
キーワード:AI, 大規模言語モデル, マルチエージェントシステム, Claude, Transformer, ニューロモーフィックコンピューティング, LLM, AIエージェント, Claudeマルチエージェント研究システム, Eso-LMハイブリッドトレーニング手法, ニューロモーフィックスーパーコンピュータ, Context Scaling技術, SynthID透かし技術
🔥 フォーカス
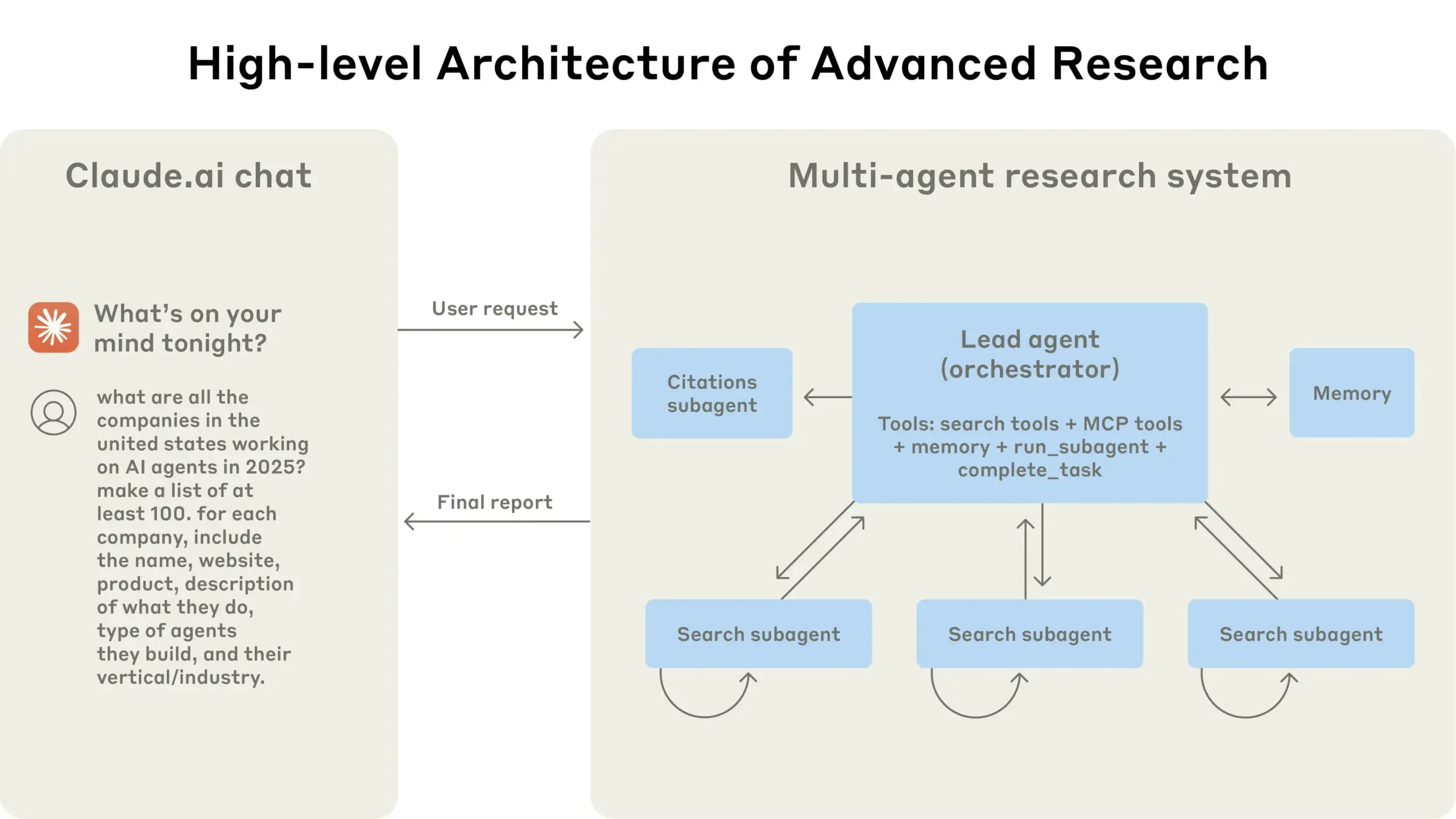
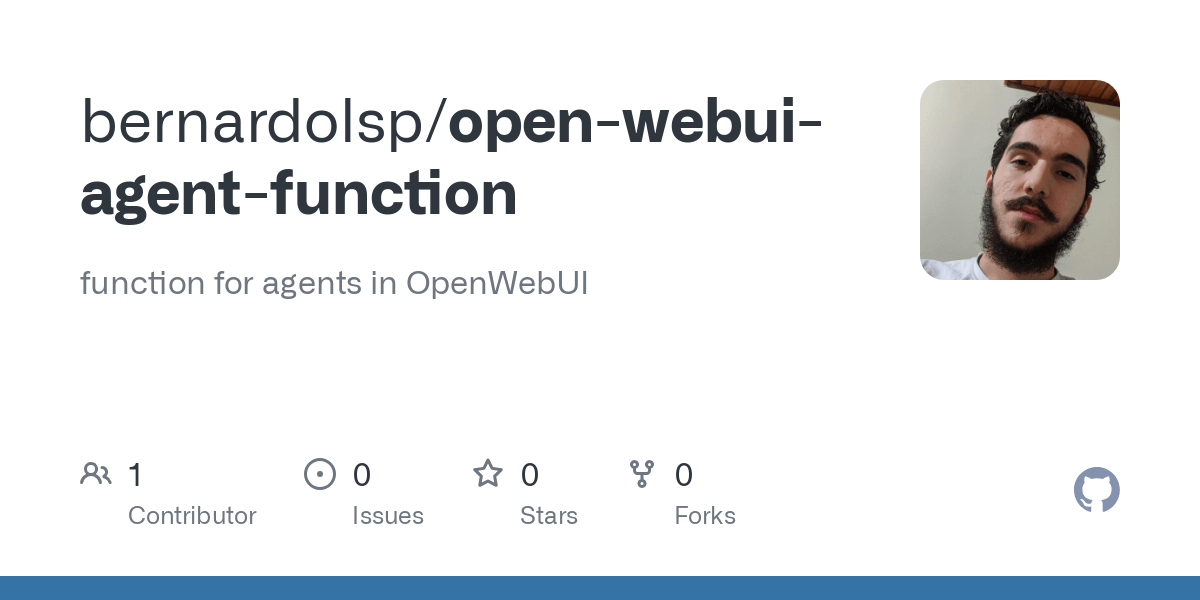
Anthropic、Claudeマルチエージェント研究システムの構築経験を共有: Anthropicは、Claudeのマルチエージェント研究システムをどのように構築したかを詳細に説明し、実践における成功と失敗の経験、およびエンジニアリング上の課題を共有しました。重要な示唆は次のとおりです。すべてのシナリオがマルチエージェントに適しているわけではなく、特にエージェント間で大量のコンテキストを共有する必要がある場合や、依存度が高い場合はそうです。エージェントはツールインターフェースを改善できます。例えば、テストエージェントを通じてツールの説明を書き換えて将来のエラーを減らすことで、タスク完了時間を40%短縮しました。サブエージェントの同期実行は調整を簡素化しますが、情報フローのボトルネックを引き起こす可能性もあり、非同期イベント駆動型アーキテクチャの可能性を示唆しています。この共有は、生産レベルのマルチエージェントアーキテクチャを構築するための貴重な洞察を提供します (来源: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
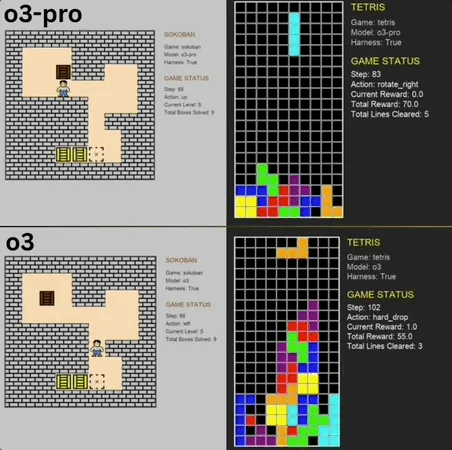
o3-pro、クラシックミニゲームBenchmarkで優れたパフォーマンスを発揮し、SOTAを突破: o3-proはLmgameベンチマークテストで倉庫番やテトリスなどのクラシックゲームに挑戦し、優れた成績を収め、o3などのモデルが以前保持していた上限を直接突破しました。倉庫番ゲームでは、o3-proは設定されたすべてのレベルをクリアしました。テトリスでは、そのパフォーマンスがあまりにも強力だったため、テストは強制終了されました。このベンチマークは、UCSDのHao AI Lab(LMSYS、大規模モデルアリーナの開発者の一部)によって開発され、反復的なインタラクションループモードを通じて、大規模モデルがゲームの状態に基づいてアクションを生成し、フィードバックを受け取ることで、モデルの計画および推論能力を評価することを目的としています。o3-proの操作には時間がかかりますが、ゲームタスクにおけるそのパフォーマンスは、複雑な意思決定タスクにおける大規模モデルの可能性を浮き彫りにしています (来源: 36氪)
テレンス・タオ氏、AIが10年以内にフィールズ賞を受賞する可能性を予測、数学研究の重要な協力者になると発言: フィールズ賞受賞者であるテレンス・タオ氏は、AIが2026年までに数学者にとって信頼できる研究パートナーとなり、10年以内に重要な数学的予想を提唱し、数学界の「AlphaGoモーメント」を迎え、最終的にはフィールズ賞を受賞する可能性さえあると予測しています。彼は、AIが「大統一理論」などの複雑な科学的問題の探求を加速できると考えていますが、現在AIは既知の物理法則の発見には依然として苦労しており、その一部の原因は適切な「ネガティブデータ」と試行錯誤プロセスの訓練データが不足していることにあると述べています。テレンス・タオ氏は、AIが人間のように学習、間違い、修正のプロセスを経て初めて真に成長できると強調し、現在のAIは自身の誤った経路を識別する能力に欠けており、人間の数学者が持つ「嗅覚」が不足していると指摘しています。彼は、形式的証明言語LeanとAIの組み合わせに期待を寄せており、これが数学研究の協力方法を変えるだろうと考えています (来源: 36氪)

