
キーワード:DeepSeek, OpenAI, 推論モデル, マルチモーダル大規模モデル, 強化学習, AIイノベーション, オープンソースモデル, DeepSeek R1推論モデル, OpenAI o4強化学習トレーニング, マルチモーダル大規模モデル人間思考マップ, Mistral AI Magistralシリーズ, 小红书dots.llm1 MoEモデル
🔥 注目ニュース
DeepSeekとOpenAIの革新的アプローチが「認知的イノベーション」を提示: DeepSeekは「限定的Scaling Law」、MLAおよびMoEアーキテクチャの革新、ソフトウェアとハードウェアの協調最適化を通じて、低コスト・高性能を実現しました。そのR1推論モデルのオープンソース化はAI認知能力のブレークスルーを推進し、中国のイノベーターが基礎研究分野で抱いていた「思考の固定観念」を打ち破り、AI基礎研究とモデル革新における中国企業のグローバルなトップレベルの実力を証明しました。一方、OpenAIはTransformerアーキテクチャとScaling Law(スケーリング則)の徹底的な活用により、大規模言語モデル革命をリードし、ChatGPTと推論モデルo1を通じて、ヒューマン・マシン・インタラクションのパラダイム変革とAI認知能力の飛躍を推進しました。両社の発展経路は、技術の本質に対する深い理解と戦略的再構築を強調しており、AI時代の起業家に貴重な組織構築とイノベーションのアイデアを提供しています。特にDeepSeekが奨励する「創発」を促すAI Labパラダイムは、技術革新主導の起業家に新たな組織モデルの参考を提供します (出典: 36氪)
OpenAIが新モデルo4をトレーニング中と報道、強化学習がAIの勢力図を再構築: SemiAnalysisは、OpenAIがGPT-4.1とGPT-4.5の中間に位置する新モデルをトレーニング中であると報じました。次世代推論モデルo4は、GPT-4.1をベースに強化学習(RL)トレーニングが行われるとのことです。RLはCoTの生成を通じてモデルの推論能力を解放し、AIエージェントの発展を推進しますが、インフラ(特に推論)と報酬関数の設計に対する要求が非常に高く、「報酬ハッキング」現象が発生しやすいという課題があります。高品質なデータはRLを拡張する鍵であり、ユーザー行動データは重要な資産となります。RLはまた、研究室の組織構造を変え、推論とトレーニングを深く融合させます。事前学習とは異なり、RLはDeepSeek R1のようにモデル能力を継続的に更新できます。小規模モデルの場合、蒸留がRLよりも優れている可能性があります。今回の報道は、AI分野、特に推論モデルが、RLに基づく継続的な進化と能力の飛躍を迎えることを示唆しています (出典: 36氪)
マルチモーダル大規模モデルが自発的に「人間の思考マップ」を形成することが判明: 中国科学院自動化研究所と脳科学・知能技術卓越革新センターの共同チームは、行動実験と神経画像解析を通じて、マルチモーダル大規模言語モデル(MLLM)が人間と非常に類似した物体概念表象システムを自発的に形成できることを実証しました。研究では、470万回の「三者択一異物識別タスク」の行動判断データを分析し、AIモデルの「概念マップ」を初めて構築しました。主な発見には以下が含まれます:異なるアーキテクチャのAIモデルが類似の低次元認知構造に収束する可能性。モデルは教師なしで高度な物体概念分類能力を発現し、人間の認知と一致。AIモデルの「思考次元」には、動物、食物、硬度などの意味ラベルを付与可能。MLLMの表象は、脳の特定領域(FFA、PPAなど)の神経活動パターンと顕著に関連し、「AIと人間が概念処理メカニズムを共有している」という証拠を提供。この研究は、AI認知の理解、脳型知能の開発、ブレイン・マシン・インターフェースに新たな視点を提供します (出典: 量子位)

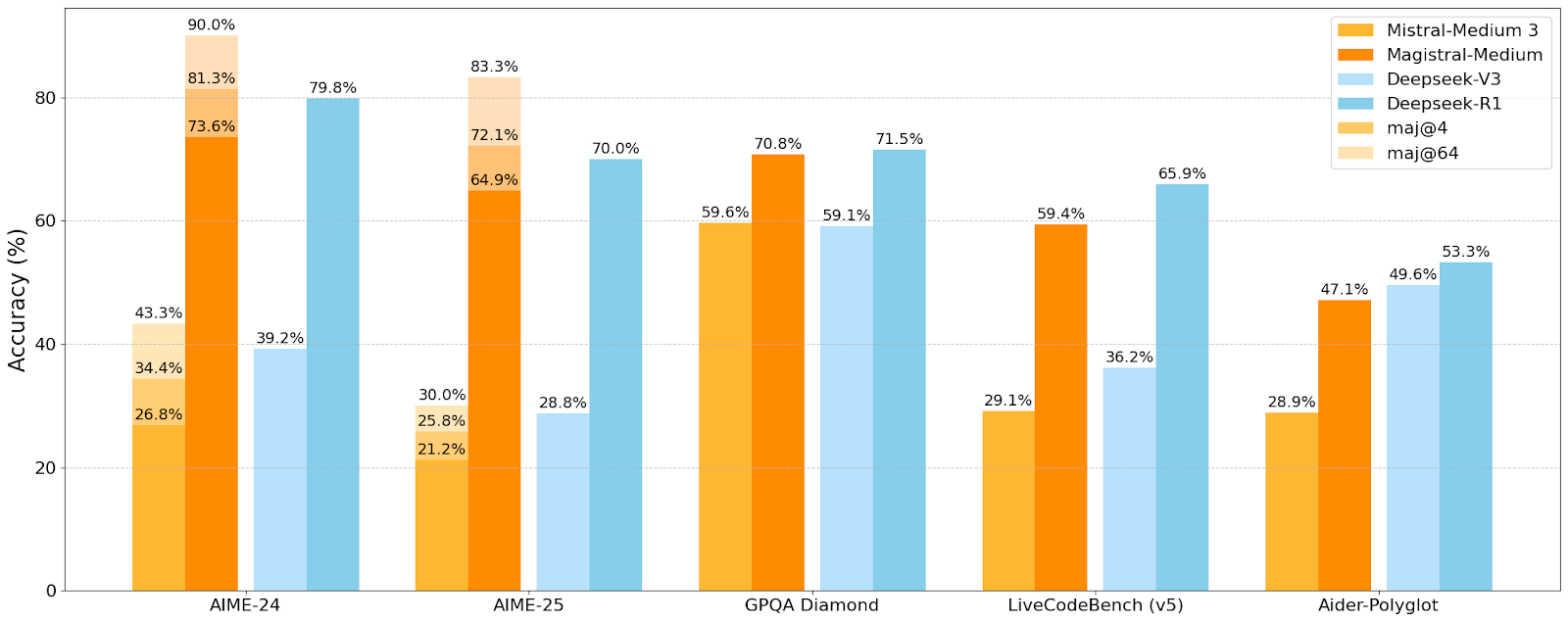
Mistral AIが初の推論モデルMagistralシリーズを発表、小規模モデルMagistral-Smallはオープンソース化: Mistral AIは、推論専用に設計された初のモデルシリーズMagistralを発表しました。これにはMagistral-SmallとMagistral-Mediumが含まれます。Magistral-SmallはMistral Small 3.1(2503)をベースに構築された24Bパラメータの効率的な推論モデルで、Magistral Mediumの軌跡を通じてSFTおよびRLトレーニングが行われ、推論能力が強化されています。