野への積極的な影響:学習者が快適ゾーンから抜け出すのを促進: コミュニティの議論では、AI Agentは企業に積極的な影響を与えるだけでなく、教育分野でも同様に大きな可能性を秘めていると考えられています。AI Agentとのインタラクションを通じて、学習者はより効果的に自身の快適ゾーンから抜け出し、学習効果の向上を促進することができます。(出典: pirroh, amasad)
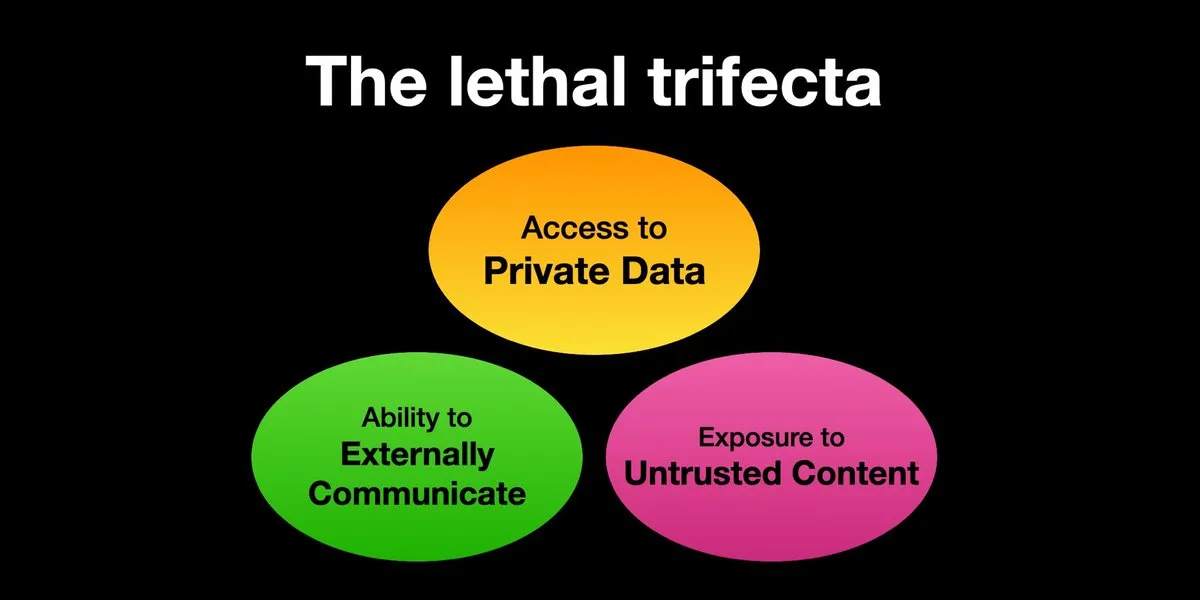
AI Agentはプロンプトインジェクション攻撃のリスクに直面、セキュリティ対策の強化が急務: Karpathy氏は、Simon Willison氏によるAI Agentが「致命的な三位一体」(Lethal Trifecta)のリスクに直面しているという警告をリツイートしました。これは、AI Agentが個人データへのアクセス、信頼できないコンテンツへの接触、および外部との通信能力を同時に持つ場合、攻撃者がシステムを騙してデータを盗むことができるというものです。これは、初期のコンピュータウイルスの「西部開拓時代」を彷彿とさせ、現在、悪意のあるプロンプトに対する防御メカニズムはまだ不完全であり、例えば、Agentが任意のスクリプトを実行する能力を制限するためのオペレーティングシステムのカーネル/ユーザースペースのようなセキュリティパラダイムが欠如しています。これにより、LLM Agentをパーソナルコンピューティングに早期採用することには懸念があります。(出典: karpathy, TheTuringPost)
AI時代、迅速な学習能力が中核的な競争力に: Mustafa Suleyman氏は、今後10年間で最大のキャリアアクセラレータは卓越した学習能力になるだろうと指摘しています。同氏は、人々が自身の学習スタイルを明確にし、AIを利用して教材を適切な形式(ポッドキャスト、クイズなど)に変換し、その後知識を応用し、このプロセスを継続的に繰り返すことで、迅速な学習と成長を実現することを提案しています。(出典: mustafasuleyman)
AI生成コンテンツの真実性と関連性:関連性が真実性に勝る可能性: ユーザーimjaredz氏は、AIが生成したリードジェネレーションメールを2000通送信したところ、AIが書いたと不満を言う人はいなかった一方、5人がメールの内容が「まさに彼らが研究していることだ」と述べたという経験を共有しました。これは、コミュニケーションにおいて、コンテンツの関連性がその「真実性」(人間が作成したかどうか)よりも重要であるかどうかについての議論を引き起こしました。(出典: imjaredz)
LLMの「理解」能力に関する議論:行動の近似は真の理解と同じではない: コミュニティでは、大規模言語モデルが強力な行動的および認知的近似能力を示しているものの、これは真の理解と同じではないという意見があります。理解には説明能力が必要であり、単に行動を示すだけでは知性や理解とは言えません。この根本的な違いはしばしば見過ごされます。この意見は、生命に関わる決定をモデルに委ねる前に、モデルが本当に汎用人工知能に近いかどうかを慎重に評価し、その能力を過度に誇張することに警戒する必要があると強調しています。(出典: farguney)