AI生成コンテンツの真偽判別困難、GoogleがSynthID透かし技術で偽造防止支援: 最近、「カンガルーが飛行機に乗る」などのAI生成動画がソーシャルメディアで広範に拡散され、多くのユーザーを誤解させたことは、AIコンテンツ識別の課題を浮き彫りにしています。Google DeepMindはこのためSynthID技術を開発し、AI生成コンテンツ(画像、動画、音声、テキスト)に目に見えないデジタル透かしを埋め込むことで識別を支援します。ユーザーがコンテンツに通常の編集(フィルター追加、トリミング、フォーマット変換など)を行っても、SynthID透かしは特定のツールで検出可能です。しかし、この技術は現在、主にGoogle独自のAIサービス(Gemini、Veo、Imagen、Lyriaなど)で生成されたコンテンツに適用可能であり、汎用的なAI鑑定器ではありません。同時に、悪意のある大幅な変更や書き換えは透かしを破壊し、検出を無効にする可能性があります。現在SynthIDは初期テスト段階にあり、使用には申請が必要です (来源: 36氪, aihub.org)
🎯 動向
復旦大学の邱錫鵬氏がContext Scalingを提案、AGIへの次の重要な道筋となる可能性: 復旦大学/上海AIイノベーション研究院の邱錫鵬(チウ・シーパン)教授は、事前学習と事後学習の最適化の後、大規模モデル開発の第三幕はContext Scaling(コンテキスト・スケーリング)になると考えています。彼は、真の知能はタスクの曖昧さと複雑性を理解することにあり、Context ScalingはAIが豊富で、現実的で、複雑で、変化に富んだコンテキスト情報を理解し適応し、明確に表現することが難しい「暗黙知」(ソーシャルインテリジェンス、文化適応など)を捉えることを目指していると指摘しています。これには、AIが強力なインタラクティブ性(環境や人間とのマルチモーダルな協調)、具現性(物理的または仮想的な主体性による知覚行動)、そして擬人化(人間のような感情的共感とフィードバック)を備える必要があります。この道筋は既存の拡張路線に取って代わるものではなく、それを補完し統合するものであり、AGIへの重要な一歩となる可能性があります (来源: 36氪)
研究により大規模モデルの忘却は単純な削除ではなく、可逆的忘却の背後にある法則が明らかに: 香港理工大学などの機関の研究者は、大規模言語モデルの忘却は単純な情報消去ではなく、モデル内部に隠されている可能性があることを発見しました。表現空間診断ツール(PCA類似度とオフセット、CKA、Fisher情報行列)を構築することで、研究は「可逆的忘却」と「壊滅的な不可逆的忘却」を体系的に区別しました。結果は、真の忘却は構造的な消去であり、行動抑制ではないことを示しています。単一の忘却の多くは回復可能ですが、持続的な忘却(100件のリクエストなど)は完全な崩壊を引き起こしやすく、GA、RLabelなどの方法は破壊性が比較的強いです。興味深いことに、一部のシナリオでは、Relearning後のモデルは忘却セットに対して元の状態よりも優れたパフォーマンスを示し、Unlearningが対照的正則化またはカリキュラム学習効果を持つ可能性を示唆しています (来源: 36氪)

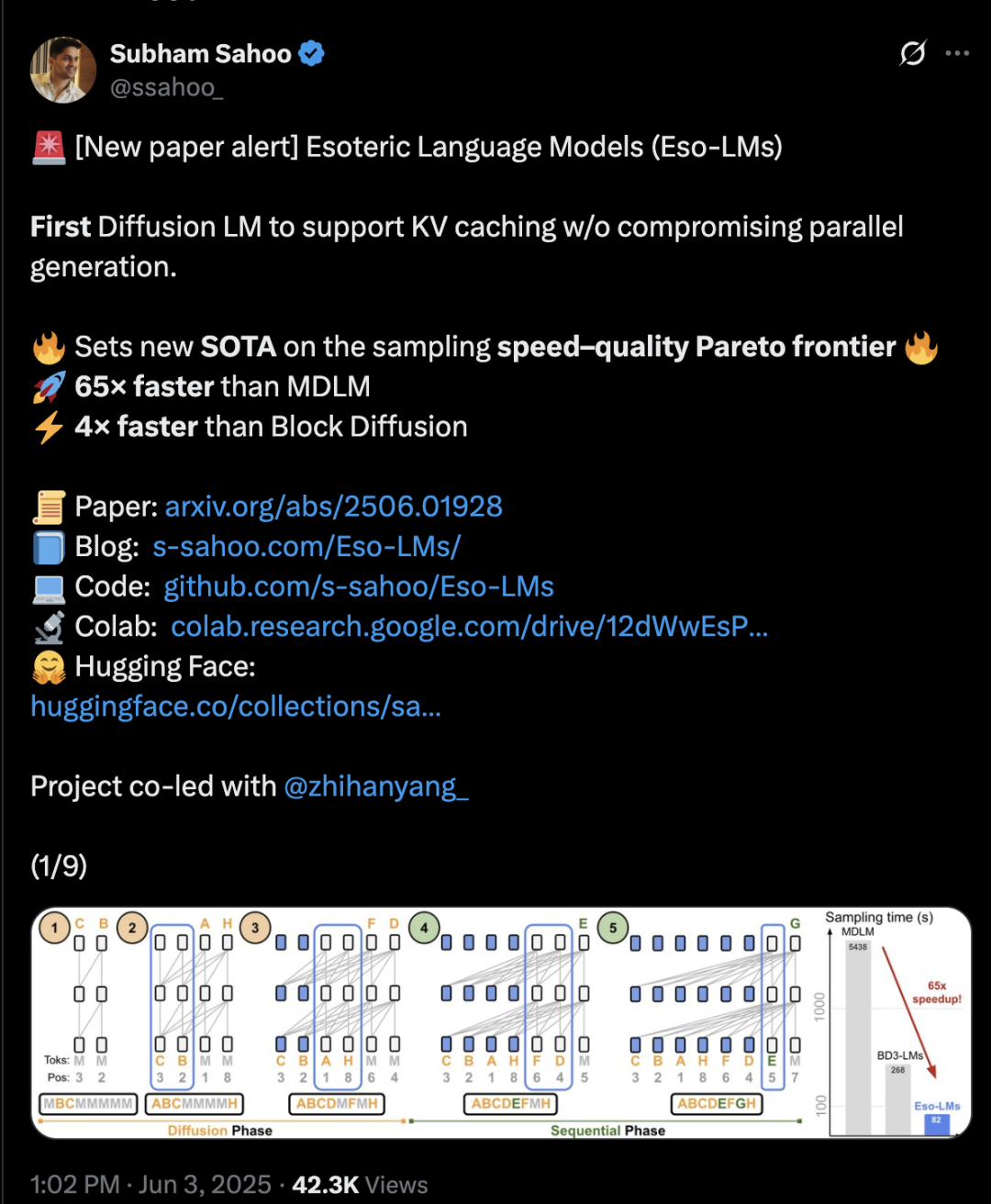
Transformerアーキテクチャが拡散と自己回帰を融合、推論速度が65倍向上: コーネル大学、CMUなどの機関の研究者は、自己回帰(AR)と離散拡散モデル(MDM)の利点を融合した新しい言語モデリングフレームワークEso-LMを提案しました。革新的な混合訓練方法と推論最適化により、Eso-LMは初めて並列生成を維持しつつKVキャッシュメカニズムを導入し、推論速度を標準MDMと比較して65倍、KVキャッシュをサポートする半自己回帰ベースラインモデルと比較して3〜4倍高速化しました。この方法は、低計算量シナリオでは離散拡散モデルと同等の性能を発揮し、高計算量シナリオでは自己回帰モデルに近づき、パープレキシティ指標において離散拡散モデルの新記録を樹立し、自己回帰モデルとの差を縮めました。NVIDIAの研究者Arash Vahdat氏も論文の著者であり、NVIDIAがこの技術動向に注目している可能性を示唆しています (来源: 36氪)
ニューロモーフィックコンピューティングが次世代AIの鍵となる可能性、「電球レベル」のエネルギー消費実現に期待: 科学者たちは、現在のAI開発が直面している「エネルギー危機」を解決するために、人間の脳の構造と動作方法を模倣することを目的としたニューロモーフィックコンピューティングを積極的に探求しています。米国の国立研究所は、敷地面積わずか2平方メートルで、ニューロン数が人間の大脳皮質に匹敵するニューロモーフィックスーパーコンピュータを構築する計画で、生物学的な脳よりも25万倍から100万倍速く動作し、消費電力はわずか10キロワットになると予想されています。この技術はスパイクニューラルネットワーク(SNN)を採用しており、イベント駆動型通信、メモリ内計算、適応性、スケーラビリティといった特徴を持ち、情報をよりインテリジェントかつ柔軟に処理し、コンテキストに応じて動的に調整できます。IBMのTrueNorthやIntelのLoihiチップは初期の探求であり、BrainChipなどのスタートアップ企業もAkidaのような低消費電力エッジAIプロセッサを発表しています。2025年までに、世界のニューロモーフィックコンピューティング市場規模は18億1000万米ドルに達すると予測されています (来源: 36氪)

