キーワード:Meta V-JEPA 2, NVIDIA 産業用AIクラウド, Sakana AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, プリンストン大学 HistBench, ビデオトレーニング用オープンソース世界モデル, 欧州製造業向けAIクラウドプラットフォーム, テキスト生成LLMアダプター, DPOファインチューニングGPT-4.1, AIエージェントの可観測性
🔥 注目
Meta、V-JEPA 2を発表:ビデオベースで訓練されたオープンソースの画像/動画ワールドモデル : Metaは、ViTアーキテクチャをベースとし、異なるサイズ(L/G/H)と解像度(286/384)のバージョンを持つ、パラメータ数12億の新しいオープンソース画像/動画ワールドモデルV-JEPA 2を発表しました。V-JEPA 2は視覚理解と予測において優れた性能を発揮し、ロボットが未知の環境でゼロショットのプランニングとタスク実行を可能にします。Metaは、AIがワールドモデルを利用して動的な環境に適応し、効率的に新しいスキルを学習するというビジョンを強調しています。同時に、MetaはMVPBench、IntPhys 2、CausalVQAという3つの新しいベンチマークも発表し、これらは既存モデルがビデオから物理世界を推論する能力を評価するためのものです。(出典: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
NVIDIA、欧州初の産業AIクラウドを構築し、製造業の発展を推進 : NVIDIAは、欧州の製造業者向けに世界初の産業AIクラウドプラットフォームを構築中であると発表しました。このAIファクトリーは、産業リーダーが設計、エンジニアリングシミュレーションからデジタルファクトリーツイン、ロボティクス技術に至るまでの製造プロセス全体におけるアプリケーションを加速することを目的としています。これは、NVIDIAがGTC ParisおよびVivaTech 2025で発表した、欧州およびその他の地域でのAIイノベーションを加速するための一連の取り組みの一つです。Jensen Huang氏は、欧州のAI計算能力は2年以内に10倍になると予測し、「動くものはすべてロボット化され、自動車がその次だ」と強調しました。(出典: nvidia, nvidia, Jensen Huang氏:欧州のAI計算能力は2年で10倍に)

Sakana AI、Text-to-LoRAを発表:テキスト記述でタスク特化型LLMアダプタを即時生成 : Sakana AIは、Text-to-LoRA技術を発表しました。これは、ユーザーのタスクに関するテキスト記述に基づいて、タスク特化型のLLMアダプタ(LoRAs)を即座に生成するハイパーネットワーク(Hypernetwork)です。この技術は、カスタマイズされた大規模モデルのハードルを下げ、技術的な専門知識や大量の計算リソースを持たない非技術系ユーザーでも自然言語を通じて基礎モデルを特化させることを可能にすることを目的としています。Text-to-LoRAは、数百の既存LoRAアダプタをエンコードし、性能を維持しながら未知のタスクにも汎化することができます。関連論文とコードはarXivとGitHubで公開され、ICML2025で発表される予定です。(出典: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
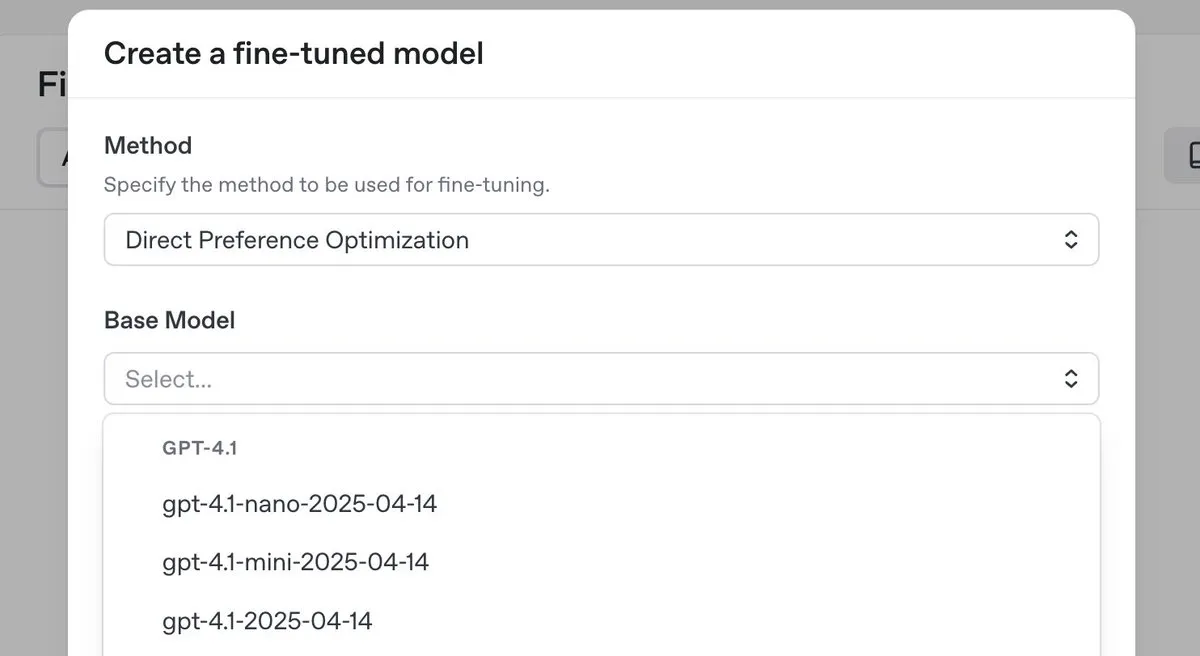
OpenAI、o3-proトップ推論モデルを発表し大幅値下げ、同時にGPT-4.1シリーズのDPOファインチューニング機能を提供開始 : OpenAIは、新しいトップ推論モデルo3-proを発表し、o3シリーズモデルの大幅な価格引き下げを行い、開発者の利用コスト削減を目指しています。同時に、OpenAIはユーザーが直接選好最適化(DPO)を使用してGPT-4.1ファミリーモデル(4.1、4.1-mini、4.1-nanoを含む)をファインチューニングできるようになったと発表しました。DPOは、固定された目標ではなくモデルの応答を比較することでカスタマイズを可能にし、特にトーン、スタイル、創造性に関して主観的な要求があるタスクに適しています。ARC Prizeは、o3の値下げ後に再テストを実施し、ARC-AGIでの性能に変化がないことを示しました。(出典: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 動向
Databricks、Lakebase、無料版およびAgent Bricksを発表し、データとAIアプリケーション開発を加速 : Databricksは、lakehouseと統合されAI向けに構築されたフルマネージドPostgresデータベースであるLakebaseがパブリックプレビュー段階に入ったことを発表しました。これはPostgresの使いやすさ、lakehouseのスケーラビリティ、Neonデータベースのブランチング技術を組み合わせたものです。同時に、Databricksは無料版プラットフォームと大量のトレーニング教材を提供し、開発者がデータエンジニアリング、データサイエンス、AIを学習するのを支援します。さらに、Databricks Appsが正式に利用可能(GA)となり、顧客がプラットフォーム上でインタラクティブなデータおよびAIアプリケーションを構築・展開できるようになりました。Databricksはまた、AIエージェント開発のための宣言的アプローチを採用したAgent Bricksを発表し、ユーザーがタスクを記述するとシステムが自動的に評価を生成しエージェントを最適化します。(出典: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