このモデルは多言語に対応し、コンテキストウィンドウは128k(推奨有効コンテキスト40k)、Apache 2.0ライセンスでオープンソース化されており、単一のRTX 4090または32GB RAMのMacBook上でローカル展開が可能です(量子化後)。ベンチマークテストでは、Magistral-SmallはAIME24、AIME25、GPQA Diamond、Livecodebench (v5)などのタスクで優れたパフォーマンスを示し、一部のより大きなモデルに匹敵するか、それを上回っています。Magistral-Mediumはさらに高性能ですが、現在はオープンソース化されていません。今回の発表は、Mistralがモデルの推論能力と多言語サポートの向上において進展を遂げたことを示しています (出典: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 動向
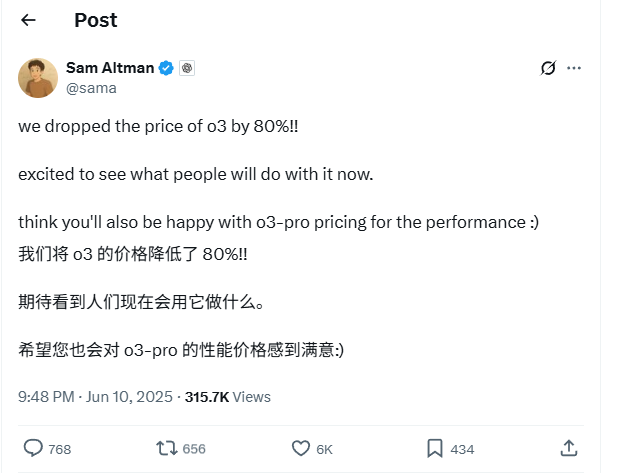
OpenAI o3モデルのAPI価格が80%大幅値下げ: OpenAIのCEOであるSam Altman氏は、o3モデルのAPI価格を80%引き下げたと発表しました。調整後、入力価格は2ドル/100万トークン、出力価格は8ドル/100万トークンとなります(一部情報源では出力5ドル/100万トークンとの記載あり、公式ドキュメントで確認が必要)。この大幅な値下げにより、o3モデルを使用したコード作成などのタスクのコストが著しく低下し、より広範な応用とイノベーションが促進されると予想されます。ユーザーは公式サイトの価格表がまだ更新されていない可能性があるため、API呼び出し前にテストを行い、実際の適用価格を確認して不必要な損失を避けるよう注意が必要です。この動きは、市場競争(Gemini 2.5 ProやClaude 4 Sonnetなど)への対応策と考えられており、AI知能のコストが継続的に低下することを示唆している可能性があります (出典: X, X, X)
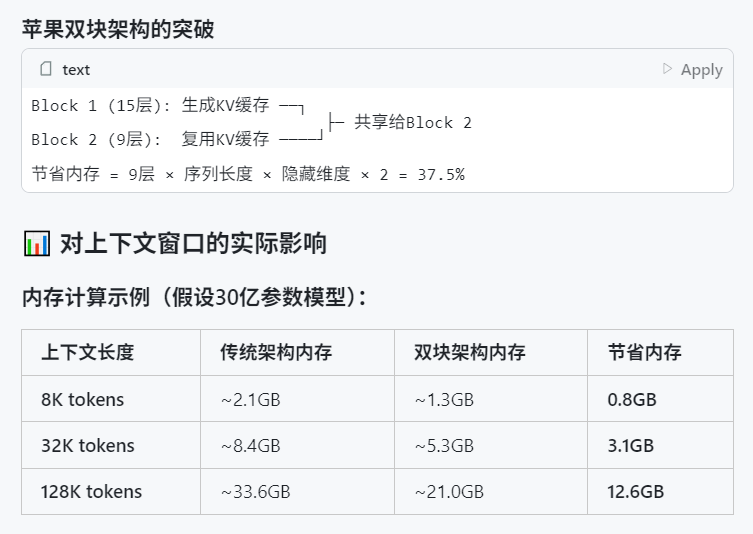
Apple WWDC 2025、AIへの言及は少ないものの、技術詳細に野心が見える: Appleは世界開発者会議(WWDC)2025でAIについて予想ほど触れませんでしたが、その技術文書から、デバイス側およびクラウド側モデルへの深い取り組みが明らかになりました。Appleは、モバイル向けモデル(約3Bサイズ)用に設計された「デュアルブロックアーキテクチャ」(メモリ占有量の削減を目的)や、サーバー側モデルで使用される「PT-MoE」(並列軌道エキスパート混合)アーキテクチャなど、高度なトレーニング、蒸留、量子化技術を採用しています。これらの技術は、Appleチップ上での低遅延推論を最適化し、KVキャッシュメモリの使用量を削減することを目的としています。AppleがAI分野で遅れをとっているとの声もありますが、モデル技術における成果(オープンソースの埋め込みモデルなど)や、異なる優先順位への関心(チャットボットだけでなくデバイス側インテリジェンスなど)は、同社独自のAI戦略を示唆しています。WWDCではまた、Safari 26がWebGPUをサポートすることも発表され、これによりデバイス側でのAIモデル(Transformers.js経由など)の実行性能が大幅に向上し、例えばブラウザ内での視覚モデルによるキャプション生成速度が約12倍向上します (出典: X, X, X)
Perplexity ProユーザーがOpenAI o3モデルを利用可能に: Perplexityは、ProサブスクリプションユーザーがOpenAIのo3モデルを利用できるようになったと発表しました。この統合により、Perplexity Proユーザーはより強力な情報処理能力と質疑応答能力を享受できるようになります。同時に、Perplexityは「Memory」機能のテストも行っており、iOS音声アシスタントを更新して、より簡潔で実用的なユーザーエクスペリエンスの提供を目指しています。また、Discover記事機能もデフォルトでより簡潔な「Summary」モードになり、詳細な「Report」モードへの切り替えオプションも提供されます (出典: X, X, X)

小紅書(Xiaohongshu)が初の142B MoE大規模モデルdots.llm1をオープンソース化、中国語評価でDeepSeek-V3を上回る: 小紅書は、同社初の大規模モデルdots.llm1をオープンソース化しました。これは1420億パラメータのMoE(混合エキスパート)モデルで、推論時には140億パラメータのみをアクティブ化します。このモデルは、事前学習段階で11.2兆の非合成トークンを使用し、主に汎用クローラーと自社クローラーからのWebデータを利用しています。小紅書チームは、スケーラブルな3段階のデータ処理フレームワークを提案し、再現性を高めるためにオープンソース化しました。dots.llm1はC-Evalで92.2点を獲得し、DeepSeek-V3を含むすべてのモデルを上回り、中国語・英語、数学、アライメントなどのタスクでアリババのQwen3-32Bの性能に匹敵します。小紅書はまた、大規模モデルのダイナミクスに関するコミュニティの理解を促進するために、中間トレーニングチェックポイントもオープンソース化しました (出典: 36氪)
