
キーワード:OpenAI, o3-pro, Meta, スーパーインテリジェンス研究所, Mistral AI, Magistral, IBM, 量子コンピュータ, o3-proの価格設定, Scale AIへの投資, Magistral-Small-2506, Starling量子コンピュータ, AIの軍事応用テスト
🔥 焦点
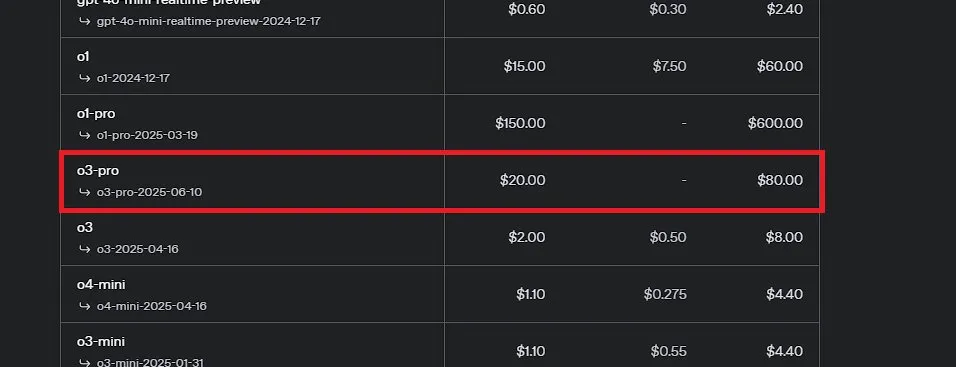
OpenAI、史上最強モデルと謳われるo3-proを発表、o3の価格を大幅引き下げ: OpenAIは、同社史上最も強力な推論モデルo3-proを正式に発表し、ChatGPT ProおよびTeamユーザーに公開、APIも同時に提供開始しました。o3-proは科学、教育、プログラミング、ビジネス、ライティング支援などの分野で前世代を上回る性能を発揮し、ウェブ検索、ファイル分析、視覚入力、Pythonプログラミングなど多様なツールをサポートします。価格は入力100万tokensあたり20ドル、出力80ドルです。同時に、従来のo3モデルの価格は80%大幅に引き下げられ、調整後の価格は入力100万tokensあたり2ドル、出力8ドルとなり、GPT-4oと同水準になります。この動きはAIモデルの価格競争を引き起こし、専門分野でのAIの深い応用を促進する可能性がありますが、o3-proには応答時間が長い、一時的な会話をまだサポートしていないなどの制限も存在します。(ソース: OpenAI, sama, OpenAIDevs, scaling01, dotey)
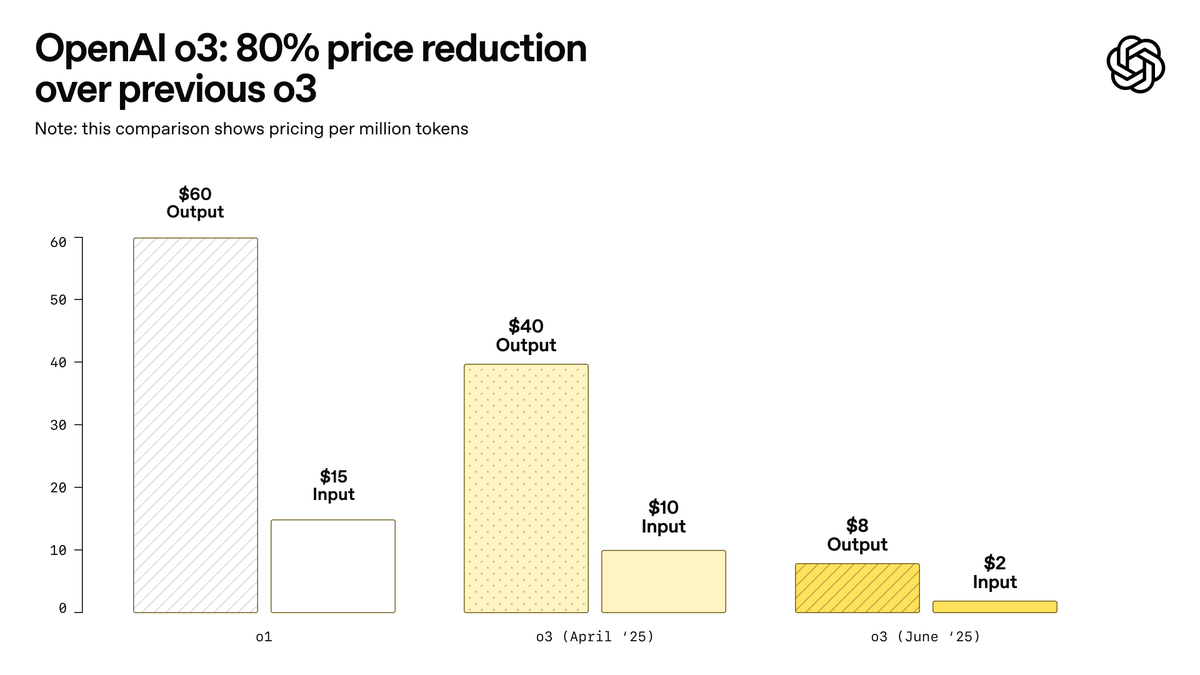
Meta、「スーパーインテリジェンスラボ」を設立しScale AIに巨額出資、AI競争力の再強化を図る: ニューヨーク・タイムズなどの複数の情報筋によると、Meta PlatformsはAI部門を再編し、新たな「スーパーインテリジェンスラボ」を設立、データラベリング企業Scale AIの株式49%を140億ドル以上で取得する計画です。Scale AIの共同創業者兼CEOであるAlexandr Wang氏がMetaに入社し、この新ラボを率いることになります。この動きは、汎用人工知能(AGI)の研究開発を加速し、MetaのAI分野における総合的な競争力、特に高品質なデータ処理とトップ人材の獲得において向上させることを目的としています。これはMetaのAI戦略の大きな転換を示しており、業界の競争環境に大きな影響を与える可能性があります。(ソース: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

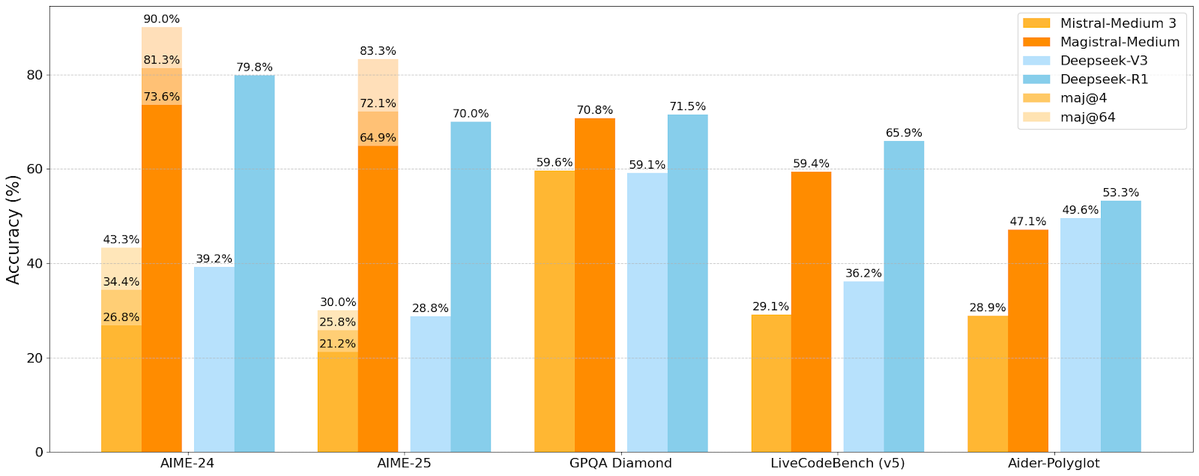
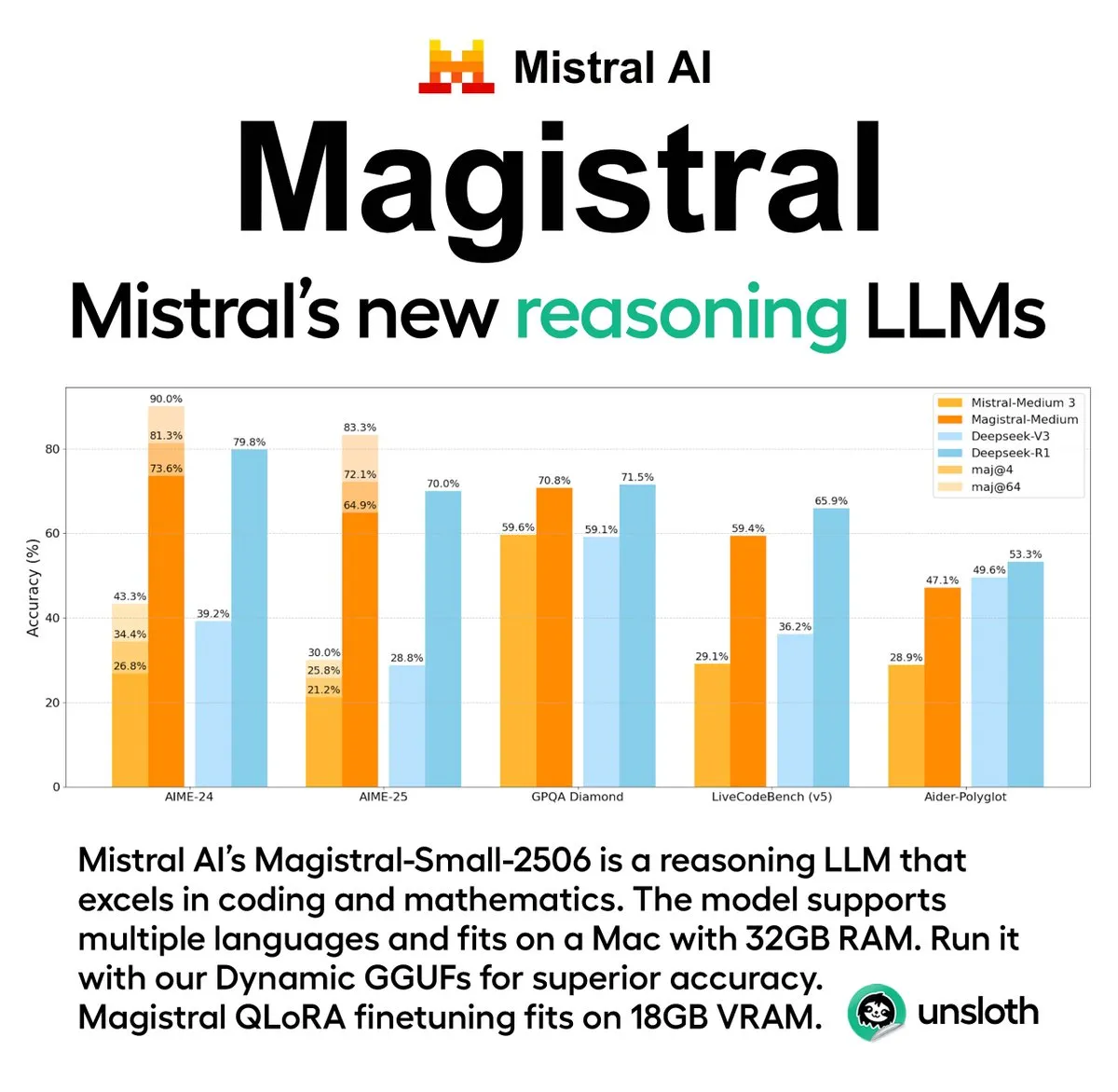
Mistral AI、初の推論モデルシリーズMagistralを発表、オープンソース版も含む: フランスのAIスタートアップ企業Mistral AIは、推論専用に設計された初のモデルシリーズMagistralを発表しました。同シリーズには、より強力なエンタープライズ向けクローズドソースモデルMagistral Mediumと、240億パラメータのオープンソースモデルMagistral Small (Magistral-Small-2506)が含まれており、後者はApache 2.0ライセンスに基づき公開されています。これらのモデルは、数学、コーディング、多言語推論において優れた性能を発揮し、より透明で分野特化型の推論能力を提供することを目指しています。Magistral MediumはLe Chatプラットフォーム上での推論速度が競合他社より10倍速いとされ、Magistral Smallはコミュニティに強力なローカル実行オプションを提供します。(ソース: Mistral AI, jxmnop, karminski3)
IBM、2028年に大規模フォールトトレラント量子コンピュータStarlingの完成を計画: IBMは量子コンピューティング開発ロードマップを発表し、2028年にStarlingと名付けられた大規模フォールトトレラント量子コンピュータを完成させ、2029年にはクラウドサービスを通じてユーザーに公開することを目指しています。Starlingシステムは約100個のモジュールと200個の論理量子ビットを含む見込みで、中核目標は効果的なエラー訂正の実現であり、これは現在の量子コンピューティング分野が直面する最大の技術的課題の一つです。このマシンはIBMの低密度パリティ検査符号(LDPC)を用いてエラー訂正を行い、リアルタイムのエラー診断の実現に取り組みます。成功すれば、これは量子コンピューティング分野における大きなブレークスルーとなり、材料科学や医薬品開発などの複雑な問題への応用を加速させる可能性があります。(ソース: MIT Technology Review)

🎯 動向
Apple WWDC 2025のAI関連進捗、開発者の期待に応えず: AppleはWWDC 2025で、新たな「リキッドグラス」デザイン言語やXcode 26へのChatGPT統合など、多数のアップデートを発表しました。しかし、開発者コミュニティはそのAI分野での進捗について「期待以下」との見方を示しています。Appleは初めて開発者向けにオンデバイスAIモデルを公開し、AI機能統合を簡素化するFoundation Modelsフレームワークを発表したものの、待望の新Siriアップデートは来年に延期される可能性があります。アナリストの郭明錤氏は、AppleのAI戦略が中心的な位置を占めているものの、技術的には大きなブレークスルーは見られず、市場の期待管理が鍵となると指摘しています。AppleはAIモデル自体の破壊的イノベーションよりも、ユーザーインターフェースやOS機能の改善に重点を置いているようです。(ソース: MIT Technology Review, jonst0kes, rowancheung)