NVIDIAとMistral AIが提携し、欧州でエンドツーエンドのクラウドプラットフォームを構築 : NVIDIAは、フランスのスタートアップ企業Mistral AIと提携し、共同でエンドツーエンドのクラウドプラットフォームを構築すると発表しました。提携の第一段階では、1万8000セットのNVIDIA Grace Blackwellシステムを導入し、2026年にはさらに多くの拠点に拡大する計画です。この提携は、NVIDIAが欧州でAIインフラ建設と「主権AI」構想を推進する一環であり、欧州にローカライズされたデータセンターとサーバーを提供することを目的としています。(出典: Jensen Huang氏:欧州のAI計算能力は2年で10倍に)
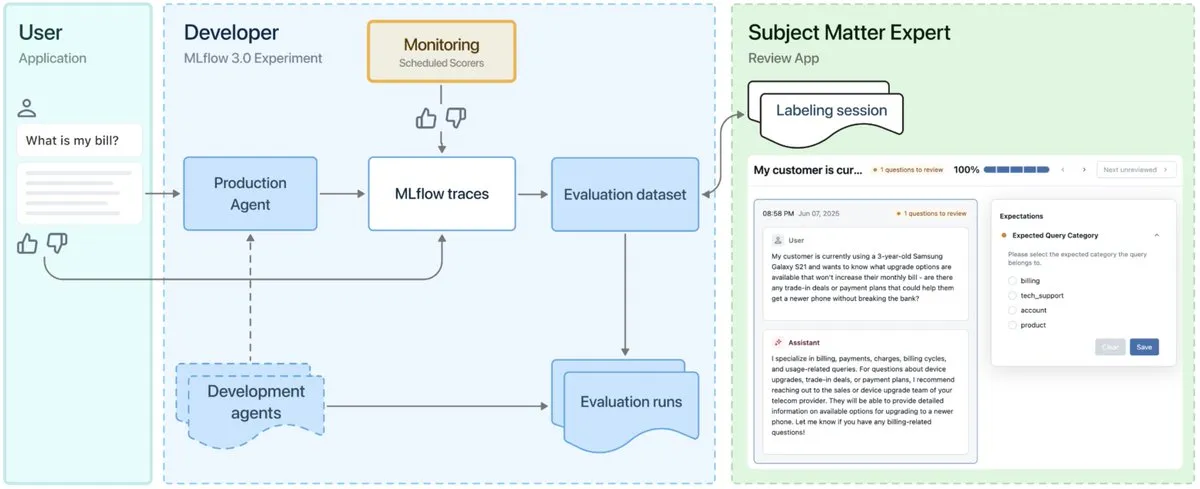
MLflow 3.0リリース、AIエージェントのオブザーバビリティと開発に特化 : MLflow 3.0が正式にリリースされました。新バージョンはAIエージェントのオブザーバビリティと開発のために再設計され、従来の構造化機械学習機能も更新されています。MLflow 3.0は、データを通じてAIシステムの継続的な改善を実現することを目指し、AIシステムの追跡、評価、監視をサポートし、人的コラボレーション、データガバナンスとセキュリティ、Databricksデータエコシステムとの統合といったエンタープライズレベルのニーズも考慮しています。(出典: matei_zaharia, matei_zaharia, lateinteraction)
プリンストン大学と復旦大学が共同でHistBenchとHistAgentを発表、歴史学研究におけるAI応用を推進 : プリンストン大学AIラボと復旦大学歴史学部が協力し、世界初の歴史研究AI評価ベンチマークHistBenchとAIアシスタントHistAgentを発表しました。HistBenchは414の歴史問題を含み、29言語と多文明の歴史をカバーし、AIの複雑な史料処理能力とマルチモーダル理解能力をテストすることを目的としています。HistAgentは歴史研究専用に設計されたエージェントで、文献検索、OCR、翻訳などのツールを統合しています。テストによると、汎用大規模モデルのHistBenchでの正答率は20%未満でしたが、HistAgentは既存モデルを大幅に上回る性能を示しました。(出典: 世界初の歴史ベンチマーク、プリンストン大学と復旦大学がAI歴史アシスタントを開発、AIが人文科学分野に進出)

Microsoft Researchと北京大学が共同でNext-Frame Diffusion (NFD) フレームワークを発表、自己回帰型ビデオ生成効率を向上 : Microsoft Researchと北京大学は共同で、Next-Frame Diffusion (NFD) という新しいフレームワークを発表しました。フレーム内並列サンプリングとフレーム間自己回帰方式により、A100 GPU上で310Mモデルを使用し、毎秒30フレームを超える高品質な自己回帰型ビデオ生成を実現しました。NFDはブロック状因果アテンションメカニズムを持つTransformerを採用し、一貫性蒸留と投機的サンプリング技術を組み合わせて効率をさらに向上させ、リアルタイムインタラクティブゲームなどのシーンへの応用が期待されています。(出典: 毎秒30フレーム超のビデオ生成、リアルタイムインタラクションをサポート、自己回帰型ビデオ生成の新フレームワークが生成効率を刷新)

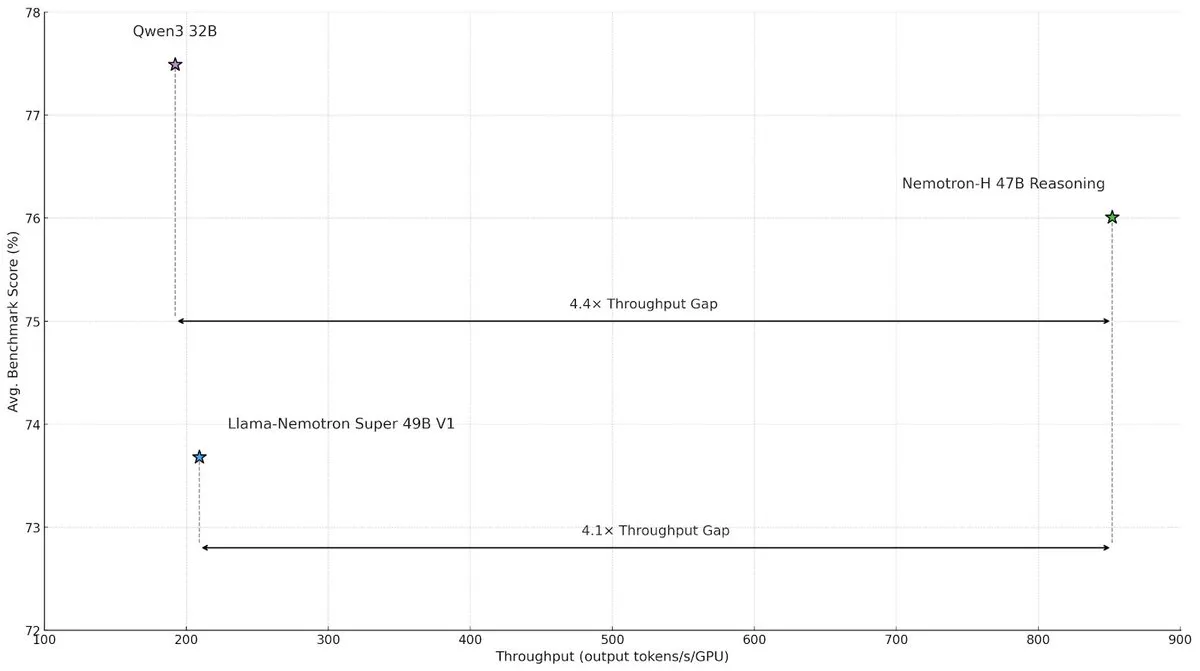
NVIDIA、Nemotron-Hハイブリッドアーキテクチャモデルを発表、大規模推論の速度と効率を向上 : NVIDIA Researchは、MambaとTransformerのハイブリッドアーキテクチャを採用したNemotron-Hモデルを発表しました。これは大規模推論タスクにおける速度のボトルネックを解決することを目的としています。このモデルは、推論能力を維持しつつ、同等のTransformerモデルよりも4倍高いスループットを実現しました。研究によると、ハイブリッドモデルはより少ないアテンション層を使用しても推論性能を維持でき、特に長い推論チェーンのシナリオでは、線形アーキテクチャの効率の利点が顕著です。(出典: _albertgu, tri_dao, krandiash)
Google DeepMindの研究者Jack Rae氏がMetaの「スーパーインテリジェンス」グループに参加 : Google DeepMindの主任研究員であるJack Rae氏が、Metaが新たに設立した「スーパーインテリジェンス」グループに参加したことが確認されました。Rae氏はDeepMind在籍中にGeminiモデルの「思考」能力を担当し、「圧縮即知能」という思想の代表的人物の一人であり、以前はOpenAIでGPT-4の開発にも携わっていました。MetaのCEOであるMark Zuckerberg氏は、Llamaモデルを改良し、より強力なAIツールを開発して業界のリーダーに追いつくため、自らトップAI人材を数千万ドル規模の報酬パッケージで採用しています。(出典: ザッカーバーグ氏の「スーパーインテリジェンス」グループ初の重鎮、Google DeepMind主任研究員、「圧縮即知能」の核心人物, DhruvBatraDB)

Mistral AI、初の推論モデルMagistralを発表、多言語推論をサポート : Mistral AIは、初の推論モデルMagistralを発表しました。これには24Bパラメータのオープンソース版Magistral Smallと、企業向けのMagistral Mediumが含まれます。このモデルは、多段階論理と思考の解釈可能性のためにファインチューニングされており、多言語推論をサポートし、特にヨーロッパ言語向けに最適化され、追跡可能な思考プロセスを提供できます。Magistralは、既存の推論モデルの蒸留データに依存せず、純粋な強化学習を通じて改良されたGRPOアルゴリズムを使用して訓練されています。しかし、そのベンチマークテスト結果は、最新版のQwenとDeepSeek R1のデータが含まれていないため、一部から疑問視されています。(出典: 新しい「SOTA」推論モデルがQwenとR1との対決を回避?欧州版OpenAIが炎上)