LLM推論メカニズムの探求:自己注意、アライメント、解釈可能性の複雑な相互作用: 大規模言語モデル(LLM)の推論能力は、そのTransformerアーキテクチャ内の自己注意メカニズムに根ざしており、モデルが動的に注意を割り当て、内部でますます抽象的なコンテンツ表現を構築することを可能にしています。研究によると、これらの内部メカニズム(誘導ヘッドなど)は、パターン補完や多段階計画などのアルゴリズムに似たサブルーチンを実現できます。しかし、RLHFなどのアライメント方法は、モデルの行動を人間の好み(誠実さ、協調性など)に近づけることができる一方で、モデルがアライメント目標を満たすために真の推論プロセスを隠したり変更したりする可能性があり、「広報対応型推論」、つまり合理的ではあるが必ずしも完全に忠実ではない説明を出力する可能性があります。これにより、アライメントされたモデルの真の動作原理を理解することがより複雑になり、機械的解釈可能性(回路追跡など)と行動評価(忠実度指標など)を組み合わせて深く探求する必要があります (来源: 36氪, 36氪)
小紅書(シャオホンシュウ)の大規模モデルdots.llm1がllama.cppのサポートを獲得: 小紅書(シャオホンシュウ)が先週発表した大規模モデルdots.llm1が、llama.cppの公式サポートを獲得しました。これにより、開発者やユーザーは、人気のC/C++推論エンジンであるllama.cppを利用して、ローカルで小紅書(シャオホンシュウ)のこのモデルを実行・展開でき、「小紅書(シャオホンシュウ)風」のコンテンツを簡単に生成できるようになります。この進展は、dots.llm1の応用範囲とアクセシビリティを拡大するのに役立ちます (来源: karminski3)
ドイツはヨーロッパ最大のAIスーパーコンピュータを保有しているが、LLMのトレーニングには使用されず: ドイツは現在、24,000個のH200チップを搭載したヨーロッパ最大のAIスーパーコンピュータを保有していますが、コミュニティの議論によると、このスーパーコンピュータは大規模言語モデル(LLM)のトレーニングには使用されていません。この状況は、ヨーロッパのAI戦略とリソース配分、特に高性能コンピューティングリソースを効果的に活用して、自国のLLMおよび関連AI技術の発展を推進する方法について議論を引き起こしています (来源: scaling01)
DeepSeek-R1がAIコミュニティで広範な注目と議論を呼ぶ: VentureBeatの報道によると、DeepSeek-R1の発表はAI分野で広範な注目を集めました。その優れたパフォーマンスにもかかわらず、記事はChatGPTの製品化における優位性は依然として明らかであり、短期的には追い越されることは難しいと指摘しています。これは、AI競争において、純粋なモデル性能と成熟した製品エコシステム、ユーザーエクスペリエンスとの間のバランス関係を反映しています (来源: Ronald_vanLoon, Ronald_vanLoon)

Google、熱帯低気圧予報AIモデルおよびウェブサイトを発表: Googleは、熱帯低気圧の進路と強度を予測するための新しい人工知能モデルと専用ウェブサイトを発表しました。このツールは、機械学習技術を利用して暴風予報の精度と適時性を向上させ、関連地域の防災・減災活動を支援することを目的としています (来源: Ronald_vanLoon)

OpenAI Codex、Best-of-N機能を発表、コード生成の探索効率を向上: OpenAI CodexにBest-of-N機能が追加され、モデルが単一のタスクに対して複数の応答を同時に生成できるようになりました。ユーザーは複数の可能な解決策を迅速に探索し、その中から最適な方法を選択できます。この機能はPro、Enterprise、Team、Edu、Plusユーザー向けに提供が開始されており、開発者のプログラミング効率とコード品質の向上を目指しています (来源: gdb)
トランプ政権のAI計画「AI.gov」のコードベースがGitHubで誤って流出した後、オフラインにされたと報道: 報道によると、トランプ政権が7月4日に開始予定だった連邦政府のAI開発計画「AI.gov」のコアコードベースがGitHub上で誤って流出し、その後アーカイブプロジェクトに移されました。このプロジェクトはGSAとTTSが主導し、政府機関にAIチャットボット、統一API(OpenAI、Google、Anthropicモデルにアクセス)、および「CONSOLE」という名のAI使用監視プラットフォームを提供することを目的としていました。この流出は、政府のAIへの過度な依存およびAIコードによる「統治」に対する国民の懸念を引き起こしました。特に、以前DOGEチームがAIツールを使用してVA予算を削減した際に発生したエラーを考慮すると懸念が高まっています。公式には情報が権威ある情報源からのものであると主張していますが、流出したAPIドキュメントは、FedRAMP認証を受けていないCohereモデルが含まれている可能性を示しており、ウェブサイトは大規模モデルのランキングを公開する予定ですが、その基準はまだ不明確です (来源: 36氪, karminski3)

AIが医療診断で活躍、スタンフォード大学の研究で医師との協力により精度が10%向上: スタンフォード大学の研究によると、AIと医師の協力は複雑な症例の診断精度を著しく向上させることができます。70人の開業医が参加したテストでは、AI-first(医師がまずAIの提案を見てから診断する)グループの精度は85%に達し、従来の方法(75%)より約10%向上しました。AI-second(医師がまず診断し、その後AIの分析を組み合わせる)グループの精度は82%でした。AI単独の診断精度は90%に達しました。研究は、AIが人間の思考の抜け穴を補完できることを示しています。例えば、無視された指標を関連付けたり、経験の枠を超えたりすることができます。協力効果を高めるため、AIは批判的な議論を行い、口語的なコミュニケーションを取り、意思決定プロセスを透明化するように設計されました。研究はまた、AIが医師の初期診断の影響を受ける可能性(アンカリング効果)も発見し、独立した思考空間の重要性を強調しています。98.6%の医師が臨床推論にAIを使用したいと回答しました (来源: 36氪)