米国防総省、AI兵器システムのテスト評価部門を縮小: 米国国防長官Pete Hegseth氏は、国防総省作戦テスト評価局(DOT&E)の規模を半減させ、人員を94人から約45人に削減すると発表しました。同局は兵器およびAIシステムの安全性と有効性のテスト・評価を担当しており、今回の調整は「官僚機構の肥大化と無駄な支出を削減し、殺傷能力を高める」ことを目的としています。この動きは、特に国防総省がAI技術(大規模言語モデルを含む)を各種軍事システムに積極的に統合している中で、AIの軍事利用における安全性と有効性のテストが悪影響を受ける可能性についての懸念を引き起こしています。(ソース: MIT Technology Review)

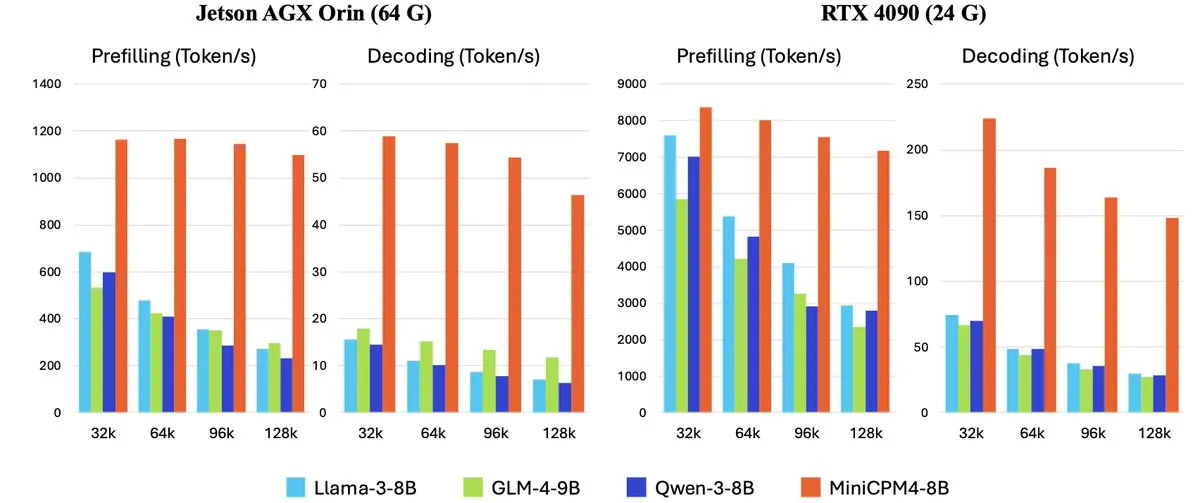
OpenBMB、オンデバイス向け高効率大規模言語モデルMiniCPM-4シリーズを発表: OpenBMB(面壁智能)は、オンデバイス向けに設計され、超高効率な動作を目指すMiniCPM-4シリーズモデルを発表しました。同シリーズには、MiniCPM4-0.5B、MiniCPM4-8B(フラッグシップモデル)、BitCPM4(1-bit量子化モデル)、レポート生成専用のMiniCPM4-Survey、およびMCP専用モデルMiniCPM4-MCPが含まれます。技術報告書では、高効率なモデルアーキテクチャ(InfLLM v2の訓練可能なスパースアテンションメカニズムなど)、高効率な学習アルゴリズム(Model Wind Tunnel 2.0など)、および高品質な訓練データ処理方法について詳述されています。これらのモデルは現在Hugging Faceでダウンロード可能です。(ソース: _akhaliq, arankomatsuzaki, karminski3)
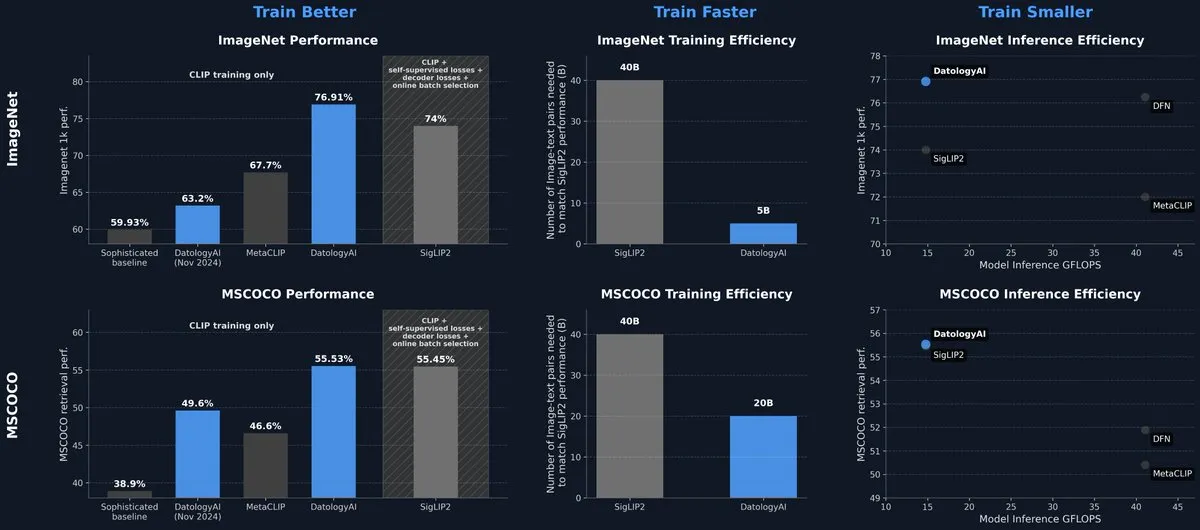
DatologyAI、データ管理のみでSOTAレベルのCLIPモデルを発表: DatologyAIは、マルチモーダル分野における最新の研究成果を発表し、アルゴリズムやアーキテクチャの革新ではなく、精密なデータ管理(data curation)を通じて、CLIP ViT-B/32モデルがImageNet 1kで76.9%の精度を達成し、SigLIP2が報告した74%を上回りました。この手法は同時に、訓練効率を8倍、推論効率を2倍向上させました。モデルは公開されており、高品質なデータがモデル性能向上に持つ巨大な可能性を浮き彫りにしています。(ソース: code_star, andersonbcdefg)
Krea AI、初の自社開発画像モデルKrea 1を発表: Krea AIは、初の画像モデルKrea 1を発表しました。このモデルは美的コントロールと画質に優れ、幅広い芸術的知識を有し、スタイル参照とカスタムトレーニングをサポートしています。Krea 1は、画像のリアリズム、繊細なテクスチャ、豊かなスタイル表現の向上を目指しています。現在、Krea 1は無料のベータテストが公開されており、ユーザーはその強力な画像生成能力を体験できます。(ソース: _akhaliq, op7418)
NVIDIA、カスタマイズ可能なオープンソース人型ロボットモデルGR00T N1を発表: NVIDIAは、カスタマイズ可能なオープンソースの人型ロボットモデルGR00T N1を発表しました。これは、人型ロボット分野の研究開発を推進し、開発者が様々なロボットアプリケーションを構築・実験するための柔軟なプラットフォームを提供することを目的としています。GR00T N1のオープンソースという特性は、より広範なコミュニティの参加を促し、人型ロボット技術の進歩を加速させることが期待されます。(ソース: Ronald_vanLoon)
RoboBrain 2.0、7Bおよび32Bのマルチモーダルロボットモデルを発表: RoboBrain 2.0は、7Bおよび32Bパラメータのマルチモーダルロボットモデルを発表し、ロボットの知覚、思考、タスク実行能力の向上を目指しています。新モデルは、インタラクティブな推論、長期計画、クローズドループフィードバック、正確な空間認識(点およびバウンディングボックス予測)、時間認識(将来軌道推定)、およびリアルタイムの構造化メモリ構築・更新によるシーン推論をサポートします。これらの能力向上は、複雑な環境におけるロボットの自律操作と意思決定レベルを推進することが期待されます。(ソース: Reddit r/LocalLLaMA)
Kling AI、CVPR 2025で動画生成モデルの最新研究を共有: Kling AI動画生成モデル責任者のPengfei Wan氏は、コンピュータビジョンのトップ会議CVPR 2025で「Klingの紹介とより強力な動画生成モデルに関する我々の研究」と題する基調講演を行います。同氏はGoogle DeepMindなどの機関の専門家と共に、動画生成技術の最新のブレークスルーと最先端の進捗について議論します。今回の発表では、Klingが動画生成技術の発展を推進してきた成果について詳しく紹介されます。(ソース: Kling_ai)