ByteDanceのDoubao大規模モデル1.6が発表され再び大幅値下げ、ビデオモデルSeedance 1.0 proも同時リリース : Volcano EngineはDoubao大規模モデル1.6を発表し、「入力長」区間による価格設定を初めて導入しました。0-32K入力区間の価格は0.8元/百万トークン、出力は8元/百万トークンで、コストは1.5バージョンと比較して63%削減されました。新しくリリースされたビデオ生成モデルSeedance 1.0 proの価格は、1000トークンあたり1分5厘で、5秒の1080Pビデオ生成は約3.67元です。Volcano Engineの社長であるTan Dai氏は、今回の値下げは企業がよく使用する32K範囲のコストに対するターゲットを絞った最適化とビジネスモデルの革新によって実現され、Agentの規模拡大を推進することを目的としていると述べました。(出典: Doubao大規模モデルが再び大幅値下げ、Volcano Engineは依然として市場シェア獲得に積極的, 「Volcano」がBaidu Cloudに迫る)
香港科技大学とHuaweiが共同でAutoSchemaKGフレームワークを提案、完全自律型知識グラフ構築を実現 : 香港科技大学KnowCompラボと香港Huawei理論部が協力し、AutoSchemaKGフレームワークを提案しました。これは事前定義されたスキーマなしで完全に自律的に知識グラフを構築できます。このシステムは大規模言語モデルを利用してテキストから直接知識トリプレットを抽出し、エンティティとイベントのスキーマを帰納します。このフレームワークに基づき、チームは9億以上のノードと59億以上のエッジを含む知識グラフシリーズATLASを構築しました。実験によると、この方法は人手を介さずに、スキーマ帰納が人間が設計したスキーマと95%のセマンティックアラインメントを達成しました。(出典: 最大のオープンソースGraphRag:知識グラフの完全自律構築)

Qijing Tech、DeepSeek大規模モデルの実行効率を向上させるソフトウェア・ハードウェア統合サーバー8カードソリューションを発表 : Qijing TechはIntelと共同でエコシステムサロンを開催し、最新のソフトウェア・ハードウェア統合サーバー8カードソリューションを発表しました。このソリューションはDeepSeek-R1/V3-671Bなどの大規模モデルを効率的に実行でき、シングルカードと比較して最大7倍の性能向上を実現します。同時に、自社開発の推論エンジンKLLM、大規模モデル管理プラットフォームAMaaS、およびオフィスアプリケーションスイート「Qijing·Zhiwen」も重要なアップグレードを行い、大規模モデルのプライベート展開が直面する高い導入障壁や不十分な実行性能といった課題の解決を目指しています。(出典: Qijing Tech & Intelエコシステムサロン開催、ハードウェア、推論エンジン、上位アプリケーションエコシステムの融合で、大規模モデルのプライベート化「最後の1マイル」を切り開く)

Black Forest Labs、FLUX.1 Kontextシリーズ画像モデルを発表、キャラクターとスタイルの一貫性を強化 : ドイツのBlack Forest Labsは、FLUX.1 Kontextシリーズのテキストから画像へのモデル(max, pro, devバージョン)を発表しました。これは画像編集時のキャラクターとスタイルの一貫性に焦点を当てています。このシリーズのモデルは、画像の局所的および全体的な変更をサポートし、テキストおよび/または画像入力から画像を生成できます。FLUX.1 Kontext devバージョンはオープンソース化される予定です。約1000のプロンプトと参照画像のペアを含む独自のベンチマークテストでは、FLUX.1 Kontext maxおよびproバージョンがOpenAI GPT Image 1やGoogle Gemini 2.0 Flashなどの競合モデルを上回る性能を示しました。(出典: DeepLearning.AI Blog)

NVIDIA、ラトガース大学などがSTORMフレームワークを提案、Mamba層によりビデオ理解に必要なTokensを削減 : NVIDIA、ラトガース大学、カリフォルニア大学バークレー校などの研究者が、テキスト-ビデオシステムSTORMを構築しました。このシステムは、SigLIPビジョントランスフォーマーとQwen2-VLのLLMの間にMamba層を導入し、単一フレームのToken埋め込み情報(同じクリップ内の他のフレームからの情報を含む)を豊かにすることで、重要な情報を失うことなくフレーム間のToken埋め込みを平均化します。これにより、システムはより少ないTokensでビデオを処理でき、MVBenchやMLVUなどのビデオ理解ベンチマークテストでGPT-4oやQwen2-VLを上回る性能を示し、同時に処理速度も3倍以上向上しました。(出典: DeepLearning.AI Blog)

Google共同創業者、人型ロボットに慎重な姿勢、専用ロボットの商業化に期待 : Google共同創業者のSergey Brin氏は、人間の形態を厳密に模倣した人型ロボットにはあまり熱心ではなく、それがロボットの効率的な作業に必要不可欠な条件ではないと考えていると述べました。一方で、専用ロボットはその「すぐに使える」特性と明確な商業化への道筋から注目されています。例えば、水中ロボットや芝刈りロボットなどは特定のシーンで大きな可能性を示しています。分析によると、現段階では実際の問題を解決できるロボットの形態と生産性が鍵であり、専用ロボットは明確なビジネスモデルと確実な需要のあるシーンを背景に、いち早く商業化を実現しています。(出典: 専用ロボットが人型ロボットに「ちょっとどいて、食卓につきたいんだ」と声をかける)

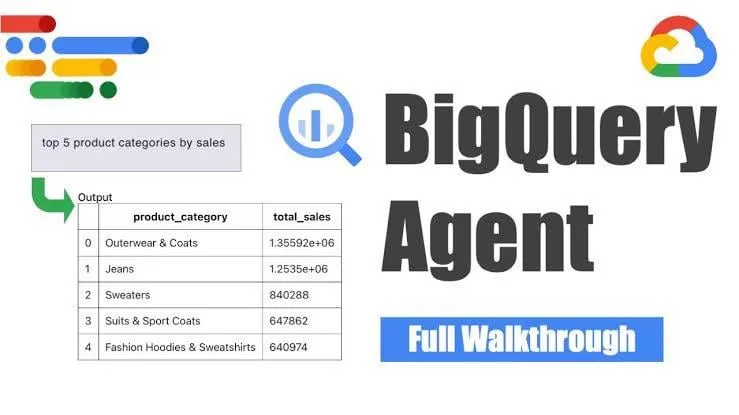
Google、BigQueryデータエンジニアリングエージェントを発表、インテリジェントなパイプライン生成を実現 : GoogleはBigQueryデータエンジニアリングエージェントを発表しました。このツールはコンテキスト認識推論を利用して、データパイプラインの生成を効率的に拡張します。ユーザーは簡単なコマンドライン指示でパイプライン要件を定義でき、エージェントはドメイン固有のプロンプトを利用して、ユーザーのデータ環境に合わせたバッチパイプラインコードを生成します。これにはデータ取り込み設定、変換クエリ、テーブル作成ロジック、DataformまたはComposerによるスケジューリング設定が含まれます。このツールは、AI支援を通じて、複数のデータドメイン、環境、変換ロジックを扱う際にデータエンジニアが直面する反復的な作業を簡素化することを目的としています。(出典: Reddit r/deeplearning)
Yandex、約50億のユーザーと楽曲のインタラクションを含む大規模公開データセットYambdaをリリース : Yandexは、推薦システム研究用に設計された大規模公開データセットYambdaをリリースしました。このデータセットには、Yandex Musicからの約50億件の匿名化されたユーザーと楽曲のインタラクションデータが含まれており、研究者に実世界の規模のデータを扱う貴重な機会を提供します。(出典: _akhaliq)