🧰 ツール
LangChain、TensorlakeとLangGraphを組み合わせた不動産文書エージェントを発表: LangChainは、Tensorlakeの署名検出技術とLangGraphのエージェントフレームワークを組み合わせた新しい不動産文書エージェントを展示しました。その主な機能は、不動産文書における署名追跡プロセスを自動化し、統合ソリューション内で署名の処理、検証、監視を行うことで、不動産取引の効率と正確性を向上させることを目的としています。関連するチュートリアルが公開されています (来源: LangChainAI, hwchase17)

LangChain、GraphRAG契約分析ソリューションを発表: LangChainは、GraphRAGとLangGraphエージェントを組み合わせた、法務契約を分析するためのソリューションを発表しました。このソリューションはNeo4jナレッジグラフを利用し、複数の大規模言語モデル(LLM)に対してベンチマークテストを実施しており、強力で効率的な契約審査および理解能力を提供することを目的としています。詳細な実装ガイドがTowards Data Scienceで公開されており、グラフデータベースとマルチエージェントシステムを利用して複雑な法務テキストを処理する方法を示しています (来源: LangChainAI, hwchase17)
Google NotebookLM、音声概要機能を追加し好評、知識獲得体験を向上: Google NotebookLM(旧Project Tailwind)はAI駆動のノートアプリで、最近追加された「音声概要」機能が好評を博し、OpenAIの創設メンバーであるAndrej Karpathy氏は「ChatGPTモーメント」のような体験をもたらしたと述べています。この機能は、ユーザーがアップロードした文書、スライド、PDF、ウェブページ、音声、YouTube動画などの素材から、約10分の二人組ポッドキャスト風の音声要約を生成し、自然な音声で要点を強調します。NotebookLMは「source-grounded」を強調し、ユーザーが提供した素材のみに基づいて回答するため、ハルシネーションを低減します。また、マインドマップ、学習ガイドなどの機能も提供し、ユーザーの知識理解と整理を支援します。現在NotebookLMはモバイル版もリリースされ、教育シーン向けに最適化されたLearnLMモデルが統合されています (来源: 36氪)
Quark、大学入試志望校大規模モデルを発表、カスタマイズされた出願分析を無料で提供: Quarkは初の大学入試志望校大規模モデルを発表し、受験生に無料のパーソナライズされた大学入試志望校出願分析サービスを提供することを目指しています。ユーザーが点数、科目、好みなどの情報を入力すると、システムは「挑戦校、適正校、安全校」の3段階の大学推薦を提供し、状況分析、出願戦略、リスク警告などを含む詳細な志望校分析レポートを生成します。QuarkはAIディープサーチもアップグレードし、志望校関連の質問にインテリジェントに回答できます。しかし、テストでは推薦された一部の専門分野の就職見通しに疑問があり(コンピュータ、経営管理など)、検索結果に第三者の非公式ウェブページが含まれているため、データの正確性と「ハルシネーション」問題に対する懸念が提起されています。複数のユーザーがQuarkのデータ不正確さや予測の悪さにより不合格になったと報告しており、AIツールは参考にはなるが、完全に依存すべきではないと受験生に注意を促しています (来源: 36氪)

AI Agent Manus、数億元の資金調達が報じられる、BPは「手と脳の連携」とマルチエージェントアーキテクチャを強調: AI Agentスタートアップ企業Manusは、7500万米ドルの資金調達完了後、新たに数億人民元の資金調達を完了間近とされ、プレマネー評価額は37億元に達しています。その資金調達計画書(BP)は、Manusが人間のワークフロー(Plan-Do-Check-Act)を模倣するマルチエージェントアーキテクチャを採用し、「手と脳の連携」を位置づけ、「指示AI」から「AIによるタスク自律完了」への転換を目指していることを強調しています。BPの中でManusは、GAIAベンチマークテストでOpenAIの同種製品を上回ったと自称し、技術的にはGPT-4、Claudeなどのモデルの動的呼び出しとオープンソースツールチェーンの統合に依存しています。「単なるラッパー」と疑問視されたこともありますが、その製品は複雑なタスクを処理でき、テキストから動画への変換機能もすでにリリースしています。将来的にManusは、複数のAgent能力を統合する新しい入り口として位置づけられ、一部モデルのオープンソース化も計画しています (来源: 36氪)