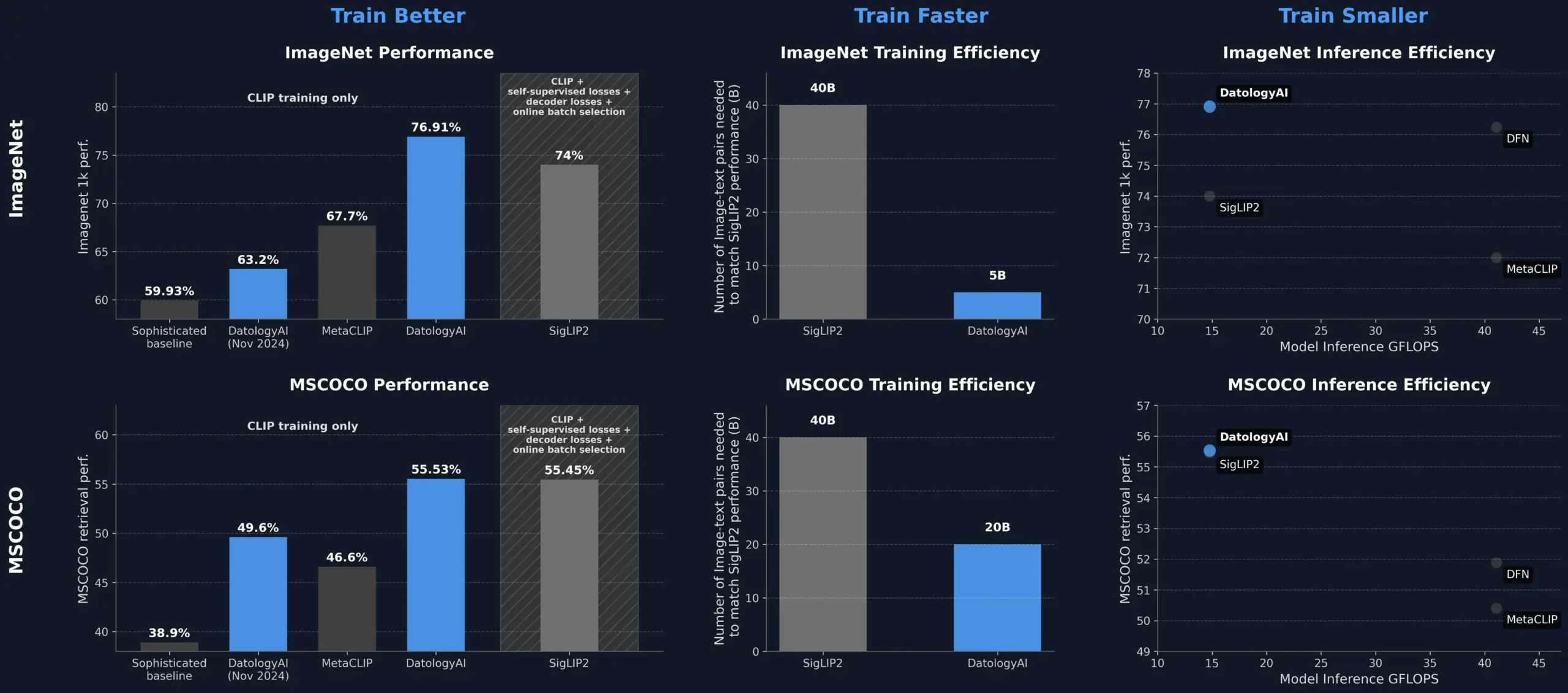
DatologyAIがデータ管理によりCLIPモデルの性能を向上させ、SigLIP2を超える: DatologyAIは、データ管理(data curation)のみでCLIPモデルの性能を著しく向上させる成果を示しました。彼らの手法により、ViT-B/32モデルはImageNet 1kで76.9%の精度を達成し、SigLIP2が報告した74%を上回りました。さらに、この手法はトレーニング効率を8倍、推論効率を2倍向上させ、関連モデルを公開しています。これは、高品質で慎重に管理されたデータセットが、高度なAIモデルのトレーニングにおいて中心的な役割を果たすことを強調しており、モデルアーキテクチャを変更しなくても、データを最適化することでモデルの潜在能力を引き出せることを示しています (出典: X, X)
快手(Kuaishou)と東北大学が統一マルチモーダル埋め込みフレームワークUNITEを共同提案: マルチモーダル検索において、異なるモダリティ(テキスト、画像、動画)のデータ分布の違いが原因で発生するクロスモーダル干渉問題を解決するため、快手と東北大学の研究者は、マルチモーダル統一埋め込みフレームワークUNITEを提案しました。このフレームワークは、「モダリティ認識マスキング対照学習」(MAMCL)メカニズムを通じて、対照学習においてクエリターゲットのモダリティと一致する負のサンプルのみを考慮し、モダリティ間の誤った競合を回避します。UNITEは「検索適応+指示ファインチューニング」の2段階トレーニングを採用し、画像-テキスト検索、動画-テキスト検索、指示検索など複数の評価でSOTA(State-of-the-Art)成績を収めました。例えば、MMEB Benchmarkではより大規模なモデルを上回り、CoVRでは大幅にリードしています。研究は、統一モダリティにおける動画-テキストデータの中心的な能力を強調し、指示タスクはテキスト主導のデータにより依存することを示しています (出典: 量子位)

NVIDIAがEarth-2気候シミュレーションAI基盤モデルを発表: NVIDIAのEarth-2プラットフォームは、キロメートル級の解像度で全球気候をシミュレートできる新しいAI基盤モデルを発表しました。このモデルは、より迅速かつ正確な気候予測を提供することを目的としており、地球の複雑な自然システムを理解し予測するための新たな道筋を提供します。この動きは、気候科学および地球システムモデリング分野におけるAIの応用が重要な一歩を踏み出したことを示しており、気候変動研究や災害警報能力の向上が期待されます (出典: X)

OpenAIサービスで大規模障害発生、ChatGPTおよびAPIに影響: OpenAIのChatGPTサービスとAPIインターフェースが、北京時間6月10日夜に大規模な障害に見舞われ、エラー率と遅延が増加しました。多くのユーザーがサービスにアクセスできない、または「Hmm…something seems to have gone wrong」などのエラーメッセージに遭遇したと報告しました。OpenAIの公式ステータスページはこの問題を確認し、エンジニアが根本原因を特定し緊急修復中であると発表しました。この障害は、ChatGPTとそのAPIに依存する世界中の多くのユーザーおよびアプリケーションに影響を与え、大規模AIサービスの安定性の重要性を改めて浮き彫りにしました (出典: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 ツール