ByteDance、Hugging Faceでビデオ修復モデルSeedVR2を公開 : ByteDanceのSeedチームはHugging Face上で、ビデオ修復用のシングルステップ拡散TransformerモデルであるSeedVR2を公開しました。このモデルはApache 2.0ライセンスを採用しており、シングルステップ推論が特徴で、高速かつ効率的であり、任意の解像度処理をサポートし、ブロック分割やサイズ制限の必要がありません。(出典: huggingface)
ByteDanceのDoubaoビデオ大規模モデルSeedance 1.0 Pro、実測テストで高評価 : ByteDanceが最新発表した画像からビデオへの大規模モデルSeedance 1.0 Proは、実測テストで良好な指示追従能力と物体生成の安定性を示しました。ユーザーからは、ビデオ生成の品質が高く、カメラワークのタイミングも正確で、Veo 2/3に次ぐとのフィードバックが寄せられています。潜在的な欠点として、純粋な物体の動きを生成する際に、モデルが画面をより合理的に見せるために手の操作を加えることがあり、これは手の出現を制限することで回避できます。(出典: karminski3, karminski3, karminski3)
Alibaba、デジタルヒューマンフレームワークMnn3dAvatarをオープンソース化、リアルタイム顔キャプチャと3Dバーチャルキャラクター作成をサポート : AlibabaはGitHub上で、Mnn3dAvatarという名のデジタルヒューマンフレームワークをオープンソース化しました。このプロジェクトはリアルタイムの顔キャプチャを実現し、表情を3Dバーチャルキャラクターにマッピングすると同時に、ユーザーが独自の3Dバーチャルキャラクターを作成することもサポートします。このフレームワークは、簡単なライブコマースやコンテンツ表示などのシーンに適しています。(出典: karminski3)
NVIDIA、人型ロボット基礎モデルGr00t N 1.5 3Bをオープンソース化し、ファインチューニングチュートリアルを提供 : NVIDIAは、人型ロボットの推論スキル専用に設計されたオープン基礎モデルであるGr00t N 1.5 3Bモデルをオープンソース化しました。これは商用ライセンスを採用しています。同時に、NVIDIAはLeRobotHF SO101と連携して使用する完全なファインチューニングチュートリアルも公開し、人型ロボット技術の発展と応用を推進することを目指しています。(出典: ClementDelangue)
Together AI、Batch APIを発表、大規模LLM推論サービスを提供し大幅値下げ : Together AIは、大規模LLM推論用に設計された新しいBatch APIをリリースしました。合成データ生成、ベンチマークテスト、コンテンツレビューと要約、ドキュメント抽出などの高スループットアプリケーションシナリオをサポートします。このAPIは、リアルタイムAPIより50%安い導入価格を導入し、1回あたり最大5万リクエストまたは100MBのバッチ処理をサポートし、15のトップモデルと互換性があります。(出典: vipulved)
Google Gemini 2.5 Proにインタラクティブなフラクタルアート生成機能が追加 : Googleは、Gemini 2.5 Proがインタラクティブなフラクタルアートの即時作成をサポートするようになったと発表しました。ユーザーは、「美しく、粒子ベースで、アニメーション化され、無限で、3Dで、対称的で、数式にインスパイアされたフラクタルアート作品を作成してください」などのプロンプトを提供することで、ユニークなビジュアルアートを生成できます。(出典: demishassabis)
Google Veo3 Fastのビデオ生成速度が2倍に向上 : Google Labsは、ビデオ生成ツールFlowのVeo3 Fastバージョンの生成速度が2倍以上に向上し、同時に720pの解像度を維持すると発表しました。このアップデートは、ユーザーがより迅速にビデオコンテンツを作成できるようにすることを目的としています。(出典: op7418)
Hugging FaceがGoogle ColabとKaggleを統合、モデル使用プロセスを簡素化 : Hugging FaceはGoogle ColabおよびKaggleと統合されました。ユーザーは任意のモデルカードから直接Colabノートブックを起動したり、Kaggle Notebookで同じモデルを開いたりすることができ、実行可能な公開コード例も付属しているため、モデルの使用と実験プロセスが簡素化されます。(出典: ClementDelangue, huggingface)
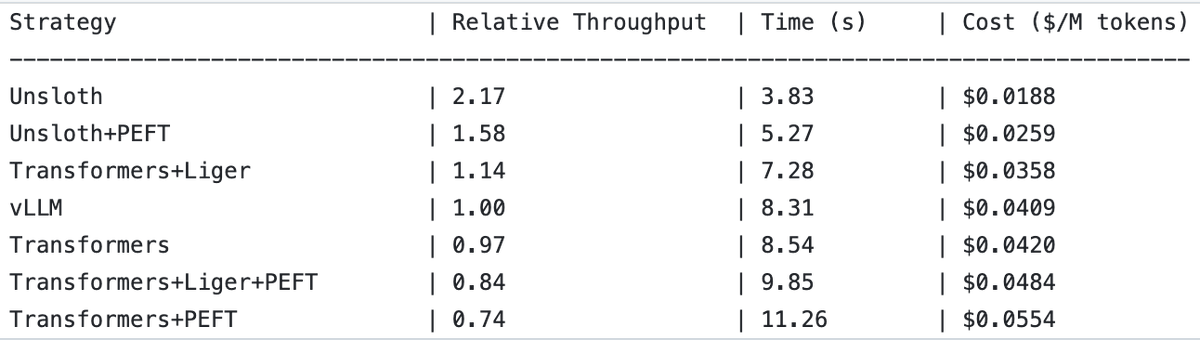
UnslothAI、報酬モデルサービスとシーケンス分類推論で2倍のスループット向上を実現 : UnslothAIが報酬モデル(RM)サービスの提供に利用可能であり、シーケンス分類推論においてvLLMの2倍のスループットを実現することが発見されました。この発見はRL(強化学習)コミュニティで注目を集めており、UnslothAIの性能向上は関連研究と応用の加速が期待されます。(出典: natolambert, danielhanchen)
Digua Robot、初のシングルSoC演算制御一体型ロボット開発キットRDK S100を発表 : Digua Robotは、業界初のシングルSoC演算制御一体型ロボット開発キットRDK S100を発表しました。このキットは人間のような大小脳アーキテクチャ設計を採用し、単一のSoC上にCPU+BPU+MCUを統合し、身体性知能の大小モデルの効率的な連携をサポートし、「知覚-決定-制御」のクローズドループを実現します。RDK S100は多様なインターフェースとソフトウェア・ハードウェア協調、エッジ・クラウド一体型の開発インフラを提供し、身体性知能製品の構築と多シーン展開の加速を目指しています。現在、20社以上の主要顧客と提携しており、市場価格は2799元です。(出典: Digua Robot、初のシングルSoC演算制御一体型ロボット開発キットを発表、20社以上の主要顧客と提携|最前線)

🧰 ツール
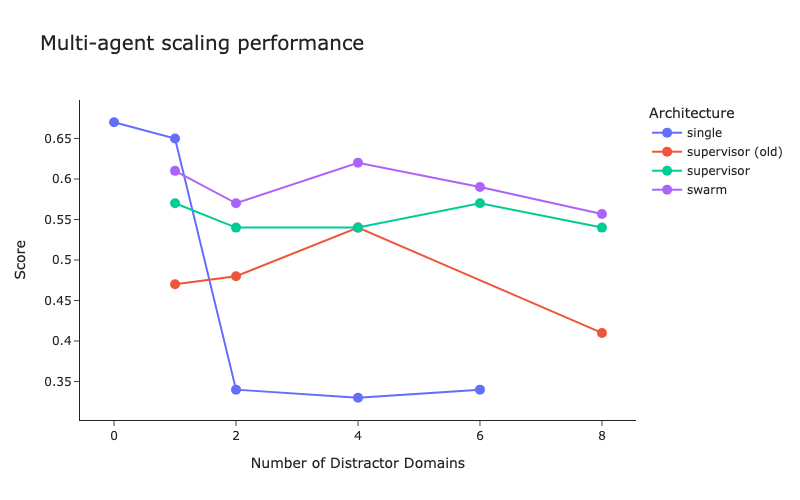
LangChain、マルチエージェントアーキテクチャのベンチマークテストおよびスーパーバイザー手法の改善を発表 : LangChainは、増加するマルチエージェントシステムに対応するため、初期のベンチマークテストを実施し、マルチエージェント間の協調を最適化する方法を検討しています。同時に、LangChainはそのスーパーバイザー(supervisor)手法にいくつかの改善を加えており、関連ブログが公開されています。(出典: LangChainAI, hwchase17)
Cartesia、Ink-Whisperを発表:音声エージェント向けに設計された高速・低コストのストリーミング音声認識モデル : Cartesiaは、音声エージェント向けに最適化された高速・低コストのストリーミング音声認識(STT)モデルであるInk-Whisperを発表しました。このモデルは実世界の条件下での精度を重視して設計されており、CartesiaのSonicテキスト読み上げ(TTS)モデルと連携して使用することで、高速な音声AIインタラクションを実現します。Ink-WhisperはVapiAI、PipecatAI、Livekitなどのプラットフォームへの接続をサポートしています。(出典: simran_s_arora, tri_dao, krandiash)

MonkeyOCR:小型、高速、オープンソースのドキュメント解析モデル : MonkeyOCRという名の3Bパラメータのドキュメント解析モデルがリリースされ、Apache 2.0ライセンスを採用しています。このモデルは、グラフ、数式、表など、ドキュメント内のさまざまな要素を解析でき、従来の解析パイプラインを置き換え、より優れたドキュメント処理ソリューションを提供することを目指しています。(出典: mervenoyann, huggingface)
LlamaIndexとCleanlabが統合、AIアシスタントの応答の信頼性を向上 : LlamaIndexはCleanlabAIとの統合を発表しました。LlamaIndexはAI知識アシスタントと本番環境レベルのエージェントを構築し、企業データから洞察を生成するために使用されます。Cleanlabの参加は、これらのAIアシスタントの応答の信頼性を向上させることを目的としており、各LLM応答にスコアを付け、リアルタイムで幻覚や不正確な応答を捕捉し、応答が信頼できない原因(検索の質の低さ、データ/コンテキストの問題、クエリの難しさ、LLMの幻覚など)の分析を支援します。(出典: jerryjliu0)