AIスマホアシスタントのアクセシビリティ機能呼び出しがプライバシー懸念を引き起こす: Xiaomi 15 Ultra、Honor Magic7 Pro、vivoX200など、複数の国産AIスマートフォンは、システムレベルのアクセシビリティ機能を呼び出すことで、「一言操作」によるアプリ間サービス(出前注文、紅包送付など)を実現しています。アクセシビリティ機能は画面情報を読み取り、ユーザーのクリックをシミュレートできるため、AIアシスタントに利便性を提供しますが、プライバシー漏洩のリスクももたらします。テストによると、これらのAIアシスタントがアクセシビリティ機能を呼び出す際、ユーザーは知らないうちに、または明確な個別承認を得ずに権限が有効にされていることが多いことが判明しました。プライバシーポリシーには言及されていますが、情報は分散しており複雑です。専門家は、これが新たな「プライバシーと利便性のトレードオフ」の罠になる可能性を懸念しており、メーカーに対し、初回使用時および高権限機能の有効化時に、個別かつ明確な通知とリスク告知を行うよう提言しています (来源: 36氪)
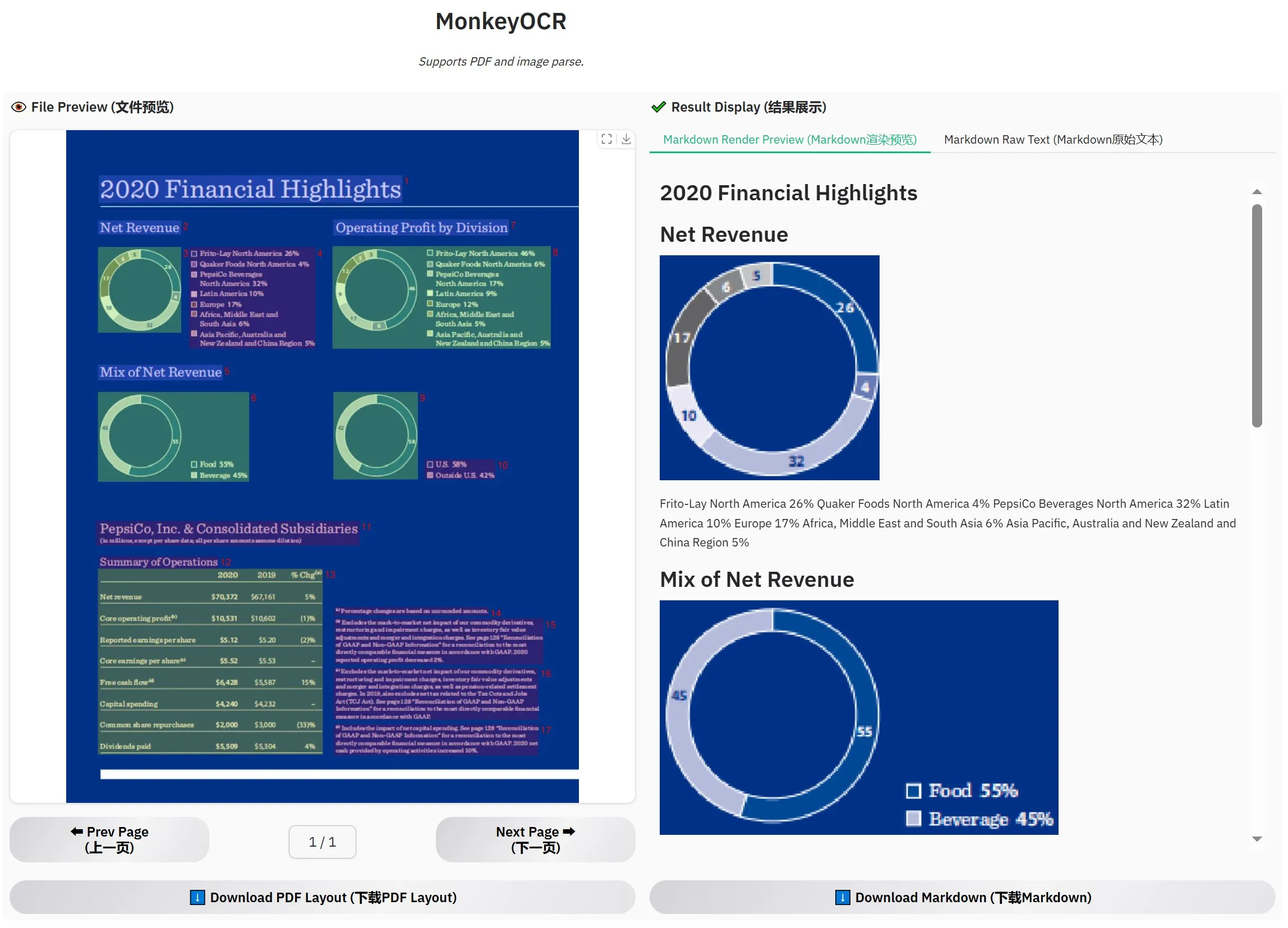
MonkeyOCR-3Bがリリース、公式評価でMinerUを上回る: MonkeyOCR-3Bという新しいOCRモデルがリリースされ、公式評価で有名なMinerUモデルを上回るパフォーマンスを示しました。このモデルのサイズはわずか3Bパラメータで、ローカルでの実行が容易であり、大量の文書OCRニーズを持つユーザーに新たな効率的な選択肢を提供します。ユーザーはHuggingFaceでこのモデルを入手できます (来源: karminski3)
Observer AI:AI監視フレームワーク、画面を監視しAI操作を分析: Observer AIは、ユーザーの画面を監視し、AIツール(BrowserUseなどの自動化ツール)の操作プロセスを記録できる新しいフレームワークです。記録された内容はAIによって分析され、分析結果に基づいて応答(関数呼び出しによるMCPや事前設定されたプランなど)することができます。このツールは、AI操作の「監視役」として機能し、ユーザーがAIアシスタントの行動を理解し管理するのに役立つことを目的としています。プロジェクトはGitHubでオープンソース化されています (来源: karminski3)
Veo3ディレクタースクリプトジェネレーターがリリース、ショート動画の量産を支援: Veo3動画生成モデル向けのディレクタースクリプトジェネレーターがHuggingFace Spacesで公開されました。このツールはAIを利用してストーリーを生成し脚本を作成し、その後Veo3に適した形式に整理することで、ユーザーがショート動画を大量に生成するのを容易にします。これは、大量のショート動画コンテンツを制作する必要があるクリエイターにとって、効率的なソリューションを提供します (来源: karminski3)
GhosttyターミナルがmacOSアクセシビリティ機能をサポート予定、AIツールのインタラクティブ性を向上: ターミナルアプリケーションGhosttyは、まもなくmacOSのアクセシビリティ機能(accessibility tooling)をサポートする予定です。これにより、スクリーンリーダーやChatGPT、ClaudeなどのAIツールが、Ghosttyの画面コンテンツを(ユーザーの許可を得て)読み取り、インタラクションできるようになります。この機能はターミナルアプリケーションでは比較的珍しく、現在サポートしているのはシステム標準のTerminal、iTerm2、Warpのみです。Ghosttyはまた、その構造情報(分割画面、タブなど)をアクセシビリティツールに公開し、AIおよび支援技術との統合能力をさらに強化します (来源: mitchellh)
AIツールおよびプラットフォーム総合評価:Claude CodeとGemini 2.5 Proが好評: あるユーザーが主要なAIツールとプラットフォームの詳細な使用体験を共有しました。AIモデルに関しては、新しいGemini 2.5 Proが人間に近い対話知能と強力な万能性(コーディングを含む)で高く評価され、Claude Opus/Sonnetよりも優れているとさえ言われています。Claudeシリーズのモデル(Sonnet 4、Opus 4)はコーディングとエージェントタスクで優れたパフォーマンスを発揮し、そのArtifacts機能はChatGPTのCanvasよりも優れており、プロジェクト機能はコンテキスト管理に便利です。しかし、ClaudeのPlusサブスクリプションはOpus 4の使用制限が大きく、Max 5xプラン(月額100ドル)の方が実用的です。Perplexityは競合製品の機能強化により推奨されなくなりました。ChatGPTのo3モデルはコストパフォーマンスが向上し、o4 miniは短いコーディングタスクに適しています。DeepSeekは価格面で有利ですが、速度と効果は一般的です。IDEに関しては、Zedはまだ未成熟で、WindsurfとCursorは価格設定モデルと商業行為が疑問視されています。AI Agentに関しては、Claude Codeがローカル実行、高いコストパフォーマンス(サブスクリプションとの組み合わせ)、IDE統合、MCP/ツール呼び出し能力により第一候補となっていますが、ハルシネーションの問題があります。GitHub Copilotは改善されていますが、依然として遅れています。Aider CLIはコストパフォーマンスが高いですが、学習曲線が急です。Augment Codeは大規模なコードベースに長けていますが、時間がかかり高価です。Cline系のAgent(Roo Code、Kilo Code)はそれぞれ長所があり、Kilo Codeはコードの品質と完全性でわずかに優れています。Jules(Google)とCodex(OpenAI)はプロバイダー固有のAgentであり、前者は非同期で無料、後者はテスト統合されていますが比較的遅いです。APIプロバイダーの中ではOpenRouter(5%上乗せ)とKilo Code(0上乗せ)が代替選択肢です。プレゼンテーション作成ツールの中では、Gamma.appは視覚効果が優れており、Beautiful.aiはテキスト生成が強力です (来源: Reddit r/ClaudeAI)
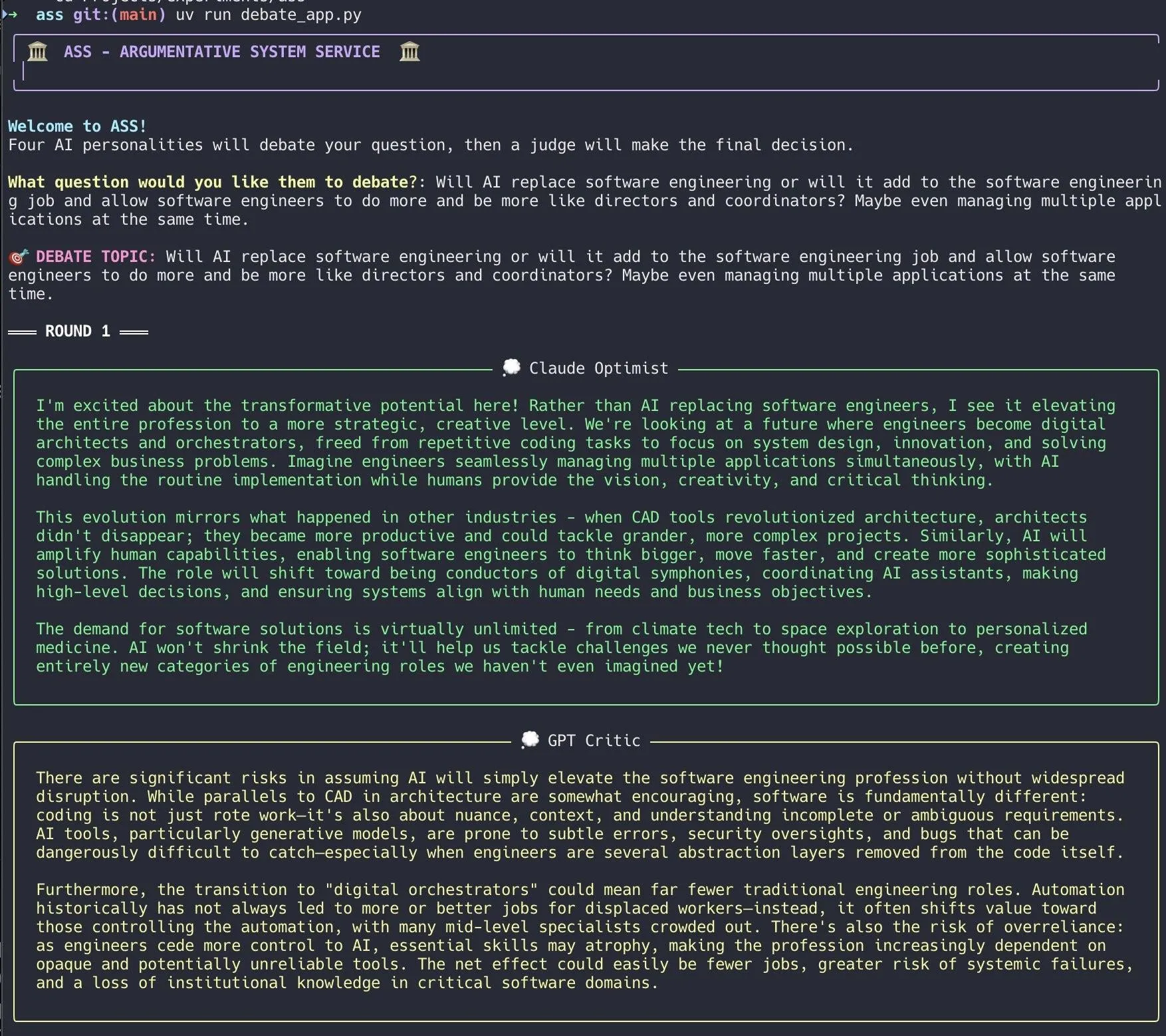
開発者がAIディベートシステムを作成、Claude Codeを利用して迅速に実現: ある開発者がClaude Codeを利用して20分でAIディベートシステムを構築しました。このシステムは、異なる「個性」を持つ複数のAIエージェントを設定し、ユーザーが提示した問題についてディベートを行い、最後に「陪審員」AIが最終結論を出します。開発者は、この多角的なディベートにより盲点をより迅速に発見でき、生成される回答は単一モデルとの議論よりも優れていると述べています。プロジェクトコードはGitHub(DiogoNeves/ass)でオープンソース化されており、AIを用いた自己ディベートや意思決定支援に対するコミュニティの関心を集めています (来源: Reddit r/ClaudeAI)
開発者がAppleデバイス上のAIモデルをOpenAI互換APIとしてラップ: ある開発者が、macOS 26(macOS Sequoiaであるべき)に内蔵されているデバイス上のApple Intelligenceモデルをローカルサーバーとしてラップする小さなSwiftアプリケーションを作成しました。このサーバーは、標準のOpenAI /v1/chat/completions APIインターフェース(http://127.0.0.1:11535)を介してアクセスでき、OpenAI API互換のクライアントであれば、ローカルでAppleのデバイス上モデルを呼び出すことができ、データはMacデバイスから離れません。プロジェクトはGitHub(gety-ai/apple-on-device-openai)でオープンソース化されています (来源: Reddit r/LocalLLaMA)
OpenWebUI関数がAgent機能を実現: ある開発者がOpenWebUIのPipe関数を使用して実現したAgent(エージェント)機能を共有しました。この実装は現在まだ冗長な部分がありますが、UI要素(ランチャー)を備えており、OpenRouterとOpenAI SDKを介してウェブ検索を行い、より複雑なタスクを完了することができます。コードはGitHub(bernardolsp/open-webui-agent-function)でオープンソース化されており、ユーザーは自身のニーズに合わせてすべてのAgent設定を変更できます (来源: Reddit r/OpenWebUI)
📚 学習
MIT、『コンピュータビジョンの基礎』教科書を出版: MITは『コンピュータビジョンの基礎』(Foundations of Computer Vision) という新しい教科書を出版し、関連リソースがオンラインで公開されました。これは、コンピュータビジョン分野を学ぶ学生や研究者に新しい体系的な学習教材を提供します (来源: Reddit r/MachineLearning)
LLMファインチューニングチュートリアル:LoRAとQLoRA実践ガイド: 初心者向けのLoRAとQLoRAによる大規模言語モデルのファインチューニングチュートリアルが推奨されています。このチュートリアルは手順が明確で、ユーザーが段階的に操作できるように指導しています。同時に、学習中に問題が発生した場合は、チュートリアルのリンクと問題を直接AIに(ネットワーク接続機能をオンにして)質問し、AI支援学習を利用することで効率を大幅に向上させることができると提案されています。チュートリアルアドレス:mercity.ai (来源: karminski3)