Model Context Protocol (MCP) サーバーエコシステムが継続的に拡大: Model Context Protocol (MCP) は、大規模言語モデル(LLM)に安全で制御可能なツールとデータソースへのアクセスを提供することを目的としています。GitHub上のmodelcontextprotocol/serversリポジトリは、MCPの参照実装とコミュニティが構築したサーバーを集約し、その多様な応用を示しています。公式およびサードパーティのサーバーは、ファイルシステム、Git操作、データベース連携(PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandraなど)、クラウドサービス(AWS, Azure, Cloudflare)、API連携(GitHub, GitLab, Slack, Google Drive, Stripe, PayPal)、検索(Brave, Algolia, Exa, Tavily)、コード実行、AIモデル呼び出し(Replicate, ElevenLabs)など、広範な領域をカバーしています。MCPのエコシステムは急速に発展しており、既に130以上の公式およびコミュニティサーバーが存在し、EasyMCP、FastMCP、MCP-Frameworkなどの開発フレームワークやMCP-CLI、MCPMなどの管理ツールが登場しています。これらは、LLMが外部ツールやデータにアクセスする際の障壁を下げ、AI Agentの発展を推進することを目的としています (出典: GitHub Trending)
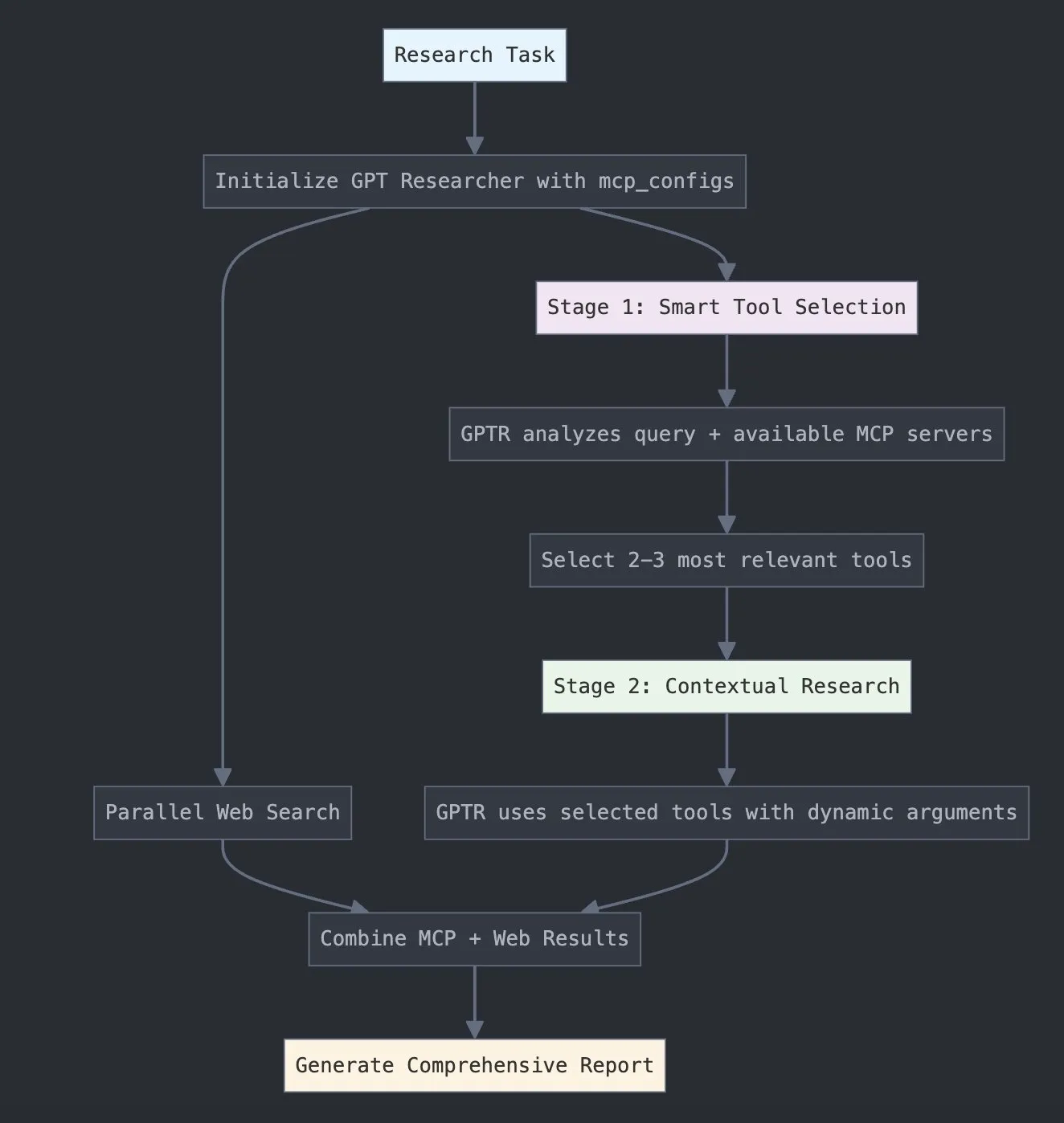
LangChainがGPT Researcher MCPを発表、研究能力を強化: LangChainは、GPT Researcherがモデルコンテキストプロトコル(MCP)アダプターを利用して、インテリジェントなツール選択と研究を実現するようになったと発表しました。この統合は、MCPとウェブ検索機能を組み合わせることで、ユーザーにより包括的なデータ収集・分析能力を提供し、AIの研究分野における応用の深さと幅をさらに向上させることを目指しています (出典: X)
Hugging FaceがVuiをリリース:100MのオープンソースNotebookLM、人間らしいTTSを実現: Hugging Face上でVuiがリリースされました。これは1億パラメータのオープンソースNotebookLMプロジェクトで、3つのモデルが含まれています:Vui.BASE(4万時間の音声会話でトレーニングされた基礎モデル)、Vui.ABRAHAM(文脈認識能力を持つ単一話者モデル)、Vui.COHOST(二人での会話が可能なモデル)。Vuiは声をクローンし、呼吸や「えーと」などの口癖、さらには非音声的な音まで模倣することができ、人間らしいテキスト読み上げ(TTS)技術の新たな進展を示しています (出典: X, X)
Consilium:複雑な問題を解決するオープンソースのマルチエージェント協力プラットフォーム: Hugging Face上でConsiliumプロジェクトが紹介されました。これはオープンソースのマルチエージェント協力プラットフォームです。ユーザーは専門家のAIエージェントチームを編成し、討論やリアルタイム調査(ウェブ、arXiv、SECファイル)を通じて、複雑な問題を共同で解決し、合意に達することができます。ユーザーが戦略を設定し、エージェントチームが答えを見つけるというもので、AIによる協調的な問題解決の新たな探求を示しています (出典: X)
UnslothがMagistral-Small-2506最適化版GGUFモデルをリリース: Mistral AIによるMagistral-Small-2506推論モデルのリリースに続き、Unslothは迅速にその最適化版GGUF形式モデルをリリースしました。これはllama.cpp、LMStudio、Ollamaなどのプラットフォームに対応しています。この迅速な対応は、オープンソースコミュニティにおけるモデル最適化とデプロイメントの活力と効率性を示しており、新しいモデルがより広範なユーザーや開発者によってより迅速に利用可能になることを可能にしています (出典: X)
📚 学習
新論文が強化学習事前学習(RPT)パラダイムを議論: 新しい論文『Reinforcement Pre-Training (RPT)』は、次世代トークン予測をRLVR(Reinforcement Learning with Verifiable Rewards)を用いた推論タスクとして再構築することを提案しています。RPTは、次トークン推論能力を奨励することで言語モデルの予測精度を向上させ、その後の強化学習ファインチューニングのための強力な基盤を提供することを目的としています。研究によると、トレーニング計算量を増やすことで予測精度が継続的に向上することが示されており、RPTが言語モデルの事前学習を推進するための効果的かつ有望な拡張パラダイムであることが示唆されています (出典: HuggingFace Daily Papers, X)