Claude Codeに「プランモード」が追加され、複雑なコード変更の制御性が向上 : AnthropicのClaude Codeに「プランモード」(Plan mode)が導入されました。この機能により、ユーザーは実際にコードを変更する前に実施計画を確認でき、各ステップが検討されていることを保証し、特に複雑なコード変更に適しています。ユーザーはショートカットキーShift + Tabを2回押すことでプランモードに入ることができ、Claude Codeは詳細な実施計画を提供し、実行前に確認を求めます。この機能はすべてのClaude Codeユーザー(ProまたはMaxサブスクリプションユーザーを含む)に提供されています。(出典: dotey, kylebrussell)
rvn-convert:Rustで実装されたSafeTensorsからGGUF v3への変換ツール : rvn-convertという名のオープンソースツールがリリースされました。これはRust言語で書かれており、SafeTensors形式のモデルファイルをGGUF v3形式に変換するために使用されます。このツールは、シングルシャードサポート、高速性、Python環境不要といった特徴を持ち、safetensorsファイルをメモリマッピングして直接ggufファイルに書き込むことで、RAMのピーク使用量やディスクのターンアラウンド問題を回避します。現在、BF16からF32へのアップサンプリング、tokenizer.jsonの埋め込みなどの機能をサポートしています。(出典: Reddit r/LocalLLaMA)
Runway APIに4Kビデオ超解像機能が追加 : Runwayは、そのAPIが4Kビデオ超解像機能をサポートするようになったと発表しました。開発者はこの機能を自身のアプリケーション、製品、プラットフォーム、ウェブサイトに統合し、ビデオコンテンツの鮮明さと品質を向上させることができます。(出典: c_valenzuelab)
You.com、研究資料を整理・管理するためのProjects機能をリリース : You.comは、「Projects」という新しいツールをリリースしました。これはユーザーが研究資料をアクセスしやすいフォルダに整理するのを支援することを目的としています。この機能は、ユーザーが会話を文脈化し構造化することをサポートし、チャット履歴の散逸や洞察の喪失を防ぎ、知識管理プロセスを簡素化します。(出典: RichardSocher)
LlamaIndex、LlamaExtractインテリジェントドキュメント抽出サービスを開始 : LlamaIndexは、LlamaExtractを発表しました。これは、複雑なドキュメントや入力スキーマから構造化データを抽出することを目的とした、エージェント駆動型のドキュメント抽出サービスです。このサービスはキーバリューペアを抽出するだけでなく、抽出された各項目について正確な出典推論、ページ参照、一致テキストを提供します。LlamaExtractはAPI形式で提供され、下流のエージェントワークフローに簡単に統合できます。(出典: jerryjliu0)

langchain-google-vertexaiがアップデート、クライアントキャッシュとツールサポートを強化 : langchain-google-vertexaiが新バージョンをリリースしました。主なアップデートには、予測クライアントキャッシュにより新しいクライアントのインスタンス化速度が500倍向上したこと、組み込みコード実行ツールのサポートが含まれます。(出典: LangChainAI, Hacubu)
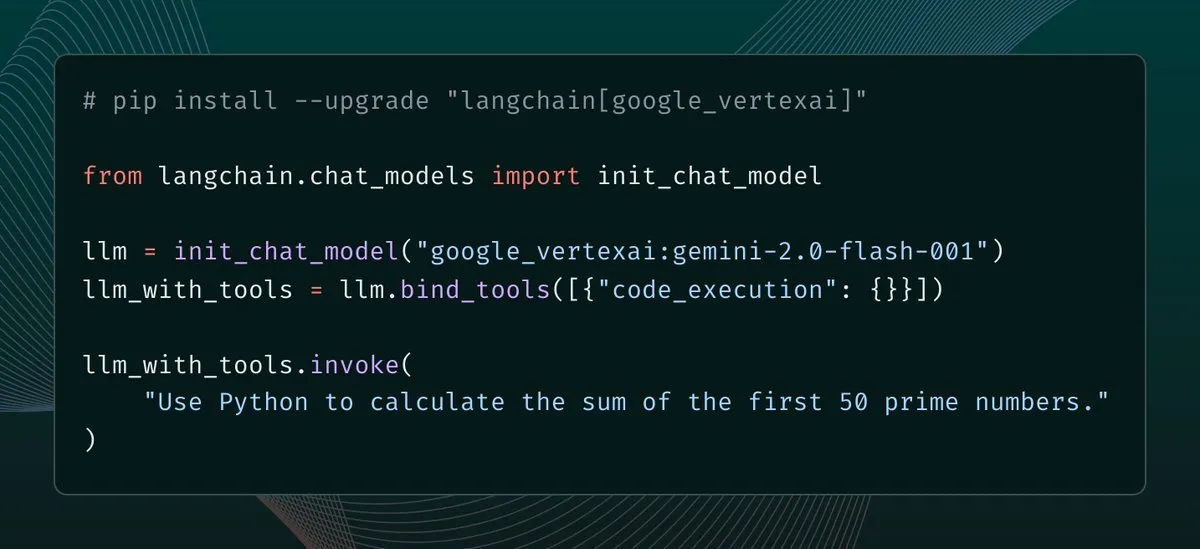
Perplexity FinanceにExcelモデル直接ダウンロード機能が追加 : Perplexity Financeは、ユーザーがそのページから直接Excelモデルをダウンロードできるようになったと発表しました。これにより、財務モデリングと研究のためのより迅速な出発点を提供します。この機能はすべてのユーザーに無料で提供され、以前はCSV形式のダウンロードのみをサポートしていました。(出典: AravSrinivas)
Viwoods、AI Paper Mini電子ペーパータブレットを発表、GPT-4oなどのAI機能を統合 : 新興電子ペーパーメーカーのViwoodsは、AI機能を搭載した電子ペーパータブレットAI Paper Miniを発表しました。このデバイスはGPT-4o、DeepSeekなど複数のAIモデルをサポートし、ChatモードとプリセットAIアシスタント(コンテンツ分析、メール生成、AI文字起こし)を提供します。特徴的な機能には、カレンダービューのタスク管理、クイックフローティングウィンドウノートなどがあります。ハードウェア面では、Paper Miniは292 ppiのCarta 1000スクリーン、4GB+128GBストレージを搭載し、スタイラスペンが付属しています。同時に、Viwoodsはより大きなサイズのAI Paperも発表しており、300ppiのCarta 1300フレキシブルスクリーンを搭載し、応答速度が向上しています。(出典: iPhone半額でAI搭載「電子ペーパータブレット」を手に入れた…)

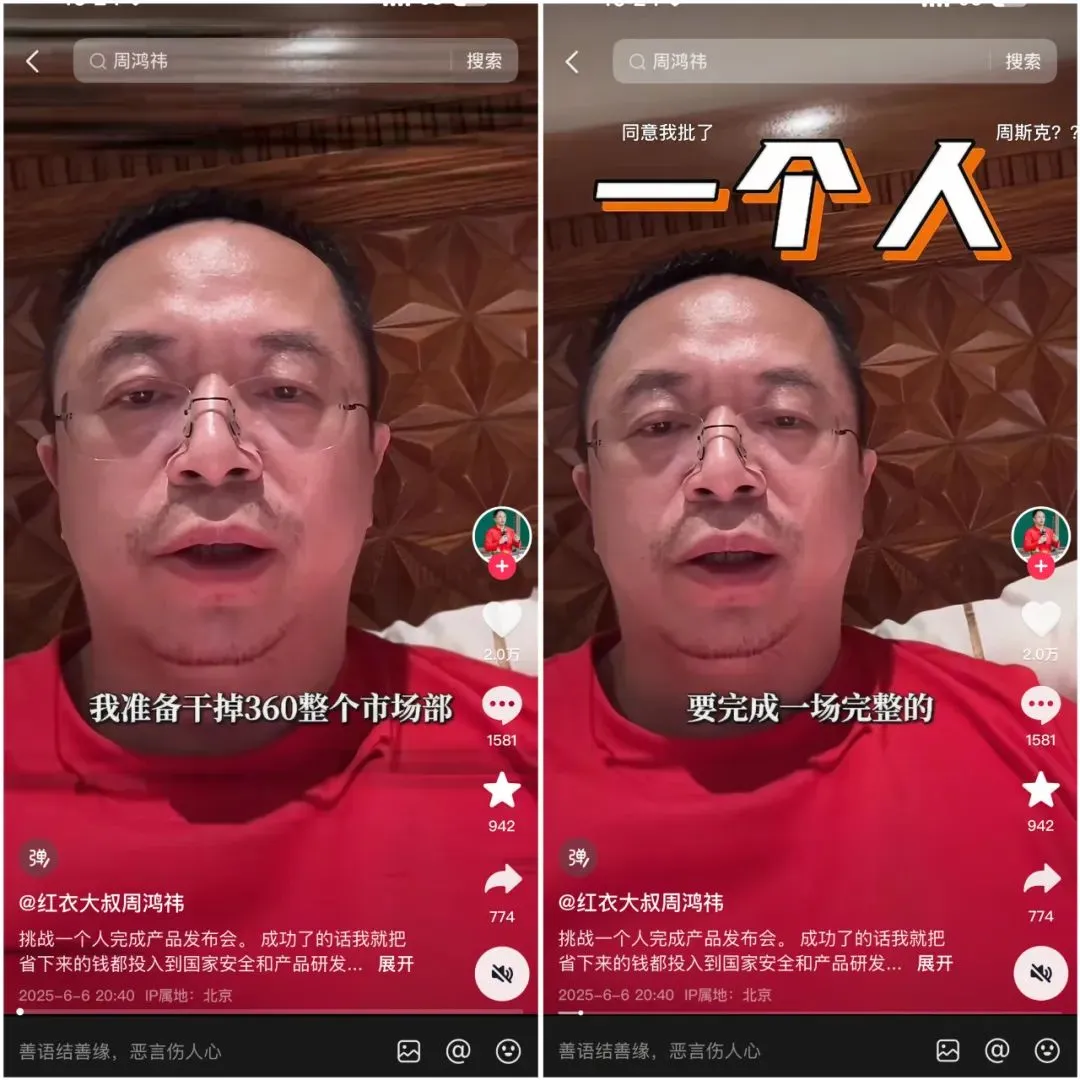
360、ナノAIスーパーサーチインテリジェントエージェントを発表、周鸿祎氏が自ら登壇 : 360グループ創業者の周鸿祎氏が司会を務め、ナノAIスーパーサーチインテリジェントエージェントを発表しました。このインテリジェントエージェントは「一言で、万物検索可能」を実現することを目指し、人手を介さずに自律的に思考し、ブラウザや外部ツールを呼び出してタスクを実行し、全プロセスの可視化とステップの追跡をサポートします。周鸿祎氏は、今回の発表会自体もナノAIを利用して準備を試みたと述べ、AIインテリジェント録音ハードウェア「ナノAI Note」およびRokidとの共同ブランドAIメガネも発表しました。(出典: 周鸿祎氏、AIで「マーケティング部をなくす」と宣言、「ナノ」はそれを実現できたか?)
📚 学習
DeepLearning.AI、新ショートコース「Apache Airflowを用いたGenAIワークフローのオーケストレーション」を開始 : DeepLearning.AIはAstronomerと協力し、Apache Airflow 3.0を使用してRAGプロトタイプを本番環境対応のワークフローに変換する方法を教える新しいショートコースを開始しました。コース内容には、ワークフローをモジュール化されたタスクに分解すること、時間駆動およびイベント駆動トリガーを使用してパイプラインをスケジュールすること、動的タスクマッピングを使用してタスクを並列実行すること、フォールトトレランスのためにリトライ/アラート/バックフィルを追加すること、パイプライン技術を拡張することが含まれます。このコースはAirflowの経験を必要としません。(出典: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain氏、RAG最適化と評価に関するミニコースを開始 : Hamel Husain氏は、RAG(Retrieval Augmented Generation)の最適化と評価に関する4部構成のミニコースを開始すると発表しました。第1部は@bclavie氏が担当し、「検索即RAG」という視点について議論し、以前の「RAGは根絶すべき思考ウイルスである」という議論に応えることを目指しています。このシリーズコースは無料で、実務家がRAG評価で直面する難題を解決するのを支援することを目的としています。(出典: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