AI技術が2025年中国大学統一入学試験を支援、各地でスマート巡回システムを導入: 2025年の中国大学統一入学試験(高考)ではAIスマート巡回システムが広く採用され、天津、江西、湖北、広東省陽江など多くの地域の試験会場でAIによる試験監督が全面的に実施されました。これらのシステムは4Kカメラ、骨格追跡、顔認識、音声監視などの技術を利用し、受験者の不正行為(早期解答、物品の受け渡し、ひそひそ話、視線の異常な逸脱など)をリアルタイムで検出し、警告を発することができます。この措置は試験の公平性を高め、試験会場の規律を確保することを目的としています。AI試験監督システムの応用は、試験管理がスマート化時代に入ったことを示し、従来の試験監督方式に変革をもたらしています。(ソース: 36氪)
Gemma 3n デスクトップモデル発表、クロスプラットフォームとIoTデバイスをサポート: Googleは、デスクトップ(Mac/Windows/Linux)およびIoTデバイス向けに最適化された、20億および40億パラメータ版のGemma 3nデスクトップモデルを発表しました。このモデルは新しいLiteRT-LMライブラリによって駆動され、効率的なローカル実行能力を提供することを目指しています。開発者はHugging FaceでのプレビューやGitHubを通じて関連リソースを入手でき、エッジデバイスにおける軽量AIモデルの応用をさらに推進します。(ソース: ClementDelangue, demishassabis)
🧰 工具
Yutori AI、リアルタイムウェブ監視AIエージェントScoutsを発表: 元Meta AI研究者が設立したYutori AIは、Scoutsと名付けられたAIエージェント製品を発表しました。Scoutsはユーザーが設定したテーマやキーワードに基づき、インターネット情報をリアルタイムで監視し、関連コンテンツが出現した際にユーザーに通知します。このツールは、ユーザーが煩雑なウェブ情報の中から自分にとって価値のあるコンテンツ(特定分野のニュース動向、市場トレンド、製品の割引情報、さらには希少な予約など)を選別するのを支援することを目的としています。Scoutsの登場は、パーソナライズされた情報取得ツールのさらなる発展を示し、AIをユーザーのデジタル「偵察兵」にします。(ソース: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit、Figmaなどのデザインをワンクリックで機能的なアプリに変換する新機能: ReplitはReplit Import機能を発表し、ユーザーがFigma、Lovable、Boltなどのプラットフォームのデザインを直接インポートし、実行可能なアプリケーションに変換できるようにしました。この機能は開発のハードルを下げ、プログラマーでなくてもデザインのアイデアを迅速に実現できるようにすることを目的としています。Replit Importはデザインの忠実度を維持し、セキュリティスキャンとキー管理を内蔵しており、Replit Agent、データベース、認証、ホスティングサービスと組み合わせることで、フルスタックアプリケーションを作成できます。(ソース: amasad, pirroh)
Hugging Face、スプレッドシートと数千のAIモデルを組み合わせるAISheetsを発表: Hugging Faceの共同創業者であるThomas Wolf氏は、実験的製品AISheetsの提供開始を発表しました。このツールは、スプレッドシートの使いやすさと、数千のオープンソースAIモデル(特にLLM)の強力な機能を組み合わせたものです。ユーザーは使い慣れたスプレッドシートインターフェースでデータ処理タスクを構築、分析、自動化し、AIモデルを利用してデータインサイトを得たりタスクを自動化したりすることができ、迅速かつシンプルで強力な新しいデータ分析方法を提供することを目指しています。(ソース: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex、AgentをMCPサーバーに変換しClaudeなどのモデルと対話可能に: LlamaIndexは、任意のAgentをモデルコンテキストプロトコル(MCP)サーバーに変換するサポートを発表しました。サンプルコードとビデオを通じて、複雑なPDFから構造化データを抽出するためのカスタムFidelityFundExtractionワークフローをMCPサーバーとしてデプロイし、Claudeモデルから呼び出す方法を紹介しています。この機能は、ツールのエージェント化レベルを向上させ、Claude DesktopやCursorなどのMCPクライアントとの統合を容易にし、既存のワークフローをより広範なAIエコシステムに接続するプロセスを簡素化することを目的としています。(ソース: jerryjliu0)
GPT Researcher、LangChainのモデルコンテキストプロトコル(MCP)を統合: GPT Researcherは現在、LangChainのモデルコンテキストプロトコル(MCP)アダプターを利用して、インテリジェントなツール選択と研究を行っています。この統合により、MCPとウェブ検索機能がシームレスに組み合わされ、包括的なデータ収集が実現します。ユーザーは関連する統合ドキュメントを参照して、この新機能の設定方法と使用方法を理解し、研究効率と深さを向上させることができます。(ソース: hwchase17)