論文がCartridgesを提案:自己学習による軽量な長文コンテキスト表現: 『Cartridges: Lightweight and general-purpose long context representations via self-study』という論文は、推論時にコーパス全体をコンテキストウィンドウに入れる代わりに、Cartridgeと呼ばれる小さなKVキャッシュをオフラインでトレーニングすることで長文テキストを処理する方法を検討しています。研究によると、「自己学習」(コーパスに関する合成会話を生成し、コンテキスト蒸留目標でトレーニングする)によってトレーニングされたCartridgeは、大幅に低いメモリ消費量(38.6倍削減)と高いスループット(26.4倍向上)でICLと同等の性能を達成し、モデルの有効コンテキスト長を拡張し、再トレーニングなしでコーパス間の組み合わせ使用もサポートできることがわかりました (出典: HuggingFace Daily Papers, X)

論文がLLMにおける幾何学的問題解決のためのグループ対照的方策最適化(GCPO)を議論: 論文『GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization』は、LLMが幾何学的問題解決において補助線を構築する際の課題に対し、GCPOフレームワークを提案しています。このフレームワークは、「グループ対照的マスク」を通じて、文脈的有用性に基づいて補助線構築に正負の報酬信号を提供し、より長い推論連鎖を促進するために長さ報酬を導入しています。GCPOに基づいて開発されたGeometryZeroモデルシリーズは、Geometry3KやMathVistaなどのベンチマークテストでベースラインモデルを上回る性能を示し、平均4.29%向上させ、限られた計算能力で小規模モデルの幾何学的推論能力を向上させる可能性を示しています (出典: HuggingFace Daily Papers)
論文『The Illusion of Thinking』が問題の複雑性を通じて推論モデルの能力と限界を探る: この研究は、大規模推論モデル(LRM)の能力、スケーリング特性、および限界を体系的に調査しています。複雑度を正確に制御できるパズル環境を使用することで、LRMは特定の複雑度を超えると精度が完全に崩壊し、直感に反するスケーリング制限を示すことがわかりました。つまり、推論努力は問題の複雑度がある程度増加すると逆に低下します。標準的なLLMと比較して、LRMは低複雑度タスクでは性能が劣り、中複雑度タスクでは優位に立ちますが、高複雑度タスクではどちらも機能しません。研究は、LRMが正確な計算において限界があり、明示的なアルゴリズムの適用が困難であり、異なる規模で推論が一貫していないことを指摘しています (出典: HuggingFace Daily Papers, X)
論文が低リソース言語におけるLLMの堅牢性評価を研究: 論文『Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models』は、大規模言語モデル(LLM)がポーランド語などの低リソース言語において、摂動(文字レベルおよび単語レベルの攻撃など)に対してどの程度敏感であるかを検討しています。研究によると、少数の文字変更を行い、小さなプロキシモデルを使用して単語の重要度を計算することで、異なるLLMの予測を著しく変化させる攻撃を作成できることがわかりました。これは、これらの言語におけるLLMに存在する可能性のあるセキュリティ脆弱性を示しており、内部のセキュリティメカニズムを回避するために悪用される可能性があります。研究者は関連するデータセットとコードを公開しています (出典: HuggingFace Daily Papers)
Rel-LLM:LLMがリレーショナルデータベースを処理する効率を向上させる新手法: ある論文がRel-LLMフレームワークを提案し、大規模言語モデル(LLM)がリレーショナルデータベースを処理する際の効率の低さという問題の解決を目指しています。従来の手法では、構造化データをテキストに変換すると、重要なリンクが失われ、入力が冗長になるという問題がありました。Rel-LLMは、グラフニューラルネットワーク(GNN)エンコーダを使用して構造化グラフプロンプトを作成し、検索拡張生成(RAG)フレームワーク内でリレーショナル構造を保持します。この手法には、時系列認識サブグラフサンプリング、異種GNNエンコーダ、グラフ埋め込みとLLM潜在空間を整列させるMLP投影層、およびグラフ表現をJSONグラフプロンプトとして構造化するステップが含まれ、自己教師あり事前学習目標を通じてグラフとテキスト表現を整列させます。実験により、GNNエンコーディングはテキストの逐次化で失われる複雑なリレーショナル構造を効果的に捉え、構造化グラフプロンプトはリレーショナルコンテキストをLLMの注意メカニズムに効果的に注入できることが示されました (出典: X)