AI Agentはソフトウェアエンジニアリングのベンチマークで目覚ましい活躍を見せるも、その「エージェント」としての本質について議論: AIがSWE-benchなどのソフトウェアエンジニアリングのベンチマークで得点を伸ばし続けている(50~60点を超えることさえある)中、コミュニティでは「エージェントコーディング時代」が本当に到来したのかどうかについて議論が行われています。「エージェントレスフレームワーク」が一般的に使用されており、言語モデルが環境内で実際に探索する環境ではない場合、それを「エージェントコーディング時代」と呼ぶのは名ばかりかもしれないという意見があります。ただし、これらのフレームワーク自体は非常に価値があるとも述べられています。(出典: huybery, terryyuezhuo)
AI生成画像のコンテンツ審査の必要性:オープンソースまたは商用ソリューションを求める声: AI生成画像技術の普及に伴い、国内の開発者は出力コンテンツのコンプライアンス問題、特にポルノや政治的にデリケートなコンテンツなどをどのように検出するかに注目し始めています。コミュニティでは、コンテンツ審査を行うための利用可能なオープンソースの小規模モデルや商用製品を求める議論が出ています。(出典: dotey)
💡 その他
AI駆動のパーソナライゼーションとコンテンツの関連性:AIメール2000通に苦情なし、5人が「まさに必要なもの」と回答: あるユーザーが、AIによって生成されたリードジェネレーションメールを2000通送信したところ、受信者からAIが作成したことに対する苦情は一切なかったと共有しました。それどころか、5人の受信者がメールの内容が「まさに彼らが現在取り組んでいる仕事だ」と述べました。この事例は、AI支援コミュニケーションにおいて、コンテンツの高い関連性が「真実性」(つまり人間によって書かれたかどうか)への懸念を上回る可能性があるかどうかについての議論を引き起こし、AIのパーソナライズされたコンテンツ生成における可能性を示唆しています。(出典: imjaredz)
人間がAIシステムのボトルネックに、人間の効率を回避または向上させる必要性: Charles Earl氏の見解によると、受信トレイのメールは山積みになっているのに、送信トレイは空っぽであるという状況は、人間が情報処理と応答のボトルネックであることを反映しています。AI時代においては、人間のボトルネックをどのように回避するか、あるいはAIなどの技術を通じて人間の作業効率をどのように向上させるかを考える必要があります。(出典: charles_irl)
AI制御スマートホームの潜在的リスク:アプリの不具合でユーザーが冷たいスマートベッドに閉じ込められる: あるユーザーが、AI制御のスマートベッド(Eight Sleep Pod3)のアプリの不具合により温度調節ができなくなり、最終的に冷たいベッドに閉じ込められた経験を共有しました。このモデルには手動制御がなく、完全にアプリに依存しているため、今回の不具合は、AIとアプリ制御のスマートホームデバイスへの過度な依存がもたらす可能性のある不便さと「ディストピア的」な体験を浮き彫りにしました。(出典: madiator)