Tesslate、UI生成モデルUIGEN-T3シリーズをリリース、複数サイズをサポート: Tesslateチームは、32B、14B、8B、4Bなど複数のパラメータ規模を持つUI生成モデルUIGEN-T3シリーズを発表しました。これらのモデルは、UIコンポーネント(パンくずリスト、ボタン、カードなど)や完全なフロントエンドコード(ログインページ、ダッシュボード、チャットインターフェースなど)の生成に特化して設計されており、Tailwind CSSをサポートしています。モデルはHugging Faceで提供されており、開発者が迅速にユーザーインターフェースを構築するのを支援することを目的としています。開発者からのフィードバックによると、標準的な量子化はモデルの品質を著しく低下させるため、最適な結果を得るにはBF16またはFP8で実行することが推奨されています。(ソース: Reddit r/LocalLLaMA)
豆包・ポッドキャストモデル発表、ワンクリックで人間らしいAIポッドキャストを生成: ByteDance傘下のVolcengineは、豆包・ポッドキャストモデルを発表しました。このモデルは、ユーザーが入力したテキスト(記事のリンクやPromptなど)に基づいて、人間らしい対話スタイルのポッドキャストを迅速に生成できます。モデルが生成する音声は、口調、間、口語表現において真人間に近く、内容に基づいて意見を交えた議論も可能です。この技術は、ByteDanceの音声技術チームのエンドツーエンドリアルタイム音声モデルに基づいており、音声モダリティでの直接的な理解と推論を実現しています。現在、この機能は豆包PC版とCoze Spaceで提供されており、音声コンテンツ作成のハードルを下げ、効率的でパーソナライズされた情報取得方法を提供することを目指しています。(ソース: 量子位)

Unsloth AI、Magistral-Small-2506のGGUF量子化版を提供: Mistral AIが新たに発表したMagistral-Small-2506推論モデルに対し、Unsloth AIはGGUF量子化版を提供しています。これにより、ユーザーはローカル環境、例えばわずか32GBのRAMを搭載したデバイスでこの240億パラメータのモデルを実行できます。この動きは、高性能推論モデルのハードウェア要件を引き下げ、より広範な開発者や研究者がローカル環境でMagistralモデルを体験・使用しやすくします。(ソース: ImazAngel)
📚 学習
LLaVA-1.5 ビジョンアシスタント構築技術の詳細解説: LearnOpenCVは、LLaVA-1.5アーキテクチャに関する技術的な詳細解説記事を公開しました。この記事では、LLaVA-1.5がどのように最先端のAIビジョンアシスタントを構築しているか、その画期的な視覚指示ファインチューニング技術(Visual Instruction Tuning)や、マルチモーダルAI分野を変革したオープンソースデータセットについて詳しく紹介しています。このガイドは、AI/MLエンジニアや研究者がマルチモーダル大規模言語モデルの動作原理と訓練方法を理解する上で重要な参考価値があります。(ソース: LearnOpenCV)
タンパク質機械学習入門ガイド公開: DL Weeklyは、初心者向けのタンパク質機械学習に関する包括的なガイドを共有しました。このガイドは、タンパク質関連の基本的なデータ型、深層学習モデル、計算方法、および基礎的な生物学の概念を網羅しており、この学際的分野に関心を持つ研究者や開発者が迅速に知識を習得できるよう支援することを目的としています。(ソース: dl_weekly)
QdrantとDataTalksClub、無料のRAGとベクトル検索コースで提携: QdrantはDataTalksClubと提携し、10週間の無料オンラインコースを提供すると発表しました。コース内容は、検索拡張生成(RAG)、ベクトル検索、ハイブリッド検索、評価方法などを含み、エンドツーエンドのプロジェクト実践も含まれます。Qdrantの専門家であるKacper Łukawski氏とDaniel Wanderung氏が直接講義を行い、学習者が高度なAIアプリケーションを構築するための実用的なスキルを習得できるよう支援することを目指しています。(ソース: qdrant_engine)
Weaviateポッドキャスト、LLMの構造化出力と制約付きデコーディングを議論: Weaviateポッドキャストの最新エピソードでは、dottxt.aiのWill Kurt氏とCameron Pfiffer氏を招き、ホストのConnor Shorten氏と共に、大規模言語モデル(LLM)の構造化出力問題について議論しました。番組では、LLMが単なるJSON形式の検証だけでなく、信頼性が高く予測可能な結果(有効なJSON、メール、ツイートなど)を生成するために、制約付きデコーディング技術をどのように活用できるかについて深く掘り下げました。また、オープンソースツールOutlinesとその実際のAIユースケースにおける応用を紹介し、この技術が将来のAIシステムに与える影響について展望しました。(ソース: bobvanluijt)
ACL2025NLP論文SynthesizeMe!:ユーザーインタラクションからパーソナライズされたプロンプトを生成: 「SynthesizeMe!」と題されたACL 2025 NLP会議論文は、ユーザーとAIのインタラクション(暗黙的および明示的なフィードバックを含む)を分析することで、自然言語のパーソナライズされたユーザーモデルを作成する新しい手法を提案しています。この手法はまず、ユーザーの嗜好を説明する推論プロセスを生成・検証し、そこから合成されたユーザープロファイルを帰納的に導き出し、情報量の多い過去のユーザーインタラクションを選別し、最終的に特定のユーザー向けにパーソナライズされたプロンプトを構築することで、LLMのパーソナライズされた報酬モデリングと応答能力の向上を目指します。DSPyもこれをdspy.MIPROv2の優れた応用事例として転送し言及しています。(ソース: lateinteraction, stanfordnlp)