論文がLLMの「過剰拒否」問題とEvoRefuse最適化手法を議論: 論文『EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions』は、大規模言語モデル(LLM)が「疑似悪意のある指示」(意味的には無害だがモデルの拒否を引き起こす入力)に対して過剰に拒否する問題を研究しています。既存の指示管理手法のスケーラビリティと多様性の不足を解決するため、論文は進化アルゴリズムを利用してプロンプトを最適化する手法であるEVOREFUSEを提案しています。これにより、LLMの拒否を継続的に引き起こす多様な疑似悪意のある指示を生成できます。これに基づき、研究者はEVOREFUSE-TEST(582件の指示を含むベンチマークテスト)とEVOREFUSE-ALIGN(3000件の指示と応答を含むアライメントトレーニングデータセット)を作成しました。実験によると、EVOREFUSE-ALIGNでファインチューニングされたLLAMA3.1-8B-INSTRUCTモデルは、最適でないアライメントデータセットでトレーニングされたモデルと比較して、過剰拒否率が最大14.31%低下し、安全性を損なうこともありませんでした (出典: HuggingFace Daily Papers)
💼 ビジネス
中科聞歌が新たな戦略的資金調達を完了、北京市石景山区産業基金が出資: エンタープライズ向けAIサービスプロバイダーの中科聞歌は、新たな戦略的資金調達を完了したと発表しました。出資者は北京市石景山区現代イノベーション産業発展基金有限公司です。今回の資金調達は、主に自社開発の意思決定インテリジェンスオペレーティングシステムDIOSの研究開発投資と市場展開に充てられ、エンタープライズ向け人工知能技術の発展と商業化を加速させます。中科聞歌は2017年に設立され、中核チームは中国科学院自動化研究所出身で、多言語理解、クロスモーダルセマンティクス、複雑なシーンでの意思決定技術に特化し、メディア、金融、行政、エネルギーなどの業界にサービスを提供しています。これまでに、国開金融、中網投、深創投などの国有資本系ファンドから10億元以上の投資を受けています (出典: 量子位)

Sakana AIが日本の北國銀行と戦略的提携、地域金融AIの発展を推進: 日本のAIスタートアップ企業Sakana AIは、石川県に本社を置く北國フィナンシャルホールディングス(Hokkoku Financial Holdings)と覚書(MOU)を締結し、地域金融とAIの連携に関する戦略的協力を開始すると発表しました。これは、三菱UFJ銀行との包括的パートナーシップ構築に続き、Sakana AIが再び金融機関と提携するもので、最先端のAI技術を日本の地域社会が直面する課題、特に金融サービス分野の解決に応用することを目指しています。Sakana AIは金融機関向けに高度に専門化されたAI技術の開発に取り組んでおり、今回の協力は日本の他の地方銀行にとってAI応用の模範となることが期待されます (出典: X, X)

CohereがEnsembleと提携し、AIプラットフォームをヘルスケア業界に導入: AI企業のCohereは、EnsembleHP(ヘルスケアソリューションプロバイダー)とのパートナーシップを発表し、同社のCohere North AIインテリジェントエージェントプラットフォームをヘルスケア業界に導入します。両社は、安全なAIインテリジェントエージェントプラットフォームを通じて、医療管理プロセスにおける摩擦を軽減し、病院や医療システムの患者体験を向上させることを目指しています。この動きは、Cohereが大規模言語モデルとAI技術を主要な垂直産業で応用推進する上で重要な一歩となります (出典: X)
🌟 コミュニティ
Ilya Sutskever氏、トロント大学名誉学位スピーチ:AIはいずれ万能になる、積極的に注目すべき: OpenAIの共同創設者であるIlya Sutskever氏は、トロント大学から名誉理学博士号(同大学で4つ目の学位)を授与された際のスピーチで、AIの進歩により「いつか我々ができる全てのことをAIができるようになる」と述べました。なぜなら、人間の脳は生物学的なコンピュータであり、AIはデジタルな脳だからです。彼は、我々はAIによって定義される非凡な時代に生きており、AIは既に学生や仕事の意味を深く変えていると考えています。彼は、懸念するよりも、最先端のAIを使用し観察することで直感を形成し、その能力の限界を理解すべきだと強調しました。AIの発展に注目し、それに伴う巨大な課題と機会に積極的に対応するよう人々に呼びかけました。なぜなら、AIは全ての人の生活に深く影響を与えるからです。彼はまた、個人的な心構えとして「現実を受け入れ、過去を悔いず、現状を改善するよう努力する」と語りました (出典: X, 36氪)