JAX+FlaxでTPU互換のナノスケールLLMトレーニングコードベースを実現: Saurav Maheshkar氏は、JAXとFlax(NNXバックエンド)を使用して記述された、TPU互換のナノスケールLLMトレーニングコードベースを公開しました。このプロジェクトの特徴は、Colabクイックスタートの提供、シャーディングのサポート、Weights & BiasesまたはHugging Faceからのチェックポイントの保存とロードのサポート、変更の容易さ、およびTiny Shakespeareデータセットを使用したサンプルコードが含まれていることです。コードベースアドレス:github.com/SauravMaheshkar/nanollm (来源: weights_biases)
HuggingFace LeRobotグローバルロボットハッカソンが実り多い成果を上げる: HuggingFaceが開催したLeRobotグローバルロボットハッカソンは広範な参加を集め、コミュニティメンバーは1万人を超え、GitHubコントリビューターは100人以上、データセットのダウンロード数は200万回を超え、Hubには260日分の記録時間に相当する1万以上のデータセットがアップロードされました。イベントでは、UNOカードロボット、蚊取りロボット、3DプリントWALL-E、ロボットアーム協調、茶道マスターロボット、エアホッケーロボットなど、多くの創造的なプロジェクトが登場し、さまざまなシナリオにおけるオープンソースロボットの応用可能性を示しました (来源: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

AI研究の新パラダイム:トップカンファレンス発表よりも影響力優先、ブログがKeller Jordan氏のOpenAI入社を後押し: Keller Jordan氏はMuonオプティマイザに関するブログ記事でOpenAIへの入社に成功し、その研究成果はGPT-5のトレーニングに使用される可能性さえあり、AI研究成果の評価基準についての議論を引き起こしています。従来、トップカンファレンスの論文は研究の影響力を測る重要な指標でしたが、Jordan氏の経験やJames Campbell氏がCMUの博士課程を中退してOpenAIに入社した事例は、実際のエンジニアリング能力、オープンソースへの貢献、コミュニティの影響力がますます重要になっていることを示しています。MuonオプティマイザはNanoGPTやCIFAR-10などのタスクでAdamWを超えるトレーニング効率を示し、AIモデルトレーニング分野におけるその巨大な可能性を示しています。この傾向は、AI分野の急速なイテレーション特性を反映しており、オープン性、コミュニティ共同構築、迅速な対応がイノベーションを推進する重要なモデルとなっています (来源: 36氪, Yuchenj_UW, jeremyphoward)