新論文、テスト時拡張(Test-Time Scaling)LLMの監視とオーバークロックを議論: 新しい論文は、o3やDeepSeek-R1などのモデルで採用されているテスト時拡張技術に注目しています。この技術はLLMが回答前により多くの推論を行うことを可能にしますが、ユーザーはその内部進捗を把握したり制御したりすることができません。研究者らはLLMの内部「クロック」を公開し、その推論プロセスを監視し、それを「オーバークロック」して加速する方法を示しました。これは大規模推論モデルの効率を理解し最適化するための新たな視点を提供します。(ソース: arankomatsuzaki)

論文、CARTRIDGESを提案:オフライン自己学習による長文脈LLMのKVキャッシュ圧縮: スタンフォード大学HazyResearchの研究者らは、CARTRIDGESと名付けられた新しい手法を提案し、長文脈LLMにおけるKVキャッシュのメモリ占有量が過大になる問題の解決を目指しています。この手法は、「自己学習」的なテスト時訓練メカニズムを通じて、オフラインでより小さなKVキャッシュ(cartridgeと呼ばれる)を訓練し、ドキュメント情報を格納することで、タスク性能を維持しつつ、平均で39倍のキャッシュメモリ削減と26倍のピークスループット向上を実現します。このcartridgeは一度訓練すれば、異なるユーザーリクエストで再利用可能であり、長文脈処理に新たな最適化の道筋を示しています。(ソース: gallabytes, simran_s_arora, stanfordnlp)

新論文Grafting:事前学習済み拡散Transformerアーキテクチャ編集を低コストで実現: スタンフォード大学の研究者らは、Graftingと名付けられた新しい手法を提案し、事前学習済みの拡散Transformerモデルアーキテクチャを編集するために使用します。この技術は、事前学習コストのわずか2%の計算量で、モデル内のアテンションメカニズムなどを新しい計算プリミティブに置き換えることを可能にし、小さな計算予算でモデルアーキテクチャのカスタマイズ設計を実現します。これは新しいモデルアーキテクチャの探求や既存モデルの効率向上に重要な意義を持ちます。(ソース: realDanFu, togethercompute)
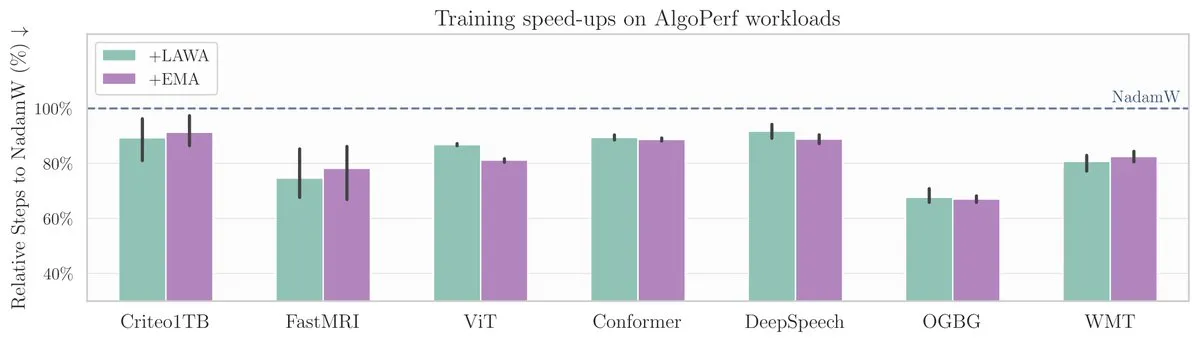
ICML新論文:平均チェックポイント手法がAlgoPerfベンチマークでモデル訓練を加速: 新しいICML論文は、平均チェックポイント(Averaging Checkpoints)という古典的な手法が、機械学習モデルの訓練速度と性能向上における応用について研究しています。研究者らは、構造化され多様な最適化アルゴリズムのベンチマークであるAlgoPerf上でこの手法をテストし、異なるタスクにおける実際の効果を探求し、モデル訓練の加速に実践的な参考を提供しています。(ソース: aaron_defazio)
Transformer可視化説明ツールがオープンソース化: DL Weeklyは、Transformerアーキテクチャに基づくモデル(GPTなど)の動作原理をユーザーが理解するのを助けることを目的とした、インタラクティブな可視化ツールを紹介しました。このツールは、モデル内部のメカニズムを可視化することで複雑な概念をより理解しやすくしており、Transformerモデルに関心のある学習者や研究者に適しています。プロジェクトはGitHubでオープンソース化されています。(ソース: dl_weekly)
浙江大学、InftyThinkを提案:セグメント化と要約により無限深度推論を実現: 浙江大学と北京大学の研究チームは、大規模モデルの新しい推論パラダイムInftyThinkを提案しました。この方法は、長い推論を複数の短いセグメントに分割し、セグメント間に要約を導入して文脈を繋ぐことで、理論上無限の深度推論を実現し、同時に高い生成スループットを維持します。この方法はモデル構造の調整に依存せず、訓練データをマルチラウンド推論形式に再構築することで、既存の事前学習、ファインチューニングプロセスと互換性があります。実験により、InftyThinkはAIME24などのベンチマークでモデルの性能を著しく向上させ、生成スループットも向上させることが示されています。(ソース: 量子位)

論文、ピクセル空間推論を議論:VLMが人間のように「目と脳を同時に使う」ことを可能に: ウォータールー大学、香港科技大学、中国科学技術大学の研究チームは、「ピクセル空間推論」(Pixel-Space Reasoning)パラダイムを提案し、視覚言語モデル(VLM)がテキストトークンを仲介として依存するのではなく、視覚的ズームや時空間マーキングなど、ピクセルレベルで直接操作・推論できるようにしました。内発的好奇心による動機付けと外発的正確性による動機付けの強化学習スキームを通じて、モデルの「認知的怠惰」を克服しました。Qwen2.5-VL-7Bに基づいて構築されたPixel-Reasonerは、V*Benchなど複数のベンチマークで優れた性能を示し、7Bモデルの性能はGPT-4oを上回りました。(ソース: 量子位)