AI人材獲得競争が激化:Metaは高額報酬を提示するもOpenAIやAnthropicには及ばず: MetaはAI人材獲得のために年俸200万ドル超を提示していると報じられていますが、依然として人材がOpenAIやAnthropicに流出する状況に直面しています。OpenAIのL6レベルの給与は150万ドル近くであり、株式の評価額上昇の可能性もMetaより優れていると見なされているため、トップ人材にとってより魅力的に映っているとの議論があります。さらに、Llamaチームの不正行為疑惑や、Meta社内のKPIプレッシャーの大きさ、下位評価者の割合の高さ(今年は15~20%)といった要因も人材の選択に影響を与えています。一方、Anthropicは(設立2年後で)約80%という高い人材定着率を誇り、トップAI研究者にとって主要な大企業の一つとなっています。この人材獲得競争の激しさは「信じられないほど」と表現されています (出典: X, X)
「Vibe Coding」経験談:AI支援プログラミングで非効率なデバッグループを避ける5つの法則: ソーシャルメディア上で、経験豊富な開発者がAI(Claudeなど)を使った「Vibe Coding」(AI支援に依存するプログラミング手法)において、非効率なデバッグループに陥るのを避けるための5つのルールを共有しました。1. 三振アウト: AIが3回問題解決に失敗したら、中止し、AIに新しい要件から再構築させる。2. コンテキストのリセット: AIは長い会話の後「忘れる」ため、8~10回のメッセージ交換ごとに有効なコードを保存し、新しいセッションを開始して問題のあるコンポーネントと簡単なアプリケーションの説明のみを貼り付けることを推奨。3. 問題を簡潔に記述: バグを一文で明確に記述する。4. 頻繁なバージョン管理: 各機能が完了したらすぐにGitにコミットする。5. 必要ならやり直す: バグ修正に時間がかかりすぎる場合(例えば2時間以上)、問題のあるコンポーネントを削除してAIに再構築させた方が良い。核心は、コードが不可逆的に破損したと認めたら、修復をきっぱりと諦めること。同時に、プログラミングを理解している方がAIをより良く指導し、デバッグできると強調しています (出典: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
李飛飛氏、World Labs設立について語る:知能の本質への探求から、空間知能はAIに欠けている重要な要素: a16zのポッドキャストで、李飛飛氏はWorld Labs設立の動機を語り、それが基盤モデルのブームに乗ったものではなく、知能の本質に対する継続的な探求であると強調しました。彼女は、言語は効率的な情報伝達手段であるものの、三次元物理世界の表現においては欠陥があり、真の汎用知能は物理空間と物体間の関係の理解の上に構築されなければならないと考えています。角膜損傷により一時的に立体視を失った経験から、彼女は物理的相互作用における三次元空間表現の重要性をより深く理解しました。World Labsは、物理世界を真に理解できるAIモデル(ワールドモデルLWM)を構築し、現在のAIにおける空間知能の欠如を補うことを目指しています。このビジョンを実現するためには、産業レベルの計算能力、データ、人材を結集する必要があると彼女は考えており、現在の技術的ブレークスルーは、AIに単眼視から完全な三次元シーン理解を再構築させることにあると指摘しています (出典: 量子位)

AI支援による大学入試:予想問題の論争から進路指導の機会と懸念まで: 大学入試(高考)前後、教育分野におけるAIの応用が広範な議論を呼んでいます。一方では、「AIによる予想問題」が話題となりましたが、大学入試問題作成の科学性、機密性、および「予想問題対策」メカニズムのため、AIによる正確な予想問題の可能性は低く、市販の予想問題集の一部は質が低いという懸念があります。他方で、AIは受験計画、問題解説、試験監督、採点などの面で積極的な役割を示しており、個別化学習計画、スマート質疑応答、AI監督システムによる公平性と効率性の向上などが挙げられます。進路指導の段階では、AIツールは受験生の点数、順位に基づいて迅速に大学や学部を推薦し、情報格差を解消します。しかし、AIによる進路指導への過度な依存も懸念されています。アルゴリズムが人気学部の選好を強化し、個人の興味や長期的な発展を無視する可能性があります。人生の選択権を完全にアルゴリズムに委ねることは、「アルゴリズムによる人生の束縛」につながる可能性があります。記事は、AI支援を理性的に捉え、知恵をもってツールを使いこなし、思考によって未来を定義することの重要性を訴えています (出典: 36氪)