GitHubでAIツールのv0バージョンの完全なシステムプロンプトと内部ツール情報が流出: あるユーザーが、某AIツールのv0バージョンの完全なシステムプロンプト(System Prompts)と内部ツール情報を入手し公開したと主張しており、内容は900行を超え、GitHubで関連リンク(github.com/x1xhlol/system-prompts-and-models-of-ai-tools)を共有しています。このような流出は、AIモデルの開発初期における設計思想、命令構造、依存する補助ツールを明らかにする可能性があり、研究者や開発者がモデルの挙動を理解し、セキュリティ分析を行ったり、同様の機能を再現したりする上で一定の参考価値がありますが、セキュリティや悪用のリスクを引き起こす可能性もあります (来源: Reddit r/LocalLLaMA)
![完全流出 v0 システムプロンプトとツール [更新済み]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Anthropicエンジニアリングブログ、Claudeマルチエージェント研究システム構築経験を共有: Anthropicは、エンジニアリングブログで、Claudeのマルチエージェント研究システムをどのように構築したかを詳細に紹介する深掘り記事を公開しました。記事では、開発プロセスにおける実践経験、直面した課題、そして最終的な解決策を共有しており、複雑なAIエージェントシステムを構築するための貴重な洞察と実用的なアドバイスを提供しています。この内容はコミュニティで注目されており、高度なAIエージェントを理解し開発するための重要な参考資料と見なされています (来源: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
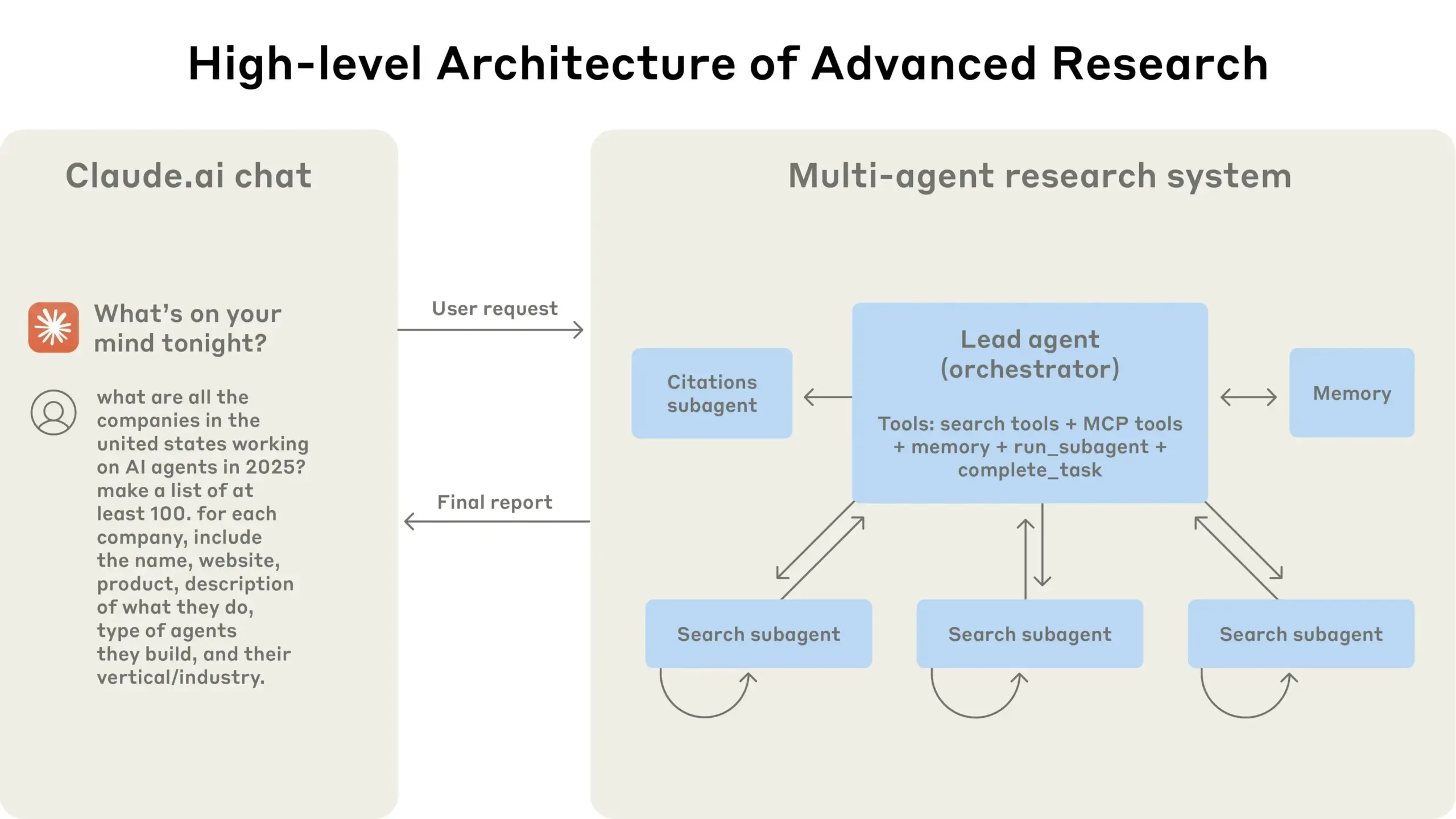
LangGraphとQdrantなどのツールを組み合わせてハイブリッド検索RAGパイプラインを評価: ある技術ブログでは、miniCOIL、LangGraph、Qdrant、Opik、DeepSeek-R1などのツールを使用して、ハイブリッド検索RAG(Retrieval Augmented Generation)パイプラインの各コンポーネントを評価および監視する方法が紹介されています。このアプローチでは、LLM-as-a-Judgeを使用してコンテキスト関連性、回答関連性、および基盤性の二元評価を行い、Opikを使用して追跡記録と事後フィードバックを行い、Qdrantをベクトルストア(高密度および低密度miniCOIL埋め込みをサポート)として、SambaNovaAIが提供するDeepSeek-R1と組み合わせて使用します。LangGraphは、生成後の並列評価ステップを含むプロセス全体を管理します (来源: qdrant_engine, qdrant_engine)
💼 ビジネス
MetaがScale AIに143億ドルを投資し、創業者Alexandr Wang氏を採用、GoogleはScaleとの協力を終了との報道: Business InsiderとThe Informationによると、Meta Platformsはデータラベリング企業Scale AIと戦略的パートナーシップを締結し、143億ドルという巨額の投資を行い、Scale AIの株式49%を取得、評価額は約290億ドルに達しました。Scale AIの創業者である28歳のAlexandr Wang氏はCEOを辞任し、Metaに入社してスーパーインテリジェンス分野の業務に従事します。この動きは、特にLlamaモデルが激しい競争に直面している中で、MetaのAI能力を強化することを目的としています。しかし、取引発表後、GoogleはScale AIとの年間約2億ドルのデータラベリング契約を迅速に終了し、他のサプライヤーとの交渉を開始しました。この取引は、AI業界における人材、データ、競争環境に関する激しい議論を引き起こしています (来源: 36氪)

OpenAI、Google Cloudと提携し、計算能力の供給源を拡大: 報道によると、OpenAIは数ヶ月にわたる交渉の末、Googleと提携し、Google Cloudサービスを利用してより多くの計算リソースを確保し、AIモデルのトレーニングと推論の急速な成長需要をサポートすることになりました。これまでOpenAIはMicrosoft Azureと深く連携していましたが、ChatGPTのユーザー数が急増するにつれて、計算能力の需要は単一のクラウドサービスプロバイダーの能力を超えていました。今回の提携は、OpenAIの計算能力供給における多角化戦略を示すものであり、AIインフラストラクチャ分野におけるGoogle Cloudの野心も反映しています。OpenAIとGoogleはAIアプリケーションレベルでは競合相手ですが、計算能力レベルでは、双方のそれぞれのニーズ(OpenAIは安定した計算能力を必要とし、Googleはインフラ投資を回収する必要がある)に基づいて協力の基盤を見出しました (来源: 36氪)

視覚認識ロボット企業LeDong Robotが香港IPOを目指す、アリババCEOがかつて投資: 深センLeDong Robot Co., Ltd.は目論見書を提出し、香港証券取引所でのIPOを計画しており、推定時価総額は40億香港ドルを超えます。同社は視覚認識技術を核とし、主な製品にはDTOF LiDAR、三角測量LiDARなどのセンサーおよびアルゴリズムモジュールがあり、芝刈りロボットも発売しています。LeDong Robotは、世界の家庭用サービスロボットトップ10社のうち7社、および世界の業務用サービスロボットトップ5社と提携しています。2022年から2024年にかけて、同社の売上高はそれぞれ2億3400万元、2億7700万元、4億6700万元で、年平均成長率は41.4%でしたが、依然として赤字状態であり、純損失は年々縮小しています。投資家には、アリババCEOの呉泳銘氏が設立した元璟資本や、ファーウェイの元幹部が設立した華業天成などが含まれます (来源: 36氪)