DeepLearning.AI、データ分析専門講座の第5コース「データストーリーテリング」を開始: DeepLearning.AIは、データ分析専門講座の第5コースとして「データストーリーテリング」を開始しました。このコースでは、洞察を提示するための適切な媒体(ダッシュボード、メモ、プレゼンテーション)の選択方法、Tableauを使用したインタラクティブなダッシュボードの設計方法、発見をビジネス目標と整合させて効果的に伝達する方法、および就職活動の指導について教えます。ビジネスパフォーマンスの向上と洞察の効果的な伝達におけるデータストーリーテリングの重要性を強調しています。(ソース: DeepLearningAI)

論文、知識の衝突が大規模言語モデルに与える影響を議論: 新しい論文は、大規模言語モデル(LLM)が文脈入力とパラメータ化された知識(つまりモデル内部の「記憶」)が衝突した際の振る舞いを体系的に評価しました。研究によると、知識の衝突は知識利用に依存しないタスクにはほとんど影響を与えません。文脈とパラメータ知識が一致する場合、モデルのパフォーマンスは向上します。指示されたとしても、モデルは内部知識を完全に抑制することはできません。衝突を説明する理由を提供すると、モデルの文脈への依存度が高まります。これらの発見は、モデルベースの評価の有効性に疑問を投げかけ、LLMをデプロイする際には知識の衝突問題を考慮する必要性を強調しています。(ソース: HuggingFace Daily Papers)
論文CyberV:ビデオ理解におけるテスト時拡張のためのサイバネティクスフレームワーク: マルチモーダル大規模言語モデル(MLLM)が長いビデオや複雑なビデオを処理する際に直面する計算需要、堅牢性、精度問題を解決するため、研究者らはCyberVフレームワークを提案しました。このフレームワークはサイバネティクスの原理に着想を得て、ビデオMLLMを適応システムとして再設計し、MLLM推論システム、センサー、コントローラーを含みます。センサーはモデルのフォワードプロセスを監視し、中間的な解釈(アテンションドリフトなど)を収集し、コントローラーはいつ、どのように自己修正をトリガーし、フィードバックを生成するかを決定します。このテスト時適応拡張フレームワークは、再訓練なしに既存のMLLMを強化でき、実験ではVideoMMMUなどのベンチマークでQwen2.5-VL-7Bなどのモデルの性能を著しく向上させることが示されています。(ソース: HuggingFace Daily Papers)
論文、LoRMAを提案:LLMのパラメータ効率的なファインチューニングのための低ランク乗法的適応: 既存のLoRAおよびMoEに基づくパラメータ効率的なファインチューニング(PEFT)手法に存在する表現の崩壊とエキスパートの負荷不均衡問題を解決するため、研究者らは低ランク乗法的適応(LoRMA)を提案しました。この手法は、PEFTアダプタエキスパートの更新方法を加法的からより豊富な行列乗法的変換に変更し、効果的な再配置操作とランク拡張戦略を導入することで、計算の複雑さとランクのボトルネックに対処します。実験により、MoA(混合アダプタ)異種手法は、性能とパラメータ効率の両方で同種MoE-LoRA手法よりも優れていることが証明されました。(ソース: Reddit r/MachineLearning)
論文、FlashDMoEを提案:単一カーネルによる高速分散MoE実装: 研究者らはFlashDMoEを発表しました。これは、分散型混合エキスパート(MoE)のフォワード伝播を完全に単一のCUDAカーネルに融合した最初のシステムです。純粋なCUDAで融合レイヤーを一から記述することにより、FlashDMoEはGPU利用率を最大9倍向上させ、遅延を6倍削減し、弱いスケーリング効率を4倍改善しました。この研究は、大規模MoEモデルの推論効率を最適化するための新しいアイデアと実装を提供します。(ソース: Reddit r/MachineLearning)
💼 ビジネス
xAIとPolymarketが提携、市場予測とGrok分析を融合: Elon Musk氏率いる人工知能企業xAIは、分散型予測市場プラットフォームPolymarketとのパートナーシップを発表しました。この提携は、Polymarketの市場予測データとX(旧Twitter)のデータ、およびGrok AIの分析能力を組み合わせ、「ハードコアな真実エンジン」を構築し、世界を形作る要因を明らかにすることを目的としています。xAIはこれが提携の始まりに過ぎず、将来的にはさらに多くの協力内容があるとしています。(ソース: xai)
AI推論チップ企業Groq、サウジアラビアから15億ドルの投資コミットメントを獲得、垂直統合戦略に注力: AI推論チップ企業Groqは、サウジアラビアから15億ドルの投資コミットメントを獲得したと発表しました。これは、LPU(Language Processing Unit)ベースのAI推論インフラストラクチャの現地での提供規模を拡大するためのものです。GroqはTPUの発明者の一人であるJonathan Ross氏によって設立され、AI推論コンピューティングに特化しています。そのLPUチップはプログラマブルなパイプラインアーキテクチャを採用し、メモリと計算ユニットを同一チップ上に統合することで、データアクセス速度とエネルギー効率を大幅に向上させています。Groqはチップ販売だけでなく、GroqRackクラスター(プライベートクラウド/AIコンピューティングセンター)やGroqCloudクラウドプラットフォーム(Tokens-as-a-Service)も提供し、Llama、DeepSeek、Qwenなどの主要なオープンソースモデルをサポートしています。同社はまた、AI推論クラウドの価値を高めるためのCompound複合AIシステムも開発しています。(ソース: 36氪)