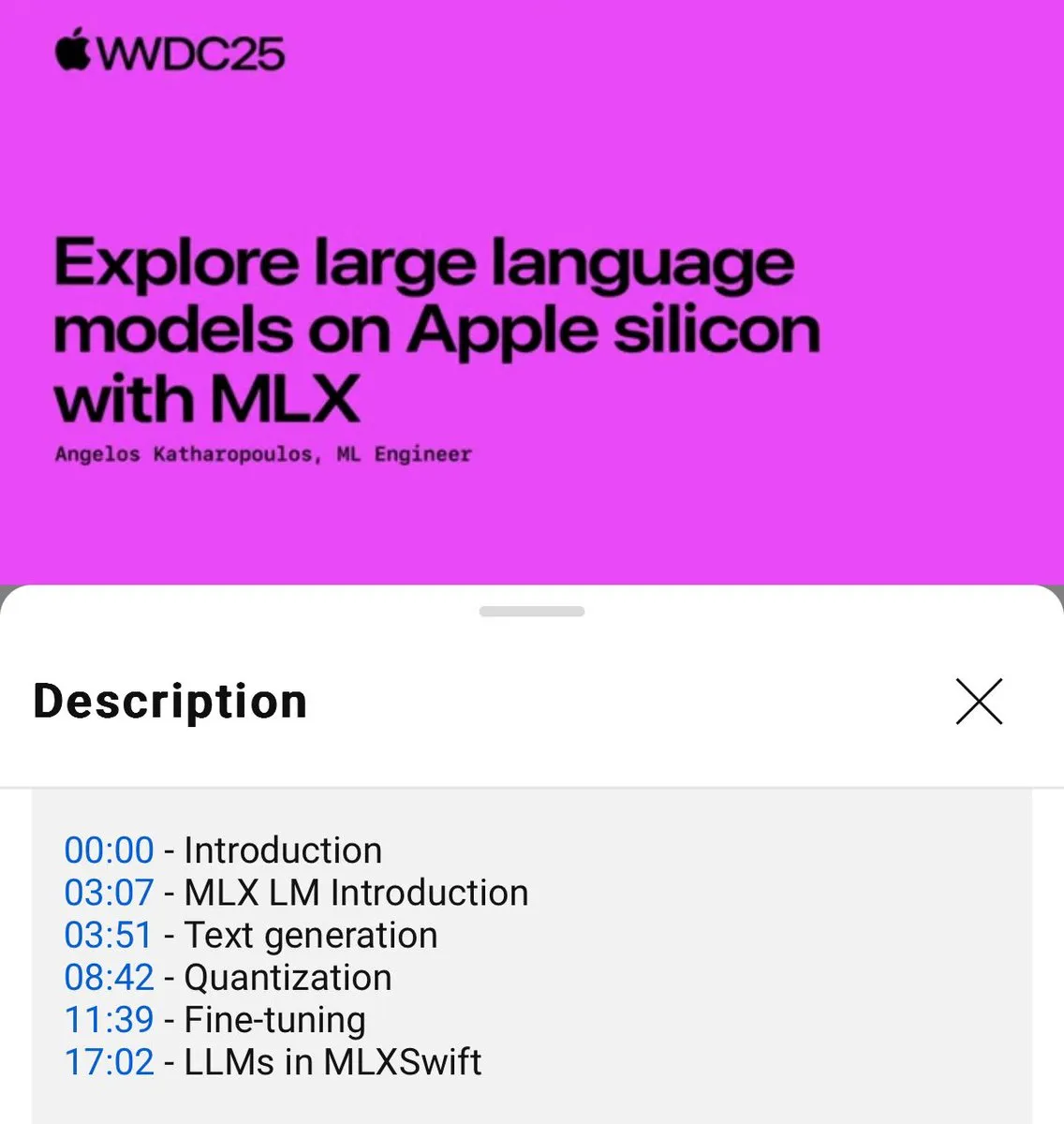
MLX言語モデルのローカル使用チュートリアルが公開(WWDC25) : WWDC25の会議で、Angelos Katharopoulos氏がMLXを使用してローカル言語モデルを迅速に開始する方法を紹介しました。チュートリアルでは、MLXLM CLIを使用した単一行コマンド操作(モデル量子化 (mlx_lm.convert)、LoRAファインチューニング (mlx_lm.lora)、モデル融合とHugging Faceへのアップロード (mlx_lm.fuse) など)をカバーしています。完全なJupyter NotebookチュートリアルはGitHubで提供されています。(出典: awnihannun)
LangChain、Harvey AIが法律AIエージェントを構築する方法を共有 : Harvey AIのBen Liebald氏が、LangChainのInterruptイベントで、法律AIエージェントを構築するための成熟した方法を共有しました。この方法は、LangSmith評価と「弁護士インザループ」(lawyer-in-the-loop)戦略を組み合わせ、複雑な法律業務に対して弁護士が信頼できるAIツールを提供することを目指しています。(出典: LangChainAI, hwchase17)