AI Agent企業の成功モデル議論:セルフサービス vs. カスタマイズサービス: コミュニティでは、AI Agent企業の成功モデルについて議論が交わされました。一方の意見では、成功しているAI Agent企業(特に中規模から大規模市場向け)の多くは、Palantirのようなモデル、つまり多数の現場開発エンジニア(FDE)とカスタマイズされたソフトウェアを採用しており、純粋なセルフサービスモデルではないと主張しています。もう一方の意見では、セルフサービスモデルの長期的な価値を堅持し、チームは最終的に重要なアプリケーションを内部で構築することを選択すると考えています。これは、AI Agent分野におけるサービスモデルと市場戦略に関する異なる考え方を反映しています (出典: X)
💡 その他
Google Diffusionシステムプロンプトが流出、その設計原則と能力の限界が明らかに: あるユーザーが、Google Diffusion(テキスト拡散言語モデル)とされるシステムプロンプトを共有しました。このプロンプトは、モデルのアイデンティティ(Gemini Diffusion、Googleによって訓練された専門的なテキスト拡散言語モデル、非自己回帰型)、中核となる原則と制約(指示への準拠、非自己回帰特性、正確性、リアルタイムアクセスなし、安全性と倫理、知識のカットオフ2023年12月、コード生成能力など)、およびHTMLウェブページとHTMLゲーム生成に関する具体的な指示を詳細に説明しています。これらの指示は、出力形式、美的デザイン、スタイル(Tailwind CSSの専門的な使用やゲーム内のカスタムCSSなど)、アイコンの使用(Lucide SVGアイコン)、レイアウトとパフォーマンス(CLS予防)、コメント要件などを網羅しています。最後に、段階的に考え、ユーザーの指示に正確に従うことの重要性が強調されています。このプロンプトは、この種のモデルの設計思想と期待される動作を理解するための窓を提供します (出典: Reddit r/LocalLLaMA)
Arvind Narayanan氏、「AIは普通の技術」論文の誕生と考察を語る: プリンストン大学のArvind Narayanan教授は、Sayash Kapoor氏と共著した論文『AI as Normal Technology』の執筆過程を共有しました。彼は当初、AGI(汎用人工知能)や実存的リスクに懐疑的でしたが、同僚の強い勧めで真剣に受け止め、関連する議論に参加することを決意しました。内省を通じて、彼は超知能に関する見解が真剣に検討する価値があること、ソーシャルメディアは真剣な議論には不向きであること、そしてAI倫理とAI安全コミュニティの双方にそれぞれの「情報繭」が存在することを認識しました。論文の初稿はICMLで不採択となりましたが、審査過程での激しい議論がかえって彼らの研究継続の決意を固めさせました。彼らはAI安全コミュニティとの意見の相違が予想以上に深いことに気づき、より生産的な分野横断的な議論の必要性を認識しました。最終的に、論文はコロンビア大学Knight First Amendment Instituteのワークショップで発表され、広範な注目と実りある議論を呼び、Narayanan氏はAI政策の未来についてより楽観的になりました (出典: X)
2000年代生まれのAI起業家群が台頭、起業ルールを再構築: 2000年代生まれのAI起業家の一群が、驚くべき速さで世界の起業ブームの中で頭角を現しています。彼らはAI技術への深い理解とネイティブなデジタル環境への鋭い洞察力を武器に、起業の法則を再定義しています。事例としては、Anysphere (Cursor) のMichael Truell氏(インターンから3年で評価額100億ドルの企業のCEOへ)、Mercorの創業者3名(2年で評価額100億ドル級のAI採用プラットフォームを構築)、MagicのEric Steinberger氏(25歳で評価額4億ドル超のAIコーディング企業を共同設立)、Axiomの洪楽潼氏(AIによる数学難問解決に特化し、製品未完成で高評価額を獲得)などが挙げられます。これらの若い起業家は一般的に以下の特徴を備えています:プログラミングが母国語であること。若くして名を成し、技術的ボーナスの好機を掴んでいること。ユーザーニーズを鋭敏に感知していること。組織と製品に対してAIネイティブな理解を持ち、極めてシンプルで効率的なチームと「AI即製品」というロジックを好むこと。彼らの成功は、AI時代の起業パラダイムの転換を示しています (出典: 36氪)