深圳の人型インタラクションロボット企業「数字華夏」、数千万元のエンジェルプラスラウンド資金調達を完了: 数字華夏(深圳)科技有限公司は最近、数千万元のエンジェルプラスラウンドの資金調達を完了し、同創偉業が単独で投資しました。同社はAGIロボットの規模商用化に焦点を当てており、主要製品にはヒューマノイドロボット「夏瀾」、汎用人型ロボット「夏起」、IPシリーズロボット「星行侠」が含まれます。「夏瀾」ロボットは精密なバイオニック技術を核とし、人間のほとんどの表情を模倣でき、マルチモーダルインタラクション能力を備えています。同社はすでに数億元の受注を獲得しており、顧客には大手ICTメーカーや地方電力会社などが含まれます。(ソース: 36氪)

🌟 コミュニティ
Sam Altman氏、ブログ記事「穏やかなシンギュラリティ」を発表、AIの漸進的革命と未来を考察: OpenAI CEOのSam Altman氏はブログ記事で、技術的特異点(シンギュラリティ)が予想よりも穏やかで「優しい」形で静かに起こっており、持続的かつ指数関数的に加速する漸進的なプロセスであるとの見解を示しました。同氏は、2025年には複雑な知的作業(プログラミングなど)を独立して完了できるAIエージェントがソフトウェア業界を再構築し、2026年には全く新しい科学的知見を発見できるシステムが登場する可能性があり、2027年には現実世界でタスクを完了できるロボットが登場するかもしれないと予測しています。Altman氏は、AIアライメント問題の解決と技術の普遍的な恩恵の確保が、繁栄する未来への鍵であると強調しています。また、OpenAI初のオープンソースウェイトモデルのリリースは、研究チームが「予想外の驚くべき成果」を上げたため、夏の終わりまで延期されることも明らかにしました。(ソース: dotey, scaling01, sama)
コミュニティ、OpenAI o3-proについて熱論:高性能だが高コスト、o3値下げが連鎖反応を引き起こす: OpenAI o3-proの発表とその高額な価格設定(出力80ドル/M tokens)がコミュニティの議論の的となっています。ユーザーは複雑な推論やプログラミングなどのタスクにおけるその強力な能力を概ね認めているものの、応答速度とコストについては懸念を示しており、簡単な挨拶「Hi」だけで80ドルかかるかもしれないと冗談めかして言うユーザーもいます。同時に、o3モデルの大幅な80%値下げは、AIモデルの価格競争を引き起こし、GPT-4oや他の競合製品に対抗するものと見なされています。コミュニティでは、o3値下げ後の性能が「低下」したかどうかについて議論があります。OpenAIはその後、ユーザーの需要に応えるため、ChatGPT Plusユーザーのo3使用上限を2倍にすると発表しました。(ソース: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Metaの高額報酬による人材獲得とAI組織への資金投入が話題に: MetaがAI研究者に提供する高額な報酬パッケージ(9桁米ドルに達するとされる)がコミュニティで議論を呼んでいます。Nat Lambert氏は、このような報酬はAI2規模の研究機関全体を資金援助できるかもしれないとコメントし、トップ人材のコストの高さを暗示しています。Metaが「スーパーインテリジェンスラボ」を設立し、Scale AIに巨額を投じる動きと合わせて、コミュニティはMetaがコストを惜しまずAI競争力を再構築しようとしていると広く認識していますが、その内部の組織政治や効率性の問題にも注目しています。Helen Toner氏が転送したChinaTalkの内容は、Metaのこの動きが組織内部の政治と自尊心の問題を打破するためであると指摘しています。(ソース: natolambert, natolambert)
Apple WWDCの新UIスタイル「リキッドグラス」がデザインとユーザビリティの議論を呼ぶ: AppleがWWDC 2025で発表した新しいUIデザインスタイル「リキッドグラス」(Liquid Glass)が、開発者やデザイナーのコミュニティで幅広い議論を引き起こしています。一部の意見では、その視覚効果が斬新で、Appleの3Dインターフェースデザインへの探求を反映しているとされています。しかし、ID_AA_Carmack(John Carmack)氏などのベテランは、半透明UIは通常ユーザビリティの面で問題があり、視覚的な妨害や低コントラストを生じやすく、読書や操作に影響を与えると指摘し、WindowsやMacも歴史的に同様のデザインを試みたものの、最終的にはユーザビリティの問題で調整されたことに言及しています。ユーザーエクスペリエンス(UX)がユーザーインターフェース(UI)の視覚効果よりも優先されるべきであるという点が議論の中心となっています。(ソース: gfodor, ID_AA_Carmack, ReamBraden, dotey)
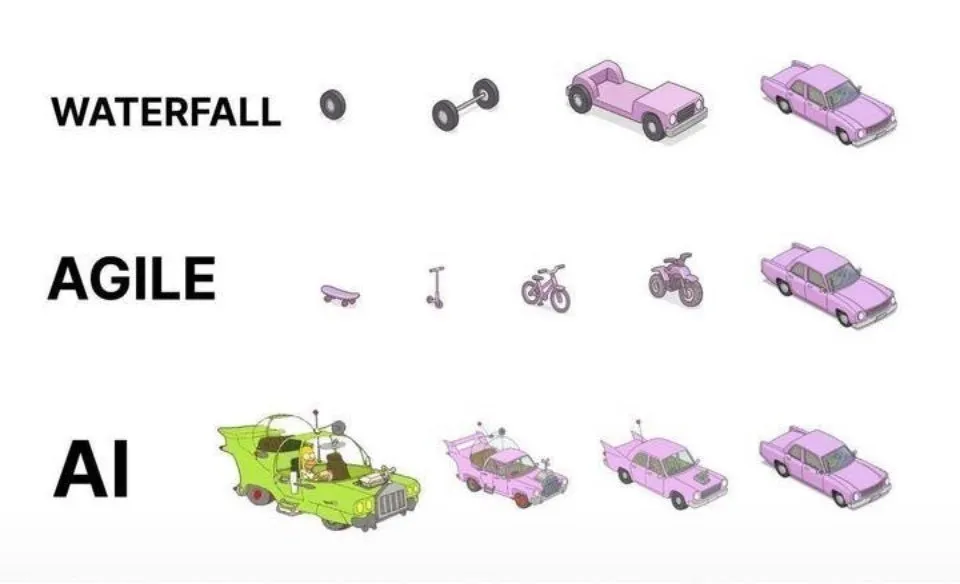