RLHFハンドブックv1.1が更新、RLVR/推論モデルのコンテンツを拡張 : RLHFハンドブック(rlhfbook.com)がv1.1に更新され、RLVR(Reinforcement Learning from Video Representations)と推論モデルに関する拡張コンテンツが追加されました。更新には、主要な推論モデルレポートの要約、一般的な実践/テクニックとその使用者、o1以前の関連する推論作業、非同期RLなどの改善が含まれています。(出典: menhguin)
論文SWE-Flow:テスト駆動型アプローチによるソフトウェアエンジニアリングデータの合成 : SWE-Flowという新しい論文は、テスト駆動開発(TDD)に基づく新しいデータ合成フレームワークを提案しています。このフレームワークは、ユニットテストを分析することで増分開発ステップを自動的に推論し、ランタイム依存グラフ(RDG)を構築して構造化された開発計画を生成します。各ステップは、部分的なコードベース、対応するユニットテスト、および必要なコード変更を生成し、それによって検証可能なTDDタスクを作成します。この方法に基づいて、SWE-Flow-Evalベンチマークデータセットが生成されました。(出典: HuggingFace Daily Papers)
論文PlayerOne:一人称視点で構築された初のリアルワールドシミュレータ : PlayerOneは、一人称視点(egocentric)で構築された初のリアルワールドシミュレータとして提案されており、動的な環境での没入型探索が可能です。ユーザーの一人称シーン画像が与えられると、PlayerOneは対応する世界を構築し、外部カメラでキャプチャされたユーザーの実際の動きと厳密に整合した一人称ビデオを生成できます。このモデルは、粗から密へのトレーニングフローを採用し、コンポーネント分離型の運動注入スキームと共同再構築フレームワークを設計しています。(出典: HuggingFace Daily Papers)
論文ComfyUI-R1:ワークフロー生成のための推論モデルの探求 : ComfyUI-R1は、ワークフロー生成を自動化するための初の大規模推論モデルです。研究者はまず4K個のワークフローを含むデータセットを構築し、長鎖思考(CoT)推論データを構築しました。ComfyUI-R1は2段階のフレームワークで訓練されます。コールドスタートのためのCoTファインチューニングと、推論能力を刺激するための強化学習です。実験によると、7Bパラメータモデルは、フォーマットの有効性、合格率、ノード/グラフレベルのF1スコアにおいて、既存の方法を大幅に上回りました。(出典: HuggingFace Daily Papers)
論文SeerAttention-R:長文推論のためのスパースアテンション適応フレームワーク : SeerAttention-Rは、推論モデルの長いデコーディング専用に設計されたスパースアテンションフレームワークです。自己蒸留ゲーティングメカニズムを通じてアテンションのスパース性を学習し、自己回帰デコーディングに適応するためにクエリプーリングを削除します。このフレームワークは、元のパラメータを変更することなく、既存の事前訓練済みモデルに軽量プラグインとして統合できます。AIMEベンチマークテストでは、わずか0.4Bトークンで訓練されたSeerAttention-Rは、4Kトークンバジェット下で、大規模スパースアテンションブロック(64/128)において、ほぼロスレスの推論精度を維持しました。(出典: HuggingFace Daily Papers)
論文SAFE:視覚-言語-行動モデルのためのマルチタスク失敗検出 : 本論文では、汎用ロボットポリシー(VLAなど)向けに設計された失敗検出器SAFEを提案します。VLAの特徴空間を分析することで、SAFEはVLAの内部特徴からタスク失敗の可能性を予測することを学習します。この検出器は、成功したデプロイメントと失敗したデプロイメントで訓練され、未知のタスクで評価され、異なるポリシーアーキテクチャと互換性があり、環境とのインタラクションにおけるVLAの安全性を向上させることを目指しています。(出典: HuggingFace Daily Papers)
論文Branched Schrödinger Bridge Matching:分岐シュレーディンガー橋の学習 : この研究では、分岐シュレーディンガー橋を学習するためのBranched Schrödinger Bridge Matching (BranchSBM) フレームワークを導入し、初期分布と目標分布の間の途中経路を予測します。既存の方法とは異なり、BranchSBMは、共通の始点から複数の異なる結果への分岐または発散進化をモデル化でき、複数の時間依存速度場と成長プロセスのパラメータ化によって実現されます。(出典: HuggingFace Daily Papers)
💼 ビジネス
Meta、データラベリング企業Scale AIを150億ドルで買収する計画が報じられる、創業者はMetaに合流か : 報道によると、Metaはデータラベリング分野のトップ企業であるScale AIを150億ドルで買収する計画です。取引が成立すれば、Scale AIの28歳の中国人創業者Alexandr Wang氏とそのチームは直接Metaに合流することになります。この動きは、MetaのCEOであるMark Zuckerberg氏がAGI(汎用人工知能)チームの強化を図り、OpenAIやGoogleなどの競合他社に追いつくための重要な一手と見なされています。Metaは最近、AI人材の採用に積極的で、トップエンジニアに数千万ドル規模の報酬パッケージを提示しています。(出典: ザッカーバーグ氏の「スーパーインテリジェンス」グループ初の重鎮、Google DeepMind主任研究員、「圧縮即知能」の核心人物, dylan522p, sarahcat21, Dorialexander)
ディズニーとユニバーサル・ピクチャーズ、AI画像企業Midjourneyを著作権侵害で提訴 : ディズニーとユニバーサル・ピクチャーズは、AI画像生成企業Midjourneyに対し、『スター・ウォーズ』や『シンプソンズ』などの有名IP作品を無断で使用したとして訴訟を起こしました。この訴訟は注目を集めており、ディズニーが勝訴した場合、大規模データで学習する他のAI企業にも連鎖的な影響を及ぼし、AI分野における著作権紛争をさらに激化させる可能性があります。(出典: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google、AI検索の衝撃を受け再び「自主退職プログラム」を実施、検索、広告など複数の重要チームに影響 : AI検索がもたらす衝撃に直面し、Googleは再び米国の複数の部門の従業員に対し「自主退職プログラム」を提示しました。対象は検索、広告、コアエンジニアリングなどの主要チームに及び、オフィス復帰ポリシーも強化しています。この動きはリソースを再編し、AIフラッグシッププロジェクトGeminiおよび「AIモード」検索体験の研究開発により多くの力を注ぐことを目的としています。Googleの従来の検索事業はAIの台頭により大きな課題に直面しており、同時に同社は規制圧力にもさらされています。(出典: AI検索の衝撃下、Googleが再び「自主退職プログラム」を実施、複数の重要チームに影響, jpt401)
🌟 コミュニティ
AI、アムステルダムの福祉詐欺検出実験で偏見を露呈、プロジェクト中止 : アムステルダムは、AIシステム(Smart Check)を使用して福祉申請を評価し詐欺を検出する試みを行いましたが、偏見テストや技術的保護措置を含む責任あるAIのベストプラクティスに従ったにもかかわらず、パイロットプロジェクトでは、このシステムは公平性と有効性を達成できませんでした。初期モデルは非オランダ国籍の申請者と男性に偏見がありましたが、調整後はオランダ国籍と女性に偏見が生じました。最終的に、無差別性を確保できないため、このプロジェクトは中止されました。この事例は、アルゴリズムの公平性、責任あるAI実践の有効性、公共サービスにおける意思決定へのAI応用に関する広範な議論を引き起こしました。(出典: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

AI生成コンテンツ表示制度:価値、限界、ガバナンスロジックの検討 : AIが生成するデマや虚偽宣伝の増加に伴い、AI表示制度がガバナンス手段として注目されています。理論上、明示的および暗黙的な表示は識別効率を高め、ユーザーの警戒心を強めることができます。しかし実際には、表示は回避、偽造、誤判定されやすく、コストも高額です。記事は、AI表示を既存のコンテンツガバナンス体系に組み込み、高リスク分野(デマ、虚偽宣伝など)に焦点を当て、生成プラットフォームと配信プラットフォームの責任を合理的に定義し、同時に一般市民の情報リテラシー教育を強化すべきであると論じています。(出典: デマが「AI」の追い風に乗るとき)
AI支援コーディングツール(Claude Codeなど)が開発者の効率と作業負担を大幅に向上 : コミュニティの多くの開発者が、AI支援コーディングツール(特にAnthropicのClaude Code)を使用した肯定的な経験を共有しています。これらのツールは、コードの作成、テスト、デバッグを支援するだけでなく、プロジェクト計画、複雑な問題解決などでもサポートを提供し、開発効率を大幅に向上させ、作業負担と締め切りへの不安を軽減します。あるユーザーは、AI支援によって自分が「止められない力」になったように感じると述べています。(出典: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI生成コンテンツのエネルギーと水資源消費が注目を集める、Sam Altman氏はChatGPTクエリ1回あたり約小さじ1/15杯の水と発言 : OpenAI CEOのSam Altman氏は、ChatGPTのクエリ1回あたり約「小さじ15分の1杯」の水を消費すると明らかにしました。このデータは、AIモデルの訓練と推論の環境影響に関する議論を引き起こしました。具体的な計算方法や訓練コストが含まれているかどうかは不明ですが、AIのエネルギーフットプリントと水資源消費は、テクノロジー業界と環境保護分野で注目される議題となっています。(出典: MIT Technology Review, Reddit r/ChatGPT)

LLMが数学の証明を本当に理解しているかについての議論:IneqMathベンチマークテストがモデルの弱点を明らかに : 新しく発表されたIneqMathベンチマークテストは、オリンピックレベルの数学的不等式の証明に焦点を当てており、LLMは時に正解を見つけることができるものの、厳密で合理的な証明を構築する点では著しいギャップがあることが研究で明らかになりました。これは、LLMが数学などの分野で本当に理解しているのか、それとも単に「推測」しているだけなのかという議論を引き起こしました。Sathya氏は、このような「正解-誤った推論」という現象はPutnamBenchなどのベンチマークテストでも見られると指摘しています。(出典: lupantech, lupantech, _akhaliq, clefourrier)
ソフトウェア開発、研究、日常業務におけるAI Agentの応用と議論 : コミュニティでは、さまざまな分野におけるAI Agentの応用が広く議論されています。例えば、n8nとClaudeを使用して詳細な研究を行うインテリジェントエージェントのワークフローを構築した経験を共有するユーザーがいます。LlamaIndexは、Artifact Memory Blockを介して増分フォーム入力エージェントを実現する方法を示しています。議論には、MCP(Model Context Protocol)を使用したAI指向のツールインターフェースの設計や、法律、インフラストラクチャ自動化(CiscoのJARVISなど)などの分野におけるAI Agentの応用も含まれています。(出典: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