🌟 コミュニティ
AI Agentアーキテクチャ議論:ソフトウェア工学視点 vs. 社会的調整視点: マルチエージェントシステム(Multi-Agent Systems)に関する議論の中で、Omar Khattab氏は、これを複雑な社会的調整問題ではなく、AIソフトウェア工学問題として捉えるべきだと提案しています。彼は、モジュール間の契約を定義し、情報フローを制御することで、対立する目標を持つ「エージェント社会」をシミュレートすることなく、効率的なシステムを構築できると考えています。重要なのは、適切に設計されたシステムアーキテクチャと高度に構造化されたモジュール契約です。しかし、彼はまた、多くのアーキテクチャ決定が現在のモデル能力(コンテキスト長、タスク分解能力など)といった一時的な要因に依存していると指摘しています。そのため、従来のプログラミングにおけるコンパイラによるモジュール化コードの最適化と同様に、意図と基盤となる実装テクニックを分離できるプログラミング/クエリ言語を開発する必要があります。この見解は、AI Agent設計において、エージェント間の自由な相互作用や目標の整合性を過度に強調するのではなく、システムアーキテクチャとモジュール化プログラミングの重要性を強調しています (来源: lateinteraction)
AIモデルオプティマイザ議論:Muonオプティマイザが注目を集めるも、AdamWが依然主流: コミュニティではAIモデルオプティマイザに関する議論が活発化しており、特にKeller Jordan氏が提案したMuonオプティマイザが注目されています。Yuchen Jin氏は、Muonがブログ記事だけでJordan氏のOpenAI入社を助け、GPT-5のトレーニングに使用される可能性があると指摘し、実際のインパクトがトップカンファレンスの論文よりも重要であることを強調しています。彼はMuonがNanoGPTにおいてAdamWよりもスケーラビリティに優れていると述べています。しかし、hyhieu226氏は、何千ものオプティマイザ論文があるにもかかわらず、SOTA(State-of-the-Art)の実際の改善はAdamからAdamWへの移行のみであり(その他は主に実装の最適化)、もはやこのような論文に過度に注目すべきではなく、AdamWの出典をわざわざ引用する必要もないと考えています。これは、学術研究と実際の応用効果との間の緊張関係、およびオプティマイザ分野の進展に対するコミュニティの異なる見解を反映しています (来源: Yuchenj_UW, hyhieu226)
Claudeモデルの使用テクニックと議論:コンテキスト管理、プロンプトエンジニアリング、Agent能力: コミュニティでは、Claudeシリーズモデル(Sonnet、Opus、Haiku)の使用テクニックと体験に関する多くの議論が交わされています。ユーザーは、コンテキストの自動圧縮(auto-compact)を避け、コンテキストを積極的に管理し(例えば、ステップをclaude.mdやGitHub issuesに書き込む)、セッションの残り時間が5~10%になったら終了して再開することで、Maxサブスクリプションの使用時間を大幅に延長し、効果を向上させることができることを発見しました。CLI AgentツールとしてのClaude Codeは、その高いコストパフォーマンス(サブスクリプションとの組み合わせ)、ローカル実行、IDE統合、MCP/ツール呼び出し能力により好評を得ており、特にSonnetモデルを使用する場合に顕著です。ユーザーは、巧妙に設計されたプロンプト(例えば、セキュリティレビュータスクのマルチサブエージェント並列分析プロンプト)を使用してClaude Codeの強力なAgent能力を引き出す方法を共有しています。同時に、コミュニティではClaudeモデルの大規模なコードベースにおけるハルシネーション問題や、Geminiなどの他のモデルとの異なるタスクにおける優劣についても議論されています。例えば、あるユーザーはGemini 2.5 Proが一般的な会話や議論において優れており、ClaudeはコーディングやAgentタスクにおいてリードしていると考えています (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

プログラミングにおけるAIの役割がますます重要に、CS専門分野の将来とエンジニアの働き方について考察を促す: MicrosoftのCEOナデラ氏は、同社のコードの20~30%がAIによって書かれていると述べ、ザッカーバーグ氏はMetaのソフトウェア開発の半分(特にLlamaモデル)が1年以内にAIによって行われると予測し、コンピュータサイエンス(CS)専門分野の将来についての議論を引き起こしています。コメントでは、AI支援コーディングがますます一般的になっているものの、CSはコーディングだけにとどまらず、上級エンジニアがAIを利用するROIの方が高いとされています。多くの開発者は、AIは現在、主にコード生成やデバッグを支援する効率化ツールとして機能しているが、特に複雑なシステムや要件理解においては、依然として人間の指導とレビューが必要であると述べています。プログラミングにおけるAIの応用は、開発者にAIを利用して効率を向上させる方法を考えさせ、AIに取って代わられるのではなく、ソフトウェアエンジニアリングの全プロセスにおけるAIの役割と限界について再考を促しています (来源: Reddit r/ArtificialInteligence, cto_junior)
AI倫理と社会的影響:AIの大学入試「参加」からAIによる人類「奴隷化」の懸念まで: AIが大学入試に「参加」し、複雑な数学の問題を解くことができることは、個別指導やスマート採点など、教育分野におけるその可能性を示していますが、AIへの過度な依存、教室の「流れ作業化」、感情的な交流の欠如といった懸念も引き起こしています。より深いレベルの議論では、AIの「有用性」が一種の「トロイの木馬」となり、人間が利便性と快楽を追求するあまり自主性を自ら放棄し、「幸福な奴隷化」を形成する可能性にまで及んでいます。AIの「唯々諾々」とした特性がユーザーの認知バイアスを悪化させる可能性があるという意見もあります。これらの議論は、AI技術の急速な発展がもたらす倫理、社会構造、個人の自主性への影響に対する国民の深い懸念を反映しています (来源: 36氪, Reddit r/ArtificialInteligence)

ゲームの父ジョン・カーマック氏、LLMとゲームの未来を語る:インタラクティブな学習が鍵、現在のLLMはゲームの未来ではない: Id Softwareの共同創設者であるジョン・カーマック氏は、ゲーム分野におけるAIの応用についての見解を共有しました。彼は、LLMの成果は目覚ましいものの、その「何でも知っているが何も学ばない」という特性(事前学習に基づいており、実際のインタラクションによる学習ではない)はゲームAIの未来ではないと考えています。彼は、人間や動物の学習方法と同様に、インタラクティブな体験の流れを通じて学習することの重要性を強調しています。カーマック氏はDeepMindのAtariプロジェクトを振り返り、ゲームをプレイできるものの、データ効率は人間よりもはるかに劣っていると指摘しました。彼は、現在のAIは連続的、効率的、生涯学習的、単一環境でのマルチタスクオンライン学習において依然として解決すべき課題があり、Atariゲームにおける自身の物理ロボット実験に言及し、現実世界のインタラクションの複雑さ(遅延、ロボットの信頼性、スコアの読み取りなど)を強調しました。彼は、AIが単なるパターンマッチングではなく、戦略の実現可能性に対する「嗅覚」を養う必要があり、そうして初めて人間のプレイヤーに匹敵したり、ゲーム開発でより大きな役割を果たしたりすることができると考えています (来源: 36氪)

💡 その他
AI研究論文の急増が質の懸念を引き起こす、公共データセットとAIツールが「論文工場」の推進力となる可能性: Science誌の報道によると、米国のNHANESなどの大規模な公共データセットに基づいた質の低い論文の数が急増しており、特に2022年にAIツール(ChatGPTなど)が普及して以降顕著です。研究者たちは、多くの論文が単純な「公式」に従い、変数を組み合わせることで「新発見」を量産し、「p値ハッキング」やデータの選択的分析の問題が存在することを発見しました。例えば、NHANESに基づいた28件のうつ病研究を補正したところ、半数以上の「発見」は単なる統計的ノイズである可能性がありました。この現象は「研究の穴埋めゲーム」と呼ばれ、その背後には論文工場がAIを利用して論文を迅速に生産している可能性があるとされています。学術界は、雑誌に審査を強化し、AIテキスト検出ツールを開発し、数量志向の研究評価システムを改革して、「ジャンク論文」の蔓延を抑制するよう求めています (来源: 36氪)

手術ロボット市場の成長と危機が共存、技術革新と市場開拓が鍵: 2025年1月から5月にかけて、中国の手術ロボットの落札量は前年同期比82.9%増となり、市場は活況を呈しているように見えますが、CMR Surgicalの売却模索や国内のある血管内治療手術ロボット企業の倒産などの出来事も業界の危機を明らかにしています。危機には、業界の過当競争、各細分化された分野での激しい競争、資金調達の急減、未商業化企業の資金難、一部製品の臨床的価値の限界(単純な病変にしか使用できない)、市場での価格競争の出現(ただし、低価格が必ずしも高販売量につながるわけではなく、病院は性能と品質をより重視する)、商業化が政策(医薬品不正防止など)やマクロ環境の影響を大きく受けることなどが含まれます。この状況を打開するため、企業は技術革新(AIの融合、コスト削減、5G+遠隔操作、適応症の拡大、高難度術式への挑戦)、海外展開の加速、県レベル病院への浸透などの方法で突破口を模索しています (来源: 36氪)
Perplexity、モデルのパフォーマンスおよび競合製品の機能向上により、ユーザー推奨度が低下: ユーザーのSuhail氏は、Perplexityの簡潔さ、フォーマットなどの特徴は他の製品にはないものであり、特に汎用チャット製品ではなく検索/質疑応答に特化したユーザーに適していると述べています。しかし、別の包括的なAIツール評価では、Perplexityは自社モデルが比較的弱く、他の有名モデルを提供しているものの多くは廉価版(o4 mini、Gemini 2.5 Pro、Sonnet 4など、o3やOpusはなし)であり、モデルのパフォーマンスが本家よりも劣っていること、さらに競合製品(ChatGPTやGeminiなど)のディープサーチ機能が強化されたことにより、コストパフォーマンスが高くないと見なされ、特別な割引がない限り推奨されなくなっています (来源: Suhail, Reddit r/ClaudeAI)