AI支援プログラミングの実践:一度きりの生成よりアジャイルな反復が優れる: ソーシャルメディア上で、dotey氏はAI(Claude Codeなど)を用いたプログラミングのベストプラクティスについて見解を述べました。同氏は、完全な要件を一度に提供してAIに巨大な半製品を生成させる方法(ウォーターフォールモデル)や、まず不完全な製品を生成してから最適化する方法(図中の第3のパターンに類似)を採用すべきではないと主張しています。なぜなら、これらは品質管理が難しく、後期のメンテナンスも困難だからです。同氏は、アジャイルな反復モデル(図中の第1のパターンに類似)を採用し、大規模プロジェクト(ERPシステムなど)を複数の独立して安定稼働可能な小バージョンに分割し、段階的に反復開発することで、各バージョンの機能の完全性と制御可能性を確保することを提唱しており、これは従来のソフトウェアエンジニアリングのベストプラクティスと一致しています。(ソース: dotey)
Mustafa Suleyman氏:AI技術は固定的な統一型から動的な個別化型へと進化: Inflection AIおよび元DeepMind共同創業者のMustafa Suleyman氏は、従来の技術は通常、固定的で統一された「画一的」なモデルであったのに対し、現在の人工知能技術は動的で、個別化され、創発的な特徴を示しているとコメントしました。同氏は、これは技術が単一の反復的な結果を提供することから、無限の可能性の経路を探求することへと変化していることを意味すると考え、AIの個別化サービスと創造的な応用における巨大な可能性を強調しました。(ソース: mustafasuleyman)
Perplexity AIがインフラ問題に遭遇、CEOが説明: Perplexity AIのCEOであるArav Srinivas氏は、ソーシャルメディア上でサービスの不安定性に関するユーザーの質問に対し、インフラの問題により、一部のトラフィックに対して劣化したユーザーエクスペリエンス(degraded UX)を有効にせざるを得なかったと述べました。同氏は、ユーザーのデータ(ライブラリやスレッドなど)は失われておらず、システムが安定すればすべての機能が正常に戻ると強調しました。これは、AIサービスが急速に発展する過程で、インフラの安定性と拡張性が直面する課題を反映しています。(ソース: AravSrinivas)
Sergey Levine氏、言語モデルとビデオモデルの学習の違いを考察: カリフォルニア大学バークレー校のSergey Levine教授は、自身の記事「プラトンの洞窟における言語モデル」で、なぜ言語モデルは次の単語を予測することから多くを学べるのに、ビデオモデルは次のフレームを予測することから学ぶことが比較的少ないのか、という深い問いを投げかけました。同氏は、LLMは人間の知識の「影」(テキストデータ)を学習することで強力な推論能力を獲得しており、これは真に物理世界を自主的に探求するのではなく、むしろ人間の認知の「リバースエンジニアリング」に近いと考えています。ビデオモデルは物理世界を直接観察しますが、現在のところ複雑な推論ではLLMに及びません。同氏は、AIの長期的な目標は、人間の知識の「影」への依存を突破し、センサーを通じて物理世界と直接対話し、自主的な探求を実現することであるべきだと提唱しています。(ソース: 36氪)
💡 その他
AI倫理と意識の議論:AIは真の意識を持つことができるのか?: MIT Technology Reviewは、AIの意識という複雑な議題に注目しています。記事は、AIの意識は知的な難問であるだけでなく、道徳的な重みを持つ議題でもあると指摘しています。AIの意識を誤って判断すると、知覚能力のあるAIを意図せずに奴隷化したり、知覚のない機械のために人間の福祉を犠牲にしたりする可能性があります。研究界は意識の本質の理解において進展を遂げており、これらの成果は人工意識の探求と対応に指針を提供するかもしれません。これは、AIの権利、責任、そして人間と機械の関係についての深い考察を引き起こしています。(ソース: MIT Technology Review)
チューリング賞受賞者Joseph Sifakis氏:現在のAIは真の知能ではなく、知識と情報の混同に警戒が必要: チューリング賞受賞者のJoseph Sifakis氏は、自身の著作やインタビューで、現在の社会のAIに対する理解には偏りがあり、情報の寄せ集めと知恵の創造を混同し、機械の「知能」を過大評価していると指摘しています。同氏は、現在真の知能システムは存在せず、AIの産業への実際の影響はごくわずかであると考えています。AIは常識的な理解に欠け、その「知能」は統計モデルの産物であり、複雑な社会状況において価値とリスクを比較検討することは困難です。同氏は、教育の核心は知識の伝達ではなく、批判的思考と創造力の育成であると強調し、AI応用の世界基準を確立し、責任の境界を明確にし、AIを人間を代替するものではなく、人間を強化するパートナーとすることを呼びかけています。(ソース: 36氪)
AI時代の広告業界再編:クリエイティブ生成からパーソナライズ配信までの変革: Google I/O 2025大会では、AIが広告業界をどのように深く再構築するかが示されました。トレンドには以下が含まれます:1) AIによるクリエイティブ自動化。画像からビデオスクリプトまでAIが生成可能で、Veo 3、Imagen 4、Flowなどのツールが高品質コンテンツ作成のハードルを下げています。2) パーソナライズのパラダイムが「千人千面」から「一人千面」へと移行し、AIインテリジェントエージェントが能動的にユーザーのニーズを理解し、取引を促進します。3) 広告とコンテンツの境界が曖昧になり、広告がAI生成の検索結果に直接組み込まれ、情報の一部となります。ブランドオーナーは、専用のインテリジェントエージェントを構築し、AI向けのサービスを提供し、変革に適応するために「ブランド効果と販売効果の統合」という長期戦略を堅持する必要があります。(ソース: 36氪)