人型ロボットの安全基準が注目を集める、物理的および心理的影響の両立が必要 : 人型ロボットが徐々に産業応用に進出し、家庭などのシーンを目指すにつれて、その安全基準が議論の焦点となっています。IEEE人型ロボット研究グループは、人型ロボットは動的安定性などの独自性を持ち、新しい安全規則が必要であると指摘しています。物理的な安全性(転倒、衝突防止など)に加えて、人間とロボットのインタラクションにおけるコミュニケーションの課題(意図の表現、複数のロボットの協調など)や心理的影響(過度な擬人化による期待過剰、感情的な安全性など)も考慮する必要があります。基準策定は革新と安全性のバランスを取り、さまざまな応用シーンのニーズを考慮する必要があります。(出典: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 その他
Docker、docker run --gpusがAMD GPUをサポートしたと発表 : Docker公式の更新により、docker run --gpusコマンドがAMD GPU上での実行もサポートするようになりました。この改善により、コンテナ化されたAI/MLワークロードにおけるAMD GPUの使いやすさが向上し、AIエコシステムにおけるAMDの応用を推進する上で積極的な意味を持ちます。(出典: dylan522p)
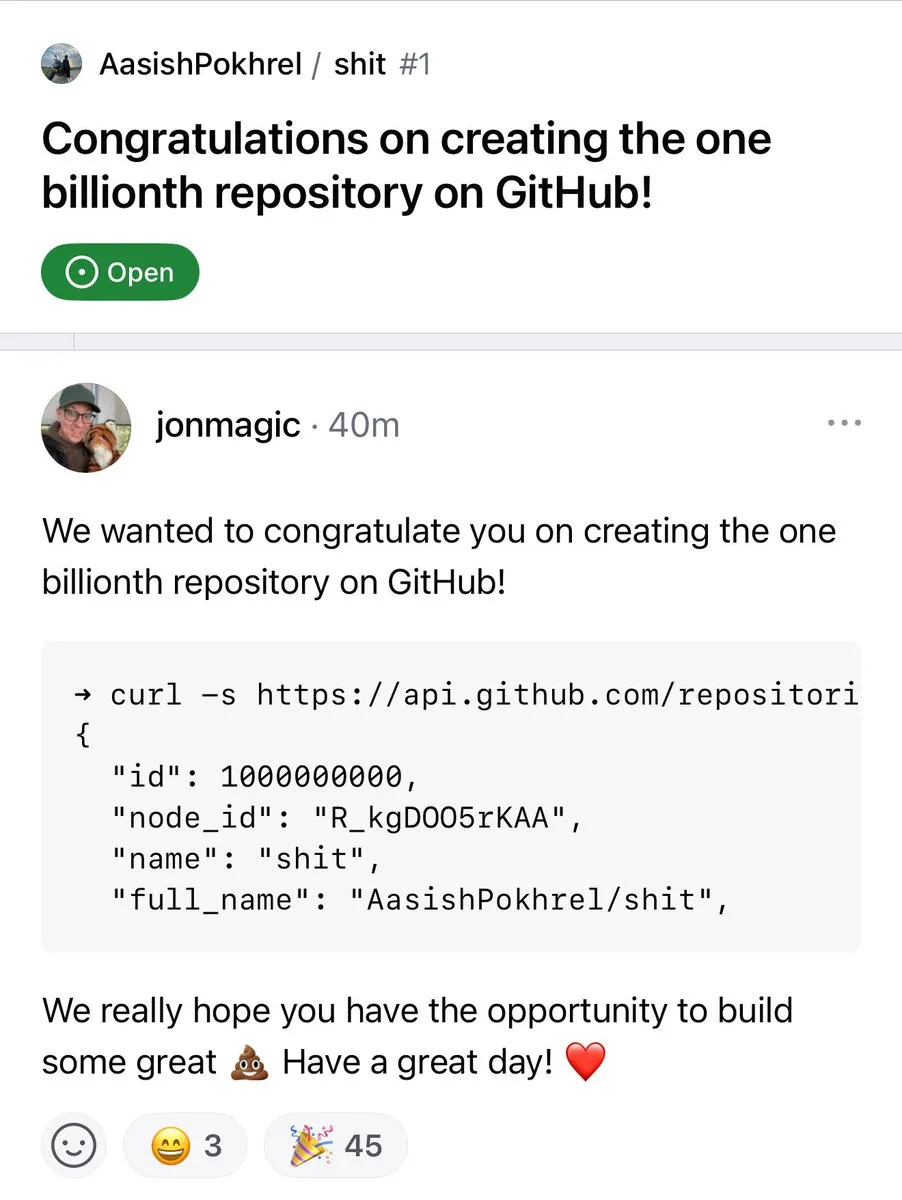
GitHubリポジトリ数が10億を突破 : GitHubプラットフォーム上のコードリポジトリ数が正式に10億の大台を突破しました。このマイルストーンは、オープンソースコミュニティとコードホスティングプラットフォームの継続的な繁栄と成長を示しています。(出典: karminski3, zacharynado)
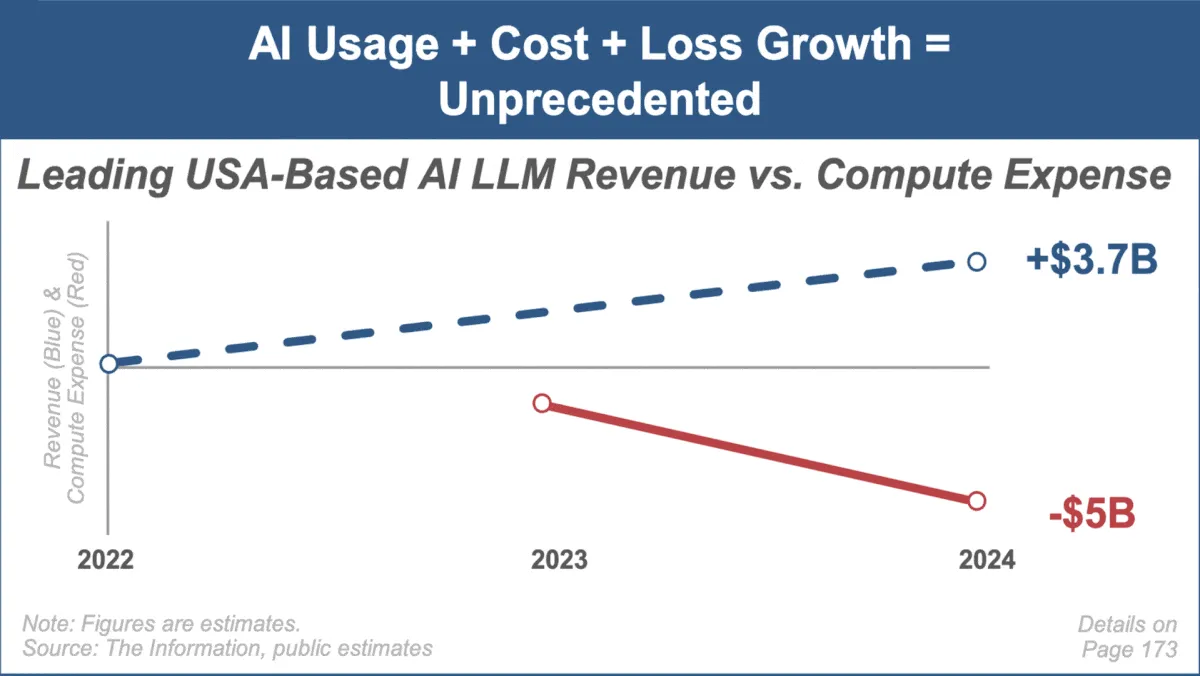
Mary Meeker氏、最新AIトレンドレポートを発表、市場の急成長と課題に焦点 : 著名な投資アナリストであるMary Meeker氏が、人工知能市場に関する初のトレンドレポート「Trends — Artificial Intelligence (May ‘25)」を発表しました。レポートは、AI分野における前例のない成長速度、ユーザー規模の急増(ChatGPTユーザー8億人など)、AI関連の設備投資の大幅な増加、そしてAIの性能と新たな能力における継続的なブレークスルーを強調しています。レポートは同時に、計算コストの上昇、モデルの急速なイテレーション、オープンソース代替品の競争など、AIビジネスモデルが直面する課題も指摘しています。(出典: DeepLearning.AI Blog)